
Как написать химический элемент в ворде
Химическая схема в Word. Сегодня в комментариях мне задали вопрос: — Как в Ворде нарисовать мезомерные эффекты в органических соединениях? Откровенно говоря, в химии я понимаю, как баран в библии. Но, как говорится «Взялся за гуж — не говори, что не дюж». Посмотрела я в Интернете, что это за «зверь» такой — мезомерный эффект, и решила описать создание такой формулы на примере «Мезомерного эффекта заместителей». Как оказалось, ничего сложного в создании такой формулы нет. Хотя для таких целей лучше использовать специальные программы, которые наверняка есть в Интернете. Но раз просят показать в Ворде, то будем делать в Ворде.
Химическая схема в Word органических соединений
Для того чтобы нарисовать такую схему в Word, нам понадобиться вспомнить статью Как нарисовать схемы в Word 2003. Если что-то будет не понятно, то переходите и смотрите. А пока займемся описанием создания химической схемы.
Устанавливаем курсор на документе, в том месте, где мы хотим расположить нашу схему. Выбираем в самом низу окна на панели Рисование инструмент Прямоугольник, и щелкаем по нему мышкой.

У нас появиться вот такая рамочка-заготовка нашей будущей схемы. Именно в ней мы и будем её создавать.

Идем на той же панели Рисование в инструменты Автофигуры, и выбираем там Блок-схема – фигуру Подготовка.

Просто щелкаем по этой фигуре мышкой, а потом переходим на наше полотно и щелкаем мышкой в том месте, где хотим расположить первый элемент формулы. Потом всё это можно будет переместить.
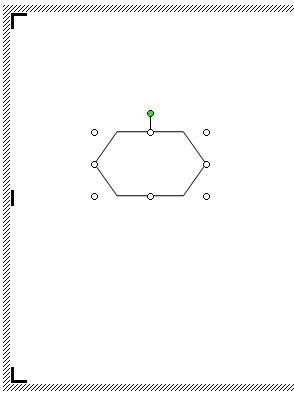
Теперь нам надо развернуть эту фигуру и немножко изменить. Подводим курсор мышки к зеленому кружочку. Вокруг этого кружочка появится круговая черная стрелка. Не отпуская клавишу, поворачиваем фигуру перемещением мышки по столу, пока фигура не повернется так, как нам необходимо.
Теперь можете отпустить клавишу. Потом подводим курсор к правому белому кружочку (он примет вид двунаправленной стрелки), и опять же, не отпуская клавишу немного растягиваем фигуру вправо.
В инструментах Автофигуры выбираем Соединительные линии – Прямая соединительная линия.

Переходим опять на нашу заготовку, подводим курсор к верхушке фигуры, совмещаем курсор с кружочком верхушки (сначала выделите фигуру щелчком мыши по ней), и не отпуская левой клавиши мыши протягиваем линию вверх.
Внутри фигуры линии будем делать инструментом Линия.
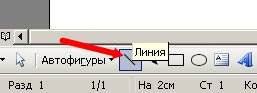
Щелкаем по этому инструменту и переходим к нашей фигуре. Сразу хочу сказать, что линии внутри фигуры делать не просто, поэтому мы будем рисовать её снаружи и переносить вовнутрь. Для удобства можно увеличить масштаб вашего документа.
Параллельную линию лучше рисовать с нажатой клавишей Alt. Длинной ее не рисуйте, иначе она при переносе приклеится к какому-нибудь маркеру (кружочки на выделенной фигуре), и придется создавать её заново. Вообще этот процесс оказался самым трудоемким. Без тренировки сразу не получится.
После создания линии, наводим на неё курсор, и когда он примет вид крестика со стрелочками на концах, нажимаем левую кнопку мыши, и не отпуская её, перемещаем линию вовнутрь фигуры, ближе к боковой грани. Не старайтесь приблизить линию очень близко – она приклеится к боковой грани.
После каждой неудачной попытки необходимо опять щелкать по инструменту Линия. С пяти попыток у меня получилось. И не забывайте нажимать и удерживать клавишу Alt, когда рисуете косые линии.
Ну вот, самое сложное мы сделали.
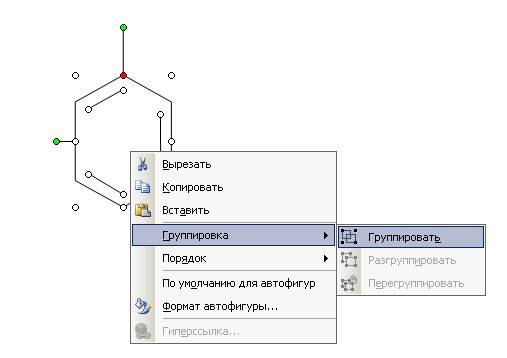
Теперь мы объединим все наши фигуры и линии в одно целое. Для этого выделите каждый элемент щелчком мыши, удерживая клавишу Ctrl, как у меня на рисунке. У каждой фигуры должны появиться маркеры.
Аккуратно щелкните правой кнопкой мыши внутри главной фигуры (так, чтобы маркеры не исчезли), и выберите из выпадающего меню – Группировка – Группировать.
Теперь эту фигуру можно перемещать и копировать.
Совет.
Создавайте эти рисунки в отдельном документе, и сохраняйте как шаблон. Потом вы просто будете копировать необходимый рисунок, вставлять его в документ и дописывать к нему формулы.
Так как нам нужен не один такой элемент, то мы скопируем его и перенесем копию в другое место.
Щелкните правой кнопкой мыши внутри фигуры, и выберите Копировать.
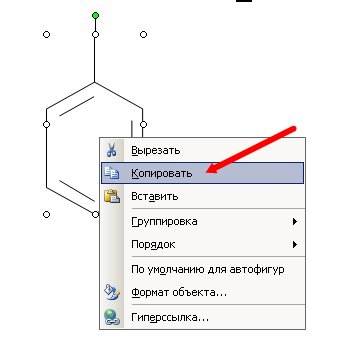
Теперь щелкните правой кнопкой мыши в любом не занятом месте будущей схемы и выберите пункт Вставить.
У вас появится вторая точно такая же фигура.
Перетащите её мышкой, куда вам необходимо.

Теперь примемся за прописывание формул и заголовка схемы.
Для этого выбираем на панели Рисование инструмент Надпись, и жмем по ней мышкой.
Переходим на поле схемы и щелкаем мышкой вверху, где у нас будет название блок-схемы.
Появится квадратное поле для написания текста. Можете его растянуть и сжать, где необходимо.

Текст форматируется так же, как и в простом документе. Если Вам не нужна рамочке вокруг текста, то можете её убрать.
Точно таким же образом пишем названия формул. Не забывайте про копирование. Все похожие надписи можно копировать вместе с рамочкой. Рамочки потом можете убрать. Символы берем из таблицы Символов (- Вставка – Символ -).
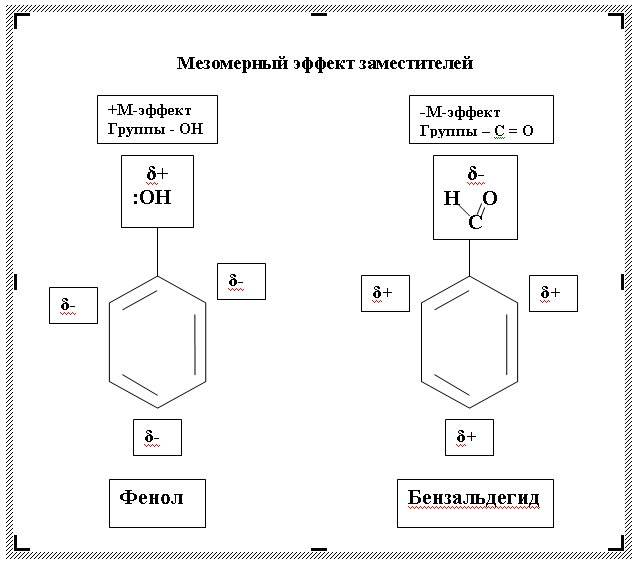
Осталось убрать рамочки и добавить стрелки.
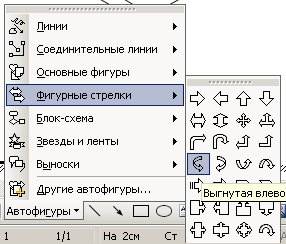
Выбираем в Автофигурах Фигурные стрелки и вставляем их. Не забываем, что все можно поворачивать и изменять. Всё можно раскрасить и приукрасить. Это уже на ваш вкус.
Все, кому приходилось работать с формулами и математическими переменными в Ворде, когда-нибудь интересовались, как поставить верхний или нижний индекс в Word. К сожалению, многих пользователей ставит в тупик задача — поставить степень числа или переменной. На самом деле всё делается достаточно просто. Именно на этот вопрос и постараемся ответить в статье. Подробнее о том, как поставить надстрочный и подстрочный знаки в Ворде далее в статье. Давайте разбираться. Поехали!

В математических функциях часто используют специальные символы
Очень удобно, что разработчики Microsoft вынесли необходимые иконки прямо на панель вкладки «Главная». Найти нужные кнопки можно в разделе «Шрифт», прямо под полем «Размер шрифта». Пользоваться ими очень просто. Сначала введите букву или цифру, к которой хотите добавить индекс. Затем нажмите на соответствующую кнопку добавления подстрочного или надстрочного знака. После этого вы заметите, что палочка курсора стала вполовину меньше. Далее, можно ввести значение. Чтобы вернуться к нормальному формату набора текста, нажмите кнопку добавления подстрочного или надстрочного знака ещё раз. Обратите внимание на то, что, когда функция активирована, соответствующая иконка инструмента будет выделена серым.
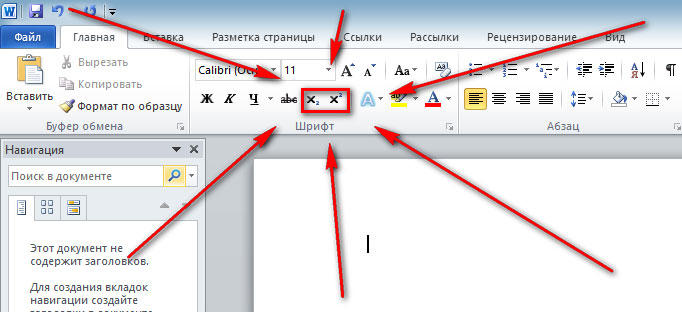
Второй способ — воспользоваться горячими клавишами. Такой подход поможет немного ускорить работу с инструментом. Чтобы поставить подстрочный знак, используйте комбинацию Ctrl и =. Если необходимо добавить надстрочное значение, примените комбинацию клавиш Ctrl, Shift, +.
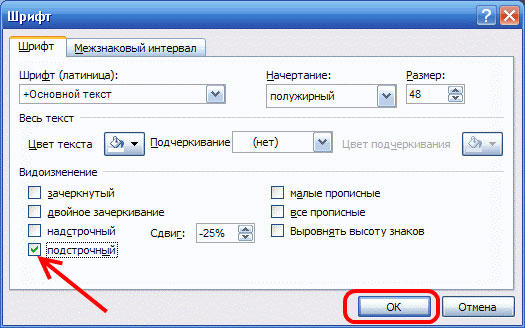
Ещё один вариант — кликнуть по специальной иконке в правом нижнем углу блока «Шрифт» в ленте инструментов, чтобы открыть полное меню. В разделе «Видоизменение» отметьте галочками пункты «надстрочный» либо «подстрочный». В зависимости от отмеченного варианта курсор примет соответствующий вид и положение.
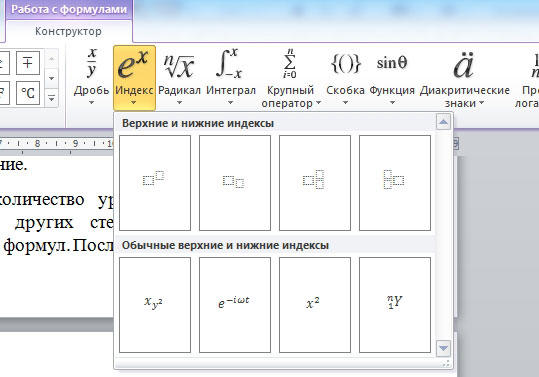
Если в документе большое количество уравнений, где много значений и переменных в квадрате или других степенях, будет удобнее работать непосредственно в конструкторе формул. После того как вы добавили уравнение, откроется вкладка «Конструктор». На панели инструментов находится специальная кнопка «Индекс». Нажав на неё, откроется меню, в котором необходимо будет выбрать нужный вариант расположения индекса. После того как вы выберите подходящий, на листе появятся два пустых поля в виде квадратов. Внутри большого введите букву или цифру, внутри маленького введите значение степени либо подпись. Достоинство такого подхода в том, что он позволяет одновременно добавлять несколько индексов для более сложных математических расчётов.
Каждый из описанных способов удобнее использовать в том или ином случае. Выбирайте тот вариант, который является более подходящим для решения ваших задач. Теперь работа с индексами в Microsoft Word больше не будет для вас проблемой. Оставляйте в комментариях своё мнение о статье, особенно если она оказалась полезной и задавайте возникшие вопросы по теме.

Microsoft Word — отличный инструмент для форматирования текста, но что если вы хотите вставить химическую формулу или диаграмму? Благодаря новой бесплатной надстройке для Word теперь вы можете вставлять высококачественные химические формулы и диаграммы прямо с ленты в Word.
Недавно Microsoft Education Labs выпустила новую надстройку Chemistry для Word 2007 и 2010. Эта бесплатная загрузка добавляет поддержку для ввода и редактирования символов, диаграмм и формул химии с использованием стандартного языка химической разметки на основе XML.
Вы можете преобразовать любое химическое название, такое как бензол, или формулу, такую как H 2 O, в химическую диаграмму, стандартное название или формулу. Являетесь ли вы профессиональным химиком, просто изучаете химию в школе или просто интересуетесь составом лимонной кислоты, это дополнение — захватывающий способ перенести химию на ваш компьютер.
Эта надстройка отлично работает на Word 2007 и 2010, включая 64-разрядную версию Word 2010. Обратите внимание, что текущая версия все еще находится в бета-версии, поэтому запускайте ее, только если вы знакомы с бета-версиями.
Начиная
Загрузите надстройку Chemistry от Microsoft Education Labs ( ссылка ниже ) и разархивируйте файл. Затем запустите ChemistryAddinforWordBeta2.Setup.msi.
Он может сообщить вам, что вам нужно установить инструменты Visual Studio для Office 3.0. Просто нажмите Да, чтобы загрузить эти инструменты.

Это откроет загрузку в браузере по умолчанию. Просто нажмите «Запустить» или «Сохранить», а затем запустите его после загрузки.

Теперь нажмите «Далее», чтобы установить Visual Studio Tools для Office как обычно.

Когда это закончится, снова запустите ChemistryAddinforWordBeta2.Setup.msi. На этот раз вы можете легко установить его с параметрами по умолчанию.

После завершения установки откройте Word, чтобы опробовать надстройку Chemistry. Вам будет предложено установить эту настройку, поэтому нажмите «Установить», чтобы включить ее.

Теперь у вас будет новая вкладка «Химия» на ленте Word. Вот лента в Word 2010 …
И вот это в Word 2007.
Использование надстройки химии
Вставить симпатичные диаграммы и формулы химии в Word очень просто с помощью надстройки Chemistry. Вы можете быстро вставить готовую диаграмму из галереи химии:

Или вы можете вставить формулу из файла. Просто нажмите «Из файла» и выберите любой форматированный файл с языком химической разметки (.cml), чтобы вставить химическую формулу.
Вы также можете преобразовать любое химическое название в его химическую форму. Просто выберите слово, щелкните правой кнопкой мыши, выберите «Преобразовать в химическую зону» и затем нажмите на его название.
Теперь вы можете увидеть химическую форму на боковой панели, если вы нажмете кнопку «Химия навигатор» и сможете вставить диаграмму в документ. Некоторые химические вещества автоматически преобразуются в диаграмму в документе, а другие просто ссылаются на нее на боковой панели. В любом случае, вы можете отобразить именно то, что вы хотите.

Вы также можете преобразовать химическую формулу непосредственно в ее химическую диаграмму. Здесь мы вошли в H 2 O и преобразовали его в химическую зону:

Это напрямую преобразует его в диаграмму прямо в документе.
Вы можете нажать кнопку «Редактировать» в верхней части и выбрать для редактирования 2D-модель химического вещества или для редактирования меток.

Когда вы нажимаете «Изменить ярлыки», вас могут спросить, какую форму вы хотите отобразить. Вот варианты для перманганата калия:

Затем вы можете редактировать имена и формулы, а также добавлять или удалять любые, которые вы хотите.

Если вы решите редактировать химическое вещество в 2D, вы даже можете редактировать отдельные атомы и изменять химическое вещество, которое вы изображаете. Этот 2D-редактор имеет множество опций, поэтому вы можете заставить вашу химическую диаграмму выглядеть так, как вы хотите.

И, если вам нужна помощь или вы хотите узнать больше о надстройке Chemistry и ее функциях, просто нажмите кнопку справки на ленте Chemistry. Откроется документ Word, содержащий примеры и пояснения, которые могут помочь в освоении всех функций этой надстройки.

Все это прекрасно работает, независимо от того, работаете ли вы в Word 2007 или 2010, 32 или 64-разрядных версиях.

Вывод
Используете ли вы химические формулы каждый день или просто хотите время от времени исследовать химический состав, это отличный способ сделать это с помощью инструментов, которые у вас уже есть на вашем компьютере. Это также поможет сделать домашнюю работу немного легче, если вы боретесь с ней в старшей школе или колледже.

При написании текстов иногда приходится использовать такой способ оформления как списки. Чаще всего это могут быть какие-то перечисления однородных элементов или перечни не связанных между собой элементов. Вначале разберем создание простых списков, а затем узнаем как в word сделать многоуровневый список на основе простого.
Список – это фрагмент текста, оформленного особым способом. Каждый элемент списка пишется с новой строки и содержит либо графический маркер, либо символьный или цифровой маркер.
Списки позволяют удобно структурировать материал. Маркированные списки визуально выделяют часть текста, а нумерованные - позволяют объединить даже слабо связанные между собой пункты. Все эти списки могут быть еще и многоуровневыми.
Создание простого списка
В ленте инструментов на вкладке Главная есть раздел Абзац. Он содержит необходимые кнопки работы со списками. Смотрите рисунок.

- Создание маркированного списка. При нажатии на треугольник справа доступен выбор вида графических маркеров списка.
- Создание нумерованного списка. При нажатии на треугольник справа доступен выбор вида нумерации списка.
- Создание многоуровнего списка. Можно выбрать разные варианты оформления.
- Уменьшение отступа списка от границы поля документа до начала абзаца.
- Увеличение отступа списка от границы поля документа до начала абзаца.
- Изменение междустрочного расстояния между элементами списка.
Существует несколько вариантов включения оформления списков, но я рекомендую воспользоваться следующим:
- Наберите текст будущего списка целиком, отбивая каждый новый элемент списка абзацем (нажимаем клавишу Enter).
- После ввода последнего элемента списка сделайте пустой абзац, нажатием клавиши Enter. Это необходимо, чтобы предотвратить применения списка к последующему тексту.
- Выделите все строки с элементами списка и нажмите кнопку для применения соответствующего вида списка.
Если вы выбрали не тот вид списка, то выделите его элементы заново и нажмите кнопку с требуемым видом списка.
Обратите внимание! Выделение нужно начинать с первого символа текста элементов списка, а не с маркера.
Изменение расстояния от маркера до текста
При создании списков может возникнуть ситуация, когда маркеры слишком сильно приближены к тексту или стоят далеко от них. Для исправления положения маркера можно воспользоваться инструментами горизонтальной линейки.

Отступ первой строки (7) – перемещает маркер влево или вправо относительно элемента списка.
Выступ (8) – перемещает элемент списка влево или вправо относительно маркера.
Отступ слева (9) – перемещает маркер и элемент списка влево или вправо.
Внимание! Для изменения положения всех маркеров списка, необходимо выделить список. Для изменения положения только в одном элементе списка, достаточно установить текстовый курсор в строку элемента списка.
Создание многоуровнего списка

Многоуровневый список создается также как и простой, только в панели инструментов необходимо нажать кнопку 3 (см. рисунок "Инструменты для работы со списками").
В открывшейся библиотеке выбираете нужный вариант многоуровневого списка. После применения этой операции вы увидите список (маркированный или нумерованный) с виду похожий на простой. Но это только потому, что в данном списке все элементы пока находятся на одном уровне.
И теперь для каждого элемента списка необходимо настроить свой уровень. Для этого поступаем так:
- Кликаем в строку с элементом списка для которого необходимо изменить уровень отступа и нажимаем кнопку 5 (см. рисунок "Инструменты для работы со списками").
- Кликаем в следующую строку и снова нажимаем кнопку 5 (можно нажать несколько раз, чтобы увеличить уровень отступа).
Практическая часть
Для закрепления навыков по форматированию текста выполните следующее задание.
Наберите или скопируйте текст в свой текстовый редактор. Создайте из данного текста многоуровневые списки.
Компьютеры и периферия Компьютеры Системные блоки Моноблоки Неттопы и компьютеры-флешки Мониторы и аксессуары Мониторы 4K мониторы Игровые мониторы Видеокабели и переходники
Используя теоретические сведения данной статьи измените текст следующим образом:
- разбейте текст на элементы списка, начиная каждый с нового абзаца,
- сделайте копию полученного текста,
- примените к первому тексту маркированный список, а ко второму - нумерованный,
- настройте уровни элементов списка.


Дорогой читатель! Вы посмотрели статью до конца. Получили вы ответ на свой вопрос? Напишите в комментариях пару слов. Если ответа не нашли, укажите что искали или откройте содержание блога.
ОЧЕНЬ ВАЖНО! Оцени лайком или дизлайком статью!
Линейка достаточно удобный и незаменимый вспомогательный инструмент во многих программах. С её помощью можно


Сидя на пятичасовом занятии по химии, я часто скользил взглядом по таблице Менделеева, висящей на стене. Чтобы скоротать время, я начал искать слова, которые мог бы написать, используя лишь обозначения элементов из таблицы. Например: ScAlEs, FeArS, ErAsURe, WAsTe, PoInTlEsSnEsS, MoISTeN, SAlMoN, PuFFInEsS.
Затем я подумал, какое самое длинное слово можно составить (мне удалось подобрать TiNTiNNaBULaTiONS), поэтому я решил написать программу на Python, которая искала бы слова, состоящие из обозначений химических элементов. Она должна была получать слово и возвращать все его возможные варианты преобразования в наборы химических элементов:
Генерирование группировок обозначений
Если бы обозначения всех элементов были одной длины, задача оказалась бы тривиальной. Но некоторые обозначения состоят из двух символов, некоторые — из одного. Это сильно усложняет дело. Например, pu в Amputations может означать плутоний (Pu) или фосфор с ураном (PU). Любое входное слово нужно разбивать на все возможные комбинации одно- и двухсимвольных обозначений.
Такие преобразования я решил назвать «группировки». Они определяют конкретное разделение слова на обозначения. Группировка может быть представлена как кортеж из единиц и двоек, где 1 представляет односимвольное обозначение, а 2 — двухсимвольное. Каждое разбиение на элементы соответствует какой-то группировке:
Анализируя задачу, в попытке найти паттерны я написал в тетради такую таблицу.
Вопрос: дана строка длиной n, сколько для неё может существовать последовательностей единиц и двоек, чтобы количество цифр в каждой последовательности равнялось n?
Ответ: fib(n + 1) !?
Я был удивлён, обнаружив последовательность Фибоначчи в таком неожиданном месте. Во время последующих изысканий я был удивлён ещё больше, узнав, что об этом паттерне было известно ещё две тысячи лет назад. Стихотворцы-просодисты из древней Индии открыли его, исследуя преобразования коротких и длинных слогов ведических песнопений. Об этом и о других прекрасных исследованиях в истории комбинаторики можете почитать в главе 7.2.1.7 книги The Art of Computer Programming Дональда Кнута.
Я был впечатлён этим открытием, но всё ещё не достиг начальной цели: генерирования самих группировок. После некоторых размышлений и экспериментов я пришёл к наиболее простому решению, какое смог придумать: сгенерировать все возможные последовательности единиц и двоек, а затем отфильтровать те, сумма элементов которых не совпадает с длиной входного слова.
Декартово произведение — это набор всех кортежей, скомпонованных из имеющегося набора элементов. Стандартная библиотека Python предоставляет функцию itertools.product() , которая возвращает декартово произведение элементов для данного итерируемого. cartesian_products — генерирующее выражение, которое собирает все возможные преобразования элементов в glyph_sizes вплоть до заданной в word_length длины.
Если word_length равно 3, то cartesian_products сгенерирует:
Затем результат фильтруется, чтобы groupings включало только те преобразования, количество элементов которых удовлетворяет word_length .
Конечно, здесь много лишней работы. Функция вычислила 14 преобразований, но остались только 3. Производительность сильно падает с увеличением длины слова. Но к этому мы вернёмся позже. А пока я получил работающую функцию и перешёл к следующей задаче.
Сопоставление слов с группировками
После вычисления всех возможных группировок для слова нужно было «сопоставить» его с каждой из группировок:
Функция обращается с каждым обозначением в группировке, как с чашкой: сначала заполняет её таким количеством символов из слова, каким сможет, а затем переходит к следующему. Когда все символы будут помещены в правильные обозначения, получившееся сопоставленное слово возвращается в виде кортежа:
После сопоставления слово готово к сравнению со списком обозначений химических элементов.
Поиск вариантов написания
Я написал функцию spell() , которая собирает вместе все предыдущие операции:
spell() получает все возможные варианты написания и возвращает только те из них, которые полностью состоят из обозначений элементов. Для эффективной фильтрации неподходящих вариантов я использовал множества (set).
Множества в Python очень похожи на математические множества. Это неупорядоченные коллекции уникальных элементов. За кулисами они реализованы как словари (хеш-таблицы) с ключами, но без значений. Поскольку все элементы множества хешируемы, то проверка на принадлежность (membership test) работает очень эффективно (в среднем О(1)). Операторы сравнения перегружаются для проверки на подмножества с использованием этих эффективных операций по проверке на принадлежность. Множества и словари хорошо описаны в замечательной книге Fluent Python Лучано Рамальо (Luciano Ramalho).
Заработал последний компонент, и я получил функционирующую программу!
Самое длинное слово?
Довольный своей реализацией основной функциональности, я назвал программу Stoichiograph и сделал для неё обёртку, использующую командную строку. Обёртка берёт слово в качестве аргумента или из файла и выводит варианты написания. Добавив функцию сортировки слов по убыванию, я натравил программу на список слов.
Отлично! Сам я бы это слово не нашёл. Программа уже решает поставленную задачу. Я поигрался ещё и нашёл более длинное слово:
Интересно. Мне захотелось узнать, действительно ли это самое длинное слово (спойлер), и я решил исследовать более длинные слова. Но сначала нужно было разобраться с производительностью.
Решение проблем с производительностью
Обработка 119 095 слов (многие из которых были довольно короткими) заняла у программы примерно 16 минут:
В среднем около 120 слов в секунду. Я был уверен, что можно делать гораздо быстрее. Мне требовалась более подробная информация о производительности, чтобы понять, где копать.
Line profiler — инструмент для определения узких мест в производительности кода на Python. Я воспользовался им для профилирования программы, когда она искала написание для 23-буквенного слова. Вот сжатая версия отчёта:
Неудивительно, что generate_groupings() работает так долго. Проблема, которую она пытается решить, — это особый случай задачи о сумме подмножеств, которая является NP-полной задачей. Поиск декартова произведения быстро становится дорогим, а generate_groupings() ищет многочисленные декартовы произведения.
Можно провести асимптотический анализ, чтобы понять, насколько всё плохо:
- Мы предполагаем, что glyph_sizes всегда содержат два элемента (1 и 2).
- product() находит r раз декартово произведение множества из двух элементов, так что временная сложность для product() равна O(2^r) .
- product() вызывается в цикле, который повторяется word_length раз, так что, если мы приравняем n к word_length , временная сложность для всего цикла будет равна O(2^r * n) .
- Но r получает разные значения при каждом прогоне цикла, так что на самом деле временная сложность ближе к O(2^1 + 2^2 + 2^3 + . + 2^(n-1) + 2^n) .
- А поскольку 2^0 + 2^1 + . + 2^n = 2^(n+1) - 1 , результирующая временная сложность равна O(2^(n+1) - 1) , или O(2^n) .
С O(2^n) можно ожидать, что время выполнения будет удваиваться при каждом инкрементировании word_length . Ужасно!
Я раздумывал над проблемой производительности много недель. Нужно было решить две взаимосвязанных, но различных задачи:
- Обработка списка слов разной длины.
- Обработка одного, но очень длинного слова.
Вторая задача оказалась гораздо важнее, потому что она влияла на первую. Хотя я сразу не придумал, как улучшить обработку во втором случае, но у меня были идеи насчёт первого, потому я с него и начал.
Задача 1: быть ленивым
Лень — добродетель не только для программистов, но и для самих программ. Решение первой задачи требовало добавления лени. Если программа будет проверять длинный список слов, то как сделать так, чтобы она выполняла как можно меньше работы?
Проверка на неправильные символы
Естественно, я подумал, что в списке наверняка есть слова, содержащие символы, не представленные в таблице Менделеева. Нет смысла тратить время на поиск написаний для таких слов. А значит, список можно будет обработать быстрее, если быстро найти и выкинуть такие слова.
К сожалению, единственными символами, не представленными в таблице, оказались j и q.
А в моём словаре только 3 % слов содержали эти буквы:
Выкинув их, я получил прирост производительности всего на 2 %:
Это было не то улучшение, на которое я надеялся, так что я перешёл к следующей идее.
Мемоизация
Мемоизация — это методика сохранения выходных данных функции и их возврата, если функция снова вызывается с теми же входными данными. Мемоизированной функции нужно на основании конкретных входных только один раз сгенерировать выходные данные. Это очень полезно при использовании дорогих функций, многократно вызываемых с одними и теми же несколькими входными данными. Но работает мемоизация только для чистых функций.
generate_groupings() была идеальным кандидатом. Она вряд ли столкнётся с очень большим диапазоном входных данных и очень дорога в выполнении при обработке длинных слов. Пакет functools облегчает мемоизацию, предоставляя декоратор @lru_cache() .
Мемоизация generate_groupings() привела к тому, что время выполнения уменьшилось — заметно, хотя и недостаточно:
Но всё же неплохо для единственного декоратора из стандартной библиотеки!
Задача 2: быть умным
Мои оптимизации немного помогли с первой задачей, но ключевой нерешённой проблемой оставалась неэффективность работы generate_groupings() , большие отдельные слова всё ещё обрабатывались очень долго:
Лень может привести к определённому прогрессу, но иногда нужно быть умным.
Рекурсия и DAG
Задремав однажды вечером, я испытал вспышку вдохновения и побежал к маркерной доске, чтобы нарисовать это:

Я подумал, что могу взять любую строку, вытащить все одно- и двухсимвольные обозначения, а затем в обоих случаях рекурсировать оставшуюся часть. Пройдя по всей строке, я найду все обозначения элементов и, что особенно важно, получу информацию об их структуре и порядке расположения. Также я подумал, что граф может быть отличным вариантом для хранения такой информации.
Если серия рекурсивных вызовов функции для прекрасного слова amputation выглядит так:
то после фильтрации всех обозначений, не удовлетворяющих таблице Менделеева, можно получить подобный граф:

Получился направленный ациклический граф (DAG), каждый узел которого содержит обозначение химического элемента. Все пути от первого узла к последнему будут валидными написаниями исходного слова в виде химических элементов!
До этого я не работал с графами, но нашёл очень полезное эссе, в котором описаны основы, включая эффективный поиск всех путей между двумя узлами. В прекрасной книге 500 Lines or Less есть глава с другим примером реализации графа на Python. Эти примеры я и взял за основу.
Реализовав и протестировав простой графовый класс, я превратил свой рисунок на доске в функцию:
Выигрыш
В то время как алгоритм «в лоб» выполнялся ужасно долго ( O(2^n) ), рекурсивный длился O(n) . Гораздо лучше! Когда я в первый раз прогнал свежеоптимизированную программу на своём словаре, то был потрясён:
Вместо 16 минут я получил 10 секунд, вместо 120 слов в секунду — 10 800 слов!
Впервые я действительно оценил силу и ценность структур данных и алгоритмов.
Самое длинное слово
С новоприобретёнными возможностями я смог отыскать самое длинное слово, разбиваемое на химические элементы: floccinaucinihilipilificatiousness. Это производное от floccinaucinihilipilification, что означает действие или привычку описывать что-то или относиться к чему-либо как к неважному, не имеющему ценности или бесполезному. Это слово часто называют самым длинным нетехническим словом в английском языке.
Floccinaucinihilipilificatiousness можно представить в виде 54 написаний, все они зашифрованы в этом прекрасном графе:

Оригинал
Хорошо потраченное время
Кто-то может сказать, что всё вышеописанное — полная ерунда, но для меня это стало ценным и важным опытом. Когда я начинал свой проект, то был относительно неопытен в программировании и не представлял, с чего начать. Дело двигалось медленно, и прошло немало времени, пока я добился удовлетворительного результата (см. историю коммитов, там видны большие перерывы, когда я переключался на другие проекты).
Тем не менее я многому научился и много с чем познакомился. Это:
- Комбинаторика
- Профилирование производительности
- Временная сложность
- Мемоизация
- Рекурсия
- Графы и деревья
Мне неоднократно помогало понимание этих концепций. Особенно оказались важны для моего проекта по симуляции n-тел рекурсии и деревья.
Наконец, приятно было отыскать ответ на собственный изначальный вопрос. Я знаю, что больше не нужно раздумывать над разбиением на химические элементы, потому что у меня теперь есть для этого инструмент, который можете получить и вы с помощью pip install stoichiograph .
Добрые люди (и несколько благонамеренных ботов) поучаствовали в обсуждении этой статьи в ветке r/programming.
Допматериалы
Я получил немалую часть вдохновения из элегантных решений некоторых интересных проблем, решения принадлежат Питеру Норвигу (Peter Norvig):
Читайте также: