4 что представляет собой репликация файла
Репликация в вычислениях включает обмен информацией для обеспечения согласованности между избыточными ресурсами, такими как программные или аппаратные компоненты, для повышения надежности, отказоустойчивости или доступности.
Репликация в вычислительной технике может относиться к:
- Репликация данных , когда одни и те же данные хранятся на нескольких устройствах хранения.
- Репликация вычислений , при которой одна и та же вычислительная задача выполняется много раз. Вычислительные задачи могут быть:
- Тиражируется в пространстве , где задачи выполняются на отдельных устройствах
- Репликация во времени , когда задачи выполняются повторно на одном устройстве
Репликация в пространстве или во времени часто связана с алгоритмами планирования. [1]
Доступ к реплицированному объекту обычно унифицирован с доступом к одному нереплицированному объекту. Сама репликация должна быть прозрачной для внешнего пользователя. В сценарии сбоя переключение реплик должно быть максимально скрыто с точки зрения качества обслуживания . [2]
Ученые-компьютерщики далее описывают репликацию как:
- Активная репликация , которая выполняется путем обработки одного и того же запроса на каждой реплике.
- Пассивная репликация , которая включает обработку каждого запроса на одной реплике и передачу результата на другие реплики.
Когда одна реплика лидера назначается посредством выбора лидера для обработки всех запросов, система использует схему первичного резервного копирования или главного подчиненного устройства , которая преобладает в кластерах с высокой доступностью . Для сравнения, если какая-либо реплика может обрабатывать запрос и распространять новое состояние, система использует схему с несколькими основными или несколькими ведущими . В последнем случае необходимо использовать некоторую форму управления распределенным параллелизмом , такую как диспетчер распределенных блокировок .
Балансировка нагрузки отличается от репликации задач, поскольку она распределяет нагрузку различных вычислений по машинам и позволяет отбросить одно вычисление в случае сбоя. Однако балансировка нагрузки иногда использует внутреннюю репликацию данных (особенно репликацию с несколькими мастерами ) для распределения данных между машинами.
Резервное копирование отличается от репликации тем, что сохраненная копия данных остается неизменной в течение длительного периода времени. [3] Реплики, с другой стороны, часто обновляются и быстро теряют любое историческое состояние. Репликация - одна из старейших и наиболее важных тем в области распределенных систем .
И репликация данных, и репликация вычислений требуют, чтобы процессы обрабатывали входящие события. Процессы репликации данных пассивны и работают только для поддержания сохраненных данных, ответа на запросы чтения и применения обновлений. Репликация вычислений обычно выполняется для обеспечения отказоустойчивости и берет на себя операцию в случае отказа одного из компонентов. В обоих случаях основные потребности заключаются в том, чтобы реплики видели одни и те же события в эквивалентном порядке, чтобы они оставались в согласованных состояниях, и любая реплика могла отвечать на запросы.
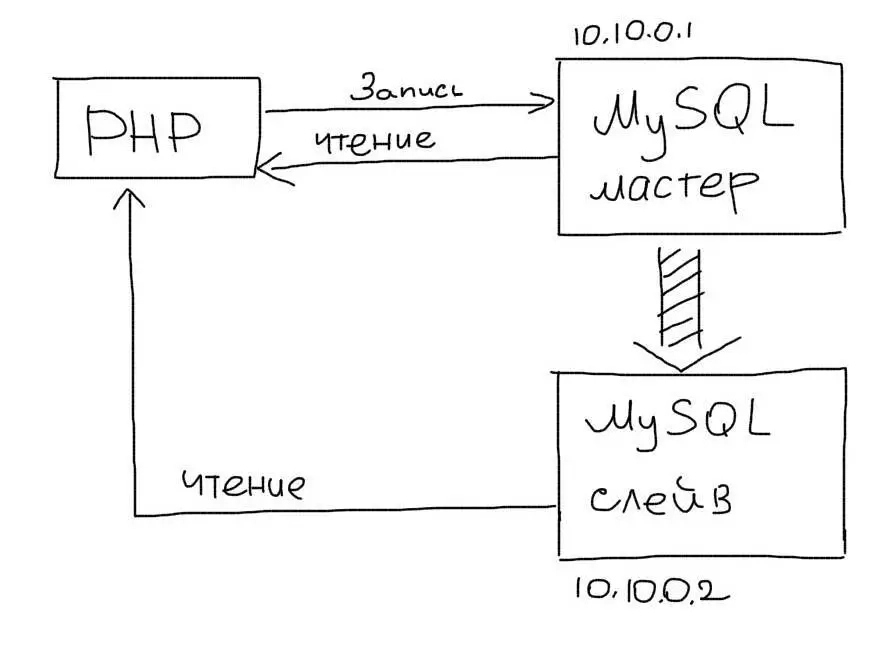
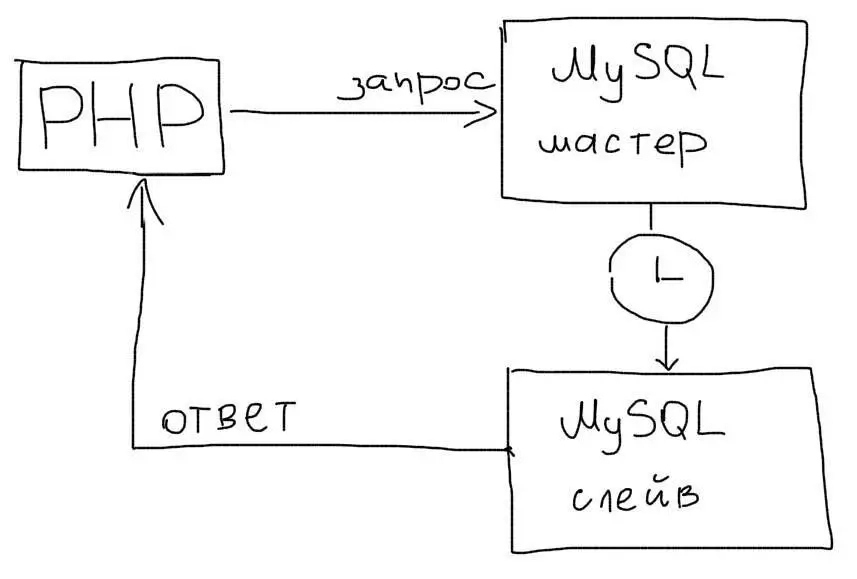
Master-Slave репликация
В этом подходе выделяется один основной сервер базы данных, который называется Мастером. На нем происходят все изменения в данных (любые запросы MySQL INSERT/UPDATE/DELETE). Слейв сервер постоянно копирует все изменения с Мастера. С приложения на Слейв сервер отправляются запросы чтения данных (запросы SELECT). Таким образом Мастер сервер отвечает за изменения данных, а Слейв за чтение.
![]()
В приложении нужно использовать два соединения – одно для Мастера, второе — для Слейва:
Используем два соединения — для Мастера и Слейва — для записи и чтения соответственно
Захват с драйвером ядра
Драйвер ядра ( в частности, драйвер фильтра ) может быть использован для перехвата вызовов функций файловой системы, захватив какую - либо деятельность , как это происходит. При этом используются технологии того же типа, что и активные антивирусные программы в реальном времени. На этом уровне фиксируются логические файловые операции, такие как открытие, запись, удаление файла и т. Д. Драйвер ядра передает эти команды другому процессу, обычно по сети на другую машину, которая имитирует операции исходной машины. Подобно репликации хранилища на уровне блоков, репликация на уровне файлов допускает как синхронный, так и асинхронный режимы. В синхронном режиме операции записи на исходном компьютере задерживаются и не могут выполняться до тех пор, пока конечный компьютер не подтвердит успешную репликацию. Синхронный режим менее распространен для продуктов репликации файлов, хотя существует несколько решений.
Решения репликации на уровне файлов позволяют принимать обоснованные решения о репликации в зависимости от местоположения и типа файла. Например, могут быть исключены временные файлы или части файловой системы, не имеющие никакой коммерческой ценности. Передаваемые данные также могут быть более детализированными; если приложение записывает 100 байт, передаются только 100 байт вместо полного блока диска (обычно 4096 байт). Это существенно снижает объем данных, отправляемых с исходного компьютера, и нагрузку на хранилище на целевом компьютере.
Недостатки этого программного решения включают необходимость внедрения и обслуживания на уровне операционной системы, а также повышенную нагрузку на вычислительную мощность машины.
Репликация журнала файловой системы
Подобно журналам транзакций базы данных , многие файловые системы могут вести журнал своей активности. Журнал можно отправлять на другой компьютер периодически или в режиме реального времени посредством потоковой передачи. На стороне реплики журнал можно использовать для воспроизведения изменений файловой системы.
Одним из наиболее заметных реализаций Microsoft «s System Center Manager Защита данных (DPM), выпущенный в 2005 году, который выполняет периодические обновления , но не предлагают репликации в режиме реального времени. [ необходима цитата ]
Самое важное
Репликация используется в большей мере для резервирования баз данных и в меньшей для масштабирования. Master-Slave репликация удобна для распределения запросов чтения по нескольким серверам. Подход ручной репликации позволит использовать преимущества репликации для технологий, которые ее не поддерживают. Зачастую репликация используется вместе с шардингом при решении вопросов масштабирования.
Этот текст был написан несколько лет назад. С тех пор упомянутые здесь инструменты и софт могли получить обновления. Пожалуйста, проверяйте их актуальность.
Репликация в вычислениях включает обмен информацией для обеспечения согласованности между избыточными ресурсами, такими как программные или аппаратные компоненты, для повышения надежности, отказоустойчивости или доступности.
Репликация в вычислительной технике может относиться к:
- Репликация данных , когда одни и те же данные хранятся на нескольких устройствах хранения.
- Репликация вычислений , при которой одна и та же вычислительная задача выполняется много раз. Вычислительные задачи могут быть:
- Тиражируется в пространстве , где задачи выполняются на отдельных устройствах
- Репликация во времени , когда задачи выполняются повторно на одном устройстве
Репликация в пространстве или во времени часто связана с алгоритмами планирования. [1]
Доступ к реплицированному объекту обычно унифицирован с доступом к одному нереплицированному объекту. Сама репликация должна быть прозрачной для внешнего пользователя. В сценарии сбоя переключение реплик должно быть максимально скрыто с точки зрения качества обслуживания . [2]
Ученые-компьютерщики далее описывают репликацию как:
- Активная репликация , которая выполняется путем обработки одного и того же запроса на каждой реплике.
- Пассивная репликация , которая включает обработку каждого запроса на одной реплике и передачу результата на другие реплики.
Когда одна реплика лидера назначается посредством выбора лидера для обработки всех запросов, система использует схему первичного резервного копирования или главного подчиненного устройства , которая преобладает в кластерах с высокой доступностью . Для сравнения, если какая-либо реплика может обрабатывать запрос и распространять новое состояние, система использует схему с несколькими основными или несколькими ведущими . В последнем случае необходимо использовать некоторую форму управления распределенным параллелизмом , такую как диспетчер распределенных блокировок .
Балансировка нагрузки отличается от репликации задач, поскольку она распределяет нагрузку различных вычислений по машинам и позволяет отбросить одно вычисление в случае сбоя. Однако балансировка нагрузки иногда использует внутреннюю репликацию данных (особенно репликацию с несколькими мастерами ) для распределения данных между машинами.
Резервное копирование отличается от репликации тем, что сохраненная копия данных остается неизменной в течение длительного периода времени. [3] Реплики, с другой стороны, часто обновляются и быстро теряют любое историческое состояние. Репликация - одна из старейших и наиболее важных тем в области распределенных систем .
И репликация данных, и репликация вычислений требуют, чтобы процессы обрабатывали входящие события. Процессы репликации данных пассивны и работают только для поддержания сохраненных данных, ответа на запросы чтения и применения обновлений. Репликация вычислений обычно выполняется для обеспечения отказоустойчивости и берет на себя операцию в случае отказа одного из компонентов. В обоих случаях основные потребности заключаются в том, чтобы реплики видели одни и те же события в эквивалентном порядке, чтобы они оставались в согласованных состояниях, и любая реплика могла отвечать на запросы.
Реализации
Многие распределенные файловые системы используют репликацию, чтобы обеспечить отказоустойчивость и избежать единой точки отказа.
Многие коммерческие системы синхронной репликации не «зависают», когда удаленная реплика выходит из строя или теряет соединение - поведение, которое гарантирует нулевую потерю данных, - но продолжают работать локально, теряя желаемую нулевую точку восстановления .
Методы оптимизации глобальной сети (WAN) могут применяться для устранения ограничений, налагаемых задержкой.
Репликация на основе файлов выполняет репликацию данных на логическом уровне (т. Е. Отдельных файлов данных), а не на уровне блоков хранения. Есть много разных способов сделать это, которые почти полностью полагаются на программное обеспечение.
Захват с драйвером ядра
Драйвер ядра ( в частности, драйвер фильтра ) может быть использован для перехвата вызовов функций файловой системы, захватив какую - либо деятельность , как это происходит. При этом используются технологии того же типа, что и активные антивирусные программы в реальном времени. На этом уровне фиксируются логические файловые операции, такие как открытие, запись, удаление файла и т. Д. Драйвер ядра передает эти команды другому процессу, обычно по сети на другую машину, которая имитирует операции исходной машины. Подобно репликации хранилища на уровне блоков, репликация на уровне файлов допускает как синхронный, так и асинхронный режимы. В синхронном режиме операции записи на исходном компьютере задерживаются и не могут выполняться до тех пор, пока конечный компьютер не подтвердит успешную репликацию. Синхронный режим менее распространен для продуктов репликации файлов, хотя существует несколько решений.
Решения репликации на уровне файлов позволяют принимать обоснованные решения о репликации в зависимости от местоположения и типа файла. Например, могут быть исключены временные файлы или части файловой системы, не имеющие никакой коммерческой ценности. Передаваемые данные также могут быть более детализированными; если приложение записывает 100 байт, передаются только 100 байт вместо полного блока диска (обычно 4096 байт). Это существенно снижает объем данных, отправляемых с исходного компьютера, и нагрузку на хранилище на целевом компьютере.
Недостатки этого программного решения включают необходимость внедрения и обслуживания на уровне операционной системы, а также повышенную нагрузку на вычислительную мощность машины.
Репликация журнала файловой системы
Подобно журналам транзакций базы данных , многие файловые системы могут вести журнал своей активности. Журнал можно отправлять на другой компьютер периодически или в режиме реального времени посредством потоковой передачи. На стороне реплики журнал можно использовать для воспроизведения изменений файловой системы.
Одним из наиболее заметных реализаций Microsoft «s System Center Manager Защита данных (DPM), выпущенный в 2005 году, который выполняет периодические обновления , но не предлагают репликации в режиме реального времени. [ необходима цитата ]
Содержание
Репликация в вычислительной технике может относиться к:
- Репликация данных , когда одни и те же данные хранятся на нескольких устройствах хранения
- Репликация вычислений , при которой одна и та же вычислительная задача выполняется много раз. Вычислительные задачи могут быть:
- Тиражируется в пространстве , где задачи выполняются на отдельных устройствах
- Репликация во времени , когда задачи выполняются повторно на одном устройстве
Репликация в пространстве или во времени часто связана с алгоритмами планирования. [1]
Доступ к реплицированному объекту обычно унифицирован с доступом к одному нереплицированному объекту. Сама репликация должна быть прозрачной для внешнего пользователя. В сценарии сбоя переключение реплик должно быть максимально скрыто с точки зрения качества обслуживания . [2]
Ученые-компьютерщики далее описывают репликацию как:
- Активная репликация , которая выполняется путем обработки одного и того же запроса на каждой реплике.
- Пассивная репликация , которая включает обработку каждого запроса на одной реплике и передачу результата на другие реплики.
Когда одна реплика лидера назначается посредством выбора лидера для обработки всех запросов, система использует схему первичного резервного копирования или главного подчиненного , которая преобладает в кластерах с высокой доступностью . Для сравнения, если какая-либо реплика может обрабатывать запрос и распространять новое состояние, система использует схему с несколькими основными или несколькими ведущими . В последнем случае необходимо использовать некоторую форму управления распределенным параллелизмом , такую как диспетчер распределенных блокировок .
Балансировка нагрузки отличается от репликации задач, поскольку она распределяет нагрузку различных вычислений по машинам и позволяет отбросить одно вычисление в случае сбоя. Однако балансировка нагрузки иногда использует внутреннюю репликацию данных (особенно репликацию с несколькими мастерами ) для распределения данных между машинами.
Резервное копирование отличается от репликации тем, что сохраненная копия данных остается неизменной в течение длительного периода времени. [3] Реплики, с другой стороны, часто обновляются и быстро теряют любое историческое состояние. Репликация - одна из старейших и наиболее важных тем в области распределенных систем .
И репликация данных, и репликация вычислений требуют, чтобы процессы обрабатывали входящие события. Процессы репликации данных пассивны и работают только для поддержания сохраненных данных, ответа на запросы чтения и применения обновлений. Репликация вычислений обычно выполняется для обеспечения отказоустойчивости и берет на себя операцию в случае отказа одного из компонентов. В обоих случаях основные потребности заключаются в обеспечении того, чтобы реплики видели одни и те же события в эквивалентном порядке, чтобы они оставались в согласованных состояниях, и любая реплика могла отвечать на запросы.
Существуют три широко цитируемые модели репликации данных, каждая из которых имеет свои собственные свойства и производительность:
- Репликация транзакций : используется для репликации транзакционных данных , например базы данных. Используется модель сериализуемости с одной копией , которая определяет допустимые результаты транзакции для реплицированных данных в соответствии с общими свойствами ACID (атомарность, согласованность, изоляция, долговечность), которые транзакционные системы стремятся гарантировать.
- Репликацияконечного автомата : предполагается, что реплицируемый процесс является детерминированным конечным автоматом и что возможна атомарная трансляция каждого события. Он основан на распределенном консенсусе и имеет много общего с моделью репликации транзакций. Иногда это ошибочно используется как синоним активной репликации. Репликация конечного автомата обычно реализуется посредством реплицированного журнала, состоящего из нескольких последовательных циклов алгоритма Paxos . Это было популяризировано системой Google Chubby и является ядром хранилища данных Keyspace с открытым исходным кодом . [4][5]
- Виртуальная синхронность : включает группу процессов, которые взаимодействуют для репликации данных в памяти или для координации действий. Модель определяет распределенный объект, называемый группой процессов . Процесс может присоединиться к группе, и ему предоставляется контрольная точка, содержащая текущее состояние данных, реплицируемых членами группы. Затем процессы могут отправлять многоадресные рассылки в группу и будут видеть входящие многоадресные рассылки в идентичном порядке. Изменения членства обрабатываются как специальная многоадресная рассылка, которая доставляет новое «представление членства» процессам в группе.
При репликации с несколькими главными серверами обновления могут отправляться на любой узел базы данных, а затем передаваться на другие серверы. Это часто желательно, но приводит к значительному увеличению затрат и сложности, что может сделать это непрактичным в некоторых ситуациях. Самая распространенная проблема при репликации с несколькими мастерами - предотвращение или разрешение конфликтов транзакций . Большинство решений для синхронной (или активной) репликации выполняют предотвращение конфликтов, в то время как асинхронные (или ленивые) решения должны выполнять разрешение конфликтов. Например, если одна и та же запись изменяется на двух узлах одновременно, система активной репликации обнаружит конфликт до подтверждения фиксации и прервет одну из транзакций. Система ленивой репликации позволит транзакции для фиксации и запуска разрешения конфликтов во время повторной синхронизации. [6] Разрешение такого конфликта может быть основано на отметке времени транзакции, на иерархии исходных узлов или на гораздо более сложной логике, которая принимает согласованные решения по всем узлам.
Репликация базы данных становится более сложной, когда она масштабируется по горизонтали и вертикали. Горизонтальное масштабирование включает больше реплик данных, а вертикальное масштабирование - реплики данных, расположенные на больших физических расстояниях. Проблемы, возникающие при горизонтальном масштабировании, могут быть решены с помощью многоуровневого протокола доступа с несколькими представлениями . Ранние проблемы вертикального масштабирования в значительной степени решались за счет повышения надежности и производительности Интернета. [7] [8]
Когда данные реплицируются между серверами баз данных, так что информация остается согласованной во всей системе базы данных, и пользователи не могут сказать или даже знать, какой сервер в СУБД они используют, считается, что система демонстрирует прозрачность репликации.
![]()
Активная (в реальном времени) репликация хранилища обычно реализуется путем распространения обновлений блочного устройства на несколько физических жестких дисков . Таким образом, любую файловую систему, поддерживаемую операционной системой, можно реплицировать без изменений, поскольку код файловой системы работает на уровне выше уровня драйвера блочного устройства. Он реализован либо аппаратно (в контроллере дискового массива ), либо программно (в драйвере устройства ).
Самый простой метод - это зеркалирование дисков , которое типично для локально подключенных дисков. Индустрия хранения сужает определения, поэтому зеркалирование - это локальная (ближняя) операция. Репликация может быть расширена по компьютерной сети , так что диски могут быть расположены в физически удаленных местах, и обычно применяется модель репликации базы данных главный-подчиненный. Целью репликации является предотвращение ущерба от сбоев или аварий, которые могут произойти в одном месте, или, в случае, если такие события действительно происходят, для улучшения возможности восстановления данных. Для репликации задержка является ключевым фактором, поскольку она определяет либо расстояние между сайтами, либо тип репликации, которую можно использовать.
Основная характеристика такой межсайтовой репликации - это то, как обрабатываются операции записи - посредством асинхронной или синхронной репликации; синхронная репликация должна ждать ответа целевого сервера в любой операции записи, тогда как асинхронная репликация этого не делает.
Синхронная репликация гарантирует «нулевую потерю данных» посредством операций атомарной записи, когда операция записи не считается завершенной, пока не будет подтверждена как локальным, так и удаленным хранилищем. Большинство приложений ожидают завершения транзакции записи, прежде чем продолжить работу, поэтому общая производительность значительно снижается. По сути, производительность падает пропорционально расстоянию, так как минимальная задержка определяется скоростью света . На расстоянии 10 км максимально быстрое прохождение туда и обратно занимает 67 мкс, тогда как вся локальная кэшированная запись завершается примерно за 10–20 мкс.
В асинхронной репликации операция записи считается завершенной, как только локальное хранилище подтверждает ее. Удаленное хранилище обновляется с небольшой задержкой . Производительность значительно увеличивается, но в случае сбоя локального хранилища не гарантируется, что удаленное хранилище будет иметь текущую копию данных (самые свежие данные могут быть потеряны).
Репликация на определенный момент времени создает периодические моментальные снимки, которые реплицируются вместо основного хранилища. Это предназначено для репликации только измененных данных, а не всего тома. Поскольку с помощью этого метода реплицируется меньше информации, репликация может происходить по менее дорогостоящим каналам связи, таким как iSCSI или T1, вместо оптоволоконных линий.
Многие распределенные файловые системы используют репликацию для обеспечения отказоустойчивости и предотвращения единой точки отказа.
Многие коммерческие системы синхронной репликации не «зависают», когда удаленная реплика выходит из строя или теряет соединение - поведение, которое гарантирует нулевую потерю данных, - а продолжают работать локально, теряя желаемую нулевую точку восстановления .
Методы оптимизации глобальной сети (WAN) могут применяться для устранения ограничений, налагаемых задержкой.
Репликация на основе файлов выполняет репликацию данных на логическом уровне (т.е. отдельных файлов данных), а не на уровне блоков хранения. Есть много разных способов сделать это, которые почти полностью зависят от программного обеспечения.
Драйвер ядра ( в частности, драйвер фильтра ) может использоваться для перехвата вызовов функций файловой системы, фиксируя любую активность по мере ее возникновения. При этом используется тот же тип технологии, что и для активных антивирусных программ в реальном времени. На этом уровне фиксируются логические файловые операции, такие как открытие, запись, удаление файла и т. Д. Драйвер ядра передает эти команды другому процессу, обычно по сети на другую машину, которая имитирует операции исходной машины. Подобно репликации хранилища на уровне блоков, репликация на уровне файлов допускает как синхронный, так и асинхронный режимы. В синхронном режиме операции записи на исходном компьютере задерживаются и не могут выполняться до тех пор, пока целевой компьютер не подтвердит успешную репликацию. Синхронный режим менее распространен в продуктах репликации файлов, хотя существует несколько решений.
Решения репликации на уровне файлов позволяют принимать обоснованные решения о репликации в зависимости от местоположения и типа файла. Например, могут быть исключены временные файлы или части файловой системы, не имеющие никакой коммерческой ценности. Передаваемые данные также могут быть более детализированными; если приложение записывает 100 байт, передаются только 100 байт вместо полного блока диска (обычно 4096 байт). Это существенно снижает объем данных, отправляемых с исходного компьютера, и нагрузку на хранилище на целевом компьютере.
Недостатки этого программного решения включают в себя необходимость внедрения и обслуживания на уровне операционной системы, а также повышенную нагрузку на вычислительную мощность машины.
Подобно журналам транзакций базы данных , многие файловые системы могут вести журнал своей активности. Журнал можно отправлять на другой компьютер периодически или в режиме реального времени посредством потоковой передачи. На стороне реплики журнал можно использовать для воспроизведения изменений файловой системы.
Одним из наиболее заметных реализаций Microsoft «s System Center Manager Защита данных (DPM), выпущенный в 2005 году, который выполняет периодические обновления , но не предлагают репликации в режиме реального времени. [ необходима цитата ]
Это процесс сравнения исходной и целевой файловых систем и обеспечения соответствия целевого файла источнику. Главное преимущество в том, что такие решения обычно бесплатны или недороги. Обратной стороной является то, что процесс их синхронизации является довольно ресурсоемким для системы, и, следовательно, этот процесс обычно выполняется нечасто.
Одна из замечательных реализаций - rsync .
Другой пример использования репликации появляется в системах с распределенной общей памятью , где многие узлы системы совместно используют одну и ту же страницу памяти. Обычно это означает, что каждый узел имеет отдельную копию (реплику) этой страницы.
Многие классические подходы к репликации основаны на модели первичного резервного копирования, в которой одно устройство или процесс имеет односторонний контроль над одним или несколькими другими процессами или устройствами. Например, первичный может выполнять некоторые вычисления, передавая журнал обновлений в резервный (резервный) процесс, который затем может взять на себя его выполнение в случае отказа основного. Этот подход является обычным для репликации баз данных, несмотря на риск того, что если часть журнала будет потеряна во время сбоя, резервная копия может быть в состоянии, отличном от состояния первичной, и тогда транзакции могут быть потеряны.
Ученый-компьютерщик Джим Грей проанализировал схемы репликации с несколькими первичными данными в рамках транзакционной модели и опубликовал широко цитируемую статью, в которой скептически относился к подходу «Опасности репликации и решение». [9] [10] Он утверждал, что, если данные не разделятся естественным образом, так что базу данных можно будет рассматривать как n n непересекающихся под-баз данных, конфликты управления параллелизмом приведут к серьезному снижению производительности, и группа реплик, вероятно, замедлится, поскольку функция n . Грей предположил, что наиболее распространенные подходы могут привести к деградации, которая масштабируется как O (n³) . Его решение, заключающееся в разделении данных, жизнеспособно только в ситуациях, когда данные действительно имеют естественный ключ разделения.
В 1985–1987 годах была предложена модель виртуальной синхронности, которая стала широко принятым стандартом (она использовалась в системах Isis Toolkit, Horus, Transis, Ensemble, Totem, Spread , C-Ensemble, Phoenix и Quicksilver, и является основа стандарта отказоустойчивых вычислений CORBA ). Виртуальная синхронизация допускает многоцелевой подход, при котором группа процессов взаимодействует для распараллеливания некоторых аспектов обработки запросов. Схема может использоваться только для некоторых форм данных в памяти, но может обеспечить линейное ускорение в размере группы.
Ряд современных продуктов поддерживает подобные схемы. Например, Spread Toolkit поддерживает ту же модель виртуальной синхронизации и может использоваться для реализации схемы репликации с несколькими первичными источниками; таким же образом можно было бы использовать C-Ensemble или Quicksilver. WANdisco разрешает активную репликацию, когда каждый узел в сети является точной копией или репликой, и, следовательно, каждый узел в сети активен одновременно; эта схема оптимизирована для использования в глобальной сети (WAN).
Выход из строя
При поломке одного из серверов в такой схеме необходимо сделать следующее:
- Исключить сервер из списка используемых.
- Настроить репликацию Master-Slave на новом сервере, используя один из рабочих серверов в качестве Мастера.
- Когда все данные репликации будут синхронизированы, включить сервер обратно в список используемых и остановить репликацию.
Выход из строя
При выходе из строя Слейва, достаточно просто переключить все приложение на работу с Мастером. После этого восстановить репликацию на Слейве и снова его запустить.
Если выходит из строя Мастер, нужно переключить все операции (и чтения и записи) на Слейв. Таким образом он станет новым Мастером. После восстановления старого Мастера, настроить на нем реплику, и он станет новым Слейвом.
Резервирование
Намного чаще репликацию Master-Slave используют не для масштабирования, а для резервирования. В этом случае, Мастер сервер обрабатывает все запросы от приложения. Слейв сервер работает в пассивном режиме. Но в случае выхода из строя Мастера, все операции переключаются на Слейв.
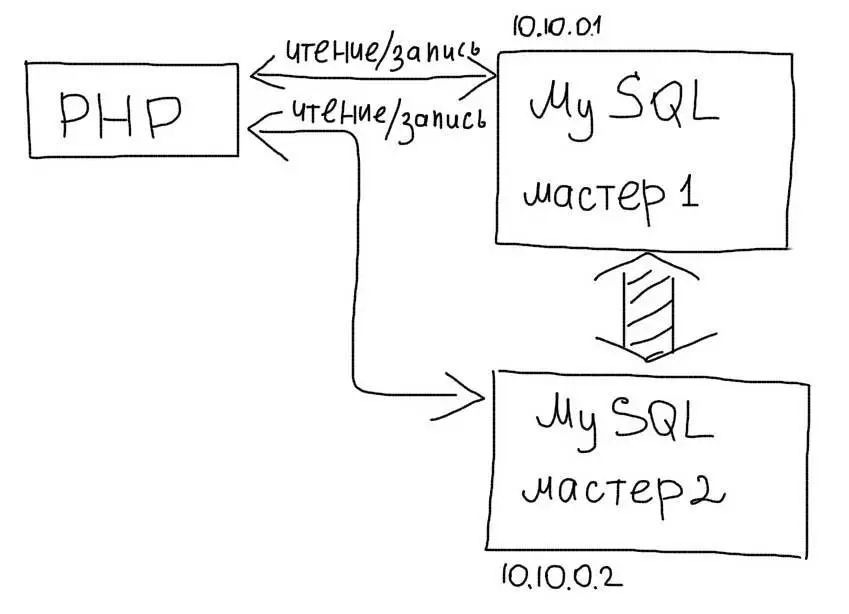
Master-Master репликация
![]()
В этой схеме, любой из серверов может использоваться как для чтения так и для записи:
При использовании такого типа репликации достаточно выбирать случайное соединение из доступных Мастеров:
Выбор случайного Мастера для обработки соединений
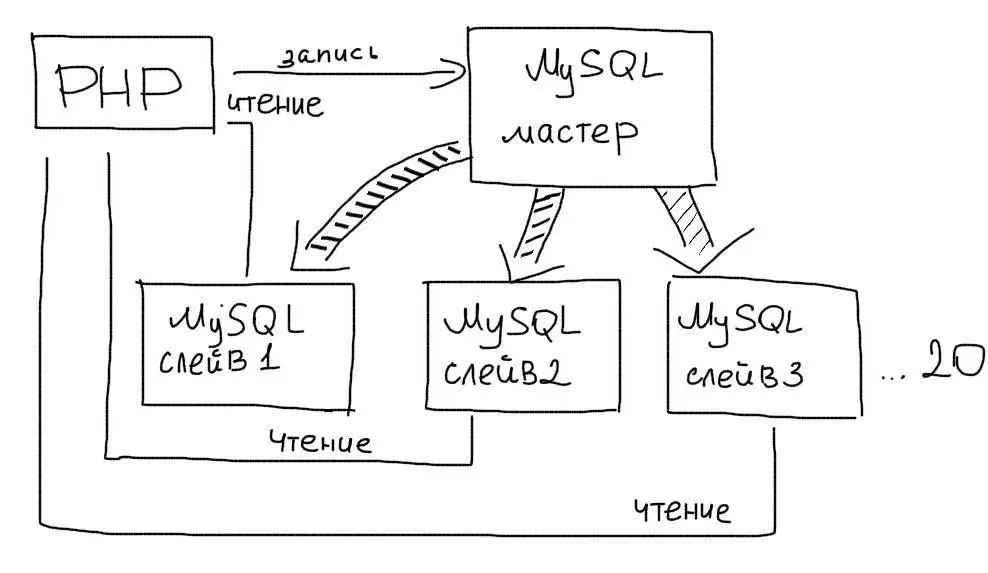
Несколько Слейвов
Преимущество этого типа репликации в том, что Вы можете использовать более одного Слейва. Обычно следует использовать не более 20 Слейв серверов при работе с одним Мастером.
![]()
Тогда из приложения Вы выбираете случайным образом один из Слейвов для обработки запросов:
Асинхронность репликации означает, что данные на Слейве могут появится с небольшой задержкой. Поэтому, в последовательных операциях необходимо использовать чтение с Мастера, чтобы получить актуальные данные:
При обращении к изменяемым данным, необходимо использовать Мастер-соединение
Модели репликации в распределенных системах
Существуют три широко цитируемые модели репликации данных, каждая из которых имеет свои собственные свойства и производительность:
- Репликация транзакций : используется для репликации транзакционных данных , например базы данных. Используется модель сериализуемости с одной копией , которая определяет действительные результаты транзакции для реплицированных данных в соответствии с общими свойствами ACID (атомарность, согласованность, изоляция, долговечность), которые транзакционные системы стремятся гарантировать.
- Репликацияконечного автомата : предполагается, что реплицируемый процесс является детерминированным конечным автоматом и что возможна атомарная трансляция каждого события. Он основан на распределенном консенсусе и имеет много общего с моделью репликации транзакций. Иногда это ошибочно используется как синоним активной репликации. Репликация конечного автомата обычно реализуется с помощью реплицированного журнала, состоящего из нескольких последовательных циклов алгоритма Paxos . Это было популяризировано системой Google Chubby и является ядром хранилища данных Keyspace с открытым исходным кодом . [4][5]
- Виртуальная синхронность : включает группу процессов, которые взаимодействуют для репликации данных в памяти или для координации действий. Модель определяет распределенную сущность, называемую группой процессов . Процесс может присоединиться к группе, и ему предоставляется контрольная точка, содержащая текущее состояние данных, реплицированных членами группы. Затем процессы могут отправлять многоадресные рассылки в группу и будут видеть входящие многоадресные рассылки в том же порядке. Изменения членства обрабатываются как специальная многоадресная рассылка, доставляющая новое «представление членства» процессам в группе.
При репликации с несколькими мастерами обновления могут отправляться на любой узел базы данных, а затем передаваться на другие серверы. Это часто желательно, но приводит к значительному увеличению затрат и сложности, что может сделать это непрактичным в некоторых ситуациях. Наиболее распространенной проблемой при репликации с несколькими мастерами является предотвращение или разрешение конфликтов транзакций . Большинство решений для синхронной (или активной) репликации выполняют предотвращение конфликтов, в то время как асинхронные (или ленивые) решения должны выполнять разрешение конфликтов. Например, если одна и та же запись изменяется на двух узлах одновременно, система активной репликации обнаружит конфликт до подтверждения фиксации и прервет одну из транзакций. Система отложенной репликации позволит обеим транзакциям фиксироваться и запускать разрешение конфликтов во время повторной синхронизации. [6] Разрешение такого конфликта может быть основано на отметке времени транзакции, на иерархии исходных узлов или на гораздо более сложной логике, которая принимает согласованные решения по всем узлам.
Репликация базы данных усложняется при ее масштабировании по горизонтали и вертикали. Горизонтальное масштабирование включает больше реплик данных, а вертикальное масштабирование - реплики данных, расположенные на больших физических расстояниях. Проблемы, возникающие при горизонтальном масштабировании, могут быть устранены с помощью многоуровневого протокола доступа с несколькими представлениями . Первые проблемы вертикального масштабирования в значительной степени решались за счет повышения надежности и производительности Интернета. [7] [8]
Когда данные реплицируются между серверами баз данных, так что информация остается согласованной во всей системе базы данных, и пользователи не могут сказать или даже знать, какой сервер в СУБД они используют, считается, что система демонстрирует прозрачность репликации.
![]()
Активная (в реальном времени) репликация хранилища обычно реализуется путем распространения обновлений блочного устройства на несколько физических жестких дисков . Таким образом, любая файловая система, поддерживаемая операционной системой, может быть реплицирована без изменений, поскольку код файловой системы работает на уровне выше уровня драйвера блочного устройства. Он реализован либо аппаратно (в контроллере дискового массива ), либо программно (в драйвере устройства ).
Самый простой метод - это зеркалирование дисков , которое типично для локально подключенных дисков. Индустрия хранения сужает определения, поэтому зеркалирование является локальной (ближней) операцией. Репликация может быть расширена по компьютерной сети , так что диски могут быть расположены в физически удаленных местах, и обычно применяется модель репликации базы данных главный-подчиненный. Целью репликации является предотвращение повреждений в результате сбоев или аварий, которые могут произойти в одном месте, или, если такие события действительно происходят, для улучшения возможности восстановления данных. Для репликации задержка является ключевым фактором, поскольку она определяет либо расстояние между сайтами, либо тип репликации, которую можно использовать.
Основной характеристикой такой межсайтовой репликации является то, как обрабатываются операции записи - посредством асинхронной или синхронной репликации; синхронная репликация должна ждать ответа целевого сервера в любой операции записи, тогда как асинхронная репликация этого не делает.
Синхронная репликация гарантирует «нулевую потерю данных» посредством операций атомарной записи, когда операция записи не считается завершенной до тех пор, пока не будет подтверждена как локальным, так и удаленным хранилищем. Большинство приложений ожидают завершения транзакции записи, прежде чем продолжить работу, поэтому общая производительность значительно снижается. По сути, производительность падает пропорционально расстоянию, поскольку минимальная задержка определяется скоростью света . На расстоянии 10 км максимально быстрое прохождение туда и обратно занимает 67 мкс, тогда как вся локальная кэшированная запись завершается примерно за 10–20 мкс.
В асинхронной репликации операция записи считается завершенной, как только локальное хранилище подтверждает ее. Удаленное хранилище обновляется с небольшой задержкой . Производительность значительно увеличивается, но в случае сбоя локального хранилища не гарантируется, что удаленное хранилище будет иметь текущую копию данных (самые свежие данные могут быть потеряны).
Репликация на определенный момент времени создает периодические моментальные снимки, которые реплицируются вместо основного хранилища. Это предназначено для репликации только измененных данных, а не всего тома. Поскольку с помощью этого метода реплицируется меньше информации, репликация может происходить по менее дорогостоящим каналам связи, таким как iSCSI или T1, вместо оптоволоконных линий.
Пакетная репликация
Это процесс сравнения исходной и конечной файловых систем и проверки того, что место назначения совпадает с источником. Ключевым преимуществом является то, что такие решения обычно бесплатны или недороги. Обратной стороной является то, что процесс их синхронизации является достаточно ресурсоемким для системы, и, следовательно, этот процесс обычно выполняется нечасто.
Одна из замечательных реализаций - rsync .
Другой пример использования репликации появляется в распределенных системах с общей памятью , где многие узлы системы совместно используют одну и ту же страницу памяти. Обычно это означает, что каждый узел имеет отдельную копию (реплику) этой страницы.
Многие классические подходы к репликации основаны на модели первичного резервного копирования, в которой одно устройство или процесс имеет односторонний контроль над одним или несколькими другими процессами или устройствами. Например, первичный может выполнять некоторые вычисления, передавая журнал обновлений в резервный (резервный) процесс, который затем может взять на себя управление в случае отказа первичного. Этот подход является обычным для репликации баз данных, несмотря на риск того, что если часть журнала будет потеряна во время сбоя, резервная копия может оказаться в состоянии, отличном от состояния первичной, и тогда транзакции могут быть потеряны.
Ученый-компьютерщик Джим Грей проанализировал схемы репликации с несколькими первичными данными в рамках транзакционной модели и опубликовал широко цитируемую статью, в которой скептически относился к подходу «Опасности репликации и решение». [9] [10] Он утверждал, что до тех пор, пока данные не разделятся естественным образом, так что базу данных можно будет рассматривать как n n непересекающихся под-баз данных, конфликты управления параллелизмом приведут к серьезному снижению производительности, и группа реплик, вероятно, замедлится, поскольку функция n . Грей предположил, что наиболее распространенные подходы, вероятно, приведут к деградации, которая масштабируется как O (n³) . Его решение, заключающееся в разделении данных, жизнеспособно только в ситуациях, когда данные действительно имеют естественный ключ разделения.
В 1985–1987 годах была предложена модель виртуальной синхронности, которая стала широко принятым стандартом (она использовалась в системах Isis Toolkit, Horus, Transis, Ensemble, Totem, Spread , C-Ensemble, Phoenix и Quicksilver, и является основа стандарта отказоустойчивых вычислений CORBA ). Виртуальная синхронизация допускает многоцелевой подход, при котором группа процессов взаимодействует для распараллеливания некоторых аспектов обработки запросов. Схема может использоваться только для некоторых форм данных в памяти, но может обеспечить линейное ускорение размера группы.
Ряд современных продуктов поддерживает подобные схемы. Например, Spread Toolkit поддерживает ту же виртуальную модель синхронизации и может использоваться для реализации схемы репликации с несколькими первичными источниками; таким же образом можно было бы использовать C-Ensemble или Quicksilver. WANdisco разрешает активную репликацию, когда каждый узел в сети является точной копией или репликой, и, следовательно, каждый узел в сети активен одновременно; эта схема оптимизирована для использования в глобальной сети (WAN).
"Replag" перенаправляется сюда. Для получения информации о задержке репликации баз данных Википедии см. Википедия: REPLAG .
Репликация в вычислениях включает обмен информацией для обеспечения согласованности между избыточными ресурсами, такими как программные или аппаратные компоненты, для повышения надежности, отказоустойчивости или доступности.
Заключение
Надеюсь, что в рамках данной статьи мне удалось дать базовое понимание процессов репликации, ознакомить с применением данного инструмента, и попробовать самостоятельно реализовать простой пример репликации в MySQL. Тема репликации, и ее практического применения крайне обширна, и если вас заинтересовала данная тема, могу порекомендовать к изучению следующие источники:
![]()
Репликация — одна из техник масштабирования баз данных. Состоит эта техника в том, что данные с одного сервера базы данных постоянно копируются (реплицируются) на один или несколько других (называемые репликами). Для приложения появляется возможность использовать не один сервер для обработки всех запросов, а несколько. Таким образом появляется возможность распределить нагрузку с одного сервера на несколько.
Обращение от редакции: Нашим защитникам из 3-го отдельного батальона УДА, которые находятся в Запорожской области, нужны вещи, чтобы противостоять врагу: квадрокоптеры и смартфоны для управления ими, прицелы ночного видения. Реквизиты для перевода средств на карту monobank – Колонович Катерина, номер карты 5375411505235312. Просим приобщиться к сбору средств. Слава Украине!
![Репликация баз данных]()
Существует два основных подхода при работе с репликацией данных:
- Репликация Master-Slave;
- Репликация Master-Master.
Синхронный режим
![]()
Синхронный режим репликации позволит гарантировать копирование данных на Слейв.
Это упростит работу в приложении, т.к. все операции чтения можно будет всегда отправлять на Слейв. Однако это может значительно уменьшить скорость работы MySQL. Синхронный режим не следует использовать в Web приложениях.
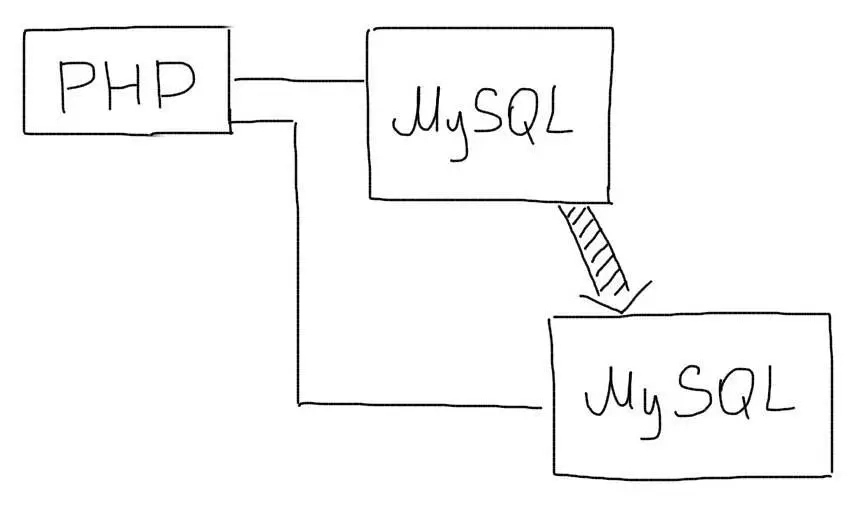
Что такое репликация, и зачем она нужна
Само по себе, понятие репликации означает процесс синхронизации нескольких копий объекта. В нашем случае, таким объектом является сервер БД, а наибольшую ценность представляют собой сами данные. Если мы имеем два и более серверов, и любым возможным способом поддерживаем синхронизированный набор данных на них — мы реализовали репликацию системы. Даже ручной вариант с mysqldump -> mysql load — это также репликация.
Стоит понимать, что сама по себе репликация данных не имеет ценности, и является лишь инструментом решения следующих задач:
- повышение производительности чтения данных. С помощью репликации мы сможем поддерживать несколько копий сервера, и распределять между ними нагрузку.
- повышение отказоустойчивости. Репликация позволяет избавиться от единственной точки отказа, которой является одиночный сервер БД. В случае аварии на основном сервере, есть возможность быстро переключить нагрузку на резервный.
- распространение данных. В современную эпоху глобализации ваше приложение может обслуживать пользователей со всего мира, и мы хотим, чтобы жители и Сиднея, и Хельсинки имели минимальную задержку доступа к нему.
- распределение нагрузки. В случае, если БД обслуживает запросы разных типов (быстрые и легкие, медленные и тяжелые), может иметь смысл развести эти запросы по разным серверам, для увеличения эффективности работы каждого типа.
- тестирование новых конфигураций. С помощью репликации есть возможность проведения тестирования новых версий сервера БД, изменения параметров конфигурации, и даже изменения типов хранилища данных.
- резервное копирование. С помощью репликации есть возможность делать механизмы резервного копирования более гибкими и вносить меньше негативных эффектов в работающую систему.
Модели репликации в распределенных системах
Существуют три широко цитируемые модели репликации данных, каждая из которых имеет свои свойства и производительность:
- Репликация транзакций : используется для репликации транзакционных данных , например базы данных. Используется модель сериализуемости с одной копией , которая определяет действительные результаты транзакции для реплицированных данных в соответствии с общими свойствами ACID (атомарность, согласованность, изоляция, долговечность), которые транзакционные системы стремятся гарантировать.
- Репликацияконечного автомата : предполагается, что реплицируемый процесс является детерминированным конечным автоматом и что возможна атомарная трансляция каждого события. Он основан на распределенном консенсусе и имеет много общего с моделью репликации транзакций. Иногда это ошибочно используется как синоним активной репликации. Репликация конечного автомата обычно реализуется с помощью реплицированного журнала, состоящего из нескольких последовательных циклов алгоритма Paxos . Это было популяризировано системой Google Chubby и является ядром хранилища данных Keyspace с открытым исходным кодом . [4][5]
- Виртуальная синхронность : включает группу процессов, которые взаимодействуют для репликации данных в памяти или для координации действий. Модель определяет распределенную сущность, называемую группой процессов . Процесс может присоединиться к группе, и ему предоставляется контрольная точка, содержащая текущее состояние данных, реплицированных членами группы. Затем процессы могут отправлять многоадресные рассылки в группу и будут видеть входящие многоадресные рассылки в том же порядке. Изменения членства обрабатываются как специальная многоадресная рассылка, доставляющая новое «представление членства» процессам в группе.
При репликации с несколькими мастерами обновления могут отправляться на любой узел базы данных, а затем передаваться на другие серверы. Это часто желательно, но приводит к значительному увеличению затрат и сложности, что может сделать это непрактичным в некоторых ситуациях. Наиболее распространенной проблемой при репликации с несколькими мастерами является предотвращение или разрешение конфликтов транзакций . Большинство решений для синхронной (или активной) репликации выполняют предотвращение конфликтов, в то время как асинхронные (или ленивые) решения должны выполнять разрешение конфликтов. Например, если одна и та же запись изменяется на двух узлах одновременно, система активной репликации обнаружит конфликт до подтверждения фиксации и прервет одну из транзакций. Система отложенной репликации позволит обеим транзакциям фиксироваться и запускать разрешение конфликтов во время повторной синхронизации. [6] Разрешение такого конфликта может быть основано на отметке времени транзакции, на иерархии исходных узлов или на гораздо более сложной логике, которая принимает согласованные решения по всем узлам.
Репликация базы данных усложняется при ее масштабировании по горизонтали и вертикали. Горизонтальное масштабирование включает больше реплик данных, а вертикальное масштабирование - реплики данных, расположенные на больших физических расстояниях. Проблемы, возникающие при горизонтальном масштабировании, могут быть устранены с помощью многоуровневого протокола доступа с несколькими представлениями . Первые проблемы вертикального масштабирования в значительной степени решались за счет повышения надежности и производительности Интернета. [7] [8]
Когда данные реплицируются между серверами баз данных, так что информация остается согласованной во всей системе базы данных, и пользователи не могут сказать или даже знать, какой сервер в СУБД они используют, считается, что система демонстрирует прозрачность репликации.
![]()
Активная (в реальном времени) репликация хранилища обычно реализуется путем распространения обновлений блочного устройства на несколько физических жестких дисков . Таким образом, любая файловая система, поддерживаемая операционной системой, может быть реплицирована без изменений, поскольку код файловой системы работает на уровне выше уровня драйвера блочного устройства. Он реализован либо аппаратно (в контроллере дискового массива ), либо программно (в драйвере устройства ).
Самый простой метод - это зеркалирование дисков , которое типично для локально подключенных дисков. Индустрия хранения сужает определения, поэтому зеркалирование является локальной (ближней) операцией. Репликация может быть расширена по компьютерной сети , так что диски могут быть расположены в физически удаленных местах, и обычно применяется модель репликации базы данных главный-подчиненный. Целью репликации является предотвращение повреждений в результате сбоев или аварий, которые могут произойти в одном месте, или, если такие события действительно происходят, для улучшения возможности восстановления данных. Для репликации задержка является ключевым фактором, поскольку она определяет либо расстояние между сайтами, либо тип репликации, которую можно использовать.
Основной характеристикой такой межсайтовой репликации является то, как обрабатываются операции записи - посредством асинхронной или синхронной репликации; синхронная репликация должна ждать ответа целевого сервера в любой операции записи, тогда как асинхронная репликация этого не делает.
Синхронная репликация гарантирует «нулевую потерю данных» посредством операций атомарной записи, когда операция записи не считается завершенной до тех пор, пока не будет подтверждена как локальным, так и удаленным хранилищем. Большинство приложений ожидают завершения транзакции записи, прежде чем продолжить работу, поэтому общая производительность значительно снижается. По сути, производительность падает пропорционально расстоянию, поскольку минимальная задержка определяется скоростью света . На расстоянии 10 км максимально быстрое прохождение туда и обратно занимает 67 мкс, тогда как вся локальная кэшированная запись завершается примерно за 10–20 мкс.
В асинхронной репликации операция записи считается завершенной, как только локальное хранилище подтверждает ее. Удаленное хранилище обновляется с небольшой задержкой . Производительность значительно увеличивается, но в случае сбоя локального хранилища не гарантируется, что удаленное хранилище будет иметь текущую копию данных (самые свежие данные могут быть потеряны).
Репликация на определенный момент времени создает периодические моментальные снимки, которые реплицируются вместо основного хранилища. Это предназначено для репликации только измененных данных, а не всего тома. Поскольку с помощью этого метода реплицируется меньше информации, репликация может происходить по менее дорогостоящим каналам связи, таким как iSCSI или T1, вместо оптоволоконных линий.
“Ручная” репликация
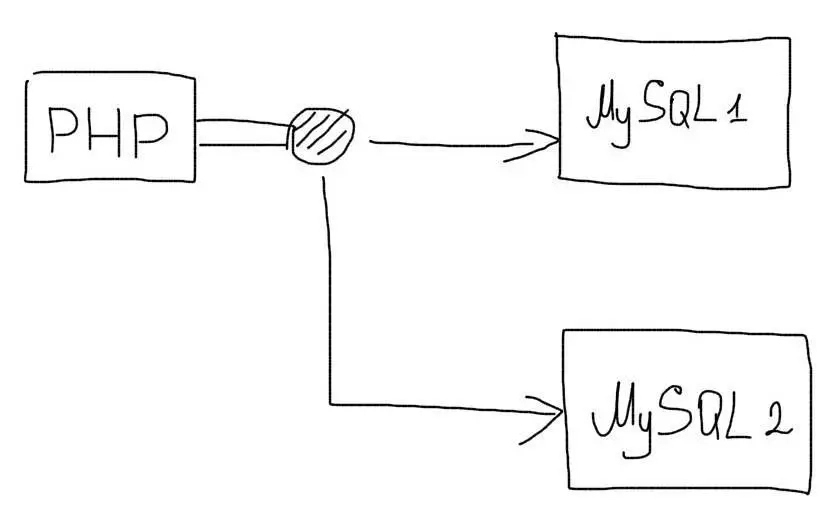
Следует помнить, что репликация — это не технология, а методика. Встроенные механизмы репликации могут принести ненужные усложнения либо не иметь какой-то нужной функции. Некоторые технологии вообще не имеют встроенной репликации.
![]()
В таких случаях, следует использовать самостоятельную реализацию репликации. В самом простом случае, приложение будет дублировать все запросы сразу на несколько серверов базы данных:
При записи данных, все запросы будут отправляться на несколько серверов. Зато операции чтения можно будет отправлять на любой сервер. Нагрузка при этом будет распределяться по всем доступным серверам:
Все операции изменения данных происходят на нескольких серверах, а чтения — на одном случайном
Это позволит использовать преимущества репликации даже если сама технология ее не поддерживает.
Реализации
Многие распределенные файловые системы используют репликацию, чтобы обеспечить отказоустойчивость и избежать единой точки отказа.
Многие коммерческие системы синхронной репликации не «зависают», когда удаленная реплика выходит из строя или теряет соединение - поведение, которое гарантирует нулевую потерю данных, - но продолжают работать локально, теряя желаемую нулевую точку восстановления .
Методы оптимизации глобальной сети (WAN) могут применяться для устранения ограничений, налагаемых задержкой.
Репликация на основе файлов выполняет репликацию данных на логическом уровне (т. Е. Отдельных файлов данных), а не на уровне блоков хранения. Есть много разных способов сделать это, которые почти полностью полагаются на программное обеспечение.
Пример построения простой репликации в MySQL
А сейчас настало время создать простую конфигурацию репликации в MySQL. Для этого мы будем использовать Docker и MySQL образы из dockerhub, а также базу данных world.
Для начала, запустим два контейнера, один из которых позже настроим как мастер, а второй — как слейв. Объединим их в сеть, чтобы они могли обращаться друг к другу.
Для мастер контейнера указано подключение volume c дампом world.sql, для того, чтобы имитировать наличие некоторой начальной базы на нем. При создании контейнера, mysql загрузит и выполнит sql скрипты, размещенные в директории docker-entrypoint-initdb.d.Для работы с конфигурационными файлами, нам потребуется текстовый редактор. Можно использовать любой удобный, я предпочитаю vim.
Первым делом, создадим учетную запись на мастере, которая будет использоваться для репликации:Далее, изменим конфигурационные файлы для мастер-сервера:
В файл my.cnf в секции [mysqld] необходимо добавить следующие параметры:
При включении/выключении двоичного журнала необходима перезагрузка сервера. В случае с Docker перезагружается контейнер.
Убедимся, что двоичный журнал включен. Конкретные значения, такие как имя файла и позиция, могут отличаться.
Для того, чтобы начать репликацию данных, необходимо “подтянуть” слейв до состояния мастера. Для этого, нужно временно заблокировать сам мастер, чтобы сделать слепок актуальных данных.
Далее, с помощью mysqldump сделаем экспорт данных из базы. Конечно, в данном примере можно использовать тот же world.sql, но приблизимся к более реалистичному сценарию.
После этого, необходимо еще раз выполнить команду SHOW MASTER STATUS, и запомнить или записать значения File и Position. Это, так называемые координаты двоичного журнала. Именно от них мы далее укажем стартовать слейву. Начиная с MySQL 5.6 стало возможным использование глобальных идентификаторов транзакций GTID вместо координат в виде файл-позиция. Это упростило настройку репликации, а также повысило стабильность ее работы. Но рассмотрение этой темы выходит за рамки данной статьи, и с ней можно ознакомиться в документации.Теперь можем снова разблокировать мастер:
Мастер настроен, и готов реплицироваться на другие сервера. Перейдем теперь к слейву. Первым делом, загрузим в него дамп, полученный с мастера.
А затем изменим конфиг слейва, добавив параметры:
После этого перезагрузим слейв:
И теперь нам нужно указать слейву, какой сервер будет являться для него мастером, и откуда начинать реплицировать данные. Вместо MASTER_LOG_FILE и MASTER_LOG_POS необходимо подставить значения, полученные из SHOW MASTER STATUS на мастере. Эти параметры вместе называются координатами двоичного журнала.
Запустим воспроизведение журнала ретрансляции, и проверим статус репликации:Если все прошло успешно, ваш статус должен иметь аналогичный вид. Ключевые параметры здесь:
- Slave_IO_State, Slave_SQL_State — состояние IO потока, принимающего двоичный журнал с мастера, и состояние потока, применяющего журнал ретрансляции соотвественно. Только наличие обоих потоков свидетельствует об успешном процессе репликации.
- Read_Master_Log_Pos — последняя позиция, прочитанная из журнала мастера.
- Relay_Master_Log_File — текущий файл журнала мастера.
- Seconds_Behind_Master — отставание слейва от мастера, в секундах.
- Last_IO_Error, Last_SQL_Error — ошибки репликации, если они есть.
И проверить, появились ли они на слейве.
Отлично! Внесенная запись видна и на слейве. Поздравляю, теперь вы создали свою первую репликацию MySQL!
Пакетная репликация
Это процесс сравнения исходной и конечной файловых систем и проверки того, что место назначения совпадает с источником. Ключевым преимуществом является то, что такие решения обычно бесплатны или недороги. Обратной стороной является то, что процесс их синхронизации является достаточно ресурсоемким для системы, и, следовательно, этот процесс обычно выполняется нечасто.
Одна из замечательных реализаций - rsync .
Другой пример использования репликации появляется в распределенных системах с общей памятью , где многие узлы системы совместно используют одну и ту же страницу памяти. Обычно это означает, что каждый узел имеет отдельную копию (реплику) этой страницы.
Многие классические подходы к репликации основаны на модели первичного резервного копирования, в которой одно устройство или процесс имеет односторонний контроль над одним или несколькими другими процессами или устройствами. Например, первичный может выполнять некоторые вычисления, передавая журнал обновлений в резервный (резервный) процесс, который затем может взять на себя управление в случае отказа первичного. Этот подход является обычным для репликации баз данных, несмотря на риск того, что если часть журнала будет потеряна во время сбоя, резервная копия может оказаться в состоянии, отличном от состояния первичной, и тогда транзакции могут быть потеряны.
Ученый-компьютерщик Джим Грей проанализировал схемы репликации с несколькими первичными данными в рамках транзакционной модели и опубликовал широко цитируемую статью, в которой скептически относился к подходу «Опасности репликации и решение». [9] [10] Он утверждал, что до тех пор, пока данные не разделятся естественным образом, так что базу данных можно будет рассматривать как n n непересекающихся под-баз данных, конфликты управления параллелизмом приведут к серьезному снижению производительности, и группа реплик, вероятно, замедлится, поскольку функция n . Грей предположил, что наиболее распространенные подходы, вероятно, приведут к деградации, которая масштабируется как O (n³) . Его решение, заключающееся в разделении данных, жизнеспособно только в ситуациях, когда данные действительно имеют естественный ключ разделения.
В 1985–1987 годах была предложена модель виртуальной синхронности, которая стала широко принятым стандартом (она использовалась в системах Isis Toolkit, Horus, Transis, Ensemble, Totem, Spread , C-Ensemble, Phoenix и Quicksilver, и является основа стандарта отказоустойчивых вычислений CORBA ). Виртуальная синхронизация допускает многоцелевой подход, при котором группа процессов взаимодействует для распараллеливания некоторых аспектов обработки запросов. Схема может использоваться только для некоторых форм данных в памяти, но может обеспечить линейное ускорение размера группы.
Ряд современных продуктов поддерживает подобные схемы. Например, Spread Toolkit поддерживает ту же виртуальную модель синхронизации и может использоваться для реализации схемы репликации с несколькими первичными источниками; таким же образом можно было бы использовать C-Ensemble или Quicksilver. WANdisco разрешает активную репликацию, когда каждый узел в сети является точной копией или репликой, и, следовательно, каждый узел в сети активен одновременно; эта схема оптимизирована для использования в глобальной сети (WAN).
Редкая современная продакшн система обходится без репликации баз данных. Это мощный инструмент на пути к повышению производительности и отказоустойчивости системы, и современному разработчику очень важно иметь хотя бы общее представление о репликации. В данной статье я поделюсь базовыми знаниями о репликации, и покажу простой пример настройки репликации в MySQL с помощью Docker.
![image]()
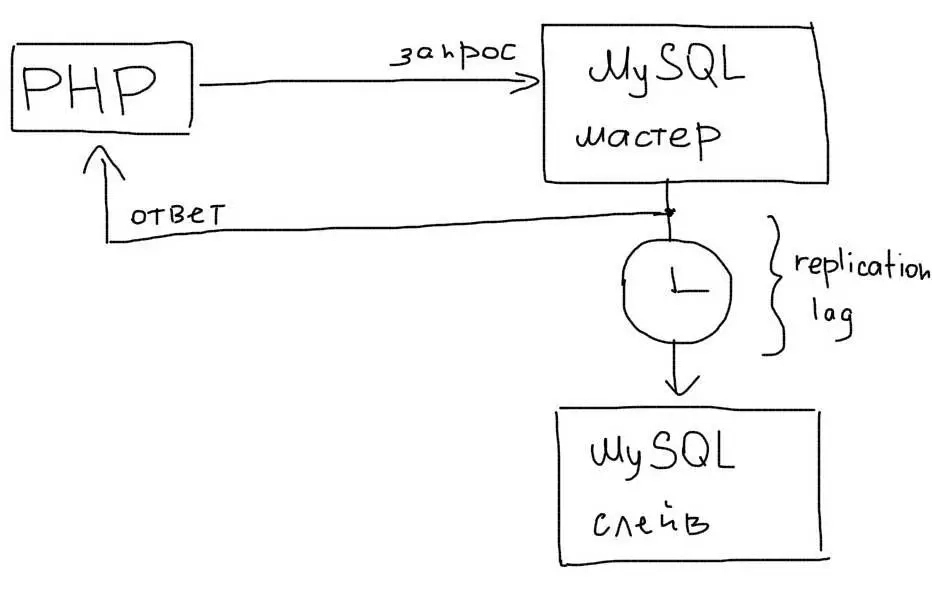
Асинхронность репликации
![]()
В MySQL репликация работает в асинхронном режиме. Это значит, что приложение не знает, как быстро данные появятся на Слейве.
Задержка в репликации (replication lag) может быть как очень маленькой, так и очень большой. Обычно рост задержки говорит о том, что сервера не справляются с текущей нагрузкой и их необходимо масштабировать дальше, например техниками горизонтального и вертикального шардинга.
Виды репликации
Существует два принципиально разных подхода к репликации: покомандная и построчная. В случае покомандной репликации, в журнал мастера протоколируются запросы изменения данных (INSERT, UPDATE, DELETE), а слейвы в точности воспроизводят те же команды у себя. При построчной же репликации в журнале окажутся непосредственно изменения строк в таблицах, и эти же фактические изменения применятся затем на слейве.
Как нет серебряной пули, так и каждый из этих методов имеет свои преимущества и недостатки. Покомандная репликация проще в реализации и понимании, снижает нагрузку на мастер и на сеть. Но тем не менее, покомандная репликация может приводить к непредсказуемым эффектам, при использовании недетерминированных функций, таких как NOW(), RAND(), и т.д. Могут быть также проблемы, вызванные рассинхронизацией данных между мастером и слейвом. Построчная же репликация приводит к более прогнозируемым результатам, так как фиксируются и воспроизводятся фактические изменения данных. Тем не менее этот метод может значительно увеличивать нагрузку на мастер-сервер, которому приходится фиксировать каждое изменение в журнале, и на сеть, через которую эти изменения распространяются.
В MySQL поддерживаются оба способа репликации, а дефолтный (можно сказать, что и рекомендуемый) изменялся в зависимости от версии. В современных версиях, например MySQL 8, по умолчанию используется построчная репликация.
Второй принцип разделения подходов к репликации — количество мастер-серверов. Наличие одного мастер сервера подразумевает, что только он принимает изменения данных, и является неким эталоном, с которого уже распространяются изменения на множество слейвов. В случае же с мастер-мастер репликацией мы получаем как и некоторый профит, так и проблемы. Один из плюсов, например, то, что мы можем давать удаленным клиентам из тех же Сиднея и Хельсинки одинаково быструю возможность записывать свои изменения в базу. Из этого исходит и главный недостаток, если оба клиента одновременно изменили одни и те же данные, чьи изменения считать окончательными, чью транзакцию коммитить, а чью откатывать.
Также, стоит отметить, что наличие мастер-мастер репликации в общем случае не может увеличить производительность записи данных в системе. Представим, что наш единственный мастер может обрабатывать до 1000 запросов в единицу времени. Добавив к нему реплицируемый второй мастер, мы не сможем обрабатывать по 1000 запросов на каждом из них, так как кроме обработки “своих” запросов, им придется применять изменения, сделанные на втором мастере. Что в случае покомандной репликации сделает суммарно возможную нагрузку на оба не больше, чем на самый слабый из них, а с построчной репликацией эффект не совсем предсказуемый, может быть как положительный, так и отрицательный, в зависимости от конкретных условий.
Модели репликации в распределенных системах
Существуют три широко цитируемые модели репликации данных, каждая из которых имеет свои собственные свойства и производительность:
- Репликация транзакций : используется для репликации транзакционных данных , например базы данных. Используется модель сериализуемости с одной копией , которая определяет действительные результаты транзакции для реплицированных данных в соответствии с общими свойствами ACID (атомарность, согласованность, изоляция, долговечность), которые транзакционные системы стремятся гарантировать.
- Репликацияконечного автомата : предполагается, что реплицируемый процесс является детерминированным конечным автоматом и что возможна атомарная трансляция каждого события. Он основан на распределенном консенсусе и имеет много общего с моделью репликации транзакций. Иногда это ошибочно используется как синоним активной репликации. Репликация конечного автомата обычно реализуется с помощью реплицированного журнала, состоящего из нескольких последовательных циклов алгоритма Paxos . Это было популяризировано системой Google Chubby и является ядром хранилища данных Keyspace с открытым исходным кодом . [4][5]
- Виртуальная синхронность : включает группу процессов, которые взаимодействуют для репликации данных в памяти или для координации действий. Модель определяет распределенную сущность, называемую группой процессов . Процесс может присоединиться к группе, и ему предоставляется контрольная точка, содержащая текущее состояние данных, реплицированных членами группы. Затем процессы могут отправлять многоадресные рассылки в группу и будут видеть входящие многоадресные рассылки в том же порядке. Изменения членства обрабатываются как специальная многоадресная рассылка, доставляющая новое «представление членства» процессам в группе.
При репликации с несколькими мастерами обновления могут отправляться на любой узел базы данных, а затем передаваться на другие серверы. Это часто желательно, но приводит к значительному увеличению затрат и сложности, что может сделать это непрактичным в некоторых ситуациях. Наиболее распространенной проблемой при репликации с несколькими мастерами является предотвращение или разрешение конфликтов транзакций . Большинство решений для синхронной (или активной) репликации выполняют предотвращение конфликтов, в то время как асинхронные (или ленивые) решения должны выполнять разрешение конфликтов. Например, если одна и та же запись изменяется на двух узлах одновременно, система активной репликации обнаружит конфликт до подтверждения фиксации и прервет одну из транзакций. Система отложенной репликации позволит обеим транзакциям фиксироваться и запускать разрешение конфликтов во время повторной синхронизации. [6] Разрешение такого конфликта может быть основано на отметке времени транзакции, на иерархии исходных узлов или на гораздо более сложной логике, которая принимает согласованные решения по всем узлам.
Репликация базы данных усложняется при ее масштабировании по горизонтали и вертикали. Горизонтальное масштабирование включает больше реплик данных, а вертикальное масштабирование - реплики данных, расположенные на больших физических расстояниях. Проблемы, возникающие при горизонтальном масштабировании, могут быть устранены с помощью многоуровневого протокола доступа с несколькими представлениями . Первые проблемы вертикального масштабирования в значительной степени решались за счет повышения надежности и производительности Интернета. [7] [8]
Когда данные реплицируются между серверами баз данных, так что информация остается согласованной во всей системе базы данных, и пользователи не могут сказать или даже знать, какой сервер в СУБД они используют, считается, что система демонстрирует прозрачность репликации.
![]()
Активная (в реальном времени) репликация хранилища обычно реализуется путем распространения обновлений блочного устройства на несколько физических жестких дисков . Таким образом, любая файловая система, поддерживаемая операционной системой, может быть реплицирована без изменений, поскольку код файловой системы работает на уровне выше уровня драйвера блочного устройства. Он реализован либо аппаратно (в контроллере дискового массива ), либо программно (в драйвере устройства ).
Самый простой метод - это зеркалирование дисков , которое типично для локально подключенных дисков. Индустрия хранения сужает определения, поэтому зеркалирование является локальной (ближней) операцией. Репликация может быть расширена по компьютерной сети , так что диски могут быть расположены в физически удаленных местах, и обычно применяется модель репликации базы данных главный-подчиненный. Целью репликации является предотвращение повреждений в результате сбоев или аварий, которые могут произойти в одном месте, или, если такие события действительно происходят, для улучшения возможности восстановления данных. Для репликации задержка является ключевым фактором, поскольку она определяет либо расстояние между сайтами, либо тип репликации, которую можно использовать.
Основной характеристикой такой межсайтовой репликации является то, как обрабатываются операции записи - посредством асинхронной или синхронной репликации; синхронная репликация должна ждать ответа целевого сервера в любой операции записи, тогда как асинхронная репликация этого не делает.
Синхронная репликация гарантирует «нулевую потерю данных» посредством операций атомарной записи, когда операция записи не считается завершенной до тех пор, пока не будет подтверждена как локальным, так и удаленным хранилищем. Большинство приложений ожидают завершения транзакции записи, прежде чем продолжить работу, поэтому общая производительность значительно снижается. По сути, производительность падает пропорционально расстоянию, поскольку минимальная задержка определяется скоростью света . На расстоянии 10 км максимально быстрое прохождение туда и обратно занимает 67 мкс, тогда как вся локальная кэшированная запись завершается примерно за 10–20 мкс.
В асинхронной репликации операция записи считается завершенной, как только локальное хранилище подтверждает ее. Удаленное хранилище обновляется с небольшой задержкой . Производительность значительно увеличивается, но в случае сбоя локального хранилища не гарантируется, что удаленное хранилище будет иметь текущую копию данных (самые свежие данные могут быть потеряны).
Репликация на определенный момент времени создает периодические моментальные снимки, которые реплицируются вместо основного хранилища. Это предназначено для репликации только измененных данных, а не всего тома. Поскольку с помощью этого метода реплицируется меньше информации, репликация может происходить по менее дорогостоящим каналам связи, таким как iSCSI или T1, вместо оптоволоконных линий.
Как MySQL реплицирует данные
Процесс репликации подразумевает собой распространение изменений данных с главного сервера (обычно он называется как мастер, master), на один или более подчиненных серверов (слейв, slave). Существуют и более сложные конфигурации, в частности с несколькими мастер-серверами, но для каждого изменения на конкретном мастер-сервере остальные мастера условно становятся слейвами, и потребляют эти изменения.
В общем виде, репликация в MySQL состоит из трех шагов:
- Мастер-сервер записывает изменения данных в журнал. Этот журнал называется двоичным журналом (binary log), а изменения — событиями двоичного журнала.
- Слейв копирует изменения двоичного журнала в свой, который называется журналом ретрансляции (relay log).
- Слейв воспроизводит изменения из журнала ретрансляции, применяя их к собственным данным.
Выход из строя
Вероятные поломки делают Master-Master репликацию непривлекательной. Выход из строя одного из серверов практически всегда приводит к потере каких-то данных. Последующее восстановление также сильно затрудняется необходимостью ручного анализа данных, которые успели либо не успели скопироваться.
Используйте Master-Master репликацию только в крайнем случае. Вместо нее лучше пользоваться техникой “ручной” репликации, описанной ниже.
Читайте также: