
Utf 16 чем открыть
У меня возникла проблема при обработке файлов в кодировке UTF-16 LE (1200): нужно заменить в них одну строчку. Алгоритм такой:
fstream работа с utf-8 файлами
Открывается файл в кодировке utf-8: fstream fin; fin.open(fOpenDlg.GetPathName(),ios::in);.
Ошибка при кодировке в UTF-8
Вот, написал код. Здесь его часть в начале файла указана кодировка UTF-8, перед строкой поставил.
Создание файла в UTF-8 кодировке
Здравствуйте! Как сделать что бы в данной ситуации файл создавался в utf-8 DWORD tmp0; .
rao, уже пробовал, но решил проверить ещё раз, изменив код таким образом:
Добавлено через 7 минут
P. S. Установка флагов std::ios::binary тоже не помогла.
Предпосылки Unicode
Первые 7 бит (128 символов 2 7 =128) в этой кодировке были отданы под символы латинского алфавита, управляющие символы (такие как переносы строк, табуляция и т.д.) и грамматические символы. Остальные отводились под национальные языки. То есть получилось что первые 128 символов всегда одинаковые, а если хочешь закодировать свой родной язык пожалуйста, используй оставшуюся емкость. Собственно так и появился огромный зоопарк национальных кодировок. И теперь сами можете представить, вот например я находясь в России беру и создаю текстовый документ, у меня по умолчанию он создается в кодировке Windows-1251 (русская кодировка использующаяся в ОС Windows) и отсылаю его кому то, например в США. Даже то что мой собеседник знает русский язык, ему не поможет, потому что открыв мой документ на своем компьютере (в редакторе с дефолтной кодировкой той же самой ASCII) он увидит не русские буквы, а кракозябры. Если быть точнее, то те места в документе которые я напишу на английском отобразятся без проблем, потому что первые 128 символов кодировок Windows-1251 и ASCII одинаковые, но вот там где я написал русский текст, если он в своем редакторе не укажет правильную кодировку будут в виде кракозябр.
Думаю проблема с национальными кодировками понятна. Собственно этих национальных кодировок стало очень много, а интернет стал очень широким, и в нем каждый хотел писать на своем языке и не хотел чтобы его язык выглядел как кракозябры. Было два выхода, указывать для каждой страницы кодировки, либо создать одну общую для всех символов в мире таблицу символов. Победил второй вариант, так создали Unicode таблицу символов.
Небольшой практикум ASCII
Возможно покажется элементарщиной, но раз уж решил объяснять все и подробно, то это надо.
Вот таблица символов ASCII:

Тут имеем 3 колонки:
- номер символа в десятичном формате
- номер символа в шестнадцатиричном формате
- представление самого символа.
Решение
Прошу прощения за долгое отсутствие: не было возможности проверить в другой среде (сейчас пробую работать в VS 2015). Получилось следующее. Вывод в консоли действительно стал читаемым, но сравнение по-прежнему не работает, а вывод в файл почему-от идёт в читаемом виде ровно через строчку То есть, например, первая строчка - " ", вторая - " 㰀䔀渀愀戀氀攀搀㸀琀爀甀攀㰀⼀䔀渀愀戀氀攀搀㸀ഀഀ" и т. д.
Добавлено через 28 минут
P. S. Удалось решить задачку со странным выводом читаемого текста путём использования флагов std::ios::binary, которые не помогли в прошлый раз. Остаётся проблема сравнения.
Добавлено через 23 часа 2 минуты
Всё получилось! Пришлось использовать посимвольные сравнение/запись, обращаясь к считанной строке, как к массиву, так как каждый символ разделён пробелом, а в конце каждой строки есть завершающий нуль-символ. Что странно, попытка искать строку с учётом этих самых пробелов не увенчалась успехом.
Считывание txt в кодировке utf-8
Возникла проблема при считывании текстовых файлов в кодировке utf-8. Вернее, считывать-то.
Записать в блокнот в кодировке UTF-8
Здравствуйте, как записывать и считывать строки в кодировке UTF-8 ?
Не сохраняется файл в кодировке utf-8 without bom
Мне нужно сохранить файл в кодировке UTF-8 без BOM. Для этого пробовал два способа - .
Как хранить строки в кодировке UTF-8?
Как сделать, чтобы в строковом типе символы находились в кодировке utf8? в данном коде слово ТЕКСТ.
Стандарт кодирования UTF-8
Стандарт закреплен в RFC (Request For Comments) 3629. Алгоритм кодирования согласно RFC:
0xxxxxxx
110xxxxx 10xxxxxx
1110xxxx 10xxxxxx 10xxxxxx
11110xx 10xxxxxx 10xxxxxx 10xxxxxx
Старший бит слева. Началом кода является управляющий символ (выделен жирным):
110 – используется 16-битная кодировка,
1110 – используется 24-битная кодировка,
11110 – используется 32 битная кодировка.
В начале каждого последующего байта – биты 10 – управляющий символ (выделен подчеркиванием), означающий продолжение кодирования.
Первые 128 ячеек таблицы Юникод повторяют таблицу ASCII. Для кодирования заглавных и строчных букв русского алфавита используются ячейки с номерами 1040-1103.
Рассмотрим пример кодирования фразы «Папа Hello».
Код в бинарном виде (старший бит справа):
00001011 11111001 (П) 00001011 00001101 (а) 00001011 11111101 (п) 00001011 00001101 (а) 00000100 (пробел) 00010010 (H) 10100110 (e) 00110110 (l) 00110110 (l) 11110110 (o).
Букве П русского алфавита согласно таблицы Юникод соответствует номер 1055, в бинарном представлении 10000011111 – 11 бит. Соответственно данный символ может быть закодирован двумя байтами с использованием префикса 110 – для первого байта и 10 – для второго байта. Английские буквы слова Hello кодируются 1 байтом, а коды совпадают с кодами в таблице ASCII.
Основными преимуществами способа кодирования UTF-8 являются многообразие символов, которые могут быть закодированы, а также возможность кодирования переменным количеством бит, что позволяет сэкономить количество информации, передаваемое в канале связи.
Unicode
С предпосылками создания общей таблицы для всех в мире символов, разобрались. Теперь собственно, к самой таблице. Unicode — именно эта таблица и есть (это не кодировка, а именно таблица символов). Она состоит из 1 114 112 позиций. Большинство этих позиций пока не заполнены символами, так что вряд ли понадобится это пространство расширять.
Разделено это общее пространство на 17 блоков, по 65 536 символов в каждом. Каждый блок содержит свою группу символов. Нулевой блок — базовый, там собраны наиболее употребляемые символы всех современных алфавитов. Во втором блоке находятся символы вымерших языков. Есть два блока отведенные под частное использование. Большинство блоков пока не заполнены.
Итого емкость символов юникода составляет от 0 до 10FFFF (в шестнадцатиричном виде).
Записываются символы в шестнадцатиричном виде с приставкой «U+». Например первый базовый блок включает в себя символы от U+0000 до U+FFFF (от 0 до 65 535), а последний семнадцатый блок от U+100000 до U+10FFFF (от 1 048 576 до 1 114 111).
Отлично теперь вместо зоопарка национальных кодировок, у нас есть всеобъемлющая таблица, в которой зашифрованы все символы которые нам могут пригодиться. Но тут тоже есть свои недостатки. Если раньше каждый символ был закодирован одним байтом, то теперь он может быть закодирован разным количеством байтов. Например для кодирования всех символов английского алфавита по прежнему достаточно одного байта например тот же символ «o» (англ.) имеет в юникоде номер U+006F, то есть тот же самый номер как и в ASCII — 6F в шестнадцатиричной и 111 в десятеричной. А вот для кодирования символа "U+103D5" (это древнеперсидская цифра сто) — 103D5 в шестнадцатиричной и 66 517 в десятеричной, тут нам потребуется уже три байта.
Решить эту проблему уже должны юникод-кодировки, такие как UTF-8 и UTF-16. Далее речь пойдет про них.
UTF-8 является юникод-кодировкой переменной длинны, с помощью которой можно представить любой символ юникода.
Давайте поподробнее про переменную длину, что это значит? Первым делом надо сказать, что структурной (атомарной) единицей этой кодировки является байт. То что кодировка переменной длинны, значит, что один символ может быть закодирован разным количеством структурных единиц кодировки, то есть разным количеством байтов. Так например латиница кодируется одним байтом, а кириллица двумя байтами.
Немного отступлю от темы, надо написать про совместимость ASCII и UTF
То что латинские символы и основные управляющие конструкции, такие как переносы строк, табуляции и т.д. закодированы одним байтом делает utf-кодировки совместимыми с кодировками ASCII. То есть фактически латиница и управляющие конструкции находятся на тех же самых местах как в ASCII, так и в UTF, и то что закодированы они и там и там одним байтом и обеспечивает эту совместимость.
Давайте возьмем символ «o»(англ.) из примера про ASCII выше. Помним что в таблице ASCII символов он находится на 111 позиции, в битовом виде это будет 01101111 . В таблице юникода этот символ — U+006F что в битовом виде тоже будет 01101111 . И теперь так, как UTF — это кодировка переменной длины, то в ней этот символ будет закодирован одним байтом. То есть представление данного символа в обеих кодировках будет одинаково. И так для всего диапазона символов от 0 до 128. То есть если ваш документ состоит из английского текста то вы не заметите разницы если откроете его и в кодировке UTF-8 и UTF-16 и ASCII (прим. в UTF-16 такие символы все равно будут закодированы двумя байтами, по этому вы не увидите разницы, если ваш редактор будет игнорировать нулевые байты), и так до момента пока вы не начнете работать с национальным алфавитом.
Сравним на практике как будет выглядеть фраза «Hello мир» в трех разных кодировках: Windows-1251 (русская кодировка), ISO-8859-1 (кодировка западно-европейских языков), UTF-8 (юникод-кодировка). Суть данного примера состоит в том что фраза написана на двух языках. Посмотрим как она будет выглядеть в разных кодировках.

В кодировке ISO-8859-1 нет таких символов «м», «и» и «р».
Теперь давайте поработаем с кодировками и разберемся как преобразовать строку из одной кодировки в другую и что будет если преобразование неправильное, или его нельзя осуществить из за разницы в кодировках.
Будем считать что изначально фраза была записана в кодировке Windows-1251. Исходя из таблицы выше запишем эту фразу в двоичном виде, в кодировке Windows-1251. Для этого нам потребуется всего только перевести из десятеричной или шестнадцатиричной системы (из таблицы выше) символы в двоичную.
01001000 01100101 01101100 01101100 01101111 00100000 11101100 11101000 11110000
Отлично, вот это и есть фраза «Hello мир» в кодировке Windows-1251.
Теперь представим что вы имеете файл с текстом, но не знаете в какой кодировке этот текст. Вы предполагаете что он в кодировке ISO-8859-1 и открываете его в своем редакторе в этой кодировке. Как сказано выше с частью символов все в порядке, они есть в этой кодировке, и даже находятся на тех же местах, но вот с символами из слова «мир» все сложнее. Этих символов в этой кодировке нет, а на их местах в кодировке ISO-8859-1 находятся совершенно другие символы. А конкретно «м» — позиция 236, «и» — 232. «р» — 240. И на этих позициях в кодировке ISO-8859-1 находятся следующие символы позиция 236 — символ "ì", 232 — "è", 240 — "ð"
Значит фраза «Hello мир» закодированная в Windows-1251 и открытая в кодировке ISO-8859-1 будет выглядеть так: «Hello ìèð». Вот и получается что эти две кодировки совместимы лишь частично, и корректно перекодировать строку из одной кодировке в другую не получится, потому что там просто напросто нет таких символов.
Тут и будут необходимы юникод-кодировки, а конкретно в данном случае рассмотрим UTF-8. То что символы в ней могут быть закодированы разным количеством байтов от 1 до 4 мы уже выяснили. Теперь стоит сказать что с помощью UTF могут быть закодированы не только 256 символов, как в двух предыдущих, а вобще все символы юникода
Работает она следующим образом. Первый бит каждого байта кодирующего символ отвечает не за сам символ, а за определение байта. То есть например если ведущий (первый) бит нулевой, то это значит что для кодирования символа используется всего один байт. Что и обеспечивает совместимость с ASCII. Если внимательно посмотрите на таблицу символов ASCII то увидите что первые 128 символов (английский алфавит, управляющие символы и знаки препинания) если их привести к двоичному виду, все начинаются с нулевого бита (будьте внимательны, если будете переводить символы в двоичную систему с помощью например онлайн конвертера, то первый нулевой ведущий бит может быть отброшен, что может сбить с толку).
01001000 — первый бит ноль, значит 1 байт кодирует 1 символ -> «H»
01100101 — первый бит ноль, значит 1 байт кодирует 1 символ -> «e»
Если первый бит не нулевой то символ кодируется несколькими байтами.
Для двухбайтовых символов первые три бита должны быть такие — 110
110 10000 10 111100 — в начале 110, значит 2 байта кодируют 1 символ. Второй байт в таком случае всегда начинается с 10. Итого отбрасываем управляющие биты (начальные, которые выделены красным и зеленым) и берем все оставшиеся ( 10000111100 ), переводим их в шестнадцатиричный вид (043С) -> U+043C в юникоде равно символ «м».
для трех-байтовых символов в первом байте ведущие биты — 1110
1110 1000 10 000111 10 1010101 — суммируем все кроме управляющих битов и получаем что в 16-ричной равно 103В5, U+103D5 — древнеперситдская цифра сто ( 10000001111010101 )
для четырех-байтовых символов в первом байте ведущие биты — 11110
11110 100 10 001111 10 111111 10 111111 — U+10FFFF это последний допустимый символ в таблице юникода ( 100001111111111111111 )
Теперь, при желании, можем записать нашу фразу в кодировке UTF-8.
Как изменить кодировку по умолчанию в Блокноте
Что ж, в качестве первого шага полезно знать возможные кодировки Блокнота:
- ANSI
- UTF-16 ЛЕ
- UTF-16 БЭ
- UTF-8
- UTF-8 с спецификацией
Кроме того, поскольку вы будете работать над редактором реестра, мы рекомендуем вам сделать резервную копию.
Тем не менее, шаги по изменению кодировки по умолчанию в Блокноте просты, а именно:
Когда вы завершите эту процедуру, настанет ваша очередь перезапустить приложение «Блокнот», что позволит вам увидеть разницу с исходной версией. В строке состояния вы можете проверить активную кодировку.
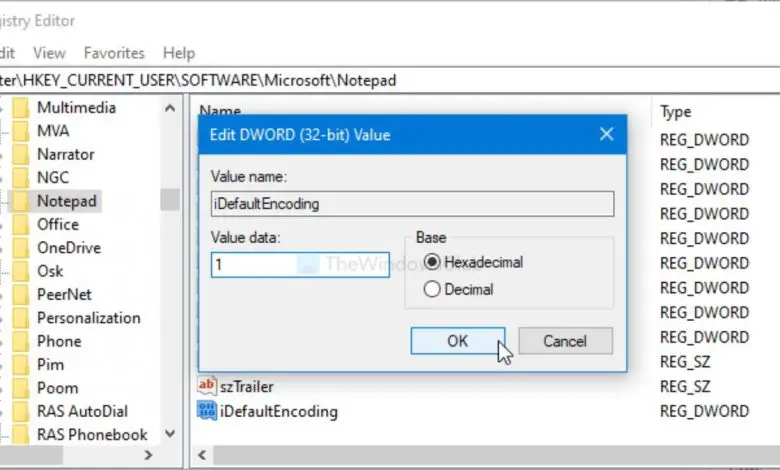
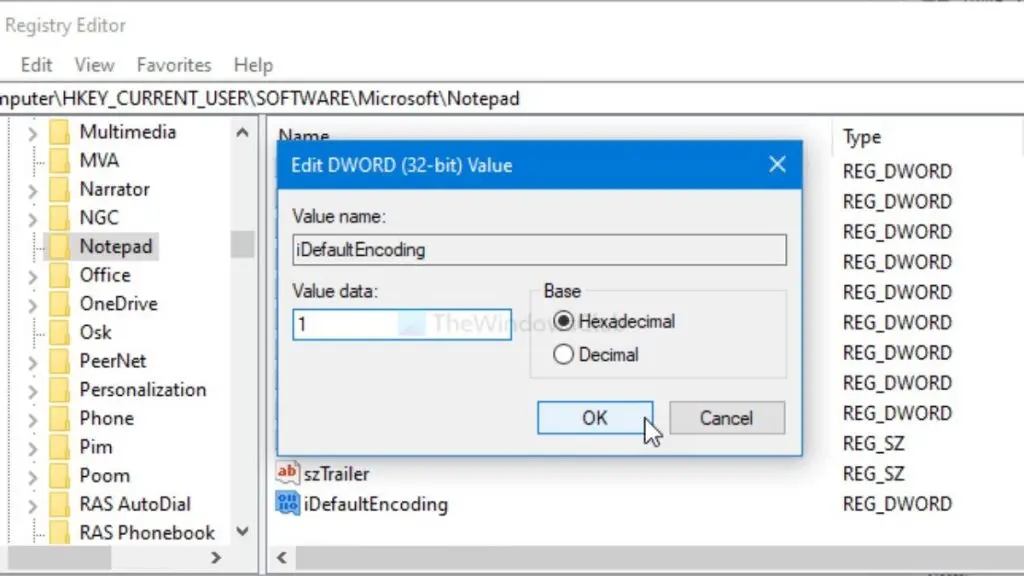
Если вы хотите вернуться к исходной кодировке, вам нужно перейти по тому же пути в редакторе реестра и щелкнуть правой кнопкой мыши iDefaultEncoding. Затем нажмите кнопку «Удалить» и подтвердите удаление.
Если вам понравилась эта статья, вы, вероятно, захотите узнать как создавать заметки, защищенные паролем .
У меня возникла проблема при обработке файлов в кодировке UTF-16 LE (1200): нужно заменить в них одну строчку. Алгоритм такой:
fstream работа с utf-8 файлами
Открывается файл в кодировке utf-8: fstream fin; fin.open(fOpenDlg.GetPathName(),ios::in);.
Ошибка при кодировке в UTF-8
Вот, написал код. Здесь его часть в начале файла указана кодировка UTF-8, перед строкой поставил.
Создание файла в UTF-8 кодировке
Здравствуйте! Как сделать что бы в данной ситуации файл создавался в utf-8 DWORD tmp0; .
rao, уже пробовал, но решил проверить ещё раз, изменив код таким образом:
Добавлено через 7 минут
P. S. Установка флагов std::ios::binary тоже не помогла.
Стандарт Юникод
Консорциум Unicode (Юникод) – некоммерческая организация, главной задачей которой являлась разработка стандарта кодирования (стандарт Юникод) с поддержкой наибольшего числа языков и символов служебного характера. Принцип кодирования на основе таблицы сохранился, а таблица (таблица Юникод) была значительно расширена.
Стандарт Юникод предоставляет пользователям таблицу Юникод и способы кодирования символов.
Символы таблицы Юникод являются элементами «универсального набора символов» UCS (Universal Coded Character Set), определенного международным стандартом ISO/IEC 10646. Таблица Юникод каждому символу UCS сопоставляет кодовую точку, которая является номером ячейки таблицы, содержащей символ.
Способы кодирования символов таблицы Юникод, т.е. преобразования номеров ячеек таблицы Юникод в бинарные коды, составляют кодовое пространство, состоящее из трех кодов семейства UTF (Unicode Transformation Format): UTF-8, UTF-16 и UTF-32
UTF-8 – стандарт кодирования, преобразующий номера ячеек таблицы Юникод в бинарные коды с использованием переменного количества бит: 8, 16, 24 или 32.
UTF-16 – стандарт кодирования, преобразующий номера ячеек таблицы Юникод в бинарные коды с использованием переменного количества бит:16 или 32.
Коды UTF-8 и UTF-16 используют разные алгоритмы кодирования набора символов UCS.
UTF-16
UTF-16 также является кодировкой переменной длинны. Главное ее отличие от UTF-8 состоит в том что структурной единицей в ней является не один а два байта. То есть в кодировке UTF-16 любой символ юникода может быть закодирован либо двумя, либо четырьмя байтами. Давайте для понятности в дальнейшем пару таких байтов я буду называть кодовой парой. Исходя из этого любой символ юникода в кодировке UTF-16 может быть закодирован либо одной кодовой парой, либо двумя.
Начнем с символов которые кодируются одной кодовой парой. Легко посчитать что таких символов может быть 65 535 (2в16), что полностью совпадает с базовым блоком юникода. Все символы находящиеся в этом блоке юникода в кодировке UTF-16 будут закодированы одной кодовой парой (двумя байтами), тут все просто.
символ «o» (латиница) — 00000000 01101111
символ «M» (кириллица) — 00000100 00011100
Теперь рассмотрим символы за пределами базового юникод диапазона. Для их кодирования потребуется уже две кодовые пары (4 байта). И механизм их кодирования немного сложнее, давайте по порядку.
Для начала введем понятия суррогатной пары. Суррогатная пара — это две кодовые пары используемые для кодирования одного символа (итого 4 байта). Для таких суррогатных пар в таблице юникода отведен специальный диапазон от D800 до DFFF. Это значит, что при преобразовании кодовой пары из байтового вида в шестнадцатиричный вы получаете число из этого диапазона, то перед вами не самостоятельный символ, а суррогатная пара.
Чтобы закодировать символ из диапазона 10000 — 10FFFF (то есть символ для которого нужно использовать более одной кодовой пары) нужно:
- из кода символа вычесть 10000(шестнадцатиричное) (это наименьшее число из диапазона 10000 — 10FFFF)
- в результате первого пункта будет получено число не больше FFFFF, занимающее до 20 бит
- ведущие 10 бит из полученного числа суммируются с D800 (начало диапазона суррогатных пар в юникоде)
- следующие 10 бит суммируются с DC00 (тоже число из диапазона суррогатных пар)
- после этого получатся 2 суррогатные пары по 16 бит, первые 6 бит в каждой такой паре отвечают за определение того что это суррогат,
- десятый бит в каждом суррогате отвечает за его порядок если это 1 то это первый суррогат, если 0, то второй
Для примера зашифруем символ, а потом расшифруем. Возьмем древнеперсидскую цифру сто (U+103D5):
- 103D5 — 10000 = 3D5
- 3D5 = 0000000000 1111010101 (ведущие 10 бит получились нулевые приведем это к шестнадцатиричному числу, получим 0 (первые десять), 3D5 (вторые десять))
- 0 + D800 = D800 ( 110110 0 000000000 ) первые 6 бит определяют что число из диапазона суррогатных пар десятый бит (справа) нулевой, значит это первый суррогат
- 3D5 + DC00 = DFD5 ( 110111 1 111010101 ) первые 6 бит определяют что число из диапазона суррогатных пар десятый бит (справа) единица, значит это второй суррогат
- итого данный символ в UTF-16 — 1101100000000000 1101111111010101
- переведем в шестнадцатиричный вид = D822DE88 (оба значения из диапазона суррогатных пар, значит перед нами суррогатная пара)
- 110110 0 000100010 — десятый бит (справа) нулевой, значит первый суррогат
- 110111 1 010001000 — десятый бит (справа) единица, значит второй суррогат
- отбрасываем по 6 бит отвечающих за определение суррогата, получим 0000100010 1010001000 (8A88)
- прибавляем 10000 (меньшее число суррогатного диапазона) 8A88 + 10000 = 18A88
- смотрим в таблице юникода символ U+18A88 = Tangut Component-649. Компоненты тангутского письма.
Блокнот - один из тех инструментов Windows, которые при определенных обстоятельствах могут помочь нам избежать неприятностей. Однако, помимо его базового использования, многие люди понятия не имеют, как настроить опыт использования этой программы. По этой причине сегодня мы хотим показать вам одно из основных руководств по этому поводу, а именно: изменить кодировку символов по умолчанию в Блокнот .
Первое, что вам нужно знать, это то, что если вы намереваетесь изменить кодировку символов по умолчанию в Блокноте в Windows 10, в следующих строках вы найдете все шаги, которые необходимо предпринять в этих ситуациях. Фактически, изменить кодировку по умолчанию с UTF-8 на ANSI или что-то еще с помощью редактора реестра не только возможно, но и довольно просто.
И в каких случаях может пригодиться эта подсказка? В некоторых очень специфических. Например, если вы оказались перед текстовым файлом, содержащим необычные символы, такие как «ð . » или похожие. Если вы хотите извлечь исходный текст и сделать его удобочитаемым, необходимо изменить кодировку символов.
Наконец, прежде чем мы начнем, имейте в виду, что, хотя Блокнот позволяет нам изменять кодировку при сохранении файла, во избежание других проблем рекомендуется изменить ее, когда мы создаем или изменяем его.
Решение
Прошу прощения за долгое отсутствие: не было возможности проверить в другой среде (сейчас пробую работать в VS 2015). Получилось следующее. Вывод в консоли действительно стал читаемым, но сравнение по-прежнему не работает, а вывод в файл почему-от идёт в читаемом виде ровно через строчку То есть, например, первая строчка - " ", вторая - " 㰀䔀渀愀戀氀攀搀㸀琀爀甀攀㰀⼀䔀渀愀戀氀攀搀㸀ഀഀ" и т. д.
Добавлено через 28 минут
P. S. Удалось решить задачку со странным выводом читаемого текста путём использования флагов std::ios::binary, которые не помогли в прошлый раз. Остаётся проблема сравнения.
Добавлено через 23 часа 2 минуты
Всё получилось! Пришлось использовать посимвольные сравнение/запись, обращаясь к считанной строке, как к массиву, так как каждый символ разделён пробелом, а в конце каждой строки есть завершающий нуль-символ. Что странно, попытка искать строку с учётом этих самых пробелов не увенчалась успехом.
Считывание txt в кодировке utf-8
Возникла проблема при считывании текстовых файлов в кодировке utf-8. Вернее, считывать-то.
Записать в блокнот в кодировке UTF-8
Здравствуйте, как записывать и считывать строки в кодировке UTF-8 ?
Не сохраняется файл в кодировке utf-8 without bom
Мне нужно сохранить файл в кодировке UTF-8 без BOM. Для этого пробовал два способа - .
Как хранить строки в кодировке UTF-8?
Как сделать, чтобы в строковом типе символы находились в кодировке utf8? в данном коде слово ТЕКСТ.
С появлением первых устройств цифровой передачи информации и электронно-вычислительных машин возникла задача кодирования текстовых символов с помощью последовательностей единиц и нулей. Минимальная единица представления информации – байт. Исходя их этого в 1963 году в США разработана, стандартизована, а впоследствии расширена кодовая таблица ASCII (American standard code for information interchange), использовавшая 8 битную кодировку. В первую очередь с помощью этой таблицы предполагалось кодирование цифр и букв английского языка. Первые 128 символов таблицы представлены на рис.1:

Рис.1. Первые 128 символов таблицы ASCII.
Номер ячейки в таблице (рис.1) является кодом символа. В качестве примера рассмотрим кодирование слова Hello. Номера ячеек таблицы ASCII, в которых размещены буквы: 72 (H), 101 (e), 108 (l), 111 (o). Код слова в бинарном представлении выглядит следующим образом:
00010010 (H) 10100110 (e) 00110110 (l) 00110110 (l) 11110110 (o) (старший бит справа).
Выделенные подчеркиванием и жирным коды в двоичном представлении соответствуют номерам ячеек в таблице (рис.1). Алгоритм формирования кода следующий:
1. Выделены жирным – биты управления кодированием (префикс). 010 – кодируется заглавная буква алфавита, 011 – строчная.
2. Выделены подчеркиванием – порядковые номера букв в английском алфавите.
Таким образом, с помощью первых 128 ячеек таблицы ASCII могли быть закодированы основные символы, цифры и буквы английского языка. Остальные 128 ячеек (8 битная кодировка позволяет закодировать 256 символов) могли использоваться для кодирования других языков. Однако, учитывая разнообразие символов и языков, 8 бит недостаточно.
Несколько советов программистам
Допустим, программист решил реализовать текстовый редактор, поддерживающий алфавит языка Бопомофо. Символы данного языка располагаются в таблице Юникод в диапазоне 12549-12589 и, следовательно, программисту необходимо выбрать стандарт UTF-16 для кодирования. Предположим, что для ввода символов решено использовать программную клавиатуру, состоящую из кнопок, каждая из которых соответствует букве алфавита языка. Кнопки – объекты класса button. Нажатие пользователем на какую-либо из кнопок порождает событие, в результате которого приложению становится известен номер ячейки таблицы Юникод. Программисту рекомендуется:
1.Хранить в памяти приложения символы таблицы Юникод и номера ячеек, соответствующие только языкам, поддержка которых планируется в текстовом редакторе. Это уменьшит объем памяти, занимаемой приложением, а также повысит скорость его работы, сузив область поиска номера ячейки.
2. При реализации приложения заранее выполнить преобразование всех номеров ячеек в их бинарные коды. Результат преобразования сохранить в файле, в формализованном виде. При загрузке приложения выполнить считывание в память номеров ячеек и их бинарных кодов UTF-16. Это позволит снизить вычислительную нагрузку приложения в ходе его работы.
3. Для хранения номеров ячеек и их бинарных кодов использовать объект класса, позволяющего осуществить это в виде ключ-значение, где ключ – номер ячейки, а значение – бинарный код. Классы, реализующие в языках программирования данный функционал, организуют работу таким образом, чтобы минимизировать время поиска ключа, используя сортировку ключей или хеширование.
Отметим проблему кодирования составных символов, которая является важным техническим аспектом. Например, символ ü может быть интерпретирован, как самостоятельный символ, которому соответствует номер ячейки 252 или может быть скомпонован из двух символов: u, которому соответствует номер ячейки 117 и символа ¨, которому соответствует номер ячейки 776. Программист должен строго придерживаться одного из вариантов представления таких символов иначе побайтовое сравнение строк будет невозможно. Рекомендуется использование второго варианта, который может облегчить поиск составных символов в тексте. Например, если пользователь осуществляет поиск символа u, то ему может быть выведен в качестве результата, как составной символ ü, так и самостоятельный u.
Данная статья имеет цель собрать воедино и разобрать принципы и механизм работы кодировок текста, подробно этот механизм разобрать и объяснить. Полезна она будет тем, кто только примерно представляет, что такое кодировки текста и как они работают, чем отличаются друг от друга, почему иногда появляются не читаемые символы, какой принцип кодирования имеют разные кодировки.
Чтобы получить детальное понимание этого вопроса придется прочитать и свести воедино не одну статью и потратить довольно значительное время на это. В данном материале же это все собрано воедино и по идее должно сэкономить время и разбор на мой взгляд получился довольно подробный.
О чем будет под катом: принцип работы одно байтовых кодировок (ASCII, Windows-1251 и т.д.), предпосылки появления Unicode, что такое Unicode, Unicode-кодировки UTF-8, UTF-16, их отличия, принципиальные особенности, совместимость и несовместимость разных кодировок, принципы кодирования символов, практический разбор кодирования и декодирования.
Вопрос с кодировками сейчас конечно уже потерял актуальность, но все же знать как они работают сейчас и как работали раньше и при этом не потратить много времени на это думаю лишним не будет.
Стандарт кодирования UTF-16
В феврале 2000 года опубликован документ RFC 2781, в котором закреплен стандарт UTF-16, позволяющий кодировать символы таблицы Юникод с помощью 16 или 32 битных значений. Символы с номерами 0-55295 и 57344-65535 кодируются с помощью 16 бит без изменений (без использования префиксов), а остальные символы, номера которых в двоичном представлении формируются количеством бит больше 16, кодируются 32 битами с использованием специального алгоритма. Рассмотрим пример кодирования фразы «Папа Hello».
Код в бинарном виде (старший бит справа):
11111000 00100000 (П) 00001100 001000000 (а) 11111100 00100000 (п) 00001100 001000000 (а) 00000100 00000000 (пробел) 00010010 00000000 (H) 10100110 00000000 (e) 00110110 00000000 (l) 00110110 00000000 (l) 111110110 00000000 (o).
Номера букв русского и английского алфавитов таблицы Юникод передаются без изменений при помощи 16 бит, старшие незначащие биты принимают нулевое значение.
Рассмотрим подробнее алгоритм кодирования символов, номера которых превышают значение 65535. Для примера в качестве символа используем букву древнетюркского алфавита, представленную на рис.2:
Рис.2. Буква древнетюркского алфавита.
Номер предложенного символа в таблице Юникод – 68620 (0х10COC).
Алгоритм преобразования номера символа в код UTF-16 состоит из нескольких шагов:
Из значения номера символа вычесть число 0х10000. Данная операция позволяет привести размерность бинарного представления номера символа к 20 битам. Для предложенного символа получим: 0х10COC – 0x10000 = 0xC0C.
Для полученного значения выделить старшие 10 бит и младшие 10 бит. В примере число 0хС0С в бинарном виде представляется, как 00000000110000001100, где жирным выделены 10 старших бит, а подчеркиванием – 10 младших.
К шестнадцатеричному значению 0xD800 (11011000 00000000) прибавить значение 0х03 (00000000 00000011), сформированное 10 старшими битами, полученными на предыдущем шаге. 0xD800 + 0х03 = 0хD803 (11011000 00000011) – 16 старших бит кодового слова UTF-16.
К шестнадцатеричному значению 0xDC00 (11011000 00000000) прибавить значение 0х0C (00000000 00001100), сформированное 10 младшими битами, полученными на шаге №2. 0xDС00 + 0х0С = DС0С (11011100 00001100) – 16 младших бит кодового слова UTF-16.
Кодовое слово UTF-16, соответствующее символу в примере, формируется из бит, полученных на шагах 3 и 4: 0хD803DC0C (11011000 00000011 11011100 00001100).
Сравнение стандартов UTF-8 и UTF-16 с точки зрения объема машинной памяти, используемой кодом для представления символов
Результаты сравнения стандартов представлены в таблице 1.
Таблица 1. Результаты сравнения стандартов.
В предыдущих главах приведены примеры кодирования фразы «Папа Hello» стандартами UTF-8 и UTF-16. Кодировкой UTF-8 используются 14 байт, кодировкой UTF-16 20 байт, что связано с избыточностью кодирования англоязычных символов во втором случае из-за использования дополнительного байта 0х00. Можно сделать вывод, что для кодирования текста содержащего набор букв русского и английского алфавитов, предпочтительно использование кодировки UTF-8.
Вывод: в зависимости от языка алфавита может быть выбрана как кодировка UTF-8, так и кодировка UTF-16. Для английского алфавита однозначно более выгодно использование кодировки UTF-8, для русского алфавита буквы представляются одинаковым количеством бит при использовании как одной, так и другой кодировки.
Читайте также: