Является ли буфер памяти устройством
Вы используете устаревший браузер. Этот и другие сайты могут отображаться в нём некорректно.
Необходимо обновить браузер или попробовать использовать другой.
Что такое буферная память?

Кэш-память – это зона для временного хранения данных. Здесь хранится информация, которая была считана с жесткого диска, но еще не передана для последующей обработки. Потребность в таком хранилище возникла в результате выявления большой разницы между тем, за какой период времени считываются данные, и пропускной способностью системы.
Своего рода буфером обладают и другие элементы ПК. К примеру, принтер, который может переходить к выполнению следующей задачи, но при этом распечатывать материал, который был задан ранее. Также буферной памятью обладают видеокарты, сетевые карты и т.д.
Основными техническими свойствами кэша является его емкость и быстродействие. Современные устройства по таким временным характеристикам, а также объему буфера значительно отличаются друг от друга. Чем больший объем кэш-памяти, тем больше информации в нем помещается. А значит, компьютер может выдать результаты, не обращаясь к винчестеру часто.
Таким образом, увеличивается сама производительность системы, и косвенно продляется срок работы жесткого диска. Последнее зависит непосредственно от пользователя и то, как и для чего он использует винчестер. К примеру, винчестер прослужит дольше, если смотреть фильмы в браузере, а не качать через торрент и открывать с помощью видеоплеера.
Создание буфера в C/C ++
Из-за ограниченности ресурсов встроенных систем структуры данных с циклическим буфером можно найти в большинстве проектов фиксированного размера, которые работают так, как если бы память по своей природе была непрерывной и циклической. Данные не нужно переставлять, поскольку память генерируется и используется, а корректируются указатели головы/хвоста. Во время создания циклической буферной библиотеки нужно, чтобы пользователи работали с библиотечными API, а не изменяли структуру напрямую. Поэтому используют инкапсуляцию кольцевого буфера на "Си". Таким образом разработчик сохранит библиотечную реализацию, изменяя ее по мере необходимости, не требуя, чтобы конечные пользователи также обновляли ее.
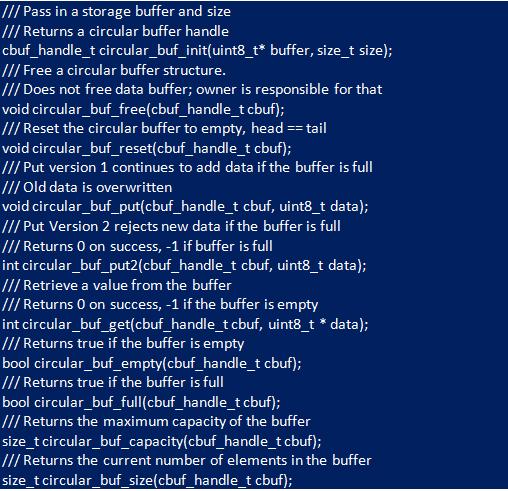
Пользователи не могут работать с «circular_but_t» указателем, создается тип дескриптора, который можно использовать вместо него. Это избавит от необходимости приводить указатель в реализации функции «.typedefcbuf_handle_t». Разработчикам нужно собрать API для библиотеки. Они взаимодействуют с библиотекой кольцевого буфера «C», используя непрозрачный тип дескриптора, который создается во время инициализации. Обычно выбирают «uint8_t» в качестве базового типа данных. Но можно использовать любой конкретный тип, проявляя осторожность, чтобы правильно обрабатывать базовый буфер и количество байтов. Пользователи взаимодействуют с контейнером, выполняя обязательные процедуры:
- Инициализировать контейнер и его размер.
- Сбросить круговой контейнер.
- Добавлять данные в кольцевой буфер на "Си".
- Получать следующее значение из контейнера.
- Затребовать информацию о текущем количестве элементов и максимальной емкости.
И «полный», и «пустой» случаи выглядят одинаково: "head" и "tail", указатели равны. Существует два подхода, различающие полный и пустой:
- Полное состояние tail + 1 == head.
- Пустое состояние head == tail.
Реализация библиотечных функций
Для создания кругового контейнера используют его структуру для управления состоянием. Чтобы сохранить инкапсуляцию, структура определяется внутри библиотечного «.c» файла, а не в заголовке. При установке нужно будет отслеживать:
- Базовый буфер данных.
- Максимальный размер.
- Текущую позицию головы, увеличивающуюся при добавлении.
- Текущий хвост, увеличивающийся при удалении.
- Флаг, указывающий, заполнен ли контейнер или нет.
Теперь, когда контейнер спроектирован, реализуют библиотечные функции. Каждый из API требует инициализированного дескриптора буфера. Вместо того чтобы засорять код условными утверждениями, применяют утверждения для обеспечения выполнения требований API в стиле.

Реализация не будет являться поточно-ориентированной, если в базовую библиотеку циклических хранилищ не были добавлены блокировки. Для инициализации контейнера у API есть клиенты, которые предоставляют базовый размер буфера, поэтому создают его на стороне библиотеки, например, для простоты «malloc». Системы, которые не могут использовать динамическую память, должны изменить «init» функцию, чтобы использовать другой метод, например, такой как выделение из статического пула контейнеров.
Другой подход заключается в нарушении инкапсуляции, что позволяет пользователям статически объявлять структуры контейнеров. В этом случае «circular_buf_init» необходимо обновить, чтобы взять указатель или «init», создать структуру стека и вернуть ее. Однако, поскольку инкапсуляция нарушена, пользователи смогут изменять ее без библиотечных процедур. После того как создан контейнер, заполняют значения и вызывают "reset". Прежде чем вернуться из «init», система гарантирует, что контейнер создан в пустом состоянии.

Преимущества

Несмотря на то, что главным преимуществом буферной памяти является быстрая обработка данных, есть еще и другие достоинства. Жесткий диск с объемным буфером может разгрузить процессор или минимально его задействовать. Таким образом, компьютер не будет перегружаться и прослужит дольше.
Также кэш является своего рода ускорителем, обеспечивающий эффективную и быструю работу всей системы. Это сокращает время запуска программного обеспечения, когда требуются данные, уже содержащиеся в кэше.
Обычному пользователю для работы вполне достаточно 32 или 64 Мб. Больший размер теряет значимость, поскольку при взаимодействии с файлами большими по объему это различие незначительно. К тому же переплачивать за более объемный буфер вряд ли кому-то захочется.
Как узнать объем буферной памяти на жестком диске?

Не каждый пользователь интересуется такой характеристикой, как объем кэша (в отличие от размера жесткого диска). Обычно информация содержится на упаковке к устройству. Также можно найти данные в сети или воспользоваться программой HD Tune, которая является бесплатной.
Она предназначена для надежного удаления данных, оценки того, в каком состоянии находится устройство, а также для сканирования и исправления ошибок в системе. Дополнительно можно через нее получить информацию о жестком диске.
Чтобы узнать объем буферной памяти в Мб, нужно скачать утилиту HD Tune и запустить ее. Далее во вкладке «Информация» нужно найти строку под названием «буфер», которая и покажет, какой по объему кэш установлен в данном устройстве.
Эксперты отмечают, что для обычного пользователя ПК подойдет размер в 128 Мб. Если же компьютер используется преимущественно для игр, стоит ориентироваться на размер кэша побольше.

Кольцевой буфер также известен, как очередь или циклический буфер и является распространенной формой очереди. Это популярный, легко реализуемый стандарт, и, хотя он представлен в виде круга, в базовом коде он является линейным. Кольцевая очередь существует как массив фиксированной длины с двумя указателями: один представляет начало очереди, а другой - хвост. Недостатком метода является его фиксированный размер. Для очередей, где элементы должны быть добавлены и удалены в середине, а не только в начале и конце буфера, реализация в виде связанного списка является предпочтительным подходом.
Интерфейс шаблонного класса
Для того чтобы реализация C ++ поддерживала любые типы данных, выполняют шаблон:
- Сброс буфера для очистки.
- Добавление и удаление данных.
- Проверка полного/пустого состояния.
- Проверка текущего количества элементов.
- Проверка общей емкости контейнера.
- Чтобы не оставить никаких данных после уничтожения буфера, используют интеллектуальные указатели C ++, чтобы гарантировать, что пользователи могут управлять данными.
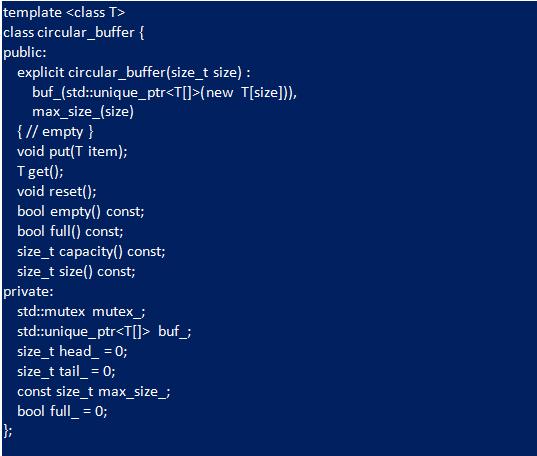
В этом примере буфер C ++ имитирует большую часть логики реализации C, но в результате получается гораздо более чистый и многократно используемый дизайн. Кроме того, контейнер C ++ использует "std::mutex" для обеспечения поточно-ориентированной реализации. При создании класса выделяют данные для основного буфера и устанавливают его размер. Это устраняет накладные расходы, требуемые с реализацией C. В отличие от нее, конструктор C ++ не вызывает "reset", поскольку указывают начальные значения для переменных-членов, круговой контейнер запускается в правильном состоянии. Поведение сброса возвращает буфер в пустое состояние. В реализации циклического контейнера C ++ «size» и «capacity» сообщает количество элементов в очереди, а не размер в байтах.
Краткое описание:
1、CacheЭто высокоскоростное хранилище, иBufferЭто обычное хранилище для временного хранения в оперативной памяти.
2、CacheОн состоит из статической оперативной памяти, которая лучше, чемBufferМедленная динамическая оперативная память быстрее.
3、BufferВ основном используется для процессов ввода / вывода, в то время какCacheИспользуется для чтения и записи процессов с диска.
4、CacheТакже может быть частью диска, иBufferЭто просто часть оперативной памяти.
5. ВCacheМожет использоваться на клавиатуре, если она не может быть использованаBufferДля редактирования опечаток.

Когда программа начинает выполняться, по умолчанию открываются три файла stdin, stdout и stderr, поэтому, когда мы используем scanf (), printf () и другие функции, нам не нужно использовать fopen () для явного открытия этих файлов.
- Процесс отображения потока данных на языке C
- Откройте поток во время компиляции. Система подключит поток к файлу или устройству. Например, если я хочу открыть zyx.txt или ввести фрагмент данных с клавиатуры, поток stdin будет подключен к файлу или клавиатуре. При открытии файла сначала загрузите файл в буфер и верните указатель на тип структуры FILE, который записывает всю необходимую информацию для управления потоком.
- Далее все операции с этим файлом zyx.txt будут сопоставлены операциям с буфером. Если я хочу изменить слово в файле, мне нужно только изменить слово в буфере.
- Только когда буфер принудительно обновляется, файл закрывается или программа завершается, содержимое буфера обновляется в файл.
- Цель потока данных
Цель потока данных - сделать вывод и ввод независимыми от устройства.
Input Stream не волнует, из какого устройства (клавиатура, файл, сеть) исходит источник данных, Output Stream не заботится о том, для какого устройства (клавиатура, файл, сеть) предназначены данные.
Реализация цикличной очереди
Приступая к реализации, определяют типы данных, а затем методы: core, push и pop. В процедурах «push» и «pop» вычисляют «следующие» точки смещения для местоположения, в котором будет происходить текущая запись и чтение. Если следующее местоположение указывает на хвост, значит, буфер заполнен и данные больше не записываются. Точно так же, когда «head» равен «tail», он пуст и из него ничего не читается.

Управление памятью (часть 4): Буферная память
Все вопросы и правила по ведению этой статьи были описаны в части 1. Автор ещё раз замечает, что он активно использует свои определения, и теоретические выкладки, которые никак не претендуют на официальный статус научных, но от этого хуже не становятся.
Буферы
Ещё один вид памяти, часто используемый, но нереализованный в виде API. Он берёт своё начало от вопросов по схемам редактирования файлов, что видимо, является темой последующих статей. Буферная память как следует из названия – это по сути дела то же, что и буферы. Но, в конце концов, такое понятие было обобщено и систематизировано, так как предлагаемая схема использования нашла себя и в других областях, отличных от вопросов буферизации. В общем случае темы буферизации и дефрагментирования являются довольно большими, очень скучно и нудно излагать их в одной статье, поэтому здесь будут лишь объяснения, связанные с буферной памятью, а все вопросы и причины, почему именно, так или иначе, таятся глубже.
Буферная память имеет несколько назначений.
Первое назначение: Целью механизма буферной памяти, (или то же что «прокси- систем») является уменьшение потребляемых ресурсов объектом приёмником, требующего сравнительно больших затрат, путём уменьшения частоты поступления потока данных в объект- приёмник.
Целью механизма буферной памяти является создание участка оперативной памяти для отработки процессов рейдеринга памяти, и других процессов, время выполнения которых зависит от размеров памяти.
Читатель может заметить ещё одну цель создания буферов. Это проведение некоторого рода операций над файлами большого размера, которые не умещаются в оперативной памяти. Однако следует считать, что этот случай попадает под первое назначение буфера, так как нехватку оперативной памяти можно понимать как большие затраты ресурсов. Таким образом под затратой ресурсов следует понимать как источник хранения данных, так и время выполнения кода.
Буферной памятью называется – объект памяти, которым владеют одновременно два объекта, не связанные между собой.
В этом определении важно два слова: «ДВА ОБЪЕКТА» и «НЕ СВЯЗАННЫЕ». В случае нарушения одного из этих условий мы автоматически попадаем в неизведанный мир Оморфо программирования.
Обычно два объекта, владеющие буферной памятью, называются по типу их отношений с буфером: «источник» / «приёмник». Один объект «источник» помещает данные в буфер, а другой объект – «приёмник» снимает их с буфера. Но (. ) сами эти объекты не связаны между собой ни какой архитектурной зависимостью кода! Между прочим, такая модель взаимодействия получила название прокси, когда существует система-посредник между двумя системами. То есть буфер иными словами является прокси-объектом, а источник – буфер – приёмник – прокси-системой.
Рабочий цикл буфера.
- Состояние сброса.
- Состояние наполнения.
- Состояние передачи.
Состоянием наполнения называется момент времени, в котором информация помещается в буфер.
Состоянием передачи называется процесс, когда информация из буфера перемещается в объект приёмник.
Графическое изображение цикла работы буфера представлено на следующем рисунке 2.1 .
Состояние сброса является начальным состоянием буферной памяти, после того как она заказана и выделена. Буферную память, как правило, заказывает третье лицо, и назначает её владельцам: источнику и приёмнику. То есть источник, и приёмник не подозревают, что они работают через буфер. Очень часто буферную память заказывает и объект приёмник, который, по сути, управляет выходным хранилищем данных. В этом случае, он подключается к объекту источнику и передаёт ему буфер. Но никогда (. ) буферную память не заказывает объект источник, на это есть много веских причин, которые выходят за рамки повествования. Можно считать, что объект источник должен быть сконструирован так, чтобы он не подозревал, что работает с буфером. Конечно, на любое правило есть исключения, но в большинстве случаев, такое утверждение указывает на неоптимальность управляющего алгоритма, либо на возможность потенциальной ошибки в нём.
- По сессионное заполнение.
- Циклическое.
- Неупорядоченное.
В первом случае источник заполняет буфер во время специальных периодов называемых сессиями, во втором случае буфер заполняет в каком-либо непрерывном цикле, и в третьем случае буфер заполняется в произвольный момент времени.
Если память в буфере занимается сегментно, то тогда возникает возможность предсказывать переполнение, и передать данные в приёмник в любой момент, когда он будет готов для приёма. В подобных алгоритмах активно используются асинхронные вызовы и событийные системы потенциалов, но можно ограничиться и традиционными способами.
Если заполнение выполняется сессиями, то возникает возможность освобождать буфер каждый раз после сессии, если приёмник готов к передачи, но этим не стоит злоупотреблять, так как система буферной памяти разрабатывалась именно чтобы сделать обращение к выделению основных блоков памяти менее частым. В этом случае можно использовать систему потенциальных предсказаний. В случае циклического заполнения процесс передачи осуществляется в зависимости после последнего гарантированного удачного помещения данных в буфер. Удачным гарантированным помещением в случае сегментной схемы считается – последний помещающийся в буфер сегмент.
Так же хочется отметить по-секторную модель, в которой имеется возможность одновременных процессов считывания и записи в буфер, это актуально при многониточном программировании, а так же в нелинейных системах. В этом случае буфер делиться на несколько секторов. Когда заполняется один сектор буфера, следующий переходит в состояние заполнения, а заполненный сектор переходит в состояние передачи.
Выделение памяти буферу.
Вопрос создания буфера открывается в момент создания объекта приёмника. И как нестранно такое утверждение – правило. Сколько же памяти следует отдавать на буфер? Вот довольно жёсткий принцип:
Размер буфера должен быть таким, чтобы суммарное время выполнения кода обслуживающее режим наполнения, было бы равно времени выполнения кода, выполняющего режим передачи. При этом код исполняемый объектом источником должен иметь приемлемое время исполнения.
В первой части определения разговор идёт касательно так называемого первого назначения буфера. Обычно код организующий выделение памяти средствами ОС является «тяжёлым кодом», то есть он требует сравнительно много времени на выполнение. Предположим, если вы выполняете какие-то циклические действия над потоком ввода из файла, то было бы чрезвычайно расточительно обращаться к диску за каждым байтом. В этом случае, с диска считывается сразу дамп памяти, а некая операция выполняется над этим дампом. Данный пример, аналогичен, так же если вместо источника диска, подставить источник – некую функцию, конвертирующую данные, либо что-то ещё.
Во второй части правила говориться о затратах на использование ресурсов источником, подобно примеру выше – это диск. Диск – медленное устройство и требует сравнительно большего времени для получения/передачи данных. Вместо диска можно подразумевать совокупность процедур, работающих с памятью, и время выполнения которых зависит от размера обрабатываемой памяти. Примером таких процедур могут служить процедуры рейдеринга памяти, выполняющих её дефрагментацию.
Однако, несмотря на всё вышесказанное, прямое использование этого правила не возможно, так как число влияющих факторов на выбор размера буфера намного больше из тех, что рассмотрены в правиле. На выбор размера буфера так же влияют: гранулярность памяти, физический размер страниц, методы выделения памяти, удобство работы обслуживающих алгоритмов, и др. Так же фактором выбора размера буфера является место его размещения и метод получения.
Буферную память можно разместить как статически, то есть заранее расположенную в секции неинициализированных данных, так и динамически выделенную.
В том случае, если буфер создаётся для кэширования вывода в файл, можно разместить буфер прямо на первых страницах файла, однако это чревато последствиями перекачки всех данных при сохранении файла. Можно размещать буфер и в хвосте файла, с каким-то запасом, и постепенно передвигать сам буфер по мере заполнения файла. Вот как это выглядит на практике:
Здесь серым цветом выделена заполняющаяся часть файла, а зелёным – буфер. Остальное – незанятое пространство. Если заполнение дойдёт до границ буфера и потребует большего пространства, тогда информация в буфере будет переработана, а сам буфер будет перемещён дальше, вот так:
По сути, данный метод является как бы обычной последовательной записью в файл, но с промежутками. И, тем не менее, это считается полноценным случаем буфера.
Буферную память целесообразно размещать в области виртуальной памяти, т.е. в файле подкачки. В любом случае размер буфера обязан быть кратен размеру страницы в данной системе. Однако гранулярность выделения памяти в Win32 является 64-bits, что создаёт жёсткие ограничения на размер буфера. Поэтому стоит выделять некоторое пространство памяти для нескольких буферов, и давать им размеры и базовые адреса по размерам страниц. (Более подробно о стратегиях выделения памяти в следующей части.)
Один буфер для многих и многоуровневая буферизация.
Широкий круг задач приходится выполнять жёстко последовательно. Например, ввод с клавиатуры может быть направлен в данный момент времени только в один источник. Этим можно воспользоваться для организации одного буфера для использования многими. Можно применить технологию ускользающих. В этом случае сброс буфера будет выполняться либо когда он наполнен, либо когда к буферу обращается другой объект-хозяин. Место под такой буфер можно зарезервировать в неинициализированном разделе, если он не превышает 8kb – 12kb оперативно памяти. Использование статических буферов является более эффективными по способу адресации, и тем эта эффективность выше, чем больше кода использует данный буфер. При этом при использовании статически размещённого буфера отпадает головная боль за слежением очистки мусора и выделения памяти, что сильно влияет на качество системы. Статические буфера желательно использовать, где только это возможно, хотя это возможно далеко не везде. К счастью существует метод многоуровневой буферизации. Как следует из названия, этот метод представляет собой наличие объекта хозяина у буфера, где объект хозяин сам является буфером. Буфер, который «стоит» ближе к действительному источнику именуется первым, а все последующие по порядку. Обычно каждый последующий буфер имеет меньшую частоту сброса, а значит, занимает больше памяти. Метод многоуровневой буферизации позволяет комбинировать достоинства нескольких приёмов размещения буферов. Например, первым буфером может являться буфер размещённый статически, а вторым – размещённый динамически. Примером использования многоуровневой системы буферизации может послужить API работы с файлами. Вы можете использовать кокой-то свой буфер для выполнения задач, когда система прозрачно для вас выполняет ещё одну буферизацию. А если вспомнить про физический буфер, находящийся в самом жёстком диске, то мы получим трёх уровневую систему буферизации ввода.
- Объект источник помещает данные в область памяти «не являющуюся буфером».
- После всех операций данные направляются в буфер.
В качестве промежуточной памяти может выступать какой либо её блок, размещённый статически и работать по методике ускользающих. Такая система нашла широкое применение на практике, и мы рассмотрим её подробней несколько позже. Важно отметить следующее, что в данной многоуровневой системе, первый объект-буфер не является либо совсем буфером, либо является буфером неполноценным, так как не отвечает одному из назначений буфера, или не имеет буферного цикла.
API буферов.
Обычно всё-таки следует организовать некоторый локальный API по работе с буферной памятью. Первая важная функция, которая должна существовать это, конечно же, CreateBuffer. Вот возможный её прототип:

Оперативная память обеспечивает нормальное функционирование персонального компьютера, а также быстрое выполнение программ и задач. От ее объема зависит, сколько задач одновременно сможет выполнять пользователь на своем компьютере. Есть в компьютере некоторые элементы, которые также оснащаются памятью. Рассмотрим, что такое буферная (или кэш) память, в чем заключаются ее задачи, преимущества и как рассчитать необходимый объем.
Кэш против буфера кеш и буфер
Область кэшаcacheИ буферbufferВсе они являются местами временного хранения, но отличаются во многих отношениях. Буферная зонаbufferВ основном существует в оперативной памяти как область, где процессор временно хранит данные, например,Когда компьютеры и другие устройства имеют разные скорости, bufferБуферизованные данные сохраняются, чтобы компьютер мог выполнять другие задачи. С другой стороны, кешcacheЭто высокоскоростная область хранения, которая может быть частью других независимых областей хранения, таких как основная память или жесткий диск. Эти два метода кэширования называются кэш-памятью и дисковым кешем соответственно.
Кеш находится между процессором и памятью, его скорость выше, чем у памяти, но стоимость высока
Для обеспечения высокой скорости кешированияcacheЭто статическая память вместо динамической памяти. Эта область используется для хранения информации, к которой почти все программы обращаются во время работы, что ускоряет ее вместо поиска информации с диска при каждом запуске программы, поскольку она будет работать намного медленнее.Буферный буфер запускается на компьютере с обычной оперативной памятьюИ отслеживание изменений в запущенной программе, временно сохраненных в изменениях, в конечном итоге сохраняется на диске, например, задача текстового процессора записывается сначала для чтения данных из сохраненного буфера, а затем обновления текстового процессора Содержимое буфера.
Буферная зонаbufferВ основном используется для процессов ввода / вывода (I / O), например, при печати. Когда файл отправляется на принтер для печати, информация сохраняется в буфере, и затем принтер может получить доступ к информации в своем собственном темпе, так что процессор может быть освобожден для выполнения других задач. При хранении некоторой информации (информации о записи) на диске также используется буфер, где данные сначала сохраняются в буфере, а затем передаются на диск во время процесса. кэшbufferВ основном используется в процессе чтения и записи на основной диск, что ускоряет процесс за счет упрощения доступа к аналогичным данным, используемым различными программами.
кэшCacheЭто может быть часть оперативной памяти или часть диска. Когда основной диск используется в качестве кеша, этот процесс называется дисковым кешем, который также используется в качестве кеша памяти, где в кеше диска хранятся последние использованные данные. Если запущенная программа хочет получить доступ к данным с диска, она сначала проверяет кэш диска, а если необходимые данные в кеше диска недоступны, она только проверяет диск. Это делает процесс доступа к данным намного быстрее, потому что доступ с диска намного медленнее. Буферная зонаBufferЭто может быть только часть оперативной памяти.
Типы кэш-памяти
Буферная память, которая располагается в одном фиксированном месте, называется кэшем с прямым отображением. Если же она находится в любом месте, тогда называется полностью ассоциативной памятью. В таком случае полностью используется объем буфера, удалить данные можно после полного заполнения, но поиск информации достаточно затруднен.
Компромиссным вариантом может послужить кэш множественный или частично-ассоциативный. В данном случае строки буфера объединяются в группы. При этом блок, который соответствует определенной группе, может размещаться в любой строке, а соответствующее значение помещается в теге. Здесь действует своего рода принцип ассоциативности, но определенный блок попадает только в ту или иную группу. Это несколько схоже с буфером прямого отображения.
Множественный ассоциативный тип буферной памяти на диске наиболее распространен, так как обладает высокой скоростью и хорошей утилизационной памятью. Но при этом кэш прямого отображения, который отличается дешевизной и простотой, уступает лишь незначительно по своим характеристикам.
Спецификация функциональных требований
Тип данных «ring_t» будет типом данных, который содержит указатель на буфер, размер его, индекс заголовка и хвоста, счетчик данных.
Функция инициализации «ring_init ()» инициализирует буфер на основе получения указателя на структуру контейнера, созданного вызывающей функцией, имеющей предопределенный размер.
Функция добавления звонка «ring_add ()» добавит байт в следующий доступный пробел в буфере.
Функция удаления кольца «ring_remove ()» удалит байт из самого старого допустимого места в контейнере.
Ring peek в функции «ring_peek ()» будет считывать число байтов «uint8_t 'count'» из кольцевого буфера в новый, предоставленный в качестве параметра, без удаления каких-либо значений, считанных из контейнера. Он вернет количество фактически прочитанных байтов.
Функция очистки кольца «ring_clear ()» установит «Tail» равным «Head» и загрузит «0» во все позиции буфера.
Стандартный вариант использования
Вспомогательная процедура вызывается процессом приложения для извлечения данных из кольцевого буфера Java. Она должен быть включена в критические разделы, если считывают контейнер более одного потока. Хвост перемещается к следующему смещению до того, как информация будет прочитана, поскольку каждый блок составляет один байт и резервируется аналогичное количество в буфере, когда объем полностью загружен. Но в более продвинутых реализациях циклического накопителя единичные разделы необязательно должны быть одинакового размера. В таких случаях стараются сохранить даже последний байт, добавив больше проверок и границ.
В таких схемах, если хвост передвигается перед чтением, информация, которая должна быть прочитана, потенциально может быть перезаписана вновь выдвинутыми данными. В общем случае рекомендуется сначала читать, а затем перемещать хвостовой указатель. Вначале определяют длину буфера, а затем создают экземпляр «circ_bbuf_t» и назначают указатель «maxlen». При этом контейнер должен быть глобальным или находиться в стеке. Так, например, если нужен кольцевой буфер длиной 32 байта, выполняют в приложении следующее (см. рисунок ниже).
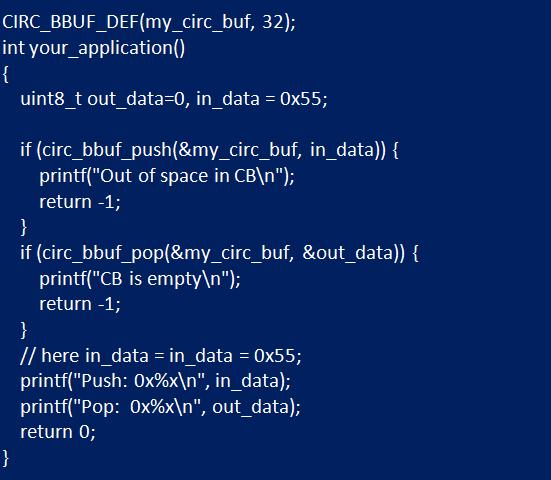
Репозиторий данных UART
Этот репозиторий дает информацию о том, как считывать данные по UART с использованием DMA, когда количество байтов для приема заранее неизвестно. В семействе микроконтроллеров кольцевой буфер STM32 может работать в разных режимах:
- Режим опроса (без DMA, без IRQ)- приложение должно опрашивать биты состояния, чтобы проверить, был ли принят новый символ, и прочитать его достаточно быстро, чтобы получить все байты. Очень простая реализация, но никто не использует ее в реальной жизни. Минусы - легко пропустить полученные символы в пакетах данных, работает только для низких скоростей передачи.
- Режим прерывания (без DMA) - кольцевой буфер UART запускает прерывание, и ЦПУ переходит к служебной программе для обработки приема данных. Наиболее распространенный подход во всех приложениях сегодня, хорошо работает в диапазоне средних скоростей. Минусы - процедура обработки прерывания выполняется для каждого полученного символа, может останавливать другие задачи в высокопроизводительных микроконтроллерах с большим количеством прерываний и одновременно операционную систему при получении пакета данных.
- Режим DMA используется для передачи данных из регистра USART RX в пользовательскую память на аппаратном уровне. На этом этапе взаимодействие с приложением не требуется, за исключением необходимости обработки полученных приложением данных. Может очень легко работать с операционными системами. Оптимизирован для высоких скоростей передачи данных > 1Mbps и маломощных приложений, в случае больших пакетов данных увеличение размера буфера может улучшить функциональность.
Теоретические основы буфера
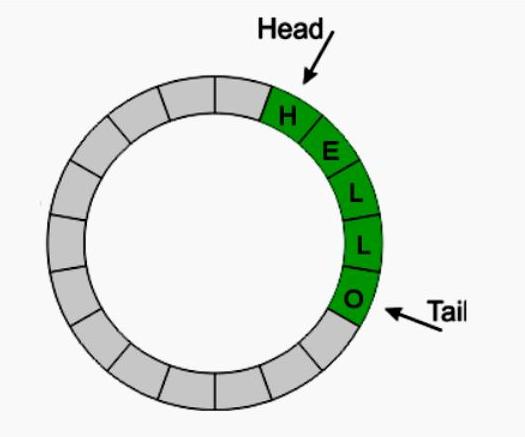
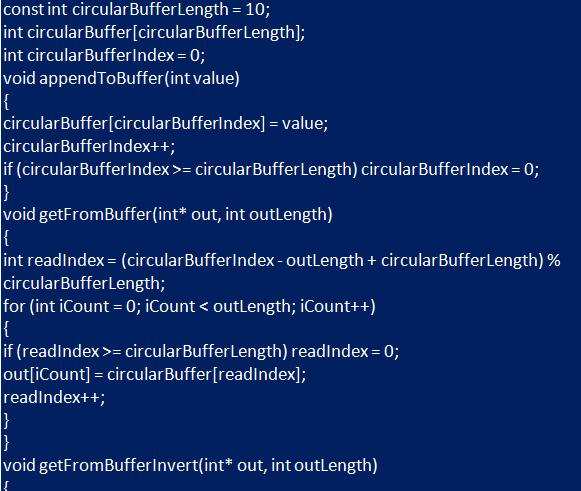
Пользователю легче сделать выбор эффективной структуры массивов после понимания основополагающей теории. Циклический буфер - структура данных, где массив обрабатывается и визуализируется в виде циклов, то есть индексы возвращаются к 0 после достижения длины массива. Это делается с помощью двух указателей на массив: «head» и «tail». Когда данные добавляются в буфер, указатель заголовка перемещается вверх. Точно так же, когда они удаляются, то хвост тоже перемещается вверх. Определение головы, хвоста, направления их движения, места записи и чтения зависят от реализации схемы.
Круговые буферы чрезмерно эффективно используются для решения проблем потребителя. То есть один поток выполнения отвечает за производство данных, а другой - за потребление. Во встроенных устройствах с очень низким и средним уровнем производитель представлен в формате ISR (информация, полученная от датчиков), а потребитель - в виде основного цикла событий.
Еще один вопрос, который возникает в отношении циклического буфера. Нужно ли сбрасывать новые данные или перезаписывать существующие, когда он заполнен? Специалисты утверждают, что нет явного преимущества одного над другим, а его реализация зависит от конкретной ситуации. Если последние имеют больше значимости для приложения, используют метод перезаписи. С другой стороны, если они обрабатываются в режиме «первым пришел - первым обслужен», то отбрасывают новые, когда кольцевой буфер заполнен.
Драйвер UART STM32
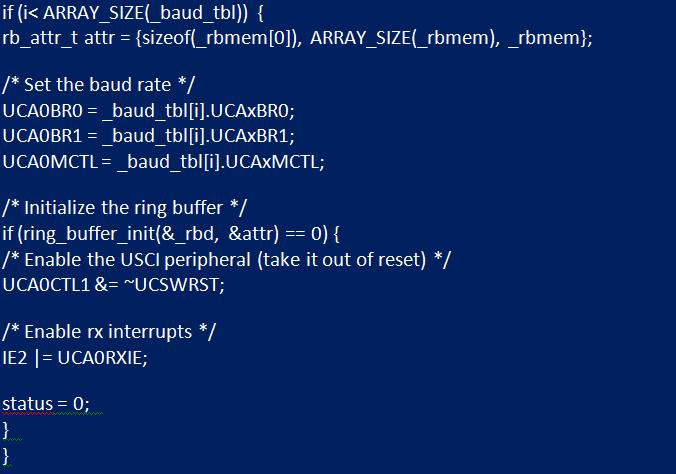
После запуска буфера, он должен быть интегрирован в драйвер UART. Сначала как глобальный элемент в файле, поэтому необходимо объявить:
- "descriptor_rbd" и буферную память "_rbmem: static rbd_t _rbd";
- "static char _rbmem [8]".
Часто модули очередей содержат статистическую информацию, позволяющую отслеживать максимальное использование. В функции инициализации «uart_init» буфер должен быть инициализирован путем вызова «ring_buffer_init» и передачи структуры атрибутов с каждым членом, которому назначены обсуждаемые значения. Если он успешно инициализируется, модуль UART выводится из сброса, прерывание приема разрешено в IFG2.
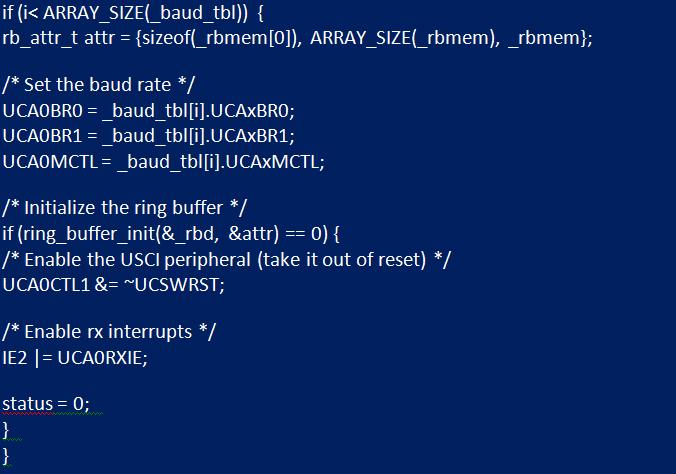
Вторая функция, которая должна быть изменена, - это "uart_getchar". Считывание полученного символа из периферийного устройства UART заменяется чтением из очереди. Если очередь пуста, функция должна вернуть -1. Далее нужно внедрить UART для получения ISR. Открывают файл заголовка "msp430g2553.h", прокручивают вниз до секции векторов прерываний, где находят вектор с именем USCIAB0RX. Именование подразумевает, что это оно используется модулями USCI A0 и B0. Статус прерывания приема USCI A0 можно прочитать из IFG2. Если он установлен, флаг должен быть очищен, а данные в приемном отсеке помещены в буфер с помощью «ring_buffer_put».
Добавление и удаление данных
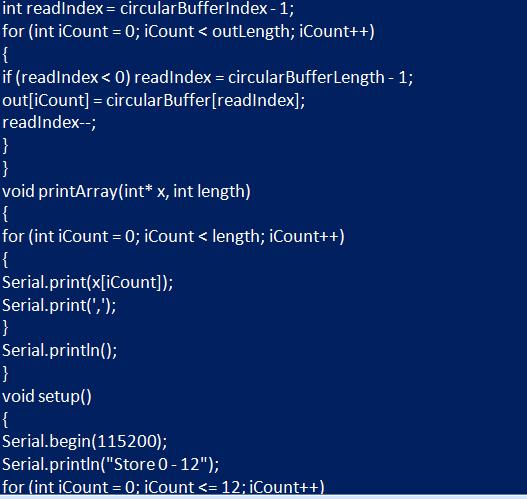
Добавление и удаление данных из буфера требует манипуляций с «head»- и «tail»-указателями. При добавлении в контейнер вставляют новое значение в текущем "head"-месте и продвигают его. Когда удаляют, получают значение текущего "tail"-указателя и продвигают «tail». Если нужно продвинуть "tail"-указатель, а также «head», необходимо проверить, вызывает ли вставка значения "full". Когда буфер уже заполнен, продвигают «tail» на шаг впереди «head».
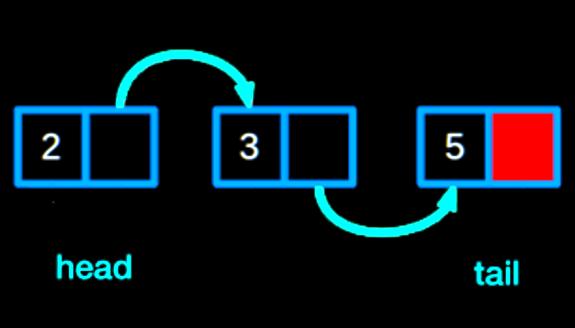
После того как указатель был продвинут, заполняют "full"-флаг, проверяя равенство "head == tail". Модульное использование оператора приведет к тому, что «head» и «tail» сбросят значения в "0", когда будет достигнут максимальный размер. Это гарантирует, что «head» и «tail» всегда будут действительными индексами базового контейнера данных: "static void advance_pointer (cbuf_handle_t cbuf)". Можно создать аналогичную вспомогательную функцию, которая вызывается при удалении значения из буфера.
Высокопроизводительные операции CAS
Кольцевой буфер "qtserialport" (последовательный порт) наследуется от QIODevice, может быть использован для получения различных последовательной информации и включает в себя все из доступных последовательных устройств. Последовательный порт всегда открыт в монопольном доступе, это означает, что другие процессы или потоки не могут получить доступ к открытому последовательному порту.
Кольцевые буферы очень полезны в программировании на "Си", например, можно оценить поток байтов, поступающих через UART.
Память играет ключевую роль в компьютерах. Память обычно использует полупроводниковые запоминающие устройства, включая оперативную память (RAM), постоянную память (ROM) и кэш (CACHE). Это просто потому, что ОЗУ является наиболее важной памятью, поэтому память обычно упоминается как ОЗУ в компьютерных системах.
Оперативная память требует постоянного источника питания, в противном случае данные будут потеряны. Если данные в ОЗУ не теряются после выключения питания, это может гарантировать, что компьютер находится в состоянии последнего выключения при каждом включении, без необходимости каждый раз перезагружать компьютер и повторно открывать приложение. Тем не менее, ОЗУ требует постоянного источника питания. Есть ли способ решить эту проблему? С развитием технологий люди придумали способ подачи небольшого количества энергии в ОЗУ, чтобы предотвратить потерю данных ОЗУ. Эта функция хорошо применяется, особенно в Win2000. Блок питания подключен во время сна, но потребляет небольшое количество энергии.
Разница между жестким диском и памятью очень большая. Вот только три основных момента: во-первых, память - это рабочее место компьютера, а жесткий диск используется для хранения временно неиспользуемой информации. Во-вторых, память сделана из полупроводниковых материалов, а жесткий диск - из магнитных материалов. 3. Информация в памяти будет потеряна при сбое питания, и информация на жестком диске может храниться в течение длительного времени. Связь между памятью и жестким диском также очень тесная. Вот только один момент: информация на жестком диске никогда не будет использоваться временно. Вы хотите использовать это? Пожалуйста, загрузите в память! Прямой обмен данными между процессором и жестким диском отсутствует. Процессор направляет жесткий диск только на обработку управляющих сигналов. Информация на жестком диске может быть обработана только после ее загрузки в память.
Память - это место, где хранятся программы и данные. Например, когда мы используем WPS для обработки документов, когда вы набираете символы на клавиатуре, они сохраняются в памяти. При выборе сохранения данные в памяти сохраняются. Сохранить на жесткий (магнитный) диск. Прежде чем понять это, мы также должны понять его физическую концепцию. ● Постоянное запоминающее устройство (ПЗУ) ПЗУ означает постоянное запоминающее устройство (Постоянное запоминающее устройство) .При изготовлении ПЗУ информация (данные или программа) сохраняется и сохраняется постоянно. Эта информация может быть только прочитана и, как правило, не может быть записана. Даже если устройство выключено, эти данные не будут потеряны. ROM обычно используется для хранения основных компьютерных программ и данных, таких как BIOS ROM. Его физическая форма, как правило, представляет собой интегрированный блок с двумя встроенными линиями (DIP). Оперативная память (RAM). Оперативная память (Random Access Memory) означает, что данные могут быть считаны или записаны. Когда питание машины отключено, сохраненные в нем данные будут потеряны. Модуль памяти, который мы обычно покупаем или обновляем, используется в качестве памяти компьютера.Модуль памяти (SIMM) представляет собой небольшую печатную плату, которая объединяет встроенный блок ОЗУ и вставляется в слот памяти компьютера, чтобы уменьшить интеграцию с ОЗУ. Пространство, занимаемое блоком. ● Кэш (Cache) Кэш также является концепцией, с которой мы часто сталкиваемся: он расположен между процессором и памятью. Это память с более высокой скоростью чтения и записи, чем память. Когда процессор записывает или считывает данные в память, эти данные также сохраняются в кэш-памяти. Когда ЦП снова нужны данные, ЦП читает данные из кеша, а не обращается к более медленной памяти.Конечно, если требуемые данные не находятся в кеше, ЦП снова будет считывать данные в памяти.
Разница между памятью и хранилищем: большинство людей часто путают два имени: память и хранилище, особенно когда речь идет о емкости обоих. Память - это объем оперативной памяти, установленной на компьютере, а объем памяти - это емкость жесткого диска на компьютере.
С точки зрения компьютерной архитектуры, жесткий диск должен быть «внешним хранилищем» компьютера. Память должна быть некоторой памятью внутри компьютера (на материнской плате), которая используется для сохранения промежуточных данных и результатов вычислений в процессе работы процессора, а когда эти данные не используются, они сохраняются на жестком диске. В компьютерной индустрии термин «память» широко используется для обозначения оперативной памяти (оперативной памяти).
1. Кэш: область кэш-памяти представляет собой высокоскоростной кэш, который представляет собой небольшую, но быструю память между процессором и основной памятью, поскольку скорость процессора намного выше, чем скорость основной памяти, процессор считывает данные из памяти Ожидание занимает много времени, и в кэше хранятся данные, которые только что использовался ЦП, или часть данных, которые используются повторно. В это время чтение данных из кэша будет выполняться быстрее, что сократит время ожидания ЦП и повысит производительность системы.
Кэш не кеширует файлы, а кеширует блоки (блоки являются наименьшей единицей чтения и записи ввода / вывода); кэш обычно используется для запросов ввода / вывода. Если несколько процессов хотят получить доступ к файлу, вы можете поместить этот файл Чтение в кэш, чтобы следующий процесс получил управление процессором и получил доступ к этому файлу для чтения непосредственно из кэша, что повысило производительность системы.
2. Буфер: буфер, используемый для хранения данных между устройствами с асинхронной скоростью или устройствами с различными приоритетами, буферы могут сократить время ожидания для межпроцессного взаимодействия. Когда скорость хранения высокая, а скорость хранения низкая При обмене данными сначала сохраняйте медленные данные, сохраняйте данные в буфере, достигайте определенного уровня для сохранения быстрого устройства, а затем считывайте данные буфера. В течение этого периода ЦП быстрого устройства может выполнять другие действия.
Буфер: Обычно используется для записи на диск, например: процесс требует считывания нескольких полей. Когда все обязательные поля считываются, поля, которые были прочитаны ранее, будут помещены в буфер.
Разница между буфером и кешем
A buffer is something that has yet to be "written" to disk. A cache is something that has been "read" from the disk and stored for later use.
Оба являются данными в оперативной памяти. Проще говоря, буфер собирается записываться на диск, а кэш считывается с диска.
Буфер выделяется различными процессами и используется в таких областях, как входные очереди. Простой пример - когда для процесса требуется чтение нескольких полей и чтение всех полей. До завершения процесс сохраняет ранее прочитанные поля в буфере.
Кэш часто используется для запросов дискового ввода-вывода. Если нескольким процессам необходим доступ к файлу, файл превращается в кэш для облегчения доступа в следующий раз. Это обеспечивает производительность системы.
Цитируемая статья 1:
Компоненты компьютерного оборудования: процессор, память, устройства ввода-вывода (I / O), прочие (основная плата, блок питания и т. Д.)
CPU: арифметическое устройство, контроллер
Память: внутренняя память (ROM / RAM), внешняя память (диск и т. д.)
I / O: устройство ввода (мышь / клавиатура), устройство вывода (монитор / принтер)
Из анализа производительности:
- кэш ЦПУ> Память> Диск> База данных
С точки зрения производительности память находится между процессором и диском. На практике память является мостом между процессором и диском. Буфер и кеш - это разные проявления памяти, а затем простой анализ понимания буфера и кеша.
1.buffer:
Буфер - это то, что еще не «записано» на диск. Переведено так: буфер записывается на диск. Буфер предназначен для увеличения скорости обмена данными между памятью и жестким диском (или другими устройствами ввода-вывода). Буфер буферизует данные для решения проблемы медленной и быстрой передачи обслуживания, при быстрой передаче данные должны передаваться побитово в более медленную область через буфер. Например: запись данных из памяти на жесткий диск записывается не напрямую, а буферизируется до определенного размера и записывается на жесткий диск.
2.cache:
Кеш - это то, что было «прочитано» с диска и сохранено для последующего использования. Кэширование реализует повторное использование данных. Медленные устройства должны кэшировать часто используемые данные через кеш. Кэшированные данные могут обеспечить высокую скорость передачи быстрым устройствам. Например: прочитайте данные с жесткого диска и поместите их в область кэша памяти, чтобы позже вы могли снова получить доступ к тому же ресурсу, скорость будет намного выше.
3. Характеристики буфера и кеша
Общие функции:
принадлежит памяти, и данные являются временными. После выключения питания данные будут потеряны.
Различия: (Сначала поймите первые два пункта, последние два пункта интересно понять)
A. буфер предназначен для записи данных; кэш - это считанные данные.
Потеря данных B.buffer повлияет на целостность данных, исходные данные не будут затронуты, потеря данных в кэше не повлияет на целостность данных, но повлияет на производительность.
C. Вообще говоря, чем больше кэш, тем выше производительность, превышающая определенный уровень, что приводит к большей частоте обращений до снижения производительности. Что касается буфера, чем больше пространство, тем меньше влияние на производительность. Кэш-память слишком мала или отсутствует, не влияет на логику программы (за исключением того, что кэш-память с большим количеством одновременных операций слишком мала или потеряна, что приводит к загруженности системы). Если буфер слишком мал, это иногда влияет на логику программы, например, вызывает потерю пакетов в сети.
D.cache может сделать приложение прозрачным, а приложение может быть записано независимо от того, существует ли кэш, и может быть кэшировано после завершения приложения. Конечно, разработчики могут использовать кеш явно. Буфер должен быть разработан человеком, который написал приложение и является частью программы.
Первый буфер используется для чтения и записи дисковых блоков, а кэш - для чтения и записи файловых дескрипторов.
Команда sync записывает все неписанные системные буферы на диск, включая измененные i-узлы, отложенный блок ввода-вывода и файлы отображения чтения-записи.
/ proc - это виртуальная файловая система, которую мы можем использовать для чтения и записи в качестве средства связи с сущностью ядра. То есть путем изменения / proc Файл для настройки текущего поведения ядра. Затем мы можем освободить память, настроив / proc / sys / vm / drop_caches.
Обратите внимание, что лучше синхронизировать перед выпуском, чтобы предотвратить потерю данных.
Из-за механизма ядра LINUX при нормальных обстоятельствах нет необходимости намеренно освобождать использованный кеш. Этот кэшированный контент может увеличить скорость чтения и записи файлов.
Как показано на рисунке выше, когда записывается новый test.txt, строка буфера / кэша увеличивается на 83М до 186,
После выполнения sync и echo 3> / proc / sys / vm / drop_caches он уменьшается до 71M, в основном из-за роли, которую играют echo 3> / proc / sys / vm / drop_caches. В кеш выпущено более 100 м.
Есть много способов просмотра памяти, у редьки и овощей есть своя любовь, поэтому я представлю несколько, которые можно выбрать в соответствии с личными предпочтениями.
Кратко представлена последовательность от графического до командного.

1.gnome-system-monitor
Отображение истории процессора, памяти и памяти, а также истории сети. Вы можете просматривать использование памяти в режиме реального времени, но вы не можете видеть использование буфера и кэша.
- cat /proc/meminfo
Просмотр динамически обновляемых виртуальных файлов. Содержание является относительно полным, и вы можете просмотреть много информации о памяти.
3.free
Быстрый способ просмотра памяти также является часто используемой командой. -h более удобный дисплей памяти -m отображается в виде M
Цитируемая статья 2:
Главная задача

Буферная память предназначена для временного хранения и чтения информации. Но этот показатель не является основным при определении эффективности работы винчестера. Важным также является алгоритм обмена данных с буфером, а также насколько хорошо проводится работа над тем, чтобы предотвратить ошибки.
В буферном хранилище находится информация, которая используется чаще всего. Производительность при этом увеличивается в несколько раз, поскольку она подгружается непосредственно из кэша. Прямого обращения к жесткому диску и его секторам нет, так как отсутствует необходимость в физическом чтении. Этот процесс достаточно длительный, хотя и измеряется в миллисекундах, но данные из буфера можно получить в разы быстрее.
Объемы кэша

При выборе персонального компьютера важно обратить внимание на такой показатель, как объем буферной памяти. Поскольку он периодически нуждается в перезагрузке и очищении, то чем больше по размерам будет кэш - тем лучше. Современные ПА оснащаются 8, 16, 32 и 64 Мб, но буферы имеют объем 128 и 256 Мб.
Хотя современные ноутбуки и компьютеры чаще всего оснащаются большим размером кэш-памяти, меньшая – уже редкость. При выборе устройства пользователи редко обращают внимание на этот показатель, поскольку он непосредственно не зависит от цены. А также параметр не является ключевым при выборе компьютера. Здесь нужно обращать внимание и на другие показатели, поскольку обычно собственной памяти системы вполне достаточно для выполнения операций.
1.2 Буфер
- Значение буфера
- Буферная классификация
Буферы делятся на три типа: полный буфер, строковый буфер и без буфера.
Полностью буферизованный
В этом случае фактическая операция ввода-вывода выполняется после заполнения стандартного кэша ввода-вывода. Типичным представителем полной буферизации является чтение и запись в файлы на диске.
Строка буфера
В этом случае, когда на входе и выходе встречается символ новой строки, выполняется фактическая операция ввода-вывода. В это время вводимые нами символы сначала сохраняются в буфере, и фактическая операция ввода-вывода выполняется при нажатии строки возврата каретки нажатием клавиши Enter. Типичными представителями являются стандартный ввод (стандартный вывод) и стандартный вывод (стандартный вывод).

- Характеристики буфера
- Размер буфера
Если мы не установим буфер самостоятельно, система по умолчанию установит буфер для стандартного ввода и вывода. Размер этого буфера обычно составляет 512 байт.
Размер буфера определяется макросом BUFSIZ в заголовочном файле stdio.h. Если вы хотите просмотреть его размер и включить заголовочный файл, просто выведите его значение следующим образом:
Размер буфера может быть изменен, и файл также может быть связан с пользовательским буфером. Подробнее см. функцию setbuf (). - Обновление буфера
Следующие условия приведут к обновлению буфера- Когда буфер заполнен;
- Когда строковый буфер встречает возврат каретки;
- Закройте файл
- Используйте определенную функцию для обновления буфера.
- scanf() and printf()
Функция scanf () используется для чтения и форматирования со стандартного ввода ввода (клавиатура), а функция printf () отправляет форматированный вывод на стандартный вывод вывода (экран).
Объявление функции scanf выглядит следующим образом:
Формат параметра - это символьный указатель, который является просто строкой C. Формат спецификатора формата:
формат - это строка, содержащая текст для записи в стандартный вывод. Он может содержать встроенные теги формата, которые могут быть заменены значениями, указанными в дополнительных параметрах, которые следуют, и отформатированы по мере необходимости.
Атрибуты тегов формата:![]()
Примеры следующие:
Функция int getchar (void) считывает следующий доступный символ с экрана и возвращает его как целое число. Эта функция будет читать только один символ в одно и то же время. Вы можете использовать этот метод внутри цикла, чтобы прочитать несколько символов с экрана.
Функция int putchar (int c) выводит символы на экран и возвращает те же символы. Эта функция будет выводить только один символ одновременно. Вы можете использовать этот метод внутри цикла для вывода нескольких символов на экране.
![]()
Результаты приведены ниже:
Когда программа вызывает getchat (), она ждет, пока пользователь введет значения с помощью клавиши ввода без клавиатуры. Когда пользователь нажимает клавишу ввода, эти входные значения, включая последний введенный возврат каретки '\ n', будут сохранены в буфере. Символ возвращается как возвращаемое значение функции.
Если вы продолжите вызывать функцию getchar () в это время, оставшееся значение, которое не было возвращено в буфере, вернет второе и т. д., пока не будет вызван getchar () Все остальные значения выводятся. В настоящее время для завершения содержимого getchar () требуется количество завершения. В конце значения находится символ возврата каретки ‘\ n’, который может быть оценен по нему.Обратите внимание, что \ n - это одинарные кавычки в приведенном выше суждении.
В языке C одинарные и двойные кавычки имеют разное значение. Одиночные кавычки изменяют один символ, а двойные кавычки изменяют строку. В строках языка C по умолчанию добавляется «\ 0» в конце строки, что означает, что строка «\ n» действительно (модифицированный escape-символ может быть посчитан как символ) За символом «\ n» следует символ «\ 0», который является строкой «\ n \ 0», и, естественно, «\ n»! = "\ N \ 0", «\ n» невозможно Отменено.
Результат с одинарными кавычками завершается, как показано ниже:
Используйте двойные кавычки без завершения, как показано ниже:- gets() and puts()
Функция gets () объявлена следующим образом:
Функция gets читает строку из stdin в буфер, на который указывает s, и знает терминатор или EOF.
Функция put () объявлена следующим образом:Функция put записывает строку s и завершающий символ новой строки в стандартный вывод.
Примеры следующие:![]()
Результат компиляции и запуска:
Реализация в ARDUINO
Кольцевой буфер Arduino относится как к проектированию плат, так и к среде программирования, которая используется для работы. Ядром Arduino является микроконтроллер серии Atmel AVR. Именно AVR выполняет большую часть работы, и во многих отношениях плата Arduino вокруг AVR представляет функциональность - легко подключаемые контакты, USB-последовательный интерфейс для программирования и связи.
Многие из обычных плат Arduino в настоящее время используют кольцевой буфер c ATmega 328, более старые платы использовали ATmega168 и ATmega8. Платы вроде Mega выбирают более сложные варианты, такие как 1280 и аналогичные. Чем быстрее Due и Zero, тем лучше используйте ARM. Существует около десятка различных плат Arduino с именами. Они могут иметь разное количество флеш-памяти, ОЗУ и порты ввода-вывода с кольцевым буфером AVR.
![Кольцевой буфер AVR]()
Переменную «roundBufferIndex» используют для хранения текущей позиции, а при добавлении в буфер произойдет ограничение массива.
![ограничениями массива]()
Это результаты выполнения кода. Числа хранятся в буфере, и, когда они заполнены, они начинают перезаписываться. Таким образом можно получить последние N чисел.
![Последние N чисел]()
В предыдущем примере использован индекс для доступа к текущей позиции буфера, потому что он достаточен для объяснения операции. Но в общем, нормальным является то, что используется указатель. Это модифицированный код для использования указателя вместо индекса. По сути, операция такая же, как и предыдущая, а полученные результаты аналогичны.
Читайте также: