
Какая должна быть задержка памяти ns
На заре вычислительной техники динамическая память вполне себе работала на частоте процессора. Мой первый опыт работы с компьютером был связан с клоном компьютера «ZX Spectrum». Процессор Z80 осуществлял обработку инструкций в среднем по 4 такта на операцию, при этом два такта использовалось на осуществление регенерации динамической памяти, что дает нам при частоте в 3,5 МГц, не более 875 000 операций в секунду.
Однако спустя некоторое время частоты процессоров достигли такого уровня, когда динамическая память уже не справлялась с нагрузкой. Для компенсации этого, было введено промежуточное звено в виде кэш-памяти, что позволило за счет операций выполняемых на небольшом объеме данных сгладить разницу в скорости работы процессора и основной памяти.
Давайте рассмотрим что представляет из себя оперативная память компьютера сейчас, и что с ней можно сделать, чтобы увеличить быстродействие компьютерной системы.
Вкратце о статической и динамической памяти
Память строится в виде таблицы, состоящей из строк и столбцов. В каждой ячейке таблицы находится информационный бит (мы обсуждаем полупроводниковую память, впрочем множество других реализаций строиться по тому же принципу). Каждая такая таблица называется «банком». В микросхеме/модуле может размещаться несколько банков. Совокупность модулей памяти проецируется в линейное адресное пространство процессора в зависимости от разрядности отдельных элементов.
Ячейка статической памяти строится на основе триггера, который обычно находиться в одном из стабильных состояний «А» или «Б»(А =! Б). Минимальное количество транзисторов для одной ячейки составляет 6 штук, при этом сложность трассировки в ячейках видимо не позволяет сделать модули статической памяти в 1 гиг, по цене обычного модуля в 8 гиг.
Ячейка динамической памяти состоит из одного конденсатора отвечающего за хранение информации и одного транзистора отвечающего за изоляцию конденсатора от шины данных. При этом в качестве конденсатора используется не навесной электролит, а паразитная емкость p-n перехода между «подложкой» и электродом транзистора (специально для этих целей увеличенная, обычно от нее стараются избавиться). Недостатком конденсатора является ток утечки (как в нем самом, так и в ключевом транзисторе) от которого очень сложно избавиться, кроме того с увеличением температуры он увеличивается что влечет вероятность искажения хранимой информации. Для поддержки достоверности, в динамической памяти применяется «регенерация», она заключается в периодическом обновлении хранимой информации не реже заданного периода в течении которого информация сохраняет достоверное значение. Типовой период регенерации составляет 8 мс, при этом чаще обновлять информацию можно, реже не рекомендуется.
В остальном принцип функционирования идентичен и заключается в следующем:
— первоначальная выборка строки памяти приводит к доступу ко всему ее содержимому помещаемому в буферную строку с которой идет дальнейшая работа, или происходит мультиплексирование обращения к столбцам (старый, медленный подход);
— запрошенные данные передаются к главному устройству (обычно это ЦПУ), или происходит модификация заданных ячеек при операции записи (тут есть небольшая разница, для статической памяти возможна непосредственная модификация ячейки выбранной строки, для динамической памяти модифицируется буферная строка, и только потом выполняется обратная запись содержимого всей строки в специальном цикле);
— закрытие и смена строки памяти так-же различна для разного типа памяти, для статической возможна мгновенная смена строки если данные не менялись, для динамической памяти необходимо содержимое буферной строки обязательно записать на место, и только потом можно выбрать другую строку.
Если на заре вычислительной техники каждая операция чтения или записи завершалась полным циклом памяти:
— выбор строки;
— операция чтения/записи из ячейки;
— смена/перевыбор строки.
Современный операции работы с микросхемами «синхронной памяти а ля DDRX» заключается в следующем:
— выбор строки;
— операции чтения/записи ячеек строки группами по 4-8 бит/слов (допускается множественное обращение в рамках одной строки);
— закрытие строки с записью информации на место;
— смена/перевыбор строки.
Такое решение позволило сэкономить время доступа к данным когда после чтения значения из ячейки «1», требуется обращение к ячейкам «2, 3, 4, или 7» расположенным в той-же строке, либо сразу после операции чтения, необходимо записать назад измененное значение.
Подробнее о работе динамической памяти в союзе с кэшем
Контроллер памяти (в чипсете или встроенный в процессор) выставляет адрес блока и номер строки (старшую часть адреса блока) в микросхему/модуль памяти. Выбирается соответствующий блок (дальше будет рассматриваться работа в рамках одного блока) и полученный «двоичный номер» декодируется в позиционный адрес строки, после чего происходит передача информации в буфер, из которого в последствии осуществляется доступ к данным. Время в тактах необходимое на данную операцию называется tRCD и отображается в схемах «9-9-9/9-9-9-27» на втором месте.
После того как строка активизирована можно обращаться к «столбцам» для этого контроллер памяти передает адрес ячейки в строке, и спустя время «CL» (указывается в выше обозначенной схеме «х-х-х» на 1 месте) данные начинают передаваться от микросхемы памяти в процессор (почему во множественном числе? потому что здесь вмешивается КЭШ) в виде пакета из 4-8 бит (для отдельно взятой микросхемы) в строку кэша (размер зависит от процессора, типовое значение 64 байта — 8 слов по 64 бита, но встречаются и другие значения). Спустя определенное количество тактов, необходимых для передачи пакета данных можно сформировать следующий запрос на чтение данных из других ячеек выбранной строки, или выдать команду на закрытие строки которая выражается в виде tRP указанное в виде третьего параметра из «х-х-х-. ». Во время закрытия строки, данные из буфера записываются обратно в строку блока, после окончания записи можно выбрать другую строку в данном блоке. Кроме этих трех параметров есть минимальное время в течении которого строка должна быть активна «tRAS», и минимальное время полного цикла работы со строкой разделяющего две команды по активизации строки (влияет на случайный доступ).
grossws 19 апреля 2016 в 12:40
CL — CAS latency, tRCD — RAS to CAS delay, tRP — row precharge, CAS — column address strobe, RAS — row address strobe.
Быстродействие полупроводниковой техники определяется задержками элементов схемы. Для того чтобы на выходе получить достоверную информацию, необходимо выждать определенное время для того чтобы все элементы приняли устойчивое состояние. В зависимости от текущего состояния банка памяти меняется время доступа к данным, но в целом можно охарактеризовать следующие переходы:
Если блок находится в состоянии покоя (нет активной строки), контроллер выдает команду выбора строки, в результате двоичный номер строки преобразуется в позиционный номер, и происходит чтение содержимого строки за время «tRCD».
После того как содержимое строки было считано в буферную зону, можно выдавать команду выбора столбца, по которой двоичный номер столбца преобразуется в позиционый номер, за время «CL», но в зависимости от выравнивания младших адресов может поменяться очередность передачи бит.
Перед тем как сменить/закрыть строку, необходимо записать данные на место, так как во время чтения, информация была фактически уничтожена. Время необходимое на восстановление информации в строке «tRP».
По полной спецификации для динамической памяти есть еще множество временных параметров определяющих очередность и задержки изменения управляющих сигналов. Одним из таких является «tRCmin» определяющее минимальное время полного цикла строки, включающее в себя: выбор строки, доступ к данным и обратную запись.
Сигнал RAS определяет факт выдачи адреса строки;
Сигнал CAS определяет факт выдачи адреса столбца.
Если раньше все управление перекладывалось на сторону контроллера памяти и управлялось данными сигналами, то сейчас идет режим команд, когда в модуль/микросхему выдается команда, а спустя некоторое время идет передача данных. Более подробно лучше ознакомиться в спецификации стандарта, например DDR4.
Если говорить о работе с dram в общем, то при массовом чтении она обычно выглядит следующим образом:
выставили адрес строки,
выставили RAS (и через такт сняли),
выждали tRCD,
выставили адрес колонки с которой читаем (и каждый следующий такт выставляем следующий номер колонки),
выставили CAS,
выждали CL, начали читать данные,
сняли CAS, прочитали остаток данных (ещё CL тактов).
При переходе не следующий ряд делается precharge (RAS + WE), выжидается tRP, выполняется RAS с установленным адресом строки и далее выполняется чтение как описано выше.
Latency чтения случайной ячейки естественным образом вытекает из описанного выше: tRP + tRCD + CL.
Нужно обязательно помнить что у оперативной памяти DDR есть две частоты:
— основная тактовая частота определяющая темп передачи команд и тайминги;
— эффективная частота передачи данных (удвоенная тактовая частота, которой и маркируются модули памяти).
Интеграция контроллера памяти увеличило быстродействия подсистемы памяти за счет отказа от промежуточного передающего звена. Увеличение каналов памяти требудет учитывать это со стороны приложения, так например четырех канальный режим при определенном расположении файлов не дает прироста производительности (12 и 14 конфигурации).
Обработка одного элемента связного списка с разным шагом (1 шаг = 16 байт)
Теперь немного математики
Процессор: рабочие частоты процессоров сейчас достигают 5 ГГц. По заявлениям производителей, схемотехнические решения (конвейеры, предсказания и прочие хитрости) позволяют выполнять одну инструкцию за такт. Для округления расчетов возьмем значение тактовой частоты в 4 ГГц что даст нам одну операцию за 0,25 нс.
Оперативная память: возьмем для примера оперативную память нового формата DDR4-2133 с таймингом 15-15-15.
процессор
Fтакт = 4 ГГц
Tтакт = 0,25 нс (по совместительству время выполнения одной операции «условно»)
Оперативная память DDR4-2133
Fтакт = 1066 МГц
Fдата = 2133 МГц
tтакт = 0,94 нс
tдата = 0,47 нс
СПДмакс = 2133 МГц * 64 = 17064 Мбайт/с (скорость передачи данных)
tRCmin = 50 нс (минимальное время между двумя активациями строк)
Время получения данных
Из регистров и кэша, данные могут быть предоставлены в течении рабочего такта (регистры, кэш 1 уровня) или с задержкой в несколько тактов процессора для кэша 2-го и 3-го уровня.
Для оперативной памяти ситуация похуже:
— время выбора строки составляет: 15 clk * 0,94 нс = 14 нс
— время до получения данных с команды выбора столбца: 15 clk * 0,94 нс = 14 нс
— время закрытия строки: 15 clk * 0,94 нс = 14 нс (кто бы подумал)
Из чего следует что время между командой запрашивающей данные из ячейки памяти (в случае если в кэш не попали) может варьироваться:
14 нс — данные находятся в уже выбранной строке;
28 нс — данные находятся в невыбранной строке при условии что предыдущая строка уже закрыта (блок в состоянии «idle»);
42-50 нс — данные находятся в другой строке, при этом текущая строка нуждается в закрытии.
Количество операций которые может выполнить (вышеобозначенный) процессор за это время составляет от 56 (14 нс) до 200 (50 нс смена строки). Отдельно стоить отметить что ко времени между командой выбора столбца и получением всего пакета данных добавляется задержка загрузки строки кэша: 8 бит пакета * 0,47 нс = 3,76 нс. Для ситуации когда данные будут доступны «программе» только после загрузки строки кэша (кто знает что и как там накрутили разработчики процессоров, память по спецификации позволяет выдать нужные данные вперед), мы получаем еще до 15-и пропущенных тактов.
В рамках одной работы я проводил исследование скорости работы памяти, полученные результаты показали, что полностью «утилизировать» пропускную способность памяти возможно только в операциях последовательного обращения к памяти, в случае произвольного доступа увеличивается время обработки (на примере связного списка из 32-х битного указателя и трех двойных слов одно из которых обновляется) с 4-10 (последовательный доступ) до 60-120 нс (смена строк) что дает разницу в скорости обработки в 12-15 раз.
Скорость обработки данных
Для выбранного модуля имеем пиковую пропускную способность в 17064 Мбайт/с. Что для частоты в 4 ГГц дает возможность обрабатывать за такт 32-х битные слова (17064 Мб / 4000 МГц = 4,266 байт на такт). Здесь накладываются следующие ограничения:
— без явного планирования загрузки кэша, процессор будет вынужден простаивать (чем выше частота, тем больше ядро просто ждет данные);
— в циклах «чтение модификация запись» скорость обработки снижается в два раза;
— многоядерные процессоры разделят между ядрами пропускную способность шины памяти, а для ситуации когда будут конкурирующие запросы (вырожденный случай), производительность работы памяти может ухудшиться в «200 раз (смена строк) * Х ядер».
17064 Мбайт/с / 8 ядер = 2133 Мбайт/с на ядро в оптимальном случае.
17064 Мбайт/с / (8 ядер * 200 пропущенных операций) = 10 Мбайт/с на ядро для вырожденного случая.
На мой взгляд медленно как-то. По сравнению с памятью DDR3-1333 9-9-9, где время полного цикла примерно равно 50 нс, но отличаются время таймингов:
— время доступа к данным уменьшается до 13,5 нс (1,5 нс * 9 тактов);
— время передачи пакета из восьми слов 6 нс (0,75 * 8 вместо 3.75 нс) и при случайном доступе к памяти, разница в скорости передачи данных практически исчезает;
— пиковая скорость составит 10 664 МБайт/с.
Не слишком все далеко ушло. Ситуацию немного спасает наличие в модулях памяти «банков». Каждый «банк» представляет собой отдельную таблицу памяти к которой можно обращаться раздельно, что дает возможность сменить строку в одном банке пока идет чтение/запись данных из строки другого, за счет уменьшения простоя позволяет «забить» шину обмена данными под завязку в оптимизированных ситуациях.
Собственно здесь пошли нелепые идеи
Таблица памяти, содержит в себе заданное количество столбцов, равное 512, 1024, 2048 бит. С учетом времени цикла по активации строк в 50 нс, мы получаем потенциальную скорость обмена данными: «1/0,00000005 с * 512 столбцов * 64 бит слово = 81 920 Мбайт/с» вместо текущих 17 064 Мбайт/с (163 840 и 327 680 МБайт/с для строк из 1024 и 2048 столбцов). Скажете: «всего раз в 5 (4,8) быстрее», на что я отвечу: «это скорость обмена, когда все конкурирующие запросы обращены к одному банку памяти, и доступная пропускная возможность увеличивается пропорционально количеству банков, и увеличением длины строки каждой таблицы (потребует увеличение длины операционной строки), что в свою очередь упирается главным образом в скорость шины обмена данными».
Смена режима обмена данными потребует передачи всего содержимого строки в кэш нижнего уровня, для чего надо разделить уровни кэша не только по скорости работы, но и по размеру кэш строки. Так например реализовав «длину» строки кэша N-го уровня в (512 столбцов * 64 размер слова) 32 768 бит, мы можем за счет уменьшения количества операций сравнения увеличить общее количество строк кэша и соответственно увеличить максимальный его объем. Но если сделать параллельную шину в кэше такого размера, мы можем получить уменьшение частоты функционирования, из чего можно применить другой подход организации кэша, если разбить указанную «Jumbo»-строку кэша на блоки по длине строки верхнего кэша и производить обмен с небольшими порциями, это позволит сохранить частоту функционирования, разделив задержку доступа на этапы: поиск строки кэша, и выборку нужного «слова», в найденной строке.
Оценим скорость такого канала:
1/0,00000005 нс = 20 МГц (частота смены строк в рамках одного блока)
20 Мгц * 32 768 бит = 655 360 Мбит/с
Для дифференциальной передачи с тем-же размером шины данных получаем:
655 360 Мбит/с / 32 канала = 20 480 Мбит/с на канал.
Такая скорость выглядит приемлемо для электрического сигнала (10 Гбит/с для сигнала со встроенной синхронизацией на 15 метров доступен, почему бы и 20 ГБит/с с внешней синхронизацией на 1 метр не осилить), однако необходимое дальнейшее увеличение скорости передачи для уменьшения задержки передачи между первым и последним битом информации, может потребовать увеличения пропускной способности, с возможной интеграцией оптического канала передачи, но это уже вопрос к схемотехникам, у меня маловато опыта работы с такими частотами.
и тут Остапа понесло
Изменение концепции проецирования кэша на основную память к использованию «основной памяти как промежуточного сверхбыстродействующего блочного накопителя» позволит переложить предсказание загрузки данных с схемотехники контроллера на алгоритм обработки (а уж кому лучше знать куда он ломанется через некоторое время, явно не контроллеру памяти), что в свою очередь позволит увеличить объем кэша внешнего уровня, без ущерба производительности.
Если пойти дальше можно дополнительно изменить концепцию ориентирования архитектуры процессора с «переключение контекста исполнительного устройства», на «рабочее окружение программы». Такое изменение может существенно улучшить безопасность кода через определение программы как набора функций с заданными точками входа отдельных процедур, доступным регионом размещения данных для обработки, и возможностью аппаратного контроля возможности вызова той или иной функции из других процессов. Такая смена позволит также эффективнее использовать многоядерные процессоры за счет избавления от переключения контекста для части потоков, а для обработки событий использовать отдельный поток в рамках доступного окружения «процесса», что позволит эффективнее использовать 100+ ядерные системы.
Материнская плата - MSI B450 Tomahawk Max
Память - 2x Crucial DDR4-3200 16384MB PC4-25600 Ballistix Sport LT
Аида выдает латентность 70.8 ns. В играх заметны фризы при быстром перемещении (установлены на SSD).
Всё, что выше 60 - по хорошему, высоковато. И в играх ощутимо весьма.
А вообще узнай чьи у тебя микросхемы в памяти и по калькулятору рязани настрой. Точно не помню, но кажется выключение Power Down mode дало -5ns.
Или procODT по калькулятору менял.
латентность тут не при чем, фризы из-за чего то другого.
70 - хороший, отличный показатель.
в биосе частота оперативки случаем не 2400? надо выбрать хмр профиль с 3200 или попробовать выставить тайминг , предварительно посчитав их с помощью проги ryzen dram calculator
upd, если выжал - снизь до 3200, вроде как дальше хуже, переразгон ничего не дает или даже ухудшает фпс
но фризы точно не с латентностью связаны
Выше 3600 там расхождение с infinity fabric начинается, и да, выше будет падение производительности.
3533 берет при латентности 69,5.
Хватит истерик. При чем здесь, вообще, латентность памяти? Что за бред вы несёте? У меня 3600х, с памятью 3600 на таймингах, согласно калькулятору без вторичек. Никаких фризов, ни в одной игре нет и в помине. Хотите узнать, что происходит с компом в момент фриза - качайте аиду (бизнес или экстрим эдишн) потом берём планшет на андроид, делаем из него рабочий стол и выводим на него окно с графиками из аиды. Уверен, что в этот момент, якобы фриза - частота проца на одном из ядер падает. Почему так? Так ведь биос настраивать нужно! Что с параметрами cool & quiet, c1e? И так далее? М? Какая Винда, сборка, чипсет драйвера, план электропитания? Антивирус какой?
Люди начитаются подобных постов и начинают ныть на форумах. Единственный грамотный комментарий затерялся где-то внизу - а он, на секунду, ведёт на статью на оверклокерс, авторства usmusa, который лучше всех разобрался в настройках материнок и процев ам4. Зачем на непрофильном ресурсе создавать слезные посты и сеять панику?
Проблема решилась. Фризы в Ведьмаке полечились откатом дров на видло до ноябрьских, а Vampyr просто не умеет в многопоток, поэтому нагрузка и скачет, а с ней и фризы. Ответственности с АМД я бы не снимал, ибо после успешного разгона по гайду, который ты кидал, не увидев профита, я было уж совсем отчаялся. Хорошо, что у меня на системе с интулом 7-ка стоит и все старые дрова под неё на флэшке есть. В NFS фризы существенно уменьшились после отключения буста. Надо еще пару игр затестить.

Для начала не паниковать. До 75 нс вполне нормальная латентность. Попробуйте для начала постепенно повысить частоту озу на 100 Мгц с обязательной перезагрузкой системы и так постепенно пока не догоните частоту до 3.200 или пока система не перестанет грузиться. Затем уже работайте с таймингами, но особо там не гонитесь. Достаточно выставить пасанский набор озу 16 - 18 - 16 - 16 - 36 - 56 и обязательно CR 1T переставьте на CR 2T, кто бы Вам ничего не говорил. CR2 она всегда снижает латентность. Уверен что достичь латентность 68 - 72 нс Вы по любому сможете. Можете и вовсе у меня все скопировать и напряжение выставить 1,35V на память.

Подскажи пожалуйста, данное значение для памяти ddr 4 2133мг норм? Просто я в этом не разбираюсь :\
Пользоваться компьютером, а если есть проблемы, то вопрос стоит задавать описывая конкретную проблему.
Задержка в памяти такая, какая есть, а не "высокая".
Eternally Against Искусственный Интеллект (238652) Саша Стеновьев, очень информативно. Что за игры, какие драйвера стоят на оборудование, ОС, настройки в играх?

попробуй такие тайминги

перестать пользоваться процем с ипанутым контролером памяти, Лиза Су клятвенно обещала, что в r5 4*** проблема с контролёром будет решена (правда она и при выходе r5 3*** тоже это обещала) . У R5 2600 и R 5 1600 контролеры памяти ни какие.
Поэтому и продолжаю пользоваться богопротивным интел 2013 г. в.
Но, Лиза Су, выполнила обещание. Она выпустила RyZen 5600X по цене 30к с божественной кольцевой шиной и сумасшедшим разгоном 4,6 ггц. Что же ты не радуешься?
Каждый компонент персонального компьютера вносит свой вклад в уровень итоговой производительности системы. Это и процессор, и видеокарта, и жёсткий диск, и конечно оперативная память. Главными характеристиками памяти является её тип, частота и тайминги.
Тайминги памяти — величина довольно абстрактная, это не секунды или миллисекунды. Это такты. Но главное (с чем напрямую связаны тайминги памяти) — это латентность памяти. Латентность памяти — время, затрачиваемое процессором на получение байта информации из оперативной памяти. В этой статье мы разберемся как понизить латентность оперативной памяти DDR4 для Ryzen.
Что лучше — латентность или частота работы памяти
Латентность оперативной памяти для Ryzen может быть вычислена с помощью специальных тестов производительности. На этикетке продаваемых модулей памяти величина затрачиваемого на обмен информацией времени между процессором и модулем памяти показана в виде набора таймингов. Основные из них: CL, TRCD, TRP и TRAS (для DDR4 TRAS неактуален), иногда к ним ещё добавляется пятый параметр — Command rate.
Частота влияет на пропускную способность памяти. Если для выполнения задачи достаточно и просто пропускной способности с запасом, то ещё больше ускорить выполнение такой задачи может помочь лишь снижение латентности памяти.
Также латентность играет важную роль в задачах, в которых нужен максимально быстрый отклик на действия пользователя или других программ.
7. Тестирование после снижения латентности
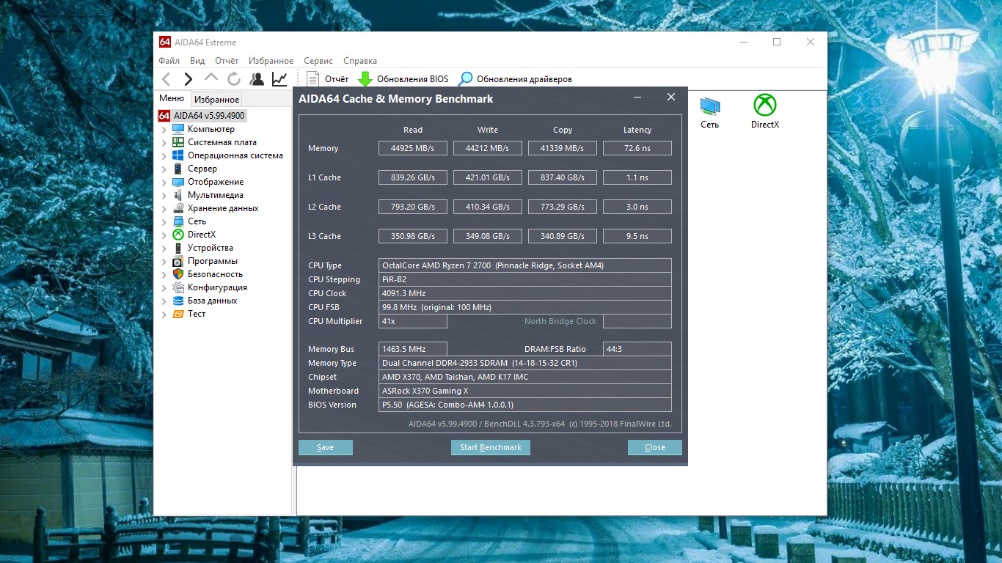
После выполнения всех тестов необходимо оценить результаты выполнения всех настроек функционирования оперативной памяти для снижения задержек чтобы понять насколько снизилась латентность оперативной памяти для Ryzen Для этого выполним вновь Тест кэша и памяти утилиты AIDA64:
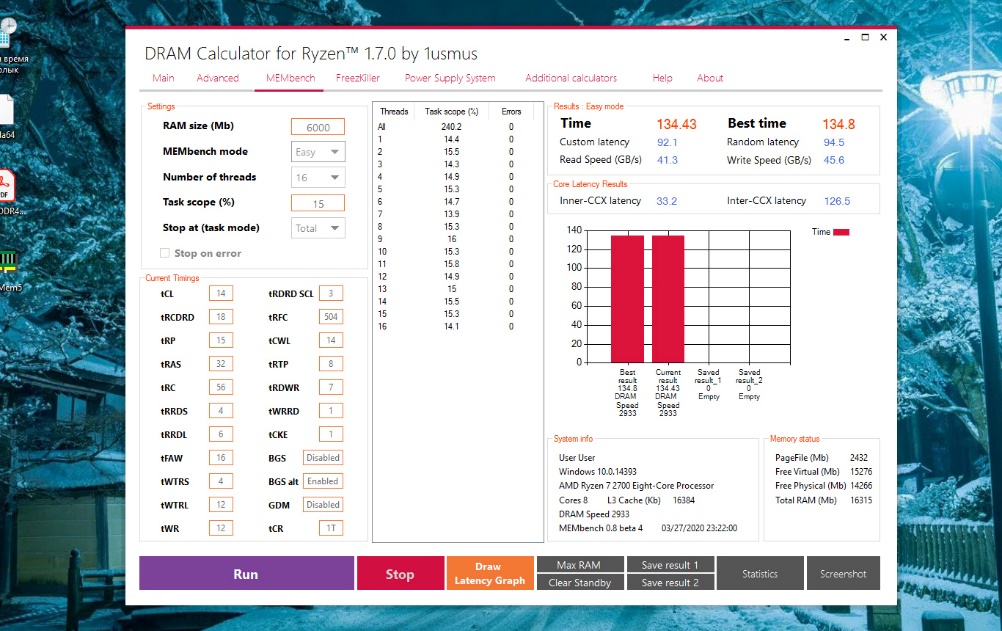
Кроме этого выполним ещё и тест MEMbench (MEMbench mode: Easy) утилиты DRAM Calculator for Ryzen:
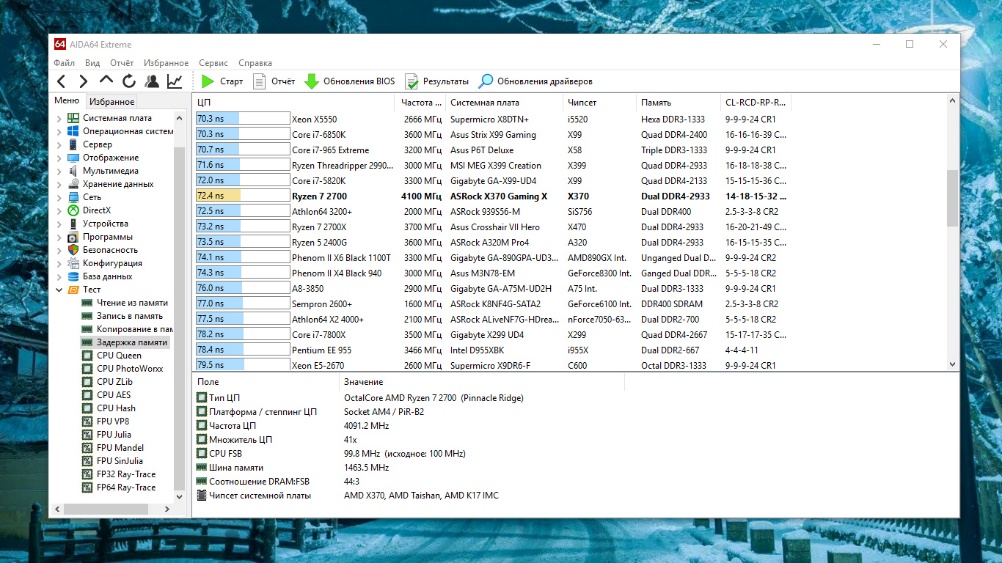
Для сравнения с другими процессорами можно дополнительно выполнить тест Задержка памяти утилиты AIDA64:
Сравним полученный уровень латентности памяти до и после подбора таймингов.
Наглядно это видно на скриншоте:
Итак, по данным утилиты AIDA64 нам удалось уменьшить латентность памяти Ryzen на 8,91 %, а по данным утилиты DRAM Calculator for Ryzen — на 10,23 %.
В тесте Задержка памяти утилиты AIDA64 наш процессор AMD Ryzen 7 2700 по латентности оперативной памяти обошёл занесённый в базу процессор AMD Ryzen 7 2700X и почти догнал Intel Core i7-5820K.
2. Технические особенности модулей памяти
С помощью программы Thaiphoon Burner мы можем более подробно посмотреть характеристики модулей памяти. Данные модули используют микросхемы Micron MT40A1G8SA-062E:J.
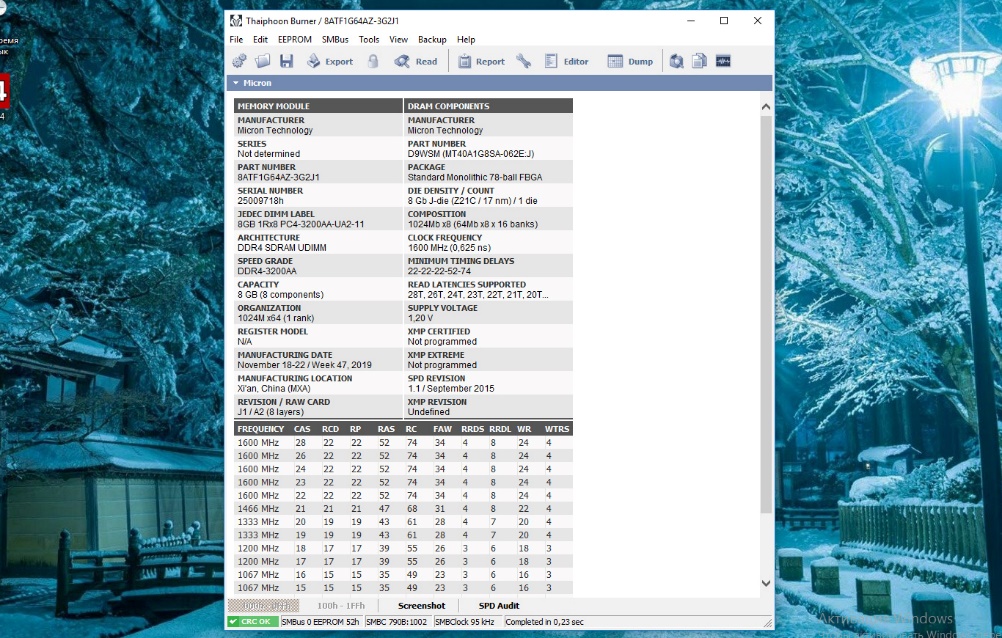
Для этих микросхем есть техническая документация в Интернет. В ней имеются интересующие нас технические характеристики:
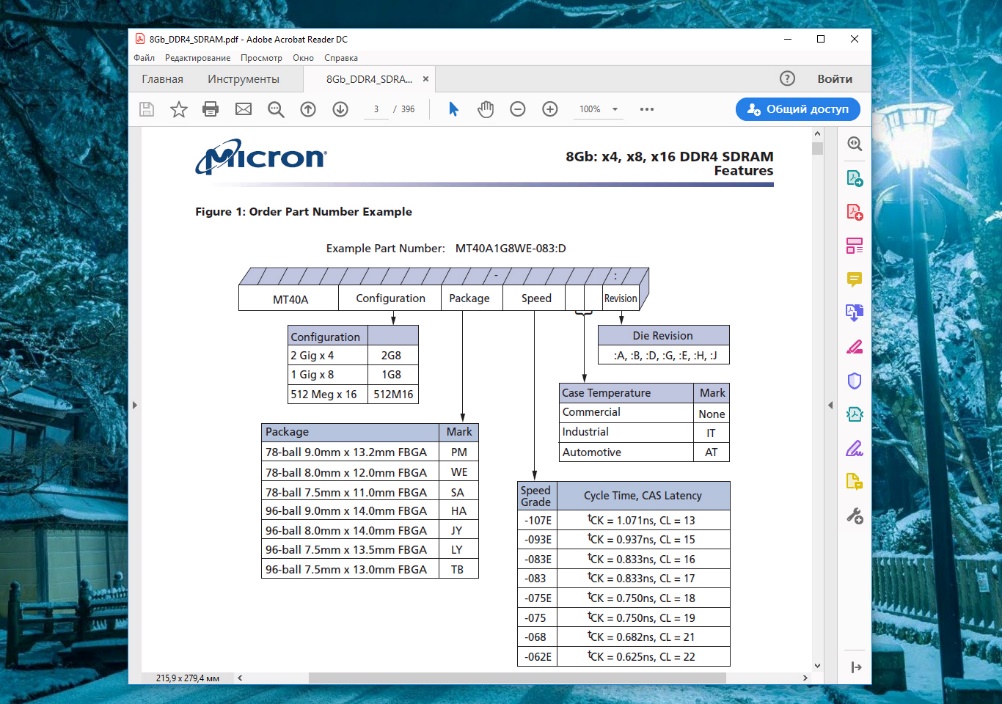
Электрические спецификации данных чипов памяти следующие:
- VDD: от -0,4 В до 1,5 В;
- TSTG: от -55 о С до 150 о С.
При этом рекомендуемая температура не должна превышать 85 о С.
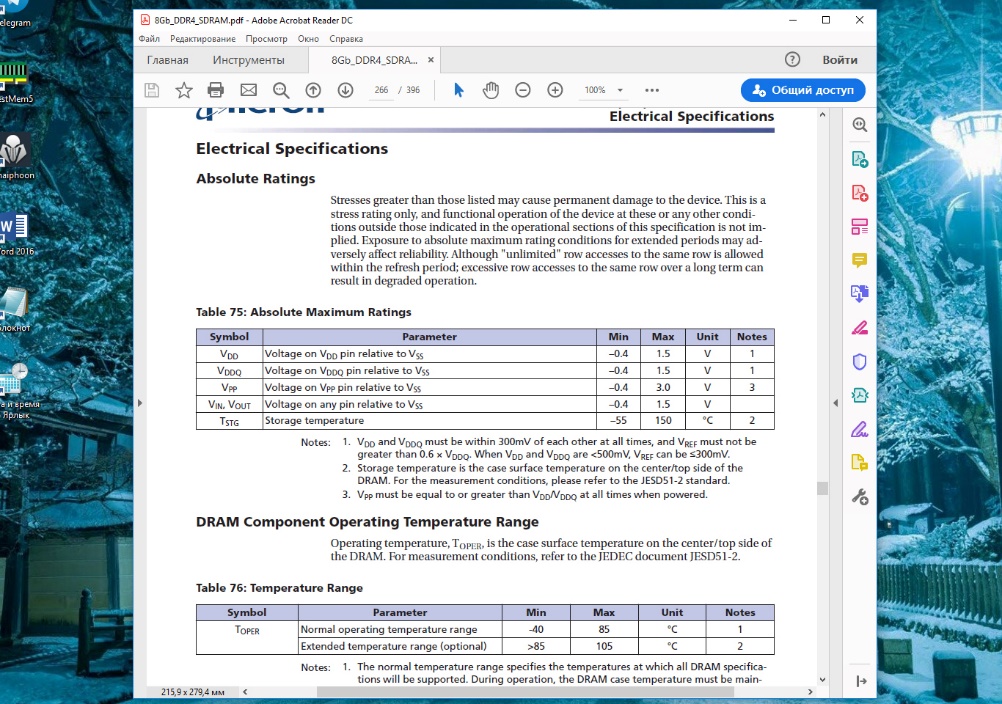
Из показанного выше следует: мы можем аккуратно повышать напряжение до 1,4 В, если при этом будем соблюдать безопасный температурный режим памяти.
Внимание: повышение напряжения влечёт за собой серьёзный нагрев чипов! Для того, чтобы избежать этого, необходимо купить для них специальные радиаторы и установить их на модули памяти. В противном случае из-за повышенных температур возможна деградация чипов памяти и, соответственно, выход модулей из строя.
В процессе изучения спецификаций чипов памяти сравнивались чипы B-die и J-die, в следствие чего были сделан вывод, что отличаются данные чипы только диапазоном температур (у J-die диапазон более широкий) и разными токами, но незначительно. В интерфейсе утилиты DRAM Calculator for Ryzen нет опции выбора чипов J-die, поэтому мы выберем в разделе Memory Type чипы Micron E/H-die, так как они в данной серии являются, судя по документации, наиболее некачественными.
Как уменьшить латентность памяти Ryzen
Лучше покупать разогнанные модули памяти с предустановленными в них профилями XMP. Такой профиль сразу позволит использовать минимальные тайминги для данного модуля, активировав его в настройках BIOS материнской платы.
Вариант посложнее — купить обычную неразогнанную память с хорошими чипами от Samsung, Hynix или Micron и самому настроить тайминги памяти. Для процессоров Ryzen имеется утилита DRAM Calculator for Ryzen, позволяющая подобрать тайминги памяти и тем самым снизить латентность (см. статью об утилите: Как пользоваться Ryzen DRAM Calculator).
Попробуем добиться некоторого снижения латентности памяти в обычных модулях, без XMP.
5. Тонкий подбор таймингов памяти
Так как между сформированными с помощью профилей V1 и V2 наборами таймингов может быть достаточное количество промежуточных вариантов, непосредственно в BIOS пробуем потихоньку уменьшать значения, взятые из рассчитанных для профиля V2, до значений аналогичных таймингов, рассчитанных для профиля V1.
Есть основные тайминги: tCL, tRCDWR, tRCDRD, tRP, tRAS и CL. Их сначала не трогаем. Остальные тайминги устанавливаем в значения, рассчитанные для V1. Проверяем работоспособность компьютера. Если компьютер работает корректно, меняем по одному указанные выше тайминги и проверяем каждый раз работоспособность. В случае, если работоспособность оказалась нарушена, откатываемся на шаг назад.
Опытным путём выясняем, что тайминги для профиля V1 работоспособны с отличием всего в одном параметре: значение tRP — вместо 14 должно равняться 15. Именно к настройкам, рассчитанным для профиля V1, следует стремиться максимально приблизиться — они наиболее интересны в плане производительности, в то время как тайминги для профиля V2 — скорее усреднённые, более безопасные.
Скриншоты с выполненными настройками:
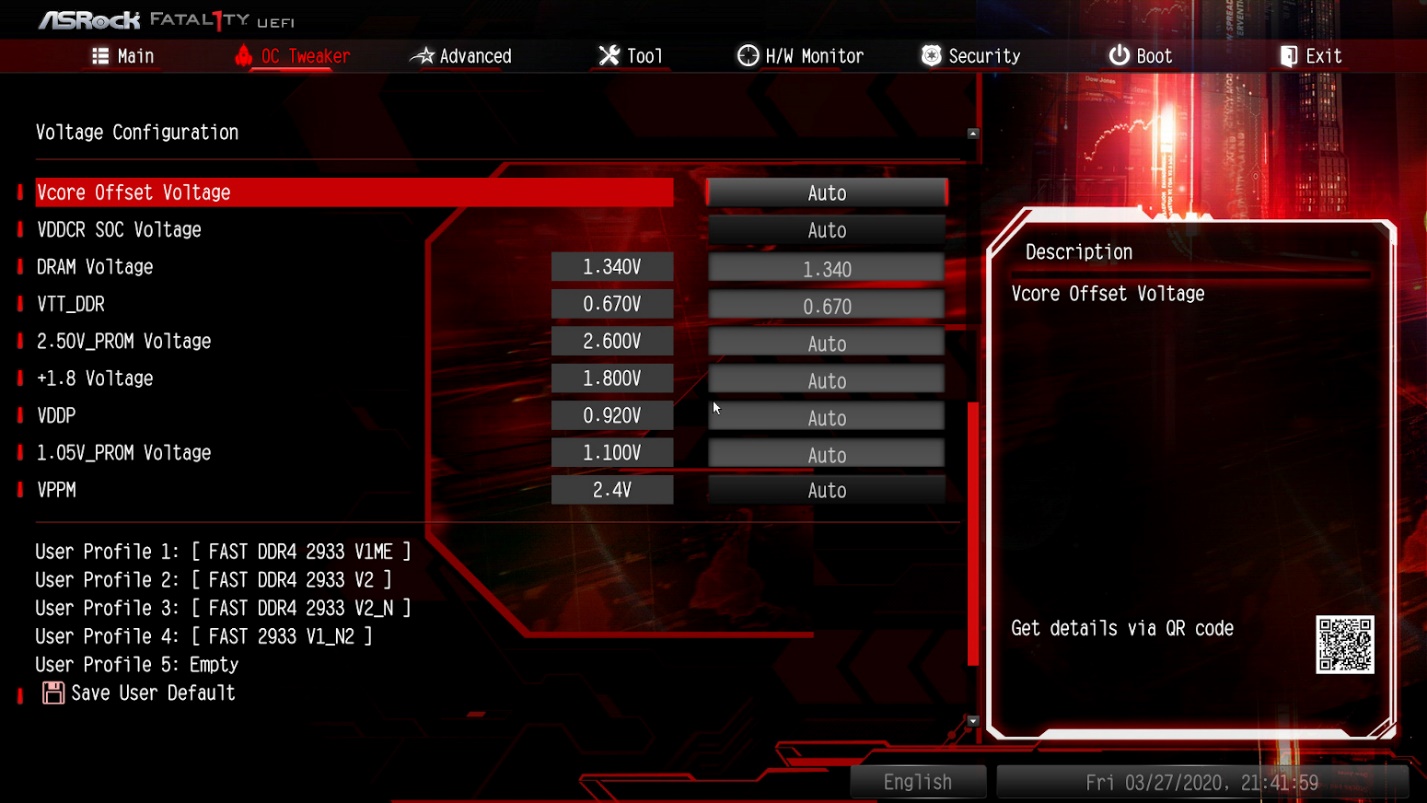
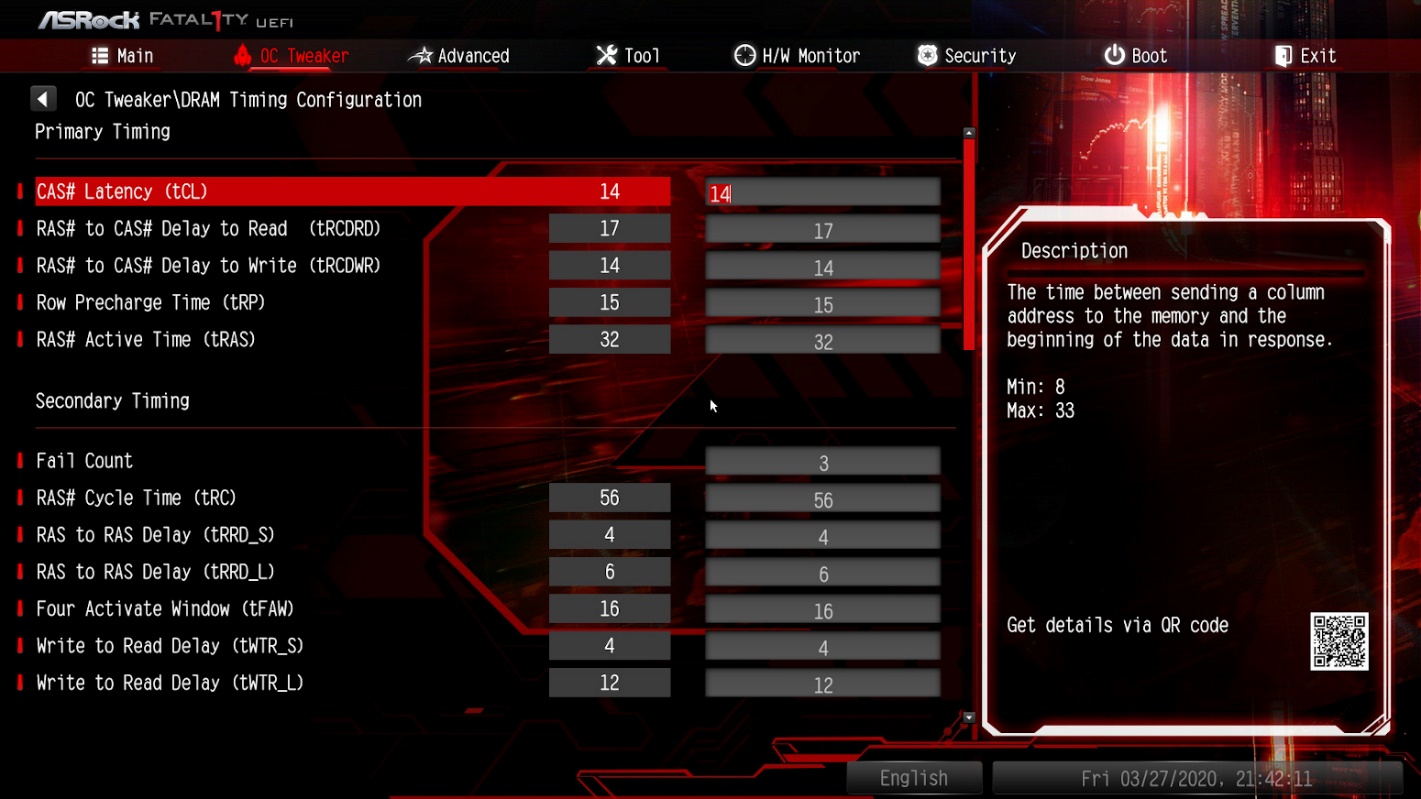
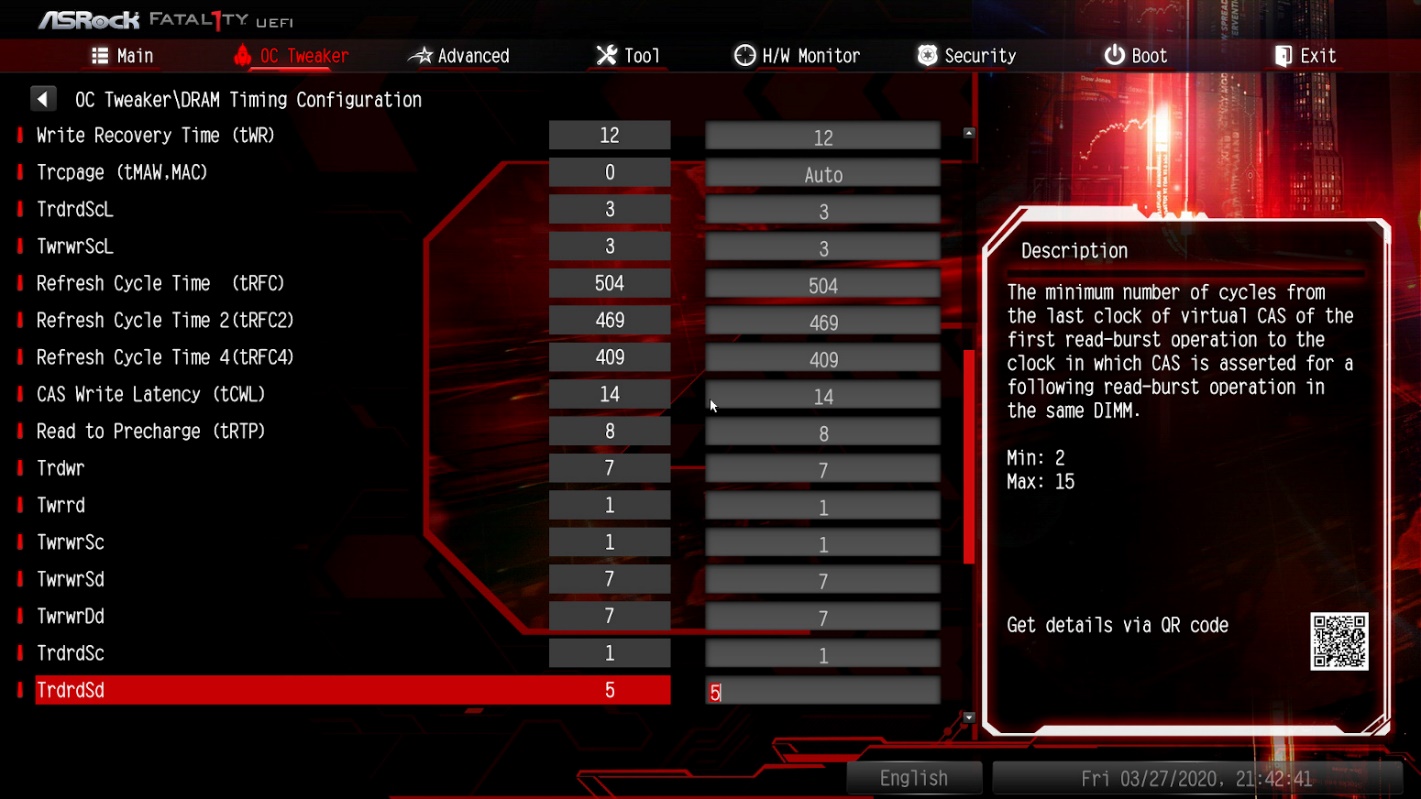
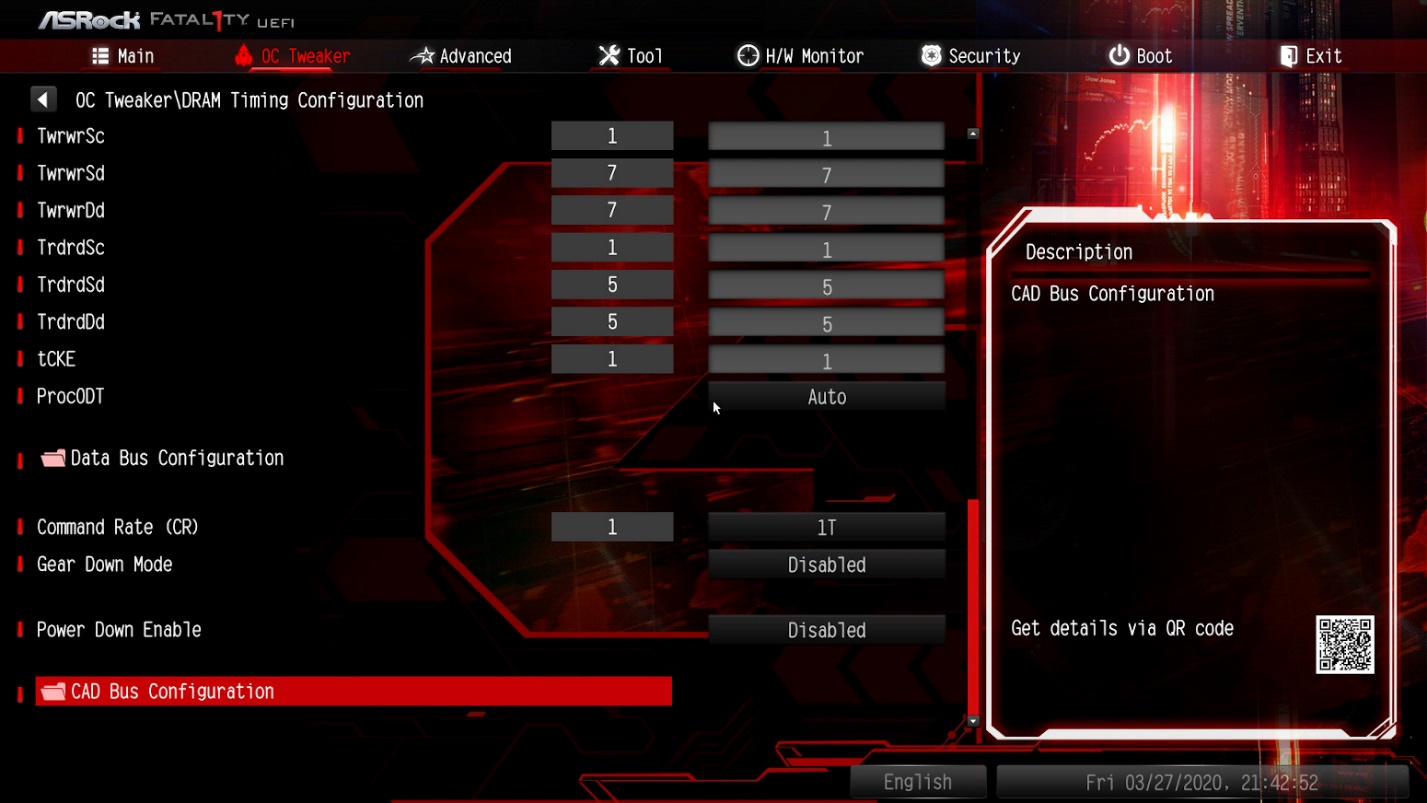
Теперь вы знаете как понизить латентность памяти, сделаем ещё немного тестов.
4. Подбор таймингов — профиль V2
Перезагрузив Windows, вновь запускаем утилиту DRAM Calculator for Ryzen, выбрав ваши параметры:
- Processor: ZEN + AM4 — поколение и сокет вашего процессора.
- Memory Type: Micron E/H-die — Производитель и B-Die ревизия чипов вашей памяти, которую вы узнали из утилиты Thaiphoon Burner.
- Profile version: V2 — версия профиля.
- Memory Rank: 1 — количество рангов вашей памяти, обычно 1.
- Frequency (MT/s): 2933 МГц — частота, которая должна получиться после разгона памяти.
- BCLK (100-104.8): 100 МГц — частота работы шины материнской платы, по умолчанию 100 МГц.
- DIMM Modules: 2 — количество модулей оперативной памяти в вашей системе.
- Motherboard: B350/X370 — чипсет вашей материнской платы.
Нажимаем на кнопку Calculate FAST для выполнения расчёта таймингов. Получаем следующие результаты:
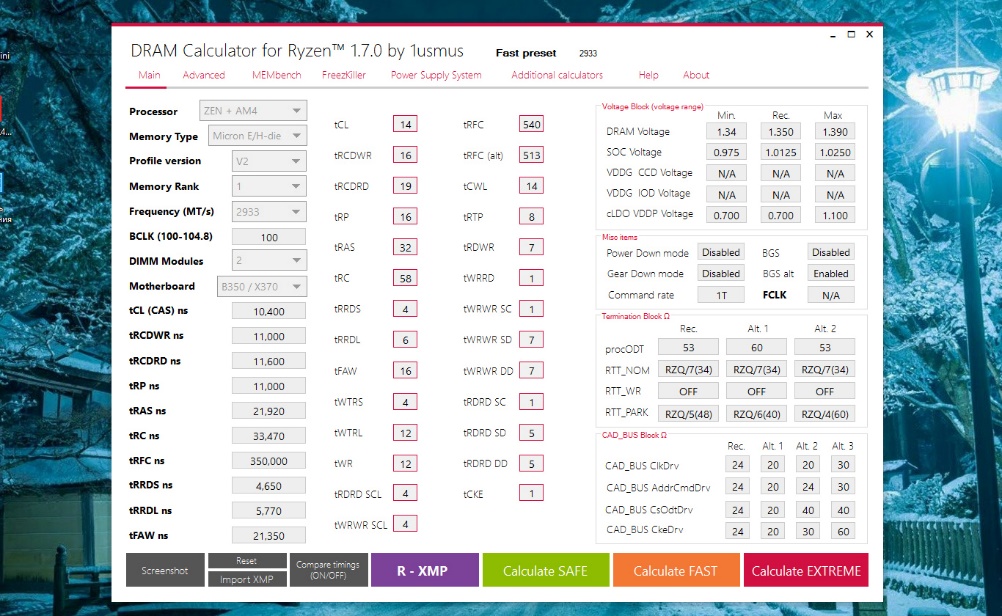
Перезагружаем компьютер, вносим изменения в значения таймингов, опять перезагружаем компьютер, загружаем настройки BIOS. Теперь компьютер работоспособен.
3. Подбор таймингов — профиль V1
Как было сказано выше, подбирать тайминги чтобы снизить латентность памяти мы будем с помощью утилиты DRAM Calculator for Ryzen. Перейдите на вкладку Main, выберите характеристики вашего оборудования:
- Processor: ZEN + AM4. Процессор в моём компьютере Ryzen 2700.
- Memory Type: Micron E/H-die.
- Profile version: V1.
- Memory Rank: 1. Данные модули памяти одноранговые.
- Frequency (MT/s): 2933 МГц. Чипы могут функционировать и при гораздо более высоких частотах. Однако, так как нашей целью является уменьшение задержек, выбрана именно данная частота — для неё не нужно дополнительно настраивать контроллер памяти в процессоре (см. статью о разгоне памяти: Как разогнать память на Ryzen).
- BCLK (100-104.8): 100 МГц.
- DIMM Modules: 2 модуля.
- Motherboard: B350/X370.
Нажимаем на кнопку Calculate FAST для выполнения расчёта таймингов. Программа выдаёт следующие результаты для выбранных нами стартовых параметров:
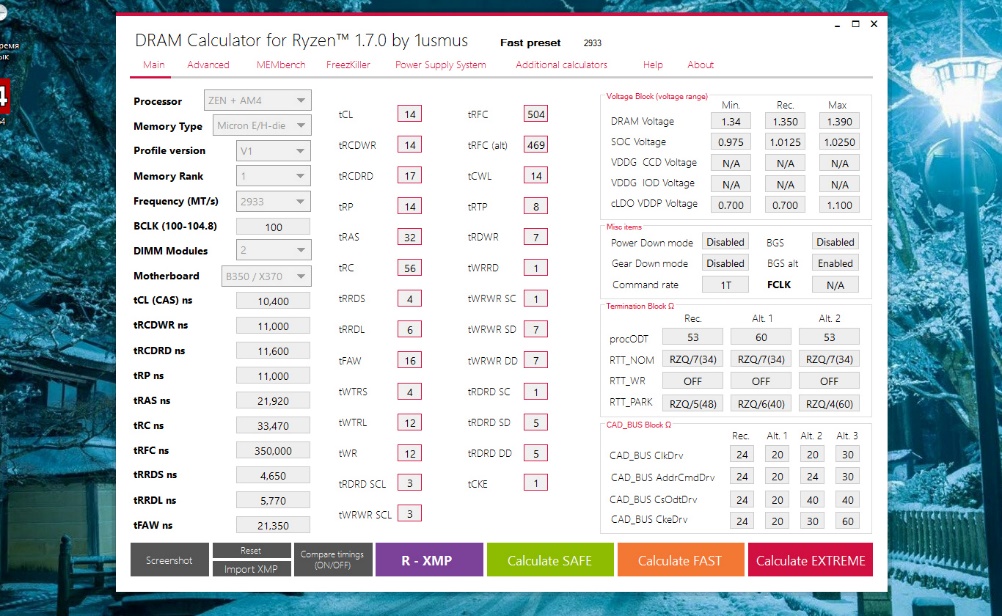
Теперь необходимо зайти в настройки BIOS (UEFI) компьютера и установить вычисленные нами ранее значения.
После установки этих значений наш стендовый компьютер, к сожалению, отказался загружаться. Вычисленные тайминги не подошли. С помощью джампера сбрасываем настройки BIOS до заводского состояния (см. статью: Как сбросить BIOS на заводские настройки). Затем надо попытаться подобрать тайминги по втором профилю. Данная версия профиля рекомендуется для менее качественных чипов памяти.
Выводы
Сегодня на практике мы изучили такое понятие, как латентность памяти для Ryzen. Фактически был построен новый профиль XMP для использованных нами конкретных модулей памяти. Используя эту инструкцию, вы также можете понизить латентность оперативной памяти DDR4 для Ryzen на своем компьютере, если желаете иметь максимальную отзывчивость системы. Также данная инструкция будет полезна тем, кто уже разогнал память по параметру частоты. В таком случае дальнейший рост производительности возможен только при снижении уровня латентности памяти (уменьшении таймингов памяти).
Я не спец по разгону оперативной памяти, но знаю, что для Ryzen это полезно.
XMP профиль 3000 CL15. Разгон до 3200 делается спокойно, прирост пропускной ощутимый.
Но после 3200 прирост идет просто никакущий, на частоте 3600 пропускная ОЗУ ниже 50 тысяч на чтение и копирование + очень высокая задержка(см. скрин). При этом смотрю обзоры и разгоны других людей даже с такой же ОЗУ и у них на более низких частотах пропускная в разы выше, до 56-60 тысяч и задержка около 62ns.
Может я что-то не так делаю? Или чипы настолько убогие, что их макс производительность на 3000-3200 :\
ОЗУ - Corsair CMK16GX4M2B3000C15 Hyniz AFR A-Die 1 Rank
Мать - ASUS B450M Pro Gaming
Проц - Ryzen 3600


Если хотите 3600 МГц и больше, с низкими таймингами и высокой производительностью - готовьте кошелёк) На такой же матери как у вас, но с другой памятью, а именно из линейки crucial ballistix sport LT на 3000 МГц, смог получить 3533 МГц. Выше 3600 гнать большого смысла уже нет. Поставьте XMP на 3200, попробуйте вручную снизить тайминги до 15-16-16-35. Должно быть лучше.
Мне не очень нравится скорость чтения, как правило, скорость чтения и копирования довольно близки, а у вас большой разрыв.
Ну и не нужно ставить самоцелью поднятие частоты. Нужно стремиться к оптимальному сочетанию частоты, таймингов и латентности. Но если на этой памяти вы сможете сделать ниже 70нс - уже будет неплохо. Опирайтесь на скорости чтения, записи и копирования.
P. S. На интел латентность будет ниже, но что поделать. Лично я не страдаю при работе с компом вообще ни разу.

P.P.S. Так у меня работают 4 планки по 8 Гб на частоте 3133 МГц. (2 гонятся лучше, но производительность у 4 выше).
Пример с сайта Overclockers, память у пользователя была такая же, другая мать и проц.
Но различия достаточно существенные. У меня частоты более высокие берутся проще, но прирост никакущий, у него танцы с бубном, но прирост есть. (
6. Проверка табильности
После завершения настройки параметров памяти конечно же необходимо протестировать стабильность её работы. Для этого можно использовать Тест стабильности системы утилиты AIDA64, его составляющие:
- Stress CPU;
- Stress FPU;
- Stress cache;
- Stress system memory.
Нажимаем кнопку Start. Тест пройдён не был.
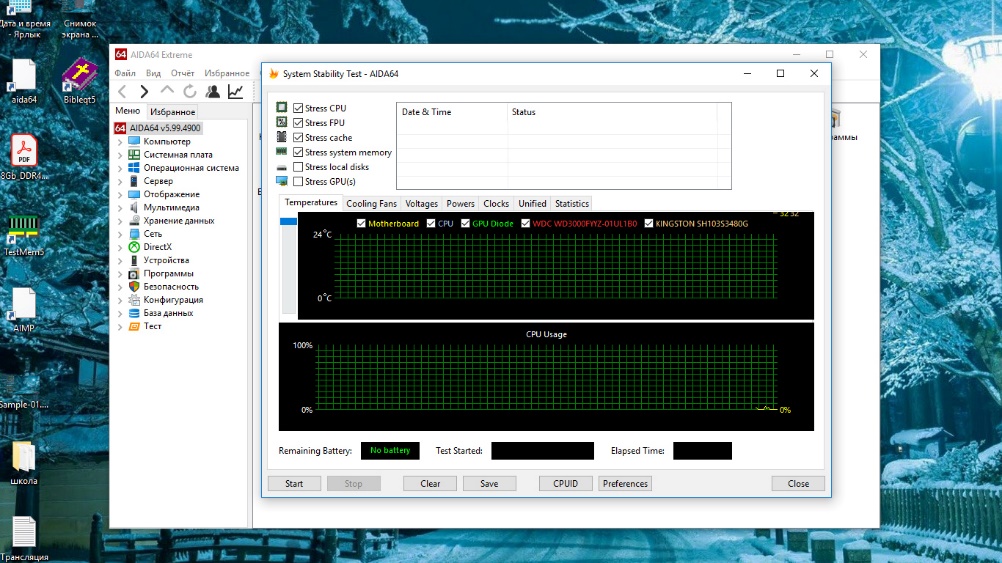
Перезапускаем компьютер, заходим в настройки BIOS и повышаем параметр напряжения DRAM Voltage до 1,36 В.
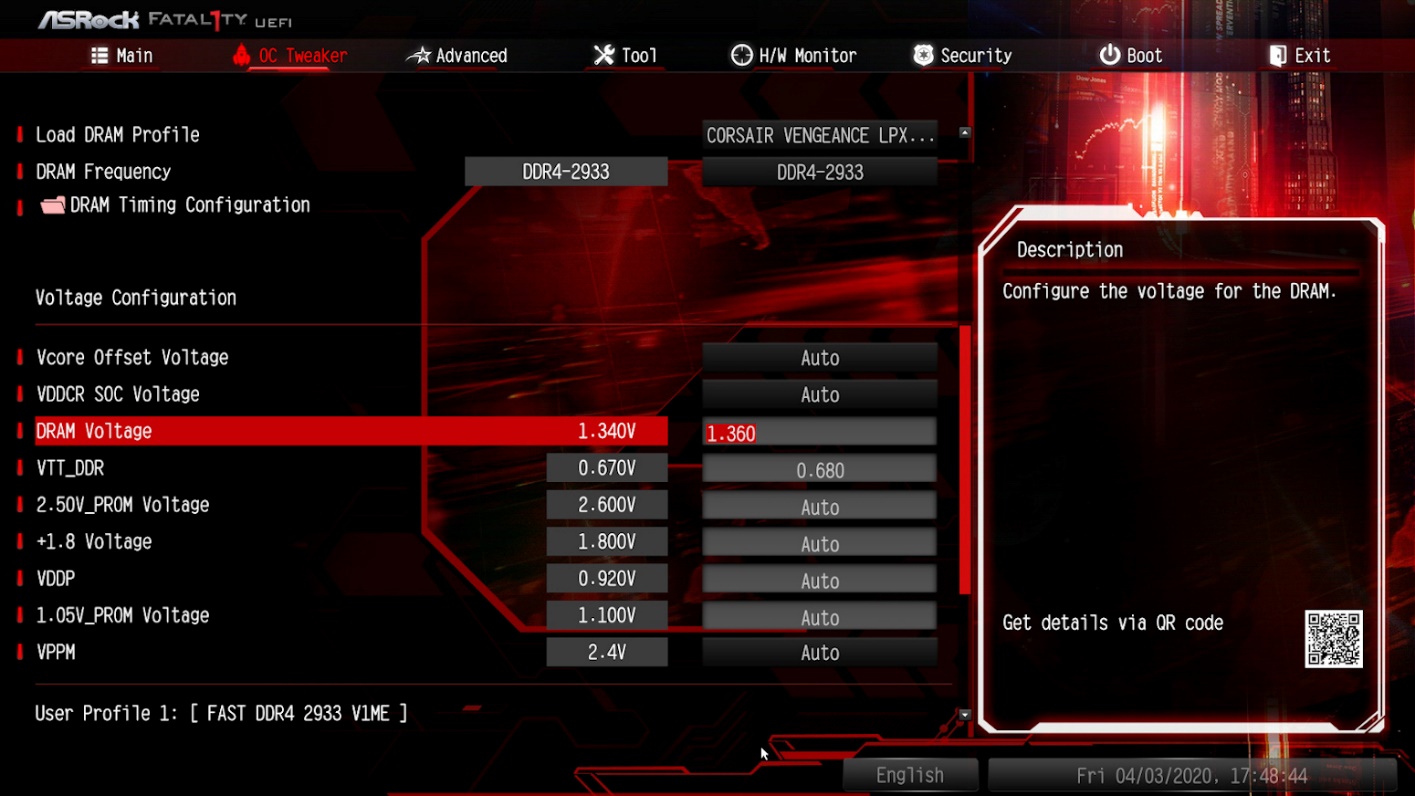
Сохраняем настройки BIOS и перезагружаемся. Вновь запускаем Тест стабильности системы утилиты AIDA64. Тест вновь завершён с ошибкой.
Опять в настройках BIOS немного повышаем значение параметра DRAM Voltage, но не выше чем максимальное возможное для ваших чипов памяти. В данном случае до 1,39 В, опять перезагружаемся и запускаем тест.
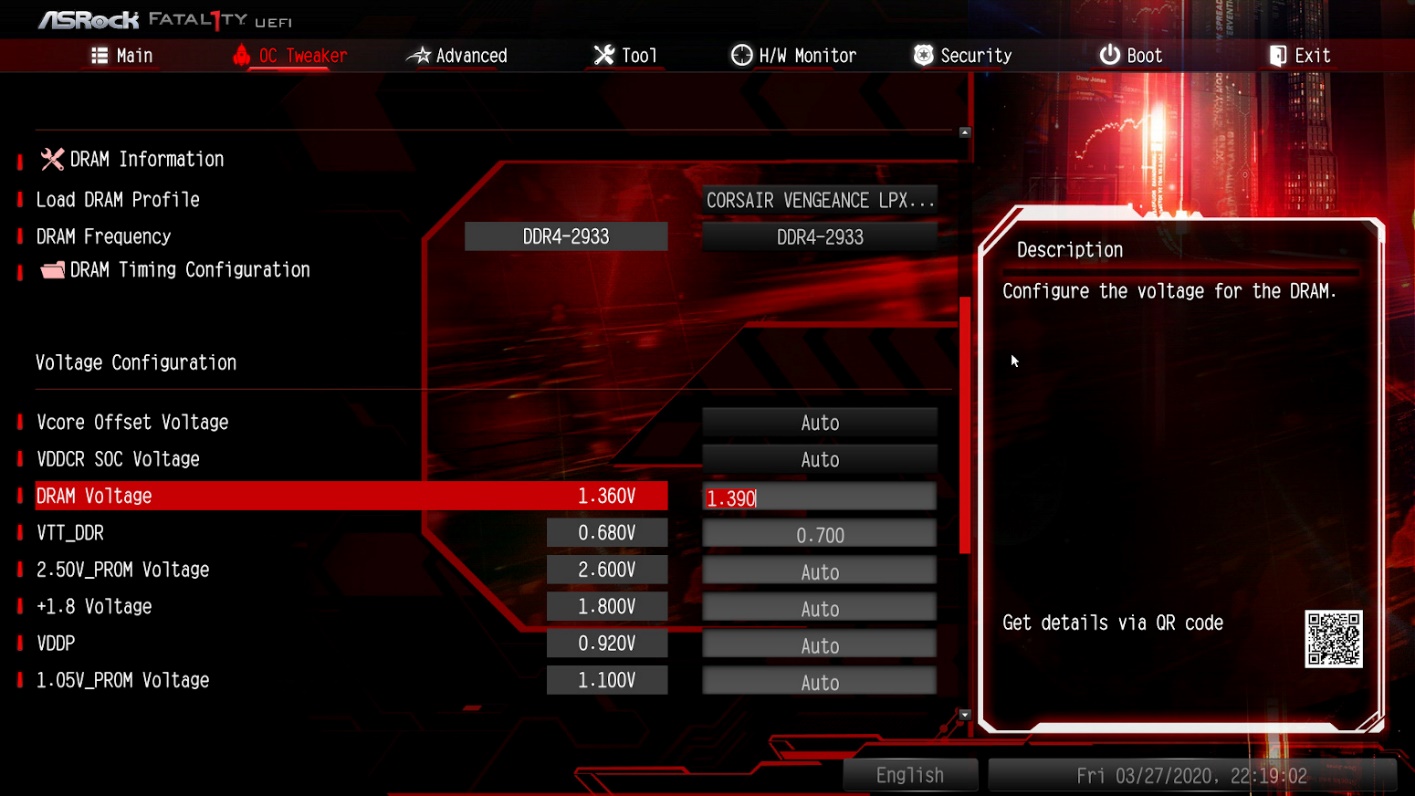
Опять ошибка. После этого перезагружаем компьютер и немного увеличиваем в настройках BIOS значения для таймингов tRCDWR и tRCDRD, например:
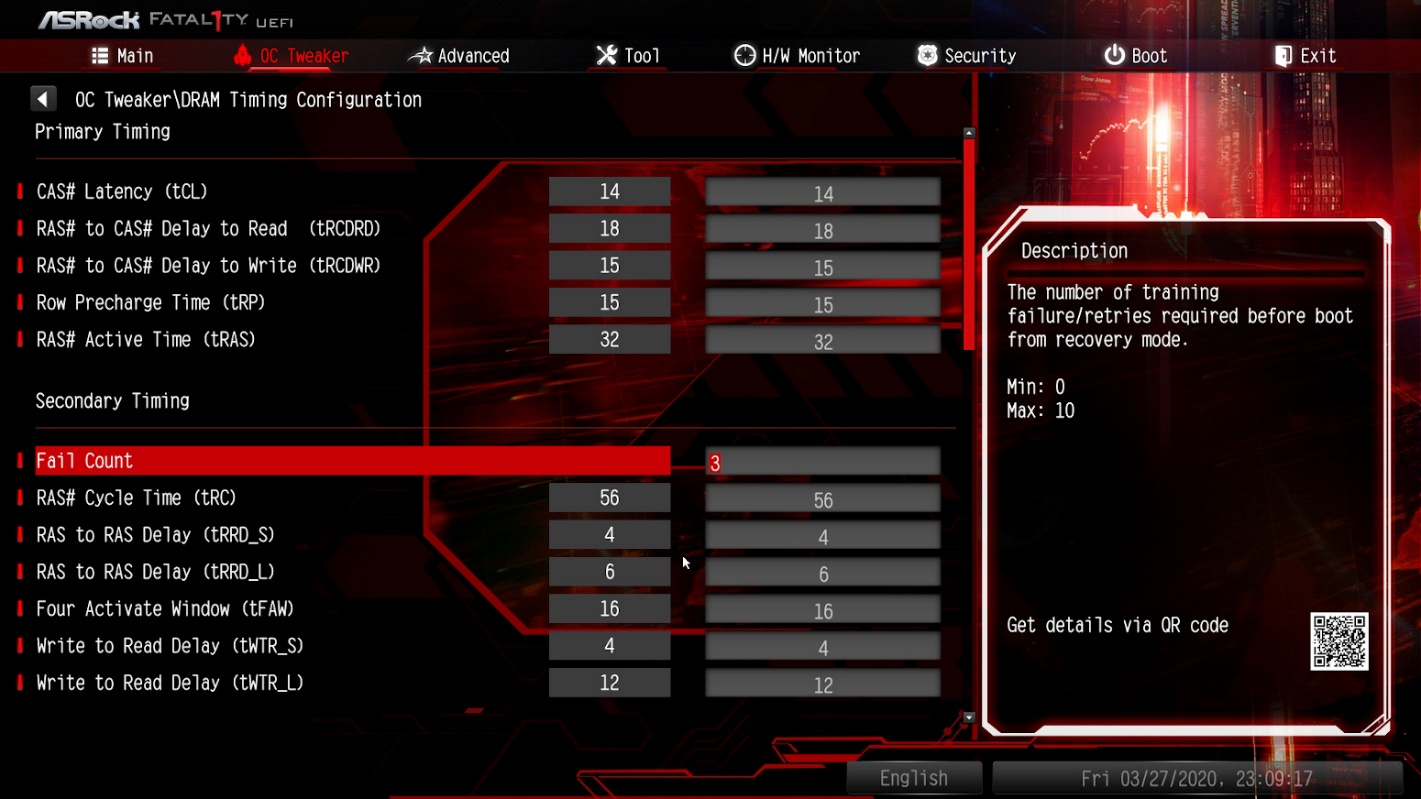
Перезагружаемся и запускаем тот же тест. Стресс-тест выполнялся 7 минут, ошибок обнаружено не было. Далее попробуем снизить значение параметра напряжения питания памяти DRAM Voltage, например, к значению 1,34 В.
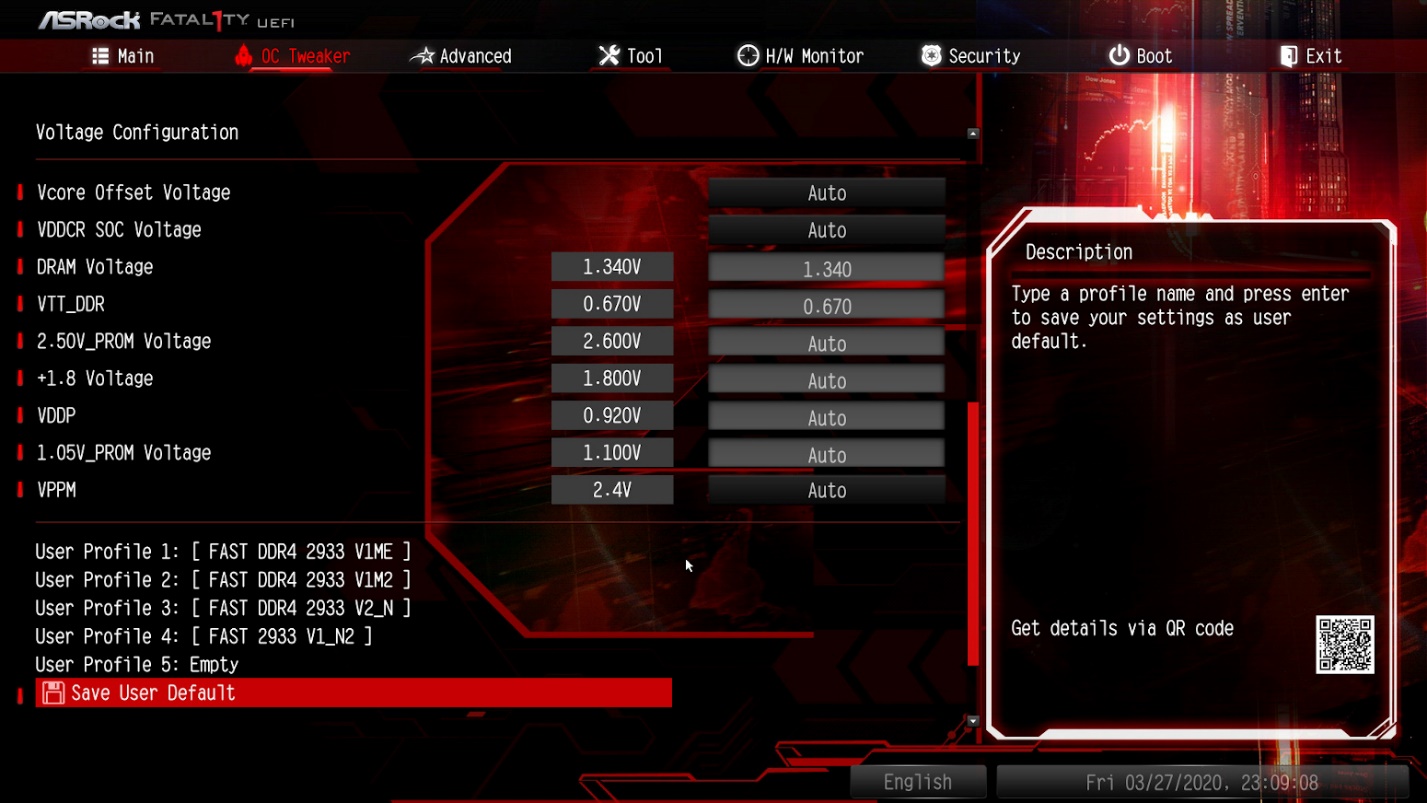
Перезагрузка и выполнение теста. Процесс длился 7 минут, ошибок не было.
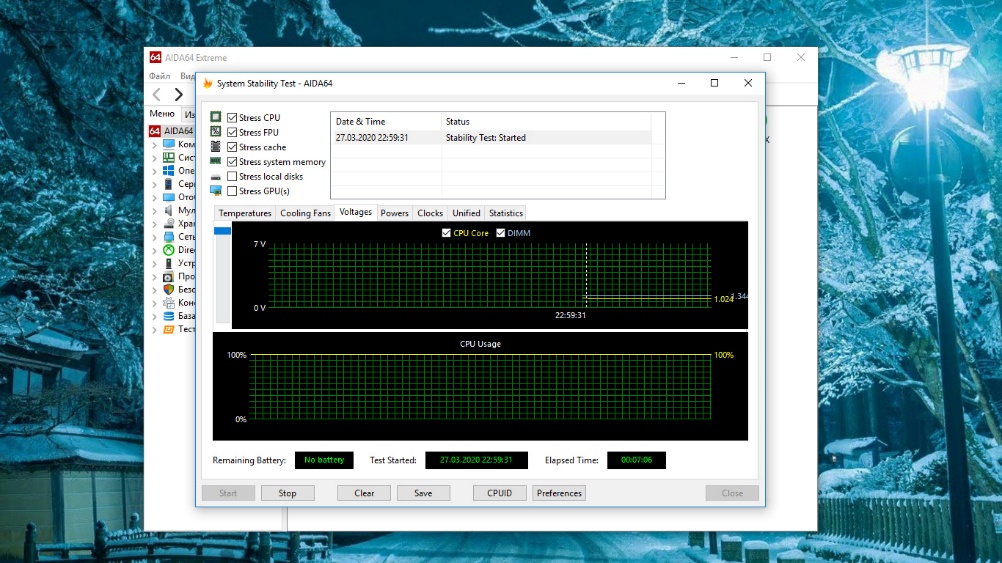
1. Тестирование до снижения латентности
Ещё до коррекции таймингов памяти проведём тестирование времени отклика (латентности) с помощью Теста кэша и памяти утилиты AIDA64:
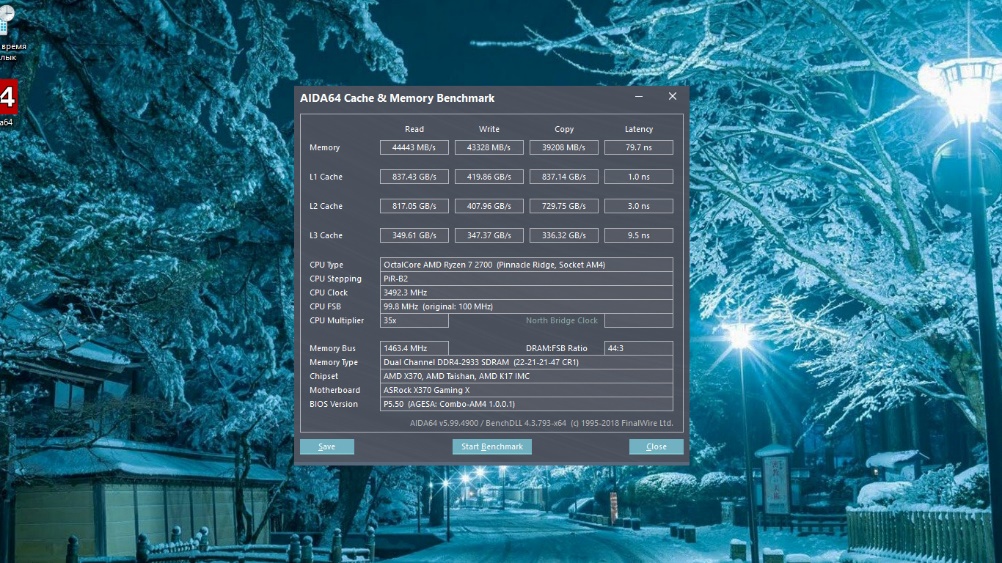
И ещё сделаем это с помощью теста MEMbench (MEMbench mode: Easy) утилиты DRAM Calculator for Ryzen:
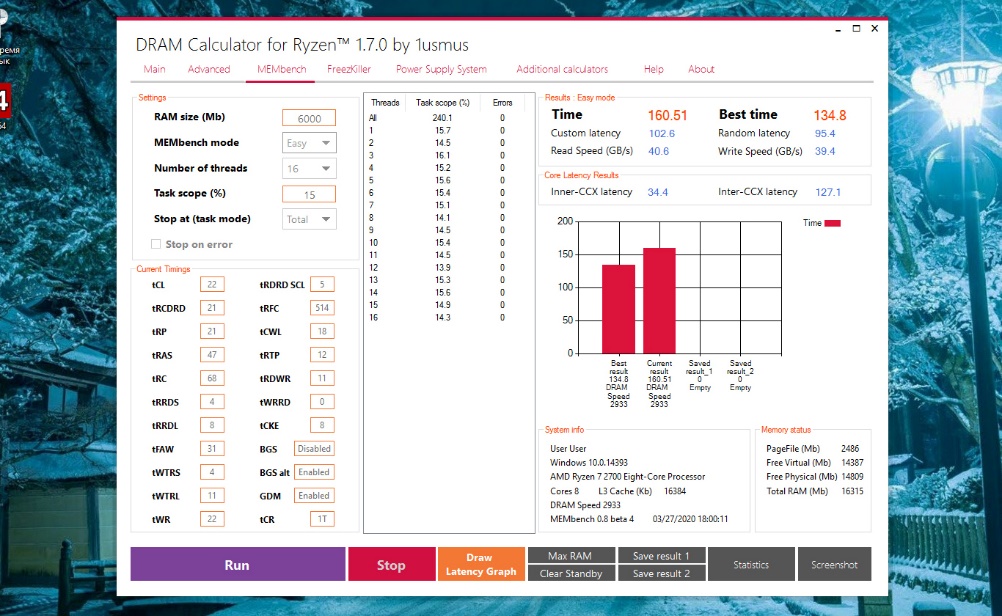
Читайте также: