
Как конструктивно выполнены современные процессоры
Существует общественное мнение, что процессор - мозг компьютера. Но как работает этот самый мозг, состоящий из миллиардов транзисторов? В этой небольшой серии статей (всего из четырех частей)портал Techspotрешил тщательно разобраться в том, что же заставляет работать ваше "железо".
В статьях будут затронуты такие темы, как принцип работы компьютерной архитектуры, дизайн микросхем процессоров, сверхбольшая масштабная интеграция (VLSI), создание чипов и грядущие тренды. Если вам всегда было интересно, как работают процессоры, то присаживайтесь прямо сейчас и наслаждайтесь чтением, потому что именно с этого и начнется данная статья.
Для началанужно понять, из чего состоит процессор, и как блоки соединяются в функциональное целое. Также будет затронута тема ядер процессоров, иерархии памяти, прогнозирования ветвлений и многого другого. Для начала, стоит дать базовое определение тому, что именно делает процессор. Если говорить простым языком, то процессор проводит операции над введенными командами, следуя конкретным инструкциям. Такой операцией может быть считывание значений из памяти, сложение этих значений, а затем сохранение их в другом отделе памяти. Или что-то более сложное - например, деление двух чисел, если результат предыдущего вычисления оказался выше нуля.
Любая программа, будь то операционная система или видеоигра, представляет собой набор инструкций, которые необходимо выполнить. Эти действия загружаются из памяти и запускаются по очереди, вплоть до окончания программы. Многие разработчики пишут программы на сложных языках программирования, например, C++ или Python, но стоит отметить, что процессор их попросту не понимает. Все, что он может - обработать нули и единицы, поэтому необходимо представить код в подобном формате.

Программы представляют собой набор низкоуровневых инструкций. Их называют языком ассемблера (assembly language), и они являются одной из частей архитектуры набора команд (ISA). Процессоры запрограммированы на распознавание и выполнение этих инструкций. Самыми распространенными архитектурами набора команд являются x86, MIPS, ARM, RISC-V и PowerPC. Каждая из них отличается друг от друга написанием кода, по аналогии с языками программирования.
Эти архитектуры можно разбить на две категории: архитектуры с фиксированной длиной и переменной длиной. RISC-V является архитектурой с фиксированной длиной, и это означает, что по количеству битов можно понять можно определить тип инструкции. Ее полная противоположность - это x86: архитектура с переменной длиной, в которой каждая инструкция может быть закодирована совершенно по-разному и с разным количеством битов в каждой части. Именно поэтому декодер инструкций на процессорах с архитектурой x86 является самой сложной деталью всего устройства.
Инструкции с фиксированной длиной декодируются легче и быстрее, но у таких архитектур существует лимит поддерживаемых инструкций. Так, самые распространенные процессоры на RISC-V с открытым доступом поддерживают около 100 инструкций, а x86 является закрытой архитектурой, поэтому никто не знает точного количества поддерживаемых инструкций. Многие считают, что это число достигает нескольких тысяч, но это лишь догадки. Тем не менее, несмотря на такую разницу, процессоры на обеих архитектурах выполняют одни и те же функции.

Примеры инструкций архитектуры RISC-V. Инструкция opcode справа занимает 7 бит, что, в свою очередь, определяет ее тип. Каждая инструкция состоит из битов, которые отвечают за то, какие регистры и функции будут выполняться. Так инструкции ассемблера превращаются в бинарный код, который процессор способен считывать.
Итак, теперь можно включать компьютер и запускать программы. Стоит отметить, что выполнение инструкции состоит из нескольких базовых шагов.
Первым таким шагом является перенос инструкции из памяти в сам процессор. На второй стадии инструкция декодируется, чтобы процессор смог понять, что это за инструкция. Типов инструкций много - от арифметических действий до инструкций памяти. После того, как процессор определил тип инструкции, он достает необходимые операнды из памяти или внутренних регистров. Объясняется это просто - вы не можете сложить числа A и B, если не знаете их значений. Стоит также упомянуть, что, так как многие современные процессоры 64-битные, то размер значения данных тоже будет составлять 64 бита.

64 бита - это пропускная способность регистра процессора; пути данных и/или адреса памяти. Чем больше бит, тем больше информации компьютер может обрабатывать за раз. Проще говоря, 64-битный процессор может обрабатывать в два раза больше информации, чем 32-битный.
После того, как процессор получил необходимые операнды, начинается выполнение инструкции и операций над введенными данными. Это может быть добавление чисел, проведение логических манипуляций или даже отсутствие действий, когда значение просто отправляется дальше. После подсчета результатапроцессор может снова обратиться к памяти, чтобы сохранить полученное значение там или же просто отложить полученное значение в одном из внутренних регистров. Только после того, как результат сохранен, процессор обновит состояние различных элементов и перейдет к выполнению следующей инструкции.
Следует отметить, что вся вышеперечисленная цепочка действий значительно упрощена, поскольку в реальных ситуациях большинство современных процессоров разделяют все эти действия на 20+ более мелких циклов, чтобы повысить эффективность. В профессиональной среде подобное называется пайплайном - чем-то вроде трубопровода, который постепенно заполняется жидкостью, но как только заполнится полностью, внутри создается постоянный поток.

Пример четырехступенчатого пайплайна. Цветные квадраты представляют собой независимые друг от друга инструкции.
Прохождение циклов - тщательно отлаженный процесс, но не все инструкции заканчиваются одновременно. Сложение, например, выполняется невероятно быстро, а вот делению или загрузке из памяти может потребоваться на выполнение несколько сотен циклов. Современные процессорывместо того, чтобы простаивать в ожидании завершения одной медленной инструкции, могут выполнять инструкции вне очереди. Процессор сам способен определить, какую инструкцию лучше выполнить в данный момент, а какие - после нее. Если выполняемая инструкция еще не готова, то система может забежать немного вперед, чтобы посмотреть, готово ли что-то другое.
Современные процессоры, кроме внеочередного выполнения инструкций, обладают также суперскалярной архитектурой. Это означает, что процессор может выполнять сразу несколько инструкций на каждом из этапов пайплайна. Для того, чтобы это было возможно, процессору необходимо иметь несколько копий каждого этапа пайплайна. Таким образом, если процессор видит две доступные для исполнения инструкции, между которыми нет никакой зависимости друг от друга, то он сможет одновременно выполнить обе. Такая технология называется одновременной многопотоковостью (SMT), более известной как гиперпотоковость (Hyper-Threading). Процессоры Intel и AMD поддерживают двухстороннюю одновременную многопотоковость, в то время как IBM разработала чипы, поддерживающие уже восьмистороннюю многопотоковость.

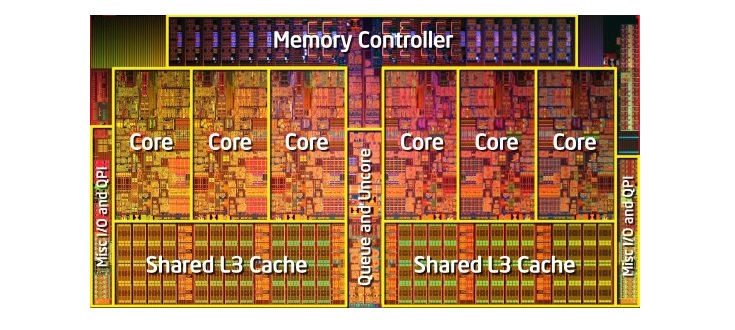
Для того, чтобы в точности прорабатывать подобную схему, процессорупомимо ядра для работы необходимы и другие элементы. В каждом процессоре расположены сотни модулей, причем каждый предназначен для специфической задачи, но в этой статье будут затронуты лишь самые важные. Основные два - это кэш и блок предсказания ветвлений.
Неопытных пользователей кэш может сбить с толку, ведь его главная задача - хранить данные, прямо как оперативная память или любой другой накопитель. Главное отличие кэша заключается в его огромной скорости и низкой задержке при работе с данными. Несмотря на то, что оперативная память обладает высокой скоростью работы с данными, она все еще в разы медленней кэша и слишком медленная для работы процессора. Если говоритьо более точных цифрах, то кэш быстрее оперативной памяти в 100 раз и в 1000 раз быстрее любого SSD. Без кэша процессоры работали бы в разы медленней.
Почти в каждом процессоре есть три уровня кэша - это называется иерархией памяти. Кэш 1 уровня (L1) самый быстрый и самый маленький, 3 уровня (L3), наоборот, крупнейший и медленный, а кэш 2 уровня (L2) - "золотая середина" между ними. Выше кэша в иерархии памяти стоят маленькие регистры, в которых сохраняется одиночное значение данных во время работы процессора. Эти регистры по скорости даже опережают кэш. Регистры используются, когда компилятор переводит высокоуровневые программы в язык ассемблера.
Когда процессор запрашивает данные из памяти, то он сначала проверяет, находятся ли эти данные в кэше первого уровня. Если они там есть, то процессор получает доступ к ним всего за пару циклов. Однако, если данных нет в кэше первого уровня, то процессор поищет их в кэше второго, а затем третьего уровня. С каждым уровнем будет снижаться скорость и увеличиваться задержка. Наконец, если в кэше данных не было, процессор начнет искать их уже в основной памяти (RAM).

В большинстве процессоров каждое ядро оснащено двумя кэшами первого уровня: один предназначен для данных, а другой - для инструкций. Кэш первого уровнязачастуюоколо 100 КБ в размере, хотя это число может отличаться в зависимости от процессора. Обычно на каждое ядро приходится по кэшу второго уровня, хотя в некоторых архитектурах процессоров может кэш может быть разделен между двумя ядрами. Размер этого кэша составляет уже несколько сотен килобайт. Самым большим (несколько десятков мегабайт) является кэш 3 уровня, который делится сразу между всеми ядрами процессора.
Во время обработки кода процессороминструкции и значения данных в большинстве случаев направляются в кэш. Так значительно увеличивается скорость выполнения задачи, поскольку процессору не нужно обращаться к главной памяти. Более подробно работа систем памяти будет рассмотрена во второй и третьей части этой серии статей.
Вторым важнейшим элементом процессора является блок предсказания ветвлений. Разветвленные инструкции являются чем-то вроде команды “если”, только в контексте процессора. Одна часть инструкций будет выполняться, если условие верно, а другая - если условие ложно. Пример: необходимо сравнить два числа, иесли числа равны, то выполнить одну функцию, а если нет - то другую. Ветвления довольно распространены изачастуюсоставляют около 20% всех инструкций программы.
На бумаге разветвленные инструкции звучат довольно просто, но для процессоров их выполнение может быть довольно проблематичным. Поскольку процессор может выполнять 10-20 инструкций одновременно, ему важно понимать, какие именно нужно обработать. Процессору может понадобиться 5 циклов, чтобы определить, является ли инструкция разветвленной, а затем до 10 циклов для того, чтобы определить верна она или нет. В это же время, процессор может начать выполнять десятки дополнительных инструкций, даже не зная правильно ли их выполнение.
Для решения этой проблемы все современные высокопроизводительные процессоры используют технологию спекулятивного выполнения. Благодаря этой технологии, процессор запоминает выполняемые разветвленные инструкции и автоматически угадывает, произойдет ли ветвление или нет. Если системе удалось угадать, то процессор будет заранее выполнять другие инструкции, что увеличивает производительность. Если же не удалось, то процессор остановит выполнение всех неподходящих инструкций и начнет выполнять задачи с правильной точки.
Блоки предсказания ветвлений - это нечто вроде ранней формы машинного обучения, поскольку блок будет постепенно заучивать принцип работы разветвленных инструкций. Благодаря тому, что блоки развивались и улучшались десятилетиями, точность прогнозов в современных процессорах превышает 90%.
Несмотря на то, что эти предсказания могут увеличить производительность процессора, они также образуют дыры в безопасности. Так, недавняя уязвимость Spectre позволяла злоумышленникам получить доступ к процессору именно через блок предсказания ветвлений. Из-за этого производители процессоров вынуждены были переписать алгоритмы работы, тем самым слегка снизив производительность.
В последние несколько десятилетий процессоры развились до невероятных высот. Благодаря умелому использованию многих элементов процессоров, производителям удалось поднять производительность на новый уровень. Увы, но эти самые производители держат все принципы работы своих технологий в строжайшем секрете, поэтому трудно понять, как работают мельчайшие детали. К счастью, большинство фундаментальных основ работы процессоров остаются неизменными, стандартизированным и общеизвестными. Если Intel вдруг внезапно решит каким-то волшебным образом увеличить скорость работы кэша, либо AMD добавит более продвинутый блок предсказания ветвлений, знайте - обе компании стараются добиться одной и той же цели.
На этом заканчивается небольшая экскурсия в мир основ работы процессоров. В следующей статье речь пойдет о том, как создаются различные компоненты процессора, о логических вентилях, частоте, энергопотреблении, печатных схемах и многом другом.

Современные процессоры имеют форму небольшого прямоугольника, который представлен в виде пластины из кремния. Сама пластина защищена специальным корпусом из пластмассы или керамики. Под защитой находятся все основные схемы, благодаря им и осуществляется полноценная работа ЦП. Если с внешним видом все предельно просто, то, что касается самой схемы и того, как устроен процессор? Давайте разберем это подробнее.
Как работает компьютерный процессор
Перед тем, как разобрать основные принципы работы CPU, желательно ознакомиться с его компонентами, ведь это не просто прямоугольная пластина, монтируемая в материнскую плату, это сложное устройство, образующееся из многих элементов. Более подробно с устройством ЦП вы можете ознакомиться в нашей статье, а сейчас давайте приступим к разбору главной темы статьи.
Видеоядро
Благодаря внедрению в процессор видеоядра он выполняет роль видеокарты. Конечно, по мощности он с ней не сравнится, но если вы покупаете CPU для несложных задач, то вполне можно обойтись и без графической карточки. Лучше всего встроенное видеоядро показывает себя в недорогих ноутбуках и дешевых настольных компьютерах.

В этой статье мы подробно разобрали из чего состоит процессор, рассказали о роли каждого элемента, его важности и зависимости от других элементов. Надеемся, что эта информация была полезна, и вы узнали новое и интересное для себя из мира CPU.

Мы рады, что смогли помочь Вам в решении проблемы.
Отблагодарите автора, поделитесь статьей в социальных сетях.
Опишите, что у вас не получилось. Наши специалисты постараются ответить максимально быстро.

Центральный процессор является основным и самым главным элементом системы. Благодаря нему выполняются все задачи связанные с передачей данных, исполнением команд, логическими и арифметическими действиями. Большинство пользователей знают, что такое ЦП, но не разбираются в принципе его работы. В этой статье мы постараемся просто и понятно объяснить, как работает и за что отвечает CPU в компьютере.
Выполняемые операции
Операция представляет собой одно или несколько действий, которые обрабатываются и выполняются компьютерными устройствами, в том числе и процессором. Сами операции делятся на несколько классов:

- Ввод и вывод. К компьютеру обязательно подключено несколько внешних устройств, например, клавиатура и мышь. Они напрямую связаны с процессором и для них выделена отдельная операция. Она выполняет передачу данных между CPU и периферийными девайсами, а также вызывает определенные действия с целью записи информации в память или ее вывода на внешнюю аппаратуру.
- Системные операции отвечают за остановку работы софта, организовывают обработку данных, ну и, кроме всего, отвечают за стабильную работу системы ПК.
- Операции записи и загрузки. Передача данных между процессором и памятью осуществляется с помощью посылочных операций. Быстродействие обеспечивается одновременной запись или загрузкой групп команд или данных.
- Арифметически-логические. Такой тип операций вычисляет значения функций, отвечает за обработку чисел, преобразование их в различные системы исчисления.
- Переходы. Благодаря переходам скорость работы системы значительно увеличивается, ведь они позволяют передать управление любой команде программы, самостоятельно определяя наиболее подходящие условия перехода.
Все операции должны работать одновременно, поскольку во время активности системы за раз запущено несколько программ. Это выполняется благодаря чередованию обработки данных процессором, что позволяет ставить приоритет операциям и выполнять их параллельно.

Работа процессора
Стандартные средства Windows позволяют отследить нагрузку на процессор, посмотреть все выполняемые задачи и процессы. Осуществляется это через «Диспетчер задач», который вызывается горячими клавишами Ctrl + Shift + Esc.

В разделе «Быстродействие» отображается хронология нагрузки на CPU, количество потоков и исполняемых процессов. Кроме этого показана невыгружаемая и выгружаемая память ядра. В окне «Мониторинг ресурсов» присутствует более подробная информация о каждом процессе, отображаются рабочие службы и связанные модули.
Сегодня мы доступно и подробно рассмотрели принцип работы современного компьютерного процессора. Разобрались с операциями и командами, важностью каждого элемента в составе ЦП. Надеемся, данная информация полезна для вас и вы узнали что-то новое.
Мы рады, что смогли помочь Вам в решении проблемы.
Отблагодарите автора, поделитесь статьей в социальных сетях.
Опишите, что у вас не получилось. Наши специалисты постараются ответить максимально быстро.
Теперь, когда мы знаем, как работают процессоры на высоком уровне, пришло время заглянуть внутрь процессора, чтобы понять, как устроены его внутренние компоненты. Эта статья является второй частью нашей серии, посвященной устройству процессоров. Если вы не читали первую часть, советуем ознакомиться с ней прежде, чем вы начнете читать дальше, поскольку в этой статье мы будем использовать понятия, освещенные ранее.
Как вы, вероятно, знаете, процессоры и большинство других современных цифровых технологий основаны на транзисторах. Самый простой способ представить транзистор – это управляемый переключатель с тремя контактами. Когда затвор включен, ток пропускается через транзистор. А когда выключен, транзистор ток не проводит. Точно так же, как и выключатель света на вашей стене, только транзистор гораздо меньше, гораздо быстрее и может управляться электрически.

В современных процессорах используются два основных типа транзисторов: pMOS и nMOS. Транзистор nMOS позволяет току течь, когда подается ненулевое напряжение на затвор, а транзистор pMOS – наоборот, проводит ток, когда напряжение на затворе стремится к нулю. Комбинируя эти типы транзисторов, мы можем создать логические вентили CMOS. В третьей части серии мы ещё остановимся подробней на физике работы процессоров.
Логический вентиль (логический элемент, гейт) – это простейшее устройство, которое принимает входной сигнал, выполняет некоторые операции и выводит результат в виде выходного сигнала. Например, вентиль AND (И) включит свой выход тогда и только тогда, когда все входы в вентиль включены. Инвертор или вентиль отрицания NOT (НЕ) включит свой выход, если вход отключен. Объединив эти два гейта, мы получим логический элемент NAND (И-НЕ), который включает свой выход, если и только если ни один из входов не включен. К другим логическим гейтам, с иной логической функциональностью, относятся OR (ИЛИ), NOR (ИЛИ-НЕ), XOR (Исключающее ИЛИ) и XNOR (Исключающее ИЛИ с инверсией).
Ниже показаны схемы двух основных логических элементов, реализованных с помощью транзисторов: вентиль отрицания (инвертор) и вентиль NAND (И-НЕ). В инверторе сверху находится транзистор pMOS, подключенный к питанию, а снизу транзистор nMOS, подключенный к земле. Транзисторы pMOS обозначаются с небольшим кружочком на затворе. Поскольку устройства pMOS срабатывают при отключенном входе, а устройства nMOS наоборот – при включенном, то несложно понять, что сигнал на выходе всегда будет противоположным сигналу на входе. Глядя на вентиль NAND, мы видим, что для него требуются четыре транзистора и что выход будет включен, пока хотя бы один из входов отключен. По такому же принципу, как формируются приведенные примеры элементарных транзисторных схем, проектируются и более сложные логические гейты и прочие схемы внутри процессоров.

Трудно представить, как из таких простейших кирпичиков – логических элементов – может получиться функционирующий компьютер. Сперва из нескольких отдельных вентилей создаётся простейшее устройство, способное выполнять какую-то простую функцию. Затем из нескольких таких простых устройств создаётся более сложное, выполняющее более сложную задачу. Процесс объединения отдельных компонентов для получения требуемой функциональности – это именно то, что применяется сегодня при создании чипов. Современные чипы имеют миллиарды транзисторов.
Вывод Суммы (Sum) включается, если A или B включены (но не оба сразу), либо если есть сигнал переноса (Cin), при этом A и B одновременно включены или выключены. Вывод переноса (Carry out) функционирует несколько сложнее – он срабатывает либо при одновременном включении A и B, либо если есть сигнал переноса и один из A или B (но не оба сразу). Чтобы соединить несколько однобитных сумматоров в один более широкий, нам попросту нужно последовательно соединить вывод переноса предыдущего бита с входом переноса текущего бита. Чем сложнее схемы, тем сложнее логика, но это самый простой способ сложить два числа. Современные процессоры используют более сложные сумматоры, рассматривать их в нашем обзоре будет излишним. Помимо сумматоров, процессоры также содержат узлы для деления и умножения, включая версии всех этих операций с плавающей запятой.

Объединение групп логических элементов для выполнения какой-либо функции, подобное этому, называется комбинационной логикой. Но этот тип логики не единственный, что встречается в компьютерах. Было бы мало толку, если бы мы не могли хранить данные или отслеживать состояние чего-либо. Для этого нам нужна секвенциальная логика, которая обеспечивает возможность хранить данные.
Секвенциальная логика строится путем подключения инверторов и других гейтов таким образом, что их выходы возвращают сигналы на вход гейтов. Эти контуры обратной связи используются для хранения одного бита данных и известны как статическое ОЗУ или SRAM (Static RAM). Статическим оно называется в противоположность динамическому (DRAM), поскольку сохраняемые в нём данные всегда напрямую связаны с положительным напряжением или землей.
Ниже показан стандартный способ имплементации одного бита SRAM на шести транзисторах. Верхний сигнал WL (Word Line, словная линия) является адресным, и когда он включен, данные, хранящиеся в этой 1-битной ячейке, подаются на битовую линию BL (Bit Line). Вывод BLB (Bit Line Bar, шина битовой линии) это просто инвертированное значение битовой линии, но физически это одна и та же линия. Помимо двух типов транзисторов, мы видим и знакомые нам схемы инверторов, выполненные на транзисторах M3/M1 и M2/M4.

SRAM используется для создания сверхбыстрых кэшей и регистров внутри процессоров. Такая память очень стабильна, но требует от шести до восьми транзисторов для хранения каждого бита данных. Это делает его чрезвычайно дорогим по стоимости, сложности и площади чипа по сравнению с Dynamic RAM. DRAM, в свою очередь, хранит данные в крошечном конденсаторе, а не с помощью логических вентилей. Динамическим оно называется потому, что напряжение на конденсаторе может динамически изменяться, поскольку оно не подключено напрямую к питанию или земле.
Поскольку для доступа к данным, хранящимся в конденсаторе, требуется только один транзистор на бит и конструкция схемы очень масштабируема, DRAM может быть «упакован» компактно и дешево. Одним из недостатков DRAM является то, что заряд в конденсаторе настолько мал, что его необходимо постоянно поддерживать. Именно поэтому при выключении компьютера все конденсаторы разряжаются и данные в оперативной памяти теряются.

Принципиальная схема DRAM. Address Line – адресная шина (словная линия); Bit Line – битовая шина (битовая линия); Transistor – транзистор; Storage capacitor – конденсатор; Ground – земля.
Такие производители, как Intel, AMD и Nvidia, не публикуют схем работы своих процессоров, поэтому и мы не можем предоставить точные схемы узлов современных процессоров. Однако этот простой сумматор позволяет получить достаточное представление о том, как даже самые сложные части процессора можно разбить на составляющие логические элементы, элементы памяти, и в конечном итоге – на транзисторы.
Теперь, когда мы знаем об устройстве некоторых компонентов процессора, нам нужно выяснить, как они соединяются и согласуются между собой. Все важнейшие узлы процессора подключены к тактовому сигналу (синхросигналу), который представляет собой чередование верхнего и нижнего уровня сигнала с заданным интервалом, называемым частотой. Логика внутри процессора обычно переключает значения и выполняет вычисления в момент переключения синхросигнала с низкого уровня на высокий. Синхронизируя все вместе, мы можем быть уверены, что данные всегда распределяются корректно по времени, тем самым исключая сбои в работе процессора.
Многие, наверное, слышали о так называемом «разгоне» – увеличении тактовой частоты процессора с целью повысить его производительность. Этот выигрыш в производительности достигается за счет более быстрого переключения транзисторов и внутрипроцессорной логики, чем предусмотрено производителем. Поскольку число тактов в секунду становится больше, то и операций может быть произведено больше, отчего и повышается производительность процессора. Но это справедливо лишь до определенного предела. Большинство современных процессоров работают с частотой от 3,0 до 4,5 ГГц, и за последнее десятилетие ситуация не сильно изменилась. Точно так же, как металлическая цепь не прочнее её самого слабого звена, процессор не может быть быстрее его самой медленной части. К концу каждого такта каждый из элементов процессора должен завершить свою работу. Если какой-то элемент не успевает, значит заданная частота слишком высока, и процессор не сможет работать. Разработчики называют эту самую медленную часть «критическим путем», и именно по ней производителем задаётся максимальная частота процессора. Выше определенной частоты транзисторы просто не могут переключаться достаточно быстро и начинают глючить или давать неправильные выходные сигналы.
Мы можем ускорить переключение транзисторов, повысив напряжение питания процессора, но это тоже срабатывает до определённого предела. Если подать слишком большое напряжение, то мы рискуем сжечь процессор. При увеличении частоты или повышении напряжения процессора, усиливаются его нагрев и потребляемая мощность. Это происходит потому, что мощность процессора прямо пропорциональна частоте и пропорциональна квадрату напряжения. Чтобы определить энергопотребление процессора, мы рассматриваем каждый транзистор как маленький конденсатор, который нужно заряжать или разряжать при изменении его значения.
Подача питания — настолько важная часть процессора, что в некоторых случаях до половины физических контактов на чипе может использоваться только для питания или заземления. Некоторые чипы при полной нагрузке могут потреблять больше 150 ампер, и весь этот ток должен крайне аккуратно управляться. Чтобы представить такое количество энергии, заметим: центральный процессор производит больше тепла на единицу площади, чем ядерный реактор.
Тактовый сигнал в современных процессорах отнимает примерно 30-40% от его общей мощности, потому что он очень сложен и должен управлять множеством различных устройств. Для сохранения энергии большинство процессоров с низким потреблением отключают части чипа во время их бездействия. Это реализуется отключением тактового сигнала (Clock Gating) или отключением питания (Power Gating).
Тактовые сигналы имеют ещё одну сложность при разработке процессора: так как их частоты постоянно растут, на их пути начинают вставать законы физики. Хоть скорость света и чрезвычайно высока, она недостаточно высока для высокопроизводительных процессоров. Если подключить тактовый сигнал к одному из концов чипа, то ко времени, когда сигнал достигнет другого конца, он уже будет значительно рассинхронизован. Чтобы синхронизировать все части чипа, тактовый сигнал распределяется при помощи так называемого H-дерева (H-Tree). Это структура, обеспечивающая равноудаленность всех конечных точек от центра.

Может показаться, что проектирование каждого отдельного транзистора, тактового сигнала и контакта питания в чипе – чрезвычайно монотонная и сложная задача, и это в самом деле так. Даже несмотря на то, что в таких компаниях, как Intel, Qualcomm и AMD работают тысячи инженеров, они не смогли бы вручную спроектировать каждый аспект чипа. Для их проектирования они используют различные специальные инструменты, помогающие создавать необходимые конструкции и схемы к ним. Такие инструменты обычно получают высокоуровневое описание того, что должен делать компонент, и определяют наилучшую аппаратную конфигурацию, удовлетворяющую этим требованиям. Зародилось технологическое направление под названием "Синтез высокого уровня" (High Level Synthesis), которое позволяет разработчикам задавать в коде желаемую функциональность, после чего компьютеры определяют, как оптимально достичь её в оборудовании.
Точно так же, как вы можете описывать компьютерные программы с помощью кода, проектировщики могут описывать кодом аппаратные устройства. Такие языки, как Verilog и VHDL позволяют разработчикам оборудования выражать функциональность любой создаваемой ими электрической схемы. После успешного выполнения симуляций и верификации таких проектов их можно материализовать в конкретные транзисторы, из которых будет состоять электрическая схема. Хоть этап верификации и не кажется столь же увлекательным, как проектирование нового кэша или ядра, он значительно важнее их. На каждого нанимаемого компанией инженера-проектировщика может приходиться пять или более инженеров по верификации.
Непросто осмыслить то, что в одном чипе может быть несколько миллиардов транзисторов и понять, что все они делают. Если разбить чип на его отдельные внутренние компоненты, становится немного легче. Из транзисторов составляются логические вентили, логические вентили соединяются в функциональные модули, выполняющие определённую задачу, а эти функциональные модули собираются вместе, образуя архитектуру компьютера, о которой мы говорили в первой части серии.
Бо́льшая часть работ по проектированию автоматизирована, но изложенное выше позволяет нам осознать, насколько сложен только что купленный нами новый процессор.
Эта вторая часть нашей серии посвящена процессу проектирования процессора. Мы рассмотрели транзисторы, логические элементы (они же вентили, гейты), подачу питания и синхронизирующих сигналов, синтез конструкции и верификацию. В третьей части мы узнаем, что требуется для физического производства чипа. Все компании любят хвастаться тем, насколько современен их техпроцесс (Intel 10 нм, Apple и AMD 7 нм, и т.д.), но что же на самом деле означают эти числа? Об этом мы расскажем в следующей части.
Мы воспринимаем центральный процессор как «мозг» компьютера, но что это значит на самом деле? Что именно происходит внутри миллиардов транзисторов, благодаря которым работает компьютер? В нашей новой мини-серии из четырёх статей мы рассмотрим процесс создания архитектуры компьютерного оборудования и расскажем о принципах его работы.
В этой серии мы расскажем о компьютерной архитектуре, проектировании процессорных плат, VLSI (very-large-scale integration), производстве чипов и тенденциях будущего в области вычислительной техники. Если вам было интересно разобраться в подробностях работы процессоров, то начинать изучение лучше с этой серии статей.
Мы начнём с очень высокоуровневого объяснения того, чем занимается процессор и как строительные блоки соединяются в функционирующую конструкцию. В том числе мы рассмотрим процессорные ядра, иерархию памяти, предсказание ветвлений и другое. Во-первых, нам нужно дать простое определение тому, что делает ЦП. Простейшее объяснение: процессор следует набору инструкций для выполнения определённой операции над множеством входящих данных. Например, это может быть считывание значения из памяти, затем прибавление его к другому значению, и наконец сохранение результата в память по другому адресу. Это может быть и нечто более сложное, например, деление двух чисел, если результат предыдущего вычисления больше нуля.
Программы, например, операционная система или игра, сами по себе являются последовательностями инструкций, которые должен выполнять ЦП. Эти инструкции загружаются из памяти и в простом процессоре выполняются одна за другой, пока программа не завершится. Разработчики программного обеспечения пишут программы на высокоуровневых языках, например, на C++ или на Python, но процессор не может их понимать. Он понимает только единицы и нули, поэтому нам нужно каким-то образом представить код в этом формате.

Программы компилируются в набор низкоуровневых инструкций, называемых языком ассемблера, который является частью архитектуры набора команд (Instruction Set Architecture, ISA). Это набор команд, которые должен понимать и выполнять ЦП. Одними из наиболее распространённых ISA являются x86, MIPS, ARM, RISC-V и PowerPC. Точно так же, как синтаксис написания функции на C++ отличается от функции, выполняющей то же действие в Python, у каждой ISA есть свой отличающийся синтаксис.
Эти ISA можно разбить на две основных категории: с фиксированной и с переменной длиной. ISA RISC-V использует инструкции с фиксированной длиной, и это означает, что определённое заранее заданное количество битов в каждой инструкции определяет, какой тип имеет эта инструкция. В x86 всё иначе, в нём используются инструкции с переменной длиной. В x86 инструкции могут кодироваться различным способом с разным количеством битов для разных частей. Из-за такой сложности декодер инструкций в процессоре x86 обычно является самой сложной частью всего устройства.
Инструкции с фиксированной длиной обеспечивают простое декодирование благодаря постоянной структуре, но ограничивают общее количество инструкций, которые могут поддерживаться ISA. В то время, как у популярных версий архитектуры RISC-V есть примерно 100 инструкций и все они имеют открытый исходный код, архитектура x86 проприетарна и никто не знает, сколько всего инструкций в ней есть. Обычно считается, что существует несколько тысяч инструкций x86, но точное число никто не публикует. Несмотря на различия между ISA, по сути все они имеют одинаковую базовую функциональность.

Пример некоторых инструкций RISC-V. Опкод справа имеет длину 7 бит и определяет тип инструкции. Кроме того, каждая инструкция содержит биты, определяющие используемые регистры и выполняемые функции. Так ассемблерные инструкции разбиваются на двоичный код, чтобы его понимал процессор.
Теперь мы готовы включить компьютер и начать выполнять программы. Выполнение инструкции имеет несколько базовых частей, которые разбиты на множество этапов процессора.
Первый этап — передача инструкции из памяти в процессор для начала выполнения. На втором этапе инструкция декодируется, чтобы ЦП мог понять, какого типа эта инструкция. Существует множество типов, в том числе арифметические инструкции, инструкции ветвления и инструкции памяти. После того, как ЦП узнает, инструкцию какого типа он выполняет, операнды для инструкции берутся из памяти или внутренних регистров ЦП. Если вы хотите сложить число A и число B, то не можете выполнять сложение, пока не знаете значений A и B. Большинство современных процессоров являются 64-битными, то есть размер каждого значения данных составляет 64 бита.

64 бита — это ширина регистра процессора, канала передачи данных и/или адреса памяти. Для обычных пользователей это означает, какой объём информации компьютер может обработать за один раз, и лучше всего это понять в сравнении с младшим родственником по архитектуре — 32-битным процессором. 64-битная архитектура может обрабатывать за раз в два раза больше бит информации (64 бит против 32).
Получив операнды для инструкции, процессор переносит их на этап выполнения, где производится операция над входящими данными. Это может быть сложение чисел, выполнение логических манипуляций с числами или просто передача чисел без их изменения. После вычисления результата может потребоваться доступ к памяти для его сохранения, или процессор может просто хранить значение в одном из своих внутренних регистров. После сохранения результата ЦП обновляет состояние различных элементов и переходит к следующей инструкции.
Это объяснение, разумеется, сильно упрощено, и большинство современных процессоров для повышения эффективности разбивает эти несколько этапов на 20 или даже больше мелких этапов. Это означает, что хотя процессор начинает и завершает в каждом цикле несколько инструкций, может потребоваться 20 или больше циклов, чтобы выполнить одну инструкцию от начала до конца. Такая модель обычно называется pipeline («трубопровод», на русский обычно переводят как «конвейер»), потому что для заполнения трубопровода жидкостью и полного её прохождения требуется время, но после заполнения расход (вывод данных) будет постоянным.

Пример 4-этапного конвейера. Разноцветные прямоугольники обозначают независящие друг от друга инструкции.
Весь проходимый инструкцией цикл — это очень тщательно скоординированный процесс, но не все инструкции могут завершаться одновременно. Например, сложение выполняется очень быстро, а деление или загрузка из памяти может занимать тысячи циклов. Вместо останова всего процессора до момента завершения одной медленной инструкции большинство современных процессоров выполняют их с изменением очерёдности. То есть они определяют, какую из инструкций выгоднее всего выполнить в текущий момент и буферизируют другие инструкции, которые пока не готовы. Если текущая инструкция ещё не готова, то процессор может перепрыгнуть вперёд по коду, чтобы посмотреть, готово ли что-то ещё.
Кроме выполнения с изменением очерёдности современные процессоры применяют технологию под названием суперскалярная архитектура. Это означает, что в любой момент времени процессор одновременно выполняет на каждом этапе конвейера множество инструкций. Он может также ожидать ещё сотни других, чтобы начать их выполнение, и для того, чтобы иметь возможность одновременного выполнения нескольких инструкций внутри процессоров есть несколько копий каждого этапа конвейера. Если процессор видит, что к выполнению готовы две инструкции, и между ними нет зависимости, то он не ждёт, пока они завершатся по отдельности, а выполняет их одновременно. Одна из популярных реализаций такой архитектуры называется Simultaneous Multithreading (SMT) и также известна, как Hyper-Threading. Процессоры Intel и AMD сейчас поддерживают двухсторонний SMT, а IBM разработала чипы, поддерживающие до восьми SMT.

Для завершения этого тщательно скоординированного выполнения процессор кроме базового ядра имеет множество дополнительных элементов. В процессоре есть сотни отдельных модулей, у каждого из которых есть специфическая функция, но мы рассмотрим только основы. Самыми важными и выгодными являются кэши и предсказатель переходов. Есть и другие дополнительные структуры, которые мы рассматривать не будем: буферы переупорядочивания, таблицы переименования регистров и станции резервирования.
Необходимость кэшей иногда может сбивать с толку, ведь они хранят данные, как и ОЗУ или SSD. Но кэши отличаются задержкой и скоростью доступа. Даже несмотря на то, что память ОЗУ чрезвычайно быстра, она на порядки величин медленнее, чем нужно для ЦП. Для ответа с передачей данных ОЗУ может потребоваться сотни циклов, и процессору в это время будет нечем заняться. А если данных нет в ОЗУ, то могут потребоваться десятки тысяч циклов для получения доступа к ним с SSD. Без кэшей процессоры бы постоянно стопорились.
Обычно процессоры имеют три уровня кэша, образующих так называемую иерархию памяти. Кэш L1 — самый маленький и быстрый, L2 находится посередине, а L3 — самый крупный и медленный из всех кэшей. Выше кэшей в иерархии находятся мелкие регистры, хранящие во время вычислений единственное значение данных. По порядку величин эти регистры являются самыми быстрыми устройствами хранения в системе. Когда компилятор преобразует высокоуровневую программу в язык ассемблера, он определяет наилучший способ использования этих регистров.
Когда ЦП запрашивает данные из памяти, то сначала проверяет, хранятся ли эти данные уже в кэше L1. Если да, то можно всего за пару циклов получить к ним доступ. Если их там нет, то процессор проверяет L2, а затем и кэш L3. Кэши реализованы таким образом, что в общем случае они прозрачны для ядра. Ядро просто запрашивает данные по указанному адресу памяти, и тот уровень в иерархии, на котором они есть, отвечает ему. При переходе к последующим уровням в иерархии памяти размер и задержки обычно растут на порядки величин. В конце концов, если ЦП не находит данные ни в одном из кэшей, то обращается в основную память (ОЗУ).

В обычном процессоре каждое ядро имеет два кэша L1: один для данных и другой для инструкций. Кэши L1 обычно имеют в целом объём порядка 100 килобайт и размер очень варьируется в зависимости от чипа и поколения процессора. Кроме того, обычно для каждого ядра есть свой кэш L2, хотя в некоторых архитектурах он может быть общим для двух ядер. Кэши L2 обычно имеют размер несколько сотен килобайт. Наконец, есть единственный кэш L3, общий для всех ядер, имеющий размер порядка десятков мегабайт.
Когда процессор выполняет код, самые часто используемые инструкции и значения данных кэшируются. Это значительно ускоряет выполнение, потому что процессору не нужно постоянно обращаться за нужными данными в основную память. Во второй и третьей частях серии мы подробнее поговорим о том, как реализованы эти системы памяти.
Кроме кэшей одним из самых важных строительных блоков современного процессора является точный предсказатель переходов. Инструкции переходов (ветвлений) схожи с конструкциями «if» для процессора. Один набор инструкций выполняется, если условие истинно, а другой — если оно ложно. Например, нам нужно сравнить два числа, и если они равны, выполнить одну функцию, а если не равны, то выполнить другую. Эти инструкции ветвления применяются чрезвычайно часто и могут составлять примерно 20% всех инструкций в программе.
На первый взгляд кажется, что эти инструкции ветвления не должны вызывать проблем, но их правильное выполнение может оказаться очень сложным для процессора. В любой момент времени процессор может находиться в процессе одновременного выполнения десяти или двадцати инструкций, поэтому очень важно знать, какие инструкции выполнять. Может потребоваться 5 циклов, чтобы определить, что текущая инструкция — это переход и ещё 10 циклов, чтобы определить истинность условия. В это время процессор уже может начать выполнение десятков дополнительных инструкций, даже не зная, действительно ли это подходящие для выполнения инструкции.
Чтобы обойти эту проблему, все современные высокопроизводительные процессоры используют методику под названием «упреждение» (speculation). Это означает, что процессор отслеживает инструкции ветвления и гадает, будет ли выполнен условный переход, или нет. Если предсказание верно, то процессор уже начал выполнять последующие инструкции, и это обеспечивает рост производительности. Если предсказание неверно, то процессор останавливает выполнение, удаляет все неверные инструкции, которые он начал выполнять, и начинает заново с правильной точки.
Такие предсказатели перехода — одни из самых простейших разновидностей машинного обучения, потому что предсказатель изучает поведение ветвей в процессе выполнения. Если он предсказывает неверно слишком часто, то начинает обучаться правильному поведению. Десятилетия исследований методик предсказания переходов привели к тому, что в современных процессорах точность предсказаний превышает 90%.
Хотя упреждение обеспечивает огромный рост производительности, потому что процессор может выполнять инструкции, которые уже готовы, вместо того, чтобы ожидать в очереди завершения выполняемых, оно в то же время создаёт уязвимости в защите. Знаменитая атака Spectre эксплуатирует баги в предсказании и упреждении переходов. Атакующий использует специально подобранный код, чтобы заставить процессор упреждающе выполнить код, благодаря чему происходит утечка значений из памяти. Для предотвращения утечки данных необходимо было переделать конструкцию отдельных аспектов упреждения, что привело к небольшому падению производительности.
За последние десятилетия используемая в современных процессорах архитектура прошла долгий путь. Инновации и разработка продуманной структуры привели к повышению производительности и более оптимальному использованию аппаратных средств. Однако разработчики центральных процессоров тщательно хранят секреты их технологий, поэтому мы не можем точно узнать, что происходит у них внутри. Тем не менее, фундаментальные принципы работы процессоров стандартированы для всех архитектур и моделей. Intel может добавлять свои секретные ингредиенты, чтобы повысить долю попаданий кэша, а AMD может добавить улучшенный предсказатель переходов, но процессоры обеих компаний выполняют одинаковую задачу.
В этом первом взгляде и обзоре мы рассмотрели основы работы процессоров. В следующей части мы расскажем, как разрабатываются компоненты, входящие в состав процессоров, поговорим о логических элементах, тактовых частотах, управлении питанием, принципиальных электросхемах и другом.
Сокет (разъем)
Благодаря тому, что процессор имеет собственный разъем (гнездовой или щелевой), вы можете легко заменить его при поломке или модернизировать компьютер. Без наличия сокета ЦП просто бы впаивался в материнскую плату, усложняя последующий ремонт или замену. Стоит обратить внимание – каждый разъем предназначен исключительно для установки определенных процессоров.

Часто пользователи по невнимательности покупают несовместимые процессор и материнскую плату, из-за чего появляются дополнительные проблемы.
Как устроен процессор компьютера
В состав ЦП входит небольшое количество различных элементов. Каждый из них выполняет свое действие, происходит передача данных и управления. Обычные пользователи привыкли отличать процессоры по их тактовой частоте, количеству кэш-памяти и ядрам. Но это далеко не все, что обеспечивает надежную и быструю работу. Стоит уделить отдельное внимание каждому компоненту.

Системная шина
По системной шине CPU соединяются устройства входящие в состав ПК. К ней напрямую подключен только он, остальные элементы подсоединяются через разнообразные контроллеры. В самой шине присутствует множество сигнальных линий, через которые происходит передача информации. Каждая линия имеет свой собственный протокол, обеспечивающий связь по контроллерам с остальными подключенными компонентами компьютера. Шина имеет свою частоту, соответственно, чем она выше, тем быстрее совершается обмен информацией между связующими элементами системы.

Кэш-память
Быстродействие ЦП зависит от его возможности максимально быстро выбирать команды и данные из памяти. За счет кэш-памяти сокращается время выполнения операций благодаря тому, что она играет роль временного буфера, обеспечивающего мгновенную передачу данных CPU к ОЗУ или наоборот.
Основной характеристикой кэш-памяти является ее различие по уровням. Если он высокий, значит память более медленная и объемная. Самой скоростной и маленькой считается память первого уровня. Принцип функционирования данного элемента очень прост – CPU считывает из ОЗУ данные и заносит их в кэш любого уровня, удаляя при этом ту информацию, к которой обращались давно. Если процессору нужна будет эта информация еще раз, то он получит ее быстрее благодаря временному буферу.
Выполнение команд
Обработка команды делится на две составные части – операционную и операндную. Операционная составляющая показывает всей системе то, над чем она должна работать в данный момент, а операндная делает то же самое, только отдельно с процессором. Выполнением команд занимаются ядра, а действия осуществляются последовательно. Сначала происходит выработка, потом дешифрование, само выполнение команды, запрос памяти и сохранение готового результата.

Благодаря применению кэш-памяти выполнение команд происходит быстрее, поскольку не нужно постоянно обращаться к ОЗУ, а данные хранятся на определенных уровнях. Каждый уровень кэш-памяти отличается объемом данных и скоростью выгрузки и записи, что влияет на быстродействие систем.
Архитектура
Внутренняя конструкция ЦП часто отличается друг от друга, каждому семейству присущ свой набор свойств и функций – это и называется его архитектурой. Пример конструкции процессора вы можете наблюдать на изображении ниже.

Но многие под архитектурой процессора привыкли подразумевать немного другое значение. Если рассматривать ее с точки зрения программирования, то она определяется по его возможности выполнять определенный набор кодов. Если вы покупаете современный CPU, то скорее всего он относится к архитектуре x86.
Основная часть CPU называется ядром, в нем содержатся все необходимые блоки, а также происходит выполнение логических и арифметических задач. Если вы посмотрите на рисунок ниже, то сможете разобрать как выглядит каждый функциональный блок ядра:

- Модуль выборки инструкций. Здесь осуществляется распознавание инструкций по адресу, который обозначается в счетчике команд. Число одновременного считывания команд напрямую зависит от количества установленных блоков расшифровки, что помогает нагрузить каждый такт работы наибольшим количеством инструкций.
- Предсказатель переходов отвечает за оптимальную работу блока выборки инструкций. Он определяет последовательность исполняемых команд, нагружая конвейер ядра.
- Модуль декодирования. Данная часть ядра отвечает за определения некоторых процессов для выполнения задач. Сама задача декодирования очень сложная из-за непостоянного размера инструкции. В самых новых процессорах таких блоков встречается несколько в одном ядре.
- Модули выборки данных. Они берут информацию из оперативной или кэш-памяти. Осуществляют они именно выборку данных, которая необходима на этот момент для исполнения инструкции.
- Управляющий блок. Само название говорит уже о важности данного компонента. В ядре он является главнейшим элементом, поскольку производит распределение энергии между всеми блоками, помогая выполнять каждое действие вовремя.
- Модуль сохранения результатов. Предназначен для записи после окончания обработки инструкции в RAM. Адрес сохранения указывается в исполняющейся задаче.
- Элемент работы с прерываниями. ЦП способен выполнять сразу несколько задач благодаря функции прерывания, это позволяет ему останавливать ход работы одной программы, переключаясь на другую инструкцию.
- Регистры. Здесь хранятся временные результаты инструкций, данный компонент можно назвать небольшой быстрой оперативной памятью. Часто ее объем не превышает несколько сотен байт.
- Счетчик команд. Он хранит в себе адрес команды, которая будет задействована на следующем такте процессора.
Взаимодействия с памятью
ПЗУ (Постоянное запоминающее устройство) может хранить в себе только неизменяемую информацию, а вот ОЗУ (Оперативная память) используется для хранения программного кода, промежуточных данных. С этими двумя видами памяти взаимодействует процессор, запрашивая и передавая информацию. Взаимодействие происходит с использованием подключенных внешних устройств, шин адресов, управления и различных контролеров. Схематически все процессы изображены на рисунке ниже.

Если разобраться о важности ОЗУ и ПЗУ, то без первой и вовсе можно было бы обойтись, если бы постоянное запоминающее устройство имело намного больше памяти, что пока реализовать практически невозможно. Без ПЗУ система работать не сможет, она даже не запустится, поскольку сначала происходит тестирование оборудования с помощью команд БИОСа.
Читайте также: