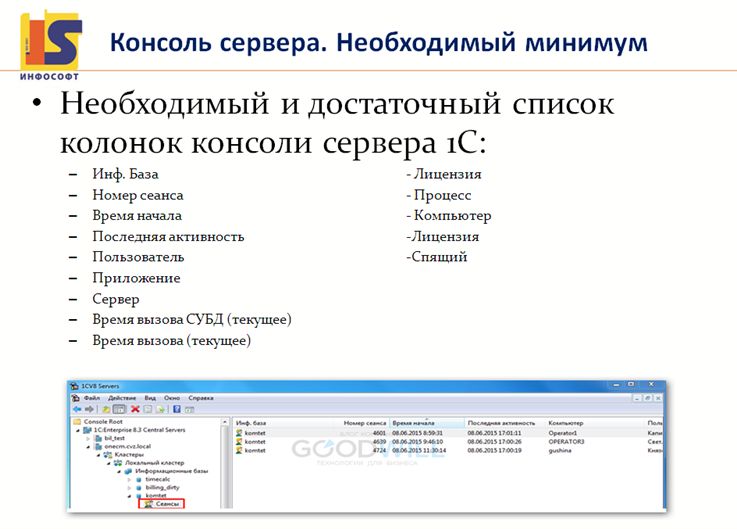
Как ускорить 1с на ms sql
Постоянно сталкивался с высказываниями ИТ специалистов «сеть нагружена на 20%… процессоры на 50%… очередей к дискам мало… Значит сеть и сервера справляются… смотрите код в 1С проблемы исключительно там».
На самом деле происходило следующее ( сервер 1С и SQL разнесены на разные компьютеры): сеть практически использовалась по максимуму(эти "20% загрузки сетевого интерфейса" = «20% полезные данные» + «80% потеря на служебной обработке»). И соответственно из-за малой ширины канала обмена «полезными» данными — SQL сервер с «Сервером 1С» постоянно ожидали друг друга, что вело к малой утилизации ресурсов CPU и дисковой системы.
Ведение: Сначала хочу заострить внимание на том что же такое 1С платформа?.
Программист в среде 1С — пишет объектную логику, а за сборку/разборку и запись объектов в «плоский вид» по таблицам базы данных отвечает сама платформа.
Основные "+" и "-" с точки зрения ORM:
"+" Программист в среде ORM получает преимущество в скорости разработки приложения из-за уменьшения количества кода и его простоты по сравнению с исключительно реляционным программным кодом (пример SQL запросы). А также освобождается от написания кода работающего непосредтсвенно с записями в таблицах Реляционной СУБД.* 1
"-" Сложности для создателей «платформ» ORM и проблемы производительности:
Использование реляционной базы данных для хранения объектно-ориентированных данных приводит к «семантическому разрыву», заставляя программистов писать программное обеспечение, которое должно уметь как обрабатывать данные в объектно-ориентированном виде, так и уметь сохранить эти данные в реляционной форме. Эта постоянная необходимость в преобразовании между двумя разными формами данных не только сильно снижает производительность, но и создает трудности для программистов, так как обе формы данных накладывают ограничения друг на друга.
*1«Уточнение». Несмотря на то, что 1С 8.х позволяет работать с реляционно-подобным кодом (только чтение) в объекте 1С «Запрос» — это все-таки не напрямую один-в-один транслируемый в реляционную СУБД запрос к таблицам хранения данных, а прежде всего «Объектный запрос» — также не минующий стадию сборки разборки объектов. Поэтому зачастую вместо много-тысяче строчных «Объектных запросов» — наиболее оптимально по быстродействию кода и скорости разработки — написать объектный не ряляционно-подобный код.
Глава 1: Расмотрим модель клиент-серверной 1С 8.х
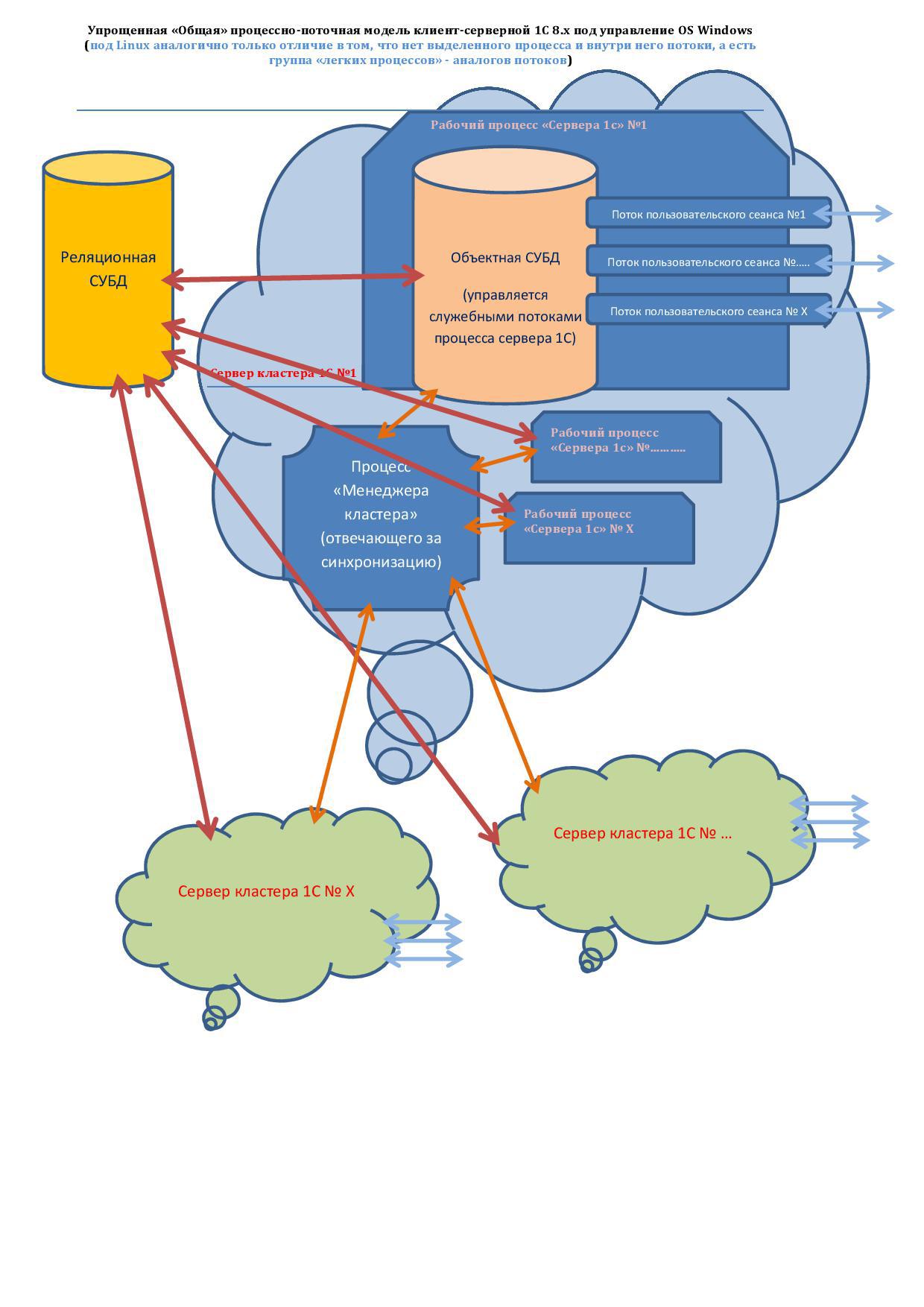
Отмечу основные «узкие» места влияющие на производительность:
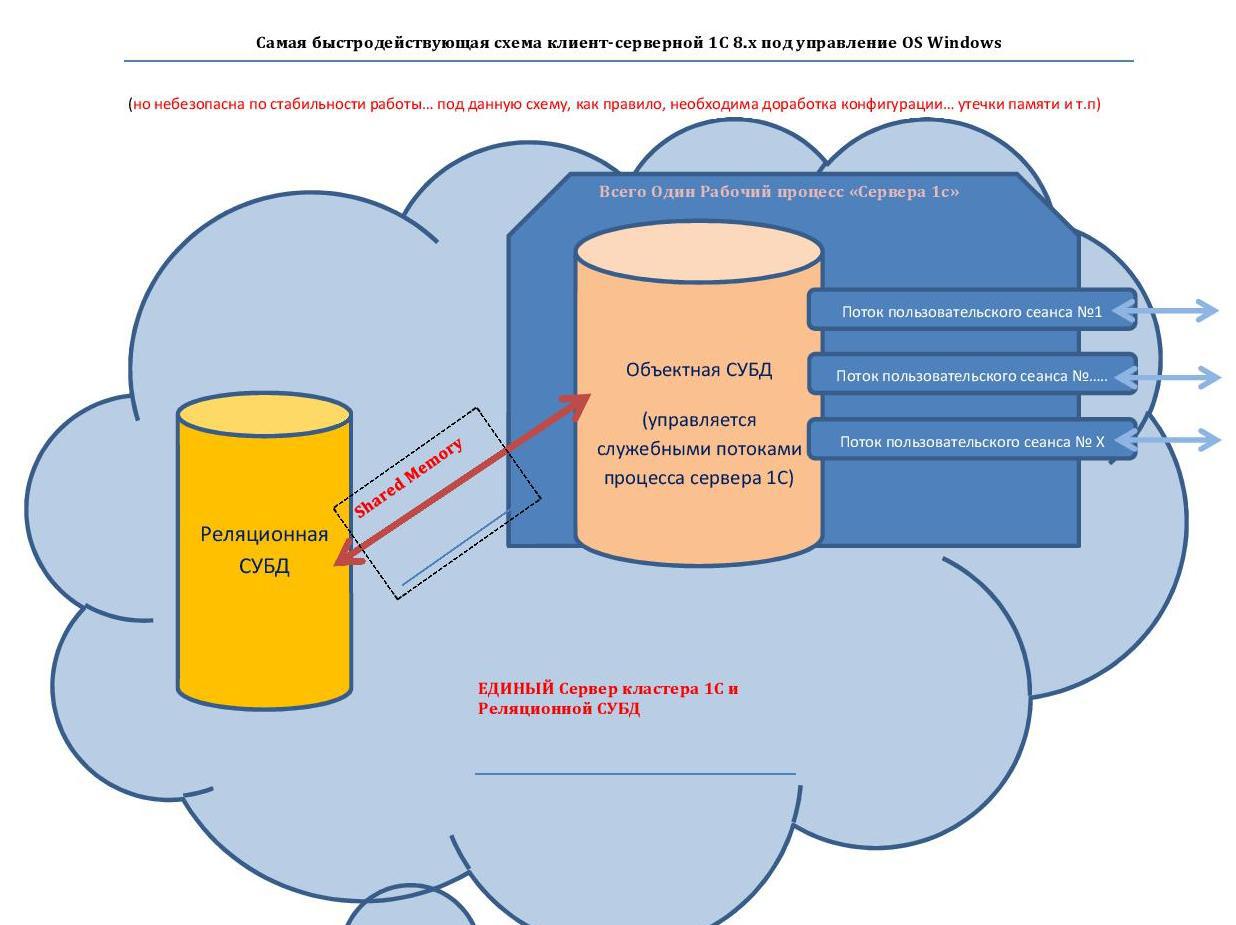
1) Первое узкое место — это коммуникационная среда передачи данных.
На рисунке стрелками показаны потоки обмена данными, где «красные» — это Реляционная СУБДОбъектная СУБ, «оранжевые» — синхронизация между Объектными СУБД.
Т.к. при использовании отдельных серверов для СУБД и кластеров 1С – коммуникационная среда это сетевые соединения – то существуют существенные задержки в передаче данных многочисленными мелкими порциями – как из-за латентности самой физической реализации интерфейсов, так и из-за латентности узлов в этой сети.
Рассмотрим на примере сетевого стандарта Ethernet Gigabit (график зависимости скорости передачи данных… ниже)
на примере работы Сервера 1С с MS SQL (по умолчанию размер коммуникационных пакетов 4 кб):
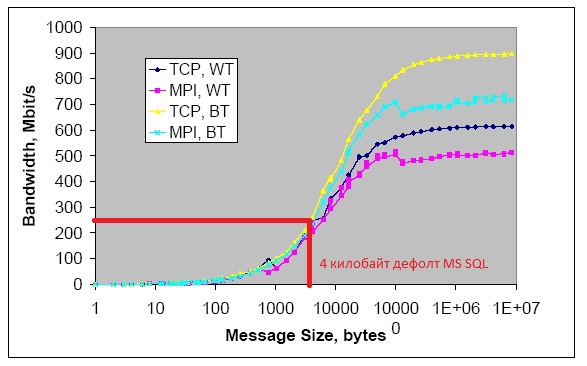
На графике видно, что при использовании пакетов ДАННЫХ =4 кб пропускная способность рассмотренной сети всего 250 Мегабит/с. (как правильно заметили в комментария к публикаци: это не пакеты протоколов например уровня TCP, а пакеты ДАННЫХ которые генерируют приложения участвующие в обмене)
…
Из практики: такое разнесение на Два отдельных сервера
MS SQL (сервер №1) < — Ethernet Gigabit --->«Сервер 1С»(сервер №1)
проигрывало по скорости работы платформы
на 50% варианту MS SQL (сервер №1) < — Shared Memory (без сети через участок памяти) --->«Сервер 1С»(сервер №1)… и это уже «на одном высоконагруженном пользовательском сеансе»
2) Узкое место — это количество отдельных компьютеров «кластеров 1С», чем их больше тем больше затраты на синхронизацию и как следствие уменьшение производительности системы.
3) Узкое место — количество отдельных процессов сервера 1с, чем их больше тем больше затрат на их синхронизацию… Но тут скорей всего необходимо найти «золотую середину» — для обеспечения стабильности. 2*
2* «Уточнение» — для MS Windows существует такое правило:
Процессы дороже чем потоки, что означает применительно к данному случаю на практике следующее: скорость обмена между двумя потоками внутри одного процесса значительно превышает, скорость обмена между потоками находящихся в разных процессах.
Поэтому например «Файловая 1С 8.х» всегда превышает по скорости однопользовательской работы платформы в клиент-серверном варианте. Все просто т.к. в случае «Файловой 1С 8.х» поток «Реляционной СУБД» общается с потоком «Объектной СУБД» внутри одного единого процесса.
4)Узкое место – одно-поточность пользовательского сеанса, т.к. каждый отдельно взятый — пользовательский сеанс не распараллеливается платформой на несколько, то его работа ограничивается использованием ресурсов одного ядра CPU => следовательно желательна максимальная скорость каждого ядра, в этом случае быстродействие платформы 1C например на 10-ядерном CPU по 1 ггц — будет значительно уступать быстродействию платформы на 4-ех ядерном CPU по 3 Ггц – естественно до определенного количества потоков.
Глава 2(Итог): Рассмотрим не масштабируемый и масштабируемый варианты — наиболее эффективных схем для платформы 1с 8.х. для OS Windows (пологаю для Linux ситуация аналогична)
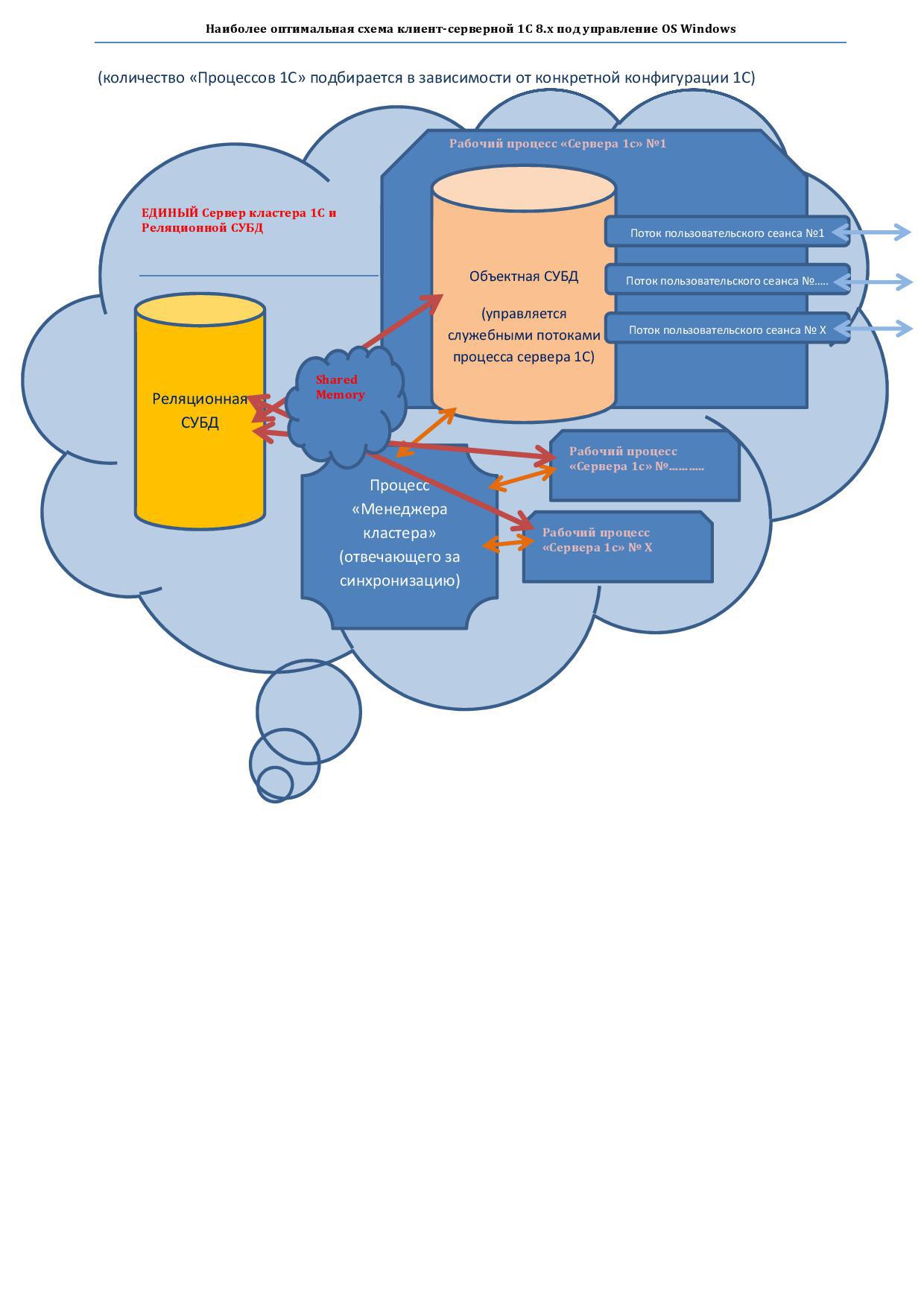
1-Вариант(не масштабируемый). В расчете на 100 «высоконагруженных пользовательских сеанса»
1) эффективен обычный 2-ух сокетный сервер с 4-ех ядерными CPU по 3 Ггц.
2) быстрая дисковая система на SSD
2-Вариант(масштабируемый). начиная со 100 «высоконагруженных пользовательских сеанса» и далее….
Тут логичней всего пойти по пути немецкой 1с-ки «Sap HANA»))
Собирать модульный «Супер-компьютер» от фирмы SGI – состоящий из «лезвий» на 2-х сокетных материнских платах, каждое лезвие соединяется друг с другом сложной топологией сверх-быстрого интерконнекта на основе NUMA-чипов, и все находится под управлением единой OS. Т.е. программы внутри такого сервера по определению имеют доступ к ресурсам любого «лезвия».
1) добавляем «лезвия» по необходимой нагрузке… из расчета примерно одно «лезвие» на 100 пользователей.
Определение имен таблиц MSSQL
Структура базы данных 1С весьма запутана и состоит из малозначимых для человека названий. 1С содержит функцию определения структуры хранения по имени объекта. В основу разработки положена эта функция ПолучитьСтруктуруХраненияБазыДанных, которая согласно русскому названию возвращает описание структуры. В этой структуре важны 2 поля Назначение, которое должно быть равно «Основная», и название таблицы ИмяТаблицыХранения.
Определение смещения дат
Таблица _YearOffset содержит число, обозначающее смещение года дат. Оно принимает значение 0 или 2000. Так со смещением 2000 дата 01.01.2014 будет храниться в базе данных как 01.01.4014. Соответственно при отборе по датам (удаление происходит за период времени) нужно учитывать смещение. Смещение можно получить следующим кодом 1С:
Установка пометки на удаление документов
Имея названия таблиц документов и зная, что поля _Date_Time, _Marked и _Posted отвечают за дату, отметку об удалении и отметку о проведении соответственно, можно одним SQL-запросом пометить их все на удаление. Делается это так:
Установка пометки на удаление в журналах документов
Не смотря на установку отметки на удаление у документов, в журналах документов хранятся дубли отметок об удалении на каждый документ. Список журналов, где участвует документ можно получить из метаданных документа так: Метаданные.ЖурналыДокументов
Отметка на удаление через поля _Marked и _Posted происходит аналогично через команду:
Удаление движений регистров
При удалении документов 1С удаляет движения документа по регистрам. В случае прямого доступа эти движения нужно удалить самостоятельно. Список регистров можно получить через метаданные ДокументМетаданные.Движения.
Команда, которой выполняется удаление движений следующая:
Заключение
Как оказалось, добиться убыстрения работы 1С примерно на 2 порядка не так сложно, достаточно выполнить 3 вида команд. В конечной обработке логика расширена за счет выбора документов по видам, добавлением таймаута, добавлением транзакции, пакетным выполнением команд.
PS. Список возникающих проблем и пути устранения:
1. Обработка игнорирует документы, где запрещено проведение, например, корректировка записей регистров. В корректировке записей регистров удаление документа связано со снятием активности записей регистров.
2. Результат удаления не отражается в планах обмена. Решается одновременным запуском обработки в связанных базах.
3. Не затрагивает таблицы итогов. Решается пересчетом итогов через Конфигуратор-Тестирование и Исправление-Пересчет итогов.
При размещении 1С в облачной инфраструктуре и среде виртуализации наиболее важными и непростыми задачами являются повышение скорости работы платформы «1С» и настройка СУБД. Для достижения максимальной производительности инфраструктуры 1С рекомендуется правильно выбирать архитектуру инфраструктуры, режимы работы, проверить и выполнить ряд важных настроек.
В зависимости от количества пользователей, размера баз данных и ограничений бюджета (с учетом стоимости дополнительных лицензий на сервер «1С:Предприятие 8» и лицензий на СУБД) платформа «1С» может работать в файловом и клиент-серверном вариантах (на основе трехуровневой архитектуры «клиент-сервер» (рис. 1): клиентское приложение, кластер серверов «1С:Предприятия 8», СУБД).

Рис. 1
Как правильно выбрать вариант/режим работы 1С: файловый или SQL?
Обычно для 1-10 пользователей выбирается файловый режим
От 10 и более пользователей выбирается режим работы с использованием SQL
В файловом варианте все пользователи могут работать на одной виртуальной машине в облаке, например на терминальном сервере.
Для клиент-серверного варианта лучше выбрать не менее двух виртуальных машин:
Сервер с клиентским приложением, например терминальный сервер с клиентской частью «1С» (толстый клиент)
Сервер «1С» и СУБД (MS SQL или PostgreSQL)
Как рассчитать мощности сервера для 1С в файловом режиме работы?
В обоих вариантах: файловом и SQL, для работы с пользовательским приложением 1С в классическом режиме, например, «удаленного рабочего стола» (так называемый «толстый клиент»), необходимы следующие минимальные ресурсы виртуального сервера:
Количество виртуальных ядер CPU = 1 или 2 для ОС + 0,25 * количество пользователей
Объем памяти RAM = 1 или 2 ГБ для ОС + 0,5 ГБ * количество пользователей
Размер диска/хранилища HDD = 20-40 ГБ для ОС и приложений + (0,1-10) ГБ * количество пользователей. Для ОС и 1С рекомендуется использовать самые быстрые диски
Как рассчитать мощности сервера для 1С в варианте работы с SQL?
В клиент-серверном варианте работы 1С, в котором используется СУБД SQL, рекомендуется разместить 1С Сервер и сервер SQL на отдельном виртуальном сервере в общей с клиентским сервером локальной подсети. Необходимы следующие минимальные мощности для этого виртуального сервера:
Размер диска/хранилища HDD = 20-40 ГБ для ОС и приложений + (10-1000) ГБ в зависимости от объема и количества баз данных. Для ОС и СУБД рекомендуется использовать самые быстрые диски
------------
ОС - операционная система, например, Windows Server
Здесь Сервер 1С - ПО "сервер "1С:Предприятия 8"
Наиболее важными и непростыми задачами являются повышение продуктивности использования платформы «1С» в облаке и настройка СУБД. Типичные проблемы при развертывании и эксплуатации облачной инфраструктуры для «1С» следующие:
Неправильный выбор мощностей
Неквалифицированная настройка сервисов виртуальной инфраструктуры
Недостаточное внимание к тестированию производительности платформы «1С»
Для достижения максимальной производительности рекомендуется проверить и выполнить ряд настроек. Прежде всего необходимо исключить свопинг, для чего с помощью системы мониторинга следует обязательно удостовериться в том, что объем оперативной памяти достаточен для работы ВМ. Кроме того, файл подкачки ОС, профили пользователей, файлы баз данных, файлы логов транзакций (SQL) и tempDB (SQL) лучше разместить на дополнительных SSD-дисках, а для файла подкачки установить фиксированный размер.
На SQL-сервере необходимо выключить все ненужные службы, например FullText Search и Integration Services, установить максимально возможный объем оперативной памяти, максимальное количество потоков (Maximum Worker Threads) и повышенный приоритет сервера (Boost Priority), задать ежедневную дефрагментацию индексов и обновление статистики, настроить автоматическое увеличение файла базы данных (не менее 200 Мбайт) и файла лога (не менее 50 Мбайт), а также полную реиндексацию не реже одного раза в неделю. При размещении серверов SQL и «1С:Предприятие» на одной ВМ следует включить протокол Shared Memory.
Следуя перечисленным выше рекомендациям, можно добиться увеличения быстродействия платформы «1С» в облаке в 1,5–2 раза.
Квалифицированное размещение ИТ-сервисов, в том числе «1С», на облачной платформе позволяет:
Существенно сократить расходы
Повысить уровни безопасности (доступ к данным, резервное копирование, антивирусная защита и др.) и технического обслуживания
Обеспечить централизованное администрирование и мониторинг
Организовать эффективную и безопасную удаленную работу
Воспользоваться гибкими возможностями масштабирования, лицензирования и оперативного перехода на необходимые версии конфигураций «1С»
ЧЕК-ЛИСТ ПО ОПТИМИЗАЦИИ ИНФРАСТРУКТУРЫ 1С С MS SQL
1. Включить возможность мгновенной инициализации файлов (Database instant file initialization)
Это позволяет ускорить работу таких операций как:
Создание базы данных
Добавление файлов, журналов или данных в существующую базу данных
Увеличение размера существующего файла (включая операции автоувеличения)
Восстановление базы данных или файловой группы
Для включения настройки:
На компьютере, где будет создан файл резервной копии, откройте приложение Local Security Policy (secpol.msc)
Разверните на левой панели узел Локальные политики, а затем кликните пункт Назначение прав пользователей
На правой панели дважды кликните Выполнение задач по обслуживанию томов
2. Включить параметр «Блокировка страниц в памяти» (Lock pages in memory)
Эта настройка определяет, какие учетные записи могут сохранять данные в оперативной памяти, чтобы система не отправляла страницы данных в виртуальную память на диске, что может повысить производительность.
Для включения настройки:
В меню Пуск выберите команду Выполнить. В поле Открыть введите gpedit.msc
В консоли Редактор локальных групповых политик разверните узел Конфигурация компьютера, затем узел Конфигурация Windows
Разверните узлы Настройки безопасности и Локальные политики
Выберите папку Назначение прав пользователя
Политики будут показаны на панели подробностей
На этой панели дважды кликните параметр Блокировка страниц в памяти
В диалоговом окне Параметр локальной безопасности — блокировка страниц в памяти выберите «Добавить» пользователя или группу
В диалоговом окне Выбор: пользователи, учетные записи служб или группы добавьте ту учетную запись, под которой у вас запускается служба MS SQL Server
Чтобы изменения вступили в силу, перезагрузите сервер или зайдите под тем пользователем, под которым у вас запускается MS SQL Server
3. Включить каталоги с файлами базы данных в правила исключения для антивируса.
Если антивирус будет сканировать файлы базы, это может сильно замедлить работу СУБД.
Для опытных администраторов: антивирус на сервер СУБД лучше не устанавливать.
4. Включить каталоги с файлами базы данных в список исключений для системы автоматического копирования.
Если на сервере установлена система автоматического копирования файлов, то, когда она будет копировать файлы базы, это может привести к замедлению работы. Копии базы необходимо делать средствами самой СУБД.
5. Отключить механизм DFSS для дисков.
Механизм Dynamic Fair Share Scheduling отвечает за балансировку и распределение аппаратных ресурсов между пользователями. Иногда его работа может негативно сказываться на производительности 1С.
Чтобы отключить его только для дисков, нужно:
Найти в реестре ветку HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\TSFairShare\Disk
Установить значение параметра EnableFairShare в 0
6. Отключить сжатие данных для каталогов, в которых лежат файлы базы.
При включенном сжатии ОС будет пытаться дополнительно обрабатывать файлы при модификации, что замедлит сам процесс записи, но сэкономит место.
Чтобы отключить сжатие файлов в каталоге, необходимо:
Открыть свойства каталога
На закладке Общие нажать кнопку Другие
Снять флаг «Сжимать» содержимое для экономии места на диске
7. Установить параметр «Максимальная степень параллелизма» (Max degree of parallelism) в значение 1.
Данный параметр определяет, во сколько потоков может выполняться один запрос. По умолчанию параметр равен 0, это означает, что сервер сам подбирает число потоков. Для баз с характерной для 1С нагрузкой рекомендуется поставить данный параметр в значение 1, т.к. в большинстве случаев это положительно скажется на работе запросов.
Для настройки параметра необходимо:
Запустить Management Studio и подключиться к нужному серверу
Открыть свойства сервера и выбрать закладку Дополнительно
Установить значение параметра равное единице
8. Ограничить максимальный объем памяти сервера MS SQL Server.
Необходимо ограничить максимальный объем памяти, потребляемый MS SQL Server, особенно это критично, если роли сервера 1С и сервера СУБД совмещены. Максимальный объем памяти, рекомендуемый для MS SQL Server, можно рассчитать по следующей формуле:
Память для MS SQL Server = Память всего – Память для ОС – Память для сервера 1С
Например, на сервере установлено 64 ГБ оперативной памяти, необходимо понять, сколько памяти выделить серверу СУБД, чтобы хватило серверу 1С.
Для нормальной работы ОС в большинстве случаев более чем достаточно 4 ГБ, обычно – 2-3 ГБ.
Чтобы определить, сколько памяти требуется серверу 1С, необходимо посмотреть, сколько памяти занимают процессы кластера серверов в разгар рабочего дня. Этими процессами являются ragent, rmngr и rphost, подробно данные процессы рассматриваются в разделе, который посвящен кластеру серверов. Снимать данные нужно именно в период пиковой рабочей активности, когда в базе работает максимальное количество пользователей. Получив эти данные, необходимо прибавить к ним 1 ГБ – на случай запуска в 1С «тяжелых» операций.
Чтобы установить максимальный объем памяти, используемый MS SQL Server, необходимо:
Запустить Management Studio и подключиться к нужному серверу
Открыть свойства сервера и выбрать закладку Память
Указать значение параметра Максимальный размер памяти сервера
9. Включить флаг «Поддерживать» приоритет SQL Server (Boost SQL Server priority).
Данный флаг позволяет повысить приоритет процесса MS SQL Server над другими процессами.
Имеет смысл включать флаг только в том случае, если на компьютере с сервером СУБД не установлен сервер 1С.
Для установки флага необходимо:
Запустить Management Studio и подключиться к нужному серверу
Открыть свойства сервера и выбрать закладку Процессоры
Включить флаг «Поддерживать приоритет SQL Server (Boost SQL Server priority)» и нажать Ок
10. Установить размер авто увеличения файлов базы данных.
Автоувеличение позволяет указать величину, на которую будет увеличен размер файла базы данных, когда он будет заполнен. Если поставить слишком маленький размер авторасширения, тогда файл будет слишком часто расширяться, на что будет уходить время. Рекомендуется установить значение от 512 МБ до 5 ГБ.
Для установки размера авторасширения необходимо:
Запустить Management Studio и подключиться к нужному серверу
Открыть свойства нужной базы и выбрать закладку Файлы
Напротив каждого файла в колонке Автоувеличение поставить необходимое значение
Данная настройка будет действовать только для выбранной базы. Если вы хотите, чтобы такая настройка действовала для всех баз, нужно выполнить эти же действия для служебной базы model. После этого все вновь созданные базы будет иметь те же настройки, что и база model.
11. Разнести файлы данных mdf и файлы логов ldf на разные физические диски.
В этом случае работа с файлами может идти не последовательно, а практически параллельно, что повышает скорость работы дисковых операций. Лучше всего для этих целей подходят диски SSD.
Для переноса файлов необходимо:
Запустить Management Studio и подключиться к нужному серверу
Открыть свойства нужной базы и выбрать закладку Файлы
Запомнить имена и расположение файлов
Отсоединить базу, выбрав через контекстное меню Задачи – Отсоединить
Поставить флаг Удалить соединения и нажать Ок
Открыть Проводник и переместить файл данных и файл журнала на нужные носители
В Management Studio открыть контекстное меню сервера и выбрать пункт Присоединить базу
Нажать кнопку Добавить и указать файл mdf с нового диска
В нижнем окне сведения о базе данных в строке с файлом лога нужно указать новый путь к файлу журнала транзакций и нажать Ок
12. Вынести файлы базы TempDB на отдельный диск.
Служебная база данных TempDB используется всеми базами сервера для хранения, промежуточных расчетов, временных таблиц, версий строк при использовании RCSI и многих других вещей. Обычно обращений к этой базе очень много, и если она будет лежать на медленных дисках, это может замедлить работу системы.
Рекомендуется хранить базу TempDB на отдельном диске для повышения производительности работы системы.
Для переноса базы TempDB на отдельный диск необходимо:
Запустить Management Studio и подключиться к нужному серверу
Создать окно запроса и выполнить скрипт:
ALTER DATABASE tempdb
MODIFY FILE (NAME = tempdev, FILENAME = 'Новый_Диск:\Новый_Каталог\tempdb.mdf')
ALTER DATABASE tempdb
MODIFY FILE (NAME = templog, FILENAME = 'Новый_Диск:\Новый_Каталог\templog.ldf')
Перезапустить MS SQL Server
13. Включить Shared Memory, если сервер 1С расположен на том же компьютере, что и сервер СУБД.
Протокол Shared Memory позволит общаться приложениям через оперативную память, а не через протокол TCP/IP.
Для включения Shared Memory необходимо:
Запустить диспетчер конфигурации SQL Server
Зайти в пункт SQL Native Client – Клиентские протоколы – Общая память – Включено
Поставить значение Да и нажать Ок
Протокол Именованные каналы нужно выключить аналогичным образом
14. Перезапустить службу MS SQL Server
Внимание! Когда все настройки выполнены, необходимо перезапустить службу MS SQL Server
В статье речь пойдет про взаимодействие сервера 1С с MS SQL. Мы очень часто слышим, как важно оптимизировать все критические участки системы заблаговременно, в плановом режиме, как надо, «от и до» во всех деталях. Но в реальной жизни бывает по-другому. Очень часто клиенты обращаются к нам, когда система уже не дает работать: «спасите, помогите, болит очень сильно, надо решать». Об одном из таких случаев я и хотел бы вам сегодня рассказать.
Рассматриваемая ситуация

Подробнее о ситуации:
- Заказчик занимается микрофинансовой деятельностью – у них большая сеть.
- Очень много пользователей, работающих в online (в пике доходит до 1000 человек). Нагрузка на базу достаточно серьезная.
- По факту база должна работать стабильно практически 24/7. Регламентное время есть (не 24 часа полной работы базы), но оно очень маленькое, в пределах 4 часов, и желательно не каждый день. За это время нужно успеть произвести с базой все регламентные операции.
- Но, по сути, у заказчика все успешно работало.

И к нам они обратились в таком формате: «У нас все было отлично, но вдруг начали возникать проблемы, причем значительные».

Начали разбираться. С чем столкнулись?
- В их оперативной базе использовался регистр накопления, где было более миллиарда записей – это был такой «собирательный образ», с которым работало очень много пользователей. Возвращаясь к докладу Андрея Бурмистрова, хочу сказать, что в этом регистре было включено разделение итогов, и когда мы в нем измеряли количество записей итогов, их было 1.2 миллиарда. Это вообще «жесть». Но проблема была скорее не в количестве записей этого регистра, сколько в том, что большая часть запросов выполнялась именно к нему.
- Работали с этим регистром, по факту, тригруппы пользователей:
- Первая группа пользователей – это, так скажем, группа пострадавших, их работа заключалась в заведении договоров на эти микрофинансовые займы. Сами они создавали минимальную нагрузку на систему, но когда из базы формировались какие-то сложные выгрузки, они ничего не могли делать, у них работа просто вставала.
- Вторая группа пользователей – это аналитики, основные зачинщики проблем. Они создавали на базу достаточно большую нагрузку, потому что делали оперативные отчеты, которые формировались по 3-5 минут. В течение этого времени с базой вообще никто не мог работать, а аналитикам эти отчеты были нужны достаточно часто.
- Третья группа пользователей – это группа коллекторов. Они делали еще более дикие выборки, общее время формирования которых доходило до получаса. Но им оперативные данные были не нужны, и в этом была принципиальная разница между второй и третьей группой, поэтому мы с ними работали очень по-разному.
![]()
Как поступает сервер 1С в случае, когда регламент MS SQL не успевает сделаться в нужное время? Как вообще работает сервер, когда у вас столько записей в будущем? Например, если вы захотите взять данные на сегодня (сегодня у нас 26 октября), а у вас последние ежемесячные итоги рассчитаны на конец сентября, тогда сервер будет всегда пытаться брать текущие итоги. Но если в обычной деятельности текущие итоги – это конец октября (что-то близкое к текущей дате), то в их случае это было сильно далеко впереди. К тому же текущие итоги, по сути, всегда берутся на конец эпохи, на 3099 год. И в данном случае, если бы даже у нас ежемесячные итоги бы рассчитаны на конец сентября, сервер все равно бы лез максимально вперед в будущее, где находятся самые последние записи. И потом такой вот лавиной цунами выкручивал бы оттуда дикие обороты полностью всего до текущей даты. Это собственно и происходило. Но даже если бы у них не было записей в будущем, то из-за того, что ежемесячные итоги у них были два с половиной года назад, а работали они чаще всего с текущими датами, они бы все равно никакого профита не получили – не смогли бы просто. А тут еще и такая ситуация наложилась.
Принятые решения по оптимизации
![]()
Конечно, ситуация печальная, но что с ней делать-то?
Закономерным решением было:
- Рассчитать ежемесячные итоги. Конечно, их нужно рассчитать не все сразу, а последовательно, потому что этот процесс занимает много времени, а регламентное окно узкое.
- И, конечно же, надо было полностью снести текущие итоги – прямо снести и отключить. Почему? Причины две. Помимо того, что они там создают паразитическую нагрузку, они же еще и постоянно плодятся – пока они включены на регистре, эти паразитические записи будут постоянно появляться. А если еще и сервер 1С будет брать всегда именно их, то от них очевидно, надо избавляться.
- Ну и все-таки надо обновить статистику.
![]()
Но все это не просто. Я бы даже сказал, что это очень непросто, потому что если использовать стандартный подход, который исповедует 1С, то у нас бы все это заняло около 13 часов. Что бы при этом происходило?
- При стандартном отключении текущих итогов на регистре из него последовательно начали бы удаляться записи. Построчно. А вы представляете, сколько там записей – там 1.2 миллиарда. Даже на мегамощностях заказчика на это ушло бы 13 часов. Мы предложили заказчику: «давайте отключим это по всем канонам 1С». Они говорят: «нет, нам такой вариант не подходит, давайте что-то думать дальше».
- И кстати, про интерфейсные настройки MS SQL – в сервереMSSQL нет никакой такой интерфейсной настройки, которая бы позволяла обновлять какие-то таблицы выборочно. А полное обновление статистики происходит целиком по всему и занимает достаточно большое время. Соответственно, просто запуск регламента еще не означает, что он будет успевать проходить.
![]()
В результате, мы приняли решение просто снести таблицу итогов и напрямую сделали truncate table из MS SQL. Сразу оговорюсь, что трюк был выполнен профессиональными каскадерами, в домашних условиях не повторять. Тем более что 1С не просто так запрещает прямые запросы к базам данных. Почему? Потому что текущие итоги и обычные ежемесячные итоги – это одна и та же таблица. И когда мы ее снесли, снеслись также и ежемесячные итоги. А 1С помнит, что там были итоги, рассчитанные два с половиной года назад. И она пытается к ним обратиться, а база ей отвечает: «какие итоги? тут ничего нет». И все, коллапс. Такие случаи надо предусматривать.
Естественно, я не рекомендую прямые запросы к базе, но у нас была вынужденная ситуация. Наверное, к этой возможности можно иногда прибегать, если продумать все возможные последствия. Потому что в таких ситуациях целостность данных оказывается под очень большим вопросом.
![]()
И следующим шагом мы обновили статистику. Для этого мы использовали скрипт, текст которого приведен на слайде. Конечно, это не наше открытие, в интернете есть различные варианты этой настройки. Мы, по сути, просто взяли в основу то, что нашли, и доработали под свои нужды, чтобы обновлять статистику только по тем объектам, которые были изменены. В результате регламент стал проходить достаточно быстро – за считанные минуты. Кому надо – пользуйтесь. В интернете есть разного рода альтернативы.
После этого нагрузка на базу в целом резко уменьшилась, и если изначально запросы выполнялись по 3.5-5 минут, они стали отрабатывать гораздо быстрее, чаще всего секунд за 15.
«Подводные камни»
![]()
Но все равно остались и аномальные случаи, когда база на небольших запросах «подвисала» очень долго.
Начали разбираться, и выяснилось, что нагрузка увеличивалась за счет того, что в системе неконтролируемо использовались внешние обработки и отчеты, у которых были разные версии, потому что заказчик их постоянно допиливал, менял. А когда у тебя онлайн в базе работает почти тысяча пользователей, контролировать запуск различных версий внешних обработок очень сложно. И если этот вопрос не решить сразу жестко, будут продолжать использовать «кто в лес, кто по дрова». В результате мы решили использовать те же самые отчеты и обработки, но прикрепленные к системе. И если они дорабатываются, то просто выпускается новая версия и сразу прикрепляется. Потому что использовать внешние обработки, свободно распространяемые по почте или как-то еще – это плохой вариант, он может приводить к большим печалям на больших нагрузках.
![]()
Казалось бы, наконец, все заработало: запросы начали выполняться быстро, оперативная работа пошла, и заказчик вздохнул с облегчением.
![]()
Но не тут-то было. Приходит начало месяца и у заказчика опять все «ложится». Там была печаль печальная.
![]()
Обычно при обращении к оперативным объектам в базе – открываешь, одна секунда, и ты уже все получил. А тут они начали открываться по 16, по 25, а некоторые еще и больше секунд. Откуда такая аномалия – непонятно. Заказчик говорит: «Вы нам сказали рассчитывать итоги и обновлять статистику – мы все делаем. Вот вам план запроса, только решите проблему, потому что у нас начался сезон, и мы однозначно не можем тратить на это время. У вас есть полчаса, час, давайте, что-то решайте».
Мы посмотрели план запроса – он вообще какой-то дикий, аномалия налицо. Вроде бы и статистика обновлена по регламенту, и итоги рассчитаны – все должно быть нормально. В результате обсуждения решили посмотреть, когда, в каком часу была обновлена статистика – и увидели, что она была обновлена ночью, а итоги рассчитаны уже утром, что и порождало такую аномалию. После этого мы уже известным вам скриптом вновь обновили статистику, и все начало «летать».
Но возник закономерный и интересный вопрос – а как так получилось? Откуда в базу закралась такая барабашка? Почему так себя ведет планировщик? Что такое вообще обновление статистики для планировщика?
![]()
Вообще планировщик – это конечно огромный черный ящик и сервер 1С с ним никак не взаимодействует. Планировщику вообще не интересно все внешнее воздействие – его не волнует, как вы написали запрос или какие вы отборы там поставили. На то, как он формирует план запроса, вы вообще никак повлиять не сможете. По факту, обновление статистики и создание индексов на таблицах – это единственное, или почти единственное, что может повлиять на поведение планировщика.
Как планировщик работает?
- Пока вы статистику не обновили, он видит, что есть итоги на конец сентября, и у него указано, какой там индекс, он знает, что раз таблица огромная, искать надо в индексе. Он находит какую-то запись, выбирает из нее все связанные подзапросы, получает данные, и никаких проблем нет.
- А тут происходит расчет итогов, который добавляет в таблицу сколько-то записей, о которых планировщик и понятия не имеет. И он начинает просто как слепой шариться по этой таблице, и искать, а где там нужные ему записи?
- А когда ты статистику обновляешь, планировщик прозрел, увидел, что все понятно, вот он, индекс, можно делать поиск по индексу и сканировать всю таблицу ему уже не надо. Он нашел нужную запись и ее отдал.
Когда таблица 10 тысяч записей – это может быть не критично. А когда в таблице сотни миллионов записей и итогов за один месяц там очень много, тогда это становится колоссально критично. Поэтому очень важно понять эту логику, как планировщик все это подтягивает. Ну и собственно, сервер 1С так же работает, потому что он тоже не особо напрягается, думая, как MS SQL сервер будет формировать эти выборки.
Инструменты для изучения проблем производительности
![]()
Теперь важно обратиться к тем инструментам, которыми мы пользовались для этого случая, и вообще для всех случаев пользуемся.
Вроде все знают, что существует корпоративный инструментальный пакет, но в реальной жизни, чтобы ты пришел к заказчику и сказал – вот он, КИТ, все настроено, все классно, открывай, анализируй, все тебе дано – так в реальности не бывает вообще. И даже настроенный профайлер – это уже чудо. Поэтому анализ начинается, конечно же, совсем по-другому.
Например, консоль сервера. Этим инструментом очень часто пренебрегают, а ведь по факту он дает ответ на многие вопросы. В нем можно посмотреть какой сеанс, какую нагрузку создает, где какие аномалии. Где у тебя длительный запрос к базе данных, а где у тебя уже длительный ответ от сервера 1С, где математика, а где диски – и дальше уже в эту сторону анализировать. Более того, в консоли сервера можно «отрубить» сеанс, который создает аномальную нагрузку, сохранив тем самым работоспособность базы. Убили сеанс, сохранили работоспособность, а потом занимаемся анализом, потому что бывает, что базу нельзя просто так рестартовать.
И здесь важно еще вот о чем сказать. Убивать сеансы – это замечательная возможность, но если вы этим сеансом проводили какой-то длительный регламент типа расчета себестоимости выпуска, восстановления последовательности партионного учета или что-то еще в этом духе, то вам придется все начинать заново, потому что никакой результат не сохранится – это очень важно иметь в виду. Потому что вся операция расчета себестоимости может длиться 8.5 часов, а если она длилась 8 ч, и вы решили ее прервать, чтобы дать работать пользователям, то вам придется все начинать заново. А надо было всего-то подождать полчаса и все.
![]()
Следующий очень важный инструмент – технологический журнал 1С. Он вроде бы тривиальный, но, тем не менее, помогает решать огромное количество вопросов. Здесь на экране показана настройка – тут максимум 15 строчек кода. С помощью этой настройки вы можете вывести все события выполнения запроса, которые длились более 10 секунд, тем самым, сразу отсечь все то, что неинтересно, и проанализировать только длительные запросы. И дальше уже, если будет нужно, погрузиться в их какой-то более детальный анализ.
И еще один инструмент – это SQL Management Studio, тоже очень интересная вещь, особенно в контрасте того, что профайлер MS SQL надо настраивать, на это требуется время, а его иногда нет. А Management Studio – это достаточно простой инструмент, и более того, он включен в любую версию MS SQL (и в SQL Express в том числе – он там в комплекте не идет, но его можно установить, лицензия это позволяет делать). Пользоваться им достаточно удобно и легко.
Ну и конечно, если время позволяет, настраиваем профайлер MS SQL, чтобы он нам выдавал то, что мы хотим видеть, потому что многие ответы находятся только там. Тем более что в отличие от технологического журнала 1С, он позволяет увидеть все запросы – это, наверное, чуть ли не главное преимущество MS SQL. У технологического журнала 1С есть ограничение, что он позволяет увидеть только те запросы, которые были успешно выполнены – это одно из серьезных ограничений при анализе подобных аномалий для СУБД PostgreSQL. А профайлер MS SQL позволяет увидеть все запросы. Можно запустить запрос, тут же его отключить, получить полный план запроса и анализировать его дальше, что там вообще происходит. Это очень большое преимущество и важно правильно этим пользоваться.
Заключение
Весь наш опыт подсказывает, что все гениальное – просто, и что чудеса очень часто решаются достаточно простыми и тривиальными способами.
Еще раз подытожим наши выводы
- Важно то, что не все итоги одинаково полезны. В данном случае, очевидно, что текущие итоги – это явный паразит в базе, с которым жить и мириться никак нельзя, его надо беспощадно сносить, отключать и т.д.
- А ежемесячные итоги как раз наоборот – крайне полезная вещь, без которой жить бывает очень сложно. Если у вас в регистрах накопления очень много записей без итогов – это печаль и боль.
- Что еще очень важно – это последовательность расчета итогов и обновления статистики. Потому что у заказчика даже мысли не промелькнуло по поводу того, что в последовательности его действий что-то может быть не так. Потому что, казалось бы – база в 2 терабайта, ну записали мы итогов на месяц, ну и что, почему это так должно сказаться на производительности? А вот может так сказываться. Последовательность действий здесь имеет крайне большое значение. И если вы используете какое-то решение «из коробки», где все по порядку настроено, то все будет работать хорошо. А если вы просто будете кусочно использовать разного рода инструменты в хаотичном порядке, то можете не достигнуть позитивного эффекта.
Лично от себя хочу добавить, что, несмотря на то, что мы достаточно давно уже занимаемся оптимизацией (в сумме, наверное, больше двух лет), меня искренне удивляет тот факт, что при решении большинства проблем помогает просто расчет итогов и обновление статистики. Прямо серьезно. Мало кто этим озадачивается – либо просто забывают, либо что-то еще. Поэтому не забывайте, обращайте внимание, это крайне важно.
Пользуйтесь инструментами, будьте молодцами!
Данная статья написана по итогам доклада, прочитанного на конференции INFOSTART EVENT 2016 DEVELOPER. Больше статей можно прочитать здесь.
В 2020 году приглашаем всех принять участие в 7 региональных митапах, а также юбилейной INFOSTART EVENT 2020 в Москве.
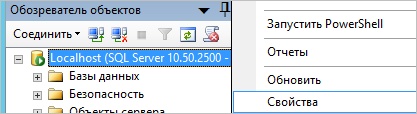
Запускаем SQL Server Management Studio и вводим данные для подключения к серверу баз данных.
Кликаем правой кнопкой мыши по серверу и выбираем Свойства:
![Открываем свойства сервера MS SQL]()
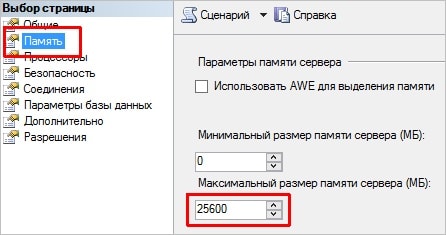
В открывшемся окне переходим на вкладку «Память» и ограничиваем потребление оперативной памяти в графе «Максимальный размер памяти сервера (МБ)»:
![Ограничиваем потребление оперативной памяти сервером MS SQL]()
* максимальный размер рассчитывается так: вся оперативная память сервера минус 4096 Мб (на нужды системы) минус 1536 * количество процессов rphost. Например, если в сервере установлено 32 Гб оперативной памяти и присутствует 2 процесса rphost, расчет будет таким: 32768 - 4096 - (2 * 1536) = 25600.
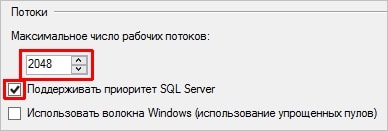
Теперь переходим на вкладку «Процессоры» и выставляем «Максимальное число рабочих потоков» в значение 2048 и ставим галочку Поддерживать приоритет SQL Server:
![Выставляем количество потоков в работе MS SQL]()
Настройки базы данных
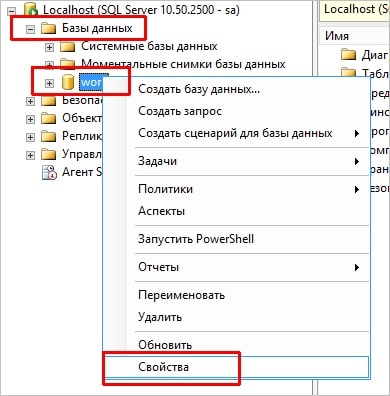
В SQL Server Management Studio раскрываем «Базы данных», кликаем правой кнопкой мыши по рабочей базе и нажимаем Свойства :
![Открываем свойства базы данных 1С]()
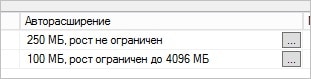
Теперь переходим на вкладку «Файлы» и в настройках Авторасширения настраиваем расширение файла базы до 250 Мб и лога до 100. Также не лишним будет ограничить размер лога до 4096 Мб:
![Настраиваем авторасширение файла БД]()
Нажимаем OK и закрываем Management Studio
Результат
Для проверки результатов оптимизации, запустим отладку, замер производительности и сформируем оборотно-сальдовую ведомость.
Читайте также: