
Что такое ядро процессора
Процессор — самая главная микросхема в компьютере, смартфоне и в самых различных цифровых устройствах. Часто процессор сравнивают с мозгом — да, отчасти это так. Внутри CPU происходят все арифметические вычисления для получения конечного результата.
Первые процессоры не имели ядер и выполняли все операции строго последовательно. Чем выше частота, тем быстрее будет выполняться та или иная операция.
Дополнительные возможности
Современные процессоры приобрели возможности работы в 2-х и 3-х канальных режимах с оперативной памятью, что значительно сказывается на ее производительности, а также поддерживают больший набор инструкций, поднимающий их функциональность на новый уровень. Графические процессоры обрабатывают видео своими силами, тем самым разгружая ЦП, благодаря технологии DXVA (от англ. DirectX Video Acceleration – ускорение видео компонентом DirectX). Компания Intel использует вышеупомянутую технологию Turbo Boost для динамического изменения тактовой частоты центрального процессора. Технология Speed Step управляет энергопотреблением CPU в зависимости от активности процессора, а Intel Virtualization Technology аппаратно создает виртуальную среду для использования нескольких операционных систем. Также современные процессоры могут делиться на виртуальные ядра с помощью технологии Hyper Threading. Например, двухъядерный процессор способен делить тактовую частоту одного ядра на два, что способствует высокой производительности обработки данных с помощью четырех виртуальных ядер.
Размышляя о конфигурации вашего будущего ПК, не забывайте про видеокарту и ее GPU (от англ. Graphics Processing Unit – графическое обрабатывающее устройство) – процессор вашей видеокарты, который отвечает за рендеринг (арифметические операции с геометрическими, физическими объектами и т.п.). Чем больше частота его ядра и частота памяти, тем меньше будет нагрузки на центральный процессор. Особенное внимание к графическому процессору должны проявить геймеры.
Доброго времени суток, сегодня хотелось бы затронуть достаточно простую тему, которая почти никем из обычных программистов неизвестна, но каждый из вас, скорее всего, ей пользовался.
Речь пойдет о симметричной мультипроцессорности(в народе — SMP) — архитектура, которая встречается во всех многозадачных операционных системах, и конечно же, является неотъемлемой их частью. Каждый знает, что чем больше ядер у процессора — тем мощнее будет процессор, да, это так, но как ОС может использовать несколько ядер одновременно? Некоторые программисты не спускаются до такого уровня абстракции — им это попросту не надо, но думаю, всем будет интересно то, как же SMP работает.
Masked Execution
Данный режим отличается от классических тем, что инструкции исполняются последовательно без использования прыжков. В инструкции хранится некоторое количество информации о том при каких условия эта инструкция будет исполнена и если условие не соблюдено то инструкция пропускается.
Ответ прост! Что бы не нагружать шину инструкций. Например в видеокартах можно загрузить тысячи ядер одной инструкцией. А если бы использовалась система прыжков то пришлось бы для каждого ядра ждать инструкцию из медленной памяти. Кеш частично решает проблему, но все еще не решает проблему полностью.
Здесь мы будем описывать несколько техник используемых в центральный процессорах и микроконтроллерах.
Инициализация «локального» APIC'а
Локальный APIC активируется во время загрузки и может быть отключен путем сброса бита 11 IA32_APIC_BASE (MSR) (это работает только с процессорами с семейством > 5, поскольку у Pentium нет такого MSR), Затем процессор получает свои прерывания непосредственно из совместимого с 8259 PIC'а. Однако в руководстве Intel по разработке программного обеспечения указано, что после отключения локального APIC'а через IA32_APIC_BASE вы не сможете включить его до полного сброса. IO APIC также может быть сконфигурирован для работы в унаследованном режиме, так чтобы он эмулировал устройство 8259.
Отключите 8259 PIC правильно. Это почти так же важно, как настройка APIC. Вы делаете это в два этапа: маскирование всех прерываний и переназначение IRQ. Маскировка всех прерываний отключает их в PIC. Ремаппинг прерываний — это то, что вы, вероятно, уже сделали, когда вы использовали PIC: вы хотите, чтобы запросы прерывания начинались с 32 вместо 0, чтобы избежать конфликтов с исключениями(в защищенном и длинном(Long) режимах процессора, т.к. первые 32 прерывания — исключения(exceptions)). Затем вы должны избегать использования этих векторов прерываний для других целей. Это необходимо, потому что, несмотря на то, что вы маскировали все прерывания PIC, он все равно мог выдавать ложные прерывания, которые затем будут неверно обрабатываться в вашем ядре в качестве исключений.
Перейдем к SMP.
Рекомендации по выбору процессора
При выборе ЦП некоторые характеристики будут важнее других – это зависит от предпочтений пользователя.
Прерывания и PIC
Как вы наверное поняли, прерывания — это функции(или же процедуры), которые вызываются в какой-либо момент времени оборудованием, или же самой программой. Всего процессор поддерживает 16 прерываний на двух PIC'ах. Процессор имеет флаги, и один из них — флаг «I» — Interrupt Control. Путем установки данного флага в 0 процессор не будет вызывать никаких аппаратных прерываний. Но, так же хочу заметить, что есть так называемые NMI — Non-Maskable Interrupts — данные прерывания всё равно будут вызываться, даже если бит I установлен в 0. При помощи программирования PIC можно запретить данные прерывания, но после возврата из любого прерывания при помощи IRET — они вновь станут не запрещенными. Замечу, что из-под обычной программы вы не сможете отследить вызов прерывания — выполнение вашей программы остановиться, и только через некоторое время возобновиться, ваша программа этого даже не заметит(да-да, можно проверить то, что было вызвано прерывание — но зачем?
PIC — Programmable Interrupt Controller
Как правило, представляет собой электронное устройство, иногда выполненное как часть самого процессора или же сложных микросхем его обрамления, входы которого присоединены электрически к соответствующим выходам различных устройств. Номер входа контроллера прерываний обозначается «IRQ». Следует отличать этот номер от приоритета прерывания, а также от номера входа в таблицу векторов прерываний (INT). Так, например, в IBM PC в реальном режиме работы (в этом режиме работает MS-DOS) процессора прерывание от стандартной клавиатуры использует IRQ 1 и INT 9.
В первоначальной платформе IBM PC используется очень простая схема прерываний. Контроллер прерываний представляет собой простой счётчик, который либо последовательно перебирает сигналы разных устройств, либо сбрасывается на начало при нахождении нового прерывания. В первом случае устройства имеют равный приоритет, во втором устройства с меньшим (или большим при обратном счёте) порядковым номером обладают большим приоритетом.
Как вы поняли, это электронная схема, которая позволяет устройствам отправлять запросы на прерывания, обычно их ровно 2.
Теперь же, давайте перейдем к самой теме статьи.
Для реализации данного стандарта на материнские платы начали ставить новые схемы: APIC и ACPI. Давайте поговорим о первом.
APIC — Advanced Programmable Interrupt Controller, улучшенная версия PIC. Он используется в многопроцессорных системах и является неотъемлемой частью всех последних процессоров Intel (и совместимых). APIC используется для сложного перенаправления прерываний и для отправки прерываний между процессорами. Эти вещи были невозможны с использованием более старой спецификации PIC.
Привилегированный режим
Это режим в котором стартует процессор. В таком режиме программа или ОС имеют полный доступ к памяти в обход MMU/MPU. Все программы запускаются в непривилегированном режиме во избежания прямого доступа к аппаратным подсистемам программ для этого не предназначенных. Например вредоносным программам. В Windows ее часто называют Ring-0, а в *nix — системным. Не стоит путать Привелигированный пользователь и Привилегированный режим ибо в руте вы все еще не можете иметь прямой доступ к аппаратуре (можно загрузить системный модуль который позволит это сделать, но об этом чуть позже :)
Архитектура фон Неймана

Особенностью таких архитектур была общая шина данных и инструкций. Большинство современных архитектур это программный фон Нейман, однако никто не запрещает делать аппаратный Гарвард. У данной архитектуры большим недостатком является большое зависимости производительности процессора от шины. (Что ограничивает общую производительность процессора).
Многозадачность и её реализация
Те, кто когда-нибудь изучал архитектуру ЭВМ знает, что процессор сам по себе не умеет выполнять несколько задач сразу, многозадачность нам даёт только ОС, которая и переключает эти задачи. Есть несколько типов многозадачности, но самый адекватный, удобный и широко используемый — вытесняющая многозадачность(главные её аспекты Вы можете прочитать на википедии). Она основана на том, что у каждого процесса(задачи) есть свой приоритет, который влияет на то, сколько процессорного времени ему будет выделено. Каждой задаче даётся один квант времени, во время которого процесс что-либо делает, после истечение кванта времени ОС передает управление другой задаче. Возникает вопрос — а как распределить ресурсы компьютера, такие, как память, устройства и т.п. между процессами? Всё очень просто: Windows делает это сама, Linux же использует систему семафоров. Но одно ядро — несерьезно, идем дальше.
Для инженерных задач
Как правило, компьютеры для инженерных задач обязаны обрабатывать много информации за короткий промежуток времени.

При покупке ЦП для такого компьютера важен многоядерный процессор. В идеале нужно искать такой чип, который предлагает гиперпоточность. Это обеспечит большую вычислительную мощность.
Расширение существующих архитектур
Достаточно популярной техникой является добавление в уже существующую архитектуру больше инструкций через расширения. Ярким примером является SSE под x86. Этим же грешит ARM и MIPS и практически все. Почему? Потому что нельзя создать унивирсальную архитектуру.
Другим вариантом является использование других архитектур для уменьшения размера инструкций.
Яркий пример: ARM со своим Thumb, MIPS с MIPS16.
В видеокартах часто встречается много ядер и из-за этой особенности появилась потребность в дополнительных решениях. Если конвейеры можно встретить даже в микроконтроллерах то решения используемых в GPU встречаются редко. Например Masked Execution (Встречается в инструкциях ARM, но не в Thumb-I/II). Еще есть другие особенность: это уклон в сторону Floating Number (Числа с плавающей запятой), Уменьшение производительности в противовес большего количества ядер и т.д.
Ищем информацию, используя MT-таблицу
Некоторая информация (которая может отсутствовать на более новых машинах), предназначенная для многопроцессорности. Сначала нужно найти структуру плавающего указателя MP. Он выровнен по 16-байтовой границе и содержит подпись в начале «_MP_» или 0x5F504D5F. ОС должна искать в EBDA, пространстве BIOS ROM и в последнем килобайте «базовой памяти»; размер базовой памяти указан в 2-байтовом значении в 0x413 в килобайтах, минус 1 КБ. Вот как выглядит структура:
Вот как выглядит таблица конфигурации, на которую указывает плавающая структура указателя:
После таблицы конфигурации лежат записи entry_count, которые содержат больше информации о системе, после чего идет расширенная таблица. Записи представляют собой либо 20 байт для представления процессора, либо 8 байт для чего-то другого. Вот как выглядят записи процессора и ввода-вывода APIC.
Вот запись IO APIC.
PIC (PIE)
Что такое PIE? (PIC не использую для избежания путаницы с МК PIC). PIE это техника благодаря которой компилятор генерирует код который будет работать в любом месте в памяти. Эта техника в совмещении с MPU позволяет компилировать высокие языки программирования которые будут работать и с MPU.
Популярная техника SIMD используется для того, что бы за один такт выполнять несколько действий над несколькими регистрами. Иногда бывают в качестве дополнений к основной архитектуре, например, как в MIPS, ARM со своими NEON/VFP/etc, x86 со своим SSE2.
Это техника Используется для оптимизации кода, генерируемого компилятором, с помощью пересортировки инструкций, увеличивая производительность процессора. Это позволяет использовать конвейер на полную.

Что такое регистр статуса? Это регистр который хранит состояние процессора. Например находится ли процессор в привилегированном режиме, чем закончилась операция последнего сравнения.
Используется в связке с Masked Execution. Некоторые разработчики специально исключают регистр статуса ибо он может являться узким местом как поступили в MIPS.
В MIPS нет отдельной инструкции загрузки константы в память, но есть инструкция addi и ori которая позволяет в связке с нулевым регистром ($0) эмулировать работу загрузки константы в регистр. В других архитектурах она присутствует. Я затронул эту тему, потому что она пригодиться нам в статьях с практикой.
Идут множество споров насчет того сколько должно быть операндов в арифметических инструкциях. Например в MIPS используется вариант с 3-мя регистрами. 2 операнда, 1 регистр записи. С другой стороны, использование двух операндов позволяет сократить код за счет уменьшения размера инструкции. Пример совмещения является MIPS16 в MIPS и Thumb-I в ARM. В плане производительности они практически идентичны (Если исключать размер инструкции как фактор).

Порядок байт. Возможно вам знакомы Выражения Big-Endian и Little-Endian. Они описывают порядок байт в инструкциях/в регистрах/в памяти/etc. Здесь думаю все просто :). Есть процессоры которые совмещают режимы, как MIPS, или которые используют одну систему команд, но имеют разный порядок байт, например ARM.

Что такое сопроцессоры? Сопроцессоры являются элементами процессора или внешней микросхемой. Они позволяют исполнять инструкции, которые слишком громоздки для основной части процессора. Как яркий пример, сопроцессоры в MIPS для деления и умножения. Или например 387 для 80386, который добавлял поддержку чисел с плавающей запятой. А в MIPS сопроцессоров было много и они выполняли свои роли: контролировали прерывания, исключения и системные вызовы. Часто сопроцессоры имеют собственные инструкции и на системах, где этих инструкций нет, (пример ARM) эмулируют ее через Trap-ы (ловушки?). Несмотря на костыльность и маленькую производительность, они часто являются единственным выбором в микроконтроллерах.
Атомартность операций обеспечивает потоко-независимое исполнение за счет инструкций, которые выполняют несколько действий за один псевдотакт.
Вариант другого решения атомарность переферии. Например для установки ножки в STM32 в высокое и низкое состояние используется разные регистры, что позволяет иметь атомарность на уровне переферии.

Вы, навярняка, слышали о L1, L2, L3 и регистрах. Если коротко, процессор анализирует часть кода, чтобы предугадать прыжки и доступ в память и зараннее просит кеш получить эти данные из памяти. Кеш зачастую бывает прозрачным для программы, но бывают и исключения из этого правила. Например, в программных ядрах в ПЛИС используется програмный кеш.
И вы кончено слышали о такой вещи, как Cache Miss или промах по кешу. Это операция которая не была предусмотрена процессорам или процессор не успел закешировать эту часть памяти. Что достаточно часто является проблемой замедления доступа к памяти. Промах проходит незаметно для программы, но не останутся незаметными просадки в производительности.Так же переключения контекстов например при прерываниях тоже заставляет страдать кеш ибо небольшой код сбивает конвейер и кеш для собственных нужд.
В современных процессорах часто используется техника теневых регистров. Они позволяют переключаться между прерываниями и пользовательским кодом практически без задержек связанных с сохранением регистров.

Спросите тогда что такое куча (Heap)? Куча это память размером намного больше чем стек (Стек обычно ~1MB). В хипе храниться все глобальное. Например все указатели полученные с помощю Malloc указывают на часть куча. А указатели хранятся в стеке или в регистрах. С помощью инструкций загрузки данных относительно регистра можно ускорить работу стека и других доступов к памяти по типу стека, поскольку не нужно постоянно использовать операции PUSH/POP, INC/DEC или ADDI, SUBI (добавить константу), чтобы получить данные глубже по стеку, а можно просто использовать доступ относительно стека с отрицательным смещением.

Не буду описывать регистры слишком подробно. Это мы затронем в практической статье.
В x86 регистров достаточно мало. В MIPS используется увеличенное количество регистров, а именно 31 ($0 имеет значение всегда равное нулю). В процессоре университета Беркли использовались регистровые окна, которые жестки ограничивали вложенность функций, при этом имея лучшую производительность. В других же, таких как AVR, ограничили использование регистров. Для примера: три 16-битных можно трактовать как шесть восьмибитных, где первые 16ть недоступны при некоторых операциях. Я считаю, что лучший метод был выбран MIPS-ом. Это мое сугубо личное мнение.
Что такое выравнивание? Оставлю-ка я этот вопрос вам :)
Это конец первой главы нулевой части. Вся серия будет крутиться вокруг темы создания собственного процессора. Собственной операционной системы. Собственного ассемблера. Собственного компилятора и много чего другого.
Нулевые части будут посвящены теории. Я сомневаюсь что доведу всю серию до победного конца, но попытка не пытка! )
Вы когда-нибудь задумывались о том, как построены современные процессоры, что такое ядра и на что они влияют? Почему процессор может выполнять сразу несколько операций, что такое многопоточность и как это все работает? Как ЦП позволяет обрабатывать компьютеру одновременно большое количество данных. Итак, давайте разбираться в архитектуре данного устройства.
Exception (исключения)
Но кроме прерываний еще существуют исключений которые возникают например при деления на ноль. Зачастую его совмещают с прерываниями и системными вызовами, как например в MIPS. Исключения не всегда присутствуют в процессоре например как в AVR или младших PIC
Запуск AP
После того, как вы собрали информацию, вам необходимо отключить PIC и подготовиться к APIC I/O. Вам также необходимо настроить BSP локального APIC'а. Затем запустите AP с использованием SIPI.
Код для запуска ядер:
Замечу, что вектор, который вы указываете при запуске говорит о начальном адресе: вектор 0x8 — адрес 0x8000, вектор 0x9 — адрес 0x9000 и т.п.
Теперь, как вы понимаете, чтобы ОС использовать много ядер, надо настроить стек для каждого ядра, каждое ядро, его прерывания и т.п., но самое важное — при использовании симметричной мультипроцессорности все ресурсы у ядер одни и те же: одна память, один PCI и т.п., и ОС остаётся лишь распараллелить задачи между ядрами.
Надеюсь, что статья получилась не достаточно нудной, и достаточно информативной. В следующий раз, думаю, можно поговорить о том, как раньше рисовали на экране(и сейчас рисуют), без использования шейдеров и крутых видеокарт.
Здравствуй, мир! Сегодня у нас серия статьей для людей со средними знаниями о работе процессора в которой мы будем разбираться с процессорными архитектурами (у меня спелл чекер ругается на слово Архитектурами/Архитектур, надеюсь я пишу слово правильно), создавать собственную архитектуру процессора и многое другое.

Принимаются любые замечания!
Исторически сложилось, что существуют много процессоров и много архитектур. Но многие архитектуры имеют схожести. Специально для этого появились "Группы" архитектур типа RISC, CISC, MISC, OISC (URISC). Кроме того они могут иметь разные архитектуры адресации памяти (фон Неймана, Гарвард). У каждого процессора есть своя архитектура. Например большинство современных архитектур это RISC (ARM, MIPS, OpenRISC, RISC-V, AVR, PIC** и т.д.), но есть архитектуры которые выиграли просто за счет других факторов (Например удобство/цена/популярность/etc) Среди которых x86, x86-64 (Стоит отметить, что x86-64 и x86 в последних процессорах используют микрокод и внутри них стоит RISC ядро), M68K. В чем же их отличие?
Reduced Instruction Set Computer — Архитектура с уменьшенным временем выполнения инструкций (из расшифровка RISC можно подумать, что это уменьшенное количество инструкций, но это не так). Данное направления развилось в итоге после того, как оказалось, что большинство компиляторов того времени не использовали все инструкции и разработчики процессоров решили получить больше производительности использую Конвейеры. В целом RISC является золотой серединой между всеми архитектурами.
Яркие примеры данной архитектуры: ARM, MIPS, OpenRISC, RISC-V
Что такое TTA? ТТА это Архитектура на основе всего одной инструкции перемещения из одного адреса памяти в другую. Данный вариант усложняет работу компилятора зато дает большую производительность. У данной архитектуры есть единственный недостаток: Сильная зависимость от шины данных. Именно это и стало причиной ее меньшей популярности. Надо отметить что TTA является разновидностью OISC.
Яркие примеры: MOVE Project
Архитектура
Также процессорам свойственно такая характеристика, как архитектура — набор свойств, присущий целому семейству процессоров, как правило, выпускаемому в течение многих лет. Говоря другими словами, архитектура – это их организация или внутренняя конструкция ЦП.
Системные вызовы
Системные вызовы используется в Операционных системах для того, чтобы программы могли общаться с операционной системой например просить ОС прочитать файл. Очень похоже на прерывания. Аналогично исключениям не всегда присутствуют в процессоре
Здесь описываются методы запрета доступа приложений к аппаратуре напрямую.
Количество ядер
MPU и MMU

MPU и MMU используется в современных системах чтобы изолировать несколько приложений. НО если MMU позволяет "передвинуть" память то MPU позволяет только блокировать доступ к памяти/запуск кода в памяти.
Сокет
Чтобы будущий процессор при апгрейде был совместим с имеющейся материнской платой, необходимо знать его сокет. Сокетом называют разъем, в который устанавливается ЦП на материнскую плату компьютера. Тип сокета характеризуется количеством ножек и производителем процессора. Различные сокеты соответствуют определенным типам CPU, таким образом, каждый разъём допускает установку процессора определённого типа. Компания Intel использует сокет LGA1156, LGA1366 и LGA1155, а AMD — AM2+ и AM3.
Кэш — объем памяти с очень большой скоростью доступа, необходимый для ускорения обращения к данным, постоянно находящимся в памяти с меньшей скоростью доступа (оперативной памяти). При выборе процессора, помните, что увеличение размера кэш-памяти положительно влияет на производительность большинства приложений. Кэш центрального процессора различается тремя уровнями (L1, L2 и L3), располагаясь непосредственно на ядре процессора. В него попадают данные из оперативной памяти для более высокой скорости обработки. Стоит также учесть, что для многоядерных CPU указывается объем кэш-памяти первого уровня для одного ядра. Кэш второго уровня выполняет аналогичные функции, отличаясь более низкой скоростью и большим объемом. Если вы предполагаете использовать процессор для ресурсоемких задач, то модель с большим объемом кэша второго уровня будет предпочтительнее, учитывая что для многоядерных процессоров указывается суммарный объем кэша L2. Кэшем L3 комплектуются самые производительные процессоры, такие как AMD Phenom, AMD Phenom II, Intel Core i3, Intel Core i5, Intel Core i7, Intel Xeon. Кэш третьего уровня наименее быстродействующий, но он может достигать 30 Мб.
Что такое ядро процессора?
Ядро — физический блок, который находится внутри процессора и занимается линейным вычислением арифметических операций. Чем больше ядер, тем быстрее процессор обрабатывает информацию — все ядра могут работать как одновременно для основной, мощной задачи, так и последовательно, выполняя поток задач.
Если в CPU 1 ядро, то оно будет постоянно переключаться между задачами — от этого снижается производительность ПК в целом.
Кстати, до того того, как изобрели многоядерные процессоры для профессиональных пользователей, производились компьютеры с несколькими физическими процессорами.
Читайте далее:
Симметричная многозадачность: инициализация
Последовательность запуска различна для разных ЦП. Руководство программиста Intel (раздел 7.5.4) содержит протокол инициализации для процессоров Intel Xeon и не охватывает более старые процессоры. Для общего алгоритма «всех типов процессоров» см. «Многопроцессорная спецификация Intel».
Для 80486 (с внешним APIC 8249DX) вы должны использовать IPIT INIT, за которым следует IPI «INIT level de-assert» без каких-либо SIPI. Это означает, что вы не можете сказать им, где начать выполнение вашего кода (векторная часть SIPI), и они всегда начинают выполнять код BIOS. В этом случае вы устанавливаете значение сброса CMOS BIOS в «warm start with far jump» (т. е. Установите положение CMOS 0x0F в значение 10), чтобы BIOS выполнил jmp far ~ [0: 0x0469] », а затем установите сегмент и смещение точки входа AP в 0x0469.
«INIT level de-assert» IPI не поддерживается на новых процессорах (Pentium 4 и Intel Xeon), а AFAIK полностью игнорируется на этих процессорах.
Для более новых процессоров (P6, Pentium 4) достаточно одного SIPI, но я не уверен, что более старые процессоры Intel (Pentium) или процессоры других производителей нуждаются в втором SIPI. Также возможно, что второй SIPI существует в случае сбоя доставки для первого SIPI (шум шины и т. д.).
Обычно я отправляю первый SIPI, а затем жду, чтобы увидеть, увеличивает ли AP счетчик количества запущенных процессоров. Если он не увеличит этот счетчик в течение нескольких миллисекунд, я отправлю второй SIPI. Это отличается от общего алгоритма Intel (который имеет задержку в 200 микросекунд между SIPI), но попытка найти источник времени, способный точно измерять задержку в 200 микросекунд во время ранней загрузки, не так-то просто. Я также обнаружил, что на реальном оборудовании, если задержка между SIPI слишком длинная (и вы не используете мой метод), главный AP может запускать ранний код запуска AP для ОС дважды (что в моем случае приведет к тому, что ОС будет думать, что мы имеем в два раза больше процессоров, чем есть на самом деле).
Вы можете транслировать эти сигналы по шине для запуска каждого присутствующего устройства. Однако при этом вы также можете включить процессоры, которые были отключены специально (потому что они были «дефектными»).
Что такое потоки и на что влияет их количество
Потоки – это виртуальный компонент или код, который разделяет физическое ядро процессора на несколько ядер. Одно ядро имеет до 2 потоков.

Например, если процессор двухъядерный, то он будет иметь 4 потока, а если восьмиядерный – 16 потоков.
Поток создается активным процессом. Каждый раз, когда открывается приложение, оно само создает поток, который будет обрабатывать задачи этого конкретного приложения. Поэтому, чем больше приложений будет открыто, тем больше потоков будет создано.
Потоки создаются операционной системой для выполнения задачи конкретного приложения. Они управляются планировщиком, который является стандартной частью каждой ОС.
Существует один поток (код того ядра, выполняющий вычисления, также известный как основной поток) на ядре, который, когда получает информацию от пользователя, создает другой поток и выделяет ему задачу. Аналогично, если он получает другую инструкцию, он формирует второй поток и выделяет ему задачу, создавая таким образом многопоточность.
Единственный факт, который ограничивает создание потоков, – количество основных потоков, предоставляемых физическим процессором. А их количество зависит от ядер.
Потоки стали жизненно важной частью вычислительной мощности, поскольку они позволяют выполнять несколько задач одновременно. Это повышает производительность компьютера, а также позволяет сделать его способным к многозадачности. Благодаря этой технологии становится возможно просматривать веб-страницы, слушать музыку и скачивать файлы в фоновом режиме одновременно.
Для стриминга
Выбор ЦП для стриминга зависит от сборки самого ПК.
Для бюджетных компьютеров подойдут любые четырехъядерные процессоры, которые смогут раскрыть видеокарту.
Для профессионального стриминга понадобится ЦП с 6, 8, 16 ядрами и тактовой частотой 4 ГГц и выше. Тут выбор будет завесить от купленной видеокарты и нужного разрешения для стрима.
Роль количества ядер, их влияние на производительность
Первоначально ЦП имели только одно ядро. Однако на рубеже XX и XXI веков инженеры пришли к выводу, что стоит увеличить их количество. Это должно было позволить получить более высокую вычислительную мощность, а также позволить обрабатывать несколько задач одновременно.

Но для начала стоит разобраться с главным мифом. Принято считать, что чем больше ядер у процессора, тем больше мощности он будет предлагать. Но на практике все не так просто. Реальное влияние на производительность оказывают и другие факторы – например, тактовая частота, объем кэша, архитектура, количество потоков.
Дополнительные ядра означают, что процессор способен одновременно справляться с большим количеством задач. Однако здесь нельзя забывать об одном: несмотря на популяризацию четырех-, шести- или восьмиядерных процессоров, приложения используют один или два потока. Поэтому количество потоков ядра также важно учитывать.
Общее понятие архитектуры процессора ПК
Под понятием архитектуры процессора подразумеваются важные с точки зрения построения и функциональности особенности чипа, которые связаны как с его программной моделью, так и с физической конструкцией.

Архитектура набора команд (ISA) – это набор инструкций процессора и других его функций (например, система и нумерация регистров или режимы адресации памяти), имеющих программную часть ядра, которые не зависят от внутренней реализации.
В свою очередь, физическое построение системы называется микроархитектурой (uarch). Это детальная реализация программной модели, которая связана с фактическим выполнением операций. Микроархитектура представляет собой конфигурацию, определяющую отдельные элементы, например, логические блоки, а также связи между ними.
Стоит отметить, что ЦП, выполняющие одинаковую программную модель, могут значительно отличаться друг от друга микроархитектурой – например, устройства от фирм AMD и Intel. Современные чипы имеют идентичную программную архитектуру x86, но абсолютно разную микроархитектуру.
Для игрового ПК
Потребности геймеров специфичны, когда дело доходит до вычислительной мощности компьютера.

Первое, что нужно учитывать – это количество ядер. В дополнение к числу ядер, геймерам также важно учитывать тактовую частоту. Для современных игр потребуется частота 3,8 ГГц или выше.
Еще стоит обратить внимание на тепловыделение. Нынешние игры довольно требовательные, поэтому процессор быстро нагревается. У системного блока должна быть качественная система охлаждения, которая поможет адекватно удовлетворить потребности устройства, чтобы компоненты не перегревались.
Что такое поток?
Можно сказать, что поток является виртуальным ядром самого ядра. Поток — параметр исключительно программный, он работает с ядром и способен дать ядру работать параллельно с разными задачами. Сколько потоков — столько и задач. Такая программная хитрость позволяет более рационально использовать вычислительную мощность ядра.
Чем больше программ вы запускаете на компьютере, тем сильнее нагружаете CPU. А он уж сам определяет как задействовать ядра и потоки для максимальной производительности. Для игр и серьезных задач с графикой вычислительная мощность для видеопотока отдается видеокарте для того, чтобы разгрузить графическое ядро CPU. Кстати, процессор видеоадаптера работает примерно также, как и основной.
Но два разобранных в статье параметра не являются самыми ключевыми. Да, чем больше потоков и ядер, тем лучше. Но есть еще и другие параметры, как архитектура процессора, техпроцесс, частота и объем кэш памяти.
Поэтому двухядерный CPU может быть намного лучше, чем четырехъядерный — последний будет проигрывать по другим параметрам.

Наверное, каждый пользователь мало знакомый с компьютером сталкивался с кучей непонятных ему характеристик при выборе центрального процессора: техпроцесс, кэш, сокет; обращался за советом к друзьям и знакомым, компетентным в вопросе компьютерного железа. Давайте разберемся в многообразии всевозможных параметров, потому как процессор – это важнейшая часть вашего ПК, а понимание его характеристик подарит вам уверенность при покупке и дальнейшем использовании.

Для офиса
Для большинства офисных компьютеров подойдут двух- или четырехъядерные процессоры. Однако если вычислительные потребности более интенсивны, например, при программировании и графическом дизайне, для начала стоит выяснить, сколько ядер потребуется для используемого программного обеспечения.
Частота является еще одним фактором, который следует принимать во внимание. Хотя частота – это не единственное, что определяет скорость, она оказывает существенное влияние. Используемое программное обеспечение будет влиять на скорость. Например, при регулярном использовании Adobe CS 6, лучше всего подойдет процессор со скоростью не менее 2 ГГц.
Прерывания
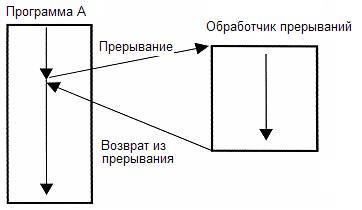
Прерывания это техника при которой исполняемый в данный момент код приостанавливается для выполнения какой-то другой задачи при каких-то условиях. Например при доступе в несуществующий участок памяти вызывается HardFault или MemoryFault прерывания или исключения. Или например если таймер отсчитал до нуля. Это позволяет не бездействовать пока нужно ждать какое-то событие.
Какие недостатки? Вызов прерывания это несколько тактов простоя и несколько при возврате из прерывания. Так же несколько инструкций в начале кода будет занято инструкциями для Таблицы прерываний.
Центральный процессор
Процессор персонального компьютера представляет собой микросхему, которая отвечает за выполнение любых операций с данными и управляет периферийными устройствами. Он содержится в специальном кремниевом корпусе, называемом кристаллом. Для краткого обозначения используют аббревиатуру — ЦП (центральный процессор) или CPU (от англ. Central Processing Unit – центральное обрабатывающее устройство). На современном рынке компьютерных комплектующих присутствуют две конкурирующие корпорации, Intel и AMD, которые беспрестанно участвуют в гонке за производительность новых процессоров, постоянно совершенствуя технологический процесс.
Для работы с графикой
При работе с графикой требования к процессору отличаются. Для обработки 2D графики – подойдут бюджетные варианты, 2 или 4 ядра с тактовой частотой 2,4 ГГц вполне справятся с задачей.
Для работы с 3D графикой лучше всего выбирать 4 или 6-ядерные чипы, с тактовой частотой 3 ГГц и выше, а также с поддержкой многопоточности.
Конвейеры
Что такое конвейеры? Если сказать очень глупым языком это несколько параллельных действий за один такт. Это очень грубо, но при этом отображает суть. Конвейеры за счет усложнения архитектуры позволяют поднять производительность. Например конвейер позволяет прочитать инструкцию, исполнить предыдущую и записать в шину данных одновременно.

На картинке более понятно, не правда?
IF — получение инструкции,
ID — расшифровка инструкции,
EX — выполнение,
MEM — доступ к памяти,
WB — запись в регистр.
Вроде все просто? А вот и нет! Проблема в том что например прыжок (jmp/branch/etc) заставляют конвейер начать исполнение (получение след. инструкции) заново таким образом вызывая задержку в 2-4 такта перед исполнение следующей инструкции.
OISC (URISC)?
One Instruction Set Computer — Архитектура с единственной инструкцией. Например SUBLEQ. Такие архитектуры часто имеют вид: Сделать действие и в зависимости от результата сделать прыжок или продолжить исполнение. Зачастую ее реализация достаточно простая, производительность маленькая, при этом снова ограничение шиной данных.
Яркие примеры: BitBitJump, ByteByteJump, SUBLEQ тысячи их!
CISC — Complex Instruction Set Computer — ее особенность в увеличенных количествах действий за инструкцию. Таким образом можно было теоретически увеличить производительность программ за счет увеличения сложности компилятора. Но по факту у CISC плохо были реализованы некоторые инструкции т.к. они редко использовались, и повышение производительности не было достигнуто. Особенностью этой группы является еще ОГРОМНАЯ Разница между архитектурами. И несмотря на названия были архитектуры с маленьким количеством инструкций.
Яркие примеры: x86, M68K
Частота
Помимо количества ядер на производительность влияет тактовая частота. Значение этой характеристики отражает производительность CPU в количестве тактов (операций) в секунду. Еще одной немаловажной характеристикой является частота шины (FSB – Front Side Bus) демонстрирующая скорость, с которой происходит обмен данных между процессором и периферией компьютера. Тактовая частота пропорциональна частоте шины.
Local APIC и IO APIC
В системе на базе APIC каждый процессор состоит из «ядра» и «локального APIC'а». Local APIC отвечает за обработку конфигурации прерываний, специфичных для процессора. Помимо всего прочего, он содержит локальную векторную таблицу (LVT), которая переводит события, такие как «внутренние часы(internal clock)» и другие «локальные» источники прерываний, в вектор прерывания (например, контакт LocalINT1 может поднимать исключение NMI, сохраняя «2» в соответствующий вход LVT).
Более подробную информацию о локальном APIC можно найти в «Руководстве по системному программированию» современных процессоров Intel.
Кроме того, имеется APIC IO (например, intel 82093AA), который является частью набора микросхем и обеспечивает многопроцессорное управление прерываниями, включающее как статическое, так и динамическое симметричное распределение прерываний для всех процессоров. В системах с несколькими подсистемами ввода / вывода каждая подсистема может иметь свой собственный набор прерываний.
Каждый вывод прерывания индивидуально программируется «as either edge or level triggered». Вектор прерывания и информация об управлении прерываниями могут быть указаны для каждого прерывания. Схема косвенного доступа к регистру оптимизирует пространство памяти, необходимое для доступа к внутренним регистрам ввода-вывода APIC. Чтобы повысить гибкость системы при назначении использования пространства памяти, пространство двух регистров ввода-вывода APIC является перемещаемым, но по умолчанию оно равно 0xFEC00000.
Техпроцесс
Техпроцесс — это размер, используемый при производстве процессоров. Он определяет величину транзистора, единицей измерения которого является нм (нанометр). Транзисторы, в свою очередь, составляют внутреннюю основу ЦП. Суть заключается в том, что постоянное совершенствование методики изготовления позволяет уменьшать размер этих компонентов. В результате на кристалле процессора их размещается гораздо больше. Это способствует улучшению характеристик CPU, поэтому в его параметрах всегда указывают используемый техпроцесс. Например, Intel Core i5-760 выполнен по техпроцессу 45 нм, а Intel Core i5-2500K по 32 нм, исходя из этой информации, можно судить о том, насколько процессор современен и превосходит по производительности своего предшественника, но при выборе необходимо учитывать и ряд других параметров.
Архитектура гарварда
Особенность этой архитектуры является отдельная шина данных и инструкций. Дает большую производительность чем фон Нейман за счет возможности за один такт использовать обе шины (читать из шины инструкций и одновременно записывать в шинну данных), но осложняет архитектуру и имеет некоторые ограничения. В основном используется в микроконтроллерах.
Ищем информацию при помощи APIC
Вы можете найти таблицу MADT (APIC) в ACPI. В таблице приведен список локальных APIC, число которых должно соответствовать количеству ядер на вашем процессоре. Подробностей этой таблицы здесь нет, но вы можете найти их в интернете.
Энергопотребление

Энергопотребление процессора тесно связано с технологией его производства. С уменьшением нанометров техпроцесса, увеличением количества транзисторов и повышением тактовой частоты процессоров происходит рост потребления электроэнергии CPU. Например, процессоры линейки Core i7 от Intel требуют до 130 и более ватт. Напряжение подающееся на ядро ярко характеризует энергопотребление процессора. Этот параметр особенно важен при выборе ЦП для использования в качестве мультимедиа центра. В современных моделях процессоров используются различные технологии, которые помогают бороться с излишним энергопотреблением: встраиваемые температурные датчики, системы автоматического контроля напряжения и частоты ядер процессора, энергосберегающие режимы при слабой нагрузке на ЦП.
Читайте также: