
Какой sql выбрать для 1с
Эта статья, надеюсь, поможет Вам определиться, что и в каком порядке Вам следует сделать, чтобы обойти возможные подводные камни. Скажу сразу, здесь не будет рекомендаций по выбору конкретного "железа" и процедуре переноса базы на SQL сервер. Это отдельные вопросы, ответы на которые можно найти в методической литературе и форумах в Интернете.
Здесь я расскажу Вам о принципах, которых Вам следует придерживаться при выборе и настройке SQL сервера.
Выбираем сервер
Я думаю, Вы переводите 1С на SQL с целью увеличения надежности и нагрузочной способности программы. Поэтому уделите особое внимание выбору сервера, на котором будет выполняться программа MS SQL Server (в статье будет рассматриваться MS SQL Server 2000, далее по тексту - SQL сервер):
-
Сразу выбирайте настоящий сервер, т.е. компьютер с серверной архитектурой. Тем самым Вы избавите себя от головной боли в будущем, когда по неизвестным причинам будет рушиться база 1С, перезагружаться компьютер, и добавление диска будет превращаться в неразрешимую задачу.
Конечно, не следует ставить 16ГБ памяти на сервер под управлением MS Windows Server 2003 Standard Edition (32-разрядная версия). Это будет пустой тратой денег, так как эта редакция Windows поддерживает только 4 ГБ памяти.
В то же время установка 2ГБ памяти при тех же условиях будет тоже нерациональной, так как SQL сервер не сможет воспользоваться всеми 2ГБ, которые теоретически ему может выделить операционная система.
Выбор объема оперативной памяти зависит как от версии операционной системы, так и от редакции SQL сервера. Например, если Вы собираетесь использовать MS Windows Server 2003 Standard Edition (32-разрядная версия) и MS SQL Server 2000 Standard Edition, ставьте 4ГБ памяти.
Примечания: ограничения по памяти для различных версий Windows Вы можете посмотреть в статьях "Memory Limits for Windows Releases" и "Memory Support and Windows Operating Systems".
Данные о максимальном объеме оперативной памяти, который может использовать каждая редакция SQL сервера, можно найти в Books Online (BOL) по строке поиска "Maximum Amount of Physical Memory". Небольшой фрагмент этой таблицы приведен ниже:
Определение количества жестких дисков
Давайте попытаемся определить, какое минимальное количество жестких дисков необходимо установить на сервер, чтобы создать благоприятные условия для работы SQL сервера. В то же время будем помнить об ответственности, которая возложена на этот сервер. Мы должны спроектировать дисковую систему так, чтобы выход из строя одного диска не привел к остановке сервера.
Начнем с операционной системы. Согласитесь, будет неприятно, если хорошо настроенный SQL сервер "упадет" из-за поломки винчестера, на котором установлена операционная система. Поэтому примем решение устанавливать систему на 2 диска, объединенные в RAID1. В этом случае даже если один винчестер выйдет из строя, сервер будет продолжать работать на втором.
Примечание: рассмотрение уровней RAID выходит за рамки данной статьи. Подробную информацию по этой теме Вы можете получить из BOL, используя строку поиска "RAID", а также из многочисленных статей в Интернете, например, "Конфигурирование и планирование подсистемы ввода-вывода".
Следующий этап - определение количества дисков для базы данных в формате SQL. SQL сервер хранит базу данных как минимум в 2х файлах:
- файл данных (*.mdf);
- файл транзакций (*.ldf).
Вы скажите, зачем мне еще 2 диска, когда операционная система установлена на RAID1, и места там еще предостаточно. Уверяю Вас, размещать файлы базы данных на том же диске, что и операционная система, не самое лучшее решение. Сейчас объясню, почему это так.
Сымитируйте работу SQL сервера, создав интенсивную нагрузку на дисковую подсистему сервера с помощью какой-нибудь специализированной программы, например, Performance Test или SQLIO. Во время выполнения теста попробуйте что-нибудь сделать на сервере. Как работается? Чувствуете, какое "торможение"? Это происходит из-за того, что тестирующая программа и операционная система используют для своих нужд один и тот же дисковый массив и мешают друг другу. Если не вынести интенсивную дисковую нагрузку на отдельные диски, операционная система либо совсем перестанет отвечать на запросы, либо будет работать очень медленно.
Надеюсь, Вы согласились, что файлы базы данных следует размещать отдельно от файлов операционной системы. Теперь зададимся вопросом, насколько рационально размещать файл данных (*.mdf) и файл транзакций (*.ldf) на одном дисковом массиве. Вспомним несколько особенностей работы SQL сервера:
- доступ к файлу данных преимущественно произвольный, т.е. в любой момент времени система может считывать и записывать самые разнообразные данные. Это приводит к тому, что головки жестких дисков постоянно перепозиционируются, а это приводит к замедлению операций ввода/вывода;
- доступ к файлу транзакций преимущественно последовательный, практически всегда в файл производится запись и лишь иногда чтение. Головки жестких дисков перемещаются в основном на соседние дорожки, что не занимает много времени;
- при внесении изменений в базу данных, эти изменения сначала фиксируются в файле транзакций, и лишь затем в файле данных во время очередной "chekpoint". Подробную информацию по работе с файлом транзакций можно получить из BOL по строке поиска "Write-Ahead Log".
Подведем итоги.
Нам необходимо 6 жестких дисков, организованных в 3 массива RAID1. Такое решение обеспечит надежность хранения данных, отказоустойчивость операционной системы и скорость обработки информации SQL сервером.
Если финансовые возможности позволяют, можно сделать SQL сервер еще более быстрым. Для этого надо вынести базу tempdb на отдельный диск или массив RAID0. Вот что говорится по этому поводу в BOL:
6 дисков - это тот необходимый минимум, который должен быть установлен на Вашем сервере. В процессе рабочей эксплуатации программы 1С может выясниться, что массив, на котором хранится файл данных (*.mdf), не успевает обрабатывать запросы. В этом случае Вам следует усилить дисковую подсистему:
- купить 2 или больше жестких дисков;
- вместо RAID1, на котором хранится файл данных, сделать RAID10 из 4, 6 и т.д. дисков
Я рекомендую размещать файл данных на массивах RAID10 или RAID1. Это самое дорогое, но в то же время самое надежное и быстрое решение (RAID0 не рассматривается, т.к. он не обеспечивает отказоустойчивости). RAID5 не подходит для работы с 1С, т.к. у него очень низкая скорость записи.
В заключение хочу дать еще один совет - создайте резерв из 2-3 винчестеров. Если вдруг что-то произойдет с жесткими дисками сервера, Вы сможете оперативно заменить их на исправные.
Предвижу Ваш вопрос - зачем такой большой резерв? В наше время характеристики жестких дисков меняются очень быстро, и новые модели приходят на смену старым. Может получиться так, что к тому моменту, когда на Вашем сервере выйдет из строя жесткий диск (например, через год), такие модели дисков уже не будут производиться.
В следующих статьях я расскажу Вам, как настроить этот сервер для работы с 1С.
Примечание: в статье отражено мое мнение по поводу выбора конфигурации для SQL сервера. Оно может не совпадать с Вашим мнением и / или мнением других специалистов.
Кнопка уже несколько лет для работы с бухгалтерскими базами использует технологию публикаций 1C Fresh. Мы уже недавно писали о нашем опыте эксплуатации. Использование нами в качестве СУБД PostgreSQL вызвало интерес и ряд вопросов, поэтому мы решили рассказать об этом подробнее.

Введение
В самом начале мы использовали в качестве СУБД традиционный для 1С MS SQL Server. Когда наш Fresh дорос до необходимости горизонтального масштабирования, стало понятно, что по экономическим соображениям нужна альтернатива продукту от Microsoft. Тогда мы внимательно посмотрели в сторону PostgreSQL, тем более что специалисты из 1С его рекомендовали к использованию в инсталляции 1С Fresh. Мы провели простое сравнение производительности на стандартных операциях и выяснили, что база Бухгалтерия Предприятия (БП) 3.0, содержащая около 600 областей работает не хуже. В то время мы переходили на схему нескольких виртуальных машин на Linux с сервером приложений и СУБД. Об этом немного рассказано в статье. Но по разным причинам через год пришли к схеме сервер приложений на Windows и СУБД с несколькими информационными базами (ИБ) на Linux. Но смеем вас заверить, что проблем с работой сервера приложений на Linux у нас не было, изменения связаны с некоторыми другими нашими особенностями работы.
Итак, в качестве сервера баз данных был выбран PostgreSQL. В этой статье Кнопка расскажет, как мы подружили одно с другим, и как это всё заработало.
В первой инсталляции использовали готовые deb-пакеты PostgreSQL 8.4.3-3.1C, предоставляемые 1С, так как это была рекомендуемая для использования версия. Но к сожалению, столкнулись с проблемой зависимостей при установке на Debian Wheezy, являющийся на тот момент oldstable выпуском, содержащим пакеты apache2.2 (поддержки apache2.4 в 1С тогда еще не было). В то время мы держали СУБД и сервер приложений на одном хосте, поэтому приходилось использовать oldstable. Для установки этой версии PostgreSQL требовался libc6 из Debian Jessie. В результате такого скрещивания получилась система, с которой особо ничего не сделаешь, даже установка NFS-клиента ломала необходимые для работы зависимости. Но переходить на другой дистрибутив Linux нам было не выгодно стратегически. Когда мы начали активно использовать микросервисы (для простоты мы называем их роботами), которые взаимодействовали с сервером приложений через COM-соединение, в базах данных начали появляться висящие коннекты, которые приводили к утечке памяти. Эта проблема решалась переходом на новую версию PostgreSQL, но в тот момент 1С еще не выпустил дистрибутив этой версии.
Мы приняли волевое решение перейти на использование сборки PostgreSQL 9.6 из репозитория Postgres Professional. Проблемы с зависимостями и утечкой памяти остались позади, и мы начали решать вопросы масштабируемости, распределения нагрузки и увеличения времени доступности. В настоящее время специалистами 1С уже обновлены сборки PostgreSQL, самая свежая 9.6.3, это вполне актуальная версия и надежнее использовать именно её. По информации от 1С новые сборки будут выпускаться оперативно.
В настоящее время мы работаем на Debian Jessie и далее мы будем рассматривать все вопросы в рамках этого дистрибутива.
Состояние нашей системы мы отслеживаем с помощью Zabbix, выглядит это вот так:

На графиках еще присутствуют старые серверы, но продуктив уже переведен с них на PostgreSQL 9.6.
А еще мы меряем количество транзакций:

И количество добавленных, измененных и удаленных строк:

В эксплуатации СУБД мы внимательно следим за нашими показателями и все настройки, приведенные ниже, родились именно из реальной эксплуатации и наблюдений. У нас сейчас 2 основных сервера СУБД, каждому из которых выделено по 8 ядер и 40 Гб памяти. Диски с базами располагаются на SSD. Этих ресурсов нам хватает для обслуживания 7 ИБ БП 3.0 с включенным режимом разделения данных (200-800 областей в одной базе). При такой конфигурации мы добились неплохой утилизации ресурсов с одной стороны и хорошего запаса для роста и пиковых нагрузок с другой.
Кластеры в PostgreSQL
При размещении нескольких ИБ на одной виртуальной машине, мы столкнулись со сложностью администрирования. Каждая ИБ желала своих настроек сервера, любая остановка СУБД отключала все базы, а еще архивация WAL совсем не имела смысла, потому что восстановление через этот механизм откатывало бы все базы на сервере.
Для начала каждую из наших баз разместили в отдельном кластере PostgreSQL, что дало возможность гибко управлять ими, запускать несколько независимых копий PostgreSQL на одном хосте, настроить потоковую репликацию, архивирование WAL, а также восстановление данных на момент времени (PiTR).
На практике процесс развертывания выглядит так:
У нас имеется машина, с установленным Debian 8 Jessie, уже установлен PostgreSQL 9.6 из репозитория Postgres Professional.
Создадим наш новый кластер:
После этого в /databases создастся каталог db_01, в котором разместятся файлы данных, а файлы конфигурации в /etc/postgresql/9.6/db_01/. Кластер будет использовать 9.6 версию PostgreSQL его экземпляр будет запущен на порту 5433. Сейчас кластер не запущен, это можно проверить командой:
Вносим изменения в конфигурационный файл кластера postgresql.conf, приблизительные значения параметров можно получить используя PgTune. За что отвечает тот или иной параметр подробно рассказано в документации, мы же поясним только те параметры, которые PgTune не учитывает.
max_parallel_workers_per_gather полезно установить значение равное количеству воркеров, которые будут использоваться параллельно для последовательного чтения таблиц. Это ускорит многие операции чтения. Исходите из количества ядер на вашем хосте, превышение этого количества не даст прироста производительности, а наоборот, произойдет деградация.
max_locks_per_transaction по-умолчанию 64, но в ходе работы значение подняли до 300. Параметр назначает количество блокировок объектов, выделяемых на транзакцию. Если будет использоваться слейв-сервер, то это значение на нём должно быть равно или больше чем на мастер-сервере.
Если файловая система не достаточно производительна, разместите pg_xlog на отдельном хранилище.
Для примера конфиг файл одного кластера:
Настало время запустить свежесозданный кластер и начать его использовать:
Для подключения по нестандартному порту в оснастке администрирования серверов 1С Предприятия в параметрах информационной базы в поле «Сервер баз данных» указать:
А еще важно не забывать про регулярное обслуживание базы. VACUUM и ANALYZE очень полезны.
Потоковая репликация
Реализация standby-сервера довольно проста.
Настроим master-сервер
Вносим изменения в файл конфигурации postgresql.conf, не забыв, что конфигурируем наш новый кластер и находится файл в /etc/postgresql/9.6/db_01/
listen_addresses = '*'
wal_level = replica
max_wal_senders = 3
wal_keep_segments = 128
Создадим новую роль replica:
И разрешим подключение для slave-сервера, поправив файл pg_hba.conf
После этого потребуется перезапустить кластер:
Теперь пришло время настроить slave-сервер. Предположим, что конфигурация его идентична мастеру, создан кластер с таким же названием, файлы данных лежат в каталоге, который смонтирован аналогично мастеру. Остановим кластер на слейве:
В файле postgresql.conf включаем режим standby:
hot_standby = on
Очищаем каталог с файлами данных на слейве /databases/db_01/ и делаем копию текущего состояния мастера на слейв:
Будет создан файл recovery.conf, поправим его по необходимости:
standby_mode = 'on'
primary_conninfo = 'user=replica password=MyBestPassword host=master.domain.local port=5433 sslmode=prefer sslcompression=1 krbsrvname=postgres'
В данном случае мы не делаем failover, который будет автоматически забирать роль мастера. Чтобы реплика начала работать в роли мастера достаточно переименовать файл recovery.conf и перезапустить кластер.
Запускаем слейв кластер:
Проверим, что репликация идет. На мастере появится процесс wal sender, а на слейве wal receiver. Более подробную информацию о репликации можно получить выполнив на мастере:
На слейве можно следить за значением, которое показывает когда проходила последняя репликация:
Резервное копирование и архивирование WAL
Первоначально резервирование производилось посредством pg_dump раз в сутки, что в совокупности с внутренним механизмом резервных копий областей в 1C Fresh давало приемлемую схему резервирования. Но иногда случаются ситуации, когда между моментом последнего бэкапа и моментом аварии проделано большое количество работы. Чтобы не потерять эти изменения нам поможет архивирование WAL-файлов.
Для включения архивирования WAL необходимо соблюсти три условия:
Параметр wal_level должен иметь значение replica или выше
Параметр archive_mode = on
В archive_command задана команды оболочки, например:
archive_command = 'test ! -f /wal_backup/db_01/%f && cp %p /wal_backup/db_01/%f'
Таким образом мы копируем архивные сегменты WAL в каталог /wal_backup/db_01/
Чтобы изменения вступили в силу, требуется рестарт кластера. Итак, когда очередной сегмент WAL будет готов, он будет скопирован, но чтобы им воспользоваться при восстановлении нужна базовая копия кластера, на которую будут применяться изменения из архивных сегментов WAL. С помощью простого скрипта мы будем создавать базовую копию и класть ее рядом с WAL-файлами.
Для того чтобы восстановить резервную копию на определенный период времени (PiTR) останавливаем кластер и удаляем содержимое
Затем распаковываем базовую копию, проверяем права и правим (либо создаем) файл recovery.conf со следующим содержанием:
restore_command = 'cp /wal_backup/db_01/%f %p'
recovery_target_time = '2017-06-12 21:33:00 MSK'
recovery_target_inclusive = true
Таким образом мы восстановим данные на момент времени 2017-06-12 21:33:00 MSK, а точка останова будет сразу после достижения этого времени.
Заключение
В боевой эксплуатации связка 1С Fresh и PostgreSQL показали себя достойно, конечно не сразу все было гладко, но мы справились. СУБД прекрасно работает под нагрузкой, которую генерируют около сотни пользователей, множество фоновых заданий и еще наши роботы день и ночь загружают и проводят выписки, создают документы из других инструментов, анализируют состояние нескольких тысяч областей.
Картинка про надежность связки 1C Fresh и PostgreSQL:

У нас более 350 Гб информационных баз отлично себя чувствуют, растут и развиваются. Чего и вам желаем!

При начале работ по установке и настройке 1С в любой компании встает вопрос выбора СУБД для обслуживания базы данных. Сотруднику, который ранее не сталкивался с этим вопросом, сложно разобраться в терминах и определиться с окончательным выбором. А ведь правильно подобранная и настроенная СУБД серьезно облегчит дальнейшую жизнь, поскольку от этого зависит, насколько оперативно будут обрабатываться команды 1С. Перед тем как определиться с СУБД, стоит узнать о специфике самых популярных из них.
Варианты работы 1С
Для начала стоит рассказать о специальном режиме работы 1С, в котором вообще не нужна внешняя СУБД. Речь идет о файловом режиме, в котором роль СУБД и сервера выполняет встроенный в 1С механизм. Это бюджетный вариант ведения учета, так как нет необходимости приобретать сервер и лицензии на него. Но данный вариант используется достаточно редко из-за небольшой скорости работы, низкой надежности и собственных ограничений 1С:
- Все таблицы представлены в виде 4 отдельных файлов, размер каждого из которых не может превышать 4 Гб:
- Описание таблицы;
- Индексы;
- Значения неограниченной длины;
- Записи.
- Ограничения длины ключа в индексах и количества полей для индексации;
- Возможные проблемы с выполнением регламентных заданий в ранних версиях 1С;
- Отсутствие возможности одновременного проведения документов;
- Прямой доступ пользователей к базе данных – любой сотрудник может случайно удалить ее или сделать копию.
Все вышеперечисленные моменты подводят к тому, что если количество пользователей больше 1, то необходимо использовать клиент-серверный вариант базы 1С. Он предпочтительнее со всех точек зрения, кроме стоимости – она действительно выше. Ведь в этом случае необходимо приобрести сервер приложений 1С и установить СУБД.
На сегодняшний день системы 1С официально поддерживают следующие виды:
- Платная MS SQL. Также существует бесплатная модификация MS SQL express edition, но у нее действует ограничение на размер базы данных – до 10 гб. Для удовлетворительного ведения учета компании этого явно недостаточно, поэтому этот вариант больше подходит для разработчиков;
- Платная Oracle BD;
- Бесплатная IBM DB2;
- Бесплатная PostgreSQL.
Особенности различных СУБД
При выборе не стоит опираться только на цену, так как СУБД сами по себе имеют множество особенностей. Их необходимо учесть заранее, поскольку, если этого не сделать, возможны существенные проблемы при работе пользователей. Самая популярная СУБД – MS SQL, поэтому знать ее отличительные особенности должны все профессионалы, работающие с ней:
- Небольшой размер БД постепенно растет по мере поступления новых данных;
- По умолчанию 1 файл с данными и 1 с логами;
- Требовательна к ресурсам;
- Нетребовательна к квалификации администратора, хорошо интегрируется с продуктами от Microsoft;
- Максимальное количество таблиц, используемых в запросе, ограничено 256.
Следующая из платных СУБД – Oracle BD:
- Высокие требования к квалификации администраторов;
- В подзапросах нельзя использовать конструкции «ПЕРВЫЕ» и «УПОРЯДОЧИТЬ»;
- При сортировке NULL ставится в конец таблицы;
- Статистические данные планов запроса ресурсозатратны.
Бесплатная PostgreSQL, популярность которой все интенсивнее растет в последнее время, и уже появляются мнения, что она способна потеснить MS SQL. Пока об этом говорить преждевременно, но знать особенности этой СУБД в современных условиях весьма полезно:
- Требования к квалификации существуют, весьма желательно понимать основные принципы и структуру БД;
- Достаточно требовательна данная СУБД и к ресурсам, но не как MS SQL;
- При сортировке NULL по умолчанию находится в начале таблицы. Но с помощью оператора NULLS LAST можно убрать эти значения в конец таблицы;
- Необходимость частой реиндексации при интенсивной работе;
- Требовательность к скорости записи и чтения жестких дисков;
- Полное внешнее соединение работает намного медленнее, чем в других СУБД;
- Облачные базы 1С:Фреш работают как раз на этой СУБД.
Об IBM DB2 можно сказать следующее:
- Средняя требовательность к квалификации специалистов;
- При создании базы резервируется место «на будущее» – базы «весят» существенно больше;
- Слабые возможности механизма временных таблиц, благодаря чему требования к ресурсам пониженные. Также скорость работы снижается и при использовании подзапросов;
- В операции like или подобно запрещено использовать шаблоны;
- В выборке не может быть более 1012 колонок;
- При группировке и сравнении различает регистр;
- Нетипизированное значение NULL;
- Ограничения длины ресурсов регистров и чисел.
К выбору СУБД нужно подходить весьма ответственно, не теряя из виду все важные факторы. При возможности стоит посоветоваться с профессионалами, уже имевшими опыт работы с базами на вышеперечисленных системах. Также стоит опираться на количество пользователей в вашей компании и сложность системы 1С. Практика администраторов 1С показывает, что производительность бесплатных СУБД ниже, чем MS SQL или Oracle.

При подборе серверного оборудования, если подразумевается эксплуатация типовых продуктов 1С, следует обратиться к фирменным рекомендациям 1С по конфигурации сервера, учитывающих количество пользователей, чтобы производительность сервера им соответствовала. При наличии подписки на ИТС, подобрать конфигурацию в соответствии с имеющимися ресурсами можно, обратившись к соответствующей статье. Например, серверы для 1С при малом внедрении должны иметь следующие характеристики:
| Количество пользователей | Процессор | Память | Диск |
|---|---|---|---|
| До 100 | 2 ядерный, HyperThreading | 8 ядер | 16 Гб |
Выбор сервера для 1С – рекомендации подбора необходимых компонент серверного оборудования
Оборудование сервера, которое оказывает влияние на производительность системы:
Процессор
При подборе модели процессора необходимо ориентироваться не только на количество ядер, но и на скорость работы, т.е. скорость обработки команд в одном потоке. При этом важно помнить, что планируемый процессор должен быть более позднего поколения, с такой же или большей частотой, чем текущий.
При расчете количества и параметров процессоров по методике 1С, получившееся дробное число необходимо округлить в сторону увеличения и после этого привести к количеству реальных процессоров. Например, если получилось 10,7, то округляя, получим 11, и кратное этому числу – 12 (два процессора по 6 ядер).
Основные показатели счетчиков:
\Processor(_Total)\% Processor Time – % загруженности процессоров;
\System(_Total)\Processor Queue Length – длина очереди к процессорам.
Диски
При подборе дисков следует руководствоваться показателями IOPS и пропускной способности, а также временем отклика в миллисекундах.
IOPS (input/output operations per second) или скорость обработки данных – это количество операций ввода-вывода, выполняемых системой хранения данных за одну секунду.
Замер IOPS обычно осуществляется по следующим показателям:
- IOPS среднее время операций произвольного чтения в секунду;
- IOPS среднее время операций произвольных записей в секунду;
- IOPS среднее число операций последовательных чтений в секунду;
- IOPS среднее число операций последовательных записей в секунду;
- Всего IOPS суммарное число записей/чтений в секунду.
На основании вышесказанного, необходимо определиться, какие именно параметры вас интересуют, и уточнить их у производителя, не полагаясь всецело только на итоговые показатели. Отметим, что указанные производителем величины воспроизвести на практике обычно не удается, поэтому перед приобретением, следует ознакомиться с существующими обзорами по выбранному продукту.
Под пропускной способностью обычно подразумевается запись/чтение файла в один поток, последовательно.
Под временем отклика подразумевается время, необходимое диску для начала операции чтения или записи.
Основные показатели счетчиков:
\PhysicalDisk(_Total)\Avg. Disk Queue Length – Очередь к дискам
\PhysicalDisk(*)\Avg. Disk Bytes/Write – Среднее время записи на диск
\PhysicalDisk(*)\Avg. Disk Bytes/Read – Среднее время чтения с диска
При выборе дискового массива следует также учитывать его отказоустойчивость, которая достигается во многом за счет дублирования информации. Рассмотрим наиболее часто употребляемый и рекомендуемый RAID 10 массив или RAID 1 + 0, известный как «чередование пары зеркал». Это обеспечивает избыточность первого зеркального отображения каждого диска, используя RAID 1, а затем чередование зеркальных дисков, с поддержкой RAID 0, повышает их производительность.
Недостатком конфигурации можно считать ее стоимость: поскольку только половина дискового пространства доступна для использования, для создания массива требуется приобрести вдвое большее число дисков. Тем не менее, именно эта конфигурация обладает оптимальной архитектурой для обеспечения отказоустойчивости, позволяя при выходе из строя нескольких дисков из разных блоков, поддержать работу системы в оперативном режиме, без снижения производительности.
Данный уровень комбинирует 0 и 1 уровень. От 1 уровня заимствуется создания пар «зеркал», а от 0 – объединение в массив. Получаются зеркальные пары, расположенные в массиве, что обеспечивает надежность и производительность. Заметим, что возможно использовать только четное число дисков и, если оба диска в одной из RAID 1 зеркальной пары выйдут из строя в одно и то же время, система больше не будет функционировать.
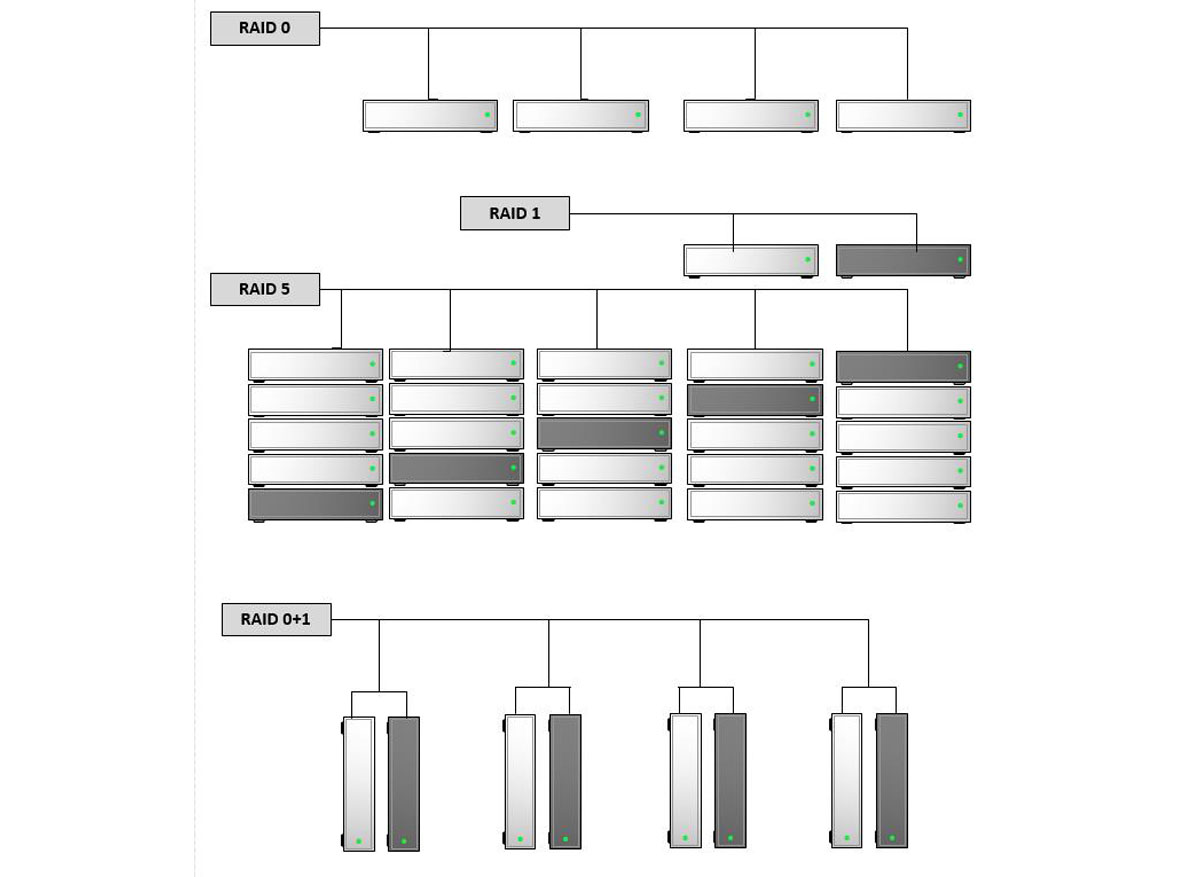
Рис.2 Общая схема RAID массивов
При подборе дисков также можно ориентироваться на:
- Рекомендации производителя. Результаты произведенных замеров предоставить поставщику дисков, чтобы он мог подобрать оборудование с расчетной скоростью больше, например, в 5раз и объемом – в 2 раза.
- Опубликованные данные программ нагрузочного тестирования. Многие производители, а также независимые ресурсы, публикуют данные по сравнительной производительности дисковых массивов.
- Выбор сервера для 1С - рекомендации. Например, получить информацию о тестировании по данной ссылке и пример использования утилиты SQLIO для сравнения производительности дисковых массивов для СУБД MS SQL Server.
- Рейтинги производителей. Информацию о надежности и долговечности носителей того или иного производителя легко найти в специализированных обзорах.
Память
При расчете целевой системы для подбора памяти сервера, необходимо просуммировать показатели следующих процессов:
Для SQL Sever наличие достаточного размера оперативной памяти является важным условием для оптимальной работы, поскольку любые изменения и данные, в том числе запросы на выборку данных, сначала загружаются в память, а затем записываются на диск. При этом многим другим операциям необходим скоростной доступ к памяти, например, при сортировке данных в предложения ORDER BY, в запросе для выполнения вычислений, для создания хэш объединения двух таблиц и пр.
Основные счетчики, которые необходимо собирать и анализировать:
Параметры рабочих процессов
Комментарии 1С: «Поддержка NUMA в кластере серверов «1С:Предприятие» полноценно пока не реализована. Сервер 1С не управляет распределением ресурсов по NUMA-узлам, полностью полагаясь в этом на операционную систему, что не всегда дает оптимальный результат».
Использование Numa-технологии в несколько процессоров, приводит к необходимости запуска определенного количество рабочих процессов для планомерной нагрузки процессоров.
Данное плановое количество рассчитывается на основании статистических данных по количеству подключений: статистический показатель – среднее количество пользователей – делится на количество Numa Nod. На основании данного показателя редактируется лимит соединений.
Например, «Количество соединений на процесс» для 12 процессоров при среднем количестве подключений – 120 ставит 10 (120/12).
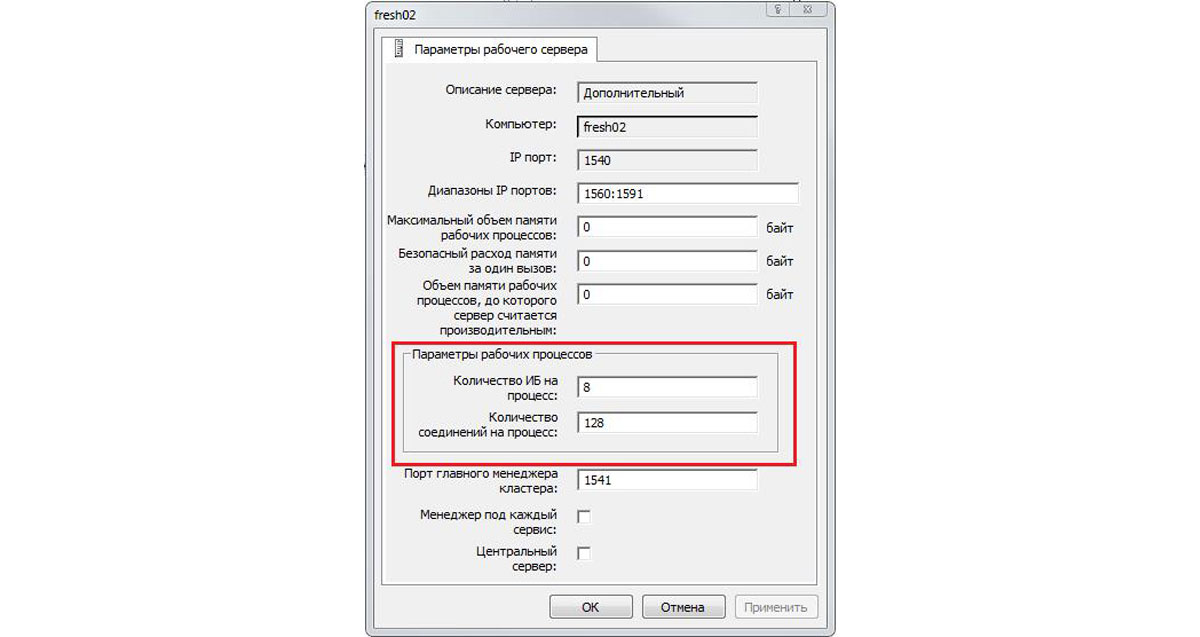
Рис.4 Параметры рабочих процессов
В процессе работы необходимо снимать показатели загрузки процессоров и корректировать количество процессов 1С, вводя корректирующие коэффициенты.
Заполнение по чек-листу настроек сервера для 1С
- На серверах разворачивайте только рабочие базы. Не держите там тестовые данные, развернутые бэкапы и другие базы разработчиков и тестировщиков.
- Определите, к каким из рабочих процессов rphost будет открыт доступ. В соответствии с политикой безопасности настройте права доступа для пользователя, под которым запущен сервер 1С. Можно также переопределить пользователей, от имени которых будут выполняться рабочие процессы и менеджер кластера.
- Настройте сбор логов и дампов с помощью технологического журнала и Windows Error Reporting Services.
События для технологического журнала:
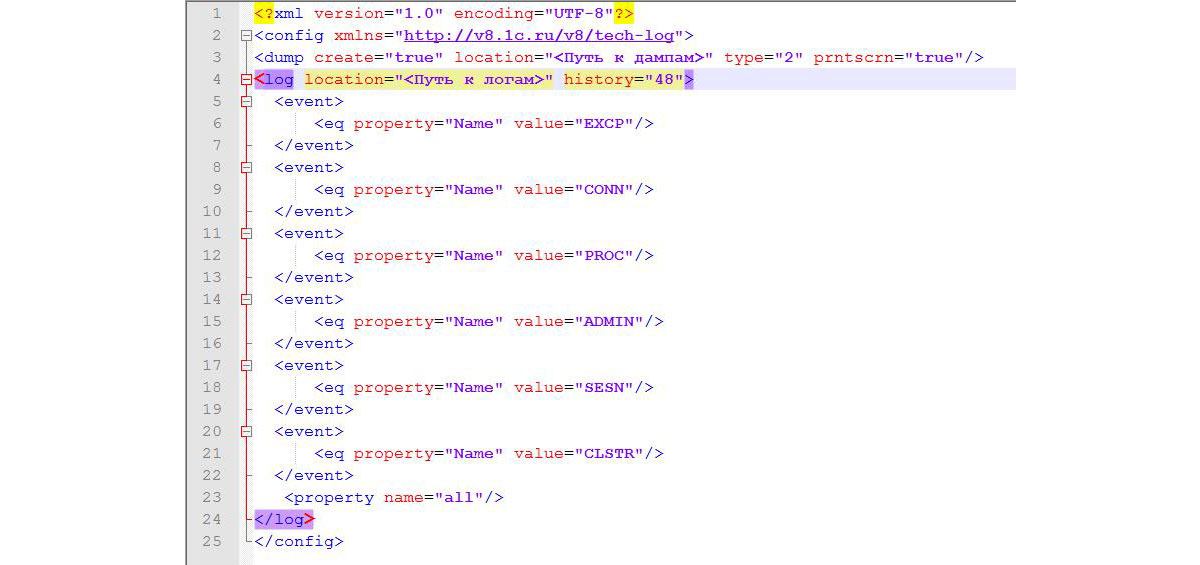
Рис.5 События для технологического журнала
- Проверьте, не блокирует ли брандмауэр соединения с сервером.
- Не используйте на рабочих серверах кластера одновременно IPv4 и IPv6.
- Для эффективного использования тактовой частоты процессора настройте схему управления питания и установите ее в положение «Высокая производительность».
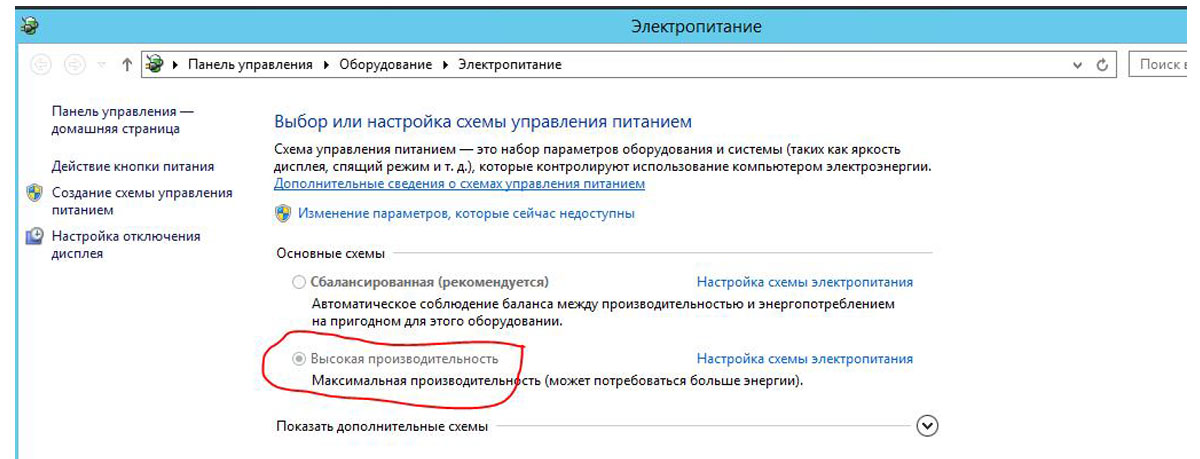
Рис.6 Электропитание
- Для релизов, с установленным режимом совместимости 8.3.8 или выше, установите актуальную версию Microsoft SQL Server Native Client на сервер 1С.
- Добавьте необходимые базы в рабочий кластер.
- Настройте число соединений и ИБ на процесс.
- Настройте время перезапуска. Если в рабочий кластер входит несколько серверов, то распределите нагрузку по серверам, используя «Требования назначения функциональности».
- Правильно разместите программные лицензии.
- При использовании режима отказоустойчивости, установите соответственный уровень отказоустойчивости и признак центрального сервера. Важно учитывать, что репликация памяти между серверами вызовет увеличение накладных расходов.
- Не настраивайте бэкапирования папок директорий сервера.
- Не производите сжатие этих папок и их содержимого.
- По возможности, отключите антивирусную защиту на сервере.
64- или 32-разрядный сервер 1С. Какой платформе отдать предпочтение?
Немного об архитектуре:
При использовании 32-разрядной ОС виртуальный размер процесса для версии Windows по умолчанию составляет 2 Гб. Если приложение использует большее адресное пространство, и система загружена со специальным параметром, размер процесса для 32-разрядной версии Windows может возрасти до 3 Гб, а для 64-разрядной — до 4 Гб.
Размер виртуального адресного пространства процесса для 64-разрядной версии Windows на системах IA64 составляет 7,152 Гб, а на системах x64 — 8,192 Гб.
1С не использует технологию AWE (Address Windowing Extension), которая позволяет процессу выделять больше физической памяти, чем может быть представлено в его виртуальном адресном пространстве.
В условиях ограничения объема процесса 1С в 2Гб и ограничения памяти 32-разрядные приложения могут использоваться для небольших компаний с небольшим количеством пользователей и не ресурсоемкими операциями. Помимо этого, как рекомендует 1С, запуск нескольких rphost позволит эффективнее использовать оперативную память сервера и снизить издержки фрагментации памяти.
В 64-разрядном сервере «1С:Предприятие» один rphost может полностью использовать и оперативную память, и процессорные ресурсы сервера. Поэтому для 64-разрядного сервера 1С нормальным считается запуск одного рабочего процесса на один сервер. При этом следует учесть аварийное завершение в процессе. В данном случае рекомендуется не менее двух.
В общем, планируется перевести пользователей на клиент-серверную версию (доступ по РДП, филиалы из разных городов) 1С. Выбираем между Postgre и MS SQL. Появились вопросы, которые никак не могу нагуглить уверенно.
Во первых - порядок лицензирования сервера. То есть в прайсе 1С есть такая вещь как "1С:Предприятие 8.3 ПРОФ. Лицензия на сервер", надо объяснить клиенту, зачем оно нужно.
Ну и порядок лицензирования MS SQL, если его выберем (postgre как я понял бесплатен, просто нуждается в грамотном админе).
Есть статья на хабре или еще что-нибудь?
(4) Сейчас вопрос в том, что предлагать и какую сумму озвучивать. Для этого надо разобраться в способе "монетизации" SQL. Хотя бы стандартный набор.
Плюс вопрос такой - насколько MS SQL любит виртуализацию, потому что админ очень ее любит, но я хз, читал, что нежелательно для сервера использовать виртуалку
(7) это всё плюсом к лицензиям 1С, я правильно понимаю? То есть условно есть 20+ лицензий 1С, на это дело еще надо 30 лицензий на сервак?
И вроде помню было обсуждение, что для использования "нестоковых" настроек, нужна КОРП лицензия, так?
(8) если коротко - то зависит от платформы. на сайте анандттеч есть статья с тестами мс скл в виртуальных средах.
(0)
Гляньте MS SQL Express, если влазите в ограничения. Она бесплатна, хорошая штука.
Postgre я пока не стал рекомендовать ни одному заказчику, ибо требует допилки.
(17) Ну "толковый админ" должен идти в комплекте с любым сервером. Из других подвохов помню только про требование КОРП лицезнии и всё вроде.
В идеале бы какой-нибудь "калькулятор", где можно было бы получить значения по лицензиям по своим параметрам)
(0) в 2020 покупать нужно не просто "1С:Предприятие 8.3 ПРОФ. Лицензия на сервер", а "1С:Предприятие 8.3 ПРОФ. Лицензия на сервер (x86-64)"
(0)>Ну и порядок лицензирования MS SQL
есть два принципиально разных варианта лицензирования
- сервер + клиенты
- по количеству ядер
если MS SQL будет использоваться только под 1С, то в прайсе 1С есть льготные лицензии:
- MS SQL Server 2019 Std Runtime - 18660 руб.
+ CAL по 9450 руб. за каждое рабочее место
вхерачить туеву хучу бабла за мелкомягких и не уметь ему дать ума - это очень грамотный подход, ага.
Между прочим, если до сих пор жили без грамотного админа, то это просто означает, что уровень решаемых задач позволяет обходиться без особых знаний, что сиквела, что постгри.
И еще. Если за постгри денег платить не нужно - ну так поставьте его и поработайте ну хотя бы 1 день или 2 дня, если админ у вас все равно будет хоть какой-то.
Ответьте сами себе честно - адин у вас есть? А если есть, то дайте ему задание и посмотрите на результат. Уровень использования у вас один фиг не доберется до каких-то критичных событий.
Вот мне что нравится в такого рода обсуждениях = хз лет тому назад один кто-то накорябал о допилках для постгри, потому что в те самые годы и не было готовых настроек для него.
Теперь же, не взирая на то, что на самих дистрибах 1С выкладывается сборка постгри, которая жестко глючить не будет, а проблемы могут появиться только если система будет реально нагружена, ну даже не знаю. может после 200 или 250 пользователей будут проблемы, а может и не будет.
А на 50, на 70, на 100 пользователей проблем не наблюдается.
Но нет. Это же страшный страшный постгри и надо приходить в ветки и рассказывать страшилки о неких сакральных знаниях, которые знают грамотные админы, а что это за знания сакральные кто-то о них что-то знает? Вы бы хоть у админов спросили, что это там такое сакральное, но ведь нет ничего! Но напугать обязательно нужно.
Насчет админа и его любви к виртуальным машинам. Пусть ставит. Потом можно будет спихивать на него различные тормоза в работе и возможные огрехи в поведении системы.
Я честно говоря не понял, Постгри тоже на Виндовозе рассматриваете в качестве СУБД?
Думаю, что настоящая стихия этих открытых СУБД: Posgres, MySQL, Oracle, sqlite является Linux. Тогда уж надо капитально переезжать на Linux, ставить стабильный CentOS 7, качать 1с сервер rpm пакеты, разворачивать субд, в вашем случае постгри на ней, тогда будет круто, а на винде это тухлый вариант, лучше оставаться на MS SQL.
(27) В прошлой организации столкнулся с тем, что при переходе не более новый релиз постгри, предоставленный 1С, начали сыпаться ошибки по правам к таблицам и связам на уровне СУБД. Начал копать, находил нечастые случаи аналогичных ошибок. По совету на одном из форумов скачал и поставил сборку от ПГПро - завелось, ошибок СУБД не нашлось.
Вывод: все, что делаете - на свой страх и риск. Есть бабло, берите мс. С точки зрения производительности, функционала и несложности использования не прогадаете, тем более, если будете пользоваться гуем. С баблом напряг, постгри - ваш вариант. Но только на линуксе. Есть свои нюансы. Есть готовые решения с патчами. Работать можно. Одно из "но" - рано или поздно, когда заходите обновить СУБД, можете уткнуться в проблему с модульной (пакетной) совместимостью на уровне ОС, на которой стоит СУБД. Но это все решаемо - гуглится.
(27) К сожалению, стратегия построения плана запроса в постгресе так и не поменялась. И всё так же он жестко лажает при запросе с подзапросами, запуская нестедлуп по таблицам с миллионами записей вместо оптимизированных на размер стратегий. И вряд ли это исправят, без радикальной переписки ядра постгреса, чтобы план строился не на запрос в целом, а уточнялся по мере исполнения подзапросов. А оно надо только 1сникам.
(33) Гуру - не гуру, но когда организация дорастает до наличия сервера и филиалов в разных городах - за этим сервером надо кому-то следить и настраивать
(0) Сроки есть? В случае MS SQL закладывайте 45 дней на проверку того, что вы не подпадаете под санкции США.
(26) PostgreSQL без грамотного админа может уйти в себя на сутки при выполнении не самого сложного запроса типовой конфигурации. MS SQL даже с настройками по дефолту и без обслуживания себе такого не позволяет.
(27) На 1 пользователе можно словить проблемы. Просто 1 ядро грузится на 100% от получаса до суток. И хорошо если это отчет, а не проведение документа. И это на дистрибутиве от 1С.
(36) Ну до конца года скорее всего не будет перехода. Мы не в РФ, так что вроде без санкций)
(37) вот вот.
Сейчас главное правильно выбрать вектор. Чтобы потом не лохануться, вертать взад может быть дорого по взаимоотношениям с клиентом
(39) вообще то, РК это Республика Крым.
И то что вы не под санкциями, не значит толком ничего. У нас с вами общее экономическое пространство, поэтому, что у нас нет половины мировых новинок автомобилей, что у вас..что в Белоруссии..
(39) Тогда в чем выбор-то? Рекомендуйте клиенту MS SQL, если ему дорого - делите с ним ответственность.
Postgres это дешево, сердито, работает. Слышал 100раз. То что Postgres круче чем MS SQL - ни разу. Грамотный, вменяемый, доступный админ понадобиться рано или поздно в любом случае.
(39) На санкции проверяют всех. Вдруг вы на 50% принадлежите кому-то из санкционного списка? Там надо раскрутить всю цепочку юр. лиц до конечных собственников, и если вдруг найдут что-то подозрительное - могут и отказать вообще.
(41) Ну мы не любим советовать то, что им явно излишне на их количестве пользователей. И если рекомендовать - надо сразу понять так сказать "счет на оплату" выкатить, чтобы каждый пункт я мог объяснить, почему столько и чего.
(44) Ну то что вам на мисте сказали, это же тоже не аргумент? Вы постгрес ставили/настраивали хоть раз? А MS SQL? Проведите изыскания: поставьте, прогоните тесты, сравните. Погуглите и все вопросы отпадут.
P.S. Мне Постгрес нравиться ровно тем, что я умею его готовить. MS SQL не умею, в редакциях не разбираюсь, ценники не видел. Но еще ни разу не слышал, что он работает хуже Postgres.
(45) Ставил MS SQL версию для ознакомления (Express вроде называется) и пробно прогонял. Но это же не дает никакого реального опыта. Но есть надежда тут встретить опытных людей, кто сможет хотя бы дать начальное понимание, что и куда.
(0) SQL просто работает. C Postgree надо быть готовым к сюрпризам.
Как вариант: начать с бесплатного Postgree. Если не осилите - переезжать на MS SQL.
(47) Тоже склоняюсь к такому варианту судя по комментариям выше. От Постгре потеряем только время на перенастройку, если не взлетит
(38) Это он пытается построить хоть сколько-нибудь выполнимый план примерно такого запроса postgesql долго выполняет запрос срез последних
Старые конфы(ББУ, БГУ 1.0, в моем случае) этим когда-то(давно) грешили. Пг-админ почти ничем не поможет, разве что только выключить в оптимизаторе nested loops для ряда конкретных случаев.
Если учитывать подобные особенности, серьезных проблем возникать не должно.
(50) вот-вот - нужно смотреть именно подробности, потому что вероятность словить такие же точно подробности может быть и существует, но это .
Ну работают в моем опыте, дай бог памяти, ну где-то еще до 2010 года начали использовать ПГ в базах.
Да, можно встретить некую загадочную ххх-ю , но для этого нужно очень сильно постараться. В типовых базах, т.е. без ручек само-разработчиков, шансы словить проблемы, даже если установлена постгри на винде, крайне низкие. А в последние годы, даже наоборот, что накосячить с обычным дистрибом постгри от 1С под винду, чтоб он заглючил. Ну это еще постараться нужно очень сильно.
Причем, если такие проблемы в базе возникают, то это будет означать, что и на сиквеле обыкновенном эта баз тоже может поймать проблемы.
И еще раз, пишите что доросла база или Компания до покупки выделенного сервера внезапно.
Уточните, если не трудно, а сколько же пользователей могло работать в этой базе в файловом режиме и без сервера?
И сколько пользователей будет работать сейчас?
И если не трудно, то может намекнете какие конфигурации у этих баз или если не хотите называть сами конфигурации, то характеристики какие-то, может там версии БСП и режим совместимости и какую платформу 1С (версию платформы) собираетесь ставить. Ну и т.д.
Инфы же нет никакой в топике. Хотя рассуждать, что МС Сиквел однозначно рулит всегда вегде и для всех - ну можно, что тут сомневаться ваапще?!
Вот для уравновешивания ссылки на обсуждение постом выше еще одна ссылка
(52) УТ (аналог вашей 11.3 или 11.4) и БК 3.0 (аналог вашей БП 3.0)
Смысл зарождения сервера именно в появлении филиалов в других городах. Пользователей то не очень много, просто раз решили делать сервак, то лучше сразу потратиться на нормальный, чтобы потом не перенастраивать. Условно - 10-15 сейчас, ожидается до 30 пользователей. Возможно часть будет работать через web, часть через РДП.
Мой совет такой. Если жестких, каких-то сумасбродных и радикальных допилов никто не успел на базы навернуть, то с точки зрения работы платформы разницы, скорей всего, не заметите. Хоть один, хоть другой вариант на этом режиме нагрузки не доберутся до критичных состояний. Однако.
Не нужно забывать о безопасности работы, когда вдруг внезапно, по каким-то обстоятельствам внезапно приключится потребность хотя бы поднять базу и архива,
а при этом окажется, что их просто нет. Т.е. что-то вроде описанного в (53)
Будет это база в любом формате, но такая технология безопасной эксплуатации должна быть продумана и отработана практически до мелочей.
Сколько на такое обеспечение будет потрачено денег - это уже второй вопрос, тем более, что на таком количестве пользователей и не самый тяжёлый.
Читайте также: