
Sequence oracle что это
Using sequences when scaling up with Oracle RAC presents more issues with contention. In this article, Jonathan Lewis explains how to avoid the problems.
The series so far:
In my first article on Sequences, I reviewed the fundamental reason why Oracle Corp. introduced the mechanism (i.e. synthetic/surrogate keys) and the mechanical threats (cache size and index contention) that still had to be addressed by the developer/DBA. In this article, I’ll spend most of my time explaining how the problems can get worse (and be addressed) as you move from single-instance Oracle to multi-instance Oracle (RAC). I’ll end the article by mentioning the newer features of sequences that appeared in the upgrades from 12c to 19c, emphasizing one RAC scalability feature.
NOTE: Literally minutes after I had emailed the final draft of this article to the Simple Talk editor, a question came up on the Oracle-L list server asking why duplicate values were appearing from a sequence with scale and extend enabled when the queries accessing it were running parallel. The answer arrived shortly afterwards: this is due to (unpublished) bug 31423645, fixed in Oracle 19.11 with back-ports possible for earlier versions of Oracle.”
Whenever you move from single-instance to multi-instance, the fundamental problem is how to avoid excessive competition between instances for “popular” data blocks. This generic issue turns into two specific issues for sequences:
- Refreshing the sequence “cache” updates a specific row in table sys.seq$ .
- Every session that’s inserting consecutive values into an index will be trying to access the same “right-hand / high-value” index leaf block.
There is another issue with sequences and RAC, though, that has to be considered before worrying about possible hot spots. How do the instances co-ordinate their use of sequence values and avoid the risk of two instances using the same value? There are two solutions: the default noorder mechanism where each instance behaves as if it doesn’t know about the other instances. The other is the order option, where the instances continuously negotiate through the use of global enqueues to determine which instance should be responsible for the sequence at any moment.
ЧАСТО ЗАДАВАЕМЫЕ ВОПРОСЫ
Вопрос: При создании последовательности, что означают опции cache и nocache ? Например, можно создать последовательность с опцией cache 20 следующим образом:
Или вы могли бы создать такую же последовательность, но с опцией nocache :
Ответ: Что касается последовательности, опция cache определяет, сколько значений последовательности будут сохранены в памяти для быстрого доступа.
Недостатком создания последовательности с cache, что если происходит отказ системы, все кэшированные значения последовательности, которые не были использованы, будут утеряны. Это приведет к разрывам в значениях, назначенной последовательности. Когда в система восстановится, Oracle будет кэшировать новые номера, с того места, где была прервана последовательность, игнорируя утерянные значения последовательности.
Примечание: Для восстановления утраченных значений последовательности, вы всегда можете выполнить команду ALTER SEQUENCE для сброса счетчика на правильное значение.
nocache означает, что ни одно из значений последовательности не хранятся в памяти. Эта опция может понизить производительность, однако, вы не должны столкнуться с разрывами в значениях, назначенной последовательности.
Вопрос: Как установить значение lastvalue в последовательность Oracle?
Ответ: Вы можете изменить lastvalue для последовательности Oracle, выполнив команду ALTER в последовательности.
Например, если последнее значение используемой последовательности Oracle был 100, и вы хотите, чтобы следующее значение было 225. Вы должны выполнить следующие команды.
Последовательность CREATE SEQUENCE – это объект базы данных, который генерирует целые числа в соответствии с правилами, установленными во время его создания. Для последовательности можно указывать как положительные, так и отрицательные целые числа. В системах баз данных последовательности применяют для самых разных целей, но в основном для автоматической генерации первичных ключей. Тем не менее к первичному ключу таблицы последовательность никак не привязана, так что в некотором смысле она является еще и объектом коллективного пользования. Если первичный ключ нужен лишь для обеспечения уникальности, а не для того, чтобы нести определенный смысл, последовательность является отличным средством. Последовательность создается командой CREATE SEQUENCE.
Performance – further thoughts
From the list of 4 combinations, it should be clear that noorder/cache N with a large cache is the most scalable option, as it separates the (index) activity of the instances and minimizes the contention for updating the seq$ table. However, it still has effects that might need further consideration.
First is the simple observation that you can expect the index to be roughly twice the “packed” size. If you do a test on a single instance inserting into an indexed column the values from 1 to 1,000,000 from one session and the values from 1,000,001 to 2,000,000 from another session, you will find that the lower range of values will result in 50/50 leaf block splits. In contrast, the upper range of values will result in 90/10 splits. If you have N instances doing inserts from a sequence with a large cache, all but the instance using the top-most range of values will be doing 50/50 leaf block splits all the time. The only comment I can make on this is that it isn’t nice, but it’s probably not terribly important.
More significant is that I’ve ignored the effects of multiple sessions in each instance using the sequence for inserts. In a single instance (of a multi-instance RAC), you could have many sessions inserting values that are very similar, and though this won’t generally produce contention between instances, it can produce contention between sessions in the same instance (i.e. buffer busy waits, index ITL waits, etc.). The “single instance” workaround I mentioned in the previous article of adding a factor like (1 + mod(sid, 16)) * 1e10 to the value supplied by the sequence is a positive danger in these circumstances. For example, entries generated by session 99 of instance 1 might end up in the same index leaf block as rows generated by session 99 of instance 2. You need to go one step further for RAC. In addition to adding a factor to spread sessions across multiple leaf blocks, you also need to add a factor that ensures that different instances will stay separated by adding an “instance factor” like (1 + mod(instance,999) * 1e14 as well. And this brings me to 12c Enhancements.
Синтаксис
CREATE SEQUENCE sequence_name
MINVALUE value
MAXVALUE value
START WITH value
INCREMENT BY value
CACHE value;
sequence_name имя последовательности, которую вы хотите создать.
Пример
Этот код создаст объект последовательность под названием supplier_seq. Первый номер последовательности 1, каждый последующий номер будет увеличиваться на 1 (т.е.. 2,3,4, . ). Это будет кэшировать до 20 значений для производительности.
Если вы опустите параметр MAXVALUE , ваша последовательность по умолчанию до:
Таким образом, вы можете упростить CREATE SEQUENCE. Написав следующее:
Теперь, когда вы создали объект последовательности для автонумерации поля счетчика, мы рассмотрим, как получить значение из этого объекта последовательности. Чтобы получить следующее значение, вам нужно использовать NEXTVAL .
Например:
Это позволит извлечь следующее значение из последовательности supplier_seq . Предложение NEXTVAL нужно использовать в SQL запросе. Например:
Этот isert запрос будет вставлять новую запись в таблицу suppliers (поставщики). Полю Supplier_id будет присвоен следующий номер из последовательности supplier_seq . Поле supplier_name будет иметь значение 'Kraft Foods'.
Создание сиквенсов
Полный синтаксис для создания сиквенса
CREATE SEQUENCE [schema.]sequencename
[INCREMENT BY number]
[START WITH number]
[MAXVALUE number | NOMAXVALUE]
[MINVALUE number | NOMINVALUE]
[CACHE number | NOCACHE]
Создание сиквенса может быть очень простым. Например сиквенс использованный на рисунке 7-6 был создан с помощью команды
create sequence seq1;
Список доступных параметров

Директива CYCLE используется очень редко так как позволяет генерировать дубликаты. Если сиквенс используется для генерации значений первичного ключа, CYCLE имеет смысл только есть функция в БД которая удаляет старые записи быстрее чем сиквенс генерирует новые.
Кеширование значений критично для производительности. Выборка из сиквенса может осуществляться только одной сессией в момент времени. Механизм генерации значений очент эффективный: он гораздо быстрее чем блокировка строки, обновление строки или управление транзакцией. Но даже несмотря на это, выборка из сиквенса может быть точкой конкуренции сессий. Директива CACHE позволяет Oracle генерировать номера блоками. Пред-сгенерированные значения выбираются быстрее чем генерация по запросу.
The default number of values to cache is only 20. Experience shows that this is usually not enough. If your application selects from the sequence 10 times a second, then set the cache value to 50 thousand. Don’t be shy about this
Default Mechanism (noorder)
Imagine you have created a sequence with the basic command
As demonstrated in the previous article, Oracle creates a row in the seq$ table with highwater = 1 and cache = 5000. The first instance to call for s1.nextval reads this row into its global memory area and returns the value 1 to the calling session, updating the table to set the table’s highwater to 5001. (Note: I have said that the “instance” is calling for a value, more accurately, I should say a session in the instance.)
What happens when the next instance calls for s1.nextval ? It will do what any instance normally does; it will read the current values of the row from seq$ and say “the current high value is 5001, the cache size is 5000; I will update seq$.highwater to 10,001 and return the value 5001 to the session”. If a third instance then calls for s1.nextval , the same procedure takes place – it reads the current state of the row, updates the highwater to 15,001, and returns 10,001 to the user session.
Any of the three instances could be the first to exhaust its cache – when it does, it will read the seq$ row again, update the highwater by 5,000 and return the value that used to be the highwater . If this is the first instance, its call to nextval will jump from 5,000 to 15,001.
The upshot of this noorder mechanism is that each instance will be working its way through a different range of numbers, and there will be no overlaps between instances. If you had sessions that logged on to the database once per second to issue a call to nextval (and they ended up connecting through a different instance each time), then the values returned would appear to be fairly randomly scattered over a range dictated by “number of instances x cache size.” Uniqueness would be guaranteed, but ordering would not.
What does this do for the two hot spots, though? I chose a cache size of 5,000 rather than leaving it to default to 20 so that there would be a reasonably large gap between instances that would help to address both points. As it stands, the seq$ block for the sequence’s row would move between instances to be updated at a fairly low frequency. The instances will spend most of their time inserting key values into leaf blocks that are spaced a few blocks apart in the index with intermittent collisions each time an instance refreshes its cache. To a very large degree, optimizing a sequence in a RAC system simply means setting a big enough cache size – in some cases cache 1e6 would be a perfectly reasonable setting.
This isn’t a complete solution to all the performance problems, and I’ll have more to say about that after a brief diversion into sequences created with the non-default order option.
Атрибуты SEQUENCE
SCHEMA
SCHEMA определяет схему, в которой создается последовательность. Если SCHEMA опущена, то :
- Oracle создает последовательность в схеме пользователя.
- MSSQL и PostgreSQL создают последовательность в схеме, к которой подключено приложение. Для MS SQL Можно использовать SQL оператор "use" для подключения к определенной схеме.
SEQUENCE_NAME
SEQUENCE_NAME определяет имя создаваемой последовательности.
START WITH
START WITH start_num — это первое значение, возвращаемое объектом последовательности. Значение должно быть не больше максимального и не меньше минимального значения объекта последовательности. По умолчанию начальным значением для нового объекта последовательности служит минимальное значение для объекта возрастающей последовательности и максимальное — для объекта убывающей.
INCREMENT BY
INCREMENT BY increment_num - приращение генерируемого значения при каждом обращении к последовательности. По умолчанию значение равно 1, если не указано явно. Для возрастающих последовательностей приращение положительное, для убывающих — отрицательное. Приращение не может быть равно 0. Для PostgreSQL можно использовать только INCREMENT.
MAXVALUE maximum_num
MAXVALUE — максимальное значение maximum_num, создаваемое последовательностью. Если оно не указано, то применяется значение по умолчанию NOMAXVALUE.
MINVALUE minimum_num
MINVALUE — минимальное значение minimum_num, создаваемое последовательностью. Если оно не указано, то применяется значение по умолчанию NOMINVALUE.
NOMAXVALUE
NOMAXVALUE в Oracle определяет максимальное значение равное 10 27 , если последовательность возрастает, или -1, если последовательность убывает. По умолчанию принимается NOMAXVALUE.
В СУБД PostgreSQL при включении данного параметры в скрипт необходимо использовать следующий синтаксис : NO MAXVALUE. Значение по умолчанию равно 2 63 -1 или -1 для возрастающей или убывающей последовательности соответственно.
NOMINVALUE
NOMINVALUE в Oracle определяет минимальное значение равное 1, если последовательность возрастает, или -10 26 , если последовательность убывает.
В СУБД PostgreSQL при включении данного параметры в скрипт необходимо использовать следующий синтаксис : NO MINVALUE. Значение по умолчанию равно -2 63 -1 или 1 для убывающей или возрастающей последовательности соответственно.
CYCLE
Применение в скрипте CYCLE позволяет последовательности повторно использовать созданные значения при достижении MAXVALUE или MINVALUE. Т.е. последовательность будет повторно гененировать значения с начальной позиции (со START'a). По умолчанию используется значение NOCYCLE. Указывать CYCLE вместе с NOMAXVALUE или NOMINVALUE нельзя.
NOCYCLE
NOCYCLE указывает, что последовательность не сможет генерировать значения после достижения максимума или минимума.
CACHE cache_num
Оператор CACHE в скрипте позволяет создавать заранее и поддерживать в памяти заданное количество значений последовательности для быстрого доступа.
В СУБД PostgreSQL минимальное значение равно 1 и соответствует значению NOCACHE.
В СУБД Oracle минимальное значение равно 2.
ORDER
Данный оператор используется только в СУБД Oracle. Он гарантирует, что номера последовательности генерируются в порядке запросов. Если упорядочение нежелательно или не установлено явным образом, Oracle применяет значение по умолчанию NOORDER, который не гарантирует, что номера последовательности генерируются в порядке запросов
Order / Nocache
Refreshing the cache: As for noorder/nocache , there is no cache, so every call to sequence.nextval is a request to update the seq$ table and invalidate the row cache entry for the sequence on all instances. In fact, I could see no difference between order / nocache and noorder / nocach e. Possibly the difference in timing between these two cases in my test was purely one of luck.
Inserting into the index: Again, the argument of noorder / nocache applies.
Синтаксис CREATE SEQUENCE
В общем виде синтаксис создания последовательности SEQUENCE для СУБД Oracle можно представить в следующем виде :
Несмотря на однозначное назначение SEQUENCE в различных СУБД имеются определенные различия, которые и будут рассмотрены в данной статье.
CREATE SEQUENCE
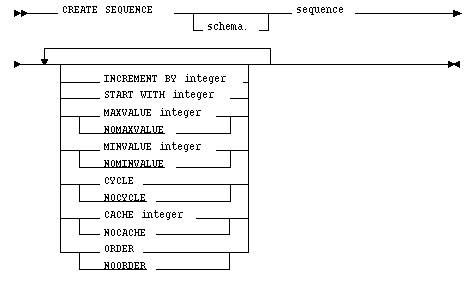
Синтаксис команды CREATE SEQUENCE
Основные ключевые слова и параметры CREATE SEQUENCE:
- schema —схема, в которой создается последовательность. Если schema опущена, Oracle создает последовательность в схеме пользователя.
- sequence — имя создаваемой последовательности
- startwith— позволяет создателю последовательности указать первое генерируемое ею значение. После создания последовательность генерирует указанное в start with значение при первой ссылке на ее виртуальный столбец NEXTVAL
- increment by n — определяет приращение последовательности при каждой ссылке на виртуальный столбец NEXVAL. Если значение не указано явно, по умолчанию устанавливается 1. Для возрастающих последовательностей устанавливается положительное n, для убывающих, или последовательностей с обратным отсчетом - отрицательное
- minvalue — определяет минимальное значение, создаваемое последовательностью. Если оно не указано, Oracle применяет значение по умолчанию NOMINVALUE
- nominvalue — указывает, что минимальное значение равно 1, если последовательность возрастает, или -10 26 , если последовательность убывает
- maxvalue — определяет максимальное значение, создаваемое последовательностью. Если оно не указано, Oracle применяет значение по умолчанию NOMAXVALUE
- nomaxvalue — указывает, что максимальное значение равно 10 27 , если последовательность возрастает, или -1, если последовательность убывает. По умолчанию принимается NOMAXVALUE
- cycle — позволяет последовательности повторно использовать созданные значения при достижении MAXVALUE или MINVALUE. Т.е. последовательность будет продолжать генерировать значения после достижения своего максимума или минимума. Возрастающая последовательность после достижения своего максимума генерирует свой минимум. Убывающая последовательность после достижения своего минимума генерирует свой максимум. Если циклический режим нежелателен или не установлен явным образом, Oracle применяет значение по умолчанию – NOCYCLE. Указывать CYCLE вместе с NOMAXVALUE или NOMINVALUE нельзя. Если нужна циклическая последовательность, необходимо указать MAXVALUE для возрастающей последовательности или MINVALUE – для убывающей
- nocycle — указывает, что последовательность не может продолжать генерировать значения после достижения своего максимума или минимума
- cachen — указывает, сколько значений последовательности ORACLE распределяет заранее и поддерживает в памяти для быстрого доступа. Минимальное значение этого параметра равно 2. Для циклических последовательностей это значение должно быть меньше, чем количество значений в цикле. Если кэширование нежелательно или не установлено явным образом, Oracle применяет значение по умолчанию – 20 значений.
- order — гарантирует, что номера последовательности генерируются в порядке запросов. Эта опция может использоваться, к примеру, когда номера последовательности предстают в качестве отметок времени. Гарантирование порядка обычно не существенно для тех последовательностей, которые используются для генерации первичных ключей. Если упорядочение нежелательно или не установлено явным образом, Oracle применяет значение по умолчанию NOORDER
- noorder — не гарантирует, что номера последовательности генерируются в порядке запросов
Пример 1 CREATE SEQUENCE Создание последовательности sequence_1.s Первое обращение к этой последовательности возвратит 1. Второе обращение возвратит 11. Каждое следующее обращение возвратит значение, на 10 большее предыдущего:
Пример 2 CREATE SEQUENCE Создание последовательности sequence_2. Последовательность убывающая, циклическая, при достижении нуля последовательность вновь обращается к старшему числу. Такой последовательностью удобно пользоваться в тех программах, где до наступления некоторого события должен быть выполнен обратный отсчет:
После создания последовательности к ней можно обращаться через псевдостолбцы CURRVAL (возвращает текущее значение последовательности) и NEXTVAL (выполняет приращение последовательности и возвращает ее следующее значение). Текущее и следующее значения последовательности пользователи базы данных получают, выполняя команду SELECT. Последовательности – не таблицы, а простые объекты, генерирующие целые числа с помощью виртуальных столбцов, поэтому нужна общедоступная таблица словаря данных DUAL, из которой будут извлекаться данные виртуальных столбцов.
Первое обращение к NEXTVAL возвращает начальное значение последовательности. Последующие обращения к NEXTVAL изменяют значение последовательности на приращение, которое было определено, и возвращают новое значение. Любое обращение к CURRVAL всегда возвращает текущее значение последовательности, а именно, то значение, которое было возвращено последним обращением к NEXTVAL.
Прежде чем обращаться к CURRVAL в текущем сеансе работы, необходимо хотя бы один раз выполнить обращение к NEXTVAL. В одном предложении SQL приращение последовательности может быть выполнено только один раз. Если предложение содержит несколько обращений к NEXTVAL для одной и той же последовательности, то ORACLE наращивает последовательность один раз, и возвращает одно и то же значение для всех вхождений NEXTVAL. Если предложение содержит обращения как к CURRVAL, так и к NEXTVAL, то ORACLE наращивает последовательность и возвращает одно и то же значение как для CURRVAL, так и для NEXTVAL, независимо от того, в каком порядке они встречаются в предложении. К одной и той же последовательности могут обращаться одновременно несколько пользователей, без какого-либо ожидания или блокировки:
Чтобы обратиться к текущему или следующему значению последовательности, принадлежащей схеме другого пользователя, пользователь должен иметь либо объектную привилегию SELECT по этой последовательности, либо системную привилегию SELECT ANY SEQUENCE, и должен дополнительно квалифицировать эту последовательность именем содержащей ее схемы: имя схемы>.имя последовательности >.CURRVAL имя схемы>.имя последовательности >.NEXTVAL Значения CURRVAL и NEXTVAL используются в следующих местах:
- в списке SELECT предложения SELECT
- в фразе VALUES предложения INSERT
- в фразе SET предложения UPDATE.
Нельзя использовать значения CURRVAL и NEXTVAL в следующих местах:
- в подзапросе
- в предложении SELECT с оператором DISTINCT
- в предложении SELECT с фразой GROUP BY или ORDER BY
- в предложении SELECT, объединенном с другим предложением SELECT оператором множеств UNION
- в фразе WHERE предложения SELECT
- в умалчиваемом (DEFAULT) значении столбца в предложении CREATE TABLE или ALTER TABLE
- в условии ограничения CHECK.
SELECT SEQUENCE. Пример 3.Действие циклической последовательности sequence_2 при достижении ею значения MINVALUE:
SQL> SELECT sequence_2.NEXTVAL FROM dual; NEXTVAL-------------- 20 SQL> SELECT sequence_2.NEXTVAL FROM dual; NEXTVAL-------------- 19 ….. SQL> SELECT sequence_2.NEXTVAL FROM dual; NEXTVAL-------------- 1 SQL> SELECT sequence_2.NEXTVAL FROM dual; NEXTVAL-------------- 0 SQL> SELECT sequence_2.NEXTVAL FROM dual; NEXTVAL-------------- 20
CREATE SEQUENCE. Пример 4. В следующем примере SEQUENCE после ссылки на столбец NEXVAL значение CURRVAL обновляется так, чтобы соответствовать значению NEXVAL, а предыдущее значение CURRVAL теряется:
SQL> SELECT sequence_2.CURRVAL FROM dual; CURRVAL-------------- 20 SQL> SELECT sequence_2.NEXTVAL FROM dual; NEXTVAL-------------- 19 SQL> SELECT sequence_2.NEXTVAL FROM dual; NEXTVAL-------------- 18 SQL> SELECT sequence_2.NEXTVAL FROM dual; NEXTVAL-------------- 17 SQL> SELECT sequence_2.CURRVAL FROM dual; CURRVAL-------------- 17
INSERT INTO emp VALUES (empseq.nextval, 'LEWIS', 'CLERK', 7902, SYSDATE, 1200, NULL, 20); UPDATE emp SET deptno = empseq.currval WHERE ename = ‘Jones’
ALTER SEQUENCE. Пример 6. Любой параметр последовательности можно изменить командой ALTER SEQUENCE. Новое значение вступает в силу немедленно. Все параметры последовательности, не указанные в команде ALTER SEQUENCE, остаются без изменений:
Когда последовательность больше не нужна, ее можно удалить. Для этого администратор базы данных или владелец последовательности должен выполнить команду DROP SEQUENCE. В результате виртуальные столбцы последовательности NEXVAL и CURRVAL - переводятся в разряд неиспользуемых. Но, если последовательность применялась для генерации значений первичных ключей, созданные ею значения останутся в базе данных. Каскадного удаления значений, сгенерированных последовательностью, при ее удалении не происходит. DROP SEQUENCE. Пример 7. Удаление последовательности SEQUENCE:
Сиквенс – это структура для генерации уникальных целочисленных значений. Только одна сессия может запросит следующее значение и таким образом увеличить счётчик. Поэтому все сгенерированные значения будут уникальными.
Сиквенс это бесценный инструмент для генерации значений первичного ключа. Многие приложения нуждаются в автоматически сгенерированных значениях первичного ключа. Например номерпокупателя и номер заказа: бизнес-аналитики могут решить что каждый заказ должен иметь уникальный номер, которые последовательно увеличивается. В других приложениях вы можете не иметь явных бизнес требований к ключам, но они понядобятся для организации ссылочной целостности. Например в учёте телефонных звонков: с точки зрения бизнес идентификатором является телефонный номер (строка) и звонком будет значение телефона и время начала звонка. Эти типы данных очень сложные для использования их как первичных ключей для больших объёмов которые обязательно будут в системе учёта звонков. Для записи этой информации гораздо легче использовать простые численные столбцы для определения первичных и внешних ключей. Значения этих столбцов могут основываться на сиквенсах.
Мехнизм сиквенсов не зависит от таблиц, механизма блокировок и транзакций. Это значит что сиквенс может генерировать тысячи уникальных значений в минуту – гораздо быстрее чем методы выборки данных, обновления и подтверждения изменений.
На рисунке 7-6 показано как две сессий выбирают значения из сиквенса SEQ1. Обратите внимание что каждый запрос SEQ1.NEXTVAL генерирует уникальный номер. Значение создаётся по порядку в зависимости от времени обращения, и значение увеличивается глобально а не для одной сессии.
Performance Impact
All the performance issues that appear in single-instance Oracle reappear in multi-instance Oracle but tend to get worse because of the need for the instances to co-ordinate their activity through the Global Cache Service or Global Enqueue Service (or both).
In particular, when an instance needs to update seq$ , it may need to call the Global Cache service to get exclusive access ( gc current get ) to the block that it needs to update. Similarly, if the sequence is being used to generate a unique key, then the instance may also need to call the global cache service to get exclusive access to the relevant index leaf block, and the “right-hand/high-value” problem that appears in single-instance Oracle can become a disaster area in multi-instance Oracle.
The possible threats are made a little more subtle, though, by the choice between declaring the sequence as order or noorder . There are 4 combinations to consider:
Noorder / cache N
Order / cache N
Noorder / nocache
Order / nocache
To give you some idea of the effect of the different options, I set up a 3-node RAC system and ran a simple PL/SQL block on each node to do 1,000 single-row inserts of sequence.nextval with a 1/100 second sleep between inserts. I then tested each of the 4 options above (with N = 5000 for the cache tests). The actual work done for the inserts was tiny (less than 1 second CPU); the excess wait time due to RAC-related wait events was as follows (in order of excess time lost):

Clearly, cache is better than nocache , and noorder is better than order . A large cache with noorder is by far the most efficient option. The overheads of global enqueue management for ordering are significant, as are the overheads of maintaining the seq$ table.
There are defects to this specific test, of course. First, it’s running VMs, so the virtual interconnect speeds are slower than they would be on big dedicated hardware; secondly, I haven’t included any indexes in this test, and the different patterns of index contention could be significant; finally, I’m only using one session per instance to do the inserts while production systems are likely to see different patterns of contention between sessions that are running on the same instance.
There are too many possible variations in the patterns of activity that different applications might have, so it’s not sensible for me to create and report tests for all of them. Just remember that you need to think about how your application will be working, then design a couple of models to work out the most appropriate strategy for your circumstances. I will, however, make a few general comments on how the different options may affect the performance of your production system based on my initial statement about the two critical points: refreshing the sequence cache and inserting into the sequence-based unique index.
Sequences in 12c
Oracle 12c (12cR2) brings several enhancements to sequences. You can associate a sequence with a table column using the identity mechanism. Alternatively, you can use “ sequence.nextval ” as a default value for a column if you’d rather not declare an identity. You can create sequences that can be used “locally” – i.e. they are private to a session. You can restart a sequence. Finally, 12c automates the business of minimizing index contention on RAC by introducing the “scale” option (though it’s not documented in the SQL Reference manual and probably shouldn’t be used until 18c).
Here’s a little script that produces the same pattern of results on 12.2.0.1 and 19c, demonstrating the new automatic scalability option:
В Oracle/PLSQL, вы можете создать автонумерацию с помощью последовательности. Последовательность является объектом Oracle, который используется для генерации последовательности чисел. Это может быть полезно, когда вам нужно создать уникальный номер в качестве первичного ключа.

Noorder / Cache N
Refreshing the cache: an instance that reaches its high water and needs to refresh its cache will have to acquire the relevant seq$ block in exclusive mode. For low cache values (e.g. the default 20), this may happen very frequently and introduce significant waits for “gc” (global cache) events. For large values (e.g. the 5,000 in my test), this may be sufficiently rare that any “gc” waits are insignificant compared to the rest of the workload.
Inserting into the index: imagine two instances and a sequence with a cache size of 5,000 where node 1 has been busier than Node 2. Node 1 is currently inserting values in the range 25,001 to 30,000 and has just reached 28,567. Node 2 is inserting values in the range 5,001 to 10,000 and has just reached 9,999. The two instances are inserting into different index leaf blocks, so there’s no contention. After one more insert, Node 2 needs to refresh its cache, so it now starts to insert values in the range 30,001 to 35,000, but Node 1 is currently inserting a few values just a little larger than 28,567. The two nodes will be inserting into the same high-value leaf block for a little while until that leaf block splits and probably leaves Node 1 inserting into one leaf block and Node 2 inserting into the one just above it. For a couple of seconds, there might be a fierce battle for ownership between the two instances, and you’re likely to see waits for various “gc” events for the index, including “gc cr block busy”, “gc buffer busy release” and “gc buffer busy acquire”. I’ll comment on the workaround, or damage limitation mechanism, for this behaviour on my way to the section on 12c enhancements.
Использование сиквенсов
Для использования сиквенса сессия может запросить следующее значения используя псевдо-столбец NEXTVAL, который заставляет сиквенс увеличить значение, или запросить последнее (текущее) значение для текущей сессии используя псевдостолбец CURRVAL. Значение NEXTVAL будет глобально уникальным: каждая сессия которая запрашивает это значение будет получать разный, увеличенный результат для каждого запроса. Значение CURRVAL будет постоянным для каждой сессии пока не будет новый запрос к NEXTVAL. Нет возможности узнать какое последнее значение было сегенрировано сиквенсом: вы можете выбрать только следующее значение вызвав NEXTVAL, и узнать последнее использованное значение для вашей сессии используя CURRVAL. Но вы не можете узнать последнее сгенерированное значение.
The CURRVAL of a sequence is the last value issued to the current session, not necessarily the last value issued. You cannot select the CURRVAL until after selecting the NEXTVAL.
Типичным примером использования сиквенса является генерация значений первичного ключа. Следующий пример использует сиквенс ORDER_SEQ для генерации уникальных значений номера заказа и сиквенс LINE_SEQ для генерации уникального значения строки заказа. Вначале создаётся сиквенс (один раз)
create sequence order_seq start with 10;
create sequence line_seq start with 10;
Затем вставка заказа и пунктов заказа в одной транзакции
insert into orders (order_id,order_date,customer_id)
insert into order_items (order_id,order_item_id,product_id)
insert into order_items (order_id,order_item_id,product_id)
Первая команда INSERT создает заказ с уникальным номером из сиквенса ORDER_SEQ для покупателя с номером 1000. Затем вторая и третья команды INSERT добавляют два элемента заказа используя текущее значение сиквенса ORDER_SEQ как значение для внешнего ключа соединяющего элементы заказа с заказом и следующее значение сиквенса LINE_SEQ для генерации уникального идентификатора каждого элемента. И наконец транзакция подтверждается.
Сиквенс не привязан к какой-то таблице. В предыдущем примере можно использовать один сиквенс для генерации значений для первичны ключей таблицы заказов и таблицы элементов заказа.
COMMIT не обязателен для подвтерждения увеличения счетчика: увеличение счётчика происходи сразу и навсегда и становится видимым для всех в момент увеличения. Нельзя отменить увеличение счётчика. Сиквенс обновляется вне зависимости от механизма управления транзакциями. Поэтому всегда будут пропавшие номера. Разрывы могут быть большими если БД перезапускается и CACHE директива использовалась для счётчика. Все номера которые были сгенерированы и не выбирались будут потеряны в момент выключения базы данных. После следующего запуска текущее значение будет последнее сгенерированное, а не последнее использованное. Таким образом для значения по умолчанию 20, каждый перезапуск приводит к потере 20 номеров.
Если бизнес-аналитики решили что не может быть разрыва в последовательности номеров, тогда можно генерировать уникальный номер по другому. Для предыдущего примера заказов текущий номер заказа можно хранить в таблице с начальным значением в 10
create table current_on(order_number number);
insert into current_on values(10);
Тогда код для создания заказа станет следующим
update current_on set order_number=order_number + 1;
insert into orders (order_number,order_date,customer_number)
values ((select order_number from current_on),sysdate,’1000′);
Это будет работать с точки зрения генерации уникального номера заказа, и так как увеличение номера заказа происходит внутри транзакции то увеличение можно отменить в случае небходимости: тогда не будет разрывов в последовательности, до тех пор пока заказ не будет сознательно удалён. Но это гораздо менее эффективно чем использование сиквенсов, так как код будет слабо производителен в многопользовательской среде. Если много сессий попробуют заблокировать и увеличить значение в строке содержащей текущий номер заказа, то всё приложение будет подвисать посклько будет ждать своей очереди.
После создания сиквенса он может быть изменена. Синтаксис команды следующий
ALTER SEQUENCE sequencename
[INCREMENT BY number]
[START WITH number]
[MAXVALUE number | NOMAXVALUE]
[MINVALUE number | NOMINVALUE]
[CACHE number | NOCACHE]
Команда ALTER такая же как команда CREATE за одним исключением: нельзя установить начальное значение. Если вы хотите обновить начальное значение – то единственный способ это удалить сиквенс и создать новый. Для изменения значения CACHE для увеличения производительности можно выполнить следующую команду
Последовательность SEQUENCE это объект базы данных, предназначенный для генерации целых чисел в соответствии с правилами, установленными при его создании. Генерируемые числа могут быть как положительные, так и отрицательные. Как правило, SEQUENCE используют для автоматической генерации значений первичных ключей. Последовательность является объектом базы данных, и генерируемое ею значения можно использовать для различных таблиц.
Default Mechanism (noorder)
Imagine you have created a sequence with the basic command
As demonstrated in the previous article, Oracle creates a row in the seq$ table with highwater = 1 and cache = 5000. The first instance to call for s1.nextval reads this row into its global memory area and returns the value 1 to the calling session, updating the table to set the table’s highwater to 5001. (Note: I have said that the “instance” is calling for a value, more accurately, I should say a session in the instance.)
What happens when the next instance calls for s1.nextval ? It will do what any instance normally does; it will read the current values of the row from seq$ and say “the current high value is 5001, the cache size is 5000; I will update seq$.highwater to 10,001 and return the value 5001 to the session”. If a third instance then calls for s1.nextval , the same procedure takes place – it reads the current state of the row, updates the highwater to 15,001, and returns 10,001 to the user session.
Any of the three instances could be the first to exhaust its cache – when it does, it will read the seq$ row again, update the highwater by 5,000 and return the value that used to be the highwater . If this is the first instance, its call to nextval will jump from 5,000 to 15,001.
The upshot of this noorder mechanism is that each instance will be working its way through a different range of numbers, and there will be no overlaps between instances. If you had sessions that logged on to the database once per second to issue a call to nextval (and they ended up connecting through a different instance each time), then the values returned would appear to be fairly randomly scattered over a range dictated by “number of instances x cache size.” Uniqueness would be guaranteed, but ordering would not.
What does this do for the two hot spots, though? I chose a cache size of 5,000 rather than leaving it to default to 20 so that there would be a reasonably large gap between instances that would help to address both points. As it stands, the seq$ block for the sequence’s row would move between instances to be updated at a fairly low frequency. The instances will spend most of their time inserting key values into leaf blocks that are spaced a few blocks apart in the index with intermittent collisions each time an instance refreshes its cache. To a very large degree, optimizing a sequence in a RAC system simply means setting a big enough cache size – in some cases cache 1e6 would be a perfectly reasonable setting.
This isn’t a complete solution to all the performance problems, and I’ll have more to say about that after a brief diversion into sequences created with the non-default order option.
Тип генерируемого SEQUENCE значения
В Oracle для последовательности установлено максимальное значение равное 10 27 , минимальное значение соответственно -10 26 .
В MS SQL тип генерируемого значения можно определить при помощи оператора [ built_in_integer_type | user-defined_integer_type]. Если тип данных не указан, то по умолчанию используется тип bigint. Синтаксис выражения CREATE SEQUENCE для СУБД MS SQL :
SEQUENCE СУБД MS SQL может быть определена с определенным типом. Допускаются следующие типы :
- tinyint — диапазон от 0 до 255;
- smallint — диапазон от -32 768 до 32 767;
- int — диапазон от -2 147 483 648 до 2 147 483 647.
- bigint — диапазон от -9 223 372 036 854 775 808 до 9 223 372 036 854 775 807
- decimal и numeric с масштабом 0.
- Любой определяемый пользователем тип данных (псевдоним типа), основанный на одном из допустимых типов.
Для SEQUENCE СУБД Apache Derby, аналогично MS SQL, может быть определен тип. Допускаются типы smallint, int, bigint. Синтаксис генератора последовательности SEQUENCE СУБД Apache Derby :
Пример
Рассмотрим на примере, как удалить последовательность в Oracle.
Этот пример удалит последовательность supplier_seq .
CREATE SEQUENCE
Sequences with ORDER
If you’re running single-instance Oracle, then your sequence values are always generated in order. Some of the values may get lost, some of them may be used out of order by the sessions that acquired them, but there is only one source for “the next value.” That value is generated by the instance as “the previous value” plus “the increment,” so the values are always generated in order.
As noted above, in multi-instance Oracle, the instances will, by default, have separate non-overlapping caches that will be out of synch with each other by an amount relating to the cache size. When you view the sequence from a global perspective, there’s no guarantee that values will be generated in order – and that’s where the RAC-specific order option comes into play.
If you declare a sequence with the order option, Oracle adopts a strategy of using a single “cache” for the values and introduces a mechanism for making sure that only one instance at a time can access and modify that cache. Oracle does this by taking advantage of its Global Enqueue services. Whenever a session issues a call to nextval , the instance acquires an exclusive SV lock (global enqueue) on the sequence cache, effectively saying, “who’s got the most up to date information about this sequence – I want control”. The one instance holding the SV lock in exclusive mode is then the only instance that can increment the cached value and, if necessary, update the seq$ table by incrementing the highwater. This means that the sequence numbers will, once again, be generated in order.
The immediate penalty you pay for invoking the order option is that you serialize the generation of values. The rate at which you can generate sequence numbers is dictated by the rate at which the Global Enqueue Server processes (LCK0/LMD) can manage to move the SV lock for the sequence between the instances. Unless your sequence is only supposed to supply values at a fairly low rate, you probably don’t want to use this option – it doesn’t scale.
It is an odd detail that while the sequence information is passed between instances through the SV enqueue, the enqueue statistics ( v$enqueue_stat ) won’t show any gets on the SV enqueue. (The system wait events ( v$system_event ) will report waits for enq: SV - contention , but the individual sessions ( v$session_event ) will show these waits only as events in waitclass other .)
DROP SEQUENCE
После того как вы создали последовательность в Oracle, вам можете понадобиться удалить её из базы данных.
Order / Cache N
Refreshing the cache: the comments from “ noorder/cache N ” regarding “gc” waits still apply, but since only one instance will need to update the seq$ table at any one moment, the impact will be greatly reduced. But this savings has been at the cost of the continuous stream of waits for the SV enqueue.
Inserting into the index: If you don’t do something to avoid the issue, the contention on the right-hand / high-value leaf block on the index will be huge. Every instance will constantly be demanding the block in current mode, and you will see a lot of waits for “gc” events for the index; you may also see several waits for “enq: TX – index contention” as the current high_value block splits. Of course, if you take action to avoid the contention on the high-value index leaf block, you must have done something that stops consecutive values belonging to the same index leaf block, which means they can’t be consecutive anymore. This suggests you didn’t really need the “order” option.
Refreshing the cache: If there’s no “cache”, the row in seq$ has to be updated on every single call to sequence.nextval . Every instance will request exclusive access to the relevant block and show lots of time lost on various “gc” waits. However, since updating the highwater also results in the dictionary cache (rowcache) being updated, there will also be a lot of time spent waiting on “row cache lock” events.
Inserting into the index: Even though you’ve specified noorder, the effect of the nocache means that the values supplied will be very well ordered with no “cache-size” gap between instances. All the instances will insert into the same high-value leaf block at the same time. There will be “gc” waits on the index as well as on seq$ . Given all the waits for seq$ and row cache locks, the extra time lost due to these waits for the index leaf block may not be extreme.
Синтаксис:
sequence_name имя последовательности, которую вы хотите удалить.
Читайте также: