
Утилита fio проверка производительности дисков
abstract: разница между текущей производительностью и производительностью теоретической; latency и IOPS, понятие независимости дисковой нагрузки; подготовка тестирования; типовые параметры тестирования; практическое copypaste howto.
Предупреждение: много букв, долго читать.
- научная публикация, в которой скорость кластерной FS оценивали с помощью dd (и включенным файловым кешем, то есть без опции direct)
- использование bonnie++
- использование iozone
- использование пачки cp с измерениема времени выполнения
- использование iometer с dynamo на 64-битных системах
Это всё совершенно ошибочные методы. Дальше я разберу более тонкие ошибки измерения, но в отношении этих тестов могу сказать только одно — выкиньте и не используйте.
bonnie++ и iozone меряют скорость файловой системы. Которая зависит от кеша, задумчивости ядра, удачности расположения FS на диске и т.д. Косвенно можно сказать, что если в iozone получились хорошие результаты, то это либо хороший кеш, либо дурацкий набор параметров, либо действительно быстрый диск (угадайте, какой из вариантов достался вам). bonnie++ вообще сфокусирована на операциях открытия/закрытия файлов. т.е. производительность диска она особо не тестирует.
dd без опции direct показывает лишь скорость кеша — не более. В некоторых конфигурациях вы можете получать линейную скорость без кеша выше, чем с кешем. В некоторых вы будете получать сотни мегабайт в секунду, при линейной производительности в единицы мегабайт.
С опцией же direct (iflag=direct для чтения, oflag=direct для записи) dd проверяет лишь линейную скорость. Которая совершенно не равна ни максимальной скорости (если мы про рейд на много дисков, то рейд в несколько потоков может отдавать большую скорость, чем в один), ни реальной производительности.
IOmeter — лучше всего перечисленного, но у него есть проблемы при работе в linux. 64-битная версия неправильно рассчитывает тип нагрузки и показывает заниженные результаты (для тех, кто не верит — запустите его на ramdisk).
Спойлер: правильная утилита для linux — fio. Но она требует очень вдумчивого составления теста и ещё более вдумчивого анализа результатов. Всё, что ниже — как раз подготовка теории и практические замечания по работе с fio.
(текущая VS максимальная производительность)
Сейчас будет ещё больше скучных букв. Если кого-то интересует количество попугаев на его любимой SSD'шке, ноутбучном винте и т.д. — см рецепты в конце статьи.
Все современные носители, кроме ramdisk'ов, крайне негативно относятся к случайным операциям записи. Для HDD нет разницы запись или чтение, важно, что головки гонять по диску. Для SSD же случайная операция чтения ерунда, а вот запись малым блоком приводит к copy-on-write. Минимальный размер записи — 1-2 Мб, пишут 4кб. Нужно прочитать 2Мб, заменить в них 4кб и записать обратно. В результате в SSD'шку уходит, например, 400 запросов в секундну на запись 4кб которые превращаются в чтение 800 Мб/с (. ) и записи их обратно. (Для ramdisk'а такая проблема могла бы быть тоже, но интрига в том, что размер «минимального блока» для DDR составляет около 128 байт, а блоки в тестах обычно 4кб, так что гранулярность DDR в тестах дисковой производительности оперативной памяти не важна).
Этот пост не про специфику разных носителей, так что возвращаемся к общей проблеме.
Мы не можем мерять запись в Мб/с. Важным является сколько перемещений головки было, и сколько случайных блоков мы потревожили на SSD. Т.е. счёт идёт на количество IO operation, а величина IO/s называется IOPS. Таким образом, когда мы меряем случайную нагрузку, мы говорим про IOPS (иногда wIOPS, rIOPS, на запись и чтение соотв.). В крупных системах используют величину kIOPS, (внимание, всегда и везде, никаких 1024) 1kIOPS = 1000 IOPS.
И вот тут многие попадают в ловушку первого рода. Они хотят знать, «сколько IOPS'ов» выдаёт диск. Или полка дисков. Или 200 серверных шкафов, набитые дисками под самые крышки.
Тут важно различать число выполненных операций (зафиксировано, что с 12:00:15 до 12:00:16 было выполнено 245790 дисковых операций — т.е. нагрузка составила 245kIOPS) и то, сколько система может выполнить операций максимум.
Число выполненых операций всегда известно и легко измерить. Но когда мы говорим про дисковую операцию, мы говорим про неё в будущем времени. «сколько операций может выполнить система?» — «каких операций?». Разные операции дают разную нагрузку на СХД. Например, если кто-то пишет случайными блоками по 1Мб, то он получит много меньше iops, чем если он будет читать последовательно блоками по 4кб.
И если в случае пришедшей нагрузки мы говорим о том, сколько было обслужено запросов «какие пришли, такие и обслужили», то в случае планирования, мы хотим знать, какие именно iops'ы будут.
Драма состоит в том, что никто не знает, какие именно запросы придут. Маленькие? Большие? Подряд? В разнобой? Будут они прочитаны из кеша или придётся идти на самое медленное место и выковыривать байтики с разных половинок диска?
- Тест диска (СХД/массива) на best case (попадание в кеш, последовательные операции)
- Тест диска на worst case. Чаще всего такие тесты планируются с знанием устройства диска. «У него кеш 64Мб? А если я сделаю размер области тестирования в 2Гб?». Жёсткий диск быстрее читает с внешней стороны диска? А если я размещу тестовую область на внутренней (ближшей к шпинделю) области, да так, чтобы проходимый головками путь был поболе? У него есть read ahead предсказание? А если я буду читать в обратном порядке? И т.д.
В результате мы получаем цифры, каждая из которых неправильная. Например: 15kIOPS и 150 IOPS.
Какая будет реальная производительность системы? Это определяется только тем, как близко будет нагрузка к хорошему и плохому концу. (Т.е. банальное «жизнь покажет»).
- Что best case всё-таки best. Потому что можно дооптимизироваться до такого, что best case от worst будет отличаться едва-едва. Это плохо (ну или у нас такой офигенный worst).
- На worst. Имея его мы можем сказать, что СХД будет работать быстрее, чем полученный показатель. Т.е. если мы получили 3000 IOPS, то мы можем смело использовать систему/диск в нагрузке «до 2000».
Ну и про размер блока. Традиционно тест идёт с размером блока в 4к. Почему? Потому что это стандартный размер блока, которым оперируют ОС при сохранении файла. Это размер страницы памяти и вообще, Очень Круглое Компьютерное Число.
Нужно понимать, что если система обрабатывает 100 IOPS с 4к блоком (worst), то она будет обрабатывать меньше при 8к блоке (не менее 50 IOPS, вероятнее всего, в районе 70-80). Ну и на 1Мб блоке мы увидим совсем другие цифры.
Всё? Нет, это было только вступление. Всё, что написано выше, более-менее общеизвестно. Нетривиальные вещи начинаются ниже.
- прочитать запись
- поменять запись
- записать запись обратно
Для удобства будем полагать, что время обработки нулевое. Если каждый запрос на чтение и запись будет обслуживаться 1мс, сколько записей в секунду сможет обработать приложение? Правильно, 500. А если мы запустим рядом вторую копию приложения? На любой приличной системе мы получим 1000. Если мы получим значительно меньше 1000, значит мы достигли предела производительности системы. Если нет — значит, что производительность приложения с зависимыми IOPS'ами ограничивается не производительностью СХД, а двумя параметрами: latency и уровнем зависимости IOPS'ов.
Начнём с latency. Latency — время выполнения запроса, задержка перед ответом. Обычно используют величину, «средняя задержка». Более продвинутые используют медиану среди всех операций за некоторый интервал (чаще всего за 1с). Latency очень сложная для измерения величина. Связано это с тем, что на любой СХД часть запросов выполняется быстро, часть медленно, а часть может попасть в крайне неприятную ситуацию и обслуживаться в десятки раз дольше остальных.
Интригу усиливает наличие очереди запросов, в рамках которой может осуществляться переупорядочивание запросов и параллельное их исполнение. У обычного SATA'шного диска глубина очереди (NCQ) — 31, у мощных систем хранения данных может достигать нескольких тысяч. (заметим, что реальная длина очереди (число ожидающих выполнения запросов) — это параметр скорее негативный, если в очереди много запросов, то они дольше ждут, т.е. тормозят. Любой человек, стоявший в час пик в супермаркете согласится, что чем длиннее очередь, тем фиговее обслуживание.
Latency напрямую влияет на производительность последовательного приложения, пример которого приведён выше. Выше latency — ниже производительность. При 5мс максимальное число запросов — 200 шт/с, при 20мс — 50. При этом если у нас 100 запросов будут обработаны за 1мс, а 9 запросов — за 100мс, то за секунду мы получим всего 109 IOPS, при медиане в 1мс и avg (среднем) в 10мс.
Отсюда довольно трудный для понимания вывод: тип нагрузки на производительность влияет не только тем, «последовательный» он или «случайный», но и тем, как устроены приложения, использующие диск.
Пример: запуск приложения (типовая десктопная задача) практически на 100% последовательный. Прочитали приложение, прочитали список нужных библиотек, по-очереди прочитали каждую библиотеку… Именно потому на десктопах так пламенно любят SSD — у них микроскопическая задержка (микросекундная) на чтение — разумеется, любимый фотошоп или блендер запускается в десятые доли секунды.
Трешинг. Я думаю, с этим явлением пользователи десктопов знакомы даже больше, чем сисадмины. Жуткий хруст жёсткого диска, невыразимые тормоза, «ничего не работает и всё тормозит».
По мере того, как мы начинаем забивать очередь диска (или хранилища, повторю, в контексте статьи между ними нет никакой разницы), у нас начинает резко вырастать latency. Диск работает на пределе возможностей, но входящих обращений больше, чем скорость их обслуживания. Latency начинает стремительно расти, достигая ужасающих цифр в единицы секунд (и это при том, что приложению, например, для завершения работы нужно сделать 100 операций, которые при latency в 5 мс означали полусекундную задержку. ). Это состояние называется thrashing.
Вы будете удивлены, но любой диск или хранилище способны показывать БОЛЬШЕ IOPS'ов в состоянии thrashing, чем в нормальной загрузке. Причина проста: если в нормальном режиме очередь чаще всего пустая и кассир скучает, ожидая клиентов, то в условии трешинга идёт постоянное обслуживание. (Кстати, вот вам и объяснение, почему в супермаркетах любят устраивать очереди — в этом случае производительность кассиров максимальная). Правда, это сильно не нравится клиентам. И в хороших супермаркетах хранилищах такого режима стараются избегать. Если дальше начинать поднимать глубину очереди, то производительность начнёт падать из-за того, что переполняется очередь и запросы стоят в очереди чтобы встать в очередь (да-да, и порядковый номер шариковой ручкой на на руке).
И тут нас ждёт следующая частая (и очень трудно опровергаемая) ошибка тех, кто меряет производительность диска.
Они говорят «у меня диск выдаёт 180 IOPS, так что если взять 10 дисков, то это будет аж 1800 IOPS». (Именно так думают плохие супермаркеты, сажая меньше кассиров, чем нужно). При этом latency оказывается запредельной — и «так жить нельзя».
Реальный тест производительности требует контроля latency, то есть подбора таких параметров тестирования, чтобы latency оставалась ниже оговоренного лимита.
И вот тут вот мы сталкиваемся со второй проблемой: а какого лимита? Ответить на этот вопрос теория не может — этот показатель является показателем качества обслуживания. Другими словами, каждый выбирает для себя сам.
Лично я для себя провожу тесты так, чтобы latency оставалась не более 10мс. Этот показатель я для себя считаю потолком производительности хранилища. (при этом в уме я для себя считаю, что предельный показатель, после которого начинают ощущаться лаги — это 20мс, но помните, про пример выше с 900 по 1мс и 10 по 100мс, у которого avg стала 10мс? Вот для этого я и резервирую себе +10мс на случайные всплески).
Выше мы уже рассмотрели вопрос с зависимыми и независимыми IOPS'ами. Производительность зависимых Iops'ов точно контролируется latency, и этот вопрос мы уже обсудили. А вот производительность в независимых iops'ах (т.е. при параллельной нагрузке), от чего она зависит?
Отдельно нужно говорить про ситуацию, когда хранилище подключено к хосту через сеть с использованием TCP. О TCP нужно писать, писать, писать и ещё раз писать. Достаточно сказать, что в линуксе существует 12 разных алгоритмов контроля заторов в сети (congestion), которые предназначены для разных ситуаций. И есть около 20 параметров ядра, каждый из которых может радикальным образом повлиять на попугаи на выходе (пардон, результаты теста).
С точки зрения оценки производительности мы должны просто принять такое правило: для сетевых хранилищ тест должен осуществляться с нескольких хостов (серверов) параллельно. Тесты с одного сервера не будут тестом хранилища, а будут интегрированным тестом сети, хранилища и правильности настройки самого сервера.
Последний вопрос — это вопрос затенения шины. О чём речь? Если у нас ssd способна выдать 400 МБ/с, а мы её подключаем по SATA/300, то очевидно, что мы не увидим всю производительность. Причём с точки зрения latency проблема начнёт проявляться задолго до приближения к 300МБ/с, ведь каждому запросу (и ответу на него) придётся ждать своей очереди, чтобы проскочить через бутылочное горлышко SATA-кабеля.
Но бывают ситуации более забавные. Например, если у вас есть полка дисков, подключенных по SAS/300x4 (т.е. 4 линии SAS по 300МБ каждая). Вроде бы много. А если в полке 24 диска? 24*100=2400 МБ/с, а у нас есть всего 1200 (300х4).
Более того, тесты на некоторых (серверных!) материнских платах показали, что встроенные SATA-контроллеры часто бывают подключены через PCIx4, что не даёт максимально возможной скорости всех 6 SATA-разъёмов.
Повторю, главной проблемой в bus saturation является не выедание «под потолок» полосы, а увеличение latency по мере загрузки шины.
Ну и перед практическими советами, скажу про известные трюки, которые можно встретить в индустриальных хранилищах. Во-первых, если вы будете читать пустой диск, вы будете читать его из «ниоткуда». Системы достаточно умны, чтобы кормить вас нулями из тех областей диска, куда вы никогда не писали.
Во-вторых, во многих системах первая запись хуже последующих из-за всяких механизмов снапшотов, thin provision'а, дедупликации, компрессии, late allocation, sparse placement и т.д. Другими словами, тестировать следует после первичной записи.
В третьих — кеш. Если мы тестируем worst case, то нам нужно знать, как будет вести себя система когда кеш не помогает. Для этого нужно брать такой размер теста, чтобы мы гарантированно читали/писали «мимо кеша», то есть выбивались за объёмы кеша.
Кеш на запись — особая история. Он может копить все запросы на запись (последовательные и случайные) и писать их в комфортном режиме. Единственным методом worst case является «трешинг кеша», то есть посыл запросов на запись в таком объёме и так долго, чтобы write cache перестал стправляться и был вынужден писать данные не в комфортном режиме (объединяя смежные области), а скидывать случайные данные, осуществляя random writing. Добиться этого можно только с помощью многократного превышения области теста над размером кеша.
Вердикт — минимум x10 кеш (откровенно, число взято с потолка, механизма точного расчёта у меня нет).
Разумеется, тест должен быть без участия локального кеша ОС, то есть нам надо запускать тест в режиме, который бы не использовал кеширование. В линуксе это опция O_DIRECT при открытии файла (или диска).
Итого:
1) Мы тестируем worst case — 100% размера диска, который в несколько раз больше предположительного размера кеша на хранилище. Для десктопа это всего лишь «весь диск», для индустриальных хранилищ — LUN или диск виртуальной машины размером от 1Тб и больше. (Хехе, если вы думаете, что 64Гб RAM-кеша это много. ).
2) Мы ведём тест блоком в 4кб размером.
3) Мы подбираем такую глубину параллельности операций, чтобы latency оставалось в разумных пределах.
На выходе нас интересуют параметры: число IOPS, latency, глубина очереди. Если тест запускался на нескольких хостах, то показатели суммируются (iops и глубина очереди), а для latency берётся либо avg, либо max от показателей по всем хостам.
Тут мы переходим к практической части. Есть утилита fio которая позволяет добиться нужного нам результата.
Нормальный режим fio подразумевает использование т.н. job-файла, т.е. конфига, который описывает как именно выглядит тест. Примеры job-файлов приведены ниже, а пока что обсудим принцип работы fio.
fio выполняет операции над указанным файлом/файлами. Вместо файла может быть указано устройство, т.е. мы можем исключить файловую систему из рассмотрения. Существует несколько режимов тестирования. Нас интересует randwrite, randread и randrw. К сожалению, randrw даёт нам зависимые iops'ы (чтение идёт после записи), так что для получения полностью независимого теста нам придётся делать две параллельные задачи — одна на чтение, вторая на запись (randread, randwrite).
И нам придётся сказать fio делать «preallocation». (см выше про трюки производителей). Дальше мы фиксируем размер блока (4к).
Ещё один параметр — метод доступа к диску. Наиболее быстрым является libaio, именно его мы и будем использовать.
При тесте диска запускать её надо от root'а.
Почему мы выбрали fio и откуда узнали, как его настраивать
Эта заметка появилась из реального случая, с которым мы столкнулись. У нас был кластер на Kubernetes v1.13 с мониторингом на Prometheus. В качестве хранилища для etcd v3.2.24 выступали твердотельные накопители. Метрики etcd показывали слишком высокие задержки fdatasync , даже когда кластер простаивал. Нам эти метрики казались весьма сомнительными, и мы не были уверены в том, что именно они представляют. Вдобавок, кластер состоял из виртуальных машин, поэтому не получалось сказать, задержка была связана с виртуализацией или во всем виноваты SSD.
Кроме того, мы рассматривали различные изменения в конфигурации аппаратного и программного обеспечения, поэтому требовался способ их оценки. Конечно, можно было бы запустить etcd в каждой конфигурации и посмотреть на соответствующие метрики Prometheus, но это потребовало бы значительных усилий. Нам же был нужен простой способ, позволяющий оценить конкретную конфигурацию. Мы хотели проверить свое понимание метрик Prometheus, поступающих от etcd.
Для этого требовалось решить две проблемы:
- Во-первых, как выглядит I/O-нагрузка, генерируемая etcd при записи в файлы WAL? Какие системные вызовы используются? Каков размер блоков записи?
- Во-вторых, допустим, ответы на вышеперечисленные вопросы у нас есть. Как воспроизвести соответствующую нагрузку с fio ? Ведь fio — чрезвычайно гибкая утилита с обилием параметров (в этом легко убедиться, например, здесь — прим. перев.).
- С помощью lsof можно просмотреть все файловые дескрипторы, используемые процессом, а также файлы, к которым они относятся.
- С помощью strace можно анализировать уже запущенный процесс или запустить процесс и понаблюдать за ним. Команда выводит все системные вызовы, совершенные данным процессом и, при необходимости, его потомками. Последнее важно для процессов, который форкается, и etcd — один из таких процессов.
Так было обнаружено, что блоки записи в WAL очень плотно сгруппированы, размер большинства лежал в диапазоне 2200-2400 байт. Именно поэтому в команде в начале этой статьи используется флаг --bs=2300 ( bs — размер в байтах каждого блока записи в fio ).
Обратите внимание, что размер блоков записи etcd может варьироваться в зависимости от версии, deployment'а, значений параметров и т.д. — это влияет на продолжительность fdatasync . Если у вас похожий сценарий использования, проанализируйте с помощью strace свои процессы etcd, чтобы получить актуальные значения.
Затем, чтобы получить четкое и всеобъемлющее представление о работе etcd с файловой системой, мы запустили ее из-под strace с флагами -ffttT . Это позволило охватить процессы-потомки и записать вывод каждого в отдельный файл. Кроме того, были получены подробные сведения о моменте старта и длительности каждого системного вызова.
Мы также воспользовались командой lsof , чтобы подтвердить свое понимание вывода strace в плане того, какой файловый дескриптор для какой цели использовался. Получился вывод strace , похожий на тот, что приведен выше. Статистические манипуляции со временами синхронизации подтвердили, что метрика wal_fsync_duration_seconds от etcd соответствует вызовам fdatasync с дескрипторами файлов WAL.
Чтобы сгенерировать с помощью fio рабочую нагрузку, аналогичную нагрузке от etcd, была изучена документация утилиты и подобраны параметры, подходящие нашей задаче. Мы убедились в том, что задействованы нужные системные вызовы, и подтвердили их продолжительность, запустив fio из strace (как это было сделано в случае etcd).
Особое внимание было уделено определению значения параметра --size . Он представляет собой общую нагрузку I/O, генерируемую утилитой fio. В нашем случае это полное число байтов, записанное на носитель. Оно прямо пропорционально числу вызовов write (и fdatasync ). Для определенного bs количество вызовов fdatasync равно size / bs .
Поскольку нас интересовал процентиль, мы стремились к тому, чтобы число проб было достаточно большим для статистической значимости. И решили, что 10^4 (что соответствует размеру в 22 Мб) будет достаточно. Меньшие значения параметра --size давали более выраженный шум (например, вызовы fdatasync , которые занимают гораздо больше времени, чем обычно, и влияют на 99-й процентиль).
Hdparm
Утилиту написал канадский разработчик Марк Лорд (Mark Lord) в далеком 2005 году. Она до сих пор поддерживается автором и является частью многих популярных дистрибутивов. Главное назначение hdparm — настройка параметров накопителей. Но инструмент можно использовать для проведения простых бенчмарков, например, измерения скорости чтения. Для этого нужно написать в консоли команду:
Система сформирует подобный ответ:
Что касается настройки накопителей, то hdparm позволяет менять объем кеш-памяти, модифицировать параметры спящего режима и электропитания, а также безопасно стирать данные на SSD. Но, как предупреждают специалисты из ArchLinux, неосторожное изменение системных параметров может сделать данные на диске недоступными и даже повредить накопитель. Перед работой с hdparm лучше ознакомиться с руководством — достаточно прописать в консоли команду man hdparm.
Это — набор бенчмарков для оценки производительности систем ввода/вывода. Авторами утилиты выступила команда разработчиков из группы AlgoDev, в которую входят сотрудники итальянского Университета Модены и Реджо-Эмилии.
Все бенчмарки представляют собой bash-скрипты, оценивающие производительность системы хранения данных — пропускную способность, латентность, работу планировщиков. К примеру, бенчмарк throughput-sync.sh «бомбардирует» СХД запросами на чтение или запись (в этом случае используется уже упомянутая утилита fio). Вот код этого скрипта.
Другой скрипт — comm_startup_lat.sh — измеряет задержку чтения данных с диска при «холодном кэше» (когда в нем нет необходимых данных). Код также можно найти в репозитории.

Фото — Agê Barros — Unsplash
Установка утилиты fio для тестирования IOPS в Linux
Для замера производительности IOPS дисков в Linux можно использовать утилиту fio (утилита доступна для CentOS в репозитории EPEL). Соотвественно для установки fio в RHEL, CentOS используется пакетный менеджер yum (dnf):
Либо apt-get в Debian, Ubuntu :

Затем вам нужно определить диски для тестирования. Тестирование выполняется путев выполнения операций записи/чтения в той директории, в которую примонтирован диск или LUN.
тесты на чтение
Запуск: fio read.ini
Содержимое read.ini
Задача подобрать такой iodepth, чтобы avg.latency была меньше 10мс.
Как получить IOPS и производительность дисковой подсистемы с помощью PowerShell?
Недавно мне на глаза попался PowerShell скрипт (автор Microsoft MVP, Mikael Nystrom), являющийся по сути надстройкой над утилитой SQLIO.exe (набора тестов для расчета производительности файлового хранилища).
Примечание. В декабре 2015 года Microsoft объявила о прекращении поддержки утилиты и замене SQLIO на более универсальный инструмент — Diskspd, удалив файлы с дистрибутивом SQLIO со своего сайта. Поэтому, вам придется искать sqlio.exe самостоятельно, либо скачать с нашего сайта (находится в архиве со скриптом).
Итак, скачайте архив содержащий 2 файла: SQLIO.exe и DiskPerformance.ps1 (disk-perf-iops.ZIP — 73Кб) и распакуйте архив в произвольный каталог.
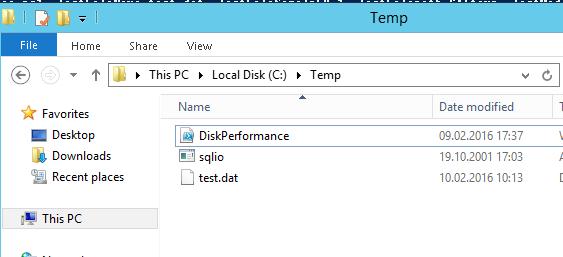
Пример запуска PowerShell скрипта для определения IOPS:
.\DiskPerformance.ps1 -TestFileName test.dat –TestFileSizeInGB 1 -TestFilepath C:\temp -TestMode Get-LargeIO -FastMode True -RemoveTestFile True -OutputFormat Out-GridView
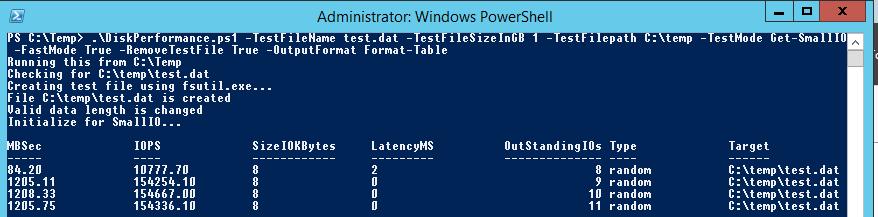
Я использовал в скрипте следующие аргументы:
- -TestFileNametest.dat— имя файла, создаваемого утилитой FSUTIL;
- –TestFileSizeInGB1 —размер файла для тестов. Допустимые варианты 1,5,10,50,100,500,1000 Гб. Размер файла должен быть больше, чем размер кэша системы. Иначе будет измеряться IOPS для данных в кэше, а не на диске;
- -TestFilepathC:\Temp— указывается диск, для которого будет выполняться расчет производительности и каталог на диске, в котором будет создаваться тестовый файл. Допустимо указать UNC путь к сетевой папке;
- —TestModeGet-LargeIO— есть два варианта измерения нагрузки, Get-SmallIO – измеряются IOPS, Get-LargeIO – измеряется скорость передачи данных. Разница между аргументами SmallIO и LargeIO, в размерах блоков при замере скорости 8 Кбайт и 512 Кбайт, и типе доступа Random или Sequential соответственно;
- -FastModeTrue— в режиме Fastmode каждый тест выполняется 10 секунд, иначе 60 сек;
- -RemoveTestFileTrue— удалить тестовый файл по окончании теста;
- -OutputFormatOut-GridView — возможен вывод результатов измерения в консоль PowerShell (Format-Table) или в отдельное окно графической таблицы (Out-Gridview);
В нашем случае дисковый массив (тестировался виртуальный vmdk диск на VMFS хранилище, расположенном на дисковой полке HP MSA 2040 с доступом через SAN) показал среднее значение IOPS около 15000 и скорости передачи данных (пропускная способность) около 5 Гбит/сек.
В следующей таблице указаны примерные значения IOPS для различных типов дисков:
| Тип | IOPS |
| SSD(SLC) | 6000 |
| SSD(MLC) | 1000 |
| 15K RPM | 175-200 |
| 10K RPM | 125-150 |
| 7.2K RPM | 50-75 |
| RAID5 из 6 дисков с 10000 RPM | 900 |
Ниже приведены ряд рекомендаций по производительности дисков в IOPS для распространенных сервисов:

30.04.2020

VyacheslavK

CentOS, Linux, Ubuntu

Комментариев пока нет
В этой статье рассмотрим способы тестирования производительности IOPS дисков или дискового массива в Linux. IOPS (input/output operations per second) – количество операций ввода-вывода, выполняемые системой хранения данных за одну секунду (это может быть как один диск, RAID массив или LUN на системе хранения). Условно IOPS можно считать количество блоков, которые успевает считаться или записаться на носитель.
Для большинства дисков производители указывают номинальные значения IOPS, но такие значение на практике не гарантируются. Для понимания производительности вашей дисковой подсистемы перед запуском проекта желательно получить значения IOPS.
Дело за вами
В статье показано, как с помощью fio можно оценить, является ли достаточно быстрым носитель, предназначенный для использования с etcd. Теперь дело за вами! Исследовать виртуальные машины с хранилищем на базе SSD можно в сервисе IBM Cloud.
Подробно о fio и etcd
Проверка latency диска с помощью ioping
Помимо IOPS есть еще один важный параметр, характеризующий качество вашей дисковой подсистемы – latency. Latency – это время задержки выполнения запроса ввода/вывода и характеризуют время доступа к системе хранения (измеряется в миллисекундах). Чем выше latency, тем больше приходится ждать вашему приложения данных от дисковой подсистемы. Для типовых систем хранения значения latency более 20 мс считаются плохими.
Для проверки latency диска используется утилита ioping:
Запустите тест latency для диска (выполняется 20 запросов):
Среднее значение 298.7 us (микросекунд), т.е. средняя latency диска в нашем случае 0.3 ms, что очень хорошо.
Значение latency может быть указано в us (микросекундах) или в ms (миллисекундах). Т.е. для получения из us значения в ms нужно разделить его на 1000.
Таким образом, вы можете провести нагрузочное тестирование дисковой подсистемы на вашем сервере до запуска проекта и получить максимальную производительность. Конечно такой тест не дает гарантий, что дисковый массив или диск будет постоянно гарантировать такую производительность, но на начальном этапе это тест, который обязательно нужно выполнить. Методика тестирования IOPS в Windows описана в этой статье.
В прошлый раз мы рассказывали об инструментах с отрытым исходным кодом для оценки производительности процессоров и памяти. Сегодня говорим о бенчмарках для файловых систем и систем хранения данных на Linux — Interbench, Fio, Hdparm, S и Bonnie.

Фото — Daniele Levis Pelusi — Unsplash
Fio (расшифровывается как Flexible I/O Tester) создает потоки ввода/вывода данных с диска, чтобы оценить производительность файловой системы Linux. Утилиту можно запустить и на Windows — нужно установить интерфейс командной строки Cygwin. Руководство по настройке есть в репозитории fio на GitHub.
Автор fio — Йенс Аксбо (Jens Axboe), ответственный за подсистему IO в Linux и разработчик утилиты blktrace для трассировки операций ввода/вывода. Он создал fio, потому что устал писать программы для тестирования специфической нагрузки вручную.
Утилита посчитает IOPS и пропускную способность системы, а также позволит оценить глубину очереди операций ввода/вывода. Утилита работает со специальными файлами (расширение .fio), в которых прописываются настройки и условия теста. Вариантов тестов несколько, например, есть произвольная запись, чтение и перезапись. Вот пример содержимого файла для первого случая:
Сегодня fio используется крупными компаниями — с утилитой работают в SUSE, Nutanix и IBM.
Interbench
Утилиту разработал Кон Коливас (Con Kolivas), австралийский анестезиолог, который известен своим вкладом в разработку ядра Linux и работой над «справедливым планировщиком процессора». Interbench помогает настроить параметры планировщика ввода/вывода и файловой системы.
Interbench эмулирует поведение планировщика CPU при выполнении интерактивных задач. Этими интерактивными задачами могут выступать работа со звуком и видео, запуск компьютерных игр или простое перетаскивание диалогового окна в операционной системе.
Исходный код, примеры и рекомендации по настройке инструмента можно найти в официальном репозитории на GitHub.
О чем мы пишем в наших блогах:

Бенчмарки для Linux-серверов: 5 открытых инструментов
Резервное копирование файлов: как подстраховаться от потери данных
Как перенести системный жесткий диск в виртуальную машину?
Тренировочный стенд для админов: чем поможет облако
Досмотры гаджетов на границе: как действовать, чтобы не потерять конфиденциальные данные?
Снэпшоты: зачем нужны «снимки»
Прим. перев.: эта статья — итоги мини-исследования, проведенного инженерами IBM Cloud в поисках решения реальной проблемы, связанной с эксплуатацией базы данных etcd. Для нас была актуальна схожая задача, однако ход размышлений и действий авторов может быть интересен и в более широком контексте.

Несколько слов о WAL'ах etcd
Таким образом, каждый раз, когда клиент добавляет ключ в KV-хранилище или обновляет значение существующего ключа, etcd добавляет описание операции в WAL, представляющий собой обычный файл в постоянном хранилище. Прежде чем продолжить работу, etcd ДОЛЖНА быть на 100% уверена, что запись в WAL действительно сохранена. Чтобы добиться этого в Linux, недостаточно использовать системный вызов write , поскольку сама операция записи на физический носитель может быть отложена. Например, Linux в течение некоторого времени может продержать WAL-запись в кэше ядра в памяти (например, в страничном кэше). Чтобы гарантировать, что данные записаны на носитель, после записи необходимо задействовать системный вызов fdatasync — именно так поступает etcd (как видно на примере следующего вывода strace ; здесь 8 — дескриптор файла WAL):
К сожалению, запись в постоянное хранилище занимает некоторое время. Затянувшееся выполнение вызова fdatasync может сказаться на производительности etcd. В документации к хранилищу указывается, что для достаточной производительности необходимо, чтобы 99-й процентиль продолжительности всех вызовов fdatasync при записи в файл WAL была меньше 10 мс. Есть и другие метрики, связанные с хранилищем, но в этой статье пойдет речь именно об этой.
Тестирование IOPS в Windows с помощью DiskSpd
Утилита не требует установки, просто скачайте и распакуйте архив на локальный диск. Для x64 битных систем используйте версию diskspd.exe из каталога amd64fre.
Я использую такую команду для тестирования диска:
diskspd.exe –c50G -d300 -r -w40 -t8 -o32 -b64K -Sh -L E:\diskpsdtmp.dat > DiskSpeedResults.txt
Важно. При использовании diskspd.exe генерируется довольно большая нагрузка на диски и CPU тестируемой системы. Поэтому, чтобы не вызвать падение производительности для пользователей, не рекомендуем запускать ее на продуктивных системах в часы пиковой нагрузки.
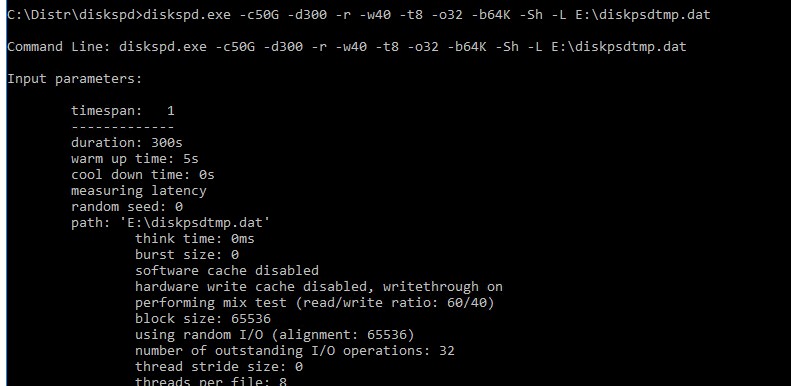
- -c50G – размер файла 50 Гб (лучше использовать большой размер файла, чтобы он не поместился в кэш контроллера СХД);
- -d30 0 – продолжительность тестирования в секундах;
- -r – произвольное чтение/запись (если нужно тестировать последовательный доступ, используйте –s);
- -t8 – количество потоков;
- -w40 – соотношение операций записи к операциям чтения 40% / 60%;
- -o32 — длина очереди;
- -b64K — размер блока;
- -Sh — не использовать кэширование;
- -L — измерять задержки (latency) ;
- E:\diskpsdtmp.dat – путь к тестовому файл.
После окончания стресс-теста из полученных таблиц можно получить средние значения производительности.
Например, в моем тесте получены следующие общие данные про производительности (Total IO):
-
MiB/s — 241 (около 252 Мб/сек, неплохо)
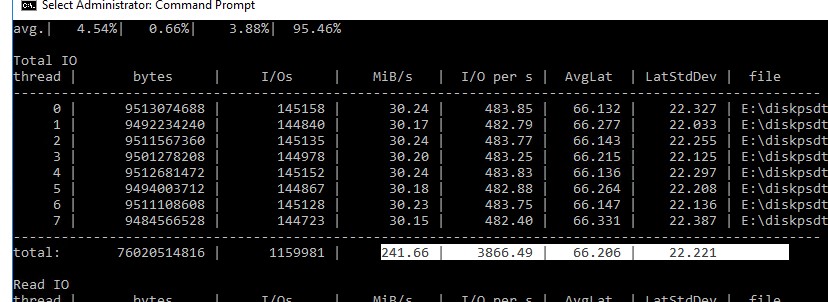
Можно получить отдельные значения только по операциям чтения (секция Read IO ) или записи (секция Write IO ).
Протестировав с помощью diskspd несколько дисков или LUN на СХД, вы сможете сравнить их или выбрать массив с нужной производительностью под свои задачи.
Краткое резюме всей статьи: fio и etcd
Производительность кластера etcd сильно зависит от скорости хранилища, лежащего в его основе. Для контроля за производительностью etcd экспортирует различные метрики Prometheus. Одной из них является wal_fsync_duration_seconds . В документации к etcd говорится, что хранилище можно считать достаточно быстрым, если 99-й процентиль этой метрики не превышает 10 мс…
Если вы обдумываете возможность организации кластера etcd на машинах под управлением Linux и хотите проверить, достаточно ли быстры накопители (например, SSD), рекомендуем воспользоваться популярным тестером I/O под названием fio. Достаточно запустить следующую команду (директория test-data должна быть расположена в примонтированном разделе тестируемого накопителя):
Осталось лишь посмотреть на вывод и проверить, укладывается ли 99-й процентиль fdatasync в 10 мс. Если это так, значит ваш накопитель работает достаточно быстро. Вот пример вывода:
- В приведенном выше примере мы подстроили параметры --size и --bs под конкретный случай. Чтобы получить содержательный результат от fio , указывайте значения, подходящие для вашего сценария использования. О том, как их выбрать, будет рассказано ниже.
- Во время тестирования только fio нагружает дисковую подсистему. В реальной жизни вполне вероятно, что на диск будут писать и другие процессы (помимо тех, что связаны с wal_fsync_duration_seconds ). Подобная дополнительная нагрузка может привести к увеличению wal_fsync_duration_seconds . Другими словами, если 99-й процентиль, полученный по итогам тестирования с fio , лишь слегка меньше 10 мс, велика вероятность, что производительность хранилища недостаточна.
- Для теста вам понадобится версия fio не ниже 3.5, поскольку более старые версии не агрегируют результаты fdatasync в виде процентилей.
- Приведенный выше вывод представляет собой лишь небольшой отрывок от общего вывода fio .
Измерение производительности дисков в IOPS с помощью fio
Выполним несколько видов тестирования производительности IOPS диска в различных сценариях нагрузки на диск (реждим тестирования, который нужон выбрать зависит от логики размещенного приложения и общей архитектуры проекта).
Тест случайных операций на чтение/запись
При запуске такого теста, будет создан файл размером 8 Гб. Затем утилита fio выполнит чтение/запись блока 4КБ (стандартный размер блока) с разделением на 75/25% по количеству операций чтения и записи и замерит производительность. Команда выглядит следующим образом:

Первую проверку я запустил на массиве из двух SSD дисков и результаты получились хорошие:
- Чтение: ~ 328MiB/s, 83000 IOPS
- Запись: ~ 110MiB/s, 28000 IOPS
Так как мы запустили тест на чтение/запись, показатели по отдельным проверкам, будут чуть выше.
Для сравнения, я замерил скорость на обычном SATA диске:

- Чтение ~ 1.7 MiB/s, 430 IOPS
- Запись ~ 0.5 MiB/s, 143 IOPS
Для HDD диска результаты, конечно гораздо хуже, чем для SSD.
Тест случайных операций на чтение
Чтобы замерить производительность дисков только для случайных операций на чтение, нужно выполнить следующую команду:
Команда поменялась в самом конце на --readwrite=randread .

Как ранее я уже говорил, скорость по отдельным замерам будет выше:
Если запустить тест только на чтение, разница со смешанным тестом достигает (200-250 MiB/s и 67000 IOPS), что достаточно ощутимо.
Тест случайных операций на запись
Для замера производительности диска для случайных операций записи, выполните команду:

Производительность операций записи на хороших SSD дисках тоже очень высокая. Как и в случае с чтением, разница со смешанным тестом достигает 200-250 MiB/s, а в IOPS 56000.
Если опираться на официальную документацию по дискам от производителя (это SSD диски от Intel), можно смело сказать, что в данном случае они не обманули.
Тесты на запись
(внимание! Ошибётесь буквой диска — останетесь без данных)
Счетчики производительности дисковой подсистемы Windows
Вы можете оценить текущий уровень нагрузки на дисковую подсистему с помощью встроенных счетчиков производительности Windows из Performance Monitor. Чтобы собрать данные по этим счетчикам:
- Запустите Perfmon ;
- Создайте новый набор сборщиков данных (Data Collector Set). Выберите Create manually;
- Выберите опцию Create data logs ->Performance counter; Performance counter;" width="530" height="262" />
- Теперь в свойствах нового набора для сбора данных добавьте следующие счетчики производительности для объекта Physical Disk (можете выбрать счётчики для конкретного диска или для всех доступных локальных дисков):
- Avg. Disk Sec./Transfer
- Avg. Disk Queue Length
- Avg Disk Bytes/Transfer
- Disk Bytes/sec
Чтобы отображать данные о производительности дисков в реальном времени нужно добавить указанные счётчик в Perfmon в разделе Monitoring Tools -> Performance Monitor.
Как интерпретировать результаты производительности дисков в Perfmon? Для быстрого анализа производительности дисковой подсистемы необходимо посмотреть на значения как минимум следующих 5 счетчиков.
При анализе данные счётчиков желательно иметь представление о конфигурации физических дисков (используется ли RAID/Stripe/количество и типы дисков, наличие кэша и т.д.).
- Disksec/Transfer – время, необходимое для выполнения одной операции записи/чтения на устройство хранения/диск — disk latency. Если задержка более 25 мс (0.25) или выше, значит дисковый массив не успевает выполнять операции. Для высоконагруженных систем значение не должно превышать 10 мс (0.1);
- Disk Transfers/sec – количество операций чтения/записи в секунду (IOPS). Это основной показатель интенсивности обращений к дискам (примерные значения в IOPS для разных типов дисков представлены в конце статьи);
- DiskBytes/Sec– средняя скорость обмена с диском (чтения/записи) за 1 секунду. Максимальные значения зависит от типа диска (150-250 Мб/секунду — для обычного диска и 500-10000 для SSD);
- SplitIO/sec– показатель фрагментации диска, когда операционной системе приходится разделять одну операцию ввода/вывода на несколько операций. Может также говорить о том, приложение запрашивает слишком большие блоки данных, которые немогут быть переданы за одну операцию;
- Avg. DiskQueueLength– длина очереди к диску (количество транзакций ожидающий обработку). Для одиночного диска длина очереди не должна превышать 2. Для RAID массива из 4 дисков длина очереди до 8 будет считаться допустимым значением.
P.S. от переводчика
С готовыми примерами использования fio для решения других задач можно ознакомиться в документации или напрямую в репозитории проекта (там их представлено намного больше, чем упоминается в документации).
Гибридные тесты
самая вкусная часть:
(внимание! Ошибётесь буквой диска — останетесь без данных)
Во время теста мы видим что-то вроде такого:
В квадратных скобках — цифры IOPS'ов. Но радоваться рано — ведь нас интересует latency.
На выходе (по Ctrl-C, либо по окончании) мы получим примерно вот такое:
^C
fio: terminating on signal 2
Нас из этого интересует (в минимальном случае) следующее:
read: iops=3526 clat=9063.18 (usec), то есть 9мс.
write: iops=2657 clat=12028.23
Не путайте slat и clat. slat — это время отправки запроса (т.е. производительность дискового стека линукса), а clat — это complete latency, то есть та latency, о которой мы говорили. Легко видеть, что чтение явно производительнее записи, да и глубину я указал чрезмерную.
В том же самом примере я снижаю iodepth до 16/16 и получаю:
read 6548 iops, 2432.79usec = 2.4ms
write 5301 iops, 3005.13usec = 3ms
Очевидно, что глубина в 64 (32+32) оказалась перебором, да таким, что итоговая производительность даже упала. Глубина 32 куда более подходящий вариант для теста.
29.10.2019
itpro
PowerShell, Windows 10, Windows Server 2012 R2, Windows Server 2016
комментариев 7
Одной из основных метрик, позволяющих оценить производительность существующей или проектируемой системы хранения данных является IOPS (Input/Output Operations Per Second — количество операций ввода/вывода). Говоря простым языком, IOPS – этой количество блоков, которое успевает считаться или записаться на носитель или файловую систему в единицу времени. Чем это число больше – тем больше производительность данной дисковой подсистемы (откровенно говоря, само по себе значение IOPS стоит рассматривать в комплексе с другими характеристиками СХД, таким как средняя задержка, пропускная способность и т.п.).
В этой статье мы рассмотрим несколько способов измерения производительности используемой системы хранения данных в IOPS под Windows (локальный жесткий, SSD диск, сетевая папка SMB, CSV том или LUN на СХД в сети SAN).
Тестирование производительности дисков с помощью файлов.
Утилита fio позволяет проверять диски не только с помощью интерактивного запуска команд, но и запускать заранее подготовленные конфигурационные файлы для тестов. Чтобы воспользоваться данным вариантом, создайте файл:
И добавьте в него содержимое:
Теперь запустите тест:
Данный тест замерит скорость чтения диска. Чтобы выполнить проверку производительности для операций записи, используйте такой конфиг:
Оцениваем хранилище с помощью fio
Оценить, подходит ли некое хранилище для использования с etcd, можно с помощью утилиты fio — популярного тестера I/O. Учитывайте, что дисковый ввод-вывод может происходить по-разному: sync/async, множество различных классов системных вызовов и т.п. Оборотная сторона медали заключается в том, что fio чрезвычайно сложна в использовании. У утилиты множество параметров, и различные комбинации их значений приводят к совершенно разным результатам. Чтобы получить вменяемую оценку в случае etcd, вы должны убедиться, что нагрузка на запись, генерируемая fio, максимально походит на нагрузку etcd при записи в WAL-файлы:
- Это означает, что генерируемая fio нагрузка, по крайней мере, должна представлять собой серию последовательных записей в файл, где каждая операции записи состоит из системного вызова write , за которым следует fdatasync .
- Чтобы включить последовательную запись, необходимо указать флаг --rw=write .
- Чтобы fio писала с использованием вызовов write (а не других системных вызовов — например, pwrite ), используйте флаг --ioengine=sync .
- Наконец, флаг --fdatasync=1 гарантирует, что за каждым write следует fdatasync .
- Два других параметра в нашем примере: --size и --bs — могут меняться в зависимости от конкретного сценария использования. В следующем разделе будет описана их настройка.
Bonnie
Утилита для оценки производительности файловой системы, разработанная в 1989 году. Её автором выступил инженер Тим Брей (Tim Bray). С помощью Bonnie он планировал оптимизировать работу вычислительных систем, задействованных в проекте New Oxford English Dictionary в Университете Ватерлоо.
Bonnie выполняет произвольное чтение и запись данных на диск. После утилита показывает такие параметры, как число обработанных байтов за CPU-секунду, а также уровень загрузки процессора в процентах. Исходный код бенчмарка можно найти на Google Code.
На основе Bonnie построен другой комплекс инструментов для тестирования жесткого диска — Bonnie++ (написан на C++, вместо C). В нем приведены дополнительные бенчмарк-инструменты. Например, zcav для оценки производительности различных зон HDD. Также Bonnie++ подходит для тестирования почтовых серверов и серверов баз данных.
Читайте также: