
Какой объем памяти необходим для размещения одного символа текста
Разрешающая способность экрана равнаРазрешающая способность экрана равна 1024х840 пикселей?
Разрешающая способность экрана равнаРазрешающая способность экрана равна 1024х840 пикселей.
Для размещения одного символа в текстовом режиме используется матрица 16х16 / Какое максимальное количество строк может быть размещено на экране?

SfsadsaРазрешающая способность дисплея равна 240х200 пикселей?
Разрешающая способность дисплея равна 240х200 пикселей.
Для размещения одного символа в текстовом режиме используется матрица 8х8 пикселей.
Какое максимальное количество текстовых строк может быть размещено на экране?

Вопросы и задания
1. Ознакомьтесь с материалами презентации к параграфу, содержащейся в электронном приложении к учебнику. Дополняет ли презентация информацию содержащуюся в тексте параграфа.
Код ОГЭ по информатике: 2.1.3. Оценка количественных параметров информационных объектов. Объем памяти, необходимый для хранения объектов
Оценка количества информации
Впервые объективный подход к измерению количества информации был предложен американским инженером Р. Хартли в 1928 г. Позже, в 1948 г., этот подход обобщил создатель общей теории информации К. Шеннон.
По приведенной выше формуле можно рассчитать, какое количество информации I несет каждый из знаков этой системы. Если в алфавите знаковой системы N знаков, то каждый знак несет количество информации: I = log2 N

Текстовая информация состоит из букв, цифр, знаков препинания, различных специальных символов. Для кодирования текстовой информации используют различные коды. Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки. Существуют различные таблицы кодировок текстовой информации.
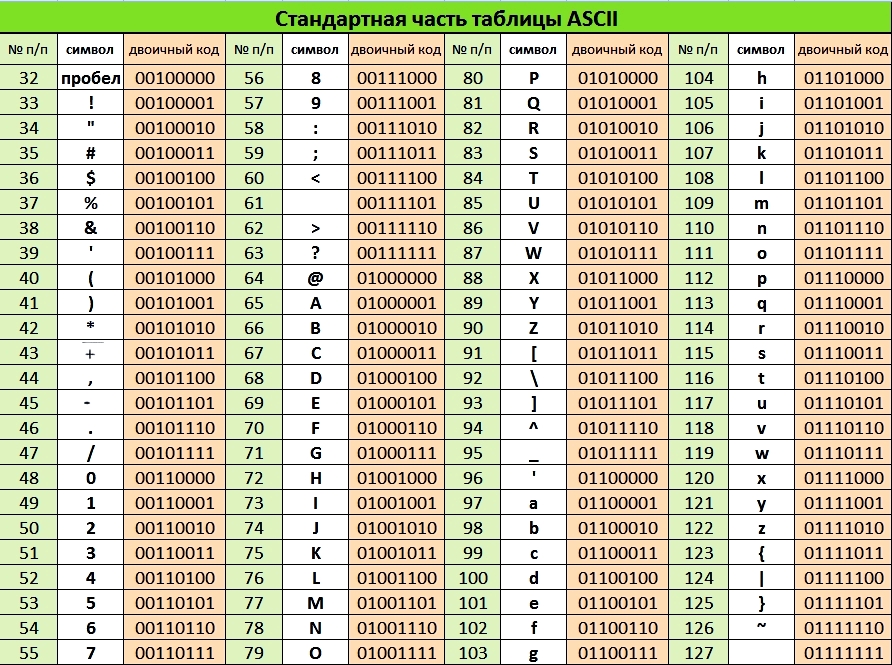
Распространенная таблица кодировки ASCII (читается «аски», American Standard Code for Information Interchange — стандартный американский код для обмена информацией) использует 1 байт для кодов информации. Если код каждого символа занимает 1 байт (8 бит), то с помощью такой кодировки можно закодировать 2 8 = 256 символов.
Таблица ASCII состоит из двух частей. Первая, базовая часть, является международным стандартом и содержит значения кодов от 0 до 127 (для цифр, операций, латинского алфавита, знаков препинания). Вторая, национальная часть, содержит коды от 128 до 255 для символов национального алфавита, т. е. в национальных кодировках одному и тому же коду соответствуют различные символы.
В настоящее время существует несколько различных кодировок второй части таблицы для кириллицы — КОИ8–Р, KOI8–U, Windows, MS–DOS, Macintosh, ISO. Наиболее распространенной является таблица кодировки Windows–1251. Из–за разнообразия таблиц кодировки могут возникать проблемы при переносе русского текста между компьютерами или различными программами.
Поскольку объем в 1 байт явно мал для кодирования разнообразных и многочисленных символов мировых алфавитов, была разработана система кодирования Unicode. В ней для кодирования символа отводится 2 байта (16 бит). Это означает, что система позволяет закодировать 2 16 = 65 536 символов. Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов.
Количество графической информации
Растровое графическое изображение состоит из отдельных точек — пикселей, образующих строки и столбцы.
Основные свойства пикселя — его расположение и цвет. Значения этих свойств кодируются и сохраняются в видеопамяти компьютера.
Качество изображения зависит от пространственного разрешения и глубины цвета.
Разрешение — величина, определяющая количество точек (пикселей) на единицу площади.
Глубина цвета — объем памяти (в битах), используемой для хранения и представления цвета при кодировании одного пикселя растровой графики или видеоизображения.
Для графических изображений могут использоваться различные палитры — наборы цветов. Количество цветов N в палитре и количество информации I, необходимое для кодирования цвета каждой точки, связаны соотношением: N = 2 I
Например, для черно–белого изображения палитра состоит из двух цветов. Можно вычислить, какое количество информации необходимо, чтобы закодировать цвет каждой точки (пикселя): 2 = 2 I —> Iпикселя = 1 бит
Чтобы определить информационный объем видеоизображения, необходимо умножить количество информации одного пикселя на количество пикселей в изображении: I = Iпикселя • X • Y, где Х — количество точек изображения по горизонтали, Y — количество точек изображения по вертикали.
Существует несколько цветовых моделей для количественного описания цвета. В основе модели RGB (сокращение от англ. Red, Green, Blue) лежат три основных цвета: красный, зеленый и синий. Все другие цвета создаются с помощью смешения их оттенков. Например, при смешивании красного и зеленого цветов получим желтый, красного и синего — пурпурный, зеленого и синего — бирюзовый. Если смешать все три основные цвета максимальной яркости, получим белый цвет.
Если один цвет имеет 4 оттенка, то общее количество цветов в модели RGB будет составлять 4 • 4 • 4 = 64. При 256 оттенках для каждого цвета общее количество возможных цветов будет равно 256 • 256 • 256 = 16 777 216 ≈ 16,7 млн.
В современных компьютерах для представления цвета обычно используются от 2–х до 4–х байт. Два байта (16 бит) позволяют различать 2 16 , то есть 65 536 цветов и оттенков. Такой режим представления изображений называется High Color. Четыре байта (32 бита) обеспечивают цветную гамму в 2 32 , то есть 4 294 967 296 цветов и оттенков (приблизительно 4,3 миллиарда). Такой режим называется True Color.
В графических редакторах применяются и другие цветовые модели. Например, модель CMYK — она основана на цветах, получающихся при отражении белого света от предмета: бирюзовом (англ. Cyan), пурпурном (англ. Magenta), желтом (англ. Yellow). Эта модель применяется в полиграфии, где чаще всего употребляется черный цвет (ключевой, англ. Key).

Измерение объемов звуковой информации
Звук является непрерывным сигналом. Для использования звука в компьютере его преобразуют в цифровой сигнал. Это преобразование называется дискретизацией: для кодирования звука производят его измерение с определенной частотой (несколько раз в секунду). частота дискретизации и точность представления измеренных значений определяют качество представления звука в компьютере. Чем выше частота дискретизации и чем больше количество разных значений, которыми можно характеризовать сигнал, тем выше качество отображения звука.
В современных компьютерах обычно применяется частота дискретизации в 22 кГц или 44,1 кГц (1 кГц — это тысяча измерений за 1 секунду), а для представления значения сигнала выделяются 2 байта (16 бит), что позволяет различать 2 16 , то есть 65 536 значений.
Конспект урока по информатике «Объем памяти для хранения объектов».

В файле разбираются задачи на определение информационного объема текстового документа. Приведены необходимые формулы для решения задач. Приведены объяснения к формулам. Далее приведены тексты задач для самостоятельного решения.
В текстовом режиме экран монитора компьютера обычно разбивается на 25 строк по 80 символов в строке определить определите объем текстовой информации занимающей весь экран монитора в кодировке Unicode?
В текстовом режиме экран монитора компьютера обычно разбивается на 25 строк по 80 символов в строке определить определите объем текстовой информации занимающей весь экран монитора в кодировке Unicode.

Сайт учителя информатики. Технологические карты уроков, Подготовка к ОГЭ и ЕГЭ, полезный материал и многое другое.
§ 4.6. Оценка количественных параметров текстовых документов
Информатика. 7 класса. Босова Л.Л. Оглавление
4.6.1. Представление текстовой информации в памяти компьютера
Текст состоит из символов — букв, цифр, знаков препинания и т. д., которые человек различает по начертанию. Компьютер различает вводимые символы по их двоичному коду. Вы нажимаете на клавиатуре символьную клавишу, и в компьютер поступает определённая последовательность электрических импульсов разной силы, которую можно представить в виде цепочки из восьми нулей и единиц (двоичного кода).
Мы уже говорили о том, что разрядность двоичного кода i и количество возможных кодовых комбинаций N связаны соотношением: 2 i = N. Восьмиразрядный двоичный код позволяет получить 256 различных кодовых комбинаций: 2 8 = 256.
С помощью такого количества кодовых комбинаций можно закодировать все символы, расположенные на клавиатуре компьютера, — строчные и прописные русские и латинские буквы, цифры, знаки препинания, знаки арифметических операций, скобки и т. д., а также ряд управляющих символов, без которых невозможно создание текстового документа (удаление предыдущего символа, перевод строки, пробел и др.).
Соответствие между изображениями символов и кодами символов устанавливается с помощью кодовых таблиц.
Все кодовые таблицы, используемые в любых компьютерах и любых операционных системах, подчиняются международным стандартам кодирования символов.
Кодовая таблица содержит коды для 256 различных символов, пронумерованных от О до 255. Первые 128 кодов во всех кодовых таблицах соответствуют одним и тем же символам:
• коды с номерами от О до 32 соответствуют управляющим символам;
• коды с номерами от 33 до 127 соответствуют изображаемым символам — латинским буквам, знакам препинания, цифрам, знакам арифметических операций и т. д.
Эти коды были разработаны в США и получили название ASCII (American Standart Code for Information Interchange — Американский стандартный код для обмена информацией).
В таблице 4.1 представлен фрагмент кодировки ASCII.

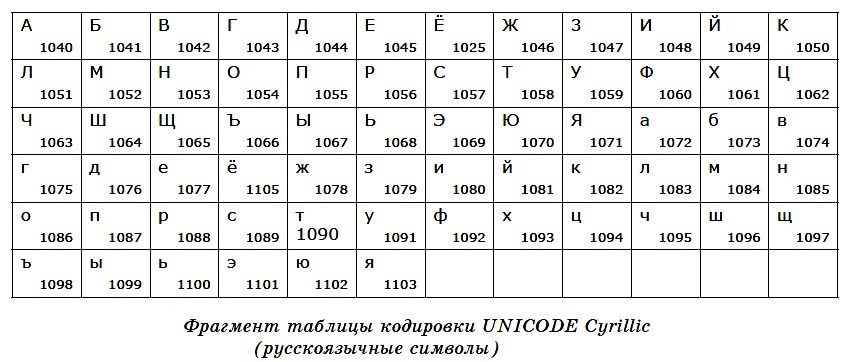
Коды с номерами от 128 до 255 используются для кодирования букв национального алфавита, символов национальной валюты и т. п. Поэтому в кодовых таблицах для разных языков одному и тому же коду соответствуют разные символы. Более того, для многих языков существует несколько вариантов кодовых таблиц (например, для русского языка их около десятка!).
В таблице 4.2 представлены десятичные и двоичные коды нескольких букв русского алфавита в двух различных кодировках.

Например, последовательности двоичных кодов
11010010 11000101 11001010 11010001 11010010
в кодировке Windows будет соответствовать слово «ТЕКСТ», а в кодировке КОИ-8 — бессмысленный набор символов «рейяр».
Как правило, пользователь не должен заботиться о перекодировании текстовых документов, так как это делают специальные про- граммы-конверторы, встроенные в операционную систему и приложения.
Восьмиразрядные кодировки обладают одним серьёзным ограничением: количество различных кодов символов в этих кодировках недостаточно велико, чтобы можно было одновременно пользоваться более чем двумя языками. Для устранения этого ограничения был разработан новый стандарт кодирования символов, получивший название Unicode. В Unicode каждый символ кодируется шестнадцатиразрядным двоичным кодом. Такое количество разрядов позволяет закодировать 65 536 различных символов:
Первые 128 символов в Unicode совпадают с таблицей ASCII; далее размещены алфавиты всех современных языков, а также все математические и иные научные символьные обозначения. С каждым годом Unicode получает всё более широкое распространение.
• «Клавиатура ПЭВМ: принципы работы; устройство клавиши» (134923),
• «Клавиатура ПЭВМ: принципы работы; сканирование клавиш» (135019),
• «Клавиатура ПЭВМ: формирование кода введенного символа» (134868),
которые помогут вам наглядно увидеть, как формируется код символа, введённого с клавиатуры.
4.6.2. Информационный объём фрагмента текста
В зависимости от разрядности используемой кодировки информационный вес символа текста, создаваемого на компьютере, может быть равен:
• 8 битов (1 байт) — восьмиразрядная кодировка;
• 16 битов (2 байта) — шестнадцатиразрядная кодировка.
Информационным объёмом фрагмента текста будем называть количество битов, байтов или производных единиц (килобайтов, мегабайтов и т. д.), необходимых для записи этого фрагмента заранее оговорённым способом двоичного кодирования.
Задача 1. Считая, что каждый символ кодируется одним байтом, определите, чему равен информационный объём следующего высказывания Жан-Жака Руссо:
Тысячи путей ведут к заблуждению, к истине — только один.
Решение. В данном тексте 57 символов (с учётом знаков препинания и пробелов). Каждый символ кодируется одним байтом. Следовательно, информационный объём всего текста — 57 байтов.
Ответ: 57 байтов.
Задача 2. В кодировке Unicode на каждый символ отводится два байта. Определите информационный объём текста из 24 символов в этой кодировке.
Решение. I = 24 • 2 = 48 байтов.
Ответ: 48 байтов.
Ответ: 2 Кб.
Задача 4. Выразите в мегабайтах объём текстовой информации в «Современном словаре иностранных слов» из 740 страниц, если на одной странице размещается в среднем 60 строк по 80 символов (включая пробелы). Считайте, что при записи использовался алфавит мощностью 256 символов.
Решение. Информационный вес символа алфавита мощностью 256 равен восьми битам (одному байту). Количество символов во всём словаре равно 740 • 80 • 60 = 3 552 ООО. Следовательно, объём этого текста в байтах равен 3 552 ООО байтов = 3 468,75 Кбайт ? 3,39 Мбайт.
Ответ: 3,39 Мбайт.
Окно текстового редактора содержит 25 строк по 60 символов в строке?
Окно текстового редактора содержит 25 строк по 60 символов в строке.
Окно графического редактора, работающего в двухцветном режиме - 80 х 25 пикселей.
Сравнить объемы памяти, необходимые для хранения текста, занимающего все окно текстового редактора, и для кодирования картинки, занимающей все рабочее поле графического редактора.
Для кодирования текста используется таблица кодировки, состоящая из 256 символов.

7. Текстовый файл?
7. Текстовый файл.
Паскаль АВС Описать функцию, которая находит максимальную длину строк текстового файла t.
Реализовать программу, определяющую длину (количество символов) в самой длинной строке произвольного текстового файла с использованием этой функции.
САМОЕ ГЛАВНОЕ
Текст состоит из символов — букв, цифр, знаков препинания и т. д., которые человек различает по начертанию. Компьютер различает вводимые символы по их двоичному коду. Соответствие между изображениями и кодами символов устанавливается с помощью кодовых таблиц.
В зависимости от разрядности используемой кодировки информационный вес символа текста, создаваемого на компьютере, может быть равен:
• 8 битов (1 байт) — восьмиразрядная кодировка;
• 16 битов (2 байта) — шестнадцатиразрядная кодировка.
Информационный объём фрагмента текста — это количество битов, байтов (килобайтов, мегабайтов), необходимых для записи фрагмента оговорённым способом кодирования.
На экране монитора , работающего в текстовом режиме , текст расположен в 20 строках по 64 символа в строке?
На экране монитора , работающего в текстовом режиме , текст расположен в 20 строках по 64 символа в строке.
Какой объем занимает этот текст в памяти компьютера , если используется 256 символьный алфавит?
Разрешающая способность монитора 640х200?
Разрешающая способность монитора 640х200.
Для размещения одного символа в текстовом режиме используется матрица 8х8 пикселей, которая называется знакоместом.
Какое максимальное количество текстовых строк может быть размещено на экране ?
Вы находитесь на странице вопроса Разрешающая способность дисплея равна 640 х 200? из категории Информатика. Уровень сложности вопроса рассчитан на учащихся 5 - 9 классов. На странице можно узнать правильный ответ, сверить его со своим вариантом и обсудить возможные версии с другими пользователями сайта посредством обратной связи. Если ответ вызывает сомнения или покажется вам неполным, для проверки найдите ответы на аналогичные вопросы по теме в этой же категории, или создайте новый вопрос, используя ключевые слова: введите вопрос в поисковую строку, нажав кнопку в верхней части страницы.
Просмотр содержимого документа
«Решение задач на определение информационного объема текста»
Задачи на определение информационного объема текста
Проверяется умение оценивать количественные параметры информационных объектов.
Теоретический материал:
N = 2 i , где N – мощность алфавита (количество символов в используемом
алфавите),
i – информационный объем одного символа (информационный
вес символа), бит
I = K*i, где I – информационный объем текстового документа (файла),
K – количество символов в тексте

Считаем количество символов в заданном тексте (перед и после тире – пробел, после знаков препинания, кроме последнего – пробел, пробел – это тоже символ). В результате получаем – 52 символа в тексте.
Решение:
I = 52*16бит = 832бит (такой ответ есть - 2)

K = 16*35*64 – количество символов в статье
Решение: Чтобы перевести ответ в Кбайты нужно разделить результат на 8 и на 1024 (8=2 3 , 1024=2 10 )

I=16*35*64*8 бит==35Кбайт Ответ: 4

Пусть x – это количество строк на каждой странице, тогда K=10*x*64 – количество символов в тексте рассказа.
Переведем информационный объем текста из Кбайт в байты.
I = 15 Кбайт = 15*1024 байт (не перемножаем)
Подставим все данные в формулу для измерения количества информации в тексте.
Выразим из полученного выражения x

x = – количество строк на каждой странице – 4
Задачи для самостоятельного решения:








-80%
Статья, набранная на компьютере, содержит 16 страниц, на каждой странице 30 строк, в каждой строке 32 символа. Определите информационный объём статьи в одной из кодировок Unicode, в которой каждый символ кодируется 16 битами.
1) 24 Кбайт 2) 30 Кбайт 3) 480 байт 4) 240 байт
Найдем общее количество символов на одной странице, для этого умножим количество строк на странице на количество символов в строке — 30 * 32 = 960 символов.
Найдем общее количество символов во всем тексте, для этого умножим количество страниц на количество символов на одной странице — 16 * 960 = 15360 символов.
Так как каждый символ кодируется 16 битами, а 16 бит = 2 байта, то весь текст займет 15360 * 2 байта = 30720 байта. Как видим, из предложенных вариантов ответа в байтах полученного нами нет, поэтому переведем полученный результат в килобайты. Для этого разделим 30720 на 1024: 30720 / 1024 = 30Кбайт.
Правильный ответ 2) 30Кбайт.
Статья, набранная на компьютере, содержит 8 страниц, на каждой странице 40 строк, в каждой строке 64 символа. В одном из представлений Unicode каждый символ кодируется 16 битами. Определите информационный объём статьи в этом варианте представления Unicode.
1) 320 байт 2) 35 Кбайт 3) 640 байт 4) 40 Кбайт
Аналогично предыдущей задаче найдем количество символов на одной странице — 40 * 64 = 2560.
Общее количество символов в статье — 2560 * 8 = 20480 символов.
Каждый символ кодируется 16 битами или 2 байтами (1 байт = 8 бит). Значит вся статья займет 20480 * 2 байта = 40960 байт.
Полученного результата в вариантах ответа нет, поэтому переведем полученное значение в килобайты, разделив его на 1024: 40960 / 1024 = 40Кбайт.
Правильный ответ 4) 40 Кбайт.
1) 10 2) 16 3) 20 4) 160
160 / 8 = 20 символов.
Правильный ответ 3) 20.
В одной из кодировок Unicode каждый символ кодируется 16 битами. Определите размер следующего предложения в данной кодировке.
Я к вам пишу – чего же боле? Что я могу ещё сказать?
1) 52 байт 2) 832 бит 3) 416 байт 4)104 бит
Для начала посчитаем количество символов в предложении. Именно символов, не букв! То есть знак пробела, знак вопроса мы тоже считаем. В итоге у нас получается 52 символа. Из условия известно, что каждый символ кодируется 16 битами. Значит, чтобы найти информационный объем всего предложения, мы должны умножить 52 на 16.
52 * 16 = 832 бита.
Среди вариантов ответа есть найденный нами. Правильный ответ 2.
В одной из кодировок Unicode каждый символ кодируется 16 битами. Определите информационный объем следующего предложения в данной кодировке.
Я памятник себе воздвиг нерукотворный.
1) 76 бит 2) 608 бит 3) 38 байт 4) 544 бит
Принцип решения подобного класса задач остается прежним — посчитать количество символов и умножить полученное число на информационный объем одного символа. В условии сказано, что каждый символ кодируется 16 битам (рекомендую ознакомиться со статьей кодирование текста для понимания принципов хранения текста в памяти компьютера). Итак, считаем количество символов в строке. Напомню очередной раз, что пробелы, знаки препинания — это тоже символы и их тоже надо считать. В предложении 38 символов. Умножив 38 символов на 16 бит получим 608 бит. В предложенных вариантах такой встречается, значит правильный ответ — 2
Задача 1.
Считая, что каждый символ кодируется одним байтом, определите, чему равен информационный объём следующего высказывания Жан-Жака Руссо:
Тысячи путей ведут к заблуждению, к истине — только один.
Решение:
В данном тексте 57 символов (с учётом знаков препинания и пробелов). Каждый символ кодируется одним байтом. Следовательно, информационный объём всего текста — 57 байтов.
Ответ: 57 байтов.
Задача 2.
В кодировке Unicode на каждый символ отводится два байта. Определите информационный объём слова из 24 символов в этой кодировке.
Решение:
I = 24 • 2 = 48 (байтов).
Ответ: 48 байтов.
Задача 4.
Выразите в мегабайтах объём текстовой информации в «Современном словаре иностранных слов» из 740 страниц, если на одной странице размещается в среднем 60 строк по 80 символов (включая пробелы). Считайте, что при записи использовался алфавит мощностью 256 символов.
Решение:
Информационный вес символа алфавита мощностью 256 равен восьми битам (одному байту). Количество символов во всём словаре равно 7 40 • 80 • 60 = 3 552 000. Следовательно, объём этого текста в байтах равен 3 552 000 байтов = 3 468,75 Кбайт ≈ 3,39 Мбайт.
Ответ: 3,39 Мбайт.
Самое главное:
В зависимости от разрядности используемой кодировки информационный вес символа текста, создаваемого на компьютере, может быть равен:
8 битов (1 байт) — восьмиразрядная кодировка;
16 битов (2 байта) — шестнадцатиразрядная кодировка.
Информационный объём фрагмента текста — это количество битов, байтов (килобайтов, мегабайтов), необходимых для записи фрагмента оговорённым способом кодирования.
Вопросы и задания:
Считая, что каждый символ кодируется одним байтом, определите, чему равен информационный объём следующего высказывания Алексея Толстого:
Не ошибается тот, кто ничего не делает, хотя это и есть его основная ошибка.
1) 512 битов 2) 608 битов 3) 8 Кбайт 4) 123 байта
(Всего символов в высказывании — 76. Поскольку на один символ отводится 1 байт, то объем высказывания равен 76 (байт) = 608 (бит). Правильный ответ: 2)
Считая, что каждый символ кодируется 16 битами, оцените информационный объем следующей фразы А. С. Пушкина в кодировке Unicode:
Привычка свыше нам дана: Замена счастию она.
1) 44 бита 2) 704 бита 3) 44 байта 4) 704 байта
(Всего символов во фразе — 44. Поскольку на один символ отводится 2 байта, то объем высказывания равен 88 (байт) = 704 (бит). Правильный ответ: 2)
В текстовом режиме экран монитора компьютера обычно разбивается на 25 строк по 80 символов в строке. Определите объём текста, занимающего весь экран монитора, в кодировке Unicode.
(Решение:
В кодировке Unicode каждый символ кодируется 2 байтами. На экран влезает 25 • 80 = 2000 символов. Соответственно, объем текста равен 2000 • 2 = 4000 (байт) ≈ 3,9 (Кбайт)
Ответ: 4000 байт)
Рассчетные задачи по теме:
В кодировке Unicode на каждый символ отводится 2 байта. Определите информационный объем слова из двадцати четырех символов в этой кодировке.
Объем равен 24*2байта = 48 байт = 48* 8 бит = 384 бита
16*n = 8*n + 480, 8*n = 480, n = 60.
. Считая,что каждый символ кодируется одним байтом, определите, чему равен информационный объем следующего высказывания Рене Декарта:
Я мыслю, следовательно, существую.
Решение: 34 символа, на 1 символ 1 байт, т. е. 34*1=34 байта = 272 бита
2. В кодировке Unicode на каждый символ отводится два байта. Определите информационныйобъем слова из двадцати четырех символов в этой кодировке.
Решение: 24 символа на каждый 2 байта, 24*2= 48 байт = 384 бита
Решение: 40960/8=5120 / 1024 = 5 Кбайт
8. Символы кодируются 8 битами. Сколько Кбайт памяти потребуется для сохранения 160 страниц текста, содержащего в среднем 192 символа на каждой странице?
Решение: 8 * 160*192 = 245760 / 8 = 30720 / 1024 = 30
Решение: 11 Кбайт = 11264 байта = 90112 бит/5632 = 16 бит на символ = 2 байта
10. Статья, набранная на компьютере, содержит 8 страниц, на каждой странице 40 строк, в каждой строке 64 символа. В одном из представлений Unicode каждый символ кодируется 16 битами. Определите информационный объём статьи в этом варианте представления Unicode.
Решение: 8*40*64*16 = 327680 бит = 40960 байт = 40 Кбайт
11. Рассказ, набранный на компьютере, содержит 4 страницы, на каждой странице 48 строк, в каждой строке 64 символа. Определите информационный объём рассказа в кодировке КОИ-8, в которой каждый символ кодируется 8 битами.
Для размещения одного символа в текстовом режиме используется матрица 8x8 пикселей, которая называется знакоместом.
Какое максимальное количество :
1) текстовых строк,
2) знакомест в строке может быть размещено на экране?

1. 200÷ 8 = 25 текстовых строк.
2. 640÷ 8 = 80 знакомест.

Разрешающая способность экрана равна 1024х840 пикселей?
Разрешающая способность экрана равна 1024х840 пикселей.
Для размещения одного символа в текстовом режиме используется матрица 16х16 / Какое максимальное количество строк может быть размещено на экране?

Задание с кратким ответом?
Задание с кратким ответом.
В текстовом режиме экран монитора обычно разбивается на 25 строк по 80 символов в строке.
Определите объем текстовой информации, занимающей весь экран монитора, в кодировке UNICODE.
Создать текстовый документ с помощью Паскаля, в котором N строк и M символов в строке, и символы - цифры 1, 2?
Создать текстовый документ с помощью Паскаля, в котором N строк и M символов в строке, и символы - цифры 1, 2.

Читайте также: