
Avx512 в каких процессорах
Аббревиатура AVX расшифровывается как Advanced Vector Extensions. Это наборы инструкций для процессоров Intel и AMD, идея создания которых появилась в марте 2008 года. Впервые такой набор был встроен в процессоры линейки Intel Haswell в 2013 году. Поддержка команд в Pentium и Celeron появилась лишь в 2020 году.
Прочитав эту статью, вы более подробно узнаете, что такое инструкции AVX и AVX2 для процессоров, а также — как узнать поддерживает ли процессор AVX.
История AVX-512

Инструкции AVX, Advanced Vector eXtensions, находятся внутри процессоров Intel в течение многих лет, но происхождение инструкций AVX-512 отличается от остальных. Причина? Его источником является проект Intel Larrabee, попытка Intel в конце 2000-х годов создать GPU / ГРАФИЧЕСКИЙ ПРОЦЕССОР которые в конечном итоге стали ускорителями Xeon Phi. Серия процессоров, предназначенных для высокопроизводительных вычислений, выпущенная Intel несколько лет назад.
Архитектура Xeon Phi / Larrabee включает специальную версию инструкций AVX с размером регистра накопителя 512 бит, что означает, что они могут работать с 16 32-битными данными. Причина такой суммы связана с тем фактом, что типичное соотношение операций на тексель для графического процессора обычно составляет 16: 1. Не будем забывать, что инструкции AVX-512 взяты из неудачного проекта Larrabee и были перенесены оттуда в Xeon Phi.
По сей день Xeon Phi больше не существует, причина в том, что то же самое можно сделать с помощью традиционного графического процессора для вычислений. Это заставило Intel передать эти инструкции своей основной линейке процессоров.
2. Утилита CPU-Z.

В строке Instructions показаны все инструкции и другие технологии, поддерживаемые вашим процессором.
Выводы
В этой статье мы довольно подробно рассказали о поддержке процессорами инструкций AVX, AVX2, а также показали несколько способов, позволяющих выяснить наличие такой поддержки конкретно вашим процессором. Надеемся, что дополнительная информация об используемом процессоре будет полезна для вас, а также поможет в выборе процессора в будущем.

Некоторые из последних процессоров Intel поддерживают семейство векторных инструкций AVX-512. Они выполняются блоками по 512 бит (64 байта). Преимущество аппаратной поддержки таких больших инструкций в том, что за один такт процессор обрабатывает больше данных.
Если код загружается 64-битными словами (8 байт), то теоретически, если не брать в учёт другие факторы, можно ускорить его выполнение в восемь раз, если использовать инструкции AVX-512.
Расширение AVX-512 для системы команд x86 поддерживает 8 регистров масок, 512-разрядные упакованные форматы для целых и дробных чисел и операции над ними, тонкое управление режимами округления (позволяет переопределить глобальные настройки), операции broadcast, подавление ошибок в операциях с дробными числами, операции gather/scatter, быстрые математические операции, компактное кодирование больших смещений.
В первоначальный набор AVX-512 входит восемь групп инструкций:
- AVX-512 Conflict Detection Instructions (CDI)
- AVX-512 Exponential and Reciprocal Instructions (ERI)
- AVX-512 Prefetch Instructions (PFI)
- AVX-512 Vector Length Extensions (VL)
- AVX-512 Byte and Word Instructions (BW)
- AVX-512 Doubleword and Quadword Instructions (DQ)
- AVX-512 Integer Fused Multiply Add (IFMA)
- AVX-512 Vector Byte Manipulation Instructions (VBMI)
Естественно, не любой код можно обратить в векторные инструкции, но и не нужно делать это со всем кодом, пишет в своём блоге Дэниель Лемир (Daniel Lemire), профессор информатики Университета Квебека. По его словам, важно оптимизировать «горячий код», который отнимает больше всего ресурсов процессора. Во многих системах «горячий код» построен из ряда циклов, которые прокручиваются миллиарды раз. Вот именно его следует оптимизировать, в этом основная выгода.
Например, если такой питоновский код перекомпилировать со стандартных 64-битных инструкций в AVX-512 с помощью MKL Numpy, то время исполнения снижается с 6-7 секунд до 1 секунды на том же процессоре.
Аппаратная поддержка глубинного обучения
Нейросети и глубинное обучение — один из ярких трендов последнего времени. Google, Facebook и другие крупные компании пытаются применить нейросети где только можно: в системах рекомендаций, распознавании лиц, переводах текстов, распознавании речи, классификации фотографий и даже в настольных играх вроде го (но это скорее ради пиара, чем для коммерческой выгоды). Кое-кто пытается применить глубинное обучение в нестандартных областях, таких как обучение автомобильного автопилота.
Среди венчурных инвесторов сейчас есть понимание, что самая эффективная схема быстро разбогатеть — запустить стартап в области глубинного обучения, который сразу купит компания из «большой пятёрки» (Facebook, Google, Apple, Microsoft, Amazon). Эти фирмы в последнее время жёстко конкурируют в области скупки талантов, так что стартап уйдёт мгновенно и за большую цену из расчёта минимум $10 млн за сотрудника. Такой бизнес-план стал сейчас ещё проще, поскольку компании выпускают инструменты для разработки с открытыми исходниками, как это сделала Google с TensorFlow.
К несчастью для Intel, эта компания здесь плетётся в хвосте и почти не участвует в игре. Профессор Лемир признаёт, что сейчас отраслевым стандартом считаются графические процессоры Nvidia. Именно на них запускают код программ для машинного обучения.
Дело не в том, что инженеры Intel проспали тренд. Просто графические процессоры сами по себе без всяких специальных инструкций лучше приспособлены для расчётов deep learning.
Тем не менее, Intel готовит контратаку, в результате которой ситуация может перевернуться с ног на голову. В сентябре компания опубликовала новое справочное руководство Intel Architecture Instruction Set Extensions Programming Reference с указанием всех инструкций, которые будут поддерживаться в будущих процессорах. Если заглянуть в этот документ, то нас ждёт приятный сюрприз. Оказывается, семейство инструкций AVX-512 разбили на несколько групп и расширили.
В частности, две группы инструкций специально предназначены для глубинного обучения: AVX512_4VNNIW и AVX512_4FMAPS. Судя по описанию, эти инструкции могут быть полезными не только в глубинном обучении, но и во многих других задачах.
- AVX512_4VNNIW: Vector instructions for deep learning enhanced word variable precision
- AVX512_4FMAPS: Vector instructions for deep learning floating-point single precision
Это очень приятная новость.
Когда такая поддержка появится в стандартных процессорах Intel, то они могут приблизиться или даже обойти по производительности глубинного обучения графику Nvidia. Разумеется, при условии соответствующей оптимизации программ. Кто знает, вдруг повторится та же история, что и с кодированием видео, когда после добавления в CPU аппаратной поддержки H.264 и H.265 процессоры Intel со встроенной графикой стали кодировать и декодировать видео быстрее, чем отдельные видеокарты Nvidia и AMD.

Это короткий пост об исследовании поведения AVX2 и AVX-512 в связи с лицензионным даунклокингом новых чипов Intel Ice Lake.
Лицензионный даунклокинг 1 — это малоизвестный эффект, при котором пределы частот опускаются ниже номинальных в случае выполнения определённых SIMD-инструкций, особенно тяжёлых инструкций с плавающей запятой или инструкций с 512-битной шириной.
Подробности о подобном виде даунклокинга можно прочитать в этом ответе на StackOverflow, и мы уже довольно детально объясняли низкоуровневую механику подобных переходов. Также можно найти инструкции о том, как воспользоваться широкими SIMD (Single Instruction Multiple Data: тип или расширение архитектуры набора команд, например, Intel AVX или ARM NEON, способные выполнять множественные идентичные операции с элементами, упакованными в SIMD-регистр) с учётом этой проблемы 2 .
Информация по ссылкам написана в контексте Skylake-SP (SKX, серверной архитектуры Intel Skylake, включающей в себя Skylake-SP, Skylake-X и Skylake-W), которые стали первым поколением чипов с поддержкой AVX-512.
Какова же ситуация с Ice Lake — с самыми новыми чипами, поддерживающими как инструкции AVX-512 из SKX, так и имеющими совершенно новый набор инструкций AVX-512? Нам придётся смотреть на эти новые инструкции издалека, и мы никогда не сможем воспользоваться ими из-за даунклокинга?
Прочитайте статью, чтобы разобраться, или просто перейдите к разделу «Итоги».
3. Поиск на сайте производителя.
Ещё один способ узнать, есть ли AVX на процессоре, воспользоваться официальным сайтом производителя процессоров. В строке поиска браузера наберите название процессора и выполните поиск. Если у вас процессор Intel, выберите соответствующую страницу в списке и перейдите на неё. На этой странице вам будет предоставлена подробная информация о процессоре.

Если у вас процессор от компании AMD, то лучше всего будет воспользоваться сайтом AMD. Выберите пункт меню Процессоры, далее — пункт Характеристики изделия и затем, выбрав тип (например, Потребительские процессоры), выполните переход на страницу Спецификации процессоров. На этой странице выполните поиск вашего процессора по названию и посмотрите подробную информацию о нём.


AVX-Turbo
Мы будем использовать утилиту avx-turbo для измерения зависимости частот от количества ядер и набора инструкций. Этот инструмент работает просто: выполняет заданный набор инструкций на заданном количестве ядер, измеряя частоту, достигнутую во время теста.
Например, тест avx256_fma_t , измеряющий затраты на тяжёлые 256-битные инструкции с высокой ILP (Instruction level parallelism: величина параллелизма на межинструкционном уровне суперскалярного процессора), выполняет следующую последовательность FMA:
Что такое SIMD-модуль?
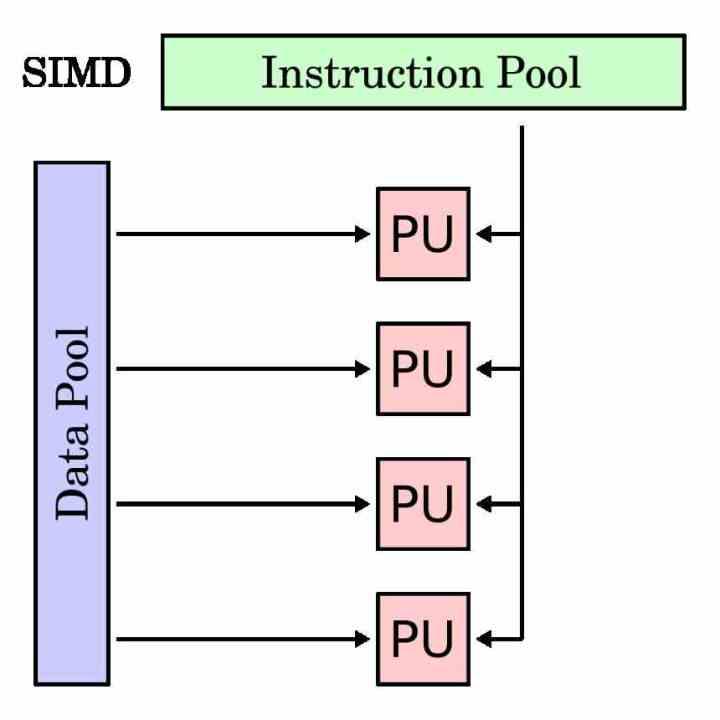
Модуль SIMD - это тип исполнительного модуля, который предназначен для одновременного выполнения одной и той же инструкции для нескольких данных. Следовательно, его регистр накопителя длиннее, чем у традиционной инструкции, поскольку он должен группировать различные данные, с которыми он должен работать с той же самой инструкцией.
Блоки SIMD традиционно использовались для ускорения так называемых мультимедийных процессов, в которых необходимо манипулировать различными данными в соответствии с одними и теми же инструкциями. Блоки SIMD позволяют распараллеливать выполнение программы в этих частях и ускорить время выполнения.
В каждом процессоре, чтобы отделить исполнительные блоки SIMD от традиционных, они имеют собственное подмножество инструкций, которое обычно является зеркалом скалярных инструкций или с одним операндом. Хотя есть случаи, которые невозможно сделать со скалярным модулем и они относятся исключительно к модулям SIMD.
Итоги
Вот, какие выводы я сделал.
- Процессор Ice Lake i5-1035 демонстрирует всего 100 МГц лицензионного даунклокинга с одним активным ядром при выполнении 512-битных инструкций.
- Во всех прочих случаях даунклокинг отсутствует.
- Турбочастота выполнения 512-битных инструкций на всех ядрах равна 3,3 ГГц, что составляет 89% от максимума частоты выполнения скалярных операций на одном ядре (3,7 ГГц), поэтому в рамках ограничений мощности и тепловыделения этот чип имеет очень «плоскую» частотную зависимость.
- В отличие от архитектуры SKX, этот чип Ice Lake не использует разделение на «лёгкие»
и «тяжёлые» инструкции для масштабирования частот: FMA-операции выполняются так же, как и более лёгкие операции.
Обсуждения и общение
Этот пост можно обсудить на on Hacker News.
Если у вас есть вопросы или другая обратная связь, то можете оставить комментарий к оригиналу поста. Мне были бы также интересны результаты на других чипах ICL, например, на версиях i3 и i7: дайте мне знать, если у вас они есть, и мы сможем получить результаты.
Линус Торвальдс (Linus Torvalds) поделился своим мнением по поводу инструкций AVX-512. Толчком для высказывания не совсем приятных слов стало появление семейства процессоров Intel Alder Lake в наборе компиляторов GNU Compiler Collection. Как оказалось, новые настольные процессоры не будут поддерживать AVX-512 инструкции.
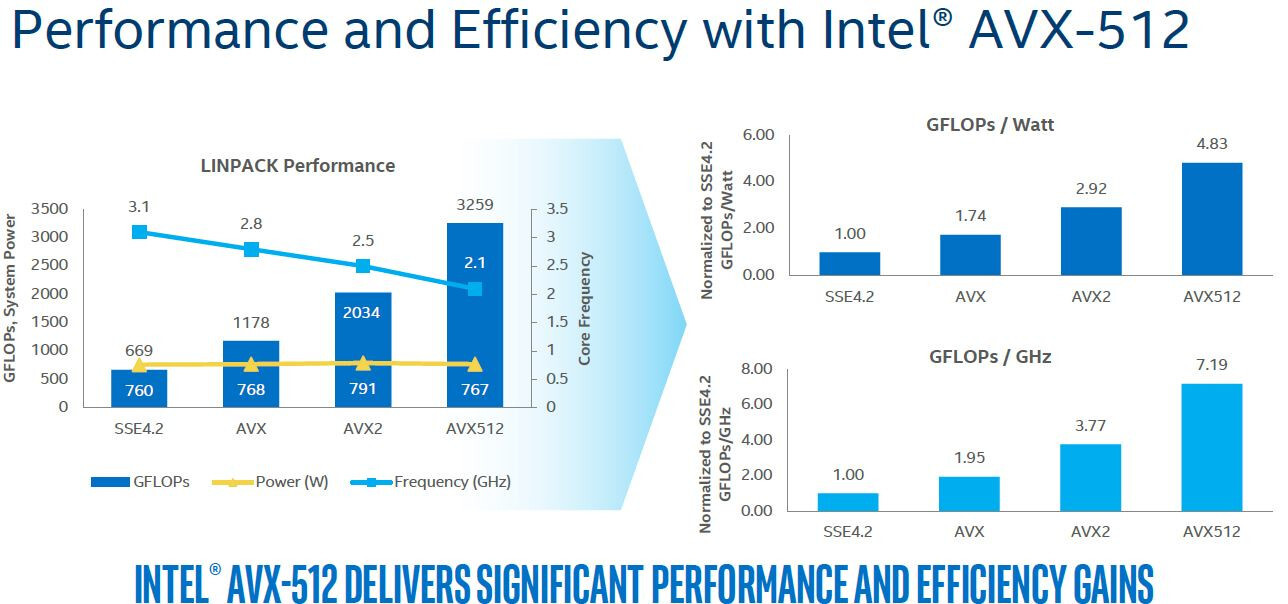
Отсутствие AVX-512 инструкций в будущих процессорах Intel обусловлено использованием разных центральных ядер. Как мы знаем, процессоры Intel Alder Lake будут использовать энергоэффективные ядра, предположительно, Gracemont и высокопроизводительные ядра Golden Cove. Именно это разделение и может быть причиной не появления инструкций AVX-512 в Intel Alder Lake.

Линус Торвальдс довольно грубо высказался в адрес Intel про AVX-512 инструкции и политику компании в плане процессоров в целом:
«Я надеюсь, что AVX-512 умрет мучительной смертью и Intel начнет исправлять реальные проблемы, вместо того, чтобы пытаться создавать магические инструкции, чтобы затем создавать тесты, на которых они могут хорошо выглядеть. Я надеюсь, что Intel вернется к основам: снова начнет работать и сконцентрируется на обычном коде.
Я говорил это раньше, и я скажу это снова: во времена расцвета x86 абсолютно все остальные добились большего успеха при загрузке FP (операции с плавающей запятой), чем Intel. Производительность процессоров Intel отстой (относительно).

Я бы предпочел, чтобы бюджет транзисторов использовался для других вещей, которые гораздо более актуальны. Просто дайте мне больше ядер (с хорошей однопоточной производительностью, но без мусора, как AVX-512), как это делает AMD.
Я хочу, чтобы мои пределы мощности были достигнуты с помощью обычного целочисленного кода, а не какого-нибудь AVX-512, который уменьшает максимальную тактовую частоту и уменьшает количество ядер в процессоре (потому что эти бесполезные мусорные блоки занимают место)».

К слову, Линус Торвальдс относительно недавно пересел на AMD после 15 лет использования процессоров Intel и, судя по всему, остался доволен.
Инструкции AVX-512 - один из уникальных элементов Intelx86 ЦП архитектуры. Но что это за инструкции, связанные с их реализацией на процессорах Intel? Продолжайте читать, чтобы понять причину существования этих инструкций, какие у них есть варианты и почему они не используются AMD в своих процессорах.

AVX и AVX2 – что это такое
AVX/AVX2 — это улучшенные версии старых наборов команд SSE. Advanced Vector Extensions расширяют операционные пакеты со 128 до 512 бит, а также добавляют новые инструкции. Например, за один такт процессора без инструкций AVX будет сложена 1 пара чисел, а с ними — 10. Эти наборы расширяют спектр используемых чисел для оптимизации подсчёта данных.
Наличие у процессоров поддержки AVX весьма желательно. Эти инструкции предназначены, прежде всего, для выполнения сложных профессиональных операций. Без поддержки AVX всё-таки можно запускать большинство игр, редактировать фото, смотреть видео, общаться в интернете и др., хотя и не так комфортно.
Ну и что?
Ну и что же из этого?
По меньшей мере, это означает, что нам нужно изменить нашу мысленную модель затратности инструкций AVX-512 относительно частот. Вместо того, чтобы говорить, что они «обычно вызывают значительный даунклокинг», про этот чип Ice Lake можно сказать, что AVX-512 вызывает незначительный или нулевой лицензионный даунклокинг, и я предполагаю, что это справедливо также для других клиентских чипов Ice Lake.
Однако это смена наших ожиданий имеет важный изъян: лицензионный даунклокинг не является единственным источником даунклокинга. Мы также можем столкнуться с ограничениями мощности, тепловыделения или тока. Некоторые конфигурации способны выполнять широкие SIMD-инструкции на всех ядрах только в течение короткого времени, а затем превышают пределы рабочей мощности. В моём случае ноутбук за 250 долларов, на котором проводилось тестирование, имел чрезвычайно плохое охлаждение, и вместо ограничений мощности я столкнулся с пределом тепловыделения (100°C) всего спустя несколько секунд после запуска тяжёлых инструкций на всех ядрах.
Однако эти прочие ограничения качественно отличаются от лицензионных ограничений. В основном 5 они ограничивают по принципу плати за то, что используешь: если вы используете широкие или тяжёлые инструкции (или оба вида), то это вызывает лишь микроскопическое повышение мощности или тепловыделения, связанное только с этими инструкциями. Это непохоже на некоторые лицензионные эффекты, при которых возникают изменения частот в пределах ядра или целого чипа, значительное время влияющие последующее выполнение, не связанное с такими типами инструкций.
Так как широкие операции обычно менее затратны по мощности, чем аналогичное количество узких операций 6 , можно сразу же понять, стоят ли того широкие операции; по крайней мере, в случаях, хорошо масштабирующихся с повышением ширины. Как бы то ни было, эта проблема в основном локальна: она не зависит от поведения соседнего кода.
Тарабарщина в виде инструкций AVX-512
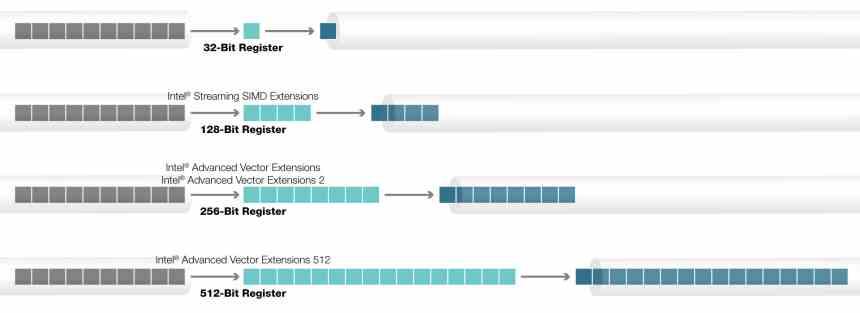
Инструкции AVX-512 не являются однородным блоком, который реализован на 100%, а скорее имеют различные расширения, которые, в зависимости от типа процессора, были добавлены или нет. Все процессоры называются AVX512F, но есть дополнительные инструкции, которые не являются частью исходного набора команд и которые Intel со временем добавила.
Как узнать, поддерживает ли процессор AVX
Далее будут показаны несколько простых способов узнать это. Некоторые из методов потребуют установки специального ПО.
Результаты Ice Lake
Я запускал avx-turbo описанным выше образом на Ice Lake i5-1035G4 — клиентском процессоре Ice Lake среднего диапазона мощности, работающего с частотой до 3,7 ГГц. Полные результаты скрыты в gist, а здесь я представлю самые важные результаты по полученным частотам (все значения указаны в ГГц):
Как и ожидалось, максимальное падение частоты происходит при увеличении количества активных ядер, но просмотрите вниз каждый столбец, чтобы оценить влияние на категории инструкций. Вдоль этой оси почти никакого даунклокинга не происходит! Только при одном активном ядре возникает снижение при широких инструкциях, и всего лишь на жалкие 100 МГц: с 3 700 МГц до 3 600 МГц при использовании любых 512-битных инструкций.
Во всех остальных случаях, в том числе и при нескольких активных ядрах, а также тяжёлых 256-битных лицензионный даунклокинг равен нулю: всё работает так же быстро, как и со скалярными инструкциями.
Виды лицензий
Здесь существует и ещё одно изменение. В архитектуре SKX есть три лицензии, или категории инструкций, относящихся к даунклокингу: L0, L1 и L2. Здесь, в клиентском ICL, их всего две 3 и они неточно соответствуют трём категориям в SKX.
Лицензии в SKX соответствуют ширине и тяжести инструкций следующим образом:
| Ширина | Лёгкие | Тяжёлые |
|---|---|---|
| Скалярные/128 | L0 | L0 |
| 256 | L0 | L1 |
| 512 | L1 | L2 |
В частности, обратите внимание на то, что тяжёлые 256-битные инструкции имеют ту же лицензию, что и лёгкие 512-битные.
В клиентских ICL схема такова:
| Ширина | Лёгкие | Тяжёлые |
|---|---|---|
| Скалярные/128 | L0 | L0 |
| 256 | L0 | L0 |
| 512 | L1 | L1 |
Здесь тяжёлые 256-битные и лёгкие 512-битные инструкции находятся в разных категориях! На самом деле, похоже, здесь не применяется концепция противопоставления лёгких и тяжёлых инструкций: разбивка на категории целиком зависит от ширины 4 .
Почему AMD еще не реализовала это на своих процессорах?

Причина этого очень проста: AMD стремится к комбинированному использованию своих ЦП и ГП при ускорении определенных типов приложений. Давайте не будем забывать происхождение AVX-512 в вышедшем из строя графическом процессоре от Intel и AMD. Благодаря своим графическим процессорам Radeon им не нужны инструкции AVX-512.
Вот почему инструкции AVX-512 являются эксклюзивными для процессоров Intel, не для полной исключительности, а потому, что AMD не заинтересована в использовании этого типа инструкций в своих ЦП, поскольку она намерена продавать свои графические процессоры, особенно недавно выпущенный AMD Instinct. высокопроизводительные вычисления с архитектурой CDNA.
Есть ли будущее у инструкций AVX-512?

Что ж, мы не знаем, это зависит от успеха Intel Xe, особенно Xe-HPC, который даст Intel архитектуру GPU на уровне AMD и NVIDIA. Это означает конфликт между инструкциями Intel Xe и AVX-512 для решения тех же проблем.
Проблема с AVX-512 заключается в том, что активация части процессора, которая его использует, в конечном итоге влияет на тактовую частоту процессора, снижая ее примерно на 25% в программе, которая использует эти инструкции в определенные моменты. Кроме того, его инструкции предназначены для высокопроизводительных вычислений и приложений искусственного интеллекта, которые не важны в том, что является домашним процессором, а появление специализированных блоков делает его пустой тратой транзисторов и пространства.
На самом деле ускорители или процессоры для конкретной области медленно заменяют блоки SIMD в ЦП, поскольку они могут делать то же самое, занимая меньше места и с незначительным энергопотреблением по сравнению.
1. Таблица сравнения процессоров на сайте Chaynikam.info.
Для того чтобы узнать, поддерживает ли ваш процессор инструкции AVX, можно воспользоваться предлагаемым способом. Перейдите на этот сайт. В правом верхнем углу страницы расположена зелёная кнопка Добавить процессор. Нажмите её.

В открывшемся окне вам будет предложено указать параметры выбора нужного процессора. Все указывать не обязательно.

В результате выполнения поиска будет сформирована таблица с параметрами выбранного из списка процессора. Прокрутите таблицу вниз. В строке Поддержка инструкций и технологий будет показана подробная информация.

Читайте также: