
Что такое блокировка конвейера в процессоре
Конвейер команд. Конвейеризация — способ обеспечения параллельности выполнения команд
Первым шагом на пути обеспечения параллельности уровня команд явилось создание конвейера команд. Идея конвейера команд была предложена в 1956 году С.А. Лебедевым. Команда подразделяется на несколько этапов, каждый из которых выполняется своей частью аппаратуры, причем, эти части могут работать параллельно. Если на выполнение каждого этапа расходуется одинаковое время (один такт), то на выходе процессора в каждый такт появляется результат очередной команды. Производительность при этом возрастает благодаря тому, что одновременно на различных ступенях конвейера выполняется несколько команд. Конвейерная обработка такого рода широко применяется во всех современных быстродействующих процессорах. Количество этапов, на которые конструкторы разбивают выполнение процессорной команды, может быть различным (в разных моделях процессоров х86 колеблется от 2 i8088 до 20 Pentium IV).
Конвейеризация — способ обеспечения параллельности выполнения команд
Выполнение типичной команды можно разделить на следующие этапы:
- выборка команды — IF (по адресу, заданному счетчиком команд, из памяти извлекается команда);
- декодирование команды / выборка операндов из регистров — ID;
- выполнение операции / вычисление эффективного адреса памяти — EX;
- обращение к памяти — MEM;
- запоминание результата — WB.
В зависимости от типа команды и способа адресации, время выполнения команды сильно варьируется. Дольше всего выполняются этапы, связанные с обращением к памяти. На рисунках показаны блоки и конвейер команд гипотетического процессора, имеющего пять блоков исполнения команд и соответственно пять этапов (ступеней). Изображены выполняемые команды, номера тактов и этапы выполнения команд. На первом такте считывается первая команда. На втором, пока декодируется первая команда, считывается вторая. На пятом такте в процессоре одновременно находятся пять команд, каждая в своем узле.

Блоки прохождения команды в процессоре
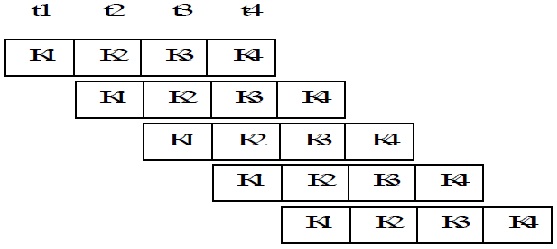
Пятиступенчатая схема конвейера
Конвейеризация увеличивает пропускную способность процессора (количество команд, завершающихся в единицу времени), но она не сокращает время выполнения отдельной команды. Имеются некоторые накладные расходы на конвейеризацию, возникающие в результате несбалансированности задержки на каждой его ступени. Частота синхронизации (такт синхронизации) не может быть выше, чем время, необходимое для работы наиболее медленной ступени конвейера. Конвейер не всегда представляет собой линейную цепочку этапов. В ряде ситуаций оказывается выгодным, когда функциональные блоки соединены между собой не последовательно, а в соответствии с логикой обработки. Отдельные блоки в цепочке могут пропускаться, а другие — образовывать циклические процедуры. Это позволяет с помощью одного конвейера вычислять более одной функции.
Поток команд — естественная последовательность команд, проходящая по конвейеру процессора. Процессор может поддерживать несколько потоков команд (суперпроцессоры 5 и 6 поколения), если для каждого потока и каждого этапа есть исполнительные элементы.
Суперконвейер команд — разбиение каждой ступени на подступени при одновременном увеличении тактовой частоты внутри конвейера; включение в состав процессора многих конвейеров, работающих с перекрытием. Дробление ступеней позволяет поднять тактовые частоты процессора. К суперконвейерным относятся процессоры, в которых число ступеней больше шести (см. таблицу).
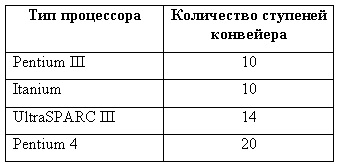
Суперконвейер
Наверняка вы знаете, что такое прерывания. Возможно, даже интересовались устройством процессора. Почти наверняка вы нигде не видели внятный рассказ про то, как именно процессор обнаруживает прерывание, переходит к обработчику и, самое главное, возвращается из него именно туда, куда положено.
Я писал эту статью год. Изначально она была рассчитана на хардварщиков. Понимание того, что я ее никогда не закончу, а также жажда славы и желание, чтобы ее прочло больше десяти человек, заставило меня адаптировать ее для относительно широкой аудитории, повыкидывав схемы, куски кода на Верилоге и километры временных диаграмм.
Если когда-нибудь вы задумывались над тем, что значат слова «the processor supports precise aborts» в даташите, прошу под кат.
Немного терминологии: процессор, процессы и прерывания
- Процессоры с экзотическими архитектурами (стековыми, потоковыми, асинхронными и так далее), потому что их доля на рынке весьма мала, а в качестве примера логичнее использовать распространенную архитектуру. RISC я выбрал исключительно по религиозным соображениям
- Многоядерные процессоры, потому что каждое процессорное ядро обрабатывает свои прерывания независимо от других ядер
- Суперскалярные, многопоточные и VLIW процессоры, потому что с точки зрения организации прерываний они похожи на скалярные процессоры (хотя, разумеется, гораздо сложнее).
- Выборка команды из памяти
- Декодирование команды
- Исполнение команды
- Запись результатов в регистры и/или память
Процессор с параллельным выполнением команд может выполнять несколько команд одновременно. Например, процессор с четырехстадийным конвейером команд может одновременно записывать результаты первой команды, испонять вторую, декодировать третью и выбирать из памяти четвертую.
- счетчика команд процессора (program counter, он же instruction pointer)
- регистров процессора (общего назначения, статусных, флагов и так далее)
- оперативной памяти
- арифметические и логические команды обновляют содержимое регистров и счетчика команд
- команды перехода обновляют содержимое счетчика команд и таблицы динамического предсказания переходов
- команды загрузки обновляют содержимое регистров, счетчика команд и кэш-памяти (при промахе кэша; если потребуется замещение линии кэша — то еще и оперативной памяти)
- команды сохранения обновляют содержимое оперативной памяти (или кэш-памяти) и счетчика команд
- Внутренним, если вызвано выполнением команды в процессоре:
- Программным (software interrupt), если вызвано специальной командой
- Исключением (exception, fault, abort – это все оно), если вызвано ошибкой при выполнении команды
- Внешним, если вызвано произошедшим снаружи процессора событием
- процессор сохраняет счетчик команд в специальный регистр адреса возврата (РАВ), одновременно записывая вектор прерывания в счетчик команд, запуская таким образом обработчик прерывания
- все прочие элементы состояния процесса сохраняются обработчиком прерывания при необходимости (например, прежде чем использовать регистры, он должен сохранить их содержимое в стек)
- перед завершением обработчика прерывания он должен восстановить все элементы состояния процесса, которые изменял (например, восстановить содержимое регистров, сохраненное в стек)
- обработчик прерывания завершается командой возврата из прерывания, которая записывает содержимое РАВ обратно в счетчик команд, то есть возвращает управление прерванному процессу
Точные и неточные прерывания
Программные прерывания и исключения могут быть точными или неточными. В некоторых случаях без точных исключений просто не обойтись — например, если в процессоре есть MMU (тогда, если случается промах TLB, управление передается соответствующему обработчику исключения, который программно добавляет нужную страницу в TLB, после чего должна быть возможность заново выполнить команду, вызвавшую промах).
В большинстве учебников по архитектуре компьютеров (включая классику типа Patterson&Hennessy и Hennessy&Patterson) точные прерывания обходятся стороной. Кроме того, неточные прерывания не представляют никакого интереса. По-моему, это отличные причины продолжить рассказ именно про точные прерывания.
Точные прерывания в процессорах с последовательным выполнением команд
Для процессоров с последовательным выполнением команд реализация точных прерываний довольно проста, поэтому представляется логичным начать с нее. Поскольку в каждый момент времени выполняется только одна команда, то в момент обнаружения прерывания все команды, предшествующие прерываемой, уже выполнены, а последующие даже не начаты.
Таким образом, для реализации точных прерываний в таких процессорах достаточно убедиться, что прерываемая команда никогда не обновляет состояние процесса до тех пор, пока не станет ясно, вызвала она исключение или нет.
Место, где процессор должен определить, позволить ли команде обновить состояние процесса или нет, называется точкой фиксации результатов (commit point). Если процессор сохраняет результаты команды, то есть команда не вызвала исключение, то говорят, что эта команда зафиксирована (на сленге — закоммичена).
- Выборка команды из памяти
- Декодирование команды
- Исполнение команды
- Запись результатов в регистры и/или память
- ошибка памяти при выборке команды
- неизвестный код операции при декодировании
- деление на ноль при исполнении
- ошибка памяти при записи результатов
- нельзя фиксировать команду и разрешать ей записывать результаты в память до тех пор, пока не станет ясно, что команда не вызвала исключение
- нельзя узнать, что исключение не вызвано, не записав результаты в память (для этого нужно получить подтверждение от контроллера памяти, что запись произведена успешно)
Как можно догадаться, эту проблему довольно сложно решить, поэтому во многих процессорах для простоты реализованы «почти точные» прерывания, то есть точными сделаны все прерывания, кроме исключений, вызванных ошибками памяти при записи результатов. В этом случае точка фиксации результатов находится между третьим и четвертым этапами цикла команды.
Важно! Нужно помнить, что счетчик команд тоже должен обновляться строго после точки фиксации результатов. При этом он изменяется вне зависимости от того, зафиксирована команда или нет — в него записывается либо адрес следующей команды, либо вектор прерывания, либо РАВ.
Точные прерывания в процессорах с параллельным выполнением команд
На сегодняшний день процессоров с последовательным выполнением команд почти не осталось (могу вспомнить разве что аналоги интеловского 8051) — их вытеснили процессоры с параллельным выполнением команд, обеспечивающие при прочих равных более высокую производительность. Простейший процессор с параллельным выполнением команд — процессор с конвейером команд (instruction pipeline).
Несмотря на многочисленные преимущества, конвейер команд значительно усложняет реализацию точных прерываний, чем много десятков лет печалит разработчиков.
В процессоре с последовательным выполнением команд этапы цикла команды зависят друг от друга. Простейший пример — счетчик команд. Вначале он используется на этапе выборки (как адрес в памяти, откуда должна быть прочитана команда), затем на этапе исполнения (для вычисления его следующего значения), и потом, если команда зафиксирована, он обновляется на этапе записи результатов. Это приводит к тому, что нельзя выбрать следующую команду до тех пор, пока предыдущая не завершит последний этап и не обновит счетчик команд. То же самое относится и ко всем прочим сигналам внутри процессора.
Процессор с конвейером команд можно получить из процессора с последовательным выполнением команд, если сделать так, чтобы каждый этап цикла команды был независим от предыдущих и последующих этапов.
- Результат выборки — закодированная команда — сохраняется в регистре, расположенном между этапами выборки и декодирования
- Результат декодирования — тип операции, значения операндов, адрес результата — сохраняются в регистрах между этапами декодирования и исполнения
- Результаты исполнения — новое значение счетчика команд для условного перехода, вычисленный в АЛУ результат арифметической операции и так далее — сохраняются в регистрах между этапами исполнения и записи результатов
- На последнем этапе результаты и так записываются в регистры и/или память, поэтому никакие вспомогательные регистры не нужны.
Производительность процессора немного упала, не так ли? На самом деле, решение лежит на поверхности – нам нужно два счетчика команд! Один должен находиться в начале конвейера и указывать, откуда читать команды, второй – в конце, и указывать на ту команду, которая должна быть зафиксирована следующей.
Первый называется «спекулятивным», второй – «архитектурным». Чаще всего спекулятивный счетчик команд не существует сам по себе, а встроен в предсказатель переходов. Выглядит это вот так:
- Если пришло внешнее прерывание, команда коммитится, но адрес следующей команды записывается не в АСК, а в РАВ. В АСК записывается адрес вектора прерывания.
- Если возникло исключение, команда не коммитится, вместо этого в АСК записывается адрес вектора соответсвующего исключения, а адрес команды записывается в РАВ.
- Если адрес команды не равен АСК, она тоже не коммитится (об этом позже). Если адрес равен АСК и исключения не произошло – процессор фиксирует команду и обновляет АСК (записывает адрес перехода в случае команды ветвления или просто инкрементирует в случае другой команды)
На этом все. Разумеется, показаный четырехстадийный конвейер прост до невозможности. На самом деле, некоторые команды могут исполняться более одного такта, и даже простой микроконтроллер умеет завершать их не в том порядке, в котором он запустил их на выполнение, при этом обеспечивая точность прерываний. Однако общий принцип организации прерываний, смею вас заверить, остается тем же.
Конфликты - это такие ситуации в конвейерной обработке , которые препятствуют выполнению очередной команды в предназначенном для нее такте.
Конфликты делятся на три группы:
- структурные,
- по управлению,
- по данным.
Структурные конфликты возникают в том случае, когда аппаратные средства процессора не могут поддерживать все возможные комбинации команд в режиме одновременного выполнения с совмещением.
Причины структурных конфликтов:
Не полностью конвейерная структура процессора, при которой некоторые ступени отдельных команд выполняются более одного такта.
Пусть этап выполнения команды i+1 занимает 3 такта. Тогда диаграмма работы конвейера будет иметь вид, представленный в табл. 9.3.
В этом случае в работе конвейера возникают так называемые "пузыри" ( pIPelINe bubble ) в обработке команд i+2 и следующих за ней начиная с такта 6, которые снижают производительность процессора.
Если какой-то блок конвейера вносит задержку, то тормозится работа всего конвейера. Образуемый при этом "пузырь" должен пройти от места своего возникновения до самого конца конвейера (если, например, возникла задержка на ступени считывания команды, то в следующем такте блок декодирования от него ничего не получит, а через 3 такта соответственно блок сохранения результатов ничего не получит от блока выполнения). Таким образом, скорость конвейера определяется скоростью самой медленной его ступени.
Этой ситуации можно было бы избежать двумя способами. Первый предполагает увеличение времени такта до такой величины, которая позволила бы все этапы любой команды выполнять за один такт. Однако при этом существенно снижается эффект конвейерной обработки , так как все этапы всех команд будут выполняться значительно дольше, в то время как обычно нескольких тактов требует выполнение лишь отдельных этапов очень небольшого количества команд. Второй способ предполагает использование таких аппаратных решений, которые позволили бы значительно снизить затраты времени на выполнение действия, приводящего к появлению "пузырей" (например, использовать матричные схемы умножения). Но это приведет к усложнению схемы процессора и сокращению на кристалле места для реализации на этой БИС других, функционально более важных узлов. Так как представленная в табл. 9.3 сcитуация возникает при реализации команд, относительно редко встречающихся в программе, то обычно разработчики процессоров ищут компромисс между увеличением длительности такта и усложнением того или иного устройства процессора.
Одним из типичных примеров таких конфликтов служит конфликт из-за доступа к запоминающим устройствам . Из табл. 9.1 ввидно, что в случае, когда операнды и команды находятся в одном запоминающем устройстве начиная с такта 3, работу конвейера придется постоянно приостанавливать, поскольку различные команды в одном и том же такте обращаются к памяти на считывание команды, выборку операнда, запись результата.
Борьба с конфликтами такого рода проводится путем увеличения количества однотипных функциональных устройств, которые могут одновременно выполнять одни и те же или схожие функции. В запоминающих устройствах в современных микропроцессорах с этой целью разделяют кэш- память для хранения команд и кэш- память данных , а также используют многопортовую схему доступа к регистровой памяти, при которой к регистрам можно одновременно обращаться по нескольким каналам для записи и считывания информации. Например, в микропроцессоре Itanium к блоку регистров общего назначения допускается одновременное обращение на выполнение 8 операций чтения и 6 операций записи. Конфликты из-за исполнительных устройств обычно сглаживаются введением в состав микропроцессора дополнительных блоков. Так, в микропроцессоре Pentium 4 для обработки целочисленных данных предусмотрено 4 АЛУ . При этом появляется возможность параллельной обработки информации в нескольких конвейерах. Процессоры, имеющие в своем составе более одного конвейера, называются суперскалярными.
Недостатком суперскалярных микропроцессоров является необходимость синхронного продвижения команд в каждом из конвейеров. В табл. 9.4 п представлена последовательность выполнения команд в микропроцессоре, имеющем два конвейера, при условии, что команде К1 требуется 3 такта на этапе EX .
При этом команды будут завершаться в порядке, отличающемся от того, который предусмотрен программой: К2-К4-К1-К6-.. .
Следовательно, для обеспечения правильной работы суперскалярного микропроцессора при возникновении затора в одном из конвейеров должны приостанавливать свою работу и другие. В противном случае может нарушиться исходный порядок завершения команд программы. Но такие приостановки существенно снижают быстродействие процессора.
Разрешение этой ситуации состоит в том, чтобы дать возможность выполняться командам в одном конвейере вне зависимости от ситуации в других конвейерах, а аппаратные средства микропроцессора должны гарантировать, что результаты выполненных команд будут записаны в приемник в том порядке, в котором команды записаны в программе. Это обеспечивается путем использования так называемого принципа неупорядоченного выполнения команд. Суть его заключается в следующем. Блок выборки и декодирования выбирает команды из памяти и заносит их в буфер команд. По мере готовности операндов и исполнительного блока соответствующего типа команды извлекаются из буфера для обработки. Порядок их исполнения может отличаться от предписанного программой.
Результаты этапа выполнения команды сохраняются в специальном буфере восстановления последовательности команд. Запись результата очередной команды из этого буфера в приемник результата проводится лишь после того, как выполнены все предшествующие команды и записаны их результаты. Преимущества такого подхода очевидны: команды максимально используют возможности всех конвейеров, присутствующих в микроархитектуре микропроцессора, что обеспечивает его максимальную производительность .
Конфликты по управлению возникают при конвейеризации команд переходов и других команд, изменяющих значение счетчика команд .
Суть конфликтов этой группы наиболее удобно проиллюстрировать на примере команд условного перехода . Пусть в программе, представленной в табл. 9.1, команда i+1 является командой условного перехода , формирующей адрес следующей команды в зависимости от результата выполнения команды i . Команда i завершит свое выполнение в такте 5. В то же время команда условного перехода уже в такте 3 должна прочитать необходимые ей признаки, чтобы правильно сформировать адрес следующей команды. Если конвейер имеет большую глубину (например, 20 ступеней), то промежуток времени между формированием признака результата и тактом, где он анализируется, может быть еще больше.
Простейший способ разрешения этой ситуации - использование так называемого метода выжидания. Он заключается в замораживании операций в конвейере путем блокировки выполнения любой команды, следующей за командой условного перехода , до тех пор, пока не станет известным направление перехода. Привлекательность такого решения заключается в его простоте. Главный недостаток - резкое уменьшение преимуществ конвейерной обработки . В инженерных задачах примерно каждая шестая команда является командой условного перехода , поэтому приостановки конвейера при выполнении команд переходов до определения истинного направления перехода существенно скажутся на производительности процессора.
Можно несколько улучшить эту ситуацию, использую схему "задержанных переходов". При этом на стадии компиляции компилятор таким образом структурирует получаемый объектный код, чтобы сделать команды, следующие за командой перехода, действительными и полезными (рис. 9.1).
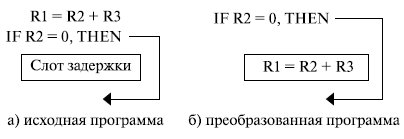
Слот задержки заполняется независимой командой, находящейся перед командой условного перехода . Эта команда выполняется за то время, пока микропроцессор формирует истинное условие, по которому должно быть определено направление выполнения программы. Одной из основных трудностей в этом подходе является определение точного времени выполнения команды, вносимой в слот задержки. Аппаратура должна гарантировать реальное выполнение этих команд перед выполнением собственно перехода.
Более эффективными для снижения потерь от конфликтов по управлению являются методы предсказания переходов. Они призваны максимально ускорить определение адреса команды, выполняемой после команды перехода .
Так как преимущества конвейерной обработки проявляются при большом числе последовательно выполненных команд, перезагрузка конвейера приводит к значительным потерям производительности. Поэтому вопросам эффективного предсказания направления ветвления разработчики всех микропроцессоров уделяют большое внимание.
Среди основных достоинств практически каждого нового микропроцессора производители анонсируют "улучшенный блок предсказания переходов". Суть конкретных механизмов, обеспечивающих эти улучшения, как правило, не детализируется. Однако здесь все-таки можно выделить несколько основных подходов.
Методы предсказания переходов делятся на статические и динамические. При использовании статических методов до выполнения программы для каждой команды условного перехода указывается направление наиболее вероятного ветвления. Это указание делается программойкомпилятором по заложенным в ней алгоритмам. Подобный подход реализован, например, в HP PA-8x00. Также это может делать и сам программист по опыту выполнения аналогичных программ либо по результатам тестового выполнения программы. Например, в системе команд микропроцессора Itanium для этого предназначена специальная команда .
Суть данного метода заключается в том, что при выполнении команды условного перехода специальный блок микропроцессора определяет наиболее вероятное направление перехода, не дожидаясь формирования признаков, на основании анализа которых этот переход реализуется.
Процессор начинает выбирать из памяти и выполнять команды по предсказанной ветви программы (так называемое исполнение по предположению, или "спекулятивное" исполнение ). Однако так как направление перехода может быть предсказано неверно, получаемые результаты с целью обеспечения возможности их аннулирования не записываются в память или регистры (то есть для них не выполняется этап WB ), а накапливаются в специальном буфере результатов.
Если после формирования анализируемых признаков оказалось, что направление перехода выбрано верно, все полученные результаты переписываются из буфера по месту назначения и выполнение программы продолжается в обычном порядке. Если направление перехода предсказано неверно, все инструкции, выбранные после перехода, помечаются, согласно интеловской терминологии, как поддельные ( bogus INsTRuctions ).
При этом буфер результатов и конвейер, содержащий команды, которые следуют за командой условного перехода и находятся на разных этапах обработки, - очищаются. Аннулируются результаты всех уже выполненных этапов этих команд. Конвейер начинает загружаться с первой команды другой ветви программы.
Следует отметить, что конфликты по управлению не исчерпываются только проблемами, связанными с командами условных переходов. Они возникают при выполнении всех команд, меняющих значение счетчика команд . Это хорошо видно из табл. 9.1. Если команда i является командой такого типа (например, команда безусловного перехода), то адрес перехода будет вычислен ею в такте 5, в то время как уже в такте 2 необходимо выбирать в микропроцессор следующую команду по этому адресу.
Методы динамического предсказания реализуются при выполнении программы в микропроцессоре. Они осуществляют предсказание направления переходов на основании результатов предыдущих выполнений данной команды.
При использовании этих методов для команд условных переходов анализируется предыстория переходов - результаты нескольких предыдущих команд ветвления по данному адресу. В этом случае возможно определение чаще всего реализуемого направления ветвления, а также выявление чередующихся переходов.
Для команд безусловных переходов однажды вычисленный целевой адрес сохраняется в специальной памяти BTB ( Branch Target Buffer ), откуда он извлекается сразу же при декодировании данной команды.
Аналогичный подход используется для команд вызова - возврата из процедуры ( анализ связок CALL - RETURN ).
Значительное преимущество конвейерной обработки перед последовательной имеет место в идеальном конвейере , в котором отсутствуют конфликты и все команды выполняются друг за другом без перезагрузки конвейера . Наличие конфликтов снижает реальную производительность конвейера по сравнению с идеальным случаем.
Конфликты - это такие ситуации в конвейерной обработке, которые препятствуют выполнению очередной команды в предназначенном для нее такте .
Конфликты делятся на три группы:
- структурные ,
- по управлению ,
- по данным.
Структурные конфликты возникают в том случае, когда аппаратные средства процессора не могут поддерживать все возможные комбинации команд в режиме одновременного выполнения с совмещением.
Причины структурных конфликтов .
Не полностью конвейерная структура процессора, при которой некоторые ступени отдельных команд выполняются более одного такта .
Пусть этап выполнения команды i+1 занимает 3 такта . Тогда диаграмма работы конвейера будет иметь вид, представленный в табл. 11.3.
При этом в работе конвейера возникают так называемые "пузыри" (обработка команд i+2 и следующих за ней, начиная с такта 6), которые снижают производительность процессора.
Эту ситуацию можно было бы ликвидировать двумя способами. Первый предполагает увеличение времени такта до такой величины, которая позволила бы все этапы любой команды выполнять за один такт . Однако при этом существенно снижается эффект конвейерной обработки , так как все этапы всех команд будут выполняться значительно дольше, в то время как обычно нескольких тактов требует выполнение лишь отдельных этапов очень небольшого количества команд. Второй способ предполагает использование таких аппаратных решений, которые позволили бы значительно снизить затраты времени на выполнение данного этапа (например, использовать матричные схемы умножения). Но это приведет к усложнению схемы процессора и невозможности реализации на этой БИС других, функционально более важных, узлов. Так как представленная в табл. 11.3 ситуация возникает при реализации команд, относительно редко встречающихся в программе, то обычно разработчики процессоров ищут компромисс между увеличением длительности такта и усложнением того или иного устройства процессора.
Недостаточное дублирование некоторых ресурсов.
Одним из типичных примеров служит конфликт из-за доступа к запоминающим устройствам. Из табл. 11.1 видно, что в случае, когда операнды и команды находятся в одном запоминающем устройстве, начиная с такта 3, работу конвейера придется постоянно приостанавливать, поскольку различные команды в одном и том же такте обращаются к памяти на считывание команды, выборку операнда, запись результата.
Борьба с конфликтами такого рода проводится путем увеличения количества однотипных функциональных устройств, которые могут одновременно выполнять одни и те же или схожие функции. Например, в современных микропроцессорах обычно разделяют кэш-память для хранения команд и кэш- память данных , а также используют многопортовую схему доступа к регистровой памяти, при которой к регистрам можно одновременно обращаться по одному каналу для записи, а по другому - для считывания информации. Конфликты из-за исполнительных устройств обычно сглаживаются введением в состав микропроцессора дополнительных блоков. Так, в микропроцессоре Pentium-4 предусмотрено 4 АЛУ для обработки целочисленных данных. Процессоры, имеющие в своем составе более одного конвейера , называются суперскалярными.
Недостатком суперскалярных микропроцессоров является необходимость синхронного продвижения команд в каждом из конвейеров . В табл. 11.4 представлена последовательность выполнения команд в микропроцессоре, имеющем два конвейера , при условии, что команде К1 требуется 3 такта на этапе EX .
При этом команды будут завершаться в последовательности
Следовательно, для обеспечения правильной работы суперскалярного микропроцессора при возникновении затора в одном из конвейеров должны приостанавливать свою работу и другие. В противном случае может нарушиться исходный порядок завершения команд программы. Но такие приостановки существенно снижают быстродействие процессора. Разрешение этой ситуации состоит в том, чтобы дать возможность выполняться командам в одном конвейере вне зависимости от ситуации в других конвейерах . Это приводит к неупорядоченному выполнению команд. При этом команды, стоящие в программе позже, могут завершиться ранее команд, стоящих впереди. Аппаратные средства микропроцессора должны гарантировать, что результаты выполненных команд будут записаны в приемник в том порядке, в котором команды записаны в программе. Для этого в микропроцессоре результаты этапа выполнения команды обычно сохраняются в специальном буфере восстановления последовательности команд. Запись результата очередной команды из этого буфера в приемник результата проводится лишь после того, как выполнены все предшествующие команды и записаны их результаты.
Конфликты по управлению возникают при конвейеризации команд переходов и других команд, изменяющих значение счетчика команд.
Суть конфликтов этой группы наиболее удобно проиллюстрировать на примере команд условного перехода. Пусть в программе, представленной в табл. 11.1, команда i+1 является командой условного перехода, формирующей адрес следующей команды в зависимости от результата выполнения команды i . Команда i завершит свое выполнение в такте 5. В то же время команда условного перехода уже в такте 3 должна прочитать необходимые ей признаки, чтобы правильно сформировать адрес следующей команды. Если конвейер имеет большую глубину (например, 20 ступеней), то промежуток времени между формированием признака результата и тактом , где он анализируется, может быть еще большим. В инженерных задачах примерно каждая шестая команда является командой условного перехода, поэтому приостановки конвейера при выполнении команд переходов до определения истинного направления перехода существенно скажутся на производительности процессора.
Наиболее эффективным методом снижения потерь от конфликтов по управлению служит предсказание переходов. Суть данного метода заключается в том, что при выполнении команды условного перехода специальный блок микропроцессора определяет наиболее вероятное направление перехода, не дожидаясь формирования признаков, на основании анализа которых этот переход реализуется. Процессор начинает выбирать из памяти и выполнять команды по предсказанной ветви программы (так называемое исполнение по предположению, или "спекулятивное" исполнение). Однако так как направление перехода может быть предсказано неверно, то получаемые результаты с целью обеспечения возможности их аннулирования не записываются в память или регистры (то есть для них не выполняется этап WB ), а накапливаются в специальном буфере результатов.
Если после формирования анализируемых признаков оказалось, что направление перехода выбрано верно, все полученные результаты переписываются из буфера по месту назначения, а выполнение программы продолжается в обычном порядке. Если направление перехода предсказано неверно, то буфер результатов очищается. Также очищается и конвейер , содержащий команды, находящиеся на разных этапах обработки, следующие за командой условного перехода. При этом аннулируются результаты всех уже выполненных этапов этих команд. Конвейер начинает загружаться с первой команды другой ветви программы. Так как конвейерная обработка эффективна при большом числе последовательно выполненных команд, то перезагрузка конвейера приводит к значительным потерям производительности. Поэтому вопросам эффективного предсказания направления ветвления разработчики всех микропроцессоров уделяют большое внимание.
Методы предсказания переходов делятся на статические и динамические. При использовании статических методов до выполнения программы для каждой команды условного перехода указывается направление наиболее вероятного ветвления. Это указание делается или программистом с помощью специальных средств, имеющихся в некоторых языках программирования, по опыту выполнения аналогичных программ либо результатам тестового выполнения программы, или программой-компилятором по заложенным в ней алгоритмам.
Методы динамического прогнозирования учитывают направления переходов, реализовывавшиеся этой командой при выполнении программы. Например, подсчитывается количество переходов, выполненных ранее по тому или иному направлению, и на основании этого определяется направление перехода при следующем выполнении данной команды.
В современных микропроцессорах вероятность правильного предсказания направления переходов достигает 90-95 %.
Конфликты по данным возникают в случаях, когда выполнение одной команды зависит от результата выполнения предыдущей команды.
При обсуждении этих конфликтов будем предполагать, что команда i предшествует команде j .
Конфликты - это такие ситуации в конвейерной обработке , которые препятствуют выполнению очередной команды в предназначенном для нее такте.
Конфликты делятся на три группы:
- структурные,
- по управлению,
- по данным.
Структурные конфликты возникают в том случае, когда аппаратные средства процессора не могут поддерживать все возможные комбинации команд в режиме одновременного выполнения с совмещением.
Причины структурных конфликтов:
Не полностью конвейерная структура процессора, при которой некоторые ступени отдельных команд выполняются более одного такта.
Пусть этап выполнения команды i+1 занимает 3 такта. Тогда диаграмма работы конвейера будет иметь вид, представленный в табл. 9.3.
В этом случае в работе конвейера возникают так называемые "пузыри" ( pIPelINe bubble ) в обработке команд i+2 и следующих за ней начиная с такта 6, которые снижают производительность процессора.
Если какой-то блок конвейера вносит задержку, то тормозится работа всего конвейера. Образуемый при этом "пузырь" должен пройти от места своего возникновения до самого конца конвейера (если, например, возникла задержка на ступени считывания команды, то в следующем такте блок декодирования от него ничего не получит, а через 3 такта соответственно блок сохранения результатов ничего не получит от блока выполнения). Таким образом, скорость конвейера определяется скоростью самой медленной его ступени.
Этой ситуации можно было бы избежать двумя способами. Первый предполагает увеличение времени такта до такой величины, которая позволила бы все этапы любой команды выполнять за один такт. Однако при этом существенно снижается эффект конвейерной обработки , так как все этапы всех команд будут выполняться значительно дольше, в то время как обычно нескольких тактов требует выполнение лишь отдельных этапов очень небольшого количества команд. Второй способ предполагает использование таких аппаратных решений, которые позволили бы значительно снизить затраты времени на выполнение действия, приводящего к появлению "пузырей" (например, использовать матричные схемы умножения). Но это приведет к усложнению схемы процессора и сокращению на кристалле места для реализации на этой БИС других, функционально более важных узлов. Так как представленная в табл. 9.3 сcитуация возникает при реализации команд, относительно редко встречающихся в программе, то обычно разработчики процессоров ищут компромисс между увеличением длительности такта и усложнением того или иного устройства процессора.
Одним из типичных примеров таких конфликтов служит конфликт из-за доступа к запоминающим устройствам . Из табл. 9.1 ввидно, что в случае, когда операнды и команды находятся в одном запоминающем устройстве начиная с такта 3, работу конвейера придется постоянно приостанавливать, поскольку различные команды в одном и том же такте обращаются к памяти на считывание команды, выборку операнда, запись результата.
Борьба с конфликтами такого рода проводится путем увеличения количества однотипных функциональных устройств, которые могут одновременно выполнять одни и те же или схожие функции. В запоминающих устройствах в современных микропроцессорах с этой целью разделяют кэш- память для хранения команд и кэш- память данных , а также используют многопортовую схему доступа к регистровой памяти, при которой к регистрам можно одновременно обращаться по нескольким каналам для записи и считывания информации. Например, в микропроцессоре Itanium к блоку регистров общего назначения допускается одновременное обращение на выполнение 8 операций чтения и 6 операций записи. Конфликты из-за исполнительных устройств обычно сглаживаются введением в состав микропроцессора дополнительных блоков. Так, в микропроцессоре Pentium 4 для обработки целочисленных данных предусмотрено 4 АЛУ . При этом появляется возможность параллельной обработки информации в нескольких конвейерах. Процессоры, имеющие в своем составе более одного конвейера, называются суперскалярными.
Недостатком суперскалярных микропроцессоров является необходимость синхронного продвижения команд в каждом из конвейеров. В табл. 9.4 п представлена последовательность выполнения команд в микропроцессоре, имеющем два конвейера, при условии, что команде К1 требуется 3 такта на этапе EX .
При этом команды будут завершаться в порядке, отличающемся от того, который предусмотрен программой: К2-К4-К1-К6-.. .
Следовательно, для обеспечения правильной работы суперскалярного микропроцессора при возникновении затора в одном из конвейеров должны приостанавливать свою работу и другие. В противном случае может нарушиться исходный порядок завершения команд программы. Но такие приостановки существенно снижают быстродействие процессора.
Разрешение этой ситуации состоит в том, чтобы дать возможность выполняться командам в одном конвейере вне зависимости от ситуации в других конвейерах, а аппаратные средства микропроцессора должны гарантировать, что результаты выполненных команд будут записаны в приемник в том порядке, в котором команды записаны в программе. Это обеспечивается путем использования так называемого принципа неупорядоченного выполнения команд. Суть его заключается в следующем. Блок выборки и декодирования выбирает команды из памяти и заносит их в буфер команд. По мере готовности операндов и исполнительного блока соответствующего типа команды извлекаются из буфера для обработки. Порядок их исполнения может отличаться от предписанного программой.
Результаты этапа выполнения команды сохраняются в специальном буфере восстановления последовательности команд. Запись результата очередной команды из этого буфера в приемник результата проводится лишь после того, как выполнены все предшествующие команды и записаны их результаты. Преимущества такого подхода очевидны: команды максимально используют возможности всех конвейеров, присутствующих в микроархитектуре микропроцессора, что обеспечивает его максимальную производительность .
Конфликты по управлению возникают при конвейеризации команд переходов и других команд, изменяющих значение счетчика команд .
Суть конфликтов этой группы наиболее удобно проиллюстрировать на примере команд условного перехода . Пусть в программе, представленной в табл. 9.1, команда i+1 является командой условного перехода , формирующей адрес следующей команды в зависимости от результата выполнения команды i . Команда i завершит свое выполнение в такте 5. В то же время команда условного перехода уже в такте 3 должна прочитать необходимые ей признаки, чтобы правильно сформировать адрес следующей команды. Если конвейер имеет большую глубину (например, 20 ступеней), то промежуток времени между формированием признака результата и тактом, где он анализируется, может быть еще больше.
Простейший способ разрешения этой ситуации - использование так называемого метода выжидания. Он заключается в замораживании операций в конвейере путем блокировки выполнения любой команды, следующей за командой условного перехода , до тех пор, пока не станет известным направление перехода. Привлекательность такого решения заключается в его простоте. Главный недостаток - резкое уменьшение преимуществ конвейерной обработки . В инженерных задачах примерно каждая шестая команда является командой условного перехода , поэтому приостановки конвейера при выполнении команд переходов до определения истинного направления перехода существенно скажутся на производительности процессора.
Можно несколько улучшить эту ситуацию, использую схему "задержанных переходов". При этом на стадии компиляции компилятор таким образом структурирует получаемый объектный код, чтобы сделать команды, следующие за командой перехода, действительными и полезными (рис. 9.1).
Слот задержки заполняется независимой командой, находящейся перед командой условного перехода . Эта команда выполняется за то время, пока микропроцессор формирует истинное условие, по которому должно быть определено направление выполнения программы. Одной из основных трудностей в этом подходе является определение точного времени выполнения команды, вносимой в слот задержки. Аппаратура должна гарантировать реальное выполнение этих команд перед выполнением собственно перехода.
Более эффективными для снижения потерь от конфликтов по управлению являются методы предсказания переходов. Они призваны максимально ускорить определение адреса команды, выполняемой после команды перехода .
Так как преимущества конвейерной обработки проявляются при большом числе последовательно выполненных команд, перезагрузка конвейера приводит к значительным потерям производительности. Поэтому вопросам эффективного предсказания направления ветвления разработчики всех микропроцессоров уделяют большое внимание.
Среди основных достоинств практически каждого нового микропроцессора производители анонсируют "улучшенный блок предсказания переходов". Суть конкретных механизмов, обеспечивающих эти улучшения, как правило, не детализируется. Однако здесь все-таки можно выделить несколько основных подходов.
Методы предсказания переходов делятся на статические и динамические. При использовании статических методов до выполнения программы для каждой команды условного перехода указывается направление наиболее вероятного ветвления. Это указание делается программойкомпилятором по заложенным в ней алгоритмам. Подобный подход реализован, например, в HP PA-8x00. Также это может делать и сам программист по опыту выполнения аналогичных программ либо по результатам тестового выполнения программы. Например, в системе команд микропроцессора Itanium для этого предназначена специальная команда .
Суть данного метода заключается в том, что при выполнении команды условного перехода специальный блок микропроцессора определяет наиболее вероятное направление перехода, не дожидаясь формирования признаков, на основании анализа которых этот переход реализуется.
Процессор начинает выбирать из памяти и выполнять команды по предсказанной ветви программы (так называемое исполнение по предположению, или "спекулятивное" исполнение ). Однако так как направление перехода может быть предсказано неверно, получаемые результаты с целью обеспечения возможности их аннулирования не записываются в память или регистры (то есть для них не выполняется этап WB ), а накапливаются в специальном буфере результатов.
Если после формирования анализируемых признаков оказалось, что направление перехода выбрано верно, все полученные результаты переписываются из буфера по месту назначения и выполнение программы продолжается в обычном порядке. Если направление перехода предсказано неверно, все инструкции, выбранные после перехода, помечаются, согласно интеловской терминологии, как поддельные ( bogus INsTRuctions ).
При этом буфер результатов и конвейер, содержащий команды, которые следуют за командой условного перехода и находятся на разных этапах обработки, - очищаются. Аннулируются результаты всех уже выполненных этапов этих команд. Конвейер начинает загружаться с первой команды другой ветви программы.
Следует отметить, что конфликты по управлению не исчерпываются только проблемами, связанными с командами условных переходов. Они возникают при выполнении всех команд, меняющих значение счетчика команд . Это хорошо видно из табл. 9.1. Если команда i является командой такого типа (например, команда безусловного перехода), то адрес перехода будет вычислен ею в такте 5, в то время как уже в такте 2 необходимо выбирать в микропроцессор следующую команду по этому адресу.
Методы динамического предсказания реализуются при выполнении программы в микропроцессоре. Они осуществляют предсказание направления переходов на основании результатов предыдущих выполнений данной команды.
При использовании этих методов для команд условных переходов анализируется предыстория переходов - результаты нескольких предыдущих команд ветвления по данному адресу. В этом случае возможно определение чаще всего реализуемого направления ветвления, а также выявление чередующихся переходов.
Для команд безусловных переходов однажды вычисленный целевой адрес сохраняется в специальной памяти BTB ( Branch Target Buffer ), откуда он извлекается сразу же при декодировании данной команды.
Аналогичный подход используется для команд вызова - возврата из процедуры ( анализ связок CALL - RETURN ).
Читайте также: