
Tpu процессор что это
В течение последних трех лет Nvidia производит графические чипы с дополнительными ядрами, помимо обычных, которые используются для шейдеров. Известные как тензорные ядра, эти таинственные устройства могут быть обнаружены в тысячи настольных ПК, ноутбуков, рабочих станций и дата центрах по всему миру. Но что это и для чего они используются? Действительно ли они нужны в видеокартах?
Сегодня мы расскажем, что такое тензор и как используются тензорные ядра в мире графики и машинного обучения.
Чтобы понять, что именно делают тензорные ядра и для чего они могут быть использованы, сначала нужно точно определиться с понятием тензор. Микропроцессоры, независимо от того от их формы, все выполняют математические операции (сложение, умножение и т.д.) над числами.
Иногда эти числа нужно сгруппировать, потому что они имеют некоторое значение друг для друга. Например, когда микросхема обрабатывает данные для визуализации графики, она может иметь дело с единичными целочисленными значениями (такими как +2 или +115) для масштабного коэффициента, или с группой чисел с плавающей запятой (+0.1, -0.5, +0.6) для согласования точки в 3D пространстве. В последнем случае для определения положения точки требуются все три элемента данных.
Тензор - описывает взаимосвязь между математическими объектами, которые связаны между собой.
Обычно они изображаются в виде массива чисел, где размер массива можно рассмотреть, как показано ниже.
Самый простой тип тензора, который вы можете получить, будет иметь нулевое измерение и состоять из одного значения - другое название для этого - скалярная величина. По мере того, как мы начинаем увеличивать количество измерений, мы можем столкнуться с другими распространенными математическими структурами:
1 измерение = вектор
2 измерения = матрица
Строго говоря, скаляр - это тензор 0 x 0, вектор - 1 x 0, а матрица - 1 x 1, но ради упрощения и понимания того, как это относится к тензорным ядрам в графическом процессоре, мы будем иметь дело только с тензорами в виде матриц.
Одной из важнейших математических операций, выполняемых с матрицами, является умножение. Рассмотрим, как две матрицы, обе с 4 строками и столбцами значений, умножаются вместе:
Окончательный результат умножения – такое же количество рядов как в первой матрице, такое же количество столбцов как во второй матрице. Так как же умножить эти два массива? Вот так:
Как видите, "простой" матричный расчет состоит из целой группы маленьких умножений и дополнений. Поскольку каждый процессор на рынке сегодня может выполнять обе эти операции, это означает, что любой настольный компьютер, ноутбук или планшет может работать с базовыми тензорами.
Однако вышеприведенный пример содержит 64 умножения и 48 прибавлений; каждое небольшое произведение приводит к тому, что где-то должно быть сохранено значение, прежде чем оно может быть накоплено с другими 3 небольшими произведениями, прежде чем это конечное значение для тензора может быть сохранено где-то еще. Итак, хотя умножения матриц математически просты, они требуют много вычислений - нужно использовать много регистров, и кэш должен справляться с большим количеством чтений и записей.
Архитектура процессора Intel Sandy Bridge - первая, предложившая AVX расширения.
Процессоры AMD и Intel на протяжении многих лет предлагали различные расширения (MMX, SSE, теперь AVX - все они SIMD [single instruction multiple data]), что позволяет процессору обрабатывать множество чисел с плавающей точкой в одно и то же время; именно то, что нужно умножению матриц.
Но существует особый тип процессора, специально разработанный для работы с SIMD: графические процессоры (GPU).
В мире графики огромное количество данных необходимо перемещать и обрабатывать в виде векторов одновременно. Возможности параллельной обработки данных GPU делают их идеальными для работы с тензорами, и все они сегодня поддерживают нечто под названием GEMM (General Matrix Multiplication).
Это "сплавленная" операция, при которой две матрицы умножаются вместе, а ответ на них затем накапливается в другой матрице. Существуют некоторые важные ограничения на то, какой формат должны принимать матрицы, и они зависимы от количества строк и столбцов, которые есть у каждой матрицы.
Требования к строкам и столбцам для GEMM: матрица A(m x k), матрица B(k x n), матрица C(m x n)
Алгоритмы, используемые для выполнения матричных операций, как правило, лучше всего работают, когда матрицы квадратные (например, использование массивов 10 x 10 будет работать лучше, чем 50 x 2) и достаточно маленькие по размеру. Но они все равно лучше работают, когда обрабатываются на аппаратном обеспечении, предназначенном исключительно для этих операций.
В декабре 2017 года Nvidia выпустила видеокарту с графическим процессором новой архитектуры под названием Volta. Она была нацелена на профессиональный рынок, поэтому ни одна модель GeForce никогда не использовала этот чип. Особенностью было то, что это был первый графический процессор, в котором были ядра только для тензорных вычислений.
Видеокарта Nvidia Titan V с чипом GV100 Volta. Да, она потянет Crysis.
Тензорные ядра Nvidia были спроектированы так, чтобы нести 64 GEMM за тактовый цикл на 4 x 4 матрицах, содержащих значения FP16 (числа с плавающей точкой размером 16 бит) или умножение FP16 с добавлением FP32. Такие тензоры очень малы по размеру, поэтому при работе с большими наборами данных, ядра будут пропускать через себя небольшие блоки больших матриц, формируя окончательный ответ.
Тензорная версия Nvidia "Where's Waldo?"
В начале этого года архитектура Ampere дебютировала в графическом процессоре A100 для дата центров, и на этот раз Nvidia повысила производительность (256 GEMM за цикл, с 64), добавила дополнительные форматы данных, а также возможность очень быстро обрабатывать разреженные тензоры (матрицы с большим количеством нулей в них).
Для программистов доступ к тензорным ядрам в любой из микросхем Volta, Turing или Ampere прост: код просто должен использовать некий флаг, чтобы сообщить API и драйверам, что вы хотите использовать тензорные ядра, тип данных должен быть один, поддерживаемый ядрами, а размеры матриц должны быть кратны 8. После этого, процессор обработает все что нужно.
Все это хорошо, но насколько лучше тензорные ядра при работе с GEMM, чем обычные ядра в GPU?
Когда Volt только появилась, Anandtech провела несколько математических тестов, используя три карты Nvidia: новую Volta, топовую карту на базе Pascal и старую Maxwell.
Термин "точность" относится к числу битов, используемых для чисел с плавающей точкой в матрицах, при этом двойная равна 64, одна - 32 и так далее. Горизонтальная ось относится к пиковому числу операций FP, выполняемых в секунду, или FLOPов для коротких (помните, что один GEMM - это 3 FLOPа).
Просто посмотрите, какой был результат при использовании тензорных ядер вместо стандартных, так называемых CUDA-ядер! Очевидно, что они фантастически справляются с такой работой, но что мы можем делать с ними?
FLOPS (также flops, flop/s, флопс или флоп/с; акроним от англ. FLoating-point Operations Per Second, произносится как флопс) — внесистемная единица, используемая для измерения производительности компьютеров, показывающая, сколько операций с плавающей запятой в секунду выполняет данная вычислительная система.
Тензорная математика чрезвычайно полезна в физике и машиностроении и используется для решения всевозможных сложных задач в области механики жидкостей, электромагнетизма и астрофизики, но компьютеры, используемые для подсчета этих чисел, как правило, выполняют матричные операции в больших кластерах CPU.
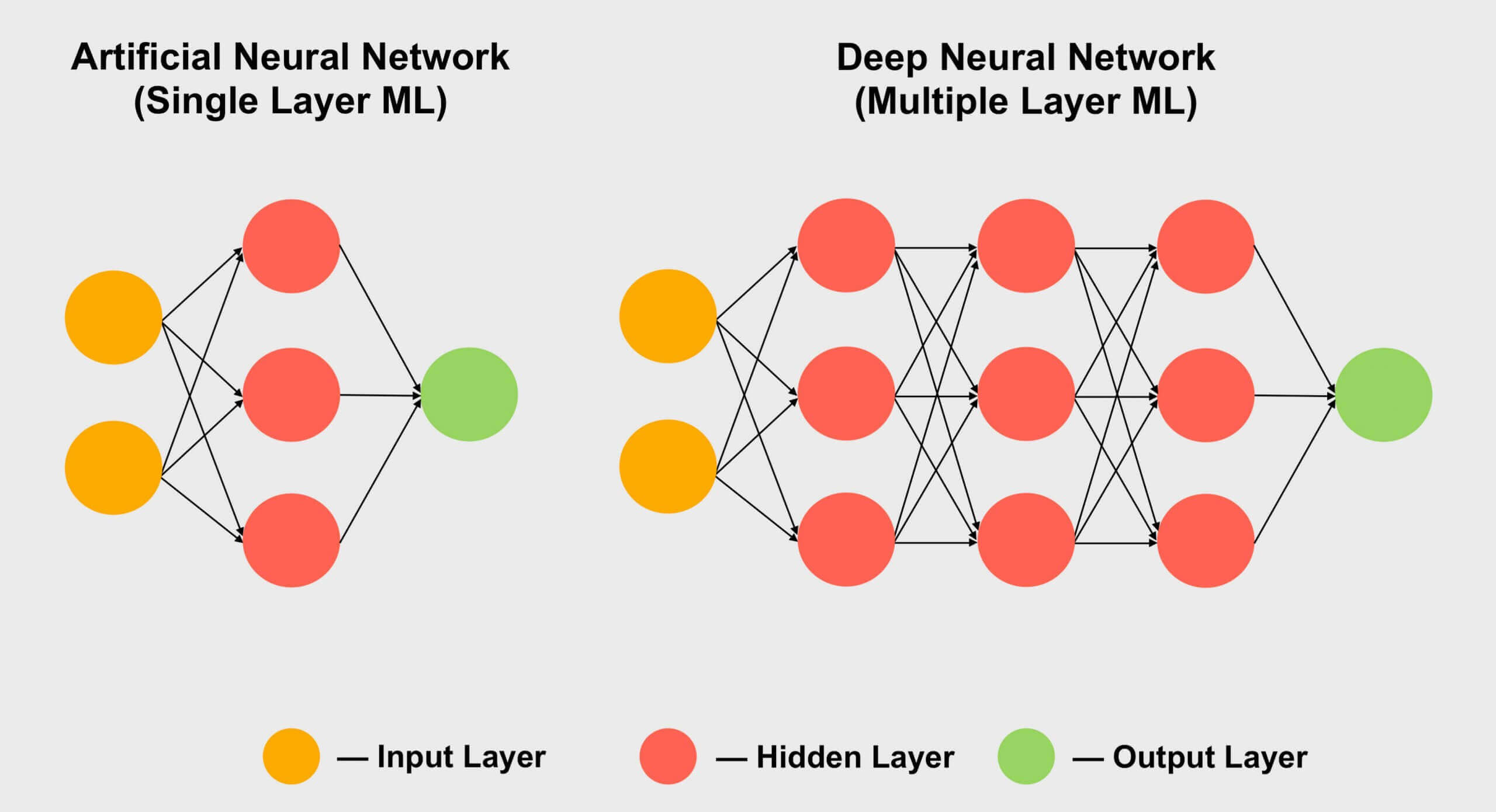
Другая область, которая любит использовать тензоры, это машинное обучение, особенно глубокое обучение (deep learning). Все это связано с обработкой огромных массивов данных, называемых нейронными сетями. Соединениям между различными значениями данных присваивается определенная масса (weight) - число, которое выражает, насколько важно это соединение.
Поэтому, когда вам нужно разобраться, как взаимодействуют все сотни, если не тысячи подключений, вам нужно умножить каждый кусочек данных в сети на все различные массы (weight) подключений. Другими словами, умножить две матрицы вместе: классическая тензорная математика!
Чипы Google TPU 3.0, спрятанные под водяным охлаждением
Именно поэтому все большие суперкомпьютеры для глубокого обучения оснащены графическими процессорами и почти всегда это Nvidia. Однако некоторые компании зашли так далеко, что сделали свои собственные процессоры с тензорными ядрами. Компания Google, например, объявила о выпуске своего первого TPU (tensor processing unit) в 2016 году, но эти чипы настолько специализированы, что они не могут делать ничего, кроме операций с матрицами.
Но что, если у вас есть видеокарта Nvidia GeForce RTX и вы не астрофизик, решающий проблемы с римановыми многообразиями, и не экспериментирующий с глубинами конволюционных нейронных сетей. Какая польза от тензорных ядер для вас?
По большей части они не используются для нормального рендеринга, кодирования или декодирования видео, что может показаться, будто вы зря потратили деньги на бесполезную функцию. Однако в 2018 году Nvidia внедрила тензорные ядра в свои потребительские продукты (Turing GeForce RTX), а также внедрила DLSS - Deep Learning Super Sampling.
Основная мысль проста: рендер кадра в низком разрешении, а после, увеличьте разрешение конечного результата так, чтобы оно совпадало с натуральными размерами экрана монитора (например, рендер при 1080p, затем измените его размер до 1400p). Таким образом, вы получите преимущество в производительности, обрабатывая меньше пикселей, но при этом получите красивое изображение на экране.
Консоли делают что-то подобное уже много лет, и многие современные компьютерные игры тоже предлагают такую возможность. В Ubisoft's Assassin's Creed: Odyssey, вы можете изменить разрешение рендеринга до 50% от разрешения монитора. К сожалению, результат выглядит не так уж и хорошо. Вот как выглядит игра на 4K, с максимальными настройками графики:
Благодаря высокому разрешению текстуры выглядят намного лучше, так как сохраняют мелкие детали. К сожалению, все эти пиксели требуют большой обработки. Теперь посмотрите, что происходит, когда игра настроена на рендеринг в 1080p (на 25% больше пикселей, чем раньше), но затем используйте шейдеры в конце, чтобы расширить ее обратно до 4K.
Разница может быть не сразу очевидна, спасибо jpeg-сжатию и перемасштабированию изображений, но доспехи персонажа и каменные образования несколько размыты. Давайте увеличим масштаб для более детального изучения:
Левая часть была отрисована в 4К; правая - в 1080p, увеличенная до 4К. Разница гораздо более выражена, когда речь идет о движении, так как размягчение (softening) всех деталей быстро превращается в размытую кашу. Некоторую часть можно было бы вернуть назад, используя усиление резкости в драйверах видеокарты, но лучше вообще этого не делать.
Именно здесь DLSS играет свою роль - в первой итерации технологии Nvidia были проанализированы отдельные игры, запущенные с низким и высоким разрешением, со сглаживанием и без него. Все эти режимы генерировали огромное количество изображений, которые обрабатывались суперкомпьютерами, которые использовали нейронную сеть для определения того, как лучше всего превратить изображение 1080p в изображение с более высоким разрешением.
Надо сказать, что DLSS 1.0 был не очень хорош, в некоторых местах детали часто терялись или странно мерцали. В ней также не использовались тензорные ядра в видеокарте (это было сделано в сети Nvidia), и каждая игра, поддерживающая DLSS, требовала собственного изучения Nvidia для генерации алгоритма масштабирования.
Когда в начале 2020 года вышла версия 2.0, были сделаны некоторые значительные улучшения. Наиболее примечательным из них было то, что суперкомпьютеры Nvidia использовались только для создания общего алгоритма масштабирования - в новой итерации DLSS данные из отрисовываемого кадра будут использоваться для обработки пикселей (через тензорные ядра вашего GPU) с помощью нейронной модели.
Мы остаемся под впечатлением от того, чего может достичь DLSS 2.0, но пока ее поддерживают очень немногие игры - всего 12, на момент написания статьи. Тем не менее, все больше разработчиков хотят реализовать ее в своих будущих релизах, и на то есть веские причины.
Есть большой прирост производительности, который можно найти, делая любой вид масштабирования (upscaling), так что вы можете поставить свой последний рубль на то, что DLSS будет продолжать развиваться.
Хотя визуальное отображение DLSS не всегда идеально, снижая нагрузку производительность рендеринга, у разработчиков есть возможность включить больше визуальных эффектов или предложить одну и ту же графику на более широком диапазоне платформ.
В качестве примера можно привести то, что DLSS часто продвигается наряду с трассировкой лучей в "играх с поддержкой RTX". Графические процессоры GeForce RTX включают в себя дополнительные вычислительные модули, называемые RT ядрами: выделенные логические модули для ускорения пересечения лучей с треугольниками и вычислений обхода иерархии ограниченных объемов (bounding volume hierarchy) (BVH). Эти два процесса представляют собой трудоемкие процедуры для разработки того, где свет взаимодействует с остальными объектами в сцене.
Как мы выяснили, трассировка лучей является супер интенсивной, поэтому, чтобы обеспечить игровое исполнение, разработчики игры должны ограничить количество выполняемых в сцене лучей и отскоков. Этот процесс может привести к появлению зернистых изображений, поэтому необходимо применять алгоритм размывания, добавляющий сложность обработки. Ожидается, что тензорные ядра будут способствовать повышению производительности при использовании шумоподавления на основе AI, хотя это еще не появилось в большинстве современных приложений, все еще использующих ядра CUDA для выполнения этой задачи. Положительным моментом является то, что DLSS 2.0 становится эффективной техникой масштабирования, поэтому тензорные ядра могут быть эффективно использованы для повышения частоты кадров после применения трассировки лучей на сцене.
Существуют и другие планы по использованию тензорных ядер в картах GeForce RTX, например, лучшая анимация персонажей или симуляция ткани. Но, как и в случае с DLSS 1.0, пройдет некоторое время, прежде чем сотни игр будут регулярно использовать специализированные матричные калькуляторы в GPU.
Итак, тензорные ядра, изящные маленькие кусочки, умеющие считать. Они встречаются только в небольшом количестве видеокарт потребительского уровня. Изменится ли это в будущем? Так как Nvidia уже значительно улучшила производительность однотензорного ядра в своей новейшей архитектуре Ampere, есть хорошие шансы, что мы увидим больше моделей среднего и бюджетного диапазона.
Хотя AMD и Intel не имеют их в своих GPU, мы можем увидеть нечто подобное в будущем. AMD действительно предлагает систему для улучшения деталей в готовых кадрах при минимальных затратах на производительность, так что они вполне могут просто придерживаться этого - тем более, что разработчикам не нужно интегрировать ее; это просто функция в драйверах.
Есть также аргумент, что место в графических чипах можно было бы использовать, чтобы просто добавить больше шейдерных ядер, что Nvidia и сделала, когда собрала бюджетные версии своих чипов Turing. Такие, как GeForce GTX 1650 вообще отказались от тензорных ядер и заменили их дополнительными шейдерами FP16.
Но пока, если вы хотите испытать супербыструю пропускную способность GEMM и все преимущества, которые это может дать, у вас есть два варианта: купить себе кучу огромных многоядерных CPU или всего один GPU с тензорными ядрами.

Тензорный процессор третьего поколения

Тензорный процессор Google — интегральная схема специального назначения (ASIC), разработанная с нуля компанией Google для выполнения задач по машинному обучению. Он работает в нескольких основных продуктах Google, включая Translate, Photos, Search Assistant и Gmail. Облачный TPU обеспечивает преимущества, связанные с масштабируемостью и лёгкостью использования, всем разработчикам и специалистам по изучению данных, запускающим передовые модели машинного обучения в облаке Google. На конференции Google Next ‘18 мы объявили о том, что Cloud TPU v2 теперь доступен для всех пользователей, включая бесплатные пробные учётные записи, а Cloud TPU v3 доступен для альфа-тестирования.
Но многие спрашивают – какая разница между CPU, GPU и TPU? Мы сделали демонстрационный сайт, где расположена презентация и анимация, отвечающая на этот вопрос. В этом посте я хотел бы подробнее остановиться на определённых особенностях содержимого этого сайта.
В 45 раз быстрее обычного процессора
Хотя набор команд CISC (англ. Complex Instruction Set Computer — «компьютер с полным набором команд») тензорного процессора и может отработать сложные команды, их существует всего около десятка. И для большинства необходимых операций требуется только пять команд, в том числе команды чтения, выполнения умножения матрицы или вычисления функции активации.
За счет оптимизации вычислений искусственного интеллекта тензорные процессоры оказываются значительно быстрее обычных процессоров (в 45 раз) или графических процессоров (в 17 раз). В то же время они работают с большей энергоэффективностью.
И Google при этом находится лишь в начале пути: с помощью простых мер производительность тензорных процессоров можно увеличивать и дальше. Одна только установка оперативной памяти GDDR5 может утроить нынешнюю вычислительную мощность.
Энергопотребление в сравнении
Сравнение производительности процессоров на потребленный ватт электроэнергии демонстрирует большую эффективность тензорных процессоров.

Вычислительная мощность/ватт
«Наш искусственный интеллект обходится без команд со стороны человека»
Профессор Дэвид Сильвер, Главный программист искусственного интеллекта
Google AlphaGo Zero
Алгоритмы RankBrain ищут имеющиеся формы в неизвестных поисковых запросах и увязывают их с семантически схожими понятиями. В итоге поисковая система должна самостоятельно обучаться и иметь возможность давать соответствующие ответы на вопросы, которые ранее не задавались.
Google использует в своих центрах обработки данных специально разработанные для этого тензорные процессоры — TPU.
Как работает GPU
Для увеличения пропускной способности по сравнению с CPU, GPU использует простую стратегию: почему бы не встроить в процессор тысячи ALU? В современном GPU содержится порядка 2500 – 5000 ALU на процессоре, что делает возможным выполнение тысяч умножений и сложений одновременно.
Такая архитектура хорошо работает с приложениями, требующими массивного распараллеливания, такими, например, как умножение матриц в нейросети. При типичной тренировочной нагрузке глубинного обучения (ГО) пропускная способность в этом случае увеличивается на порядок по сравнению с CPU. Поэтому на сегодняшний день GPU является наиболее популярной архитектурой процессоров для ГО.
Но GPU всё равно остаётся процессором общего назначения, который должен поддерживать миллион различных приложений и ПО. А это возвращает нас к фундаментальной проблеме узкого места архитектуры фон Неймана. Для каждого вычисления в тысячах ALU, GPU необходимо обратиться к регистрам или разделяемой памяти, чтобы прочесть и сохранить промежуточные результаты вычислений. Поскольку GPU выполняет больше параллельных вычислений на тысячах своих ALU, он также тратит пропорционально больше энергии на доступ к памяти и занимает большую площадь.
Как работает TPU
Когда мы в Google разрабатывали TPU, мы построили архитектуру, предназначенную для определённой задачи. Вместо разработки процессора общего назначения, мы разработали матричный процессор, специализированный для работы с нейросетями. TPU не сможет работать с текстовым процессором, управлять ракетными двигателями или выполнять банковские транзакции, но он может обрабатывать огромное количество умножений и сложений для нейросетей с невероятной скоростью, потребляя при этом гораздо меньше энергии и умещаясь в меньшем физическом объёме.
Главное, что позволяет ему это делать – радикальное устранение узкого места архитектуры фон Неймана. Поскольку основной задачей TPU является обработка матриц, разработчикам схемы были знакомы все необходимые шаги вычислений. Поэтому они смогли разместит тысячи множителей и сумматоров, и соединить их физически, сформировав большую физическую матрицу. Это называется архитектурой конвейерного массива. В случае с Cloud TPU v2 используются два конвейерных массива по 128 х 128, что в сумме даёт 32 768 ALU для 16-битных значений с плавающей точкой на одном процессоре.
Посмотрим, как конвейерный массив выполняет подсчёты для нейросети. Сначала TPU загружает параметры из памяти в матрицу множителей и сумматоров.
Затем TPU загружает данные из памяти. По выполнению каждого умножения результат передаётся следующим множителям, при одновременном выполнении сложений. Поэтому на выходе будет сумма всех умножений данных и параметров. В течение всего процесса объёмных вычислений и передачи данных доступ к памяти совершенно не нужен.
Поэтому TPU демонстрирует большую пропускную способность при подсчётах для нейросетей, потребляя гораздо меньше энергии и занимая меньше места.
Краткий урок математики
Чтобы понять, чем же заняты тензорные ядра и для чего их можно использовать, нам сначала разобраться, что такое тензоры. Все микропроцессоры, какую бы задачу они ни выполняли, производят математические операции над числами (сложение, умножение и т.д.).
Иногда эти числа необходимо группировать, потому что они обладают определённым значением друг для друга. Например, когда чип обрабатывает данные для рендеринга графики, он может иметь дело с отдельными целочисленными значениями (допустим, +2 или +115) в качестве коэффициента масштабирования или с группой чисел с плавающей точкой (+0.1, -0.5, +0.6) в качестве координат точки в 3D-пространстве. Во втором случае для позиции точки требуются все три элемента данных.
Тензор — это математический объект, описывающий соотношения между другими математическими объектами, связанными друг с другом. Обычно они отображаются в виде массива чисел, размерность которого показана ниже.

Простейший тип тензора имеет нулевую размерность и состоит из единственного значения; иначе он называется скалярной величиной. При увеличении количества размерностей мы сталкиваемся с другими распространёнными математическими структурами:
- 1 измерение = вектор
- 2 измерения = матрица
Одна из самых важных математических операций, выполняемых над матрицами — это умножение (или произведение). Давайте взглянем на то, как перемножаются друг на друга две матрицы, имеющие по четыре строки и столбца данных:

Окончательным результатом умножения всегда будет то же количество строк, что и в первой матрице, и то же количество столбцов, что и во второй. Как же перемножить эти два массива? Вот так:

На пальцах это посчитать не удастся
Как вы видите, вычисление «простого» произведения матриц состоит из целой кучи небольших умножений и сложений. Так как любой современный центральных процессор может выполнять обе эти операции, простейшие тензоры способен выполнять каждый настольный компьютер, ноутбук или планшет.
Однако показанный выше пример содержит 64 умножений и 48 сложений; каждое небольшое произведение даёт значение, которое нужно где то хранить, прежде чем его можно будет сложить с другими тремя небольшими произведениями, чтобы позже можно было сохранить окончательное значение тензора. Поэтому, несмотря на математическую простоту умножений матриц, они затратны вычислительно — необходимо использовать множество регистров, а кэш должен уметь справляться с кучей операций считывания и записи.

Архитектура Intel Sandy Bridge, в которой впервые появились расширения AVX
На протяжении многих лет в процессорах AMD и Intel появлялись различные расширения (MMX, SSE, а теперь и AVX — все они являются SIMD, single instruction multiple data), позволяющие процессору одновременно обрабатывать множество чисел с плавающей запятой; это как раз то, что требуется для перемножения матриц.
Но существует особый тип процессоров, который специально спроектирован для обработки операций SIMD: графические процессоры (graphics processing unit, GPU).
Структура тензорного процессора
Быстрое сложение и умножение — сильная сторона тензорного процессора. В ответственном за это модуле с матрицей в качестве центрального компонента производятся вычисления нейронных сетей. Она занимает около четверти площади процессора. Остальное место используется для быстрой подачи вводных данных. Они поступают через PCI Express и оперативную память DDR3. Результаты вычислений возвращаются на сервер через PCI Express и интерфейс хоста.
Умнее, чем обычный калькулятор?
В мире графики одновременно необходимо передавать и обрабатывать огромные объёмы информации в виде векторов. Благодаря своей способности параллельной обработки GPU идеально подходят для обработки тензоров; все современные графические процессоры поддерживают функциональность под названием GEMM (General Matrix Multiplication).
Это «склеенная» операция, при которой перемножаются две матрицы, а результат затем накапливается с другой матрицей. Существуют важные ограничения на формат матриц и все они связаны с количеством строк и столбцов каждой матрицы.

Требования GEMM к строкам и столбцам: матрица A(m x k), матрица B(k x n), матрица C(m x n)
Алгоритмы, используемые для выполнения операций с матрицами, обычно лучше всего работают, когда матрицы квадратные (например, массив 10 x 10 будет работать лучше, чем 50 x 2) и довольно небольшие по размеру. Но они всё равно будут работать лучше, если обрабатываются на оборудовании, которое предназначено исключительно для таких операций.
В декабре 2017 года Nvidia выпустила графическую карту с GPU, имеющим новую архитектуру Volta. Она была нацелена на профессиональные рынки, поэтому этот чип не использовался в моделях GeForce. Уникальным он был потому, что стал первым графическим процессором, имеющим ядра только для выполнения тензорных вычислений.

Графическая карта Nvidia Titan V, на которой установлен чип GV100 Volta. Да на ней можно запустить Crysis
Тензорные ядра Nvidia были предназначены для выполнения по 64 GEMM за тактовый цикл с матрицами 4 x 4, содержащими значения FP16 (числа с плавающей запятой размером 16 бит) или умножение FP16 со сложением FP32. Такие тензоры очень малы по размеру, поэтому при обработке настоящих множеств данных ядра обрабатывают небольшие части больших матриц, выстраивая окончательный ответ.

В начале этого года архитектура Ampere дебютировала в графическом процессоре дата-центра A100, и на этот раз Nvidia повысила производительность (256 GEMM за цикл вместо 64), добавила новые форматы данных и возможность очень быстрой обработки разреженных тензоров (sparse tensor) (матриц со множеством нулей).
Программисты могут получить доступ к тензорным ядрам чипов Volta, Turing и Ampere очень просто: код всего лишь должен использовать флаг, сообщающий API и драйверам, что нужно применять тензорные ядра, тип данных должен поддерживаться ядрами, а размерности матриц должны быть кратными 8. При выполнении всех этих условий всем остальным займётся оборудование.
Всё это здорово, но насколько тензорные ядра лучше в обработке GEMM, чем обычные ядра GPU?
Когда появилась Volta, сайт Anandtech провёл математические тесты трёх карт Nvidia: новой Volta, самой мощной из линейки Pascal и старой карты Maxwell.
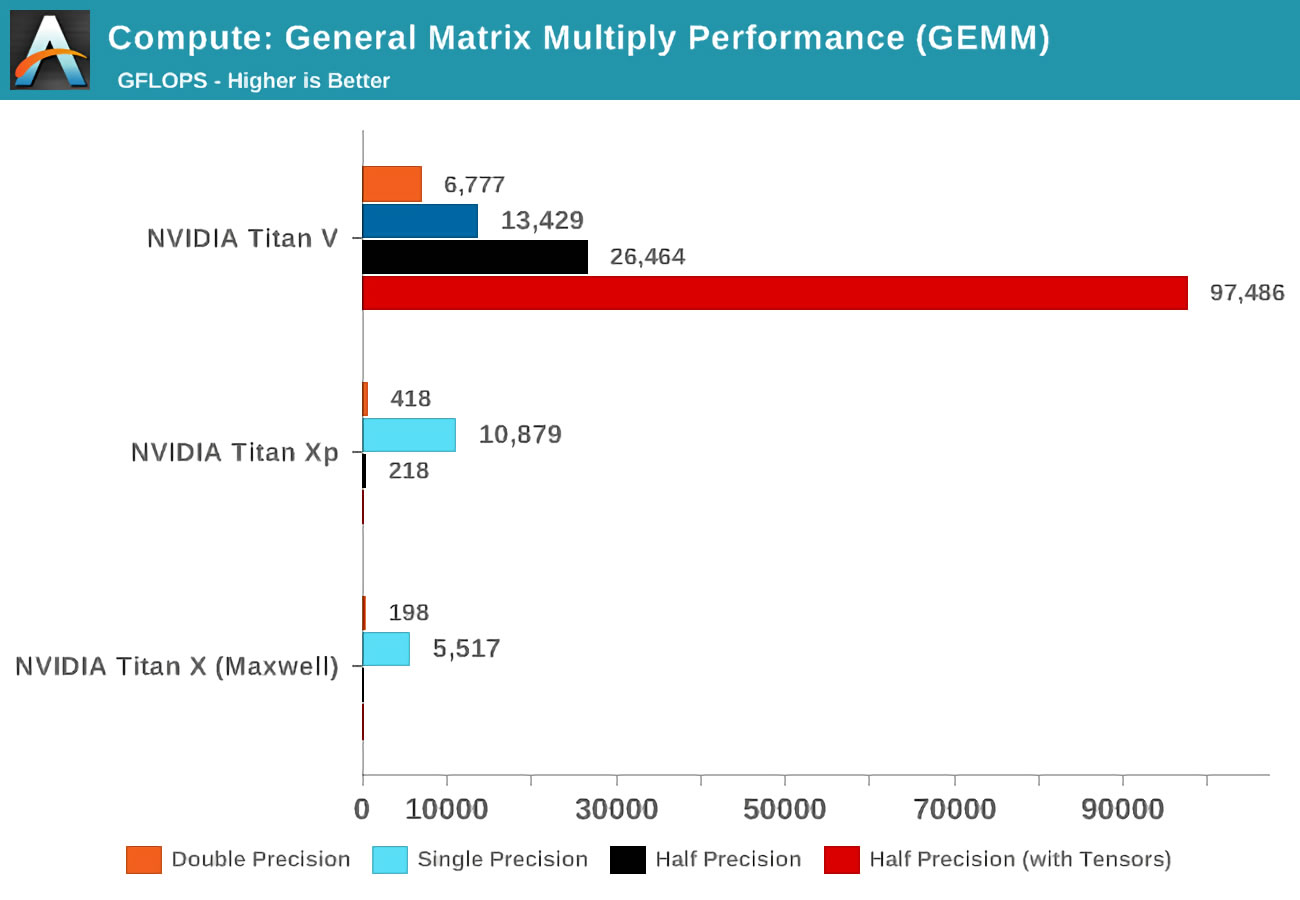
Понятие точности (precision) относится к количеству бит, использованных для чисел с плавающей запятой в матрицах: двойная (double) обозначает 64, одиночная (single) — 32, и так далее. По горизонтальной оси отложено максимальное количество операций с плавающей запятой, выполняемое за секунду, или сокращённо FLOPs (помните, что одна GEMM — это 3 FLOP).
Просто взгляните на результаты при использовании тензорных ядер вместо так называемых ядер CUDA! Очевидно, что они потрясающе справляются с подобной работой, но что же мы можем делать при помощи тензорных ядер?
Гонки с центральным и графическим процессорами
Тензорные процессоры вычисляют со скоростью 225 000 прогнозов для нейронной сети в секунду. CPU и GPU не выдерживают конкуренции.

Как работают нейросети
Перед тем, как начать сравнивать CPU, GPU и TPU, посмотрим, какого рода вычисления требуются для машинного обучения – а конкретно, для нейросетей.
Представьте, к примеру, что мы используем однослойную нейросеть для распознавания рукописных цифр, как показано на следующей диаграмме:

Если картинка будет сеткой размером 28х28 пикселей серой шкалы, её можно преобразовать в вектор из 784 значений (измерений). Нейрон, распознающий цифру 8, принимает эти значения и перемножает их со значениями параметра (красные линии на диаграмме).
Параметр работает как фильтр, извлекая особенности данных, говорящих о схожести изображения и формы 8:
Это наиболее простое объяснение классификации данных нейросетями. Перемножение данных с соответствующими им параметрами (окраска точек) и их сложение (сумма точек справа). Наивысший результат обозначает наилучшее совпадение введённых данных и соответствующего параметра, которое, скорее всего, и будет правильным ответом.
Проще говоря, нейросетям требуется делать огромное количество перемножений и сложений данных и параметров. Часто мы организовываем их в виде матричного перемножения, c которым вы могли столкнуться в школе на алгебре. Поэтому проблема состоит в том, чтобы выполнить большое количество матричных перемножений как можно быстрее, потратив как можно меньше энергии.
Преимущество: уменьшение стоимости в 5 раз
Какие же преимущества даёт архитектура TPU? Стоимость. Вот стоимость работы Cloud TPU v2 на август 2018 года, на время написания статьи:

Обычная и TPU-шная стоимость работы для разных регионов Google Cloud
Стэнфордский университет раздаёт набор тестов DAWNBench, измеряющих быстродействие систем с глубинным обучением. Там можно посмотреть на различные комбинации задач, моделей и вычислительных платформ, а также на соответствующие результаты тестов.
На момент завершения соревнования в апреле 2018 минимальная стоимость тренировки на процессорах с архитектурой, отличной от TPU, равнялась $72,40 (для тренировки ResNet-50 с 93% точностью на ImageNet на спотовых инстансах). При помощи Cloud TPU v2 такую тренировку можно провести за $12,87. Это меньше 1/5 стоимости. Такова сила архитектуры, предназначенной специально для нейросетей.

Каждое устройство Cloud TPU состоит из четырёх «чипов TPUv2». В чипе 16 ГБ памяти и два ядра, каждое ядро с двумя юнитами для умножения матриц. Вместе два ядра выдают 45 TFLOPS, в общей сложности 180 TFLOPS и 64 ГБ памяти на один TPU
Большинство из нас осуществляет глубинное обучение на Nvidia GPU. В настоящее время практически нет альтернатив. Тензорный процессор Google (Tensor Processing Unit, TPU) — специально разработанный чип для глубинного обучения, который должен изменить ситуацию.
Через девять месяцев после первоначального анонса две недели назад Google наконец-то выпустила TPUv2 и открыла доступ первым бета-тестерам на платформе Google Cloud. Мы в компании RiseML воспользовались возможностью и прогнали парочку быстрых бенчмарков. Хотим поделиться своим опытом и предварительными результатами.
Давно мы ждали появления конкуренция на рынке оборудования для глубинного обучения. Она должна разрушить монополию Nvidia и определить, как будет выглядеть будущая инфраструктура глубинного обучения.
Имейте в виду, что TPU пока в ранней бета-версии, о чём явно и повсеместно напоминает Google — так что некоторые обсуждаемые оценки могут измениться в будущем.
В то время как первое поколение чипов TPUv1 ориентировалось на ускорение вывода данных, нынешнее второе поколение в первую очередь фокусируется на ускорении обучения. В основе TPUv2 — систолический массив, отвечающий за умножение матриц, которые активно используются в глубинном обучении. Согласно слайдам Джеффа Дина, каждое устройство Cloud TPU состоит из четырёх «чипов TPUv2». В чипе 16 ГБ памяти и два ядра, каждое ядро с двумя юнитами для умножения матриц. Вместе два ядра выдают 45 TFLOPS, в общей сложности 180 TFLOPS и 64 ГБ памяти на один TPU. Для сравнения, у нынешнего поколения Nvidia V100 всего 125 TFLOPS и 16 ГБ памяти.
Чтобы использовать тензорные процессоры на платформе Google Cloud, нужно запустить Cloud TPU (предварительно получив на него квоту). Нет необходимости (и возможности) назначить Cloud TPU конкретному инстансу виртуальной машины. Вместо этого доступ TPU из инстанса осуществляется по сети. Каждому Cloud TPU присваивается имя и IP-адрес, которые следует указать в коде TensorFlow.

Создание нового Cloud TPU. Обратите внимание, что у него есть IP-адрес. Анимация GIF
TPU поддерживаются только в TensorFlow версии 1.6, которая пока в статусе релиз-кандидата. Кроме того, для VM не нужны никакие драйверы, поскольку весь необходимый код включён в состав TensorFlow. Код для выполнения на TPU оптимизируется и компилируется JIT-компилятором XLA, тоже входящим в состав TensorFlow.
Чтобы эффективно использовать TPU, код должен быть основан на высокоуровневых абстракциях класса Estimator. Затем переходим к классу TPUEstimator, который выполняет множество необходимых задач для эффективного использования TPU. Например, настраивает очереди данных для TPU и распараллеливает вычисления между ядрами. Определённо есть способ обойтись без использования TPUEstimator, но нам пока не известны такие примеры или документация.
Когда всё настроено, запускайте свой код TensorFlow как обычно. TPU обнаружатся при загрузке, график расчётов скомпилируется и будет передан туда. Интересно, что TPU ещё умеет напрямую читать и записывать в облачное хранилище контрольные точки и сводки (event summaries). Для этого нужно разрешить запись в облачное хранилище в аккаунте Cloud TPU.
Конечно, самое интересное — реальная производительность тензорных процессоров. В репозитории TensorFlow на GitHub есть набор проверенных и оптимизированных моделей TPU. Ниже показаны результаты экспериментов с ResNet и Inception. Ещё мы хотели посмотреть, как обсчитывается модель, не оптимизированная для TPU, поэтому адаптировали модель для классификации текста на архитектуре долгой краткосрочной памяти (LSTM) для запуска на TPU. Вообще-то Google рекомендует использовать более крупные модели (см. раздел «Когда использовать TPU»). У нас модель поменьше, так что особенно интересно посмотреть, даст ли TPU какое-нибудь преимущество.
Для всех моделей мы сравнили скорость обучения на одном Cloud TPU с одним графическим процессором Nvidia P100 и V100. Нужно заметить, что полноценное сравнение должно включать в себя сравнение окончательного качества и сходимости моделей, а не просто пропускную способность. Наши эксперименты — это лишь поверхностные первые бенчмарки, а подробный анализ оставим на будущее.
Тесты для TPU и P100 запускались на инстансах n1-standard-16 платформы Google Cloud (16 виртуальных CPU Intel Haswell, память 60 ГБ). Для графического процессора V100 использовались инстансы p3.2xlarge на AWS (8 виртуальных CPU, 60 ГБ памяти). Все системы под Ubuntu 16.04. Для TPU установили TensorFlow 1.6.0-rc1 из репозитория PyPi. Тесты для GPU запускались из контейнеров nvidia-docker с образами TensorFlow 1.5 (tensorflow:1.5.0-gpu-py3), включающими поддержку CUDA 9.0 и cuDNN 7.0.
Посмотрим сначала на производительность моделей, которые официально оптимизированы для TPU. Ниже показана производительность по количеству обрабатываемых изображений в секунду.

Размеры пакетов: 1024 на TPU и 128 на GPU. Для последних взяли реализацию из репозитория бенчмарков TensorFlow. В качестве данных для обучения — симуляция набора данных ImageNet от Google в облачном хранилище (для TPU) и на локальных дисках (для GPU)
На ResNet-50 один тензорный процессор Cloud TPU (8 ядер и 64 ГБ ОЗУ) были примерно в 8,4 раза быстрее, чем один P100, и примерно в 5,1 раза быстрее, чем V100. Для InceptionV3 разница в производительности почти такая же (~8,4 и ~4,8, соответственно). На вычислениях с меньшей точностью (fp16) V100 значительно прибавляет в скорости.

Понятно, что кроме скорости нужно учитывать и цену. В таблице показана производительность, нормализованная по цене с ежесекундным биллингом. TPU всё равно явно выигрывает.
Наша кастомная модель — это двунаправленная LSTM для классификации текста с 1024 скрытыми юнитами. LSTM являются основными строительными блоками в современных нейросетях, так что это хорошее дополнение для официальных моделей машинного зрения.
Оригинальный код уже использовал фреймворк Estimator, так что очень легко адаптировать его для TPUEstimator. Хотя есть одна большая оговорка: на TPU мы не смогли добиться сходимости модели, хотя та же модель (размер пакетов и прочее) на GPU работала нормально. Думаем, это из-за какого-то бага, который будет исправлен — либо в нашем коде (если найдёте его, сообщите нам!), либо в TensorFlow.
Оказалось, что TPU обеспечивает даже бóльшую прибавку в производительности на модели LSTM (21402 образца/с): в ~12,9 раза быстрее, чем Р100 (1658 образцов/с) и в ~7,7 раза быстрее, чем V100 (2778 образцов/с)! Учитывая, что модель сравнительно небольшая и никак не оптимизировалась, это очень многообещающий результат. Но пока баг не исправлен, эти результаты будем считать предварительными.
На протестированных моделях TPU очень хорошо проявили себя как по производительности, так и с точки зрения экономии денег, по сравнению с последними поколениями GPU. Это противоречит предыдущим оценкам.

Результаты предыдущих бенчмарков. Источник: Forbes
Хотя Google продвигает TPU как оптимальное решение для масштабирования больших моделей, наши предварительные результаты на маленькой модели оказались очень многообещающими. В целом, опыт использования TPU и адаптации кода TensorFlow уже неплох для бета-версии.
Мы считаем, что когда TPU станут доступны более широкой аудитории, то могут стать реальной альтернативой Nvidia GPU.

В течение последних трёх лет Nvidia создавала графические чипы, в которых помимо обычных ядер, используемых для шейдеров, устанавливались дополнительные. Эти ядра, называемые тензорными, уже есть в тысячах настольных PC, ноутбуков, рабочих станций и дата-центров по всему миру. Но что же они делают и для чего применяются? Нужны ли они вообще в графических картах?
Сегодня мы объясним, что такое тензор, и как тензорные ядра используются в мире графики и глубокого обучения.
Ускоритель для нейронных сетей
По сравнению с обычными процессорами тензорные специализируются на использовании искусственных нейронных сетей. Они состоят из множества связанных в сеть математических функций, которые имитируют человеческий мозг с его нервными клетками и их связями. Подобно нашему мозгу, нейронная сеть требует соответствующего ввода. Происходит обучение, к примеру, распознаванию речи, изображений — или правилам игры «Го».
Искусственная нейронная сеть включает несколько уровней нейронов. Каждый нейрон использует взвешенную сумму выходных значений связанных нейронов в предыдущем уровне. Правильная сравнительная оценка — ключ к успеху в Machine Learning, но ее сначала надо сделать, что на практике часто означает множественные операции с плавающей точкой.
В этой дисциплине лучшим выбором на самом деле являются графические процессоры. Чтобы потом отсортировать результаты поиска или предугадать ходы, нейронной сети больше не нужна высокая точность вычислений с плавающей запятой. Этот процесс требует выполнения очень большого количества операций умножения и сложения целых чисел.
Тензорные процессоры в вычислительном центре Google
Google с 2016 года использует TPU в своих вычислительных центрах. На плате обычно располагают несколько процессоров одним кластером. В основном они используются блоками по четыре штуки.


Тензорный процессор Google состоит в основном из вычислительного блока, матрицы 256×256 единиц. Он работает с восьмибитными целыми числами, достигает вычислительной мощности, составляющей 92 триллиона операций в секунду, и хранит результаты в памяти.
На диаграмме показано, что матрица занимает лишь около четверти площади процессора. Остальные компоненты отвечают за постоянное обеспечение ядер новыми данными. Команды тензорные процессоры сами себе не подают — они поступают с подключенного сервера через PCI Express. Этим же путем передаются в ответ и конечные результаты.
Сравнительные оценки, необходимые для вычислений нейронной сети, поставляет модуль памяти First-In/First-Out. Так как там мало что меняется для конкретного приложения, достаточно подключения через оперативную память DDR3. Промежуточные результаты помещаются в буферный накопитель объемом 24 Мбайт и снова поступают в вычислительный блок.
Тензорные ядра в потребительских GPU (GeForce RTX)
Но что если я куплю графическую карту Nvidia GeForce RTX, не являясь ни астрофизиком, решающим задачи римановых многообразий, ни специалистом, экспериментирующим с глубинами свёрточных нейронных сетей. Как я могу использовать тензорные ядра?
Чаще всего они не применяются для обычного рендеринга, кодирования или декодирования видео, поэтому может показаться, что вы потратили деньги на бесполезную функцию. Однако Nvidia встроила тензорные ядра в свои потребительские продукты в 2018 году (Turing GeForce RTX), внедрив при этом DLSS — Deep Learning Super Sampling.

Принцип прост: рендерим кадр в довольно низком разрешении, а после завершения повышаем разрешение конечного результата так, чтобы он совпадал с «родными» размерами экрана монитора (например, рендерим в 1080p, а затем изменяем размер до 1400p). Благодаря этому повышается производительность, ведь обрабатывается меньшее количество пикселей, а на экране всё равно получается красивое изображение.
Консоли имели такую функцию уже многие годы, и многие современные игры для PC тоже обеспечивают эту возможность. В Assassin's Creed: Odyssey компании Ubisoft можно уменьшить разрешение рендеринга до всего 50% от разрешения монитора. К сожалению, результаты выглядят не так красиво. Вот как игра выглядит в 4K с максимальными настройками графики:

В высоких разрешениях текстуры выглядят красивее, потому что сохраняют в себе больше деталей. Однако для вывода этих пикселей на экран требуется много обработки. Теперь взгляните на то, что происходит при установке рендеринга на 1080p (25% от предыдущего количества пикселей), с использованием шейдеров в конце для растягивания картинки до 4K.

Из-за сжатия jpeg разница может быть заметной не сразу, но видно, что броня персонажа и скала вдали выглядят размытыми. Давайте приблизим часть изображения для более детального изучения:

Изображение слева отрендерено в 4K; изображение справа — это 1080p, растянутые до 4K. Разница гораздо заметнее в движении, потому что смягчение всех деталей быстро превращается в размытую кашу. Частично чёткость можно восстановить благодаря эффекту резкости драйверов графической карты, но лучше бы нам вообще не приходилось этим не заниматься.
Именно здесь в ход идёт DLSS — в первой версии этой технологии Nvidia анализировались несколько выбранных игр; они запускались в высоких разрешениях, низких разрешениях, со сглаживанием и без него. Во всех этих режимах был сгенерирован набор изображений, загруженный затем в суперкомпьютеры компании, которые использовали нейронную сеть, чтобы определить, каким образом лучше всего превратить изображение в разрешении 1080p в идеальную картинку в более высоком разрешении.

Нужно сказать, что DLSS 1.0 не был идеальным: детали часто терялись и в некоторых местах возникало странное мерцание. К тому же он не использовал сами тензорные ядра графической карты (он выполнялся в сети Nvidia) и каждой игре с поддержкой DLSS для генерации алгоритма повышения масштаба требовалось отдельное исследование компанией Nvidia.

Когда в начале 2020 года вышла версия 2.0, в неё были внесены серьёзные улучшения. Самым важным стало то, что суперкомпьютеры Nvidia теперь использовались только для создания общего алгоритма увеличения масштаба — в новой версии DLSS для обработки пикселей с помощью нейронной модели (тензорными ядрами GPU) используются данные из отрендеренного кадра.

Нас впечатляют возможности DLSS 2.0, но пока его поддерживает очень мало игр — на момент написания статьи их было всего 12. Всё больше разработчиков хочет реализовать его в своих будущих играх, и на то есть причины.
Благодаря любому увеличению масштаба можно добиться серьёзного роста производительности, поэтому можно быть уверенными, что DLSS продолжит эволюционировать.

Хотя визуальные результаты работы DLSS не всегда идеальны, освободив занятые рендерингом ресурсы, разработчики смогут добавить больше визуальных эффектов или обеспечить один уровень графики на более широком диапазоне платформ.
Например, DLSS часто рекламируют вместе с трассировкой лучей (ray tracing) в играх с «поддержкой RTX». Карты GeForce RTX содержат дополнительные вычислительные блоки, называемые RT-ядрами, это специализированные логические блоки для ускорения вычислений пересечения луча с треугольником и обхода иерархии ограничивающих объёмов (bounding volume hierarchy, BVH). Эти два процесса являются очень длительными процедурами, определяющими способ взаимодействия света с другими объектами сцены.
Как мы выяснили, ray tracing — очень трудоёмкий процесс, поэтому чтобы обеспечить в играх приемлемый уровень частоты кадров, разработчики должны ограничить количество лучей и выполняемых в сцене отражений. При выполнении этого процесса могут создаваться зернистые изображения, поэтому необходимо применять алгоритм устранения шумов, что повышает сложность обработки. Ожидается, что тензорные ядра повысят производительность этого процесса благодаря устранению шумов с использованием ИИ, однако это ещё предстоит реализовать: большинство современных приложений по-прежнему использует для этой задачи ядра CUDA. С другой стороны, благодаря тому, что DLSS 2.0 становится вполне практичной техникой повышения размера, тензорные ядра можно будет эффективно использовать для повышения частоты кадров после применения в сцене трассировки лучей.
Существуют и другие планы по использованию тензорных ядер карт GeForce RTX, например, улучшение анимаций персонажей или симуляция тканей. Но как и в случае с DLSS 1.0, пройдёт ещё немало времени, прежде чем появятся сотни игр, использующие специализированные матричные вычисления на GPU.
Многообещающее начало
Итак, ситуация такова — тензорные ядра, отличные аппаратные блоки, которые, однако, встречаются только в некоторых картах потребительского уровня. Изменится ли что-то в будущем? Так как Nvidia уже значительно улучшила производительность каждого тензорного ядра в своей архитектуре Ampere, есть большая вероятность того, что они будут устанавливаться и в модели нижнего и среднего ценового уровня.
Хотя таких ядер пока нет в GPU компаний AMD и Intel, возможно, в будущем мы их увидим. У AMD есть система повышения резкости или улучшения деталей в готовых кадрах ценой небольшого снижения производительности, поэтому компания, возможно, будет придерживаться этой системы, особенно учитывая то, что её не нужно интегрировать разработчикам, достаточно включить её в драйверах.
Существует также мнение, что пространство на кристаллах в графических чипах лучше было бы потратить на дополнительные шейдерные ядра — так поступила Nvidia при создании бюджетных версий своих чипов Turing. В таких продуктах, как GeForce GTX 1650, компания полностью отказалась от тензорных ядер и заменила их дополнительными FP16-шейдерами.
Но пока, если вы хотите обеспечить сверхбыструю обработку GEMM и воспользоваться всеми её преимуществами, то у вас есть два варианта: купить кучу огромных многоядерных CPU или просто один GPU с тензорными ядрами.

Искусственный интеллект думает не так, как человек, и вычисляет не так, как программа. Поэтому компания Google разработала тензорный процессор — элемент аппаратного обеспечения, адаптированный под ИИ.

Искусственный интеллект уже давно прочно вошел в нашу жизнь. Чаще всего мы даже не задумываемся над этим вопросом, когда привычно пользуемся голосовым помощником в смартфоне или автоматическим распознаванием изображений в программе. Даже поиск Google не обходится без машинного обучения, области искусственного интеллекта.
Уже около двух лет работает технология под названием RankBrain, которая служит для умной сортировки результатов поиска. Около 15% ежедневных запросов являются новыми для Google, то есть до этого они не формулировались ни одним пользователем.

![Как работает CPU для Google: свободный искусственный интеллект]()
Сверхчеловеческий интеллект

Свое название процессоры получили от библиотеки программного обеспечения TensorFlow. Основное предназначение TPU состоит в ускорении алгоритмов искусственного интеллекта, которые делают ставку на библиотеки свободного программного обеспечения.
Изначально TPU обрели популярность в качестве аппаратной платформы для AlphaGo —искусственного интеллекта, который победил лучших в мире игроков в азиатскую игру го. В отличие от шахмат, разработка программного обеспечения для го на профессиональном уровне на протяжении многих лет считалась невозможной.
Последующая разработка AlphaGo Zero смогла самостоятельно обучиться игре на основе заданных ей правил. Через три дня она достигла профессионального уровня, через три недели — догнала предшествующую версию AlphaGo, обучение которой стоило громадных усилий и потребовало проведения миллионов профессиональных партий. Выяснилось, что искусственный интеллект ранее ограничивал изучение ходов со стороны человека. Еще через шесть недель AlphaGo Zero уже невозможно было обыграть.
Математика, делающая всё лучше
Тензорные вычисления чрезвычайно полезны в физике и проектировании, они используются для решения всевозможных сложных задач в механике жидкостей, электромагнетизме и астрофизике, однако компьютеры, которые использовались для обработки подобных чисел, обычно выполняли операции с матрицами в больших кластерах из центральных процессоров.
Ещё одна область, в которой любят применять тензоры — это машинное обучение, особенно её подраздел «глубокое обучение». Его смысл сводится к обработке огромных наборов данных в гигантских массивах, называемых нейронными сетями. Соединениям между различными значениями данных задаётся определённый вес — число, выражающее важность конкретного соединения.
Поэтому когда нам нужно разобраться, как взаимодействуют все эти сотни, если не тысячи соединений, нужно умножить каждый элемент данных в сети на все возможные веса соединений. Другими словами, перемножить две матрицы, а это классическая тензорная математика!

Чипы Google TPU 3.0, закрытые системой водяного охлаждения
Именно поэтому во всех суперкомпьютерах глубокого обучения используются GPU, и почти всегда это Nvidia. Однако некоторые компании даже разработали собственные процессоры из тензорных ядер. Google, например, в 2016 году объявила о разработке своего первого TPU (tensor processing unit), но эти чипы настолько специализированные, что не могут выполнять ничего, кроме операций с матрицами.
Как работает CPU
Как подходит к такой задаче CPU? CPU – процессор общего назначения, основанный на архитектуре фон Неймана. Это значит, что CPU работает с ПО и памятью как-то так:
Главное преимущество CPU – гибкость. Благодаря архитектуре фон Неймана, вы можете загружать совершенно разное ПО для миллионов различных целей. CPU можно использовать для обработки текстов, управления ракетными двигателями, выполнения банковских транзакций, классификации изображений при помощи нейросети.
Но поскольку CPU такой гибкий, оборудование не всегда знает заранее, какой будет следующая операция, пока не прочтёт следующую инструкцию от ПО. CPU нужно хранить результаты каждого вычисления в памяти, расположенной внутри CPU (так называемые регистры, или L1-кэш). Доступ к этой памяти становится минусом архитектуры CPU, известным как узкое место архитектуры фон Неймана. И хотя огромное количество вычислений для нейросетей делает предсказуемым будущие шаги, каждое арифметико-логическое устройство CPU (ALU, компонент, хранящий и управляющий множителями и сумматорами) выполняет операции последовательно, каждый раз обращаясь к памяти, что ограничивает общую пропускную способность и потребляет значительное количество энергии.
Тензорные процессоры (TPU)
Успехи искусственного интеллекта Google выглядят впечатляюще. Одна из причин состоит в том, что компания Google разработала специальные аппаратные средства, а это ускоряет нейронные сети намного эффективнее, чем стандартные центральные и графические процессоры. Поразительно, но тензорные процессоры отчасти используют обычные компоненты ПК. Они находятся на одной сменной плате SATA и связываются через PCI Express с другими тензорными процессорами.
Читайте также: