
Замена диска в сервере hp
Решил написать эту статью после знакомства с публикацией «HP, Dell и IBM: компоненты, отвечающие за надёжность сервера», поскольку имею другое мнение насчёт некоторых моментов. Эта статья не претендует на инновационные подходы, а просто описывает полученный опыт и, надеюсь, предотвратит банальные ошибки.
Итак, начнём с того, что попробуем выяснить, зачем бесперебойность и беспрерывность серверам? Собственно, серверам бесперебойность не обязательна, но она нужна сервисам, которые предоставляют эти сервера. Наилучшая беспрерывность обеспечивается только распределёнными системами, которые могут функционировать независимо друг от друга с автоматическим переключением между ними (для скорости) и разнесённые географически (катастрофоустойчивость). Но это выдвигает особые (не всегда реализуемые) требования к программному обеспечению. Недостатками таких решений являются повышеная стоимость, проблемы с репликацией данных, передача состояния для бесшовного переключения на резервную систему. Дополнительными плюсами является то, что при правильной реализации системы, возможно повышение быстродействия — клиенты делятся между двумя или более локациями, а при сбое перераспределяются.
Но есть задачи, настолько критичные и специфические, что требуют особой бесперебойности серверов, для них делают особые сервера, например менфреймы, с возможностью горячей замены всех компонентов, включая процессоры, память и даже материнские платы. Но такие решения стоят гораздо дороже обычных серверов и те кто их покупает — понимаю зачем это надо.
Вернёмся к серверам начального и среднего уровней. Существенно повышает беспрерывность работы серверов возможность горячей замены компонентов.
Мои дополнения
EVENT (18 Aug 10:54): Option ROM POST Information: 1764-Slot 0 Drive Array - Capacity Expansion Process is Temporarily Disabled.
EVENT (18 Aug 10:54): Option ROM POST Information: Expansion will resume when battery is enabled. Action: Connect Smart Storage Battery Module.
Стоило только снова загрузиться в SSA:
Пока идёт процесс трансформации, сервер находится в состоянии Degraded(Transforming). Есть риск потерять данные, так что лучше подстраховаться. Дело в том, что всё это время кеш RAID-контроллера отключен. Вернее, он используется для трансформации.
После завершения трансформации нужно руками запустить процесс расширения логического диска. Он проходит быстро. При этом предупреждают, что на windows 2000 расширять нельзя - диск станет недоступным.
Всем привет. Есть сервер HP c RAID контроллером HP Smart Array P410i. Сейчас установлены такие диски:
logicaldrive 1 (68.3 GB, RAID 1, OK)
physicaldrive 1I:1:1 (port 1I:box 1:bay 1, SAS, 72 GB, OK)
physicaldrive 1I:1:2 (port 1I:box 1:bay 2, SAS, 72 GB, OK)
SEP (Vendor ID PMCSIERA, Model SRC 8x6G) 250 (WWID: 5001438010E45A1F)
На них установлена ОС и всё остальное. У меня есть пара новых дисков по 300Gb, которые нужно установить вместо текущих. Как это сделать? В интернетах пишут, что можно "на горячую" вытащить диск, вставить новый, дождаться ребилда массива, повторить со вторым диском. Но меня смущает, что диски бОльшего размера, чем установленные. И как потом можно расширить виртуальный диск?
Простой 6 комментариев
szelga, спасибо, похоже то что нужно! Заменить диски один за другим, дожидаясь ребилда, потом растянуть логический том.

- Сделать бэкап.
- Выдернуть диск.
- Подождать пять минут.
- Воткнуть новый диск.
- Дождаться ребилда.
- Готово.
А какая разница? Ладно если диск меньшего размера - могут данные не влезть.

а кому сейчас нужны SAS диски
любой самый дешевый ssd nvme быстрей и надежней в десятки раз. А их цена уже вполне приемлема.
В чем профит то ?
vlarkanov, разница в них настолько велика что сас нужно выкидывать и покупать nvme тем более цена у них прям таки скажем смешная. А обычный софтовый рейд тут будет все-равно быстрее.
но ближе к тема.
1. добовляешь диск и вмассив
2. клонируешь на них текщие диски и разделы
3. удаляешь старые диски
4. расширяешь раздел на диске.
Тем же кому и раньше.
Вот надо вам десяток террабайт дискового пространства - зачем вам nvme на десять террабайт? Проще SAS поставить.
А кто сказал что нужна скорость? Может устраивает текущая? Тогда зачем платить больше?
А по поводу надежности - чем они надежней? Такая же надежность - так же ломаются.
АртемЪ, кому нужно много место давно уже уехали в яндекс облако ;) его отказоустойчивость в отношение цены просто неконкурентно с любым другим решением.
Надежность заключается в отсутствие механических деталей,шпинделя всего связанного с ним.
А то что раньше SSD имели лимиты на чтение запись так это было очень давно, сейчас их наработка уходит далеко за 5 стандартных лет для SAS, порой доходя до 30 что сами понимаете далеко за циклом жизни любого диска.
НО его можно купить на любой барахолке а не искать по всему городу.
Отсутствие I-O лагов связаных со спецификой вращения шпинделя ( тут дело не в скорости)
В общем понятно когда есть оборудование то хочется его использовтать. Тем более если диски новые. НО по факту я бы сказал что все это уже устарело.
Вот и получается что у вас есть просто устаревшее оборудование, и если вы его используете это не плохо и не хорошо Но нужно четко понимта что в бюджет 10К можно получить решение не просто значительно лучше а их даже сравнивать нет смысла, и это даже на обычном совтовом рейде обслуживать который дешевле и намного.
Ага, прямо все. Вы пробовали сливать бэкап несколько треррабайт на яндекс диск со скоростью в пару десятков килобит в секунду? Желаю удачи.
Да вне конкуренции, ибо она чуть выше нуля. Можно сказать отсутствует.
Если рассматривать текущий случай - у человека есть SAS диски, а NVMe надо покупать.
Можно поподробнее, чем SSD надежнее и самое интересное чем отказоустойчивее? Надежность SSD выше только в случае мобильных дисков, в остальных случаях - такая же насколько мне известно. Или у вас есть другая информация?
Механика ломается, электроника тоже. У SSD с той же вероятностью сгорит контроллер или зависнет прошивка.
Лимиты как были, так и есть они никуда не делись. И они есть и у HDD. Просто в эти лимиты упереться нереально в большинстве случаев.
Виктор Таран, диски тут нужны чтобы загрузить ос и запустить приложение. Остальная магия творится в оперативной памяти, нагрузки на диски нет. Ssd тут просто не нужны.
Ага, прямо все. Вы пробовали сливать бэкап несколько треррабайт на яндекс диск со скоростью в пару десятков килобит в секунду? Желаю удачи.
Следите за магией
"Яндекс диск"
"Яндекс облако"
это совершенно разные вещи разрабатываемые вообще разными командами.
Если рассматривать текущий случай - у человека есть SAS диски, а NVMe надо покупать, конечно явно лучше чем покупать, вот вопрос в том что нужно ли такое решение в целом.

В SSD дисках есть четкий параметр наработки на отказ
Время наработки на отказ 1500000. В той модели что я вам скинул ( а это самая дешевая модель). замечу это фактически при 100% загрузке его все это время.
Если вам удобней в годах
Вы уверены что хоть 1 производитель SAS дисков нанес бы такую маркировку на свое устройство ?
Безопасная жизнь sas дисков это 5 лет далее их нужно менять в не зависимости от SMART.
Да естественно как и SAS так и SSD диски могут ломаться, и как правило это пеhвый год его жизни из-за скрытых дефектов, но времена тотального сгорания SSD уже давно в прошлом.
А вот технологическое преимущество твердотелов теперь недостижимо для механики.
И это я не говорю про ударопрочность, а именно физически, нет подшиприков которые расшатываются, нет головки которая трясется, не размагничиваются магниты, нет наводок, нет вращение шпиндиля, нет необходимости ждать когда докрутится шпиндель до сектора, нет зон уверенного и бытрого чтения ( диск к центру читается естественно медленней но онадежней) и тд и тп.
Только механика ломается 100% а детали могут сломаться.
Это основы инженерного дела, любая деталь с механической частью будет менее устойчива нежеле деталь с отсутствием механики. Это аксиома для любых вещей а не только для ssd исключение вывод новой технологии когда старые решения еще надежней новых. НО SSD это уже далеко не новая технология и родовые болячки там уже давно умерли.
К примеру родовая болячка классических HDD дисков была их катигорическая боязть сотрясений, для них выпускались даже резиновые отвертки, поскольку даже корябоние металлической отверткой могли привести к сотрясению диска и его смерти, естественно сейчас это как страшный сон.( хотя ронять их все-равно не стоит)
Вы не встретите в самолете механических приводово, все они уже давно цифровые именно в виду надежности, все что там осталось механического это то что невозможно удалить поскольку нет решения без механики.
Диск 2. СХД HP MSA 2040
Второй диск меняю в СХД MSA 2040. Ранее уже менял подобные диски:
Диск HDD 900ГБ, форм-фактор 2.5', поставляется с салазками для MSA. Для управления дисками используется утилита Storage Management Utility, вот так там выглядит дохлый диск:

Он же на MSA с оранжевым светодиодом:

Извлекаю старый диск.


Распаковываю новый диск.

Устанавливаю новый диск.


Теперь нужно зайти в Storage Management Utility и добавить этот диск как Global Spare.

Сразу скажу, что после этого новый диск вышел из строя. Жду ответа техподдержки, замена диска оказалась неуспешной.
Диск 3. Сервер HP ProLiant DL360 Gen9
Третий диск меняю в сервере HP ProLiant DL360 Gen9. Не первый раз меняю диски в этих серверах:
Диск HDD 1ТБ, форм-фактор 2.5', поставляется с салазками. Битый диск светится оранжевым:

Для мониторинга состояния дисков в серверах ProLiant девятого поколения используется утилита iLO 4. Скриншоты не делал. но там тоже видно какой диск вышел из строя.
Извлекаю битый диск.

Устанавливаю новый диск.

Всё просто, салазки перекручивать не нужно, операция быстрая. На всех дисках массива горит индикатор "не извлекать", начинается перестроение массива.
Горячая замена блоков питания
В моей практике, сгоревших БП (блоков питания) было немного, но наличие в сервере hot-swap БП, подключённых по схеме N+N во многих случаях существенно увеличивает бесперебойность работы сервера. Если в сервере больше двух БП, то зачастую реализована схема N+1, что не позволяет питать сервер от двух независимых источников или линий питания. Электропитание с подачей в стойку двух независимых линий повышает бесперебойность в самых различных ситуациях, например при обслуживании или аварии систем энергообеспечения в датацентре. Был случай, в сервере вышел из строя БП и создал короткое замыкание, что привело к срабатыванию защиты PDU и его отключению, соседние сервера с БП по схеме 1+1, подключённые также к другому PDU продолжили работу. Резервирование БП позволяет изменять подключение сервера к сети энергообеспечения, не прерывая его работу, например, оптимизировать укладку кабелей (конечно, правильно укладывать кабеля надо при установке сервера, но мы живём в не идеальном мире).
Вопреки заблуждению сертификация 80 Plus указывает на энергоеффективность блока питания, и не обязывает производителя к обеспечению какого либо уровня надёжности.
Также резервирование БП предотвращает большинство проблем связанных с кабелями питания. Плохой контакт некачественных кабелей, случайное их выдергивание персоналом при работах. Если у вас сервер с одним блоком питания, использование для него качественного и неизношенного кабеля, который плотно устанавливается в гнездо, и при нагрузке не издаёт посторонних звуков (потрескивание) более важно — невозможна замена без остановки сервера. В случае сервера с резервированными БП, плохой контакт кабеля может привести к выходу блока питания из строя.
Подробная информация
Откройте Утилиту настройки массивов на сервере HP Proliant.
Выберите в списке Контроллер Smart Array.
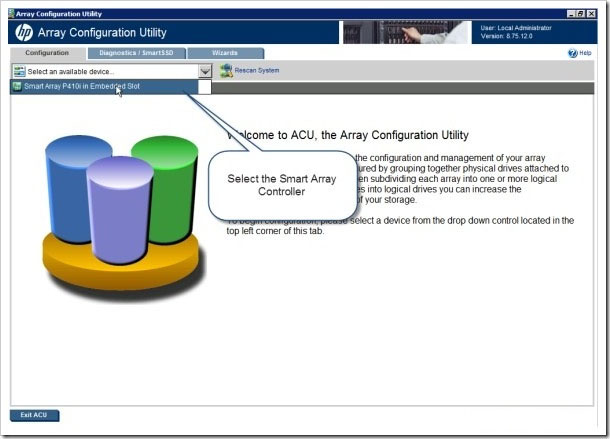
Щелкните, чтобы выбрать имя массива для развертывания (в данном случае – SAS Array B).
На правой панели окна ACU пользователь обнаружит функцию под названием Развернуть массив.
Щелкните Развернуть массив.
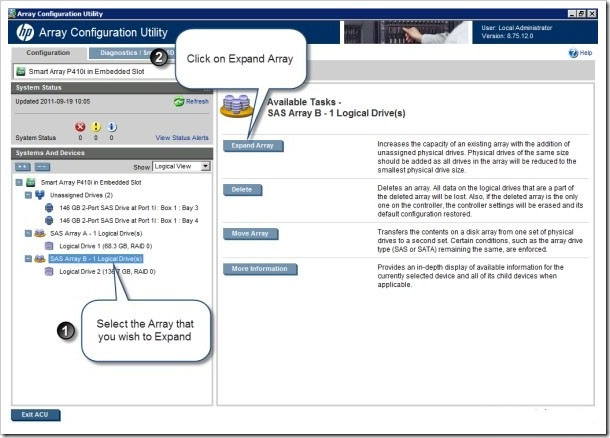
Выберите новый физический жесткий диск для добавления в массив.
Щелкните Сохранить, чтобы внести изменения в контроллер.
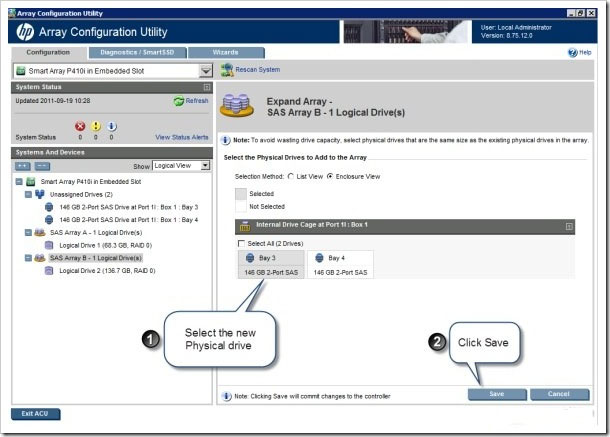
Начнется развертывание массива, а в ACU отобразится состояние преобразования.
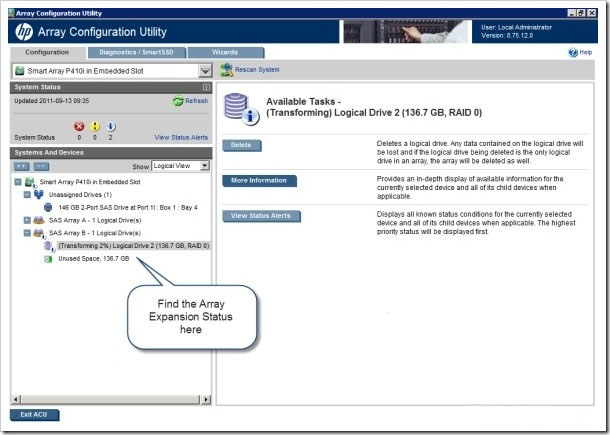
Подождите до завершения процесса развертывания массива.
Функция развертывания массива добавила 136,7 ГБ свободного пространства в массив SAS Array B.
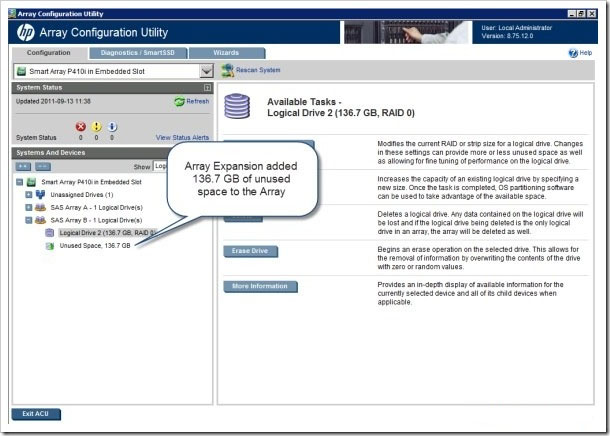
NOTE: При выполнении контроллером Smart Array развертывания массива или расширения логического диска, все другие развертывания и расширения запрещены для данного контроллера до завершения процесса.
По завершении развертывания массива у пользователя появляется 136,7 ГБ свободного пространства, доступного в массиве SAS Array B. Для использования добавленного пространства хранилища необходимо расширить логический диск на эту область.
Щелкните, чтобы выбрать логический диск для расширения (здесь выбран логический диск 2).
На правой панели окна ACU щелкните Расширить логический диск.
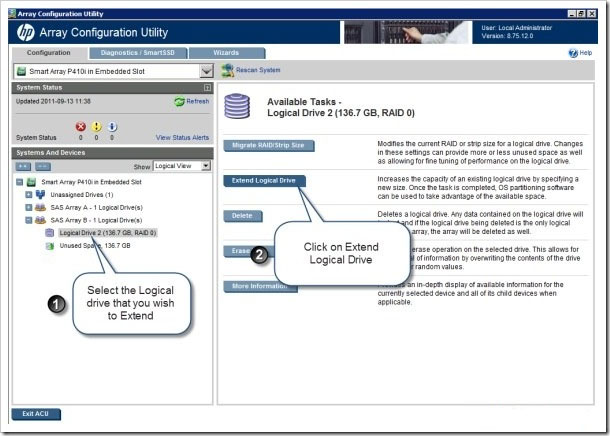
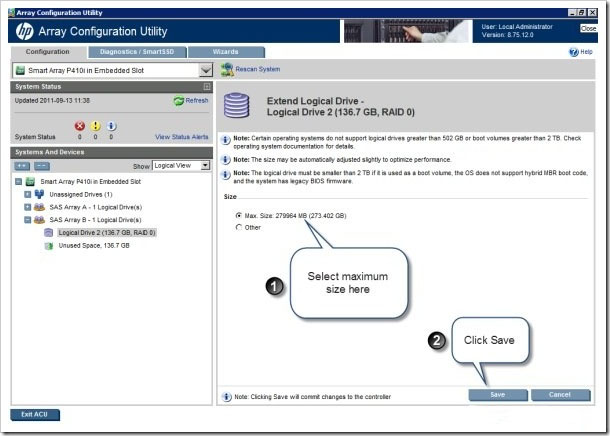
Теперь пользователь может выбрать доступный Максимальный размер и нажать кнопку Сохранить.
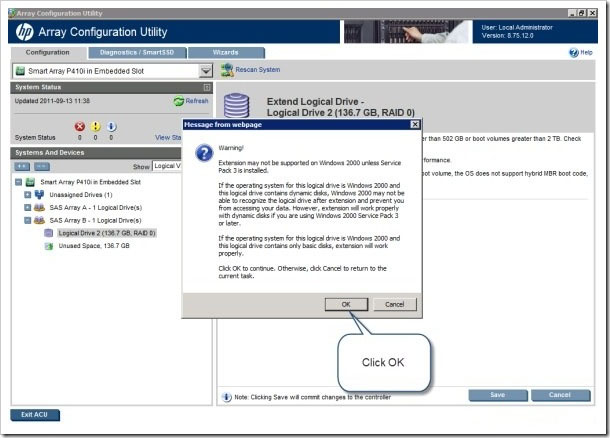
Выполняется расширение логического диска 2. В ACU отобразится состояние преобразования.
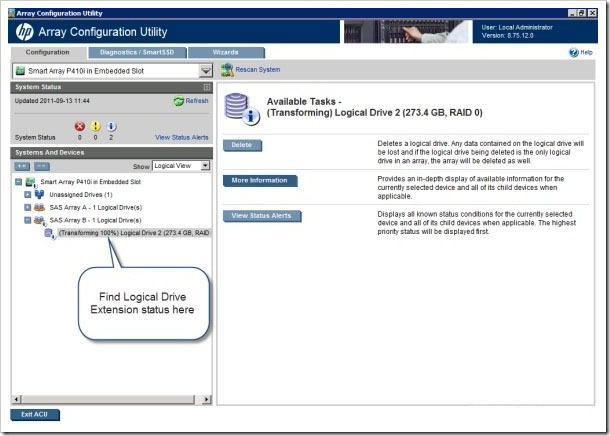
Подождите до завершения процесса расширения логического диска.
По завершении экран примет следующий вид.
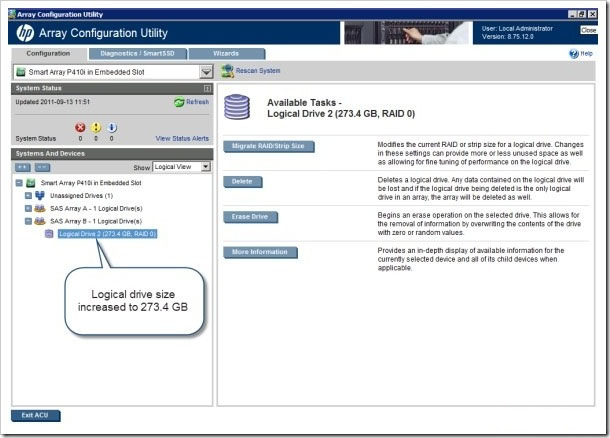
По завершении логический диск 2 будет расширен, а его размер увеличен до 273,4 ГБ.
Горячая замена блоков питания
В моей практике, сгоревших БП (блоков питания) было немного, но наличие в сервере hot-swap БП, подключённых по схеме N+N во многих случаях существенно увеличивает бесперебойность работы сервера. Если в сервере больше двух БП, то зачастую реализована схема N+1, что не позволяет питать сервер от двух независимых источников или линий питания. Электропитание с подачей в стойку двух независимых линий повышает бесперебойность в самых различных ситуациях, например при обслуживании или аварии систем энергообеспечения в датацентре. Был случай, в сервере вышел из строя БП и создал короткое замыкание, что привело к срабатыванию защиты PDU и его отключению, соседние сервера с БП по схеме 1+1, подключённые также к другому PDU продолжили работу. Резервирование БП позволяет изменять подключение сервера к сети энергообеспечения, не прерывая его работу, например, оптимизировать укладку кабелей (конечно, правильно укладывать кабеля надо при установке сервера, но мы живём в не идеальном мире).
Вопреки заблуждению сертификация 80 Plus указывает на энергоеффективность блока питания, и не обязывает производителя к обеспечению какого либо уровня надёжности.
Также резервирование БП предотвращает большинство проблем связанных с кабелями питания. Плохой контакт некачественных кабелей, случайное их выдергивание персоналом при работах. Если у вас сервер с одним блоком питания, использование для него качественного и неизношенного кабеля, который плотно устанавливается в гнездо, и при нагрузке не издаёт посторонних звуков (потрескивание) более важно — невозможна замена без остановки сервера. В случае сервера с резервированными БП, плохой контакт кабеля может привести к выходу блока питания из строя.
Диск 4. Сервер HPE ProLiant DL360 Gen9. NVMe.
Четвёртый диск не получится установить в работающий сервер. Диск представляет собой PCIe плату NVMe.

Устанавливаем в сервер HPE ProLiant DL360 Gen9. Выключаем сервер, выдвигаем на салазках, снимаем крышку.

В данный сервер можно установить одну полноразмерную PCIe плату и две низкопрофильные. Второй и третий слоты я уже занял, диск будет устанавливаться в первый полноразмерный слот. Снимаю райзер, понадобится отвертка torx.

Кручу-верчу. В райзер устанавливается две PCIe платы. Одна уже установлена, устанавливаю вторую.

Диск в райзере. Устанавливаю райзер в сервер.

Закрываю крышку, включаю сервер. NVMe платы нельзя собрать в RAID через имеющийся RAID контроллер, у меня они собраны с помощью mdadm в операционной системе Ubuntu. Два диска были в RAID1, третий диск позволит увеличить объём массива в два раза, с преобразованием RAID1 в RAID5.
Горячая замена дисков
Горячую замену дисков можно производить практически со всеми вариантами интерфейсов. Конечно, есть и некоторые ограничения.
IDE устройства редко переносят отключение/подключение второго устройства на шлейф — велик риск пропадания работающего устройства из системы. Главная проблема интерфейса IDE в правильной обработке операционной системой этого события. Так как интерфейс IDE не предусматривает горячей замены, в большинстве случаев необходимо вручную запустить сканирование устройств для определения нового оборудования. Важный момент — интерфейс подключается/отключается к обесточенному диску (подключение: сначала интерфейс, потом питание, отключение: сначала питание, потом интерфейс).
ОТКАЗ ОТ ОБЯЗАТЕЛЬСТВ: выполняя отключение/подключение устройств IDE Вы делаете это на свой страх и риск — никто не гарантирует сохранение работоспособности оборудования, и стабильность работы ОС.
Интерфейсы FC, SAS, SATA (AHCI) — поддерживают горячую замену дисков в полном объеме, проблемы могут быть в операционной системе. Если дисковый контроллер SATA находится в режиме совместимости IDE — то, возможно, понадобится вручную запустить сканирование шины. В режиме AHCI в большинстве случаев диск определится автоматически. Рекомендую использовать AHCI, если ваша ОС это позволяет, т.к. этот режим также повышает производительнось диска; TRIM поддерживается только в этом режиме работы контроллера.
При отключении дисков для продления срока их службы рекомендую предварительно отключать их программным методом и извлекать после остановки шпинделя, т.е. через примерно 30 секунд после выключения для дисков 7200RPM. Если диск невозможно отключить программно и он установлен в hot-swap корзинке, рекомендую вытащить диск на минимальное расстояние, при котором диск будет отключен, подождать остановки шпинделя и извлечь окончательно. В большинстве систем — это расстояние полностью отведённой ручки корзинки. Конечно, эти действия не несут практического смысла, если диск вышел из строя, но, возможно, он просто «завис» и вам не поменяют его по гарантии и придется использовать в некритичном оборудовании.
Так же важно понимать, что диск находится в составе RAID или как отдельное блочное устройство. При использовании отдельного диска необходимо предварительно его отмонтировать для избежания сбоев в работе ОС и программного обеспечения. Даже если диск не используется в текущий момент, после извлечения примонтированого диска зачастую наблюдаются лаги всей ОС. Конечно же, диск, на котором установлена ОС, извлечь без «зависания» не получится.
Большинство серверов позволяет подсветить индикатором диск по команде с сервера, по возможности пользуйтесь этой функцией, для минимизации ошибочных извлечений дисков. Например на серверах SuperMicro номер корзинки указан на самой корзинке, и может не совпадать с номером слота на бэкплейне. Такая-же проблема есть у многих производителей.
Так же перед отключением желательно получить информацию о диске (модель, объем, серийный номер) для сопоставления сразу после извлечения диска. Во многих случаях при ошибочном извлечении другого диска это позволит устранить ошибку сразу, а иногда даже предотвратить сбой в работе или потерю данных.
В случае использования RAID-массивов, рекомендую отключать диски программно (помечать как сбойные), перед извлечением это устранит снижение производительности дисковой системы сразу после отключения диска.
Проблем с SSD дисками при частом горячем подключении/извлечении не заметил, хотя использовал несколько именно в таком режиме.
На этом первая часть заканчивается, в следующей частях про RAID массивы, память для серверов, системы удалённого управления и про важность мониторинга.

Сегодня не самый обычный пост, я еду в ЦОД менять и устанавливать диски. Любопытно, что все диски разные, оборудование тоже разное. Для мониторинга состояния дисков потребуется самые разные инструменты. Вроде бы всего 4 диска, а подходы самые разные. Поехали.
Диск 1. Сервер Supermicro
Первый диск будем менять в сервере Supermicro. Сервер Supermicro 4U: CSE-846BE16-R920B. Когда-то давно на нём собирали массивы:
Диск HDD 6ТБ, форм-фактор 3.5'. Вот так выглядит сбойный диск, красный светодиод манит админа.

Перед заменой диска необходимо убедиться, что проблема именно с диском. Сервер работает, выключить его нельзя. Соответственно, в утилиту Avago Config Utility для управления SAS-контроллером войти не удастся. На сервере работает операционная система Ubuntu. Для мониторинга состояния массива будем использовать утилиту storcli. Пример работы у меня уже есть, правда в Oracle Linux, но в данном случае это не принципиально:
Посмотрим, что у нас там с диском. Диск в состоянии "UBad-Unconfigured Bad". Всё понятно, нужно менять.
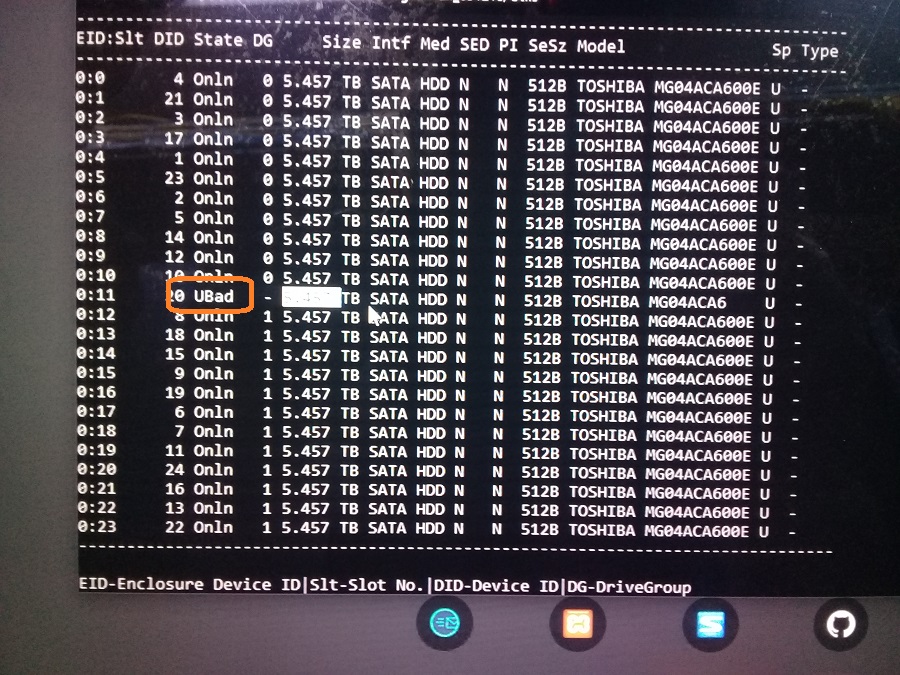
Данный сервер поддерживает горячую замену дисков, мне же проще. Выдергиваем старый диск.

Красный светодиод продолжает гореть на дисковой корзине. Перекручиваем салазки на новый диск.

Устанавливаем диск в слот.

После установки диска загорится синий диод, красный начнёт мигать.

Начинается перестроение массива. Перестроение займёт много времени, больше суток.

Потом, через пару дней проверил, массив в порядке:

Замена диска прошла без проблем.
Потом
Забегая вперёд можно сказать, что три из четырёх дисков встали нормально, массивы работают в штатном режиме. А вот четвёртый диск HP MSA 2040 подкачал, новый и не заработал. Техподдержка пока молчит.
Информация
В данном документе описано как развернуть массив и расширить логический диск. Развертывание массивов и расширение логических дисков поддерживается только, если установлен контроллер HP Smart Array c кэш-памятью и батарей. Контроллеры HP Smart Array поддерживают устройства Battery-Backed Write Cache (BBWC) или Flash-Backed Write Cache (FBWC). В первую очередь убедитесь, что сервер оснащен кэш-памятью и батареей.
Если на сервере не установлены устройства BBWC или FBWC, сначала установите батарею. Ознакомьтесь с QuickSpecs серверов и установите нужную версию BBWC/FBWC для контроллера HP Smart Array. После установки BBWC/FBWC функции развертывания и расширения будут доступны в ACU.
Потом-потом
Прислали новый диск для HP MSA 2040, со второй попытки диск встал успешно, пришлось ехать в ЦОД ещ1 раз.

Приветствую тебя, юный подаван. У нас стоит глобальная задача по переводу 1С на SSD диски. Сегодня решаем чисто железную часть - тупо меняем диски. У нас есть сервер HPE Proliant DL360 Gen9. Задача стоит не просто заменить один диск другим. Мы вынем старые HDD 600 GB, и поставим новые SSD.
На сервере из 4-х дисков собран RAID10. Разбираем его и делаем RAID1 из первых двух дисков. По сути - уменьшаем массив в два раза. Используем его потом под систему. Итак, 3 и 4 диски больше не нужны. Выключаем сервер.

Вот наш бывший массив:

1 и 2 диски оставляем - это для RAID 1. 3 и 4 вынимаем.


Достаём новые SSD.

Для нового SSD зеркала закупили диски:

Обратная сторона новых SSD.

Маркировка DS на новых дисках, насколько я понял, означает integrated HPE Digitally Signed Firmware (DS), т.е. прошивка с цифровой подписью. Типа прошивка из надёжного источника.

С помощью Smart Storage Administrator вы можете добавить к существующему RAID массиву дополнительные диски и расширить логический том.
Нашёл статью в помощь:
Интерфейс немного устарел, но принцип действия такой же как описано.
Читайте также: