
Зачем нужен индексный файл
Например, создадим файл, идентичный по структуре исходному.
//При этом применяется метод ОписаниеПоля, который возвращает характеристики поля с указанным номером
//синтаксис: ОписаниеПоля(,,,,)
Для работы с файлом DBF неизвестной структуры часто применяются следующие методы:
ПолучитьЗначениеПоля();
УстановитьЗначениеПоля(,);
Работа с удаленными записями
Файлы DBF устроены таким образом, что удаление записи не приводит к физическому удалению записи из файла. Запись просто помечается на удаление и пропускается при переборе. Таким образом размер файла остается прежним. Чтобы физически удалить все помеченные на удаление записи нужно применить метод Сжать. Средства встроенного языка позволяют работать с такими записями, перебирать их и даже отменять пометку на удаление.
Можно удалить все записи в файле одним движением. При этом они физически удаляются и не могут быть восстановлены.
Стоит еще отметить про метод Очистить(), что он очищает все поля текущей записи. Атрибуты, соответствующие полям типа "строковый" приобретают значение «пустая строка», числовой — 0, логический — 0, дата — «пустая дата».
Работа с индексами
Для организации упорядочивания содержимого файла БД и поиска в ней по значению одного или нескольких полей применяется механизм индексов. Его применение можно сравнить с сортировкой картотеки по определенному признаку (совокупности признаков). Однако, в отличие от картотеки, файл БД может иметь сразу несколько индексов, и, соответственно, являться упорядоченным одновременно по нескольким признакам. Индексы хранятся в индексном файле. Индексный файл может содержать информацию более чем об одном индексе. Рекомендуется для одного файла DBF иметь один индексный файл, в котором хранятся все индексы для этого файла.
Каждый индекс имеет наименование, признак уникальности, выражение индекса и фильтр. Наименование индекса используется для идентификации индекса. Выражение индекса и фильтр представляют собой написанные на специальном языке выражения, вычисление значения которых для каждой записи позволяет определить ее место при упорядочивании и необходимость помещения ее в упорядоченный список (индекс может содержать упоминание не обо всех записях таблицы, а только об удовлетворяющих выражению фильтра). Уникальный индекс (имеющий установленным признак уникальности) позволяет иметь в индексе ссылки на записи только с различным значением индексного выражения.
Основное правило: индекс нужен, чтобы быстро искать нужную запись.
Нужно быстро найти Комаров. В неупорядоченном исходном файле искать его можно только последовательным перебором всех записей, что будет очень долго при большом числе записей. В индексе найти Комарова можно очень быстро, поскольку индекс отсортирован по полю Фамилия. При этом мы узнаем физический номер записи в файле DBF и производим прямое позиционирование на нужную запись.
После создания структуры базы данных можно добавить индексы следующим образом:
//Синтаксис: ДобавитьИндекс(, , , , )
После сбоя рекомендуется заново переформировать все индексы
В 1С существует специальный язык для задания выражений и фильтра индекса. Подробнее о нем, смотрите в документации на встроенный язык.
Отбор по значению поля
Часто возникают вопросы по фильтрации файла БД по значению
определенного поля.
Предположим , что в предыдущем примере сотрудники работают в разных
подразделениях «Офис» и «Филиал» ,
и нужно вывести всех сотрудников работающих в офисе.
Нетрудно увидеть, что в языке нет явных способов получить записи
по фильтру, но имея индекс тем не менее, данную операцию
можно эффективно (без перебора всех записей) осуществить.
1. Создадим файл индекса, если он ранее не был создан
2. Откроем Файл базы с индексом
3.Прейдем на первую запись
4. И так как все записи упорядочены по индексу - достаточно пройтись
по записям, пока не встретится запись с другим значением поля "Otdel" :

Программирование и разработка
Когда вы создаёте веб-страницы в редакторе кода, таком как Visual Studio Code, Sublime Text, вам необходимо создать index.html, потому что эта страница выполняет важную работу. Создание первой страницы index.html считается лучшим методом веб-разработки.
Итак, что такое страница index.html и почему она имеет значение? В этой статье рассказывается о index.html и о том, почему вы всегда должны создавать эту страницу при создании веб-сайта.
Как создать правильный robots.txt
Через службу Services
Проделываем всё, как описано разделом выше, но на этапе выбора типа запуска вместо «Автоматически» выбираем опцию «Отключить», жмём кнопку «Стоп», а затем – «Применить».

Но чтобы изменения вступили в силу, придётся выполнить перезагрузку компьютера, после чего вы сможете попробовать оценить, насколько шустрее он стал работать.
ВАЖНО. Если файлов на диске много, то и операция включения, и отключения индексации может занять много времени, при этом на некоторые файлы служба будет ругаться, поэтому желательно нажать кнопку «Пропустить всё».

Если вы посчитаете, что производительность ПК никак не изменилась, то можете включить функцию тем же порядком, который описан выше.
Восстановление индексного файла
«Служба поиска» – это обычная системная утилита, в работе которой тоже могут наблюдаться сбои. В подобных случаях индексная база данных оказывается не совсем актуальной, в результате поиск будет работать некорректно – сильно замедлится, а то и вовсе окажется безрезультатным.
Итак, теперь вы знаете, для чего нужна индексация, и можете сделать для себя выводы, нужна она вам или нет. Функция, безусловно, полезная, и хорошо то, что отказаться от неё можно выборочно, а как отключить индексацию конкретного диска или папки, вы уже знаете.
Robots.txt - это файл с текстовыми стандартизированными рекомендациями для роботов поисковых систем: какие разделы сайта следует сканировать, а какие - нет. Поскольку файл предназначен для набора инструкций по индексации, его также называют индексным.
Корректная настройка файла robots.txt требуется для быстрой индексации страниц сайта и попадания в ТОП. В статье мы рассмотрим следующие основные моменты (нажмите на название пункта для быстрого перехода):
Вывод
Создать страницу index.html в редакторе кода легко. Помните, что вы можете создавать другие HTML-страницы в дополнение к index.html, например, about.html или contact.html.
Включив страницу index.html в свои проекты веб-разработки, вы поможете посетителям вашего сайта иметь хорошо спроектированный сайт и поможете защитить файлы в вашем каталоге от уязвимостей.
Опытные или пытливые пользователи, часто пользующиеся папкой «Мои документы», при вызове из контекстного меню опции «Свойства» в главной вкладке «Общие» наверняка замечали строчку «Разрешить индексировать содержимое файлов» с чекбоксом слева. По умолчанию там будет стоять галочка, но может и не стоять. Материал ниже познакомит вас, для чего нужна эта опция, нужно ли там ставить галочку или убрать её и как это отразится на работоспособности операционной системы.

Как изменить параметры индексирования
Отключить индексирование файлов в OS Windows 10/8/7 можно и выборочно. Это, по идее, позволит повысить производительность ПК, поскольку вы оставите для индексации только те локации, которые посчитаете важными с точки зрения поиска.
Для этого выполняем следующие действия:
Ту же операцию можно выполнить и другим способом, при этом можно отключить индексацию только всего диска. Это может быть полезно, например, если вы хотите исключить из индексации в Windows 10/8 диск SSD, который, как уже отмечалось выше, индексировать не имеет смысла.
Для этого нужно открыть «Мой компьютер» и кликнуть ПКМ по диску, который хотите отключить. В появившемся меню выбираем пункт «Свойства» и снимаем галочку со строки «Разрешить индексировать контекстные файлы». Помните, что операция отключения может оказаться длительной.


Что такое и для чего нужно индексирование содержимого файлов
Под неприметной галочкой скрывается достаточно активная системная служба Windows, которая предназначена для ускорения поиска файлов на жёстком диске компьютера, а зачастую и их содержимого, если речь идёт, например, о текстовом документе. Если файлов у вас очень много и вы часто ищете среди них нужные, то считается, что при активированной функции индексации вы потратите на поиски минимум времени.
Давайте разберёмся теперь, как работает служба индексирования в Windows 10 (в предыдущих версиях она тоже присутствует, но наибольшим интеллектом её наделили в 8.1 и 10). При каждом добавлении нового файла или модификации существующего данные о нём в закодированном (индексированном) виде заносятся в специальную базу данных, что помогает ускорить поиск. Вы замечали, что, воспользовавшись поиском и набрав всего несколько символов, вы уже получаете список результатов, удовлетворяющих вашему набору. Если среди них есть требуемый, вводить дальше символы уже не нужно, и вы экономите время (с учётом вероятности допустить ошибку где-то в середине или конце строки).
Хотя сам процесс индексирования файлов на жёстком диске происходит в фоновом режиме, если вы выполняете массовые операции с файлами (например, копируете с флешки или скачиваете новое приложение), служба индексации может несколько снизить производительность компьютера, с такой же интенсивностью осуществляя операции чтения/записи в базу данных индексов.
Отключив индексацию, вы сможете немного повысить скорость работы ПК, причём в некоторых случаях заметно, а в некоторых вы и вовсе не ощутите разницы.
Чтобы принять взвешенное решение о необходимости активации или деактивации этой опции, следует учитывать также и мощность процессора, и количество ОП, и тип диска (жёсткий или SSD).
Если CPU шустрый (i5, i7 или выше), а HDD обычный, индексация не помешает. Если процессор медленный, независимо от типа диска, индексирование содержимого файлов стоит убрать. Лишней будет галочка и для дисков типа SSD, причём для процессоров любой производительности.

То есть вывод напрашивается очевидный: отключение опции оправдано для слабых CPU и твердотельных накопителей. Но интересен и другой вопрос: а насколько замедлится функция поиска при отключённой индексации? Переживать по этому поводу не стоит: разница будет, конечно, заметной, но не всегда. А главное – качество поиска от этого нисколько не пострадает.
ВНИМАНИЕ. На самом деле встроенным поиском Windows массовый пользователь ПК пользуется относительно редко, так что выводы можно сделать довольно очевидные.
И ещё один нюанс. Зачем нужна индексация файлов, если среднестатистический пользователь старается хранить свои файлы (музыку, картинки, фильмы, документы) в нескольких папках, которые к тому же расположены в одном месте?
Ответ тоже вполне очевиден: ради контекстного поиска по ключевым словам. Но эта функция сносно работает только в Windows 10/8.1, уже в «семёрке» она реализована настолько неудачно, что смысла использования такого поиска уже не будет.
Но если в ваших пользовательских папках файлов очень много, то можно включить индексирование только для этих папок. Нагрузка на процессор будет намного меньше, а поиск – быстрее.
Как видим, нюансы есть, и их много. Давайте резюмируем достоинства и недостатки использования этой функции.
Как проверить robots.txt
Требования Яндекс и Google к Роботс ти экс ти
Веб-краулеры способны воспринимать инструкции определенного вида из индексных файлов, отвечающих их требованиям. Поэтому, чтобы роботы правильно восприняли ваши рекомендации при сканировании, важно соблюдать несколько правил составления и размещения Robots.txt.
Кодировка UTF-8;Кодировка UTF-8 Размер файла - не более 32 КБ;Размер файла - не более 500 КБ Файл является текстовым;Файл является текстовым Файл доступен - ответ сервера на запрос робота - 200 ОК;Файл доступен - ответ сервера на запрос робота - 200 ОК Если ответ сервера другой - робот Яндекса считает, что сайт полностью открыт для индексации;Если файл robots.txt отвечает кодами 500, робот Google считает, что на сайте временные проблемы и не сканирует его, пока robots.txt не ответит другом кодом. Через 30 дней таких попыток, робот будет использовать кеш файла Роботс.
Что такое индекс базы данных и зачем он нужен?
Чтобы понять зачем нужны индексы в базе данных и что он собой представляет, сейчас рассмотрим простой пример.
Представьте себе, что у вас есть полочка для книг. При этом изначально эта полочка с книгами пуста. Книги вам то приносят, то уносят, то делают в них какие-то корректировки (к примеру, мемуары или может быть черновики) и тому подобное.
Так как полочка маленькая, то вы как-то не особо задумывались о какой-либо системе классификации, а просто вставляете книги в любые пустые места.
Каждый раз когда-то вам или кому-то необходимо найти определенную книгу, возникает необходимость просматривать все книги с самого начала полочки до первой попавшейся (если нужна только одна книга) или полностью все (если нужно собрать все копии). В принципе, для одной полочки это весьма необременительно.
Теперь, представьте себе, что речь идет не об одной полочке, а об огромном помещении, где находятся тысячи книг.
Тут-то вы и начинаете задумываться о том, что неплохо бы ввести какую-то систему классификации, например, по названию книги. Конечно, полностью сортировать все эти тысячи книг в алфавитном порядке вы не собираетесь, плюс с этим возникло бы куча других вопросов (как добавить книгу в уже заполненную полку и прочие).
Поэтому вы поступаете проще, вы берете каталог, где возможно добавлять листочки. При этом каждую страницу выделяете только под одно название книги, а сами страницы располагаете в каталоге в порядке возрастания названий. Содержание этих страниц весьма просто — вы записываете в каком стеллаже, на какой полке и какой по счету является книга. Если книг несколько, то строчек в этой странице становится несколько.
Таким образом, чтобы найти одну или все нужные книги по названию, вам достаточно открыть этот каталог и быстро пролестнуть до нужной страницы, а затем пройтись по всем указанным стеллажам. При этом для упрощения, вы так же можете первые буквы названий так же индексировать. То есть добавляете наклейку на каждую первую страницу с указанной буквой (таким образом можете сразу перейти, например, к букве «Р», не пролистывая все названия до нее).
Конечно, для поддержки такой системы требуется дополнительное время, но все же оно существенно меньше, чем попытка найти вслепую книгу из тысячи (пара минут против нескольких часов и более).
Так вот, в данном примере, если переносить это в базу данных:
Помещение — это таблица в базе данных. Если чуть проще, то любое скопище однотипных данных (тех же книг), по сути, представляет собой таблицу.
Поиск книги — это sql-запросы получения данных. При этом важно отметить, что сами по себе они не меняются. То есть вам как нужно было найти «Термодинамику», так и осталось нужным найти «Термодинамику». Другое дело, как вы будете это осуществлять — прочесывая тысячи книг или открыв каталог.
Каталог — это и есть упрощенный вариант индекса в базе данных. То есть, индекс это набор дополнительных данных, записанных в удобном виде, который позволяет существенно быстрее осуществлять поиск, хоть и требующий дополнительных усилий для поддерживания его актуальности.
Имя книги (страничка) — это ключ в индексе. То уникальное значение, которое может ссылаться как на одну какую-то запись, так и на несколько. Стоит отметить, что даже если записей для каждого значения будет несколько, это все равно быстрее, чем полный перебор всех данных.
Если суммировать, то можно увидеть, что наличие индекса может быть весьма выгодным. Например, для одной домашней полочки с десятком книг — индекс в общем-то не сильно нужен, а вот когда речь заходит о более больших объемах, то индекс будет весьма полезным.
Так же можно заметить, что добавление индекса не требует того, чтобы сами sql-запросы были переписаны, так как последние являются лишь выражением на упрощенном языке для базы данных. Если продолжить аналогию, то это как попросить кого-то найти вам «Флора и фауна». При этом каким образом и сколько этот кто-то будет искать книгу, будет решать сам этот человек. В данном примере «найти книгу» — это sql-запрос, а этот «кто-то» это база данных.
Через командную строку
Опытные пользователи предпочитают не открывать множественные окна, а использовать командную строку, вводя одну команду. Правда, этот способ тоже не лишён недостатков – команду нужно помнить, плюс всегда существует вероятность допущения ошибки в наборе. Тем не менее у неё немало поклонников.
Как это делается:
Если возникнет необходимость снова активировать службу поиска с индексацией, в командной строке набираем видоизменённую фразу: sc config «wsearch» start=delayed-auto && sc start «wsearch».

Что такое index.html?
index.html легко распознаётся на большинстве серверов как страница по умолчанию, поэтому многие разработчики предпочитают использовать index.html в качестве имени страницы по умолчанию.
Что должно быть написано в роботс
Ниже рассмотрены основные правила (директивы), с помощью которых можно корректно составить robots.txt.
Плюсы и минусы службы индексирования файлов
Минус один – практически постоянная запись данных в индексный файл о месте расположения других файлов может действительно замедлить работу компьютера. На дисках SSD индексация файлов тоже не нужна – твердотельные накопители сами по себе работают гораздо быстрее классических жёстких дисков, так что поиск будет быстрым и без индексации. А вот постоянная запись для SSD вредна, ведь у них имеется ограничение на количество таких операций в жизненном цикле.
Достоинство тоже одно: ускорение поиска при использовании встроенных средств Windows, он становится немного интеллектуальным и в состоянии как бы предугадывать ваши намерения.
Какие бывают индексы?
Вообще, в зависимости от типов баз данных, индексы могут быть очень разными и реализоваться за счет специфических математических механизмов. Но, наиболее частым является древовидный индекс, так как поддерживать такой индекс относительно просто и максимальная скорость поиска в нем составляет логарифм по числу максимального количества дочерних узлом от общего количества записей (плюс минус некоторые технические моменты).
Дерево (древовидный индекс) — это специального вида структура, у которой есть корневая вершина и у каждого узла может быть несколько дочерних узлов. При этом каждый узел встречается только один раз и может иметь всего один родительский узел. Выглядит это так:
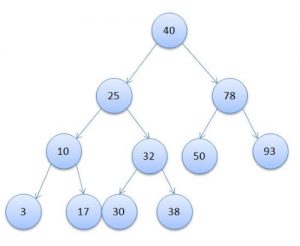
Как видите, очень похоже на перевернутое обычное зеленое дерево, у которого ветки растут не вверх, а вниз.
Максимальное количество дочерних узлов, как вероятно уже догадались по картинке, это то количество дочерних узлов, больше которого у одного узла не может быть.
Теперь поясню откуда берется логарифм. Дело в том, что дерево обычно заполняется по определенным правилам. К примеру, если у узла максимально может быть всего два дочерних узла (так называемое бинарное дерево), то обычно левый дочерний узел имеет значение меньше текущего, а правый большее значение. Поэтому если вам нужно найти, например, число 30 в дереве с рисунка чуть выше, то вам понадобится всего 4 сравнения (40 — 25 — 32 — 30). Именно из-за этой особенности поиска и берется логарифм (так как каждое сравнение сокращает количество проверяемых элементов в два раза). При этом обычно значение логарифма округляют в большую сторону.
Так же отмечу, что такая скорость достигается за счет того, что дерево строится специальным образом, чтобы не возникало таких ситуаций, как на картинке ниже, где максимальная скорость поиска будет сравнима с простым перебором всех записей.
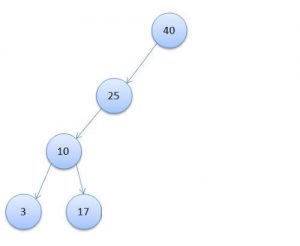
Как видите, чтобы здесь найти запись с ключом «3» понадобится 4 сравнения (40 — 25 — 10 — 3), хотя всего записей 5.
Практически во всех базах данных, существует деление по уникальности:
Уникальный индекс — это такой индекс, у которого все значения встречаются только один раз. Проводя аналогию, когда каждая книга присутствует только в одном экземпляре и никогда названия книг не совпадают.
Неуникальный индекс — это такой индекс, у которого значения могут повторяться. Проводя аналогию, существуют книги с одними и теми же названиями, но разными авторами, или же просто встречаются копии.
Важно отметить, что если для таблицы создается уникальный индекс, то это означает, что при попытке добавить запись со значением, которое уже встречалось, или же изменить значение какой-то записи на существующее, то база данных не позволит сделать такое действие и будет ругаться (выдавать ошибки). В случае же с неуникальным индексом таких проблем нет.
Так же стоит знать, что индексы делятся по количеству входящих в них полей:
Обычные индексы — состоят из одного поля. Здесь, вероятно, все понятно. Обычный каталог страничек.
Составные индексы — строятся по нескольким полям, при этом расположение полей является важным.
Чуть подробнее про составные индексы. Рассмотрим аналогию с теми же книгами. До этого индекс строился только по названию. Теперь же представим, что книги с одинаковыми названиями часто встречаются. В такой ситуации, легко может получится, что страничка каталога будет состоять из координат сотен книг (десятки авторов и у каждого по десять копий). Бегать их всех проверять — так же немалое количество времени. Поэтому вместо того, чтобы страничка просто перечисляла все местонахождения книг, можно сделать так, чтобы странички с именами книг указывали на дополнительные каталоги, где аналогичным образом проиндексированы авторы.
Немного упрощая, поиск будет выглядит примерно так.
1. Вначале вы ищите в каталоге с именами необходимую страничку с названием.
2. Затем в этой страничке смотрите, где находится соответствующий каталог с авторами.
3. Берете этот каталог и уже в нем находите страничку, где указано месторасположение всех книг с этим автором и названием.
При этом важно понимать, что для каждого названия будет создаваться собственный каталог авторов. То есть в обратном порядке, к сожалению, поиск не осуществить. Если же требуется поиск вначале по автору, а уже затем по названиям книг, то необходимо создавать отдельный составной каталог (составной индекс).
Существуют и другие моменты, но чаще всего достаточно знать хотя бы эти базовые знания.
Закрыть сайт от индексации (Disallow)
Установить полный запрет на индексацию всего сайта может быть актуально для ресурсов, находящихся в процессе разработки, полных дублей или сайтов без контентного наполнения. Чтобы закрыть от индексации полностью весь сайт, пропишите в файле robots.txt правила:
Так же полный запрет (разрешено ничего) означает директива Allow, в которой не задано без какого-либо значения:

Зачем нужен индексный файл?
Robots.txt применяется, в первую очередь, для избежания попадания отдельных страниц в индексную базу. Запрет сканирования актуален:
Важным предназначением robots.txt является перераспределение краулингового бюджета.
Как известно, поисковая система выделяет конечное число лимитов в день, или краулинговый бюджет. Его хватает на сканирование определенного числа страниц сайта.
Поэтому важно, чтобы лимит расходовался на важные для продвижения посадочные страницы, а не на страницы, которые, например, не содержат контент (и впоследствии будут исключены из выдачи Яндекса как недостаточно качественные).
Ниже показана схема сканирования сайта с robots.txt и без него.

Как создать страницу index.html
Теперь вы понимаете, что такое страница index.html и почему она важна. Давайте посмотрим, как именно мы можем создать страницу index.html с помощью Visual Studio Code (или VS Code), редактора кода.
Если у вас не установлен VS Code, ознакомьтесь с этим полезным руководством по началу работы с Visual Studio Code.
Начнём с создания нового файла.
На главной панели инструментов VS Code создайте новый файл.

Затем вам будет показан пустой файл кода с таким именем, как «Без названия» или «Без названия-1».

Затем перейдите в «Файл», «Сохранить как» и сохраните имя файла как «index» с типом файла «html».

Теперь вы увидите «index.html» в качестве имени вашего файла.

По умолчанию в файле index.html должно быть несколько элементов. К ним относятся HTML-теги, такие как,и. Вы также должны объявить тип документа, используя «DOCTYPE HTML».
У вас есть страница index.html. Теперь вы можете создавать дополнительные файлы, чтобы оживить ваш сайт.
Как включить индексирование поиска в Windows 10
Делается это буквально в несколько кликов:
Как отключить индексирование дисков в Windows 10
Как обычно, создатели ОС предусмотрели несколько вариантов выполнения этой задачи.
Открыть сайт для индексации (Allow)
Отсутствие запрещающего правила Disallow: / означает, что сайт открыт для индексации. Т.е. одним из вариантов открыть сайт для поисковых роботов будет исключение из файла роботс этой директивы. Также возможно указание конкретной рекомендации по индексации:
Многие слышали о том, что индексы в базах данных это весьма полезная штука. Но, одно дело слышать, а другое представлять себе их устройство хотя бы на базовом уровне. Поэтому в рамках данной статьи для начинающих, я рассмотрю этот вопрос, применяя простые и понятные каждому выражения и аналогии из жизни.
Основные директивы
Название поискового бота.
Директива User-agent указывает, к какому роботу применимы задаваемые правила. Универсальным вариантом является общее правило для всех роботов:
User-agent: *
Однако, для улучшения индексации рекомендуется прописывать правила для отдельных роботов, например, для Яндекс и Google:
User-agent: Yandex
.
User-agent: Googlebot
.
Запрет индексации.
С помощью директивы Disallow указывают разделы, куда роботу заходить не рекомендуется. Например, чтобы закрыть от индексации страницы поиска используют правила:
Disallow: */search/
или
Disallow: *?s=
Рекомендация к индексации.
Директива Allow помогает направлять робота по нужным разделам сайта. Она часто используется для указания пути к страницам, верхний уровень которых запрещен для индексации, например:
Disallow: /buy-car/
Allow: /buy-car/new-cars/$
Это правило запрещает индексацию всего раздела /buy-car/ (включая все внутренние страницы), кроме 1 подраздела /buy-car/new-cars/ .
Путь к карте сайта.
Карта сайта используется для указания актуальной структуры веб-ресурса и обычно располагается по стандартному адресу /sitemap.xml.
Робот Google воспринимает только 4 указанные выше директивы, игнорируя остальные правила.
Для поискового робота Яндекс имеются дополнительные инструкции, которые на сегодняшний день утратили актуальность:
- Host - основное зеркало сайта. Директива полностью заменена на 301 редирект. Статья в блоге Яндекса.
- Crawl-delay - интервал времени на загрузку страницы сайта. Полноценной заменой служит инструмент Вебмастера.
Актуальным дополнительным правилом для Яндекс остается Clean-param.
Параметры url, которые не нужно учитывать в индексе.
Директиву используются для страниц с GET-параметрами или метками (UTM) в URL, т.е. страниц, которые содержат одинаковый контент. Обработка страниц по правилу препятствует многократной загрузке контента, повышая эффективность обхода.
Специальные символы в Robots.txt
* (звездочка) - означает произвольный набор символов. Например, User-agent: * - это указание для всех поисковых ботов без исключения. По умолчанию, ко всем правилам без спецсимвола на конце добавляется звездочка.
$ (доллар) - нужен для отмены действия звездочки, которая по умолчанию. Например,
Disallow: /buy-car/ - запрещает для индексации весь раздел (включая внутренние страницы),
Disallow: /buy-car/ $ - запрещает индексацию только страницы /buy-car/.

Читайте также: