
Что такое ассоциативность кэша
Разработчики кэш-памяти столкнулись с проблемой, состоящей в том, что потенциально в кэш-памяти может оказаться любая ячейка огромной основной памяти. Если рабочий набор данных, используемых в программе, достаточно большой, то это означает, что за каждое место в кэш-памяти будут соревноваться многие фрагменты основной памяти. Как ранее уже сообщалось, нередко соотношение между кэш-памятью и основной памятью составляет 1 к 1000.
Что такое кэш?
TL;DR: это небольшая, но очень быстрая память, расположенная в непосредственной близости от логических блоков центрального процессора.
Однако мы, разумеется, можем узнать о кэше гораздо больше…
Давайте начнём с воображаемой волшебной системы хранения: она бесконечно быстра, может одновременно обрабатывать бесконечное количество операций передачи данных и всегда обеспечивает надёжное и безопасное хранение данных. Конечно же, ничего подобного и близко не существует, однако если бы это было так, то структура процессора была бы гораздо проще.
Процессорам бы тогда требовались только логические блоки для сложения, умножения и т.п, а также система управления передачей данных, ведь наша теоретическая система хранения способна мгновенно передавать и получать все необходимые числа; ни одному из логических блоков не приходится простаивать в ожидании передачи данных.
Но, как мы знаем, такой волшебной технологии хранения не существует. Вместо неё у нас есть жёсткие диски или твердотельные накопители, и даже самые лучшие из них далеки от возможностей обработки, необходимых для современного процессора.

Великий Т'Фон хранения данных
Причина этого заключается в том, что современные процессоры невероятно быстры — им требуется всего один тактовый цикл для сложения двух 64-битных целочисленных значений; если процессор работает с частотой 4 ГГЦ, то это составляет всего 0,00000000025 секунды, или четверть наносекунды.
В то же время, вращающемуся жёсткому диску требуются тысячи наносекунд только для нахождения данных на дисках, не говоря уже об их передаче, а твердотельным накопителям — десятки или сотни наносекунд.
Очевидно, что такие приводы невозможно встроить внутрь процессоров, поэтому между ними будет присутствовать физическое разделение. Поэтому ещё добавляется время на перемещение данных, что усугубляет ситуацию.

Увы, но это Великий А'Туин хранения данных
Именно поэтому нам нужна ещё одна система хранения данных, расположенная между процессором и основным накопителем. Она должна быть быстрее накопителя, способна одновременно управлять множеством операций передачи данных и находиться намного ближе к процессору.
Ну, у нас уже есть такая система, и она называется ОЗУ (RAM); она присутствует в каждом компьютере и выполняет именно эту задачу.
Почти все такие хранилища имеют тип DRAM (dynamic random access memory); они способны передавать данные гораздо быстрее, чем любой накопитель.

Однако, несмотря на свою огромную скорость, DRAM не способна хранить такие объёмы данных.
Одни из самых крупных чипов памяти DDR4, разработанных Micron, хранят 32 Гбит, или 4 ГБ данных; самые крупные жёсткие диски хранят в 4 000 раз больше.
Итак, хоть мы и повысили скорость нашей сети данных, нам потребуются дополнительные системы (аппаратные и программные), чтобы разобраться, какие данные должны храниться в ограниченном объёме DRAM, готовые к обработке процессором.
DRAM могут изготавливаться в корпусе чипа (это называется встроенной (embedded) DRAM). Однако процессоры довольно малы, поэтому в них не удастся поместить много памяти.

10 МБ DRAM слева от графического процессора Xbox 360. Источник: CPU Grave Yard
Подавляющее большинство DRAM расположено в непосредственной близости от процессора, подключено к материнской плате и всегда является самым близким к процессору компонентом. Тем не менее, эта память всё равно недостаточно быстра…
DRAM требуется примерно 100 наносекунд для нахождения данных, но, по крайней мере, она способна передавать миллиарды битов в секунду. Похоже, нам нужна ещё одна ступень памяти, которую можно разместить между блоками процессора и DRAM.
На сцене появляется оставшаяся ступень: SRAM (static random access memory). DRAM использует микроскопические конденсаторы для хранения данных в виде электрического заряда, а SRAM для той же задачи применяет транзисторы, которые работают с той же скоростью, что и логические блоки процессора (примерно в 10 раз быстрее, чем DRAM).

Разумеется, у SRAM есть недостаток, и он опять-таки связан с пространством.
Память на основе транзисторов занимает гораздо больше места, чем DRAM: в том же размере, что чип DDR4 на 4 ГБ, можно получить меньше 100 МБ SRAM. Но поскольку она производится по тому же технологическому процессу, что и CPU, память SRAM можно встроить прямо внутрь процессора, максимально близко к логическим блокам.
С каждой дополнительной ступенью мы увеличивали скорость перемещаемых данных ценой хранимого объёма. Мы можем продолжить и добавлять новые ступени,, которые будут быстрее, но меньше.
И так мы добрались до более строгого определения понятия кэша: это набор блоков SRAM, расположенных внутри процессора; они обеспечивают максимальную занятость процессора благодаря передаче и сохранению данных с очень высокими скоростями. Вас устраивает такое определение? Отлично, потому что дальше всё будет намного сложнее!
Компоненты ПК
Самое читаемое
- Арифметико логическое устройство (АЛУ)
- Страничный механизм в процессорах 386+. Механизм трансляции страниц
- Организация разделов на диске
- Диск Picture CD
- White Book/Super Video CD
- Прямой доступ к памяти, эмуляция ISA DMA (PC/PCI, DDMA)
- Карты PCMCIA: интерфейсы PC Card, CardBus
- Таблица дескрипторов прерываний
- Разъемы процессоров
- Интерфейс Slot A
Полностью ассоциативный КЭШ
Схема полностью ассоциативного КЭШа представлена на рисунке (см. рисунок ниже).
Опишем алгоритм работы системы с КЭШ-памятью. В начале работы КЭШ-память пуста. При выполнении первой же команды во время выборки ее код, а также еще несколько соседних байтов программного кода, — будут перенесены (медленно) в одну из строк КЭШа, и одновременно старшая часть адреса будет записана в соответствующий тег. Так происходит заполнение КЭШ-строки.
Если следующие выборки возможны из этого участка, они будут сделаны уже из КЭШа (быстро) — "КЭШ-попадание". Если же окажется, что нужного элемента в КЭШе нет, — "КЭШ-промахом". В этом случае обращение происходит к ОЗУ (медленно), и при этом одновременно заполняется очередная КЭШ-строка.
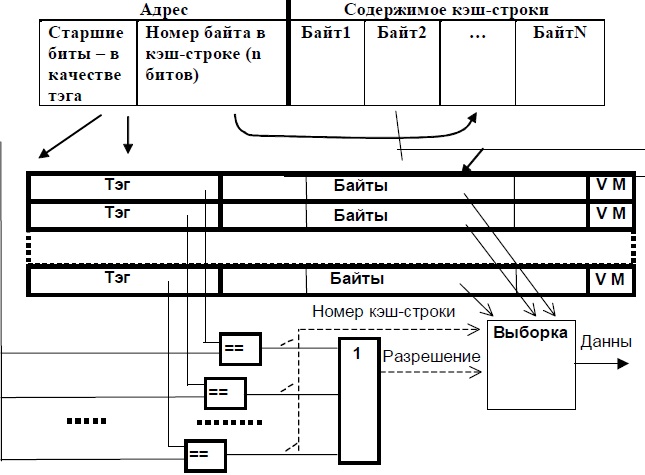
Схема полностью ассоциативной КЭШ-памяти
Обращение к КЭШу происходит следующим образом. После формирования исполнительного адреса его старшие биты, образующие тег, аппаратно (быстро) и одновременно сравниваются с тегами всех КЭШ-строк. При этом возможны только две ситуации из трех, перечисленных ранее: либо все сравнения дадут отрицательный результат (КЭШ-промах), либо положительный результат сравнения будет зафиксирован в точности для одной строки (КЭШ-попадание).
При считывании, если зафиксировано КЭШ-попадание, младшие разряды адреса определяют позицию в КЭШ-строке, начиная с которой следует выбирать байты, а тип операции определяет количество байтов. Очевидно, что если длина элемента данных превышает один байт, то возможны ситуации, когда этот элемент (частями) расположен в двух (или более) разных КЭШ-строках, тогда время на выборку такого элемента увеличится. Противодействовать этому можно, выравнивая операнды и команды по границам КЭШ-строк, что и учитывают при разработке оптимизирующих трансляторов или при ручной оптимизации кода.
Если произошел КЭШ-промах, а в КЭШе нет свободных строк, необходимо заменить одну строку КЭШа на другую строку.
Основная цель стратегии замещения — удерживать в КЭШ-памяти строки, к которым наиболее вероятны обращения в ближайшем будущем, и заменять строки, доступ к которым произойдет в более отдаленном времени или вообще не случится. Очевидно, что оптимальным будет алгоритм, который замещает ту строку, обращение к которой в будущем произойдет позже, чем к любой другой строке-КЭШ.
К сожалению, такое предсказание практически нереализуемо, и приходится привлекать алгоритмы, уступающие оптимальному. Вне зависимости от используемого алгоритма замещения, для достижения высокой скорости он должен быть реализован аппаратными средствами.
Среди множества возможных алгоритмов замещения наиболее распространенными являются четыре, рассматриваемые в порядке уменьшения их относительной эффективности. Любой из них может быть применен в полностью ассоциативном КЭШ.
Наиболее эффективным является алгоритм замещения на основе наиболее давнего использования ( LRU — Least Recently Used ), при котором замещается та строка КЭШ-памяти, к которой дольше всего не было обращения. Проводившиеся исследования показали, что алгоритм LRU, который "смотрит" назад, работает достаточно хорошо в сравнении с оптимальным алгоритмом, "смотрящим" вперед.
Наиболее известны два способа аппаратурной реализации этого алгоритма. В первом из них с каждой строкой КЭШ-памяти ассоциируют счетчик. К содержимому всех счетчиков через определенные интервалы времени добавляется единица. При обращении к строке ее счетчик обнуляется. Таким образом, наибольшее число будет в счетчике той строки, к которой дольше всего не было обращений и эта строка — первый кандидат на замещение.
Второй способ реализуется с помощью очереди, куда в порядке заполнения строк КЭШ-памяти заносятся ссылки на эти строки. При каждом обращении к строке ссылка на нее перемещается в конец очереди. В итоге первой в очереди каждый раз оказывается ссылка на строку, к которой дольше всего не было обращений. Именно эта строка прежде всего и заменяется.
Другой возможный алгоритм замещения — алгоритм, работающий по принципу "первый вошел, первый вышел" ( FIFO — First In First Out ). Здесь заменяется строка, дольше всего находившаяся в КЭШ-памяти. Алгоритм легко реализуется с помощью рассмотренной ранее очереди, с той лишь разницей, что после обращения к строке положение соответствующей ссылки в очереди не меняется.
Еще один алгоритм — замена наименее часто использовавшейся строки (LFU — Least Frequently Used). Заменяется та строка в КЭШ-памяти, к которой было меньше всего обращений. Принцип можно воплотить на практике, связав каждую строку со счетчиком обращений, к содержимому которого после каждого обращения добавляется единица. Главным претендентом на замещение является строка, счетчик которой содержит наименьшее число.
Простейший алгоритм — произвольный выбор строки для замены. Замещаемая строка выбирается случайным образом. Реализовано это может быть, например, с помощью счетчика, содержимое которого увеличивается на единицу с каждым тактовым импульсом, вне зависимости от того, имело место попадание или промах. Значение в счетчике определяет заменяемую строку.
Кроме тега и байтов данных в КЭШ-строке могут содержаться дополнительные служебные поля, среди которых в первую очередь следует отметить бит достоверности V (от valid — действительный имеющий силу) и бит модификации M (от modify — изменять, модифицировать). При заполнении очередной КЭШ-строки V устанавливается в состояние "достоверно", а M — в состояние "не модифицировано". В случае, если в ходе выполнения программы содержимое данной строки было изменено, переключается бит M, сигнализируя о том, что при замене данной строки ее содержимое следует переписать в ОЗУ. Если по каким-либо причинам произошло изменение копии элемента данной строки, хранимого в другом месте (например в ОЗУ), переключается бит V. При обращении к такой строке будет зафиксирован КЭШ-промах (несмотря на то, что тег совпадает), и обращение произойдет к основному ОЗУ. Кроме того, служебное поле может содержать биты, поддерживающие алгоритм LRU.
3.3.1 Ассоциативность
Можно было бы реализовать кэш-память, в которой каждая кэш-строка может хранить копию любой ячейки памяти. Это называется полностью ассоциативной кэш-памятью (fully associative cache). Чтобы получить доступ к кэш-строке, ядро процессора должно было бы сравнить теги всех до единой кэш-строк с тегом запрашиваемого адреса. Тег должен будет хранить весь адрес, который не будет указываться смещение в кэш-строке (это означает, что значение S, показанное на рисунке в разделе 3.2, будет равно нулю).
Есть кэш-память, которая реализована подобным образом, но взглянуть на размеры кэш-памяти L2, используемой в настоящее время, то видно, что это непрактично. Учтите, что 4 Мб кэш-памяти с кэш-строками размером в 64Б должна иметь 65 536 записей. Чтобы получить адекватную производительность, логические схемы кэш-памяти должны быть в состоянии в течение нескольких циклов выбрать из всех этих записей ту, которая соответствует заданному тегу. Затраты на реализацию такой схемы будут огромными.

Рис.3.5: Схематическое изображение полностью ассоциативной кэш-памяти
Для каждой кэш-строки требуется, чтобы компаратор выполнил сравнение тега большого размера (заметьте, S равно нулю). Буква, стоящая рядом с каждым соединением, обозначает ширину соединения в битах. Если ничего не указано, то ширина соединения равна одному биту. Каждый компаратор должен сравнивать два значения, ширина каждого из которых равна Т бит. Затем, исходя из результата, должно выбираться и стать доступным содержимое соответствующей кэш-строки. Для этого потребуется объединить столько наборов линий данных О, сколько есть сегментов кэш-памяти (cache buckets). Число транзисторов, необходимых для реализации одного компаратора будет большим в частности из-за того, что компаратор должен работать очень быстро. Итеративный компаратор использовать нельзя. Единственный способ сэкономить на количестве компараторов, это снизить их число с помощью итеративного сравнения тегов. Это не подходит по той же самой причине, по которой не подходят итеративные компараторы: на это потребуется слишком много времени.
Полностью ассоциативная кэш-память практична для кэш-памяти малого размера (например, кэш-память TLB в некоторых процессорах Intel является полностью ассоциативной), но эта кэш-память должна быть небольшой - действительно небольшой. Речь идет максимум о нескольких десятках записей.
Для кэш-памяти L1i, L1d и кэш-памяти более высокого уровня необходим другой подход. Все, что можно сделать, это ограничить поиск. В самом крайнем случае каждый тег отображается точно в одну кэш-запись. Расчет прост: для кэш-памяти 4MB/64B с 65 536 записями мы можем напрямую обращаться к каждому элементу и использовать для этого с 6-го по 21-й биты адреса (16 битов). Младшие 6 битов являются индексом кэш-строки.

Рис.3.6: Схематическое изображение кэш-памяти с прямым отображением
Как видно из рисунка 3.6 реализация такой кэш-памяти с прямым отображением (direct-mapped cache) может быть быстрой и простой. Для нее требуется только один компаратор, один мультиплексор (на этой схеме приведены два, поскольку тег и данные разделены, но это не является строгим конструктивным требованием) и некоторая логическая схема для выбора контента, содержащего действительно допустимые кэш-строки. Компаратор сложный из-за требований, касающихся скорости, но теперь он только один; в результате можно потратить больше усилий, чтобы сделать его более быстрым. Реальная сложность такого подхода заключена в мультиплексорах. Количество транзисторов в простом мультиплексоре растет по закону O(log N), где N является количеством кэш-строк. Это приемлемо, но может получиться медленный мультиплексор, и в этом случае скорость можно увеличить, если потратиться на транзисторы в мультиплексорах и для увеличения скорости распараллелить часть работы. Общее количество транзисторов будет расти медленное в сравнении с ростом размера кэш-памяти, что делает это решение очень привлекательным. Но у такого подхода есть недостаток: он работает только в случае, если адреса, используемые в программе, равномерно распределены относительно битов, используемых для прямого отображения. Если это не так, и это обычно бывает, некоторые кэш-записи используются активно и, поэтому, неоднократно высвобождаются, в то время как другие практически вообще не используются, либо остаются пустыми.

Рис.3.7: Схематическое изображение кэш-памяти с множественной ассоциативностью
Эту проблему можно решить с помощью кэш-памяти с множественной ассоциативностью (set associative). Кэш-память с множественностью ассоциативностью сочетает в себе черты кэш-памяти с полной ассоциативностью и кэш-памяти с прямым отображением, что позволяет в значительной степени избежать недостатков этих решений. На рис.3.7 показана схема кэш-памяти с множественной ассоциативностью. Память под теги и под данные разделена на наборы, выбор которых осуществляется в соответствие с адресом. Это похоже на кэш-память с прямым отображением. Но вместо того, чтобы для каждого значения из набора использовать отдельный элемент, один и тот же набор используется для кэширования некоторого небольшого количества значений. Теги для всех элементов набора сравниваются параллельно, что похоже на функционирование полностью ассоциативной кэш-памяти.
Результатом является кэш-память, которая достаточно устойчива к промахам из-за неудачного или преднамеренного выбора адресов с одними и теми же номерами наборов в одно и то же время, а размер кэш-памяти не ограничен количеством компараторов, которые могут работать параллельно. Если кэш-память увеличивается (смотрите рисунок), то увеличивается только количество столбцов, а не количество строк. Число строк увеличивается только в том случае, если повышается ассоциативность кэш-памяти. Сегодня процессоры для кэш-памяти L2 используют уровни ассоциативности до 16 и выше. Для кэш-памяти L1 обычно используется уровень, равный 8.
Таблица 3.1: Влияние размера кэш-памяти, ассоциативности и размера кэш-строки
| Размер кэш-памяти L2 | Ассоциативность | |||||||
|---|---|---|---|---|---|---|---|---|
| Прямое отображение | 2 | 4 | 8 | |||||
| CL=32 | CL=64 | CL=32 | CL=64 | CL=32 | CL=64 | CL=32 | CL=64 | |
| 512k | 27 794 595 | 20 422 527 | 25 222 611 | 18 303 581 | 24 096 510 | 17 356 121 | 23 666 929 | 17 029 334 |
| 1M | 19 007 315 | 13 903 854 | 16 566 738 | 12 127 174 | 15 537 500 | 11 436 705 | 15 162 895 | 11 233 896 |
| 2M | 12 230 962 | 8 801 403 | 9 081 881 | 6 491 011 | 7 878 601 | 5 675 181 | 7 391 389 | 5 382 064 |
| 4M | 7 749 986 | 5 427 836 | 4 736 187 | 3 159 507 | 3 788 122 | 2 418 898 | 3 430 713 | 2 125 103 |
| 8M | 4 731 904 | 3 209 693 | 2 690 498 | 1 602 957 | 2 207 655 | 1 228 190 | 2 111 075 | 1 155 847 |
| 16M | 2 620 587 | 1 528 592 | 1 958 293 | 1 089 580 | 1 704 878 | 883 530 | 1 671 541 | 862 324 |
В таблице 3.1 показано количество промахов кэш-памяти L2 для некоторой программы (в данном случае — для компилятора gcc, который, по мнению разработчиков ядра Linux, является наиболее важным бенчмарком) при изменении размера кэш-памяти, размера кэш-строки, а также значения множественной ассоциативности. В разделе 7.2 мы познакомимся с инструментальным средством, предназначенным для моделирования кэш-памяти, которое необходимо для этого теста.
Просто, если это еще не очевидно, взаимосвязь всех этих значений в том, что размер кэш-памяти равен
размер кэш-строки х ассоциативность х количество множеств
Отображение адресов в кэш-память вычисляется как
O = log2 от размера кэш-строки
S = log2 от числа наборов
согласно рисунку в разделе 3.2.

Рис.3.8: Размер кэш-памяти и уровень ассоциативности (CL=32)
Рис. 3.8 делает данные таблицы более понятными. На рисунке приведены данные для кэш-строки фиксированного размера, равного 32 байта. Если посмотреть на цифры для заданного размера кэш-памяти, то видно, что ассоциативность действительно может существенно помочь сократить число промахов кэш-памяти. Для кэш-памяти размером 8 МБ при переходе от прямого отображения на кэш-память с 2-канальной ассоциативностью экономится почти 44% кэш-памяти. В случае, если используется кэш-память со множественной ассоциативностью, то процессор может хранить в кэш-памяти рабочий набор большего размера, чем в случае кэш-памяти с прямым отображением.
В литературе иногда можно прочитать, что введение ассоциативности имеет тот же самый эффект, как удвоение размера кэш-памяти. Это, как это видно для случая перехода от кэш-памяти размером 4 МБ к кэш-памяти размером 8 МБ, верно в некоторых крайних случаях. Но это, конечно, не верно при последующем увеличении ассоциативности. Как видно из данных, последующее увеличение ассоциативности дает существенно меньший выигрыш. Нам, однако, не следует абсолютно не учитывать этот факт. В программе нашего примера пик использования памяти равен 5,6 MB. Так что при размере кэш-памяти в 8 Мб, что те же самые кэш-наборы будут использоваться многократно (более, чем дважды). С увеличением рабочего набора экономия может увеличиться, поскольку, как мы видим, при меньших размерах кэш-памяти преимущество от использования ассоциативности будет больше.
В целом, увеличение ассоциативность кэш-памяти выше 8, как кажется, дает слабый эффект при одном потоке рабочей нагрузки. С появлением многоядерных процессоров, которые используют общую кэш-память L2, ситуация меняется. Теперь у вас в основном есть две программы, которые обращаются к одной и той же кэш-памяти, в результате чего на практике эффект от использования ассоциативности должен увеличиться вдвое (или в четыре раза для четырехядерных процессоров). Таким образом, можно ожидать, что с увеличением числа ядер, ассоциативность общей кэш-памяти должна расти. Как это станет делать невозможным (16-канальную ассоциативность реализовывать уже трудно) разработчики процессоров начнут использовать общую кэш-память уровня L3 и далее, в то время как кэш-память уровня L2 будет, потенциально, совместно использоваться некоторым подмножеством ядер.
Другой эффект, который мы можем увидеть на рис.3.8, это то, как увеличение размера кэш-памяти способствует увеличению производительности. Эти данные нельзя интерпретировать без знания размера рабочего набора. Очевидно, что кэш-память такого размера, как основная память, должен привести к лучшим результатам, нежели кэш-память меньшего размера, так что в целом нет никаких ограничений на увеличение размера кэш-памяти и получения ощутимых преимуществ.
Как уже упоминалось выше, размер рабочего набора в его пиковом значении равен 5,6 Мб. Это значение не позволяет нам рассчитать размер памяти, который бы принес максимальную выгоду, но позволяет оценить этот размер. Проблема в том, что вся память используется не непрерывно и, следовательно, у нас есть конфликты даже при наличии 16M кэш-памяти и рабочего набора, размер которого равен 5,6M (вспомните преимущество 2-канальной ассоциативной кэш-памяти размером в 16 МБ над версией с прямым отображением). Но можно с уверенностью сказать, что при такой нагрузке преимущество кэш-памяти размером в 32 МБ будет несущественным. Однако кто сказал, что рабочий набор должен оставаться неизменным? С течением времени рабочие нагрузки растут и то же самое должно касаться размера кэш-памяти. Когда покупаются машины и принимается решение, за какой размер кэш-памяти требуется заплатить, стоит измерить размер рабочего набора. Почему это важно, можно увидеть на рис. 3.10.

Рис.3.9: Размещение памяти, используемой при тестировании
Запускается два типа тестов. В первом тесте элементы обрабатываются последовательно. В тестовой программе используется указатель n , но элементы массива связаны друг с другом, так что они обходятся в том порядке, в котором они находятся в памяти. Этот вариант показан в нижней части рис.3.9. Есть одна обратная ссылка, идущая от последнего элемента. Во втором тесте (верхняя часть рисунка) элементы массива обходятся в произвольном порядке. В обоих случаях элементы массива образуют циклический односвязный список.

Почти все разработчики знают, что кэш процессора — это такая маленькая, но быстрая память, в которой хранятся данные из недавно посещённых областей памяти — определение краткое и довольно точное. Тем не менее, знание «скучных» подробностей относительно механизмов работы кэша необходимо для понимания факторов влияющих на производительность кода.
Пример 1: доступ к памяти и производительность
Как вы думаете, насколько второй цикл быстрее первого?
int [] arr = new int [64 * 1024 * 1024];
Первый цикл умножает все значения массива на 3, второй цикл только каждое шестнадцатое значение. Второй цикл совершает только 6% работы первого цикла, но на современных машинах оба цикла выполняются примерно за равное время: 80 мс и 78 мс соответственно (на моей машине).
Разгадка проста — доступ к памяти. Скорость работы этих циклов в первую очередь определяется скоростью работы подсистемы памяти, а не скоростью целочисленного умножения. Как мы увидим в следующем примере, количество обращений к оперативной памяти одинаково и в первом и во втором случае.
Пример 2: влияние строк кэша
Копнём глубже — попробуем другие значения шага, не только 1 и 16:
Вот время работы этого цикла для различных значений шага K:

Обратите внимание, при значениях шага от 1 до 16 время работы практически не изменяется. Но при значениях больше 16, время работы уменьшается примерно вдвое каждый раз когда мы увеличиваем шаг в два раза. Это не означает, что цикл каким-то магическим образом начинает работать быстрее, просто количество итераций при этом так же уменьшается. Ключевой момент — одинаковое время работы при значениях шага от 1 до 16.
Причина этого в том, что современные процессоры осуществляют доступ к памяти не побайтно, а небольшими блоками, которые называют строками кэша. Обычно размер строки составляет 64 байта. Когда вы читаете какое-либо значение из памяти, в кэш попадает как минимум одна строка кэша. Последующий доступ к какому-либо значению из этой строки происходит очень быстро.
Из-за того, что 16 значений типа int занимают 64 байта, циклы с шагами от 1 до 16 обращаются к одинаковому количеству строк кэша, точнее говоря, ко всем строкам кэша массива. При шаге 32, обращение происходит к каждой второй строке, при шаге 64, к каждой четвёртой.
Понимание этого очень важно для некоторых способов оптимизации. От места расположения данных в памяти зависит число обращений к ней. Например, из-за невыровненных данных может потребоваться два обращения к оперативной памяти, вместо одного. Как мы выяснили выше, скорость работы при этом будет в два раза ниже.
Пример 3: размеры кэшей первого и второго уровня (L1 и L2)
Современные процессоры, как правило, имеют два или три уровня кэшей, обычно их называют L1, L2 и L3. Для того, чтобы узнать размеры кэшей различных уровней, можно воспользоваться утилитой CoreInfo или функцией Windows API GetLogicalProcessorInfo. Оба способа так же предоставляют информацию о размере строки кэша для каждого уровня.
На моей машине CoreInfo сообщает о кэшах данных L1 объёмом по 32 Кбайт, кэшах инструкций L1 объёмом по 32 Кбайт и кэшах данных L2 объёмом по 4 Мбайт. Каждое ядро имеет свои персональные кэши L1, кэши L2 общие для каждой пары ядер:
Проверим эту информацию экспериментально. Для этого, пройдёмся по нашему массиву инкрементируя каждое 16-ое значение — простой способ изменить данные в каждой строке кэша. При достижении конца, возвращаемся к началу. Проверим различные размеры массива, мы должны увидеть падение производительности когда массив перестаёт помещаться в кэши разных уровней.
int steps = 64 * 1024 * 1024; // количество итераций
int lengthMod = arr.Length - 1; // размер массива -- степень двойки

На моей машине заметны падения производительности после 32 Кбайт и 4 Мбайт — это и есть размеры кэшей L1 и L2.
Пример 4: параллелизм инструкций
Теперь давайте взглянем на кое-что другое. По вашему мнению, какой из этих двух циклов выполнится быстрее?
int steps = 256 * 1024 * 1024;
int [] a = new int [2];
// первый
for ( int i = 0; i
// второй
for ( int i = 0; i
Оказывается, второй цикл выполняется почти в два раза быстрее, по крайней мере, на всех протестированных мной машинах. Почему? Потому, что команды внутри циклов имеют разные зависимости по данным. Команды первого имеют следующую цепочку зависимостей:

Во втором цикле зависимости такие:

Функциональные части современных процессоров способны выполнять определённое число некоторых операций одновременно, как правило, не очень большое число. Например, возможен параллельный доступ к данным из кэша L1 по двум адресам, так же возможно одновременное выполнение двух простых арифметических команд. В первом цикле процессор не может задействовать эти возможности, но может во втором.
Пример 5: ассоциативность кэша
-
Кэш прямого отображения, данные каждой строки кэша в оперативной памяти хранятся только в одной заранее определённой ячейке кэша. Простейший способ вычисления отображения: индекс_строки_в_памяти % количество_ячеек_кэша. Две строки, отображённые на одну и ту же ячейку, не могут находится в кэше одновременно.
К примеру, на моей машине кэш L2 размером в 4 Мбайт является 16-входовым частично-ассоциативным кэшем. Вся оперативная память разделена на множества строк по младшим битам их индексов, строки из каждого множества соревнуются за одну группу из 16 ячеек кэша L2.
Так как кэш L2 имеет 65 536 ячеек (4 * 2 20 / 64) и каждая группа состоит из 16 ячеек, всего мы имеем 4 096 групп. Таким образом, младшие 12 битов индекса строки определяют к какой группе относится эта строка (2 12 = 4 096). В результате, строки с адресами кратными 262 144 (4 096 * 64) разделяют одну и ту же группу из 16-ти ячеек и соревнуются за место в ней.
Чтобы эффекты ассоциативности проявили себя, нам необходимо постоянно обращаться к большому количеству строк из одной группы, например, используя следующий код:
public static long UpdateEveryKthByte( byte [] arr, int K)
const int rep = 1024 * 1024; // количество итераций
Stopwatch sw = Stopwatch.StartNew();
int p = 0;
for ( int i = 0; i < rep; i++)
arr[p]++;
p += K; if (p >= arr.Length) p = 0;
>
Метод инкрементирует каждый K-ый элемент массива. По достижении конца, начинаем заново. После довольно большого количества итераций (2 20 ), останавливаемся. Я сделал прогоны для различных размеров массива и значений шага K. Результаты (синий — большое время работы, белый — маленькое):

Синим областям соответствуют те случаи, когда при постоянном изменении данных кэш не в состоянии вместить все требуемые данные одновременно. Яркий синий цвет говорит о времени работы порядка 80 мс, почти белый — 10 мс.
-
Почему появляются вертикальные линии? Вертикальные линии соответствуют значениям шага при которых осуществляется доступ к слишком большому числу строк (больше 16-ти) из одной группы. Для таких значений, 16-входовый кэш моей машины не может вместить все необходимые данные.
Некоторые из плохих значений шага — степени двойки: 256 и 512. Для примера рассмотрим шаг 512 и массив в 8 Мбайт. При этом шаге, в массиве имеются 32 участка (8 * 2 20 / 262 144), которые ведут борьбу друг с другом за ячейки в 512-ти группах кэша (262 144 / 512). Участка 32, а ячеек в кэше под каждую группу только 16, поэтому места на всех не хватает.
Другие значения шага, не являющиеся степенями двойки, просто невезучие, что вызывает большое количество обращений к одинаковым группам кэша, а так же приводит к появлению вертикальных синих линий на рисунке. На этом месте любителям теории чисел предлагается задуматься.
Даже если бы кэш был полностью ассоциативным, это не позволило бы сохранить в нём 8 Мбайт данных. Заметьте, что в уже рассмотренном примере с шагом 512 и размером массива 8 Мбайт, нам необходим только 1 Мбайт кэша, чтобы сохранить все нужные данные, но это невозможно сделать из-за недостаточной ассоциативности кэша.
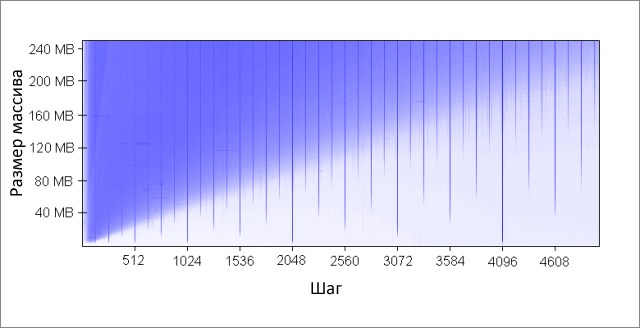
Ассоциативность кэша — интересная штука, которая может проявить себя при определённых условиях. В отличие от остальных рассмотренных в этой статье проблем, она не является настолько серьёзной. Определённо, это не то, что требует постоянного внимания при написании программ.
Пример 6: ложное разделение кэша
На многоядерных машинах можно столкнуться с другой проблемой — согласование кэшей. Ядра процессора имеют частично или полностью раздельные кэши. На моей машине кэши L1 раздельны (как и обычно), так же имеются два кэша L2, общие для каждой пары ядер. Детали могут различаться, но в целом современные многоядерные процессоры имеют многоуровневые иерархические кэши. Причём самые быстрые, но и самые маленькие кэши, принадлежат индивидуальным ядрам.
Когда одно из ядер модифицирует значение в своём кэше, другие ядра больше не могут использовать старое значение. Значение в кэшах других ядер должно быть обновлено. Более того, должна быть обновлена полностью вся строка кэша, так как кэши оперируют данными на уровне строк.
Продемонстрируем эту проблему на следующем коде:
private static int [] s_counter = new int [1024];
private void UpdateCounter( int position)
for ( int j = 0; j < 100000000; j++)
s_counter[position] = s_counter[position] + 3;
>
>
Если на своей четырёхядерной машине я вызову этот метод с параметрами 0, 1, 2, 3 одновременно из четырёх потоков, то время работы составит 4.3 секунды. Но если я вызову метод с параметрами 16, 32, 48, 64, то время работы составит только 0.28 секунды.
Почему? В первом случае, все четыре значения, обрабатываемые потоками в каждый момент времени, с большой вероятностью попадают в одну строку кэша. Каждый раз когда одно ядро увеличивает очередное значение, оно помечает ячейки кэша, содержащие это значение в других ядрах, как невалидные. После этой операции, все остальные ядра должны будут закэшировать строку заново. Это делает механизм кэширования неработоспособным, убивая производительность.
Пример 7: сложность железа
Даже теперь, когда принципы работы кэшей для вас не секрет, железо по-прежнему будет преподносить вам сюрпризы. Процессоры отличаются друг от друга методами оптимизации, эвристиками и прочими тонкостями реализации.
Кэш L1 некоторых процессоров может осуществлять параллельный доступ к двум ячейкам, если они относятся к разным группам, но если они относятся к одной, только последовательно. Насколько мне известно, некоторые даже могут осуществлять параллельный доступ к разным четвертинкам одной ячейки.
Процессоры могут удивить вас хитрыми оптимизациями. Например, код из предыдущего примера про ложное разделение кэша не работает на моём домашнем компьютере так, как задумывалось — в простейших случаях процессор может оптимизировать работу и уменьшить негативные эффекты. Если код немного модифицировать, всё встаёт на свои места.
Вот другой пример странных причуд железа:
private static int A, B, C, D, E, F, G;
Если вместо подставить три разных варианта, можно получить следующие результаты:

Инкрементирование полей A, B, C, D занимает больше времени, чем инкрементирование полей A, C, E, G. Что ещё страннее, инкрементирование полей A и C занимает больше времени, чем полей A, C и E, G. Не знаю точно каковы причины этого, но возможно они связаны с банками памяти (да-да, с обычными трёхлитровыми сберегательными банками памяти, а не то, что вы подумали). Имеющих соображения на этот счёт, прошу высказываться в комментариях.
У меня на машине вышеописанного не наблюдается, тем не менее, иногда бывают аномально плохие результаты — скорее всего, планировщик задач вносит свои «коррективы».
Из этого примера можно вынести следующий урок: очень сложно полностью предсказать поведение железа. Да, можно предсказать многое, но необходимо постоянно подтверждать свои предсказания с помощью измерений и тестирования.
Заключение
Надеюсь, что всё рассмотренное помогло вам понять устройство кэшей процессоров. Теперь вы можете использовать полученные знания на практике для оптимизации своего кода.
За счет чего же мы наблюдаем постоянный рост производительности однопоточных программ? В данный момент мы находимся на той ступени развития микропроцессорных технологий, когда прирост скорости работы однопоточных приложений зависит только от памяти. Количество ядер растет, но частота зафиксировалась в пределах 4 ГГц и не дает прироста производительности.
Скорость и частота работы памяти — это то основное за счет чего мы получаем «свой кусок бесплатного торта» (ссылка). Именно поэтому важно использовать память, настолько эффективно, насколько мы можем это делать, а тем более такую быструю как кэш. Для оптимизации программы под конкретный компьютер, полезно знать характеристики кэш-памяти процессора: количество уровней, размер, длину строки. Особенно это важно в высокопроизводительном коде — ядра систем, математические библиотеки.
Как же определить характеристики кэша автоматический? (естественно cpuinfo распарсить не считается, хотя-бы потому-что в конечном итоге мы бы хотели получить алгоритм, который можно без труда реализовать в других ОС. Удобно, не правда ли? ) Именно этим мы сейчас и займемся.
Немного теории
В данный момент существуют и широко используются три разновидности кэш-памяти: кэш с прямым отображением, ассоциативный кэш и множественно-ассоциативный кэш.
Кэш с прямым отображением (direct mapping cache)
— данная строка ОЗУ может быть отображена в единственную строку кэша, но в каждую строку кэша может быть отображено много возможных строк ОЗУ.

Ассоциативный кэш (fully associative cache)
— любая строка ОЗУ может быть отображена в любую строку кэша.

Множественно-ассоциативный кэш
— кэш-память делится на несколько «банков», каждый из которых функционирует как кэш с прямым отображением, таким образом строка ОЗУ может быть отображена не в единственную возможную запись кэша (как было бы в случае прямого отображения), а в один из нескольких банков; выбор банка осуществляется на основе LRU или иного механизма для каждой размещаемой в кэше строки.

LRU — вытеснение самой «долго не использованной» строки, кэш памяти.
Чтобы определить количество уровней кэша нужно рассмотреть порядок обращений к памяти, на котором будет четко виден переход. Разные уровни кэша отличаются прежде всего скоростью отклика памяти. В случае «кэш-промаха» для кэша L1 будет произведен поиск данных в следующих уровнях памяти, при этом если размер данных больше L1 и меньше L2 — то скоростью отклика памяти будет скорость отклика L2. Предыдущее утверждение так же верно в общем случаи.
Ясно что нужно подобрать тест на котором, мы будем четко видеть кэш промахи и протестировать его на различных размерах данных.
Зная логику множественно-ассоциативных кэшей, работающих по алгоритму LRU не трудно придумать алгоритм на котором кэш «валится», ничего хитрого — проход по строке. Критерием эффективности будем считать время одного обращения к памяти. Естественно нужно последовательно обращаться ко всем элементам строки, повторяя многократно для усреднения результата. К примеру возможны случаи, когда строка умещается в кэше но для первого прохода мы грузим строку из оперативной памяти и потому получаем совсем неадекватное время.
Хочется увидеть что-то подобное ступенькам, проходя по строкам разной длины. Для определения характера ступенек рассмотрим пример прохода по строке для прямого и ассоциативного кэша, случай с множественно-ассоциативным кэшем будет среднем между кэшем с прямым отображением и ассоциативным кэшем.
Как только размер данных превышает размер кэш-памяти,
полностью ассоциативный кэш «промахивается» при каждом обращении к памяти.

Рассмотрим разные размеры строк. — показывает максимальное количество промахов, которое потратит процессор для доступа к элементам массива при следующем проходе по строке.

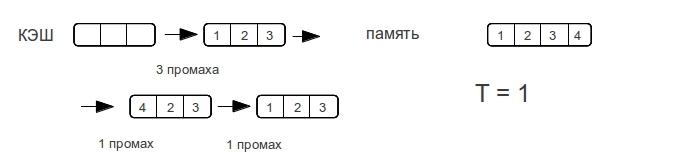
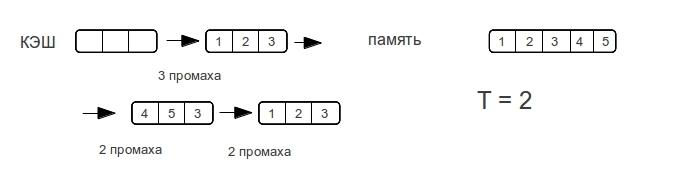
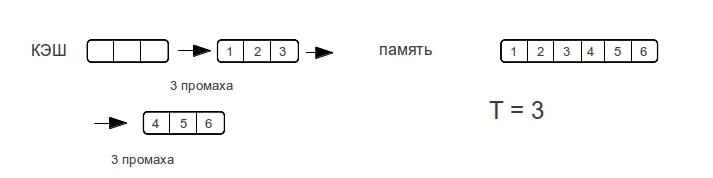
Как видно время доступа к памяти возрастает не резко, а по мере увеличения объема данных. Как только размер данных превысит размер кэша, то промахи будут при каждом обращении к памяти.
Потому у ассоциативного кэша ступенька будет вертикальной, а у прямого — плавно возрастать вплоть до двойного размера кэша. Множественно ассоциативный кэш будет средним случаем, «бугорком», хотя бы потому, что время-доступа не может быть лучше прямого.
Если-же говорить о памяти — то самая быстрая это кэш, следом идет оперативная, самая медленная это swap, про него мы в дальнейшем говорить не будем. В свою очередь у разных уровней кэша (как правило сегодня процессоры имеют 2-3 уровня кэша) разная скорость отклика памяти: чем больше уровень, тем меньше скорость отклика. И поэтому, если строка помещается в первый уровень кэша, (который кстати полностью ассоциативный) время отклика будет меньше, чем у строки значительно превышающей размеры кэша первого уровня. По-этому на графике времени отклика памяти от размеров строки будет несколько плато — плато* отклика памяти, и плато вызванные различными уровнями кэша.
Приступим к реализации
Для реализации будем использовать Си (ANSI C99).
Быстро написан код, обычный проход по строкам разной длины, меньше 10мб, выполняющийся многократно. (Будем приводить небольшие куски программы, несущие смысловую нагрузку).

Очевидно что это может происходить по двум причинам: либо в процессоре нет кэш памяти, либо процессор так хорошо угадывает обращения к памяти. Поскольку первый вариант ближе к фантастике причина всему хорошее предсказание обращений.
Дело в том, что сегодня далеко не топовые процессоры, помимо принципа пространственной локальности, предсказывают также и арифметическую прогрессию в порядке обращения к памяти. Поэтому нужно рандомизовать обращения к памяти.
Длина рандомизованного массива должна быть сопоставимой с длиной основной строки, чтобы избавиться от большой гранулярности обращений, так же длина массива не должна быть степенью двойки, из-за этого происходили «наложения» — следствием чего могут — быть выбросы. Лучше всего задать гранулярность константно, в том числе, если гранулярность простое число, то можно избежать эффектов наложений. А длина рандомиованого массива — функция от длинны строки.
После чего мы удивили столь долгожданную «картинку», о которой говорили в начале.


Программа разбита на 2 части — тест и обработка данных. Написать скрипт в 3 строки для запуска или 2 раза запустить ручками решайте сами.
Листинг файла size.с Linux
Листинг файла size.с Windows
В общем- то думаю все понятно, но хотелось бы оговорить несколько моментов.
Массив A объявлен как volatile — эта директива гарантирует нам что к массиву A всегда будут обращения, то-есть их не «вырежут» ни оптимизатор, ни компилятор. Так-же стоит оговорить то что вся вычислительная нагрузка выполняется до замера времени, что позволяет нам, уменьшить фоновое влияние.
Файл переведен в ассемблер на Ubuntu 12.04 и компилятором gcc 4.6 — циклы сохраняются.
Обработка данных
Для обработки данных логично использовать производные. И несмотря на то что с повышением порядка дифференцирования шумы возрастают, будет использована вторая производная и её свойства. Как бы не была зашумлена вторая производная, нас интересует лишь знак второй производной.
Находим все точки, в которых вторая производная больше нуля (с некоторой погрешностью потому-что вторая производная, помимо того что считается численно, — сильно зашумлена ). Задаем функцию зависимости знака второй производной функции от размера кэша. Функция принимает значение 1 в точках, где знак второй производной больше нуля, и ноль, если знак второй производной меньше или равен нулю.
Точки «взлетов» — начало каждой ступеньки. Также перед обработкой данных нужно убрать одиночные выбросы, которые не меняют смысловой нагрузки данных, но создают ощутимый шум.
Листинг файла data_pr.с
Тесты
CPU/ОС/версия ядра/компилятор/ключи компиляции — будут указаны для каждого теста.
Intel Pentium CPU P6100 @2.00GHz / Ubuntu 12.04 / 3.2.0-27-generic / gcc -Wall -O3 size.c -lrt
Давайте поговорим о «граблях»
Грабля обнаружилась при обработке данных на серверном процессоре Intel Xeon 2.4/L2 = 512 кб/Windows Server 2008

Проблема заключается в маленьком количестве точек, попадающих на интервал выхода на плато, — соответственно, скачок второй производной незаметен и принимается за шум.
Можно решить эту проблему методом наименьших квадратов, либо прогонять тесты в по ходу определения зон плато.
Вы здесь: Главная Память. Нижний уровень КЭШ-память Ассоциативная память
Мини блог
Оценка объема оборудования
Типовой объем КЭШ-памяти в современной системе — 8…1024 кбайт, а длина КЭШ-строки 4…32 байт. Дальнейшая оценка делается для значений объема КЭШа 256 кбайт и длины строки 32 байт, что характерно для систем с процессорами Pentium и PentiumPro. Длина тега при этом равна 27 бит, а количество строк в КЭШе составит 256К/ 32=8192. Именно столько цифровых компараторов 27 битных кодов потребуется для реализации вышеописанной структуры.
Приблизительная оценка затрат оборудования для построения цифрового компаратора дает значение 10 транз/бит, а общее количество транзисторов только в блоке компараторов будет равно:
10*27*8192 = 2 211 840,
что приблизительно в полтора раза меньше общего количества транзисторов на кристалле Pentium. Таким образом, ясно, что описанная структура полностью ассоциативной КЭШ-памяти ( ассоциативная память ) реализуема только при малом количестве строк в КЭШе, т.е. при малом объеме КЭШа (практически не более 32…64 строк). КЭШ большего объема строят по другой структуре.

Во всех центральных процессорах любого компьютера, будь то дешёвый ноутбук или сервер за миллионы долларов, есть устройство под названием «кэш». И с очень большой вероятностью он обладает несколькими уровнями.
Наверно, он важен, иначе зачем бы его устанавливать? Но что же делает кэш, и для чего ему разные уровни? И что означает «12-канальный ассоциативный кэш» (12-way set associative)?
Интерфейсы
Архитектура ЭВМ
Ассоциативная память
В ассоциативной памяти элементы выбираются не по адресу, а по содержимому. Поясним последнее понятие более подробно. Для памяти с адресной организацией было введено понятие минимальной адресуемой единицы (МАЕ) как порции данных, имеющей индивидуальный адрес. Введем аналогичное понятие для ассоциативной памяти, и будем эту минимальную единицу хранения в ассоциативной памяти называть строкой ассоциативной памяти (СтрАП). Каждая СтрАП содержит два поля: поле тега (англ. tag — ярлык, этикетка, признак) и поле данных. Запрос на чтение к ассоциативной памяти словами можно выразить следующим образом: выбрать строку (строки), у которой (у которых) тег равен заданному значению.
Особо отметим, что при таком запросе возможен один из трех результатов:
- имеется в точности одна строка с заданным тегом;
- имеется несколько строк с заданным тегом;
- нет ни одной строки с заданным тегом.
Поиск записи по признаку — это действие, типичное для обращений к базам данных, и поиск в базе зачастую чвляется ассоциативным поиском. Для выполнения такого поиска следует просмотреть все записи и сравнить заданный тег с тегом каждой записи. Это можно сделать и при использовании для хранения записей обычной адресуемой памяти (и понятно, что это потребует достаточно много времени — пропорционально количеству хранимых записей!). Об ассоциативной памяти говорят тогда, когда ассоциативная выборка данных из памяти поддержана аппаратно. При записи в ассоциативную память элемент данных помещается в СтрАП вместе с присущим этому элементу тегом. Для этого можно использовать любую свободную СтрАП. Рассмотрим разновидности структурной организации КЭШ-памяти или способы отображения оперативной памяти на КЭШ.
3.3.1 Ассоциативность
Можно было бы реализовать кэш-память, в которой каждая кэш-строка может хранить копию любой ячейки памяти. Это называется полностью ассоциативной кэш-памятью (fully associative cache). Чтобы получить доступ к кэш-строке, ядро процессора должно было бы сравнить теги всех до единой кэш-строк с тегом запрашиваемого адреса. Тег должен будет хранить весь адрес, который не будет указываться смещение в кэш-строке (это означает, что значение S, показанное на рисунке в разделе 3.2, будет равно нулю).
Есть кэш-память, которая реализована подобным образом, но взглянуть на размеры кэш-памяти L2, используемой в настоящее время, то видно, что это непрактично. Учтите, что 4 Мб кэш-памяти с кэш-строками размером в 64Б должна иметь 65 536 записей. Чтобы получить адекватную производительность, логические схемы кэш-памяти должны быть в состоянии в течение нескольких циклов выбрать из всех этих записей ту, которая соответствует заданному тегу. Затраты на реализацию такой схемы будут огромными.
Рис.3.5: Схематическое изображение полностью ассоциативной кэш-памяти
Для каждой кэш-строки требуется, чтобы компаратор выполнил сравнение тега большого размера (заметьте, S равно нулю). Буква, стоящая рядом с каждым соединением, обозначает ширину соединения в битах. Если ничего не указано, то ширина соединения равна одному биту. Каждый компаратор должен сравнивать два значения, ширина каждого из которых равна Т бит. Затем, исходя из результата, должно выбираться и стать доступным содержимое соответствующей кэш-строки. Для этого потребуется объединить столько наборов линий данных О, сколько есть сегментов кэш-памяти (cache buckets). Число транзисторов, необходимых для реализации одного компаратора будет большим в частности из-за того, что компаратор должен работать очень быстро. Итеративный компаратор использовать нельзя. Единственный способ сэкономить на количестве компараторов, это снизить их число с помощью итеративного сравнения тегов. Это не подходит по той же самой причине, по которой не подходят итеративные компараторы: на это потребуется слишком много времени.
Полностью ассоциативная кэш-память практична для кэш-памяти малого размера (например, кэш-память TLB в некоторых процессорах Intel является полностью ассоциативной), но эта кэш-память должна быть небольшой - действительно небольшой. Речь идет максимум о нескольких десятках записей.
Для кэш-памяти L1i, L1d и кэш-памяти более высокого уровня необходим другой подход. Все, что можно сделать, это ограничить поиск. В самом крайнем случае каждый тег отображается точно в одну кэш-запись. Расчет прост: для кэш-памяти 4MB/64B с 65 536 записями мы можем напрямую обращаться к каждому элементу и использовать для этого с 6-го по 21-й биты адреса (16 битов). Младшие 6 битов являются индексом кэш-строки.
Рис.3.6: Схематическое изображение кэш-памяти с прямым отображением
Как видно из рисунка 3.6 реализация такой кэш-памяти с прямым отображением (direct-mapped cache) может быть быстрой и простой. Для нее требуется только один компаратор, один мультиплексор (на этой схеме приведены два, поскольку тег и данные разделены, но это не является строгим конструктивным требованием) и некоторая логическая схема для выбора контента, содержащего действительно допустимые кэш-строки. Компаратор сложный из-за требований, касающихся скорости, но теперь он только один; в результате можно потратить больше усилий, чтобы сделать его более быстрым. Реальная сложность такого подхода заключена в мультиплексорах. Количество транзисторов в простом мультиплексоре растет по закону O(log N), где N является количеством кэш-строк. Это приемлемо, но может получиться медленный мультиплексор, и в этом случае скорость можно увеличить, если потратиться на транзисторы в мультиплексорах и для увеличения скорости распараллелить часть работы. Общее количество транзисторов будет расти медленное в сравнении с ростом размера кэш-памяти, что делает это решение очень привлекательным. Но у такого подхода есть недостаток: он работает только в случае, если адреса, используемые в программе, равномерно распределены относительно битов, используемых для прямого отображения. Если это не так, и это обычно бывает, некоторые кэш-записи используются активно и, поэтому, неоднократно высвобождаются, в то время как другие практически вообще не используются, либо остаются пустыми.
Рис.3.7: Схематическое изображение кэш-памяти с множественной ассоциативностью
Эту проблему можно решить с помощью кэш-памяти с множественной ассоциативностью (set associative). Кэш-память с множественностью ассоциативностью сочетает в себе черты кэш-памяти с полной ассоциативностью и кэш-памяти с прямым отображением, что позволяет в значительной степени избежать недостатков этих решений. На рис.3.7 показана схема кэш-памяти с множественной ассоциативностью. Память под теги и под данные разделена на наборы, выбор которых осуществляется в соответствие с адресом. Это похоже на кэш-память с прямым отображением. Но вместо того, чтобы для каждого значения из набора использовать отдельный элемент, один и тот же набор используется для кэширования некоторого небольшого количества значений. Теги для всех элементов набора сравниваются параллельно, что похоже на функционирование полностью ассоциативной кэш-памяти.
Результатом является кэш-память, которая достаточно устойчива к промахам из-за неудачного или преднамеренного выбора адресов с одними и теми же номерами наборов в одно и то же время, а размер кэш-памяти не ограничен количеством компараторов, которые могут работать параллельно. Если кэш-память увеличивается (смотрите рисунок), то увеличивается только количество столбцов, а не количество строк. Число строк увеличивается только в том случае, если повышается ассоциативность кэш-памяти. Сегодня процессоры для кэш-памяти L2 используют уровни ассоциативности до 16 и выше. Для кэш-памяти L1 обычно используется уровень, равный 8.
Таблица 3.1: Влияние размера кэш-памяти, ассоциативности и размера кэш-строки
| Размер кэш-памяти L2 | Ассоциативность | |||||||
|---|---|---|---|---|---|---|---|---|
| Прямое отображение | 2 | 4 | 8 | |||||
| CL=32 | CL=64 | CL=32 | CL=64 | CL=32 | CL=64 | CL=32 | CL=64 | |
| 512k | 27 794 595 | 20 422 527 | 25 222 611 | 18 303 581 | 24 096 510 | 17 356 121 | 23 666 929 | 17 029 334 |
| 1M | 19 007 315 | 13 903 854 | 16 566 738 | 12 127 174 | 15 537 500 | 11 436 705 | 15 162 895 | 11 233 896 |
| 2M | 12 230 962 | 8 801 403 | 9 081 881 | 6 491 011 | 7 878 601 | 5 675 181 | 7 391 389 | 5 382 064 |
| 4M | 7 749 986 | 5 427 836 | 4 736 187 | 3 159 507 | 3 788 122 | 2 418 898 | 3 430 713 | 2 125 103 |
| 8M | 4 731 904 | 3 209 693 | 2 690 498 | 1 602 957 | 2 207 655 | 1 228 190 | 2 111 075 | 1 155 847 |
| 16M | 2 620 587 | 1 528 592 | 1 958 293 | 1 089 580 | 1 704 878 | 883 530 | 1 671 541 | 862 324 |
В таблице 3.1 показано количество промахов кэш-памяти L2 для некоторой программы (в данном случае — для компилятора gcc, который, по мнению разработчиков ядра Linux, является наиболее важным бенчмарком) при изменении размера кэш-памяти, размера кэш-строки, а также значения множественной ассоциативности. В разделе 7.2 мы познакомимся с инструментальным средством, предназначенным для моделирования кэш-памяти, которое необходимо для этого теста.
Просто, если это еще не очевидно, взаимосвязь всех этих значений в том, что размер кэш-памяти равен
размер кэш-строки х ассоциативность х количество множеств
Отображение адресов в кэш-память вычисляется как
O = log2 от размера кэш-строки
S = log2 от числа наборов
согласно рисунку в разделе 3.2.
Рис.3.8: Размер кэш-памяти и уровень ассоциативности (CL=32)
Рис. 3.8 делает данные таблицы более понятными. На рисунке приведены данные для кэш-строки фиксированного размера, равного 32 байта. Если посмотреть на цифры для заданного размера кэш-памяти, то видно, что ассоциативность действительно может существенно помочь сократить число промахов кэш-памяти. Для кэш-памяти размером 8 МБ при переходе от прямого отображения на кэш-память с 2-канальной ассоциативностью экономится почти 44% кэш-памяти. В случае, если используется кэш-память со множественной ассоциативностью, то процессор может хранить в кэш-памяти рабочий набор большего размера, чем в случае кэш-памяти с прямым отображением.
В литературе иногда можно прочитать, что введение ассоциативности имеет тот же самый эффект, как удвоение размера кэш-памяти. Это, как это видно для случая перехода от кэш-памяти размером 4 МБ к кэш-памяти размером 8 МБ, верно в некоторых крайних случаях. Но это, конечно, не верно при последующем увеличении ассоциативности. Как видно из данных, последующее увеличение ассоциативности дает существенно меньший выигрыш. Нам, однако, не следует абсолютно не учитывать этот факт. В программе нашего примера пик использования памяти равен 5,6 MB. Так что при размере кэш-памяти в 8 Мб, что те же самые кэш-наборы будут использоваться многократно (более, чем дважды). С увеличением рабочего набора экономия может увеличиться, поскольку, как мы видим, при меньших размерах кэш-памяти преимущество от использования ассоциативности будет больше.
В целом, увеличение ассоциативность кэш-памяти выше 8, как кажется, дает слабый эффект при одном потоке рабочей нагрузки. С появлением многоядерных процессоров, которые используют общую кэш-память L2, ситуация меняется. Теперь у вас в основном есть две программы, которые обращаются к одной и той же кэш-памяти, в результате чего на практике эффект от использования ассоциативности должен увеличиться вдвое (или в четыре раза для четырехядерных процессоров). Таким образом, можно ожидать, что с увеличением числа ядер, ассоциативность общей кэш-памяти должна расти. Как это станет делать невозможным (16-канальную ассоциативность реализовывать уже трудно) разработчики процессоров начнут использовать общую кэш-память уровня L3 и далее, в то время как кэш-память уровня L2 будет, потенциально, совместно использоваться некоторым подмножеством ядер.
Другой эффект, который мы можем увидеть на рис.3.8, это то, как увеличение размера кэш-памяти способствует увеличению производительности. Эти данные нельзя интерпретировать без знания размера рабочего набора. Очевидно, что кэш-память такого размера, как основная память, должен привести к лучшим результатам, нежели кэш-память меньшего размера, так что в целом нет никаких ограничений на увеличение размера кэш-памяти и получения ощутимых преимуществ.
Как уже упоминалось выше, размер рабочего набора в его пиковом значении равен 5,6 Мб. Это значение не позволяет нам рассчитать размер памяти, который бы принес максимальную выгоду, но позволяет оценить этот размер. Проблема в том, что вся память используется не непрерывно и, следовательно, у нас есть конфликты даже при наличии 16M кэш-памяти и рабочего набора, размер которого равен 5,6M (вспомните преимущество 2-канальной ассоциативной кэш-памяти размером в 16 МБ над версией с прямым отображением). Но можно с уверенностью сказать, что при такой нагрузке преимущество кэш-памяти размером в 32 МБ будет несущественным. Однако кто сказал, что рабочий набор должен оставаться неизменным? С течением времени рабочие нагрузки растут и то же самое должно касаться размера кэш-памяти. Когда покупаются машины и принимается решение, за какой размер кэш-памяти требуется заплатить, стоит измерить размер рабочего набора. Почему это важно, можно увидеть на рис. 3.10.
Рис.3.9: Размещение памяти, используемой при тестировании
Запускается два типа тестов. В первом тесте элементы обрабатываются последовательно. В тестовой программе используется указатель n , но элементы массива связаны друг с другом, так что они обходятся в том порядке, в котором они находятся в памяти. Этот вариант показан в нижней части рис.3.9. Есть одна обратная ссылка, идущая от последнего элемента. Во втором тесте (верхняя часть рисунка) элементы массива обходятся в произвольном порядке. В обоих случаях элементы массива образуют циклический односвязный список.
Почти все разработчики знают, что кэш процессора — это такая маленькая, но быстрая память, в которой хранятся данные из недавно посещённых областей памяти — определение краткое и довольно точное. Тем не менее, знание «скучных» подробностей относительно механизмов работы кэша необходимо для понимания факторов влияющих на производительность кода.
Пример 1: доступ к памяти и производительность
Как вы думаете, насколько второй цикл быстрее первого?
int [] arr = new int [64 * 1024 * 1024];
Первый цикл умножает все значения массива на 3, второй цикл только каждое шестнадцатое значение. Второй цикл совершает только 6% работы первого цикла, но на современных машинах оба цикла выполняются примерно за равное время: 80 мс и 78 мс соответственно (на моей машине).
Разгадка проста — доступ к памяти. Скорость работы этих циклов в первую очередь определяется скоростью работы подсистемы памяти, а не скоростью целочисленного умножения. Как мы увидим в следующем примере, количество обращений к оперативной памяти одинаково и в первом и во втором случае.
Пример 2: влияние строк кэша
Копнём глубже — попробуем другие значения шага, не только 1 и 16:
Вот время работы этого цикла для различных значений шага K:
Обратите внимание, при значениях шага от 1 до 16 время работы практически не изменяется. Но при значениях больше 16, время работы уменьшается примерно вдвое каждый раз когда мы увеличиваем шаг в два раза. Это не означает, что цикл каким-то магическим образом начинает работать быстрее, просто количество итераций при этом так же уменьшается. Ключевой момент — одинаковое время работы при значениях шага от 1 до 16.
Причина этого в том, что современные процессоры осуществляют доступ к памяти не побайтно, а небольшими блоками, которые называют строками кэша. Обычно размер строки составляет 64 байта. Когда вы читаете какое-либо значение из памяти, в кэш попадает как минимум одна строка кэша. Последующий доступ к какому-либо значению из этой строки происходит очень быстро.
Из-за того, что 16 значений типа int занимают 64 байта, циклы с шагами от 1 до 16 обращаются к одинаковому количеству строк кэша, точнее говоря, ко всем строкам кэша массива. При шаге 32, обращение происходит к каждой второй строке, при шаге 64, к каждой четвёртой.
Понимание этого очень важно для некоторых способов оптимизации. От места расположения данных в памяти зависит число обращений к ней. Например, из-за невыровненных данных может потребоваться два обращения к оперативной памяти, вместо одного. Как мы выяснили выше, скорость работы при этом будет в два раза ниже.
Пример 3: размеры кэшей первого и второго уровня (L1 и L2)
Современные процессоры, как правило, имеют два или три уровня кэшей, обычно их называют L1, L2 и L3. Для того, чтобы узнать размеры кэшей различных уровней, можно воспользоваться утилитой CoreInfo или функцией Windows API GetLogicalProcessorInfo. Оба способа так же предоставляют информацию о размере строки кэша для каждого уровня.
На моей машине CoreInfo сообщает о кэшах данных L1 объёмом по 32 Кбайт, кэшах инструкций L1 объёмом по 32 Кбайт и кэшах данных L2 объёмом по 4 Мбайт. Каждое ядро имеет свои персональные кэши L1, кэши L2 общие для каждой пары ядер:
Проверим эту информацию экспериментально. Для этого, пройдёмся по нашему массиву инкрементируя каждое 16-ое значение — простой способ изменить данные в каждой строке кэша. При достижении конца, возвращаемся к началу. Проверим различные размеры массива, мы должны увидеть падение производительности когда массив перестаёт помещаться в кэши разных уровней.
int steps = 64 * 1024 * 1024; // количество итераций
int lengthMod = arr.Length - 1; // размер массива -- степень двойки
На моей машине заметны падения производительности после 32 Кбайт и 4 Мбайт — это и есть размеры кэшей L1 и L2.
Пример 4: параллелизм инструкций
Теперь давайте взглянем на кое-что другое. По вашему мнению, какой из этих двух циклов выполнится быстрее?
int steps = 256 * 1024 * 1024;
int [] a = new int [2];
// первый
for ( int i = 0; i
// второй
for ( int i = 0; i
Оказывается, второй цикл выполняется почти в два раза быстрее, по крайней мере, на всех протестированных мной машинах. Почему? Потому, что команды внутри циклов имеют разные зависимости по данным. Команды первого имеют следующую цепочку зависимостей:
Во втором цикле зависимости такие:
Функциональные части современных процессоров способны выполнять определённое число некоторых операций одновременно, как правило, не очень большое число. Например, возможен параллельный доступ к данным из кэша L1 по двум адресам, так же возможно одновременное выполнение двух простых арифметических команд. В первом цикле процессор не может задействовать эти возможности, но может во втором.
Пример 5: ассоциативность кэша
-
Кэш прямого отображения, данные каждой строки кэша в оперативной памяти хранятся только в одной заранее определённой ячейке кэша. Простейший способ вычисления отображения: индекс_строки_в_памяти % количество_ячеек_кэша. Две строки, отображённые на одну и ту же ячейку, не могут находится в кэше одновременно.
К примеру, на моей машине кэш L2 размером в 4 Мбайт является 16-входовым частично-ассоциативным кэшем. Вся оперативная память разделена на множества строк по младшим битам их индексов, строки из каждого множества соревнуются за одну группу из 16 ячеек кэша L2.
Так как кэш L2 имеет 65 536 ячеек (4 * 2 20 / 64) и каждая группа состоит из 16 ячеек, всего мы имеем 4 096 групп. Таким образом, младшие 12 битов индекса строки определяют к какой группе относится эта строка (2 12 = 4 096). В результате, строки с адресами кратными 262 144 (4 096 * 64) разделяют одну и ту же группу из 16-ти ячеек и соревнуются за место в ней.
Чтобы эффекты ассоциативности проявили себя, нам необходимо постоянно обращаться к большому количеству строк из одной группы, например, используя следующий код:
public static long UpdateEveryKthByte( byte [] arr, int K)
const int rep = 1024 * 1024; // количество итераций
Stopwatch sw = Stopwatch.StartNew();
int p = 0;
for ( int i = 0; i < rep; i++)
arr[p]++;
p += K; if (p >= arr.Length) p = 0;
>
Метод инкрементирует каждый K-ый элемент массива. По достижении конца, начинаем заново. После довольно большого количества итераций (2 20 ), останавливаемся. Я сделал прогоны для различных размеров массива и значений шага K. Результаты (синий — большое время работы, белый — маленькое):
Синим областям соответствуют те случаи, когда при постоянном изменении данных кэш не в состоянии вместить все требуемые данные одновременно. Яркий синий цвет говорит о времени работы порядка 80 мс, почти белый — 10 мс.
-
Почему появляются вертикальные линии? Вертикальные линии соответствуют значениям шага при которых осуществляется доступ к слишком большому числу строк (больше 16-ти) из одной группы. Для таких значений, 16-входовый кэш моей машины не может вместить все необходимые данные.
Некоторые из плохих значений шага — степени двойки: 256 и 512. Для примера рассмотрим шаг 512 и массив в 8 Мбайт. При этом шаге, в массиве имеются 32 участка (8 * 2 20 / 262 144), которые ведут борьбу друг с другом за ячейки в 512-ти группах кэша (262 144 / 512). Участка 32, а ячеек в кэше под каждую группу только 16, поэтому места на всех не хватает.
Другие значения шага, не являющиеся степенями двойки, просто невезучие, что вызывает большое количество обращений к одинаковым группам кэша, а так же приводит к появлению вертикальных синих линий на рисунке. На этом месте любителям теории чисел предлагается задуматься.
Даже если бы кэш был полностью ассоциативным, это не позволило бы сохранить в нём 8 Мбайт данных. Заметьте, что в уже рассмотренном примере с шагом 512 и размером массива 8 Мбайт, нам необходим только 1 Мбайт кэша, чтобы сохранить все нужные данные, но это невозможно сделать из-за недостаточной ассоциативности кэша.
Ассоциативность кэша — интересная штука, которая может проявить себя при определённых условиях. В отличие от остальных рассмотренных в этой статье проблем, она не является настолько серьёзной. Определённо, это не то, что требует постоянного внимания при написании программ.
Пример 6: ложное разделение кэша
На многоядерных машинах можно столкнуться с другой проблемой — согласование кэшей. Ядра процессора имеют частично или полностью раздельные кэши. На моей машине кэши L1 раздельны (как и обычно), так же имеются два кэша L2, общие для каждой пары ядер. Детали могут различаться, но в целом современные многоядерные процессоры имеют многоуровневые иерархические кэши. Причём самые быстрые, но и самые маленькие кэши, принадлежат индивидуальным ядрам.
Когда одно из ядер модифицирует значение в своём кэше, другие ядра больше не могут использовать старое значение. Значение в кэшах других ядер должно быть обновлено. Более того, должна быть обновлена полностью вся строка кэша, так как кэши оперируют данными на уровне строк.
Продемонстрируем эту проблему на следующем коде:
private static int [] s_counter = new int [1024];
private void UpdateCounter( int position)
for ( int j = 0; j < 100000000; j++)
s_counter[position] = s_counter[position] + 3;
>
>
Если на своей четырёхядерной машине я вызову этот метод с параметрами 0, 1, 2, 3 одновременно из четырёх потоков, то время работы составит 4.3 секунды. Но если я вызову метод с параметрами 16, 32, 48, 64, то время работы составит только 0.28 секунды.
Почему? В первом случае, все четыре значения, обрабатываемые потоками в каждый момент времени, с большой вероятностью попадают в одну строку кэша. Каждый раз когда одно ядро увеличивает очередное значение, оно помечает ячейки кэша, содержащие это значение в других ядрах, как невалидные. После этой операции, все остальные ядра должны будут закэшировать строку заново. Это делает механизм кэширования неработоспособным, убивая производительность.
Пример 7: сложность железа
Даже теперь, когда принципы работы кэшей для вас не секрет, железо по-прежнему будет преподносить вам сюрпризы. Процессоры отличаются друг от друга методами оптимизации, эвристиками и прочими тонкостями реализации.
Кэш L1 некоторых процессоров может осуществлять параллельный доступ к двум ячейкам, если они относятся к разным группам, но если они относятся к одной, только последовательно. Насколько мне известно, некоторые даже могут осуществлять параллельный доступ к разным четвертинкам одной ячейки.
Процессоры могут удивить вас хитрыми оптимизациями. Например, код из предыдущего примера про ложное разделение кэша не работает на моём домашнем компьютере так, как задумывалось — в простейших случаях процессор может оптимизировать работу и уменьшить негативные эффекты. Если код немного модифицировать, всё встаёт на свои места.
Вот другой пример странных причуд железа:
private static int A, B, C, D, E, F, G;
Если вместо подставить три разных варианта, можно получить следующие результаты:
Инкрементирование полей A, B, C, D занимает больше времени, чем инкрементирование полей A, C, E, G. Что ещё страннее, инкрементирование полей A и C занимает больше времени, чем полей A, C и E, G. Не знаю точно каковы причины этого, но возможно они связаны с банками памяти (да-да, с обычными трёхлитровыми сберегательными банками памяти, а не то, что вы подумали). Имеющих соображения на этот счёт, прошу высказываться в комментариях.
У меня на машине вышеописанного не наблюдается, тем не менее, иногда бывают аномально плохие результаты — скорее всего, планировщик задач вносит свои «коррективы».
Из этого примера можно вынести следующий урок: очень сложно полностью предсказать поведение железа. Да, можно предсказать многое, но необходимо постоянно подтверждать свои предсказания с помощью измерений и тестирования.
Заключение
Надеюсь, что всё рассмотренное помогло вам понять устройство кэшей процессоров. Теперь вы можете использовать полученные знания на практике для оптимизации своего кода.
За счет чего же мы наблюдаем постоянный рост производительности однопоточных программ? В данный момент мы находимся на той ступени развития микропроцессорных технологий, когда прирост скорости работы однопоточных приложений зависит только от памяти. Количество ядер растет, но частота зафиксировалась в пределах 4 ГГц и не дает прироста производительности.
Скорость и частота работы памяти — это то основное за счет чего мы получаем «свой кусок бесплатного торта» (ссылка). Именно поэтому важно использовать память, настолько эффективно, насколько мы можем это делать, а тем более такую быструю как кэш. Для оптимизации программы под конкретный компьютер, полезно знать характеристики кэш-памяти процессора: количество уровней, размер, длину строки. Особенно это важно в высокопроизводительном коде — ядра систем, математические библиотеки.
Как же определить характеристики кэша автоматический? (естественно cpuinfo распарсить не считается, хотя-бы потому-что в конечном итоге мы бы хотели получить алгоритм, который можно без труда реализовать в других ОС. Удобно, не правда ли? ) Именно этим мы сейчас и займемся.
Немного теории
В данный момент существуют и широко используются три разновидности кэш-памяти: кэш с прямым отображением, ассоциативный кэш и множественно-ассоциативный кэш.
Кэш с прямым отображением (direct mapping cache)
— данная строка ОЗУ может быть отображена в единственную строку кэша, но в каждую строку кэша может быть отображено много возможных строк ОЗУ.
Ассоциативный кэш (fully associative cache)
— любая строка ОЗУ может быть отображена в любую строку кэша.
Множественно-ассоциативный кэш
— кэш-память делится на несколько «банков», каждый из которых функционирует как кэш с прямым отображением, таким образом строка ОЗУ может быть отображена не в единственную возможную запись кэша (как было бы в случае прямого отображения), а в один из нескольких банков; выбор банка осуществляется на основе LRU или иного механизма для каждой размещаемой в кэше строки.
LRU — вытеснение самой «долго не использованной» строки, кэш памяти.
Чтобы определить количество уровней кэша нужно рассмотреть порядок обращений к памяти, на котором будет четко виден переход. Разные уровни кэша отличаются прежде всего скоростью отклика памяти. В случае «кэш-промаха» для кэша L1 будет произведен поиск данных в следующих уровнях памяти, при этом если размер данных больше L1 и меньше L2 — то скоростью отклика памяти будет скорость отклика L2. Предыдущее утверждение так же верно в общем случаи.
Ясно что нужно подобрать тест на котором, мы будем четко видеть кэш промахи и протестировать его на различных размерах данных.
Зная логику множественно-ассоциативных кэшей, работающих по алгоритму LRU не трудно придумать алгоритм на котором кэш «валится», ничего хитрого — проход по строке. Критерием эффективности будем считать время одного обращения к памяти. Естественно нужно последовательно обращаться ко всем элементам строки, повторяя многократно для усреднения результата. К примеру возможны случаи, когда строка умещается в кэше но для первого прохода мы грузим строку из оперативной памяти и потому получаем совсем неадекватное время.
Хочется увидеть что-то подобное ступенькам, проходя по строкам разной длины. Для определения характера ступенек рассмотрим пример прохода по строке для прямого и ассоциативного кэша, случай с множественно-ассоциативным кэшем будет среднем между кэшем с прямым отображением и ассоциативным кэшем.
Как только размер данных превышает размер кэш-памяти,
полностью ассоциативный кэш «промахивается» при каждом обращении к памяти.
Рассмотрим разные размеры строк. — показывает максимальное количество промахов, которое потратит процессор для доступа к элементам массива при следующем проходе по строке.
Как видно время доступа к памяти возрастает не резко, а по мере увеличения объема данных. Как только размер данных превысит размер кэша, то промахи будут при каждом обращении к памяти.
Потому у ассоциативного кэша ступенька будет вертикальной, а у прямого — плавно возрастать вплоть до двойного размера кэша. Множественно ассоциативный кэш будет средним случаем, «бугорком», хотя бы потому, что время-доступа не может быть лучше прямого.
Если-же говорить о памяти — то самая быстрая это кэш, следом идет оперативная, самая медленная это swap, про него мы в дальнейшем говорить не будем. В свою очередь у разных уровней кэша (как правило сегодня процессоры имеют 2-3 уровня кэша) разная скорость отклика памяти: чем больше уровень, тем меньше скорость отклика. И поэтому, если строка помещается в первый уровень кэша, (который кстати полностью ассоциативный) время отклика будет меньше, чем у строки значительно превышающей размеры кэша первого уровня. По-этому на графике времени отклика памяти от размеров строки будет несколько плато — плато* отклика памяти, и плато вызванные различными уровнями кэша.
Приступим к реализации
Для реализации будем использовать Си (ANSI C99).
Быстро написан код, обычный проход по строкам разной длины, меньше 10мб, выполняющийся многократно. (Будем приводить небольшие куски программы, несущие смысловую нагрузку).
Очевидно что это может происходить по двум причинам: либо в процессоре нет кэш памяти, либо процессор так хорошо угадывает обращения к памяти. Поскольку первый вариант ближе к фантастике причина всему хорошее предсказание обращений.
Дело в том, что сегодня далеко не топовые процессоры, помимо принципа пространственной локальности, предсказывают также и арифметическую прогрессию в порядке обращения к памяти. Поэтому нужно рандомизовать обращения к памяти.
Длина рандомизованного массива должна быть сопоставимой с длиной основной строки, чтобы избавиться от большой гранулярности обращений, так же длина массива не должна быть степенью двойки, из-за этого происходили «наложения» — следствием чего могут — быть выбросы. Лучше всего задать гранулярность константно, в том числе, если гранулярность простое число, то можно избежать эффектов наложений. А длина рандомиованого массива — функция от длинны строки.
После чего мы удивили столь долгожданную «картинку», о которой говорили в начале.
Программа разбита на 2 части — тест и обработка данных. Написать скрипт в 3 строки для запуска или 2 раза запустить ручками решайте сами.
Листинг файла size.с Linux
Листинг файла size.с Windows
В общем- то думаю все понятно, но хотелось бы оговорить несколько моментов.
Массив A объявлен как volatile — эта директива гарантирует нам что к массиву A всегда будут обращения, то-есть их не «вырежут» ни оптимизатор, ни компилятор. Так-же стоит оговорить то что вся вычислительная нагрузка выполняется до замера времени, что позволяет нам, уменьшить фоновое влияние.
Файл переведен в ассемблер на Ubuntu 12.04 и компилятором gcc 4.6 — циклы сохраняются.
Обработка данных
Для обработки данных логично использовать производные. И несмотря на то что с повышением порядка дифференцирования шумы возрастают, будет использована вторая производная и её свойства. Как бы не была зашумлена вторая производная, нас интересует лишь знак второй производной.
Находим все точки, в которых вторая производная больше нуля (с некоторой погрешностью потому-что вторая производная, помимо того что считается численно, — сильно зашумлена ). Задаем функцию зависимости знака второй производной функции от размера кэша. Функция принимает значение 1 в точках, где знак второй производной больше нуля, и ноль, если знак второй производной меньше или равен нулю.
Точки «взлетов» — начало каждой ступеньки. Также перед обработкой данных нужно убрать одиночные выбросы, которые не меняют смысловой нагрузки данных, но создают ощутимый шум.
Листинг файла data_pr.с
Тесты
CPU/ОС/версия ядра/компилятор/ключи компиляции — будут указаны для каждого теста.
Intel Pentium CPU P6100 @2.00GHz / Ubuntu 12.04 / 3.2.0-27-generic / gcc -Wall -O3 size.c -lrt
Давайте поговорим о «граблях»
Грабля обнаружилась при обработке данных на серверном процессоре Intel Xeon 2.4/L2 = 512 кб/Windows Server 2008
Проблема заключается в маленьком количестве точек, попадающих на интервал выхода на плато, — соответственно, скачок второй производной незаметен и принимается за шум.
Можно решить эту проблему методом наименьших квадратов, либо прогонять тесты в по ходу определения зон плато.
Вы здесь: Главная Память. Нижний уровень КЭШ-память Ассоциативная память
Не только числа
Кэш повышает производительность, ускоряя передачу данных в логические блоки и храня поблизости копию часто используемых инструкций и данных. Хранящаяся в кэше информация разделена на две части: сами данные и место, где они изначально располагаются в системной памяти/накопителе — такой адрес называется тег кэша (cache tag).
Когда процессор выполняет операцию, которой нужно считать или записать данные из/в память, то он начинает с проверки тегов в кэше Level 1. Если нужные данные там есть (произошло кэш-попадание (cache hit)), то доступ к этим данным выполняется почти сразу же. Промах кэша (cache miss) возникает, если требуемый тег не найден на самом нижнем уровне кэша.
В кэше L1 создаётся новый тег, а за дело берётся остальная часть архитектуры процессора выполняющая поиск в других уровнях кэша (при необходимости вплоть до основного накопителя) данных для этого тега. Но чтобы освободить пространство в кэше L1 под этот новый тег, что-то обязательно нужно перебросить в L2.
Это приводит к почти постоянному перемешиванию данных, выполняемому всего за несколько тактовых циклов. Единственный способ добиться этого — создание сложной структуры вокруг SRAM для обработки управления данными. Иными словами, если бы ядро процессора состояло всего из одного ALU, то кэш L1 был бы гораздо проще, но поскольку их десятки (и многие из них жонглируют двумя потоками инструкций), то для перемещения данных кэшу требуется множество соединений.

Для изучения информации кэша в процессоре вашего компьютера можно использовать бесплатные программы, например CPU-Z. Но что означает вся эта информация? Важным элементом является метка set associative (множественно-ассоциативный) — она указывает на правила, применяемые для копирования блоков данных из системной памяти в кэш.
Представленная выше информация кэша относится к Intel Core i7-9700K. Каждый из его кэшей Level 1 разделён на 64 небольших блока, называемые sets, и каждый из этих блоков ещё разбит на строки кэша (cache lines) (размером 64 байта). «Set associative» означает, что блок данных из системы привязывается к строкам кэша в одном конкретном сете, и не может свободно привязываться к какому-то другому месту.

Инклюзивный кэш L1+L2, victim cache L3, политики write-back, есть даже ECC. Источник: Fritzchens Fritz
Ещё один аспект сложности кэша связан с тем, как хранятся данные между разными уровнями. Правила задаются в inclusion policy (политике инклюзивности). Например, процессоры Intel Core имеют полностью инклюзивные кэши L1+L3. Это означает, что одни данные в Level 1, например, могут присутствовать в Level 3. Может показаться, что это пустая трата ценного пространства кэша, однако преимущество заключается в том, что если процессор совершает промах при поиске тега в нижнем уровне, ему не потребуется обыскивать верхний уровень для нахождения данных.
В тех же самых процессорах кэш L2 неинклюзивен: все хранящиеся там данные не копируются ни на какой другой уровень. Это экономит место, но приводит к тому, что системе памяти чипа нужно искать ненайденный тег в L3 (который всегда намного больше). Victim caches (кэши-жертвы) имеют похожий принцип, но они используются для хранения информации, переносимой с более низких уровней. Например, процессоры AMD Zen 2 используют victim cache L3, который просто хранит данные из L2.
Существуют и другие политики для кэша, например, при которых данные записываются и в кэш, и основную системную память. Они называются политиками записи (write policies); большинство современных процессоров использует кэши write-back — это означает, что когда данные записываются на уровень кэшей, происходит задержка перед записью их копии в системную память. Чаще всего эта пауза длится в течение того времени, пока данные остаются в кэше — ОЗУ получает эту информацию только при «выталкивании» из кэша.

Графический процессор Nvidia GA100, имеющий 20 МБ кэша L1 и 40 МБ кэша L2
Для проектировщиков процессоров выбор объёма, типа и политики кэшей является вопросом уравновешивания стремления к повышению мощности процессора с увеличением его сложности и занимаемым чипом пространством. Если бы можно было создать 1000-канальные ассоциативные кэши Level 1 на 20 МБ такими, чтобы они при этом не занимали площадь Манхэттена (и не потребляли столько же энергии), то у нас у всех бы были компьютеры с такими чипами!
Самый нижний уровень кэшей в современных процессорах за последнее десятилетие практически не изменился. Однако кэш Level 3 продолжает расти в размерах. Если бы десять лет назад у вас было 999 долларов на Intel i7-980X, то вы могли бы получить кэш размером 12 МБ. Сегодня за половину этой суммы можно приобрести 64 МБ.
Подведём итог: кэш — это абсолютно необходимое и потрясающее устройство. Мы не рассматривали другие типы кэшей в CPU и GPU (например, буферы ассоциативной трансляции или кэши текстур), но поскольку все они имеют такую же простую структуру и расположение уровней, разобраться в них будет несложно.
Был ли у вас компьютер с кэшем L2 на материнской плате? Как насчёт слотовых Pentium II и Celeron (например, 300a) на дочерних платах? Помните свой первый процессор с общим L3?
На правах рекламы
Наша компания предлагает в аренду серверы с процессорами от Intel и AMD. В последнем случае — это эпичные серверы! VDS с AMD EPYC, частота ядра CPU до 3.4 GHz. Максимальная конфигурация — 128 ядер CPU, 512 ГБ RAM, 4000 ГБ NVMe.
Ассоциативная память
Кэш: многоуровневая парковка

На приведённом выше изображении процессор (CPU) обозначен прямоугольником с пунктирной границей. Слева расположены ALU (arithmetic logic units, арифметико-логические устройства); это структуры, выполняющие математические операции. Хотя строго говоря, они не являются кэшем, ближайший к ALU уровень памяти — это регистры (они упорядочены в регистровый файл).
Каждый из них хранит одно число, например, 64-битное целое число; само значение может быть элементом каких-нибудь данных, кодом определённой инструкции или адресом памяти каких-то других данных.
Регистровый файл в десктопных процессорах довольно мал, например, в каждом из ядер Intel Core i9-9900K есть по два банка таких файлов, а тот, который предназначен для целых чисел, содержит всего 180 64-битных целых чисел. Другой регистровый файл для векторов (небольших массивов чисел) содержит 168 256-битных элементов. То есть общий регистровый файл каждого ядра чуть меньше 7 КБ. Для сравнения: регистровый файл потоковых мультипроцессоров (так в GPU называются аналоги ядер CPU) Nvidia GeForce RTX 2080 Ti имеет размер 256 КБ.
Регистры, как и кэш, являются SRAM, но их скорость не превышает скорость обслуживаемых ими ALU; они передают данные за один тактовый цикл. Но они не предназначены для хранения больших объёмов данных (только одного элемента), поэтому рядом с ними всегда есть более крупные блоки памяти: это кэш первого уровня (Level 1).

Одно ядро процессора Intel Skylake. Источник: Wikichip
На изображении выше представлен увеличенный снимок одного из ядер десктопного процессора Intel Skylake.
ALU и регистровые файлы расположены слева и обведены зелёной рамкой. В верхней части фотографии белым обозначен кэш данных первого уровня (Level 1 Data cache). Он не содержит много информации, всего 32 КБ, но как и регистры, он расположен очень близко к логическим блокам и работает на одной скорости с ними.
Ещё одним белым прямоугольником справа показан кэш инструкций первого уровня (Level 1 Instruction cache), тоже имеющий размер 32 КБ. Как понятно из названия, в нём хранятся различные команды, готовые к разбиению на более мелкие микрооперации (обычно обозначаемые μops), которые должны выполнять ALU. Для них тоже существует кэш, который можно классифицировать как Level 0, потому что он меньше (содержит всего 1 500 операций) и ближе, чем кэши L1.
Вы можете задаться вопросом: почему эти блоки SRAM настолько малы? Почему они не имеют размер в мегабайт? Вместе кэши данных и инструкций занимают почти такую же площадь на чипе, что основные логические блоки, поэтому их увеличение приведёт к повышению общей площади кристалла.
Но основная причина их размера в несколько килобайт заключается в том, что при увеличении ёмкости памяти повышается время, необходимое для поиска и получения данных. Кэшу L1 нужно быть очень быстрым, поэтому необходимо достичь компромисса между размером и скоростью — в лучшем случае для получения данных из этого кэша требуется около 5 тактовых циклов (для значений с плавающей запятой больше).

Кэш L2 процессора Skylake: 256 КБ SRAM
Но если бы это был единственный кэш внутри процессора, то его производительность наткнулась бы на неожиданное препятствие. Именно поэтому в ядра встраивается еще один уровень памяти: кэш Level 2. Это обобщённый блок хранения, содержащий инструкции и данные.
Он всегда больше, чем Level 1: в процессорах AMD Zen 2 он занимает до 512 КБ, чтобы кэши нижнего уровня обеспечивались достаточным объёмом данных. Однако большой размер требует жертв — для поиска и передачи данных из этого кэша требуется примерно в два раза больше времени по сравнению с Level 1.
Во времена первого Intel Pentium кэш Level 2 был отдельным чипом, или устанавливаемым на отдельной небольшой плате (как ОЗУ DIMM), или встроенным в основную материнскую плату. Постепенно он перебрался в корпус самого процессора, и, наконец, полностью интегрировался в кристалл чипа; это произошло в эпоху таких процессоров, как Pentium III и AMD K6-III.
За этим достижением вскоре последовал ещё один уровень кэша, необходимый для поддержки более низких уровней, и появился он как раз вовремя — в эпоху расцвета многоядерных чипов.

Чип Intel Kaby Lake. Источник: Wikichip
На этом изображении чипа Intel Kaby Lake в левой части показаны четыре ядра (интегрированный GPU занимает почти половину кристалла и находится справа). Каждое ядро имеет свой «личный» набор кэшей Level 1 и 2 (выделены белыми и жёлтым прямоугольниками), но у них также есть и третий комплект блоков SRAM.
Кэш третьего уровня (Level 3), хоть и расположен непосредственно рядом с одним ядром, является полностью общим для всех остальных — каждое ядро свободно может получать доступ к содержимому кэша L3 другого ядра. Он намного больше (от 2 до 32 МБ), но и намного медленнее, в среднем более 30 циклов, особенно когда ядру нужно использовать данные, находящиеся в блоке кэша, расположенного на большом расстоянии.
Ниже показано одно ядро архитектуры AMD Zen 2: кэши Level 1 данных и инструкций по 32 КБ (в белых прямоугольниках), кэш Level 2 на 512 КБ (в жёлтых прямоугольниках) и огромный блок кэша L3 на 4 МБ (в красном прямоугольнике).

Увеличенный снимок одного ядра процессора AMD Zen 2. Источник: Fritzchens Fritz
Но постойте: как 32 КБ могут занимать больше физического пространства чем 512 КБ? Если Level 1 хранит так мало данных, почему он непропорционально велик по сравнению с кэшами L2 и L3?
Читайте также: