
Как часто менять диски в сервере
С ростом разрешения IP-камер растут объёмы видеоархива и, как следствие, требования к размеру дисковой подсистемы видеосервера. Все большее количество жестких дисков ведет к использованию в системах видеонаблюдения RAID-массивов и многодисковых полок.
При этом жёсткий диск, какой бы вы не использовали, это та деталь, которая рано или поздно точно выйдет из строя. RAID-массив позволяет предотвратить потерю информации, но как сказывается работа HDD в RAID на его сроке службы? И какова вероятность поломки жесткого диска? Давайте разбираться.
Видеоролик по теме статьи:
На канале VIDEOМАХ регулярно публикуются обучающие видео, демонстрации работы технологий, записи мероприятий.
Подпишитесь, чтобы быть в курсе новых технологий видеонаблюдения.Подпишись на канал
Особенности долгой эксплуатации RAID-массивов
Выход из строя HDD – это неизбежный финал для любой системы хранения. Если диски собраны в отказоустойчивый RAID-массив, то они распознаются как неисправные намного раньше и требуют замены чаще, но за счёт этого система хранения данных способна функционировать долгие годы, требуя только лишь периодической замены дисков. И здесь нужно учитывать один важный момент: полноценная и надёжная работа RAID-массива возможна только при использовании однотипных жестких дисков в его составе, мало того, с одной версией прошивки. Любая комбинация дисков с отличиями от этого правила не гарантирует его долговременную работу и может привести к быстрому выходу из строя и потере всего видеоархива.
Технологии, как известно, не стоят на месте, и производители HDD постоянно выпускают на рынок новые модели и поколения устройств, снимая с производства морально устаревшие. Что делать в ситуации, когда, например, через два года эксплуатации администратор системы обнаружил, что вышедший из строя жёсткий диск уже снят с производства и заменить его однотипным невозможно? Вот это начинается головная боль! И, как следствие, напрашивается решение: необходимо держать запас жестких дисков, желательно на весь срок службы системы видеонаблюдения.
Горячая замена дисков
Горячую замену дисков можно производить практически со всеми вариантами интерфейсов. Конечно, есть и некоторые ограничения.
IDE устройства редко переносят отключение/подключение второго устройства на шлейф — велик риск пропадания работающего устройства из системы. Главная проблема интерфейса IDE в правильной обработке операционной системой этого события. Так как интерфейс IDE не предусматривает горячей замены, в большинстве случаев необходимо вручную запустить сканирование устройств для определения нового оборудования. Важный момент — интерфейс подключается/отключается к обесточенному диску (подключение: сначала интерфейс, потом питание, отключение: сначала питание, потом интерфейс).
ОТКАЗ ОТ ОБЯЗАТЕЛЬСТВ: выполняя отключение/подключение устройств IDE Вы делаете это на свой страх и риск — никто не гарантирует сохранение работоспособности оборудования, и стабильность работы ОС.
Интерфейсы FC, SAS, SATA (AHCI) — поддерживают горячую замену дисков в полном объеме, проблемы могут быть в операционной системе. Если дисковый контроллер SATA находится в режиме совместимости IDE — то, возможно, понадобится вручную запустить сканирование шины. В режиме AHCI в большинстве случаев диск определится автоматически. Рекомендую использовать AHCI, если ваша ОС это позволяет, т.к. этот режим также повышает производительнось диска; TRIM поддерживается только в этом режиме работы контроллера.
При отключении дисков для продления срока их службы рекомендую предварительно отключать их программным методом и извлекать после остановки шпинделя, т.е. через примерно 30 секунд после выключения для дисков 7200RPM. Если диск невозможно отключить программно и он установлен в hot-swap корзинке, рекомендую вытащить диск на минимальное расстояние, при котором диск будет отключен, подождать остановки шпинделя и извлечь окончательно. В большинстве систем — это расстояние полностью отведённой ручки корзинки. Конечно, эти действия не несут практического смысла, если диск вышел из строя, но, возможно, он просто «завис» и вам не поменяют его по гарантии и придется использовать в некритичном оборудовании.
Так же важно понимать, что диск находится в составе RAID или как отдельное блочное устройство. При использовании отдельного диска необходимо предварительно его отмонтировать для избежания сбоев в работе ОС и программного обеспечения. Даже если диск не используется в текущий момент, после извлечения примонтированого диска зачастую наблюдаются лаги всей ОС. Конечно же, диск, на котором установлена ОС, извлечь без «зависания» не получится.
Большинство серверов позволяет подсветить индикатором диск по команде с сервера, по возможности пользуйтесь этой функцией, для минимизации ошибочных извлечений дисков. Например на серверах SuperMicro номер корзинки указан на самой корзинке, и может не совпадать с номером слота на бэкплейне. Такая-же проблема есть у многих производителей.
Так же перед отключением желательно получить информацию о диске (модель, объем, серийный номер) для сопоставления сразу после извлечения диска. Во многих случаях при ошибочном извлечении другого диска это позволит устранить ошибку сразу, а иногда даже предотвратить сбой в работе или потерю данных.
В случае использования RAID-массивов, рекомендую отключать диски программно (помечать как сбойные), перед извлечением это устранит снижение производительности дисковой системы сразу после отключения диска.
Проблем с SSD дисками при частом горячем подключении/извлечении не заметил, хотя использовал несколько именно в таком режиме.
На этом первая часть заканчивается, в следующей частях про RAID массивы, память для серверов, системы удалённого управления и про важность мониторинга.
Эта статья не определяет строгий регламент замены дисков. Используйте эту информацию к сведению.
Разумеется вы хотите чтобы ваши диски никогда не отказывали, но увы это может случиться рано или поздно. Чтобы снизить вероятность потери данных рекомендуется использовать отказоустойчивые конфигурации RAID с различными алгоритмами избыточности. Однако даже при этих условиях отказы вероятны.
Вы можете встретить рекомендации о профилактической замене дисков как можно чаще, но это не всегда верно.
Надо учесть, что интенсивность отказов электронных компонентов (отношение числа отказавших объектов в единицу времени к среднему числу объектов, исправно работающих в данный отрезок времени) неравномерно распределяются по времени
Типичная зависимость интенсивности отказов от времени: I — влияние скрытых дефектов, период приработки и отказов некачественных изделий; II — период нормальной эксплуатации; III — период старения (отказы вызваны износом деталей, диффузией или старением материалов)
Потому новый диск может оказаться менее надежным чем тот, что уже был в эксплуатации. И разумеется следует избегать использования для важных данных устройств с признаками старения.
Для определения текущего состояния диска мы рекомендуем использовать утилиты производителя диска:
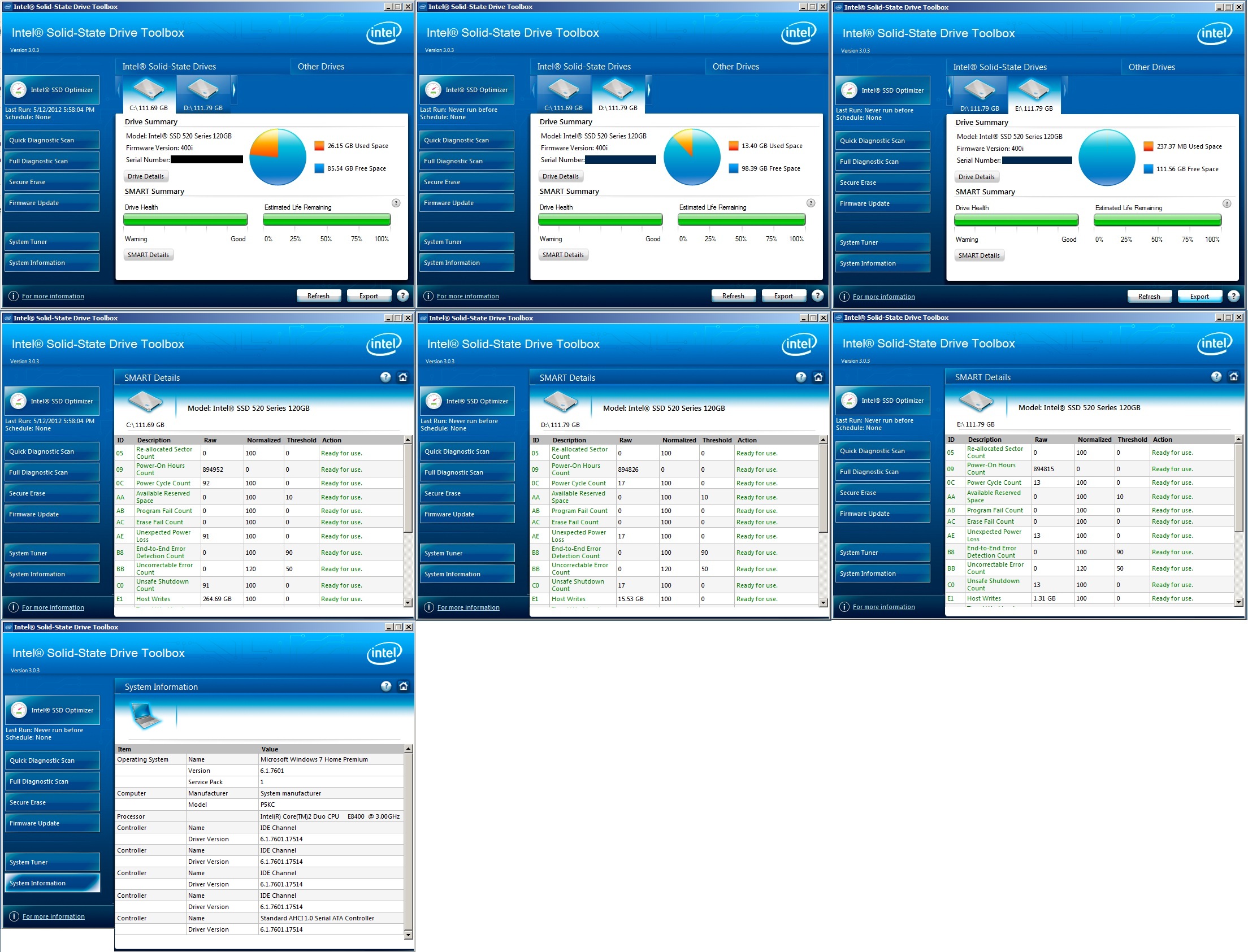
Intel® SSD Toolbox
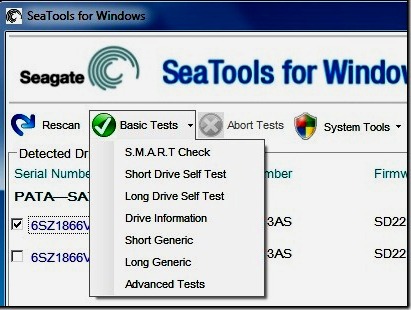
Seagate SeaTools

HGST Windows Drive Fitness Test
Горячая замена блоков питания
В моей практике, сгоревших БП (блоков питания) было немного, но наличие в сервере hot-swap БП, подключённых по схеме N+N во многих случаях существенно увеличивает бесперебойность работы сервера. Если в сервере больше двух БП, то зачастую реализована схема N+1, что не позволяет питать сервер от двух независимых источников или линий питания. Электропитание с подачей в стойку двух независимых линий повышает бесперебойность в самых различных ситуациях, например при обслуживании или аварии систем энергообеспечения в датацентре. Был случай, в сервере вышел из строя БП и создал короткое замыкание, что привело к срабатыванию защиты PDU и его отключению, соседние сервера с БП по схеме 1+1, подключённые также к другому PDU продолжили работу. Резервирование БП позволяет изменять подключение сервера к сети энергообеспечения, не прерывая его работу, например, оптимизировать укладку кабелей (конечно, правильно укладывать кабеля надо при установке сервера, но мы живём в не идеальном мире).
Вопреки заблуждению сертификация 80 Plus указывает на энергоеффективность блока питания, и не обязывает производителя к обеспечению какого либо уровня надёжности.
Также резервирование БП предотвращает большинство проблем связанных с кабелями питания. Плохой контакт некачественных кабелей, случайное их выдергивание персоналом при работах. Если у вас сервер с одним блоком питания, использование для него качественного и неизношенного кабеля, который плотно устанавливается в гнездо, и при нагрузке не издаёт посторонних звуков (потрескивание) более важно — невозможна замена без остановки сервера. В случае сервера с резервированными БП, плохой контакт кабеля может привести к выходу блока питания из строя.
Эмпирический метод
Самый точный и объективный метод получения информации о сроке службы и надёжности устройства – это обработка большого количества статистической информации. Если вы попробуете поискать информацию об исследованиях надёжности работы HDD в крупных системах хранения данных, то с удивлением обнаружите, что ее практически нет. Производители HDD исследований на отказоустойчивость и срок службы своих жестких дисков либо не проводят, либо не публикуют. Есть скудные данные и запутанные отчеты компаний-крупных потребителей дисков, дата-центров. Разобраться в них достаточно сложно.
Позволим себе привести анализ статистики выходов из строя HDD в составе серверов видеонаблюдения, которую мы собираем в сервисном центре Видеомакс. А результаты интересные! Вот некоторые факты:
- Вероятность выхода из строя HDD в каждый год из первых 3-х лет эксплуатации находится в районе 1%, что совпадает с данными, которые нам предоставляет производитель HDD
- Вероятность выхода из строя HDD, при работе в составе RAID-систем примерно в два раза выше. О причинах, мы поговорим в этой статье немного позже
- Вероятность выхода из строя любого диска в составе RAID-массива сильно превышает сумму вероятностей поломки каждого из них. При этом ещё и прослеживается зависимость от количества дисков в массиве
Анализ статистики и опыта эксплуатации многодисковых серверов показывает, что вероятность выхода из строя все же выше, чем ожидается изначально. Неужели производители дисков не готовы ещё к выпуску достаточно надёжных изделий, позволяющих не заботиться об их сроке службы, как мы не заботимся о сроке службы памяти или процессоров, установленных в видеосервер? А что значит увеличенная вероятность выхода из строя HDD в многодисковых видеосерверах и в RAID-массивах? Попробуем обратиться к школьному курсу математики.

Потом-потом
Прислали новый диск для HP MSA 2040, со второй попытки диск встал успешно, пришлось ехать в ЦОД ещ1 раз.
Диск 2. СХД HP MSA 2040
Второй диск меняю в СХД MSA 2040. Ранее уже менял подобные диски:
Диск HDD 900ГБ, форм-фактор 2.5', поставляется с салазками для MSA. Для управления дисками используется утилита Storage Management Utility, вот так там выглядит дохлый диск:

Он же на MSA с оранжевым светодиодом:

Извлекаю старый диск.


Распаковываю новый диск.

Устанавливаю новый диск.


Теперь нужно зайти в Storage Management Utility и добавить этот диск как Global Spare.

Сразу скажу, что после этого новый диск вышел из строя. Жду ответа техподдержки, замена диска оказалась неуспешной.
Вероятность выхода из строя HDD в RAID массиве
Вначале мы сказали о том, что статистика выходов из строя HDD показывает, что в составе RAID массивов жесткие диски выходят из строя в несколько раз чаще. Означает ли это, что RAID-массив портит диски?

В процент полного отказа жёсткого диска, который и указан в документации производителя, не заложены случаи, когда работа жесткого диска нарушена частично, но RAID-массив, заранее подстраховываясь и основываясь на состоянии диска, прогнозирует его дальнейшее поведение, исключая такой диск из работы до его полного выхода из строя. И по обращениям в техническую поддержку и сервисный центр компании Видеомакс, именно такое состояние, когда жёсткий диск ещё совершенно работоспособен, но работа массива уже нарушена, является наиболее частой причиной выхода из строя HDD в массиве.
Если принять, что вероятность отторжения диска из массива в два раза выше, чем вероятность его полной поломки, то таблица с вероятностью поломки HDD в массиве выглядит следующим образом:
| Кол-во HDD в RAID массиве на сервере | 1 год | 2 года | 3 года |
|---|---|---|---|
| 2 | 6% | 12% | 18% |
| 3 | 8% | 16% | 24% |
| 4 | 12% | 24% | 36% |
| 5 | 14% | 28% | 42% |
| 6 | 18% | 36% | 54% |
| 7 | 20% | 40% | 60% |
| 8 | 22% | 44% | 66% |
| 9 | 26% | 52% | 78% |
| 10 | 28% | 56% | 84% |
| 11 | 30% | 60% | 90% |
| 12 | 34% | 68% | 102% |
| 13 | 36% | 72% | 108% |
| 14 | 38% | 76% | 114% |
| 15 | 40% | 80% | 120% |
| 16 | 42% | 84% | 126% |
| 17 | 46% | 92% | 138% |
| 18 | 48% | 96% | 144% |
| 19 | 50% | 100% | 150% |
| 20 | 52% | 104% | 156% |
| 21 | 54% | 108% | 162% |
| 22 | 56% | 112% | 168% |
| 23 | 58% | 116% | 174% |
| 24 | 60% | 120% | 180% |
Из таблицы видно, что вероятность выхода из строя HDD в 24-х дисковом видеосервере в течении 2-х лет составляет больше 100%, а в течении 3-х лет почти 200%. Т.е. жёсткий диск в RAID-массиве обязательно выйдет из строя даже в гарантийный период эксплуатации оборудования.
Означает ли это, что не стоит объединять HDD в RAID-массив? Возможно тогда они прослужат дольше? Диски вне RAID прослужат дольше, это факт. Но рано или поздно диски все равно доработают до своего полного износа, и тогда заказчик потеряет архив, но в отличие от RAID-массива, уже безвозвратно. О RAID мы подробно рассказывали в одной из статей на нашем сайте.
Диск 1. Сервер Supermicro
Первый диск будем менять в сервере Supermicro. Сервер Supermicro 4U: CSE-846BE16-R920B. Когда-то давно на нём собирали массивы:
Диск HDD 6ТБ, форм-фактор 3.5'. Вот так выглядит сбойный диск, красный светодиод манит админа.

Перед заменой диска необходимо убедиться, что проблема именно с диском. Сервер работает, выключить его нельзя. Соответственно, в утилиту Avago Config Utility для управления SAS-контроллером войти не удастся. На сервере работает операционная система Ubuntu. Для мониторинга состояния массива будем использовать утилиту storcli. Пример работы у меня уже есть, правда в Oracle Linux, но в данном случае это не принципиально:
Посмотрим, что у нас там с диском. Диск в состоянии "UBad-Unconfigured Bad". Всё понятно, нужно менять.
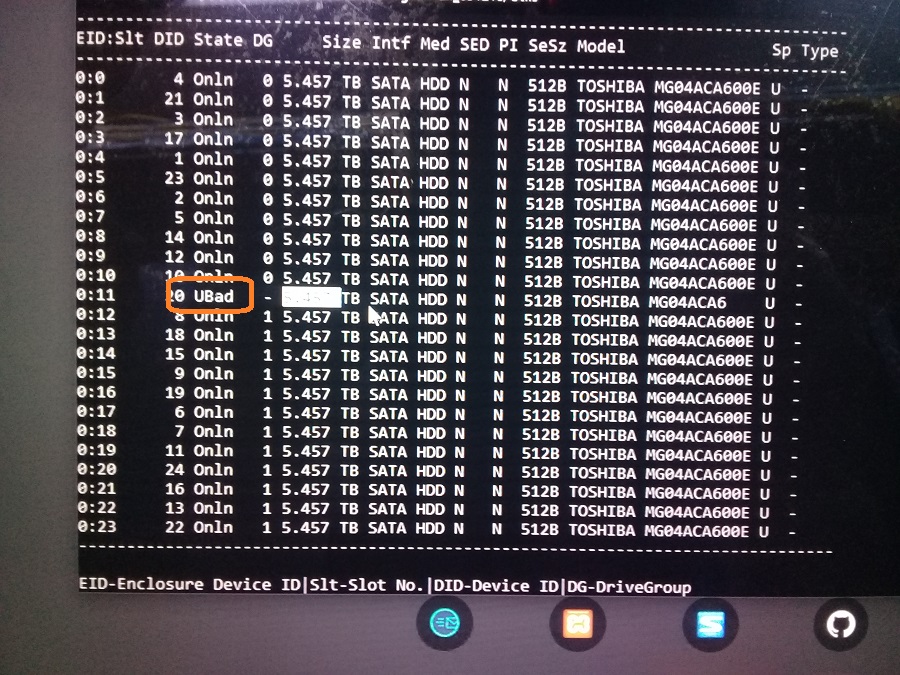
Данный сервер поддерживает горячую замену дисков, мне же проще. Выдергиваем старый диск.

Красный светодиод продолжает гореть на дисковой корзине. Перекручиваем салазки на новый диск.

Устанавливаем диск в слот.

После установки диска загорится синий диод, красный начнёт мигать.

Начинается перестроение массива. Перестроение займёт много времени, больше суток.

Потом, через пару дней проверил, массив в порядке:

Замена диска прошла без проблем.
Решения VIDEOMAX
Компания Видеомакс уже более 10 лет занимается производством видеосерверов, и всё это время мы тщательно изучаем вопросы надёжности и долговечности работы жестких дисков. За эти годы нами накоплен огромный опыт в этом направлении, которым мы готовы поделиться с читателем, и который мы учитываем при проектировании изделий VIDEOMAX. Тем более, что подобных исследований практически не встречается в общедоступных источниках, и даже ни один производитель жестких дисков не сможет ответить на вопросы, которые встают перед нами в процессе создания высоконадёжных решений для систем видеонаблюдения.
Меры обеспечения долгой и бесперебойной работы системы видеонаблюдения от VIDEOMAX:
- При производстве изделий VIDEOMAX мы используем жесткие диски исключительно серверного класса. Об этом мы подробно рассказывали в нашей статье «Жесткие диски для видеонаблюдения».
- Дисковые массивы более 24-х Тб доступны исключительно в решениях класса Pro. Дисковые массивы собранные в RAID6 гарантируют сохранение работоспособности видеосервера при выходе до 2-х дисков из строя в изделиях VIDEOMAX-Pro.
- Мы предлагаем комплекты запасных частей для видеосервера, содержащие необходимое количество дисков и других запасных частей для оперативной замены вышедших из строя. VIDEOMAX-ZIP содержат в своем составе жесткие диски того же номинала и прошивки, что и используемые при производстве изделия VIDEOMAX.
На собственном опыте и статистике эксплуатации наших решений мы рассчитали зависимость необходимого количества жестких дисков от срока эксплуатации изделия и, позаботившись о своих партнёрах, избавили их от мучительных расчётов, представив удобную систему подбора комплектов ЗИП. Причем, мы учли не только вероятность выхода из строя жестких дисков, но также и других уязвимых, по собранной нами статистике, частей видеосервера, таких как вентиляторы и блоки питания. Такой набор комплектующих позволит не заботиться администратору об оперативном приобретении неисправной комплектующей в течение всего срока эксплуатации оборудования.

Решил написать эту статью после знакомства с публикацией «HP, Dell и IBM: компоненты, отвечающие за надёжность сервера», поскольку имею другое мнение насчёт некоторых моментов. Эта статья не претендует на инновационные подходы, а просто описывает полученный опыт и, надеюсь, предотвратит банальные ошибки.
Итак, начнём с того, что попробуем выяснить, зачем бесперебойность и беспрерывность серверам? Собственно, серверам бесперебойность не обязательна, но она нужна сервисам, которые предоставляют эти сервера. Наилучшая беспрерывность обеспечивается только распределёнными системами, которые могут функционировать независимо друг от друга с автоматическим переключением между ними (для скорости) и разнесённые географически (катастрофоустойчивость). Но это выдвигает особые (не всегда реализуемые) требования к программному обеспечению. Недостатками таких решений являются повышеная стоимость, проблемы с репликацией данных, передача состояния для бесшовного переключения на резервную систему. Дополнительными плюсами является то, что при правильной реализации системы, возможно повышение быстродействия — клиенты делятся между двумя или более локациями, а при сбое перераспределяются.
Но есть задачи, настолько критичные и специфические, что требуют особой бесперебойности серверов, для них делают особые сервера, например менфреймы, с возможностью горячей замены всех компонентов, включая процессоры, память и даже материнские платы. Но такие решения стоят гораздо дороже обычных серверов и те кто их покупает — понимаю зачем это надо.
Вернёмся к серверам начального и среднего уровней. Существенно повышает беспрерывность работы серверов возможность горячей замены компонентов.
Наиболее важные атрибуты S.M.A.R.T.
Из таблицы SSD дисков INTEL
Весовые значения параметров - чем больше тем важнее. Значение 0 определено для параметров имеющих в основном статистическое значение.
У SSD дисков есть ограничение на количество циклов перезаписи. Производители для разных моделей иногда сообщают о лимите от 3000 до 100000 циклов. А параметры 233, 241, 242, 249 позволяют оценить какая часть этого ресурса уже использована.
Худшие сбои в работе персональных компьютеров связаны с блоками питания и жесткими дисками. Первое из этих устройств может привести к сгоранию или серьезному повреждению других компонентов, а второе – к потере сохраненных файлов – их восстановление занимает много времени, очень дорого, а иногда невозможно.
Конечно, независимо от качества и типа используемого жесткого диска, всегда стоит иметь копии самых важных файлов. Но, не менее полезно знать возможности оборудования, чтобы точно понимать, когда мы можем ожидать проблем.
Срок службы SSD
Доступность полупроводниковых дисков увеличивается. Это связано с падением цен на оборудование, благодаря которому большее количество пользователей может позволить себе SSD накопители.
Стоит ли переходить с HDD на твердотельную модель? На самом деле, такое изменение приносит только пользу. Скорость SSD гораздо выше, чем у HDD, что лучше всего видно при работе операционной системы. Если вы решите использовать интерфейс M.2, программное обеспечение будет запускаться моментально.
Однако, значительное улучшение скорости действий – не единственное преимущество SSD. Стоит подчеркнуть, что полупроводниковые модели гораздо больше подходят для различных типов нагрузок, связанных с переносом оборудования или вибрациями, возникающими во время работы.
Всё благодаря использованию постоянной флеш-памяти. Благодаря этому, срок службы SSD значительно увеличивается.
Что важно, однако, многое в этом случае зависит от того, как устроена флэш-память. При покупке диска стоит обратить внимание на параметр, связанный с максимальным количеством циклов перезаписи. Мы можем приобрести устройство с более коротким (дешевле) или более длительным (дороже) сроком службы.
В любом случае, твердотельные накопители окажутся более надежными, чем модели HDD. Они способны работать гораздо дольше, чем упомянутые три года. Как правило, это время увеличивается вдвое. Конечно, есть способы продлить срок службы диска SSD.
Наиболее важным является уменьшение количества записей во флэш-ячейках с помощью специального буфера в оперативной памяти. Используя специальные программы, мы можем увеличить срок службы диска SSD.
Независимо от того, какой диск мы выберем, стоит регулярно следить за его работой. Используйте систему SMART, а также внешние программы. С их помощью мы можем проверить температуру диска, выявить ошибки, поврежденные сектора или другие критические проблемы. Таким образом, можно во время заметить, что диск работает не очень хорошо.

Сегодня не самый обычный пост, я еду в ЦОД менять и устанавливать диски. Любопытно, что все диски разные, оборудование тоже разное. Для мониторинга состояния дисков потребуется самые разные инструменты. Вроде бы всего 4 диска, а подходы самые разные. Поехали.
Диск 3. Сервер HP ProLiant DL360 Gen9
Третий диск меняю в сервере HP ProLiant DL360 Gen9. Не первый раз меняю диски в этих серверах:
Диск HDD 1ТБ, форм-фактор 2.5', поставляется с салазками. Битый диск светится оранжевым:

Для мониторинга состояния дисков в серверах ProLiant девятого поколения используется утилита iLO 4. Скриншоты не делал. но там тоже видно какой диск вышел из строя.
Извлекаю битый диск.

Устанавливаю новый диск.

Всё просто, салазки перекручивать не нужно, операция быстрая. На всех дисках массива горит индикатор "не извлекать", начинается перестроение массива.
Сколько лет выдержит диск – зависит от его типа
Как известно, на рынке мы можем найти два типа дисков – магнитные HDD и полупроводниковые SSD. Гибридные модели (SSHD) также продаются в некоторых магазинах, объединяя оба решения, но их доступность невелика.
В случае устройств с дисками HDD мы имеем дело с движущимися частями (пластинами и головками), поэтому они гораздо более уязвимы к механическим повреждениям, чем SSD-накопители, конструкция которых основана на флэш-памяти. Это, в основном, относится к ноутбукам, которые часто переносятся во время работы.

Все это означает, что HDD диски менее надежны, чем полупроводниковые модели. Многое также зависит от конкретных параметров диска.
Потом
Забегая вперёд можно сказать, что три из четырёх дисков встали нормально, массивы работают в штатном режиме. А вот четвёртый диск HP MSA 2040 подкачал, новый и не заработал. Техподдержка пока молчит.
Сколько выдержит диск HDD
Мы будем иметь дело с теоретически более слабыми устройствами. Как мы уже упоминали, их конструкция основана на движущихся деталях, которые демонстрируют довольно низкую устойчивость к ударам и другим типам нагрузок.
Стоит обратиться к статистике, которая показывает, что за первые 18 месяцев использования дисков HDD около 10 процентов из них выходят из строя. Конечно, на влияние на это оказывает режим их эксплуатации. Предел, после которого проблемы начинают накапливаться и диски чаще портятся, составляет 3 года. Это средний срок устойчивой работы дисков HDD.
Стоит помнить, что срок службы нашего жесткого диска HDD может быть продлен довольно легко. Однако, есть несколько важных правил, о которых следует помнить:
- Установка – свобода установки диска в персональные компьютеры значительна, но, устройства работают лучше, если они установлены в горизонтальном положении.
- Эксплуатация – наибольшее внимание следует уделить температурам, которые генерируются внутри корпуса. Мы можем легко проверить, как нагревается жесткий диск в настройках системы и с помощью специальных программ (например, HD Tune). Если температура слишком высокая, рассмотрите возможность установки дополнительного охлаждения или очистки существующего оборудования. Что важно, чрезмерный нагрев дисков часто происходит при установке большего количества дисков. При установке оставляйте между ними достаточно места, чтобы обеспечить эффективную циркуляцию воздуха.
- Стабильность – ещё раз стоит подчеркнуть подверженность HDD дисков различным вибрациям и другим нагрузкам. Важно монтировать устройство таким образом, чтобы оно не двигалось во время работы. Поэтому мы должны хорошо разместить их в направляющей и закрутить все винты. Когда дело доходит до ноутбуков, хорошей идеей будет ограничить перемещение всего устройства.
- Контроль – если с диском что-то не так, мы можем узнать это до отказа. Используя систему SMART или внешние программы, мы можем контролировать его состояние, а также выявлять любые ошибки. Благодаря этому, мы можем попытаться сохранить оборудование или хотя бы перенести ключевые данные в облако или на другой носитель.
Диск 4. Сервер HPE ProLiant DL360 Gen9. NVMe.
Четвёртый диск не получится установить в работающий сервер. Диск представляет собой PCIe плату NVMe.

Устанавливаем в сервер HPE ProLiant DL360 Gen9. Выключаем сервер, выдвигаем на салазках, снимаем крышку.

В данный сервер можно установить одну полноразмерную PCIe плату и две низкопрофильные. Второй и третий слоты я уже занял, диск будет устанавливаться в первый полноразмерный слот. Снимаю райзер, понадобится отвертка torx.

Кручу-верчу. В райзер устанавливается две PCIe платы. Одна уже установлена, устанавливаю вторую.

Диск в райзере. Устанавливаю райзер в сервер.

Закрываю крышку, включаю сервер. NVMe платы нельзя собрать в RAID через имеющийся RAID контроллер, у меня они собраны с помощью mdadm в операционной системе Ubuntu. Два диска были в RAID1, третий диск позволит увеличить объём массива в два раза, с преобразованием RAID1 в RAID5.
S.M.A.R.T.
Для определения статуса диска обычно используется технология оценки состояния жёсткого диска встроенной аппаратурой самодиагностики, а также механизм предсказания времени выхода его из строя - S.M.A.R.T. (англ. self-monitoring, analysis and reporting technology)
В отчетах S.M.A.R.T. содержатся данные:
ATTRIBUTE_NAME – название атрибута. Так как разные фирмы производители дисков могут называть атрибуты по своему (сокращать, синонимы), лучше всего ориентироваться по ID атрибута.
TYPE - некоторые из программ в данном необязательном поле отображают информацию из флажков атрибутов или признаки их критичности (Critical или Pre-Fail , отражающих ухудшение характеристик оборудования, и Old-age для атрибутов, отражающих выработку ресурса);
Математический метод. Теория вероятности
Давайте попробуем рассмотреть видеосервер с установленными дисками как модель устройства, состоящего из совокупности компонентов с одинаковой вероятностью выхода из строя. Формула выглядит следующим образом …
Где p - вероятность выхода из строя одного HDD, а n – количество дисков в массиве. Для дисков Seagate® Constellation® ES.2 эту величину можно приравнять к годовой интенсивности отказов равной 0,73%.
Воспользовавшись формулой, мы получаем таблицу, где указана вероятность выхода из строя хотя бы одного HDD в зависимости от количества жестких дисков в составе сервера видеонаблюдения и в зависимости от количества лет эксплуатации изделия. По уверениям производителей вероятность поломки одного HDD в первые три года эксплуатации практически одинакова по годам. Это подтверждается и данными статистики отказов из сервисного центра Видеомакс. Итак, расчётные данные по вышеприведённой формуле следующие:
| Кол-во HDD в сервере | 1 год | 2 года | 3 года |
|---|---|---|---|
| 2 | 3% | 6% | 9% |
| 3 | 4% | 8% | 12% |
| 4 | 6% | 12% | 18% |
| 5 | 7% | 14% | 21% |
| 6 | 9% | 18% | 27% |
| 7 | 10% | 20% | 30% |
| 8 | 11% | 22% | 33% |
| 9 | 13% | 26% | 39% |
| 10 | 14% | 28% | 42% |
| 11 | 15% | 30% | 45% |
| 12 | 17% | 34% | 51% |
| 13 | 18% | 36% | 54% |
| 14 | 19% | 38% | 57% |
| 15 | 20% | 40% | 60% |
| 16 | 21% | 42% | 63% |
| 17 | 23% | 46% | 69% |
| 18 | 24% | 48% | 72% |
| 19 | 25% | 50% | 75% |
| 20 | 26% | 52% | 78% |
| 21 | 27% | 54% | 81% |
| 22 | 28% | 56% | 84% |
| 23 | 29% | 58% | 87% |
| 24 | 30% | 60% | 90% |
Расчетные данные показывают, что вероятность выхода из строя одного HDD в изделии много больше, чем сумма вероятностей каждого из жестких дисков, входящих в состав изделия. Этот результат подтверждает реальная статистика и опыт.
Читайте также: