
Oracle enterprise metadata management что это
At the end of November of 2014, the second version was released -OMM 12.1.3.1.0- with new features and some bugs fixed.
But first things first, what is Oracle Metadata Management? And why we want to use it?
One of the biggest problems that we face today, is the proliferation of different systems, data sources, solutions for BI, for ETL, etc in the same company. So not only for final users but also for technical people (from SysAdmin, Data Scientist, Data Steward to Developers) is quite difficult to track which data is used by which applications. In some cases is almost impossible to perform an impact analysis if someone wants to change a table or if the way that a sales measure is calculated needs to change. With more systems involved, the problem is bigger.
Oracle Metadata Management (OMM) comes to provide a solution to this problem. It is a complete metadata management platform that can reverse engineer (harvest) and catalog metadata from any source: relational, Big data, ETL, BI, data modelling, etc.
OMM allows us to perform interactive searching, data lineage, impact analysis, semantic definition and semantic usage analysis within the catalog. And the really important thing is the metadata from different providers (Oracle or/and third-party) can be related (stitched) so you will have the complete path of data from source to report or vice versa. In addition, it manages versioning and comparison of metadata models.
The Oracle Metadata Management solution offers two products: OEMM (Oracle Enterprise Metadata Management) and OMM for OBI (Oracle Metadata Management for Oracle Business Intelligence). With the first one we can use metadata providers from Oracle and third-party technologies. Using OMM for OBI allows us to use metadata for databases, OBIEE, ODI and DAC.
We will see in this series of posts how to use each of these options, the difference between them and which will be the best option depending of your environment.
In this first post we will focus on the installation process and the requirements for it.
Minimum Requirements for a small test environment
It is important to note and it is also well explained in the Readme document, that the following are the minimum requirements for a tutorial or a small business case, not for a larger system.
Any of these browsers or newer versions of them with at least Adobe Flash v8 plugging can be used: Microsoft Internet Explorer (IE) v10, Mozilla Firefox v30 or newer, Google Chrome v30, Apple Safari v6.
2 GHZ or higher quad core processor
4 GB RAM (8 GB if 64bit OS using 64bits Web Application Server)
10 GB of disk space (all storage is primarily in the database server)
Operating System
Other operating systems require manual install/setup, so are not supported by this version.
Web Application Server
The installer comes with the Apache Tomcat as Web Application Server and Oracle JRE 6 as Java Run Environment. Others web application servers (including Oracle WebLogic) require manual install/setup, and are not supported by this version.
Database Server
For the Database Server you can only use an Oracle Database from 10gR2 to 12 64-bit as a repository for OMM. You can create a new instance or reuse your existing Oracle database server but we need to have admin privileges in the database.
A very important observation is that the character set MUST be AL32UTF8 (UTF8). This is because the Oracle Intermedia Search can only index columns of type VARCHAR or CLOB (not the national variants NVARCHAR and NCLOB respectively). Otherwise you will receive this error message when you run the OMM for the first time:

To solve this, you can create a new instance of the database, or if your database has data already, there a couple of notes in My Oracle Support 260192.1 and 788156.1 to change any character set to AL32UTF8.
In addition, the CTXSYS user must be exist in the database. In case it doesn’t exist, the creation and granting privileges script can be found in /ctx/admin/catctx.sql.
Preparing to install
Step 2 - Create a Database Schema as Repository. Before start the installation, a database schema needs to be created as a repository for OMM to keep all its objects like models, configurations, etc (we will see all of these objects in next posts)
For that reason create a user in the database:
“create user MIR identified by quota unlimited on users”
And give to it the following grants:
“grant create session to MIR;
grant create procedure to MIR;
grant create sequence to MIR;
grant create table to MIR;
grant create trigger to MIR;
grant create type to MIR;
grant create view to MIR”
We also need to give grants to the new to user to execute a package from CTXSYS and another one from SYS.
“grant execute on CTXSYS.CTX_DDL to MIR;
grant execute on SYS.DBMS_LOCK TO MIR;”
If you prefer (and also could be a more accurate solution) you can create specific tablespaces (user tablespace and temp tablespace) for that user. I asked to David Allan, who is always very generous with his time and knowledge, if this schema will be part of the RCU in future releases but there is no plan to incorporate the MIR schema to it.
Installation and Post-Install tasks
Step 3 - Install the software. We can start now to run the installation. The downloaded zip file contains an exe file, double-click on it to start the installation.
In the first screen, select the type of product that you want to install: OEMM or OMM for OBI. We choose the Oracle Enterprise Metadata Management and press Next.

In the next screen, you have access to the Readme document and release notes pressing the View Readme button. After the installation you can find them in the OMM_Home/Documentation folder.

The next screen show you the destination location that you can change if you want. Keep the ports number suggested on the next screen.

The last screen of the installation ask you to restart the computer in order to use the product.

Step 4 - Start OMM Server as a service. After you restart the computer, you need to configure the OMM Server as a Service and start it. You can do this through the option that is showed in the start menu and press the Start button or going directly to the windows services screen and press the right button on the OMM service and start it.


We need to enter the connection details using the schema that we created in the database. Enter MIR as the Database User Id, its password and the database URL, and then press the Test Connection button. After you receive the Successful message, press the Save button to run the initialization process where OEMM create the objects in the database schema to manage the repository.

This process takes some minutes until you get the confirmation that the initialization process is also successful.


This is the main page of the OEMM where we are going to harvest (reverse-engineer) the metadata from different providers in the next posts.

In case you want to change the password of the Administrator user go to Tools > Administration on the top right of the page. Select the Administrator user and the user will be appear below.

If you prefer to create another user with Administration privileges, just press the Add User button (plus icon) in the Administration page and enter the details for the new user:

We are using the Native LDAP authentication approach for this demo, but OEMM can also use an External LDAP for authentication.
About the product documentation you can access it through the Help option which is on the top right of the page. In the Contents tab you have all the topics (Harvesting, Administration, etc) separated by folder and in each of them all the details about the specific topic
Installation of OMM for OBI
There are no differences in the installation process for OEMM and OMM for OBI. Just be sure to select the one that you want in the first screen of the installation. This is the page to login to the OMM for OBI.

In the next post, we will see how is the harvest (importing metadata) process using different metadata providers like OBIEE, ODI and others.
OAS / DV & HR Reporting (A Learning Experience)
I wanted to share a personal learning experience around HR reporting using Oracle Analytics Server (OAS) and Data Visualisation (DV). In my experience, more often than not, the old school Oracle BI development tool skillset (BI Apps / OBIEE / BI Publisher) usually reside in the IT department. Often IT cannot respond

Load Profile

Здесь отображается общая информация по тому, как была загружена БД за выбранный период.
| № | Параметр | Описание |
|---|---|---|
| 1 | DB Time(s) | Сумма времени утилизации процессора и время ожидания (без простоя) |
| 2 | DB CPU(s) | Нагрузка на процессор |
| 3 | Background CPU(s) | Загрузка процессора фоновыми задачами |
| 4 | Redo size | Объем чтения |
| 5 | Logical reads | Среднее количество логических чтений блоков |
| 6 | Block changes | Среднее значение измененных блоков |
| 7 | Physical reads | Физическое чтение в блоках |
| 8 | Physical writes | Количество записей в блоках |
| 9 | Read I/O requests | Количество чтений |
| 10 | Write I/O requests | Количество записей |
| 11 | Read I/O (MB) | Объем чтения |
| 12 | Write I/O (MB) | Объем записей |
| 13 | IM scan rows | Количество строк в In-Memory Compression Units (IMCU), которые были доступны |
| 14 | Session Logical Read IM | Чтения в In-Memory |
| 15 | User calls | Пользовательские вызовы |
| 16 | Parses | Разборы |
| 17 | Logons | Количество входов |
| 18 | Excecutes | Количество вызовов |
| 19 | Rollback | Количество откатов данных |
| 20 | Transacions | Количество транзакций |
Introducing Rittman Mead Lineage Tool
Introduction Rittman Mead Lineage Tool analyses ODI Mappings and produces neat visualisations of source-to-target mappings. The Lineage Tool is quick to set up and easy to run. Rittman Mead Lineage Tool: from ODI Mappings to Mapping Lineage VisualisationThe Lineage Tool can be used to reverse-engineer legacy ELT logic as the
В этой статье я хочу рассказать, как можно решать задачу impact анализа или анализа влияния в сложной, многоуровневой инфраструктуре корпоративного хранилища данных на примере нашего DWH в Тинькофф Банке.

- «Что будет, если поменять поле в таблице?»
- «На каких ETL процессах это скажется?»
- «Какие отчеты будут затронуты?»
- «Какие бизнес процессы могут пострадать?»
Далее в статье я расскажу, как и с помощью чего можно уменьшить головную боль и быстро проводить impact-анализ в инфраструктуре DWH.
Прежде чем окунуться в impact-анализ, коротко опишу что из себя представляет наше DWH. По структуре наше хранилище более походит на Corporate Information Factory Билла Инмона. Есть много слоев обработки данных, группы целевых витрин и нормализованная модель представляют презентационный слой хранилища данных. Всё это работает на MPP СУБД Greenplum. ETL процессы построения хранилища разработаны на SAS Data Integration Studio. В качестве платформы отчетности в банке используется SAP Business Object. Перед хранилищем находится ODS, реализованный на СУБД Oracle. Из моей предыдущей статьи про DataLake в Тинькофф Банке известно, что ETL на Hadoop мы строим на Informatica Big Data Edition.
Как правило, задача анализа влияния внутри одного enterprise инструмента решается несложно. Все инструменты обладают метаданными и функциональными возможностями работы с этими метаданными, такими как, например, получить список зависимых объектов от выбранного объекта.
Вся сложность анализа влияния возникает тогда, когда процесс выходит за рамки одного инструмента. Например, в DWH окружение состоит из СУБД источников, СУБД DWH, ETL, BI. Здесь что бы уменьшить головную боль, нужно уметь консолидировать метаданные из разных инструментов и строить зависимости между ними. Задача неновая и на рынке существуют промышленные системы для её решения.
Нам важно было, что бы такая система смогла построить для нас всё сложное дерево, а точнее граф наших метаданных, начиная от таблиц Oracle в ODS и заканчивая отчетами в SAP (см. Рис. 1).
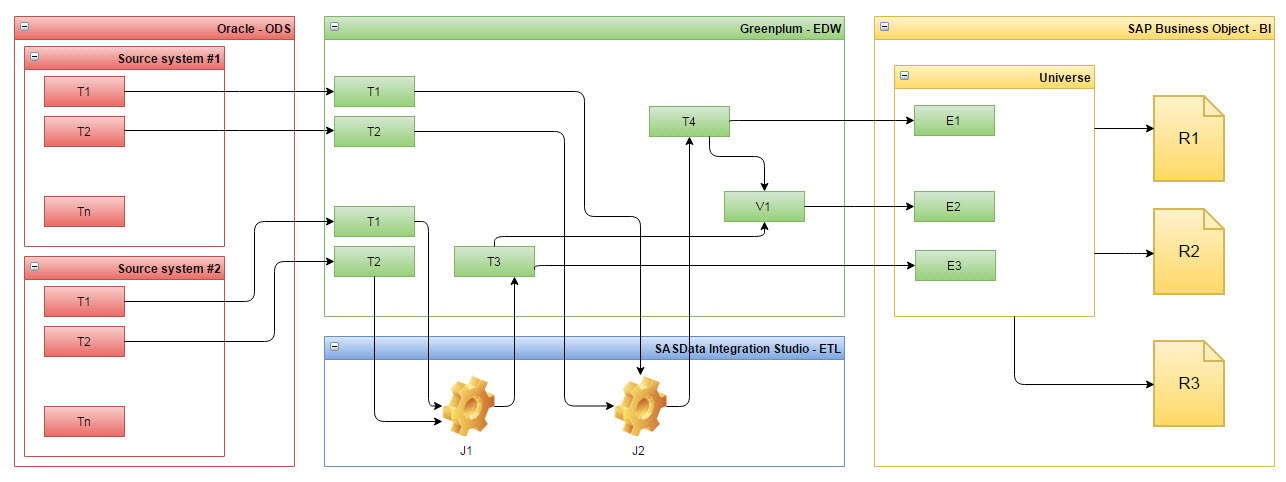
Рис. 1 Пример зависимостей метаданных из нескольких систем, на примере систем в Тинькофф Банке
Система должна была провязать объекты Greenplum между собой, как и через джобы SAS, в которых таблицы Greenplum выступают как источники и приемники данных, так и просто связать таблицы со строящимися на них представлениями.
Мы выбрали Informatica Metadata Manager и успешно внедрили первые модели метаданных у себя, в Тинькофф Банке. Далее в статье я расскажу, как и что мы научились делать при помощи этого инструмента.
- Моделировать метаданные, т.е. создавать модели метаданных, например, СУБД, ETL инструментов или даже бизнес приложений
- На основе созданных или поставляемых в комплекте моделей создавать процессы загрузки/обновления метаданных у себя в репозитории
- Создавать правила связывания между объектами метаданных как внутри модели, так между моделями
- Создавать связи, которые нельзя подвести под правила, как и внутри модели, так и кроссмодельные
- Работать в визуальном веб-интерфейсе с загруженными метаданными ваших систем
Теперь по порядку и более детально про то, что может инструмент и как готовить Informatica Metadata Manager.
В коробке с Informatica Metadata Manager поставляется некоторый набор моделей, с которыми, если у вас куплена лицензия, можно начинать работать сразу после установки продукта.
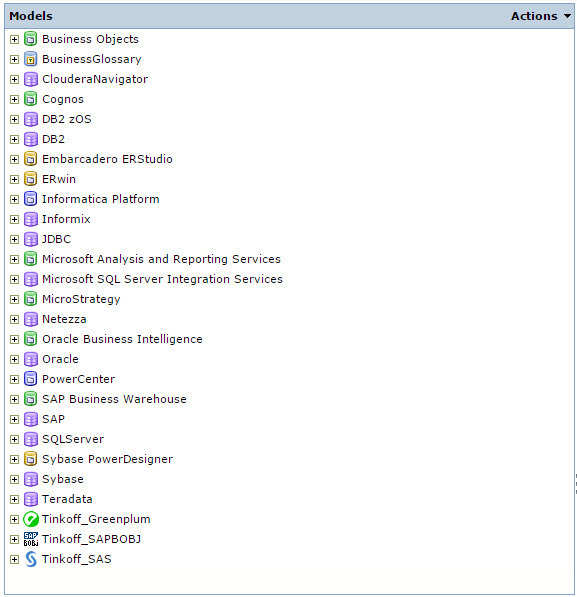
Рис. 2 Модели Informatica Metadata Manager
На Рис. 2 те модели что не начинаются с префикса Tinkoff идут из коробки. Модель в терминах Informatica Metadata Manager – это набор классов, из которых построена определенная иерархия, которая отвечает структуре метаданных источника, т.е. некоторой информационной системы. Например, модель метаданных СУБД Oracle в Informatica Metadata Manager выглядит следующим образом, см. Рис. 3. Думаю, те кто работал с СУБД Oracle в этой иерархии увидят много знакомого, из того с чем привыкли работать.
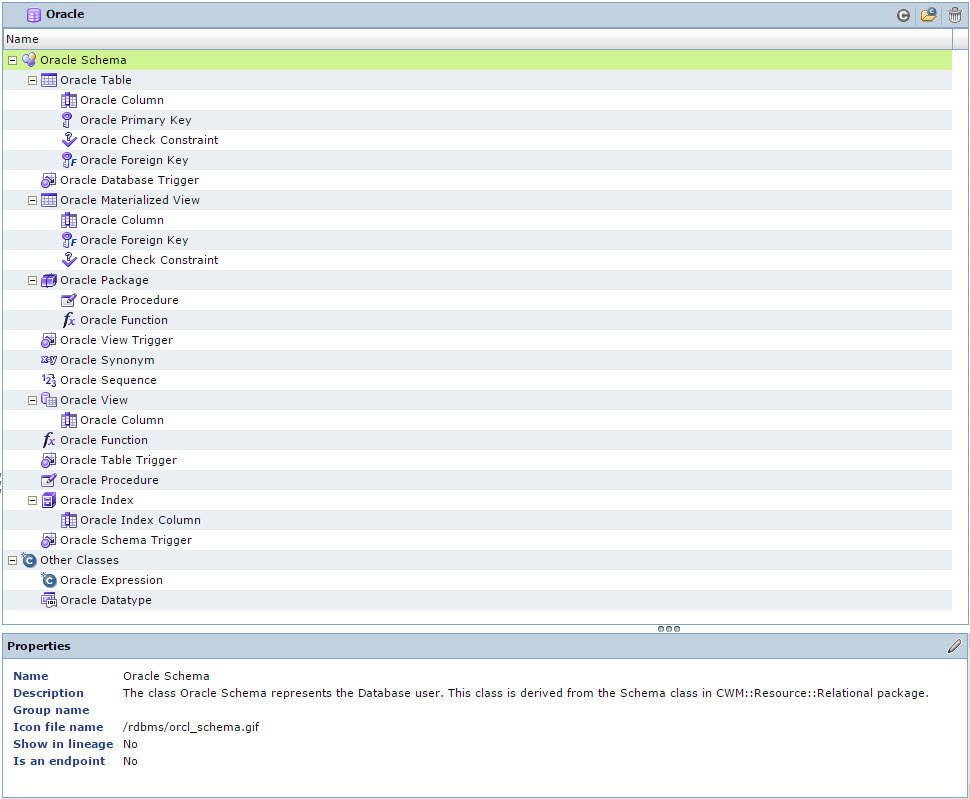
Рис. 3 Модель метаданных СУБД Oracle
Модели метаданных СУБД Greenplum или SAS Data Integration Studio в Informatica Metadata Manager из коробки не предусмотрены и мы сами их спроектировали под наши задачи. Очень важно понимать, какие задача должна решать модель, когда вы начинаете работать с готовой моделью или проектируете свою. У нас получились простые модели (см. Рис. 4 и Рис. 5), но в тоже время эти модели отвечали нашим требованиям. А основное наше требование – это уметь строить lineage от таблиц ODS, которые находятся в Oracle, до отчетов, которые построены на universe-ах в SAP Business Objects.
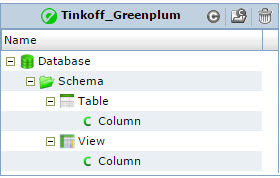
Рис. 4 Модель метаданных СУБД Greenplum
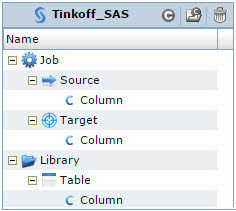
Рис. 5 Модель метаданных SAS Data Integration Studio
Относительно модели метаданных SAP Business Objects возникла дилемма – использовать преднастроенную модель или разработать свою.
Готовая модель, а точнее первый её уровень иерархии выглядит так – см. Рис. 6.
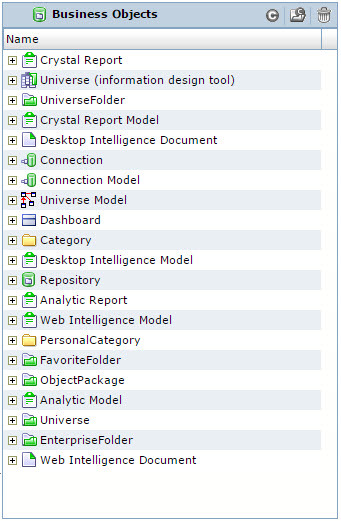
Рис. 6 Преднастроенная модель метаданных Business Objects
| Критерий | Преднастроенная модель | Своя модель |
|---|---|---|
| Полнота модели | Избыточная | Оптимальная |
| Отвечает изначально сформулированным требованиям | Наверное, отвечает | Отвечает |
| Стоимость разработки загрузки/обновления метаданных | Бесплатно | Зависит от сложности модели и от знания структуры метаданных SAP Business Objects |
| Стоимость модели | Стоимость лицензии на metadata exchange options for SAP Business Objects | Бесплатно |
Один критерий не в пользу своей модели был факт сложности структуры метаданных SAP Business Objects. Но, у нас для аудита BI платформы используется сторонний продукт — 360eyes, который мы и взяли за источник метаданных SAP Business Objects для Informatica Metadata Manager. Модель получилось очень простой, см. Рис. 7, которая отвечала нашим сформулированным требованиям.
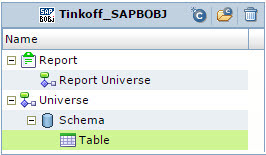
Рис. 7 Модель метаданных SAP Business Objects
Модели созданы, теперь их надо наполнить метаданными. Модели, которые поставляются в коробке с Informatica Metadata Manager имеют свои преднастроенные загрузчики, которые уже знают, как извлечь, например, из словарей СУБД Oracle список таблиц и представлений. Для моделей метаданных, которые вы проектируете сами, загрузчик придется разработать самим. Но пугаться здесь не стоит, процесс довольно прозрачный, и напоминает разработку ETL процедуры по четко сформулированному ТЗ. На основе вами созданной модели Informatica Metadata Manager простой командой поможет вам создать шаблон загрузки и вот у вас готов набор CSV файлов которые надо наполнить метаданными вашей системы. Дальше всё зависит от вас и от того на сколько вы хорошо знаете и умеете работать с метаданными ваших систем. Кстати, процесс получение метаданных из ваших систем это, наверное, один из самых трудоемких шагов в построении всего процесса работы с метаданными в Informatica Metadata Manager.
Мы написали весь необходимый код, который собрал нам из pg_catalog Greenplum, из метаданных SAS и из репозитория 360eyes данные для созданных шаблонов загрузки и запустили регулярный процесс. Для обновления метаданных Oracle, на котором у нас работает ODS, мы использовали преднастроенную модель (см. Рис. 3). Метаданные в Informatica Metadata Manager обновляются каждую ночь.
Метаданные систем регулярно обновляются в репозитории Informatica Metadata Manager, теперь надо связать объекты метаданных разных систем между собой. Для этого в Informatica Metadata Manager есть возможность написания правил (Rule Set), правила могут работать как внутри модели так и между моделями. Правила из себя представляют XML файл несложной структуры:
Приведенное правильно говорит о том, что нужно построить связь внутри модели SAPBOBJ между объектами класса «Universe» и объектами класса «Report Universe» по условию равенства их наименования.
Бывают ситуации, что объекты метаданных нужно связать между собой, но правило под эту связь разработать не получается. Простой пример: Представление «A» построено на таблице «B» и «С». Для таких ситуаций в Informatica Metadata Manager есть возможность подгружать дополнительные связи, так называемые Enumerated Links. Enumerated Links представляет из себя CSV файл, в котором прописываются полные пути уже в репозитории Informatica Metadata Manager к двум объектам метаданных, которые необходимо связать. При помощи Enumerated Links у нас строится связь между таблицами и представлениями Greenplum.
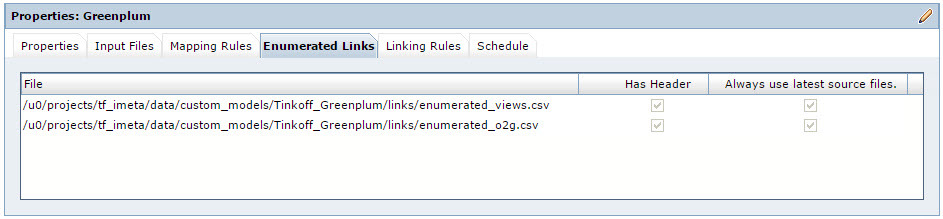
Рис. 8 Свойства Enumerated Links
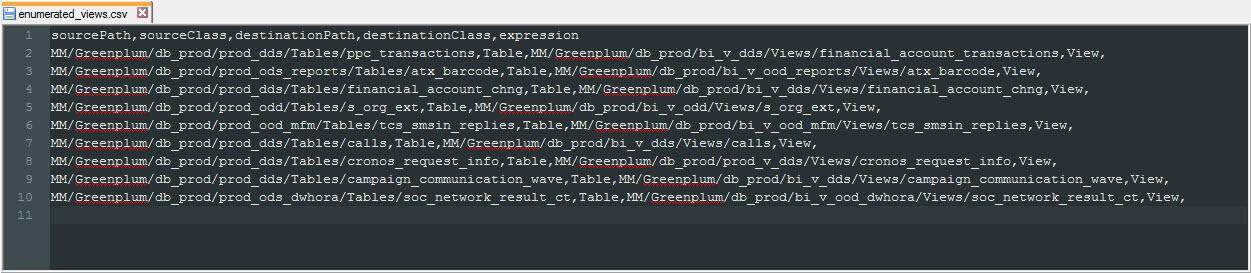
Рис. 9 CSV файл для загрузки Enumerated Links
В данном случаем CSV файл Enumerated Links мы формируем сами также, как и сами метаданные для загрузки, на основе pg_catalog. Через Enumerated Links мы связываем в модели Greenplum объекты класса «Table» с объектами класса «View». Связь формируем через указание полного пути к объекту метаданных уже в репозитории Informatica Metadata Manager.
Что мы получили? Основное что мы получили это возможность строить lineage по всем объектам метаданных входящих в инфраструктуру нашего DWH, т.е. производить анализ влияния, по двум направлениями: Impact Upstream и Impact Downstream.
Например, хотим посмотреть, что зависит от таблицы ODS. Находим нужную нам таблицу, или в каталоге моделей, или при помощи поиска и запускаем на этой таблице lineage. Получаем такую красивую картинку, см. Рис. 10. Здесь мы видим, что от выбранной таблицы зависит ряд ETL процессов на SAS-е, а также два Universe-а и семь отчетов в SAP Business Objects.
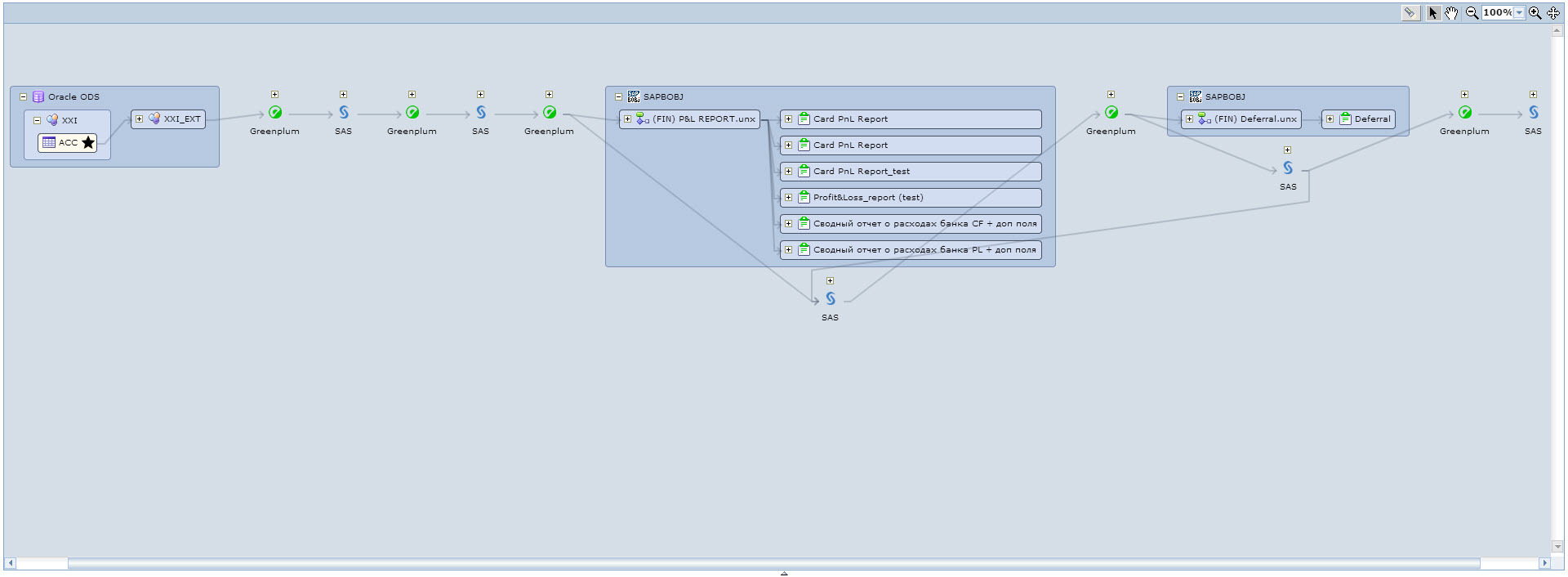
Рис. 10 Lineage от таблицы ODS
В веб-интерфейсе можно раскрыть каждую область полученного lineage и от каждого объекта на диаграмме можно запустить linage прям из этого окна.
Или, например, хотим посмотреть данные каких таблиц участвуют в построении отчета. Находим нужный отчет и запускаем на нём lineage. Получаем следующую красивую картинку, см. Рис. 11. Здесь мы видим, что выбранный отчет строится на одном Universe, который использует таблицы Greenplum из четырех схем, которые в свою очередь наполняются из ODS и некоторыми ETL процессами на SAS.
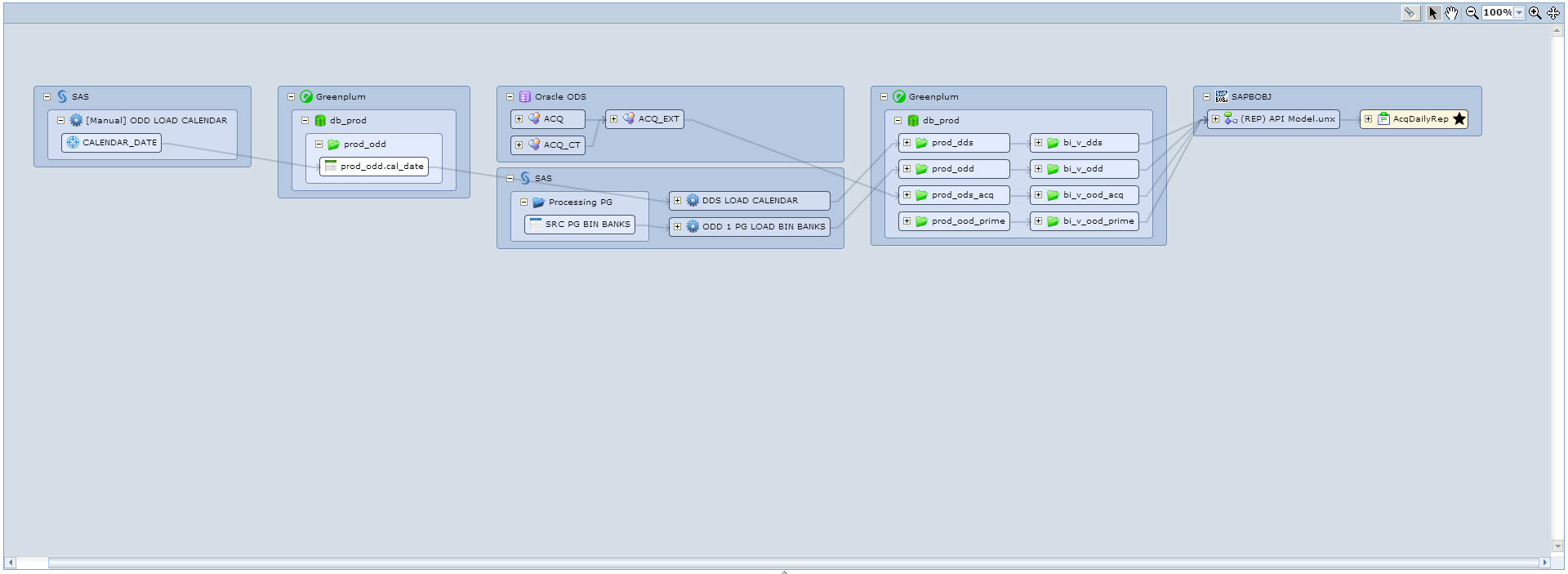
Рис. 11 Lineage от отчета в SAP Business Objects
Каждый результат lineage можно экспортировать в Excel, который в полном объем отражает все зависимости от выбранного объекта метаданных.
Готовить Informatica Metadata Manager мы научились. Дальше только работать, искать новые варианты его использования, реализовывать новые модели, подключать новых пользователей.

Привет! Меня зовут Александра, я работаю в команде тестирования производительности. В этой статье расскажу базовые сведения об OEM от Oracle. Статья будет полезна для тех, кто только знакомится с платформой, но и не только для них. Основная цель статьи — помочь провести быстрый анализ производительности БД и поиск отправных точек для более глубокого анализа.
OEM (Oracle Enterprise Manager) — платформа для управления БД. OEM предоставляет графический интерфейс для выполнения большого количества операций с базами данных: резервное копирование, просмотр аварийных журналов, графиков производительности.
Parallel Executions
Раздел дает представление о показателях, связанных с параллельным выполнением запросов. Параллельный запрос делится на несколько процессов для ускорения выполнения запроса. Параллельное выполнение полезно при выполнении тяжелых запросов. Подробнее можно прочесть в официальной документации Oracle.
Performance Home
На вкладке Performance Home можно увидеть основные графики утилизации БД.
Active Session History (ASH) Report
В данной таблице находятся самые тяжелые SQL запросы, на которые приходится наибольший процент активности и наибольшее время ожидания.
В таблице содержится статистика по запросам, на которые приходится наибольший процент выборочной активности и подробная информация о их плане выполнения. Вы можете использовать эту информацию, чтобы определить, какая часть выполнения SQL операторов значительно повлияла на затраченное время SQL оператора.
Oracle Fusion Middleware - семейство связующих технологий Oracle для создания инфраструктуры приложений.
Под брендом Oracle Fusion Middleware корпорация Oracle объединила все интеграционные программные продукты.
Oracle Fusion Middleware включает в себя:
- всю совокупность продуктов Oracle Application Server, включая все редакции сервера приложений;
- дополняющие сервер приложений Oracle инструментальные продукты, такие как: Oracle JDeveloper, Oracle TopLink and Application Development Framework (ADF), Oracle Internet Developer Suite, Oracle BI Beans, Oracle Warehouse Builder;
- семейство интеграционных продуктов: Oracle InterConnect, Oracle B2B, Oracle BPEL Pro-cess Manager, Oracle Business Activity Monitoring (BAM), Oracle Enterprise Service Bus (ESB);
- семейство концентраторов данных Oracle Data Hubs, таких как: Oracle Customer DataHub, Oracle Financial Consolidation Hub и Oracle Product Information Management Hub;
- семейство продуктов обеспечения безопасности: Oracle Identity Management, OracleCoreId Access and Identity, Oracle Web Services Manager, Oracle CoreId Federation and CoreId Provisioning;
- функциональные расширения сервера приложений, такие как: Oracle Portal, OracleBusiness Intelligence (BI), Oracle XML Publisher, Oracle Business Rules, Oracle Mobile,Oracle Sensor Edge Server;
- Оracle Collaboration Suite и его модули Content Services, RealTime Collaboration,Unified Messaging, Workspaces с новыми функциональными возможностями.
Недавно Oracle выпустила новый программный продукт семейства Fusion Middleware - Data Integrator, предназначенный для интеграции больших объемов данных, поступающих из различных корпоративных приложений. Решение призвано облегчить интеграцию таких критических для управления бизнесом приложений, как бизнес-аналитика (Business Intelligence), хранилище данных (Data Warehouse), управление основными данными (Master Data Management), сервисно-ориентированная архитектура (Service-Oriented Architecture), мониторинг деятельности (Business Activity Monitoring), а также миграция и консолидация ПО (Application Migration and Consolidation).
Oracle Data Integrator обеспечивает интеграцию разнородной информации, производительность при использовании инновационной технологии ELT (Extract, Load, Transform), поддерживает обработку как пакетных заданий, так и работу в режиме реального времени. Кроме того, приложение позволяет снизить стоимость разработки и поддержки интегрированных систем, используя язык декларативных моделей и библиотеки программных кодов, называемые модулями знаний (Knowledge Modules).
Новая разработка основана на технологии, созданной недавно приобретенной компании Sunopsis. Oracle Data Integrator исключает необходимость использования специализированного ETL-сервера, производя операции по трансформации данных либо внутри приложения-источника, либо внутри хранилища данных, что, по утверждению разработчиков, увеличивает скорость обработки и снижает стоимость ПО.
Сертификация ФСТЭК
8 декабря 2015 года представительство Oracle в Росии объявило о получении сертификата Федеральной службы по техническому и экспортному контролю (ФСТЭК) России на программное обеспечение Oracle Fusion Middleware для оптимизированного программно-аппаратного комплекса Oracle Exalogic.
Сертификат подтверждает: платформа Oracle Fusion Middleware для Oracle Exalogic - программное средство общего назначения, имеющее встроенные средства защиты от несанкционированного доступа к информации, не содержащей сведений, составляющих государственную тайну. Оно соответствует требованиям технических условий. Встроенные средства защиты реализуют функции идентификации и аутентификации, управления доступом, регистрации событий безопасности, обеспечения доступности информации.
Oracle Exalogic Elastic Cloud — оптимизированный программно-аппаратный комплекс, разработанный для обеспечения максимальной производительности, надежности и масштабируемости приложений на платформе Oracle Fusion Middleware, консолидации приложений Oracle и других производителей. Он совместим с продуктами Oracle, Java и другими приложениями, обеспечивает низкую совокупную стоимость владения, пониженные риски, высокую продуктивность пользователей и комплексную поддержку.
Сертификаты Федеральной службы по техническому и экспортному контролю подтверждают, что клиенты могут использовать встроенные в продукты Oracle механизмы для защиты конфиденциальной информации и персональных данных в соответствии с требованиями Российского законодательства.
Host CPU и Instance CPU
Здесь стоит обратить внимание на %Idle и %Total CPU. Если показатель %Idle низкий, а %Total CPU высокий, это может свидетельствовать о том, что процессор является узким местом.
Top 10 Foreground Events by Total Wait Time
В разделе находится топ-10 событий, которые ожидали ресурсов дольше остальных.
При анализе необходимо обратить внимание на класс события ожидания. Если wait class System I/O, User I/O или Other, это нормально для БД. Если класс события ожидания Concurrency, это может свидетельствовать о проблемах.
Классы события ожидания можно посмотреть в разделе Wait Classes by Total Wait Time. В разделе находится статистика по классам события ожидания с сортировкой по времени ожидания.
Описание некоторых событий ожидания:
| № | Событие ожидания | Описание |
|---|---|---|
| 1 | DB CPU | Отображает процессорное время, затраченное на пользовательские операции над БД. Это событие должно находиться на первом месте списка |
| 2 | db file sequential read | Метрика сигнализирует, что пользовательский процесс не находит нужный блок в buffer cache, загружает его с диска в SGA и ждет физического ввода/вывода |
| 3 | db file scattered read | Указывает на проблему с фулл-сканами, возможно, нужны индексы |
| 4 | read by other session | Может говорить о том, что размер блока слишком большой или задержка (latency) слишком большая |
| 5 | enq TX – row lock contention | Событие возникает при ожидании блокировки строки для дальнейшей ее модификации DML-запросом. Если показатель больше 10%, необходимо разбираться в причинах. Более детальную информацию можно посмотреть в разделе Segments by Row Lock Waits, в котором есть сведения о том, какие таблицы были заблокированы и какими запросами |
| 6 | DB FILE SEQUENTIAL READ | Если среднее значение параметра больше 100 мс, это может свидетельствовать о том, что диск работает медленно |
| 7 | LOG FILE SYNC | Значение AVG WAIT более 20 мс может свидетельствовать о проблемах |
| 8 | DB FILE SCATTERED READ | Если это событие выполняется — возможно, имеет смысл создать дополнительные индексы. Для более подробной информации нужно перейти к разделу Segments By Physical Read, в котором находится информация по таблицам и индексам, в которых происходит физическое чтение |
| 9 | direct path read temp ИЛИ direct path write temp | Эти события дают информацию по использованию временных файлов |
| 10 | Buffer Busy Wait | Событие указывает на то, что несколько процессов пытаются обратиться к одному блоку памяти, то есть пока первый процесс работает с конкретным блоком памяти, остальные процессы находятся в статусе ожидания |
Throughput

Раздел Throughput отображает пропускную способность. Пропускная способность базы данных измеряет объем работы, которую база данных выполняет за единицу времени.
Пики на графике Throughput должны соответствовать пикам на графике Average Active Sessions. Если заметен рост времени ожидания, необходимо убедиться, что увеличивается пропускная способность. Если пропускная способность низкая, а время ожидания растет — необходимо изменить настройки БД.

Latency показывает задержку чтения блоков. Это разница между временем выполнения чтения и временем обработки чтения БД. Показатель должен стремиться к нулю.
Оптимальным считается значение до 10 мс. Этот график — основной показатель производительности в этом блоке. Если зафиксирован рост времени задержки, нужно посмотреть, не растет ли количество I/O операций и их вес, также на рост Latency может влиять утилизация CPU.
Статистику по I/O можно смотреть в разрезе функций, в разрезе типов и в разрезе групп потребителей ресурсов (группы пользователей). Для этого на графике необходимо выбрать соответствующий Breakdown. Графики показывают количество I/O-операций в секунду и их вес в разрезе выбранного значения Breakdown. Для большей детализации можно провалиться глубже в статистику, выбрав соответствующее значение на графике или в легенде, и посмотреть статистику именно по выбранному значению.
I/O Function

График дает представление об уровне утилизации диска приложениями или джобами. То есть на графике можно увидеть, какие процессы больше всего читали и писали за определенный период.
Можно выделить следующие категории:
| № | Категория | Описание |
|---|---|---|
| 1 | Фоновые процессы | Включают в себя ARCH, LGWR, DBWR (полный список фоновых процессов есть в документации) |
| 2 | Активность | XML DB, Streams AQ, Data Pump, Recovery, RMAN |
| 3 | Тип I/O | Включает прямую запись и чтение (в том числе чтение из кэша) |
| 4 | Другое | Включает операции ввода/вывода управляющих файлов |
I/O Type

Выводит статистику по тяжести операций ввода-вывода. Маленькими считаются операции, которые обрабатывают до 128 КБ. К большим операциям ввода-вывода относятся: сканирование таблиц и индексов, прямая загрузка данных, резервное копирование, восстановление и архивирование.
Consumer group
Дает представление об утилизации диска в разрезе групп пользователей: показывает, какая группа пользователей выполняет операции чтения и записи в определенный период. Включает в себя фоновые процессы.
Instance Efficiency Percentages

| № | Показатель | Критерии |
|---|---|---|
| 1 | Buffer nowait | Если показатель меньше 95%, значит, буферы data block buffer используются неправильно. Возможно, нужно увеличить data block buffer size |
| 2 | Buffer Hit | Если показатель меньше 95%, значит, буферы data block buffer используются неправильно. Возможно, нужно увеличить data block buffer size |
| 3 | Library cache hit | Если показатель меньше 95% — нужно расширять shared pool (либо причина в bind-переменных) |
| 4 | Redo NOWAIT | Если показатель меньше 95%, это говорит о проблеме в redo log buffer или redo log |
| 5 | Parse CPU to Parse Elapsd | Показатель должен быть больше или равен 90%, тогда большинство процессов не ожидает ресурсов, что говорит о правильной работе базы данных |
| 6 | Non-Parse CPU | Показатель должен приближаться к 100%, это значит, что большинство ресурсов CP используется в различных операциях, кроме parsing, что говорит о правильной работе базы данных. Если Non-Parse CPU низкий, значит, база много времени тратит на разбор запроса вместо реальной работы |
| 7 | In-memory sort | Значение меньше 100 говорит о том, что сортировка идет через диск, а также есть потенциальные проблемы с PGA_AGGREGATE_TARGET,SORT_AREA_SIZE,HASH_AREA_SIZE и bitmap setting |
| 8 | Soft Parse | Чем он выше, тем меньше у нас Hard Parse |
| 9 | Latch Hit | Чем он выше, тем меньше мы ждем Latches (если он низкий — у нас проблемы с CPU-Bound и Latches) |
Analyzing Brand Reputation with Oracle Analytics
This post illustrates how to use Oracle Analytics to perform brand reputation analysis without machine learning or marketing experience.

Services

Службы на этом графике представляют собой группы приложений. Отображаются только сессии активных служб, находящиеся в ожидании в определенный момент времени. Например, служба SYS$USERS — это установка пользовательского сеанса.
Average Active Sessions
- Если зафиксирован рост активных сессий, то должна расти пропускная способность (график Throughput).
- Если Active Sessions превышает CPU Cores/CPU Threads, это свидетельствует о проблемах производительности.
- Если зафиксирован рост времени отклика операций, но при этом активные сессии не превышают CPU, это значит, что узкое место не в CPU и нужно более детально смотреть, по каким классам события ожидания фиксируется рост, после чего можно на графике нажать на соответствующий класс и провалиться глубже в детализацию (откроется отчет ASH — Active Session History).
ASH Report

ASH Report (Active Session History) дает более подробную информацию по потреблению ресурсов. Чтобы перейти к графику, в меню Performance нужно выбрать пункт Performance Hub/ASH Report. Также перейти к ASH Report можно при выборе класса события ожидания на графике Average Active Session.
- События ожидания и группы событий ожидания.
- Группы пользователей, пользователи, сервисы, инстансы.
- SQL-запросы.
AWR (Automatic Workload Repository) дает подробную информацию о процессах, происходящих с БД в определенный период. Для построения AWR-отчета нужно выбрать пункт меню Performance/AWR/AWR Report. Также есть возможность сравнивать два временных промежутка. Для этого нужно выбрать пункт меню Performance/AWR/Compare Period Report.
Ниже будут описаны наиболее показательные разделы AWR-отчета, описание остальных разделов можно поискать в официальной документации.
Average Runnable Process

Этот график дает общее понимание использования CPU.
| № | Показатель | Описание |
|---|---|---|
| 1 | Instance Foreground CPU | Отображает утилизацию CPU процессами текущего инстанса, напрямую запущенными клиентом, например выполнение запросов. Список событий ожидания текущего инстанса можно посмотреть в AWR-отчете |
| 2 | Instance Background CPU | Отображает утилизацию CPU фоновыми процессами текущего инстанса, например LGWR. Список событий фонового процесса текущего инстанса можно посмотреть в AWR-отчете или в официальной документации Oracle |
| 3 | Non-database Host CPU | Отображает утилизацию CPU процессами, не относящимися к текущему инстансу |
| 4 | Load Average | Отображает среднюю длину очереди процессов, ожидающих выполнения |
| 5 | CPU Treads/CPU Cores | Отображает лимит максимально возможного использования CPU |
2019: Исправление 37 уязвимостей
17 октября 2019 года стало известно, что компания Oracle исправила 219 опасных уязвимостей в разных линейках продуктов, более 140 из которых могут быть проэксплуатированы удаленно неавторизованным злоумышленником. 19 уязвимостей были обозначены как критические и получили оценку выше 9,0 по шкале CVSS.
Больше всего уязвимостей исправлено в платформе для цифровой трансформации бизнеса на предприятии и в облаке Fusion Middleware — 37 исправлений. Свободная реляционная система управления базами данных MySQL получила 34 исправления уязвимостей. В платформе Java SE исправлено 20 уязвимостей.
Другие продукты, получившие исправления уязвимостей, включают Construction and Engineering (13 исправлений), приложения PeopleSoft (13), Oracle Retail (12), платформы для управления рисками (12), Oracle Database (10), ПО для вирутализации (11), E-Business Suite (10), Enterprise Manager (7), Oracle Financial Services (7) и Oracle Food and Beverage (7).
Также были исправлены уязвимости в Policy Automation (4 исправления), Siebel CRM (4), Oracle Supply Chain (3), GraalVM (3), приложениях Oracle Hospitality (3), Hyperion (3), приложениях Oracle Health Sciences (2), Oracle Support Tools (2), JD Edwards (1) и NoSQL Database (1) [1] .
Foreground Wait Class, Foreground Wait events и Background Wait Events
Показывают классы и события, которые провели в ожидании большего всего. Foreground Wait events дополняет информацию раздела Top 10 Foreground Events By Total Wait Time. Background Wait Events показывает детализацию по событиям ожидания фоновых процессов.
Sign up for more like this.
Модернизировано семейство Fusion Middleware
2 ноября 2015 года корпорация Oracle анонсировала возможности семейства программного обеспечения Fusion Middleware.
В составе вышедшей версии содержатся сотни улучшений, которые помогут заказчикам и партнерам создавать и использовать динамичные интеллектуальные бизнес-приложения, стимулировать инновации, консолидировать системы и поддерживать непрерывность бизнес-процессов непосредственно на предприятии и в облаке.
В составе этой версии корпорация Oracle объявила о выпуске крупнейшего за последнее десятилетие обновления Oracle WebLogic Server и представила первую в мире платформу Java корпоративного класса, предназначенную для использования в облачной среде. Усовершенствованы другие компоненты Oracle Fusion Middleware, включая Oracle BPM Suite, Oracle Data Integration, Oracle SOA Suite, Oracle WebCenter и Oracle Developer Tools.
Целью технологического форума Oracle Database 12c, который прошел в Москве 22 марта 2016 г., было освещение главных новинок в области хранения корпоративных данных и управления ими. Нас особенно заинтересовала первая секция форума, посвященная облачным вычислениям.

Доклад, посвященный лучшим практикам управления гибридным облаком, Прабакер Гонглур, старший директор по развитию направления Oracle Database 12c в корпорации Oracle, начал с важной мысли: гибридное облако — уже реальность. Что это такое? Это объединение частного и публичного облаков, в котором реализовано перекрестное контролируемое использование данных и приложений между ними. Гибридное облако очень удобно для разработки и тестирования, интеграции B2B-решений, внедрения требовательных к ИТ-ресурсам продуктов, пробной эксплуатации новых сервисов.
Единого для всех сценария перехода в гибридное облако, разумеется, не существует. Одни компании ищут возможности оптимизировать расходы на физическую ИТ-инфраструктуру и виртуализуют локальные ресурсы, переводя их в частное облако. Другие планомерно переводят ресурсы в частное облако для того, чтобы постепенно, отрабатывая рабочие процессы на уровне виртуализации, переводить их в публичное облако. Некоторые компании просто переводят в публичное облако отдельные проекты. Для всех подобных случаев характерен также переход от капиталовложений к операционным затратам, который в силу экономических причин сейчас во многом является требованием времени.
Легко выделить типичные примеры использования гибридного облака на предприятиях. Организации, которые занимаются разработкой и тестированием приложений в промышленных масштабах — неважно, для собственных потребностей или в качестве основной деятельности — переводят инфраструктуру разработки и тестирования в публичное облако, чем добиваются существенного ускорения развертывания этих систем и оптимизации управления ими, при этом бизнес-критичные приложения они продолжают использовать локально. Для ряда организаций — например, зависимых от сезонных колебаний на рынке — периодический перенос нагрузки в публичное облако является условием существования бизнеса, поэтому им важно обеспечивать динамическое распределение нагрузки на ИТ-ресурсы и быстрый переход в публичное облако по требованию. Еще одним популярным паттерном является, например, выполнение резервного копирования и бизнес-аналитических приложений в публичном облаке, в то время как транзакционная обработка выполняется локально.
Разумеется, размещение ИТ-ресурсов в гибридном облаке имеет смысл только в том случае, если компания может полноценно владеть этими ресурсами и управлять ими. Облако является облаком, когда автоматизированы предоставление услуг, их администрирование и оплата. Компании с большой, сложной ИТ-инфраструктурой это понимают особенно хорошо, потому что управлять такими инфраструктурами без автоматизации невозможно. Поставщик соответствующих платформ и технологий обязан обеспечить унификацию процедур управления частным и публичным облаком; стабильное качество сервиса в частном и публичном облаке, а также его соответствие регламентам; прозрачность управления публичным и частным облаком и потоков действий (user flows) между ними.
Но и в этом случае использование гибридного облака не самоцель. Для того чтобы эта технология привлекала предприятия, она должна обеспечивать оптимизацию ресурсов — т. е. использование ресурсов в частном и публичном облаке должно быть самым экономным способом их размещения, при этом обязательны механизмы точного расчета требований для инфраструктуры частного облака и платформенных сервисов публичного облака. Отдельным вызовом становится возможность динамического распределения нагрузки между частным и публичным облаком.

Компания Oracle реализует и предоставляет на выбор своим клиентам все облачные модели. И именно Enterprise Manager, начиная с версии 12cR5, является единым инструментом управления для локальных и облачных ресурсов, он обеспечивает предприятиям не только единый взгляд на локальные и облачные ресурсы, но и возможность переноса нагрузки в облако Oracle Cloud и обратно (Рис. 1).


Новая возможность SQL Performance Analyzer, которая называется SPA Quick Check, позволяет быстро оценить влияние плановых системных изменений на SQL-нагрузку на рабочей системе. Она разработана для использования на рабочих системах, не оказывает влияния на работу конечных пользователей и создает минимальную дополнительную нагрузку.
Обеспечение качества сервиса для частных и публичных облаков достигается новыми возможностями Oracle Enterprise Manager 13c. Отдельно упомянем инструментарий Oracle Real Application Testing, который кроме тестирования инфраструктурных изменения базы данных теперь ещё предлагает интегрированный набор средств для комплексного сквозного управления консолидацией баз данных Database Consolidation Workbench.
- клонирование подключаемых баз данных в Oracle Cloud для Oracle Database 12c;
- клонирование или миграция подключаемых баз данных из Oracle Cloud в локальные контейнерные базы данных;
- клонирование для сценариев разработки и тестирования — с использованием маскирования данных.
Более подробно представляя Oracle Enterprise Manager 13c, Сергей Томин, ведущий консультант департамента технологического консалтинга Oracle СНГ, рассказал о том, что изначально тремя основными целями при разработке предыдущей версии Enterprise Manager 12c были: во-первых, дать заказчикам полноценное решение для управления и мониторинга корпоративного уровня (т. е. решение, которое позволяет управлять сотнями и тысячами объектов), во-вторых, сделать возможным интегрированное управление всем стеком приложений и глубокую диагностику от уровня приложения до уровня базы данных и дисков с прозрачным переходом между уровнями, в-третьих, самое главное, создать коммерческое решение для управления частными облаками, всем жизненным циклом облака — планированием, развертыванием, тестированием, учетом потребления ресурсов и биллингом.
Благодаря успешной реализации этих функций Oracle Enterprise Manager 12c получил заслуженное признание пользователей. Крупнейшая сеть розничных магазинов шаговой доступности 7-Eleven использует Enterprise Manager для быстрого развертывания инфраструктуры своих мобильных приложений. Крупнейшая сеть аптек Walgreens использует Enterprise Manager для контроля конфигураций, для контроля соблюдения регламентных требований и автоматизации применения патчей — теперь они тратят на эти операции вдвое меньше усилий. Банк Societe General использует новую возможность Enterprise Manager, тонкое клонирование, для создания тонких клонов тестовых баз данных и экономит при этом 90 % времени и дискового пространства. В Allied Irish Banks используется Replication Application Testing для тестирования инфраструктурных изменений базы данных, благодаря чему на 25 % сократились затраты усилий на тестирование.
Oracle Enterprise Manager используется и для управления самим публичным облаком Oracle. Например, на самом крупном сайте Cloud Public Oracle он управляет 2,5 млн единиц мониторинга, контролируя более 25 тыс. экземпляров сервисов, и каждый день обрабатывает 3,4 млн событий, выполняет 2 млн заданий, 11 млн тестовых транзакций.
Enterprise Manager 13c предоставляет единый интерфейс для управления как публичным, так и частным облаком. Enterprise Manager позволяет легко переносить нагрузки баз данных из ЦОДа в публичное облако Oracle и обратно.
Предоставляя доступ к ПО и инфраструктуре по требованию в режиме самообслуживания с возможностью масштабирования и учёта потребления ресурсов, Enterprise Manager обеспечивает следующие преимущества.
- Повышение качества обслуживания. ИТ-организации стремятся не только сократить затраты, но и найти решения, позволяющие повысить производительность, доступность и безопасность. Облачные клиенты получают естественные преимущества от средств высокой доступности, встроенных в облако.
- Гибкость использования ресурсов. Возможность увеличивать и уменьшать вычислительную мощность базы данных делает приложения гибкими и легко адаптируемыми к меняющимся рабочим нагрузкам.
- Ускоренное предоставление баз данных. Базы данных в облаке могут предоставляться очень быстро. Это сокращает общее время развертывания производственных приложений и платформ для разработки и ускоряет создание тестовых конфигураций.
- Возможность количественно измерять использование ресурсов базы данных в облаке для составления бюджета, планирования и распределения административных ресурсов в зависимости от использования ресурсов.
Кроме того, решение автоматизирует патчирование всех компонентов программно-аппаратного комплексов Oracle Engineered Systems, а инструментарий управления комплаенсом поддерживает STIG стандарт и предлагает единое окно управления комплаенсом для локальных и облачных компонентов, которое позволяет настраивать и проверять правила комплаенса в режиме реального времени.
В числе новых возможностей Oracle Enterprise Manager 13c управление дрейфом конфигураций, т. е. отслеживание изменения динамичных конфигураций любого масштаба — при этом источник для сравнения может быть как «живым» объектом, так и сохраненной базисной конфигурацией.
Непрерывный (“always on”) мониторинг позволяет получать по e-mail уведомления о критически важных событиях даже во время плановых простоях управляющего сервера Enterprise Manager.
Большое количество агентов Enterprise Manager стало проще разворачивать и обновлять с помощью “золотых образов”.
Крайне важна для корпоративных заказчиков возможность управления промежуточным программным обеспечением. Oracle Enterprise Manager поддерживает мультиарендность WebLogic 12.2, имеет встроенные возможности WebLogic Admin Console (Change Center, запись WLST скриптов, управление JDBC Data Source, конфигурирование домена, кластера, сервера, возможности аудита) и улучшенную функциональность диагностики — Java Workload Explorer для глубокой диагностики JVM и Middleware Diagnostics Advisor для обнаружения известных проблем, включая утечки памяти, зависшие потоки, JDBC/JMS проблемы и т. д.
Заказчики Oracle высоко оценивают возможности нового решения. Так, Наото Касиваги (Naoto Kashiwagi), руководитель команды промежуточного ПО и облачных технологий NEC Japan, и Йоки Морияма (Yoki Moriyama), заместитель генерального директора компании, говорят: «Enterprise Manager является мощным средством для управления нашими большими системами, которые обслуживают большие сделки. Мы используем Enterprise Manager для управления сотнями объектов настолько важных, что мы не можем позволить себе пропустить ни одного предупреждения, и мы должны эффективно обслуживать эти системы без ошибок».
Борис Пищик, ведущий консультант департамента технологического консалтинга Oracle СНГ, рассказал об облачной платформе Oracle для ИТ-мониторинга — Oracle Management Cloud.
- Мониторинг на уровне конечных пользователей веб-приложений и компонентов инфраструктуры как локальных так облачных.
- Поддержка планирования мощностей и ресурсов.
- Широкий охват для анализа метрик и событий.
- Сбор журналов, поиск, агрегирование, понимание топологии.
- Автоматизированное выявление аномалий.
- Удобный пользовательский интерфейс, панели управления.
Application Performance Monitoring обеспечивает диагностику на различных уровнях: от уровня конечного пользователя до журналов инфраструктуры. Сервис ведет постоянный мониторинг приложений для выявления проблем, своевременно предупреждает о проблемах, которые могут повлиять на работу пользователей, и предлагает удобные средства поиска первопричин возникновения проблем. Функциональность предлагает единый интерфейс для эксплуатации ИТ и разработчиков и обеспечивает проактивный мониторинг опыта конечных пользователей, который достигается постоянным контролем производительности веб-страниц и AJAX, регулярными замерами производительности запросов и возможностью сопоставления проблем пользователей с «узкими местами» в производительности инфраструктуры.
Log Analytics — это новый облачный сервис, предназначенный для консолидации журнальных файлов из разных источников. Log Analytics обеспечивает мониторинг, агрегирование, индексирование, анализ, поиск и корреляцию всех журнальных данных от приложений и компонентов инфраструктуры (локальной и облачной) в реальном масштабе времени. Для анализа журналов применяются машинные алгоритмы, позволяющие распознавать и группировать записи, основанные на общих шаблонах, и быстро находить первопричины проблем.
Инструментарий IT Analytics позволяет определять закономерности функционирования текущего ИТ-ландшафта, выявлять проблемные участки и эффективно планировать мощности. Его главные задачи: анализ ресурсов (выявление неравномерной нагрузки, анализ потребления ресурсов в разных разрезах и по различным периодам) и планирование их роста, анализ производительности с использованием встроенных средств аналитики для выявления «узких мест», ресурсоемких SQL-запросов и т. п., визуализация картины производительности по типам ресурсов и по ключевым индикаторам.
Результатом внедрения Oracle Management Cloud становится повышение качества сопровождения и эксплуатации. Также, заказчик не должен делать капиталовложения в поддержку и администрирование данных сервисов, с появлением Oracle Management Cloud это больше не его ответственность.
- Быстрое развертывание новых баз данных.
- Клонирование больших баз данных.
- Снижение рутинной нагрузки, автоматизация и ускорение работы облачных баз данных.
- Стандартизация.
- Консолидация.
- Детальный учет использования вычислительных ресурсов.
- Более эффективное использование вычислительных ресурсов (включая диски).
- Повышение надежности работы существующих баз данных.
- Построение гибкой, легко наращиваемой ИТ-инфраструктуры.

Подход Oracle основан на понятии гибридного облака — объединении частного и публичного облаков, в котором реализовано перекрестное контролируемое использование данных и приложений между ними. Гибридное облако очень удобно для разработки и тестирования, интеграции B2B-решений, внедрения требовательных к ИТ-ресурсам продуктов, пробной эксплуатации новых продуктов.

Компания Oracle реализует и предоставляет на выбор своим клиентам все облачные модели — публичное, частное и гибридное облако (Рис. 5). С одной стороны, предлагаются продукты, на базе которых можно развернуть Oracle-системы в ЦОДе, превратив их в частное облако. С другой стороны, во всем мире есть центры обработки данных Oracle, которые предоставляют услуги публичного облака. Продукт Oracle Enterprise Manager позволяет связать оба подхода, связать одно облако с другим и управлять ими при помощи единого интерфейса.
Наиболее популярными сейчас и в мире, и в России облачными сервисами Oracle являются платформенные сервисы — база данных как сервис и сервер приложений как сервис.
Два главных способа предоставления услуги «база данных как сервис», т. е. Oracle PaaS (DBaaS), таковы: клиенты работают либо с виртуальными машинами Oracle VM, либо с серверами Exadata. Если клиенты работают традиционными виртуальными машинами, для них существует несколько преднастроенных размеров виртуальных машин, которые характеризуются определенным количеством процессоров и объемом памяти. Решение на основе серверов Exadata предназначено для клиентов с очень большими требованиями к объему и производительности баз данных. Кроме того, оно дает возможность использования ячеек Exadata для высоких нагрузок.
База данных по требованию заказывается с портала самообслуживания в необходимой версии, конфигурации и с требуемой степенью консолидации (Рис. 6). Для создания облака Oracle требуется только Enterprise Manager. Нового оборудования, новых настроек, нового подхода к системе управления доступом или к рабочим станциям не требуется. Enterprise Manager настраивается на пулы баз данных DBaaS, пулы WebLogic или пулы виртуализации. Затем частное облако Oracle можно использовать для подключения к внешним системам.

Быстрое развертывание новых баз данных возможно благодаря удобному порталу самообслуживания и каталогу шаблонов, который хранит набор процедур развертывания в виде шаблонов сервисов и предлагает разные варианты шаблонов, для разных версий СУБД, конфигураций и т. д. Процедура Database Provisioning позволяет захватывать конфигурации баз данных и сохранять процедуры развертывания для последующего использования.
Новая процедура клонирования баз данных Snap Clone использует передовые возможности систем хранения и может быть реализована как аппаратными, так и програмными средствами. И если на традиционное клонирование базы данных уходит в среднем полторы недели, то решение, выполняющее автоматизированное клонирование, позволяет получать базы данных объемом в несколько терабайт в течение часа.
Для управления гибридным облаком Enterprise Manager версий 12c R5 и 13c содержит Hybrid Agent, который нужно установить в облачный сервис. После установки Hybrid Agent начнет взаимодействовать с Enterprise Manager, передавая информацию об облачной системе.
Процитированные доклады далеко не исчерпывают всю тематику очередного технологического форума Oracle Database 12c. Мы хотим закончить этот обзор напоминанием, которое сделал в своем докладе Прабакер Гонглур — о том, что многие ИТ-департаменты уже сейчас строят комбинированную инфраструктуру, используя как частные, так и публичные облака, и уже сейчас понимают, что они обязаны управлять ресурсами — где бы те ни находились. Поэтому они пытаются строить собственные частные облака в соответствии с аналогичными архитектурными и эксплуатационными требованиями — или доверяют тем поставщикам облачных ресурсов, которые соответствуют требованиям масштабируемости, производительности, мониторинга, безопасности и регламентов. Положительный опыт компаний, ставших клиентами Oracle Cloud, говорит о том, что они правильно выбрали поставщика.
SQL statistics

Раздел содержит несколько таблиц со статистикой по SQL-запросам, отсортированным по определенному критерию.
Подробнее про оптимизацию запросов и примеры типичных проблем в запросах можно почитать в статье Проактивная оптимизация производительности БД Oracle.
| № | Параметр | Описание |
|---|---|---|
| 1 | SQL ordered by Elapsed Time | Топ SQL-запросов по затраченному времени на их выполнение |
| 2 | SQL ordered by CPU Time | Топ SQL-запросов по процессорному времени |
| 3 | SQL ordered by User I/O Wait Time | Топ SQL-запросов по времени ожидания ввода/вывода для пользователя |
| 4 | SQL ordered by Gets | Запросы к БД, упорядоченные по убыванию логических операций ввода/вывода. При анализе стоит учитывать, что для PL/SQL-процедур их количество прочитанных Buffer Gets будет состоять из суммы всех запросов в рамках этой процедуры |
| 5 | SQL ordered by Reads | Этот раздел схож с предыдущим: в нем указываются все операции ввода/вывода, наиболее активно физически считывающие данные с жесткого диска. Именно на эти запросы и процессы надо обратить внимание, если система не справляется с объемом ввода/вывода |
| 6 | SQL ordered by Physical Reads (UnOptimized) | В этом разделе выводятся неоптимизированные запросы. В Oracle неоптимизированными считаются все запросы, которые не обслуживаются DSFC или Exadata Cell Smart Flash Cache (ECSFC) |
| 7 | SQL ordered by Executions | Наиболее часто выполняемые запросы |
| 8 | SQL ordered by Parse Calls | Отображает количество попыток разбора SQL-запросов до его выполнения |
| 9 | SQL ordered by Sharable Memory | Запросы, занимающие больший объем памяти общего пула SGA |
| 10 | SQL ordered by Version Count | Здесь показано количество SQL-операторов экземпляров одного и того же оператора в разделяемом пуле |
| 11 | Complete List of SQL Text | Показывает полный SQL-запрос, не только его хэш. В этой таблице можно найти неоптимальные запросы (например, запросы по всем столбцам таблицы «select * from. », запросы с большим количеством «like» и т. п.) |
Читайте также: