
Datastore cluster настройка vmware
This is a great feature in vSphere 5 because you don’t have to keep an eye on the datastores anymore to balance the space for your VMs. Besides this Datastore Clusters minimizes I/O load on those datastores. Long story-short, it provides load balancing mechanisms based on I/O, space capacity, and smart virtual machine placement. To give you an example, just imagine for a moment that you have three datastores configured on your ESXi hosts. You want to create 10 VMs, but first you need to think on what datastores those VMs should sit. With Datastore Clusters you deploy the VMs, and vCenter will choose on what datastores the VMs will be deployed. If you already have hundreds of VMs running in your VMware Infrastructure, after you create a Datastore Cluster, vCenter 5 will automatically (if set to automatic) move VMs and VMDKs between datastores until the configuration criteria (set during the cluster configuration) is satisfied. You can’t create Datastore Clusters if your ESXi hosts are independent, they need to be in a cluster.
To start creating a Datastore Cluster got to the vCenter Home page and click the Datastores and Datastore Cluster icon.
Right-click the Datacenter name and choose New Datastore Cluster. You can also use the icon from the Toolbar.
Give the Datastore Cluster a name then click Next to continue. If you leave the Turn on Storage DRS box checked, you enable the following functions:
– Space load balancing among datastores within a datastore cluster.
– I/O load balancing among datastores within a datastore cluster.
– Initial placement for virtual disks based on space and I/O workload.
Here we have two options, manual or automatic. If you leave it to No automation (Manual mode) vCenter will notify you with recommendations about virtual machine migration. As you can guess by now, the Fully Automated option will automatically migrate VMs to different datastores in the Datastore Cluster. You can switch this option back and forth at any time after you create the Datastore Cluster.
We have quite a few options here. If you disable the Enable I/O metrics for SDRS recommendations option you will disable some elements of Storage DRS:
– I/O load balancing among datastores within a datastore cluster
– Initial placement for virtual disks based on I/O workload
The Storage DRS Tresholds section will make recommendations or migrate VMs when values are exceeded. On the Advanced Options section you will see the utilization difference, the imbalance threshold and the interval check for the imbalances.
Select the cluster you wish to add this Datastore Cluster to then click Next to continue.
This is where you select the datastores that will be part of this Datastore Cluster. Make sure the datastores that you select here are visible by all the ESXi hosts that will use this Datastore Cluster.
On the Ready to Complete page, review your changes and click Finish to commit the changes.
After the operation completes you should have a Datastore Cluster created and visible in you vCenter console.
Итого, по мотивам предыдущих частей данной эпопеи: раз, два, три, мы имеем парочку хостов ESXi и vCenter Server, который этими хостами умеет управлять.
Следующее обязательное условие для построения кластера — общее хранилище с кластерной файловой системой VMware — VMFS (или NFS ресурс). Данное хранилище должно быть доступно одновременно всем узлам будущего кластера и на нем будут храниться файлы виртуальных машин. В двух словах про эти самые файлы.
Каждая виртуальная машина для гапервизора ESXi, это с одной стороны — набор файлов на диске, с другой стороны — процесс, или набор процессов в которые завернуты процессы гостевой операционной системы. Ниже на картинке — примерный список файлов типичной виртуальной машины:
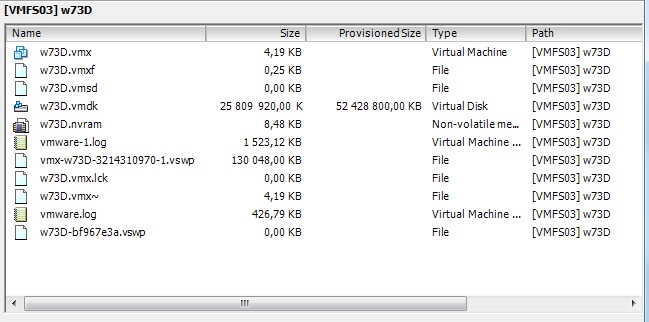
В данном примере машина называется w73D, это имя фигурирует в названиях ее файлов, в большинстве файлов отличается только расширение.
w73D.vmx — содержит параметры конфигурации виртуальной машины, такие как размер ОЗУ, количество ядер процессора, конфигурацию устройств ввода-вывода и множество других параметров
w73D.vmdk — файл виртуального диска, который видит гостевая операционная система как физический винчестер. Если добавить еще парочку дисков в виртуальную машину — файлов с расширением *.vmdk тоже будет несколько
w73D.nvram — файл состояния BIOS виртуальной машины
w73D-bf967e3a.vswp — swap файл виртуальной машины, который создается во время запуска ВМ и его размер равняется размеру незарезервированной оперативной памяти виртуальной машины (в данном примере вся память ВМ зарезервирована) и используется в случае конкуренции за оперативную память между виртуальными машинами
Это основные файлы, и которых состоит ВМ. Есть также дополнительные файлы, которые используются для системных нужд, некоторые из них:
vmware.log — здесь и так понятно: лог системных событий, связанных с виртуальной машиной
w73D.vmsd — информация о снапшотах виртуальной машины
w73D.vmx.lck — используется для блокировки ВМ от запуска одновременно на двух узлах
И т.д… лезть в дебри и перечислять все не буду, статья ознакомительная.
В кластерной конфигурации VMware vSphere все файлы виртуальных машин, которые предполагается защищать с помощью VMware HA и двигать с помощью VMware DRS и vMotion предполагается хранить на общем хранилище (в контексте VMware — Datastore) которое доступно всем узлам кластера одновременно.
Для этих целей можно использовать конечно же Fibre Channel, FCoE, iSCSI или даже NFS хранилище. Конечно, хорошо если у вас есть модная СХД с подключением по FC или FCoE, там вопросов практически не возникает, но это дорого (если говорить про ДЕМО-стенд), и даже крутые компании не всегда могут себе позволить юзать дорогущий сторедж в качестве «песочницы».
Поэтому рассмотрим iSCSI и NFS как вариант общей хранилки «для бедных», хотя бы потому, что для демонстрации его можно собрать на коленке за полчаса (но фирменная СХД с подключением по iSCSI или NFS тоже стоит хороших денег, дружно вспомним про NetApp ;))
Если выбирать между iSCSI и NFS то здесь тоже есть небольшая диллема, у каждого варианта есть недостатки, если в двух словах, то iSCSI более глючный, а NFS более тормознутый (задо надежней и проще). Да, определенно есть любители айскази, которые закидают меня помидорами и скажут что все глюки от кривых ручек, но в контексте ESXi есть несколько официально признанных багов, при работе с iSCSI, особенно при использовании Software iSCSI адаптера со стороны ESXi, хотя есть конторки, пользующие такую конфигурацию в продуктиве, отловившие и поборовшие все глюки, каждому, как говорится, свое.
Кароче, для данной демонстрации я выбираю NFS, не смотря на его тормознутость, а вы смотрите сами. NFS сервером может притвориться в принципе любой линукс, но еще проще — готовое решение на подобии Open-E или Openfiler.
- скачиваем готовый модуль в виде ISO или OVA/OVF
- развертываем на физической или виртуальной машине подминая под себя побольше дискового пространства
- прибиваем айпишник
- создаем через веб-морду (для любителей порнушки — через командную строку)
- .
- PROFIT!
Описывать подробно установку и настройку NFS ресурса не буду, ибо:
- лень
- там все интуитивно понятно
- не охота очередной раз отходить от темы
Допустим, NFS мы развернули, теперь нужно примаппить его к узлам будущего кластера.
Для этого: наступаем на узел -> лезем в Configuration -> Storage -> Add Storage (см. картинко ниже)
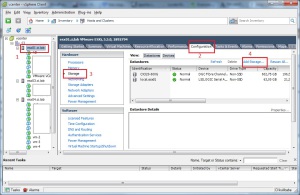
В открывшемся окне выбираем «Network File System» и следуя инструкциям указываем:
- Адрес или имя узла NFS сервера
- Путь к папке на сервере
- Имя хранилища, которое будет отображаться в списке датасторов
Если мы все сделали правильно, то у нас появится на вкладке «Datastores«. Повторяем действия для всех узлов будущего кластера, при этом имя хранилища у всех узлов должно быть одинаковое.
В случае с блочным хранилищем FC или FCoE, прежде всего, LUN должен быть презентован всем узлам будущего кластера, после этого, создаем на нем файловую систему VMFS посредством «Add Storage» на одном из узлов, а на остальных — ВНИМАНИЕ!! — делаем правой кнопкой -> «Rescan for Datastores». Если данный LUN добавить повторно на другом узле, пока он не успел отсканниться — получится какашка.
Что с этим всем теперь делать? — можно создать на новоиспеченном хранилище одну или несколько виртуальных машин. Содержимое хранилища можно посмотреть тыцнув на нем правой и выбрав «Browse Datastore«. В случае с NFS — можно подключить его с другим серверам или юзерским машинкам, даже с виндой, т.к. NFS это универсальная сетевая файловая система, чего нельзя сказать про VMFS, которую умеет читать только ESXi.
На сегодня все, в следующей статье надеюсь завершить историю с созданием кластера, попытаюсь рассказать о настройках кластерных фич и тестировании их работы.
Я старался расписывать максимально подробно и доступно, но если по данной, или предыдущим статьям есть вопросы — задавайте, постараюсь ответить.
Давно хотел написать цепочку статей о VMware кластерах. Их архитектуру, принципы построения с инструкциями и примерами установки.
Я не собираюсь писать целые тома с техническими подробностями, хочу лишь поверхностно охватить данную тему. Но даже для поверхностного раскрытия понадобится несколько статей и это первая из них — теоретические основы.
Тех, кто еще не понял, предупреждаю — это статьи для новичков в данной теме, скорее для общего развития чем для приобретения глубокого технического опыта и знаний.
Основные возможности VMware vSAN
- Встроенный функционал защиты и обеспечения высокой доступности данных с отказоустойчивостью, асинхронной репликацией на большие расстояния и растянутыми кластерами между географически разнесенными сайтами.
- Использование распределенного RAID и зеркалирования кэша для защиты данных от потери отдельного диска, сервера или целой стойки
- Минимизация задержек хранилищ за счет ускорения операций чтения/записи с дисков за счет встроенного кэша на сервере, хранящиегося на локальных SSD дисках
- Программная дедупликация и сжатие данных при минимальными затратами ресурсов CPU и памяти
- Возможность без простоя наращивать емкость и производительность сети хранения за счет добавления новых серверов и дисков
- Политики хранения виртуальных машин позволяют автоматизировать балансировку и выделение ресурсов хранения и QoS.
- Полная интеграция со стеком VMware, включая vMotion, DRS, высокую доступность (High Availability), отказоустойчивость (Fault Tolerance), Site Recovery Manager, vRealize Automation и vRealize Operations.
- Поддержка iSCSI подключений
Резюме
В итоге, я использую lvmcache в режиме write-through и раздел для кэша размером 60Gb. Немного пожертвовав ресурсами CPU и RAM хоста — вместо 210Gb очень быстрого и 1.3Tb медленного дискового пространства я получил 680Gb быстрого и 158Gb очень быстрого, при этом появилась отказоустойчивость (но при неожиданном выходе из строя диска придется поучаствовать в процессе доступа к данным).
Краш-тест
Отключение питания
После включения и загрузки хоста ВМ svm загрузилась с проверкой ФС (данные остались в кэше), на хосте примонтировался NFS датастор, далее загрузились остальные ВМ, проблем и потери данных не наблюдалось.
Выход из строя HDD (имитация)
Решил отключить питание SATA диска. К сожалению, горячая замена не поддерживается, необходимо аварийно выключать хост. Сразу после отключения диска появляется информация в Events.

Неприятным моментом оказалось, что при потере диска гипервизор просит для ВМ svm ответить на вопрос — «You may be able to hot remove this virtual device from the virtual machine and continue after clicking Retry. Click Cancel to terminate this session» — машина находится в состоянии фриза.
Если представить, что с диском была временная, незначительная проблема (например, причина в шлейфе), то после устранения проблемы и включения хоста все загружается в штатном режиме.
Выход из строя SSD
Наиболее неприятная ситуация — выход ssd из строя. Доступ к данным осуществляется в аварийном режиме. При замене ssd необходимо повторить процедуру настройки системы.
Аварийный доступ к данным
Один из дисков подключается к рабочей станции, далее необходимо «собрать» RAID, отключить кэш и получить доступ к данным, примонтировав LVM том:
Также я пробовал загрузить систему непосредственно с диска, настроил сеть и на другом хосте подключил NFS датастор — ВМ доступны.
Архитектура решения
Кластер VMware строится из 2-х или больше (минимум 2, максимум — 32) серверов ESXi, которые управляются с помощью VMware vCenter.
Для построения кластера нам также понадобится общее хранилище — система хранения данных (далее СХД). СХД может быть Fibre Channel, iSCSI или NFS-ресурс. На СХД хранится один или несколько разделов, в кластерной файловой системе VMFS, которые доступны для чтения и записи одновременно всем ESXi-серверам кластера. Разделы хранят на себе файлы виртуальных машин (виртуальные диски, файлы конфигурации и т.п.), которые также доступны всем серверам одновременно.
Именно за счет общего хранилища и независимости виртуальной машины от физической платформы, достигается быстрое перемещение/восстановление виртуальных машин.
Ниже несколько картинок от VMware для лучшего понимания.
Принцип работы VMware HA + DRS схематически:
vMotion:
И Fault Tolerance:
В данной статье рассматривается платформа vSphere от VMware, но у других производителей ПО, например, Citrix XenServer или Microsoft Hyper-V концепция практически такая же, за исключением нюансов в технологиях и возможностях, а также, разницы в цене решения.
С теорией вроде бы все, переходим к практике. В следующей статье расскажу с картинками об установке и начальному конфигурированию платформы для нашего кластера.

05.02.2020

itpro

VMWare

комментариев 17
VMware Virtual SAN (vSAN) это высокопроизводительное решение для хранения данных корпоративного класса для гиперконвергентной инфраструктуры. vSAN позволяет объединять SSD накопители и обычные диски, подключенные к локальным ESXi серверам, в общее высокоустойчивое хранилище данных, к которому могут обращаться все узлы кластера vSphere. Если ранее для обеспечения высокой доступности администраторам VMware нужно было использовать SAN, NAS или DAS, то в случае vSAN потребность в выделенном внешнем общем хранилища исключается, при этом добавляется новый программный уровень, который может использовать локальные диски отдельных локальных серверов для обеспечения такой же отказоустойчивости и набора функций SAN.
Поддержка vSAN встроена в ядро гипервизора, благодаря чему решения по выполнению операций ввода/вывода и перемещению данных принимаются максимально быстро (большинство других решений организации виртуальных сред хранения реализуется в виде отдельного аплайнса, работающего над гипервизором). В этой статье мы расскажем об основных особенностях VMware vSAN и покажем процесс развертывания и настройки vSAN 6.5.
Примечание. Аналогом vSAN у Microsoft является технология Storage Spaces Direct (S2D), появившаяся в Windows Server 2016.

VMware vSAN: системные требования
- Требуется VMware vCenter Server 6.5 и хосты с ESXi 6.5
- Минимум 3 хоста в кластере (максимум 64), однако можно реализовать vSAN и на двух хостах, но потребуется отдельный хост-свидетель
- Каждый сервера ESXi в кластере vSAN должен иметь как минимум один SSD диск (флешку) для кэша, и как минимум один SSD/HDD для данных
- Наличие SATA/SAS HBA или RAID-контроллера в режиме pass-through или в режиме RAID 0
- Минимум 1 ГБ сетевая карта (рекомендуется 10 Гб)
- Все хосты должны быть подключены к сети vSAN через сеть L2 или L3
- На физических коммутаторах, которые обрабатывают трафик vSAN должна быть включено многоадресное вещание (мультикаст)
- Поддерживаются как IPv4 так и IPv6.
- Информацию о совместимости с конкретным железом нужно смотреть в соответствующем документе на сайте VMware
Обслуживание (Замена диска)
Если с диском вот-вот случится беда (по результатам S.M.A.R.T.), для того чтобы заменить его на рабочий необходимо выполнить следующую процедуру (на ВМ svm):
В настройках ВМ нужно «оторвать» погибающий vHDD, затем заменить HDD на новый.
После чего подготовить RDM накопитель и добавить к ВМ svm:
Реализация VMware
Давайте посмотрим на доступные виды кластеров и на преимущества, которые они нам дают.
Реализация HA-кластера у VMware такова: несколько физических хостов объединяется в кластер и при выходе из строя одного из хостов, виртуальные машинки, которые были на нем, запускаются на других хостах кластера, на которых зарезервированы ресурсы. При этом время простоя виртуальной машины, равняется времени загрузки ее операционной системы.
Как видим, кластером высокой доступности VMware HA сложно назвать, т.к. при отказе оборудования мы все равно получаем небольшое время простоя. Для избежания этого простоя, совместно с VMware HA обычно используют кластеризацию самого приложения (напр. MS Exchange кластер, или MS SQL кластер).
Что бы сократить время простоя сервиса (виртуалки) до нуля (или времени очень близкому к нулю), можно также использовать технологию VMware Fault Tolerance. Фишка ее заключается в том, что при работе виртуальной машины на одном физическом хосте, ее «призрак» (синхронная реплика) работает на другом хосте кластера и при выходе из строя основного хоста (и соответственно виртуальной машины) происходит мгновенное переключение ввода-вывода и активизация призрака. При этом время простоя виртуальной машины равняется нулю, как говорит маркетинг VMware, в реальности все немного не так (на практике замечаются небольшие подтормаживания 1-2 сек и потеря одного «пинга»).
Надо признать, что Fault Tolerance на практике используется очень редко из-за своих достаточно серьезных ограничений и требований, но зато в качестве маркетинговой фичи упоминается при любой малейшей возможности :)
Итак, с высокой доступностью разобрались. Теперь посмотрим что же собой представляет DRS.
Если не вдаваться в подробности, то VMware DRS — достаточно простая штука, которая выбирает на каком физическом хосте запустить виртуальную машину, или на какой хост смигрировать работающую виртуалку, с целью выровнять нагрузку на всех хостах кластера.
DRS объединяет ресурсы кластера в один большой пул и в полу-автоматическом или полностью автоматизированном режиме распределяет виртуальные машины равномерным слоем по физическим хостам кластера.
DRS имеет пару штук настроек и может либо выдвигать рекомендации по запуску, или перемещению виртуальных машин на серверах кластера, либо автоматически мигрировать виртуалки с помощью технологии vMotion в зависимости от текущей нагрузки.
Нужно упомянуть о том, что VMware DRS как в принципе и HA, это не всегда полезно и круто. У данных технологий есть свои нюансы, которые стоит учитывать при разработке проекта.
Настройка сети и портов vSAN
Перед настройкой vSAN нужно убедится, что на каждом хосте кластере настроен порт VMkernel для трафика vSAN. В веб-клиенте vSphere по очереди выберите каждый сервер, на котором вы хотите использовать vSAN. Выберите вкладку Configure-> Networking -> VMKernel Adapters -> нажмите Add Host Networking. Убедитесь, что выбран тип VMkernel Network Adapter и нажмите Далее.

Создайте новый виртуальный коммутатор (New standard switch) и нажмите Next.

С помощью зеленого значка плюса привяжите физические адаптеры к коммутатору. В продуктивных средах желательно обеспечить дополнительное резервирование за счет использования несколько физических NIC.

Укажите имя порта VMkernel и, если нужно, его VLAN ID. Обязательно поставьте галку напротив опции Virtual SAN и нажмите Next.

Укажите сетевые параметры порта VMkernel.

Если вы настраиваете сеть vSAN на тестовом стенде с ограниченным количеством физических интерфейсов, выберите сеть управления (Management Network) и в списке поддерживаемых служб поставьте галку у пункта Virtual SAN. При такой конфигурации трафик vSAN будет идти через общую сеть управления, чего в продуктивных развертываниях делать не стоит.
Концепция
Для начала разберемся, что мы называем кластером. В разрезе VMware, кластер — это группа хостов (физических серверов), связанных между собой сетью, которые управляются единым сервисом и совместно выполняют определенные функции, как один большой организм.
На платформе от VMware — vSphere можно построить 2 вида кластеров: HA (High-availability) кластер и DRS (Distributed Resource Scheduler) кластер, которые работают на уровне виртуальной машины.
HPC (High-performance computing) кластер, в котором вычислительные мощности всех физических хостов объединяются в одну и все это дело работает как один большой компутер да еще и производит мега-супер-пупер крутые параллельные вычисления, на VMware построить не получится!
Концепция
Для начала разберемся, что мы называем кластером. В разрезе VMware, кластер — это группа хостов (физических серверов), связанных между собой сетью, которые управляются единым сервисом и совместно выполняют определенные функции, как один большой организм.
На платформе от VMware — vSphere можно построить 2 вида кластеров: HA (High-availability) кластер и DRS (Distributed Resource Scheduler) кластер, которые работают на уровне виртуальной машины.
HPC (High-performance computing) кластер, в котором вычислительные мощности всех физических хостов объединяются в одну и все это дело работает как один большой компутер да еще и производит мега-супер-пупер крутые параллельные вычисления, на VMware построить не получится!
Лицензирование VMware vSAN
vSAN лицензируется в расчете по CPU, виртуальным машинам или конкурентным пользователю и поставляется в трех редакциях: Standard, Advanced и Enterprise.
- Enterprise лицензия – требуется для использования QoS и растянутых кластеров
- Advanced лицензия нужна для поддержки дедубликации, сжатия и RAID 5/6
- Standard – базовый функционал
Лицензия vSAN можно использовать на любой версии vSphere 6.5.
Есть дополнительные способы сэкономить за счет использовании пакета Virtual SAN для ROBO, или приобретения набора лицензий Standard илиAdvanced в количестве 25 штук для удаленных филиалов. Более подробную информацию о лицензировании vSAN смотрите на сайте VMware.
lvmcache

lvmcache обеспечивает прозрачное кэширование данных медленных устройств HDD на быстрых устройствах SSD. LVM cache размещает наиболее часто используемые блоки на быстром устройстве. Включение и выключение кэширования можно производить, не прерывая работы.
При попытке чтения данных выясняется, имеются ли эти данные в кэше. Если требуемых данных там нет, то чтение происходит с HDD, и попутно данные записываются в кэш (cache miss). Дальнейшее чтение данных будет происходить из кэша (cache hit).
Запись
— Режим write-through — когда происходит операция записи, данные записываются и в кэш, и на HDD диск, более безопасный вариант, вероятность потери данных при аварии мала;
— Режим write-back — когда происходит операция записи, данные записываются сначала в кэш, после чего сбрасываются на диск, имеется вероятность потери данных при аварии. (Более быстрый вариант, т.к. сигнал о завершении операции записи передается управляющей ОС после получения данных кэшем).
Так выглядит сброс данных из кэша (write-back) на диски:

Производительность
Производительность измерялась синтетическим тестом (для сравнения, я снял показания с кластера на работе (в ночное время)).
Используемое ПО на тестовой ВМ:
— ОС CentOS 7.3.1611 (8 vCPU, 12Gb vRAM, 100Gb vHDD)
— fio v2.2.8
Полученные результаты представлены в таблицах (* во время тестов отмечал среднюю загрузку ЦП на ВМ svm):
| Тип диска | FIO depth 1 (iops) | FIO depth 24 (iops) | ||
|---|---|---|---|---|
| randread | randwrite | randread | randwrite | |
| HDD | 77 | 99 | 169 | 100 |
| SSD | 5639 | 17039 | 40868 | 53670 |
| SSD Cache | FIO depth 1 (iops) | FIO depth 24 (iops) | CPU/Ready* % | ||
|---|---|---|---|---|---|
| randread | randwrite | randread | randwrite | ||
| Off | 103 | 97 | 279 | 102 | 2.7/0.15 |
| On | 1390 | 722 | 6474 | 576 | 15/0.1 |
| Тип диска | FIO depth 1 (iops) | FIO depth 24 (iops) | ||
|---|---|---|---|---|
| randread | randwrite | randread | randwrite | |
| 900Gb 10k (6D+2P) | 122 | 1085 | 2114 | 1107 |
| 4Tb 7.2k (8D+2P) | 68 | 489 | 1643 | 480 |
Результаты, которые можно потрогать руками, получились при одновременном запуске пяти ВМ с Windows 7 и офисным пакетом (MS Office 2013 Pro + Visio + Project) в автозагрузке. По мере нагревания кэша, ВМ грузились быстрее, при этом HDD практически не участвовал в загрузке. При каждом запуске отмечал время полной загрузки одной из пяти ВМ и полной загрузки всех ВМ.
| № | Datastore | Первый запуск | Второй запуск | Третий запуск | |||
|---|---|---|---|---|---|---|---|
| Время загрузки первой ВМ | Время загрузки всех ВМ | Время загрузки первой ВМ | Время загрузки всех ВМ | Время загрузки первой ВМ | Время загрузки всех ВМ | ||
| 1 | HDD VMFS6 | 4мин. 8сек. | 6мин. 28сек. | 3мин. 56сек. | 6мин. 23сек. | 3мин. 40сек. | 5мин. 50сек. |
| 2 | NFS (SSD Cache Off) | 2мин. 20сек. | 3мин. 2сек. | 2мин. 34сек. | 3мин. 2сек. | 2мин. 34сек. | 2мин. 57сек. |
| 3 | NFS (SSD Cache On) | 2мин. 33сек. | 2мин. 50сек. | 1мин. 23сек. | 1мин. 51сек. | 1мин. 0сек. | 1мин. 13сек. |
Время загрузки одиночной ВМ составило:
— HDD VMFS6 - 50 секунд
— NFS с выключенным кэшем - 35 секунд
— NFS с включенным и нагретым кэшем - 26 секунд

Настройка vSAN
Как мы уже говорили, для настройки vSAN дополнительно доставлять что+то на гипервизор не нужно, весь функционал уже имеется. Вся что требуется от администратора – настроить vSAN через интерфейс веб клиента vSphere (vSAN пока не поддерживает модный HTML5 клиент).
Чтобы включить vSAN найдите нужный кластер в консоли vSphere и перейдите на вкладку Configure. Разверните раздел Virtual SAN и выберите General. В нем должно быть указано, что Virtual SAN не включен. Нажмите на кнопку Configure.

По умолчанию в хранилище vSAN будут добавлены любые подходящие диски. Чтобы вручную выбрать диски, измените параметр назначения дисков на Manual. Здесь же можно включить опцию сжатия данных, отказоустойчивости.

На странице валидации сети должны появится подтверждения о том, что каждый хост в кластере подключен к сети vSAN.

Проверьте выбранные настройки и нажмите Finish. Дождитесь окончания выполнения задачи, после чего виртуальная сеть SAN объединит все локальные диски серверов выбранного кластера в распределенное хранилище vSAN. Данное хранилище представляет собой один единый VMFS датастор, на который вы сразу же можете поместить виртуальные машины. Настройки vSAN в дальнейшем можно будет изменить в том же разделе (вкладка кластера Configure -> Virtual SAN).
В данной статье хочу рассказать о том, как немного повысить производительность хоста ESXi с помощью SSD кэширования. На работе и дома я использую продукты от компании VMware, домашняя лаборатория построена на базе Free ESXi 6.5. На хосте запущены виртуальные машины как для домашней инфраструктуры, так и для тестирования некоторых рабочих проектов (как-то мне пришлось запустить на нем инфраструктуру VDI). Постепенно приложения толстых ВМ начали упираться в производительность дисковой системы, а на SDD все не помещалось. В качестве решения был выбран lvmcache. Логическая схема выглядит так:

Основой всей схемы является ВМ svm на базе CentOS 7. Ей презентованы HDD диски средствами RDM и небольшой диск VMDK с датастора SSD. Кэширование и зеркалирование данных реализуются программными средствами — mdadm и lvmcache. Дисковое пространство ВМ монтируется к хосту как NFS датастор. Часть датастора SSD отведена ВМ, которым требуется производительная дисковая подсистема.
Вычислительный узел собран на десктопном железе:
MB: Gygabyte GA-Z68MX-UD2H-B3 (rev. 1.0)
HDD: 2 x Seagate Barracuda 750Gb, 7200 rpm
SSH: OCZ Vertex 3 240Gb
На материнской плате имеется 2 RAID контроллера:
— Intel Z68 SATA Controller
— Marvell 88SE9172 SATA Controller
Завести 88SE9172 в ESXi у меня не получилось (There is a bug in the firmware of some Marvell adapters (at least 88SE91xx)), решил оставить оба контроллера в режиме ACHI.
Технология RDM (Raw Device Mapping) позволяет виртуальной машине обращаться напрямую к физическому накопителю. Связь обеспечивается через специальные файлы «mapping file» на отдельном томе VMFS. RDM использует два режима совместимости:
— Виртуальный режим — работает так же, как и в случае с файлом виртуального диска, позволяет использовать преимущества виртуального диска в VMFS (механизм блокировки файлов, мгновенные снэпшоты);
— Физический режим — предоставляет прямой доступ к устройству для приложений, которые требуют более низкого уровня управления.
В виртуальном режиме на физическое устройство отправляются операции чтения\записи. RDM устройство представлено в гостевой ОС как файл виртуального диска, аппаратные характеристики скрыты.
В физическом режиме на устройство передаются практически все команды SCSI, в гостевой ОС устройство представлено как реальное.
Подключив дисковые накопители к ВМ средствами RDM, можно избавиться от прослойки VMFS, а в физическом режиме совместимости их состояние можно будет мониторить в ВМ (с помощью технологии S.M.A.R.T.). К тому же, если что-то случится с хостом, то получить доступ к ВМ можно, примонтировав HDD к рабочей системе.
Настройка системы
На хосте создается SSD датастор. Я выбрал такую схему использования доступного пространства:
220Gb — DATASTORE_SSD
149Gb — Отведено для особых ВМ
61Gb — Том для кэша и метаданных
10Gb — Host Swap Cache
Виртуальная сеть выглядит следующим образом:

Создан новый vSwitch:
Networking → Virtual Switches → Add standart virtual switch — указываем желаемое имя виртуального свитча (svm_vSwitch, в названиях я использую префикс svm_), остальное оставляем как есть.
К нему через порт группу подключается VMkernel NIC:
Networking → VMkernel NICs → Add VMkernel NIC
— Port group — New Port group
— New port group — Имя порт группы — svm_PG
— Virtual switch — svm_vSwitch
— IPv4 settings — Configuration — Static — указываем IP и маску сети
Создана порт группа, к которой будет подключена ВМ svm:
Networking → Port Groups → Add port group — указываем имя (svm_Network) и свитч svm_vSwitch
Подготовка дисков
Необходимо зайти на хост по ssh и выполнить следующие команды:
Подготовка ВМ
Теперь эти диски можно подключить (Existing hard disk) к новой ВМ. Шаблон CentOS 7, 1vCPU, 1024Gb RAM, 2 RDM disk, 61Gb ssd disk, 2 vNIC (порт группы VM Network, svm_Network) – во время установки ОС используем Device Type – LVM, RAID Level — RAID1
Настройка NFS сервера довольно проста:
Подготавливаем тома кэша и метаданных для включения кэширования тома cl_svm/data:
Уведомления о изменении состояния массива:
Чтобы изменения вступили в силу, нужно перезапустить службу mdmonitor:
Почта с ВМ отправляется средствами ssmtp. Так как я использую RDM в режиме виртуальной совместимости, то проверять состояние дисков будет сам хост.
Подготовка хоста
Добавляем NFS датастор в ESXi:
Настройка автозапуска ВМ:
Host → Manage → System → Autostart → Edit Settings
Enabled — Yes
Start delay — 180sec
Stop delay — 120sec
Stop action — Shut down
Wait for heartbeat — No
Virtual Machines → svm → Autostart → Increase Priority
(Автозапуск не сработал, пришлось удалить ВМ из Inventory и добавить заново)
Данная политика позволит ВМ svm запуститься первой, гипервизор примонтирует NFS датастор, после этого будут включаться остальные машины. Выключение происходит в обратном порядке. Время задержки запуска ВМ подобрано по итогам краш-теста, т. к. при малом значении Start delay NFS датастор не успевал примонтироваться, и хост пытался запустить ВМ, которые еще недоступны. Также можно поиграться параметром NFS.HeartbeatFrequency .
Более гибко автостарт ВМ можно настроить с помощью командной строки:
Небольшая оптимизация
Включить Jumbo Frames на хосте:
Jumbo Frames: Networking → Virtual Switches → svm_vSwitch указать MTU 9000;
Networking → Vmkernel NICs → vmk1 указать MTU 9000
В Advanced Settings установить следующие значения:
NFS.HeartbeatFrequency = 12
NFS.HeartbeatTimeout = 5
NFS.HeartbeatMaxFailures = 10
Net.TcpipHeapSize = 32 (было 0)
Net.TcpipHeapMax = 512
NFS.MaxVolumes = 256
NFS.MaxQueueDepth = 64 (было 4294967295)
Включить Jumbo Frames на ВМ svm:
Читайте также: