
Может ли обучить современный компьютер идентифицировать определенный объект на фотографии
Про нейронные сети, как один из инструментов решения трудноформализуемых задач уже было сказано достаточно много. И здесь, на хабре, было показано, как эти сети применять для распознавания изображений, применительно к задаче взлома капчи. Однако, типов нейросетей существует довольно много. И так ли хороша классическая полносвязная нейронная сеть (ПНС) для задачи распознавания (классификации) изображений?
1. Задача
- Для распознавания рукописного символа довольно трудно составить формализованный (не интеллектуальный) алгоритм и это становится понятно, стоит только взглянуть на одну и туже цифру написанную разными людьми
- Задача довольно актуальна и имеет отношение к OCR (optical character recognition)
- Существует свободно распространяемая база рукописных символов, доступная для скачивания и экспериментов
- Существует довольно много статей на эту тему и можно очень легко и удобно сравнить различные подходы
2. «Обычные» нейросети.

Большинство людей под «обычными» или «классическими» нейросетями понимает полносвязные нейронные сети прямого распространения с обратным распространением ошибки:
Как следует из названия в такой сети каждый нейрон связан с каждым, сигнал идет только в направлении от входного слоя к выходному, нет никаких рекурсий. Будем называть такую сеть сокращенно ПНС.
Сперва необходимо решить как подавать данные на вход. Самое простое и почти безальтернативное решение для ПНС — это выразить двумерную матрицу изображения в виде одномерного вектора. Т.е. для изображения рукописной цифры размером 28х28 у нас будет 784 входа, что уже не мало. Дальше происходит то, за что нейросетевиков и их методы многие консервативные ученые не любят — выбор архитектуры. А не любят, поскольку выбор архитектуры это чистое шаманство. До сих пор не существует методов, позволяющих однозначно определить структуру и состав нейросети исходя из описания задачи. В защиту скажу, что для трудноформализуемых задач вряд ли когда-либо такой метод будет создан. Кроме того существует множество различных методик редукции сети (например OBD [1]), а также разные эвристики и эмпирические правила. Одно из таких правил гласит, что количество нейронов в скрытом слое должно быть хотя бы на порядок больше количества входов. Если принять во внимание что само по себе преобразование из изображения в индикатор класса довольно сложное и существенно нелинейное, одним слоем тут не обойтись. Исходя из всего вышесказанного грубо прикидываем, что количество нейронов в скрытых слоях у нас будет порядка 15000 (10 000 во 2-м слое и 5000 в третьем). При этом для конфигурации с двумя скрытыми слоями количество настраиваемых и обучаемых связей будет 10 млн. между входами и первым скрытым слоем + 50 млн. между первым и вторым + 50 тыс. между вторым и выходным, если считать что у нас 10 выходов, каждый из которых обозначает цифру от 0 до 9. Итого грубо 60 000 000 связей. Я не зря упомянул, что они настраиваемые — это значит, что при обучении для каждой из них нужно будет вычислять градиент ошибки.
Ну это ладно, что уж тут поделаешь, красота искусственный интеллект требует жертв. Но вот если задуматься, на ум приходит, что когда мы преобразуем изображение в линейную цепочку байт, мы что-то безвозвратно теряем. Причем с каждым слоем эта потеря только усугубляется. Так и есть — мы теряем топологию изображения, т.е. взаимосвязь между отдельными его частями. Кроме того задача распозравания подразумевает умение нейросети быть устойчивой к небольшим сдвигам, поворотам и изменению масштаба изображения, т.е. она должна извлекать из данных некие инварианты, не зависящие от почерка того или иного человека. Так какой же должна быть нейросеть, чтобы быть не очень вычислительно сложной и, в тоже время, более инвариантной к различным искажениям изображений?
3. Сверточные нейронные сети
- Локальное восприятие.
- Разделяемые веса.
- Субдискретизация.
4. Обучение
Для того чтобы можно было начать обучение нашей сети нужно определиться с тем, как измерять качество распознавания. В нашем случае для этого будем использовать самую распространенную в теории нейронных сетей функцию среднеквадратической ошибки (СКО, MSE) [3]:
В этой формуле Ep — это ошибка распознавания для p-ой обучающей пары, Dp — желаемый выход сети, O(Ip,W) — выход сети, зависящий от p-го входа и весовых коэффициентов W, куда входят ядра свертки, смещения, весовые коэффициенты S- и F- слоев. Задача обучения так настроить веса W, чтобы они для любой обучающей пары (Ip,Dp) давали минимальную ошибку Ep. Чтобы посчитать ошибку для всей обучающей выборки просто берется среднее арифметическое по ошибкам для всех обучающих пар. Такую усредненную ошибку обозначим как E.
Для минимизации функции ошибки Ep самыми эффективными являются градиентные методы. Рассмотрим суть градиентных методов на примере простейшего одномерного случая (т.е. когда у нас всего один вес). Если мы разложим в ряд Тейлора функцию ошибки Ep, то получим следующее выражение:
Здесь E — все та же функция ошибки, Wc — некоторое начальное значение веса. Из школьной математики мы помним, что для нахождения экстремума функции необходимо взять ее производную и приравнять нулю. Так и поступим, возьмем производную функции ошибки по весам, отбросив члены выше 2го порядка:
из этого выражения следует, что вес, при котором значение функции ошибки будет минимальным можно вычислить из следующего выражения:
Т.е. оптимальный вес вычисляется как текущий минус производная функции ошибки по весу, деленная на вторую производную функции ошибки. Для многомерного случая (т.е. для матрицы весов) все точно также, только первая производная превращается в градиент (вектор частных производных), а вторая производная превращается в Гессиан (матрицу вторых частных производных). И здесь возможно два варианта. Если мы опустим вторую производную, то получим алгоритм наискорейшего градиентного спуска. Если все же захотим учитывать вторую производную, то обалдеем от того сколько вычислительных ресурсов нам потребуется, чтобы посчитать полный Гессиан, а потом еще и обратить его. Поэтому обычно Гессиан заменяют чем-то более простым. Например, один из самых известных и успешных методов — метод Левенберга-Марквардта (ЛМ) заменяет Гессиан, его аппроксимацией с помощью квадрадного Якобиана. Подробности здесь рассказывать не буду.
Но что нам важно знать об этих двух методах, так это то, что алгоритм ЛМ требует обработки всей обучающей выборки, тогда как алгоритм градиентного спуска может работать с каждой отдельно взятой обучающей выборкой. В последнем случае алгоритм называют стохастическим градиентом. Учитывая, что наша база содержит 60 000 обучающих образцов нам больше подходит стохастический градиент. Еще одним преимуществом стохастического градиента является его меньшая подверженность попаданию в локальный минимум по сравнению с ЛМ.
Существует также стохастическая модификация алгоритма ЛМ, о которой я, возможно, упомяну позже.
Представленные формулы позволяют легко вычислить производную ошибки по весам, находящимся в выходном слое. Вычислить ошибку в скрытых слоях позволяет широко известный в ИИ метод обратного распространения ошибки.
5. Реализация
6. Результаты
В программе на matlabcentral прилагается файл уже натренированной нейросети, а также GUI для демонстрации результатов работы. Ниже приведены примеры распознавания:
По ссылке имеется таблица сравнения методов распознавания на базе MNIST. Первое место за сверточными нейросетями с результатом 0.39% ошибок распознавания [4]. Большинство из этих ошибочно распознанных изображений не каждый человек правильно распознает. Кроме того в работе [4] были использованы эластические искажения входных изображений, а также предварительное обучение без учителя. Но об этих методах как нибудь в другой статье.
Ссылки.
- Yann LeCun, J. S. Denker, S. Solla, R. E. Howard and L. D. Jackel: Optimal Brain Damage, in Touretzky, David (Eds), Advances in Neural Information Processing Systems 2 (NIPS*89), Morgan Kaufman, Denver, CO, 1990
- Y. LeCun and Y. Bengio: Convolutional Networks for Images, Speech, and Time-Series, in Arbib, M. A. (Eds), The Handbook of Brain Theory and Neural Networks, MIT Press, 1995
- Y. LeCun, L. Bottou, G. Orr and K. Muller: Efficient BackProp, in Orr, G. and Muller K. (Eds), Neural Networks: Tricks of the trade, Springer, 1998
- Ranzato Marc'Aurelio, Christopher Poultney, Sumit Chopra and Yann LeCun: Efficient Learning of Sparse Representations with an Energy-Based Model, in J. Platt et al. (Eds), Advances in Neural Information Processing Systems (NIPS 2006), MIT Press, 2006
P.S. Всем спасибо за комментарии и за отзывы. Это моя первая статья на хабре, так что буду рад видеть предложения, замечания, дополнения.
Мультиканальное вовлечение граждан
Повсеместное использование аналитики
Создание множества независимых систем по учету трудовых ресурсов в каждом регионе
Цифровая идентификация граждан +
Мультиканальное вовлечение граждан
Рабочая сила в цифровом формате
Уменьшение количества использования аналитических отчетах на всех этапах государственного управления
Цифровая идентификация граждан +
Мультиканальное вовлечение граждан
Повсеместное использование аналитики
Рабочая сила в цифровом формате
Создание неизменяющегося подхода для противодействия киберугрозам
Цифровая идентификация граждан +
Всё из перечисленного +
История в медицинской карточке +
Стоимость биржевых инструментов +
Обновить техническое обеспечение компании, используя самую современную технику
Обучить всех сотрудников использовать Excel для обработки данных
Обучить всех сотрудников языкам программирования, способных запускать нейронные сети
Сильная внутренняя экспертиза команды в области подхода управления с помощью данных +
Хранить данные в бумажном виде в архиве
Обновить техническое обеспечение компании, используя самую современную технику
Обучить всех сотрудников использовать Excel для обработки данных
Обучить всех сотрудников языкам программирования, способных запускать нейронные сети
Понимать, какой информацией располагает компания, а чего не хватает +
Хранить данные в бумажном виде в архиве
Обновить техническое обеспечение компании, используя самую современную технику
Обучить всех сотрудников использовать Excel для обработки данных
Обучить всех сотрудников языкам программирования, способных запускать нейронные сети
Определить методы сбора, анализа и интерпретации результатов +
Хранить данные в бумажном виде в архиве
Достаточные знания и компетенции
Профицит квалифицированных кадров
Дефицит квалифицированных кадров +
Достаточные знания и компетенции
Достаточные знания и компетенции
Профицит квалифицированных кадров
Задачи цифровой трансформации общества
Социально значимые задачи +
Основной независимый ресурс наборов открытых государственных данных, на котором собраны и структурированы существующие на сегодня в России наборы данных.+
Открытый ресурс, в который выгружают персональные данные граждан с целью продажи и передачи третьим лицам
В терминологии специалистов – историческое событие, после которого было открыто, что можно использовать данные в управлении процессами (продажи, менеджмент и т.д.)
Аналитическая панель, наглядное представление информации о бизнес-процессах, трендах, зависимостях и других метриках в компактном виде, которое позволяет увидеть значения конкретных показателей и динамику их изменений
Способ защиты данных с помощью визуальных решений
Создание информационных систем, создание отчетов, обеспечение финансирования
Накопление данных, анализ данных, первичную обработку данных
Поиск источников данных, извлечение данных, преобразование данных +
Постановку и решение задач, построение графиков, визуализацию
Поиск аномалий, классификацию, восстановление регрессии
Математическая модель, построенная по принципу сигнальной системы живых организмов.
Приложения, помогающие обучаться, создавать образы и обобщать информацию.
Математическая модель, построенная по принципу организации колоний общественных насекомых.
Всемирная система объединённых компьютерных сетей для хранения, обработки и передачи информации
Математическая модель, а также её программное или аппаратное воплощение, построенная по принципу организации и функционирования биологических нейронных сетей — сетей нервных клеток живого организма. +
Мобильные приложения крупных компаний
Платформы, которые охватывают все сферы жизни человека и помогают ему получать услуги от бизнеса и государства дистанционно +
Сайты органов государственной власти
Сервисы, запущенные на современных суперкомпьютерах.
Платформы, построенные по принципу организации и функционирования биологических нейронных сетей — сетей нервных клеток живого организма.
Машинное обучение – одно из направлений Искусственного Интеллекта. Данное направление состоит из методов, которые позволяют делать выводы на основе данных.
Искусственный интеллект – одно из направлений Машинного Обучения. Данное направление занимается имитированием поведения человека.
Искусственный Интеллект и Машинное Обучение – это направления Глубокого обучения нейронных сетей.
Искусственный Интеллект – это алгоритмы, связанные с обучением цифровых нейронных сетей. Машинное обучение - это алгоритмы работы с табличными данными.
Искусственный Интеллект занимается задачами имитации деятельности мозга человека. Машинное обучение – это процесс, в ходе которого обучается Искусственный Интеллект. +
Давно хотел написать общую статью, содержащую в себе самые основы Image Recognition, некий гайд по базовым методам, рассказывающий, когда их применять, какие задачи они решают, что возможно сделать вечером на коленке, а о чём лучше и не думать, не имея команды человек в 20.

Какие-то статьи по Optical Recognition я пишу давненько, так что пару раз в месяц мне пишут различные люди с вопросами по этой тематике. Иногда создаётся ощущение, что живёшь с ними в разных мирах. С одной стороны понимаешь, что человек скорее всего профессионал в смежной теме, но в методах оптического распознавания знает очень мало. И самое обидное, что он пытается применить метод из близрасположенной области знаний, который логичен, но в Image Recognition полностью не работает, но не понимает этого и сильно обижается, если ему начать рассказывать что-нибудь с самых основ. А учитывая, что рассказывать с основ — много времени, которого часто нет, становится всё ещё печальнее.
Обратите внимание, статья 2014 года. А сейчас 2021. С тех пор произошло пару революций в ComputerVision. Делает ли это приведенные тут методы неправильными? Нет. Но, скорее всего это не то что вы хотите использовать в качестве первой линии. Что использовать сегодня? Сложно сказать, очень много вариаций. Если хотите оставаться в курсе событий — советую читать мой канал (vk, telegram) про более новые методы/подходы.
- При решении задачи всегда идти от простейшего. Гораздо проще повесить на персону метку оранжевого цвета, чем следить за человеком, выделяя его каскадами. Гораздо проще взять камеру с большим разрешением, чем разрабатывать сверхразрешающий алгоритм.
- Строгая постановка задачи в методах оптического распознавания на порядки важнее, чем в задачах системного программирования: одно лишнее слово в ТЗ может добавить 50% работы.
- В задачах распознавания нет универсальных решений. Нельзя сделать алгоритм, который будет просто «распознавать любую надпись». Табличка на улице и лист текста — это принципиально разные объекты. Наверное, можно сделать общий алгоритм(вот хороший пример от гугла), но это будет требовать огромного труда большой команды и состоять из десятков различных подпрограмм.
- OpenCV — это библия, в которой есть множество методов, и с помощью которой можно решить 50% от объёма почти любой задачи, но OpenCV — это лишь малая часть того, что в реальности можно сделать. В одном исследовании в выводах было написано: «Задача не решается методами OpenCV, следовательно, она неразрешима». Старайтесь избегать такого, не лениться и трезво оценивать текущую задачу каждый раз с нуля, не используя OpenCV-шаблоны.
Список приведённых тут методов не полон. Предлагаю в комментариях добавлять критические методы, которые я не написал и приписывать каждому по 2-3 сопроводительных слова.
Часть 1. Фильтрация
В эту группу я поместил методы, которые позволяют выделить на изображениях интересующие области, без их анализа. Большая часть этих методов применяет какое-то единое преобразование ко всем точкам изображения. На уровне фильтрации анализ изображения не производится, но точки, которые проходят фильтрацию, можно рассматривать как области с особыми характеристиками.
Бинаризация по порогу, выбор области гистограммы
Самое просто преобразование — это бинаризация изображения по порогу. Для RGB изображения и изображения в градациях серого порогом является значение цвета. Встречаются идеальные задачи, в которых такого преобразования достаточно. Предположим, нужно автоматически выделить предметы на белом листе бумаги:
Выбор порога, по которому происходит бинаризация, во многом определяет процесс самой бинаризации. В данном случае, изображение было бинаризовано по среднему цвету. Обычно бинаризация осуществляется с помощью алгоритма, который адаптивно выбирает порог. Таким алгоритмом может быть выбор матожидания или моды. А можно выбрать наибольший пик гистограммы.
Бинаризация может дать очень интересные результаты при работе с гистограммами, в том числе в ситуации, если мы рассматриваем изображение не в RGB, а в HSV . Например, сегментировать интересующие цвета. На этом принципе можно построить как детектор метки так и детектор кожи человека.
Классическая фильтрация: Фурье, ФНЧ, ФВЧ
Классические методы фильтрации из радиолокации и обработки сигналов можно с успехом применять во множестве задач Pattern Recognition. Традиционным методом в радиолокации, который почти не используется в изображениях в чистом виде, является преобразование Фурье (конкретнее — БПФ ). Одно из немногих исключение, при которых используется одномерное преобразование Фурье, — компрессия изображений. Для анализа изображений одномерного преобразования обычно не хватает, нужно использовать куда более ресурсоёмкое двумерное преобразование.
Мало кто его в действительности рассчитывает, обычно, куда быстрее и проще использовать свёртку интересующей области с уже готовым фильтром, заточенным на высокие (ФВЧ) или низкие(ФНЧ) частоты. Такой метод, конечно, не позволяет сделать анализ спектра, но в конкретной задаче видеообработки обычно нужен не анализ, а результат.
Самые простые примеры фильтров, реализующих подчёркивание низких частот (фильтр Гаусса) и высоких частот (Фильтр Габора).
Для каждой точки изображения выбирается окно и перемножается с фильтром того же размера. Результатом такой свёртки является новое значение точки. При реализации ФНЧ и ФВЧ получаются изображения такого типа:
Вейвлеты
Но что если использовать для свёртки с сигналом некую произвольную характеристическую функцию? Тогда это будет называться "Вейвлет-преобразование". Это определение вейвлетов не является корректным, но традиционно сложилось, что во многих командах вейвлет-анализом называется поиск произвольного паттерна на изображении при помощи свёртки с моделью этого паттерна. Существует набор классических функций, используемых в вейвлет-анализе. К ним относятся вейвлет Хаара, вейвлет Морле, вейвлет мексиканская шляпа, и.т.д. Примитивы Хаара, про которые было несколько моих прошлых статей (1, 2), относятся к таким функциям для двумерного пространства.
Выше приведено 4 примера классических вейвлетов. 3х-мерный вейвлет Хаара, 2х-мерные вейвлет Мейера, вейвлет Мексиканская Шляпа, вейвлет Добеши. Хорошим примером использования расширеной трактовки вейвлетов является задачка поиска блика в глазу, для которой вейвлетом является сам блик:
Классические вейвлеты обычно используются для сжатия изображений, или для их классификации (будет описано ниже).
Корреляция
После такой вольной трактовки вейвлетов с моей стороны стоит упомянуть собственно корреляцию, лежащую в их основе. При фильтрации изображений это незаменимый инструмент. Классическое применение — корреляция видеопотока для нахождения сдвигов или оптических потоков. Простейший детектор сдвига — тоже в каком-то смысле разностный коррелятор. Там где изображения не коррелируют — было движение.
Фильтрации функций

Интересным классом фильтров является фильтрация функций. Это чисто математические фильтры, которые позволяют обнаружить простую математическую функцию на изображении (прямую, параболу, круг). Строится аккумулирующее изображение, в котором для каждой точки исходного изображения отрисовывается множество функций, её порождающих. Наиболее классическим преобразованием является преобразование Хафа для прямых. В этом преобразовании для каждой точки (x;y) отрисовывается множество точек (a;b) прямой y=ax+b, для которых верно равенство. Получаются красивые картинки:
(первый плюсег тому, кто первый найдёт подвох в картинке и таком определении и объяснит его, второй плюсег тому, кто первый скажет что тут изображено)
Преобразование Хафа позволяет находить любые параметризуемые функции. Например окружности. Есть модифицированное преобразование, которое позволяет искать любые фигуры. Это преобразование ужасно любят математики. Но вот при обработке изображений, оно, к сожалению, работает далеко не всегда. Очень медленная скорость работы, очень высокая чувствительность к качеству бинаризации. Даже в идеальных ситуациях я предпочитал обходиться другими методами.
Аналогом преобразования Хафа для прямых является преобразование Радона . Оно вычисляется через БПФ, что даёт выигрыш производительности в ситуации, когда точек очень много. К тому же его возможно применять к не бинаризованному изображению.
Фильтрации контуров
Прочие фильтры

Сверху приведены фильтры, модификации которых помогают решить 80-90% задач. Но кроме них есть более редкие фильтры, используемые в локальных задачах. Таких фильтров десятки, я не буду приводить их все. Интересными являются итерационные фильтры (например активная модель внешнего вида), а так же риджлет и курвлет преобразования, являющиеся сплавом классической вейвлет фильтрации и анализом в поле радон-преобразования. Бимлет-преобразование красиво работает на границе вейвлет преобразования и логического анализа, позволяя выделить контуры:
Но эти преобразования весьма специфичны и заточены под редкие задачи.
Часть 2. Логическая обработка результатов фильтрации
Фильтрация даёт набор пригодных для обработки данных. Но зачастую нельзя просто взять и использовать эти данные без их обработки. В этом разделе будет несколько классических методов, позволяющих перейти от изображения к свойствам объектов, или к самим объектам.
Морфология

Переходом от фильтрации к логике, на мой взгляд, являются методы математической морфологии (1, 2 , 3). По сути, это простейшие операции наращивания и эрозии бинарных изображений. Эти методы позволяют убрать шумы из бинарного изображения, увеличив или уменьшив имеющиеся элементы. На базе математической морфологии существуют алгоритмы оконтуривания, но обычно пользуются какими-то гибридными алгоритмами или алгоритмами в связке.
Контурный анализ

В разделе по фильтрации уже упоминались алгоритмы получения границ. Полученные границы достаточно просто преобразуются в контуры. Для алгоритма Кэнни это происходит автоматически, для остальных алгоритмов требуется дополнительная бинаризация. Получить контур для бинарного алгоритма можно например алгоритмом жука.
Контур является уникальной характеристикой объекта. Часто это позволяет идентифицировать объект по контуру. Существует мощный математический аппарат, позволяющий это сделать. Аппарат называется контурным анализом (1, 2 ).
Если честно, то у меня ни разу ни получилось применить контурный анализ в реальных задачах. Уж слишком идеальные условия требуются. То граница не найдётся, то шумов слишком много. Но, если нужно что-то распознавать в идеальных условиях — то контурный анализ замечательный вариант. Очень быстро работает, красивая математика и понятная логика.
Особые точки
Особые точки это уникальные характеристики объекта, которые позволяют сопоставлять объект сам с собой или с похожими классами объектов. Существует несколько десятков способов позволяющих выделить такие точки. Некоторые способы выделяют особые точки в соседних кадрах, некоторые через большой промежуток времени и при смене освещения, некоторые позволяют найти особые точки, которые остаются таковыми даже при поворотах объекта. Начнём с методов, позволяющих найти особые точки, которые не такие стабильные, зато быстро рассчитываются, а потом пойдём по возрастанию сложности:
Первый класс. Особые точки, являющиеся стабильными на протяжении секунд. Такие точки служат для того, чтобы вести объект между соседними кадрами видео, или для сведения изображения с соседних камер. К таким точкам можно отнести локальные максимумы изображения, углы на изображении (лучший из детекторов, пожалуй, детектор Хариса), точки в которых достигается максимумы дисперсии, определённые градиенты и.т.д.
Второй класс. Особые точки, являющиеся стабильными при смене освещения и небольших движениях объекта. Такие точки служат в первую очередь для обучения и последующей классификации типов объектов. Например, классификатор пешехода или классификатор лица — это продукт системы, построенной именно на таких точках. Некоторые из ранее упомянутых вейвлетов могут являются базой для таких точек. Например, примитивы Хаара, поиск бликов, поиск прочих специфических функций. К таким точкам относятся точки, найденные методом гистограмм направленных градиентов (HOG).
Третий класс. Стабильные точки. Мне известно лишь про два метода, которые дают полную стабильность и про их модификации. Это SURF и SIFT. Они позволяют находить особые точки даже при повороте изображения. Расчёт таких точек осуществляется дольше по сравнению с остальными методами, но достаточно ограниченное время. К сожалению эти методы запатентованы. Хотя, в России патентовать алгоритмы низя, так что для внутреннего рынка пользуйтесь.
Часть 3. Обучение
ретья часть рассказа будет посвящена методам, которые не работают непосредственно с изображением, но которые позволяют принимать решения. В основном это различные методы машинного обучения и принятия решений. Недавно Яндыкс выложил на Хабр курс по этой тематике, там очень хорошая подборка. Вот тут оно есть в текстовой версии. Для серьёзного занятия тематикой настоятельно рекомендую посмотреть именно их. Тут я попробую обозначить несколько основных методов используемых именно в распознавании образов.
В 80% ситуаций суть обучения в задаче распознавания в следующем:
Имеется тестовая выборка, на которой есть несколько классов объектов. Пусть это будет наличие/отсутствие человека на фотографии. Для каждого изображения есть набор признаков, которые были выделены каким-нибудь признаком, будь то Хаар, HOG, SURF или какой-нибудь вейвлет. Алгоритм обучения должен построить такую модель, по которой он сумеет проанализировать новое изображение и принять решение, какой из объектов имеется на изображении.
Как это делается? Каждое из тестовых изображений — это точка в пространстве признаков. Её координаты это вес каждого из признаков на изображении. Пусть нашими признаками будут: «Наличие глаз», «Наличие носа», «Наличие двух рук», «Наличие ушей», и.т.д… Все эти признаки мы выделим существующими у нас детекторами, которые обучены на части тела, похожие на людские. Для человека в таком пространстве будет корректной точка [1;1;1;1;..]. Для обезьяны точка [1;0;1;0. ] для лошади [1;0;0;0. ]. Классификатор обучается по выборке примеров. Но не на всех фотографиях выделились руки, на других нет глаз, а на третьей у обезьяны из-за ошибки классификатора появился человеческий нос. Обучаемый классификатор человека автоматически разбивает пространство признаков таким образом, чтобы сказать: если первый признак лежит в диапазоне 0.5 По существу цель классификатора — отрисовать в пространстве признаков области, характеристические для объектов классификации. Вот так будет выглядеть последовательное приближение к ответу для одного из классификаторов (AdaBoost) в двумерном пространстве:
Существует очень много классификаторов. Каждый из них лучше работает в какой-то своей задачке. Задача подбора классификатора к конкретной задаче это во многом искусство. Вот тут немножко красивых картинок на тему.
Простой случай, одномерное разделение

Разберём на примере самый простой случай классификации, когда пространство признака одномерное, а нам нужно разделить 2 класса. Ситуация встречается чаще, чем может представиться: например, когда нужно отличить два сигнала, или сравнить паттерн с образцом. Пусть у нас есть обучающая выборка. При этом получается изображение, где по оси X будет мера похожести, а по оси Y -количество событий с такой мерой. Когда искомый объект похож на себя — получается левая гауссиана. Когда не похож — правая. Значение X=0.4 разделяет выборки так, что ошибочное решение минимизирует вероятность принятия любого неправильного решения. Именно поиском такого разделителя и является задача классификации.
Маленькая ремарка. Далеко не всегда оптимальным будет тот критерий, который минимизирует ошибку. Следующий график — это график реальной системы распознавания по радужной оболочке. Для такой системы критерий выбирается такой, чтобы минимизировать вероятность ложного пропуска постороннего человека на объект. Такая вероятность называется «ошибка первого рода», «вероятность ложной тревоги», «ложное срабатывание». В англоязычной литературе «False Access Rate ».
Что делать если измерений больше двух?
Алгоритмов много. Даже очень много. Если хотите подробно узнать про каждый из них читайте курс Воронцова, ссылка на который дана выше, и смотрите лекции Яндыкса. Сказать, какой из алгоритмов лучше для какой задачи часто заранее невозможно. Тут я попробую выделить основные, которые в 90% помогут новичку с первой задачей и реализацию которых на вашем языке программирования вы достоверно найдёте в интернете.
k-means (1, 2, 3 ) — один из самых простых алгоритмов обучения. Конечно, он в основном для кластеризации, но и обучить через него тоже можно. Работает в ситуации, когда группы объектов имеют неплохо разнесённый центр масс и не имеют большого пересечения.
AdaBoost (1, 2, 3) АдаБуста — один из самых распространённых классификаторов. Например каскад Хаара построен именно на нём. Обычно используют когда нужна бинарная классификация, но ничего не мешает обучить на большее количество классов.
SVM (1, 2, 3, 4 ) Один из самых мощных классификаторов, имеющий множество реализаций. В принципе, на задачах обучения, с которыми я сталкивался, он работал аналогично адабусте. Считается достаточно быстрым, но его обучение сложнее, чем у Адабусты и требуется выбор правильного ядра.
Ещё есть нейронные сети и регрессия. Но чтобы кратко их классифицировать и показать, чем они отличаются, нужна статья куда больше, чем эта.
________________________________________________
Надеюсь, у меня получилось сделать беглый обзор используемых методов без погружения в математику и описание. Может, кому-то это поможет. Хотя, конечно, статья неполна и нет ни слова ни о работе со стереоизображениями, ни о МНК с фильтром Калмана, ни об адаптивном байесовом подходе.
Если статья понравится, то попробую сделать вторую часть с подборкой примеров того, как решаются существующие задачки ImageRecognition.
И напоследок

Распознавание изображений (часть искусственного интеллекта (ИИ)) является еще одной популярной тенденцией, набирающей обороты в настоящее время – к 2021 году ожидается, что ее рынок достигнет почти 39 миллиарда долларов. Теперь пришло время присоединиться к тренду и узнать, что такое распознавание изображений и как оно работает.
Как работает распознавание изображений?
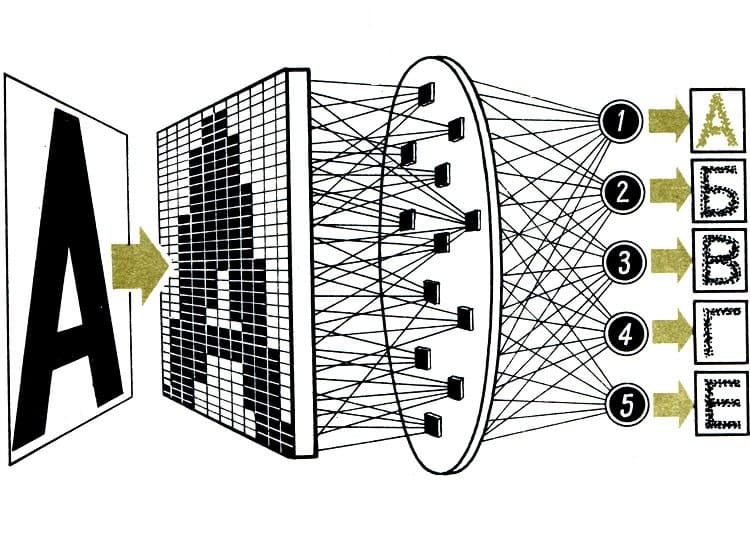
Теперь несколько слов о том, как работает распознавание изображений. Первым шагом здесь является сбор и организация данных. В отличие от людей, компьютеры воспринимают изображение как векторное или растровое изображение.

Поэтому после создания конструкций, изображающих объекты и особенности изображения, компьютер анализирует их. Затем данные упорядочиваются – важная информация извлекается, а ненужная исключается. Вторым этапом процесса распознавания изображений является построение прогнозирующей модели. Алгоритм классификации должен быть тщательно обучен, иначе он не сможет выполнять свои функции. Когда все сделано и протестировано, вы можете пользоваться функцией распознавания изображений.
Histogram of Oriented Gradients (HOG) или гистограмма направленного градиента
Алгоритм извлечения признаков преобразует изображение фиксированного размера в вектор признаков фиксированного размера. В случае обнаружения пешеходов дескриптор объекта HOG вычисляется для фрагмента изображения размером 64 \times 128 и возвращает вектор размером 3780 . Обратите внимание, что исходный размер этого фрагмента изображения был 64 \times 128 \times 3 = 24,576 , который сокращен до 3780 дескриптором HOG.
HOG основан на идее, что внешний вид локального объекта может быть эффективно описан распределением (гистограммой) направлений краев (направленных градиентов). Шаги по вычислению дескриптора HOG для изображения размером 64 × 128 перечислены ниже.
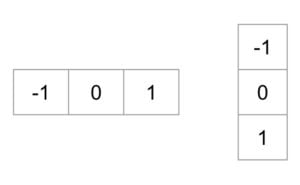
Расчет градиента: вычисление градиентов x и y изображений и, исходя из исходного изображения. Это можно сделать, отфильтровав исходное изображение следующими ядрами.
-
Используя изображения градиента и, можно вычислить величины g_x и g_y направления градиента, используя следующие уравнения:
Анатомия классификатора изображений

На следующей диаграмме показаны этапы работы традиционного классификатора изображений.
Интересно, что многие традиционные алгоритмы классификации изображений компьютерного зрения следуют этому конвейеру, в то время как алгоритмы, основанные на глубоком обучении, полностью обходят этап извлечения признаков. Давайте рассмотрим эти шаги более подробно.
Краткая история распознавания изображений и обнаружения объектов
Наша история начинается в 2001 году; В этом году Пол Виола и Майкл Джонс изобрели эффективный алгоритм распознавания лиц. Их демонстрация, показывающая, что лица обнаруживаются в реальном времени на веб-камере, была самой ошеломляющей демонстрацией компьютерного зрения и его потенциала на то время. Скоро, алгоритм был реализован в OpenCV એ , и метод Виолы — Джонса એ стал синонимом обнаружение лиц.
Каждые несколько лет появляется новая идея, которая заставляет людей делать паузу и принимать к сведению. В области обнаружения объектов эта идея появилась в 2005 году в статье Навнит Далала и Билла Триггса. Их дескриптор функции, гистограмма направленных градиентов એ (HOG), значительно превзошел существующие алгоритмы обнаружения пешеходов.

Примерно каждые десять лет появляется новая идея, настолько эффективная и мощная, что вы отказываетесь от всего, что было до нее, и всем сердцем принимаете новое. Глубокое обучение એ — идея этого десятилетия. Алгоритмы глубокого обучения существуют уже давно, но они стали мейнстримом в компьютерном зрении благодаря его оглушительному успеху на конкурсе ImageNet Large Scale Visual Recognition Challenge (ILSVRC) 2012 года. В этом конкурсе алгоритм, основанный на глубоком обучении Алекса Крижевского, Ильи Суцкевер,и Джеффри Хинтон потрясли мир компьютерного зрения с поразительной точностью 85% — на 11% лучше, чем алгоритм, занявший второе место! В ILSVRC 2012 это была единственная запись, основанная на глубоком обучении. В 2013, все победившие работы были основаны на глубоком обучении, и в 2015 году несколько алгоритмов под общим названием Свёрточная нейронная сеть એ (CNN) превзошли уровень естественного распознавания человеком 95%.
При таком огромном успехе в распознавании изображений обнаружение объектов на основе глубокого обучения было неизбежным. Такие методы, как Faster R-CNN, производят челюсти. Отбрасывание результатов по нескольким классам объектов. Мы узнаем об этом в следующих публикациях, но пока имейте в виду, что если вы не изучили алгоритмы распознавания изображений и обнаружения объектов на основе глубокого обучения для своих приложений, вы можете упустить огромную возможность получить лучшие результаты.
Теперь готовы вернуться к основной цели этого поста — разобраться в распознавании изображений с помощью традиционных методов компьютерного зрения.
Шаг 1: предварительная обработка
Часто входное изображение предварительно обрабатывается для нормализации эффектов контрастности и яркости. Очень распространенный этап предварительной обработки — вычесть среднее значение интенсивности изображения и разделить его на стандартное отклонение. Иногда гамма-коррекция дает немного лучшие результаты. При работе с цветными изображениями преобразование цветового пространства (например, цветовое пространство RGB в LAB) может помочь получить лучшие результаты.
Обратите внимание, что я не прописываю, какие шаги предварительной обработки являются хорошими. Причина в том, что никто заранее не знает, какой из этих шагов предварительной обработки даст хорошие результаты. Вы пробуете несколько разных, и некоторые из них могут дать немного лучшие результаты. Вот абзац из Далала и Триггса
Мы оценили несколько представлений входных пикселей, включая цветовые пространства в оттенках серого, RGB и LAB, опционально со степенным (гамма) выравниванием. Эти нормализации имеют лишь умеренное влияние на производительность, возможно, потому, что последующая нормализация дескриптора дает аналогичные результаты. Мы используем информацию о цвете, когда она доступна. Цветовые пространства RGB и LAB дают сравнимые результаты, но ограничение оттенками серого снижает производительность на 1,5% при 10–4 кадрах в секунду. Гамма-сжатие с квадратным корнем для каждого цветового канала улучшает производительность при низких значениях FPPW (на 1% при 10–4 кадрах в секунду), но логарифмическое сжатие слишком велико и ухудшает его на 2% при 10–4 кадрах в секунду.
Как вы видете, авторы не знали заранее, какую предварительную обработку использовать. Они делали разумные предположения и использовали метод проб и ошибок.
В рамках предварительной обработки входное изображение или фрагмент изображения также обрезаются и изменяются до фиксированного размера. Это важно, потому что следующий шаг, извлечение признаков, выполняется на изображении фиксированного размера.
Шаг 3: алгоритм классификации (подробнее)
В предыдущем разделе мы узнали, как преобразовать изображение в вектор признаков. В этом разделе мы узнаем, как алгоритм классификации принимает этот вектор признаков в качестве входных данных и выводит метку класса (например, кошка или фон).
Прежде чем алгоритм классификации сможет творить чудеса, нам нужно обучить его, показывая тысячи примеров кошек и фонов. Различные алгоритмы обучения работают по‑разному, но общий принцип заключается в том, что алгоритмы обучения рассматривают векторы признаков как точки в пространстве более высоких измерений, и попытайтесь найти плоскости/поверхности, которые разделяют пространство более высоких измерений таким образом, что все примеры, принадлежащие к тому же классу, находятся на одной стороне плоскости/поверхности.
Чтобы упростить задачу, давайте более подробно рассмотрим один алгоритм обучения, который называется Support Vector Machines (SVM) или метод опорных векторов એ . Как работает метод опорных векторов (SVM) для классификации изображений?
Метод опорных векторов — один из самых популярных алгоритмов контролируемой двоичной классификации. Хотя идеи, используемые в SVM, существуют с 1963 года, текущая версия была предложена в 1995 году Кортесом и Вапником.
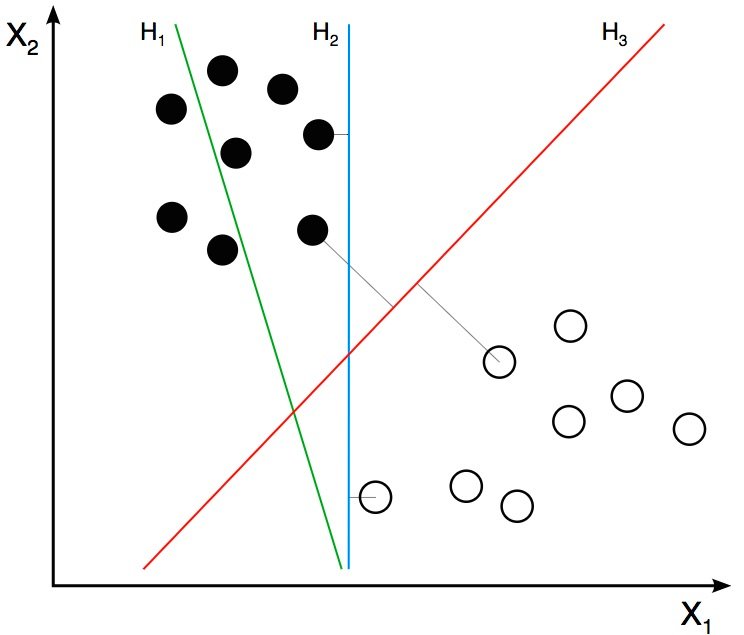
На предыдущем шаге мы узнали, что дескриптор HOG изображения является вектором признаков длиной 3 780. Мы можем думать об этом векторе как о точке в 3 780-мерном пространстве. Визуализировать пространство большого измерения невозможно, поэтому немного упростим ситуацию и представим, что вектор признаков был двухмерным.
В нашем упрощенном мире теперь у нас есть 2D-точки, представляющие два класса (например, кошки и фон). На изображении выше два класса представлены двумя разными типами точек. Все черные точки принадлежат одному классу, а белые точки — другому классу. Во время тренировки мы предоставляем алгоритм с множеством примеров из двух классов. Другими словами, мы сообщаем алгоритму координаты двумерных точек, а также то, какая точка — черная или белая.
Различные алгоритмы обучения выясняют, как по-разному разделить эти два класса. Линейная SVM пытается найти лучшую линию, разделяющую два класса. На рисунке выше H1, H2 и H3 — это три линии в этом двухмерном пространстве. H1 не разделяет два класса и поэтому не является хорошим классификатором. H2 и H3 разделяют два класса, но интуитивно кажется, что H3 — лучший классификатор, чем H2, потому что H3, кажется, разделяет два класса более четко. Почему? Потому что H2 находится слишком близко к некоторым черным и белым точкам. С другой стороны, H3 выбирается таким образом, чтобы он находился на максимальном расстоянии от членов двух классов.
Учитывая 2D-функции на рисунке выше, SVM найдет для вас линию H3. Если вы получите новый двумерный вектор признаков, соответствующий изображению, которого алгоритм никогда раньше не видел, то можете просто проверить, на какой стороне линии лежит точка, и присвоить ей соответствующую метку класса. Если ваши векторы признаков находятся в 3D, SVM найдет подходящую плоскость, которая максимально разделяет два класса. Как вы, возможно, догадались, если ваш вектор признаков находится в 3 780‑мерном пространстве, SVM найдет соответствующую гиперплоскость.
Оптимизация SVM
Пока все хорошо, но я знаю, что у вас есть один важный вопрос, на который нет ответа. Что, если объекты, принадлежащие двум классам, нельзя разделить с помощью гиперплоскости? В таких случаях, SVM по-прежнему находит лучшую гиперплоскость, решая задачу оптимизации, которая пытается увеличить расстояние гиперплоскости от двух классов, одновременно пытаясь обеспечить правильную классификацию многих обучающих примеров. Этот компромисс контролируется параметром C. Когда значение C мало, выбирается гиперплоскость с большим запасом за счет большего числа ошибочных классификаций. И наоборот, когда C велико, выбирается гиперплоскость меньшего поля, которая пытается правильно классифицировать гораздо больше примеров.
Теперь вы можете быть сбиты с толку, какое значение выбрать для C. Выберите то значение, которое лучше всего работает на тестовом наборе, которого не было в обучающей выборке.
4. Анализ изображения.

Вам нужно краткое изложение конкретного изображения? Используйте ИИ для анализа изображений. В результате все объекты изображения (формы, цвета и т. д.) будут проанализированы, и вы получите полезную информацию об изображении.

Начинаю серию уроков (мини-курс) о распознавании изображений и обнаружении объектов.
В первой части краткое объяснение понятий распознавание изображений с использованием традиционных методов компьютерного зрения. Я называю методы, не основанные на глубоком обучении, традиционными методами компьютерного зрения, потому что они быстро заменяются методами, основанными на глубоком обучении. Тем не менее, традиционные подходы к компьютерному зрению используются по-прежнему во многих приложениях. Многие из этих алгоритмов также доступны в библиотеках компьютерного зрения, таких как OpenCV એ , и очень хорошо работают «из коробки».
Мини-курс, который я пишу, будет состоять из 8 уроков по приблизительно следующей тематике:
- Распознавание изображений с использованием традиционных методов компьютерного зрения
- Обнаружение объектов с использованием традиционных методов компьютерного зрения
- Как обучить и протестировать собственный детектор объектов OpenCV
- Распознавание изображений с использованием глубокого обучения
Что такое распознавание изображений?
Как всегда, давайте начнем с основ. Прежде всего, вы должны помнить, что распознавание и обработка изображений не являются синонимами. Обработка изображения означает преобразование изображения в цифровую форму и выполнение определенных операций с ним. В результате можно извлечь некоторую информацию из такого изображения.
Этапы обработки изображений:
- Обработка цветного изображения – обработка цветов.
- Улучшение изображения – улучшение качества изображения и извлечение скрытых деталей.
- Восстановление изображения – очистка изображения от пятен и других неприятных вещей.
- Представление и описание – визуализация данных.
- Получение изображения – захват и конвертация изображения.
- Сжатие и распаковка изображений – изменение размера и разрешения изображения.
- Морфологическая обработка – описание структуры объектов изображения.
- Распознавание изображений – выявление особенностей объектов изображения.
Теперь вы видите, что распознавание изображений является одним из этапов обработки изображений. Те специфические особенности, которые были упомянуты, включают людей, места, здания, действия, логотипы и другие возможные переменные на изображениях. Следовательно, распознавание изображений – это процесс идентификации и обнаружения объекта в цифровом изображении и одно из применений компьютерного зрения. Иногда это также называют классификацией изображений, и это применяется в большом количестве отраслей.
1. Распознавание лиц.
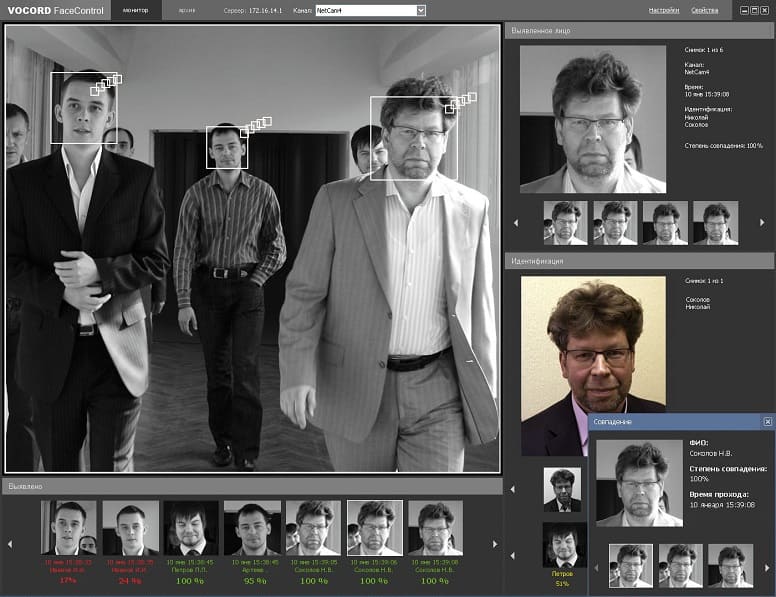
С помощью ИИ система распознавания лиц сопоставляет черты лица с изображения, а затем сравнивает эту информацию с базой данных, чтобы найти совпадение. Распознавание лиц используется производителями мобильных телефонов (как способ разблокировки смартфона), социальными сетями (распознавание людей на изображении, которое вы загружаете, и их пометка), и т.д. Тем не менее, такие системы вызывают много проблем конфиденциальности, так как иногда данные могут быть собраны без разрешения пользователя. Кроме того, даже самые передовые системы не могут гарантировать 100% точность. Что если система распознавания лиц смешивает случайного пользователя с преступником? Это не то, чего кто-то хочет, но это все еще возможно. Однако технологии постоянно развиваются поэтому однажды эта проблема может исчезнуть.
3. Распознавание образов.

Распознавание образов означает поиск и извлечение определенных рисунков в заданном изображении. Это могут быть текстуры, выражения лица и т.д.
2. Распознавание объектов.

Системы распознавания объектов выбирают и идентифицируют объекты из загруженных изображений (или видео). Визуальный поиск, вероятно, является наиболее популярным приложением этой технологии.
Шаг 2: извлечение признаков
Некоторыми хорошо известными функциями, используемыми в компьютерном зрении, являются функции типа Хаара, представленные Виолой и Джонсом, гистограмма направленных градиентов (HOG), Масштабно-инвариантная трансформация признаков એ Scale-Invariant Feature Transform (SIFT), ускорение надежного элемента Speeded Up Robust Feature (SURF) и т.д.
В качестве конкретного примера давайте посмотрим на извлечение признаков с помощью гистограммы ориентированных градиентов (HOG).
Как ИИ помогает распознавать изображения?
Искусственный интеллект делает возможными все функции распознавания изображений. Чтобы дать вам лучшее понимание, вот некоторые из них:
Распознавание изображений (также известное как классификация изображений)
Алгоритм распознавания изображений (также известный как классификатор изображений) принимает изображение (или фрагмент изображения) в качестве входных данных и выводит то, что содержит изображение. Другими словами, вывод — это метка класса (например, «кошка», «собака», «таблица» и т.д.). Как алгоритм распознавания изображений узнает содержимое изображения? Хорошо, вам нужно обучить алгоритм, чтобы узнать различия между разными классами. Если вы хотите найти кошек на изображениях, вам необходимо обучить алгоритм распознавания изображений с тысячами изображений кошек и тысячами изображений фона, которые не содержат кошек. Разумеется, подобный алгоритм может понимать только те объекты/классы, которые он знает.
Чтобы упростить задачу, в этом посте мы сосредоточимся только на двухклассовых (бинарных) классификаторах. Вы можете подумать, что это очень ограничивающее предположение, но имейте в виду, что многие популярные детекторы объектов (например, детектор лиц и детектор пешеходов) имеют под капотом бинарный классификатор. Например, внутри детектора лиц находится классификатор изображений, который сообщает, является ли участок изображения лицом или фоном.
Читайте также: