
Notepad удалить все после запятой
Вставляем в поле «Найти» вот это: (/.+)$ , а поле «Заменить на» оставляем пустым.
Как в Notepad++ удалить текст в каждой строке до конца строки после заданного
Как в Notepad ++ добавить символ в начале каждой строки?
В меню замены ставишь галочку Регулярные выражения
В строке «Заменить на» – свой символ
Как удалить все строки длиннее, например, 10 символов?
^[^\r\n]?\r\n — обращаем внимание на цифру 11 (10+1) Если все строки длинее 15 символов, то там должно быть 16
Заменить на пустую строку.
Как удалить строки меньше 40 символов?
Как удалить пустую строку в Notepad++
Выбираем «Регулярные выражения»
Меняем \n\r на \0
Как удалить строку и перенос строки?
Делаем поиск по регулярке:
Затем заходим в раздел TextFX -> TextFX Edit -> Delete Blank Lines
Добавление знаков в начале и конце строки
В «заменить на» — \1
Добавление круглых скобок () в поле найти обязательно, иначе текст будет удален.
Удаление пустых строк, содержащих пробелы
В поле «найти» вводим ^[ ]*$ или ^\s*$
Окно «Заменить» оставить пустым
Удаление всех символов в строке после обнаружения в строке пробела
Как убрать разные символы после строки notepad++?
Допустим, в строке kalach;skkdjlskdk
нужно очистить все, что после kalach;
Удаление символов от начала строки до нужного символа, например »
заменяем на пустую строку
Некоторые Регулярные выражения в notepad++:
. — Точка представляет один любой символ
^ — Начало строки
$ — Конец строки
\s — Пробел
\S — Не Пробел
\w — буква, цифра или подчёркивание _
\d — Любая цифра
\D — Любой символ, но не цифра
6 — Любая цифра
[a-z] — Любая буква от a до z (весь латинский набор символов) в нижнем регистре
[A-Z] — Любая буква от a до z в ВЕРХНЕМ регистре
[a-zA-Z] — Любая буква от a до z в любом регистре
[a-Z] — То же самое
* — «Повторитель». Означает, что предшествующий символ может повторяться (0 или более раз)
.* — Абсолютно любой набор символов. Например, условие
— найдет все что между тегами (например внутри тега
(^.*$) — Любой текст между началом и концом строки
(62*.) — ищет любые двухзначные в данном случае цифры
\n\r — Ищет пустые строки. Вроде как если оставить пустым окно «Заменить» то удаляет пустые строки, но можно поставить вот это \0
^\s*$ — Ищет пустые строки содержащие пробел.
^[ ]*$ — Ищет пустые строки содержащие пробел.
Я думаю, что ни для кого не секрет, что любую задачу можно решить несколькими способами, каждый из которых эффективнее в своем отдельно взятом случае.
Мы с вами уже не первый раз сталкиваемся с программой Notepad++ (в одной из статей мы рассмотрели вариант удаления текста до и после определенного символа), а сегодня рассмотрим еще один вариант постановки задачи – удаление нужного количества первых/последних символов каждой строки.
1. Для начала откройте в программе файл, содержащий в себе необходимые данные для обработки.
2. Далее нажмите комбинацию клавиш CTRL+F на клавиатуре, переключитесь на вкладку «Заменить»

и выполните последние шаги в зависимости от поставленных целей.
Как удалить первые N символов каждой строки в Notepad++?
Для того чтобы удалить первые N символов, в разделе «Режим поиска» отмечаем пункт «Регуляр. выражения», а в поле «Найти» вставляем:
«2» здесь – это количество необходимых символов, которое необходимо удалить.

Нижнее же поле «Заменить на» заполняете:
и жмете «Заменить все».
Как удалить последние N символов каждой строки в Notepad++?
Для удаления последних N символов вам необходимо проделать все в точности так, как и в предыдущем варианте, меняется лишь следующее.
В поле «Найти» вы вставляете:
и жмете на «Заменить все».
«2» здесь – это все тоже количество необходимых символов, которое необходимо удалить.
Все описанные варианты отлично подойдут для обработки больших данных. Но есть еще один способ, который также позволяет удалить нужное количество символов с каждой из сторон.
Суть в этом способе следующая.
На клавиатуре вы зажимаете клавишу «Alt», после чего просто выделяете нужные участки каждой строки.
На анимации выше видно, что таким способом можно выделить абсолютно любой одинаковый участок одновременно на всех строках вашего файла.
Я пытаюсь избавиться от всего после столбца в Notepad++. Режим столбца не является опцией. Это возможно?
что у меня есть:
если данные в первом столбце никогда не содержат пробелов, вы можете использовать регулярное выражение find and replace, чтобы получить желаемое.
в режиме регулярного выражения найдите:
^ указывает, что любое совпадение должно начинаться в начале строки.
([^ ]*) - любое выражение, не содержащее пробела. Матч жадный, поэтому это будет соответствовать всему до первого пробела (или конца строки, что наступит раньше).
.* все остальное на линии.
ссылается на часть матча в скобках. То есть вся строка заменяется только битом из первого столбца.
вот простое регулярное выражение, которое можно использовать для достижения того же эффекта. Заменить
(обратите внимание на пробел)
ни с чем. Это удалит все после и включая первый пробел. Это будет работать до тех пор, пока ваши IP-адреса никогда не будут начинаться с пробелов (как в вашем примере).
Если вы используете Windows, и если вы не возражаете конечные пробелы (вы можете найти / заменить их впоследствии), используйте Блок Select характеристика:
- нажмите и удерживайте Alt ключ
- С помощью мыши выделите участок для удаления (весь блок текста)
- отпустить Alt ключ
- удалить этот блок текста
- повторить при необходимости
на регулярные выражения быстрее, но вы можете сделать некоторые действительно сложные вещи с помощью макросов, если это более сложная задача.
вы можете записать макрос:
- курсор на строке 1
- нажмите начать запись
- нажмите клавишу home
- Hold Ctrl при нажатии клавиши стрелка вправо (семь раз)
- Hold Shift пока вы нажмите клавишу конец
- нажмите клавишу удалить
- нажмите клавишу стрелка вниз
- нажмите остановить запись
- нажмите "Запустить макрос несколько раз"
- введите в строках документа минус 1, так как первая строка завершена.
курсор после 70.97.110.40 .
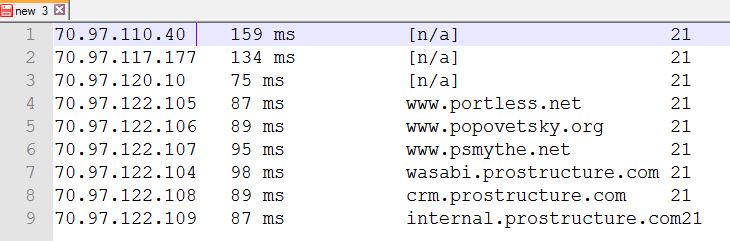
пресс Alt и перетащите курсор вправо и вниз, чтобы выбрать ненужную часть.
пресс Backspace или удалить .
вот несколько альтернативных методов для данного ответа.
если у вас данные fixed width , вы также можете использовать следующие регулярные выражения в поиске:
заменить на:
это здорово, если данные, которые вы хотите сохранить, содержат пробел, как кто-то упомянул. Кроме того, для данных фиксированной ширины можно использовать Column Mode Editing . Это аккуратный немного функция, которая позволяет редактировать несколько строк данных в одном месте столбца. См.Режим Редактирования Колонки.
он упоминает клавиши со стрелками, но вы также можете использовать Page Up/Down для более быстрого метода, а также End и Home ключи. Мышь также работает. Но вы можете использовать это для нерегламентированного метода удаления данных после определенной точки, особенно если это всего несколько строк. Это также хорошо для копирования данных, но способ его вставки немного странный, так что сначала тебе нужно привыкнуть к этому.
В Экселе это удаляется легким шаблоном найти и заменить: ",*" - удалится запятая и все после нее. Как сделать то же самое в .replace ?
Какой символ в "регулярных" выражениях заменяет * на "все что после"?
Либо как указать в том же реплейсе, чтобы удалялось несколько любых символов, например 2 после запятой и включая запятую?
Мне помог такой код .split(",")[0]
Как я понял делит строку на две части, и возвращает первый кусок до запятой т.е. [0] . Но вопрос открытый как это сделать в replace :)
Если задача состоит именно в удалении первой запятой и всего что после нее, вот это сработает:
Regexp для вашей задачи - наверняка перебор.
Скажите пожалуйста а почему перебор? Они слишком сложные для понимания новичку или грузят систему? Хотелось бы просто знать этот грааль аналог звездочки * в экселе :)
Сложные, вы, например, не смогли сходу его написать, кто-то другой может не понять. А в терминах "найти символ и отрезать все после" вы прекрасно описали задачу сами, осталась реализация. Код для работы с regexp внутри огромен и требует времени на исполнение. Ну и зачем делать сложно, если можно просто?
Спасибо работает, скажите а почему у вас после print нету скобок () - видел такое в видео уроках. У меня такое на винде и в линуксе не прокатывает. Это зависит от версии питона или каких то настроек?
к моему коду почему то не пристыковался ваш вариант. А вот с split все ок. Пример такой: money.replace("\xa0" , "").split(",")[0] - тут я еще удаляю некие пробелы в цифрах, а потом уже запятые.
Подключаем модуль для работы с регулярными выражениями:
Регулярку задаём без открывающего и закрывающего слеша, но с r перед строкой. Второй аргумент - строка (не регулярка!), которой заменить. Данная регулярка отсечёт все цифры после запятой, вместе с ней. Другие символы будут проигнорированы, однако для работы со строковыми представлениями чисел этого достаточно.
А .replace , теперь (не знаю, как раньше), не работает с регулярными выражениями, - только с простыми строками.
Подробнее про модуль re тут.
@jfs в начале вопроса очень чётко указаны исходные данные: есть число. В числе никаких других символов, кроме цифр, после запятой быть не может, иначе это уже строка.
Если имеется число в строковом представлении формата "12345.123", то чтобы отбросить цифры после запятой, достаточно int(float("12345.123")) = 12345
Воспользуйтесь floor() из модуля math.
спасибо но речь не об округлении (как я понял), а именно о приведении данных в тот вид который подойдет как для экселя так и для гугл спредшится (на сколько помню один кушает запятые а другой точки - что не может не раздражать), поэтому по привычки от запятых и точек в "деньгах" стараюсь избавлятся. Это в частном случае - а в общем интересно узнать именно спецсимвол который обозначает "всё после этого" в экселе это *, а в питоне?
@Amaroc: math.floor(f) не округляет. Эта функция возвращает наибольшее целое число меньше либо равное f (отличается от int(f) ). Это было бы возможным ответом, если бы на входе у вас были числа с плавающей точкой, а не строки.
Чтобы удалить все символы после первой запятой, включая саму запятую, из строки:
Все(!) ответы, приведённые на данный момент, кроме s.split(',', 1)[0] не справляются с этой простой задачей, например:
s[:s.find(',')] может молча вернуть неправильный ответ, если в строке нет запятых. Правильное решение должно обрабатывать случай s.find(',') == -1 , то есть когда ',' not in s :
re.sub(r',\d+', '', MyString) удаляет запятые, которыми следуют цифры, оставляя все остальные символы. Чтобы удалить все символы после запятой, используя регулярное выражение:
то есть аналогом ",*" шаблона является ',.*' регулярное выражение.
Чтобы удалить произвольную пунктуацию, можно использовать r"\p+" regex: Как найти символы из кортежа ('!',',','?') в строке и удалить их?
Если входные данные в Excel, то следует убедиться что числа с плавающей точкой экспортируются в csv, используя точку, а не запятую в качестве разделителя — это может помочь правильно округлить результат, если данные рассматриваются как числа, а не строки. Или можно использовать библиотеки, которые позволяют работать с Еxcel файлами (например: xlrd , openpyxl ) или самим Excel напрямую.

Список будет регулярно пополняться. Какие-то дополнительные ситуации разбираются в комментариях.
Роман Моренец
С 2009 года веб-дизайн - моя основная сфера деятельности. Создаю проекты разного уровня сложности, оказываю поддержку, разрабатываю индивидуальные решения, помогаю новичкам.
Быстрое разворачивание нового проекта с bitnami
Woocommerce: настраиваем многовалютность
Добрый день. помогите, как удалить не нужные строки, оставив только те где есть слово "артикул" + какое-то дополнение к этому слову. например: hjfdhdjhf hidufdda артикул 22 hdpfssf артикул 33 раjdнsd артикул 44 Спасибо))
Сергей, здравствуйте! Спасибо за ваш комментарий. А порядок строк важен? Просто, если нет, то можно с помощью плагина TextFX (для Notepad++) отсортировать выделенные строки по алфавиту, а потом просто удалить все лишние строки
Ребята, привет. Помогите с регулярными выражениями в Notepad++ Нужно в блоке P1-P2 begin text text tetxt123 ttt wd P1 s2. s3. s4. S5. S8. s3 s3 s9 s3 s6 s7 P2 adsd asdfdsfdf text121 from ae qweqwd end заменить символ s3 на ss Спасибо!
Влад, здравствуйте! Вам тут, скорее всего, не нужны регулярные выражения. Просто сделать поиск-замену
Подскажите регулярку для notepad++, надо удалить все html-теги внутри тега но оставить их содержимое Пример: 123 456
Выход: 123 456

Алексей, здравствуйте!
Извините, не разобрался как правильно оформить пример. Есть тег desc, внутри него кучв тегов и текст. Нужно удалить все теги внутри тега desc , но оставить текст. Пример: бла бла ой ой Выход: бла бла ой ой
Я так понимаю, wordpress обрезает теги в комментарии. Вот тот вариант, который я предложил, не подходит? Он убирает как раз все теги и только теги
Попытка номер три )) Есть XML документ. Среди прочих тегов, есть HTML-код, заключённый в тег DESC Пример: . тегDESC тегP 123 тегBR ещеТеги 456 тегDESC . Выход: . тегDESC 123 456 тегDESC . Нужно удалить все теги между началом и концом тега DESC, но оставить текст. Надеюсь, сейчас сумел объяснить.
Здравствуйте Подскажите регулярку. Мне нужно удалить абсолютно все, что есть внутри тегов Здесь теги, пробелы, переносы строк, буквы, цифры и фразы Что-то все перепробовал, ничего не помогает.
Помогите пожалуйста написать регулярку: . "dVFO/dVFOFoBhGYg/Cover.jpg" target=_blank".. строка продолжается (и в ней несколько таких "элементов") - притом формат картинки и её название могут быть другими. Нужно заменить только все "последние" (самые ближние к таргету - самые "правые") слэши на "/s1600/" Помогите пожалуйста.
Привет. Как соеденить три текста чтобы строчки чередовались. сначала три первые строчки потом три вторые потом три третьи и.т.д
Добрый день,может кто-то помочь с регуляркой?) есть в тексте строки вида: zpunk.dk;imap.zpunk.dk;993;true как сделать,чтобы в и тоге было: < "Domains": [ "zpunk.dk" ], "Type": "imap", "Hostname": "imap.zpunk.dk", "Port": 993, "SocketType": "SSL", "UserName": "%EMAILADDRESS%" >, за ранее благодарен)
Здравствуйте! Попробуйте это сделать через эксель. Сначала в notepad++ заменить пакетно все ";" на табуляции. После этого перенести весь текст в эксель и там добавляя колонки, вставить весь нужный дополнительный контент.
Очень нужна помощь!! Пожалуйста. Как удалить в файлах все внешние ссылки, оставив акоры (тайтлы). внимине - ВСЕ внешние ссылки КРОМЕ одной домена (собственно домена самого сайта. Т.к. внутренние ссылки тоже являются абсолютными). Заранее спасибо!!
Уточнение : ищем Число в Теге cid797\cid - меняем и увеличиваем на единицу в конце числа 797. Получаем cid7971/cid Нашли следующее cid797/cid меняем уже на cid7972/cid Далее нашли следующие значение в тегах cid797/cid меняем уже на cid7973/cid
То есть в итоге должны остаться только числа? Или текст в перемешку с измененными числами? Первый вариант возможен, нужно сначала очистить все кроме искомого числа, а дальше использовать Редактор Колонок в блокноте. Второй вариант сложнее представить.
Нашел выход из этой ситуации: Найти: (.*)\(.*\)() Заменить на: \1\2 или $1$2 Поставить галочку регулярные выражения - это тег в котором производится поиск и удаление данных в скобках (вместе со скобками)
Здравствуйте. Подскажите пожалуйста как внутри конкретного тега удалить часть текста заключенного в скобки вместе с этими скобками. Тоесть Текст 1 (Текст 2) чтобы получилось Текст 1 Я нашел выражение \(.*\) (через регулярные выражения). Оно делает то что нужно, но я не понимаю как ограничить поиск только по конкретному тегу , что бы замена не происходила в других тегах документа. Спасибо.
Нашел выход из этой ситуации: Найти: (.*)\(.*\)() Заменить на: \1\2 или $1$2 Поставить галочку регулярные выражения - это тег в котором производится поиск и удаление данных в скобках (вместе со скобками)
Добрый день, Роман. Подскажите пожалуйста, с помощью какого регулярного выражения в notepad++ можно удалить повторы слов в группе строк, пример до обработки: Окрошка классическая Окрошка классическая на кухне Окрошка домашняя в кастрюле Рецепт окрошка домашняя в казане После: Окрошка классическая на кухне домашняя в кастрюле Рецепт казане
Егор, здравствуйте! Это не совсем задача для регулярных выражений, я бы вам посоветовал обратить внимание на Эксель. Предварительно в notepad++ заменить все пробелы (то есть отступы между словами) на табы. После этого скопировать полученный текст в эксель. В итоге каждое слово поместится в отдельной ячейке. После этого выбрать команду - условное форматирование - повторяющиеся значения. И вы получите список всех дублирующих слов. Дальше точно не помню, предлагаю вам погуглить, как оставить только уникальные значения. Затем полученный список можно снова перенести в notepad++, где обратно заменить табы на пробелы.
здравствуйте , вы можете помочь в нотпаде++ можно сделать следующее, имею такой формат sonka.p@tiscali.cz,drosera13@109.123.210.15,25 как сделать, чтобы получилось 109.123.210.15,25,sonka.p@tiscali.cz,drosera13 т.е чтобы еще и одна @ удалилась
Валентин, здравствуйте! Спасибо за ваш вопрос! Не совсем понятно, что именно вы хотите сделать. Нужно порядок поменять?
Читайте также: