
Proxmox ограничить потребление памяти zfs
Proxmox is a great open source alternative to VMware ESXi. ZFS is a wonderful alternative to expensive hardware RAID solutions, and is flexible and reliable. However, if you spin up a new Proxmox hypervisor you may find that your VM's lock up under heavy IO load to your ZFS storage subsystem. Here a dozen tips to help resolve this problem.
Ensure that the 'ashift' parameter is set correctly for each of your pools. Generally speaking, ashift should be set as follows:
- ashift=9 for older HDD's with 512b sectors
- ashift=12 for newer HDD's with 4k sectors
- ashift=13 for SSD's with 8k sectors
If you're unsure about the sector size of your drives, you can consult the list of drive ID's and sector sizes hard coded into ZFS. If you're still unsure, it's better to set a higher ashift than a lower one. Note that ashift can only be set when creating a vdev, and cannot be modified once a vdev is created. You can see what ashift is set to for an existing pool by running sudo zdb .
Avoid raidz pools for running VM's. Use mirror vdevs instead. The write amplification associated with raidz1+ vdevs will kill performance.
Create your ZFS vdevs from whole disks, not partitions. sudo zdb will show whole_disk: 1 if you properly assign a whole disk (rather than a partition) to a vdev.
Enable lz4 compression on your pools. sudo zfs set compression=lz4 $POOL . lz4 is fast and you're likely IO bound, not CPU bound, so enabling compression will likely be a net win for performance. Note that you can disable compression on individual datasets that store incompressible data.
Disable atime on your pools. sudo zfs set atime=disabled $POOL .

Consider setting a higher volblocksize for specific workloads. The default "recordsize" in ZFS is 128K, but Proxmox by default uses an 8K "volblocksize" for zvols. Setting this higher did more than anything else to reduce hypervisor and guest lockup during heavy IO. I recommend experimenting with values between 16k and 64k to find what works best for your system. Note that "volblocksize" is set by Proxmox each time a zvol is created (usually when a VM is created), and cannot be modified after a zvol is created. The "volblocksize" is configurable in the Proxmox UI from 'Datacenter -> Storage -> $ID -> Edit -> Block Size"
If your workload is doing a lot of synchronous writes, you'll likely want to add an (enterprise grade) SSD to cache the ZIL. This can be added to a pool as follows: sudo zpool add $POOL log $SSD_DEVICE eg sudo zpool add spinningdisks log /dev/nvme0n1p4 . If you do alot of synchronous writes, but can't afford an enterprise SSD, and you like to live dangerously, you can disable sync on a per pool or per dataset basis eg sudo zfs set sync=disabled $POOL/$DATASET

Configure your VM's to use 'SCSI Controller: VirtIO SCSI Single'. Enable discard and iothread.
Inside your guest OS, enable trim. For example, on Debian 10: sudo systemctl enable fstrim.timer . This will discard unused blocks once a week, freeing up space on the underlying ZFS filesystem. Note that this requires that the 'discard=1' option is set on the disk per step 8 above.
Beware that since ZFS is a copy on write filesystem, writes will most definitely get slower as the pool becomes more and more full (and fragmented). If a pool gets more than 70% full, and writes become noticably slower, you can remedy this only by moving the data to another pool, deleting and recreating the pool, and moving the data back.
ZFS replication is your friend, and can help you create a hyper converged infrastructure, seamlessly migrating workloads between nodes without the need for shared storage. More on that in a subsequent post.
Credit to Martin Heiland for his comprehensive writeup on ZFS tuning for VM workloads from a few years back.
Persisting UI Settings to Tails
Tails is very useful for tasks that require attention to opsec. The "amnesiac OS" is adept at avoiding malware infestation, as it boots clean every time. This is great, except for UI/UX preferences that you struggle to survive without. Tails supports use of persistent volumes, which allow you to
Подскажите - как рассчитать минимальный и оптимальный объём памяти, который надо иметь на сервере для использования ZFS? (в зависимости от объёма диска/хранилища и конфигурации).
Например, хочу сделать зеркало из 2х hdd 3Тб (5400 rpm) на базе zfs - сколько памяти надо иметь на сервере (в смысле - только для обслуживания zfs, не считая остальных потребителей памяти)? чтобы не было «тормозов»)

Для файлового сервера есть понятие минимального объёма ОЗУ. Всё что больше, он с удовольствием отъест.
Я когда-то из 32 Гб доступных оставлял порядка 10 Гб свободной ОЗУ прокмоксу. Хранилище, правда, где-то 1 Тб суммарно было, но ехало все нормально (по «субъективным ощущениям»).

Нет каких-то жёстких требований. По дефолту arc жрёт половину оперативной памяти, если ты считаешь, что это много, можно поменять. Думаю, 4 Гб на 3Tb зеркало хватит (я имею ввиду только под arc), но если у тебя есть возможность отдать больше, хуже от этого точно не будет.
Black_Shadow ★★★★★ ( 26.01.22 13:04:59 )
Последнее исправление: Black_Shadow 26.01.22 13:07:45 (всего исправлений: 2)

Это как на заправке. Мне полный бак. Чем больше тем лучше. Ну а если проблемы то мне всего на 1000 руб. залейте. Ну а если серьезней. Память под кеш можно ограничить. ZFS а точнее arc если его не ограничивать то как уже написали старается забить на 50% память, так что думай ограничивать или нет.
Нет каких-то жёстких требований. По дефолту arc жрёт половину оперативной памяти, если ты считаешь, что это много, можно поменять. Думаю, 4 Гб на 3Tb зеркало хватит (я имею ввиду только под arc), но если у тебя есть возможность отдать больше, хуже от этого точно не будет.
- А формула какая-то есть для расчёта? Cейчас на сервере 16 Мб, условно из них 8 Гб на сам прохмокс и ВМ, оставшихся 8 Гб на хранилище 3Тб видимо хватит.
А если я захочу к этому тому ещё добавить зеркало 6 Тб - сколько надо будет памяти в сервер добавить?
- Сама ОС сервера находится на NVMe диске 256 Гб. На нём есть свободное место. Я читал, что кэш и журнал zfs можно разместить отдельно от данных на SDD для увеличения производительности.
Т.е. я вижу как вариант - взять отдельный чистый раздел на системном NVMe диске и разместить там кэш и журнал zfs тома.
Вопросы: а) стоит ли так делать в принципе? б) как вычислить необходимый размер этого раздела? в) стоит ли это делать, если это одиночный NVMe диск, а не зеркало?
а) нестоит если умрет твой NVMe от использования L2ARC по быстрый умрет все. Но ессли умрет ssd с L2ARC то zfs переживет это и даже не поморщится.
б) ну у меня и 256 гб стоит (самый дешманский) потеря этого бойца не сильно влияет на всю работу в целом
в) не стоит смотри ответ а)
а) не стоит если умрет твой NVMe от использования L2ARC по быстрый умрет все. Но ессли умрет ssd с L2ARC то zfs переживет это и даже не поморщится.
правильно ли я понинимаю, что если и использовать ssd для размещения L2ARC, то это должен быть физически отдельный ssd, ни для чего иного больше не используемый?
насколько это вообще необходимо - ssd для размещения L2ARC? В каком случае это нужно делать?
Может быть проще дополнительную планку памяти в сервер воткнуть и будет тот же результат?)
Когда-то давно, во времена zfs 0.6, писалось про оптимальный 1Gb RAM на каждый 1Tb хранилища. Без дедупликации, разумеется.
zemidius ★ ( 26.01.22 14:06:03 )
Последнее исправление: zemidius 26.01.22 14:07:06 (всего исправлений: 1)
Может быть проще дополнительную планку памяти в сервер воткнуть и будет тот же результат?)
и это правильная мысль. с лучшим результатом.
если в твоём юзкейсе преобладает синхронная запись - делай log на ssd, но он должен быть enterprise level.
ARC - это адаптивный кэш, в зависимости от «просьб» ОС он может ужиматься от zfs_arc_max до zfs_arc_min. Т е ты выставляешь нижнюю и верхнюю границы и он живет в этих границах, динамически меняя свой размер
он называется «Адаптивный» совсем не потому что он динамический.
Может быть проще дополнительную планку памяти в сервер воткнуть и будет тот же результат?)
и это правильная мысль. с лучшим результатом. если в твоём юзкейсе преобладает синхронная запись - делай log на ssd, но он должен быть enterprise level.
- Почему здесь именно enterprise level? Для надёжности или производительности?
Что будет, если этот ssd с логом сдохнет? zfs том разрушится или автоматически перенесёт log на другой диск?
- Правильно ли я понимаю, что минимальный надор дисков для моего случая такой:
а) NVMe/SSD 2 шт - системный диск/зеркало
б) NVMe/SSD 1 шт - диск для лога zfs
в) HDD 2 шт - зеркало для хранилища данных, zfs
В свзи с этим ещё вопросы
как лучше организовать зеркало на системном (загрузочном) NVMe диске - средствами mdam или zfz?
если на ssd хранить не L2ARC, а только log zfs, то в этом случае можно объединить а) и б) - т.е. этот лог будет в отдельном разделе системного диска?
да - все правильно, не по тому, что он динамический. Адаптивный он внутри, все так
1 и да и нет это вопрос филосовский.
2 ну кто запретил гугол или яндекс прочитай про кешироване zfs и потом подумай, а нужет тебе L2ARC или хватит ARC в памяти

Для комфортного использования требуется 4 Гбайт ОЗУ, но конкретная нагрузка может сильно различаться.
А формула какая-то есть для расчёта? Cейчас на сервере 16 Мб, условно из них 8 Гб на сам прохмокс и ВМ, оставшихся 8 Гб на хранилище 3Тб видимо хватит.
Формул нет, всё зависит от конкретно твоего случая. ZFS будет работать и с 1 Gb arc.
А если я захочу к этому тому ещё добавить зеркало 6 Тб - сколько надо будет памяти в сервер добавить?
Тебе никто не ответит на этот вопрос. Смотри статистику, каков % попаданий в кэш, устраивает ли тебя текущая скорость чтения.
Сама ОС сервера находится на NVMe диске 256 Гб. На нём есть свободное место. Я читал, что кэш и журнал zfs можно разместить отдельно от данных на SDD для увеличения производительности.
Можно отделять на отдельный SSD, а можно и не отделять. Первое время помониторь скорость износа SSD на твоих данных, и если нужно, вынеси на отдельный диск, чтобы не потерять важные данные.
SSD можно использовать в качестве l2arc и slog. l2arc - кэш чтения второго уровня. Всё, что вытесняется из arc, попадает в l2arc. Под l2arc тоже расходуется оперативка. Вот, например, здесь видно, как l2arc отожрал 2.3 гига:
Теперь про slog. Есть такая штука, как zil (ZFS intent log). Zil используется для синхронной записи. Запись бывает синхронной и асинхронной. При асинхронной записи транзакции собираются в группы, и, через некоторое время пишутся в пул. При синхронной записи транзакции пишутся в zil, и остаются в оперативной памяти, чтобы потом быть обработанными так же, как и в случае с асинхронной записью, то есть, быть записанными в пул. В результате, получается так, что в случае нормальной работы zil никогда не читается, а нужен только при некорректном завершении работы, чтобы восстановить не записанные в пул синхронные транзакции. По умолчанию, zil находится на тех же устройствах, что и данные пула, но для него можно выделить отдельное устройство, это называется slog. В качестве slog вполне можно использовать раздел на устройстве, которое уже используется для l2arc.
Теперь про необходимость enterprise ssd. Конечно, для того, чтобы максимально избежать потери нужных данных, нужен enterprise ssd (отличается от обычного наличием конденсаторов, подпитывающих кэш внутри ssd). При использовании обычного SSD, при отключении питания могут пропасть последние несколько транзакций, которые SSD не успел записать во флэш память. Надо понимать, что это, как правило, данные, которые были сгенерированы за последние доли секунды перед отключением питания. Если у тебя какая-нибудь база данных, куда постоянно пишутся новые данные, и нельзя потерять ни одного байта при некорректном отключении питания, то да, тебе нужен enterprise ssd. В остальных случаях, и с обычными, домашними SSD всё прекрасно работает.
Размер slog маленький, зависит от интенсивности записи, обычно несколько гигабайт.
В случае потери slog, пул по умолчанию не запустится, но потеряются только те данные, которые были в slog, пул можно будет импортировать вручную и удалить отсутствующий slog.
Так что, если у тебя критически важная система с постоянной записью, то нужно зеркало. Но, некоторые даже в продакшн прекрасно живут без slog с sync=disabled (без синхронной записи), и всё, что они теряют при некорректном выключении - последние несколько секунд работы системы.
Black_Shadow ★★★★★ ( 26.01.22 17:12:56 )
Последнее исправление: Black_Shadow 26.01.22 17:15:19 (всего исправлений: 1)
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
zmeister
New Member
I am just starting out with Proxmox / LXC / ZFS. I have tried Proxmox before and loved it, however this time I have a different setup!
Server specs:
16 GB RAM (DDR4)
2x 450GB NVME SSD (ZFS Mirror)
Intel Xeon E3-1230v6 - 4c/8t - 3.5GHz
I am only using one empty LXC container at the moment - it is not using any RAM (30MB). The node reports that 9GB of RAM is used! And only ~500MB in buffers/cache.
Previously on this same (brand new) node I created another 4-5 containers (they are all stopped now) with variable RAM set - allocated over the 16GB of physical RAM I have, however all of those containers were never used as they were empty and they all reported ~20-30MB RAM used.
The question I have is why an empty node has such high RAM usage. I only have 16GB of RAM, so if ZFS is caching some disk accesses then I don't really need it. I have a very fast NVME SSD drive.
Would you please have a look at the below data to see where this RAM is going? I am not technical enough in this configuration.
Please see the attachment with htop memory screenshot.
I thought this is a bit odd as I would expect the node to only be around 1GB in use. Because buffers/cache is only reporting 500MB, I believe the 8.5GB is active memory in use? This means it will not be freed for the containers to use?
If I only have 6GB of workable memory from 16GB physical RAM, it is very cost inefficient for me with this server.
I would really appreciate your help if you could help me pinpoint where exactly this RAM is being used, and whether any optimisations should be made?
Attachments
zmeister
New Member
An addition: after reboot the node is reporting 1.2 GB RAM usage.
I will try to replicate the high RAM usage again.
Anyone have any idea of what might be happening though?
dietmar
Proxmox Staff Member
ZFS uses this as cache. See
Best regards,
Dietmar
Do you already have a Commercial Support Subscription? - If not, Buy now and read the documentation
LnxBil
Famous Member
So in short: Linux caches a lot . with ZFS, the normal free command is not enough, because as @dietmar pointed out, ZFS does things a little differently. The lesson to learn here is that free RAM is always bad and windows reports all buffers and caches as free, so people believe in this "I need free ram" nonsense.
RobFantini
Renowned Member
I like the info on this thread.As usual great advice from pve support and linux bill.
on most nodes we use rpool + have 10 ceph OSD's .
since pve > datacenter > summary can not be used to determine if a node is low on memory, what would you use to determine that?
AND
with a system having just a few containers and plenty of ram:
pve shows memory usage at 90%
htop shows some swap was used:
no kvm's are used
pce memory config:
LnxBil
Famous Member
Normally, you should monitor swap in/out instead of absolute values. Swapping on your PVE host (or any other server) is always bad. To get better performance while swapping, we often use zram to have a first in-RAM compressed swap layer. You should avoid swapping to disk at all costs. You should also monitor your wait times of your CPU.
Otherwise monitor the free space and buffer/cache. The sum should not be lower than approx. 10% of your system, if you use ZFS, you should also monitor your arc max size. We nowadays use influx and grafana to graph all hosts and find bottlenecks over time. It is important to find and then define your baseline. If you're using CEPH and ZFS, you should have more RAM reserved than using other "simpler" filesystems.
RobFantini
Renowned Member
we normally use zram, will recheck that it is installed on all nodes.
I'll look at those tools, we currently use zabbix I'll check if that has something we can use.
also it seems that since Meltdown and Spectre patches to kernel that cpu and memory requirements have increased. the fix for us is to just add ram to pve systems and vm's .
RobFantini
Renowned Member
I checked with 'systemctl status systemd-swap' and zram is working on all systems.
Question: is there a cli tool similar to htop that shows actual free memory available for virtual machines?
LnxBil
Famous Member
Question: is there a cli tool similar to htop that shows actual free memory available for virtual machines?
You mean free inside of your PVE QEMU hosts?
free shows on your host its available space. This is from a big database system which as actually no free space and that is on purpose, but a lot is available if it is demanded (this machine has also 200GB of hugepages, more on that further down):
If Linux needs memory, it takes memory and if there is nothing left (free empty and all possible buffers cleared), not recently used parts get swapped out. There are some tweakable settings like vm.swapiness and vm.min_free_kbytes to define when this happens. You can also monitor /proc/buddyinfo for contiguous memory segments. You can also run out of memory, if there are no contiguous segments left, e.g. you require a contiguous 4 MB block, but there is nothing free, your malloc will also fail despite having GBs of free space. Unfortunately, memory fragmentation is a real thing.
One thing I can suggest (only for the sake of completeness) is to improve this a little bit is to use hugepages (2M instead of 4K pages) for your VMs. If you use hugepages, you can monitor used pages more easily, but you have to decide in advance how many GB of RAM go into this. Performance-wise hugepages are in general approx. at least 10% faster for bigger equipped RAM machines due to less overhead in memory maps and fragmentation. Yet I still don't know what the official status on this is. I did some benchmarks with PVE 3.4 back in the days . but it was a long time ago. The drawback of hugepages is that acclaimed hugepages cannot be used with system application and are reserved or split from the normal memory, so you have some kind of second class memory system, so you can end up with a system that has enough hugepages, but not enough normal pages and you will swap aggressively. This is often a tradeoff between performance and maintainability.

За последние несколько лет я очень тесно работаю с кластерами Proxmox: многим клиентам требуется своя собственная инфраструктура, где они могут развивать свой проект. Именно поэтому я могу рассказать про самые распространенные ошибки и проблемы, с которыми также можете столкнуться и вы. Помимо этого мы конечно же настроим кластер из трех нод с нуля.
Proxmox кластер может состоять из двух и более серверов. Максимальное количество нод в кластере равняется 32 штукам. Наш собственный кластер будет состоять из трех нод на мультикасте (в статье я также опишу, как поднять кластер на уникасте — это важно, если вы базируете свою кластерную инфраструктуру на Hetzner или OVH, например). Коротко говоря, мультикаст позволяет осуществлять передачу данных одновременно на несколько нод. При мультикасте мы можем не задумываться о количестве нод в кластере (ориентируясь на ограничения выше).
Сам кластер строится на внутренней сети (важно, чтобы IP адреса были в одной подсети), у тех же Hetzner и OVH есть возможность объединять в кластер ноды в разных датацентрах с помощью технологии Virtual Switch (Hetzner) и vRack (OVH) — о Virtual Switch мы также поговорим в статье. Если ваш хостинг-провайдер не имеет похожие технологии в работе, то вы можете использовать OVS (Open Virtual Switch), которая нативно поддерживается Proxmox, или использовать VPN. Однако, я рекомендую в данном случае использовать именно юникаст с небольшим количеством нод — часто возникают ситуации, где кластер просто “разваливается” на основе такой сетевой инфраструктуры и его приходится восстанавливать. Поэтому я стараюсь использовать именно OVH и Hetzner в работе — подобных инцидентов наблюдал в меньшем количестве, но в первую очередь изучайте хостинг-провайдера, у которого будете размещаться: есть ли у него альтернативная технология, какие решения он предлагает, поддерживает ли мультикаст и так далее.
Установка Proxmox
Proxmox может быть установлен двумя способами: ISO-инсталлятор и установка через shell. Мы выбираем второй способ, поэтому установите Debian на сервер.
Перейдем непосредственно к установке Proxmox на каждый сервер. Установка предельно простая и описана в официальной документации здесь.
Добавим репозиторий Proxmox и ключ этого репозитория:
Обновляем репозитории и саму систему:
После успешного обновления установим необходимые пакеты Proxmox:
Заметка: во время установки будет настраиваться Postfix и grub — одна из них может завершиться с ошибкой. Возможно, это будет вызвано тем, что хостнейм не резолвится по имени. Отредактируйте hosts записи и выполните apt-get update

Изображение 1. Веб-интерфейс ноды Proxmox
Репликация инстансов на соседний гипервизор
В кластере Proxmox есть возможность репликации данных с одного гипервизора на другой: данный вариант позволяет осуществлять переключение инстанса с одного сервера на другой. Данные будут актуальны на момент последней синхронизации — ее время можно выставить при создании репликации (стандартно ставится 15 минут). Существует два способа миграции инстанса на другую ноду Proxmox: ручной и автоматический. Давайте рассмотрим в первую очередь ручной вариант, а в конце я предоставлю вам Python скрипт, который позволит создавать виртуальную машину на доступном гипервизоре при недоступности одного из гипервизоров.
Для создания репликации необходимо перейти в веб-панель Proxmox и создать виртуальную машину или LXC контейнер. В предыдущих пунктах мы с вами настроили vmbr1 мост с NAT, что позволит нам выходить во внешнюю сеть. Я создам LXC контейнер с MySQL, Nginx и PHP-FPM с тестовым сайтом, чтобы проверить работу репликации. Ниже будет пошаговая инструкция.
Загружаем подходящий темплейт (переходим в storage —> Content —> Templates), пример на скриншоте:

Изображение 10. Local storage с шаблонами и образами ВМ
Нажимаем кнопку “Templates” и загружаем необходимый нам шаблон LXC контейнера:

Изображение 11. Выбор и загрузка шаблона
Теперь мы можем использовать его при создании новых LXC контейнеров. Выбираем первый гипервизор и нажимаем кнопку “Create CT” в правом верхнем углу: мы увидим панель создания нового инстанса. Этапы установки достаточно просты и я приведу лишь конфигурационный файл данного LXC контейнера:
Контейнер успешно создан. К LXC контейнерам можно подключаться через команду pct enter , я также перед установкой добавил SSH ключ гипервизора, чтобы подключаться напрямую через SSH (в PCT есть небольшие проблемы с отображением терминала). Я подготовил сервер и установил туда все необходимые серверные приложения, теперь можно перейти к созданию репликации.
Кликаем на LXC контейнер и переходим во вкладку “Replication”, где создаем параметр репликации с помощью кнопки “Add”:

Изображение 12. Создание репликации в интерфейсе Proxmox

Изображение 13. Окно создания Replication job
Я создал задачу реплицировать контейнер на вторую ноду, как видно на следующем скриншоте репликация прошла успешно — обращайте внимание на поле “Status”, она оповещает о статусе репликации, также стоит обращать внимание на поле “Duration”, чтобы знать, сколько длится репликация данных.

Изображение 14. Список синхронизаций ВМ
Теперь попробуем смигрировать машину на вторую ноду с помощью кнопки “Migrate”
Начнется миграция контейнера, лог можно просмотреть в списке задач — там будет наша миграция. После этого контейнер будет перемещен на вторую ноду.
Ошибка “Host Key Verification Failed”
Иногда при настройке кластера может возникать подобная проблема — она мешает мигрировать машины и создавать репликацию, что нивелирует преимущества кластерных решений. Для исправления этой ошибки удалите файл known_hosts и подключитесь по SSH к конфликтной ноде:
Примите Hostkey и попробуйте ввести эту команду, она должна подключить вас к серверу:
Verify TLS certificate via CLI
Особенности сетевых настроек на Hetzner
Переходим в панель Robot и нажимаем на кнопку “Virtual Switches”. На следующей странице вы увидите панель создания и управления интерфейсов Virtual Switch: для начала его необходимо создать, а после “подключить” выделенные сервера к нему. В поиске добавляем необходимые сервера для подключения — их не не нужно перезагружать, только придется подождать до 10-15 минут, когда подключение к Virtual Switch будет активно.
После добавления серверов в Virtual Switch через веб-панель подключаемся к серверам и открываем конфигурационные файлы сетевых интерфейсов, где создаем новый сетевой интерфейс:
Давайте разберем подробнее, что это такое. По своей сути — это VLAN, который подключается к единственному физическому интерфейсу под названием enp4s0 (он у вас может отличаться), с указанием номера VLAN — это номер Virtual Switch’a, который вы создавали в веб-панели Hetzner Robot. Адрес можете указать любой, главное, чтобы он был локальный.
Отмечу, что конфигурировать enp4s0 следует как обычно, по сути он должен содержать внешний IP адрес, который был выдан вашему физическому серверу. Повторите данные шаги на других гипервизорах, после чего перезагрузите на них networking сервис, сделайте пинг до соседней ноды по IP адресу Virtual Switch. Если пинг прошел успешно, то вы успешно установили соединение между серверами по Virtual Switch.
Я также приложу конфигурационный файл sysctl.conf, он понадобится, если у вас будут проблемы с форвардингом пакетом и прочими сетевыми параметрами:
Добавление IPv4 подсети в Hetzner
Перед началом работ вам необходимо заказать подсеть в Hetzner, сделать это можно через панель Robot.
Создадим сетевой мост с адресом, который будет из этой подсети. Пример конфигурации:
Теперь переходим в настройки виртуальной машины в Proxmox и создаем новый сетевой интерфейс, который будет прикреплен к мосту vmbr2. Я использую LXC контейнер, его конфигурацию можно изменять сразу же в Proxmox. Итоговая конфигурация для Debian:
Обратите внимание: я указал 26 маску, а не 29 — это требуется для того, чтобы сеть на виртуальной машине работала.
Добавление IPv4 адреса в Hetzner
Ситуация с одиночным IP адресом отличается — обычно Hetzner дает нам дополнительный адрес из подсети сервера. Это означает, что вместо vmbr2 нам требуется использоваться vmbr0, но на данный момент его у нас нет. Суть в том, что vmbr0 должен содержать IP адрес железного сервера (то есть использовать тот адрес, который использовал физический сетевой интерфейс enp2s0). Адрес необходимо переместить на vmbr0, для этого подойдет следующая конфигурация (советую заказать KVM, чтобы в случае чего возобновить работу сети):
Перезапустите сервер, если это возможно (если нет, перезапустите сервис networking), после чего проверьте сетевые интерфейсы через ip a:
Как здесь видно, enp2s0 подключен к vmbr0 и не имеет IP адрес, так как он был переназначен на vmbr0.
Теперь в настройках виртуальной машины добавляем сетевой интерфейс, который будет подключен к vmbr0. В качестве gateway укажите адрес, прикрепленный к vmbr0.
Sign up for more like this.

В завершении
Надеюсь, что данная статья пригодится вам, когда вы будете настраивать Proxmox кластер в Hetzner. Если позволит время, то я расширю статью и добавлю инструкцию для OVH — там тоже не все очевидно, как кажется на первый взгляд. Материал получился достаточно объемным, если найдете ошибки, то, пожалуйста, напишите в комментарии, я их исправлю. Всем спасибо за уделенное внимание.
Автор: Илья Андреев, под редакцией Алексея Жадан и команды «Лайв Линукс»
Подвернулась мне задача — запустить Proxmox и несколько виртуалок на сервере всего с 2 дисками. При этом требовалось обеспечить ну хоть какую-то надежность и простоту исправления проблем связанных с выходом из строя одного из дисков. Далее в заметке подробное описание тестирования решения на стенде.
Вводная
Я считаю что читатель данной заметки может самостоятельно установить Proxmox на ноду и не буду рассматривать установку и настройку самого гипервизора. Рассмотрим только настройки касающиеся ZFS RAID1 и тестирование ситуации сбоя одного из дисков.
Железо на котором предстояло развернуть проект представляло из себя ноду Supermicro, видимо в исполнении 2 node in 1U с псевдо-рейдом интегрированном в чипсет от Intel который не поддерживается в Proxmox. В связи с этим попробуем испытать решение предлагаемое «из коробки» в версии 4.0. Хоть убейте — я не помню был-ли такой вариант установки в Proxmox 3.6, может и был, но не отложилось в памяти из-за невостребованности такой конфигурации. В тестовой стойке у нас отыскался аналогичный сервер и я принялся за проверку решения, предоставляемого ребятами из Proxmox Server Solutions.
Установка
Как и предупреждал — не буду показывать установку полностью, заострю внимание только на важных моментах.
Выбираем zfs RAID1:
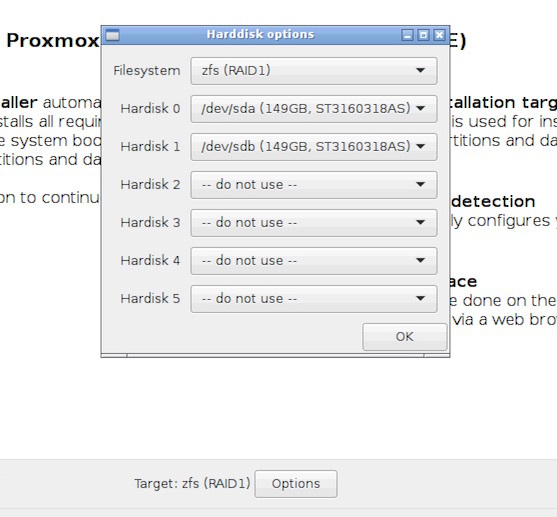
Сервер тестовый и нет подписки на коммерческий репозиторий. В /etc/apt/sources.list подключаем бесплатный:
В /etc/apt/sources.list.d/pve-enterprise.list закомментируем коммерческий.
Ну и вдруг забудете:
Смотрим что нам нарезал инсталлятор на дисках (привожу только часть вывода):
Глянем на наш массив:
По умолчанию инсталлятор Proxmox установил загрузчик на оба раздела — отлично!
Тестирование
Имитируем отказ жесткого диска следующим образом:
— выключаем сервер;
— выдергиваем одну из корзин;
— включаем сервер.
Сервер прекрасно грузится на любом из оставшихся дисков, массив работает в режиме DEGRADED и любезно подсказывает какой диск нам надо сменить и как это сделать:
Если вернуть извлеченный диск на место — он прекрасно «встает» обратно в зеркало:
Инсценируем замену диска на новый. Я просто взял другую корзину с таким-же диском из старого сервера. Ставим корзину на горячую для большей правдоподобности:
Условно неисправный диск у нас /dev/sdb и учитывая одинаковую емкость и геометрию копируем таблицу разделов 1:1 с исправного диска /dev/sda
Генерируем уникальные UUID для /dev/sdb
Ставим загрузчик на замененный диск и обновляем GRUB:
Осталось только заменить сбойный диск в массиве на свежеустановленный, но тут всплывает одна проблема, порожденная методом адресации дисков в массиве примененной в инсталляторе. А именно — диски включены в массив по физическому адресу и команда zpool replace rpool /dev/sdb2 покажет нам вот такую фигу:
Что совершенно логично, нельзя сменить сбойный диск на /dev/sdb2 так как сбойный диск и есть /dev/sdb2, а зачем нам повторять недоработку инсталлятора? Привяжем диск по UUID, я вообще уже забыл то время когда диски прибивались гвоздями вида /dev/sdХХ — UUID наше все:
Нас предупредили о необходимости дождаться окончания синхронизации прежде чем перезагружаться. Проверим статус массива:
Для общего порядку включим и sda2 в массив используя UUID:
Пока я копипастил предыдущие 2 команды из консоли в редактор массив уже синхронизировался:
Вывод
Когда нет аппаратного Raid-контроллера вполне удобно применить размещение корневого раздела на доступном в Proxmox 4.0 «из коробки» zfs RAID1. Конечно-же всегда остается вариант переноса /boot и корня на зеркала созданные средствами mdadm, что тоже неоднократно было использовано мной и до сих пор работает не нескольких серверах, но рассмотренный вариант проще и предлагается разработчиками продукта «из коробки».
Дополнение
Было несколько вопросов, пока руки дошли только до проверки работоспособности autoexpand. Тестовые диски на 160Gb были заменены на 500Gb.
После замены первого диска:
После замены второго:
Все манипуляции происходят онлайн, без перезагрузки сервера и остановки виртуальных машин.
Сделал инструкцию по классической установке Proxmox на soft raid1, таких инструкций много, но в 4-й версии есть свои мелкие детали. Кому интересно — читаем
Установка и настройка ZFS
ZFS — это файловая система, которая может использоваться совместно с Proxmox. С помощью нее можно позволить себе репликацию данных на другой гипервизор, миграцию виртуальной машины/LXC контейнера, доступ к LXC контейнеру с хост-системы и так далее. Установка ее достаточно простая, приступим к разбору. На моих серверах доступно три SSD диска, которые мы объединим в RAID массив.
Обновляем список пакетов:
Устанавливаем требуемые зависимости:
Устанавливаем сам ZFS:
Если вы в будущем получите ошибку fusermount: fuse device not found, try ‘modprobe fuse’ first, то выполните следующую команду:
Теперь приступим непосредственно к настройке. Для начала нам требуется отформатировать SSD и настроить их через parted:
Аналогичные действия необходимо произвести и для других дисков. После того, как все диски подготовлены, приступаем к следующему шагу:
zpool create -f -o ashift=12 rpool /dev/sda4 /dev/sdb4 /dev/sdc4
Применим некоторые настройки для ZFS:
Теперь нам надо рассчитать некоторые переменные для вычисления zfs_arc_max, я это делаю следующим образом:
В данный момент пул успешно создан, также мы создали сабпул data. Проверить состояние вашего пула можно командой zpool status. Данное действие необходимо провести на всех гипервизорах, после чего приступить к следующему шагу.
Теперь добавим ZFS в Proxmox. Переходим в настройки датацентра (именно его, а не отдельной ноды) в раздел «Storage», кликаем на кнопку «Add» и выбираем опцию «ZFS», после чего мы увидим следующие параметры:
ID: Название стораджа. Я дал ему название local-zfs
ZFS Pool: Мы создали rpool/data, его и добавляем сюда.
Nodes: указываем все доступные ноды
Данная команда создает новый пул с выбранными нами дисками. На каждом гипервизоре должен появится новый storage под названием local-zfs, после чего вы сможете смигрировать свои виртуальные машины с локального storage на ZFS.
Synology + Proxmox + NUT UPS
The recent apocalyptic wind storms and fires in Colorado have given me a reason to finally suss out proper UPS (uninterruptible power supply) config in my homelab. My environment consists of a primary rack, an 'annex' rack, a bunch of Ubiquity networking gear, three or so servers, a Synology NAS,
Установка Nginx и Let’s Encrypt сертификата
Мне не очень нравится ситуация с сертификатом и IP адресом, поэтому я предлагаю установить Nginx и настроить Let’s Encrypt сертификат. Установку Nginx описывать не буду, оставлю лишь важные файлы для работы Let’s encrypt сертификата:
Команда для выпуска SSL сертификата:
Не забываем после установки SSL сертификата поставить его на автообновление через cron:
Заметка: чтобы отключить информационное окно о подписке, выполните данную команду:
Сетевые настройки
Перед подключением в кластер настроим сетевые интерфейсы на гипервизоре. Стоит отметить, что настройка остальных нод ничем не отличается, кроме IP адресов и названия серверов, поэтому дублировать их настройку я не буду.
Создадим сетевой мост для внутренней сети, чтобы наши виртуальные машины (в моем варианте будет LXC контейнер для удобства) во-первых, были подключены к внутренней сети гипервизора и могли взаимодействовать друг с другом. Во-вторых, чуть позже мы добавим мост для внешней сети, чтобы виртуальные машины имели свой внешний IP адрес. Соответственно, контейнеры будут на данный момент за NAT’ом у нас.
Работать с сетевой конфигурацией Proxmox можно двумя способами: через веб-интерфейс или через конфигурационный файл /etc/network/interfaces. В первом варианте вам потребуется перезагрузка сервера (или можно просто переименовать файл interfaces.new в interfaces и сделать перезапуск networking сервиса через systemd). Если вы только начинаете настройку и еще нет виртуальных машин или LXC контейнеров, то желательно перезапускать гипервизор после изменений.
Теперь создадим сетевой мост под названием vmbr1 во вкладке network в веб-панели Proxmox.

Изображение 2. Сетевые интерфейсы ноды proxmox1

Изображение 3. Создание сетевого моста

Изображение 4. Настройка сетевой конфигурации vmbr1
Настройка предельно простая — vmbr1 нам нужен для того, чтобы инстансы получали доступ в Интернет.
Теперь перезапускаем наш гипервизор и проверяем, создался ли интерфейс:

Изображение 5. Сетевой интерфейс vmbr1 в выводе команды ip a
Заметьте: у меня уже есть интерфейс ens19 — это интерфейс с внутренней сетью, на основе ее будет создан кластер.
Повторите данные этапы на остальных двух гипервизорах, после чего приступите к следующему шагу — подготовке кластера.
Также важный этап сейчас заключается во включении форвардинга пакетов — без нее инстансы не будут получать доступ к внешней сети. Открываем файл sysctl.conf и изменяем значение параметра net.ipv4.ip_forward на 1, после чего вводим следующую команду:
В выводе вы должны увидеть директиву net.ipv4.ip_forward (если не меняли ее до этого)
Настройка Proxmox кластера
Теперь перейдем непосредственно к кластеру. Каждая нода должна резолвить себя и другие ноды по внутренней сети, для этого требуется изменить значения в hosts записях следующих образом (на каждой ноде должна быть запись о других):
Также требуется добавить публичные ключи каждой ноды к остальным — это требуется для создания кластера.
Создадим кластер через веб-панель:

Изображение 6. Создание кластера через веб-интерфейс
После создания кластера нам необходимо получить информацию о нем. Переходим в ту же вкладку кластера и нажимаем кнопку “Join Information”:

Изображение 7. Информация о созданном кластере
Данная информация пригодится нам во время присоединения второй и третьей ноды в кластер. Подключаемся к второй ноде и во вкладке Cluster нажимаем кнопку “Join Cluster”:

Изображение 8. Подключение к кластеру ноды
Разберем подробнее параметры для подключения:
- Peer Address: IP адрес первого сервера (к тому, к которому мы подключаемся)
- Password: пароль первого сервера
- Fingerprint: данное значение мы получаем из информации о кластере
Вторая нода успешно подключена! Однако, такое бывает не всегда. Если вы неправильно выполните шаги или возникнут сетевые проблемы, то присоединение в кластер будет провалено, а сам кластер будет “развален”. Лучшее решение — это отсоединить ноду от кластера, удалить на ней всю информацию о самом кластере, после чего сделать перезапуск сервера и проверить предыдущие шаги. Как же безопасно отключить ноду из кластера? Для начала удалим ее из кластера на первом сервере:
После чего нода будет отсоединена от кластера. Теперь переходим на сломанную ноду и отключаем на ней следующие сервисы:
Proxmox кластер хранит информацию о себе в sqlite базе, ее также необходимо очистить:
Данные о коросинке успешно удалены. Удалим оставшиеся файлы, для этого необходимо запустить кластерную файловую систему в standalone режиме:
Перезапускаем сервер (это необязательно, но перестрахуемся: все сервисы по итогу должны быть запущены и работать корректно. Чтобы ничего не упустить делаем перезапуск). После включения мы получим пустую ноду без какой-либо информации о предыдущем кластере и можем начать подключение вновь.
Читайте также: