
Linux проверка smart диска
Жёсткие диски имеют встроенный диагностический инструмент SMART (Self-Monitoring, Analysis, and Reporting Technology), постоянно проверяющий диск на наличие потенциальных проблем. SMART предупредит вас в случае возможности выхода диска из строя, чтобы помочь избежать потери важных данных.
Although SMART runs automatically, you can also check your disk’s health by running the Disks application:
Выводы
В этой статье мы рассмотрели как выполняется проверка диска на битые секторы Linux, чтобы вовремя предусмотреть возможные сбои и не потерять данные. Но на битых секторах проблемы с диском не заканчиваются. Там есть множество параметров стабильности работы, которые можно отслеживать с помощью таблицы SMART. Читайте об этом в статье Проверка диска в Linux.
Дополнительная информация
- Диски и другие устройства хранения информации — Check on disk space and control how disk space is allocated and used.
You can choose the displayed language by adding a language suffix to the web address so it ends with e.g. .html.en or .html.de.
If the web address has no language suffix, the preferred language specified in your web browser's settings is used. For your convenience:
[ Change to English Language | Change to Browser's Preferred Language ]
The material in this document is available under a free license, see Legal for details.
For information on contributing see the Ubuntu Documentation Team wiki page. To report errors in this documentation, file a bug.
Одно из самых важных устройств компьютера - это жесткий диск, именно на нём хранится операционная система и вся ваша информация. Единица хранения информации на жестком диске - сектор или блок. Это одна ячейка в которую записывается определённое количество информации, обычно это 512 или 1024 байт.
Битые сектора, это повреждённые ячейки, которые больше не работают по каким либо причинам. Но файловая система всё ещё может пытаться записать в них данные. Прочитать данные из таких секторов очень сложно, поэтому вы можете их потерять. Новые диски SSD уже не подвержены этой проблеме, потому что там существует специальный контроллер, следящий за работоспособностью ячеек и перемещающий данные из нерабочих в рабочие. Однако традиционные жесткие диски используются всё ещё очень часто. В этой статье мы рассмотрим как проверить диск на битые секторы Linux.
Заключение
Определенно, S.M.A.R.T. – это именно та технология, которую стоит добавить в свой инструментарий для мониторинга работоспособности дисков ваших серверов. Вам также стоит взглянуть на S.M.A.R.T. Disk Monitoring Daemon smartd(8), который может помочь вам автоматизировать мониторинг с помощью отчетов системного журнала.
Учитывая статистическую природу прогнозирования сбоев, я не уверен, что агрессивный S.M.A.R.T. мониторинг будет сильно полезен на персональных компьютерах. Помните, что каким бы ни был накопитель, однажды он все равно выйдет из строя – и, как мы видели ранее, в одной трети случаев он сделает это без предупреждения. Поэтому ничто не обеспечит целостность ваших данных лучше, чем RAID технология и резервные копии!
Привет, Хабр! Любой, кто хоть раз сталкивался с неожиданной смертью флешки, жесткого диска или SSD-накопителя, расскажет вам, насколько важно отслеживать SMART-параметры и замерять скорость в бенчмарках. Независимо от системы. И если с Windows достаточно вбить в поиске CrystalMark, то пользователям Linux подобный лайфхак не подойдет. Зато подойдет этот текст, где вся история пропитана поисками.

Понимание выходных данных команд smartctl
На выходе получается много информации, которую не всегда легко понять. Наиболее интересной, вероятно, является та часть, которая помечена как “Vendor Specific SMART Attributes with Thresholds”. Она сообщает различные статистические данные, собранные S.M.A.R.T. устройством, и позволяет сравнить эти значения (текущие или худшие за все время) с некоторым порогом, определенным поставщиком.
Например, вот мои отчеты о переназначенных секторах на диске:
Вы можете заметить атрибут «Pre-fail». Он означает, что значение является аномальным. Таким образом, если значение превышает пороговое, велика вероятность сбоя. Другая категория »Old_age" используется для атрибутов, отвечающих значениям «нормального износа».
Последнее поле (здесь со значением «3») соответствует исходному значению атрибута, которое сообщает диск. Обычно это число имеет физическое значение. Здесь это фактическое количество переназначенных секторов. Для других атрибутов это может быть температура в градусах Цельсия, время в часах или минутах или количество раз, когда для диска было выполнено определенное условие.
В дополнение к исходному значению, диск с поддержкой S.M.A.R.T. должен сообщать «нормализованные значения» (значения полей, самые худшие и пороговые). Эти значения нормируются в диапазоне 1-254 (0-255 для пороговых значений). Прошивка диска выполняет эту нормализацию с помощью некоторого внутреннего алгоритма. Кроме того, разные производители могут нормализовать один и тот же атрибут по-разному. Большинство значений представлены в процентах, причем чем выше, тем лучше, но так бывает не всегда. Когда параметр ниже или равен пороговому значению, указанному производителем, диск считается неисправным в терминах этого атрибута. Помня о всех указаниях из первой части статьи, когда атрибут, показывающий ранее значение “pre-fail” все-таки дал сбой, наиболее вероятно, что скоро диск выйдет из строя.
В качестве второго примера возьмем “seek error rate”:
На самом деле (и это основная проблема отчетности S.M.A.R.T.), точное значение полей каждого атрибута понимает только поставщик. В моем случае Seagate использует логарифмическую шкалу для нормализации значения. Таким образом, «71» означает примерно одну ошибку на 10 миллионов запросов (10 в степени 7,1). Забавно, что самым худшим показателем за все время была одна ошибка на 1 миллион запросов (10 в 6-й степени).
Если я правильно понимаю, то это значит, что головки моего диска сейчас расположены точнее, чем раньше. Я не следил за этим диском внимательно, поэтому анализирую полученные данные весьма субъективно. Возможно накопитель просто надо было немного «обкатать» с тех пор как он был введен в эксплуатацию? Или может быть это следствие механического износа деталей и, следовательно, теперь имеет место меньшая сила трения? В любом случае, какова бы ни была причина, это значение является скорее показателем производительности, чем ранним предупреждением об ошибке. Так что меня оно не сильно беспокоит.
Помимо вышеприведенного и трех крайне подозрительных ошибок, записанных около шести месяцев назад, этот диск находится в удивительно хорошем состоянии (по данным S.M.A.R.T.) для стокового диска ноутбука, проработавшего более 1100 дней (26423 часа).
Из любопытства я провел этот же тест на гораздо более новом ноутбуке, оснащенном SSD:
Первое, что бросается в глаза, так это то, что несмотря на наличие S.M.A.R.T., устройства нет в базе данных smartctl . Но это не помешает инструменту собирать данные с SSD, однако он не сможет сообщить точные значения различных атрибутов, специфичных для поставщика:
Выше вы видите выходные данные абсолютно нового SSD. Данные понятны даже в случае отсутствия нормализации или метаинформации для данных конкретного поставщика, как в моем случае с “Unknown_SSD_Attribute.” Я могу только надеяться, что в последующих версиях smartctl в базе данных появятся данные об этой модели диска, и я смогу лучше определять потенциальные проблемы.
Check your disk’s health using the Disks application
Откройте Обзор и откройте приложение Диски .
Select the disk you want to check from the list of storage devices on the left. Information and status of the disk will be shown.
Click the menu button and select SMART Data & Self-Tests… . The Overall Assessment should say “Disk is OK”.
See more information under SMART Attributes , or click the Start Self-test button to run a self-test.
Проверьте свой SSD в Linux с помощью smartctl
До сих пор мы рассматривали данные, собранные во время нормальной работы накопителя. Однако протокол S.M.A.R.T. также поддерживает несколько команд для автономного тестирования для запуска диагностики по требованию.
Автономное тестирование может проводиться во время обычных операций с диском, если не было указано иное. Поскольку тест и запросы ввода-вывода хоста будут конкурировать, производительность диска упадет на время теста. Спецификация S.M.A.R.T. определяет несколько видов автономного тестирования:
Короткое автономное тестирование ( -t short )
Такой тест проверит электрическую и механическую, производительность, а также производительность чтения диска. Короткое автономное тестирование обычно занимает всего несколько минут (обычно от 2 до 10).
Расширенное автономное тестирование ( -t long )
Этот тест занимает почти в два раза больше времени. Как правило, это просто более детальная версия короткого автономного тестирования. Кроме того, этот тест будет сканировать всю поверхность диска на наличие ошибок данных без ограничения по времени. Продолжительность теста будет пропорциональна размеру диска.
Транспортировочное автономное тестирование ( -t conveyance )
Этот тестовый набор предложен в качестве сравнительно быстрого способа проверки на возможные повреждения, возникшие во время транспортировки устройства.
Вот примеры, взятые с тех же дисков, что были выше. Я предлагаю вам угадать, где какой:
Сейчас производится проверка. Давайте дождемся завершения, чтобы посмотреть результат:
Проведем тот же тест на другом диске:
И еще раз, отправим в сон на две минуты и посмотрим результат:
Интересно, что в этом случае мы видим, что производители диска и компьютера, похоже, уже тестировали диск (на времени жизни в 0 часов и 12 часов). Я сам определенно был гораздо менее озабочен состоянием диска, чем они. Итак, поскольку я уже показал быстрые тесты, то и расширенный тоже запущу, чтобы посмотреть как это происходит.
Судя по всему на этот раз ждать придется гораздо дольше, чем при проведении короткого теста. Так что давайте посмотрим:
В последнем тесте обратите внимание на различие в результатах, полученных с помощью короткого и расширенного теста, даже если они были выполнены один за другим. Ну, возможно, этот диск не в таком уж и хорошем состоянии! Отмечу, что тест остановился после первой ошибки чтения. Поэтому, если вы хотите получить исчерпывающую информацию обо всех ошибках чтения, вам придется продолжать тест после каждой ошибки. Я призываю вас взглянуть на одну очень хорошо написанную страницу руководства smartctl(8) для получения дополнительной информации о параметрах -t select , N-max и -t select , чтобы уметь делать так:
Что не относится к S.M.A.R.T.?
Все это, конечно, круто. Однако S.M.A.R.T. – это не хрустальный шар. Он не может спрогнозировать отказ со стопроцентной вероятностью и не может гарантировать, что накопитель не выйдет из строя без предупреждения. В лучшем случае S.M.A.R.T. стоит использовать для оценки вероятности поломки.
Учитывая статистический характер прогнозирования отказов, технология S.M.A.R.T. особенно интересует компании, использующие большое количество устройств для хранения данных. Чтобы выяснить, насколько точно S.M.A.R.T. может прогнозировать отказы и сообщать о необходимости замены дисков в центрах обработки данных или серверных мейнфреймах, даже проводились специальные исследования.
В 2016 году Microsoft и университет штата Пенсильвания провели исследование, связанное с SSD.
Согласно этому исследованию, некоторые атрибуты S.M.A.R.T. считаются хорошими индикаторами неизбежности отказа. В особенности в статье упоминаются:
Счетчик переназначенных (Realloc) секторов:
Несмотря на то, что основополагающие технологии радикально отличаются, этот показатель остается востребованным как в мире SSD, так и в мире жестких дисков. Стоит отметить, что из-за особенностей алгоритмов балансировки износа, используемых в SSD, когда несколько секторов выходят из строя, то с большой вероятностью можно предположить, что скоро выйдут из строя еще больше.
Ошибки в цикле Program/Erase (P/E):
Это признак проблем с основным оборудованием флеш-памяти, связанных с тем, что диск не может удалить данные из блока или сохранить их там. Дело в том, что процесс производства несовершенен, поэтому появление таких ошибок вполне можно ожидать. Однако флеш-память имеет ограниченное число циклов записи/удаления. По этой причине внезапное увеличение числа событий может сигнализировать о том, что диск достигает своего предела, и вполне ожидаемо, что другие ячейки памяти также начнут выходить из строя.
CRC и неисправимые ошибки («Data Error ”):
События такого типа могут быть вызваны ошибками хранения, либо проблемами с внутренним каналом связи накопителя. Этот индикатор учитывает как исправленные ошибки (без проблем сообщенные хост-системе), так и неисправленные ошибки (из-за которых происходит блокировка диска, сообщившего хост-системе о невозможности чтения). Другими словами, исправляемые ошибки невидимы для операционной системы, тем не менее они влияют на производительность накопителя, увеличивая вероятность переназначения сектора.
SATA downshift count:
Из-за временных помех, проблем с каналом связи между накопителем и хостом или из-за внутренних проблем с накопителем, интерфейс SATA может переключиться на более низкую скорость передачи сигналов. Снижение скорости соединения ниже номинального уровня оказывает очевидное влияние на производительность диска. Таким образом, этот показатель является наиболее значимым, в особенности, когда он коррелирует с наличием одного или нескольких предыдущих показателей.
В исследовании Microsoft и университета штата Пенсильвания не раскрывались модели исследуемых дисков, однако, по словам авторов, большинство дисков поступают от одного и того же поставщика в течение уже нескольких поколений.
В ходе исследования также были отмечены значительные различия в надёжности между различными моделями. Например, «худшая» изученная модель показывает двадцатипроцентную частоту отказов через 9 месяцев после первой ошибки переназначения и до 36-ти процентов отказов в течение 9 месяцев после первого появления ошибок данных. «Худшей» моделью было названо более старое поколение дисков, рассматриваемых в статье.
С другой стороны, с теми же симптомами, что приведены выше, накопители нового поколения отказали в 3% и 20% в соответствии с теми же ошибками. Трудно сказать, можно ли объяснить эти цифры улучшением конструкции накопителя и производственного процесса, или здесь роль играет эффект устаревания накопителя.
«Существует большая вероятность появления симптомов, предшествующих отказу SSD, которые активно себя проявляют и быстро прогрессируют, сильно сокращая время жизни накопителя до нескольких месяцев.»
Другими словами, одна случайная ошибка, о которой сообщил S.M.A.R.T., определенно не должна рассматриваться как сигнал о неизбежном отказе. Однако, когда исправный SSD начинает сообщать о все большем количестве ошибок, следует ждать краткосрочного или среднесрочного сбоя.
Но как узнать, в каком состоянии сейчас ваш SSD? Для удовлетворения своего любопытства, либо из желания начать внимательно следить за своими накопителями, вы можете использовать инструмент мониторинга smartctl .
Бенчмарк и просмотр S.M.A.R.T. на Ubuntu
Классическая проверка жестких дисков и просмотр параметров S.M.A.R.T. в Ubuntu выполняются через терминал, с использованием Smartmontools. Ровно тем же инструментарием SmartCtl можно проверить данные с диска, не вводя команды в терминале. Для этого достаточно установить графическое приложение GSmartControl, находящееся в свободном доступе на популярных репозиториях.


Зато при подключении SSD-диска 3-х летней давности, в меню приложения GSmartControl вся информация из S.M.A.R.T. доступна буквально парой кликов. Тут и актуальная температура, и счетчик исполнений циклов, и общее время работы. Подробнее о значениях каждого из параметров можно прочитать в постах у хабровчан, вбив аббревиатуру в поиск.

Сразу вопрос: а почему свежий NVMe–накопитель Kingston A2000 не распознается приложением GSmartControl? И главное, почему установленный через терминал Smartmontools выдает ту же ошибку доступа к данным самодиагностики?
Оцените статью:
Об авторе
13 комментариев
Для любителей гуя есть gsmartcontrol
Какие нахрен битые сектора. в каком веке живете? Или вы про Self тест?
А в каком веке перестали сыпаться ХДД?
Если ты настолько туп что не понимаешь что такое бэд блоки, то какого хрена ты вообще тут пишешь
Ты будешь очень удивлен, когда узнаешь, что битые сектора еще на стадии производства жестких дисков появляются. Причина этого: несовершенство технологии производство, как бы не парадоксально это звучало. По этой же причине с одной матрицы, на которой выращивают процессора получают как сверхвысокопроизводительные процессора с высокой стоимостью, так и самые дешевые целерончики. Так вот, те битые сектора, которые определяют еще на производстве помечают и заносят в специальный список. который хранится, в зависимости от производителя харда или в специальном разделе, или во флешпамяти или там и там. Наличие заводских бэдов подтверждает график чтения диска. Его можно увидеть прогнав новый диск (из заводской упаковки) какой нибудь утилитой типа Виктории или МХДД. Провалы в графике чтения, который представляет собой логарифмическую кривую это и есть подтверждение наличия заводских сбойных секторов: то есть на этих областях головка харда переходит по указанному адресу. То есть там алгоритм такой: головка доходит до нужного адреса на диске: считывает с него инфу, и если видит что-то подобное: этот блок сбойный, если вы хотите что-то записать, то вместо него работает вооон тот блок, расположенный воооон там.
э
Уважаемый автор, что-то я не понял про "просто" fsck. У него параметром "-l" не подставляется файл от "badblocks" с перечнем битых секторов, а выполняется совсем другая операция.
Может подскажете что теперь делать в этом случае? Т. е. например у меня флэшка битая и файловая система там не ext, и в наличии только консоль.
И снова здравствуйте. Перевод следующей статьи подготовлен специально для студентов курса «Администратор Linux». Поехали!

Что такое S.M.A.R.T.?
S.M.A.R.T. (расшифровывается как Self-Monitoring, Analysis, and Reporting Technology) – это технология, вшитая в накопители, такие как жесткие диски или SSD. Ее основная задача – это мониторинг состояния.
На деле, S.M.A.R.T. контролирует несколько параметров во время обычной работы с диском. Он мониторит такие параметры как количество ошибок чтения, время запуска диска и даже состояние окружающей среды. Помимо этого, S.M.A.R.T. также может проводить тесты с использованием накопителя.
В идеале, S.M.A.R.T. позволит прогнозировать предсказуемые отказы, такие как отказы, вызванные механическим износом или ухудшением состояния поверхности диска, а также непредсказуемые отказы, вызванные каким-либо неожиданным дефектом. Поскольку обычно диски не выходят из строя внезапно, S.M.A.R.T. помогает операционной системе или системному администратору идентифицировать те диски, которые скоро выйдут из строя, чтобы их можно было заменить и избежать потери данных.
Получится у Linux прочитать S.M.A.R.T.–параметры диска Kingston A400?
Момент установки был волнителен как никогда. Прежде чем было принято решение брать другой диск для проверки, были испробованы различные команды в терминале и бесчисленные попытки обновления софта. Порой казалось, что вот сейчас все получится, но результата не удавалось достичь. Надежды на успех были минимальны.

Ура, победа! Твердотельный накопитель Kingston A400 распознается без каких-либо ограничений и все данные самодиагностики S.M.A.R.T. доступны в полном объеме. Значения ошибок и температура доступна к просмотру, причем и в классическом приложении Диски. Там же можно запустить бенчмарк чтения и записи, с ручным выставлением параметров объема ячейки и количества операций. В сочетании с GsmartControl получается удобное средство для контроля производительности дисковой подсистемы, в частности температурного.

В случае с твердотельным накопителем Kingston A400 емкостью 480 ГБ, пиковые значения температуры, по данным приложения GSmatControl, не превышали 60 °С. Результат действительно интересный. Согласно ему, выходит, что системный Kingston A400 выглядит предпочтительнее для Linux, как раз благодаря низкому тепловыделению. NVMe–накопитель грелся в Windows до 70-ти градусов и лучше использовать его с операционкой Microsoft.

Что интересно, за пару месяцев подготовки этого материала, не только разрушились надежды обнаружить с обновлением драйвера и поддержку Kingston A2000 в Linux, но и потерял свою актуальность дистрибутив из репозиториев Fedora для утилиты KDiskMark. Еще в феврале-марте никаких проблем с его установкой из штатного магазина не возникало, а теперь увы.

А жаль, ведь результаты записи в этом бенчмарке гораздо адекватнее значений, выводимых штатными “Дисками”, независимо от введенных значений. Запись упорно держится в районе 300 МБ/с, хотя визуально предпосылок к обрезанной скорости нет.
Check your disk’s health using the Disks application
Откройте Обзор и откройте приложение Диски .
Select the disk you want to check from the list of storage devices on the left. Information and status of the disk will be shown.
Click the menu button and select SMART Data & Self-Tests… . The Overall Assessment should say “Disk is OK”.
See more information under SMART Attributes , or click the Start Self-test button to run a self-test.
Почему память не вечна?
Углубляться в физику производства чипов памяти и объем работ по литографии — удел отдельных энциклопедических записей. Нам достаточно вспомнить, как сильно нагревались некоторые металлические USB-флешки при записи больших архивов. Это было горячо, но многие твердотельные накопители работают без остановки, при температурах свыше 70°С. Ожидать, что такая нагрузка не скажется на долговечности SSD–накопителя, весьма опрометчиво.
За реальным примером износа далеко идти не нужно. В работающем 24/7 ноутбуке, заводской конфиг изначально включал лишь медленный жесткий диск. Пустой M.2 слот был заполнен самым доступным SSD на 240 Гигов, исправно служащим и по сей день в роли системного. С момента покупки прошло уже два года, а по данным CrystalDiskInfo остаток ресурса составляет всего 87%.
По ошибкам – критических значений пока не выявлено, но куда интереснее информация, полученная при запущенном фоном бенчмарке CrystalDiskMark. Результаты измерения скорости при стандартных значениях ячеек и объема данных вполне соответствуют SATA-SSD. Но температура платы достигала 70°С в пиковые моменты, что много для чипов памяти. Тем более, этот M.2–накопитель установлен в адаптере под слот форм-фактора 2.5”.
На скриншоте температуры системного диска вы могли заметить второй, существенно более холодный носитель. Это представитель бюджетной линейки NVMe PCIe SSD-накопителей в форм-факторе M.2, поддерживающий до 4-х линий по шине PCIe Gen 3.0. Всего в линейке есть три разновидности по объему: 250, 500 и 1000 ГБ, но младшая ограничена по скорости чтения и записи. Поэтому выгоднее брать одну из старших, как 500 ГБ модификацию в данном случае. Кстати, а как она себя проявит под нагрузкой?

До 60°С Kingston A2000 подобрался буквально пару раз при выполнении тестов на чтение. А вот запись сумела разогреть его до 69°С без особых проблем. Со второго прогона, выставив размер файла 0.5 ГБ, диск показал практически паспорт. Этот M.2-накопитель приобретался как раз для переноса на него системы Windows, но прежде стало интересно взглянуть, какие ощущения подарит работа операционной системы на быстром 2-х гигабайтном NVMe–накопителе, и насколько велика окажется разница в сравнении с диском SATA.
А для этого на свежий Kingston A2000 была установлена актуальная версия Ubuntu, скачанная с официального сайта и смонтированная на USB–флешку.

What if the disk isn’t healthy?
Even if the Overall Assessment indicates that the disk isn’t healthy, there may be no cause for alarm. However, it’s better to be prepared with a backup to prevent data loss.
If the status says “Pre-fail”, the disk is still reasonably healthy but signs of wear have been detected which mean it might fail in the near future. If your hard disk (or computer) is a few years old, you are likely to see this message on at least some of the health checks. You should backup your important files regularly and check the disk status periodically to see if it gets worse.
Если состояние ухудшается, возможно, стоит показать компьютер или диск профессионалу для дальнейшей диагностики или ремонта.
О параметрах S.M.A.R.T.
Сама аббревиатура S.M.A.R.T. литературно расшифровывается как система контроля и самодиагностики диска. Она выполняется контроллером памяти, который нередко указывается в спецификациях SSD–диска. Одна из задач контроллера в распределении нагрузки на ячейки памяти, для равномерного заполнения ресурса по операциям записи. А вообще причина в том, что жесткие диски и твердотельные накопители смертны.
Причем “смертны неожиданно”, если цитировать Воланда. Но так было раньше, до появления стандартизированных инструментов самодиагностики S.M.A.R.T., без которых трудно представить современную диагностику и прогнозирование износа оборудования. В пакет собираемой информации входят ошибки по чтению и записи на каждый блок, и еще около полусотни параметров, названных атрибутами.
Именно атрибуты S.M.A.R.T. позволяют утилите CrystalDiskInfo выводить остаток ресурса, температуру, общее число записанных на диск данных, а также суммарную наработку по часам. Для Ubuntu этот софт не выпускается, но владельцам компьютеров под управлением данной системы он и не требуется.
Проблема в Ubuntu или диске?
В нашем случае, для Ubuntu актуальная версия Smartmontools датирована версией 7.1 из конца 2019 года. Под Windows и Linux, типа Fedora, доступна версия 7.2 от конца октября 2020 года. Но причина оказалась даже не в этом, а в отсутствии информации об SSD–диске Kingston A2000 в самой свежей версии базы драйверов под Linux-системы.
Для проверки, та же операция по обновлению базы была проведена на свежем дистрибутиве Fedora 33. В таблице релизов Smartmontools для этой системы заявлена актуальная версия приложения 7.2. А ручное обновление базы дисков, используемое GsmartTools, также выполняется через терминал, вводом команды: sudo/usr/sbin/update-smart-drivedb
Результат ожидаемо не привел к положительному результату. С одной стороны, разработчиков можно понять, но пользоваться хочется современным SSD–накопителем, не привязывая себя к определенной операционной системе. А в случае с Linux остается только попробовать другую актуальную модель из доступной линейки дисков: модель Kingston A400. Этот SATA-SSD выполнен в форм-факторе 2.5”, так что есть шанс узнать еще и данные по температуре у подобного твердотельника.

Использование smartctl для мониторинга состояния вашего SSD в Linux
Чтобы следить за S.M.A.R.T статусом вашего диска, я предлагаю использовать инструмент smartctl , который является частью пакета smartmontool (по крайней мере на Debian/Ubuntu).
smartctl – это инструмент командной строки, но это особенно помогает в случаях, когда вам нужно автоматизировать сбор данных, например, с ваших серверов.
Первый шаг в использовании smartctl – это проверка того, есть ли на вашем диске S.M.A.R.T. и поддерживается ли он инструментом:
Как видите, мой внутренний жесткий диск ноутбука действительно поддерживает S.M.A.R.T. и он включен. Итак, как теперь получить S.M.A.R.T статус? Есть ли какие-то зафиксированные ошибки?
Выдача отчета «о всей S.M.A.R.T. информации о диске» — это опция -a :
Какие итоги мы смогли вынести из увиденного?
Первый и самый очевидный вывод, по итогам поиска утилит мониторинга твердотельных дисков на Linux, оказался довольно очевиден: для новинок железа и подробного тестирования куда лучше подходит Windows. Операционка от Microsoft хорошо заточена под обновление драйверов отдельных компонентов, на нее ориентируются производители игрового железа и даже среди дисковых утилит там есть, из чего выбрать.
С Linux-системами все несколько сложнее. Там меньше конкуренция и ниже фокус внимания разработчиков софта. В нашей конкретной ситуации два SSD-накопителя, выпущенные в схожее время, проявили себя по-разному. Модель A400 распознается системами Ubuntu и Fedora, в утилитах Диски и GSmartControl доступен полный отчет по S.M.A.R.T. – параметрам, а вот модель A2000 так и не получила системных драйверов на апрель 2021 года. Узнать, как проявит себя ваш SSD-накопитель на актуальной сборке, получится лишь на практике. С другой стороны, даже SATA-SSD A400 хватает для быстрой и комфортной работы в качестве системного диска, а ощутить разницу с NVMe в прикладных задачах не так и просто.
Но объективная оценка и субъективное восприятие скорости работы системы и отдельных приложений – это тема отдельного материала. Например, сравнения Windows и Linux по части требовательности к ресурсам аппаратных компонентов и более внимательным сравнением нагрузки на дисковую подсистему. А заодно можно будет сравнить важность системных драйверов для SSD и их влияние на итоговые результаты. Подопытные для наших тестов уже под рукой, о результатах расскажем совсем скоро.

Что такое KIWY? Kingston Is With You — Kingston всегда с вами.
Продукция, решения и технологии Kingston широко применяются и используются по всему миру корпорациями, центрами обработки данных и обычными людьми каждый день – от авиации и космических станций до смартфонов, ПК и фоторамок. Самые неожиданные сферы использования решений Kingston узнайте тут.
Для получения дополнительной информации о продуктах Kingston обращайтесь на официальный сайт компании.
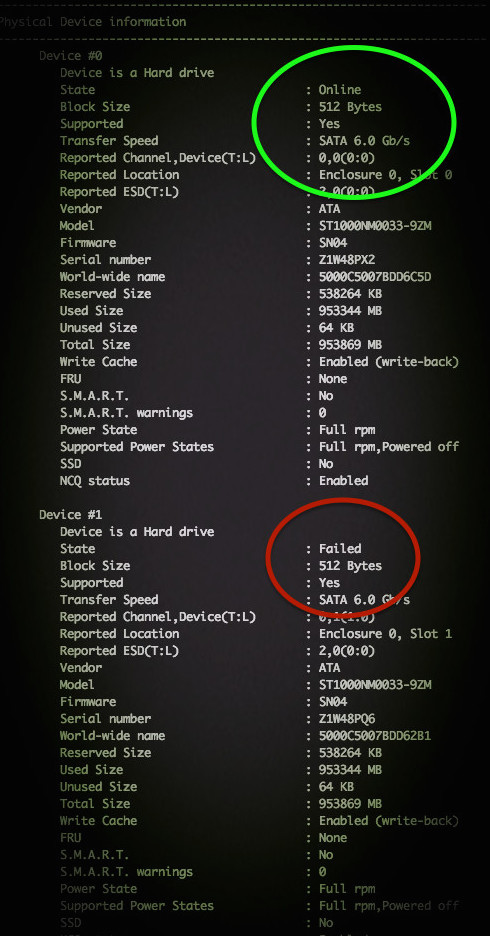
Команду «smartctl -d ata -a /dev/sdb» можно использовать для проверки жесткого диска и текущего состояния его соединения с системой. Но как с помощью команд smartctl проверить SAS или SCSI диски, спрятанные за RAID контроллером Adaptec в системах под управлением Linux ОС? Для этого необходимо использовать последовательные синтаксисы проверки SAS или SATA. Как правило — это логические диски для каждого массива физических накопителей в операционной системы. Команду /dev/sgX возможно использовать в качестве перехода через контроллеры ввода/вывода, которые обеспечиваюь прямой доступ к каждому физическому диску, подключенному к RAID контроллеру Adaptec.

Распознает ли Linux контроллер Adaptec RAID?
Для проверки Вы можете использовать следующую команду:
В результате выполнения команды получите следующее:
Загрузка и установка Adaptec Storage Manager для Linux
Необходимо установить Adaptec Storage Manager в соответсвии собранному дисковому массиву.
Проверяем состояния SATA диска
Команда для сканирования накопителя выглядит довольно просто:
В результате у Вас должно получится следующее:
Таким образом, /dev/sda — это одно устройство, которое было определено как SCSI устройство. Выходит, что у нас SCSI собран из 4 дисков, расположенных в /dev/sg . Введите следующую smartclt команду, чтобы проверить диск позади массива /dev/sda:
Контроллер должен сообщать о состоянии накопителя и уведомлять про ошибки (если такие имеются):
Для SAS диск используют следующий синтаксис:
В результате получим что то похожее на:
А вот команда для проверки следующего диска с интерфейсом SAS, названного /dev/sg2:
В /dev/sg1 заменяется номер диска. Например, если это RAID10 из 4-х дисков, то будет выглядеть так:
Проверить жесткий диск можно с помощью следующих команд:
Использование Adaptec Storage Manager
Другие простые команды для проверки базового состояния выглядят следующим образом:
Обратите внимание на то, что более новая версия arcconf расположена в архиве /usr/Adaptec_Event_Monitor. Таким образом, весь путь должен выглядеть так:
Вы можете самостоятельно проверить состояние массива Adaptec RAID на Linux с помощью ввода простой команды:
Или (более поздняя версия):
Примерный результат на фото:
По традиции, немного рекламы в подвале, где она никому не помешает. Напоминаем, что в связи с тем, что общая емкость сети нидерландского дата-центра, в котором мы предоставляем услуги, достигла значения 5 Тбит / с (58 точек присутствия, включения в 36 точек обмена, более, чем в 20 странах и 4213 пиринговых включений), мы предлагаем выделенные серверы в аренду по невероятно низким ценам, только неделю!.
Проверка диска на битые секторы Linux
Для поиска битых секторов можно использовать утилиту badblocks. Если вам надо проверить корневой или домашний раздел диска, то лучше загрузится в LiveCD, чтобы файловая система не была смонтирована. Все остальные разделы можно сканировать в вашей установленной системе. Вам может понадобиться посмотреть какие разделы есть на диске. Для этого можно воспользоваться командой fdisk:
sudo fdisk -l /dev/sda1

Или если вы предпочитаете использовать графический интерфейс, это можно сделать с помощью утилиты Gparted. Просто выберите нужный диск в выпадающем списке:

В этом примере я хочу проверить раздел /dev/sda2 с файловой системой XFS. Как я уже говорил, для этого используется команда badblocks. Синтаксис у неё довольно простой:
$ sudo badblocks опции /dev/имя_раздела_диска
Давайте рассмотрим опции программы, которые вам могут понадобится:
- -e - позволяет указать количество битых блоков, после достижения которого дальше продолжать тест не надо;
- -f - по умолчанию утилита пропускает тест с помощью чтения/записи если файловая система смонтирована чтобы её не повредить, эта опция позволяет всё таки выполнять эти тесты даже для смонтированных систем;
- -i - позволяет передать список ранее найденных битых секторов, чтобы не проверять их снова;
- -n - использовать безопасный тест чтения и записи, во время этого теста данные не стираются;
- -o - записать обнаруженные битые блоки в указанный файл;
- -p - количество проверок, по умолчанию только одна;
- -s - показывать прогресс сканирования раздела;
- -v - максимально подробный режим;
- -w - позволяет выполнить тест с помощью записи, на каждый блок записывается определённая последовательность байт, что стирает данные, которые хранились там раньше.
Таким образом, для обычной проверки используйте такую команду:
sudo badblocks -v /dev/sda2 -o ~/bad_sectors.txt
Это безопасно и её можно выполнять на файловой системе с данными, она ничего не повредит. В принципе, её даже можно выполнять на смонтированной файловой системе, хотя этого делать не рекомендуется. Если файловая система размонтирована, можно выполнить тест с записью с помощью опции -n:
sudo badblocks -vn /dev/sda2 -o ~/bad_sectors.txt
После завершения проверки, если были обнаружены битые блоки, надо сообщить о них файловой системе, чтобы она не пыталась писать туда данные. Для этого используйте утилиту fsck и опцию -l:
fsck -l ~/bad_sectors.txt /dev/sda1
Если на разделе используется файловая система семейства Ext, например Ext4, то для поиска битых блоков и автоматической регистрации их в файловой системе можно использовать команду e2fsck. Например:
sudo e2fsck -cfpv /dev/sda1
Параметр -с позволяет искать битые блоки и добавлять их в список, -f - проверяет файловую систему, -p - восстанавливает повреждённые данные, а -v выводит всё максимально подробно.
Читайте также: