
Что такое блок в файловых системах
Linux поддерживает множество файловых систем, таких как ext4 , ZFS , XFS , Btrfs , Reiser4 и другие.
Различные типы файловых систем решают разные проблемы, и их использование зависит от приложения.
Размер файла
Что такое размер файла? Ответ вроде бы прост: совокупность всех байтов его содержимого, от начала до конца файла.
Зачастую всё содержимое файла представляется как расположенное байт за байтом:

Так же мы воспринимаем и понятие размер файла. Чтобы его узнать, выполняем ls -l file.c или команду stat (т.е. stat file.c ), которая делает системный вызов stat() .
В ядре Linux структурой памяти, представляющей файл, является inode. И метаданные, к которым мы обращаемся с помощью команды stat , находятся именно в inode.
Здесь можно увидеть знакомые атрибуты, такие как время доступа и модификации, а также i_size — это и есть размер файла, как он был определён выше.
Размышлять в терминах размера файла интуитивно понятно, но больше нас интересует, как в действительности используется пространство.
«Упаковка хвостов»
Возможность tail packing, ещё называемая блочным перераспределением (block suballocation), позволяет файловым системам использовать пустое пространство в конце последнего блока («хвосты») и распределять его среди различных файлов, эффективно упаковывая «хвосты» в единый блок.

Замечательно иметь такую возможность, что позволяет сохранить много пространства, особенно если у вас большое количество маленьких файлов… Однако она приводит к тому, что существующие инструменты неточно сообщают об используемом пространстве. Потому что с ней мы не можем просто добавить все занятые блоки всех файлов для получения реальных данных по использованию диска. Эту фичу поддерживают файловые системы BTRFS и ReiserFS.
Номер сектора относительно блочного устройства, содержащего ФС (не весь диск)
(Обратите внимание, что это hdparm --fibmap относится ко всему диску, а не к разделу или какому-либо другому blockdev, содержащему FS. Это также требует root.)
filefrag -e работает хорошо и использует универсальный и эффективный FIEMAP ioctl , поэтому он должен работать практически на любой файловой системе (включая часто странный BTRFS, даже для файлов, сжатых BTRFS). Он вернется к FIBMAP для файловых систем / ядер без поддержки FIEMAP.
Файловая система ZFS
ZFS (Zettabyte File System) остается одной из наиболее технически продвинутых и полнофункциональных файловых систем с момента ее появления в октябре 2005 года. Это локальная файловая система (например, ext4) и менеджер логических томов (например, LVM ), созданные Sun Microsystems. ZFS публиковалась под лицензией с открытым исходным кодом, пока Oracle не купила Sun Microsystems и не закрыла лицензию.
Вы можете думать о ZFS как о диспетчере томов и как о RAID-массиве одновременно, что позволяет добавлять дополнительные диски к вашему тому ZFS, что позволяет одновременно добавить дополнительное пространство в вашу файловую систему. В дополнение к этому ZFS обладает некоторыми другими функциями, которых нет в традиционных RAID.
ZFS сильно зависит от памяти, поэтому для запуска вам потребуется не менее 8 ГБ. На практике используйте столько, сколько можете получить в соответствии с вашим аппаратным обеспечением или бюджетом.
ZFS обычно используется сборщиками данных, пользователями NAS и другими гиками, которые предпочитают полагаться на собственную избыточную систему хранения, а не на облако. Это отличная файловая система для управления несколькими дисками с данными, которая может соперничать с некоторыми из лучших конфигураций RAID.
ZFS похожа на другие подходы к управлению хранилищем, но в некотором смысле радикально отличается. ZFS обычно не использует Linux Logical Volume Manager (LVM) или разделы диска, и обычно удобно удалять разделы и структуры LVM перед подготовкой носителя для zpool .
Zpool - это аналог LVM. Zpool охватывает одно или несколько устройств хранения, а члены zpool могут быть нескольких различных типов. Основные элементы хранения - одиночные устройства, зеркала и raidz. Все эти элементы хранения называются vdevs.
ZFS может обеспечить целостность хранилища намного лучше, чем любой RAID-контроллер, поскольку он досконально знает структуру файловой системы. Безопасность данных - важная особенность конструкции ZFS. Все блоки, записанные в zpool, тщательно проверяются контрольной суммой для обеспечения согласованности и правильности данных.
Для использования на сервере, где вы хотите почти полностью исключить любую возможность потери данных и стабильности, вы можете изучить ZFS.
debugfs
Третий метод получения файловых LBA - это использование debugfs . Этот метод потребует немного математики, но я подумал, что важно показать, как можно преобразовать значение экстентов, сообщаемое debugfs LBA, в те, которые могут быть любопытными.
Итак, начнем с inode файла.
ПРИМЕЧАНИЕ: мы также могли бы использовать имя файла внутри, debugfs но для этой демонстрации я собираюсь использовать вместо этого inode.
Теперь давайте рассмотрим stat информацию debugfs о нашем иноде.
Важная информация находится в разделе экстентов. Это фактически блоки файловой системы, которые используются этим индексом. Нам просто нужно конвертировать их в LBA. Мы можем сделать это с помощью следующего уравнения.
ПРИМЕЧАНИЕ. Предполагая, что наша файловая система использует блоки размером 4 КБ, а базовое оборудование использует 512-байтовые блоки, нам нужно умножить значения на 8.
Лучшие варианты использования файловой системы XFS
У вас большой сервер? У вас большие требования к хранилищу или у вас есть локальный медленный диск SATA ?
Если и ваш сервер, и ваше устройство хранения большие и нет необходимости уменьшать размер файловой системы, XFS , вероятно, будет лучшим выбором. XFS - отличная файловая система, которая хорошо масштабируется для больших серверов. Но даже с меньшими массивами хранения XFS работает очень хорошо, когда средние размеры файлов велики, например, размером в сотни мегабайт.
Что такое файловая система Linux
Почти каждый бит данных и программ, необходимых для загрузки системы Linux и поддержания ее работы, сохраняется в файловой системе. Например, сама операционная система, компиляторы, прикладные программы, разделяемые библиотеки, файлы конфигурации, файлы журналов, точки монтирования мультимедиа и т.д.
Файловые системы работают в фоновом режиме. Как и остальная часть ядра операционной системы, они практически невидимы при повседневном использовании.
Файловая система Linux обычно представляет собой встроенный уровень операционной системы Linux, используемый для управления данными хранилища. Он контролирует, как данные хранятся и извлекаются. Он управляет именем файла, размером файла, датой создания и другой информацией о файле.
Возможности ZFS
HDPARM
Я не уверен на 100%, что это то, что вы ищете, но я верю, что вы можете сделать это с помощью команды hdparm , особенно с ее --fibmap переключателем.
Контрольные суммы
Файловые системы последнего поколения хранят также контрольные суммы (checksums) для блоков данных во избежание незаметного повреждения данных. Эта возможность позволяет обнаруживать и корректировать случайные ошибки и, конечно, ведёт к дополнительным накладным расходам в использовании диска пропорционально размеру файлов.
Более современные системы вроде BTRFS и ZFS поддерживают контрольные суммы для данных, а у более старых, таких как ext4, реализованы контрольные суммы для метаданных.
Блок файловой системы
После форматирования диска или раздела сектора на диске разделены на небольшие группы. Такая группа секторов называется блоком. Размер блока может быть разным и задается как параметр ключа команды форматирования. Например
ключ -b задает размер блока в байтах, в данном случае размер блока будет 4096 байт
Размер блока может быть разным. Это зависит от типа файловой системы
- Ext2 — 1Кб, 2Кб, 4Кб, 8Кб
- Ext3 — 1Кб, 2Кб, 4Кб, 8Кб
- Ext4 — от 1Кб до 64Кб
При выборе размера блока нужно учесть ряд моментов
- Максимальный размер файла
- Максимальный размер файловой системы
- Производительность
Размер блока влияет на скорость чтения/записи с диска. Представим себе файл размеров в несколько сот мегабайт, который считывается с диска блоками по 1Кб. Тот же файл будет считываться быстрее если размер блока файловой системы будет 4Кб или 8Кб. Это ясно. Поэтому при форматировании имеет смысл задать блок большего размера, если планируется использовать файлы большого размера
Также верно и обратное утверждение. В случае хранения небольших файлов лучше использовать блоки минимального размера
Ядро Linux работает с размером блока файловой системы, а не с размером сектора диска (обычно 512 байт). Важно понимать, что размер блока файловой системы не может быть меньше размера сектора диска и всегда будет кратным ему. Также ядро ожидает, что размер блока файловой системы будет меньше или равно размеру системной страницы
Размер системной страницы можно увидеть выполнив команду
Как увидеть, что хранится в суперблоке?
Для этого воспользуемся командой dumpe2fs
Еще один вывод команды показывает информацию о суперблоке
пример
Скажем, у нас есть образец файла.
Теперь, когда мы бежим hdparm .
Что такое файловая система Linux
Почти каждый бит данных и программ, необходимых для загрузки системы Linux и поддержания ее работы, сохраняется в файловой системе. Например, сама операционная система, компиляторы, прикладные программы, разделяемые библиотеки, файлы конфигурации, файлы журналов, точки монтирования мультимедиа и т.д.
Файловые системы работают в фоновом режиме. Как и остальная часть ядра операционной системы, они практически невидимы при повседневном использовании.
Файловая система Linux обычно представляет собой встроенный уровень операционной системы Linux, используемый для управления данными хранилища. Он контролирует, как данные хранятся и извлекаются. Он управляет именем файла, размером файла, датой создания и другой информацией о файле.
Файловая система btrfs
Btrfs - это файловая система Linux общего назначения нового поколения, которая предлагает уникальные функции, такие как расширенное интегрированное управление устройствами, масштабируемость и надежность. Он распространяется под лицензией GPL и открыт для внесения вклада кем угодно. Для файловой системы используются разные имена, в том числе «Butter FS» , «B-tree FS» и «Better FS» .
Разработка Btrfs началась в Oracle в 2007 году. Она была объединена с основным ядром Linux в начале 2009 года и дебютировала в версии Linux 2.6.29.
Btrfs не является преемником файловой системы ext4 по умолчанию, используемой в большинстве дистрибутивов Linux, но предлагает лучшую масштабируемость и надежность. Btrfs - это файловая система с копированием при записи ( Copy-on-Write - CoW ), предназначенная для устранения различных недостатков в текущих файловых системах Linux. Основное внимание уделяется отказоустойчивости, самовосстановлению и простоте администрирования.
Btrfs может поддерживать до 16 эксбибайт раздела и файл того же размера. Если вас смущают цифры, все, что вам нужно знать, это то, что Btrfs может поддерживать до шестнадцати раз больше данных Ext4 .
Как восстановить поврежденный суперблок?
Для начала нужно проверить файловую систему утилитой fsck
В случае если fsck обнаружила ошибку чтения суперблока можно попробовать сделать следующее:
Для начала определим где расположены резервные копии суперблока. Для этого выполняем
ключ -n говорит команде не создавать файловую систему, но показать вывод какой мог бы быть при реальном создании файловой системы
Далее восстановливаем суперблок из бекапа при помощи e2fsck
В данном случае в блоке 819200 хранится резервная копия суперблока. После применения команды пробуем снова монтировать файловую систему. Либо как вариант использовать ключ sb команды mount, который указывает на расположение копии суперблока
XFS только
Если вы используете xfs, то xfs_bmap имеет более хороший вывод: он показывает вам, где есть дыры, а filefrag просто имеет следующий экстент, начиная с более позднего сектора. Он использует блоки 512B, а не размер блока файловой системы. (обычно 4k в Linux). Он показывает, в какой группе размещения находится каждый экстент и как он выровнен по границам полосы RAID.
-l избыточно, когда -v используется, но по какой-то причине я всегда печатаю -vpl . -pl более компактный вывод.
Журналирование
Возможности журналирования для ext2 появились в ext3. Журнал — циклический лог, записывающий обрабатываемые транзакции с целью улучшить устойчивость к сбоям питания. По умолчанию он применяется только к метаданным, однако можно его активировать и для данных с помощью опции data=journal , что повлияет на производительность.
Это специальный скрытый файл, обычно с номером inode 8 и размером 128 МБ, объяснение про который можно найти в официальной документации:
Журнал, представленный в файловой системе ext3, используется в ext4 для защиты ФС от повреждений в случае системных сбоев. Небольшой последовательный фрагмент диска (по умолчанию это 128 МБ) зарезервирован внутри ФС как место для сбрасывания «важных» операций записи на диск настолько быстро, насколько это возможно. Когда транзакция с важными данными полностью записана на диск и сброшена с кэша (disk write cache), запись о данных также записывается в журнал. Позже код журнала запишет транзакции в их конечные позиции на диске (операция может приводить к продолжительному поиску или большому числу операций чтения-удаления-стирания) перед тем, как запись об этих данных будет стёрта. В случае системного сбоя во время второй медленной операции записи журнал позволяет воспроизвести все операции вплоть до последней записи, гарантируя атомарность всего, что пишется на диск через журнал. Результатом является гарантия, что файловая система не застрянет на полпути обновления метаданных.
пример
Таким образом, в нашем примере наш начальный и конечный экстенты одинаковы, поскольку наш файл соответствует одному экстенту.
Таким образом, наши LBA 282439184..282439191.
filefrag
Другой хороший метод для определения начала и конца файла - это filefrag . Вам нужно будет использовать соответствующие переключатели, чтобы получить желаемый результат. Одним из преимуществ этого инструмента hdparm является то, что его может запустить любой пользователь, поэтому нет sudo необходимости. Вам нужно будет использовать -b512 переключатель, чтобы выходные данные отображались в 512-байтовых блоках. Также нам нужно сказать, filefrag чтобы быть многословным.
Метаданные размещения блоков
Эти данные сильно зависят от используемой файловой системы — в каждой из них по-своему реализовано сопоставление блоков с файлами. Традиционный подход ext2 — таблица i_block с прямыми и непрямыми блоками (direct/indirect blocks).

Эту же таблицу можно увидеть в структуре памяти (фрагмент из fs/ext2/ext2.h ):
Для больших файлов такая схема приводит к большим накладным расходам, поскольку единственный (большой) файл требует сопоставления тысяч блоков. Кроме того, есть ограничение на размер файла: используя такой метод, 32-битная файловая система ext3 поддерживает файлы не более 8 ТБ. Разработчики ext3 спасали ситуацию поддержкой 48 бит и добавлением extents:
Идея по-настоящему проста: занимать соседние блоки на диске и просто объявлять, где extent начинается и каков его размер. Таким образом мы можем выделять файлу большие группы блоков, минимизируя количество метаданных и заодно используя более быстрый последовательный доступ.
Примечание для любопытных: у ext4 предусмотрена обратная совместимость, то есть в ней поддерживаются оба метода: непрямой (indirect) и extents. Увидеть, как распределено пространство, можно на примере операции записи. Запись не идёт напрямую в хранилище — из соображений производительности данные сначала попадают в файловый кэш. После этого в определённый момент кэш записывает информацию на постоянное хранилище.
Кэш файловой системы представлен структурой address_space , в которой вызывается операция writepages. Вся последовательность выглядит так:
… где ext4_map_blocks() вызовет функцию ext4_ext_map_blocks() или ext4_ind_map_blocks() в зависимости от того, используются ли extents. Если взглянуть на первую в extents.c , можно увидеть упоминания дыр (holes), о которых будет рассказано ниже.
Как работает Copy-on-Write и зачем вам это нужно
В традиционной файловой системе при изменении файла данные считываются, изменяются, а затем записываются обратно в то же место. В файловой системе с копией при записи он считывает данные, изменяет их и записывает в новое место. Это предотвращает потерю данных во время транзакции чтения-изменения-записи, поскольку данные всегда находятся на диске.
Поскольку вы не «перенаправляете» до тех пор, пока новый блок не будет полностью записан, если пропадет питание или выйдет из строя в середине записи, вы получите либо старый блок, либо новый блок, но не наполовину записанный поврежденный блокировать. Таким образом, вам не нужно проверять файловые системы при запуске, и вы снижаете риск повреждения данных.
Вы можете сделать снимок файловой системы в любой момент, создав запись снимка в метаданных с текущим набором указателей. Это защищает старые блоки от последующего сбора мусора и позволяет файловой системе представить том в том виде, в котором он был во время моментального снимка. Другими словами, у вас есть возможность мгновенного отката. Вы даже можете клонировать этот том, чтобы сделать его доступным для записи на основе снимка.
И то filefrag и другое xfs_bmap покажет вам заранее выделенные экстенты.
hdparm --fibmap полезно, только если вы хотите, чтобы номер сектора относился ко всему жесткому диску , а не к разделу, в котором находится файловая система. Он не работает поверх программного RAID (или, вероятно, чего-то еще между файловой системой и жестким диском). Также требуется рут. Несмотря на название опции, она фактически использует, FIEMAP когда доступно (более новый ioctl карты экстентов, а не старый медленный ioctl карты блоков).
Из статьи Анатомия файловой системы Linux М. Тима Джонса я прочитал, что Linux рассматривает все файловые системы с точки зрения общего набора объектов, и это объекты суперблок , inode , dentry и файл . Несмотря на то, что остальная часть параграфа объясняет вышеизложенное, мне не очень понравилось это объяснение.
Может ли кто-нибудь объяснить мне эти термины?
Прежде всего, и я понимаю, что это не был один из терминов из вашего вопроса, вы должны понимать метаданные . Вкратце и украденные из Википедии, метаданные - это данные о данных. То есть метаданные содержат информацию о части данных. Например, если я владею автомобилем, у меня есть набор информации об автомобиле, который не является частью самого автомобиля. Информация, такая как регистрационный номер, марка, модель, год выпуска, информация о страховке и так далее. Вся эта информация в совокупности называется метаданными. Как вы увидите, в файловых системах Linux и UNIX метаданные существуют на нескольких уровнях организации.
Суперблок , по существу , метаданные файловой системы и определяет тип файловой системы, размера, состояние, а также информации о других структурах метаданных (метаданные метаданных). Суперблок очень важен для файловой системы и поэтому хранится в нескольких избыточных копиях для каждой файловой системы. Суперблок - это структура метаданных очень высокого уровня для файловой системы. Например, если суперблок раздела / var становится поврежденным, то рассматриваемая файловая система (/ var) не может быть смонтирована операционной системой. Обычно в этом случае вам нужно запустить fsck который автоматически выберет альтернативную резервную копию суперблока и попытается восстановить файловую систему. Сами резервные копии хранятся в группах блоков, распределенных по файловой системе, причем первые хранятся со смещением в 1 блок от начала раздела. Это важно в случае необходимости ручного восстановления. Вы можете просмотреть информацию о резервном копировании суперблока с помощью команды, dumpe2fs /dev/foo | grep -i superblock которая полезна в случае попытки восстановления вручную. Предположим, что команда dumpe2fs выводит строку Backup superblock at 163840, Group descriptors at 163841-163841 . Мы можем использовать эту информацию, а также дополнительные знания о структуре файловой системы, чтобы попытаться использовать эту резервную копию суперблока: /sbin/fsck.ext3 -b 163840 -B 1024 /dev/foo . Обратите внимание, что для этого примера я принял размер блока 1024 байта.
Инода существует, или, файловую систему и представляет собой метаданные о файле. Для ясности все объекты в системе Linux или UNIX являются файлами; актуальные файлы, каталоги, устройства и так далее. Обратите внимание, что среди метаданных, содержащихся в inode, нет имени файла, как думают люди, это будет важно позже. Inode содержит по существу информацию о владельце (пользователь, группа), режиме доступа (права на чтение, запись, выполнение) и типе файла.
Dentry это клей , который держит дескрипторы и файлы вместе, связывая номер индексных дескрипторов файлов с именами файлов. Dentries также играют роль в кэшировании каталогов, что в идеале позволяет хранить наиболее часто используемые файлы для быстрого доступа. Обход файловой системы является еще одним аспектом dentry, поскольку он поддерживает связь между каталогами и их файлами.
Файл , в дополнение к тому , что люди , как правило , думают о том, когда представлены слова, на самом деле просто блок логически связанных произвольных данных. Сравнительно очень скучно, учитывая всю работу, проделанную (выше), чтобы отслеживать их.
Я полностью понимаю, что несколько предложений не дают полного объяснения какой-либо из этих концепций, поэтому, пожалуйста, не стесняйтесь спрашивать дополнительные детали, когда и где это необходимо.
@Tok: Будет ли он сбрасываться следующим образом (как показано в ответе): Суперблок резервного копирования в 163840, дескрипторы группы в 163841-163841 или это так: Суперблок резервного копирования в 163840, дескрипторы группы в 163841-163842? Это была ошибка опечатки? :-)
@TOK: резервный суперблок в 163840, дескрипторы групп в 163841-163842, какую информацию передает дескрипторы групп?
@Sen - теоретически групповые дескрипторы могут занимать несколько блоков, но для большинства настольных систем вы увидите, что они занимают только один блок и называются $ ((BackupBlock + 1)) - $ ((BackupBlock + 1))
@Sen - дескриптор группы описывает группу блоков. Что это обозначает? Больше метаданных. По существу, дескриптор группы содержит битовую карту блоков (номер блока битовой карты выделения блоков), битовую карту инода (такую же, но для инодов), таблицу инодов (номер блока начального блока для таблицы инодов), количество свободных блоков и количество инодов, и количество использованных каталогов. Все это основано на файловой системе ext2. Дескрипторы групп очень важны для правильной работы файловой системы и дублируются вместе с суперблоком.
файл
Файл просто означает группу байтов, расположенных в определенном порядке. Это то, что нормальные люди называют содержимым файла. Когда Linux открывает файл, он также создает объект file, который содержит данные о том, где хранится файл и какие процессы его используют. Файловый объект (но не сами данные файла) выбрасывается при закрытии файла.
Inode
Inode (сокращение от «индексный узел») - это набор атрибутов файла, который хранит Linux. Для каждого файла существует один индекс (хотя в некоторых файловых системах Linux вынужден создавать собственные индексы, поскольку информация распространяется по файловой системе). Inode хранит информацию о том, кто владеет файлом, его размер и кому разрешено открывать файл. Каждый индекс также содержит уникальный номер раздела файловой системы; это как серийный номер файла, описанного этим индексом.
Dentry
Дентри (сокращение от «запись каталога») - это то, что ядро Linux использует для отслеживания иерархии файлов в каталогах. Каждый dentry сопоставляет номер индекса с именем файла и родительским каталогом.
Суперблок
Суперблок - это уникальная структура данных в файловой системе (хотя существует несколько копий для защиты от повреждения). Суперблок содержит метаданные о файловой системе, например, какой inode является каталогом верхнего уровня и типом используемой файловой системы.
Суперблок , индексный узел (или inode ), запись каталога (или dentry ) и, наконец, файловый объект являются частью виртуальной файловой системы (VFS) или виртуальной файловой системы . Цель VFS - предоставить клиентским приложениям доступ к различным типам конкретных файловых систем единообразным способом.
Отношения главных объектов в VFS
Дескриптор представляет собой структуру данных в файловой системе Unix / Linux. Inode хранит метаданные о обычном файле, каталоге или другом объекте файловой системы. Inode действует как интерфейс между файлами и данными. Индод может ссылаться на файл или каталог или символическую ссылку на другой объект. Он содержит уникальный номер (i-номер), атрибуты файла, включая имя, дату, размер и разрешения на чтение / запись, а также указатель на местоположение файла. Это аналог таблицы FAT в мире DOS / Windows.
Программы, сервисы, тексты, изображения и т. Д. Являются файлами . Устройства ввода и вывода и, как правило, все устройства считаются файлами в соответствии с системой.
Суперблок является контейнером для метаданных высокого уровня о файловой системе. Суперблок - это структура, которая существует на диске (фактически, в нескольких местах на диске для резервирования), а также в памяти. Он обеспечивает основу для работы с файловой системой на диске, так как определяет параметры управления файловой системой (например, общее количество блоков, свободных блоков, корневой индексный узел).
Dentry - это интерфейс между файлами и Inodes. Dentries также играют роль в кэшировании каталогов, что в идеале позволяет хранить наиболее часто используемые файлы для быстрого доступа.
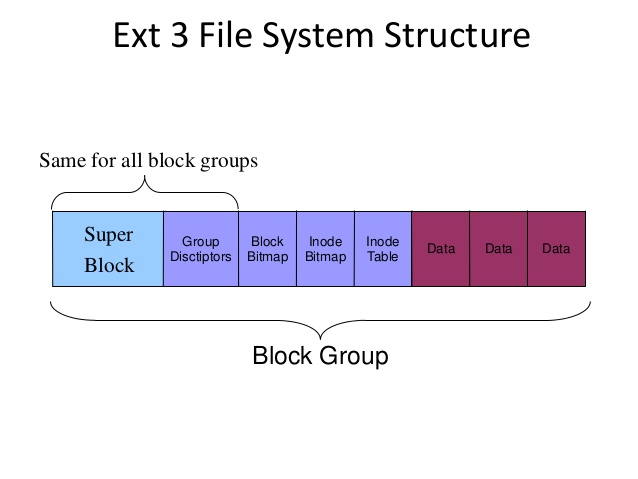
Суперблок содержит информацию, необходимую для монтирования и управления работой файловой системы в целом (например, для размещения новых файлов).
Блоки и размер блока
Для внутреннего хранения файла файловая система разбивает хранилище на блоки. Традиционным размером блока были 512 байт, но более актуальное значение — 4 килобайта. Вообще же при выборе этого значения руководствуются поддерживаемым размером страницы на типовом оборудовании MMU (memory management unit, «устройство управления памятью» — прим. перев.).
Файловая система вставляет порезанный на части (chunks) файл в эти блоки и следит за ними в метаданных. В идеале всё выглядит так:

… но в действительности файлы постоянно создаются, изменяются в размере, удаляются, поэтому реальная картина такова:

Это называется внешней фрагментацией (external fragmentation) и обычно приводит к падению производительности. Причина — вращающейся головке жёсткого диска приходится переходить с места на место, чтобы собрать все фрагменты, а это медленная операция. Решением данной проблемы занимаются классические инструменты дефрагментации.
Что происходит с файлами меньше 4 КБ? Что происходит с содержимым последнего блока после того, как файл был порезан на части? Естественным образом будет возникать неиспользуемое пространство — это называется внутренней фрагментацией (internal fragmentation). Очевидно, этот побочный эффект нежелателен и может привести к тому, что многое свободное пространство не будет использоваться, особенно если у нас большое количество очень маленьких файлов.
Итак, реальное использование диска файлом можно увидеть с помощью stat , ls -ls file.c или du file.c . Например, содержимое 1-байтового файла всё равно занимает 4 КБ дискового пространства:
Таким образом, мы смотрим на две величины: размер файла и использованные блоки. Мы привыкли думать в терминах первого, однако должны — в терминах последнего.
Группы блоков файловой системы
Блоки, о которых мы говорили ранее обьеденяются в группы блоков, что позитивно отражается на операциях чтения/записи так как уменьшается время чтения/записи больших обьемов данных
Файловая система EXT разбивает все доспупное пространство на группы блоков равного размера. Эти группы располагаются последовательно, одна за другой
| Загрузочный блок | Группа блоков 1 | Группа блоков 2 | Группа блоков 2 | Группа блоков 3 |
Количество блоков в группе неизменно и может быть расчитано по формуле
Взглянем на вывод команды mke2fs
Отметим то, о чем говорили выше
- Размер блока 4096 байт
- 800 блоковых групп
- 32768 блоков в группе (8*4096)
Также видны блоки в которых хранятся резервные копии суперблока
Файловые системы COW (copy-on-write)
Следующее (после семейства ext) поколение файловых систем принесло очень интересные возможности. Пожалуй, наибольшего внимания среди фич файловых систем вроде ZFS и BTRFS заслуживает их COW (copy-on-write, «копирование при записи»).
Когда мы выполняем операцию copy-on-write или клонирования, или копии reflink, или поверхностной (shallow) копии, на самом деле никакого дублирования extent'ов не происходит. Просто создаётся аннотация в метаданных для нового файла, которая отсылает к тем же самым extents оригинального файла, а сам extent помечается как разделяемый (shared). При этом в пользовательском пространстве создаётся иллюзия, что существуют два отдельных файла, которые можно отдельно модифицировать. Когда какой-то процесс захочет написать в разделяемый extent, ядро сначала создаст его копию и аннотацию, что этот extent принадлежит единственному файлу (по крайней мере, на данный момент). После этого у двух файлов появляется больше отличий, однако они все ещё могут разделять многие extents. Другими словами, extents в файловых системах с поддержкой COW можно делить между файлами, а ФС обеспечит создание новых extents только в случае необходимости.

Как видно, клонирование — очень быстрая операция, не требующая удваивания пространства, которое используется в случае обычной копии. Именно эта технология и стоит за возможностью создания мгновенных снапшотов в BTRFS и ZFS. Вы можете буквально клонировать (или сделать снапшот) всей корневой файловой системы меньше чем за секунду. Очень полезно, например, перед обновлением пакетов на случай, если что-то сломается.
BTRFS поддерживает два метода создания shallow-копий. Первый относится к подтомам (subvolumes) и использует команду btrfs subvolume snapshot . Второй — к отдельным файлам и использует cp --reflink . Такой алиас (опять же, для ~/.zshrc или ~/.bashrc ) может пригодиться, если вы хотите по умолчанию делать быстрые shallow-копии:
cp='cp --reflink=auto --sparse=always'
Следующий шаг — если есть не-shallow-копии или файл, или даже файлы, с дублирующимися extents, можно дедуплицировать их, чтобы они использовали (через reflink) общие extents и освободили пространство. Один из инструментов для этого — duperemove, однако учтите, что это естественным образом приводит к более высокой фрагментации файлов.
Если мы попытаемся теперь разобраться, как дисковое пространство используется файлами, всё будет не так просто. Утилиты вроде du или dutree всего лишь считают используемые блоки, не учитывая, что некоторые из них могут быть разделяемыми, поэтому они покажут больше занятого места, чем на самом деле используется.
Аналогичным образом, в случае BTRFS стоит избегать команды df , поскольку пространство, занятое файловой системой BTRFS, она покажет как свободное. Лучше пользоваться btrfs filesystem usage :
К сожалению, я не знаю простых способов отслеживания занятого пространства отдельными файлами в файловых системах с COW. На уровне подтома с помощью утилит вроде btrfs-du мы можем получить приблизительное представление о количестве данных, которые уникальны для снапшота и которые разделяются между снапшотами.
Есть ли команда, которая выведет начальный и конечный блоки любого файла?
@ BeowulfNode42: ext4, ntfs, fat32 - это те, с которыми я часто сталкиваюсь . так что желательно для этих трех .
Вопрос должен быть улучшен (точнее): моим первым ответом была бы какая-то программа, которая открывает файл, читает первый блок, затем ищет последний блок и читает его тоже. Так что же такое «выход» блока? Содержимое блока, логический адрес блока (внутри файла, внутри файловой системы, внутри раздела или внутри блочного устройства) или физический адрес блока (становится интересным, если диск является частью какого-либо RAID или LVM). Ответы кажутся намного лучше, чем вопрос.
Разрежённые файлы
Большинство современных файловых систем поддерживают разрежённые файлы (sparse files). У таких файлов могут быть дыры, которые в действительности не записаны на диск (не занимают дисковое пространство). На этот раз реальный размер файла будет больше, чем используемые блоки.

Такая особенность может оказаться очень полезной, например, для быстрой генерации больших файлов или для предоставления свободного пространства виртуальному жёсткому диску виртуальной машины по запросу.
Чтобы медленно создать 10-гигабайтный файл, который занимает около 10 ГБ дискового пространства, можно выполнить:
Чтобы создать такой же большой файл мгновенно, достаточно лишь записать последний байт… или даже сделать:
Или же воспользоваться командой truncate :
Дисковое пространство, выделенное файлу, можно изменить командой fallocate , которая делает системный вызов fallocate() . С этим вызовом доступны и более продвинутые операции — например:
- Предварительно выделить пространство для файла вставкой нулей. Такая операция увеличивает и использование дискового пространства, и размер файла.
- Освободить пространство. Операция создаст дыру в файле, делая его разрежённым и уменьшая использование пространства без влияния на размер файла.
- Оптимизировать пространство, уменьшив размер файла и использование диска.
- Увеличить пространство файла, вставив дыру в его конец. Размер файла увеличивается, а использование диска не меняется.
- Обнулить дыры. Дыры станут не записанными на диск extents, которые будут читаться как нули, не влияя на дисковое пространство и его использование.
Команда cp поддерживает работу с разрежёнными файлами. С помощью простой эвристики она пытается определить, является ли исходный файл разрежённым: если это так, то результирующий файл тоже будет разрежённым. Скопировать же неразрежённый файл в разрежённый можно так:
… а обратное действие (сделать «плотную» копию разрежённого файла) выглядит так:
Таким образом, если вам нравится работать с разрежёнными файлами, можете добавить следующий алиас в окружение своего терминала ( ~/.zshrc или ~/.bashrc ):
Когда процессы читают байты в секциях дыр файловая система предоставляет им страницы с нулями. Например, можно посмотреть, что происходит, когда файловый кэш читает из файловой системы в области дыр в ext4. В этом случае последовательность в readpage.c будет выглядеть примерно так:
(cache read miss) ext4_aops-> ext4_readpages() -> . -> zero_user_segment()
После этого сегмент памяти, к которому процесс пытается обратиться с помощью системного вызова read() , получит нули напрямую из быстрой памяти.
Особенности Btrfs
- Copy-on-Write и создание снепшотов - Сделайте инкрементное резервное копирование безболезненным даже из файловой системы в процессе работы или виртуальной машины (VM).
- Контрольные суммы на уровне файла - метаданные для каждого файла включают контрольную сумму, которая используется для обнаружения и исправления ошибок.
- Сжатие - файлы можно сжимать и распаковывать "на лету", что увеличивает скорость чтения.
- Автоматическая дефрагментация - файловые системы настраиваются фоновым потоком, пока они используются.
- Подтомы - файловые системы могут совместно использовать единый пул пространства вместо того, чтобы помещаться в свои собственные разделы.
- RAID - Btrfs выполняет свои собственные реализации RAID , поэтому LVM или mdadm не требуются для наличия RAID. В настоящее время поддерживаются RAID 0, 1 и 10. RAID 5 и 6 считаются нестабильными.
- Разделы необязательны - хотя Btrfs может работать с разделами, он может напрямую использовать необработанные устройства (/dev/).
- Дедупликация данных - поддержка дедупликации данных ограничена; однако дедупликация со временем станет стандартной функцией Btrfs. Это позволяет Btrfs экономить место, сравнивая файлы через двоичные файлы diff .
Хотя это правда, что Btrfs все еще считается экспериментальным и в настоящее время находится в активной разработке, время, когда Btrfs станет файловой системой по умолчанию для систем Linux, приближается. Некоторые дистрибутивы Linux уже начали переходить на него в своих текущих выпусках.
Файловая система ext4
В 1992 году была запущена файловая Extended File System или ext специально для операционной системы Linux. Она уходит своими корнями в операционную систему Minix. В 1993 году было выпущено обновление под названием Extended File System 2 или ext2 , которое в течение многих лет было файловой системой по умолчанию во многих дистрибутивах Linux. К 2001 году ext2 была обновлена до ext3 , которая ввела журналирование для защиты от повреждений в случае сбоев или сбоев питания.
Ext4 была представлена в 2008 году и является файловой системой Linux по умолчанию с 2010 года. Она была разработана как прогрессивная версия файловой системы ext3 и преодолевает ряд ограничений в ext3 . Она имеет значительные преимущества перед своим предшественником, такие как улучшенный дизайн, лучшая производительность, надежность и новые функции.
В настоящее время ext4 является файловой системой по умолчанию в большинстве дистрибутивов Linux. Она может поддерживать файлы и файловые системы размером до 16 терабайт. Она также поддерживает неограниченное количество подкаталогов (файловая система ext3 поддерживает только до 32 000). Кроме того, ext4 обратно совместима с ext3 и ext2 , что позволяет монтировать эти старые версии с драйвером ext4 .
Есть причина, по которой ext4 является выбором по умолчанию для большинства дистрибутивов Linux. Она опробована, протестирована, стабильна, отлично работает и широко поддерживается. Если вам нужна стабильность, ext4 - лучшая файловая система Linux для вас.
Однако несмотря на все свои функции, ext4 не поддерживает прозрачное сжатие, прозрачное шифрование или дедупликацию данных.
Файловая система Reiser4
ReiserFS - это файловая система общего назначения с журналированием, первоначально разработанная и реализованная командой Namesys во главе с Хансом Райзером. Представленная в версии 2.4.1 ядра Linux, это была первая файловая система с журналированием, включенная в стандартное ядро.
За исключением обновлений безопасности и исправлений критических ошибок, Namesys прекратила разработку ReiserFS. Reiser4 является преемницей файловой системы ReiserFS. Добавилось шифрование, улучшил производительность и многое другое.
Reiser4 обеспечивает наиболее эффективное использование дискового пространства среди всех файловых систем во всех сценариях и рабочих нагрузках. ReiserFS предлагает преимущества перед другими файловыми системами, особенно когда дело доходит до обработки большого количества небольших файлов. Она поддерживает ведение журнала для быстрого восстановления в случае возникновения проблем. Структура файловой системы основана на деревьях. Кроме того, Reiser4 потребляет немного больше ресурсов ЦП, чем другие файловые системы.
Reiser4 обладает уникальной способностью оптимизировать дисковое пространство, занимаемое небольшими файлами (менее одного блока). Они полностью хранятся в своем индексном дескрипторе, без выделения блоков в области данных.
Помимо реализации традиционных функций файловой системы Linux, reiser4 предоставляет пользователям ряд дополнительных возможностей: прозрачное сжатие и шифрование файлов, полное ведение журнала данных, а также практически неограниченную (с помощью архитектуры подключаемых модулей) расширяемость.
Однако в настоящее время нет поддержки прямого ввода-вывода (началась работа по реализации), квот и POSIX ACL.
Прим перев.: Автор оригинальной статьи — испанский Open Source-энтузиаст nachoparker, развивающий проект NextCloudPlus (ранее известен как NextCloudPi), — делится своими знаниями об устройстве дисковой подсистемы в Linux, делая важные уточнения в ответах на простые, казалось бы, вопросы…
Сколько пространства занимает этот файл на жёстком диске? Сколько свободного места у меня есть? Сколько ещё файлов я смогу вместить в оставшееся пространство?

Ответы на эти вопросы кажутся очевидными. У всех нас есть инстинктивное понимание работы файловых систем и зачастую мы представляем хранение файлов на диске аналогично заполнению корзины яблоками.
Однако в современных Linux-системах такая интуиция может вводить в заблуждение. Давайте разберёмся, почему.
Ссылки
я попробовал filefrag с доступными размерами блоков 1024 и 2048 .. debugfs с большими размерами файлов : 0 - 12187 .. я не тороплюсь и пойму . это большая помощь, спасибо .
Файловая система XFS
XFS - это высокомасштабируемая файловая система, разработанная Silicon Graphics и впервые развернутая в операционной системе IRIX на базе Unix в 1994 году. Это файловая система с журналированием которая отслеживает изменения в журнале перед фиксацией изменений в основной файловой системе. Преимущество заключается в гарантированной целостности файловой системы и ускоренном восстановлении в случае сбоев питания или сбоев системы.
Первоначально XFS была создана для поддержки чрезвычайно больших файловых систем с размерами до 16 эксабайт и размером файлов до 8 эксабайт. Она имеет долгую историю работы на больших серверах и массивах хранения.
Одной из примечательных особенностей XFS является гарантированная скорость ввода-вывода. Это позволяет приложениям зарезервировать пропускную способность. Файловая система рассчитывает доступную производительность и корректирует свою работу в соответствии с существующими резервированиями.
XFS имеет репутацию системы, работающей в средах, требующих высокой производительности и масштабируемости, и поэтому регулярно оценивается как одна из самых производительных файловых систем в больших системах с корпоративными рабочими нагрузками.
Сегодня XFS поддерживается большинством дистрибутивов Linux и теперь стала файловой системой по умолчанию в Red Hat Enterprise Linux, Oracle Linux, CentOS и многих других дистрибутивах.
пример
Специфичные для файловой системы возможности
Помимо актуального содержимого файла ядру также необходимо хранить все виды метаданных. Метаданные inode'а мы уже видели, но есть и другие данные, с которыми знаком каждый пользователь UNIX: права доступа, владелец, uid, gid, флаги, ACL.
Наконец, существуют ещё и другие структуры — вроде суперблока (superblock) с представлением самой файловой системы, vfsmount с представлением точки монтирования, а также информация об избыточности, именные пространства и т.п. Как мы увидим далее, некоторые из этих метаданных также могут занимать значительное место.
Так что же такое суперблок?
Самым простым определением суперблока могло бы быть следующее утверждение
Суперблок — это блок в котором хранятся метаданные файловой системы
Аналогично тому, как i-ноды хранят метаданные о файлах, суперблок хранит метаданные о файловой ситеме. Если вдруг суперблок поврежден, то не возможно будет примонтировать файловую систему. Обычно при загрузке система проверяет суперблок и при необходимости исправляет его, что в результате приводит к корректному монтированию файловых систем
Некоторые данные, которые хранятся в суперблоке. Например
- Количество блоков в файловой системе
- Количество свободных блоков в файловой системе
- Количество i-нод в блоковой группе
- Блоки в блоковой группе
- Количество запусков файловой системы со времени последней проверки fsck
- UUID файловой системы
- Состояние файловой системы (была ли корректно размонтирована, обнаруженые ошибки и т.д.)
- Тип файловой системы
- Операционная система в которой была отформатирована данная файловая система
- Время последнего монтирования
- Время последней записи
Основная копия суперблока хранится в самой первой группе блоков. Она названа основной, потому что считывается системой в процессе монтирования файловой системы. Так как отсчет блоковых групп начинается с 0 то можно говорить о том, что суперблок хранится в начале блоковой группы 0
Суперблок весьма критичен для файловой системы. Поэтому в каждой блоковой группе есть копии суперблока. Это дает нам право думать, что поврежденный суперблок будет восстановлен всякий раз, когда это будет необходимо
Может показаться, что наличие в каждой блоковой группе резервных копий суперблока приводит к потреблению большого дискового пространства. Для этого в последних версиях систем была реализована функция «sparse_super» целью которой было создание резервных копий в группе блоков 0, 1, 3, 5, 7
Читайте также: