
Как включить cuda на видеокарте amd
Вопрос этот тянется очень давно. АМД разработчики говорят - да да да. Уже как 4 года курирую этот вопрос и все больше и больше убеждаюсь что она не реализуется в ближайшем как мин 10 лет.
На руках имеется современная не дорогая видеокарта RX590 - на панели настроек указав программу и выбрал все настройки брать с программы , далее выбрал - переопределить настройки программы - эффекта почти нет. Программа работающая с CUDA не может подхватить видеокарту.
Более того Nvidia потеряет в продажах профессиональных видеокартах (они очень дорогие) если передаст эту технологию.
К вопросу пришел со стороны покупки видеокарты(с последующей докупкой sli/crossfire)
и существует ли аналогичная технология которая подхватит ведущие программы по рендеренгу , различные САПРы и тп ?
Добавлено через 1 час 7 минут
имеется софт 2019 года с поддержкой(минимальные требования ОpenCL 1.2) тогда как на видеокарте поддержка версии 2.0
смутил тот факт что у аналогов нет вообще поддержки ОpenCL (опечатка)
Подскажите, какой алгоритм/алгоритмы реализовать с технологией CUDA?
Привет! Настало время для диплома (бакалавр). Интересуют параллельные вычисления и непосредственно.

Экономия на AMD - миф или реальность?
Собираю системник с 0 ( до этого стоял древний комп на athlone, потом ноут на amdшке же).
Маленький супер-компьютер для вычислений с помощью видеокарт NVIDIA с применением технологии CUDA.
В моей голове созрела идея собрать машину для вычислений с помощью видеокарт NVIDIA с применением.
Приложение для AMD-видеокарт
Вопрос таков: есть ли на данный момент какое-нибудь работающее приложение для настройки видеокарты.
портирование CUDA под AMD - скорее всего как утка - для продаж видеокарт
Corel 2020 посчитала технологию OpenCL 2.0 - очень слабой
это уже на форуме AMD писалось.
Я хотел бы расширить свой набор навыков в GPU computing. Я знаком с raytracing и realtime graphics (OpenGL), но следующее поколение графики и высокопроизводительных вычислений, похоже, находится в GPU computing или что-то в этом роде.
в настоящее время я использую графическую карту AMD HD 7870 на своем домашнем компьютере. Могу ли я написать код CUDA для этого? (моя интуиция нет, но поскольку Nvidia выпустила двоичные файлы компилятора, я могу ошибаться).
второй более общий вопрос есть, с чего начать с GPU-вычислений? Я уверен, что это часто задаваемый вопрос, но лучшее, что я видел, было от 08', и я думаю, что поле изменилось довольно много с тех пор.
нет, вы не можете использовать CUDA для этого. CUDA ограничивается оборудованием NVIDIA. OpenCL было бы лучшей альтернативой.
У самого Хроноса есть список ресурсов. Как и StreamComputing.сайт ЕС. Для ваших конкретных ресурсов AMD вы можете посмотреть на страница SDK приложения AMD.
обратите внимание, что в настоящее время существует несколько инициатив по переводу/кросс-компиляции CUDA на разные языки и Апис. Один такой пример бедра. Обратите внимание, однако, что это все еще не означает, что CUDA работает на графических процессорах AMD.
вы не можете использовать CUDA для программирования GPU, поскольку CUDA поддерживается только устройствами NVIDIA. Если вы хотите изучить GPU Computing, я бы предложил вам запустить CUDA и OpenCL одновременно. Это было бы очень полезно для вас.. Говоря о CUDA, вы можете использовать mCUDA. Для этого не требуется графический процессор NVIDIA..
Я думаю, что это будет возможно в ближайшее время в AMD FirePro GPU, см. пресс-релиз здесь но поддержка идет 2016 Q1 для инструментов разработки:
программа раннего доступа для инструментов "инициатива Больцмана" запланирована на 1 квартал 2016 года.
вы можете запустить код NVIDIA® CUDA™ на Mac, а также на графических процессорах OpenCL 1.2 в целом, используя кинза . Раскрытие информации: я автор. Пример использования:
Юп. :) Вы можете использовать Hipify для преобразования кода CUDA очень легко в код HIP, который может быть скомпилирован на оборудовании AMD и nVidia довольно хорошо. Вот некоторые ссылки
Я использовал Nsight для программирования для CUDA, это довольно круто. Также вы можете попробовать профиль, графический плагин говорит вам, сколько ресурсов вы используете.

На новом рабочем месте меня посадили за ПК, оборудованный процессором Ryzen 2600 и видеокартой Radeon RX 580. Попробовав обучать нейронные сети на процессоре, я понял, что это не дело: уж слишком медленным был процесс. После недолгих поисков я узнал, что существует как минимум 2 способа запуска современных библиотек машинного обучения на видеокартах Radeon: PlaidML и ROCm. Я попробовал оба и хочу поделиться результатами.
Зачем оно нужно?
Современные видеокарты – это настоящие вычислительные монстры, вся мощь которых обычно тратится на игры. Неглупые люди смекнули, что если организовать программистам прямой доступ к вычислительным блокам видеочипов, то можно всю эту колоссальную мощь задействовать под любые другие задачи, а не только обработку 3D-графики.
Первой в реализации этой идеи преуспела компания NVIDIA со своей архитектурой параллельных вычислений CUDA (Compute Unified Device Architecture). При помощи расширенного синтаксиса языка C и особого компилятора разработчики получили возможность задействовать для вычислительных задач графический чип. AMD, в свою очередь, представила Stream SDK – свое фирменное видение CUDA.
Результат был феноменальный – процессы, связанные с обработкой медиаданных, что подразумевает высокий уровень распараллеливания, завершались в разы быстрее, чем в случае вычислений силами центрального процессора. Особенно явно преимущество GPU проявлялось при рендеринге в программах 3D-моделирования и видеообработке.

Год спустя после выхода CUDA консорциум Khronos Group выпустил фреймворк OpenCL. Фактически он должен был унифицировать код для доступа к вычислительным мощностям процессоров на разных архитектурах, включая видеоядра. С этого момента в профессиональный софт начала активно внедряться поддержка нового фреймворка.
На сегодняшний день OpenCL поддерживают программы Adobe, медиаконвертеры, ряд популярных 3D-рендеров, CAD и софт для математического моделирования.

Лезу исследовать
Авторы PlaidML — vertex.ai, входящая в группу проектов Intel(!). Цель разработки — максимальная кроссплатформенность. Конечно, это добавляет уверенности в продукте. Их статья рассказывает, что PlaidML конкурентноспособен с Tensorflow 1.3 + cuDNN 6 за счет "тщательной оптимизации".
Однако, продолжим. Следующая статья в какой-то степени раскрывает нам внутреннее устройство библиотеки. Основное отличие от всех других фреймворков — это автоматическая генерация ядер вычислений(в нотации Tensorflow "ядро" — это полный процесс выполнения определенной операции в графе). Для автоматической генерации ядер в PlaidML очень важны точные размеры всех тензоров, константы, шаги, размеры сверток и граничные значения, с которыми далее придется работать. Например, утверждается, что дальнейшее создание эффективных ядер различается для батчсайзов 1 и 32 или для сверток размеров 3х3 и 7х7. Имея эти данные фреймворк сам сгенерирует максимально эффективный способ распараллеливания и исполнения всех операций для конкретного устройства с конкретными характеристиками. Если посмотреть на Tensorflow, то при создании новых операций нам необходимо реализовать и ядро для них — и реализации сильно различаются для однопоточных, многопоточных или CUDA-совместимых ядер. Т.е. в PlaidML явно больше гибкости.
Идем далее. Реализация написана на самописном языке Tile. Данный язык обладает следующими основными преимуществами — близость синтаксиса к математическим нотациям (да с ума же сойти!):

И автоматическая дифференциация всех объявляемых операций. Например, в TensorFlow при создании новой пользовательской операции настоятельно рекомендуется написать функцию для вычисления градиентов. Таким образом, при создании собственных операций на языке Tile нам нужно сказать лишь, ЧТО мы хотим посчитать, не задумываясь о том, КАК это считать в отношении аппаратных устройств.
Дополнительно производится оптимизация работы с DRAM и аналогом L1-кэша в GPU. Вспомним схематичное устройство:

Для оптимизации используются все доступные данные об оборудовании — размер кэша, ширина линии кэша, полоса пропускания DRAM и тд. Основные способы — обеспечение одновременного считывания достаточно больших блоков из DRAM(попытка избежать адресации в разные области) и достижение того, что данные, загруженные в кэш, используются несколько раз(попытка избежать перезагрузок одних и тех же данных несколько раз).
Все оптимизации проходят во время первой эпохи обучения, при этом сильно увеличивая время первого прогона:

Кроме того, стоит отметить, что данный фреймворк завязан на OpenCL. Главный плюс OpenCL в том, что это стандарт для гетерогенных систем и ничего не мешает Вам запустить kernel на CPU. Да, именно тут кроется один из главных секретов кроссплатформенности PlaidML.
Выводы
По результатам тестов я оставил себе SAPPHIRE NITRO R9 380 – карта стоит заметно дешевле наикрутейшей R9 390X, но в Premiere Pro производительность двух адаптеров практически идентична. Учитывая, что адаптер покупался для выполнения работы, а значит зарабатывания денег, потраченных 17 тысяч рублей совсем не жалко. Тем более, что и в GTA V карта показала себя молодцом, но это тема совсем для другой заметки.
Что касается опыта применения OpenCL, то нельзя не признать – в мир видеомонтажа пришел спаситель: рендеринг превратился в удовольствие. По сравнению даже с разогнанным Intel Core i5, видеочипы играючи обрабатывают видео с наложенными эффектами в Premiere Pro. При таких результатах тестирования не стоит вопроса, использовать ли рендеринг силами GPU. Вопрос лишь в том, какую видеокарту под это приспособить. Что-нибудь из верхнего игрового сегмента будет в самый раз, например, AMD Radeon R9 3xx. Мои нужды полностью удовлетворил SAPPHIRE NITRO R9 380. Но адаптеры среднего и даже начального уровня также поддерживают OpenCL, а значит заметно ускорят вашу работу в профессиональном софте.
Железо
Прекрасный мир OpenCL я открыл для себя лишь этим летом, купив сразу две видеокарты AMD Radeon серии 300: SAPPHIRE NITRO R9 380 и SAPPHIRE Tri-X R9 390X. Одну из них планировалось сдать обратно в магазин в зависимости от результатов домашних тестов. Карты покупались для надомного видеомонтажа, выбор в сторону Radeon был вполне осознанным: с одной стороны, CUDA работает быстрее, чем OpenCL. С другой, как выяснилось, OpenCL поддерживается значительно большим количеством профессионального софта, чем CUDA, а производительность карт NVIDIA в OpenCL оставляет желать лучшего.

Из предложенного ассортимента карты SAPPHIRE мне понравились более остальных. В отличие от любителей референсного дизайна, SAPPHIRE использует в системе охлаждения классические вентиляторы, которые работают значительно тише референсных центробежных ветродуев – к таким у меня выработалась стойкая неприязнь после беглого знакомства с видеокартой-пылесосом Radeon 4870x2.
Дома при распаковке двух огромных коробок я почувствовал себя замшелым мастодонтом – видеокарты немаленькие. SAPPHIRE R9 390X так и вовсе огромная, с тремя вентиляторами и радиатором, превышающим размеры печатной платы. Сперва я даже поволновался, влезут ли эти монстры в мой корпус. К счастью, влезли, но из корзины для жестких дисков пришлось демонтировать один хард. Киловаттный блок питания также был не лишним – R9 390X требует два четырехконтактных разъема питания, а такой ток вытянет не каждый БП.

- Процессор: Intel Core i5-2500K, разогнанный до 3.7 ГГц
- Оперативная память: 12 Гбайт DDR-1333
- Материнская плата: ASUS P8Z77-V PRO
- Накопители: системный SSD A-DATA 120 Гб, для контента HDD WD Black WD20EARS 2 Тб
- Блок питания: Corsair 1000 Вт
Если Adobe Premiere Pro CS4 был тяжким грузом в офисе, то дома можно было организовать рабочее пространство по своему вкусу. Едва ли я когда-нибудь задумался бы о покупке Premiere Pro, если бы Adobe не выкатила замечательную, на мой взгляд, систему подписки Creative Cloud. Теперь за 600 рублей в месяц я имею легальный и постоянно обновляемый Premiere Pro CC. И он-то, в отличие от офисного старикана, нативно поддерживает рендеринг с помощью OpenCL и CUDA!
Если ваша видеокарта работает с OpenCL или CUDA, то еще на стадии создания проекта в Premiere Pro можно выбрать рендер. За аппаратное ускорение отвечает Mercury Playback Engine GPU (OpenCL) или (CUDA). В уже готовом проекте рендер можно изменить через Project Settings из меню File.
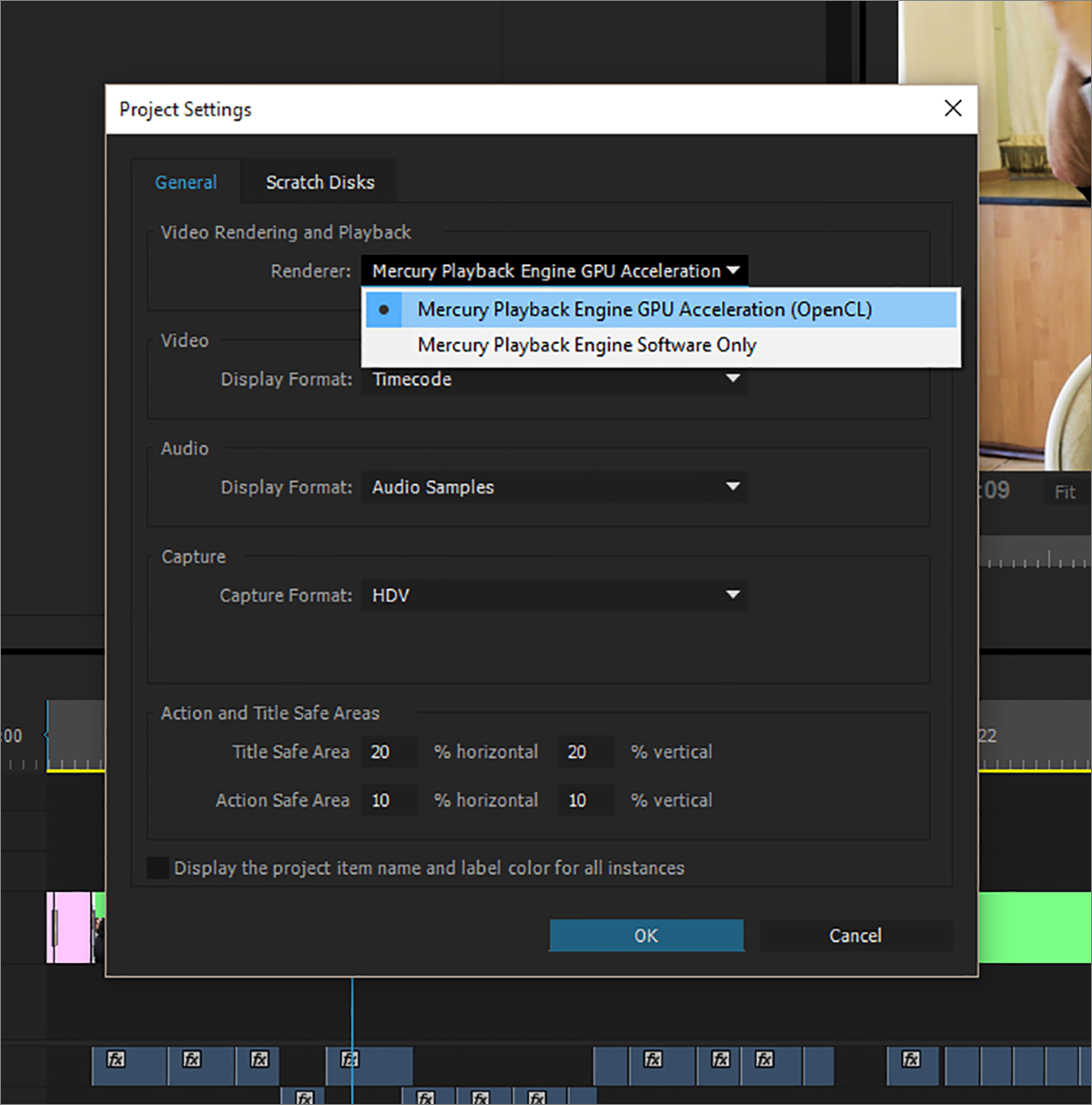
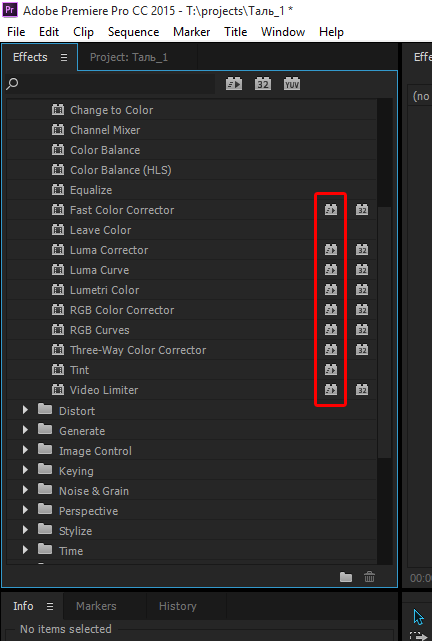
Как я уже говорил, с помощью OpenCL можно переложить на видеокарту вычисления по применению видеоэффектов. Однако не все эффекты в Premiere Pro поддерживают OpenCL – узнать об этом можно по наличию или отсутствию вот такого значка в списке.
Лучше CUDA или OpenCL?
Очень частый и очень интересный вопрос вынесен в подзаголовок. Эти две технологии, как непохожие братья. Как и многострадальный PhysX, CUDA – технология закрытая, поддерживаемая только чипами NVIDIA и далеко не всем специализированным ПО. OpenCL – экстраверт, код открыт любому энтузиасту, любое ПО с поддержкой вычислений на GPU по определению работает с OpenCL.
Программисты NVIDIA не лаптем щи хлебают – если взять две сферические видеокарты в вакууме с одинаковой производительностью, то CUDA на чипе NVIDIA показывает в среднем на 20% большую производительность, чем OpenCL на чипе AMD. Но есть, как говорится, нюанс – если CUDA от NVIDIA работает быстро и хорошо, то OpenCL на картах этой компании немного уступает скорости обработки OpenCL от AMD. Несколько лет назад ситуация была совсем плачевная, но со временем с помощью драйверов разрыв удалось наверстать. Тем не менее, удельная производительность NVIDIA GeForce в OpenCL до сих пор немного ниже таковой у AMD Radeon. Поэтому в самом дурном положении окажутся те, кто приобрёл карту NVIDIA для работы с приложением, поддерживающим исключительно OpenCL — сам адаптер выйдет дороже, а его эффективность может быть ниже, чем у Radeon. Такая игра свеч не стоит.

Заключение
Конечно, обучение на RX 460 всё еще идет в 5-6 раз медленнее, чем на 1060, но вы сравните и ценовые категории видеокарт! Потом у меня появилась RX 580 8gb(мне одолжили!) и время прогона эпохи сократилось до 20 сек, что уже почти сопоставимо.
В блоге vertex.ai есть честные графики (больше — лучше):
Видно, что PlaidML конкурентноспособен по отношению к Tensorflow+CUDA, но точно не быстрее для актуальных версий. Но в такую открытую схватку разработчики PlaidML, вероятно, и не планируют вступать. Их цель — универсальность, кроссплатформенность.
Оставлю здесь и не совсем сравнительную таблицу со своими замерами производительности:
| Вычислительное устройство | Время прогона эпохи (батч — 16), с |
|---|---|
| AMD FX-8320 tf | 200 |
| RX 460 2GB plaid | 35 |
| RX 580 8 GB plaid | 20 |
| 1060 6GB tf | 8 |
| 1060 6GB plaid | 10 |
| Intel i7-2600 tf | 185 |
| Intel i7-2600 plaid | 240 |
| GT 640 plaid | 46 |
Последняя статья в блоге vertex.ai и последние правки в репозитории датированы маем 2018 года. Кажется, если разработчики данного инструмента не перестанут релизить новые версии и всё больше людей, обиженных Nvidia, будут ознакомлены с PlaidML, то про vertex.ai скоро будут говорить намного чаще.
Привет, Гиктаймс! Открыв недавно для себя прекрасный мир ускорения обработки данных силами видеокарт с помощью OpenCL, я решил написать небольшой вводный материал для новичков, не знакомых с этой технологией на практике. В Интернете нередко встречаются вопросы «какой прирост производительности я получу?», но ответы бывают либо абстрактными, либо излишне теоретизированными.
Этот пост призван наглядно показать, как применение OpenCL способно ускорить рендеринг видео в программах видеомонтажа. Глубокого погружения в теорию и матан вы не встретите – подробных теоретических статей про OpenCL на Гиктаймсе и Хабре предостаточно и без меня. Здесь будет только описание задачи и результаты тестов, поэтому прошу относиться к тексту именно как к простому вводному гайду для начинающих.

Гуглю
Окей. Я иду гуглить, как юзать Radeon под Tensorflow. Заведомо зная, что это экзотическая задача, я особо не надеялся найти что-то толковое. Собирать под Ubuntu, заведётся или нет, получить кирпич — фразы, выхваченные с форумов.
И вот я пошел другим путём — я гуглю не "Tensorflow AMD Radeon", а "Keras AMD Radeon". Меня моментально кидает на страничку PlaidML. Я завожу его за 15 минут(правда, пришлось сдаунгрейдить Keras до 2.0.5) и ставлю учиться сеть. Первое наблюдение — эпоха идет 35 сек вместо 200.
Тесты
В качестве тестового проекта я выбрал двухминутный ролик, состоящий из множества отрезков с видео Full HD с битрейтом 72 Мбит/с и фреймрейтом 24 кадра в секунду. Поверх всего этого безобразия был наложен ускоряемый эффект Lumetri Color, которым я провел цветокорррекцию. На выходе должен был получиться ролик в формате h.264, в разрешении 1920х1080 (то есть без изменений), битрейтом 6-7 Мбит/с, применялась двухпроходное кодирование.
Для подтверждения работы видеокарты я снимал параметры GPU-Z – глядя на частоту графического ядра, легко понять, когда рендеринг видео идет силами центрального процессора, а когда GPU.
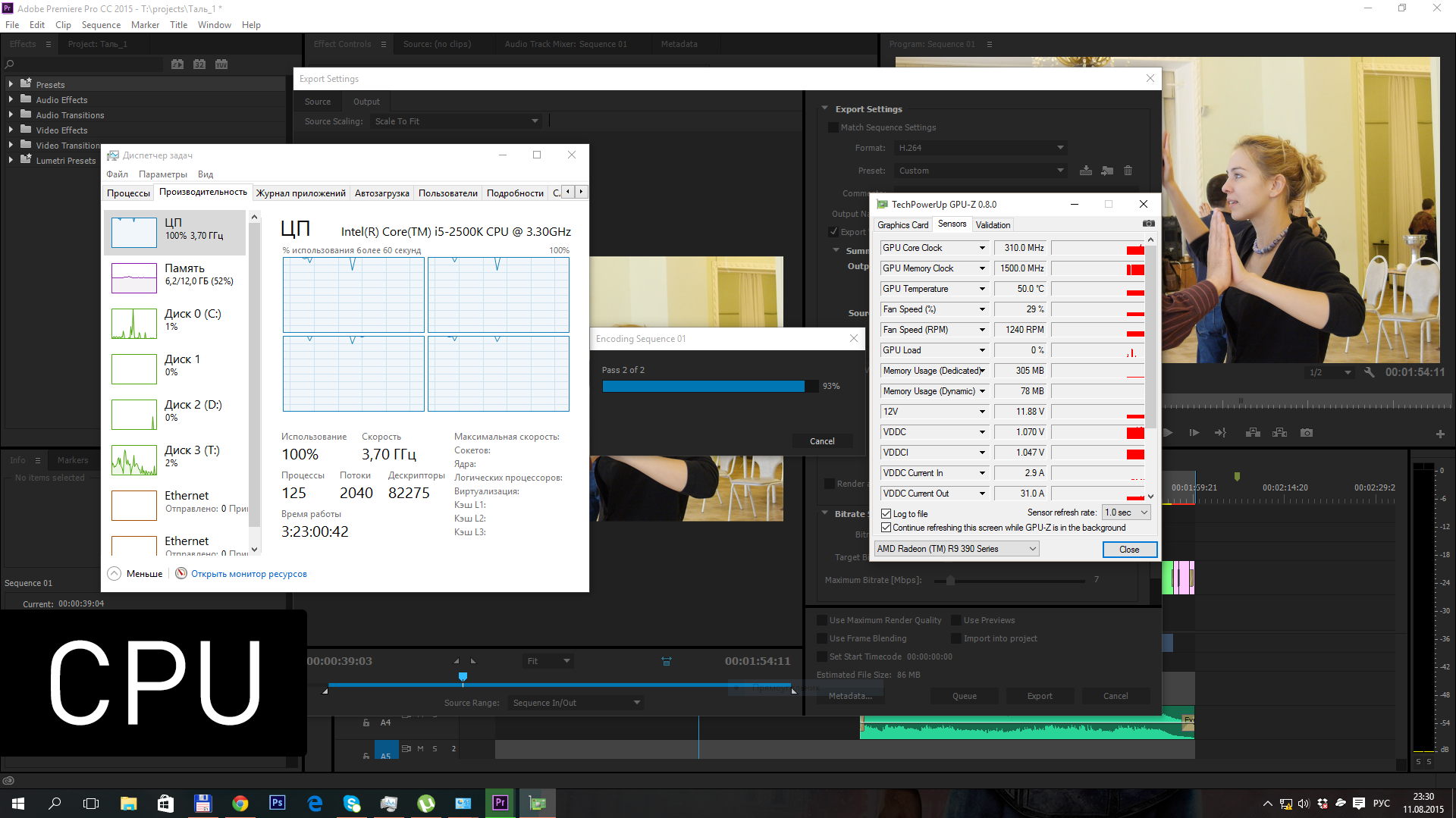
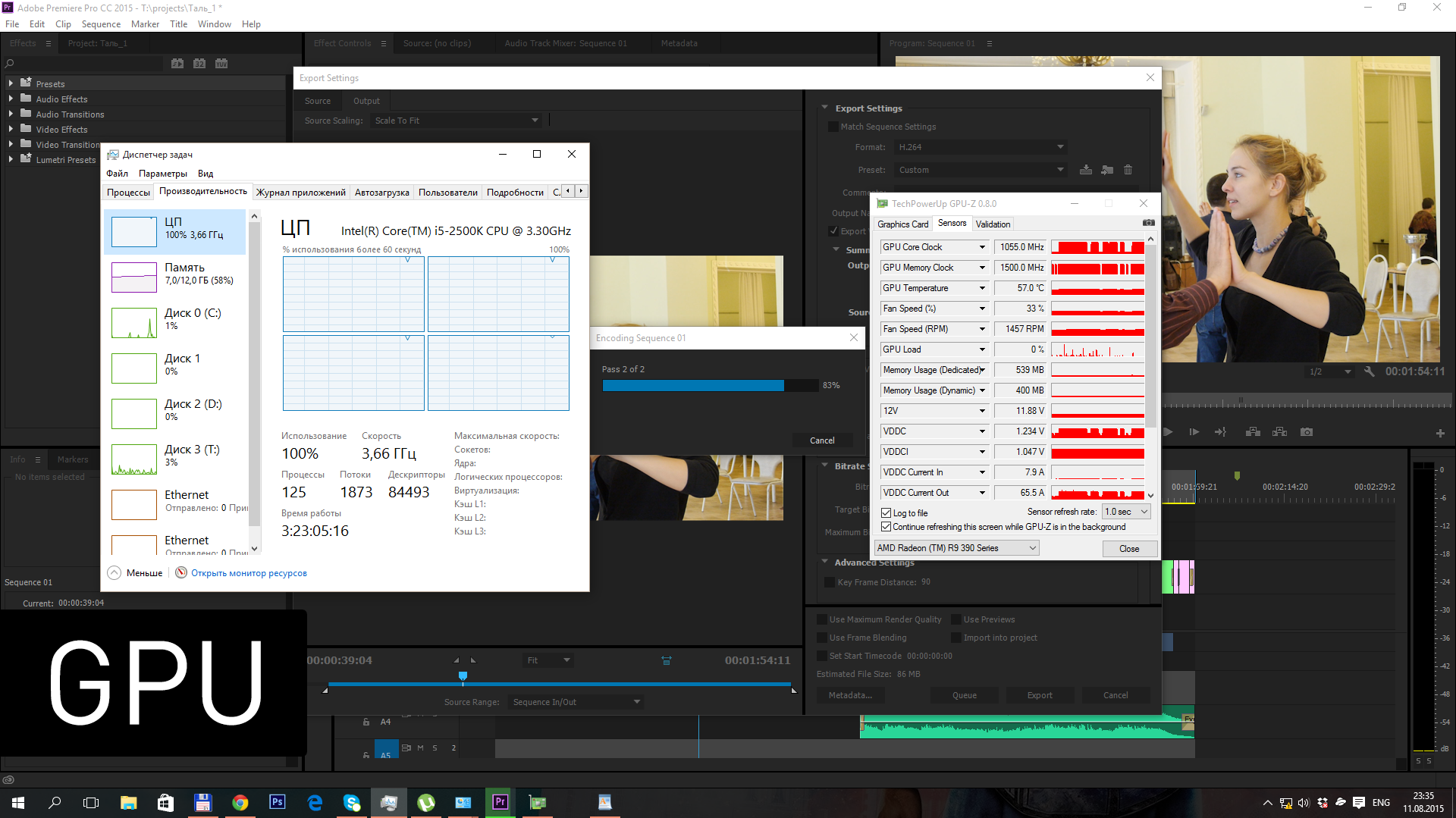
В первом тестовом прогоне я отключил эффект Lumetri Color, так что весь рендеринг заключался в изменении битрейта видео.
Прогон 1:
проект 2 минуты, h.264, 6-7 mbps, без эффектов
| CPU | 3:09 |
| SAPPHIRE Tri-X R9 390X | 2:33 |
| SAPPHIRE NITRO R9 380 | 2:38 |
Без применения эффектов разница в скорости рендеринга между процессором и мощной современной видеокартой очень невелика. При обработке видео общей длительностью около часа выигрыш от использования OpenCL будет более заметным, но все равно очень незначительным. Тем не менее, практически всегда в процессе монтажа к видео применяют эффекты цветокоррекции, поэтому данный тест стоит считать «синтетическим».
Прогон 2:
проект 2 минуты, h.264, 6-7 mbps, эффект Lumetri Color
| CPU | 11:33 |
| SAPPHIRE Tri-X R9 390X | 2:42 |
| SAPPHIRE NITRO R9 380 | 2:48 |
Результаты говорят сами за себя – если обе видеокарты играючи рендерили видео чуть медленнее риалтайма, то процессор на рендеринг каждой минуты тратил почти шесть минут. И это только с одним включенным эффектом! Если перед тестом я рассчитывал в том числе обработать часовой ролик с цветокоррекцией на всей продолжительности, то после полученных результатов от этой идеи решил отказаться. В своей работе я применяю цветокоррекцию для небольших отрезков видео, и час-два рендера меня не сильно напрягают. Терять же четыре-пять часов в тестовых целях мне было некогда.
Экстраполируя результаты, можно считать, что с цветокоррекцией длительностью 60 минут процессор справился бы за 4.5 часа, тогда как видеокартам потребовалось бы менее одного часа!
PlaidML: кроссплатформенность во главе угла
TensorFlow служит бэкэндом для Keras, интерпретируя его синтаксис и преобразуя его в инструкции, которые могут выполняться на процессоре или GPU. К сожалению, он поддерживает только видеокарты с технологией Nvidia CUDA.
PlaidML - альтернативный бэкэнд для Keras с поддержкой OpenCL. Его можно использовать для обучения моделей Keras на встроенной графике процессора, дискретном или даже внешнем графическом процессоре AMD. Он работает на Windows, Linux и Mac.
UPD: В своём комментарии пользователь MikeLP указал, что:
Keras задумывался как высокоуровневый интерфейс. Соответственно остальные бекенды, как PlaidML могли обеспечить работу с другими видеоускорителями без закрытой технологии CUDA. И так было до тех пор, пока авторы не заявили, что Keras будет развиваться только в рамках Tensorflow. Все — «накрылась медным тазом ваша качалка». И получается что PlaidML может работать только с Keras, a не с tf.Keras — API разбежалось. Cоответственно смысл юзать PlaidML, когда он не совместим с последней версией Keras API в Tensorflow. Пацаны из PlaidML (они часть Intel) были вынуждены поменять roadmap и идти в другом направлении.
По моему мнению, PlaidML ещё актуален, т.к. включение Keras в Tensorflow произошло недавно и API не успел существено поменяться. Однако дальшейшие перспективы Keras+PlaidML выглядят туманно.
Установка PlaidML очень проста. Нужно поставить Python-пакет и выбрать устройство в пошаговом конфигураторе:
В коде нужно прописать использование PlaidML как бэкэнда:
После этого все вычисления будут выполняться на видеокарте. Запустим бенчмарк:
Сравним результаты нашего видеоадаптера с некоторыми другими. RX 580 и Ryzen 2600 я тестировал локально, результаты остальных устройств взяты от других пользователей:

Свою рабочую станцию мне выдалось собирать, будучи студентом. Достаточно логично, что я отдавал предпочтение вычислительным решениям AMD. потому что это дешево выгодно по соотношению цена/качество. Я долго подбирал компоненты, в итоге уложился в 40к с комплектом из FX-8320 и RX-460 2GB. Сначала этот комплект казался идеальным! Мы с соседом по комнате слегка майнили Monero и мой набор показывал 650h/s против 550h/s на наборе из i5-85xx и Nvidia 1050Ti. Правда, от моего набора в комнате бывало слегка жарковато по ночам, но это решилось, когда я приобрел башенный кулер к CPU.
Сказка кончилась
Что-ж, угадайте мой первый ход после всего этого? Да, я пошёл выторговывать 1050Ti у моего соседа. С аргументами о ненужности CUDA для него, с предложением обмена на мою карту с доплатой. Но всё тщетно. И вот я уже выкладываю свою RX 460 на Авито и рассматриваю заветную 1050Ti на сайтах Ситилинка и Технопоинта. Даже в случае успешной продажи карты мне пришлось бы найти еще 10к(я студент, пусть и работающий).
Читайте также: