
Замена жесткого диска сервера
Решил написать эту статью после знакомства с публикацией «HP, Dell и IBM: компоненты, отвечающие за надёжность сервера», поскольку имею другое мнение насчёт некоторых моментов. Эта статья не претендует на инновационные подходы, а просто описывает полученный опыт и, надеюсь, предотвратит банальные ошибки.
Итак, начнём с того, что попробуем выяснить, зачем бесперебойность и беспрерывность серверам? Собственно, серверам бесперебойность не обязательна, но она нужна сервисам, которые предоставляют эти сервера. Наилучшая беспрерывность обеспечивается только распределёнными системами, которые могут функционировать независимо друг от друга с автоматическим переключением между ними (для скорости) и разнесённые географически (катастрофоустойчивость). Но это выдвигает особые (не всегда реализуемые) требования к программному обеспечению. Недостатками таких решений являются повышеная стоимость, проблемы с репликацией данных, передача состояния для бесшовного переключения на резервную систему. Дополнительными плюсами является то, что при правильной реализации системы, возможно повышение быстродействия — клиенты делятся между двумя или более локациями, а при сбое перераспределяются.
Но есть задачи, настолько критичные и специфические, что требуют особой бесперебойности серверов, для них делают особые сервера, например менфреймы, с возможностью горячей замены всех компонентов, включая процессоры, память и даже материнские платы. Но такие решения стоят гораздо дороже обычных серверов и те кто их покупает — понимаю зачем это надо.
Вернёмся к серверам начального и среднего уровней. Существенно повышает беспрерывность работы серверов возможность горячей замены компонентов.
Горячая замена блоков питания
В моей практике, сгоревших БП (блоков питания) было немного, но наличие в сервере hot-swap БП, подключённых по схеме N+N во многих случаях существенно увеличивает бесперебойность работы сервера. Если в сервере больше двух БП, то зачастую реализована схема N+1, что не позволяет питать сервер от двух независимых источников или линий питания. Электропитание с подачей в стойку двух независимых линий повышает бесперебойность в самых различных ситуациях, например при обслуживании или аварии систем энергообеспечения в датацентре. Был случай, в сервере вышел из строя БП и создал короткое замыкание, что привело к срабатыванию защиты PDU и его отключению, соседние сервера с БП по схеме 1+1, подключённые также к другому PDU продолжили работу. Резервирование БП позволяет изменять подключение сервера к сети энергообеспечения, не прерывая его работу, например, оптимизировать укладку кабелей (конечно, правильно укладывать кабеля надо при установке сервера, но мы живём в не идеальном мире).
Вопреки заблуждению сертификация 80 Plus указывает на энергоеффективность блока питания, и не обязывает производителя к обеспечению какого либо уровня надёжности.
Также резервирование БП предотвращает большинство проблем связанных с кабелями питания. Плохой контакт некачественных кабелей, случайное их выдергивание персоналом при работах. Если у вас сервер с одним блоком питания, использование для него качественного и неизношенного кабеля, который плотно устанавливается в гнездо, и при нагрузке не издаёт посторонних звуков (потрескивание) более важно — невозможна замена без остановки сервера. В случае сервера с резервированными БП, плохой контакт кабеля может привести к выходу блока питания из строя.
Горячая замена дисков
Горячую замену дисков можно производить практически со всеми вариантами интерфейсов. Конечно, есть и некоторые ограничения.
IDE устройства редко переносят отключение/подключение второго устройства на шлейф — велик риск пропадания работающего устройства из системы. Главная проблема интерфейса IDE в правильной обработке операционной системой этого события. Так как интерфейс IDE не предусматривает горячей замены, в большинстве случаев необходимо вручную запустить сканирование устройств для определения нового оборудования. Важный момент — интерфейс подключается/отключается к обесточенному диску (подключение: сначала интерфейс, потом питание, отключение: сначала питание, потом интерфейс).
ОТКАЗ ОТ ОБЯЗАТЕЛЬСТВ: выполняя отключение/подключение устройств IDE Вы делаете это на свой страх и риск — никто не гарантирует сохранение работоспособности оборудования, и стабильность работы ОС.
Интерфейсы FC, SAS, SATA (AHCI) — поддерживают горячую замену дисков в полном объеме, проблемы могут быть в операционной системе. Если дисковый контроллер SATA находится в режиме совместимости IDE — то, возможно, понадобится вручную запустить сканирование шины. В режиме AHCI в большинстве случаев диск определится автоматически. Рекомендую использовать AHCI, если ваша ОС это позволяет, т.к. этот режим также повышает производительнось диска; TRIM поддерживается только в этом режиме работы контроллера.
При отключении дисков для продления срока их службы рекомендую предварительно отключать их программным методом и извлекать после остановки шпинделя, т.е. через примерно 30 секунд после выключения для дисков 7200RPM. Если диск невозможно отключить программно и он установлен в hot-swap корзинке, рекомендую вытащить диск на минимальное расстояние, при котором диск будет отключен, подождать остановки шпинделя и извлечь окончательно. В большинстве систем — это расстояние полностью отведённой ручки корзинки. Конечно, эти действия не несут практического смысла, если диск вышел из строя, но, возможно, он просто «завис» и вам не поменяют его по гарантии и придется использовать в некритичном оборудовании.
Так же важно понимать, что диск находится в составе RAID или как отдельное блочное устройство. При использовании отдельного диска необходимо предварительно его отмонтировать для избежания сбоев в работе ОС и программного обеспечения. Даже если диск не используется в текущий момент, после извлечения примонтированого диска зачастую наблюдаются лаги всей ОС. Конечно же, диск, на котором установлена ОС, извлечь без «зависания» не получится.
Большинство серверов позволяет подсветить индикатором диск по команде с сервера, по возможности пользуйтесь этой функцией, для минимизации ошибочных извлечений дисков. Например на серверах SuperMicro номер корзинки указан на самой корзинке, и может не совпадать с номером слота на бэкплейне. Такая-же проблема есть у многих производителей.
Так же перед отключением желательно получить информацию о диске (модель, объем, серийный номер) для сопоставления сразу после извлечения диска. Во многих случаях при ошибочном извлечении другого диска это позволит устранить ошибку сразу, а иногда даже предотвратить сбой в работе или потерю данных.
В случае использования RAID-массивов, рекомендую отключать диски программно (помечать как сбойные), перед извлечением это устранит снижение производительности дисковой системы сразу после отключения диска.
Проблем с SSD дисками при частом горячем подключении/извлечении не заметил, хотя использовал несколько именно в таком режиме.
На этом первая часть заканчивается, в следующей частях про RAID массивы, память для серверов, системы удалённого управления и про важность мониторинга.
Собственно хотелось бы понять последовательность действий.
Как правило когда RAID создается, то все диски форматируются.
Если у меня из 2 дисков 1 вышел из строя, что нужно делать по шагам?
Мои предположения:
1) Разбить рэйд
2) заменить битый диск на новый
3) собрать рэйд
На 3 шаге,я предполагаю, система отформатирует оба диска и я останусь ни с чем.
И попутно - как можно оба диска заменить в RAID-1 вместе с переносом всех данных?

У RAID есть forced rebuild, с которым регулярно косячит масса людей, уничтожая данные при замене диска, и "правильный" rebuild, который выполняется с учётом замены только одного диска.
Форматированием, как я понимаю, вы называете именно forced rebuild, либо инициализацию.
В зависимости от того, как вы создавали массив, у вас должны быть средства управления им. Наверняка где-то там вы и увидели информацию о том, что один из дисков необходимо заменить. Изучите соответствующую справку/документацию на предмет того, как правильно заменять диски без потери данных.
Однако, с учётом того, сколько случаев потери данных при замене диска в RAID мы видим, я бы всё равно рекомендовал сделать копию хотя бы важных данных перед заменой (а лучше всех). Наличие копии данных также позволит вам просто создать новый RAID1 с нуля и потом скопировать на него файлы.

1)Отключаете неисправный.
2)Подключаете исправный.
3)Даете команду контроллера на rebuild.
1)Убрать старые диски.
2)Поставить новые диски.
3)Дать команду контроллеру на построение RAID.
4)Восстановить все данные из бэкапа.
А есть способ переноса данных плавно?
Ну типа поменяли 1 диск, синхронизировали, поменяли 2 диск, синхронизировали?
sbh, Можно и так.
Это собственно вариант замены одного диска - замена одного диска, без остановки работы.
После того как замените и убедитесь что все отлично - меняем другой диск.
АртемЪ, помоему если заменить диск - контроллер скажет что новый не является членом рэйда. чтобы его добавить нужно создать рйэд, а в момент создания оба диска форматируются.
sbh, Вы отключаете один диск- рэйд работает в режиме degrade - потеря избыточности.
Добавляете диск и делаете ребилд массива - рэйд снова в работе.
Вообще RAID1 делают для единственной цели - обеспечить непрерывную работу, даже в случае отказа диска.
Поэтому любой контроллер способен справится с ситуацией отказа или удаления одного из дисков, и корректно перестроить массив при добавлении нового диска.
Какие именно команды нужно давать контроллеру - тут зависит от контроллера, надо читать доки.

Сегодня не самый обычный пост, я еду в ЦОД менять и устанавливать диски. Любопытно, что все диски разные, оборудование тоже разное. Для мониторинга состояния дисков потребуется самые разные инструменты. Вроде бы всего 4 диска, а подходы самые разные. Поехали.
Диск 1. Сервер Supermicro
Первый диск будем менять в сервере Supermicro. Сервер Supermicro 4U: CSE-846BE16-R920B. Когда-то давно на нём собирали массивы:
Диск HDD 6ТБ, форм-фактор 3.5'. Вот так выглядит сбойный диск, красный светодиод манит админа.

Перед заменой диска необходимо убедиться, что проблема именно с диском. Сервер работает, выключить его нельзя. Соответственно, в утилиту Avago Config Utility для управления SAS-контроллером войти не удастся. На сервере работает операционная система Ubuntu. Для мониторинга состояния массива будем использовать утилиту storcli. Пример работы у меня уже есть, правда в Oracle Linux, но в данном случае это не принципиально:
Посмотрим, что у нас там с диском. Диск в состоянии "UBad-Unconfigured Bad". Всё понятно, нужно менять.
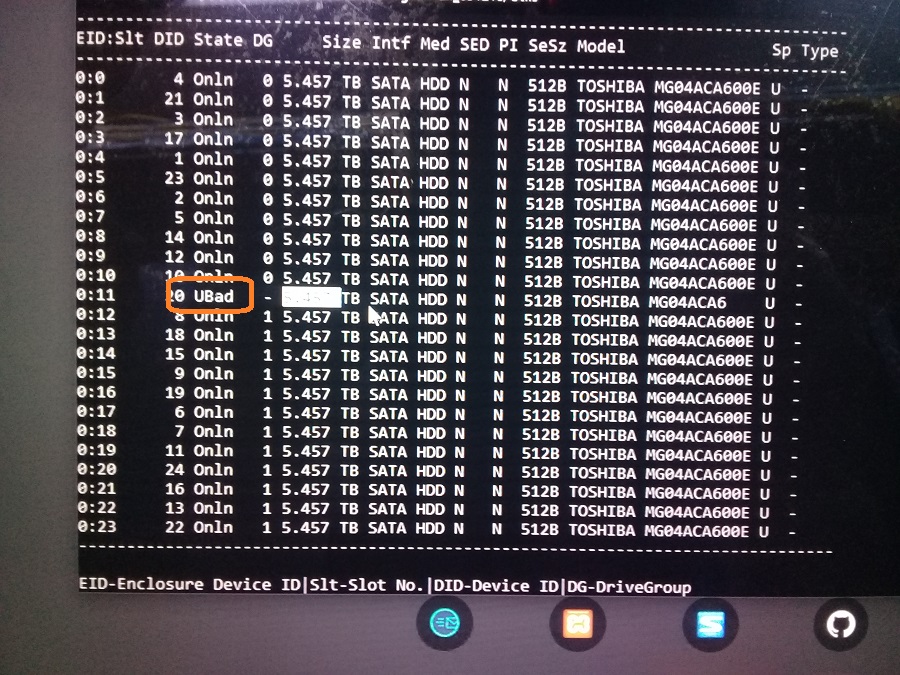
Данный сервер поддерживает горячую замену дисков, мне же проще. Выдергиваем старый диск.

Красный светодиод продолжает гореть на дисковой корзине. Перекручиваем салазки на новый диск.

Устанавливаем диск в слот.

После установки диска загорится синий диод, красный начнёт мигать.

Начинается перестроение массива. Перестроение займёт много времени, больше суток.

Потом, через пару дней проверил, массив в порядке:

Замена диска прошла без проблем.
Диск 2. СХД HP MSA 2040
Второй диск меняю в СХД MSA 2040. Ранее уже менял подобные диски:
Диск HDD 900ГБ, форм-фактор 2.5', поставляется с салазками для MSA. Для управления дисками используется утилита Storage Management Utility, вот так там выглядит дохлый диск:

Он же на MSA с оранжевым светодиодом:

Извлекаю старый диск.


Распаковываю новый диск.

Устанавливаю новый диск.


Теперь нужно зайти в Storage Management Utility и добавить этот диск как Global Spare.

Сразу скажу, что после этого новый диск вышел из строя. Жду ответа техподдержки, замена диска оказалась неуспешной.
Диск 3. Сервер HP ProLiant DL360 Gen9
Третий диск меняю в сервере HP ProLiant DL360 Gen9. Не первый раз меняю диски в этих серверах:
Диск HDD 1ТБ, форм-фактор 2.5', поставляется с салазками. Битый диск светится оранжевым:

Для мониторинга состояния дисков в серверах ProLiant девятого поколения используется утилита iLO 4. Скриншоты не делал. но там тоже видно какой диск вышел из строя.
Извлекаю битый диск.

Устанавливаю новый диск.

Всё просто, салазки перекручивать не нужно, операция быстрая. На всех дисках массива горит индикатор "не извлекать", начинается перестроение массива.
Диск 4. Сервер HPE ProLiant DL360 Gen9. NVMe.
Четвёртый диск не получится установить в работающий сервер. Диск представляет собой PCIe плату NVMe.

Устанавливаем в сервер HPE ProLiant DL360 Gen9. Выключаем сервер, выдвигаем на салазках, снимаем крышку.

В данный сервер можно установить одну полноразмерную PCIe плату и две низкопрофильные. Второй и третий слоты я уже занял, диск будет устанавливаться в первый полноразмерный слот. Снимаю райзер, понадобится отвертка torx.

Кручу-верчу. В райзер устанавливается две PCIe платы. Одна уже установлена, устанавливаю вторую.

Диск в райзере. Устанавливаю райзер в сервер.

Закрываю крышку, включаю сервер. NVMe платы нельзя собрать в RAID через имеющийся RAID контроллер, у меня они собраны с помощью mdadm в операционной системе Ubuntu. Два диска были в RAID1, третий диск позволит увеличить объём массива в два раза, с преобразованием RAID1 в RAID5.
Потом
Забегая вперёд можно сказать, что три из четырёх дисков встали нормально, массивы работают в штатном режиме. А вот четвёртый диск HP MSA 2040 подкачал, новый и не заработал. Техподдержка пока молчит.
Потом-потом
Прислали новый диск для HP MSA 2040, со второй попытки диск встал успешно, пришлось ехать в ЦОД ещ1 раз.

Приветствую тебя, юный подаван. У нас стоит глобальная задача по переводу 1С на SSD диски. Сегодня решаем чисто железную часть - тупо меняем диски. У нас есть сервер HPE Proliant DL360 Gen9. Задача стоит не просто заменить один диск другим. Мы вынем старые HDD 600 GB, и поставим новые SSD.
На сервере из 4-х дисков собран RAID10. Разбираем его и делаем RAID1 из первых двух дисков. По сути - уменьшаем массив в два раза. Используем его потом под систему. Итак, 3 и 4 диски больше не нужны. Выключаем сервер.

Вот наш бывший массив:

1 и 2 диски оставляем - это для RAID 1. 3 и 4 вынимаем.


Достаём новые SSD.

Для нового SSD зеркала закупили диски:

Обратная сторона новых SSD.

Маркировка DS на новых дисках, насколько я понял, означает integrated HPE Digitally Signed Firmware (DS), т.е. прошивка с цифровой подписью. Типа прошивка из надёжного источника.


Как запросить замену диска в сервере у IBM-011Она сигнализирует, что диск в данном RAID массиве вышел из строя. В некоторых случаях он еще не умер, а просто валился из RAID, для начала просто его вытащите и снова воткните, если через некоторое время лампочка продолжает гореть то приступаем к следующему шагу. Да еще хотел отметить, что посмотреть статус RAID в сервере IBM, можно утилитой MSM.
Заходим в нее и видим, что на вкладке Physical у нас один из винтов красного цвета, это значит что он все вышел из строя, намертво.

Как запросить замену диска в сервере у IBM-Сломанный диск
После, этого нам нужно обратиться в тех поддержку компании IBM, и собрать для них логи. Как собрать логи утилитой DSA читайте тут. Так же на каждом сервере вам нужно записать его MTM, SN и Product ID, найти их можно слева от винтов, еще техническая поддержка может вас попросить выслать ibm fru номер жесткого диска.

Как запросить замену диска в сервере у IBM-12
После сбора логов отправляем письмо в техническую поддержу, по адресу
Далее ждем когда приедет курьер и привезет диски. Заменяем их на убитые HDD и начинается процесс Rebild в RAID.

Как запросить замену диска в сервере у IBM-13
Наблюдать его статус можно через MSM утилиту.

Как запросить замену диска в сервере у IBM-Rebuil RAID
и также можно посмотреть сколько по времени это займет, на главной странице утилиты вы увидите ползунок

Как запросить замену диска в сервере у IBM-03
Нажав More details вы увидите более подробную информацию

Как запросить замену диска в сервере у IBM-04
Популярные Похожие записи:
40 Responses to Как запросить замену диска в сервере у IBM
Добрый день. Подскажите пож-та, сейчас у меня рейд в статусе разрушен, один диск вылетел, установил новый (той же серии) но ни чего не происходит. Желтая лампочка при этом не горит и не горела, ни на самом диске ни на панели. Может быть надо где настроить, что бы горела желтая лампочка? Server X3300 M4, диски не родные (не IBM). Спасибо
Спасибо за скорый ответ. Модель контроллера M1115. В моем случае меня интересует почему не горят желтые лампочки на самом диске и на панели сверху? Спасибо еще раз
а в каком статусе у вас видится в MSM ваш новый диск и какой статус RAID?
MSM пока не установил еще, в Megaraide диск был красным цветом, а рейд кажется в статусе разрушен (вроде бы так)
Нужно посмотреть с помощью MSM, статусы и логи так быстрее можно понять проблему, либо можно логи снять утилитой MEGACLI, но MSM нагляднее все показывает
проблем после установки MSM не было? у меня сейчас сервер работает, 200 чел онлайн
установил, один диск — Uncofig good, Virtual drive — degraded.
Хотел ссылку на скрин скинуть суда, не получается
Сделайте его правым кликом Online если такого нет то попробуйте его сделать как Assign Global Hot Spare
И покажите ещ пож скрин с dashboard
Я произвел на тестовом, после Assign Global Hot Spare должен начаться ребилд
Если вы его не сделаете то потеряете, ребилд это стандартная операция восстановления RAID, которая перекидывает дублирующая информацию на hdd дублер.
ночью на всякий случай сделаю бэкап, а после все что Вы писали! Спасибо! А на счет желтых индикаторов не подскажите почему не горят?
индикатор загорится как только начнется ребилд, сейчас диск находится в подвешенном состоянии ни туда ни сюда, отпишитесь пож как у вас все пройдет
пока еще не делал, в это воскресенье буду делать. Просьба не удалять статью и комментарии. спасибо
Добрый день. Сделал как Вы писали Asifn Global Hot Spare, начался ребилд. Сейчас работает как надо, спасибо большое за помощь.
рад что мой опыт вам помог и вы научились чему то новому
Иван, помогите советом, если есть возможность ответить.
У нас на сервере IBM System x3400 M3 Server -7379ZLP полетел один жёсткий диск. Проверили документы, оказалось, что уже не гарантийный. Сервер вообще не загружался (даже БИОС не грузил), просто чёрный экран. Вытащили все три диска, поставили три новых диска, но не фирмы IBM, БИОС загрузился. Стали думать как был сконфигурирован RAID, контроллер LSI, поддерживающий только RAID 0,1, и 10, а диска всего три. Стали звонить в техподдержку фирмы, где приобретали, они посоветовали позвонить всё же в IBM и уточнить на счёт гарантии, позвонили, оказывается наш сервер ещё гарантийный, вытащили новые диски, вставили старые, БИОС сервера загрузился, собрали логи для IBM, они обещали выслать один новый жёсткий диск, но по срокам пока не понятно, когда придёт. БИОС загрузился, но винда не загружается. Наш RAID получается развалился после замены дисков? Похоже что на двух дисках был собран RAID 1, а третий был для бэкапов. Как думаете есть возможность запустить винду с одного диска? Я его подключал отдельно к компу, он живой на нём системные файлы и пакпи.
Добрый день, при загрузке можно попасть в bios подобное меню LSI и посмотреть какой рейд у вас был.
Вероятнее всего был RAID0, так как RAID-1 это зеркало и при выходе одного диска остался бы жить. Третий диск видимо забыли использовать, хотя могли сделать как hot swap.
Срок поставки зависит от уровня поддержки, мне в среднем за 3-4 дня рабочих приходят.
А при загрузке W ошибки какие на экране появляются?
Зашёл в биос, действительно RAID0 был. Значит придётся винду переустанавливать. Не понимаю для чего на сервере RAID0 делать.
Видимо, человек создававший его не знал принципов его работы и какой он отказоустойчивый:)
Сегодня из IBM привезли жёсткий диск, буду восстанавливать работоспособность сервера. Сделаю RAID1 вместо RAID0.
Мудрое решение, успехов.
Добрый день!
контроллер LSI 5110e. RAID10 на 6 дисках.
Намедни получил почтой предупреждение о «Predictive Failure Count»
Посмотрел в MSM а также поэкспериментировал с CLI
Drive /c0/e252/s0 State :
Shield Counter = 0
Media Error Count = 11
Other Error Count = 0
Drive Temperature = 33C (91.40 F)
Predictive Failure Count = 5
S.M.A.R.T alert flagged by drive = Yes
SN = 6XR3H3PF0000M228GXJ5
Model Number = ST9600205SS
Хотя состояние RAID все еще optimal.
Естественно такая модель уже не продается, можно ли закупить аналогичный по характеристикам винт на замену сбойному?
поидее можно, но там должно быть одинаковое количество байт в диске
Да, поставил аналогичный. все прошло нормально. Ребилд автоматически запустился и отработал за полтора часа.
Ларчик как говорится просто открывался, видимо он FRU как то использует.
Добрый день!
Планируется лиликбез по замене BBU на Raid ?
Добрый, а что у вас за рейд и контроллер и что именно интересует?
IBM System x3630 M3 с контроллером ServeRAID M5015, как физически установить разобрался. Больше интересует какие могут быть подводные камни. На что перед заменой надо обратить внимание.
Да по идее их нет, создаете рейд и мониторите потом его на ошибки, если что меняете диски, все как то так.
Наверно имели ввиду батарею на рейде менять в случае ошибок. Спасибо!
Приветствую! Имеется сервер IBM X3650 M4, контроллер M5110e. Вышел из строя один диск в raid1. Поставщики нашли такой же и доставили. Старый диск я извлёк из корзины при работающем сервере, новый установил. В программу MSM этот диск отобразился со статусом Unconfigured good. Но ребилд не начинался автоматом.
После этого в контекстном меню нового диска выбрал «Assign Global Hot Spare», но и после этого ребилд не начался.
Сейчас ситуация как на скриншоте, новый диск постоянно мигает оранжевым светодиодом (уже 14 часов). Если это идёт ребилд, то почему в MSM на вкладке Dashboard в Background operations пусто?
Не пойму, что я сделал не так и что мне делать дальше? Как запустить ребилд из под винды, чтобы не тормозить работу?
Добрый вечер, есть сервер IBM X3500 M4, RAID 50 из 6 Sas дисков, контроллер М5110. Сегодня на сервере загорелась желтая лампочка с восклицательным знаком и с картинкой БД. Сразу стал смотреть, все диски мигают только зеленой лампочкой. Зашел в MegaRaid Storage Manager на одном диске Media Error Count = 1. На втором Media Error Count = 809, Pred Fail Count = 1. Также в Megaraid все диски на данный момент в нормальном состоянии, как лучше поступить? Есть запасной не родной диск. Стоит ли его вставлять на замену диску с ошибками?
Если запасной подходит по разметки (Размеру), то можете попробовать, если есть сервисный контракт, то пишите в саппорт.
Читайте также: