
Основные команды sql oracle
SQL команды – база, которую необходимо знать при работе с языком SQL. Язык SQL или S tructured Query Language (язык структурированных запросов) предназначен для управления данными в системе реляционных баз данных (RDBMS). В этой статье будет рассказано о часто используемых командах SQL, с которыми должен быть знаком каждый программист.
Обратите внимание, что в некоторых системах баз данных требуется указывать точку с запятой в конце каждого оператора. Точка с запятой является стандартным указателем на конец каждого оператора в SQL. В примерах используется MySQL, поэтому точка с запятой требуется.
Фактически, SQL является набором стандартов, для написания запросов к БД. Последняя действующая редакция стандартов языка SQL – ISO/IEC 9075:2016.
Основываясь на указанных стандартах языка SQL, ряд организаций выпустили свои, расширенные версии стандартов указанного языка. Подобные версии иногда называют диалектами SQL.
Варианты спецификаций SQL разрабатываются компаниями и сообществами и служат, соответственно, для работы с разными СУБД (Системами Управления Базами Данных) – системами программ, заточенных под работу с продуктами из своей инфраструктуры.
Наиболее применяемые на сегодня СУБД, использующие свои стандарты (расширения) SQL:
- MySQL – СУБД, принадлежащая компании Oracle;
- PostgreSQL – свободная СУБД, поддерживаемая и развиваемая сообществом;
- Microsoft SQL Server – СУБД, принадлежащая компании Microsoft. Применяет диалект Transact-SQL (T-SQL).
Благодаря тому, что диалекты SQL что создаются, специфицируются и используются разными организациями, имеют как общие черты, так и ряд отличий в возможностях расширений.
Общими чертами диалектов являются основные конструкции, применимые практически без отличий во многих реляционных БД. Основные отличия диалектов состоят в различиях использованных типов данных, количеством, реализацией и детальными возможностями команд. Разные диалекты применяют как разные наборы зарезервированных слов, так и разные наборы команд.
Для чего используется ключевое слово ORDER BY?
Для сортировки данных в порядке возрастания ( ASC ) или убывания ( DESC ).
Выбираются пользователи, которые будут отсортированы по имени в порядке убывания. Дополните ответ на этот вопрос по SQL тем, что без указания DESC данные были бы отсортированы по умолчанию — в порядке возрастания:
DML и записи
В командах INSERT и DELETE можно использовать записи PL/SQL. Пример:
Это важное нововведение облегчает работу программиста по сравнению с работой на уровне отдельных переменных или полей записи. Во-первых, код становится более компактным — с уровня отдельных значений вы поднимаетесь на уровень записей. Нет
необходимости объявлять отдельные переменные или разбивать запись на поля при передаче данных команде DML. Во-вторых, повышается надежность кода — если вы работаете с записями типа %ROWTYPE и обходитесь без явных манипуляций с полями, то в случае модификации базовых таблиц и представлений вам придется вносить значительные изменения в программный код.
В разделе «Ограничения, касающиеся операций вставки и обновления» приведен список ограничений на использование записей в командах DML. Но сначала мы посмотрим, как использовать DML на основе записей в командах INSERT и UPDATE.
Основные команды SQL
Команды языка определения данных
Команды языка определения данных DDL (Data Definition Language, язык определения данных) — это подмножество SQL, используемое для определения и модификации различных структур данных.
К данной группе относятся команды предназначенные для создания, изменения и удаления различных объектов базы данных. Команды CREATE (создание), ALTER (модификация) и DROP (удаление) имеют большинство типов объектов баз данных (таблиц, представлений, процедур, триггеров, табличных областей, пользователей и др.). Т.е. существует множество команд DDL, например, CREATE TABLE, CREATE VIEW, CREATE PROCEDURE, CREATE TRIGGER, CREATE USER, CREATE ROLE и т.д.
Некоторым кажется, что применение DDL является прерогативой администраторов базы данных, а операторы DML должны писать разработчики, но эти два языка не так-то просто разделить. Сложно организовать аффективный доступ к данным и их обработку, не понимая, какие структуры доступны и как они связаны. Также сложно проектировать соответствующие структуры, не зная, как они будут обрабатываться.
Инструкции SQL по Управлению доступом
Предоставляет пользователю привилегии доступа
Отменяет пользовательские привилегии доступа
Добавляет в базу данных новую роль
Предоставляет роль, содержащую привилегии доступа
Удаляет роль из базы данных
Что такое СУБД?
Допустим, есть большая база данных, которой пользуются многие сотрудники: кто-то ищет информацию, а кто-то изменяет или даже удаляет её. Чтобы правильно обрабатывать все эти запросы, нужно специальное программное обеспечение, и именно такое ПО получило название системы управления базами данных (СУБД).
Для чего нужен оператор UNION?
Он используется для объединения полученных данных из двух или более запросов, которые должны иметь одинаковое количество столбцов с одинаковыми типами данных и расположенных в том же порядке.
6.2 Одномерный массив
Запросы, которые возвращают несколько строк одной колонки, можно использовать не только как двумерные таблицы, но и как массивы.
Допустим, мы хотим узнать названия и идентификаторы всех книг, написанных определенным автором, но только если в библиотеке таких книг больше трех. Разобьем это на два шага:
1. Получаем список авторов с количеством книг больше 3. Дополняя наш прошлый пример:
| author |
|---|
| Robin Sharma |
| Dan Brown |
Можно записать как: ['Robin Sharma', 'Dan Brown']
2. Теперь используем этот результат в новом запросе:
| title | bookid |
|---|---|
| The Lost Symbol | 2 |
| Who Will Cry When You Die? | 3 |
| Inferno | 4 |
Это то же самое, что:
INSERT
INSERT – это вид запроса SQL, при применении которого СУБД выполняет добавление новых записей в БД.
Добавим в «tAuthors» нового автора – Уильяма Шекспира, 51 год. Соответственно в поле AuthorFirstName добавится Уильям, в AuthorLastName добавится Шекспир, в AuthorAge – 51. В AuthorId, в нашем случае, автоматически добавится значение, инкрементированное от предыдущего на 1.
Основные типы SQL запросов по их видам
Настройка базы данных для примеров
Создайте базу данных для демонстрации работы команд. Для работы вам понадобится скачать два файла: DLL.sql и InsertStatements.sql. После этого откройте терминал и войдите в консоль MySQL с помощью следующей команды (статья предполагает, что MySQL уже установлен в системе):
Затем введите пароль.
Выполните следующую команду. Назовём базу данных «university»:

7.3 Insert
Пожалуй, единственное, что отличается от других типов запросов, это INSERT . Формат такой:
Где a , b , c это названия колонок, а x , y и z это значения, которые нужно вставить в эти колонки, в том же порядке. Вот, в принципе, и все.
Взглянем на конкретный пример. Вот запрос с INSERT , который заполняет всю таблицу "books":
Для чего нужен оператор INSERT INTO SELECT?
Данный оператор копирует данные из одной таблицы и вставляет их в другую, при этом типы данных в обеих таблицах должны соответствовать.
Когда используется PRIMARY KEY?
PRIMARY KEY — это первичный ключ, который используется в качестве основного ключа и может быть использован для связи с дочерней таблицей, содержащей внешний ключ.
3.2 WHERE — какие данные показываем
WHERE просто-напросто ведет себя как фильтр строк, которые мы хотим вывести. В нашем случае мы хотим видеть только те строки, где значение в колонке author — это “Dan Brown”.
Команда DELETE
Команда DELETE удаляет одну, несколько или все строки таблицы. Базовый синтаксис:
Условие WHERE не обязательно; если оно не задано, удаляются все строки таблицы. Несколько примеров команды DELETE:
- Удаление всей информации из таблицы books:
- Удаление из таблицы books всей информации о книгах, изданных до определенной даты, с возвратом их общего количества:
Конечно, все эти команды DML в реальных приложениях обычно бывают гораздо сложнее. Например, команда может обновлять сразу несколько столбцов с данными, сгенерированными вложенным запросом. Начиная с Oracle9i, имя таблицы можно заменить табличной функцией, возвращающей результирующий набор строк, с которыми работает команда DML.
Секция RETURNING в командах DML
Допустим, вы выполнили команду UPDATE или DELETE и хотите получить ее результаты для дальнейшей обработки. Вместо того чтобы выполнять отдельный запрос, можно включить в команду условие RETURNING, с которым нужная информация будет записана непосредственно в переменные программы. Это позволяет сократить сетевой трафик и затраты ресурсов сервера, а также свести к минимуму количество курсоров, открываемых и используемых приложением.
Рассмотрим несколько примеров, демонстрирующих эту возможность.
В следующем блоке секция RETURNING записывает в переменную новый оклад работника, вычисляемый командой UPDATE:
Допустим, команда UPDATE изменяет более одной строки. В этом случае можно не просто сохранить возвращаемые значения в переменных, а записать их как элементы коллекции при помощи синтаксиса BULK COLLECT. Этот прием продемонстрирован на примере команды FORALL:
SQL запосы
Коснемся классификации SQL запросов.
Выделяют такие виды SQL запросов:
- DDL (Data Definition Language)– язык определения данных. Задачей DDL запросов является создание БД и описание ее структуры. Запросами такого вида устанавливаются правила того, в каком виде различные данные будут размещаться в БД.
- DML (Data Manipulation Language) – язык манипулирования данными. В число запросов этого типа входят различные команды, используя которые непосредственно производятся некоторые манипуляции с данными. DML-запросы нужны для добавления изменений в уже внесенные данные, для получения данных из БД, для их сохранения, для обновления различных записей и для их удаления из БД. В число элементов DML-обращений входит основная часть SQL операторов.
- DCL (Data Control Language) – язык управления данными. Включает в себя запросы и команды, касающиеся разрешений, прав и других настроек СУБД.
- TCL (Transaction Control Language) – язык управления транзакциями. Конструкции такого типа применяют чтобы управлять изменениями, которые производятся с использованием DML запросов. Конструкции TCL позволяют нам производить объединение DML запросов в наборы транзакций.
6.3 Отдельные значения
Бывают запросы, результатом которых являются всего одна строка и одна колонка. К ним можно относиться как к константным значениям, и их можно использовать везде, где используются значения, например, в операторах сравнения. Их также можно использовать в качестве двумерных таблиц или массивов, состоящих из одного элемента.
Давайте, к примеру, получим информацию о всех книгах, количество которых в библиотеке превышает среднее значение в данный момент.
Среднее количество можно получить таким образом:
И это можно использовать в качестве скалярной величины 3 .
Теперь, наконец, можно написать весь запрос:
Это то же самое, что:
| bookid | title | author | published | stock |
|---|---|---|---|---|
| 3 | Who Will Cry When You Die? | Robin Sharma | 2006-06-15 00:00:00 | 4 |
Краткое введение в DML
Полное описание всех возможностей DML в языке Oracle SQL выходит за рамки моей статьи, поэтому мы ограничимся кратким обзором базового синтаксиса, а затем изучим специальные возможности PL/SQL, относящиеся к DML, включая:
- примеры команд MDL;
- атрибуты курсоров команд DML;
- синтаксис PL/SQL, относящийся к DML, например конструкция RETURNING.
За более подробной информацией обращайтесь к документации Oracle и другим описаниям SQL.
Формально команда SELECT считается командой DML. Однако разработчики под термином «DML» почти всегда понимают команды, изменяющие содержимое таблицы базы данных (то есть не связанные с простым чтением данных).
В языке SQL определены четыре команды DML:
- INSERT — вставляет в таблицу одну или несколько новых строк.
- UPDATE — обновляет в одной или нескольких существующих строках таблицы значения одного или нескольких столбцов.
- DELETE — удаляет из таблицы одну или несколько строк.
- MERGE — если строка с заданными значениями столбцов уже существует, выполняет обновление. В противном случае выполняется вставка.
Какие ещё ограничения вы знаете, как они работают и указываются?
SQL-ограничения (constraints) указываются при создании или изменении таблицы. Это правила для ограничения типа данных, которые могут храниться в таблице. Действие с данными не будет выполнено, если нарушаются установленные ограничения.
- UNIQUE — гарантирует уникальность значений в столбце;
- NOT NULL — значение не может быть NULL ;
- INDEX — создаёт индексы в таблице для быстрого поиска/запросов;
- CHECK — значения столбца должны соответствовать заданным условиям;
- DEFAULT — предоставляет столбцу значения по умолчанию.
А что такое Self JOIN?
Такой вопрос тоже может прозвучать на собеседовании по SQL. Это выражение используется для того, чтобы таблица объединилась сама с собой, словно это две разные таблицы. Чтобы такое реализовать, одна из таких «таблиц» временно переименовывается.
Например, следующий SQL-запрос объединяет клиентов из одного города:
Какими бывают подстановочные знаки?
- % — заменить ноль или более символов;
- _ — заменить один символ.
Данный запрос позволяет найти данные всех пользователей, имена которых содержат в себе «test».
А в этом случае имена искомых пользователей начинаются на «t», после содержат какой-либо символ и «est» в конце.
Команды языка управления данными
С помощью команд языка управления данными ( DCL (Data Control Language) ) можно управлять доступом пользователей к базе данных. Операторы управления данными включают в себя применяемые для предоставления и отмены полномочий команды GRANT и REVOKE, а также команду SET ROLE, которая разрешает или запрещает роли для текущего сеанса.
Создание и настройка базы данных
Нам нужна будет для примеров БД MS SQL Server 2017 и MS SQL Server Management Studio 2017.
Рассмотрим последовательность действий того, как создать SQL запрос. Воспользовавшись Management Studio, для начала создадим новый редактор скриптов. Чтобы это сделать, на стандартной панели инструментов выберем «Создать запрос». Или воспользуемся клавиатурной комбинацией Ctrl+N.
Нажимая кнопку «Создать запрос» в Management Studio, мы открываем тестовый редактор, используя который можно производить написание SQL запросов, сохранять их и запускать.
Используем для начала простые запросы SQL, благодаря которым можно создать и настроить новую БД, чтобы получить возможность в дальнейшем с ней работать.
Создадим новую БД с именем «b_library» для библиотеки книг. Чтобы это делать наберем в редакторе такой SQL запрос:
Далее выделим введенный текст и нажмем F5 или кнопку «Выполнить». У нас создастся БД «b_library».
Все дальнейшие манипуляции мы можем провести с этой созданной нами БД. Для этого сначала подключимся к этой базе:
В БД «b_library» создадим таблицу авторов «tAuthors» с такими столбцами: AuthorId, AuthorFirstName, AuthorLastName, AuthorAge:
CREATE TABLE tAuthors (
AuthorId INT IDENTITY (1, 1) NOT NULL,
AuthorFirstName NVARCHAR (20) NOT NULL,
AuthorLastName NVARCHAR (20) NOT NULL,
AuthorAge INT NOT NULL
);
Заполним нашу таблицу таким авторами: Александр Пушкин, Сергей Есенин, Джек Лондон, Шота Руставели и Рабиндранат Тагор. Для этого используем такой SQL запрос:
INSERT tAuthors VALUES
(‘Александр’, ‘Пушкин’, ’37’),
(‘Сергей’, ‘Есенин’, ’30’),
(‘Джек’, ‘Лондон’, ’40’),
(‘Шота’, ‘Руставели’, ’44’),
(‘Рабиндранат’, ‘Тагор’, ’80’);
Мы можем посмотреть в «tAuthors» записи, путем отправления в СУБД простого SQL запроса:
В нашей БД «b_library» мы создали первую таблицу «tAuthors», заполнили «tAuthors» авторами книг и теперь можем рассмотреть различные примеры SQL запросов, которыми мы сможем взаимодействовать с БД.
Выберите только уникальные имена
SELECT DISTINCT возвращает разные значения, даже если в выбранном столбце есть дубли.
Чем VARCHAR отличается от NVARCHAR?
Главное отличие в том, что VARCHAR хранит значения в формате ASCII, где символ занимает один байт, а NVARCHAR хранит значения в формате Unicode, где символ «весит» 2 байта. Тип VARCHAR следует использовать, если вы уверены, что в значениях не будет Unicode-символов. Например, VARCHAR можно применить к адресам электронной почты, состоящих из ASCII-символов.
Какие типы СУБД в соответствии с моделями данных вы знаете?
Этот вопрос по SQL предполагает не просто назвать, но и дать краткое описание каждому типу.
- Реляционные, которые поддерживают установку связей между таблицами с помощью первичных и внешних ключей. Пример — MySQL.
- Flat File — базы данных с двумерными файлами, в которых содержатся записи одного типа и отсутствует связь с другими файлами, как в реляционных. Пример — Excel.
- Иерархические подразумевают наличие записей, связанных друг с другом по принципу отношений один-к-одному или один-ко-многим. А вот для отношений многие-ко-многим следует использовать реляционную модель. Пример — Adabas.
- Сетевые похожи на иерархические, но в этом случае «ребёнок» может иметь несколько «родителей» и наоборот. Примеры — IDS и IDMS.
- Объектно-ориентированные СУБД работают с базами данных, которые состоят из объектов, используемых в ООП. Объекты группируются в классы и называются экземплярами, а классы в свою очередь взаимодействуют через методы. Пример — Versant.
- Объектно-реляционные обладают преимуществами реляционной и объектно-ориентированной моделей. Пример — IBM Db2.
- Многомерная модель является разновидностью реляционной и использует многомерные структуры. Часто представляется в виде кубов данных. Пример — Oracle Essbase.
- Гибридные состоят из двух и более типов баз данных. Используются в том случае, если одного типа недостаточно для обработки всех запросов. Пример — Altibase HDВ.
Что такое нормализация и денормализация?
Нормализация отношений в SQL призвана организовать информацию в базе данных таким образом, чтобы она не занимала много места и с ней было удобно работать. Это удаление избыточных данных, устранение дублей, идентификация наборов связанных данных через PRIMARY KEY , etc.
Соответственно, денормализация является обратным процессом, который вносит в нормализованную таблицу избыточные данные.
Подробнее о пяти нормальных формах и форме Бойса-Кодда можно узнать из данного видеокурса:
Команда MERGE
В команде MERGE задается условие проверки, а также два действия для его выполнения (matched) или невыполнения (not matched). Пример:
Как найти дубли в поле email?
Функция COUNT() возвращает количество строк из поля email . Оператор HAVING работает почти так же, как и WHERE , вот только применяется не для всех столбцов, а для набора, созданного оператором GROUP BY .
Команды языка манипулирования данными
Команды языка манипулирования данными DML (Data Manipulation Language) позволяют пользователю перемещать данные в базу данных и из нее:
- INSERT — осуществляет вставку строк в таблицу.
- DELETE — осуществляет удаление строк из таблицы.
- UPDATE — осуществляет модификацию данных в таблице.
- SELECT — осуществляет выборку данных из таблиц по запросу.
Каждый, кто работает с SQL в среде Oracle, должен вооружиться книгами: справочником по языку SQL, таким как «Oracle SQL: The Essential Reference? (O’Reilly), руководством по оптимизации производительности, например «Oracle SQL Tuning Pocket Reference» (O’Reilly).
Для простоты ниже мы приведем несколько основных команд SQL.
3.3 SELECT — как показываем данные
Теперь, когда у нас есть все нужные нам колонки из нужной нам таблицы, нужно решить, как именно показывать эти данные. В нашем случае нужны только названия и идентификаторы книг, так что именно это мы и выберем с помощью SELECT . Заодно можно переименовать колонку используя AS .
Весь запрос можно визуализировать с помощью простой диаграммы:

Команды SQL для работы с базами данных
Изучить все тонкости работы с SQL можно в он – лайн университете skillbox
Если вы похожи на меня, то согласитесь: SQL — это одна из тех штук, которые на первый взгляд кажутся легкими (читается как будто по-английски!), но почему-то приходится гуглить каждый простой запрос, чтобы найти правильный синтаксис.
А потом начинаются джойны, агрегирование, подзапросы, и получается совсем белиберда. Вроде такой:
Буэ! Такое спугнет любого новичка, или даже разработчика среднего уровня, если он видит SQL впервые. Но не все так плохо.
Легко запомнить то, что интуитивно понятно, и с помощью этого руководства я надеюсь снизить порог входа в SQL для новичков, а уже опытным предложить по-новому взглянуть на SQL.
Не смотря на то, что синтаксис SQL почти не отличается в разных базах данных, в этой статье для запросов используется PostgreSQL. Некоторые примеры будут работать в MySQL и других базах.
В SQL много ключевых слов, но SELECT , FROM и WHERE присутствуют практически в каждом запросе. Чуть позже вы поймете, что эти три слова представляют собой самые фундаментальные аспекты построения запросов к базе, а другие, более сложные запросы, являются всего лишь надстройками над ними.
Давайте взглянем на базу данных, которую мы будем использовать в качестве примера в этой статье:



У нас есть книжная библиотека и люди. Также есть специальная таблица для учета выданных книг.
- В таблице "books" хранится информация о заголовке, авторе, дате публикации и наличии книги. Все просто.
- В таблице “members” — имена и фамилии всех записавшихся в библиотеку людей.
- В таблице “borrowings” хранится информация о взятых из библиотеки книгах. Колонка bookid относится к идентификатору взятой книги в таблице “books”, а колонка memberid относится к соответствующему человеку из таблицы “members”. У нас также есть дата выдачи и дата, когда книгу нужно вернуть.
Давайте начнем с простого запроса: нам нужны имена и идентификаторы (id) всех книг, написанных автором “Dan Brown”
Запрос будет таким:
А результат таким:
| id | title |
|---|---|
| 2 | The Lost Symbol |
| 4 | Inferno |
Довольно просто. Давайте разберем запрос чтобы понять, что происходит.
Назовите четыре основных типа соединения в SQL
Чтобы объединить две таблицы в одну, следует использовать оператор JOIN . Соединение таблиц может быть внутренним ( INNER ) или внешним ( OUTER ), причём внешнее соединение может быть левым ( LEFT ), правым ( RIGHT ) или полным ( FULL ).
- INNER JOIN — получение записей с одинаковыми значениями в обеих таблицах, т.е. получение пересечения таблиц.
- FULL OUTER JOIN — объединяет записи из обеих таблиц (если условие объединения равно true) и дополняет их всеми записями из обеих таблиц, которые не имеют совпадений. Для записей, которые не имеют совпадений из другой таблицы, недостающее поле будет иметь значение NULL .
- LEFT JOIN — возвращает все записи, удовлетворяющие условию объединения, плюс все оставшиеся записи из внешней (левой) таблицы, которые не удовлетворяют условию объединения.
- RIGHT JOIN — работает точно так же, как и левое объединение, только в качестве внешней таблицы будет использоваться правая.
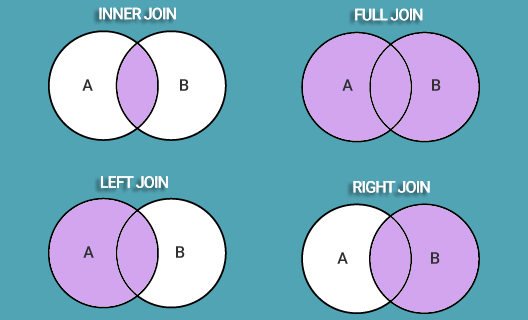
Рассмотрим пример соединения SQL таблиц с использованием INNER JOIN . Следующий запрос выбирает все заказы с информацией о клиенте:
SELECT
1) Выведем все имеющиеся у нас БД:
2) Выведем все таблицы в созданной нами ранее БД «b_library»:
Вставка на основе записей
В командах INSERT записи можно использовать как для добавления единственной строки, так и для пакетной вставки (с использованием команды FORALL). Также возможно создание записей с помощью объявления %ROWTYPE на основе таблицы, в которую производится вставка, или явного объявления командой TYPE на основе типа данных, совместимого со структурой таблицы.
Приведем несколько примеров.
- Вставка в таблицу книг данных из записи с объявлением %ROWTYPE
Обратите внимание: имя записи не заключается в скобки. Если мы используем запись вида
Также можно выполнить вставку данных, взятых из записи, тип которой определен программистом, но этот тип должен быть полностью совместим с определением %ROWTYPE . Другими словами, нельзя вставить в таблицу запись, содержащую подмножество столбцов таблицы.
- Вставка с помощью команды FORALL — этим способом в таблицу вставляются коллекции записей.
DELETE
DELETE – SQL запрос, выполняя который в СУБД производится операция удаления определенной строки из таблицы в БД.
Обратимся к «tAuthors» с командой на удаление строки, где AuthorId = 5:
Чтобы увидеть изменения, снова обратимся к базе для вывода всех записей:
Мы видим, что запись автора под номером 5 теперь отсутствует в «tAuthors» и, соответственно, не выводится с другими записями.
Объясните разницу между командами DELETE и TRUNCATE
Команда DELETE — это DML-операция, которая удаляет записи из таблицы, соответствующие заданному условию:
При этом создаются логи удаления, то есть операцию можно отменить.
А вот команда TRUNCATE — это DDL-операция, которая полностью пересоздаёт таблицу, и отменить такое удаление невозможно:
Ограничения, касающиеся операций вставки и обновления
Если вы захотите освоить операции вставки и обновления с использованием записей, имейте в виду, что на их применение существуют определенные ограничения.
SQL команды
Выделяют следующие группы команд SQL:
Примеры простых запросов SQL к базам данных.
Рассмотрим основные запросы SQL.
Использование записей с условием RETURNING
В команду DML может включаться секция RETURNING, возвращающая значения столбцов (и основанных на них выражений) из обработанных строк. Возвращаемые данные могут помещаться в запись и даже в коллекцию записей:
Заметьте, что в предложении RETURNING перечисляются все столбцы таблицы. К сожалению, Oracle пока не поддерживает синтаксис с символом *.
8. Проверка
Мы подошли к концу, предлагаю небольшой тест. Посмотрите на тот запрос в самом начале статьи. Можете разобраться в нем? Попробуйте разбить его на секции SELECT , FROM , WHERE , GROUP BY , и рассмотреть отдельные компоненты подзапросов.
Вот он в более удобном для чтения виде:
Этот запрос выводит список людей, которые взяли из библиотеки книгу, у которой общее количество выше среднего значения.
| Full Name |
|---|
| Lida Tyler |
Надеюсь, вам удалось разобраться без проблем. Но если нет, то буду рад вашим комментариям и отзывам, чтобы я мог улучшить этот пост.
Вопросы по SQL на собеседованиях — обычное дело, и чтобы не завалиться, нужно хорошо понимать, как работать с базами данных. В этом списке представлены основные вопросы и задачи по SQL, которые часто встречаются на собеседованиях, а также ответы на них.
Как выбрать записи с нечётными Id?
Один из самых распространённых вопросов на собеседовании. SQL запрос для выбора записей с нечётными id должен выглядеть следующим образом:
Если остаток от деления id на 2 равен нулю, перед нами чётное значение, и наоборот.
Что делают псевдонимы Aliases?
SQL-псевдонимы нужны для того, чтобы дать временное имя таблице или столбцу. Это нужно, когда в запросе есть таблицы или столбцы с неоднозначными именами. В этом случае для удобства в составлении запроса используются псевдонимы. SQL-псевдоним существует только на время запроса.
Как работают подстановочные знаки?
Это специальные символы, которые нужны для замены каких-либо знаков в запросе. Они используются вместе с оператором LIKE , с помощью которого можно отфильтровать запрашиваемые данные.
7.1 Update
Синтаксис запроса UPDATE семантически совпадает с запросом на чтение. Единственное отличие в том, что вместо выбора колонок SELECT 'ом, мы задаем знаения SET 'ом.
Если все книги Дэна Брауна потерялись, то нужно обнулить значение количества. Запрос для этого будет таким:
WHERE делает то же самое, что раньше: выбирает строки. Вместо SELECT , который использовался при чтении, мы теперь используем SET . Однако, теперь нужно указать не только имя колонки, но и новое значение для этой колонки в выбранных строках.
Команды SQL по Определению данных
Добавляет новую таблицу в базу данных
Удаляет таблицу из базы данных
Изменяет структуру существующей таблицы
Добавляет новое представление в базу данных
Удаляет представление из базы данных
Создает индекс для столбца
Удаляет индекс столбца
Добавляет новую схему в базу данных
Удаляет схему из базы данных
Добавляет новый домен значений данных
Изменяет определение домена
Удаляет домен из базы данных
UPDATE
UPDATE – SQL запрос, позволяющий внести изменения или дописывать новую информацию в те записи, которые уже существуют.
Внесем корректировки в шестую запись (AuthorId = 6). Значения изменим для полей имени, фамилии и возраста автора.
UPDATE tAuthors SET AuthorFirstName = ‘Лев’, AuthorLastName=’Толстой’, AuthorAge = ’82’ WHERE AuthorId = ‘6’;
Затем, обратимся к БД, чтобы вывести все имеющиеся записи:
Мы видим изменения информации в записи автора под номером 6.
А что такое внешний ключ?
Внешний ключ или FOREIGN KEY также является атрибутом ограничения и обеспечивает связь двух таблиц. По сути, это поле или несколько полей, которые ссылаются на PRIMARY KEY в родительской таблице.
В данном случае внешний ключ, привязанный к полю user_id в таблице order , ссылается на первичный ключ id в таблице users , и именно по этим полям происходит связывание двух таблиц.
DML и обработка исключений
Если в блоке PL/SQL инициируется исключение, Oracle не выполняет откат изменений, внесенных командами DML этого блока. Логическими транзакциями приложения должен управлять программист, который и определяет, какие действия следует выполнять в этом случае. Рассмотрим следующую процедуру:
Обратите внимание: перед инициированием исключения задается значение параметра OUT. Давайте запустим анонимный блок, вызывающий эту процедуру, и проанализируем результаты :
Код выводит следующие значения:
Как видите, исключение было инициировано, но строки из таблицы книг при этом остались удаленными; дело в том, что Oracle не выполняет автоматического отката изменений. С другой стороны, переменная table_count сохранила исходное значение. Таким образом, в программах, выполняющих операции DML, вы сами отвечаете за откат транзакции — а вернее, решаете, хотите ли вы выполнить откат. Принимая решение, примите во внимание следующие соображения:
- Если для блока выполняется автономная транзакция, в обработчике исключения необходимо произвести ее откат или закрепление (чаще откат).
- Для определения области отката используются точки сохранения. Можно произвести откат транзакции до конкретной точки сохранения, тем самым оставив часть изменений, внесенных в течение сеанса.
Если исключение передается за пределы «самого внешнего» блока (то есть остается необработанным), то в среде выполнения PL/SQL, и в частности в SQL*Plus, автоматически осуществляется откат транзакции, и все изменения отменяются.
Команда INSERT
Существует две базовые разновидности команды INSERT:
О Вставка одной строки с явно заданным списком значений:
О Вставка в таблицу одной или нескольких строк, определяемых командой SELECT, которая извлекает данные из других таблиц:
Рассмотрим несколько примеров команд INSERT в блоке PL/SQL. Начнем со вставки новой строки в таблицу books. Обратите внимание: если в секции VALUES заданы значения всех столбцов, то список столбцов можно опустить:
Можно также задать список имен столбцов, а их значения указать в виде переменных, а не литералов:
ВСТРОЕННАЯ ПОДДЕРЖКА ПОСЛЕДОВАТЕЛЬНОСТЕЙ В ORACLE11G
До выхода Oracle11 программисту, желавшему получить следующее значение из последовательности, приходилось вызывать функцию NEXTVAL в команде SQL. Это
можно было сделать прямо в команде INSERT, которой требовалось значение:
или в команде SELECT из старой доброй таблицы dual:
Начиная с Oracle11g, следующее (и текущее) значение можно получить при помощи оператора присваивания — например:
Теория
3.1 FROM — откуда берем данные
Сейчас это может показаться очевидным, но FROM будет очень важен позже, когда мы перейдем к соединениям и подзапросам.
FROM указывает на таблицу, по которой нужно делать запрос. Это может быть уже существующая таблица (как в примере выше), или таблица, создаваемая на лету через соединения или подзапросы.
7. Операции записи
Большинство операций записи в базе данных довольно просты, если сравнивать с более сложными операциями чтения.
Инструкции SQL по Управлению транзакциями
Завершает текущую транзакцию
Отменяет текущую транзакцию
Определяет характеристики доступа к данным в текущей транзакции
Явно начинает новую транзакцию
Устанавливает точку восстановления транзакции
4. Соединения (джойны)
Теперь мы хотим увидеть названия (не обязательно уникальные) всех книг Дэна Брауна, которые были взяты из библиотеки, и когда эти книги нужно вернуть:
| Title | Return Date |
|---|---|
| The Lost Symbol | 2016-03-23 00:00:00 |
| Inferno | 2016-04-13 00:00:00 |
| The Lost Symbol | 2016-04-19 00:00:00 |
По большей части запрос похож на предыдущий за исключением секции FROM . Это означает, что мы запрашиваем данные из другой таблицы. Мы не обращаемся ни к таблице “books”, ни к таблице “borrowings”. Вместо этого мы обращаемся к новой таблице, которая создалась соединением этих двух таблиц.
borrowings JOIN books ON borrowings.bookid=books.bookid — это, считай, новая таблица, которая была сформирована комбинированием всех записей из таблиц "books" и "borrowings", в которых значения bookid совпадают. Результатом такого слияния будет:

А потом мы делаем запрос к этой таблице так же, как в примере выше. Это значит, что при соединении таблиц нужно заботиться только о том, как провести это соединение. А потом запрос становится таким же понятным, как в случае с «простым запросом» из пункта 3.
Давайте попробуем чуть более сложное соединение с двумя таблицами.
Теперь мы хотим получить имена и фамилии людей, которые взяли из библиотеки книги автора “Dan Brown”.
На этот раз давайте пойдем снизу вверх:
Шаг Step 1 — откуда берем данные? Чтобы получить нужный нам результат, нужно соединить таблицы “member” и “books” с таблицей “borrowings”. Секция JOIN будет выглядеть так:
Результат соединения можно увидеть по ссылке.
Шаг 2 — какие данные показываем? Нас интересуют только те данные, где автор книги — “Dan Brown”
Шаг 3 — как показываем данные? Теперь, когда данные получены, нужно просто вывести имя и фамилию тех, кто взял книги:
Супер! Осталось лишь объединить три составные части и сделать нужный нам запрос:
| First Name | Last Name |
|---|---|
| Mike | Willis |
| Ellen | Horton |
| Ellen | Horton |
Отлично! Но имена повторяются (они не уникальны). Мы скоро это исправим.
Грубо говоря, агрегирования нужны для конвертации нескольких строк в одну. При этом, во время агрегирования для разных колонок используется разная логика.
Давайте продолжим наш пример, в котором появляются повторяющиеся имена. Видно, что Ellen Horton взяла больше одной книги, но это не самый лучший способ показать эту информацию. Можно сделать другой запрос:
Что даст нам нужный результат:
| First Name | Last Name | Number of books borrowed |
|---|---|---|
| Mike | Willis | 1 |
| Ellen | Horton | 2 |
Почти все агрегации идут вместе с выражением GROUP BY . Эта штука превращает таблицу, которую можно было бы получить запросом, в группы таблиц. Каждая группа соответствует уникальному значению (или группе значений) колонки, которую мы указали в GROUP BY . В нашем примере мы конвертируем результат из прошлого упражнения в группу строк. Мы также проводим агрегирование с count , которая конвертирует несколько строк в целое значение (в нашем случае это количество строк). Потом это значение приписывается каждой группе.
Каждая строка в результате представляет собой результат агрегирования каждой группы.
Можно прийти к логическому выводу, что все поля в результате должны быть или указаны в GROUP BY , или по ним должно производиться агрегирование. Потому что все другие поля могут отличаться друг от друга в разных строках, и если выбирать их SELECT 'ом, то непонятно, какие из возможных значений нужно брать.
В примере выше функция count обрабатывала все строки (так как мы считали количество строк). Другие функции вроде sum или max обрабатывают только указанные строки. Например, если мы хотим узнать количество книг, написанных каждым автором, то нужен такой запрос:
| author | sum |
|---|---|
| Robin Sharma | 4 |
| Dan Brown | 6 |
| John Green | 3 |
| Amish Tripathi | 2 |
Здесь функция sum обрабатывает только колонку stock и считает сумму всех значений в каждой группе.

Подзапросы это обычные SQL-запросы, встроенные в более крупные запросы. Они делятся на три вида по типу возвращаемого результата.
При выборке из таблицы прибавьте к дате 1 день
Функция DATE_ADD() прибавляет к дате заданный промежуток времени. Синтаксис выглядит следующим образом:
Команды языка управления транзакциями
Команды языка управления транзакциями ( TCL (Тгаnsасtiоn Соntrol Language) ) команды позволяют определить исход транзакции.
Команды управления транзакциями управляют изменениями в базе данных, которые осуществляются командами манипулирования данными.
Транзакция (или логическая единица работы) – неделимая с точки зрения воздействия на базу данных последовательность операторов манипулирования данными (чтения, удаления, вставки, модификации) такая, что либо результаты всех операторов, входящих в транзакцию, отображаются в БД, либо воздействие всех этих операторов полностью отсутствует.
COMMIT — заканчивает («подтверждает») текущую транзакцию и делает постоянными (сохраняет в базе данных) изменения, осуществленные этой транзакцией. Также стирает точки сохранения этой транзакции и освобождает ее блокировки. Можно также использовать эту команду для того, чтобы вручную подтвердить сомнительную распределенную транзакцию.
ROLLBACK — выполняет откат транзакции, т.е. отменяет все изменения, сделанные в текущей транзакции. Можно также использовать эту команду для того, чтобы вручную отменить работу, проделанную сомнительной распределенной транзакцией.
Понятие транзакции имеет непосредственную связь с понятием целостности базы данных. Очень часто база данных может обладать такими ограничениями целостности, которые просто невозможно не нарушить, выполняя только один оператор изменения БД. Например, невозможно принять сотрудника в отдел, название и код которого отсутствует в базе данных.
В системах с развитыми средствами ограничения и контроля целостности каждая транзакция начинается при целостном состоянии базы данных и должна оставить это состояние целостными после своего завершения. Несоблюдение этого условия приводит к тому, что вместо фиксации результатов транзакции происходит ее откат (т.е. вместо оператора COMMIT выполняется оператор ROLLBACK), и база данных остается в таком состоянии, в котором находилась к моменту начала транзакции, т.е. в целостном состоянии.
В связи со свойством сохранения целостности БД транзакции являются подходящими единицами изолированности пользователей, т.е., если с каждым сеансом работы с базой данных ассоциируется транзакция, то каждый пользователь начинает работу с согласованным состоянием базы данных, т.е. с таким состоянием, в котором база данных могла бы находиться, даже если бы пользователь работал с ней в одиночку.
Команда UPDATE
Команда UPDATE обновляет один или несколько столбцов или одну или несколько строк таблицы. Ее синтаксис выглядит так:
Предложение WHERE не обязательно; если оно не задано, обновляются все строки таблицы.
Несколько примеров команды UPDATE:
- Перевод названий книг таблицы books в верхний регистр:
- Выполнение процедуры, удаляющей компонент времени из даты издания книг, которые были написаны заданным автором, и переводящей названия этих книг в символы верхнего регистра. Как видно из примера, команду UPDATE можно выполнять как саму по себе, так и в блоке PL/SQL:
DROP
DROP – ключевое слово в SQL, применяемое для удаления данных с помощью запроса. К примеру удаление некоторой таблицы из БД.
После рассмотрения ряда простых запросов к БД мы можем полностью удалить нашу таблицу «tAuthors» целиком, выполнив простой SQL запрос:
Далее рассмотрим сложные запросы SQL.
Практика
Команды Программного SQL
Определяет курсор запроса
Возвращает описание плана доступа к данным в запросе
Открывает курсор для получения результатов запроса
Извлекает строку из результатов запроса
Подготавливает инструкцию SQL к динамическому выполнению
Динамически выполняет инструкцию SQL
Описывает подготовленный запрос
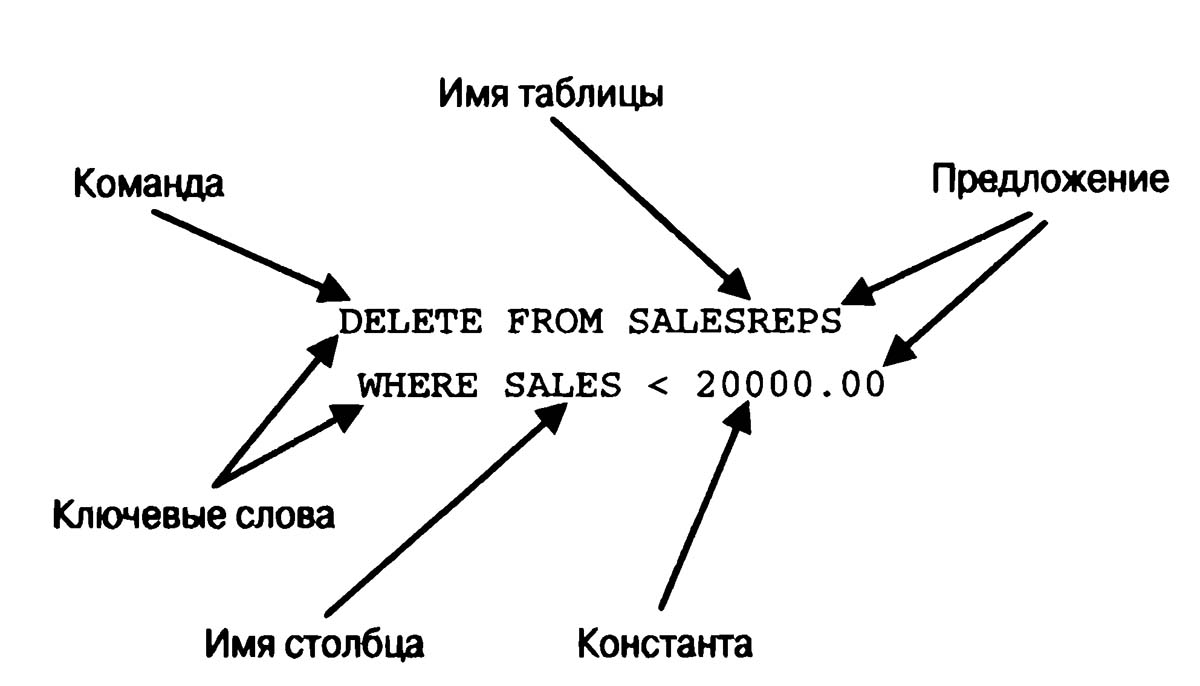
Рис. 1. Структура инструкции SQL
Каждая инструкция SQL начинается с команды, т.е. ключевого слова, описывающего действие, выполняемое инструкцией. Типичными командами являются CREATE (создать), INSERT (добавить), delete (удалить) и COMMIT (зафиксировать). После команды идет одно или несколько предложений. Предложение может описывать данные, с которыми работает инструкция, или содержать уточняющую информацию о действии, выполняемом инструкцией. Каждое предложение также начинается с ключевого слова, такого как WHERE (где), FROM (откуда), into (куда) или HAVING (имеющий). Одни предложения в инструкции являются обязательными, а другие — нет. Конкретная структура и содержимое предложения могут изменяться. Многие предложения содержат имена таблиц или столбцов; некоторые из них могут содержать дополнительные ключевые слова, константы и выражения.
В стандарте ANSI/ISO определен набор зарезервированных (а также незарезервированных) ключевых слов, которые используются в инструкциях SQL. В соответствии со стандартом, зарезервированные ключевые слова нельзя использовать для именования объектов базы данных, таких как таблицы, столбцы и пользователи. Во многих реализациях СУБД этот запрет ослаблен, но тем не менее следует избегать использования ключевых слов в качестве имен таблиц и столбцов. В табл. 1 перечислены ключевые слова, включенные в стандарт ANSI/ISO SQL:2006.
Таблица 1. Зарезервированные ключевые слова SQL:2006


Язык PL/SQL плотно интегрирован с базой данных Oracle. Из кода PL/SQL можно выполнять любые команды DML (Data Manipulation Language), в том числе INSERT , UPDATE , DELETE и MERGE и, конечно же, запросы на выборку.
Команды DDL (Data Definition Language) выполняются только в режиме динамического SQL.
Несколько SQL-команд можно сгруппировать на логическом уровне в одну транзакцию, чтобы их результаты либо все вместе сохранялись (закрепление), либо все вместе отменялись (откат). В этой статье рассматриваются SQL-команды, используемые в PL/ SQL для управления транзакциями.
Чтобы оценить важность транзакций в Oracle, необходимо хорошо понимать их основные свойства:
- Атомарность. Вносимые в ходе транзакции изменения состояния имеют атомарный характер: либо выполняются все изменения сразу, либо не выполняется ни одно из них.
- Согласованность. Транзакция корректно изменяет состояние базы данных. Действия, выполняемые как единое целое, не нарушают ограничений целостности, связанных с данным состоянием.
- Изолированность. Возможно параллельное выполнение множества транзакций, но с точки зрения каждой конкретной транзакции остальные кажутся выполняемыми до или после нее.
- Устойчивость. После успешного завершения транзакции измененные данные закрепляются в базе данных и становятся устойчивыми к последующим сбоям. Начатая транзакция либо фиксируется командой COMMIT , либо отменяется командой ROLLBACK . В любом случае будут освобождены заблокированные транзакцией ресурсы (команда ROLLBACK TO может снять только часть блокировок). Затем сеанс, как правило, начинает новую транзакцию. По умолчанию в PL/SQL неявно определяется одна транзакция на весь сеанс, и все выполняемые в ходе этого сеанса изменения данных являются частью транзакции. Однако применение технологии автономных транзакций позволяет определять вложенные транзакции, выполняемые внутри главной транзакции уровня сеанса.
Из блока кода PL/SQL можно выполнять MDL-команды ( INSERT , UPDATE , DELETE и MERGE ), оперирующие любыми доступными таблицами и представлениями.
При использовании модели разрешений создателя права доступа к этим структурам определяются во время компиляции, если вы используете модель прав определяющей стороны. Если же используется модель разрешений вызывающей стороны с конструкцией AUTHID CURRENT_USER , то права доступа определяются во время выполнения программы.
Инструкции SQL для обработки данных
Извлекает данные из базы данных
Добавляет новые строки в базу данных
Обновляет данные, имеющиеся в базе данных
Добавляет/обновляет/удаляет новые и старые строки на основе условий
Удаляет строки из базы данных
6.1 Двумерная таблица
Есть запросы, которые возвращают несколько колонок. Хороший пример это запрос из прошлого упражнения по агрегированию. Будучи подзапросом, он просто вернет еще одну таблицу, по которой можно делать новые запросы. Продолжая предыдущее упражнение, если мы хотим узнать количество книг, написанных автором “Robin Sharma”, то один из возможных способов — использовать подзапросы:
| author | sum |
|---|---|
| Robin Sharma | 4 |
Найдите в таблице среднюю зарплату работников
Функция AVG() применяется только к числовым типам данных и возвращает среднее значение по столбцу.

В SQL имеется около сорока инструкций (наиболее важные и часто используемые из них представлены в таблицах ниже). Каждая из них "просит" СУБД выполнить определенное действие, например извлечь данные, создать таблицу или добавить в таблицу новые данные. Все инструкции SQL имеют подобную структуру, которая изображена на рис. 1.
Атрибуты курсора для операций DML
Для доступа к информации о последней операции, выполненной командой SQL, Oracle предоставляет несколько атрибутов курсоров, неявно открываемых для этой операции. Атрибуты неявных курсоров возвращают информацию о выполнении команд INSERT, UPDATE, DELETE, MERGE или SELECT INTO. В этом разделе речь пойдет об использовании атрибутов SQL% для команд DML.
бедует помнить, что значения атрибутов неявного курсора всегда относятся к последней выполненной команде SQL, независимо от того, в каком блоке выполнялся неявный курсор. До открытия первого SQL-курсора сеанса значения всех неявных атрибутов равны NULL. (Исключение составляет атрибут %ISOPEN, который возвращает FALSE.) Значения, возвращаемые атрибутами неявных курсоров, описаны в табл. 1.
Таблица 1. Атрибуты неявных курсоров для команд DML


Давайте посмотрим, как эти атрибуты используются.
- С помощью атрибута SQL%FOUND можно определить, обработала ли команда DML хотя бы одну строку. Допустим, автор издает свои произведения под разными именами, а записи с информацией обо всех книгах данного автора необходимо время от времени обновлять. Эту задачу выполняет процедура, обновляющая данные столбца author и возвращающая логический признак, который сообщает, было ли произведено хотя бы одно обновление:
- Атрибут SQL%ROWCOUNT позволяет выяснить, сколько строк обработала команда DML. Новая версия приведенной выше процедуры возвращает более полную информацию:
Обновление на основе записей
Также существует возможность обновления целой строки таблицы по данным записи PL/SQL. В следующем примере для обновления строки таблицы books используется запись, созданная со спецификацией %ROWTYPE. Обратите внимание на ключевое слово ROW, которое указывает, что вся строка обновляется данными из записи:
Существует несколько ограничений, касающихся обновления строк на основе записей.
- При использовании ключевого слова ROW должна обновляться вся строка. Возможность обновления подмножества столбцов пока отсутствует, но не исключено, что она появится в следующих версиях Oracle. Для любых полей, значения которых остались равными NULL, соответствующему столбцу будет присвоено значение NULL.
- Обновление не может выполняться с использованием вложенного запроса.
7.2 Delete
Запрос DELETE это просто запрос SELECT или UPDATE без названий колонок. Серьезно. Как и в случае с SELECT и UPDATE , блок WHERE остается таким же: он выбирает строки, которые нужно удалить. Операция удаления уничтожает всю строку, так что не имеет смысла указывать отдельные колонки. Так что, если мы решим не обнулять количество книг Дэна Брауна, а вообще удалить все записи, то можно сделать такой запрос:
Что такое первичный ключ?
Первичный ключ или PRIMARY KEY предназначен для однозначной идентификации каждой записи в таблице и является строго уникальным ( UNIQUE ): две записи таблицы не могут иметь одинаковые значения первичного ключа. Нулевые значения ( NULL ) в PRIMARY KEY не допускаются. Если в качестве PRIMARY KEY используется несколько полей, их называют составным ключом.
Здесь в качестве первичного ключа используется поле id.
Читайте также: