
Отличие архитектуры процессора от архитектуры эвм
Архитектурой компьютера считается его представление на некотором общем уровне, включающее описание пользовательских возможностей программирования, системы команд, системы адресации, организации памяти и т. д. Архитектура определяет принципы действия, информационные связи и взаимное соединение основных логических узлов компьютера: процессора, оперативного запоминающего устройства (ОЗУ, ОП), внешних ЗУ и периферийных устройств. Общность архитектуры разных компьютеров обеспечивает их совместимость с точки зрения пользователя.
Структура компьютера — это совокупность его функциональных элементов и связей между ними. Элементами могут быть самые различные устройства — от основных логических узлов компьютера до простейших схем. Структура компьютера графически представляется в виде структурных схем, с помощью которых можно дать описание компьютера на любом уровне детализации
Принципы (архитектура) фон Неймана
В основу построения большинства компьютеров положены следующие общие принципы, сформулированные в 1945 г. американским ученым Джоном фон Нейманом.
1. Принцип программного управления. Из него следует, что программа состоит из набора команд, которые выполняются процессором автоматически друг за другом в определенной последовательности.
Выборка программы из памяти осуществляется с помощью счетчика команд. Этот регистр процессора последовательно увеличивает хранимый в нем адрес очередной команды на длину команды. Так как команды программы расположены в памяти друг за другом, то тем самым организуется выборка цепочки команд из последовательно расположенных ячеек памяти.
Если после выполнения команды следует перейти не к следующей, а к какой-то другой, используются команды условного или безусловного переходов (ветвления), которые заносят в счетчик командномер ячейки памяти, содержащей следующую команду. Выборка команд из памяти прекращается после достижения и выполнения команды «стоп».
Таким образом, процессор исполняет программу автоматически, без вмешательства человека.
2. Принцип однородности памяти. Программы и данные хранятся в одной и той же памяти. Поэтому компьютер не различает, что хранится в данной ячейке памяти — число, текст или команда. Над командами можно выполнять такие же действия, как и над данными. Это открывает целый ряд возможностей. Например, программа в процессе своего выполнения также может подвергаться переработке, что позволяет задавать в самой программе правила получения некоторых ее частей (так в программе организуется выполнение циклов и подпрограмм). Более того, команды одной программы мо- -гут быть получены как результаты исполнения другой программы. На этом принципе основаны методы трансляции — перевода текста программы с языка программирования высокого уровня на язык конкретной машины.
3. Принцип адресности. Структурно основная память состоит из перенумерованных ячеек; процессору в произвольный момент времени доступна любая ячейка. Отсюда следует возможность давать имена областям памяти, так, чтобы к запомненным в них значениям можно было впоследствии обращаться или менять их в процессе
выполнения программ с использованием присвоенных имен.

Компьютеры, построенные на этих принципах, относятся к типу фон-неймановских. Существуют и другие классы компьютеров, принципиально отличающиеся от фон-неймановских. Здесь, например, может не выполняться принцип программного управления, т. е. они могут работать без счетчика (регистра адреса) команд, указывающего на выполняемую команду программы. Для обращения к какой-либо переменной, хранящейся в памяти, этим компьютерам не обязательно давать ей имя. Такие компьютеры называются не-фон-неймановскими.
Логические узлы (агрегаты) ЭВМ, простейшие типы архитектур
Центральное устройство. ЦУ представляет основную компоненту ЭВМ и, в свою очередь, включает ЦП — центральный процессор (central processing unit - CPU) и ОП - оперативную (главную) память (main storage, core storage, random access memory - RAM).
Процессор непосредственно реализует операции обработки информации и управления вычислительным процессом, осуществляя выборку машинных команд и данных из оперативной памяти и запись в ОП, включение и отключение ВУ. Основными блоками процессора являются:
устройство управления (УУ) с интерфейсом процессора (системой сопряжения и связи процессора с другими узлами ма-' шины);
Оперативная память предназначена для временного хранения данных и программ в процессе выполнения вычислительных и логических операций.
ЦУ описывается следующими характеристиками:
Внешние устройства (ВУ). ВУ обеспечивают эффективное взаимодействие компьютера с окружающей средой — пользователями, объектами управления, другими машинами. ВУ разделяются на следующие группы:интерактивные устройства (ввода/вывода); устройства хранения (массовые накопители); устройства массового ввода информации, устройства массового вывода информации.
В специализированных управляющих ЭВМ (технологические процессы, связь, ракеты и пр.) внешними устройствами ввода являются датчики (температуры, давления, расстояния и пр.), вывода — манипуляторы (гидро-, пневмо-, сервоприводы рулей, вентилей и др.).
В универсальных ЭВМ (человеко-машинная обработка информации) в качестве ВУ выступают терминалы, принтеры и др. устройства.
Каналы связи (внутримашинный интерфейс) служат для сопряжения центральных узлов машины с ее внешними устройствами.
Однотипные ЦУ и устройства хранения данных могут использоваться в различных типах машин. Известны примеры того, как фирмы, начавшие свою деятельность с производства управляющих машин, совершенствуя свою продукцию, перешли к выпуску систем, которые в зависимости от конфигурации ВУ могут исполнять как роль универсальных, так и управляющих машин (Hewlett-Packard и Digital Equipment Corporation).
Если абстрагироваться от подробностей, то основные классические типы архитектур можно определить как следующие: «звезда», иерархическая, магистральная Архитектура «звезда». Здесь ЦУ (рис. 2.1, а) соединено непосредственно с ВУ и управляет их работой (ранние модели машин).
Классическая архитектура (фон Неймана) - одно арифметико-логическое устройство (АЛУ), через которое проходит поток данных, и одно устройство управления (УУ), через которое проходит поток команд — программа (рис. 2.2). Это однопроцессорный компьютер.
Вычислительная машина включает пять базовых компонент и состоит из следующих типов устройств:
Иерархическая архитектура — ЦУ соединено с периферийными процессорами (вспомогательными процессорами, каналами и пр.), управляющими в свою очередь контроллерами, к которым подключены группы ВУ (системы IBM 360—375);
Магистральная структура (общая шина - unibas) — процессор (процессоры) и блоки памяти (ОП) взаимодействуют между собой и с ВУ (контроллерами ВУ) через внутренний канал, общий для всех устройств (машины DEC, ПЭВМ IBM PC-совместимые).
К этому типу архитектуры относится также архитектура персонального компьютера: функциональные блоки здесь связаны между собой общей шиной, называемой также системной магистралью.
Физически магистраль представляет собой многопроводную линию с гнездами для подключения электронных схем. Совокупность проводов магистрали разделяется на отдельные группы: шину адреса, шину данных и шину управления.
Периферийные устройства (принтер и др.) подключаются к аппаратуре компьютера через специальные контроллеры — устройства управления периферийными устройствами.
Контроллер — устройство, которое связывает периферийное оборудование или каналы связи с центральным процессором, освобождая процессор от непосредственного управления функционированием данного оборудования.
Здравствуй, мир! Сегодня у нас серия статьей для людей со средними знаниями о работе процессора в которой мы будем разбираться с процессорными архитектурами (у меня спелл чекер ругается на слово Архитектурами/Архитектур, надеюсь я пишу слово правильно), создавать собственную архитектуру процессора и многое другое.

Принимаются любые замечания!
Исторически сложилось, что существуют много процессоров и много архитектур. Но многие архитектуры имеют схожести. Специально для этого появились "Группы" архитектур типа RISC, CISC, MISC, OISC (URISC). Кроме того они могут иметь разные архитектуры адресации памяти (фон Неймана, Гарвард). У каждого процессора есть своя архитектура. Например большинство современных архитектур это RISC (ARM, MIPS, OpenRISC, RISC-V, AVR, PIC** и т.д.), но есть архитектуры которые выиграли просто за счет других факторов (Например удобство/цена/популярность/etc) Среди которых x86, x86-64 (Стоит отметить, что x86-64 и x86 в последних процессорах используют микрокод и внутри них стоит RISC ядро), M68K. В чем же их отличие?
Reduced Instruction Set Computer — Архитектура с уменьшенным временем выполнения инструкций (из расшифровка RISC можно подумать, что это уменьшенное количество инструкций, но это не так). Данное направления развилось в итоге после того, как оказалось, что большинство компиляторов того времени не использовали все инструкции и разработчики процессоров решили получить больше производительности использую Конвейеры. В целом RISC является золотой серединой между всеми архитектурами.
Яркие примеры данной архитектуры: ARM, MIPS, OpenRISC, RISC-V
Что такое TTA? ТТА это Архитектура на основе всего одной инструкции перемещения из одного адреса памяти в другую. Данный вариант усложняет работу компилятора зато дает большую производительность. У данной архитектуры есть единственный недостаток: Сильная зависимость от шины данных. Именно это и стало причиной ее меньшей популярности. Надо отметить что TTA является разновидностью OISC.
Яркие примеры: MOVE Project
Прерывания
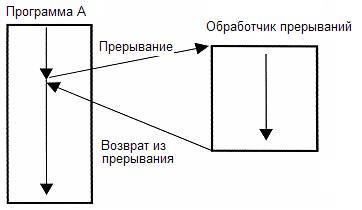
Прерывания это техника при которой исполняемый в данный момент код приостанавливается для выполнения какой-то другой задачи при каких-то условиях. Например при доступе в несуществующий участок памяти вызывается HardFault или MemoryFault прерывания или исключения. Или например если таймер отсчитал до нуля. Это позволяет не бездействовать пока нужно ждать какое-то событие.
Какие недостатки? Вызов прерывания это несколько тактов простоя и несколько при возврате из прерывания. Так же несколько инструкций в начале кода будет занято инструкциями для Таблицы прерываний.
Системные вызовы
Системные вызовы используется в Операционных системах для того, чтобы программы могли общаться с операционной системой например просить ОС прочитать файл. Очень похоже на прерывания. Аналогично исключениям не всегда присутствуют в процессоре
Здесь описываются методы запрета доступа приложений к аппаратуре напрямую.
Архитектура гарварда
Особенность этой архитектуры является отдельная шина данных и инструкций. Дает большую производительность чем фон Нейман за счет возможности за один такт использовать обе шины (читать из шины инструкций и одновременно записывать в шинну данных), но осложняет архитектуру и имеет некоторые ограничения. В основном используется в микроконтроллерах.
Привилегированный режим
Это режим в котором стартует процессор. В таком режиме программа или ОС имеют полный доступ к памяти в обход MMU/MPU. Все программы запускаются в непривилегированном режиме во избежания прямого доступа к аппаратным подсистемам программ для этого не предназначенных. Например вредоносным программам. В Windows ее часто называют Ring-0, а в *nix — системным. Не стоит путать Привелигированный пользователь и Привилегированный режим ибо в руте вы все еще не можете иметь прямой доступ к аппаратуре (можно загрузить системный модуль который позволит это сделать, но об этом чуть позже :)
Конвейеры
Что такое конвейеры? Если сказать очень глупым языком это несколько параллельных действий за один такт. Это очень грубо, но при этом отображает суть. Конвейеры за счет усложнения архитектуры позволяют поднять производительность. Например конвейер позволяет прочитать инструкцию, исполнить предыдущую и записать в шину данных одновременно.

На картинке более понятно, не правда?
IF — получение инструкции,
ID — расшифровка инструкции,
EX — выполнение,
MEM — доступ к памяти,
WB — запись в регистр.
Вроде все просто? А вот и нет! Проблема в том что например прыжок (jmp/branch/etc) заставляют конвейер начать исполнение (получение след. инструкции) заново таким образом вызывая задержку в 2-4 такта перед исполнение следующей инструкции.
MPU и MMU

MPU и MMU используется в современных системах чтобы изолировать несколько приложений. НО если MMU позволяет "передвинуть" память то MPU позволяет только блокировать доступ к памяти/запуск кода в памяти.
PIC (PIE)
Что такое PIE? (PIC не использую для избежания путаницы с МК PIC). PIE это техника благодаря которой компилятор генерирует код который будет работать в любом месте в памяти. Эта техника в совмещении с MPU позволяет компилировать высокие языки программирования которые будут работать и с MPU.
Популярная техника SIMD используется для того, что бы за один такт выполнять несколько действий над несколькими регистрами. Иногда бывают в качестве дополнений к основной архитектуре, например, как в MIPS, ARM со своими NEON/VFP/etc, x86 со своим SSE2.
Это техника Используется для оптимизации кода, генерируемого компилятором, с помощью пересортировки инструкций, увеличивая производительность процессора. Это позволяет использовать конвейер на полную.

Что такое регистр статуса? Это регистр который хранит состояние процессора. Например находится ли процессор в привилегированном режиме, чем закончилась операция последнего сравнения.
Используется в связке с Masked Execution. Некоторые разработчики специально исключают регистр статуса ибо он может являться узким местом как поступили в MIPS.
В MIPS нет отдельной инструкции загрузки константы в память, но есть инструкция addi и ori которая позволяет в связке с нулевым регистром ($0) эмулировать работу загрузки константы в регистр. В других архитектурах она присутствует. Я затронул эту тему, потому что она пригодиться нам в статьях с практикой.
Идут множество споров насчет того сколько должно быть операндов в арифметических инструкциях. Например в MIPS используется вариант с 3-мя регистрами. 2 операнда, 1 регистр записи. С другой стороны, использование двух операндов позволяет сократить код за счет уменьшения размера инструкции. Пример совмещения является MIPS16 в MIPS и Thumb-I в ARM. В плане производительности они практически идентичны (Если исключать размер инструкции как фактор).

Порядок байт. Возможно вам знакомы Выражения Big-Endian и Little-Endian. Они описывают порядок байт в инструкциях/в регистрах/в памяти/etc. Здесь думаю все просто :). Есть процессоры которые совмещают режимы, как MIPS, или которые используют одну систему команд, но имеют разный порядок байт, например ARM.

Что такое сопроцессоры? Сопроцессоры являются элементами процессора или внешней микросхемой. Они позволяют исполнять инструкции, которые слишком громоздки для основной части процессора. Как яркий пример, сопроцессоры в MIPS для деления и умножения. Или например 387 для 80386, который добавлял поддержку чисел с плавающей запятой. А в MIPS сопроцессоров было много и они выполняли свои роли: контролировали прерывания, исключения и системные вызовы. Часто сопроцессоры имеют собственные инструкции и на системах, где этих инструкций нет, (пример ARM) эмулируют ее через Trap-ы (ловушки?). Несмотря на костыльность и маленькую производительность, они часто являются единственным выбором в микроконтроллерах.
Атомартность операций обеспечивает потоко-независимое исполнение за счет инструкций, которые выполняют несколько действий за один псевдотакт.
Вариант другого решения атомарность переферии. Например для установки ножки в STM32 в высокое и низкое состояние используется разные регистры, что позволяет иметь атомарность на уровне переферии.

Вы, навярняка, слышали о L1, L2, L3 и регистрах. Если коротко, процессор анализирует часть кода, чтобы предугадать прыжки и доступ в память и зараннее просит кеш получить эти данные из памяти. Кеш зачастую бывает прозрачным для программы, но бывают и исключения из этого правила. Например, в программных ядрах в ПЛИС используется програмный кеш.
И вы кончено слышали о такой вещи, как Cache Miss или промах по кешу. Это операция которая не была предусмотрена процессорам или процессор не успел закешировать эту часть памяти. Что достаточно часто является проблемой замедления доступа к памяти. Промах проходит незаметно для программы, но не останутся незаметными просадки в производительности.Так же переключения контекстов например при прерываниях тоже заставляет страдать кеш ибо небольшой код сбивает конвейер и кеш для собственных нужд.
В современных процессорах часто используется техника теневых регистров. Они позволяют переключаться между прерываниями и пользовательским кодом практически без задержек связанных с сохранением регистров.

Спросите тогда что такое куча (Heap)? Куча это память размером намного больше чем стек (Стек обычно ~1MB). В хипе храниться все глобальное. Например все указатели полученные с помощю Malloc указывают на часть куча. А указатели хранятся в стеке или в регистрах. С помощью инструкций загрузки данных относительно регистра можно ускорить работу стека и других доступов к памяти по типу стека, поскольку не нужно постоянно использовать операции PUSH/POP, INC/DEC или ADDI, SUBI (добавить константу), чтобы получить данные глубже по стеку, а можно просто использовать доступ относительно стека с отрицательным смещением.

Не буду описывать регистры слишком подробно. Это мы затронем в практической статье.
В x86 регистров достаточно мало. В MIPS используется увеличенное количество регистров, а именно 31 ($0 имеет значение всегда равное нулю). В процессоре университета Беркли использовались регистровые окна, которые жестки ограничивали вложенность функций, при этом имея лучшую производительность. В других же, таких как AVR, ограничили использование регистров. Для примера: три 16-битных можно трактовать как шесть восьмибитных, где первые 16ть недоступны при некоторых операциях. Я считаю, что лучший метод был выбран MIPS-ом. Это мое сугубо личное мнение.
Что такое выравнивание? Оставлю-ка я этот вопрос вам :)
Это конец первой главы нулевой части. Вся серия будет крутиться вокруг темы создания собственного процессора. Собственной операционной системы. Собственного ассемблера. Собственного компилятора и много чего другого.
Нулевые части будут посвящены теории. Я сомневаюсь что доведу всю серию до победного конца, но попытка не пытка! )
Мы воспринимаем центральный процессор как «мозг» компьютера, но что это значит на самом деле? Что именно происходит внутри миллиардов транзисторов, благодаря которым работает компьютер? В нашей новой мини-серии из четырёх статей мы рассмотрим процесс создания архитектуры компьютерного оборудования и расскажем о принципах его работы.
В этой серии мы расскажем о компьютерной архитектуре, проектировании процессорных плат, VLSI (very-large-scale integration), производстве чипов и тенденциях будущего в области вычислительной техники. Если вам было интересно разобраться в подробностях работы процессоров, то начинать изучение лучше с этой серии статей.
Мы начнём с очень высокоуровневого объяснения того, чем занимается процессор и как строительные блоки соединяются в функционирующую конструкцию. В том числе мы рассмотрим процессорные ядра, иерархию памяти, предсказание ветвлений и другое. Во-первых, нам нужно дать простое определение тому, что делает ЦП. Простейшее объяснение: процессор следует набору инструкций для выполнения определённой операции над множеством входящих данных. Например, это может быть считывание значения из памяти, затем прибавление его к другому значению, и наконец сохранение результата в память по другому адресу. Это может быть и нечто более сложное, например, деление двух чисел, если результат предыдущего вычисления больше нуля.
Программы, например, операционная система или игра, сами по себе являются последовательностями инструкций, которые должен выполнять ЦП. Эти инструкции загружаются из памяти и в простом процессоре выполняются одна за другой, пока программа не завершится. Разработчики программного обеспечения пишут программы на высокоуровневых языках, например, на C++ или на Python, но процессор не может их понимать. Он понимает только единицы и нули, поэтому нам нужно каким-то образом представить код в этом формате.

Программы компилируются в набор низкоуровневых инструкций, называемых языком ассемблера, который является частью архитектуры набора команд (Instruction Set Architecture, ISA). Это набор команд, которые должен понимать и выполнять ЦП. Одними из наиболее распространённых ISA являются x86, MIPS, ARM, RISC-V и PowerPC. Точно так же, как синтаксис написания функции на C++ отличается от функции, выполняющей то же действие в Python, у каждой ISA есть свой отличающийся синтаксис.
Эти ISA можно разбить на две основных категории: с фиксированной и с переменной длиной. ISA RISC-V использует инструкции с фиксированной длиной, и это означает, что определённое заранее заданное количество битов в каждой инструкции определяет, какой тип имеет эта инструкция. В x86 всё иначе, в нём используются инструкции с переменной длиной. В x86 инструкции могут кодироваться различным способом с разным количеством битов для разных частей. Из-за такой сложности декодер инструкций в процессоре x86 обычно является самой сложной частью всего устройства.
Инструкции с фиксированной длиной обеспечивают простое декодирование благодаря постоянной структуре, но ограничивают общее количество инструкций, которые могут поддерживаться ISA. В то время, как у популярных версий архитектуры RISC-V есть примерно 100 инструкций и все они имеют открытый исходный код, архитектура x86 проприетарна и никто не знает, сколько всего инструкций в ней есть. Обычно считается, что существует несколько тысяч инструкций x86, но точное число никто не публикует. Несмотря на различия между ISA, по сути все они имеют одинаковую базовую функциональность.

Пример некоторых инструкций RISC-V. Опкод справа имеет длину 7 бит и определяет тип инструкции. Кроме того, каждая инструкция содержит биты, определяющие используемые регистры и выполняемые функции. Так ассемблерные инструкции разбиваются на двоичный код, чтобы его понимал процессор.
Теперь мы готовы включить компьютер и начать выполнять программы. Выполнение инструкции имеет несколько базовых частей, которые разбиты на множество этапов процессора.
Первый этап — передача инструкции из памяти в процессор для начала выполнения. На втором этапе инструкция декодируется, чтобы ЦП мог понять, какого типа эта инструкция. Существует множество типов, в том числе арифметические инструкции, инструкции ветвления и инструкции памяти. После того, как ЦП узнает, инструкцию какого типа он выполняет, операнды для инструкции берутся из памяти или внутренних регистров ЦП. Если вы хотите сложить число A и число B, то не можете выполнять сложение, пока не знаете значений A и B. Большинство современных процессоров являются 64-битными, то есть размер каждого значения данных составляет 64 бита.

64 бита — это ширина регистра процессора, канала передачи данных и/или адреса памяти. Для обычных пользователей это означает, какой объём информации компьютер может обработать за один раз, и лучше всего это понять в сравнении с младшим родственником по архитектуре — 32-битным процессором. 64-битная архитектура может обрабатывать за раз в два раза больше бит информации (64 бит против 32).
Получив операнды для инструкции, процессор переносит их на этап выполнения, где производится операция над входящими данными. Это может быть сложение чисел, выполнение логических манипуляций с числами или просто передача чисел без их изменения. После вычисления результата может потребоваться доступ к памяти для его сохранения, или процессор может просто хранить значение в одном из своих внутренних регистров. После сохранения результата ЦП обновляет состояние различных элементов и переходит к следующей инструкции.
Это объяснение, разумеется, сильно упрощено, и большинство современных процессоров для повышения эффективности разбивает эти несколько этапов на 20 или даже больше мелких этапов. Это означает, что хотя процессор начинает и завершает в каждом цикле несколько инструкций, может потребоваться 20 или больше циклов, чтобы выполнить одну инструкцию от начала до конца. Такая модель обычно называется pipeline («трубопровод», на русский обычно переводят как «конвейер»), потому что для заполнения трубопровода жидкостью и полного её прохождения требуется время, но после заполнения расход (вывод данных) будет постоянным.

Пример 4-этапного конвейера. Разноцветные прямоугольники обозначают независящие друг от друга инструкции.
Весь проходимый инструкцией цикл — это очень тщательно скоординированный процесс, но не все инструкции могут завершаться одновременно. Например, сложение выполняется очень быстро, а деление или загрузка из памяти может занимать тысячи циклов. Вместо останова всего процессора до момента завершения одной медленной инструкции большинство современных процессоров выполняют их с изменением очерёдности. То есть они определяют, какую из инструкций выгоднее всего выполнить в текущий момент и буферизируют другие инструкции, которые пока не готовы. Если текущая инструкция ещё не готова, то процессор может перепрыгнуть вперёд по коду, чтобы посмотреть, готово ли что-то ещё.
Кроме выполнения с изменением очерёдности современные процессоры применяют технологию под названием суперскалярная архитектура. Это означает, что в любой момент времени процессор одновременно выполняет на каждом этапе конвейера множество инструкций. Он может также ожидать ещё сотни других, чтобы начать их выполнение, и для того, чтобы иметь возможность одновременного выполнения нескольких инструкций внутри процессоров есть несколько копий каждого этапа конвейера. Если процессор видит, что к выполнению готовы две инструкции, и между ними нет зависимости, то он не ждёт, пока они завершатся по отдельности, а выполняет их одновременно. Одна из популярных реализаций такой архитектуры называется Simultaneous Multithreading (SMT) и также известна, как Hyper-Threading. Процессоры Intel и AMD сейчас поддерживают двухсторонний SMT, а IBM разработала чипы, поддерживающие до восьми SMT.

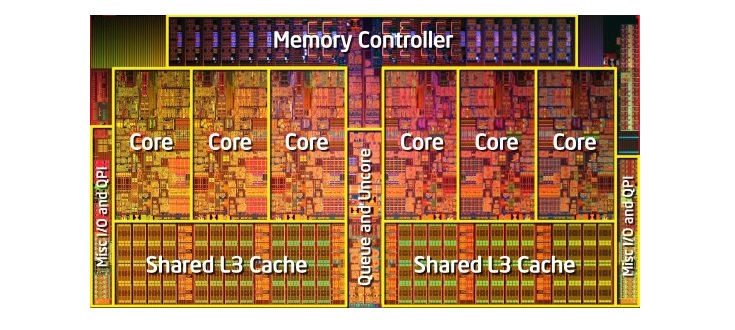
Для завершения этого тщательно скоординированного выполнения процессор кроме базового ядра имеет множество дополнительных элементов. В процессоре есть сотни отдельных модулей, у каждого из которых есть специфическая функция, но мы рассмотрим только основы. Самыми важными и выгодными являются кэши и предсказатель переходов. Есть и другие дополнительные структуры, которые мы рассматривать не будем: буферы переупорядочивания, таблицы переименования регистров и станции резервирования.
Необходимость кэшей иногда может сбивать с толку, ведь они хранят данные, как и ОЗУ или SSD. Но кэши отличаются задержкой и скоростью доступа. Даже несмотря на то, что память ОЗУ чрезвычайно быстра, она на порядки величин медленнее, чем нужно для ЦП. Для ответа с передачей данных ОЗУ может потребоваться сотни циклов, и процессору в это время будет нечем заняться. А если данных нет в ОЗУ, то могут потребоваться десятки тысяч циклов для получения доступа к ним с SSD. Без кэшей процессоры бы постоянно стопорились.
Обычно процессоры имеют три уровня кэша, образующих так называемую иерархию памяти. Кэш L1 — самый маленький и быстрый, L2 находится посередине, а L3 — самый крупный и медленный из всех кэшей. Выше кэшей в иерархии находятся мелкие регистры, хранящие во время вычислений единственное значение данных. По порядку величин эти регистры являются самыми быстрыми устройствами хранения в системе. Когда компилятор преобразует высокоуровневую программу в язык ассемблера, он определяет наилучший способ использования этих регистров.
Когда ЦП запрашивает данные из памяти, то сначала проверяет, хранятся ли эти данные уже в кэше L1. Если да, то можно всего за пару циклов получить к ним доступ. Если их там нет, то процессор проверяет L2, а затем и кэш L3. Кэши реализованы таким образом, что в общем случае они прозрачны для ядра. Ядро просто запрашивает данные по указанному адресу памяти, и тот уровень в иерархии, на котором они есть, отвечает ему. При переходе к последующим уровням в иерархии памяти размер и задержки обычно растут на порядки величин. В конце концов, если ЦП не находит данные ни в одном из кэшей, то обращается в основную память (ОЗУ).

В обычном процессоре каждое ядро имеет два кэша L1: один для данных и другой для инструкций. Кэши L1 обычно имеют в целом объём порядка 100 килобайт и размер очень варьируется в зависимости от чипа и поколения процессора. Кроме того, обычно для каждого ядра есть свой кэш L2, хотя в некоторых архитектурах он может быть общим для двух ядер. Кэши L2 обычно имеют размер несколько сотен килобайт. Наконец, есть единственный кэш L3, общий для всех ядер, имеющий размер порядка десятков мегабайт.
Когда процессор выполняет код, самые часто используемые инструкции и значения данных кэшируются. Это значительно ускоряет выполнение, потому что процессору не нужно постоянно обращаться за нужными данными в основную память. Во второй и третьей частях серии мы подробнее поговорим о том, как реализованы эти системы памяти.
Кроме кэшей одним из самых важных строительных блоков современного процессора является точный предсказатель переходов. Инструкции переходов (ветвлений) схожи с конструкциями «if» для процессора. Один набор инструкций выполняется, если условие истинно, а другой — если оно ложно. Например, нам нужно сравнить два числа, и если они равны, выполнить одну функцию, а если не равны, то выполнить другую. Эти инструкции ветвления применяются чрезвычайно часто и могут составлять примерно 20% всех инструкций в программе.
На первый взгляд кажется, что эти инструкции ветвления не должны вызывать проблем, но их правильное выполнение может оказаться очень сложным для процессора. В любой момент времени процессор может находиться в процессе одновременного выполнения десяти или двадцати инструкций, поэтому очень важно знать, какие инструкции выполнять. Может потребоваться 5 циклов, чтобы определить, что текущая инструкция — это переход и ещё 10 циклов, чтобы определить истинность условия. В это время процессор уже может начать выполнение десятков дополнительных инструкций, даже не зная, действительно ли это подходящие для выполнения инструкции.
Чтобы обойти эту проблему, все современные высокопроизводительные процессоры используют методику под названием «упреждение» (speculation). Это означает, что процессор отслеживает инструкции ветвления и гадает, будет ли выполнен условный переход, или нет. Если предсказание верно, то процессор уже начал выполнять последующие инструкции, и это обеспечивает рост производительности. Если предсказание неверно, то процессор останавливает выполнение, удаляет все неверные инструкции, которые он начал выполнять, и начинает заново с правильной точки.
Такие предсказатели перехода — одни из самых простейших разновидностей машинного обучения, потому что предсказатель изучает поведение ветвей в процессе выполнения. Если он предсказывает неверно слишком часто, то начинает обучаться правильному поведению. Десятилетия исследований методик предсказания переходов привели к тому, что в современных процессорах точность предсказаний превышает 90%.
Хотя упреждение обеспечивает огромный рост производительности, потому что процессор может выполнять инструкции, которые уже готовы, вместо того, чтобы ожидать в очереди завершения выполняемых, оно в то же время создаёт уязвимости в защите. Знаменитая атака Spectre эксплуатирует баги в предсказании и упреждении переходов. Атакующий использует специально подобранный код, чтобы заставить процессор упреждающе выполнить код, благодаря чему происходит утечка значений из памяти. Для предотвращения утечки данных необходимо было переделать конструкцию отдельных аспектов упреждения, что привело к небольшому падению производительности.
За последние десятилетия используемая в современных процессорах архитектура прошла долгий путь. Инновации и разработка продуманной структуры привели к повышению производительности и более оптимальному использованию аппаратных средств. Однако разработчики центральных процессоров тщательно хранят секреты их технологий, поэтому мы не можем точно узнать, что происходит у них внутри. Тем не менее, фундаментальные принципы работы процессоров стандартированы для всех архитектур и моделей. Intel может добавлять свои секретные ингредиенты, чтобы повысить долю попаданий кэша, а AMD может добавить улучшенный предсказатель переходов, но процессоры обеих компаний выполняют одинаковую задачу.
В этом первом взгляде и обзоре мы рассмотрели основы работы процессоров. В следующей части мы расскажем, как разрабатываются компоненты, входящие в состав процессоров, поговорим о логических элементах, тактовых частотах, управлении питанием, принципиальных электросхемах и другом.
Вы наверняка знаете, что мир процессоров разбит на два лагеря. Если вы смотрите это видео со смартфона, то для вас работает процессор на архитектуре ARM, а если с ноутбука, для вас трудится чип на архитектуре x86.
А теперь еще и Apple объявила, что переводит свои Mac на собственные процессоры Apple Silicon на архитектуре ARM. Мы уже рассказывали, почему так происходит. А сегодня давайте подробно разберемся, в чем принципиальные отличия x86 и ARM. И зачем Apple в это все вписалась?
Итак, большинство мобильных устройств, iPhone и Android'ы работают на ARM'е. Qualcomm, HUAWEI Kirin, Samsung Exynos и Apple A13/A14 Bionic — это все ARM-процессоры.
А вот на компьютере не так — там доминирует x86 под крылом Intel и AMD. Именно поэтому на телефоне мы не можем запустить Word с компьютера.
x86 — так называется по последним цифрам семейства классических процессоров Intel 70-80х годов.

Чем же они отличаются?
Есть два ключевых отличия.
Первое — это набор инструкций, то есть язык который понимает процессор
x86 процессоры используют сложный набор инструкций, который называется CISC - Complex Instruction Set Computing.
ARM процессоры наоборот используют упрощенный набор инструкций — RISC - Reduced Instruction Set Computing.
Кстати ARM расшифровывается как Продвинутые RISC машины - Advanced RISC Machines.
Наборы инструкций ещё принято назвать архитектурой или ISA - Instruction Set Architecture.
Второе отличие — это микроархитектура. Что это такое?
От того на каком языке говорят процессоры, зависит и то, как они проектируются. Потому как для выполнения каждой инструкции на процессоре нужно расположить свой логический блок. Соответственно, разные инструкции — разный дизайн процессора. А дизайн — это и есть микроархитектура.
Но как так произошло, что процессоры стали говорить на разных языках?
История CISC
Памятка программиста, 1960-е годы. Цифровой (машинный) код «Минск-22».
Всё началось в 1960-х. Поначалу программисты работали с машинным кодом, то есть реально писали нолики и единички. Это быстро всех достало и появился Assembler. Низкоуровневый язык программирования, который позволял писать простые команды типа сложить, скопировать и прочее. Но программировать на Assembler'е тоже было несладко. Потому как приходилось буквально “за ручку” поэтапно описывать процессору каждое его действие.
Поэтому, если бы вы ужинали с процессором, и попросили передать его вам соль, это выглядело бы так:
- Эй процессор, посмотри в центр стола.
- Видишь соль? Возьми её.
- Теперь посмотри на меня.
- Отдай мне соль. — Ага, спасибо!
- А теперь снова возьми у меня соль.
- Поставь её откуда взял
- Спасибо большое! Продолжай свои дела.
- Кхм… Процессор, видишь перец?
- И так далее.
Этот подход стал настоящим спасением как для разработчиков, так и для бизнеса. Захотел клиент новую инструкцию — не проблема, были бы деньги — мы сделаем. А деньги у клиентов были.
Недостатки CISC
Но был ли такой подход оптимальным. С точки зрения разработчиков — да. Но вот микроархитектура страдала.
Представьте, вы купили квартиру и теперь вам нужно обставить её мебелью. Площади мало, каждый квадратный метр на счету. И вот представьте, если бы CISC-процессор обставил мебелью вам гостиную, он бы с одной стороны позаботился о комфорте каждого потенциального гостя и выделил бы для него своё персональное место.
С другой стороны, он бы не щадил бюджет. Диван для одного человека, пуф для другого, кушетка для третьего, трон из Игры Престолов для вашей Дейенерис. В этом случае площадь комнаты бы очень быстро закончилась. Чтобы разместить всех вам бы пришлось увеличивать бюджет и расширять зал. Это не рационально. Но самое главное, CISC-архитектура существует очень давно и те инструкции, которые были написаны в 60-х годах сейчас уже вообще не актуальны. Поэтому часть мебели, а точнее исполнительных блоков, просто не будут использоваться. Но многие из них там остаются. Поэтому появился RISC…
Преимущества RISC
С одной стороны писать на Assembler'е под RISC процессоры не очень-то удобно. Если в лоб сравнивать код, написанный под CISC и RISC процессоры, очевидно преимущество первого.
Так выглядит код одной и той же операции для x86 и ARM.
x86
Представьте, что вы проектируете процессор. Расположение блоков на х86 выглядело бы так.
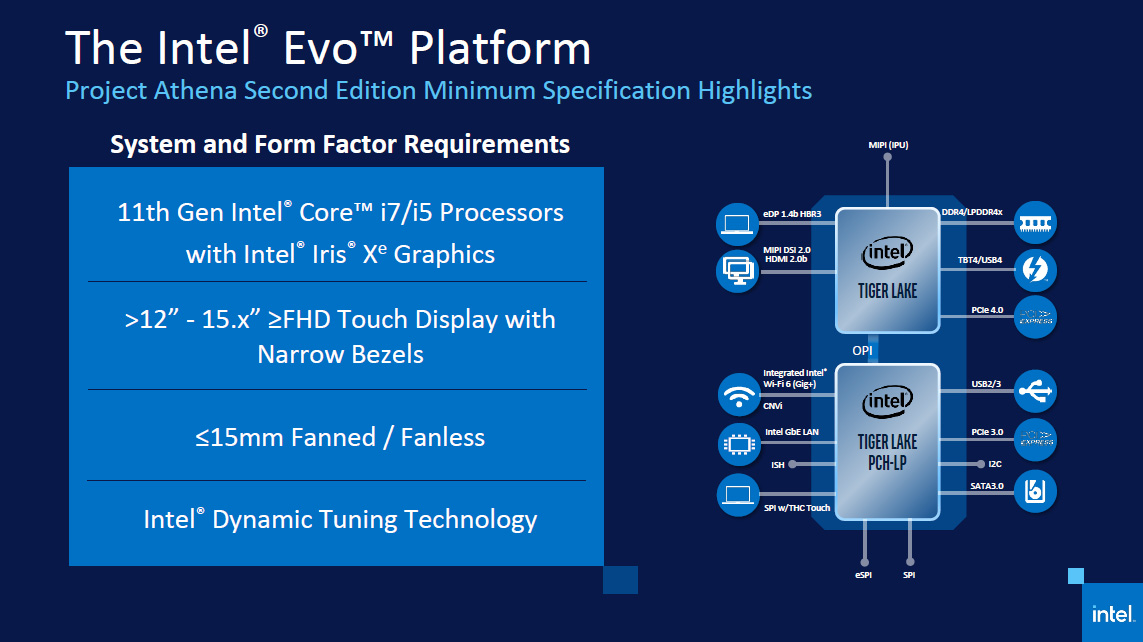
Каждый цветной квадрат — это отдельные команды. Их много и они разные. Как вы поняли, здесь мы уже говорим про микроархитектуру, которая вытекает из набора команд. А вот ARM-процессор скорее выглядит так.

Ему не нужны блоки, созданные для функций, написанных 50 лет назад.
По сути, тут блоки только для самых востребованных команд. Зато таких блоков много. А это значит, что можно одновременно выполнять больше базовых команд. А раритетные не занимают место.
Еще один бонус сокращенного набора RISC: меньше места на чипе занимает блок по декодированию команд. Да, для этого тоже нужно место. Архитектура RISC проще и удобнее, загибайте пальцы:
- проще работа с памятью,
- более богатая регистровая архитектура,
- легче делать 32/64/128 разряды,
- легче оптимизировать,
- меньше энергопотребление,
- проще масштабировать и делать отладку.
Поэтому наши смартфоны, которые работают на ARM процессорах с архитектурой RISC, долго живут, не требуют активного охлаждения и такие быстрые.
Лицензирование
Но это все отличия технические. Есть отличия и организационные. Вы не задумывались почему для смартфонов так много производителей процессоров, а в мире ПК на x86 только AMD и Intel? Все просто — ARM это компания которая занимается лицензированием, а не производством.
Даже Apple приложила руку к развитию ARM. Вместе с Acorn Computers и VLSI Technology. Apple присоединился к альянсу из-за их грядущего устройства — Newton. Устройства, главной функцией которого было распознавание текста.
Даже вы можете начать производить свои процессоры, купив лицензию. А вот производить процессоры на x86 не может никто кроме синей и красной компании. А это значит что? Правильно, меньше конкуренции, медленнее развитие. Как же так произошло?

Ну окей. Допустим ARM прекрасно справляется со смартфонами и планшетами, но как насчет компьютеров и серверов, где вся поляна исторически поделена? И зачем Apple вообще ломанулась туда со своим Apple Silicon.
Что сейчас?
Допустим мы решили, что архитектура ARM более эффективная и универсальная. Что теперь? x86 похоронен?
На самом деле, в Intel и AMD не дураки сидят. И сейчас под капотом современные CISC-процессоры очень похожи на RISC. Постепенно разработчики CISC-процессоров все-таки пришли к этому и начали делать гибридные процессоры, но старый хвост так просто нельзя сбросить.

Но уже достаточно давно процессоры Intel и AMD разбивают входные инструкции на более мелкие микро инструкции (micro-ops), которые в дальнейшем — сейчас вы удивитесь — исполняются RISC ядром.
Да-да, ребята! Те самые 4-8 ядер в вашем ПК — это тоже RISC-ядра!
Надеюсь, тут вы окончательно запутались. Но суть в том, что разница между RISC и CISC-дизайнами уже сейчас минимальна.
А что остается важным — так это микроархитектура. То есть то, насколько эффективно все организовано на самом камне.
Ну вы уже наверное знаете, что Современные iPad практически не уступают 15-дюймовым MacBook Pro с процессорами Core i7 и Core i9.

А что с компьютерами?
Недавно компания Ampere представила свой 80-ядерный ARM процессор. По заявлению производителя в тестах процессор Ampere показывает результат на 4% лучше, чем самый быстрый процессор EPYC от AMD и потребляет на 14% меньше энергии.

Компания Ampere лезет в сегменты Cloud и Workstation, и показывает там отличные цифры. Самый быстрый суперкомпьютер в мире сегодня работает на ARM ISA. С обратной стороны, Intel пытается все таки влезть в сегмент low power и для этого выпускает новый интересный процессор на микроархитектуре lakefield.
Пока у ноутбуков и процессоров от Intel есть одно неоспоримое достоинство - (охлаждение и) единство архитектуры. Пока на рынке ARM-процессоров существуют Qualcomm, Samsung, MediaTek, в мире x86 творится монополия и разработчикам сильно легче делать софт и игры под “взрослые” процессоры.
И Apple та компания, которая способна мотивировать достаточное количество разработчиков пилить под свой ARM. Но суть этого перехода скорее не в противостоянии CISC и RISC. Поскольку оба подхода сближаются, акцент смещается на микроархитектуру, которую делает Apple для своих мобильных устройств. И судя по всему микроархитектура у них крута. И они хотели бы ее использовать в своих компьютерах.
И если бы Intel лицензировал x86 за деньги другим людям, то вероятно Apple просто адаптировали свою текущую микроархитектуру под x86. Но так как они не могут этого сделать, они решили просто перейти на ARM. Проблема для нас с микроархитектурой в том, что она коммерческая тайна. И мы про нее ничего не знаем.
Итоги

Спрос на ARM в итоге вырастет. Для индустрии это не просто важный шаг, а архиважный. Линус Торвальдс говорил, что пока рабочие станции не станут работать на ARM — на рынке серверов будут использовать x86.
И вот это случилось — в перспективе это миллионы долларов, вложенных в серверные решения. Что, конечно, хорошо и для потребителей. Нас ждет светлое будущее и Apple, действительно, совершила революцию!
Редактор материала: Антон Евстратенко. Этот материал помогли подготовить наши зрители Никита Куликов и Григорий Чирков. Спасибо ребята!
Под архитектурой ЭВМ понимается совокупность общих принципов организации аппаратно-программных средств и их характеристик, определяющая функциональные возможности ЭВМ при решении соответствующих классов задач.
Открытая архитектура - предполагает наличие единого стандарта при разработке устройств, располагающихся на материнской плате и плате расширения.
Структура компьютера — это некоторая модель, устанавливающая состав, порядок и принципы взаимодействия входящих в нее компонентов
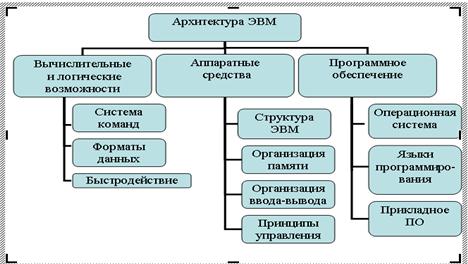
Рисунок 3 – архитектура ЭВМ.
В настоящее время наибольшее распространение в ЭВМ получили 2 типа архитектуры: Принстонская (фон Неймана) и Гарвардская. Обе они выделяют 2 основных узла ЭВМ: центральный процессор и память компьютера. Различие заключается в структуре памяти: в принстонской архитектуре программы и данные хранятся в одном массиве памяти и передаются в процессор по одному каналу, тогда как гарвардская архитектура предусматривает отдельные хранилища и потоки передачи для команд и данных.
Согласно Джону фон Нейману, любая ЭВМ должна включать четыре основных блока - процессор, оперативную память, внешнюю память и комплекс устройств ввода-вывода
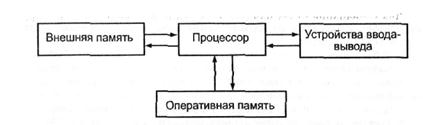
Рисунок 4 – Структурная схема ЭВМ
Эта схема, широко использовавшаяся в первых вычислительных машинах, имела один существенный недостаток: управление вводом-выводом и выполнение команд осуществлялось одним устройством управления. При такой структуре ЭВМ все виды программной обработки на время выполнения операций ввода-вывода прекращались из-за занятости процессора, что существенно снижало быстродействие машины.
Для устранения этого недостатка в схему был включен дополнительный компонент - канал ввода-вывода (устройство, обеспечивающее прямое взаимодействие процессора и периферийных устройств).
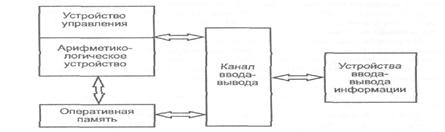
Гарвардская архитектура — архитектура ЭВМ, отличительным признаком которой является раздельное хранение и обработка команд и данных. Архитектура была разработана Говардом Эйкеном в конце 1930-х годов в Гарвардском университете
Типичные операции (сложение и умножение) требуют от любого вычислительного устройства нескольких действий: выборку двух операндов, выбор инструкции и её выполнение, и, наконец, сохранение результата.
Идея, реализованная Эйкеном, заключалась в физическом разделении линий передачи команд и данных. В первом компьютере Эйкена «Марк I» для хранения инструкций использовалась перфорированная лента, а для работы с данными — электромеханические регистры. Это позволяло одновременно пересылать и обрабатывать команды и данные, благодаря чему значительно повышалось общее быстродействие.
В более подробное описание, определяющее конкретную архитектуру, также входят: структурная схема ЭВМ, средства и способы доступа к элементам этой структурной схемы, организация и разрядность интерфейсов ЭВМ, набор и доступность регистров, организация памяти и способы её адресации, набор и формат машинных команд процессора, способы представления и форматы данных, правила обработки прерываний.
По перечисленным признакам и их сочетаниям среди архитектур выделяют:
2. По особенностям набора регистров, формата команд и данных: CISC, RISC, VLIW;
3. По количеству центральных процессоров: однопроцессорные, многопроцессорные, суперскалярные; многопроцессорные по принципу взаимодействия с памятью: симметричные многопроцессорные (SMP), масcивно-параллельные (MPP), распределенные.
Большинство многопроцессорных систем сегодня используют архитектуру SMP.
SMP системы позволяют любому процессору работать над любой задачей независимо от того, где в памяти хранятся данные для этой задачи; с должной поддержкой операционной системы, SMP системы могут легко перемещать задачи между процессорами эффективно распределяя нагрузку. С другой стороны, память гораздо медленнее процессоров, которые к ней обращаются, даже однопроцессорным машинам приходится тратить значительное время на получение данных из памяти. В SMP только один процессор может обращаться к памяти в данный момент времени.
Массивно-параллельная архитектура (англ. Massive Parallel Processing, MPP) — класс архитектур параллельных вычислительных систем Особенность архитектуры состоит в том, что память физически разделена. Система строится из отдельных модулей, содержащих процессор, локальный банк операционной памяти, коммуникационные процессоры или сетевые адаптеры, иногда — жесткие диски и/или другие устройства ввода/вывода. Доступ к банку операционной памяти из данного модуля имеют только процессоры из этого же модуля. Модули соединяются специальными коммуникационными каналами. в отличие от SMP-систем, в машинах с раздельной памятью каждый процессор имеет доступ только к своей локальной памяти, в связи с чем не возникает необходимости в потактовой синхронизации процессоров.

Распределённые вычисления, метакомпьютинг (англ. grid — сеть) - способ решения трудоёмких вычислительных задач с использованием нескольких компьютеров, объединённых в параллельную вычислительную систему (одновременное решения различных частей одной вычислительной задачи несколькими процессорами (или ядрами одного процессора) одного или нескольких компьютеров)
В суперскалярных процессорах также есть несколько вычислительных модулей, но задача распределения между ними работы решается аппаратно. Это сильно усложняет дизайн процессора, и может быть чревато ошибками. В процессорах VLIW задача распределения решается во время компиляции и в инструкциях явно указано, какое вычислительное устройство должно выполнять какую команду.
Суперскалярность — архитектура вычислительного ядра, использующая несколько декодеров команд, которые могут нагружать работой множество исполнительных блоков. Планирование исполнения потока команд является динамическим и осуществляется самим вычислительным ядром. Если в процессе работы команды, обрабатываемые конвейером, не противоречат друг другу, и одна не зависит от результата другой, то такое устройство может осуществить параллельное выполнение команд. В суперскалярных системах решение о запуске инструкции на исполнение принимает сам вычислительный модуль, что требует много ресурсов
Архитектура фон Неймана

Особенностью таких архитектур была общая шина данных и инструкций. Большинство современных архитектур это программный фон Нейман, однако никто не запрещает делать аппаратный Гарвард. У данной архитектуры большим недостатком является большое зависимости производительности процессора от шины. (Что ограничивает общую производительность процессора).
Masked Execution
Данный режим отличается от классических тем, что инструкции исполняются последовательно без использования прыжков. В инструкции хранится некоторое количество информации о том при каких условия эта инструкция будет исполнена и если условие не соблюдено то инструкция пропускается.
Ответ прост! Что бы не нагружать шину инструкций. Например в видеокартах можно загрузить тысячи ядер одной инструкцией. А если бы использовалась система прыжков то пришлось бы для каждого ядра ждать инструкцию из медленной памяти. Кеш частично решает проблему, но все еще не решает проблему полностью.
Здесь мы будем описывать несколько техник используемых в центральный процессорах и микроконтроллерах.
OISC (URISC)?
One Instruction Set Computer — Архитектура с единственной инструкцией. Например SUBLEQ. Такие архитектуры часто имеют вид: Сделать действие и в зависимости от результата сделать прыжок или продолжить исполнение. Зачастую ее реализация достаточно простая, производительность маленькая, при этом снова ограничение шиной данных.
Яркие примеры: BitBitJump, ByteByteJump, SUBLEQ тысячи их!
CISC — Complex Instruction Set Computer — ее особенность в увеличенных количествах действий за инструкцию. Таким образом можно было теоретически увеличить производительность программ за счет увеличения сложности компилятора. Но по факту у CISC плохо были реализованы некоторые инструкции т.к. они редко использовались, и повышение производительности не было достигнуто. Особенностью этой группы является еще ОГРОМНАЯ Разница между архитектурами. И несмотря на названия были архитектуры с маленьким количеством инструкций.
Яркие примеры: x86, M68K
Exception (исключения)
Но кроме прерываний еще существуют исключений которые возникают например при деления на ноль. Зачастую его совмещают с прерываниями и системными вызовами, как например в MIPS. Исключения не всегда присутствуют в процессоре например как в AVR или младших PIC
Расширение существующих архитектур
Достаточно популярной техникой является добавление в уже существующую архитектуру больше инструкций через расширения. Ярким примером является SSE под x86. Этим же грешит ARM и MIPS и практически все. Почему? Потому что нельзя создать унивирсальную архитектуру.
Другим вариантом является использование других архитектур для уменьшения размера инструкций.
Яркий пример: ARM со своим Thumb, MIPS с MIPS16.
В видеокартах часто встречается много ядер и из-за этой особенности появилась потребность в дополнительных решениях. Если конвейеры можно встретить даже в микроконтроллерах то решения используемых в GPU встречаются редко. Например Masked Execution (Встречается в инструкциях ARM, но не в Thumb-I/II). Еще есть другие особенность: это уклон в сторону Floating Number (Числа с плавающей запятой), Уменьшение производительности в противовес большего количества ядер и т.д.
Читайте также:
- Оперативная память обеспечивает запуск компьютера или нет
- Asus m3a78 pro какой процессор поставить
- Сравнение процессоров intel core i7 9750h и amd ryzen 5 4600h
- Как разогнать процессор intel core 2 quad q9500
- По каким признакам текстовый процессор видит что строка должна быть помещена в автособираемое