
Какой информационный вес одного символа компьютерного алфавита
Единицей измерения количества информации является бит – это наименьшаяединица.
1 Кб (килобайт) = 1024 байта= 2 10 байтов
1 Мб (мегабайт) = 1024 Кб = 2 10 Кб
1 Гб (гигабайт) = 1024 Мб = 2 10 Мб
1 Тб (терабайт) =1024 Гб = 2 10 Гб
Формулы, которые используются при решении типовых задач:
Информационный вес символа алфавита и мощность алфавита связаны между собой соотношением: N = 2 i .
i – информационный вес одного символа.
Основная литература:
- Босова Л. Л. Информатика: 7 класс. // Босова Л. Л., Босова А. Ю. – М.: БИНОМ, 2017. – 226 с.
Дополнительная литература:
- Босова Л. Л. Информатика: 7–9 классы. Методическое пособие. // Босова Л. Л., Босова А. Ю., Анатольев А. В., Аквилянов Н.А. – М.: БИНОМ, 2019. – 512 с.
- Босова Л. Л. Информатика. Рабочая тетрадь для 7 класса. Ч 1. // Босова Л. Л., Босова А. Ю. – М.: БИНОМ, 2019. – 160 с.
- Босова Л. Л. Информатика. Рабочая тетрадь для 7 класса. Ч 2. // Босова Л. Л., Босова А. Ю. – М.: БИНОМ, 2019. – 160 с.
- Гейн А. Г. Информатика: 7 класс. // Гейн А. Г., Юнерман Н. А., Гейн А.А. – М.: Просвещение, 2012. – 198 с.
Теоретический материал для самостоятельного изучения.
Что же такое символ в компьютере? Символом в компьютере является любая буква, цифра, знак препинания, специальный символ и прочее, что можно ввести с помощью клавиатуры. Но компьютер не понимает человеческий язык, он каждый символ кодирует. Вся информация в компьютере представляется в виде нулей и единичек. И вот эти нули и единички называются битом.
Информационный вес символа двоичного алфавита принят за минимальную единицу измерения информации и называется один бит.
Алфавит любого понятного нам языка можно заменить двоичным алфавитом. При этом мощность исходного алфавита связана с разрядностью двоичного кода соотношением: N = 2 i .
Эту формулу можно применять для вычисления информационного веса одного символа любого произвольного алфавита.
Рассмотрим пример:
Алфавит древнего племени содержит 16 символов. Определите информационный вес одного символа этого алфавита.
Составим краткую запись условия задачи и решим её:
16 = 2 i , 2 4 = 2 i , т. е. i = 4
Ответ: i = 4 бита.
Информационный вес одного символа этого алфавита составляет 4 бита.
Математически это произведение записывается так: I = К · i.
32 = 2 i , 2 5 = 2 i , т.о. i = 5,
I = 180 · 5 = 900 бит.
Ответ: I = 900 бит.
I = 23 · 8 = 184 бита.
Как и в математике, в информатике тоже есть кратные единицы измерения информации. Так, величина равная восьми битам, называется байтом.
Бит и байт – это мелкие единицы измерения. На практике для измерения информационных объёмов используют более крупные единицы: килобайт, мегабайт, гигабайт и другие.
1 Кб (килобайт) = 1024 байта= 2 10 байтов
1 Мб (мегабайт) = 1024 Кб = 2 10 Кб
1 Гб (гигабайт) = 1024 Мб = 2 10 Мб
1 Тб (терабайт) =1024 Гб = 2 10 Гб
Материал для углубленного изучения темы.
Как текстовая информация выглядит в памяти компьютера.
Набирая текст на клавиатуре, мы видим привычные для нас знаки (цифры, буквы и т.д.). В оперативную память компьютера они попадают только в виде двоичного кода. Двоичный код каждого символа, выглядит восьмизначным числом, например 00111111. Теперь возникает вопрос, какой именно восьмизначный двоичный код поставить в соответствие каждому символу?
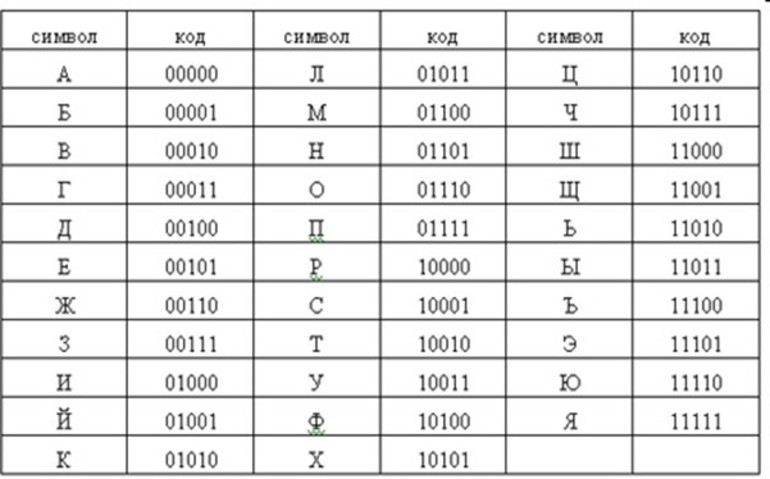
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код ‑ просто порядковый номер символа в двоичной системе счисления.
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.Таблица для кодировки – это «шпаргалка», в которой указаны символы алфавита в соответствии порядковому номеру. Для разных типов компьютеров используются различные таблицы кодировки.
Таблица ASCII (или Аски), стала международным стандартом для персональных компьютеров. Она имеет две части.

В этой таблице латинские буквы (прописные и строчные) располагаются в алфавитном порядке. Расположение цифр также упорядочено по возрастанию значений. Это правило соблюдается и в других таблицах кодировки и называется принципом последовательного кодирования алфавитов. Благодаря этому понятие «алфавитный порядок» сохраняется и в машинном представлении символьной информации. Для русского алфавита принцип последовательного кодирования соблюдается не всегда.
Запишем, например, внутреннее представление слова «file». В памяти компьютера оно займет 4 байта со следующим содержанием:
01100110 01101001 01101100 01100101.
А теперь попробуем решить обратную задачу. Какое слово записано следующим двоичным кодом:
01100100 01101001 01110011 01101011?
В таблице 2 приведен один из вариантов второй половины кодовой таблицы АSСII, который называется альтернативной кодировкой. Видно, что в ней для букв русского алфавита соблюдается принцип последовательного кодирования.

Вывод: все тексты вводятся в память компьютера с помощью клавиатуры. На клавишах написаны привычные для нас буквы, цифры, знаки препинания и другие символы. В оперативную память они попадают в форме двоичного кода.
Из памяти же компьютера текст может быть выведен на экран или на печать в символьной форме.
Разбор решения заданий тренировочного модуля
Информационный вес символа алфавита и мощность алфавита связаны между собой соотношением: N = 2 i .
Описание термина
Понятие мощности алфавита находится в основании изучения информатики. Алфавитом принято называть набор многочисленных символов. Сумма всех их в определённом языке и есть алфавитная мощность. Иными словами, это количество всех символов, входящих в конкретно взятый язык. Сюда входят не только буквы, но и прочие обозначения, в частности:

- числа;
- спецсимволы;
- двоеточия;
- пробел;
- скобки;
- запятые;
- точки;
- многоточия и прочее.
Основным постулатом в информатике является тот факт, что устройство разбирает введённую информацию исключительно в двоичном коде в форме нуля и единицы. В итоге получается, что абсолютно любой символ алфавита может быть успешно закодирован при помощи соответствующего подбора этих двух цифровых символов. Самая маленькая последовательность, применяемая при обозначении какой-либо цифры, буквы или другого знака, состоит из двух элементов.
Информационная масса отдельно взятого символа обычно изображается в форме информационной стандартной измерительной единицы, которая называется «бит». Восемь битов становятся равны одному байту.
Определение информационного объёма в тексте
Почти всегда при наборе текста на компьютерах и других электронных устройствах приходится сталкиваться с написанием различных символов. К ним следует отнести:
- заглавные и жирные буквы;
- курсив;
- скобки;
- знаки препинания;
- вычислительные операции и прочее.
По всем расчётам получается, что мощность компьютерного алфавита составляет 256 различных символов и вариантов. В соответствии с формулой Хартли, N = 256, а i — масса любого из значков в клавиатурном алфавите соответствует одному байту, или восьми битам.

Размер любой напечатанной фразы может быть вычислен по формуле V=K ⋅ log2N. В этом случае N обозначает количество всех символов в алфавите, а K — это численность знаков непосредственно в напечатанной фразе. Так, например, имеется произвольный текст объёмом в 25 листов. На каждом из них расположено по 45 строчек текста, содержащих по 58 символов.
Исходя из этого, на любой отдельной странице будет 45*58 = 2610 байт информации. В целом же по всему тексту этот объём будет равен 2610*25 = 65250 байт. Для обозначения мощности алфавита в информатике общепринятым вариантом является буква N из формулы Хартли. Именно ее чаще всего указывают в большинстве учебников и профессиональной литературе.
Для удобства их всегда переводят в увеличенные величины — кило-, мега-, гигабайты и прочее. Для их упрощённого обозначения используются специальные сокращения: Кб, Мб, Гб и так далее. 1 Кб равняется 1024 байтам (2 байта в десятой степени), 1 Мб составляет 1024 Кб (2 Кб в десятой степени) и так далее. Исходя из этого, 65250 байт будут составлять 63,72 килобайта.
Поскольку один отдельный символ состоит из 8 битов, то устанавливать их кодировку целиком не представляется возможным. Вместо этого предпочтительнее образовать кодировку трёхбитовых комбинаций. Расчёт этого действия проводится по формуле Хартли, где n-ная степень будет равняться трём. В результате получается N, равная 8.
Отображение символов в двоичном коде
Алфавитная мощность может быть использована на практике только при наличии двоичного кода. В качестве примера можно использовать упрощённый алфавит, состоящий всего из четырёх символов. В этом случае разрядность их и информационное представление описываются следующим образом:
Из этого списка можно сделать вывод о том, что если алфавитная мощность равняется 4, то масса отдельного единичного символа будет составлять 2 бита. Если же есть алфавит, состоящий из 8 символов, то при подборе двоичного трёхзначного кода для него комбинационное количество будет следующим:
- 1 — 000;
- 2 — 001;
- 3 — 010;
- 4 — 011;
- 5 — 100;
- 6 — 101;
- 7 — 110;
- 8 — 111.
Иными словами, если алфавитная мощность равна 8, то вес отдельно взятого символа для двоичного трёхзначного кода составит 3 бита.
Примеры расчёта мощности

«Однажды, в студеную зимнюю пору,
Я из лесу вышел; был сильный мороз»
будет 67 символов вместе с пробелами, то есть, в соответствии с условиями задания, 67 байт. Их количество умножают на 8 (количество битов в байте), и на выходе получается 536 битов.
Вычисление мощности алфавита

Эта формула была изобретена американским инженером Ральфом Хартли более сотни лет тому назад. Она применяется для работы с равновероятными событиями и используется для определения мощности конкретного буквенного набора, которая обозначается буквой N (информационная масса или объём). n означает численность бит в словесной единице, иными словами, количество знаков внутри двоичного кода. Так, если n равен 1, то N тоже равен 1, при n = 2 N = 4, при n = 3 N = 8, при n = 4 N = 16.
Чтобы сформулировать теорию о численности информации в набранном словосочетании, пользуются формулой I=K*i. В этом случае К обозначает численность всех символов в предложении, а i — это информационная масса символа.
При ответе на вопрос, как найти мощность алфавита, нужно сказать, что в русском языке 33 буквы, поэтому это можно выразить как N = 33. Для сравнения, аналогичный показатель в английском, немецком и французском языках равняется 26, в испанском — 27. Венгерский язык, например, является 40-символьным.
Существует также и клавиатурный язык, куда входят не только буквы, но и дополнительные знаки. Так, в русском языке есть ещё 10 цифр и 11 символов, а также пробел и пара скобок. Их мощность прибавляется к аналогичному буквенному показателю, и на выходе получается N = 33+10+11+1+2=57. В некоторых случаях букву «ё» не выделяют в качестве отдельного самостоятельного символа, и в таком случае полная мощность русского алфавита становится равна 56.
Сайт учителя информатики. Технологические карты уроков, Подготовка к ОГЭ и ЕГЭ, полезный материал и многое другое.
Информатика. 7 класса. Босова Л.Л. Оглавление
1.6.1. Алфавитный подход к измерению информации
Для количественного выражения любой величины необходима, прежде всего, единица измерения. Измерение осуществляется путём сопоставления измеряемой величины с единицей измерения. Сколько раз единица измерения «укладывается» в измеряемой величине, таков и результат измерения.
Обратите внимание, что название единицы измерения информации «бит» (bit) происходит от английского словосочетания binary digit — «двоичная цифра».
За минимальную единицу измерения информации принят 1 бит. Считается, что таков информационный вес символа двоичного алфавита.
1.6.2. Информационный вес символа произвольного алфавита
Ранее мы выяснили, что алфавит любого естественного или формального языка можно заменить двоичным алфавитом. При этом мощность исходного алфавита N связана с разрядностью двоичного кода i, требуемой для кодирования всех символов исходного алфавита, соотношением: N = 2 i .
Разрядность двоичного кода принято считать информационным весом символа алфавита. Информационный вес символа алфавита выражается в битах.
Информационный вес символа алфавита i и мощность алфавита N связаны между собой соотношением: N = 2 i .
Задача 1. Алфавит племени Пульти содержит 8 символов. Каков информационный вес символа этого алфавита?
Решение. Составим краткую запись условия задачи.

Известно соотношение, связывающее величины i и N : N = 2 i .
С учётом исходных данных: 8 = 2 i . Отсюда: i = 3.
Полная запись решения в тетради может выглядеть так:



1.6.4. Единицы измерения информации
В наше время подготовка текстов в основном осуществляется с помощью компьютеров. Можно говорить о «компьютерном алфавите», включающем следующие символы: строчные и прописные русские и латинские буквы, цифры, знаки препинания, знаки арифметических операций, скобки и др. Такой алфавит содержит 256 символов. Поскольку 256 = 2 8 , информационный вес каждого символа этого алфавита равен 8 битам. Величина, равная восьми битам, называется байтом. 1 байт — информационный вес символа алфавита мощностью 256.
1 байт = 8 битов
Бит и байт — «мелкие» единицы измерения. На практике для измерения информационных объёмов используются более крупные единицы:
1 килобайт = 1 Кб = 1024 байта = 2 10 байтов
1 мегабайт = 1 Мб = 1024 Кб = 2 10 Кб = 2 20 байтов
1 гигабайт = 1 Гб = 1024 Мб = 2 10 Мб = 2 20 Кб = 2 30 байтов
1 терабайт = 1 Тб = 1024 Гб = 2 10 Гб = 2 20 Мб = 2 30 Кб = 2 40 байтов

Ответ: 8 битов, 256 символов.
Ответ: 70 байтов.
Самое главное.
1 бит — минимальная единица измерения информации.
Информационный вес символа алфавита i и мощность алфавита N связаны между собой соотношением: N = 2 i .
1 байт = 8 битов.
Байт, килобайт, мегабайт, гигабайт, терабайт — единицы измерения информации. Каждая следующая единица больше предыдущей в 1024 (210) раза.
Вопросы и задания.
Алфавитный подход используется для измерения количества информации в тексте, представленном в виде последовательности символов некоторого алфавита. Такой подход не связан с содержанием текста. Количество информации в этом случае называется информационным объемом текста, который пропорционален размеру текста — количеству символов, составляющих текст. Иногда данный подход к измерению информации называют объемным подходом.
Каждый символ текста несет определенное количество информации. Его называют информационным весом символа. Поэтому информационный объем текста равен сумме информационных весов всех символов, составляющих текст.
Здесь предполагается, что текст — это последовательная цепочка пронумерованных символов. В формуле (1) i1 обозначает информационный вес первого символа текста, i2 — информационный вес второго символа текста и т.д.; K — размер текста, т.е. полное число символов в тексте.
Все множество различных символов, используемых для записи текстов, называется алфавитом. Размер алфавита — целое число, которое называется мощностью алфавита. Следует иметь в виду, что в алфавит входят не только буквы определенного языка, но все другие символы, которые могут использоваться в тексте: цифры, знаки препинания, различные скобки, пробел и пр.
Определение информационных весов символов может происходить в двух приближениях:
1) в предположении равной вероятности (одинаковой частоты встречаемости) любого символа в тексте;
2) с учетом разной вероятности (разной частоты встречаемости) различных символов в тексте.
Приближение равной вероятности символов в тексте
Если допустить, что все символы алфавита в любом тексте появляются с одинаковой частотой, то информационный вес всех символов будет одинаковым. Пусть N — мощность алфавита. Тогда доля любого символа в тексте составляет 1/N-ю часть текста. По определению вероятности (см. “Измерение информации. Содержательный подход” ) эта величина равна вероятности появления символа в каждой позиции текста:
p = 1/N
Согласно формуле К.Шеннона (см. “Измерение информации. Содержательный подход” ), количество информации, которое несет символ, вычисляется следующим образом:
i = log2(1/p) = log2N (бит) (2)
Следовательно, информационный вес символа (i) и мощность алфавита (N) связаны между собой по формуле Хартли (см. “Измерение информации. Содержательный подход” )
2 i = N.
Зная информационный вес одного символа (i) и размер текста, выраженный количеством символов (K), можно вычислить информационный объем текста по формуле:
I = K · i (3)
Эта формула есть частный вариант формулы (1), в случае, когда все символы имеют одинаковый информационный вес.
Из формулы (2) следует, что при N = 2 (двоичный алфавит) информационный вес одного символа равен 1 биту.
С позиции алфавитного подхода к измерению информации 1 бит — это информационный вес символа из двоичного алфавита.
Более крупной единицей измерения информации является байт.
1 байт — это информационный вес символа из алфавита мощностью 256.
Поскольку 256 = 2 8 , то из формулы Хартли следует связь между битом и байтом:
2 i = 256 = 2 8
Отсюда: i = 8 бит = 1 байт
Для представления текстов, хранимых и обрабатываемых в компьютере, чаще всего используется алфавит мощностью 256 символов. Следовательно,
1 символ такого текста “весит” 1 байт.
Помимо бита и байта, для измерения информации применяются и более крупные единицы:
1 Кб (килобайт) = 2 10 байт = 1024 байта,
1 Мб (мегабайт) = 2 10 Кб = 1024 Кб,
1 Гб (гигабайт) = 2 10 Мб = 1024 Мб.
Приближение разной вероятности встречаемости символов в тексте
В этом приближении учитывается, что в реальном тексте разные символы встречаются с разной частотой. Отсюда следует, что вероятности появления разных символов в определенной позиции текста различны и, следовательно, различаются их информационные веса.
Статистический анализ русских текстов показывает, что частота появления буквы “о” составляет 0,09. Это значит, что на каждые 100 символов буква “о” в среднем встречается 9 раз. Это же число обозначает вероятность появления буквы “о” в определенной позиции текста: po = 0,09. Отсюда следует, что информационный вес буквы “о” в русском тексте равен:
Самой редкой в текстах буквой является буква “ф”. Ее частота равна 0,002. Отсюда:
Отсюда следует качественный вывод: информационный вес редких букв больше, чем вес часто встречающихся букв.
Как же вычислить информационный объем текста с учетом разных информационных весов символов алфавита? Делается это по следующей формуле:
Здесь N — размер (мощность) алфавита; nj — число повторений символа номер j в тексте; ij — информационный вес символа номер j.
Методические рекомендации
Алфавитный подход в курсе информатики основой школы
В курсе информатики в основной школе знакомство учащихся с алфавитным подходом к измерению информации чаще всего происходит в контексте компьютерного представления информации. Основное утверждение звучит так:
Количество информации измеряется размером двоичного кода, с помощью которого эта информация представлена
Поскольку любые виды информации представляются в компьютерной памяти в форме двоичного кода, то это определение универсально. Оно справедливо для символьной, числовой, графической и звуковой информации.
Один знак (разряд) двоичного кода несет 1 бит информации.
При объяснении способа измерения информационного объема текста в базовом курсе информатики данный вопрос раскрывается через следующую последовательность понятий: алфавит — размер двоичного кода символа — информационный объем текста.
Логика рассуждений разворачивается от частных примеров к получению общего правила. Пусть в алфавите некоторого языка имеется всего 4 символа. Обозначим их: , , , . Эти символы можно закодировать с помощью четырех двухразрядных двоичных кодов: — 00, — 01, — 10, — 11. Здесь использованы все варианты размещений из двух символов по два, число которых равно 2 2 = 4. Отсюда делается вывод: информационный вес символа из 4-символьного алфавита равен двум битам.
Обобщая частные примеры, получаем общее правило: с помощью b-разрядного двоичного кода можно закодировать алфавит, состоящий из N = 2 b — символов.
Пример 1. Для записи текста используются только строчные буквы русского алфавита и “пробел” для разделения слов. Какой информационный объем имеет текст, состоящий из 2000 символов (одна печатная страница)?
Решение. В русском алфавите 33 буквы. Сократив его на две буквы (например, “ё” и “й”) и введя символ пробела, получаем очень удобное число символов — 32. Используя приближение равной вероятности символов, запишем формулу Хартли:
2 i = 32 = 2 5
Отсюда: i = 5 бит — информационный вес каждого символа русского алфавита. Тогда информационный объем всего текста равен:
I = 2000 · 5 = 10 000 бит
Пример 2. Вычислить информационный объем текста размером в 2000 символов, в записи которого использован алфавит компьютерного представления текстов мощностью 256.
Решение. В данном алфавите информационный вес каждого символа равен 1 байту (8 бит). Следовательно, информационный объем текста равен 2000 байт.
В практических заданиях по данной теме важно отрабатывать навыки учеников в пересчете количества информации в разные единицы: биты — байты — килобайты — мегабайты — гигабайты. Если пересчитать информационный объем текста из примера 2 в килобайты, то получим:
2000 байт = 2000/1024 1,9531 Кб
I = 1/512 · 1024 · 1024 · 8 = 16 384 бита.
Поскольку такой объем информации несут 1024 символа (К), то на один символ приходится:
i = I/K = 16 384/1024 = 16 бит.
Отсюда следует, что размер (мощность) использованного алфавита равен 2 16 = 65 536 символов.
Объемный подход в курсе информатики в старших классах
Изучая информатику в 10–11-х классах на базовом общеобразовательном уровне, можно оставить знания учащихся об объемном подходе к измерению информации на том же уровне, что описан выше, т.е. в контексте объема двоичного компьютерного кода.
При изучении информатики на профильном уровне объемный подход следует рассматривать с более общих математических позиций, с использованием представлений о частотности символов в тексте, о вероятностях и связи вероятностей с информационными весами символов.
Знание этих вопросов оказывается важным для более глубокого понимания различия в использовании равномерного и неравномерного двоичного кодирования (см. “Кодирование информации” ), для понимания некоторых приемов сжатия данных (см. “Сжатие данных” ) и алгоритмов криптографии (см. “Криптография” ).
Пример 4. В алфавите племени МУМУ всего 4 буквы (А, У, М, К), один знак препинания (точка) и для разделения слов используется пробел. Подсчитали, что в популярном романе “Мумука” содержится всего 10 000 знаков, из них: букв А — 4000, букв У — 1000, букв М — 2000, букв К — 1500, точек — 500, пробелов — 1000. Какой объем информации содержит книга?
Решение. Поскольку объем книги достаточно большой, то можно допустить, что вычисленная по ней частота встречаемости в тексте каждого из символов алфавита характерна для любого текста на языке МУМУ. Подсчитаем частоту встречаемости каждого символа во всем тексте книги (т.е. вероятность) и информационные веса символов
Общий объем информации в книге вычислим как сумму произведений информационного веса каждого символа на число повторений этого символа в книге:
Обращаем Ваше внимание, что в соответствии с Федеральным законом N 273-ФЗ «Об образовании в Российской Федерации» в организациях, осуществляющих образовательную деятельность, организовывается обучение и воспитание обучающихся с ОВЗ как совместно с другими обучающимися, так и в отдельных классах или группах.
Рабочие листы и материалы для учителей и воспитателей
Более 2 500 дидактических материалов для школьного и домашнего обучения
Столичный центр образовательных технологий г. Москва
Получите квалификацию учитель математики за 2 месяца
от 3 170 руб. 1900 руб.
Количество часов 300 ч. / 600 ч.
Успеть записаться со скидкой
Форма обучения дистанционная
- Онлайн
формат - Диплом
гособразца - Помощь в трудоустройстве
311 лекций для учителей,
воспитателей и психологов
Получите свидетельство
о просмотре прямо сейчас!
Измерение информации.
Алфавитный подход к измерению информации.
Для количественного выражения любой величины необходима, прежде всего, единица измерения. Измерение осуществляется путём сопоставления измеряемой величины с единицей измерения. Сколько раз единица измерения «укладывается» в измеряемой величине, таков и результат измерения.
Обратите внимание, что название единицы измерения информации «бит» (bit) происходит от английского словосочетания binary digit — «двоичная цифра».
За минимальную единицу измерения информации принят 1 бит. Считается, что таков информационный вес символа двоичного алфавита.
1.6.2. Информационный вес символа произвольного алфавита
Ранее мы выяснили, что алфавит любого естественного или формального языка можно заменить двоичным алфавитом. При этом мощность исходного алфавита N связана с разрядностью двоичного кода i, требуемой для кодирования всех символов исходного алфавита, соотношением: N = 2 i.
Разрядность двоичного кода принято считать информационным весом символа алфавита. Информационный вес символа алфавита выражается в битах.
Информационный вес символа алфавита i и мощность алфавита N связаны между собой соотношением: N = 2 i.
Задача 1. Алфавит племени Пульти содержит 8 символов. Каков информационный вес символа этого алфавита?
Решение. Составим краткую запись условия задачи.
Известно соотношение, связывающее величины i и N: N = 2 i.
С учётом исходных данных: 8 = 2 i. Отсюда: i = 3.
Полная запись решения в тетради может выглядеть так:



1.6.4. Единицы измерения информации
В наше время подготовка текстов в основном осуществляется с помощью компьютеров. Можно говорить о «компьютерном алфавите», включающем следующие символы: строчные и прописные русские и латинские буквы, цифры, знаки препинания, знаки арифметических операций, скобки и др. Такой алфавит содержит 256 символов. Поскольку 256 = 28, информационный вес каждого символа этого алфавита равен 8 битам. Величина, равная восьми битам, называется байтом. 1 байт — информационный вес символа алфавита мощностью 256.
1 байт = 8 битов
Бит и байт — «мелкие» единицы измерения. На практике для измерения информационных объёмов используются более крупные единицы:
1 килобайт = 1 Кб = 1024 байта = 210 байтов
1 мегабайт = 1 Мб = 1024 Кб = 210 Кб = 220 байтов
1 гигабайт = 1 Гб = 1024 Мб = 210 Мб = 220 Кб = 230 байтов
1 терабайт = 1 Тб = 1024 Гб = 210 Гб = 220 Мб = 230 Кб = 240 байтов


Читайте также: