
1с sql как работает
В данной статье пойдет речь о том как в 1С 8.1-8.2 можно использовать прямые запросы к СУБД MS SQL. Статья навеяна реальным внедрением. Я постарался описать общие моменты которые необходимо знать для того что бы спуститься на уровень СУБД и начать использовать прямые запросы к СУБД в обход 1С Сервера приложений.
Введение.
В одной из компаний где я когда-то работал, имелась собственная разработка на 1С 8.2 платформе.
Однажды мы пришли к понимаю что наша система работает не очень быстро. Оставалось понять в каком направлении двигаться, что бы оптимизировать работу системы. После долгих исследований и экспериментов, мы решили в серьез взяться за перенос некоторых операций на плечи СУБД, а именно на плечи MS SQL с помощью выполнения прямых запросов на стороне SQL Server, в обход сервера приложений 1С.
Тот случай был единственным где подобное решение было рациональным. Но те навыки что я получил в тот момент, с легкостью можно использовать для интеграций системы 1С с другими информационными системами.
Cтруктура базы данных 1С на уровне СУБД выглядит не совсем внятно.
Постараюсь описать что же из себя представляет эта структура. Описание будет не полное. Постараюсь описать лишь самое интересное и важное, из того что нужно понимать спускаясь на уровень СУБД.
Рассматриваем структуру хранения данных.
Каждый объект метаданных имеет определенный вид наименования таблиц. Например РегистрСведений начинается с "_InfoRg. ", далее идет номер (идентификатор/индекс) регистра. А вот таблички начинающиеся с _InfoRgChng это таблицы содержащие в себе регистрацию изменений в регистре. Перечислять в данной статье все префиксы я не буду. Это можно сделать с помощью средсв 1С. По мере необходимости.
Ещё интереснее у нас хранятся данные составных полей. Точнее те поля, которые могут примнимать разнотипные значения.
Допустим у нас есть поле. И оно может хранить в себе Строку, Дату, Число, ссылку на справочник клиентов, и ссылку на справочник сотрудников. В 1С мы видим одно единственное поле. На деле же такое поле в базе данных будет иметь ряд полей. Давайте рассмотрим этот пример. Предположим что индекс нашего поля - 8818.
| Наименование поля | Описание |
| _Fld8818_TYPE(binary(1)) | В данном поле хранится тип значения, который хранится в текущей записи. Тип представляет из себя индекс. Целое число. |
| _Fld8818_N(Numeric(x)) | Здесь будет храниться значение числа. Тип числа (разрядность и длинна равная x) будет зависеть от настроек в самом конфигураторе 1С |
| _Fld8818_T(datetime) | В данном поле будет храниться значение типа Дата и Время |
| _Fld8818_S(nvarchar(1024)) | В этом поле значение в виде строки. Причем длина строки зависит от настроек. |
| _Fld8818_RTRef(binary(4)) | В данном поле, при условии что в записи хранится ссылка, будет указан тип ссылки. То есть, на какую таблицу ссылается ссылка, справочник это или документ, что за документ или справочник. |
| _Fld8818_RRRef(binary(16)) | А это уже будет сама ссылка на конкретную запись, в конкретной таблице |
Если с простыми типами данных все ясно, то тип ссылки не так прост.
Наверняка вы зададите вопрос: Как можно определить тип ссылки? То есть, что означает индекс хранящийся в поле _Fld8818_RTRef?
Если мы переведем этот индекс из шестнадцатеричной системы счисления в десятичную, и затем посмотрим на список таблиц базы данных, то обязательно найдем таблицу, в имени которой содержится данный индекс. То есть мы можем по этому индексу получить таблицу, в которой содержится элемент, на который ссылается ссылка в нашем поле.
Зная индекс, мы можем найти необходимую таблицу простым запросом:
Где 1950 — искомый индекс.
Получаем структуру хранения средствами платформы 1С.
Остается вопрос, как нам определить, как некоторая таблица в конфигурации 1С, именуется на уровне СУБД, а так же, соответствие полей на уровне СУБД и конфигурации?
В этом нам поможет встроенная функция поставляемая вместе с платформой:
Данная функция возвращает структуру в которой мы можем по имени объекта в МетаДанных, получить имя объекта в базе данных. Точно так же в структуре содержаться и все поля объектов, и их наименования в базе данных. Но здесь уже начинаются подводные грабли. Которых вроде как и нет, и в тоже время они есть.
Важный момент. При вызове метода, обязательно нужно передать во второй параметр значение «Истина». Что это означает? Этот параметр означает будет ли структура отображать данные в формате 1С: Предприятие, либо в формате СУБД. В чем же разница?
Допустим мы отображаем данные в формате 1С: Предприятие.
Например, если мы попытаемся с помощью этой структуры узнать как называется в базе данных поле «Клиент», то получим к примеру такое имя «Fld1234». Вроде бы все хорошо. Но если мы попытаемся написать запрос к MS SQL:
Мы в 80% случаев — получим ошибку. Почему? А потому что это лишь общий вид наименования поля. Но стоит знать о том что во первых любое имя поля начинается с нижнего подчеркивания. Казалось бы прибавим к наименованию поля символ "_" и делов то! Но нет. Далее ещё интересней. В зависимости от содержимого поля и его типа, поле имеет определенный постфикс в наименовании. Например RRef — это значит что в поле содержится ссылка. А если просто значение то этого постфикса нет. А помните составные типы данных? Там вообще может быть куча различных постфиксов, при этом полей начинающихся на "_Fld1234" будет гораздо больше чем одно. И как же нам обойти это?
Легко. Те кто знает MS SQL, сразу догадались что на помощь придет системное представление INFORMATION_SCHEMA.COLUMNS
С помощью этого представления мы можем отобрать информацию по наименованию таблицы, и по тому ключевому наименованию поля.
Пример запроса:
Данный запрос выдаст нам ряд полей, имена которых начинаются на "_Fld1234". Нам же останется эти данные обработать в нашей программе для использования в запросах к базе.
Но какие минусы у этого метода? Во первых для того что бы обратиться к базе, нам необходимо настроенное подключение к БД, через 1С. То есть дополнительные настройки. Но они нам в любом случае пригодятся, но представьте, у вас большой запрос. Нужно получить имена 20 полей. И каждый раз при этом обращаться к базе и искать там имена полей? Получать и использовать подключение? Это не очень оптимально. Плюс к тому полученные из базы данные, придется ещё как-то обрабатывать. Дополнительные действия. Да и словом - изобретение велосипеда.
Вот тут то нам и приходит на помощь функция
Когда значение параметра ИменаБазыДанных = Истина, то функция в результирующую структуру сразу передает всю необходимую информацию по объектам. Включая все физические поля Базы данных. Если поле составное, то в структуре будут видны все физические поля составного поля. Это значительно облегчает нашу работу.
Использование прямых запросов. Отборы. Соединения и обращения через точку.
Как же нам использовать отбор в прямых запросах? Как отобрать данные по конкретному документу? Или по конкретному значению?
Все довольно просто, но снова есть нюансы.
Поля формата Дата. По умолчанию при использовании MS SQL сервера, дата 1С в базу помещается с прибавлением к году 2000. То есть дата в системе 1С «01.01.2013» будет выглядеть как «01.01.4013». Но и это ещё не все. Для того что бы в запросе произвести сравнение даты и оно прошло корректно, нам необходимо дату конвертировать в определенный формат.
По умолчанию в базе данных MSSQL используется формат ymd. Это означает что в дате сперва указан год, месяц и затем число. А выглядит дата следующим образом: 4013-01-01. Для использования в условиях сравнения или для прочих манипуляций нам эту дату нужно обрамлять в опострофы, так же как и строки.
Для преобразования даты в формат SQL я написал для себя такую простенькую функцию:
Данная функция возвращает готовую дату, в нужном формате в виде строки, остается только подставить в текст запроса. Если у вас в MS SQL по каким то причинам установлен иной формат даты, можно на момент исполнения запроса его поменять. Делается это так:
Либо надо будет переделать представление даты в своем запросе.
Теперь нам нужно отобрать записи по определенному элементу справочника. Как это сделать?
Изначально, когда я не знал о существовании функции ЗначениеВСтрокуВнутр(), для своих нужно я написал пару функций, для получения ссылок на справочники и на документы. Выглядят они так:
Как видно в коде, мы строим простой запрос, и получаем из базы значение ID, которое храниться в базе данных. Объект — это у нас наименование справочника либо документа, а код — код элемента справочника или документа.
Функция master.dbo.fn_varbintohexstr() — позволяет преобразовать значение формата binary в строку.
Но использовать эту функцию — не обазательно.
Полученный ID имеет примерно такой вид: 0xa8ed00221591466911e17da9fd549878
В запросе мы его можем сравнивать как строку
Но в таком случае запрос будет отрабатывать дольше. Так как на преобразование в строку тоже нужно время.
Поэтому лучше сравнение делать таким образом:
Предыдущий вариант использовать можно, но на самом деле, имеется более универсальный и оптимальный способ получить ссылку. Он приведен в функции что показана ниже:
А давайте представим что нам нужно в запросе сделать внутреннее соединение. И сравнение должно происходить с полем через точку?
То есть, для сравнения нам необходимо проверять одно условие, что дата в основной таблице, равна дате, которая содержится в документе, ссылка на который содержится в присоединяемой таблице.
В 1С это будет выглядеть примерно так
Как же описать это с помощью MS SQL? В том месте запроса, где описываются соединения, компилятор запросов ещё не знает о том что в таблице регистра есть ссылка на регистратор, и что это в свою очередь есть документ, а у этого документа есть дата. Описать ещё одно соединение? Не поможет. Словом я пытался это сделать всяко. Но в итоге решение свелось к вложенному запросу. (если кто-то найдет реальную альтернативу, буду рад узнать ваш способ).
Выше приведенный фрагмент на чистом SQL будет выглядить так:
В запросе мы видим, что во вложенном запросе делаем выборку из таблицы документа, где ID документа равен ID который записан в поле нашей таблицы «Источник», и далее полученное значение _Date_Time сравниваем с датой из нашей таблицы. Все логично и просто. Думаю теперь мы понимаем, во что превращаются наши обращения к полям и объектам через точку, в запросах 1С, когда они транслируются на SQL запрос. И теперь становится понятно почему такие обращения затормаживают работу запросов.
Очень рекомендую вам поэксперементировать с различными запросами, используя инструмент SQL Server Profiler. С его помощью вы сможете увидеть, во что превращаются ваши запросы написанные на языке запросов 1С, пройдя трансляцию на сервере приложений 1С. Особенно интересно вам будет посмотреть что из себя представляют такие виртуальные таблицы как "СрезПоследних".
Тот пример который я описал выше, с внутренним соединеним, 1С сервер скорее всего реализует немного по другому. Но у него свои методы, с использованием переменных, значения которых заполняются серверов приложений перед выполнением запроса.
Ниже я приведу один пример.
Допустим у нас есть запрос в формате 1С:
Как мы видим, ситуация аналогичная, как я приводил выше, только соединение не внутреннее, а левое. Как же 1С Сервер приложений траслирует такой запрос?
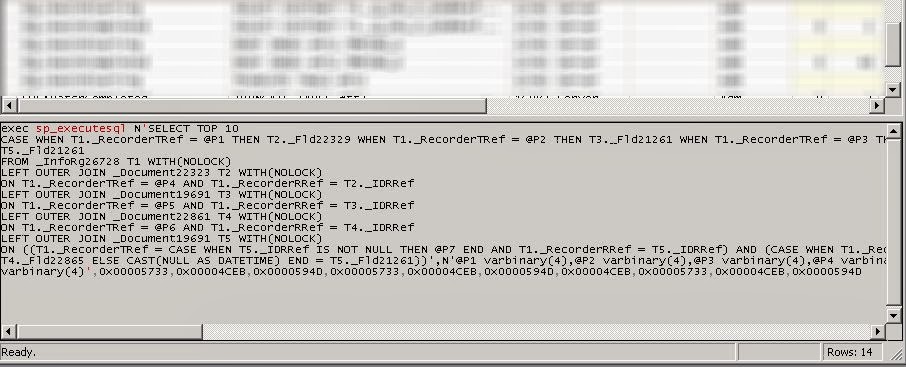
С помощью SQL Server Profiler мы сможем это увидеть. На картинке выше, показан запрос сервера приложений. Как я и писал выше, мы видим что сервер приложений использует переменные, в которые заранее пишет соответствующие ID. Но нам при использовании прямых запросов, проще было использовать именно вложенный запрос, для нас это универсальное решение, так как не придется подставлять значения переменным.
Будет замечательно если вы самостоятельно изучите различные запросы в таком виде. Возможно это поможет вам оптимизировать ваши запросы.
Для решения каких задач нам могут понадобиться прямые запросы к базе данных?
Думаю данная возможность понадобиться при активной разработки своих собственных решений, либо при реструктуризации готовых решений. В тех случаях, когда в отладочных целях, либо ещё по каким-то причинам, нам придётся переносить большие объемы данных с одной таблицы в другую, либо разбивать данные на несколько таблиц.
Для интеграции 1С с другими, сторонними разработками. Например вывод данных из 1С в какую-нибудь стороннюю программу анализа продаж или что-то похожее.
Оптимизация массивных обработок данных. Когда нам необходимо обработать большое количество данных, при этом внося какие-то изменения, корректировки и т.п. Например копирование записей регистра сведений с изменением какого-либо поля средствами 1С, займет куда больше времени, чем выполнение операции T-SQL Update
Учимся получать доступ к СУБД из 1С.
Для работы с СУБД на прямую, в обход сервера приложений 1С, нам потребуется использовать COM объекты - ADO.
Первым делом нам понадобится строка подключения к базе данных. У нас даже есть возможность формировать эту строку через стандартный интерфейс Windows. Это значительно облегчает процесс подключения к БД.
Интерфейс настройки подключения к базе данных.
Давайте рассмотрим пример работы с ADO.
В данном фрагменте кода, мы создаем объект подключения к базе данных. А так же с помощью объекта DataLinks, получаем строку подключения к базе данных используя пользовательский интерфейс настройки этого самого подключения.
После того как мы получим строку подключения, нам скорее всего захочется отдельные её части разместить на форме, для того что бы пользователь мог исправлять отдельно взятые опции подключения. Следовательно строку необходимо распарсить. Я пока (на момент написания статьи) нашел лишь один способ это сделать, и привожу его ниже. Если кто-то подскажет более элегантный способ парсинга строк, будет здорово.
Теперь мы сохранили параметры подключения базы данных на форме, при желании можем их сохранить в базу данных.
Далее надо предусмотреть вариант, когда пользователь (чаще всего мы сами), изменит наименование базы данных или тайм аут прямо в форме обработки, минуя форму редактирования строки подключения. На такой случай создадим такую функцию, которая будет формировать строку подключения собирая данные из визуальных контролов формы. Выглядит она примерно так:
Теперь когда все (или почти все) вопросы со строкой подключения решены, давайте попытаемся воспользоваться ею, для обращения к базе данных.
В первую очередь, думаю нам понадобится функция для проверки подключения. Опишем её таким образом:
После выполнения данной функции нам станет ясно, можно ли работать дальше, или соединение с базой установить не удалось, и следовательно дальше что-либо делать с подключением — бесполезно. Кстати, для оптимизации функцию получения объекта ADODB.Connection можно разместить в общем модуле, в настройках которого выставлено «Повторное использование». Это позволит не создавать каждый раз новый объект подключения, а будет использоваться уже созданный объект. В теории это позволит сократить время вызова соединения, а так же совсем чуть-чуть сэкономит ресурсы системы.
Причем заметьте, что свойству ActiveConnection мы присваиваем ранее созданное подключение к базе. Теперь когда объект у нас создан, нам остается лишь воспользоваться им. Если нам необходимо просто выполнить запрос, который не вернет никаких результатов, то будет достаточно одной простой команды, которая показана ниже.
1С умеет работать в двух режимах – файловом и серверном. При серверном варианте база данных находится не в файле, а в СУБД на сервере.
СУБД (SQL) – это система управления базами данных. Устно часто называют как «эс-ку-эль» или «скуль» или «сиквел». С 1С используются такие СУБД как MS SQL, Postgre SQL, Oracle.

Подробнее про серверный вариант работы Вы можете прочитать в уроке про сервер 1С. А здесь мы обсудим использование 1С с SQL.
Что такое SQL 1С
База данных – это набор таблиц (каждая табличка как одна страничка в Excel), в которых можно хранить данные.
Язык SQL – это способ запроса данных из этих таблиц. Язык SQL стандартизирован и практически одинаков во всех современных СУБД. Язык запросов 1С также является одним из вариантов реализации языка SQL.
СУБД – это комплекс программ и драйверов. Функции СУБД заключаются в том, чтобы самостоятельно организовать базу данных тем способом, который ей нравится (в некоторых СУБД база данных — это файл, в некоторых – раздел на диске с самостоятельной файловой системой) и обеспечить доступ к данным с помощью запросов на языке SQL.
В файловом варианте база данных 1С хранится в файле на диске и для доступа к данным 1С использует свой собственный движок. Однако этот вариант работает только для небольших баз данных и небольшого количества пользователей.
В серверном варианте базу данных 1С необходимо положить в СУБД. Клиент 1С (программа с которой работает пользователь) не соединяется напрямую к СУБД. Для трансляции запросов используется специальная программа сервер 1С (сервер приложений 1С).
Для запроса данных из SQL 1С используются запросы на языке 1С. Они могут быть использованы явно (программист написал в коде программы на языке 1С) или неявно (программист вызывает функцию платформы, которая генерит запрос или такая функция вызывается сама – в форме списка справочника/документа, например).
Сервер 1С транслирует запрос в язык SQL (соответствующую модификацию, поддерживаемую конкретным СУБД) и передает на выполнение в СУБД (SQL 1С).
Кратко о лицензировании различных СУБД
Краткая информация если Вам захочется посмотреть стоимость и в прайс-листах встретятся незнакомые слова:
- Существуют лицензии различных SQL специально для 1С (т.е. «для использования с 1С»)
- Лицензии runtime – купленный SQL можно использовать только с 1С (дешевле)
- Лицензии full-use – купленный SQL можно использовать с разными программами (дороже)
- Существуют лицензии «по количеству процессов сервера» (без ограничения количество работающих пользователей) — PVU
- Существуют комплект лицензий «по сокетам/по клиентам» — LUS
o Одна лицензия на работу SQL на сервере
o Лицензии по количеству сокетов/клиентов (т.е. на 5 соединений, на 10 соединений и т.п.).
Здесь и ниже указана очень только обзорная информация по лицензированию, так как лицензирование у всех СУБД очень сложное, есть разные ситуации, скидки, наличие/отсутствие подписки на ИТС, ограничения и правила «по умолчанию»..
Дополнительно необходимо упомянуть, что СУБД может иметь требования к операционной системе (чтобы она была тоже серверная, например, Windows Server). В варианте MS SQL так и есть, но есть и вариант «обхода» — SQL Developer Edition.
Главная — Статьи — Базы данных, sql, 1с sql — Если 1С тормозит, то какая конфигурация сервера 1С нужна ?
.jpg)
Введение
Многие в поисках ответа на данный вопрос (почему тормозит 1с sql) находят множество информации. Полезной и не очень. Тут я хочу поделиться своим непосредственным опытом работы с данной системой построенной на СУБД SQL Server.
Вообще тема SQL и 1с достаточно обьемная и обширная. Если вам действительно нужно научится работать с этой связкой, устанавливать ее или настраивать, то нужно набраться терпения, и читать читать. Эта статья отчасти раскроет тему, и даст ответы на вопросы касаемо именно производительности железа в связке с софтом. Чтобы более четко представлять о том как именно работает файловая база или SQLная база программ 1с можно, даже скорее нужно прочитать статью SQL Server для 1С, sql 1c 7.7, sql 1c 8.1 данный материал взят с сайта миста.ру, эту статью очень много куда уже скопировали, но я ее не просто копировал, я ее переработал и дополнил, как раз по окончанию первого апгрейда основного сервера. Так что статья обязательна к прочтению.
Для понимания причин, вызывающих медленную работу 1С на базе СУБД SQL Server нужно уяснить несколько простых вещей.
- Железо, сервер, на котором все крутится
- Софт, операционная система, СУБД, сервер предприятия, платформы клиентов.
- Конфигурация базы данных 1С
- Размер базы данных (как в файловом варианте, так и в СУБД)
- Количество пользователей
Тут же возникнут вопросы а как рассчитывать конфигурацию сервера исходя из размера базы, и количества пользователей. Каковая же оптимальная конфигурация сервера для 1С.
Выбор конфигурации сервера для 1С
Приведу информацию, которой отрыто делиться разработчик 1с. В табл. 1 приведены наиболее типичные параметры серверов которые используют в качестве сервера баз данных, (данные получены по результатам опросов).

Это минимальные требования, и на таком конфиге нормально будет работать база размером не более 5 гигабайт и количество пользователей не более 10.
На основании анализов проведенных внедрений конфигурации «Управление торговлей» и аналогичных решений, а также на основании оценок специалистов, имеющих достаточный опыт внедрения 1С:Предприятия , приведены следующие примеры параметров оборудования которое используется в клиент-серверном варианте:

В приведенной таблице, подразумевается что сервер 1С:Предприятия и сервер MS SQL установлены и работают расположены на одном компьютере.

По поводу того что Сервер предприятия 1С и SQL Server должны устанавливаться на один и тот же компьютер, или на разные тоже момент достаточно спорный и много где обсуждаемый. А вообще зависит от многих факторов.
Реальный опыт администрирования СУБД и сервера предприятий 1С
На примере живого опыта, на предприятии когда я пришел, стоял сервер на базе Intel Xeon S5000, два 2х ядерных процессора, 5гб оперативной памяти FB DIMM, 2 жестких диска в зеркальном массиве, и еще 2 диска в обычном. Вся эта конфигурация с трудом вытягивала SQLную базу размером в 27 гигабайт, работало в ней 40 человек одновременно. Висело все очень сильно. Система стояла Windows 2003 server + SQL 2000 SP4 (кстати если используется 2000й sql для базы 1с, то четвертый сервис пак просто необходим).
Так как серверная платформа могла больше, я заменил старые уставшие жесткие диски, добавил памяти, переустановил все ПО заново, и настроил его. Диски были установлены обычные, 6 штук SATA2 емкостью 320 гигабайт в RAID 10. Тест скорости получившегося дискового массива показал 220 мб/сек, (чтение). По сравнению с предыдущими десками (60-80 мб/сек) это было очень быстро! Софт остался прежний W2003 R1 SP1 + SQL 2000 SP4, Windows установил 64х битный, SQL 2000 в 64х битной редкции нет в природе. Сервер 1С предприятия тоже остался 32х битным. Так как без помощи 1С программиста (отсутствующего на тот момент) не получилось перенести конфигурацию на SQL 2005. После проделанной работы, в целом производительность всей системы заметно увеличилась, пользователям стало работать более комфортно. Да и график нагрузки системы в WINDOWS показывал что «качать» сервер стал более продуктивнее. Спустя год база увеличилась с 27 гигабайт до 50. Еще через год уже 80. Обороты предприятия увеличивались, штат сотрудников удвоился, прибавились еще вне офисные менеджеры с ноутбуками, которые подключались к базе для оформления заказов прямо с торговых точек в городе. Все это до поры тянул один сервер.
И вот спустя 2 года с момента первого апгрейда назревал второй. Так как раздувшаяся база до 80 гигов и количество пользователей окучивающих эту базу стало около 60ти. Еще такой момент, системный диск C:\ имел обьем всего 30 гигабайт (два года назад этого было за глаза) стал ежедневно забиваться логами 1с сервера предприятий. Перенести которые не представлялось возможным.
Было решено установить свежие 1 терабайтные диски, добавить памяти и поставить 2008 windows и 2008 SQL, Сервер предприятия 8.2 все 64х битное. Предварительно закупив неслабую машинку на десктопных железках, я поставил туда все ПО, перенес бекап базы, поднял его там и все проверил, чтобы апгрейд и переустановка всей системы на самом сервере прошла более гладко и безболезненно. Данная предварительная подготовка пошла на пользу.
После установки новых дисков в массив (все также остался 10 RAID), установки дополнительных модулей памяти, общий обьем которой теперь составлял 14 гигабайт, и на новом софте, все вновь стало работать ощутимо быстрее. Скорость чтении с поверхности нового RAID массива составляла 320 мегабайт, что в 1,5 раза быстрее предыдущего.
На базе всех этих переделок можно также составить таблицу системных требований, размера базы и количества пользователей.
После апгрейда, я вновь провел тест который написал господин Гилев, как на платформе версии 8.1 так и на платформе 8.2. Результаты тестов особо не радовали. Но это не столь важный показатель. Т.к. пробные проведения документов и формирования отчетов, занимали гораздо меньше времени, по сравнению с предыдущей конфигурацией железа и софта.
Также для разгрузки основного сервера, терминальные пользователи были перенесены на дополнительный сервер. Так как терминальные сессии тоже достаточно аппетитно кушают оперативную память, примерно 200-300 мегабайт на одного пользователя при активной работе, а если их 10 это уже 3 гигабайта.
Еще одним нововведением стало создание не одного рабочего процесса RPHOST, как было ранее, их сделано 4.

При этом каждый процесс стал занимать от 150 до 400 мегабайт. Особо это ничего заметного не дало, но в теории вылеты пользователей из программы должны сократится, то есть стабильность работы повышается.
Регламентные задания SQL
Регламентные задания в SQL для баз 1С. Еще во время первого апгрейда, я нашел информацию о том, что по мимо резервирования основной рабочей базы (это как бы естественно и обязательно) в SQL нужно настраивать регламентные задания (профилактические процедуры с базой данных. В ходе которых удаляются ненужные записи, очищаются временные таблицы ,и отчасти происходит проверка целостности базы.

В первое время после настройки этих заданий процедур, размер базы даже немного снизился, чему нельзя было не радоваться. Но потом уже такого не наблюдал. С переходом на 2008 SQL, также были настроены регламентные задания. И замечен интересный факт. Размер самой базы не изменялся после произведенных процедур. А вот размер заархивированного бекапа рабочей базы немного уменьшился. Все таки есть чтото в этом новом 2008 SQL…
О том как настравивать регламентные задания будет опубликовано в другой статье, отдельно, чтобы не раздувать эту статью.
RAID массив для 1С SQL
Почему нужно использовать именно рэйд для базы данных. Этому причин несколько.
Что такое RPHOST?
Rphost это процесс службы самого сервера предприятий. И для него естественно жрать память. И процессор. Но в разумных пределах.
Также очень популярен в интернете вопрос: rphost грузит процессор или rphost жрет память. Да такой факт действительно наблюдается. Имеется еще один дежурный сервер, используемый для резервирования всех имеющихся баз данных. Кстати это очень удобно, иметь отдельную машину чисто под бекапы. Так вот на данном сервере тоже стоит сервер предприятий, винда там 2003 R1 SP1. И именно на этой ОС наиболее распространен глюк с RPHOST ом. Из всех прочитанных лекарств ничего не помогает, кроме как перезапуск службы. И то спустя 15 минут, он вновь сьедает полностью одно ядро и 500 мегабайт памяти. На W2008 такого не обнаруживалось, данный процесс потреблял процессорное время одного ядра при явной нагрузке кем то и пользователей отчетом или проведением большого документа.
Что еще можно сказать о поведении сервера под новым ПО и свежим релизом сервера предприятий 8.2. Тут есть что расскзать.
Первое отличие это то что при зависании сервера или потери с ним связи (такое уже один раз произошло) у клиентов платформа зависает, и ее нужно перезапускать. На платформе 8.1 выскакивало окошко с ошибкой, и выбором закрыть или перезапустить программу, в 8.2 пока тупо виснет, возможно исправят.
Второе отличие, элементы интерфейса немного отличаются и пользователи не сразу «втыкают» куда теперь кликать.
Конфигарация базы (УТ 10.3) изначально сильно изменена, но при переносе ее на платформу 8.2 с 8.1 все обошлось стандартными средствами. Я имею ввиду конвертацию базы под новую платформу.
По общим наблюдениям 64х битное ПО как то более рационально использует оперативную память и нагрузку на процессоры. Это больше касается SQL сервера. В отличии от старого двухтысячника, который сьедал всю оперативную память имеющуюся в системе, 2008й потребляет ровно столько, сколько ему выделено в настройках. Это безусловно плюс. Причем ненадо ничего перегружать. При изменении выделяемого обьема памяти, она сразу освобождается или занимается процессом SQL.

Таким образом, производительность всей системы в целом, под системой подразумевается:
- аппаратная часть
- серверный софт
- платформа 1с
зависит от того:
какая конфигурация 1С используется (насколько правильно в ней написаны запросы)
сколько пользователей пользует одновременно базу
Каков обьем базы (ее физический размер на диске) в большинстве случаев 1с тормозит изз за банального не соблюдения каких то простых вещей.
Итоги
В моем случае серверная платформа на базе достаточно старой материнской платы Intel S5000 работает уже четвертый год, размер базы на этом сервере (только под моим присмотром) вырос с 27 гигабайт до 80ти. Может быть, тормоза 1с или SQL вы наблюдаете на машине, не справляющейся своей аппаратной мощью с распухшей базой, или нехватка оперативной памяти. Читайте информацию, не стесняйтесь задавать вопросы на форумах (благое дело таких форум несколько в Рунете). Вам обязательно подскажут и помогут решить вопрос. Либо можете всегда обратится к фирмам, системным интеграторам или франчайзи 1С которые проведут профессиональный аудит и скажут в чем причина того, что 1с тормозит.
Теги: rphost жрет память, rphost жрет процессор, 1С тормозит, конфигурация сервера 1С
В этот раз хотелось бы снова поговорить о прямых запросах к СУБД. Да, автор статьи слышал о том, что 1С крайне не рекомендует этим заниматься. Однако же заниматься этим мы будем с одной оговоркой – базы, с которыми предстоит поработать имеют отличное от 1С происхождение. Уже предчувствую возгласы – есть же «Внешние источники данных» в конфигурации, ими и пользуйтесь. Пользовались, умеем, однако же мнения публики об этом объекте конфигурации весьма противоречивы и многие из них далеко не восторженные. Основное преимущество их – понятная всякому, даже начинающему, программисту 1C методика работы с ними – либо аналогично объектам вроде документов и справочников, либо очень напоминающая непериодический независимый регистр сведений.
Вместе с тем есть и неприятные особенности. Прежде всего – отдельные типы данных «внешний источник» переваривает со скрипом. А чтобы положить в этот источник ссылку объекта в том виде, в каком она хранится в СУБД приходится указывать тип «Уникальный идентификатор», преобразовывать идентификаторы объектов в строки и заниматься перестановками групп символов. Случалось и так, что при указании строки подключения в пользовательском режиме ошибался, но вместо повторного запроса таковой просто получил бесконечные исключения при попытке обращения к нему.
В тоже время, для работы с иными базами данных «Внешний источник данных» нам совершенно не обязателен. Ведь научить 1C выполнять запросы к MS SQL или иной СУБД большой проблемы не составляет. Зато преимуществ получается сразу довольно много. Как ни крути, а СУБД – запросы как способ интеграции во многом выигрывают даже у WEB-сервисов, а у выгрузок/загрузок через файловую систему подавно.
Начнем с самого простого. Имеем стороннюю базу с полезными нам данными. Имеем 1С, которой эти данные полезны, но которая их не имеет. Как же их достать? В MS SQL отлаживаем запрос, на стороне 1С обеспечиваем формирование его текста с необходимыми условиями отбора и создаем пару функций, позволяющих подключиться к СУБД и получить из нее таблицу значений. Ну а дальше вопрос её обработки, зависящий от конкретной задачи и особенностей выбранного пути её решения.
В общем-то на этом вопрос получения данных из внешней базы закрывается. Но остается второй, куда более обширный вопрос – как же наоборот, выгрузить данные из 1С в базу данных на «чистом» SQL? Web-сервисы, COM-соединения и промежуточные файлы не рассматриваем ввиду тематики статьи, хотя они имеют место быть и часто даже оказываются уместными, про эти вещи и без меня написано достаточно. А в рамках данной статьи нам будут интересны именно пути, предполагающие прямое взаимодействие с SQL.
Способ 1. Очевидный (но не лучший).
Уверен, что это первое, что приходит в голову разработчику, по крайней мере не из касты 1С – вооружаемся SQL-профайлером, любой консолью запросов и любой обработкой, раскрывающей структуру хранения базы данных и готовим прямой запрос к данным 1С. Далее этот запрос размещается где-нибудь в недрах стороннего продукта и обеспечивает получение данных. Это в теории. На практике же кроме использования на уровне СУБД нумерованных имен вместо отражающих смысл хранимой информации вылезают «подводные камни», подробнее о которых можно посмотреть здесь. Но в любом случае на выходе имеем нечто подобное:
Из плюсов можно отметить разве что возможность передать эти задачи IT-специалистам из областей, отличных от 1С и в частности – занимающимся поддержкой целевой базы. Правда тут тоже есть свои ньюансы, т.к. радиус кривизны рук сильно варьируется не только среди 1С-ников, и на сервере с СУБД могут «завестись» интересные задания, гоняющие одни и те же данные через десяток таблиц и пытающиеся обработать миллионы строк из какого-нибудь регистра с себестоимостью в нашей 1С, а разобраться в них, не принимая участия в непосредственном создании окажется крайне затруднительно. Но не забывайте, что когда-нибудь могут попросить помочь с этим разобраться и Вас.
Способ 2. Удобный (хотя и не столь очевидный)
Мысль эта посещает не сразу, а когда посещает часто бывает уже поздновато, но все-таки: Если со стороны внешней базы не получается прочесть данные с нормальными именами полей, то почему бы не заставить 1С работать на запись? Реализация этого мероприятия несколько сложнее, чем чтения из внешней базы, тем не менее ничего сверхъестественного из себя не представляет. Прежде всего потребуется еще одна функция, которая будет выполнять SQL запросы, не предполагающие возврат какого-либо результата.
Далее обратим внимание на структуру данных, таблиц, в которые будем писать. Помимо целевых полей, нам потребуется ключ, позволяющий однозначно идентифицировать принадлежность строк данных во внешней базе объектам 1С. Иначе говоря, смотрим как 1С хранит ссылки объектов и добавляем во всякой таблице с выгружаемыми нами данными поля с аналогичным типом данных и размерностью, т.е. binary(16)
Определяемся предполагает ли наша разработка соответствие одному объекту базы 1С одной записи внешней таблицы (как пример – отражение записи справочника), или же записей может быть несколько (отражение или имитация движений документов или табличных частей объектов). Для второго случая добавляем поле с номерами строк.
Не обязательно, но полезно при разборе полетов – Дата и время фактической записи во внешнюю таблицу.


Осталось самое главное – обеспечить запись данных в SQL. Как именно это будет выполняться – в подписке при непосредственном изменении (записи) объекта в 1C, регламентным заданием по расписанию, или по требованию пользователя зависит только от контекста задачи и личных вкусов разработчика. Нам же важен сам механизм. В зависимости от наличия одной строки (идентифицируется Ссылкой однозначно) или группы строк (т.е. строка идентифицируется по Ссылке и автономеру строки) запись будет слегка отличаться.
Принцип работы таков:
- Обеспечиваем выборку и при необходимости программную обработку данных. Функциям в качестве основного аргумента подходит как результат запроса, так и таблица значений.
- Собираем параллельно два запроса в формате SQL, первый удаляет из внешней таблицы записи по значению ключевого поля, второй добавляет свежие. Не забываем, что длина неограниченной строки в реальной жизни ограничена и составляет в районе 200 000+ символов, после которых растет только значение, определяемое через СтрДлина(), но не сама строка. Данный факт сам собой задает нам размер объема данных, которые могут быть обработаны за одно обращение к SQL. После превышения предельной длины строки немедленно выполняем запросы и приступаем к формированию новых. Тем самым, обработка данных ведется блоками. Даже если бы нам очень не хотелось морочиться с её обеспечением, это пришлось бы сделать применительно к большинству практических задач.
- По завершении обхода еще раз выполняем запрос и записывает тем самым последнюю порцию данных.
Примеры обращения:
И, наконец проверяем результат:


С некоторых пор при экспорте данных из 1С на уровне SQL стараюсь работать только на запись. Проблем с быстродействием замечено не было. Затраты времени – минимальны, фактически процесс разработки сводится к написанию запроса. Думается, что и для поклонников каноничного объекта «Внешние источники данных» аналогичный инструмент может быть легко реализован, хотя и без гарантий отсутствия некоторых проблем с совместимостью и преобразованиями типов. Среди основных достоинств замечены:
Установка и настройка MS SQL Server для 1С:Предприятие
Тему установки MS SQL Server обычно обходят стороной. Действительно, трудно не установить эту СУБД, даже делая это в первый раз, столь же трудно не запустить в связке с ней Сервер 1С:Предприятия. Однако есть ряд неочевидных тонкостей, которые способны существенно отравить жизнь администратору, о чем мы сегодня и расскажем.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
MS SQL Server занимает первое место по количеству внедрений в связке с 1С:Предприятием, во многом это объясняется низким порогом вхождения, осилить данную связку вполне способен человек без опыта, сугубо по методу Next - Next - Finish. И, что самое интересное, все это будет работать. Скажем больше, в подавляющем большинстве случаев настройки SQL-сервера по умолчанию более чем достаточно для обеспечения производительной работы сервера 1С:Предприятия и трогать их не только не нужно, но даже вредно.
Однако есть другая категория настроек, которая отвечает за расположение и выделение физических ресурсов и которую обычно тоже никто не трогает до тех пор, пока не начнет испытывать проблемы с производительностью.
Прежде всего следует вспомнить про системную базу tempdb, которая активно используется 1С для хранения временных таблиц и промежуточных результатов. Причем она используется сразу всеми базами 1С, работающими на сервере. А так как по умолчанию она располагается в папке установки SQL-сервера, т.е. на системном диске, то при увеличении нагрузки именно tempdb становится бутылочным горлышком для всего сервера. Очень часто это приводит к ситуациям: купили быстрые HDD / SSD, дисковых ресурсов хватает, а 1С тормозит, что способно вызвать у начинающих администраторов серьезные затруднения.
Второй момент. Кодировка сравнения tempdb должна совпадать с кодировкой сравнения информационных баз, иначе это может в ряде случаев привести к неожиданным результатам, вплоть до серьезных ошибок в расчетах.
В тоже время указанных сложностей совсем не сложно избежать, достаточно лишь потратить пару лишних минут при установке или внимательно просмотреть настройки уже установленного сервера.
Подготовка к установке
Еще на стадии планирования следует уделить некоторое внимание дисковой подсистеме. Для хранения пользовательских баз данных и системной базы tempdb следует выделить отдельный раздел, а еще лучше дисковый массив из быстрых дисков или SSD. В нагруженных системах имеет смысл разнести базы данных и журналы транзакций по разным дисковым массивам. Также рекомендуется отформатировать эти разделы с размером кластера в 64 КБ.

Установка MS SQL Server для работы с 1С:Предприятие
Как мы уже говорили, установка SQL-сервера предельно проста, и мы не будем описывать этот процесс подробно, обратив внимание лишь на необходимые настройки. Начнем с выбора компонентов, так как 1С не использует большинство механизмов SQL-сервера и если вы не собираетесь их использовать для иных целей, то оставляем только Службы ядра СУБД и Соединения с клиентскими средствами. В предыдущих версиях эти компоненты назывались Database Engine, Средства связи клиентских средств, также в них можно опционально установить Средства управления (однако лучше установить свежую версию средств управления отдельно).

На закладке Учетные записи служб обязательно установите флаг Предоставить право на выполнение задач обслуживания тома службе ядра СУБД SQL Server.

Затем следует проверить параметры сортировки, если у вас правильно настроены региональные настройки, то скорее всего там ничего изменять не придется, но проконтролировать данный параметр желательно, там должно быть Cyrillic_General_CI_AS.

В Конфигурации сервера укажите Смешанный режим проверки подлинности и задайте пароль суперпользователю SQL - sa. Также укажите ниже администраторов данного экземпляра SQL-сервера, как минимум следует добавить текущего пользователя, но если администрировать данный экземпляр будут другие ваши коллеги, то имеет смысл сразу их указать.

Следующая закладка - Каталоги данных - требует самого пристального внимания. Обязательно укажите в качестве места хранения пользовательских баз место на производительном массиве или отдельном диске. Несмотря на то, что расположение базы можно указывать при ее создании, задание правильных настроек по умолчанию избавляет вас от лишней работы, а также от ситуации, когда база создается средствами 1С и оказывается в каталоге по умолчанию, т.е. на системном диске. Также сразу можете указать каталог для хранения резервных копий.

Современные версии MS SQL содержат отдельную закладку TempDB, для настройки одноименной базы, в предыдущих версиях данных настроек нет и о том, как настроить данную базу будет рассказано ниже. Здесь же мы выставляем для базы: количество файлов - 4, начальный размер - от 1 ГБ до 10 ГБ, авторасширение - 512 МБ, аналогичный размер и авторасширение устанавливается для файла журнала. Также не забываем проконтролировать размещение TempDB на отдельном разделе/диске.

Остальные настройки можно оставить по умолчанию и завершить установку.
Для управления сервером СУБД следует скачать и установить SQL Server Management Studio (SSMS), ее можно установить как на сервер, так и на компьютер администратора, чтобы управлять с него всеми доступными SQL-серверами. Никаких особенностей в установке SSMS нет.
Настройка операционной системы
Если у вас имеется уже установленный экземпляр MS SQL, либо вы не выполнили всех рекомендаций по установке, то следует проверить ряд настроек операционной системы. Запустим редактор локальной политики безопасности secpol.msc и перейдем в раздел Локальные политики - Назначение прав пользователя. Откроем политику Выполнение задач по обслуживанию томов и убедимся, что в списке пользователей присутствует учетная запись от имени которой работает SQL Server - NT SERVICE\MSSQLSERVER.

Если ваш экземпляр MS SQL Server установлен отдельно от Сервера 1С:Предприятие, то выполните аналогичную настроку для политики Блокировка страниц в памяти.
Настройка MS SQL Server для работы с 1С:Предприятие
Если вы имеете дело с уже установленным экземпляром SQL-сервера, убедитесь, что кодировка сравнения Cyrillic_General_CI_AS, для этого откройте Managment Studio, выберите необходимый экземпляр SQL-сервера и щелкнув на нем правой кнопкой мыши перейдите к Свойствам:

В противном случае данные следует выгрузить средствами 1С, а сервер переустановить (или установить еще один экземпляр, если данный используется другими службами).
Затем перейдите к закладке Память, за основу для расчетов принимается объем выделенного SQL-серверу размера памяти (RAM). Обычно это объем памяти сервера за вычетом ОЗУ для ОС и иных служб, например, Сервера 1С:Предприятие. Для сервера с объемом ОЗУ в 32 ГБ мы будем исходить из доступного объема в 24 ГБ, выделив 8 ГБ для ОС и сервера 1С. Но данные соотношения не являются эталоном и в вашем случае это могут быть иные числа.
Для расчета минимального объема памяти применяется формула:
Для максимального применяется полный размер RAM, за вычетом 1 ГБ на каждые выделенные 16 ГБ ОЗУ (все объемы указываются в МБ):

В разделе Параметры базы данных можно проконтролировать места хранения пользовательских баз и журналов, а также изменить их при необходимости. Все изменения будут применены только к вновь создаваемым базам данных, уже существующие БД потребуется перенести в новое расположение вручную (если в этом есть необходимость).

В разделе Дополнительно - Параллелизм установите параметр:

Следующая настройка будет связана с безопасностью. Для подключения 1С к серверу чаще всего используется учетная запись sa, что, мягко говоря, небезопасно, так как дает вошедшему под ней полный доступ к SQL-серверу. Учитывая, что администрированием баз 1С часто занимаются сторонние специалисты, то имеет смысл создать для них отдельную учетную запись.
Для этого раскройте Безопасность - Имена для входа и создайте новое имя (учетную запись), укажите проверку подлинности SQL-сервер и задайте пароль.

Затем перейдите на закладку Роли сервера и разрешите dbcreator, processadmin и public.

После чего используйте для подключения к SQL-серверу из 1С именно эту учетную запись.
Все создаваемые базы данных создаются на основе служебной базы model и к ним применяются все настройки этой БД, поэтому перейдем в Базы данных - Служебные базы данных и откроем свойства базы model. В разделе Файлы укажите значения начального размера базы от 1 ГБ до 10 ГБ, начальный размер журнала транзакций от 1 ГБ до 2 ГБ и авторасширение в 512 МБ. Выбирая начальный размер базы, нужно исходить из соображений чтобы размер файла превосходил загружаемый размер образа информационной базы 1С.

В разделе Параметры укажите Модель восстановления в соответствии с применяемой политикой резервного копирования и установите параметр:

Для уже существующих баз потребуется выполнить аналогичные настройки, за исключением параметра Начального размера, его следует выставить больше, чем текущий размер файлов базы и лога транзакций. Для базы данных желательно указать планируемый размер БД за длительный период эксплуатации, а для файла журнала размер, исключающий его авторасширение в процессе работы.
После внесения всех изменений в конфигурацию службу SQL сервера потребуется перезапустить.
Настройка сетевых протоколов
Для настройки сетевых протоколов откроем Диспетчер конфигурации SQL Server и перейдем в раздел Сетевая конфигурация SQL Server - Сетевые протоколы для MSSQLSERVER, где MSSQLSERVER - имя вашего экземпляра, и установим следующие настройки:

- Общая память (Shared Memory) - Включено
- Именованные каналы (Named pipes) - Отключен
- TCP/IP - Включено
Настройка базы tempdb
В предыдущих версиях MS SQL Server нет возможности настроить параметры базы tempdb при установке, также вы могли выполнить установку со значениями по умолчанию, либо вам достался уже установленный экземпляр, в этих случаях нужно произвести дополнительную настройку. Откроем Managment Studio и перейдем в Базы данных - Служебные базы данных в свойства базы tempdb. В разделе Файлы разобьем базу на четыре файла данных и установим для них начальный размер от 1ГБ до 10 ГБ, но не менее текущего размера файла, авторасширение - 512 МБ. Аналогичные настройки установим и для файла журнала.

Перенос базы tempdb
Довольно часто встречаются ситуации, когда tempdb требуется перенести в другое место. Например, сервер был установлен с параметрами по умолчанию и tempdb находится на системном разделе, или вы приобрели SSD и хотите перенести туда не только базы, но и tempdb (что является правильным решением). Также при большой нагрузке на tempdb его рекомендуется выносить на отдельный диск.
Для того, чтобы изменить место расположения файла tempdb откройте Managment Studio, выберите Создать запрос и в открывшемся окне введите следующий текст, где E:\NEW_FOLDER - новое расположение для базы:
Данный запрос состоит из двух секций, верхняя переносит файл данных, нижняя - журнал транзакций. Если вы разделили базу на четыре файла данных, то следует изменить запрос, создав для каждого файла данных свою секцию.
Создав запрос нажмите Выполнить, после выполнения запроса перезапустите SQL-сервер, файлы базы и лога tempdb будут созданы в новом месте, файлы по старому расположению следует удалить вручную.

Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
Читайте также: