
Raid 1 не работает один диск linux
В данной статье рассмотрим, как удалить неисправный жёсткий диск из массива Linux RAID1 (программное обеспечение RAID) и добавить новый жёсткий диск в массив RAID1 без потери данных. Для копирования схемы раздела диска будем использовать gdisk. Данная программа также работает на большинстве жёстких дисков с GPT (GUID Partition Table).
Задание 2 (Эмуляция отказа одного из дисков)
- Если вы поставили галочку hot swap, то вам доступно удаление дисков на лету:
- Выполните удаление диска ssd1 в свойствах машины.
- Найдите директорию, где хранятся файлы вашей виртуальной машины и удалите ssd1.vmdk.
- Убедитесь что ваша виртуальная машина по-прежнему работает
- Выполните перезагрузку виртуальной машины и убедитесь что она по-прежнему работает
- Проверьте статус RAID-массива: cat /proc/mdstat
- Добавьте в интерфейсе VM новый диск такого же размера и назовите его ssd3.
- Выполните операции:
- Посмотрите что новый диск приехал в систему командой fdisk -l
- Скопируйте таблицу разделов со старого диска на новый: sfdisk -d /dev/XXXX | sfdisk /dev/YYY
- Посмотрите результат командой fdisk -l
- Добавьте в рейд массив новый диск: mdadm --manage /dev/md0 --add /dev/YYY
- Посмотрите результат: cat /proc/mdstat . Вы должны увидеть что началась синхронизация
Теперь нужно вручную выполните синхронизацию разделов, не входящих в RAID. Для этого воспользуемся утилитой dd, скопировав с "живого" диска на новенький, который вы недавно поставили:
Опишите своими словами что вы сделали и какой результат получили в итоге проделанного задания.
Результат: удалён диск ssd1, сохранен диск ssd2, добавлен диск ssd3.
Замена диска в рейде mdadm

Речь пойдет о дешевых дедиках от selectel. Я их много где использую и в целом готов рекомендовать. Это обычные десктопные системники за скромные деньги. Свое мнение об этих серверах, а так же сравнение с полноценными серверами сделаю в конце, в отдельном разделе.
На сервере была установлена система Debian из стандартного шаблона Selectel. Вот особенности дисковой подсистемы этих серверов и шаблона.
- 2 ssd диска, объединенные в mdadm
- /boot раздел на /dev/md0 размером 1G
- корень / на /dev/md1 и поверх lvm на весь массив
В целом, хорошая и надежная разбивка, чему будет подтверждение дальше. На сервере был установлен proxmox, настроен мониторинг mdadm. Мониторинг дисков не сделал. В какой-то момент получил уведомление в zabbix, что mdadm развалился. Сервер при этом продолжал работать. Ситуация штатная. Пошел в консоль сервера, чтобы все проверить. Посмотрел состояние рейда.
Убедился, что один диск выпал из массива. В системном логе увидел следующее.

Попробовал посмотреть информацию о выпавшем диске.
Информации не было, утилита показывала ошибку обращения к диску. Получилось посмотреть модель и серийный номер только работающего диска.
Я не стал разбираться, что там к чему с диском. Если вижу проблемы, сразу меняю. Предупредил заказчика, что с диском проблемы, нужно планировать замену. Так как железо десктопное, "сервер" надо выключать. Согласовали время после 22 часов. Я в это время уже сплю, поэтому написал тикет в тех поддержку, где указал время и серийный номер диска, который нужно было оставить. Я сделал на этом акцент, объяснил, что сбойный диск не отвечает, поэтому его серийник посмотреть не могу. Расписал все очень подробно, чтобы не оставить почвы для недопонимания или двойного толкования. Я в этом уже спец, но все равно не помогло.
Я спокойно согласился на эту операцию, потому что часто делаются бэкапы и они гарантированно рабочие. Настроен мониторинг бэкапов и делается регулярное полуручное восстановление из них. Договоренность была такая, что хостер после замены дожидается появления окна логина, а заказчик проверяет, что сайт работает. Все так и получилось - сервер загрузился, виртуалки поднялись, сайт заработал. На том завершили работы.
Утром я встал и увидел, что весь системный лог в ошибках диска, рабочего диска в системе нет, а есть один глючный и один новый. Сразу же запустил на всякий случай ребилд массива и он вроде как даже прошел без ошибок. Перезагрузка временно оживила сбойный диск. В принципе, на этом можно было бы остановиться, заменить таки сбойный диск и успокоиться. Но смысл в том, что этот сбойный диск почти сутки не был в работе и данные на нем старые. Это не устраивало. Потом пришлось бы как-то склеивать эти данные с данными из бэкапов. В случае с базой данных это не тривиальная процедура. Созвонился с заказчиком и решили откатываться на рабочий диск, который вытащили накануне ночью.
Я создал тикет и попросил вернуть рабочий диск на место. К счастью, он сохранился. К нему добавить еще один полностью чистый. Хостер оперативно все сделал и извинился. В завершении прислал скриншот экрана сервера.
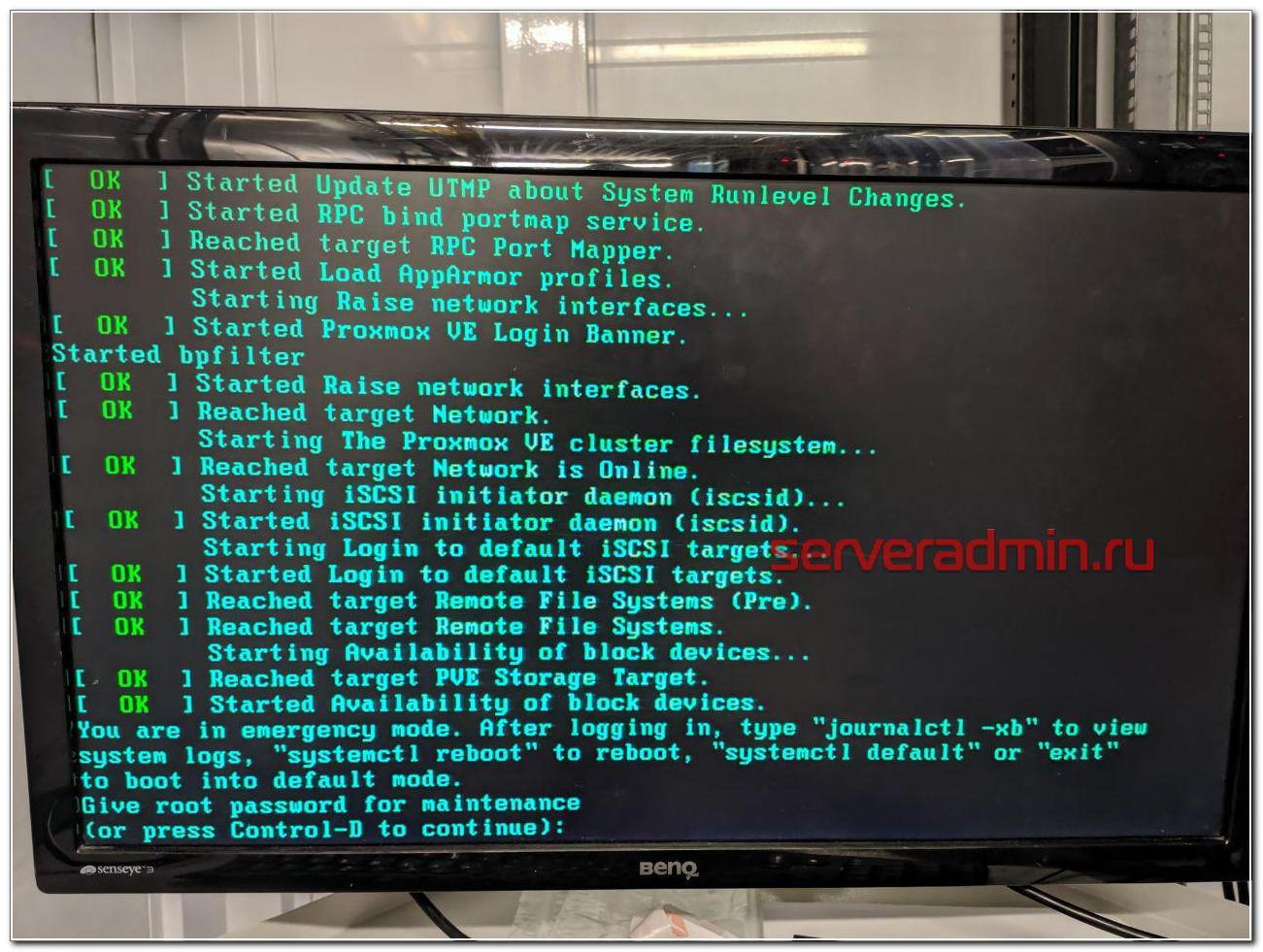
И самоустранился. Дальше решать проблему загрузки он предложил загрузившись в режиме rescue. Этот режим доступен через панель управления сервером в админке, даже если сервер не имеет ipmi консоли. Как я понял, по сети загружается какой-то live cd для восстановления. Я в нем загрузился, убедился, что данные на месте, но понять причину ошибки не смог. Может быть и смог бы, если бы дольше покопался, но это очень неудобно делать, не видя реальной консоли сервера. Я попросил подключить к серверу kvm over ip, чтобы я мог подключиться к консоли. Тех поддержка без лишних вопросов оперативно это сделала.
К слову, мне известны случаи, когда техподдержка selectel потом сама чинила загрузку и возвращала mdadm в рабочее состояние. Видел такие переписки в тикетах у своих клиентов до того, как они обращались ко мне. Но я не стал настаивать на таком решении проблемы, так как боялся, что будет хуже. К тому же это было утро воскресенья и специалистов, способных это сделать, могло просто не быть. Плюс, я не думаю, что они обладали бы большими компетенциями, чем я. Я бы за их зарплату не пошел работать в ЦОД.
После того, как я подключился к консоли сервера, восстановление загрузки было делом техники.
Задание 1 (Установка ОС и настройка LVM, RAID)
Создайте новую виртуальную машину, выдав ей следующие характеристики:
- 1 gb ram
- 1 cpu
- 2 hdd (назвать их ssd1, ssd2 и назначить равный размер, поставить галочки hot swap и ssd)
- SATA контроллер настроен на 4 порта:
Начать установку Linux и дойдя до выбора жестких дисков сделать следующее:
-
Partitioning method: manual, после чего вы должны увидеть такую картину:
- Partition size: 512M
- Mount point: /boot
- Create MD device
- Software RAID device type: Выберите зеркальный массив
- Active devices for the RAID XXXX array: Выбрать оба диска
- Spare devices: Оставить 0 по умолчанию
- Active devices for the RAID XX array: выбрать разделы, которые вы создавали под raid
- Finish
- logical volume name: root
- logical volume size: 2\5 от размера вашего диска
- logical volume name: var
- logical volume size: 2\5 от размера вашего диска
- logical volume name: log
- logical volume size: 1\5 от размера вашего диска
Закончить установку ОС, поставив grub на первое устройство (sda) и загрузить систему.
Выполните копирование содержимого раздела /boot с диска sda (ssd1) на диск sdb (ssd2)
Выполнить установку grub на второе устройство:
Посмотреть диски в системе:
Найдите диск на который не была выполнена установка grub и выполните эту установку:
Опишите своими словами что вы сделали и какой результат получили в итоге проделанного задания.
После выполнения этого задания рекомендуется сохранить резервную копию папки с виртуальной машиной или сделать vagrant box.
Результат: Виртуальная машина с дисками ssd1, ssd2.
4-Добавление нового жёсткого диска
После замены жёсткого диска /dev/sdb, включим систему.
Первым делом необходимо создать точно такое же разбиение на разделы, что и в /dev/sda. Выполним это командой sgdisk из пакета gdisk. Если у Вас не установлен gdisk, установите его, выполнив для Debian и Ubuntu следующее:
Для rpm-дистрибутивов Linux, таких как CentOS:
Следующий шаг необязательный, но рекомендуемый. Для проверки того, что у нас есть резервная копия схемы раздела, воспользуемся sgdisk для записи схем раздела обоих дисков в файл. В нашем случае файл сохраним в /root folder.
В случае неудачи можно восстановить таблицу разделов с помощью опции --load-backup в sgdisk .
Теперь скопируем схему раздела из /dev/sda в /dev/sdb:
Затем необходимо рандомизировать GUID на новом жёстком диске, чтобы убедится, что он уникален.
для проверки, что оба жёстких диска имеют одинаковое разбиение на разделы.
Далее добавим /dev/sdb1 в /dev/md0 и /dev/sdb2 в /dev/md1:
Теперь оба массива (/dev/md0 и /dev/md1) будут синхронизированы.
Результат можно увидеть по команде:
Во время синхронизации выходные данные должны выглядеть следующим образом:
А по окончании синхронизации выходные данные должны выглядеть следующим образом:
В нашем пошаговом руководстве, я расскажу о нескольких методах восстановления информации с программных RAID 5, 0 или 1, которые собраны под «Linux».

Если один или несколько физических накопителей повреждены, то кажется что восстановить данные просто невозможно. На самом деле это не так, объем информации, который можно достать из массива, сильно зависит от типа RAID и количества сломанных носителей.
Программный RAID крайне ненадежная штука, отключите всего один накопитель и весь массив перестанет определяться системой. Массив с поломанным носителем, можно пересобрать при помощи специальных программ, в наших тестах я буду использовать Hetman RAID Recovery. После запуска, она автоматически определит тип контроллера, название программы или производителя материнской платы, на основе технологий которых был собран RAID. Потом утилита соберет его из оставшихся «живых» накопителей, просканирует и найдет всю оставшуюся информацию, которую можно будет сохранить в другое место.
Установочный файл программы есть только под ОС Windows. Чтобы запустить ее под Linux понадобиться, либо установить дополнительную систему на компьютер, либо воспользоваться виртуальной машиной под Windows. В нашем случае, я выбрал второй вариант.

Восстанавливаем файлы с RAID-1
Тестовый массив первого типа состоит из двух одинаковых накопителей. Этот тип очень надежен сам по себе, так как может состоять из четного количества физических дисков, которые работают как «полное зеркало». Если поврежден только один носитель, то все устройство невозможно смонтировать в Linux.

Запускаем программу, она нашла и пересобрала устройство, все параметры указаны верно.

Так как, «живой» диск содержит полноценную копию всей информации, то запускаем быстрый анализ, отмечаем нужные нам файлы и каталоги, сохраняем на любой другой диск.

Восстанавливаем данные с RAID 5

Тестовый RAID 5 состоит из 5 физических дисков, один из них гарантированно сломан. Добавляем их в виртуальную машину с Windows, запускаем Hetman RAID Recovery, массив обнаружен и все настройки и свойства указаны верно.

Как и положено один накопитель пустой. Так как это RAID 5, то снова запускаем быстрый анализ, находим нужные данные с помощью функции превью и восстанавливаем их. Когда процесс сохранения закончится, все файлы будут находится в выбранном каталоге.

Теперь рассмотрим вариант когда повреждены два физических носителя из пяти. Программа обнаружила RAID, и два «винчестера» пустые.

Восстановить данные с такого массива, задача непростая, запускаем полное сканирование, в зависимости от размеров «винчестеров» оно может длиться вплоть до суток. В итоге, программа нашла нетронутые данные, но несколько файлов частично или полностью стерты, их не получиться восстановить.

Если повреждены два или более физических носителя, RAID 5 становиться полностью неработоспособным, что сулит 100% потерю всех данных. Поэтому наш результат можно считать удовлетворительным.
Материалы для изучения
- RAID
- LVM
- Именование дисков в ОС Linux
- Что такое раздел
- Что такое таблица разделов и где она хранится
- Что такое grub
Используемые утилиты
- Просмотр информации о дисках:
- lsblk -o NAME,SIZE,FSTYPE,TYPE,MOUNTPOINT
- fdisk -l
- Просмотр информации и работа с LVM
- pvs
- pvextend
- pvcreate
- pvresize
- vgs
- vgreduce
- lvs
- lvextend
- Просмотр информации и работа с RAID:
- сat /proc/mdstat
- mdadm
- Точки монтирования:
- mount
- umount
- cat /etc/fstab
- cat /etc/mtab
- Переразметка диска:
- fdisk /dev/XXX
- Копирование разделов:
- dd if=/dev/xxx of=/dev/yyy
- Работа с таблицей разделов:
- partx
- sfdisk
- mkfs.ext4
- Работа с загрузчиком:
- grub-install /dev/XXX
- update-grub
- misc
- lsof
- apt
- rsync
You are in emergency mode
У меня много примеров того, как я восстанавливал загрузку сломавшихся linux дистрибутивов.
В данной ситуации с mdadm я был уверен, что все получится, так как сам массив с системой жив, данные доступны. Надо только разобраться, почему система не загружается. Напомню, что ошибка загрузки была следующая.
Дальше нужно ввести пароль root и вы окажетесь в системной консоли. Первым делом я проверил состояние массива mdadm.
Состояние массива md0, на котором располагается раздел /boot - inactive. Вот, собственно, и причина того, почему сервер не загружается. Судя по всему, когда был подключен сбойный диск, mdadm отключил массив, чтобы предотвратить повреждение данных. Не понятно, почему именно на разделе /boot, но по факту было именно это. Из-за того, что массив остановлен, загрузиться с него не получалось. Я остановил массив и запустил снова.
После этого массив вышел из режима inactive и стал доступен для дальнейшей работы с ним. Я перезагрузил сервер и убедился, что он нормально загружается. Сервер фактически был в рабочем состоянии, просто с развалившимся массивом mdadm, без одного диска.
Если вам это не поможет, предлагаю еще несколько советов, что можно предпринять, чтобы починить загрузку. Первым делом проверьте файл /etc/fstab и посмотрите, какие разделы и как там монтируются. Вот мой пример этого файла.
Вам нужно убедиться, что указанные lvm разделы /dev/mapper/vg0-root и /dev/mapper/vg0-swap_1 действительно существуют. Для этого используйте команду:
Подробно об этой команде, о работе с lvm и вообще с дисками я рассказываю в отдельной статье - настройка диска в debian. Если с lvm разделами все нормально, проверьте /boot. У меня он монтируется по uuid. Посмотреть список uuid всех разделов можно командой.
Как вы видите, у меня uuid раздела для загрузки полностью совпадает с тем, что указано в fstab. Если по какой-то причине uuid изменился (разобрали и собрали новый массив), отредактируйте fstab.
Все дальнейшие действия я делал уже по ssh. Скопировал таблицу разделов с рабочего диска sda на чистый sdb.
Проверил таблицы разделов и убедился, что они идентичные.

Скопировал раздел BIOS boot partition с рабочего диска на новый.
Потом добавил разделы диска sdb2 и sdb3 в рейд массив.
Дождался окончания ребилда и убедился, что он прошел. Проверил состояние массива.

В завершении устанавливаем загрузчик на оба диска.
После этого я перезагрузился и убедился, что все работает нормально. По хорошему, теперь надо было бы поменять загрузочный диск с первого на второй и убедиться, что со второго тоже нормально грузится. Я не стал этого делать, и так простой и так был велик. Главное, чтобы массив был на месте, а починить загрузку, если что, дело техники.
Вот и все по замене диска в массиве mdadm. После доступа к консоли сервера, мне потребовалось минут 10, чтобы вернуть сервер в рабочее состояние.
В чем отличия программного и аппаратного рейда
Сейчас расскажу, чем принципиально отличается программный рейд контроллер (mdadm) от аппаратного, для тех, кто этого до конца не понимает. Если бы у меня вышел из строя диск на аппаратном рейд контроллере, установленном в полноценный сервер, проблема по замене сбойного диска в RAID решалась бы в следующей последовательности:
- Рейд контроллер оповещает о том, что с диском проблемы и выводит его из работы. В случае с софтовым рейдом система может зависнуть в случае проблем с диском, прежде чем пометит его как проблемный и перестанет к нему обращаться.
- Я оставляю тикет в тех поддержку, где прошу заменить сбойный диск. Информацию о нем я посмотрю в панели управления рейд контроллером.
- Сотрудник тех поддержки видит сбойный диск, так как индикация на нем, скорее всего, будет мигать красной лампочкой. Это не гарантия того, что рукожоп все сделает правильно, но тем не менее, шансов, что он ошибется, меньше. Я сталкивался с ситуацией, когда и в этом случае диск меняли не тот.
- При появлении нового диска raid контроллер автоматически начинает ребил массива.
Если же у вас в сервере уже установлен запасной диск на случай выхода из строя диска в составе raid массива, то все еще проще:
- При выходе из строя диска, контроллер помечает его как сбойный, вводит в работу запасной диск и начинает ребилд.
- Вы получаете оповещение о том, что вышел из строя диск и оставляете тикет в тех поддержку на замену запасного диска.
И это все. В обоих случаях у вас вообще нет простоя. Вот принципиальная разница между mdadm и железным raid контроллером. Стоимость полноценного сервера с контроллером и постоянным ipmi доступом к консоли в среднем в 3 раза выше, чем у сервера на десткопном железе с софтовым рейдом при схожей производительности. Это все при условии, что вам достаточно одного процессора и 64G памяти. Это потолок для десктопных конфигураций. Дальше считайте сами, что вам выгоднее. Если возможен простой в несколько часов на замену диска или других комплектующих, то смело можно использовать десктопное железо. Mdadm обеспечивает сопоставимую гарантию сохранности данных в сравнении с железным контроллером. Вопрос лишь в простое и производительности. Ну и своевременные бэкапы добавляют уверенности в том, что вы переживете неполадки с железом.
При использовании железного рейда на hdd дисках, есть возможно получить очень значительный прирост скорости за счет кэша контроллера. Для ssd дисков я особо не замечал разницы. Но это все на глазок, никаких замеров и сравнений я не делал. Нужно еще понимать, что десктопное железо в целом менее надежное. К примеру, в том же селектеле на дешевых серверах я ловил перегрев или очень высокую температуру дисков. Прыгала в районе 55-65 градусов. Все, что ниже 60-ти, тех поддержка футболила, говоря, что это допустимая температура, судя по документации к дискам. Это так и есть, но мы же понимаем, что диск, постоянно работающий на 59 градусах с бОльшей долей вероятности выйдет из строя.
Вот еще пример разницы в железе. Если у вас в нормальном сервере выйдет из строя планка памяти, сервер просто пометит ее как сбойную и выведет из работы. Информацию об этом вы увидите в консоли управления - ilo, idrac и т.д. В десктопном железе у вас просто будет постоянно виснуть сервер и вам придется долго выяснять, в чем же проблема, так как доступа к железу у вас нет, чтобы проще было запланировать тестирование сервера. А если вы закажете это у тех поддержки, то есть ненулевая вероятность, что станет хуже - сервер уронят, перепутают провода подключения дисков и т.д. В общем, это всегда риск. Проще сразу съезжать с такой железки на другую.
Лабораторная работа состоит из 3-х частей:
- Настройка работоспособной системы с использованием lvm, raid.
- Эмуляция отказа одного из дисков.
- Замена дисков на лету, с добавлением новых дисков и переносом разделов.
Вывод
Как показали тесты, количество восстанавливаемой информации напрямую зависит от типа массива. Данные с RAID 5 или 1 можно восстановить практически в полном объеме, благодаря «зеркалам» или избыточности информации. Даже при поломке нескольких жестких дисков, шансы вернуть большую часть нужных файлов достаточно высока.
Выход из строя хоть одного носителя, для RAID 0 становиться критическим. В большинстве случаев вы сможете восстановить только малую часть хранящихся данных. Что касается программы, то она смогла в автоматическом режиме распознать подключенные диски и правильно определить тип массива, что дало возможность уже восстанавливать файлы.
Полную версию статьи со всеми дополнительными видео уроками смотрите в источнике.
Все настроено так, что при исправном подключении двух дисков все работает, система загружается с любого из двух дисков и рэйд нормально подымается.
Имитирую сбой одного из дисков, отключаю от него питание и . (не важно какой именно отключаю из дисков, grub2 загрузчик начинает загрузку, меню загрузки отрабатывается) и попадаем в Emergency mode Рэйд не подымается Для каждого из 4-ёх рэйд-массива
- Warning: /dev/disk/by-id/md-uuid-. does not exist
- (вместо точек UUID каждого устройства рэйд-массива, которые прописаны в mdadm.conf)
- и еще одна строка
- Warning: /dev/disk/by-uuid/. -. -. -. does not exist
- (UUID /dev/md127)
- Genereting «/run/initramfs/rdsosreport.txt
И какой-то тупик, почему система не отрабатывает загрузку с одного доступного диска?? Кто-то сталкивался с такой темой? Для Centos 7 не очень много инфы по правильно и рабочей настройке Software Raid..
В настройках grub корневая система как указана?
да, такое наблюдается. При этом если штатно (--fail, затем --remove) вывести один диск из массива, то с оставшегося загрузка будет производится нормально. А если диск выпал аварийно, то хрен. Грузиться с rescue и выводить отпавший из массива.
Значит программный Raid для отказоустойчивости не совсем подходит видимо. Аппаратный лучше тогда использовать? Кто-то может посоветовать оптимальный по цене и по качеству контроллер, который полностью совместим под Linux, с системой мониторинга, чтоб в случае сбоев продолжал фунциклировать и грузиться и работать с одним диском при этом уведомлял что произошел сбой..
Ну у вас же диск не с бухты Барахты отвалится и не будет вообще определяться системой.
У вас в начале на нём появятся ошибки и система пометит его как сбойный и сама удалит из рейд.
А если вы хотите на ходу сами заменить диск, то в начале руками уделяете его из массива, за если снимаете питание давая ядру соответветствующую команду, за если вынимаете его, вставляете новый, даёте и команду просканирвоать Ата каналы, что бы нашелся новый диск, затем создаете на нем такую же разметку. У вас же raid не просто на дисках, а на разделах рейд аутодетект? И вот потом добавляете его в массив.
А на ходу просто так диски никто не дергать, все делаетеся на рабочей системе.
А если вы по какой то причине выключили сервер, вынули диск, то значит можете руками и удалить диск или добавить новый.
Повторюсь, рейд должен быть собран не просто на дисках, /dev/sdX, а на разделах диска /dev/sdXN с типом рей автодетект.
Ну и вы что сервера перезагружаете каждый день?
Я пытаюсь сделать отказоустойчивую систему, поэтому моделирую ситуацию по полному сбою диска, это вариант не исключается же..
Автодетек это значит выставленный тип в Fdisk - FD ? В Centos 7 это уже не работает, нету такого параметра в Fdisk. Тип показывает Linux RAID У меня кстати непонятно почему, только для двух развелов показывает такой тип
Для первого и второго тоже создан рэйд, но тип дисков почему-то остался как был до установки рэйда. может потому, что там metdata 0,90 для первых двух. Даже не знаю как проверить это, поскольку в 7-ом Centos нет возможности выставить тип разделу - RAID (для 4-ого и 5-ого разделов этот тип поставился сразу после команды создания массива mdadm --create. )
У тебя странное понимание отказоустойчивости raid. Выключение - это уже «отказ» для raid. Если тебе нужно другое «понимание отказоустойчивости», то тебе не нужен raid.
Отказоустойчивость в моем понимании - это продолжении работы системы в случае подобного отказа одного из дисков. \ Для этого вроде и придумывали RAID изначально.
При отключении _отказали_ все диски. Просто некоторые реализации raid чисто случайно умеют автоматически собирать рабочий массив из отказавших дисков. В твоем случае нужен не raid, а спец загрузчик (который не на raid), который умеет собирать raid из отказавших (выключенных) дисков.
Странная реализация рэйда. где же найти такой спецзагрузчик? не лучше ли уйти на аппаратный рэйд?
Что у тебя сейчас происходит? Boot и efi «как бы» в рейде. Во время загрузки рейд на них не рабтает, потому что линуксовый софт-рейд, а линукс не загружен, работать нечему. И система грузится с чисто случайного неотказоустойчивого раздела. А когда загружен, смысл нахождения boot и efi в рейде вообще не понятен - от какого отказа защищаешься? Если от «ненадежной» записи, то тебе в наркоманский тред про надежную запись на диск для переписи шаманов с бубнами камлащих над sync, direct и тп.
Чтобы сделать отказоустойчивый дублированный загрузчик, нужен неотказоустойчивый загрузчик такого загрузчика. Успехов.
А можно как-то повнятнее и конкретнее? Вижу что эмоций много в ответе, но суть я сильно понял ))
Небольшое отступление: данная л\р является синтетической.
Некоторые задания которые здесь описаны можно сделать гораздо проще, но поскольку задача л/р — познакомиться с функционалом raid, lvm то некоторые операции искусственно усложнены.
ВНИМАНИЕ
Данная лабораторная работа связана с такой тонкой материей как сохранность данных — это такая область, которая позволяет из-за мельчайшей ошибки — одной лишней буквы или цифры потерять все ваши данные.
Поскольку вы выполняете лабораторную работу вам ничего не грозит, разве что придется начать делать ее заново.
В реальной жизни все гораздо серьезнее, поэтому следует очень внимательно вводить имена дисков, понимая что именно вы выполняете текущей командой и с какими дисками работаете.
Второй важный момент — именование дисков и разделов: в зависимости от ситуации номера дисков могут отличаться от тех значений, что представлены в командах в лабораторной работе.
Так, например, если удалить диск sda из массива, а затем добавить новый диск, то новый диск будет отображаться в системе с именем sda. Если же выполнить перезагрузку перед добавлением нового диска, то новый диск будет иметь имя sdb, а старый станет именоваться sda
Лабораторная работа должна выполняться под суперпользователем (root) поскольку большая часть команд требует повышенных привилегий и не имеет смысла постоянно повышать привилегии через sudo.
Как восстановить данные RAID-0
Наш тестовый RAID 0 включает 5 жестких дисков, этот тип один из самых ненадежных. Фактически, это вообще не RAID, так как он не хранит избыточную информацию о хранящихся файлах. Если выйдет из строя хоть один «винчестер», то все устройство целиком нельзя монтировать в ОС. Все данные становятся недоступны.
Тип RAID-0 – это массив физических носителей с чередованием. Он показывает хорошую производительность благодаря высокой скорости чтения/записи, но отказ оборудования для него будет критическим. Посмотрим, сможем ли мы восстановить хоть часть потерянных данных.

Добавляем диски в виртуальную машину и запускаем утилиту. Hetman Partition Recovery со скрежетом смогла правильно определить тип и свойства массива, один диск отображается пустым.

Быстрое сканирование бессмысленно, сразу запускаем глубокий анализ. Все живые файлы удалось обнаружить и просмотреть превью, но также много поврежденных данных. Выбираем файлы с помощью превью и кликаем «Восстановить».

Заключение
Надеюсь, моя статья была интересной. Для тех, кто никогда не работал с ЦОДами будет полезно узнать, чего можно от них ожидать. Я скучаю по временам, когда все сервера, которые я администрировал, были в серверной, куда никому не было доступа и куда я мог в любой момент попасть и проверить их. Сейчас все стало не так. И твои сервера уже не твои. Их может сломать, уронить, что-то перепутать сотрудник тех поддержки дата центра.
Сейчас большой тренд на переход в облака. Я смотрю на эти облака и не понимаю, как с ними можно нормально взаимодействовать. Заявленная производительность не гарантированная, нагрузка плавает в течении суток. Упасть может в любой момент и ты не будешь понимать вообще в чем проблема. Твои виртуалки могут быть по ошибке удалены и кроме извинений и компенсации в 3 копейки ты ничего не получить. Каждое обращение в ТП как лотерея. Думаешь, что сломают в этот раз. Если сервера железные, то когда пишу тикет на доступ к железу, я морально и технически всегда готов к тому, что этот сервер сейчас отключится и я больше не смогу к нему подключиться.
В целом, опыт работы с облаками у меня негативный. Несколько раз пробовал для сайтов и все время съезжал. Нет гарантированного времени отклика. А это сейчас фактор ранжирования. Для очень быстрого сайта остается только один вариант - свое железо, а дальше уже кому какое по карману. Зависит от надежности и допустимого времени простоя.
Я про облака заговорил, потому что тенденции к тому, что от железных серверов надо отказываться и все переносить в облака. С одной стороны удобно должно быть. Как минимум, не будет указанных выше в статье проблем. А с другой стороны добавляется куча других проблем. Я пока сижу на железяках разного качества и стоимости. А у вас как?
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, научиться непрерывной поставке ПО, мониторингу и логированию web приложений, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и установке Linux на виртуалку. Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
Проверьте себя на вступительном тесте и смотрите подробнее программу ссылке.
Цели статьи
- Рассказать поучительную историю о том, какие могут быть проблемы при аренде серверов в ЦОД.
- Показать на примере, как надо действовать при выходе из строя диска в рейде mdadm.
- Простыми словами объяснить, в чем разница между программным и аппаратным рейдом.
3 Удаление неисправного жёсткого диска
Для удаления /dev/sdb, пометим /dev/sdb1 и /dev/sdb2 как неисправные и удалим их из соответствующих массивов RAID (/dev/md0 и /dev/md1).
Для начала отметим /dev/sdb1 как неисправный:
Выходные данные в
должны выглядеть следующим образом:
Затем удалим /dev/sdb1 из /dev/md0:
Выходные данные должны быть следующими:
должно быть следующим:
Теперь проделаем тоже самое с /dev/sdb2 (который является частью /dev/md1):
Затем выключим систему:
и заменим старый жёсткий диск /dev/sdb на новый (по крайней мере объём нового жесткого диска должен совпадать со старым –если размер на несколько МБ меньше, то перестроить массивы будет невозможно).
2 Как узнать, что жёстких диск неисправен?
Если жёсткий диск неисправен, в журнале регистрации событий появится большое количество ошибок, например в /var/log/messages или /var/log/syslog.
Можно также выполнить:
и вместо строки [UU] получится [U_], что означает, что массив RAID1 неполон.
Требования к инструментам для выполнения л\р:
- Средства виртуализации, например Virtualbox
- Установочный образ linux, например Debian9
- Наличие интернета для скачивания нескольких пакетов
- Подключение по ssh к установленной VM (опционально)
Задание 3 (Добавление новых дисков и перенос раздела)
Это самое сложное и объемное задание из всех представленных. Очень внимательно проверяйте что вы делаете и с какими дисками и разделами. Рекомендуется снять копию перед его выполнением. Это задание независимо от задания №2, его можно выполнять после задания №1 с поправкой на имена дисков.
Вторая часть задания этой лабораторной должна привести в точно такое же состояние которое было после выполнения первой части.
Для того чтобы вам было проще работать могу рекомендовать не удалять физически диски с хостовой машины, а только лишь отсоединять их в свойствах машины. С точки зрения ОС в ВМ это будет выглядеть абсолютно одинаково, но вы сможете в случае чего подключить диск обратно и продолжить выполнение работы откатившись на пару пунктов назад, в случае если у вас возникли проблемы. Например вы могли выполнить неверно или забыть скопировать на новый диск раздел /boot. Я могу лишь посоветовать несколько раз перепроверять с какими дисками и разделами вы работаете, а еще лучше выписать на листочек соответствие дисков, разделов и "физическому" номеру диска. Красивое и понятное дерево рисует команда lsblk , пользуйтесь ей как можно чаще для анализа того что вы сделали и что нужно сделать.
Представьте себе что ваш сервер работал долгое время на 2-х ssd дисках, как вдруг.
Проэмулируйте отказ диска ssd2, удалив из свойств ВМ диск и перезагрузившись.
Посмотрите текущее состояние дисков и RAID:
Вам повезло — начальство разрешило закупить несколько новых дисков:
2 SATA большого объема для давно назревшей задачи вынесения раздела с логами на отдельный диск. 2 SSD на замену погибшему, а также на замену пока еще функционирующему.
Следует учитывать, что корзина сервера поддерживает установку только 4х дисков. одновременно, поэтому добавить все диски сразу нельзя.
Объем HDD выбрать в 2 раза больше чем SSD.
Объем SSD выбрать в 1,25 раза больше бывших SSD.
Добавьте один новый ssd диск, назвав его ssd4, а после добавления проверьте что произошло:
В первую очередь следует озаботиться сохранностью данных старого диска. На этот раз мы будем переносить данные с помощью LVM:
В первую очередь необходимо скопировать файловую таблицу со старого диска на новый:
Подставьте вместо x,y правильные диски и разберите что делает данная команда.
С помощью команды dd скопируйте данные /boot на новый диск:
Если /boot остался смонтирован на старом диске, его следует перемонтировать на живой диск:
Установите загрузчик на новый ssd диск:
Зачем мы выполняем эту операцию?
Создайте новый рейд-массив с включением туда только одного нового ssd диска:
Команда приведенная выше не отработает без указания специального ключа.Прочитайте справку и добавьте этот ключ к команде.
Следующим этапом необходимо настроить LVM
-
Выполните команду pvs для просмотра информации о текущих физических томах.
Создайте новый физический том включив в него ранее созданный RAID массив:
Увеличим размер Volume Group system с помощью такой команды:
Выполните команды и запишите что вы увидели и что поменялось.
На каком физическом диске сейчас находятся LV var, log, root?
Выполните перемещение данных со старого диска на новый, подставив правильные имена устройств.
Повторите операцию для всех logical volume.
Выполните команды и запишите что вы увидели и что поменялось.
Изменим наш VG, удалив из него диск старого raid. Подставьте правильное имя raid.
Выполните команды и запишите что вы увидели и что поменялось.
Удалите ssd3 диск и добавьте ssd5, hdd1, hdd2 согласно вышеописанным ТЗ, в итоге получив:
- ssd4 — первый новый ssd
- ssd5 — второй новый ssd
- hdd1 — первый новый hdd
- hdd2 — второй новый hdd
Проверьте что произошло после добавления дисков:
Восстановим работу основного raid массива:
Выполните копирование таблицы разделов, подставив правильные диски:
Обратите внимание, что когда мы скопировали таблицу разделов со старого диска лказалось что новый размер не использует весь объем жесткого диска. Поэтому в скором времени нам потребуется изменить размер этого раздела и расширить raid. Убедитесь в этом сами, введя команду:
Скопируйте загрузочный раздел /boot с диска ssd4 на ssd5:
Установите grub на новый диск (ssd5).
Изменим размер второго раздела диска ssd5.
Запустите утилиту для работы с разметкой дисков:
Перечитаем таблицу разделов и проверим результат:
Добавим новый диск к текущему raid массиву (не забудьте подставить правильные диски):
Расширим количество дисков в нашем массиве до 2-х штук:
Посмотрите результат: у нас размечено 2 массива, но оба раздела входящие в этот массив имеют разные размеры:
Увеличим размер раздела на диске ssd4
Запустите утилиту для работы с разметкой дисков:
Перечитаем таблицу разделов и проверим результат.
Обратите внимание, теперь sda2, sdc2 разделы имеют размер > чем размер raid-устройства.
На этом этапе размер raid можно теперь расширить:
Просмотрите lsblk и запишите что изменилось.
Однако, хоть мы и изменили размер raid, сами размеры vg root,var,log не изменились
Посмотрите чему равен размер PV:
Расширим размер нашего PV:
Посмотрите чему равен размер PV:
Добавим вновь появившееся место VG var, root:
На этом этапе вы завершили миграцию основного массива на новые диски. работа с ssd1,ssd2 закончена.
Наша следующая задача — переместить /var/log на новые диски, для этого создадим новый массив и lvm на hdd дисках.
Посмотрим какие имена имеют новые hdd диски:
Создадим raid массив:
Создадим новый PV на рейде из больших дисков:
Создадим в этом PV группу с названием data:
Создадим логический том размером всего свободного пространства и назовем его val_log:
Отформатируем созданные раздел в ext4:
Перенесем данные логов со старого раздела на новый
Примонтируем временно новое хранилище логов:
Выполним синхронизацию разделов:
Выясним какие процессы работают сейчас с /var/log:
Останавливаем эти процессы:
Выполним финальную синхронизацию разделов (тех данных что могли измениться с момента последней синхронизации):
Поменяем местами разделы:
Проверяем что получилось:
Самое важно на этом этапе — не забыть изменить таблицу раделов (ext4, например). Поскольку как бы мы не изменяли всякие raid, lvm — пока ФС на разделе не будет уведомлена о том что теперь размер раздела изменился, мы не сможем использовать новое пространство. Используйте команду resize2fs для изменения ФС.
-
Выполним перезагрузку. Если вы все сделали правильно — вы снова попадете в вашу ОС (это нужно для того чтобы убедиться что все работает. Никакого смысла кроме самопроверки этот шаг не несет)
Выполните проверки, что все что мы хотели сделать действительно было сделано:
[ОПЦИОНАЛЬНО] Выполните действия
-
Перезагрузитесь нажимая F12, чтобы указать при загрузке разные диски, для того чтобы убедиться что вы можете загрузиться с любого из ssd дисков, так чтобы мы не боялись отказа одного из них.
Теперь у вас есть ненужный LV log в VG system. Распределите это пространство между root или var, но вместо использования конструкции 100%FREE укажите размер руками с помощью ключа -L:
Хочу рассказать поучительную историю, которая случилась со мной на днях. На одном из серверов в ЦОД вышел из строя диск в составе рейда mdadm. Ситуация типовая, с которой регулярно сталкиваюсь. Оставил заявку в техподдержку на замену диска с указанием диска, который надо поменять. В цоде заменили рабочий диск и оставили сбойный. Дальше история, как я решал возникшую проблему.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курcе по администрированию MikroTik. Автор курcа, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
1 Предварительные замечания
Рассмотрим в качестве примера 2 жёстких диска, /dev/sda и /dev/sdb, с разделами /dev/sda1, /dev/sda2, /dev/sdb1 и /dev/sdb2.
/dev/sdb неисправен и нам потребуется заменить его.
Введение
Когда первый раз сталкиваешься с рукожопством сотрудников техподдержки дата центра, впадаешь в ступор и думаешь, ну как так то? Сейчас я спокойно отношусь к таким ситуациям и действую исходя из самых худших ожиданий. На днях я столкнулся с ситуацией, когда мне заменили не тот диск в сервере с RAID1. Вместо сбойного диска вынули рабочий и заменили чистым. К счастью все закончилось хорошо, но обо всем по порядку.
Не скажу, что у меня прям большой опыт аренды серверов, но он есть. Я регулярно обслуживаю 10-15 серверов, расположенных в разных дата центрах, как российских, так и европейских. Первый негативный опыт я получил именно в Европе и был очень сильно удивлен и озадачен. Я, как и многие, был под влиянием либеральной пропаганды на тему того, что у нас все плохо, а вот Европа образец надежности, стабильности и сервиса. Как же я ошибался. Сейчас отдам предпочтение нашим дата центрам. По моему мнению и опыту, у нас тех поддержка и сервис в целом лучше, чем там, без привязки к стоимости. В Европе дешевле схожие услуги, так как там масштабы сервисов в разы больше.
Приведу несколько примеров косяков саппорта, с которыми сталкивался.
Было много всяких инцидентов помельче, нет смысла описывать. Хотя нет, один все же опишу. Устанавливал свой сервер в ЦОД. Решил пойти в маш зал и проконтролировать монтаж. Если есть такая возможность, крайне рекомендую ей воспользоваться. Местный рукожоп неправильно прикрепил салазки и сервер во время монтажа стал падать. Я его поймал, тем спас его и сервера других клиентов. В итоге помог с монтажом. Сам бы он просто не справился. Я не представляю, что было, если бы я не пошел в машзал. К чести руководства, я написал претензию, где подробно описал данный случай и попросил бесплатно месячную аренду. Мне ее предоставили. Советую всем так поступать. Зачастую, руководство может быть не в курсе того, что происходит в реальности. Надо давать обратную связь.
Уровень моего доверия к тех поддержке дата центров и хостингов вы примерно представляете :) Ну и вот случилось очередное ЧП. Подробнее остановлюсь на этой ситуации, так как она случилась вчера, свежи воспоминания.
Читайте также: