
Oracle с чего начать
Нужно ли программисту прикладных приложений понимать как работает БД? Том Кайт, признанный специалист Oracle, автор знаменитой колонки asktom, в своей книге «Oracle для профессионалов. Архитектура и основные особенности.» настаивает, что это просто необходимо. Даже если в вашей команде есть грамотный администратор, знание того, как работает СУБД Oracle поможет вам лучше понимать друг друга и эффективней взаимодействовать, не говоря уже о случае, когда такого специалиста у вас нет. В данном топике я упомяну об основных вещах, понимание которых позволит грамотно работать с БД Oracle и использовать некоторые её особенности с большой отдачей для вашего приложения. Если же вы уже прочитали вышеупомянутую книгу Тома Кайта, то можете просто исползовать эту статью в качестве памятки. Одно замечание — книжку я читал давно, и тогда еще последней версией БД Oracle была 9i, курсы по администрированию я тоже проходил по девятке, так что, если в десятке и выше что-то поменялось и добавилось, то не обессудьте. Хотя я пишу о довольно фундаментальных вещах, которые вряд ли сильно поменяись.
Что позволяет БД Oracle работать так быстро?
Когда вы меняете данные в БД, то ваши изменения сначала идут в кэш, а потом асинхронно в нескольких потоках (число можно сконфигурировать) пишутся на диск. Синхронно же пишется специальных лог (оперативный журнальный файл), чтобы была возможность восстановить данные после сбоя, если они еще не успели с кэша сброситься на диск. Данный подход позволяет выиграть в скорости, так как в этом случае на диск все пишется последовательно в один файл, причем можно настроить так, чтобы писалось параллельно на два или больше дисков, тем самым увеличивая надежность защиты от потери изменений. Описанных файлов должно быть несколько, и они используются по кругу: как только все данные защищенные одним из лог файлов были записаны фоновым процессом в блоки данных на диск, то данный лог файл может быть переиспользован. Таким образом в какой-то мере это позволяет еще и сэкономить, имея ультрабыстрые диски небольшого размера только для небольших журнальных файлов используемых по кругу.
Обычно я рассказываю об этом, когда мне предлагают что-то сохранять просто в файл на диске, так как это будет «быстрее» за счет того, что мы будет писать все данные последовательно и головке жесткого диска не надо будет бегать и искать рэндомные блоки. Я все же настаиваю, что мы тут ничего не выиграем, так как будем писать на медленный диск, который скоро всего активно используется множеством других процессов для записи огромного количества различных логов, а Oracle синхронно тоже пишет у себя на диск только последовательно, как я описал выше.
Уровни изоляции транзакций
В Oracle вообще нет уровня изоляции READ_UNCOMMITED. Дело в том, что в других базах данных он используется для достижения максимального параллелизма путем удаления блокировок чтения. Но в Oracle чтение и так всегда выполняется без блокировок, таким образом мы уже имеем все преимущества, которые может дать этот уровень, не вводя никаких дополнительных ограничений.
Вообще, в Oracle явно доступно всего два уровня изоляции: по умолчанию используется READ_COMMITTED, но при желании вы можете установить SERIALIZABLE.
Однако на уровне операторов (SELECT, UPDATE и т.д.) у вас по умолчанию уже есть REPEATABLE_READ, т.е. в рамках одного оператора вы всегда получаете согласованное чтение, что достигается конечно же за счет сегмента отката. Мне всегда очень нравился пример приводимый Томом Кайтом для описания того, что это дает. Допустим у вас есть очень большая таблица со счетами и вы выполняете SELECT на получение суммы. В Oracle, в отличие от многих других БД, даже если в середине вашего запроса другая транзакция переведет некоторую суммы с первого счета на последний, вы в итоге все равно получите данные актуальные на начало вашего запроса, так как дойдя до последний строчки ваш SELECT увидит, что строчка была изменена, пойдет в сегмент отката и прочитает данные, которые были в этой ячейке на момент начала выполнения запроса. Во многих других базах данных, вы получите ответ в виде суммы, никогда не существующей в вашей таблице. Однако в Oracle в данном случае есть опасность получить ORA-01555: snapshot too old.
В дополнение к стандартным уровням изоляции в Oracle еще есть так называемые READ_ONLY транзакции, которые дают REPEATABLE_READ в рамках всей транзакции, а не только в рамках одного оператора. Но как следует из названия, в такой транзакции вы можете выполнять только чтение.
Связывание переменных
Наверное об этом уже наслышан каждый программист, но я все же упомяну о такой обязательной техники, как связывание переменных. Дело в том, что для каждого уникального запроса строится план разбора и кладется в кэш. Если различных запросов очень много, как, например, весьма распространенный запрос по ID, то на каждый запрос буден генериться свой план, к тому же они будут вытеснять из кэша все другие планы, что может в разы увеличить время отклика вашей базы данных.
Стоит так же заметить, что не стоит этим злоупотреблять и использовать связывание для столбцов с небольшим количеством различных значений, как-то флаг is_deleted, ведь различных запросов в этом случае будет не так много, а, возможно, для более конкретного запроса СУБД удастся построить более эффективный план.
Табличные пространства
Любые данные, хранящиеся в базе Oracle, должны находиться в каком-то табличном пространстве. Табличное пространство (tablespace) – это логическая структура; нельзя попросить операционную систему показать вам табличное пространство. Каждое табличное пространство состоит из физических структур, называемых файлами данных (data files). В одном табличном пространстве может быть один или несколько файлов данных, тогда как каждый файл данных принадлежит ровно одному табличному пространству. При создании таблицы можно указать, в какое табличное пространство ее поместить. Тогда Oracle найдет для нее место в одном из файлов данных, составляющих указанное табличное пространство.
На рисунке 2 показано соотношение между табличными пространствами и файлами данных. Здесь мы видим два табличных пространства в базе данных Oracle.
При создании новой таблицы ее можно поместить в табличное пространство DATA1 или DATA2. Физически таблица окажется в одном из файлов данных, составляющих указанное табличное пространство.
Начиная с версии Oracle Database 10g Release 2 для всех типов таблиц по умолчанию подразумеваются локально управляемые табличные пространства. В таком табличном пространстве можно создавать большие файлы, то есть при работе в 64-разрядных системах задействуется возможность создавать сверхбольшие файлы.
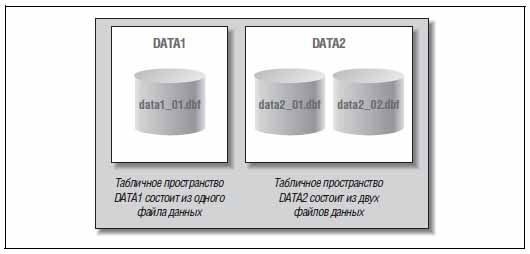
Рис. 2. Табличные пространства и файлы данных Oracle
В Oracle9i появился механизм файлов, управляемых Oracle (Oracle Managed Files, OMF), позволяющий автоматически создавать, именовать и, если понадобится, удалять все файлы, составляющие базу данных. OMF упрощает обслуживание базы данных, поскольку не нужно помнить имена всех составляющих ее файлов. К тому же не возникают проблемы из-за ошибок человека, ответственного за именование файлов. Начиная с версии Oracle Database 10g сочетание OMF и табличных пространств с большими файлами делает работу с файлами данных совершенно прозрачной.
Максимальное количество файлов данных в базе Oracle - 64 000. Поскольку табличное пространство с большими файлами может содержать файл, который в 1024 раза больше файла в табличном пространстве с малыми файлами, а размер блока в табличном пространстве с большими файлами для 64-разрядных операционных систем составляет 32 Кбайт, общий размер базы данных Oracle может достигать 8 экзабайт (1 экзабайт = 1 000 000 терабайт) . Табличные пространства с большими файлами предназначены для использования совместно с подсистемой автоматического управления хранением Automatic Storage Management (ASM), иными менеджерами логических томов, поддерживающими расслоение, и RAID-массивами .
Обзор
Live SQL - это бесплатная облачная служба, предоставляемая Oracle. Она предоставляет разработчикам и администраторам баз данных онлайн-платформу разработки для тестирования и обмена сценариями SQL, PL / SQL, руководствами и передовыми практиками.
Вы можете получить доступ к базе данных Oracle (режим схемы) через эту службу онлайн, написать свои собственные операторы SQL и сценарии, испытать различные функции SQL и улучшить свой уровень программирования SQL в процессе обучения и практики.
В настоящее время (2020/3) версия Live SQL для базы данных - 19c, поэтому вы можете легко испытать новейшие функции 19c без установки базы данных.
Еще пара заметок для программиста
Если у вас колонка имеет тип VARCHAR2(100), то попытка туда запихнуть строку longString.substring(0, 100) не факт, что увенчается успехом, так как ограничение 100 в определении колонки по умолчанию относится к количеству байтов, а не символов, поэтому при наличии двухбайтовых символов вы можете попасть впросак. На самом деле данное поведение можно немного сконфигурировать, подробнее можно почитать тут. Хорошо если вы еще не пытаетесь выполнить вставку в бесконечном цикле, по принципу делать пока не получиться, ведь это «получиться» в данном случае никогда не наступит.
Ну и общая рекомендация для всех типов БД: никогда не делайте update всех колонок в таблице при изменении одного поля объекта. Кажется весьма очевидным, но как показывает практика, данный антипаттерн часто имеет место быть, поэтому я настоятельно рекомендую проверить, что ваши фреймворки делают UPDATE только действительно измененных полей.
Неблокирующее чтение и сегмент отката
Одной из наиболее замечательных особенностей СУБД Oracle является неблокирующее чтение, которое достигается за счет сегмента отката. Запросы к Oracle на чтение никогда не блокируются, так как данные почти всегда могут быть прочитаны из сегмента отката.
Сегмент отката дает еще одну плюшку: из него можно попытаться считать немного устаревшие данные для какой-нибудь таблицы, которые были в ней на определенный момент. Называется данная фича — flashback.
Однако иногда сегмент отката может подложить свинью: если у вас есть большой job для bulk удаления данных (удаление генерирует всех больше данных в сегменте отката), то вы можете получить ORA-01555: snapshot too old. Главное что в этом случае надо помнить — это то, что не надо переписывать ваш job, чтобы он коммитил через каждые N операций, а нужно использовать отдельный специально созданный сегмент отката для таких операций.
Инициализация базы данных
При запуске экземпляра Oracle считываются параметры инициализации. Они определяют, как база данных должна использовать физическую инфраструктуру и иную конфигурационную информацию об экземпляре. Параметры инициализации хранятся в файле параметров инициализации экземпляра, который обычно называют просто INIT.ORA, или, начиная с версии Oracle9i, в репозитории, который называется файлом параметров сервера (или SPFILE). Количество обязательных параметров инициализации уменьшается с выходом каждой новой версии Oracle. В дистрибутиве Oracle есть пример файла инициализации, пригодный для запуска базы данных. Либо можно воспользоваться программой Database Configuration Assistant (DCA), которая подскажет обязательные значения (например, имя базы данных).
Вот обязательные параметры инициализации для версии Oracle Database 11g:
Местонахождение управляющих файлов.
Локальное имя базы данных.
Местонахождение архивного журнала.
Параметр, включающий архивирование журналов.
Местонахождение области быстрого восстановления (flash recovery area) (каталог, файловая система или группа дисков ASM).
Максимальный размер области быстрого восстановления базы данных в байтах.
Размер блока базы данных в байтах (например, для 4 Кбайт указывается значение 4096).
Максимальное число процессов операционной системы, обслуживающих одновременный доступ к базе данных.
Максимальное число сеансов работы с базой данных.
Максимальное число открытых в базе данных курсоров.
Минимальное число разделяемых серверов базы данных.
REM O TE_LI S TENER
Имя удаленного прослушивателя.
Версия базы данных, с которой должна поддерживаться совместимость, в тех случаях, когда то или иное средство затрагивает формат файла (например, 11.1.0, 10.0.0).
Размер области памяти, автоматически выделяемой для SGA и PGA экземпляра.
Для команд языка определения данных (DDL) - время (в секундах) ожидания возможности установить монопольную блокировку, прежде чем сообщить об ошибке.
Язык, определенный в подсистеме поддержки национальных языков (National Language Support, NLS) для базы данных.
Территория, определенная в подсистеме поддержки национальных языков для базы данных.
В качестве признака взятого курса на автоматизацию отметим, что в версии Oracle Database 11g параметр UNDO_MANAGEMENT по умолчанию устанавливается в режим автоматического управления откатом (undo). Механизм отката применяется при откате транзакций, а также для восстановления базы данных, обеспечения согласованности по чтению и реализации ретроспекции. (Однако записи о повторном выполнении располагаются в физических журналах повтора, или наката, redo log; в них хранятся изменения, произведенные в сегментах данных и блоках сегментов отката, там же хранится таблица транзакций для сегментов отката.) Время хранения информации для отката Oracle теперь подбирает автоматически, исходя из того, как сконфигурировано табличное пространство отката.
Изучите поставляемую с вашей версией СУБД документацию в части дополнительных параметров инициализации, поскольку эта информация изменяется от версии к версии.
С чего же начать? Часто спрашивают меня начинающие специалисты. Одна из трудностей при изучении такого крупного продукта, как СУБД Oracle, заключается в том, чтобы составить представление о его работе, не увязнув в деталях. Задача этой книги – по знакомить вас с идеями и технологиями, лежащими в основе сервера базы данных Oracle, текущая версия которого называется Oracle Database 11g. Книга предназначена для широкого круга администраторов баз данных Oracle, разработчиков и пользователей – от начинающих до опытных. Мы надеемся, что, освоив базовые принципы продукта, вы сможете самостоятельно ориентироваться в множестве разнообразных средств Oracle, документации и многочисленных книгах и публикациях, посвященных этой СУБД.
В состав программного обеспечения, предлагаемого корпорацией Oracle, входит также сервер приложений Application Server и ПО промежуточного слоя Fusion Middleware, средства бизнес анализа и бизнес приложения (E_Business Suite, PeopleSoft, JD Edwards, Siebel, Hyperion и Project Fusion). Поскольку эта книга посвящена прежде всего СУБД, мы лишь бегло коснемся этих продуктов при обсуждении соответствующих вопросов, относящихся к базе данных.
Мы постараемся рассмотреть в данном блоге наиболее широкий спектр тем. Многие из них мы более подробно рассмотрим позже, но отдельные вопросы – например, краткая история Oracle и состав различных комплектаций продуктов корпорации Oracle, – обсуждаются только здесь.
За последние 30 лет корпорация Oracle из рядового поставщика программного обеспечения в области баз данных выросла в признанного лидера рынка СУБД. Если ранние продукты были типичными для начинающей компании, то теперь качество и глубина СУБД Oracle таковы, что многие считают ее технические возможности передовыми в отрасли. В каждой новой версии совершенствуются масштабируемость, функциональность и средства управления базой данных.
Итак, читайте мой блог, чтобы эффективно и достаточно быстро начать изучать СУБД Oracle/

Также очень сильно помогает наличие навыков по программированию или разработке, потому что будет часто доводиться работать вместе с разработчиками. Чаще всего для баз данных Oracle применяется операционная система UNIX, а именно — версии UNIX производства компаний Hewlett-Packard (HP) и Sun Microsystems (Sun). Компания IBM поставляет AIX-вариант операционной системы UNIX, но предлагает к ней свой собственный патентованный продукт для построения баз данных под названием DB2 Universal Database.
При желании обучиться на профессионального администратора баз данных Oracle Database 11g, нужно проходить два следующих тренировочных курса от компании Oracle или какого-нибудь другого поставщика: Oracle Database 11g:
- Administration Workshop I (Oracle Database 11g: семинар по администрированию I);
- Oracle Database 11g: Administration Workshop II (Oracle Database 11g: семинар по администрированию II).
Всего существуют три уровня сертификации для администраторов баз данных Oracle. Первый подразумевает получение сертификата OCA (Oracle Certified Associate — дипломированный младший специалист по Oracle), второй — сертификата OCP (Oracle Certified Professional — дипломированный профессионал по Oracle), который чаще все- го стремятся получить люди, профессионально занимающиеся базами данных Oracle, и третий, последний — сертификата OCM (Oracle Certified Master — дипломированный мастер по Oracle), для которого требуется сдавать длинный двухдневный практический экзамен.
Все кандидаты на получение сертификата администратора баз данных Oracle Database 11g обязаны проходить один физический или онлайновый курс из списка одобренных, чтобы отвечать новому требованию практического курса. Те, у кого на фирме используются кластеры RAC (Real Application Clusters — кластеры реальных приложений) или распределенные базы данных Oracle, должны проходить дополнительные, специализированные курсы обучения. Тем, у кого на фирме используется операционная система UNIX, и у кого нет опыта работы с ней, может быть лучше начинать с прохождения базового курса по UNIX (или Linux) от HP, Sun, Red Hat или другого производителя.
Для получения сертификата администратора баз данных Oracle проходит такой курс не обязательно, но он, несомненно, будет полезен для тех, кто является новичком в среде UNIX или Linux. Сама компания Oracle тоже предлагает несколько курсов по администрированию систем Linux, и даже возможность получения сертификата по управлению Oracle в Linux в рамках программы Oracle Certified Expert Program. Конечно, те, кто планирует использовать базы данных Oracle в среде Windows, вполне могут обойтись и без прохождения длинного и формального курса по управлению Windows при условии, что довольно хорошо знакомы с операционной системой Windows, а то и вообще работают системным администратором Windows.
С началом работы в должности администратора баз данных Oracle Database 11g будет обнаруживаться, что настоящий мир баз данных Oracle гораздо шире и сложнее того, о котором рассказывалось на различных посещавшихся курсах. По мере обнаружения каждой новой грани базы данных будет становиться все понятнее и понятнее, как устроено программное обеспечение, почему оно работает и почему иногда оно не работает. Только тогда о базах данных и применяемом для управления ими программном обеспечении можно будет узнать больше всего. Прочитав действительно все материалы, которые предлагает Oracle и другие, все равно не стоит беспокоиться, потому что всегда появляются новые версии, с новыми функциональными возможностями и новыми механизмами работы, что практически гарантирует бесконечное поступление новой информации.
Проработав администратором баз данных один или два года, вы уже будете знать достаточно для того, чтобы компетентно осуществлять администрирование баз данных и устранять типичные возникающие с ними проблемы. Те, кто за это время также не будет переставать совершенствовать и свои навыки программирования (главным образом посредством написания сценариев для оболочки UNIX и работы с PL/SQL), смогут даже начать создавать сложные сценарии для осуществления мониторинга и настройки производительности баз данных. После этого те, кто двинется дальше, смогут узнавать еще гораздо больше о программном обеспечении своих баз данных и тем самым повышать свои знания и свой вклад в работу организации. Компания Oracle постоянно выпускает новые средства, которые тоже можно осваивать для улучшения производительности производственных баз данных. Хотя разработчики, тестировщики и системные администраторы тоже вовсю стараются во благо организации, именно администратор баз данных в конечном итоге будет прокладывать путь к новым и эффективным способам применения новых возможностей базы данных.
Индексы
Кроме всем известных индексов в виде B-деревьев в Oracle еще есть так называемые битовые индексы, которые показывают очень высокую производительность на запросах к таблицам в которых есть колонки с очень разреженными значениями. Особенно эффективно в этом случае будут работать запросы (по сравнению с обычными индексами) в которых присутствуют сложные комбинации OR и AND к разряженным столбцам. Данный индекс храниться не в B-дереве, а в битовых картах, что и дает возможность быстрого выполнения описанных запросов. Вопрос в количестве уникальных значений в таблице при которых данный индекс еще будет более предпочтителен весьма сложен: это может быть как 10 уникальных значений, так и 10 000. Здесь надо создавать индекс на конкретной таблице и смотреть что получается. Главное не пытайтесь использовать данный индекс на таблицах с большим количеством вставок и обновлений индексируемой колонки, так как такие операции будут блокировать довольно большие участки в индексируемой таблице и ваша система может встать колом или даже поймаете deadlock.
Одна из вещей, которая меня всегда очень радовала в Oracle — это возможность создания индекса по функции. Т.е. если вам в запросах приходиться использовать какую-нибудь функцию, то вы можете построить по ней индекс и значительно ускорить операции чтения.
Еще одно интересное свойство индексов, о котором необходимо знать, это то, что в индексе не хранятся значения NULL. Таким образом если вы будете делать запросы с условием или <> по индексируемой колонке, то в ответ строчек со значением NULL в индексируемой колонке вы обратно не получите. С другой стороны данное свойство можно очень эффективно использовать дня некоторых специфичных случаев. Например, у вас есть очень большая табличка в которой хранятся ордера, которая никогда не чистится. И существует фоновый процесс, который обязан все ордера отсылать в какую-нибудь backoffice систему. Первое решение, которое напрашивается — это завести еще одну колонку с флагом is_sent, где изначально стоит 0 и при отсылке мы будем проставлять 1. Т.е. фоновый процесс при каждом запуске будет делать запрос к таблице с условием is_sent=0. Битовый индекс вы здесь использовать не можете, так как табличка очень активно пополняется. Обычный индекс на основе В-дерева будет занимать очень много места, так как нужно хранить ссылки на огромное количество строчек. Но если мы слегка поменяем нашу логику и в качестве пометки отсылки, и в колонку is_sent будем класть NULL вместо 1, то индекс у нас будет крошечный, так как в любой момент в нем будут храниться только не NULL значения, а их будет очень мало.
Структура базы данных Oracle Database
База данных состоит из табличных пространств, управляющих файлов, журналов, архивных журналов, файлов трассировки изменения блоков, ретроспективных журналов и файлов резервных копий (RMAN). В этом разделе мы познакомимся со многими из этих структур, а также с другими компонентами, составляющими в совокупности базу данных.
6. Code Library
[Библиотека кода] - это сценарии SQL и учебные пособия по SQL, которыми пользуются другие пользователи.


5. My Tutorials

[Мои учебные пособия] Пользователи записывают учебные пособия и пути, которые они выучили.
Начните путь к написанию SQL
Щелкните [Начать кодирование сейчас], чтобы начать писать SQL.


Введите свой собственный SQL в [Таблица SQL], нажмите [Выполнить], чтобы выполнить SQL, и просмотрите результаты выполнения в нижней части окна.
Что позволяет БД Oracle работать так быстро?
Когда вы меняете данные в БД, то ваши изменения сначала идут в кэш, а потом асинхронно в нескольких потоках (число можно сконфигурировать) пишутся на диск. Синхронно же пишется специальных лог (оперативный журнальный файл), чтобы была возможность восстановить данные после сбоя, если они еще не успели с кэша сброситься на диск. Данный подход позволяет выиграть в скорости, так как в этом случае на диск все пишется последовательно в один файл, причем можно настроить так, чтобы писалось параллельно на два или больше дисков, тем самым увеличивая надежность защиты от потери изменений. Описанных файлов должно быть несколько, и они используются по кругу: как только все данные защищенные одним из лог файлов были записаны фоновым процессом в блоки данных на диск, то данный лог файл может быть переиспользован. Таким образом в какой-то мере это позволяет еще и сэкономить, имея ультрабыстрые диски небольшого размера только для небольших журнальных файлов используемых по кругу.
Обычно я рассказываю об этом, когда мне предлагают что-то сохранять просто в файл на диске, так как это будет «быстрее» за счет того, что мы будет писать все данные последовательно и головке жесткого диска не надо будет бегать и искать рэндомные блоки. Я все же настаиваю, что мы тут ничего не выиграем, так как будем писать на медленный диск, который скоро всего активно используется множеством других процессов для записи огромного количества различных логов, а Oracle синхронно тоже пишет у себя на диск только последовательно, как я описал выше.
Параметры Live SQL
В левой части браузера находятся различные меню параметров службы Live SQL. Вы можете использовать различные функции, щелкнув каждое меню.
Файлы базы данных Oracle
База данных Oracle состоит из физических файлов трех основных типов:
- управляющие файлы (control files);
- файлы данных (datafiles);
- журнальные файлы, или журналы (redo log files).
На рис. 3 показаны эти три типа файлов и отношения между ними.
В управляющем файле хранится информация о местонахождении других физических файлов, составляющих базу данных, - файлов данных и журналов. Там же хранится важнейшая информация о содержимом и состоянии базы данных:
- имя базы данных;
- время создания базы данных;
- имена и местонахождение файлов данных и журнальных файлов;
- информация о табличных пространствах;
- информация о файлах данных в автономном режиме;
- история журналов и информация о порядковом номере текущего журнала;
- информация об архивных журналах;
- информация о наборах и фрагментах резервных копий, файлах данных и журналах;
- информация о копиях файлов данных;
- информация о контрольных точках.
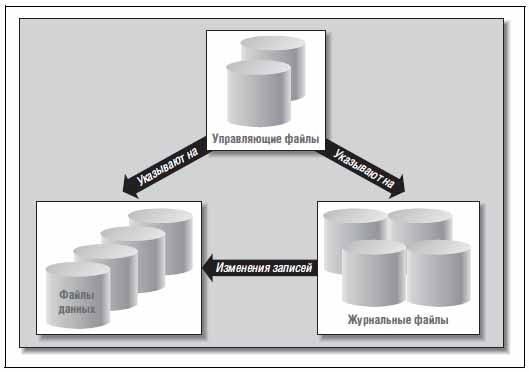
Рис. 3. Файлы, составляющие базу данных
Управляющие файлы не только содержат важную информацию, необходимую при запуске экземпляра, они полезны и при удалении базы данных. Начиная с версии Oracle Database 10g с помощью команды DROP DATABASE можно удалить все файлы, перечисленные в управляющем файле базы данных, а также сам управляющий файл.
Пустые строки
В оракл есть одна очень интересная особенность, от которой они теперь уже никогда не смогут избавиться. Дело в том, что если вы кладете в БД пустую строку, то она сохраниться как NULL. Таким образом при последующем чтении вы никогда не получите пустой строки, а только NULL. Имейте так же в виду, что по этой же причине пустые строки не попадают в индекс, так что если вы будете делать запросы, план выполнения которых, будет использовать индекс, то ваше пустые (вернее NULL) строки вы никогда не получите, но об этом чуть позже.
Среда обучения Oracle SQL в Интернете - Live SQL
Самая удобная онлайн-среда обучения Oracle SQL - Live SQL
Таблицы бывают разные
Кроме обычных таблиц в oracle как и во многих других БД есть так называемые индекс-таблицы, когда данные таблицы непосредственно лежат в индекс-дереве первичного ключа. Таким образом достигается сразу две вещи: во первых для чтения данных по первичному ключу вы имеете на одно чтение меньше, во вторых данные в таблице получаются упорядоченными по первичному ключу, так что операция ORDER BY PK будет выполняться без дополнительной сортировки. К недостаткам можно отнести тот факт, что отличить логирование в оперативные журнальные файлы данного индекса вы уже не сможете.
Еще один замечательный тип таблиц — это кластерные таблицы, которые позволяют хранить данные из двух или более таблиц кластеризованные по одному значению ключа в одном блоке данных. Это может быть весьма эффективно если вы всегда используете какие-нибудь таблицы совместно.
На основе кластерных таблиц есть еще кластерные хэш-таблицы, в которых для доступа вместо B-дерева используется таблица на основе хеша кластерного ключа. Звучит, конечно, очень интересно, но, честно говоря, на практике никогда не сталкивался.
Войдите и зарегистрируйтесь

Введите соответствующее содержание, чтобы создать учетную запись, а затем войдите в систему.
Примите отказ от ответственности при первом входе в систему.

Подвисание некоторых запросов на запись
При зависании некоторых ваших запросов в произвольный момент времени стоит заглянуть в alert.log на предмет наличия incomplete checkpoint. Это говорит о том, что ваши оперативные журнальные файлы слишком большие или их слишком мало, таким образом, защищаемые ими данные не успевают сбрасываться из кэша на диск, а СУБД заполнила уже все доступные оперативные журнальные файлы и хочет использовать их по кругу повторно, чего делать ни в коем случае нельзя, вот и появляется пауза. Хотя если ваше приложение работает на java, то в первую очередь я бы загляну на наличия Full GC в логах.
подводить итоги
Эта статья в основном знакомит с удобной обучающей средой Oracle SQL - облачным сервисом Live SQL, надеюсь, она вам поможет!
Начать одним щелчком мыши
Введите следующий URL-адрес в браузере, чтобы получить доступ к веб-сайту Live SQL.

▲ Интерфейс Live SQL
Stand by копия
Вышеупомянутые архивные файлы можно отправлять по сети и на лету применять к копии БД. Таким образом у вас всегда под рукой будет горячая копия с минимальным запаздыванием данных. В некоторых приложениях, где нет необходимости показывать данные с точностью до последнего момента, можно настроить такую БД только на чтение и разгрузить основной экземпляр БД, причем таких экземпляров на чтение может быть несколько.
Позвольте Oracle кэшировать ваши данные эффективно
В Oracle все данные читаются-пишутся не прямо на диск, а через кэш. По умолчанию кэш основан на LRU алгоритме, так что если вы читаете какую-нибудь очень большую табличку по идентификатору в больших количествах, запрашивая в каждый раз новую строчку, то такие запросы могут вытеснять из кэша небольшую статическую табличку, которой бы самое милое дело постоянно находиться в кэше. Для таких целей при создании таблицы вы можете указать специальный вид кэша, куда будут ходить запросы к вашим таблицам. Так для первой таблицы в вышеописанном примере подойдет кэш RECYCLE, который по сути не хранит никакие данные, а сразу их выбрасывает из кэша. А для второй таблицы подойдет кэш KEEP, который позволить хранить в кэше небольшие статические таблице и запросы ко всем остальным таблицам не будут вытеснять данные статических таблиц из кэша.
Заключение
Я попытался описать большинство вещей, который на мой взгляд могут пригодится программисту. Так как их довольно много, то я их только обозначил, часто не вдаваясь в детали. Как конкретно сделать необходимую настройку можно всегда прочитать в упомянутой книжке Тома Кайта, найти в колонке asktom или просто нагуглить. Главное знать что гуглить, и, надеюсь, данный топик вам это подсказал.

Данная статья - это обзор концепций и структур, относящихся к ядру СУБД Oracle Database. Разобравшись в архитектуре сервера Oracle, вы заложите фундамент для понимания остальных обширных средств, предоставляемых базой данных Oracle. СУБД Oracle Database состоит из физических и логических компонентов.
1. SQL Worksheet
Меню [Таблица SQL] - это окно выполнения SQL, через которое можно выполнять онлайн-упражнения SQL.
Конкретное использование выглядит следующим образом:

Базы данных и экземпляры Oracle
Многие пользователи Oracle Database употребляют термины экземпляр и база данных как синонимы. На самом деле это разные (хотя и взаимосвязанные) вещи. Различие существенно, так как проливает свет на архитектуру Oracle.
В Oracle термином база данных описывается физическое хранилище информации, а термином экземпляр – программное обеспечение, работающее на сервере и предоставляющее доступ к информации в базе данных Oracle Database. Экземпляр исполняется на конкретном компьютере или сервере; база данных хранится на дисках, подключенных к этому серверу. Эта взаимосвязь изображена на рисунке 1 ниже:
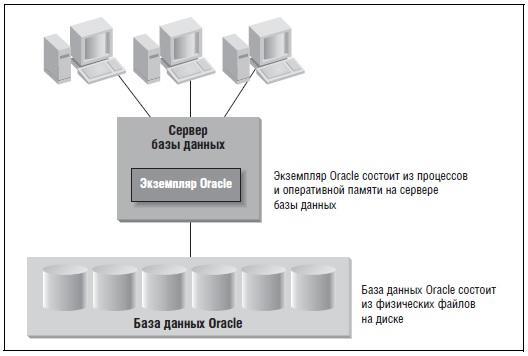
Рис. 1. Экземпляр и база данных
База данных Oracle Database – физическая сущность: она состоит из файлов, хранящихся на дисках. Экземпляр – сущность логическая: он состоит из структур в оперативной памяти и процессов, работающих на сервере.
Например, Oracle использует область разделяемой памяти System Global Area (SGA, системная глобальная область) и области памяти в каждом процессе – Program Global Area (PGA, программная глобальная область). Экземпляр может быть частью одной и только одной базы данных. Напротив, с одной базой данных может быть ассоциировано несколько экземпляров. Время жизни экземпляров ограничено, тогда как база данных при должном обслуживании может существовать вечно.
Пользователи не имеют прямого доступа к информации, хранящейся в базе данных Oracle; они должны запрашивать информацию у экземпляра Oracle.
В реальном мире есть хорошая аналогия экземплярам и базам данных. Можно считать экземпляр мостом к базе данных, а саму ее – островом. Транспорт попадает на остров и уходит с него по мосту. Если мост перекрыт, то остров на месте, но транспорту туда не попасть. В терминологии Oracle, если экземпляр запущен, то данные могут попадать в базу и уходить из нее. Физическое состояние базы данных при этом изменяется. Если же экземпляр остановлен, то пользователи не могут обращаться к базе данных, пусть даже физически она никуда не делась. База данных в этом случае статична, никаких изменений в ней не происходит. Экземпляр снова запущен – и данные тут как тут.
2. My Session
Меню «Моя сессия» - это информация о сессии.

Ниже представлены 3 подменю, а именно:
Информацию о предыдущем сеансе, включая набор операторов SQL, которые вы вводили с помощью этой среды в прошлом, вы можете просмотреть, щелкнув [Просмотр сеанса], или вы можете перезагрузить и запустить эти операторы или сохранить их как сценарии.
Используйте различную информацию об ограничении ресурсов Live SQL, такую как максимальный период сеанса, количество сеансов и используемое пространство. Если эти ограничения достигнуты, самая старая информация о сеансе будет удалена.

Каждый запрос страницы Live SQL - это новый сеанс базы данных. Чтобы сохранить состояние NLS выполнения оператора SQL на каждой странице Live SQL, Live SQL запомнит ваши настройки NLS и применит их, чтобы гарантировать, что каждый сеанс имеет правильный NLS.
Эта страница [NLS] используется для записи и отображения настроек NLS.

3. Quick SQL
Меню [Quick SQL] может генерировать операторы SQL с помощью сокращенного синтаксиса SQL. Конкретный сокращенный синтаксис SQL см. На подстранице [Quick SQL Samples].



Механизм восстановления данных
В СУБД Oracle можно включить архивацию вышеописанных оперативных журнальных файлов, и все изменения будут архивироваться. Таким образом при потере любого диска с блоками данных мы можем восстановить их на любой момент времени, включая момент прямо перед падением, накатив на последние архивные журнальные файлы текущий оперативный журнал.
4. My Scripts

[Мои сценарии] - это ваша собственная страница сценария, вы можете сохранить выполненный контент как сценарий или загрузить свой собственный локальный сценарий в среду с помощью функции загрузки, что удобно в использовании.
Читайте также: