Mdf файл sql что это
At a minimum, every SQL Server database has two operating system files: a data file and a log file. Data files contain data and objects such as tables, indexes, stored procedures, and views. Log files contain the information that is required to recover all transactions in the database. Data files can be grouped together in filegroups for allocation and administration purposes.
Файловые группы
- Эта файловая группа содержит первичный файл данных и все вторичные файлы, не входящие в другие файловые группы.
- Пользовательские файловые группы могут создаваться для удобства администрирования, распределения и размещения данных.
Например, Data1.ndf , Data2.ndf и Data3.ndf могут быть созданы на трех дисках соответственно и отнесены к файловой группе fgroup1 . В этом случае можно создать таблицу на основе файловой группы fgroup1 . Запросы данных из таблицы будут распределены по трем дискам, и это улучшит производительность. Подобного улучшения производительности можно достичь и с помощью одного файла, созданного на чередующемся наборе дискового массива RAID. Тем не менее файлы и файловые группы позволяют без труда добавлять новые файлы на новые диски.
Все файлы данных хранятся в файловых группах, перечисленных в следующей таблице.
| Файловая группа | Описание |
|---|---|
| Первичная | Файловая группа, содержащая первичный файл. Все системные таблицы являются частью первичной файловой группы. |
| Данные, оптимизированные для памяти | В основе оптимизированной для памяти файловой группы лежит файловая группа файлового потока. |
| Файловый поток | |
| Определяемые пользователем маршруты | Любая файловая группа, созданная пользователем при создании или изменении базы данных. |
Общая архитектура хранения
Данные в базе данных Microsoft SQL Server, как и в любой другой базе данных, физически хранятся в виде обычных файлов операционной системы, при этом в SQL Server внешне это выглядит, на самом деле, достаточно понятно.
Дело в том, что существует всего 3 типа файлов, которые могут существовать у базы данных в SQL Server. При этом, конечно же, каждый файл относится к какой-то конкретной базе данных, иными словами, у каждой базы данных есть свои индивидуальные файлы.
Стоит отметить, что в простейшем виде большинство баз данных, реализованных в SQL Server, будет состоять всего из двух файлов (mdf и ldf), именно это и создаёт понятную внешнюю картину физического хранения данных в Microsoft SQL Server.
По мере увеличения данных, увеличения нагрузки на базу данных, безусловно потребуется оптимизация хранения данных, за счёт их распределения по нескольким дискам, поэтому в крупных базах данных появляются дополнительные файлы данных (ndf), благодаря которым мы можем распределить данные одной базы данных на несколько дисков.
Рекомендации
Рекомендации при работе с файлами и файловыми группами:
- Для большинства баз данных достаточно использовать один файл данных и один файл журнала транзакций.
- При использовании множества файлов данных создайте вторую файловую группу с дополнительным файлом и сделайте ее файловой группой по умолчанию. Тогда в первичном файле будут храниться только системные таблицы и объекты.
- Чтобы увеличить производительность, по возможности разнесите файлы и файловые группы по нескольким доступным дискам. Объекты, активно конкурирующие за свободное пространство, поместите в разные файловые группы.
- Используйте файловые группы для целенаправленного размещения объектов на конкретных физических дисках.
- Помещайте разные таблицы, использующиеся в одних и тех же запросах с соединениями, в разные файловые группы. Этот этап увеличит производительность, так как для поиска соединяемых данных можно будет использовать параллельный ввод-вывод.
- Часто используемые таблицы и некластеризованные индексы, относящиеся к ним, помещайте в разные файловые группы. Использование разных групп файлов увеличит производительность, так как можно будет использовать параллельный ввод и вывод, если файлы находятся на разных жестких дисках.
- Не помещайте файлы журнала транзакций на тот же физический диск, где находятся другие файлы и файловые группы.
- Если необходимо расширить том или раздел, в котором находятся файлы базы данных, с помощью таких средств, как Diskpart, следует сначала выполнить резервное копирование всех системных и пользовательских баз данных и остановить службы SQL Server. Кроме того, после успешного расширения томов дисков рекомендуется выполнить команду DBCC CHECKDB , чтобы обеспечить физическую целостность всех баз данных в томе.
Дополнительные рекомендации по управлению файлами журнала транзакций см. в разделе Управление размером файла журнала транзакций.
В этой статье описывается, как присоединить базу данных в SQL Server с помощью SQL Server Management Studio или Transact-SQL. Эту функцию можно использовать для копирования, перемещения или обновления базы данных SQL Server.
Присоединение базы данных
Установите соединение с компонентом Компонент Database Engine.
На стандартной панели выберите пункт Создать запрос.
Выполните инструкцию CREATE DATABASE с предложением FOR ATTACH .
Скопируйте приведенный ниже пример в окно запроса и нажмите кнопку Выполнить. В этом примере производится присоединение всех файлов базы данных AdventureWorks2012 с ее последующим переименованием в MyAdventureWorks .
Если в вашей базе данных содержатся дополнительные файлы данных (чаще всего .MDF или .NDF), их необходимо включить в инструкцию CREATE DATABASE . FOR ATTACH . Кроме того, в инструкцию также следует включить все файловые группы для данных FILESTREAM. Дополнительные сведения о присоединении базы данных с поддержкой FILESTREAM см. в статье Перемещение базы данных с поддержкой FILESTREAM.
Кроме того, можно вызвать хранимую процедуру sp_attach_db или sp_attach_single_file_db . Но эти расширенные хранимые процедуры в будущих версиях SQL Serverбудут удалены. Избегайте использования этого компонента в новых разработках и запланируйте изменение существующих приложений, в которых он применяется. Вместо этого рекомендуется использовать CREATE DATABASE . FOR ATTACH .
Использование SQL Server Management Studio (SSMS)
Default (Primary) Filegroup
When objects are created in the database without specifying which filegroup they belong to, they are assigned to the default filegroup. At any time, exactly one filegroup is designated as the default filegroup. The files in the default filegroup must be large enough to hold any new objects not allocated to other filegroups.
The PRIMARY filegroup is the default filegroup unless it is changed by using the ALTER DATABASE statement. Allocation for the system objects and tables remains within the PRIMARY filegroup, not the new default filegroup.
Filestream Filegroup
For more information on filestream filegroups, see FILESTREAM and Create a FILESTREAM-Enabled Database.
Рекомендации по работе с файлами и файловыми группами
- Для всех баз данных рекомендуется создать дополнительную файловую группу и сделать ее файловой группой по умолчанию, чтобы в файловой группе PRIMARY и в первичном файле хранились только системные таблицы и объекты;
- Чтобы увеличить производительность, разносите файлы и файловые группы по нескольким физическим дискам, при этом объекты, активно конкурирующие за свободное пространство, поместите в разные файловые группы;
- Используйте файловые группы для целенаправленного размещения объектов на конкретных физических дисках, например, размещайте большие и быстрорастущие таблицы на отдельных дисках;
- Если несколько таблиц очень часто используются в одних и тех же запросах с соединениями, можно поместить эти таблицы в разные файловые группы и тем самым увеличить производительность, так как для поиска соединяемых данных можно будет использовать параллельный ввод-вывод;
- Часто используемые таблицы и некластеризованные индексы, относящиеся к ним, можно помещать в разные файловые группы и на разные диски, что также увеличит производительность за счет параллельного ввода-вывода;
- Не помещайте файлы журнала транзакций на тот же физический диск, где находятся другие файлы и файловые группы. Иными словами, файл журнала транзакций по возможности помещайте на отдельный, достаточно быстрый диск.
Типы файлов в SQL Server
- Файлы данных – это файлы, в которых хранятся сами данные. Такие файлы бывают двух типов:
- Первичный файл данных – имеет расширение .mdf (Master Data File). Данный файл присутствует в любой базе данных. Кроме данных, он еще содержит сведения, необходимые для запуска базы данных, и ссылки на другие файлы в базе данных;
- Вторичный файл данных – имеет расширение .ndf (Not Master Data File). Данные типы файлов база данных может и не содержать, они создаются дополнительно к первичному файлу. С помощью именно таких файлов мы можем распределять данные на несколько дисков.
![Скриншот 1]()
По умолчанию файлы базы данных располагаются в каталоге, который Вы указали в момент установки SQL Server на этапе настройки ядра в поле «Каталог пользовательской базы данных» для файлов данных, и в поле «Каталог журналов пользовательской базы данных» для журнала транзакций.
Однако при создании базы данных, или добавлении файла к базе данных, Вы можете указать свой путь к каталогу, в котором хранить создаваемый файл.
Filegroups
- The filegroup contains the primary data file and any secondary files that aren't put into other filegroups.
- User-defined filegroups can be created to group data files together for administrative, data allocation, and placement purposes.
For example: Data1.ndf , Data2.ndf , and Data3.ndf , can be created on three disk drives, respectively, and assigned to the filegroup fgroup1 . A table can then be created specifically on the filegroup fgroup1 . Queries for data from the table will be spread across the three disks; it will improve performance. The same performance improvement can be accomplished by using a single file created on a RAID (redundant array of independent disks) stripe set. However, files and filegroups let you easily add new files to new disks.
All data files are stored in the filegroups listed in the following table.
Filegroup Description Primary The filegroup that contains the primary file. All system tables are part of the primary filegroup. Memory Optimized Data A memory-optimized filegroup is based on filestream filegroup Filestream User-defined Any filegroup that is created by the user when the user first creates or later modifies the database. Файловая группа файлового потока
Дополнительные сведения о файловых группах файлового потока см. в статьях FILESTREAM и Создание базы данных с поддержкой FILESTREAM.
Перед перемещением базы данных
Если вы перемещаете базу данных, перед ее отсоединением от существующего экземпляра SQL Server просмотрите связанные с ней файлы и их текущее расположение на странице Свойства базы данных.
В обозревателе объектов среды SQL Server Management Studio подключитесь к экземпляру компонента Компонент SQL Server Database Engine , а затем раскройте его.
Раскройте список Базы данных и выберите имя пользовательской базы данных, которую необходимо отсоединить.
Щелкните правой кнопкой мыши имя базы данных и выберите Свойства. Выберите страницу Файлы и просмотрите записи в таблице Файлы базы данных.
Убедитесь, что перед отсоединением, перемещением и присоединением базы данных вы проверили все связанные с ней файлы. Затем переходите к этапам отсоединения, копирования файлов и присоединения базы данных, описанным в следующем разделе. Дополнительные сведения см. в разделе Отсоединение базы данных.
Правила проектирования файлов и файловых групп
Для файлов и файловых групп действуют следующие правила:
- файл или файловая группа не могут использоваться несколькими базами данных. Например, файлы sales.mdf и sales.ndf, содержащие данные и объекты базы данных sales, не могут использоваться никакой другой базой данных.
- файл может быть элементом только одной файловой группы;
- файлы журнала транзакций не могут входить ни в какие файловые группы.
безопасность
Разрешения на доступ к файлам устанавливаются во время ряда операций с базами данных, включая их отсоединение и присоединение. При присоединении и отсоединении базы данных ядро СУБД пытается олицетворить учетную запись Windows работающего подключения, чтобы предоставить учетной записи разрешения для доступа к файлам базы данных и журналов. Для учетных записей со смешанным режимом безопасности, использующих учетные данные SQL Server, олицетворение может завершиться сбоем.
В следующей таблице перечислены разрешения файлов базы данных и журналов после завершения присоединения или отсоединения, а также указано, может ли ядро СУБД олицетворить подключающуюся учетную запись.
Операция Возможно олицетворение учетной записи подключения Кому предоставляются разрешения на доступ к файлам Detach Да Только учетной записи, выполняющей операцию. Администратор операционной системы может добавить дополнительные учетные записи, если они понадобятся после отсоединения базы данных. Detach Нет Учетной записи службы SQL Server (MSSQLSERVER) и членам локальной группы администраторов Windows. Attach Да Учетной записи службы SQL Server (MSSQLSERVER) и членам локальной группы администраторов Windows. Attach Нет Учетной записи службы SQL Server (MSSQLSERVER). Дополнительные сведения о разрешениях файловой системы, предоставляемых идентификаторам безопасности служб для SQL Server, см. в статье Настройка разрешений файловой системы для доступа к ядру СУБД.
Не рекомендуется подключать или восстанавливать базы данных, полученные из неизвестных или ненадежных источников. В этих базах данных может содержаться вредоносный код, вызывающий выполнение непредусмотренных инструкций Transact-SQL или появление ошибок из-за изменения схемы или физической структуры базы данных. Перед тем как использовать базу данных, полученную из неизвестного или ненадежного источника, выполните на тестовом сервере инструкцию DBCC CHECKDB для этой базы данных, а также изучите исходный код в базе данных, например хранимые процедуры и другой пользовательский код. Дополнительные сведения о присоединении баз данных и сведения об изменениях, вносимых при присоединении баз данных в метаданные, см. в статье Присоединение и отсоединение базы данных (SQL Server).
Permissions
Требуется разрешение CREATE DATABASE , CREATE ANY DATABASE или ALTER ANY DATABASE .
Использование Transact-SQL
Перед перемещением базы данных
Если вы перемещаете базу данных, перед ее отсоединением от существующего экземпляра SQL Server просмотрите связанные с ней файлы и их текущее расположение в представлении системного каталога sys.database_files . Для получения дополнительной информации см. sys.database_files (Transact-SQL).
В SQL Server Management Studio выберите Создать запрос, чтобы открыть редактор запросов.
Скопируйте скрипт Transact-SQL ниже в редактор запросов и нажмите Выполнить. Этот скрипт показывает расположение физических файлов базы данных. Убедитесь, что при перемещении базы данных путем отсоединения и присоединения вы проверили все файлы.
Убедитесь, что перед отсоединением, перемещением и присоединением базы данных вы проверили все связанные с ней файлы. Затем переходите к этапам отсоединения, копирования файлов и присоединения базы данных, описанным в следующем разделе. Дополнительные сведения см. в разделе Отсоединение базы данных.
Стратегия заполнения файлов и файловых групп
В файловых группах для каждого файла используется стратегия пропорционального заполнения. При записи данных в файловую группу компонент Компонент SQL Server Database Engine записывает в каждый файл количество данных, пропорциональное свободному пространству этого файла, вместо записи всех данных в первый файл до его заполнения. Затем запись производится в следующий файл. Например, если в файле f1 свободно 100 МБ, а в файле f2 — 200 МБ, то в файл f1 записывается одна часть данных, а в файл f2 — две части, и так далее. Таким образом, оба файла будут заполнены примерно в одно и то же время, и достигается простейшее распределение данных между хранилищами.
Например, файловая группа состоит из трех файлов, для всех разрешено автоматическое увеличение. Когда свободное пространство во всех файлах группы закончится, будет расширен только первый файл. Когда заполнится первый файл и в файловую группу снова нельзя будет записывать новые данные, будет расширен второй файл. Когда заполнится второй файл и в файловую группу опять нельзя будет записывать новые данные, будет расширен третий файл. Когда заполнится третий файл и в файловую группу нельзя будет записывать новые данные, будет снова расширен первый файл и т. д.
Memory Optimized Data Filegroup
For more information on memory-optimized filegroups, see Memory Optimized Filegroup.
После обновления базы данных SQL Server
Размер файла
Файлы SQL Server могут автоматически увеличиваться в размерах, превосходя первоначально заданные показатели. При определении файла пользователь может указывать требуемый шаг роста. Каждый раз при заполнении файла его размер увеличивается на указанный шаг роста. Если в файловой группе имеется несколько файлов, их автоматический рост начинается лишь по заполнении всех файлов.
Дополнительные сведения о страницах и их типах см. в разделе Руководство по архитектуре страниц и экстентов.
Кроме того, можно указать максимальный размер каждого файла. Если максимальный размер файла не указан, файл может продолжать увеличиваться в размерах, пока не займет все доступное место на диске. Эта функция особенно полезна в случаях, когда SQL Server используется в качестве базы данных, внедренной в приложение, где пользователь не имеет удобного доступа к системному администратору. По мере необходимости пользователь может предоставить файлам возможность увеличиваться в размерах автоматически, тем самым снимая с администратора часть забот по наблюдению за свободным пространством базы данных и по распределению дополнительного пространства вручную.
Дополнительные сведения об управлении файлами журнала транзакций см. в разделе Управление размером файла журнала транзакций.
Система отслеживания измененных данных (CDC)
Для подключения базы данных из экземпляра SQL Server 2014 (12.x) или более ранней версии, в котором было включено отслеживание измененных данных (CDC), необходимо выполнить следующую команду, чтобы обновить метаданные отслеживания изменений:
![Архитектура хранения данных в Microsoft SQL Server]()
Файлы моментального снимка базы данных
Вид файла, используемый для хранения копируемых во время записи данных моментального снимка базы данных, зависит от того, создается ли моментальный снимок пользователем или используется внутренними механизмами.
- Данные моментального снимка базы данных, созданного пользователем, хранятся в одном или нескольких разреженных файлах. Технология разреженных файлов является свойством файловой системы NTFS. Изначально разреженный файл не содержит данных пользователя, и место на диске под него не выделяется. Общие сведения об использовании разреженных файлов в моментальных снимках базы данных и о том, как растут моментальные снимки базы данных, см. в разделе Просмотр размера разреженного файла моментального снимка базы данных.
- Моментальные снимки базы данных могут использоваться внутренними механизмами при выполнении определенных команд DBCC. Эти команды включают DBCC CHECKDB, DBCC CHECKTABLE, DBCC CHECKALLOC и DBCC CHECKFILEGROUP. Внутренним моментальным снимком базы данных используются разреженные дополнительные потоки данных исходных файлов базы данных. Подобно разреженным файлам, дополнительные потоки данных являются свойством файловой системы NTFS. Использование разреженных дополнительных потоков данных позволяет связать несколько расположений данных с одним файлом или папкой, не затрагивая при этом размер файла или статистику тома.
Database Snapshot Files
The form of file that is used by a database snapshot to store its copy-on-write data depends on whether the snapshot is created by a user or used internally:
- A database snapshot that is created by a user stores its data in one or more sparse files. Sparse file technology is a feature of the NTFS file system. At first, a sparse file contains no user data, and disk space for user data hasn't been allocated to the sparse file. For general information about the use of sparse files in database snapshots and how database snapshots grow, see View the Size of the Sparse File of a Database Snapshot.
- Database snapshots are used internally by certain DBCC commands. These commands include DBCC CHECKDB, DBCC CHECKTABLE, DBCC CHECKALLOC, and DBCC CHECKFILEGROUP. An internal database snapshot uses sparse alternate data streams of the original database files. Like sparse files, alternate data streams are a feature of the NTFS file system. The use of sparse alternate data streams allows for multiple data allocations to be associated with a single file or folder without affecting the file size or volume statistics.
Экстенты
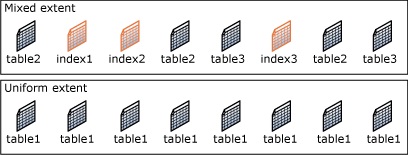
Экстент — это набор из 8 физически непрерывных страниц.
Экстенты являются основными единицами организации пространства. Как было отмечено, экстент состоит из восьми непрерывных страниц или 64 КБ. Это означает, что в одном мегабайте базы данных SQL Server содержится 16 экстентов.
Экстенты используются для эффективного управления страницами.
В SQL Server есть два типа экстентов:
- Однородные экстенты (Uniform) – это экстенты, которые принадлежат одному объекту, и все восемь страниц экстента может использовать только этот владеющий объект;
- Смешанные экстенты (Mixed) – это экстенты, которые могут находиться в общем пользовании максимум у восьми объектов. Каждая из восьми страниц в экстенте может находиться во владении разных объектов.
![Скриншот 3]()
SQL Server до 2016 версии не выделяет целые экстенты для таблиц с небольшими объемами данных. Под новую таблицу или индекс обычно выделяются страницы из смешанных экстентов. Когда таблица или индекс вырастают до восьми страниц, они переключаются на использование однородных экстентов для последующих распределений. Если Вы создаете индекс для существующей таблицы, в которой достаточно строк для создания восьми страниц в индексе, все выделения для индекса будут в однородных экстентах.
Начиная с SQL Server 2016 по умолчанию для большей части распределений в пользовательской базе данных и базе данных tempdb используются однородные экстенты. Это не касается распределений, принадлежащих первым восьми страницам цепочки IAM. Для распределений баз данных master и msdb, и model сохраняется предыдущее поведение.
SQL Server использует два типа карт распределения для выделения экстентов:
- Глобальная карта распределения (GAM) – на GAM-страницах записано, какие экстенты были размещены. В каждой карте GAM содержится 64 000 экстентов или почти 4 ГБ данных. В карте GAM приходится по одному биту на каждый экстент в покрываемом им интервале. Если бит равен 1, то экстент свободен; если бит равен 0, то экстент размещен.
- Общая глобальная карта распределения (SGAM) – на SGAM-страницах записано, какие экстенты в текущий момент используются в качестве смешанных экстентов и имеют как минимум одну неиспользуемую страницу. В каждой карте SGAM содержится 64 000 экстентов или почти 4 ГБ данных. В карте SGAM приходится по одному биту на каждый экстент в покрываемом им интервале. Если бит равен 1, то экстент используется как смешанный экстент и имеет свободную страницу. Если бит равен 0, то экстент не используется как смешанный экстент, или он является смешанным экстентом, но все его страницы используются.
Каждый экстент обладает следующими наборами битовых шаблонов в картах GAM и SGAM, основанными на его текущем использовании.
Текущее использование экстента Настройка битов карты GAM Настройка битов карты SGAM Свободно, в текущий момент не используется 1 0 Однородный экстент или заполненный смешанный экстент 0 0 Смешанный экстент со свободными страницами 0 1 Таким образом, упрощенный алгоритм управления экстентами страниц следующий:
- Для выделения однородного экстента SQL Server производит на карте GAM поиск бита 1 и заменяет его на бит 0;
- Для поиска смешанного экстента со свободными страницами SQL Server производит поиск на карте SGAM бита 1;
- Для выделения смешанного экстента SQL Server производит на карте GAM поиск бита 1, заменяет его на бит 0, а затем устанавливает значение соответствующего бита на карте SGAM равным 1;
- Для освобождения экстента SQL Server устанавливает бит GAM равным 1, а соответствующий бит SGAM равным 0.
Заметка! Всем тем, кто только начинает свое знакомство с языком SQL, рекомендую прочитать книгу «SQL код» – это самоучитель по языку SQL для начинающих программистов. В ней очень подробно рассмотрены основные конструкции языка.
Уровень совместимости базы данных
После обновления базы данных с помощью присоединения она становится доступной. База данных автоматически обновится до уровня внутренней версии нового экземпляра. Если база данных содержит полнотекстовые индексы, то в процессе обновления будет произведен их импорт, сброс или перестроение в зависимости от установленного значения свойства сервера Режим обновления полнотекстового каталога . Если выбран режим обновления Импортировать или Перестроить, полнотекстовые индексы будут недоступны во время обновления. В зависимости от объема индексируемых данных импорт может занять несколько часов, а перестроение — в несколько (до 10) раз больше. Обратите внимание, что если при обновлении выбран режим Импортировать, а полнотекстовый каталог недоступен, то связанные с ним полнотекстовые индексы будут перестроены.
После обновления уровень совместимости базы данных останется неизменным, если только он не является в новой версии неподдерживаемым. В последнем случае обновленный уровень совместимости базы данных устанавливается как самый низкий из поддерживаемых. Например, если подключить к экземпляру SQL Server 2019 (15.x) базу данных, имеющую уровень совместимости 90, то после обновления он будет изменен на 100, что является наименьшим поддерживаемым уровнем для SQL Server 2019 (15.x). Дополнительные сведения см. в разделе Уровень совместимости инструкции ALTER DATABASE (Transact-SQL).
Rules for designing Files and Filegroups
The following rules pertain to files and filegroups:
- A file or filegroup cannot be used by more than one database. For example, file sales.mdf and sales.ndf, which contain data and objects from the sales database, can't be used by any other database.
- A file can be a member of only one filegroup.
- Transaction log files are never part of any filegroups.
Файловая группа данных, оптимизированных для памяти
Дополнительные сведения об оптимизированных для памяти файловых группах см. в разделе Оптимизированные для памяти файловые группы.
Файловая группа по умолчанию (первичная)
Если в базе данных создаются объекты без указания файловой группы, к которой они относятся, они назначаются файловой группе по умолчанию. В любом случае только одна файловая группа создается как файловая группа по умолчанию. Файлы в файловой группе по умолчанию должны быть достаточно большими, чтобы вмещать новые объекты, не назначенные другим файловым группам.
Файловая группа PRIMARY является группой по умолчанию, если только она не была изменена инструкцией ALTER DATABASE. Системные объекты и таблицы распределяются внутри первичной файловой группы, а не новой файловой группой по умолчанию.
Логические и физические имена файлов
Файлы SQL Server имеют два типа имен файлов.
logical_file_name: имя, используемое для ссылки на физический файл во всех инструкциях Transact-SQL. Логическое имя файла должно соответствовать правилам для идентификаторов SQL Server и быть уникальным среди логических имен файлов в соответствующей базе данных.
os_file_name: имя физического файла, включающее путь к каталогу. Оно должно соответствовать правилам для имен файлов операционной системы.
Дополнительные сведения об аргументах NAME и FILENAME см. в статье Параметры ALTER DATABASE ((Transact-SQL)) для файлов и файловых групп.
Файлы данных и файлы журналов SQL Server могут использоваться как в файловой системе FAT, так и в системе NTFS. В системах Windows рекомендуется использовать файловую систему NTFS по причинам ее большей безопасности.
Файловые группы, доступные как для чтения, так и для записи, а также файлы журналов не поддерживаются со сжатой файловой системой NTFS. В сжатую файловую систему NTFS разрешено помещать лишь доступные только для чтения базы данных и доступные только для чтения вторичные файловые группы. Для экономии места настоятельно рекомендуется использовать сжатие данных вместо сжатия файловой системы.
Если на одном компьютере запущено несколько экземпляров SQL Server, каждый экземпляр получает отдельный каталог по умолчанию для хранения файлов баз данных, созданных в этом экземпляре. Дополнительные сведения см. в разделе Расположение файлов для экземпляра по умолчанию и именованных экземпляров SQL Server.
Ограничения
Пример файлов и файловых групп
В следующем примере создается база данных на основе экземпляра SQL Server. База данных содержит первичный файл данных, пользовательскую файловую группу и файл журнала. Первичный файл данных входит в состав первичной файловой группы, а пользовательская файловая группа состоит из двух вторичных файлов данных. Инструкция ALTER DATABASE придает пользовательской файловой группе статус файловой группы по умолчанию. Затем создается таблица, определяющая пользовательскую файловую группу. (В этом примере используется универсальный путь к c:\Program Files\Microsoft SQL Server\MSSQL.1 , чтобы не указывать версию SQL Server.)
Данная иллюстрация обобщает все вышесказанное (кроме данных файлового потока).
Файлы базы данных
SQL Server имеют три типа файлов.
Файл Описание Первичная Содержит сведения, необходимые для запуска базы данных, и ссылки на другие файлы в базе данных. В каждой базе данных имеется один первичный файл данных. Для имени первичного файла данных рекомендуется расширение MDF. Вторичная Необязательные определяемые пользователем файлы данных. Данные могут быть распределены на несколько дисков, в этом случае каждый файл записывается на отдельный диск. Для имени вторичного файла данных рекомендуется расширение NDF. Журнал транзакций Журнал содержит информацию для восстановления базы данных. Для каждой базы данных должен существовать хотя бы один файл журнала. Для файлов журнала транзакций рекомендуется расширение LDF. Например, простая база данных с именем Sales включает один первичный файл, содержащий все данные и объекты, и один файл журнала, содержащий сведения журнала транзакций. Более сложная база данных с именем Orders может содержать один первичный файл и пять вторичных файлов. Данные и объекты внутри базы данных распределяются по всем шести файлам, а четыре файла журнала содержат сведения журнала транзакций.
По умолчанию и данные, и журналы транзакций помещаются на один и тот же диск и имеют один и тот же путь для обработки однодисковых систем. Для производственных сред это может быть неоптимальным решением. Рекомендуется помещать данные и файлы журнала на разные диски.
Устройство файлов базы данных SQL Server
Мы с Вами поговорили о том, как на верхнем уровне хранятся данные в SQL Server, теперь давайте немного поговорим о том, как хранятся данные на более низком уровне, т.е. как организовано внутреннее хранение данных в тех самых файлах данных.
В файлах данных в SQL Server все данные хранятся на страницах, которые группируются в экстенты.
Поэтому давайте чуть более подробно поговорим о страницах и экстентах.
Дисковое пространство, выделенное для размещения файлов базы данных (MDF или NDF), логически разделяется на страницы. Иными словами, внутреннее пространство файлов данных разделено на страницы и именно в этих страницах хранятся наши данные.
Все дисковые операции ввода-вывода в SQL Server выполняются на уровне страницы и это означает, что SQL Server считывает или записывает целые страницы данных.
Например, в процессе оптимизации запросов мы очень часто говорим о количестве логических чтений, которые выполняются на уровне запроса, так вот – это количество как раз и представляет собой количество считанных страниц данных.
Если провести аналогию, то файл базы данных в SQL Server (MDF или NDF) представляет собой бумажную книгу, содержимое которой написано на страницах. Иными словами, в SQL Server все строки данных точно так же, как и в бумажной книге, записываются на страницы, которые имеют одинаковый физический размер 8 килобайт.
Основную часть файла данных занимают страницы с данными, как и у книги страницы с содержимым, а на некоторых страницах могут находиться метаданные об этом содержимом, например, как оглавление или алфавитный указатель в бумажной книге.
Как уже было отмечено размер страницы в SQL Server составляет 8 КБ. Это значит, что в одном мегабайте базы данных SQL Server содержится 128 страниц.
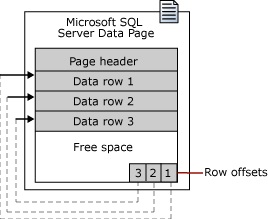
Каждая страница начинается с 96-байтового заголовка, который используется для хранения системных данных о странице. Эти данные включают номер страницы, тип страницы, объем свободного места на странице и идентификатор единицы распределения объекта, которому принадлежит страница.
Строки данных заносятся на страницу последовательно, сразу же после заголовка. В конце страницы располагается таблица смещения строк.
Таблица смещения строк содержит одну запись для каждой строки на странице. Каждая запись смещения строк регистрирует, насколько далеко от начала страницы находится первый байт строки. Таким образом, таблицы смещения строк помогает SQL Server быстро находить строки на странице. Записи в таблице смещения строк находятся в обратном порядке относительно последовательности строк на странице.
![Скриншот 2]()
В следующей таблице представлены типы страниц, которые используются в файлах данных базы данных SQL Server.
Тип страницы Описание Data page Строки с данными, за исключением типов text, ntext, image, nvarchar(max), varchar(max), varbinary(max) и xml. Index page Содержимое индекса. Text/Image Текст/изображение. Типы данных больших объектов: text, ntext, image, nvarchar(max), varchar(max), varbinary(max) и данные xml.
Столбцы переменной длины, когда размер строки данных превышает 8 КБ: varchar, nvarchar, varbinary и sql_variant.Global Allocation Map (GAM) Глобальная карта распределения. На GAM-страницах записано, какие экстенты были размещены. В каждой карте GAM содержится 64 000 экстентов или почти 4 ГБ данных. В карте GAM приходится по одному биту на каждый экстент в покрываемом им интервале. Если бит равен 1, то экстент свободен, если бит равен 0, то экстент размещен. Shared Global Allocation Map (SGAM) Общая глобальная карта распределения. На SGAM-страницах записано, какие экстенты в текущий момент используются в качестве смешанных экстентов и имеют как минимум одну неиспользуемую страницу. В каждой карте SGAM содержится 64 000 экстентов или почти 4 ГБ данных. В карте SGAM приходится по одному биту на каждый экстент в покрываемом им интервале. Если бит равен 1, то экстент используется как смешанный экстент и имеет свободную страницу. Если бит равен 0, то экстент не используется как смешанный экстент, или он является смешанным экстентом, но все его страницы используются. Page Free Space (PFS) Сведения о размещении страниц и доступном на них свободном месте. Index Allocation Map (IAM) Карта распределения индекса. Сведения об экстентах, используемых таблицей или индексом для единицы распределения. Bulk Changed Map (BCM) Карта массовых изменений данных. Сведения об экстентах, измененных массовыми операциями со времени последнего выполнения инструкции BACKUP LOG для единицы распределения. Differential Changed Map (DCM) Карта изменений для разностной резервной копии. Сведения об экстентах, измененных с момента последнего выполнения инструкции BACKUP DATABASE для единицы распределения. Предварительные требования
Прежде чем продолжить, ознакомьтесь со следующими предварительными требованиями:
Если вы перемещаете базу данных из одного экземпляра в другой, ее необходимо сначала отсоединить от любого существующего экземпляра SQL. Попытка присоединить неотсоединенную базу данных приведет к возникновению ошибки. Дополнительные сведения см. в разделе Отсоединение базы данных.
При присоединении базы данных должны быть доступны все ее файлы данных. Они часто имеют расширения .MDF или .NDF (файлы данных), а также .LDF (файлы журнала транзакций). Кроме того, должны присутствовать и быть доступными все файловые группы для данных FILESTREAM. Дополнительные сведения о присоединении базы данных с поддержкой FILESTREAM см. в статье Перемещение базы данных с поддержкой FILESTREAM.
Если у какого-либо файла данных путь отличается от того, каким он был при первом создании или последнем присоединении, необходимо указать текущий путь к файлу.
Учетная запись службы ядра СУБД должна обладать разрешениями на чтение файлов в их новом расположении.
Если MDF-файлы и LDF-файлы находятся в разных каталогах и один из путей содержит \\?\GlobalRoot , при присоединении базы данных произойдет сбой.
Файловые группы
В Microsoft SQL Server есть возможность объединять файлы данных в файловые группы.
Файловая группа в SQL Server – это логический контейнер, который объединяет несколько файлов данных.
Файловые группы нужны нам в основном для более гибкого управления хранением данных в SQL Server. Дело в том, что с помощью файловых групп мы можем одни таблицы хранить в одних файлах, а другие в других, иными словами, благодаря файловым группам мы можем распределять таблицы по разных файлам и по разным дискам.
Например, мы знаем, что одна таблица у нас будет очень большой и на ее хранение потребуется несколько дисков, поэтому ее (т.е. только одну эту таблицу), мы можем поместить в отдельную файловую группу, в которую добавить несколько файлов, каждый из которых будет храниться на отдельном диске. Все остальные таблицы мы будем хранить в другой файловой группе, т.е. уже в других файлах и, соответственно, на других дисках.
Без файловых групп мы этого сделать не можем, т.е. мы можем, конечно же, создать дополнительные файлы данных, но распределять данные по этим файлам будет сам SQL Server, т.е. на это мы уже не можем повлиять.
Таким образом, при создании таблиц мы можем указать, в какой файловой группе создавать эту таблицу. Если в базе данных создавать объекты без указания файловой группы (в большинстве случаев так и делается), к которой они относятся, они создаются в файловой группе по умолчанию.
По умолчанию в SQL сервере создана файловая группа PRIMARY, и если Вы не создавали дополнительных файловых групп, то все объекты базы данных будут храниться именно в этой файловой группе.
Файловую группу по умолчанию можно переопределить инструкцией ALTER DATABASE, т.е. можно создать файловую группу и назначить ее файловой группой по умолчанию, при этом стоит отметить, что все системные объекты хранятся в файловой группе PRIMARY, а не в новой файловой группе по умолчанию. Иными словами, файловая группа PRIMARY – это особенная файловая группа, в которой хранятся системные объекты и которую нельзя удалить.
Также стоит отметить, что один файл данных может входить в состав только одной файловой группы.
Примечание! Файлы журнала транзакций не могут входить в файловые группы.
File Size
SQL Server files can grow automatically from their originally specified size. When you define a file, you can specify a specific growth increment. Every time the file is filled, it increases its size by the growth increment. If there are multiple files in a filegroup, they won't autogrow until all the files are full.
For more information about pages and page types, see Pages and Extents Architecture Guide.
Each file can also have a maximum size specified. If a maximum size isn't specified, the file can continue to grow until it has used all available space on the disk. This feature is especially useful when SQL Server is used as a database embedded in an application where the user doesn't have convenient access to a system administrator. The user can let the files autogrow as required to reduce the administrative burden of monitoring free space in the database and manually allocating additional space.
For more information on transaction log file management, see Manage the size of the transaction log file.
Файлы базы данных SQL Server
Logical and Physical File Names
SQL Server files have two file name types:
logical_file_name: The logical_file_name is the name used to refer to the physical file in all Transact-SQL statements. The logical file name must comply with the rules for SQL Server identifiers and must be unique among logical file names in the database.
os_file_name: The os_file_name is the name of the physical file including the directory path. It must follow the rules for the operating system file names.
For more information on the NAME and FILENAME argument, see ALTER DATABASE File and Filegroup Options (Transact-SQL).
SQL Server data and log files can be put on either FAT or NTFS file systems. On Windows systems, we recommend using the NTFS file system because the security aspects of NTFS.
Read/write data filegroups and log files are not supported on an NTFS compressed file system. Only read-only databases and read-only secondary filegroups are allowed to be put on an NTFS compressed file system. For space savings, it is highly recommended to use data compression instead of file system compression.
When multiple instances of SQL Server are running on a single computer, each instance receives a different default directory to hold the files for the databases created in the instance. For more information, see File Locations for Default and Named Instances of SQL Server.
Database Files
SQL Server databases have three types of files, as shown in the following table.
File Description Primary Contains startup information for the database and points to the other files in the database. Every database has one primary data file. The recommended file name extension for primary data files is .mdf. Secondary Optional user-defined data files. Data can be spread across multiple disks by putting each file on a different disk drive. The recommended file name extension for secondary data files is .ndf. Transaction Log The log holds information used to recover the database. There must be at least one log file for each database. The recommended file name extension for transaction logs is .ldf. For example, a simple database named Sales has one primary file that contains all data and objects and a log file that contains the transaction log information. A more complex database named Orders can be created that includes one primary file and five secondary files. The data and objects within the database spread across all six files, and the four log files contain the transaction log information.
By default, the data and transaction logs are put on the same drive and path to handle single-disk systems. This choice may not be optimal for production environments. We recommend that you put data and log files on separate disks.
File and Filegroup Example
The following example creates a database on an instance of SQL Server. The database has a primary data file, a user-defined filegroup, and a log file. The primary data file is in the primary filegroup and the user-defined filegroup has two secondary data files. An ALTER DATABASE statement makes the user-defined filegroup the default. A table is then created specifying the user-defined filegroup. (This example uses a generic path c:\Program Files\Microsoft SQL Server\MSSQL.1 to avoid specifying a version of SQL Server.)
The following illustration summarizes the results of the previous example (except for the Filestream data).
Data File Pages
Pages in a SQL Server data file are numbered sequentially, starting with zero (0) for the first page in the file. Each file in a database has a unique file ID number. To uniquely identify a page in a database, both the file ID and the page number are required. The following example shows the page numbers in a database that has a 4-MB primary data file and a 1-MB secondary data file.
A file header page is the first page that contains information about the attributes of the file. Several of the other pages at the start of the file also contain system information, such as allocation maps. One of the system pages stored in both the primary data file and the first log file is a database boot page that contains information about the attributes of the database.
Присоединение базы данных
В обозревателе объектов SQL Server Management Studio подключитесь к экземпляру Компонент SQL Server Database Engine и разверните его представление в SSMS.
Щелкните правой кнопкой мыши узел Базы данных и выберите Присоединить.
В диалоговом окне Присоединение базы данных выберите Добавить, чтобы указать присоединяемую базу данных. В диалоговом окне Поиск файлов базы данных выберите расположение базы данных и разверните дерево каталогов, чтобы найти и выбрать ее MDF-файл, например:
C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA\AdventureWorks2012_Data.mdf
При попытке выбора базы данных, которая уже присоединена, возникает ошибка.
Базы данных для присоединения
Отобразятся сведения о выбранных базах данных.
Отображается значок, указывающий на состояние операции присоединения. Возможные варианты значков перечислены в описании Состояние ниже.Расположение файла MDF
Отображается путь и имя выбранного MDF-файла.Имя базы данных
Отображается имя базы данных.Присоединить как
Необязательный параметр, указывает другое имя, под которым присоединяется база данных.Владелец
Содержит раскрывающийся список возможных владельцев базы данных, из которого при необходимости можно выбрать другого владельца.Состояние
Отображает состояние базы данных в соответствии со следующей таблицей:Значок Текст состояния Описание (Нет значка) (Нет текста) Присоединение не начато или находится в режиме ожидания для этого объекта. Это состояние по умолчанию при открытии диалогового окна. Зеленый, указывающий направо треугольник Выполняется Операция присоединения была запущена, но не завершена. Зеленый флажок Успешно Объект успешно присоединен. Красный кружок с белым крестом внутри Error При выполнении операции присоединения возникла ошибка, и операция не была успешно завершена. Кружок с двумя черными квадратами (слева и справа) и двумя белыми квадратами (сверху и снизу) Остановлена Присоединение не было завершено, поскольку вы остановили его выполнение. Кружок, содержащий изогнутую стрелку, указывающую в направлении против часовой стрелки Выполнен откат Операция присоединения была успешной, но был выполнен ее откат из-за ошибки, возникшей при вложении другого объекта. Добавление
Найдите необходимые основные файлы базы данных. Когда вы выбираете MDF-файл, необходимые сведения автоматически вводятся в соответствующие поля сетки Базы данных для присоединения.Удалить
Удаляет выбранный файл из сетки Базы данных для присоединения .Сведения о базе данных " "
Отображаются имена файлов, которые необходимо присоединить. Чтобы проверить или изменить путь к файлу, нажмите кнопку Обзор ( … ).Имя исходного файла
Отображается имя присоединенного файла, принадлежащего базе данных.Тип файла
Указывается тип файла: Данные или Журнал.Текущий путь к файлу
Отображается путь к выбранному файлу базы данных. Путь может быть изменен вручную.Для чего использовать присоединение?
При перемещении файлов базы данных в пределах одного экземпляра рекомендуется использовать запланированное перемещение ALTER DATABASE вместо отсоединения и присоединения. Дополнительные сведения см. в статье Move User Databases.
Не рекомендуется использовать отсоединение и присоединение для резервного копирования и восстановления. При отсоединении файлов для внешнего резервного копирования из SQL Server резервные копии журналов транзакций или восстановление до точки во времени будут недоступны.
File and Filegroup Fill Strategy
Filegroups use a proportional fill strategy across all the files within each filegroup. As data is written to the filegroup, the SQL Server Database Engine writes an amount proportional to the free space in the file to each file within the filegroup, instead of writing all the data to the first file until full. It then writes to the next file. For example, if file f1 has 100 MB free and file f2 has 200 MB free, one extent is given from file f1, two extents from file f2, and so on. In this way, both files become full at about the same time, and simple striping is achieved.
For example, a filegroup is made up of three files, all set to automatically grow. When space in all the files in the filegroup is exhausted, only the first file is expanded. When the first file is full and no more data can be written to the filegroup, the second file is expanded. When the second file is full and no more data can be written to the filegroup, the third file is expanded. If the third file becomes full and no more data can be written to the filegroup, the first file is expanded again, and so on.
Recommendations
Recommendations when working with files and filegroups:
- Most databases will work well with a single data file and a single transaction log file.
- If you use multiple data files, create a second filegroup for the additional file and make that filegroup the default filegroup. In this way, the primary file will contain only system tables and objects.
- To maximize performance, create files or filegroups on different available disks as possible. Put objects that compete heavily for space in different filegroups.
- Use filegroups to enable placement of objects on specific physical disks.
- Put different tables used in the same join queries in different filegroups. This step will improve performance, because of parallel disk I/O searching for joined data.
- Put heavily accessed tables and the nonclustered indexes that belong to those tables on different filegroups. Using different filegroups will improve performance, because of parallel I/O if the files are located on different physical disks.
- Don't put the transaction log file(s) on the same physical disk that has the other files and filegroups.
- If you need to extend a volume or partition on which database files reside using tools like Diskpart, you should back up all system and user databases and stop SQL Server services first. Also, once disk volumes are extended successfully, you should consider running DBCC CHECKDB command to ensure the physical integrity of all databases residing on the volume.
For more information on transaction log file management recommendations, see Manage the size of the transaction log file.
Каждая база данных SQL Server имеет как минимум два рабочих системных файла: файл данных и файл журнала. Файлы данных содержат данные и объекты, такие как таблицы, индексы, хранимые процедуры и представления. Файлы журнала содержат сведения, необходимые для восстановления всех транзакций в базе данных. Файлы данных могут быть объединены в файловые группы для удобства распределения и администрирования.
Читайте также: