
Метод ворда кластерного анализа
Кластерный анализ
Термин кластерный анализ (впервые ввел Tryon, 1939) в действительности включает в себя набор различных алгоритмов классификации. Общий вопрос, задаваемый исследователями во многих областях, состоит в том, как организовать наблюдаемые данные в наглядные структуры, т.е. развернуть таксономии. Например, биологи ставят цель разбить животных на различные виды, чтобы содержательно описать различия между ними. В соответствии с современной системой, принятой в биологии, человек принадлежит к приматам, млекопитающим, амниотам, позвоночным и животным. Заметьте, что в этой классификации, чем выше уровень агрегации, тем меньше сходства между членами в соответствующем классе. Человек имеет больше сходства с другими приматами (т.е. с обезьянами), чем с "отдаленными" членами семейства млекопитающих (например, собаками) и т.д. В последующих разделах будут рассмотрены общие методы кластерного анализа, см. Объединение (древовидная кластеризация), Двувходовое объединение и Метод K средних.
Проверка статистической значимости
Заметим, что предыдущие рассуждения ссылаются на алгоритмы кластеризации, но ничего не упоминают о проверке статистической значимости. Фактически, кластерный анализ является не столько обычным статистическим методом, сколько "набором" различных алгоритмов "распределения объектов по кластерам". Существует точка зрения, что в отличие от многих других статистических процедур, методы кластерного анализа используются в большинстве случаев тогда, когда вы не имеете каких-либо априорных гипотез относительно классов, но все еще находитесь в описательной стадии исследования. Следует понимать, что кластерный анализ определяет "наиболее возможно значимое решение". Поэтому проверка статистической значимости в действительности здесь неприменима, даже в случаях, когда известны p-уровни (как, например, в методе K средних).
Техника кластеризации применяется в самых разнообразных областях. Хартиган (Hartigan, 1975) дал прекрасный обзор многих опубликованных исследований, содержащих результаты, полученные методами кластерного анализа. Например, в области медицины кластеризация заболеваний, лечения заболеваний или симптомов заболеваний приводит к широко используемым таксономиям. В области психиатрии правильная диагностика кластеров симптомов, таких как паранойя, шизофрения и т.д., является решающей для успешной терапии. В археологии с помощью кластерного анализа исследователи пытаются установить таксономии каменных орудий, похоронных объектов и т.д. Известны широкие применения кластерного анализа в маркетинговых исследованиях. В общем, всякий раз, когда необходимо классифицировать "горы" информации к пригодным для дальнейшей обработки группам, кластерный анализ оказывается весьма полезным и эффективным.
Приведенный в разделе Основная цель пример поясняет цель алгоритма объединения (древовидной кластеризации). Назначение этого алгоритма состоит в объединении объектов (например, животных) в достаточно большие кластеры, используя некоторую меру сходства или расстояние между объектами. Типичным результатом такой кластеризации является иерархическое дерево.
Рассмотрим горизонтальную древовидную диаграмму. Диаграмма начинается с каждого объекта в классе (в левой части диаграммы). Теперь представим себе, что постепенно (очень малыми шагами) вы "ослабляете" ваш критерий о том, какие объекты являются уникальными, а какие нет. Другими словами, вы понижаете порог, относящийся к решению об объединении двух или более объектов в один кластер.
В результате, вы связываете вместе всё большее и большее число объектов и агрегируете (объединяете) все больше и больше кластеров, состоящих из все сильнее различающихся элементов. Окончательно, на последнем шаге все объекты объединяются вместе. На этих диаграммах горизонтальные оси представляют расстояние объединения (в вертикальных древовидных диаграммах вертикальные оси представляют расстояние объединения). Так, для каждого узла в графе (там, где формируется новый кластер) вы можете видеть величину расстояния, для которого соответствующие элементы связываются в новый единственный кластер. Когда данные имеют ясную "структуру" в терминах кластеров объектов, сходных между собой, тогда эта структура, скорее всего, должна быть отражена в иерархическом дереве различными ветвями. В результате успешного анализа методом объединения появляется возможность обнаружить кластеры (ветви) и интерпретировать их.
Объединение или метод древовидной кластеризации используется при формировании кластеров несходства или расстояния между объектами. Эти расстояния могут определяться в одномерном или многомерном пространстве. Например, если вы должны кластеризовать типы еды в кафе, то можете принять во внимание количество содержащихся в ней калорий, цену, субъективную оценку вкуса и т.д. Наиболее прямой путь вычисления расстояний между объектами в многомерном пространстве состоит в вычислении евклидовых расстояний. Если вы имеете двух- или трёхмерное пространство, то эта мера является реальным геометрическим расстоянием между объектами в пространстве (как будто расстояния между объектами измерены рулеткой). Однако алгоритм объединения не "заботится" о том, являются ли "предоставленные" для этого расстояния настоящими или некоторыми другими производными мерами расстояния, что более значимо для исследователя; и задачей исследователей является подобрать правильный метод для специфических применений.
Евклидово расстояние. Это, по-видимому, наиболее общий тип расстояния. Оно попросту является геометрическим расстоянием в многомерном пространстве и вычисляется следующим образом:
Заметим, что евклидово расстояние (и его квадрат) вычисляется по исходным, а не по стандартизованным данным. Это обычный способ его вычисления, который имеет определенные преимущества (например, расстояние между двумя объектами не изменяется при введении в анализ нового объекта, который может оказаться выбросом). Тем не менее, на расстояния могут сильно влиять различия между осями, по координатам которых вычисляются эти расстояния. К примеру, если одна из осей измерена в сантиметрах, а вы потом переведете ее в миллиметры (умножая значения на 10), то окончательное евклидово расстояние (или квадрат евклидова расстояния), вычисляемое по координатам, сильно изменится, и, как следствие, результаты кластерного анализа могут сильно отличаться от предыдущих.
Квадрат евклидова расстояния. Иногда может возникнуть желание возвести в квадрат стандартное евклидово расстояние, чтобы придать большие веса более отдаленным друг от друга объектам. Это расстояние вычисляется следующим образом (см. также замечания в предыдущем пункте):
Расстояние городских кварталов (манхэттенское расстояние). Это расстояние является просто средним разностей по координатам. В большинстве случаев эта мера расстояния приводит к таким же результатам, как и для обычного расстояния Евклида. Однако отметим, что для этой меры влияние отдельных больших разностей (выбросов) уменьшается (так как они не возводятся в квадрат). Манхэттенское расстояние вычисляется по формуле:
Расстояние Чебышева. Это расстояние может оказаться полезным, когда желают определить два объекта как "различные", если они различаются по какой-либо одной координате (каким-либо одним измерением). Расстояние Чебышева вычисляется по формуле:
Степенное расстояние. Иногда желают прогрессивно увеличить или уменьшить вес, относящийся к размерности, для которой соответствующие объекты сильно отличаются. Это может быть достигнуто с использованием степенного расстояния. Степенное расстояние вычисляется по формуле:
где r и p - параметры, определяемые пользователем. Несколько примеров вычислений могут показать, как "работает" эта мера. Параметр p ответственен за постепенное взвешивание разностей по отдельным координатам, параметр r ответственен за прогрессивное взвешивание больших расстояний между объектами. Если оба параметра - r и p , равны двум, то это расстояние совпадает с расстоянием Евклида.
Процент несогласия. Эта мера используется в тех случаях, когда данные являются категориальными. Это расстояние вычисляется по формуле:
расстояние(x,y) = (Количество xi yi)/ i
Правила объединения или связи
На первом шаге, когда каждый объект представляет собой отдельный кластер, расстояния между этими объектами определяются выбранной мерой. Однако когда связываются вместе несколько объектов, возникает вопрос, как следует определить расстояния между кластерами? Другими словами, необходимо правило объединения или связи для двух кластеров. Здесь имеются различные возможности: например, вы можете связать два кластера вместе, когда любые два объекта в двух кластерах ближе друг к другу, чем соответствующее расстояние связи. Другими словами, вы используете "правило ближайшего соседа" для определения расстояния между кластерами; этот метод называется методом одиночной связи. Это правило строит "волокнистые" кластеры, т.е. кластеры, "сцепленные вместе" только отдельными элементами, случайно оказавшимися ближе остальных друг к другу. Как альтернативу вы можете использовать соседей в кластерах, которые находятся дальше всех остальных пар объектов друг от друга. Этот метод называется метод полной связи. Существует также множество других методов объединения кластеров, подобных тем, что были рассмотрены.
Одиночная связь (метод ближайшего соседа). Как было описано выше, в этом методе расстояние между двумя кластерами определяется расстоянием между двумя наиболее близкими объектами (ближайшими соседями) в различных кластерах. Это правило должно, в известном смысле, нанизывать объекты вместе для формирования кластеров, и результирующие кластеры имеют тенденцию быть представленными длинными "цепочками".
Полная связь (метод наиболее удаленных соседей). В этом методе расстояния между кластерами определяются наибольшим расстоянием между любыми двумя объектами в различных кластерах (т.е. "наиболее удаленными соседями"). Этот метод обычно работает очень хорошо, когда объекты происходят на самом деле из реально различных "рощ". Если же кластеры имеют в некотором роде удлиненную форму или их естественный тип является "цепочечным", то этот метод непригоден.
Невзвешенное попарное среднее. В этом методе расстояние между двумя различными кластерами вычисляется как среднее расстояние между всеми парами объектов в них. Метод эффективен, когда объекты в действительности формируют различные "рощи", однако он работает одинаково хорошо и в случаях протяженных ("цепочного" типа) кластеров. Отметим, что в своей книге Снит и Сокэл (Sneath, Sokal, 1973) вводят аббревиатуру UPGMA для ссылки на этот метод, как на метод невзвешенного попарного арифметического среднего - unweighted pair-group method using arithmetic averages.
Взвешенное попарное среднее. Метод идентичен методу невзвешенного попарного среднего, за исключением того, что при вычислениях размер соответствующих кластеров (т.е. число объектов, содержащихся в них) используется в качестве весового коэффициента. Поэтому предлагаемый метод должен быть использован (скорее даже, чем предыдущий), когда предполагаются неравные размеры кластеров. В книге Снита и Сокэла (Sneath, Sokal, 1973) вводится аббревиатура WPGMA для ссылки на этот метод, как на метод взвешенного попарного арифметического среднего - weighted pair-group method using arithmetic averages.
Невзвешенный центроидный метод. В этом методе расстояние между двумя кластерами определяется как расстояние между их центрами тяжести. Снит и Сокэл (Sneath and Sokal (1973)) используют аббревиатуру UPGMC для ссылки на этот метод, как на метод невзвешенного попарного центроидного усреднения - unweighted pair-group method using the centroid average.
Взвешенный центроидный метод (медиана). тот метод идентичен предыдущему, за исключением того, что при вычислениях используются веса для учёта разницы между размерами кластеров (т.е. числами объектов в них). Поэтому, если имеются (или подозреваются) значительные отличия в размерах кластеров, этот метод оказывается предпочтительнее предыдущего. Снит и Сокэл (Sneath, Sokal 1973) использовали аббревиатуру WPGMC для ссылок на него, как на метод невзвешенного попарного центроидного усреднения - weighted pair-group method using the centroid average.
Метод Варда. Этот метод отличается от всех других методов, поскольку он использует методы дисперсионного анализа для оценки расстояний между кластерами. Метод минимизирует сумму квадратов (SS) для любых двух (гипотетических) кластеров, которые могут быть сформированы на каждом шаге. Подробности можно найти в работе Варда (Ward, 1963). В целом метод представляется очень эффективным, однако он стремится создавать кластеры малого размера.
Для обзора других методов кластеризации, см. Двухвходовое объединение и Метод K средних.
Ранее этот метод обсуждался в терминах "объектов", которые должны быть кластеризованы (см. Объединение (древовидная кластеризация)). Во всех других видах анализа интересующий исследователя вопрос обычно выражается в терминах наблюдений или переменных. Оказывается, что кластеризация, как по наблюдениям, так и по переменным может привести к достаточно интересным результатам. Например, представьте, что медицинский исследователь собирает данные о различных характеристиках (переменные) состояний пациентов (наблюдений), страдающих сердечными заболеваниями. Исследователь может захотеть кластеризовать наблюдения (пациентов) для определения кластеров пациентов со сходными симптомами. В то же самое время исследователь может захотеть кластеризовать переменные для определения кластеров переменных, которые связаны со сходным физическим состоянием.
После этого обсуждения, относящегося к тому, кластеризовать наблюдения или переменные, можно задать вопрос, а почему бы не проводить кластеризацию в обоих направлениях? Модуль Кластерный анализ содержит эффективную двувходовую процедуру объединения, позволяющую сделать именно это. Однако двувходовое объединение используется (относительно редко) в обстоятельствах, когда ожидается, что и наблюдения и переменные одновременно вносят вклад в обнаружение осмысленных кластеров.
Так, возвращаясь к предыдущему примеру, можно предположить, что медицинскому исследователю требуется выделить кластеры пациентов, сходных по отношению к определенным кластерам характеристик физического состояния. Трудность с интерпретацией полученных результатов возникает вследствие того, что сходства между различными кластерами могут происходить из (или быть причиной) некоторого различия подмножеств переменных. Поэтому получающиеся кластеры являются по своей природе неоднородными. Возможно это кажется вначале немного туманным; в самом деле, в сравнении с другими описанными методами кластерного анализа (см. Объединение (древовидная кластеризация) и Метод K средних), двувходовое объединение является, вероятно, наименее часто используемым методом. Однако некоторые исследователи полагают, что он предлагает мощное средство разведочного анализа данных (за более подробной информацией вы можете обратиться к описанию этого метода у Хартигана (Hartigan, 1975)).
Этот метод кластеризации существенно отличается от таких агломеративных методов, как Объединение (древовидная кластеризация) и Двувходовое объединение. Предположим, вы уже имеете гипотезы относительно числа кластеров (по наблюдениям или по переменным). Вы можете указать системе образовать ровно три кластера так, чтобы они были настолько различны, насколько это возможно. Это именно тот тип задач, которые решает алгоритм метода K средних. В общем случае метод K средних строит ровно K различных кластеров, расположенных на возможно больших расстояниях друг от друга.
В примере с физическим состоянием (см. Двувходовое объединение), медицинский исследователь может иметь "подозрение" из своего клинического опыта, что его пациенты в основном попадают в три различные категории. Далее он может захотеть узнать, может ли его интуиция быть подтверждена численно, то есть, в самом ли деле кластерный анализ K средних даст три кластера пациентов, как ожидалось? Если это так, то средние различных мер физических параметров для каждого кластера будут давать количественный способ представления гипотез исследователя (например, пациенты в кластере 1 имеют высокий параметр 1, меньший параметр 2 и т.д.).
С вычислительной точки зрения вы можете рассматривать этот метод, как дисперсионный анализ (см. Дисперсионный анализ) "наоборот". Программа начинает с K случайно выбранных кластеров, а затем изменяет принадлежность объектов к ним, чтобы: (1) - минимизировать изменчивость внутри кластеров, и (2) - максимизировать изменчивость между кластерами. Данный способ аналогичен методу "дисперсионный анализ (ANOVA) наоборот" в том смысле, что критерий значимости в дисперсионном анализе сравнивает межгрупповую изменчивость с внутригрупповой при проверке гипотезы о том, что средние в группах отличаются друг от друга. В кластеризации методом K средних программа перемещает объекты (т.е. наблюдения) из одних групп (кластеров) в другие для того, чтобы получить наиболее значимый результат при проведении дисперсионного анализа (ANOVA).
Обычно, когда результаты кластерного анализа методом K средних получены, можно рассчитать средние для каждого кластера по каждому измерению, чтобы оценить, насколько кластеры различаются друг от друга. В идеале вы должны получить сильно различающиеся средние для большинства, если не для всех измерений, используемых в анализе. Значения F-статистики, полученные для каждого измерения, являются другим индикатором того, насколько хорошо соответствующее измерение дискриминирует кластеры.
Все права на материалы электронного учебника принадлежат компании StatSoft
История "кластерного анализа" и его терминология. Расстояние между объектами (метрика). Плотность и локальность кластеров. Особенности иерархических агломеративных методов и итерационных методов кластеризации. Устойчивость и качество кластеризации.
| Рубрика | Экономико-математическое моделирование |
| Вид | реферат |
| Язык | русский |
| Дата добавления | 07.11.2010 |
| Размер файла | 619,8 K |
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
СОДЕРЖАНИЕ
1.История «кластерного анализа»
2.1Объект и признак
2.2Расстояние между объектами (метрика)
2.3Плотность и локальность кластеров
2.4Расстояние между кластерами
3. Методы группировки
3.1Особенности иерархических агломеративных методов
3.2Особенности итерационных методов кластеризации
4. Кластеризация признаков
5. Устойчивость и качество кластеризации
Список используемой литературы
"Кластерный анализ - совокупность математических методов, предназначенных для формирования относительно "отдаленных" друг от друга групп "близких" между собой объектов по информации о расстояниях или связях (мерах близости) между ними. По смыслу аналогичен терминам: автоматическая классификация, таксономия, распознавание образов без учителя." Такое определение кластерного анализа дано в последнем издании "Статистического словаря". Фактически "кластерный анализ" - это обобщенное название достаточно большого набора алгоритмов, используемых при создании классификации. В ряде изданий используются и такие синонимы кластерного анализа, как классификация и разбиение. Кластерный анализ широко используется в науке как средство типологического анализа. В любой научной деятельности классификация является одной из фундаментальных составляющих, без которой невозможны построение и проверка научных гипотез и теорий. Таким образом, в своей работе своей основной целью я считаю необходимым рассмотреть вопросы кластерного анализа (основы кластерного анализа), а так же рассмотреть его терминологию и привести некоторые примеры использования данного метода с обработкой данных.
1. ИСТОРИЯ «КЛАСТЕРНОГО АНАЛИЗА»
Анализ отечественных и зарубежных публикаций показывает, что кластерный анализ находит применение в самых разнообразных научных направлениях: химия, биология, медицина, археология, история, география, экономика, филология и т.д. В книге В.В.Налимова "Вероятностная модель языка" описано применение кластерного анализа при исследовании 70 аналитических проб. Большая часть литературы по кластерному анализу появилась в течение последних трех десятилетий, хотя первые работы, в которых упоминались кластерные методы, появились достаточно давно. Польский антрополог К.Чекановский выдвинул идею "структурной классификации", содержавшую основную идею кластерного анализа - выделение компактных групп объектов.
В 1925 г. советский гидробиолог П.В. Терентьев разработал так называемый "метод корреляционных плеяд", предназначенный для группировки коррелирующих признаков. Этот метод дал толчок развитию методов группировки с помощью графов. Термин "кластерный анализ" впервые был предложен Трионом. Слово "cluster" переводится с английского языка как "гроздь, кисть, пучок, группа". По этой причине первоначальное время этот вид анализа называли "гроздевым анализом". В начале 50-х годов появились публикации Р.Люиса, Е.Фикса и Дж. Ходжеса по иерархическим алгоритмам кластерного анализа. Заметный толчок развитие работ по кластерному анализу дали работы Р.Розенблатта по распознающему устройству (персептрону), положившие начало развитию теории "распознавания образов без учителя".
Толчком к разработке методов кластеризации явилась книга "Принципы численной таксономии", опубликованная в 1963г. двумя биологами - Робертом Сокэлом и Питером Снитом. Авторы этой книги исходили из того, что для создания эффективных биологических классификаций процедура кластеризации должна обеспечивать использование всевозможных показателей характеризующих исследуемые организмы, производить оценку степени сходства между этими организмами и обеспечивать размещение схожих организмов в одну и ту же группу. При этом сформированные группы должны быть достаточно "локальны", т.е. сходство объектов (организмов) внутри групп должно превосходить сходство групп между собой. Последующий анализ выделенных группировок, по мнению авторов, может выяснить, отвечают ли эти группы разным биологическим видам. Так, Сокэл и Снит предполагали, что выявление структуры распределения объектов в группы, помогает установить процесс образования этих структур. А различие и сходство организмов разных кластеров (групп) могут служить базой для осмысления происходившего эволюционного процесса и выяснения его механизма.
В эти же годы было предложено множество алгоритмов таких авторов, как Дж. Мак-Кин, Г. Болл и Д. Холл по методам k-средних; Г. Ланса и У. Уильямса, Н. Джардайна и др. - по иерархическим методам. Заметный вклад в развитие методов кластерного анализа внесли и отечественные ученые - Э.М.Браверман, А.А.Дорофеюк, И.Б.Мучник, Л.А,Растригин, Ю.И.Журавлев, И.И.Елисеева и др. В частности, в 60-70 гг. большой популярностью пользовались многочисленные алгоритмы разработанные новосибирскими математиками Н.Г.Загоруйко, В.Н.Елкиной и Г.С.Лбовым. Это такие широко известные алгоритмы, как FOREL, BIGFOR, KRAB, NTTP, DRET, TRF и др. На основе этих пакетов был создан специализированный пакет программ ОТЭКС. Не менее интересные программные продукты ППСА и Класс-Мастер были созданы московскими математиками С.А.Айвазяном, И.С.Енюковым и Б.Г.Миркиным.
В том или ином объеме методы кластерного анализа имеются в большинстве наиболее известных отечественных и зарубежных статистических пакетах: SIGAMD, DataScope, STADIA, СОМИ, ПНП-БИМ, СОРРА-2, СИТО, SAS, SPSS, STATISTICA, BMDP, STATGRAPHICS, GENSTAT, S-PLUS и т.д. Конечно, спустя 10 лет после выхода этого обзора, изменилось достаточно много, появились новые версии многих статистических программ, появились и абсолютно новые программы, использующие как новые алгоритмы, так и сильно возросшие мощности вычислительной техники. Однако большинство статистических пакетов используют алгоритмы предложенные и разработанные в 60-70 гг.
По приблизительным оценкам специалистов число публикаций по кластерному анализу и его приложениям в различных областях знания удваивается каждые три года. Каковы же причины столь бурного интереса к этому виду анализа? Объективно существуют три основные причины этого явления. Это появление мощной вычислительной техники, без которой кластерный анализ реальных данных практически не реализуем. Вторая причина заключается в том, что современная наука все сильнее опирается в своих построениях на классификацию. Причем этот процесс все более углубляется, поскольку параллельно этому идет все большая специализация знания, которая невозможна без достаточно объективной классификации.
Третья причина - углубление специальных знаний неизбежно приводит к увеличению количества переменных, учитываемых при анализе тех или иных объектов и явлений. Вследствие этого субъективная классификация, которая ранее опиралась на достаточно малое количество учитываемых признаков, часто оказывается уже ненадежной. А объективная классификация, с все возрастающим набором характеристик объекта, требует использования сложных алгоритмов кластеризации, которые могут быть реализованы только на базе современных компьютеров. Именно эти причины и породили "кластерный бум". Однако, в среде медиков и биологов кластерный анализ еще не стал достаточно популярным и обыденным методом исследования.
2 ТЕРМИНОЛОГИЯ
2.1 ОБЪЕКТ И ПРИЗНАК
Введем первоначально такие понятия, как объект и признак. Объект - от латинского objectum - предмет. Применительно к химии и биологии под объектами мы будем подразумевать конкретные предметы исследования, которые изучаются с помощью физических, химических и иных методик. Такими объектами могут быть, например, пробы, растения, животные и т.д. Некоторую совокупность объектов, доступную исследователю для изучения,называют выборкой, или выборочной совокупностью. Количество объектов в такой совокупности принято называть объемом выборки. Обычно объем выборки обозначают латинской буквой "n" или "N" .
Признак (синонимы - свойство, переменная, характеристика; англ. - variable - переменная.) - представляет собой конкретное свойство объекта. Эти свойства могут выражаться как числовыми, так и не числовыми значениями. Например, артериальное давление (систолическое или диастолическое) измеряют в миллиметрах ртутного столба, вес - в килограммах, рост в сантиметрах и т.д. Такие признаки являются количественными. В отличие от этих непрерывных числовых характеристик (шкал), ряд признаков может иметь дискретные, прерывистые значения. В свою очередь такие дискретные признаки принято делить на две группы.
1) Первая группа - ранговые, или как их еще называют порядковые переменные (шкалы). Таким признакам присуще свойство упорядоченности этих значений. К ним можно отнести стадии того или иного заболевания, возрастные группы, балльные оценки знаний учащихся, 12-балльную шкалу магнитуд землетрясений по Рихтеру и т.д.
2) Вторая же группа дискретных признаков не имеет такой упорядоченности и носит название номинальных (от слова "номинал" - образец ) или классификационных признаков. Примером таких признаков может быть состояние пациента - "здоров" или "болен", пол пациента, период наблюдения - "до лечения" и "после лечения" и т.д. В этих случаях принято говорить, что такие признаки относятся к шкале наименований.
Понятия объекта и признака, принято называть матрицей "Объект-свойство" или "Объект-признак". Матрицей будет прямоугольная таблица, состоящая из значений признаков описывающих свойства исследуемой выборки наблюдений. В данном контексте одно наблюдение будет записываться в виде отдельной строки состоящей из значений используемых признаков. Отдельный же признак в такой матрице данных будет представлен столбцом, состоящим из значений этого признака по всем объектам выборки.
2.2 РАССТОЯНИЕ МЕЖДУ ОБЪЕКТАМИ (МЕТРИКА)
Введём понятие "расстояние между объектами". Данное понятие является интегральной мерой сходства объектов между собой. Расстоянием между объектами в пространстве признаков называется такая величина dij , которая удовлетворяет следующим аксиомам:
1. dij > 0 (неотрицательность расстояния)
3. dij + djk > dik (неравенство треугольника)
4. Если dij не равно 0, то i не равно j (различимость нетождественных объектов)
5. Если dij = 0, то i = j (неразличимость тождественных объектов)
Меру близости (сходства) объектов удобно представить как обратную величину от расстояния между объектами. В многочисленных изданиях посвященных кластерному анализу описано более 50 различных способов вычисления расстояния между объектами. Кроме термина "расстояние" в литературе часто встречается и другой термин - "метрика", который подразумевает метод вычисления того или иного конкретного расстояния. Наиболее доступно для восприятия и понимания в случае количественных признаков является так называемое "евклидово расстояние" или "евклидова метрика". Формула для вычисления такого расстояния:
В данной формуле использованы следующие обозначения:
· dij - расстояние между i-тым и j-тым объектами;
· xik - численное значение k-той переменной для i-того объекта;
· xjk - численное значение k-той переменной для j-того объекта;
· v - количество переменных, которыми описываются объекты.
Таким образом, для случая v=2, когда мы имеем всего два количественных признака, расстояние dij будет равно длине гипотенузы прямоугольного треугольника, которая соединяет собой две точки в прямоугольной системе координат. Эти две точки будут отвечать i-тому и j-тому наблюдениям выборки. Нередко вместо обычного евклидового расстояния используют его квадрат d 2 ij. Кроме того, в ряде случаев используется "взвешенное" евклидово расстояние, при вычислении которого для отдельных слагаемых используются весовые коэффициенты. Для иллюстрации понятия евклидовой метрики используем простой обучающий пример. Матрица данных, приведенная ниже в таблице, состоит из 5 наблюдений и двух переменных.
Существует огромное количество алгоритмов кластеризации. Основная идея большинства из них – объединить одинаковые последовательности в один класс или кластер на основе сходства. Как правило, выбор алгоритма определяется поставленной задачей. Что касается текстовых данных, то здесь сравниваемыми составляющими служат последовательности слов и их атрибутов (например, вес слова в тексте, тип именованной сущности, тональность и пр.). Таким образом, тексты изначально преобразуются в вектора, с которыми производят разного типа манипуляции. При этом, как правило, возникает ряд проблем, связанных с: выбором первичных кластеров, зависимостью качества кластеризации от длины текста, определением общего количества кластеров и т.п. Но наиболее сложной проблемой является отсутствие связи между близкими по смыслу текстами, в которых используется разная лексика. В таких случаях объединение должно происходить не только на основе сходства, а еще и на основе семантической смежности или ассоциативности.

Например,
В Лондоне передумали объявлять России новую холодную войну
Борис Джонсон: Запад не находится в состоянии новой холодной войны с РФ
В британском МИД заявили, что Запад не хочет новой холодной войны с Россией
Все три примера являются одной новостью, тем не менее, лексика используется разная. В таких случаях уже не помогают алгоритмы кластеризации, основанные на лексическом сходстве.
Задачи такого типа решаются двумя путями: 1) составлением тезаурусов и 2) использованием разного рода «хитрых» алгоритмов, устанавливающих ассоциативно-семантические связи между словами, как-то: латентно-семантический анализ (LSA), вероятностный латентно-семантический анализ (pLSA), латентное размещение Дирихле (LDA) и т.п.
Первый путь – получение тезаурусов – достаточно трудоемок и полностью определяется поставленной задачей. Это значит, что создать универсальный тезаурус пока не представляется возможным.
Второй путь – алгоритмический – также имеет свои недостатки. Прежде всего, это «туманность» самих методов и неочевидность их применения для текстовых данных. Скажем, LDA требует условия нормальности распределения, что при решении лингвистических задач не всегда удовлетворяется. Как правило, все эти алгоритмы имеют большое количество параметров, определение которых является эмпирическим и может существенно повлиять на качество решения (например, сокращение сингулярных значений диагональной матрицы в LSA очень нелинейно влияет на результат).
Мы попробовали обойти ряд вышеуказанных проблем, воспользовавшись результатами работы алгоритма Word2Vec.
Результаты и выводы
В кластеризации сложно говорить о качестве результата, поскольку это сильно зависит от кластеризуемого материала. В этом смысле делать «золотой» стандарт особого резона нет. Но есть смысл проверить модели на разных корпусах для классификации (о чем речь пойдет, опять же, во второй части статьи).
Как показали тесты по классификации документов векторным методом на униграммах (сравнение по косинусу), модели кластеризации почти не уступают в точности моделям на «словах». Это значит, классификация «без учителя» (модели в этом смысле универсальны) может показывать результаты лишь немного хуже, чем полноценное обучение с учителем. Ухудшение составляет 1-10% и зависит от тестируемого материла. Но это ведь и не является целью! Просто это значит, что модели кластеризации, полученные с помощью алгоритма Word2Vec вполне валидны для их применения на любом типе материала с любым количеством классов (в данном случае кластеров).
Качество результата определяется фильтрующими порогами: например, если нам нужно просто выявить нечеткие дубли, то нужно задать более жесткие параметры; и наоборот, если нужно просто посмотреть основные тематики выходящего материала, то можно выставить более мягкие параметры.
В целом, алгоритм универсален: он может работать на любом количестве материала. Хотя при больших объемах лучше работать окнами по 10-100 тысяч документов; полученные таким образом первичные кластеры затем объединяются в пост кластеризации. Алгоритм так же слабо чувствителен к длине документа: желательно, чтобы «длинные» документы были семантически однородны (принадлежали одной теме).
Тем не менее, в данном алгоритме существует ряд проблем. Прежде всего, это зависимость результата от количества классов в модели: иногда это может стать чувствительным, особенно для «слабых» кластеров, т.е. кластеров с небольшим объемом документов. Вторая проблема следует из-за неидеального определения семантических классов, вследствие чего иногда близкие по смыслу документы попадают в разные кластеры (отличающиеся, скажем, парой классов). Такие проблемы устраняются дополнительным пост объединением, основанным на факторизации документов: выделении именованных объектов и связей между ними. Но такая задача решается уже проще, ибо количество кластеров небольшое относительно первичного объема документов и большая часть из них уже объединена.
В своей дипломной работе я проводил обзор и сравнительный анализ алгоритмов кластеризации данных. Подумал, что уже собранный и проработанный материал может оказаться кому-то интересен и полезен.
О том, что такое кластеризация, рассказал sashaeve в статье «Кластеризация: алгоритмы k-means и c-means». Я частично повторю слова Александра, частично дополню. Также в конце этой статьи интересующиеся могут почитать материалы по ссылкам в списке литературы.
Так же я постарался привести сухой «дипломный» стиль изложения к более публицистическому.
Понятие кластеризации
Кластеризация (или кластерный анализ) — это задача разбиения множества объектов на группы, называемые кластерами. Внутри каждой группы должны оказаться «похожие» объекты, а объекты разных группы должны быть как можно более отличны. Главное отличие кластеризации от классификации состоит в том, что перечень групп четко не задан и определяется в процессе работы алгоритма.
- Отбор выборки объектов для кластеризации.
- Определение множества переменных, по которым будут оцениваться объекты в выборке. При необходимости – нормализация значений переменных.
- Вычисление значений меры сходства между объектами.
- Применение метода кластерного анализа для создания групп сходных объектов (кластеров).
- Представление результатов анализа.
Меры расстояний
Итак, как же определять «похожесть» объектов? Для начала нужно составить вектор характеристик для каждого объекта — как правило, это набор числовых значений, например, рост-вес человека. Однако существуют также алгоритмы, работающие с качественными (т.н. категорийными) характеристиками.
После того, как мы определили вектор характеристик, можно провести нормализацию, чтобы все компоненты давали одинаковый вклад при расчете «расстояния». В процессе нормализации все значения приводятся к некоторому диапазону, например, [-1, -1] или [0, 1].
- Евклидово расстояние
Наиболее распространенная функция расстояния. Представляет собой геометрическим расстоянием в многомерном пространстве: - Квадрат евклидова расстояния
Применяется для придания большего веса более отдаленным друг от друга объектам. Это расстояние вычисляется следующим образом: - Расстояние городских кварталов (манхэттенское расстояние)
Это расстояние является средним разностей по координатам. В большинстве случаев эта мера расстояния приводит к таким же результатам, как и для обычного расстояния Евклида. Однако для этой меры влияние отдельных больших разностей (выбросов) уменьшается (т.к. они не возводятся в квадрат). Формула для расчета манхэттенского расстояния: - Расстояние Чебышева
Это расстояние может оказаться полезным, когда нужно определить два объекта как «различные», если они различаются по какой-либо одной координате. Расстояние Чебышева вычисляется по формуле: - Степенное расстояние
Применяется в случае, когда необходимо увеличить или уменьшить вес, относящийся к размерности, для которой соответствующие объекты сильно отличаются. Степенное расстояние вычисляется по следующей формуле:
,
где r и p – параметры, определяемые пользователем. Параметр p ответственен за постепенное взвешивание разностей по отдельным координатам, параметр r ответственен за прогрессивное взвешивание больших расстояний между объектами. Если оба параметра – r и p — равны двум, то это расстояние совпадает с расстоянием Евклида.
Классификация алгоритмов
- Иерархические и плоские.
Иерархические алгоритмы (также называемые алгоритмами таксономии) строят не одно разбиение выборки на непересекающиеся кластеры, а систему вложенных разбиений. Т.о. на выходе мы получаем дерево кластеров, корнем которого является вся выборка, а листьями — наиболее мелкие кластера.
Плоские алгоритмы строят одно разбиение объектов на кластеры. - Четкие и нечеткие.
Четкие (или непересекающиеся) алгоритмы каждому объекту выборки ставят в соответствие номер кластера, т.е. каждый объект принадлежит только одному кластеру. Нечеткие (или пересекающиеся) алгоритмы каждому объекту ставят в соответствие набор вещественных значений, показывающих степень отношения объекта к кластерам. Т.е. каждый объект относится к каждому кластеру с некоторой вероятностью.
Объединение кластеров
- Одиночная связь (расстояния ближайшего соседа)
В этом методе расстояние между двумя кластерами определяется расстоянием между двумя наиболее близкими объектами (ближайшими соседями) в различных кластерах. Результирующие кластеры имеют тенденцию объединяться в цепочки. - Полная связь (расстояние наиболее удаленных соседей)
В этом методе расстояния между кластерами определяются наибольшим расстоянием между любыми двумя объектами в различных кластерах (т.е. наиболее удаленными соседями). Этот метод обычно работает очень хорошо, когда объекты происходят из отдельных групп. Если же кластеры имеют удлиненную форму или их естественный тип является «цепочечным», то этот метод непригоден. - Невзвешенное попарное среднее
В этом методе расстояние между двумя различными кластерами вычисляется как среднее расстояние между всеми парами объектов в них. Метод эффективен, когда объекты формируют различные группы, однако он работает одинаково хорошо и в случаях протяженных («цепочечного» типа) кластеров. - Взвешенное попарное среднее
Метод идентичен методу невзвешенного попарного среднего, за исключением того, что при вычислениях размер соответствующих кластеров (т.е. число объектов, содержащихся в них) используется в качестве весового коэффициента. Поэтому данный метод должен быть использован, когда предполагаются неравные размеры кластеров. - Невзвешенный центроидный метод
В этом методе расстояние между двумя кластерами определяется как расстояние между их центрами тяжести. - Взвешенный центроидный метод (медиана)
Этот метод идентичен предыдущему, за исключением того, что при вычислениях используются веса для учета разницы между размерами кластеров. Поэтому, если имеются или подозреваются значительные отличия в размерах кластеров, этот метод оказывается предпочтительнее предыдущего.
Обзор алгоритмов
Алгоритмы иерархической кластеризации
Среди алгоритмов иерархической кластеризации выделяются два основных типа: восходящие и нисходящие алгоритмы. Нисходящие алгоритмы работают по принципу «сверху-вниз»: в начале все объекты помещаются в один кластер, который затем разбивается на все более мелкие кластеры. Более распространены восходящие алгоритмы, которые в начале работы помещают каждый объект в отдельный кластер, а затем объединяют кластеры во все более крупные, пока все объекты выборки не будут содержаться в одном кластере. Таким образом строится система вложенных разбиений. Результаты таких алгоритмов обычно представляют в виде дерева – дендрограммы. Классический пример такого дерева – классификация животных и растений.
Для вычисления расстояний между кластерами чаще все пользуются двумя расстояниями: одиночной связью или полной связью (см. обзор мер расстояний между кластерами).
К недостатку иерархических алгоритмов можно отнести систему полных разбиений, которая может являться излишней в контексте решаемой задачи.
Алгоритмы квадратичной ошибки
Задачу кластеризации можно рассматривать как построение оптимального разбиения объектов на группы. При этом оптимальность может быть определена как требование минимизации среднеквадратической ошибки разбиения:
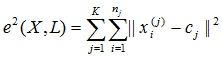
где cj — «центр масс» кластера j (точка со средними значениями характеристик для данного кластера).
- Случайно выбрать k точек, являющихся начальными «центрами масс» кластеров.
- Отнести каждый объект к кластеру с ближайшим «центром масс».
- Пересчитать «центры масс» кластеров согласно их текущему составу.
- Если критерий остановки алгоритма не удовлетворен, вернуться к п. 2.
К недостаткам данного алгоритма можно отнести необходимость задавать количество кластеров для разбиения.
Нечеткие алгоритмы
- Выбрать начальное нечеткое разбиение n объектов на k кластеров путем выбора матрицы принадлежности U размера n x k.
- Используя матрицу U, найти значение критерия нечеткой ошибки:
,
где ck — «центр масс» нечеткого кластера k:
. - Перегруппировать объекты с целью уменьшения этого значения критерия нечеткой ошибки.
- Возвращаться в п. 2 до тех пор, пока изменения матрицы U не станут незначительными.
Алгоритмы, основанные на теории графов
Суть таких алгоритмов заключается в том, что выборка объектов представляется в виде графа G=(V, E), вершинам которого соответствуют объекты, а ребра имеют вес, равный «расстоянию» между объектами. Достоинством графовых алгоритмов кластеризации являются наглядность, относительная простота реализации и возможность вносения различных усовершенствований, основанные на геометрических соображениях. Основными алгоритмам являются алгоритм выделения связных компонент, алгоритм построения минимального покрывающего (остовного) дерева и алгоритм послойной кластеризации.
Алгоритм выделения связных компонент
В алгоритме выделения связных компонент задается входной параметр R и в графе удаляются все ребра, для которых «расстояния» больше R. Соединенными остаются только наиболее близкие пары объектов. Смысл алгоритма заключается в том, чтобы подобрать такое значение R, лежащее в диапазон всех «расстояний», при котором граф «развалится» на несколько связных компонент. Полученные компоненты и есть кластеры.
Для подбора параметра R обычно строится гистограмма распределений попарных расстояний. В задачах с хорошо выраженной кластерной структурой данных на гистограмме будет два пика – один соответствует внутрикластерным расстояниям, второй – межкластерным расстояния. Параметр R подбирается из зоны минимума между этими пиками. При этом управлять количеством кластеров при помощи порога расстояния довольно затруднительно.
Алгоритм минимального покрывающего дерева
Алгоритм минимального покрывающего дерева сначала строит на графе минимальное покрывающее дерево, а затем последовательно удаляет ребра с наибольшим весом. На рисунке изображено минимальное покрывающее дерево, полученное для девяти объектов.
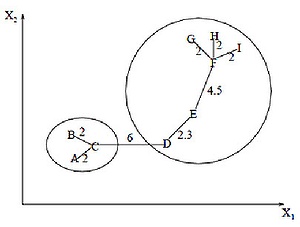
Путём удаления связи, помеченной CD, с длиной равной 6 единицам (ребро с максимальным расстоянием), получаем два кластера: и . Второй кластер в дальнейшем может быть разделён ещё на два кластера путём удаления ребра EF, которое имеет длину, равную 4,5 единицам.
Послойная кластеризация
Алгоритм послойной кластеризации основан на выделении связных компонент графа на некотором уровне расстояний между объектами (вершинами). Уровень расстояния задается порогом расстояния c. Например, если расстояние между объектами , то .
Алгоритм послойной кластеризации формирует последовательность подграфов графа G, которые отражают иерархические связи между кластерами:

,

где G t = (V, E t ) — граф на уровне с t ,
,
с t – t-ый порог расстояния,
m – количество уровней иерархии,
G 0 = (V, o), o – пустое множество ребер графа, получаемое при t 0 = 1,
G m = G, то есть граф объектов без ограничений на расстояние (длину ребер графа), поскольку t m = 1.
Сравнение алгоритмов
Немного о применении
В своей работе мне нужно было из иерархических структур (деревьев) выделять отдельные области. Т.е. по сути необходимо было разрезать исходное дерево на несколько более мелких деревьев. Поскольку ориентированное дерево – это частный случай графа, то естественным образом подходят алгоритмы, основанными на теории графов.
В отличие от полносвязного графа, в ориентированном дереве не все вершины соединены ребрами, при этом общее количество ребер равно n–1, где n – число вершин. Т.е. применительно к узлам дерева, работа алгоритма выделения связных компонент упростится, поскольку удаление любого количества ребер «развалит» дерево на связные компоненты (отдельные деревья). Алгоритм минимального покрывающего дерева в данном случае будет совпадать с алгоритмом выделения связных компонент – путем удаления самых длинных ребер исходное дерево разбивается на несколько деревьев. При этом очевидно, что фаза построения самого минимального покрывающего дерева пропускается.
В случае использования других алгоритмов в них пришлось бы отдельно учитывать наличие связей между объектами, что усложняет алгоритм.
Отдельно хочу сказать, что для достижения наилучшего результата необходимо экспериментировать с выбором мер расстояний, а иногда даже менять алгоритм. Никакого единого решения не существует.
Описание алгоритма
Идея алгоритма в сравнении не самих слов или составленных из них последовательностей (так называемых н-грамм), а семантических классов, в которые они попадают.
Для обучения требуется большой объем текстового материала (сотни тысяч, а лучше десятки миллионов словоупотреблений; чем больше выборка, тем меньше тематическая привязка модели к тексту, тем реже нужно подстраивать под текст модель). В результате обучения получается список, где почти к каждому слову текста приписан какой-либо класс (количество классов указывается на этапе обучения). Затем этот список на основе частотных распределений слов в тексте и в соответствующем им классе приводится к формату: слово — класс — вес, сглаженный по определенному алгоритму. Здесь важными параметрами являются общее количество классов и коэффициенты сглаживания (более подробно во второй части публикации).
Вот пример небольшого семантического класса.
| кроху | дочку |
| мамочку | тещу |
| воспитательницу | дочу |
| детку | родню |
| учительницу | младшую |
| сестренку | жену |
| малышку | папину |
| сестру | бывшую |
| тетю | бабушку |
| бабулю | старшую |
| подружку | подругу |
| мамку | любовницу |
| супругу | гражданку |
| тётю | семью |
| внучку | девочку |
| девичью | мамину |
| ее |
В этот более-менее однородный ассоциативно-семантический класс попадает местоимение «ее», которое, в принципе, уместно, но малоинформативно. Оно может помешать при кластеризации материала, поскольку частотно и «перетянет одеяло» на себя. Такие «выбросы» можно убрать последующим сглаживанием модели.
По полученной модели все слова из тестовой выборки преобразуются в цифры, соответствующие семантическим классам, и дальнейшие манипуляции происходят только с цифрами. Для кластеризации используется простой алгоритм сравнения накопленных документов между собой. Сравниваются целочисленные типы (int), поэтому скорость получается достаточно высокой. При этом на сравнение наложен ряд фильтров, типа ограничений по количеству семантических классов в одном документе, минимального количества документов в кластере, меры близости – количество совпавших классов. Логика алгоритма организована так, что один и тот же документ может попадать в разные кластеры (поскольку первичные кластеры не определены). Вследствие такой «нечеткости» первичный результат представляет собой достаточно объемный набор близких по тематике кластеров. Поэтому требуется пост кластеризация, которая просто объединяет близкие кластеры, сравнивая их по количеству одинаковых документов (по их id).
Таким образом, используя вышеописанную логику, удается достичь не только высокой скорости кластеризации, но и не заморачиваться ни определением первичных кластеров, ни общим их количеством.
Word2Vec
Описание алгоритма можно найти в Википедии или другом информационном ресурсе. Алгоритм создавался, прежде всего, для поисковых задач, поэтому напрямую его использовать для других лингвистических целей нужно с аккуратностью.
Алгоритм имеет два способа обучения и несколько вариантов демонстрации результатов. Нас, в частности, будет интересовать представление результата classes – получение ассоциативно-семантических классов (с использованием k-mean, кстати).
Как показывают эксперименты, даже на небольших коллекциях в несколько миллионов словоупотреблений получаются более-менее «осмысленные» классы слов. Но как использовать такой результат, если у слов нет веса (например, предлоги и «ключевые» слова имеют одинаковое представление в такой модели)? Другой проблемой является то, что классы не идеальны и, например, служебные слова могут попасть в семантически значимый класс. Использовать стоп-лист? Тогда есть риск выплеснуть из корыта вместе с водой ребенка. Вообще применение стоп-списков имеет свои существенные недостатки (например, выкидывая местоимения, мы теряем общероссийское молодёжное общественное политическое движение «НАШИ»; выбрасывая однобуквенные слова, мы не обнаружим информации о «Ъ» — сокращение газеты «Коммерсантъ» и т.д.).
Наконец, какое количество классов будет оптимальным для кластеризации текста? Зависит ли это от объема обучающей или тестовой выборки, тематики текста, его объема? На эти ключевые вопросы мы ответим во второй части публикации, а пока кратко опишем алгоритм.
Читайте также: