
Какой файл получается после сканирования текста если распознавание текста не проводилось
Наверное, каждый из нас сталкивался с задачей, когда нужно перевести бумажный документ в электронный вид. Особенно это часто нужно делать тем кто учиться, работает с документацией, переводит тексты при помощи электронных словарей и т.д.
В этой статье мне хотелось бы поделиться некоторыми азами этого процесса. Вообще, сканирование и распознавание текста — довольно трудоемко, так, как большинство операций придется делать вручную. Мы попытаемся разобраться по шагам, что, как и почему.
Не все сразу понимают одну вещь. После сканирования (пригона всех листов на сканере) у вас будут картинки формата BMP, JPG, PNG, GIF (могут быть и другие форматы). Так вот с этой картинки нужно получить текст — это процедура называется распознаванием. В таком порядке и будет изложение ниже.
1. Что нужно для сканирования и распознавания?
Для перевода печатных документов в текстовый вид, вам для начала нужен сканер и соответственно, «родные» программы и драйверы, которые с ним шли. При помощи них можно будет сканировать документ и сохранить его для дальнейшей обработки.
Можно воспользоваться и другими аналогами, но софт, который шел со сканером в комплекте, обычно работает быстрее и имеет больше опций.
В зависимости от того, какой у вас сканер — скорость работы может существенно различаться. Есть сканеры, которые могут получить картинку с листа за 10 сек., есть которые будут получать за 30 сек. Если сканируете книгу на 200-300 листов — думаю, не трудно подсчитать во сколько раз будет разница во времени?
2) Программа для распознавания
В нашей статье я буду показывать вам работу в одной из лучших программ для сканирования и распознавания абсолютно любых документов — ABBYY FineReader. Т.к. программа платная, то сразу дам ссылку и на другую — ее бесплатный аналог Cunei Form. Правда, я бы не стал их сравнивать, ввиду того, что FineReader выигрывает по всем параметрам, рекомендую все же попробовать именно ее.
ABBYY FineReader 11
Одна из лучших программ в своем роде. Она предназначена для того, чтобы распознать текст на картинке. Встроено множество опций и функций. Может разобрать кучу шрифтов, поддерживает даже рукописные варианты (правда, лично не пробовал, думаю, хорошо вряд ли будет распознавать рукописный вариант, если только у вас не идеальный каллиграфический почерк). Более подробно о работе с ней будет рассказано ниже. Здесь же отметим, что в статье будет рассказано о работе в программе 11 версии.
Как правило, разные версии ABBYY FineReader не сильно отличаются друг от друга. Вы без труда сделаете то же самое и в другой. Главные отличия могут быть в удобстве, быстроте работы программы и ее возможностях. Например, более ранние версии отказываются открывать документ PDF и DJVU…
3) Документы для сканирования
Да, вот так вот, решил вынести документы отдельной графой. В большинстве случаев сканируют какие-нибудь учебники, газеты, статьи, журналы и пр. Т.е. те книги и ту литературу которая пользуется спросом. Я это к чему веду? Из личного опыта могу сказать, что многое, что вы захотите сканировать — возможно уже есть в сети! Сколько раз лично я экономил время, когда находил ту или иную книгу уже сканированную в сети. Мне оставалось только скопировать текст в документ и продолжить с ним работу.
Из этого простой совет — прежде чем что-то сканировать, проверьте, может уже кто-то отсканировал и вам не нужно терять свое время.
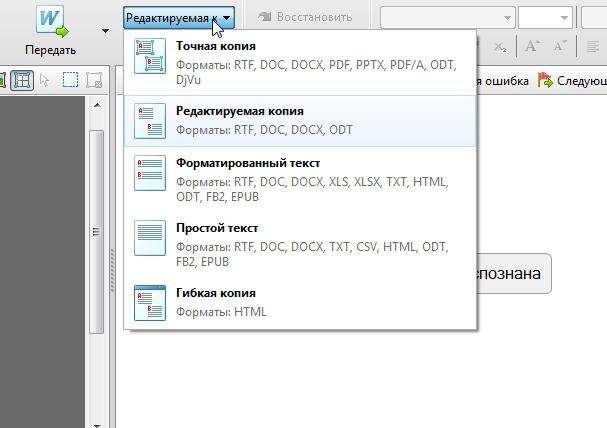
Тип копии
При сохранении документа (в режиме редактирования) вам предложат сохранить его в трех видах копии. Точная копия – это полная копия сканированного документа со всем произведенным форматированием. Если вы потом планируете редактировать текст после сканирования в ворде, то лучше всего выбрать именно этот вариант.
Редактируемая копия помогает сохранить уже отредактированный текст. Хорошо подходит, если вам предстоит обильное последующее редактирование. Простой текст – идеально подходит для тех, кто хочет получить в итоге обычный текст без всех остальных элементов страницы.
Вот, собственно и все. Сложно, долго и нудно, но гораздо быстрее сканировать и распознать текст (даже рукописный) программой, чем переписывать 100500 документов вручную. Ну а если вам и этим некогда заниматься – обращайтесь за помощью в студенческий сервис. Тут вам быстро, дешево и качественно выполнят все, что нужно.
Наталья – контент-маркетолог и блогер, но все это не мешает ей оставаться адекватным человеком. Верит во все цвета радуги и не верит в теорию всемирного заговора. Увлекается «нейрохиромантией» и тайно мечтает воссоздать дома Александрийскую библиотеку.

Возможно ли изменение сканированного текста? Можно ли отредактировать сканированный текст, чтобы потом использовать его с другими целями? Да, дорогие друзья! Сегодня это не только возможно, но и вполне легко делается.
При наличии необходимости, желания, а также некоторых технических возможностей вам легко дастся:
- сканирование рукописного текста (например, конспекта),
- сканирование текста с фотографии или картинки,
- редактирование,
- распознавание текста после сканирования,
- преобразование текста в виде картинки в обычный текст, в котором вы можете изменить сканированный текст (например, в документе pdf) документа и др.
В общем, сделать с текстом на картинке сегодня можно все то же самое, что и с обычным текстом в вордовском документе. А делать это жизненно важно и полезно тем, кто постоянно имеет дела с многочисленной документацией и тратит много времени – то есть и для студентов в том числе. Давайте разбираться, как это делается.
Чем отличается сканирование от распознавания?
Как оказалось, сканирование и распознавание текста – это разные вещи. Сканирование листов документа – это его перевод текста в электронный вид. Делается это через сканер или при помощи обычного фотографирования на смартфон или цифровую камеру.
Распознавание – это преобразование сканированного документа (текста) в электронный вид.
Что нам понадобится для сканирования и распознавания текста по фото ?
Для сканирования и распознавания текста нам не обойтись без кое-каких вещей:
- Сканер. Собственно, роль сканера может выполнять не только этот вид техники, но и фотоаппарат (в смартфоне, например). Если вы пользуетесь сканером, убедитесь, что на компьютере установлены системные драйвера и программы, необходимые для его полноценной работы. Если сканера нет, но вы собираетесь его купить, обратите внимание на скорость обработки одного листа. Некоторые приборы обрабатывают лист за 10 секунд, другим для этого понадобится 30 и более. И если работать вам придется с объемными материалами по 300-400 листов, то этот фактор имеет значение.
- Программы для распознавания текста или онлайн-сервисы. Мы уже писали статью по сервисам, которые помогают распознать текст после сканирования документа через сканер. Но сейчас хотели бы посоветовать вам программу ABBYY FineReader. Несмотря на то, что она платная, ее функционал поистине впечатляет. И если вы будете работать с огромными объемами документов, она станет вашим незаменимым помощником. Впрочем, есть и бесплатный ее аналог Cunei Form, которая отлично справляется со сканированием и распознаванием текста онлайн. Правда, ее функционал сильно ограничен по сравнению с предыдущим собратом.
- Документы для сканирования. Студентам часто приходиться сталкиваться со сканированием документа в виде журналов, статей, книг, конспектов, распечаток, откуда потом зачастую нужно скопировать текст. И просто так, в виде совета – перед началом сканирования постарайтесь поискать эти документы в сети. Если до вас этими материалами уже пользовались, существует огромная вероятность, что добрый человек уже проделал всю работу за вас. Атк что вам останется только скопировать текст готового сканированного документа и заняться редактированием текста после сканирования.
Параметры сканирования текста
Итак, сканер купили, документы подготовили, программы установили. Что дальше? Дальше нам нужно будет сделать нужные настройки, которые тоже порой помогают существенно облегчить задачу, например, распознать сканированный текст в определенном формате, редактировать текст после сканирования в определенном режиме и так далее.
В общем, от настроек будет зависеть качество и скорость вашей работы. Итак, разбираемся вместе.
DPI-качество
Это разрешение изображения, которое будет важно при редактировании текста в сканированном документе. Ставьте в настройках качество не меньше 300 DPI, а если возможно - то больше. Чем выше эта величина, тем более четким получится изображение после сканирования.
Цветность
Благодаря этому параметру можно влиять на скорость сканирования текста. Как правило, в сканерах есть 3 режима: черно-белый (подходит для листов с обычным печатным текстом), серый (подходит для работы с документами с таблицами и простыми картинками), цветной (для журналов, книг и остальных документов, где цвет играет значение). Чем меньше цвета, тем выше скорость обработки документа.
Фото
Для сканирования можно использовать не только сканер, но и фотографирование. Но здесь будьте осторожны – любое смазывание, нечеткость и прочие искажения изображения могут повлиять на дальнейшее распознавание и редактирование текста в сканированном документе.
Распознавание
Итак, отсканировали и получили странички в электронном виде. Затем открываем программу для распознавания (например, FineReader) и начинаем распознавать текст. Некоторые программы (в том числе и наша) делают этот процесс с ошибками. Тогда область с ошибкой нужно будет выделять вручную.
Работа с текстом
В области Текст можно будет выделить текст. Любые таблицы и изображения можно будет удалить. А вот для работы с необычными и редкими символами придется поработать ручками. Вот как это выглядит в программе:

Картинки
Эта область в программе используется для работы с изображениями и с теми областями текста, которые плохо поддались распознаванию.

Таблицы
Кнопка выделения таблиц помогает работать с таблицами. Однако эта функция не очень хорошо развита. Иногда проще использовать редактор Картинка для работы с таблицами. Это сэкономит кучу времени и нервов, а доработать все потом можно в обычном ворде.

Лишние элементы
Если на странице остались элементы, которые вам совершенно не нужны или бесполезны, выделите ненужную область и удалите ее с помощью ластика. Достаточно перейти в режим редактирования и провести работу. Причем чем больше ненужных элементов вы уберете, тем быстрее будет происходить процесс распознавания текста.
Проверка ошибок и сохранение результатов работы
Как мы уже говорили, ошибки могут возникать тогда, когда вы используете некачественные, смазанные, нечеткие изображения или документы с редкими символами. Поэтому всегда проверяйте документ после процесса распознавания.
Нашли? Замечательно – просто введите нужный символ. Кстати, в программе есть режим проверки, который поможет быстро и без вашего участия проверить документ на наличие ошибок программы. И сразу же после окончания проверки можете прямо из программы импортировать документ (сохранить его в формате) в ворд или любую другую программу.

Тип копии
При сохранении документа (в режиме редактирования) вам предложат сохранить его в трех видах копии. Точная копия – это полная копия сканированного документа со всем произведенным форматированием. Если вы потом планируете редактировать текст после сканирования в ворде, то лучше всего выбрать именно этот вариант.
Редактируемая копия помогает сохранить уже отредактированный текст. Хорошо подходит, если вам предстоит обильное последующее редактирование.
Простой текст – идеально подходит для тех, кто хочет получить в итоге обычный текст без всех остальных элементов страницы.
Этапы распознавания текста
Распознавание текста документов проводится в несколько этапов:
- Сканирование оригинала. Обычно этот процесс осуществляется в черно-белом режиме, однако при необходимости мы выполняем его в цвете или градациях серого.
- Распознавание структуры страниц. Для этого наши специалисты используют специальное программное обеспечение — Abbyy Finereader. На данный момент эта система считается лучшей, и ее алгоритм непрерывно совершенствуется, что позволяет обрабатывать документы любой сложности и практически в любом состоянии.
- Распознавание текста. На этом этапе особенно важно правильно установить параметры программы Abbyy Finereader, чтобы минимизировать ошибки распознавания. Их количество зависит от таких факторов, как полиграфическое качество исходника, размер и контрастность текста, сложность взаимного размещения элементов на странице.
- Проверка правильности распознавания. Выполняется визуально с целью выявления неправильно распознанных символов.
- Проверка орфографических ошибок. На четвертом этапе, как правило, не удается избавиться от всех ошибок, поэтому дополнительно мы проверяем орфографию, например, в текстовом редакторе Microsoft Word.
- Форматирование и оформление электронного документа. В текстовом редакторе Microsoft Word устанавливается единый формат и стиль документа, размер и тип шрифта, производится размещение и структурирование таблиц. При необходимости вручную вводится текст, формулы, таблицы, которые не удалось распознать автоматически. Мы не выполняем полностью автоматическое распознавание документа, а работаем в полуавтоматическом режиме с обязательным проведением корректировки после каждого этапа обработки. В результате в электронной версии не полностью сохраняется форматирование оригинала, но на выходе получается качественный, легко читаемый документ.
Работая с системой распознавания Abbyy Finereader много лет, наши специалисты детально изучили ее функционал и выработали особые приемы и методы обработки исходников, позволяющие проводить распознавание документов различных типов и в любом состоянии.
Благодаря современному оборудованию, идеально настроенному программному обеспечению и четко отработанному технологическому процессу себестоимость работ значительно уменьшилась, поэтому мы имеем возможность предложить заказчикам весьма привлекательные цены.
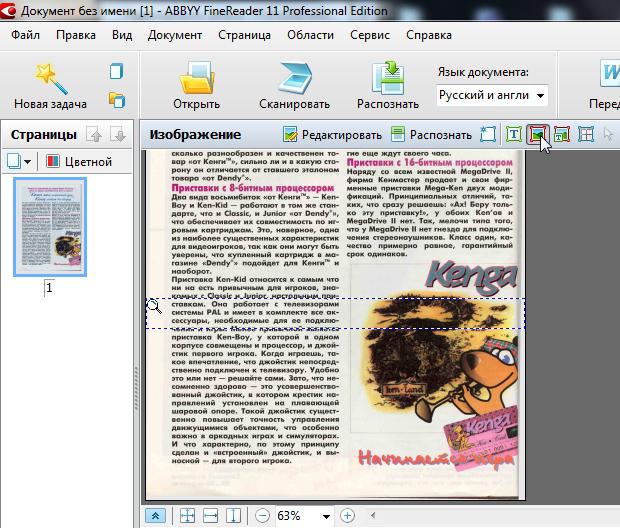
3.1 Текст
Эта область используется для выделения текста. Картинки и таблицы нужно исключать из нее. Редкие и необычный шрифты придется вводить вручную…
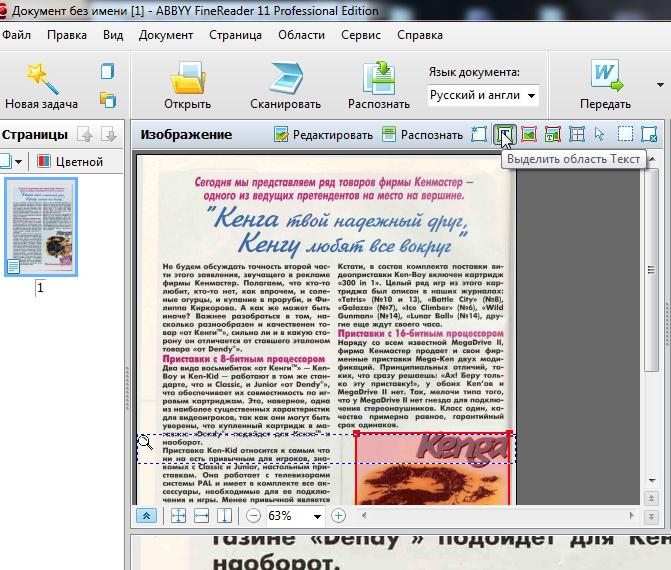
Для выделения текстовой области, обратите внимание на панель в верхней части FineReader. Там есть кнопка «Т» (см. скриншот ниже, указатель мышки как раз на этой кнопке). Щелкаете по ней, затем на картинке ниже выделяете аккуратно прямоугольную область, в которой располагается текст. Кстати, в некоторых случаях нужно создавать текстовых блоков по 2-3, а иногда по 10-12 на страницу, т.к. форматирование текста может быть разным и одним прямоугольником всю область не выделить.
Важно отметить, что в текстовую область не должны попадать картинки! В дальнейшем это вам сэкономит кучу времени…
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2013-11-03_10-07-33](https://pcpro100.info/wp-content/uploads/2013/11/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2013-11-03_10-07-33.jpg)
Доверьте работу профессионалам
Наша компания на рынке с 2006 года. Профессиональное оборудование и опытный персонал. Сотни тысяч обработанных документов и книг. Всё это позволяет нам предложить вам оптимальные по соотношению цена/качество услуги.
от 1,5 руб./страница
от 4 руб./страница
от 10 руб./фото
от 2 руб./стр
от 60 руб./стр
от 2 руб./анкета
Стоимость распознавания с ручной настройкой, проверкой и форматированием в среднем составляет
от 16 руб. до 39 руб. за одну страницу исходного документа.
Она зависит от времени потраченного оператором на обработку одной страницы, которое в свою очередь зависит от состояния исходного изображения (сильный фон, копия, недостаточная контрастность) и сложности структуры самого документа (наличие таблиц, рисунков, сносок, многоязычность и т.п.)
В таблице представлены примеры изображений и стоимости их распознавания:
Исходная страница
Характеристика
Стоимость

16 руб. за страницу

23 руб. за страницу

Сложная страница 1 степени
39 руб. за страницу
Почему мы?
Наша компания профессионально предоставляет услуги распознавания текста документов, начиная с 2006 года. За это время мы распознали сотни тысяч страниц документов.
Наши клиенты, как правило, обращаются к нам снова и снова и вот почему:
- Большой опыт (наши операторы имеют стаж работы от 2-х до 10 лет)
- Высокое качество
- Разумные цены
- Постоплата (вы получаете результат и только после этого оплачиваете)
- Бережное обращение с документами
Типы исходных материалов для определения стоимости оцифровки
Простой текст — единый текстовый фрагмент с простым стилем оформления.
Простая таблица — структура данных из 1-12 строк, с однотипным форматированием ячеек и текстом в них.
Сложная таблица — структура данных, занимающая всю страницу, не разбитая на ячейки либо с неоднородными (объединенными) ячейками и текстом.
Рисунок — графический элемент, как правило, с подписью.
Формула — комбинация сложных символов и элементов, отображение которой возможно только с помощью специального редактора формул.
Закажите эту услугу со скидкой!
Для детального обсуждения условий сотрудничества, получения консультации и оформления заказа на любую из наших услуг:
- Оставаясь на рабочем месте
- В удобное время
- За считанные минуты
Что нам понадобится для сканирования и распознавания текста по фото ?
Для сканирования и распознавания текста нам не обойтись без кое-каких вещей:
- Сканер. Собственно, роль сканера может выполнять не только этот вид техники, но и фотоаппарат (в смартфоне, например). Если вы пользуетесь сканером, убедитесь, что на компьютере установлены системные драйвера и программы, необходимые для его полноценной работы. Если сканера нет, но вы собираетесь его купить, обратите внимание на скорость обработки одного листа. Некоторые приборы обрабатывают лист за 10 секунд, другим для этого понадобится 30 и более. И если работать вам придется с объемными материалами по 300-400 листов, то этот фактор имеет значение.
- Программы для распознавания текста или онлайн-сервисы. Мы уже писали статью по сервисам, которые помогают распознать текст после сканирования документа через сканер. Но сейчас хотели бы посоветовать вам программу ABBYY FineReader. Несмотря на то, что она платная, ее функционал поистине впечатляет. И если вы будете работать с огромными объемами документов, она станет вашим незаменимым помощником. Впрочем, есть и бесплатный ее аналог Cunei Form, которая отлично справляется со сканированием и распознаванием текста онлайн. Правда, ее функционал сильно ограничен по сравнению с предыдущим собратом.
- Документы для сканирования. Студентам часто приходиться сталкиваться со сканированием документа в виде журналов, статей, книг, конспектов, распечаток, откуда потом зачастую нужно скопировать текст. И просто так, в виде совета – перед началом сканирования постарайтесь поискать эти документы в сети. Если до вас этими материалами уже пользовались, существует огромная вероятность, что добрый человек уже проделал всю работу за вас. Атк что вам останется только скопировать текст готового сканированного документа и заняться редактированием текста после сканирования.
Картинки
Эта область в программе используется для работы с изображениями и с теми областями текста, которые плохо поддались распознаванию.
Параметры сканирования текста
Итак, сканер купили, документы подготовили, программы установили. Что дальше? Дальше нам нужно будет сделать нужные настройки, которые тоже порой помогают существенно облегчить задачу, например, распознать сканированный текст в определенном формате, редактировать текст после сканирования в определенном режиме и так далее.
В общем, от настроек будет зависеть качество и скорость вашей работы. Итак, разбираемся вместе.
DPI-качество
Это разрешение изображения, которое будет важно при редактировании текста в сканированном документе. Ставьте в настройках качество не меньше 300 DPI, а если возможно - то больше. Чем выше эта величина, тем более четким получится изображение после сканирования.
3. Распознавание текста документа
Будем считать, что заветные сканированные страницы вы получили. Чаще всего они представляют собой форматы: tif, bmb, jpg, png. В общем-то, для ABBYY FineReader — это не сильно важно…
После открытия в ABBYY FineReader картинки, программа, как правило, на автомате начинает выделять области и распознавать их. Но иногда она делает это не правильно. Для этого-то мы и рассмотрим выделение нужных областей вручную.
Важно! Не все сразу понимают, что после открытия документа в программе, слева в окне отображается исходный документ, в котором вы и выделяете различные области. После нажатия на кнопку «распознавания» программа в окне справа выведет вам готовый текст. После распознавания, кстати, целесообразно проверить текст на ошибки в том же самом FineReader.
Лишние элементы
Если на странице остались элементы, которые вам совершенно не нужны или бесполезны, выделите ненужную область и удалите ее с помощью ластика. Достаточно перейти в режим редактирования и провести работу. Причем чем больше ненужных элементов вы уберете, тем быстрее будет происходить процесс распознавания текста.
Делать самому или доверить профессионалам?
Ответ на этот вопрос зависит от того насколько вы цените своё время.
Пример
Для работы с фрагментами текста из книг и других документов вам необходимо преобразовать в электронную форму 50 печатных страниц. Предположим, что оборудование для сканирования и программное обеспечение для распознавания текста есть в наличии. Если вы не занимаетесь этим регулярно, то на выполнение работы вам потребуется не менее 9 часов.
Однако вы можете предоставить исходные материалы нашим специалистам и:
- получить качественный результат на следующий день в удобной вам форме.
- подождать около 20 минут (время сканирования) и забрать оригиналы, а готовый электронный документ получить на указанный адрес электронной почты или скачать с нашего FTP-сервера.
Стоимость наших услуг составит приблизительно 800р. - 1500р. для 50 страниц в зависимости качества исходников.
Таким образом, при самостоятельном выполнении этой работы вы сэкономите 90-170 рублей за один час своей работы.
Возможно ли изменение сканированного текста? Можно ли отредактировать сканированный текст, чтобы потом использовать его с другими целями? Да, дорогие друзья! Сегодня это не только возможно, но и вполне легко делается.
При наличии необходимости, желания, а также некоторых технических возможностей вам легко дастся:
- сканирование рукописного текста (например, конспекта),
- сканирование текста с фотографии или картинки,
- редактирование,
- распознавание текста после сканирования,
- преобразование текста в виде картинки в обычный текст, в котором вы можете изменить сканированный текст (например, в документе pdf) документа и др.
В общем, сделать с текстом на картинке сегодня можно все то же самое, что и с обычным текстом в вордовском документе. А делать это жизненно важно и полезно тем, кто постоянно имеет дела с многочисленной документацией и тратит много времени – то есть и для студентов в том числе. Давайте разбираться, как это делается.
4. Распознавание файлов PDF/DJVU
Вообще, этот формат распознавания не будет отличаться ничем другим от остальных — т.е. работать с ним можно так же как с картинками. Единственное, программа не должна быть слишком старой версии, если файлы PDF/DJVU у вас не открываются — обновите версию до 11.
Небольшой совет. После открытия документа в FineReader — он автоматически начнет распознавать документ. Часто в файлах PDF/DJVU определенная область страницы не нужна во всем документе! Чтобы удалить такую область на всех страницах сделайте следующее:
1. Зайдите в раздел редактирования изображения.
2. Включите опция «обрезки».
3. Выделите область, нужную вам на всех страницах.
4. Нажмите применить ко всем страницам и обрежьте.
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2013-11-03_10-19-21](https://pcpro100.info/wp-content/uploads/2013/11/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2013-11-03_10-19-21.jpg)
* Порядок определения сложности страницы при распознавании текста
Тип сложности страницы определяется в зависимости от количества баллов рассчитанных для страницы
Количество баллов сложности для страницы вычисляется суммированием значений расчетных баллов для каждого элемента страницы
Таблицы
Кнопка выделения таблиц помогает работать с таблицами. Однако эта функция не очень хорошо развита. Иногда проще использовать редактор Картинка для работы с таблицами. Это сэкономит кучу времени и нервов, а доработать все потом можно в обычном ворде.

Наши цены
| Автоматическое распознавание за страницу (без проверки и корректировки результатов) | 3р. |
| Распознавание. Простая страница* (за страницу) | 16р. |
| Распознавание. Стандартная страница* (за страницу) | 23р. |
| Распознавание. Сложная страница 1 степени* (за страницу) | 39р. |
| Распознавание. Сложная страница 2 степени* (за страницу) | 56р. |
| Распознавание. Сложная страница 3 степени* (за страницу) | 85р. |
| Распознавание. Сложная страница 4 степени* (за страницу) | 115р. |
| Сверхсложная страница* (за страницу) | 190р. |
Наценки
к базовой стоимости распознавания текста
| Наличие на странице текста на иностранном языке (коэффициент) | умнож. на 1,3 |
| Распознавание ксерокопии или наличие на странице засветов или шумов (коэффициент) | умнож. на 1,5 |
| Наличие 2-х колонок текста на странице (коэффициент) | умнож. на 1,3 |
| Наличие 3-х колонок текста на странице (коэффициент) | умнож. на 1,5 |
| Ввод формул в редакторе формул (за элемент) | 35р. |
5. Проверка ошибок и сохранение результатов работы
Казалось бы, какие еще могут быть проблемы, когда все области были выделены, затем распознаны — бери да сохраняй… Не тут то было!
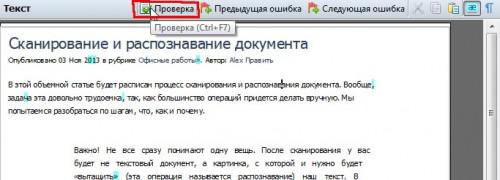
Во-первых, нужна проверка документа!
Чтобы ее включить, после распознавания, в окне справа, будет кнопка «проверка», см. скриншот ниже. После ее нажатия программа FineReader будет автоматически показывать вам те области, где у программы возникли ошибки и она не смогла достоверно определить тот или иной символ. Вам останется только выбирать, либо вы согласны с мнением программы, либо вводите свой символ.
Кстати, в половине случаев, примерно, программа будет вам предлагать готовое правильное слово — вам останется толкьо мышкой выбрать нужный вариант.
Во-вторых, после проверки вам нужно выбрать формат, в который вы сохраните результат своей работы.
Здесь FineReader дает вам развернуться на полную катушку: можно просто передать информацию в Word один в один, а можно сохранить ее в одном из десятков форматов. Но хотелось бы выделить другой важный аспект. Какой формат бы не выбрали, более важно выбрать тип копии! Рассмотрим самые интересные варианты…
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2013-11-03_10-24-08](https://pcpro100.info/wp-content/uploads/2013/11/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2013-11-03_10-24-08.jpg)
Все области, которые вы выделяли на странице в распознанном документе будут соответствовать точь в точь исходному документу. Очень удобный вариант, когда вам важно не потерять форматирование текста. Кстати, шрифты так же будут очень похожи на оригинал. Рекомендую при таком варианте передавать документ в Word, чтобы уже там продолжить дальнейшую работу.
Этот вариант хорош тем, что вы получите уже форматированный вариант текста. Т.е. отступов с «километр», которые возможно были в исходном документе — вы не встретите. Полезная опция, когда вы будете значительно редактировать информацию.
Правда, не стоит выбирать, если вам важно сохранить стилистику оформления, шрифты, отступы. Иногда, если распознавание прошло не очень успешно — ваш документ может «перекосить» из-за измененного форматирования. В этом случае целесообразно выбрать точную копию.
Вариант для тех, кому нужен просто текст со странице без всего остального. Подойдет для документов без картинок и таблиц.
На этом статья по сканированию и распознаванию документа подошла к концу. Надеюсь, что при помощи этих простых советов вы сможете решить свои задачи…
от 1,5 руб./страница
от 4 руб./страница
от 10 руб./фото
от 2 руб./стр
от 60 руб./стр
от 2 руб./анкета
3 руб. за страницу за автоматическое распознавание.
Подробнее на странице Распознавание текста.
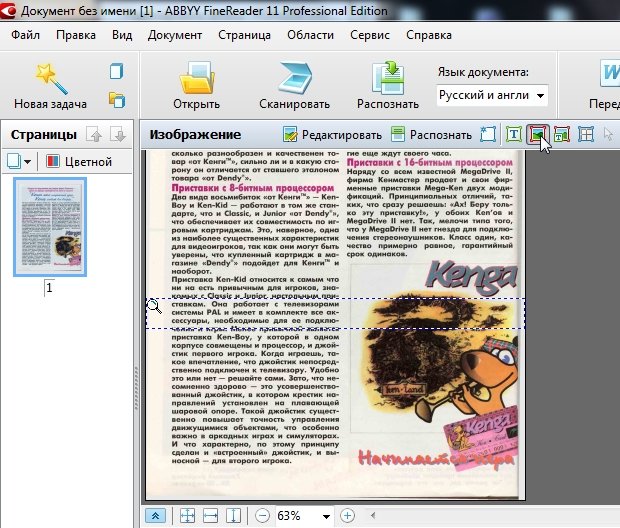
3.2 Картинки
Используется для выделения картинок и тех областей, которые тяжело распознать из-за плохого качества, или необычности шрифта.
На скриншоте ниже указатель мышки находится на кнопке, используемой для выделения области «картинка». Кстати, в эту область можно выделить абсолютно любую часть страницы, а FineReader вставит ее потом в документ как обычную картинку. Т.е. просто «тупо» скопирует…
Обычно эту область используют для выделения плохо отсканированных таблиц, для выделения нестандартного текста и шрифта, само-собой картинок.
Цветность
Благодаря этому параметру можно влиять на скорость сканирования текста. Как правило, в сканерах есть 3 режима: черно-белый (подходит для листов с обычным печатным текстом), серый (подходит для работы с документами с таблицами и простыми картинками), цветной (для журналов, книг и остальных документов, где цвет играет значение). Чем меньше цвета, тем выше скорость обработки документа.
Как мы уже говорили, для сканирования можно использовать не только сканер, но и фотографирование. Но здесь будьте осторожны – любое смазывание, нечеткость и прочие искажения изображения могут повлиять на дальнейшее распознавание и редактирование текста в сканированном документе.
3.3 Таблицы
На скриншоте ниже показана кнопка для выделения таблиц. Вообще, лично я ее использую крайне редко. Дело в том, что вам придется довольно рутинно рисовать (фактически) каждую линию на таблице и показывать что и как программе. Если таблица небольшая и в не очень хорошем качестве, я рекомендую для этих целей использовать область «картинка». Тем самым сэкономите кучу времени, а таблицу можно потом в Word сделать быстренько на основе картинки.
![]()
3.4 Ненужные элементы
Важно отметить. Иногда на странице есть ненужные элементы, которые мешают распознать текст, или вообще не дают вам выделить нужную область. Их можно при помощи «ластика» удалить вовсе.
Для этого переходим в режим редактирования изображения.
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2013-11-03_10-14-11](https://pcpro100.info/wp-content/uploads/2013/11/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2013-11-03_10-14-11.jpg)
Выбираем инструмент «ластик» и выделяем ненужную область. Она сотрется и на ее месте будет белый лист бумаги.
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2013-11-03_10-14-21](https://pcpro100.info/wp-content/uploads/2013/11/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2013-11-03_10-14-21.jpg)
Кстати, рекомендую использовать вам эту опцию как можно чаще. Старайтесь все текстовые области которые вы выделили, где вам не нужен кусок текста, или присутствуют любые ненужные точки, размытости, искажения — удалять ластиком. Благодаря этому распознавание будет быстрее!
Чем отличается сканирование от распознавания?
Как оказалось, сканирование и распознавание текста – это разные вещи. Сканирование листов документа – это его перевод текста в электронный вид. Делается это через сканер или при помощи обычного фотографирования на смартфон или цифровую камеру.
Распознавание – это преобразование сканированного документа (текста) в электронный вид.
Кстати! Для наших читателей сейчас действует скидка 10% на любой вид работы
2. Параметры сканирования текста
Здесь я не будут рассказывать о ваших драйверах для сканера, программах, которые вместе с ним шли, ибо все модели сканеров разные, ПО тоже везде разное и угадать и тем более показать наглядно как выполнять операцию — нереально.
Но во всех сканерах есть одни и те же настройки, которые сильно могут повлиять на скорость и качество вашей работы. Вот о них таки как раз и поговорим здесь. Буду перечислять по порядку.
1) Качество сканирования — DPI
Во-первых, качество сканирования поставьте в опциях не ниже 300 DPI. Желательно даже выставить побольше, если это возможно. Чем выше показатель DPI — тем четче получиться ваша картинка, ну и тем самым, быстрее пройдет дальнейшая обработка. К тому же чем выше качество сканирования — тем меньше ошибок вам в последствии придется исправлять.
Оптимальный вариант обеспечивает, обычно, 300-400 DPI.
Этот параметр очень сильно влияет на время сканирования (кстати, DPI тоже влияет, но те так сильно, и только когда пользователь ставит высокие значения).
Обычно выделяют три режима:
— черно-белый (отлично подойдет для простого текста);
— серый ( подойдет для текста с таблицами и картинками);
— цветной (для цветных журналов, книг, в общем, документов, где важна цветность).
Обычно от выбора цветности зависит время сканирования. Ведь если документ у вас большой, то даже лишние 5-10 секунд на странице в целом выльются в приличное время…
Документ вы можете получить не только сканированием, но и сфотографировав его. Как правило, в этом случае у вас будут некоторые другие проблемы: искажение картинки, смазанность. Из-за этого может потребоваться более длительная дальнейшая правка и обработка полученного текста. Лично я не рекомендую пользоваться фотоаппаратами для этого дела.
Важно отметить, что не каждый такой документ получится распознать, т.к. качество сканирования у него может быть крайне низким…
Сроки
В среднем на распознавание одного документа в 200-300 страниц, или книги такого же объёма уходит от 2 до 5 рабочих дней.
На крупных проектах большой штат позволяет нам обрабатывать до нескольких тысяч страниц в день.
Проверка ошибок и сохранение результатов работы
Как мы уже говорили, ошибки могут возникать тогда, когда вы используете некачественные, смазанные, нечеткие изображения или документы с редкими символами. Поэтому всегда проверяйте документ после процесса распознавания.
Нашли? Замечательно – просто введите нужный символ. Кстати, в программе есть режим проверки, который поможет быстро и без вашего участия проверить документ на наличие ошибок программы. И сразу же после окончания проверки можете прямо из программы импортировать документ (сохранить его в формате) в ворд или любую другую программу.
Этапы сканирования и распознавание текста
Опуская процесс подготовки оригиналов, сам процесс сканирования и распознавания можно разделить на следующие этапы.
1. Выбор режима сканирования. Для успешного распознавания и минимизации ошибок, специалист сканирования должен, прежде всего, правильно подготовить документ для распознавания, настроить оборудование для получения максимально качественной цифровой копии оригинала. Свежеотпечатанный на принтере текст и старая газета с выцветшим шрифтом и пожелтевшей бумаге требуют к себе разного подхода на всех этапах сканирования и распознавания. Однако профессиональные опытные специалисты с помощью новейших программно-аппаратных средств отлично справляются с любыми задачами такого рода.
Также на этом этапе важно определиться с режимом сканирования. Для текстового черно-белого документа, не содержащего картинок и иллюстраций (или же эти элементы так же черно-белые), достаточно выбрать режим черно-белого сканирования или режим градации серого. Однако если текст не черно-белый, присутствуют цветные элементы, картинки, графики, схемы, и нам нужно получить точную копию, режим сканирования должен быть соответствующим, то есть цветным. Если цветность не принципиальна, то можно ограничиться режимом сканирования в градациях серого.

2. Далее приступаем к распознаванию текста. Для начала с помощью специализированных программ анализируется структура документов. На этом этапе важен контроль специалиста, так как возможные ошибки на этом этапе потребуют серьезных усилий по их устранению в последствии.
Следующий этап - непосредственное распознавание текста. Этот процесс так же доверяем компьютерной программе распознавания текста.
Далее происходит проверка на предмет синтаксических и орфографических ошибок, расставляются, по необходимости, знаки препинания и специальные символы.

4. И последний этап это форматирование документа. Проверяется и если нужно корректируется размер шрифта, стили заголовков и текста, разбивается на абзацы, главы, проверяется нумерация страниц и оглавление документа. Также проверяется общая структура документа и верстка. Графические элементы, картинки, графики, схемы и другие иллюстрации так же проходят проверку на предмет соответствия.
После проведения всех вышеописанных процедур, мы получаем точную и самое главное редактируемую копию оригинала. Теперь мы с легкостью можем вносить изменения, копировать и делится этим документом, получить необходимое количество твердых копий. На основании этого документа можно создавать свои собственные документы. При этом документ будет храниться, без риска быть испорченным, потерянным или украденным.

Работа с текстом
В области Текст можно будет выделить текст. Любые таблицы и изображения можно будет удалить. А вот для работы с необычными и редкими символами придется поработать ручками. Вот как это выглядит в программе:
Распознавание
Итак, отсканировали и получили странички в электронном виде. Затем открываем программу для распознавания (например, FineReader) и начинаем распознавать текст. Некоторые программы (в том числе и наша) делают этот процесс с ошибками. Тогда область с ошибкой нужно будет выделять вручную.
Читайте также: