
Http файлы что это
Internet - одно из самых выдающихся открытий 20 века. В развитых странах мира большинство людей получают самую последнюю информацию из этой сети. Так для чего же нужен Internet? Самое главное предназначение этой сети - передача информации от одного компьютера к другому. Сегодня я хочу рассказать Вам, как можно с помощью стандартных средств Visual Basic получать и передавать информацию через Internet.
Заключение
Плюс заказчик получает готовую функциональность, реализацию которой не нужно оплачивать – все можно сделать силами одного 1С-ника.
Используйте VPN

Если вам нужно организовать удаленный офис либо объединить в единую сеть магазины или сеть точек общественного питания, используйте для администрирования VPN – этого достаточно.
Немного теории
Воровство через Internet
Когда Вы находитесь в сети Internet, то любой другой пользователь Internet может связаться с Вами. Так вот, если на Вашем компьютере есть файлы, открытые Вами специально для публичного доступа, то он сможет их прочитать! На этом основаны некоторые методы взлома домашних компьютеров для получения паролей и прочей информации. Представьте себе, что Вы были так любезны, что открыли свой диск для других пользователей (неважно, по какой причине: может по незнанию, а может для друзей) и вышли в Internet. При выходе в сеть Ваш провайдер присвоил Вам IP адрес. Он, кстати, может быть постоянным или же разным для каждого сеанса связи. Ну да ладно, это, в принципе не важно. Так вот, зная IP адрес других пользователей этого провайдера, вычислить Ваш IP адрес не составляет большого труда, и если ввести этот адрес куда следует, то можно увидеть, например, содержимое Вашего диска . Теперь заходим в папку Windows (или как там она у Вас называется), себе файлы .pwl и вот они все Ваши пароли. Я не буду Вам объяснять, как все это делается, хочу только сказать, что это вполне реально.
Ха, скажете Вы, кому надо взламывать мой компьютер!? Отвечаю. Существует сотни пользователей, которые постоянно сканируют сеть Internet в поисках таких ресурсов. Представте себе, что в сети Internet, в одно и то же время, находится десятки (или тысячи) пользователей Internet из Вашего города, и все они имеют IP адрес, который отличается несколькими последними цифрами. Создается специальная программа, которая осуществляет простой перебор всех возможных IP адресов и выводящая отчет о , в котором указывает IP адреса с доступными для ресурсами. Остается только себе нужную информацию с таких компьютеров. Если у Вашего провайдера не найдется таких пользователей, то никто не мешает поискать их по другим возможным IP адресам. Мораль состоит в том, что не надо открывать все файлы для других и вообще нужно немного думать головой, а когда Ваш компьютер будет взломан, то сами понимаете что может быть: И плакали Ваши денежки:
Разделите сервисы

Соответственно, если вашу фирму начнут проверять на прочность, вздрогнет вся система, и работать будет невозможно.
Поэтому я не зря изобразил на слайде подводную лодку: если в ней случается пробоина, закупоривается один отсек, а остальная часть подводной лодки продолжает функционировать. Я тоже рекомендую разносить внутренние сервисы на одну машину, а сервисы, которые должны общаться с внешним миром на другую, возможно, даже на несколько машин.
Методы протокола¶
Результат выполнения этого метода не кэшируется.
Кроме обычного метода GET, различают ещё условный GET и частичный GET. Условные запросы GET содержат заголовки If-Modified-Since, If-Match, If-Range и подобные. Частичные GET содержат в запросе Range. Порядок выполнения подобных запросов определён стандартами отдельно.
Аналогичен методу GET, за исключением того, что в ответе сервера отсутствует тело. Запрос HEAD обычно применяется для извлечения метаданных, проверки наличия ресурса (валидация URL) и чтобы узнать, не изменился ли он с момента последнего обращения.
Заголовки ответа могут кэшироваться. При несовпадении метаданных ресурса с соответствующей информацией в кэше копия ресурса помечается как устаревшая.
Применяется для передачи пользовательских данных заданному ресурсу. Например, в блогах посетители обычно могут вводить свои комментарии к записям в HTML-форму, после чего они передаются серверу методом POST и он помещает их на страницу. При этом передаваемые данные (в примере с блогами — текст комментария) включаются в тело запроса. Аналогично с помощью метода POST обычно загружаются файлы.
В отличие от метода GET, метод POST не считается идемпотентным[4], то есть многократное повторение одних и тех же запросов POST может возвращать разные результаты (например, после каждой отправки комментария будет появляться одна копия этого комментария).
Фундаментальное различие методов POST и PUT заключается в понимании предназначений URI ресурсов. Метод POST предполагает, что по указанному URI будет производиться обработка передаваемого клиентом содержимого. Используя PUT, клиент предполагает, что загружаемое содержимое соответствуют находящемуся по данному URI ресурсу.
Аналогично PUT, но применяется только к фрагменту ресурса.
Удаляет указанный ресурс.
Возвращает полученный запрос так, что клиент может увидеть, что промежуточные сервера добавляют или изменяют в запросе.
Устанавливает связь указанного ресурса с другими.
Убирает связь указанного ресурса с другими.
Наиболее востребованными являются методы GET и POST — на человеко-ориентированных ресурсах, POST — роботами поисковых машин и оффлайн-браузерами.
Прокси-сервер
Протоколы и Стандарты
Связь через Internet и обмен данными облегчены развитием стандартных протоколов связи. Самое важное в Internet - язык, на котором общаются все компьютеры. Основной язык Internet - это протокол TCP/IP. Этот протокол позволяет любому компьютеру, связанному с Internet быть уникально идентифицированным и позволяет любому такому же компьютеру посылать или получать информацию от любого другого связанного с Internet компьютера.
Одно из наиболее частых использований Internet обращение к файлам, сохраненным на удаленном компьютере. Стандартный протокол Internet для доступа к такому файлу - протокол передачи файлов (FTP). Он позволяет удаленным пользователям соединяться с компьютером и получать доступ к файлам, специально открытым для публичного просмотра.
Организуйте промежуточное звено

Есть варианты с промежуточным сервисом:
Один из таких вариантов был показан на онлайн-митапе «Web-клиенты для 1С». Есть некий промежуточный сервис, написанный на каком-то стороннем языке, этот сервис смотрит наружу, получает запросы от клиентов, организует для этих запросов некие квесты – накладывается фильтрация, проверяются токены, организуется ограничение частоты вызова определенных методов или двухфакторная аутентификация. Только тогда, когда все эти квесты пройдены, запрос идет во внутреннюю сеть. Вариант неплохой, рабочий, многие его используют.
Есть еще вариант с промежуточной базой, которая получает запросы, отслеживает, что в этом запросе все хорошо, и тогда уже передает его во внутреннюю систему.
Получается, что эти промежуточные звенья принимают первый удар на себя, а если с ними что-нибудь случится, ваша информационная база будет в безопасности.
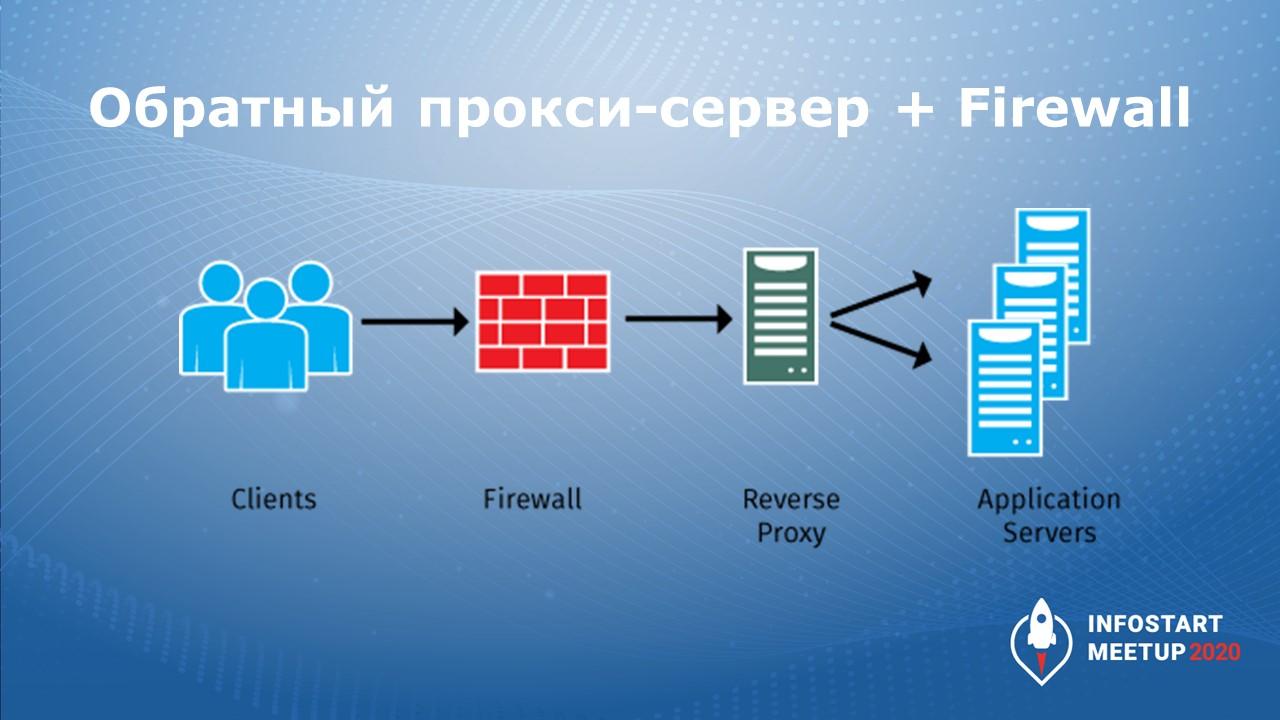
То же самое можно делать и другими средствами:
можно установить файрвол, который ограничивает доступ, делает фильтрацию IP, закрывает порты;
за файрволом можно поставить реверсный прокси, на котором тоже настроены какие-то фильтры – реверсный прокси-сервер может выполнять функцию балансировки – он разграничивает нагрузку между сервисами и дополнительно уменьшает трафик за счет кеширования.
Это тоже рабочий вариант.
World Wide Web
Web - набор протоколов, которые работают по Internet. В настоящее время три необходимых технологии определяют World Wide Web и осуществляют связь между клиентом Сети и сервером Web связанными по TCP/IP сети.
HTML документ может содержать ссылки к рисункам, изображениям, звуку, и т.д., а также ссылки на другие документы в сети Internet. Ссылки в документах даются в специальном формате URL, показывающем местоположение специфического ресурса Internet.
Способность HTML документа содержать ссылку на другие документы создает коллекцию связанных документов. Эта коллекция документов называется WWW или World Wide Web.
GET для безопасных действий, POST для небезопасных

Дальше нужно определиться с тем, по каким методам будет работать ваш сервис – будет ли он использовать только GET или POST, или он будет использовать смешанные методы.
GET вызывает так называемые безопасные действия – он получает параметры и отдает некие данные из информационной базы.
POST предназначен для более опасных действий – если вы хотите передавать логин-пароль, то GET для этих случаев не подойдет, лучше передавать в теле POST.
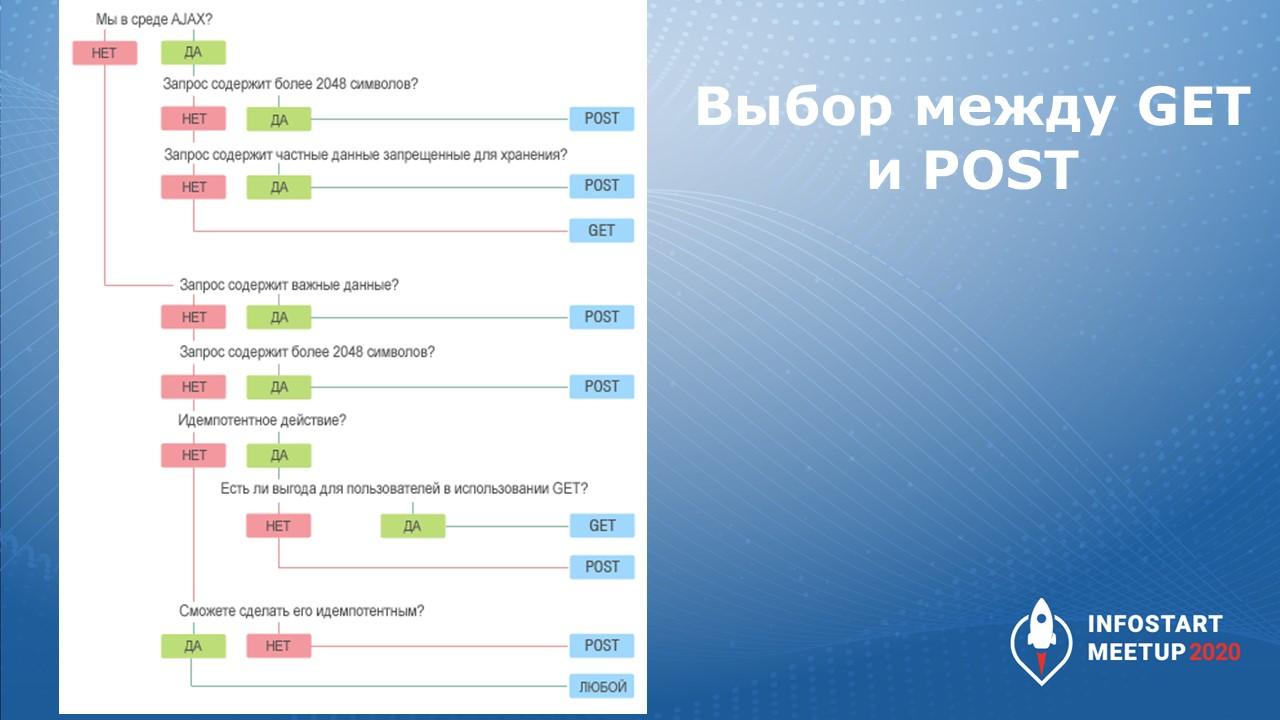
Чтобы определиться, какой метод вам больше подходит, есть картинка, которая очень наглядно помогает выбрать тот или иной метод.
Повторюсь, что основные минусы GET по сравнению с POST – это то, что запрос можно кешировать, запросы могут оставаться в истории браузера, параметры передаются в URL, и GET не предназначен для передачи больших объемов данных.
Это – наглядный пример MITM-атаки.
Как перечеркнуть все усилия по обеспечению безопасности

В феврале этого года я выложил статью «Выполнятор – как я породил монстра и лишился сна!». Это случай из 2017-го года. Я тоже человек грешный, я реализовал некое очень страшное решение через метод «Выполнить()».
Самое интересное, что такие статьи выходят на Инфостарте регулярно, я примерно раз в месяц вижу новую статью с таким решением.
Если я вижу такую статью, я пытаюсь пообщаться с автором и объяснить, почему так делать не стоит – об этом я расскажу дальше.
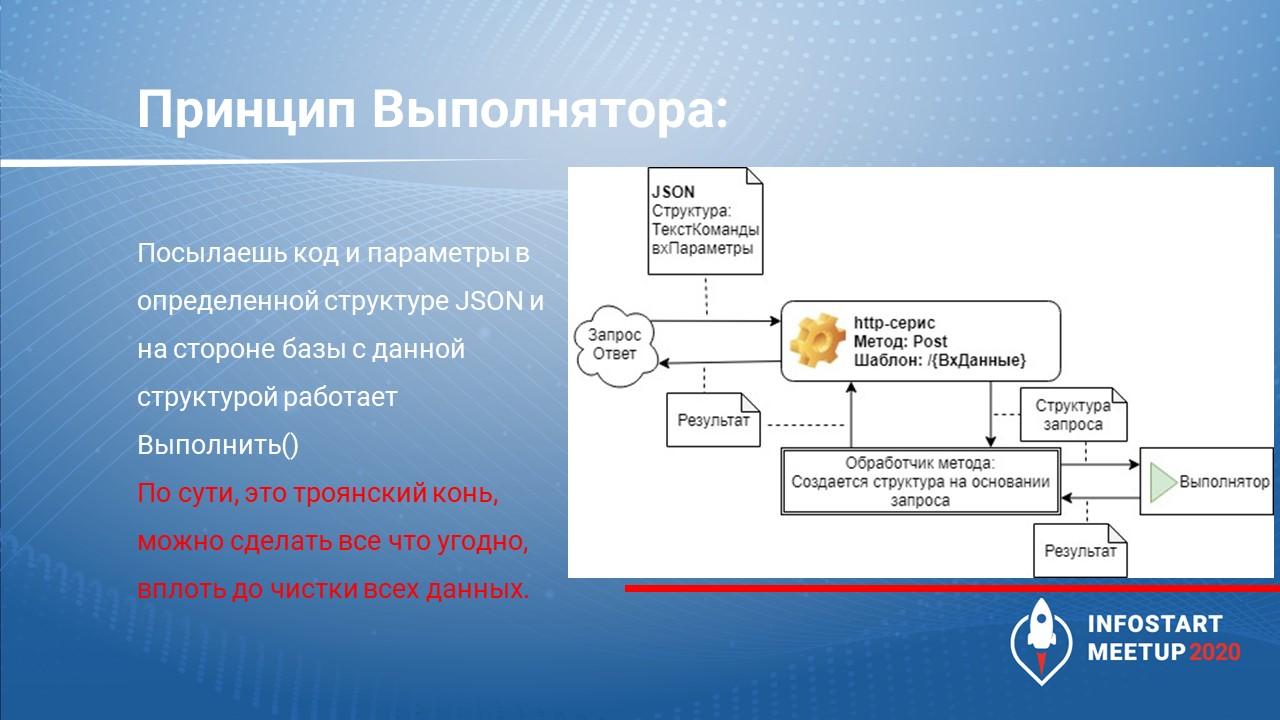
Все эти «Выполняторы» работают по одному принципу с небольшими отличиями:
кто-то передает текст команды,
кто-то передает текст команды и параметры,
кто-то передает текст запроса и параметры;
кто-то передает просто текст запроса.
Дальше это все попадает в некий метод «Выполнить()», где все это выполняется. Это некий троянский конь, через который с вашей системой можно что угодно сделать, вплоть до очистки всех данных.

Есть статья на ИТС «Ограничения на использование Выполнить и Вычислить на сервере». Если вы решили сделать универсальное решение, то ознакомьтесь с этой статьей, все вопросы уйдут.

Когда я общался с авторами, я интересовался, почему они сделали такое решение:
Некоторые, как и я, хотели выйти из конфигуратора – статья про «Выполнятор» как раз показывает, что так делать неправильно.
Кто-то говорил, что ему не нравится писать код в двух местах – в конфигурации-источнике и конфигурации-приемнике.

Основные минусы «Выполняторов»:
Практически невозможно отловить неоптимальный код. В базе-источнике будет видно только то, что выполняются некие методы. Вы не отловите, какой там код в какой момент пришел.
Плюс вы постоянно пересылаете весь код и параметры, что тоже нехорошо. Это то же самое, как если вы придете в библиотеку, положите перед библиотекарем три тома «Войны и мир» и спросите: «Что написано во втором томе на 300-й странице в пятом параграфе?» Получается, что вам, чтобы спросить какую-то вещь, нужно постоянно носить эти книжки. Это тоже не совсем хорошо.
И возможность потерять все свои данные – я про это уже говорил.
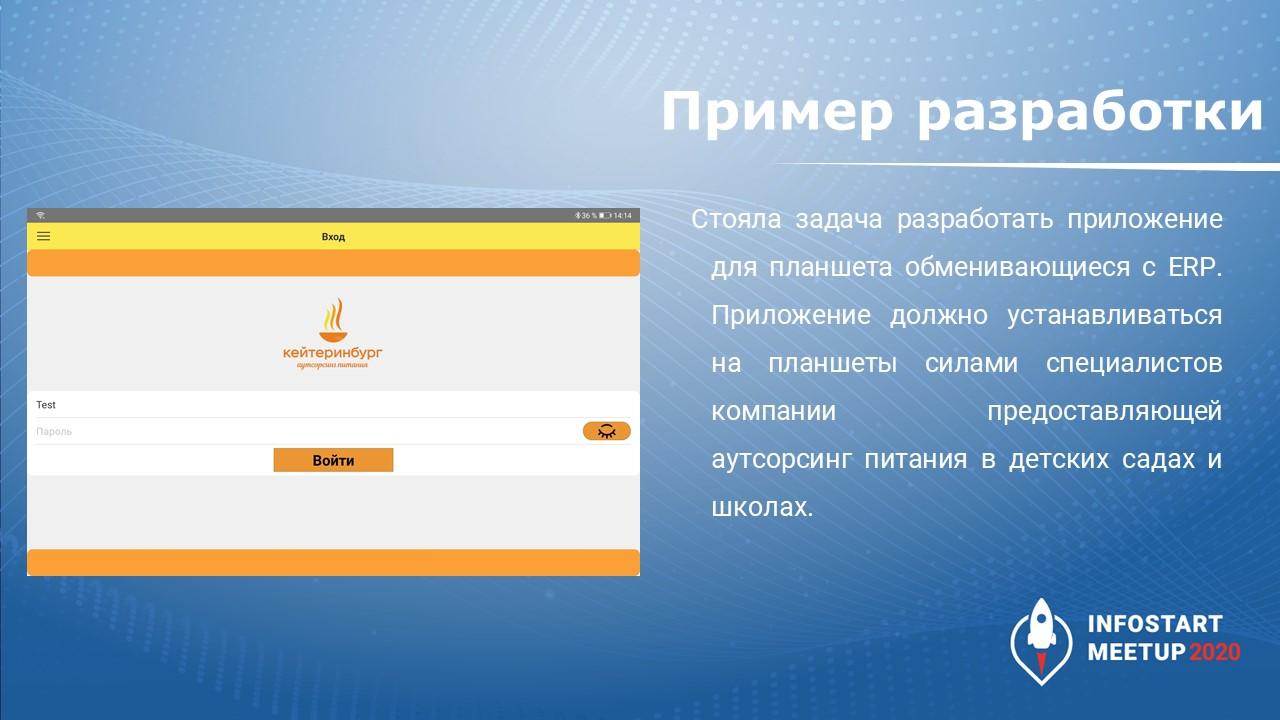
Стояла задача создать мобильное приложение, которое будет обмениваться с ERP. Мы планировали его устанавливать на планшеты пользователей и настраивать силами сотрудников ИТ-отдела.
Для этой цели у меня в ERP был создан план обмена, на узле которого хранится не логин/пароль, а некий сформированный хэш. И с мобильного приложения тоже гоняется не логин/пароль, а некий хэш. Эти хэши сравниваются и обмен производится только при их совпадении.

алгоритмы и методы – это отдельные справочники;
различные методы логирования;
запуск фоновых заданий для алгоритмов.
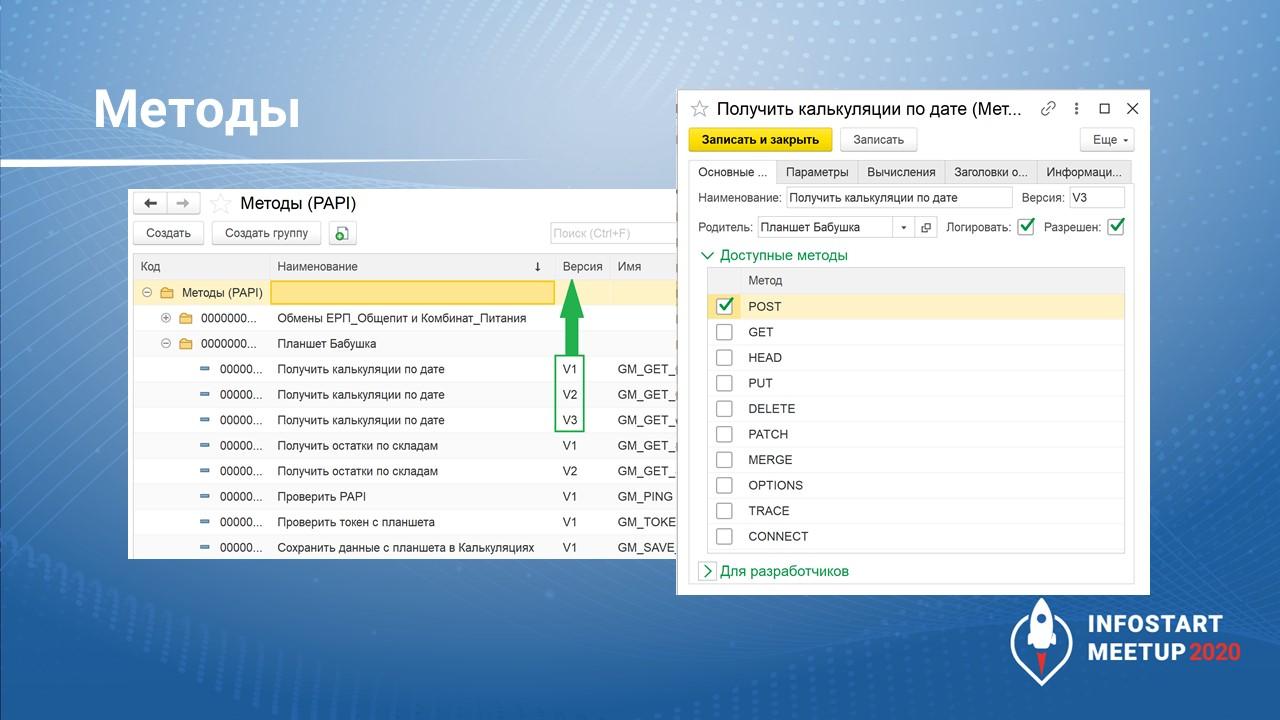
можно указать конкретный метод, который будет обработан;
на закладке «Параметры» рассчитываются параметры, которые будут использованы на закладке «Вычисления»;
указывается алгоритм, который формирует ответ от базы;
можно задать заголовки ответа и т.д.
Учитывая, что система универсальных методов уже была, на разработку полноценного рабочего окружения для мобильного приложения ушло 3 недели.
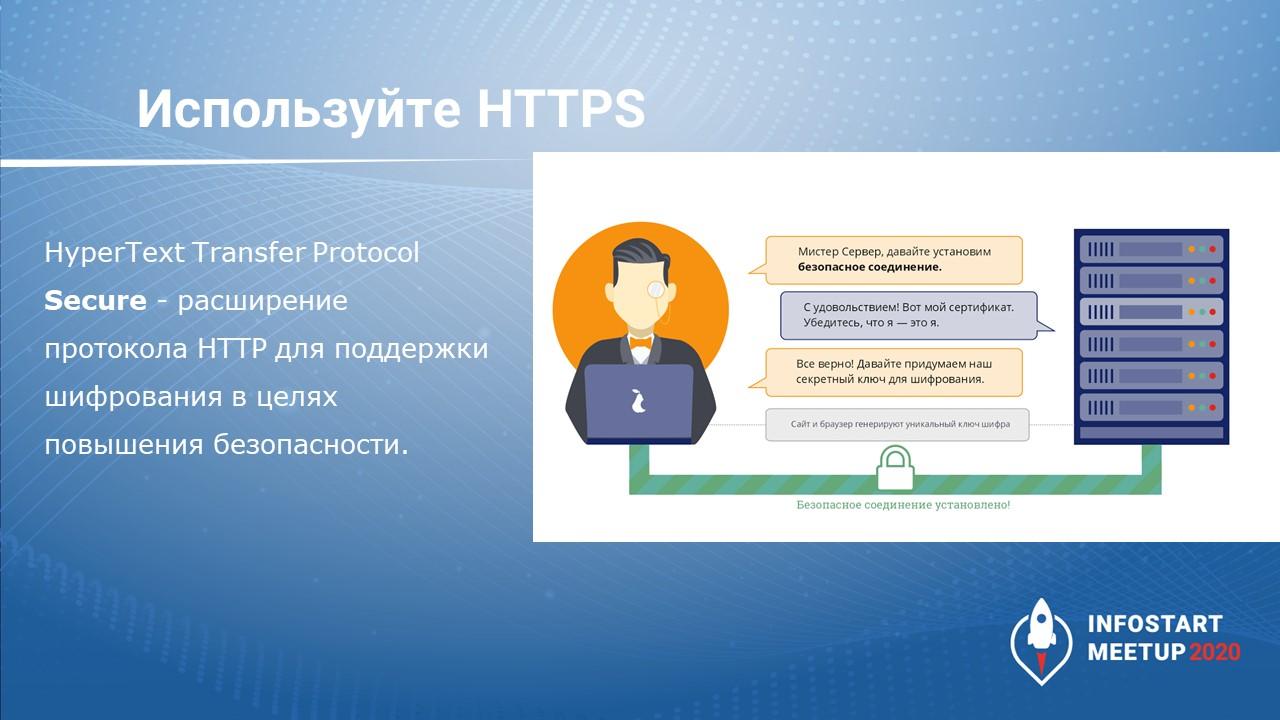
Let’s Encrypt – лучше, чем самоподписанный сертификат, но есть минусы

Часто встречается, что приходишь в какую-то крупную организацию, и там используют самоподписанные сертификаты. Если сервисы используются для внутренних целей, этого достаточно. Но если вы собираетесь выставить сервис наружу для обновления какого-то мобильного приложения, такой самоподписанный сертификат не подойдет. Лучше использовать бесплатный сервис Let’s Encrypt.

Но у сервиса Let’s Encrypt есть минусы по сравнению с платными сервисами:
Нет гарантии, что с Let’s Encrypt не случится то же самое, что случилось со Startcom и Wosign. 5 лет назад был случай, что крупные производители браузеров перестали им доверять – эти сертификаты потеряли доверие.
Еще нет гарантии сертификата. Например, если клиент зайдет на сайт, который подтвержден сертификатом платного центра, и потеряет деньги в результате фишинга, то эти платные центры обязуются выплатить некую сумму (от 10 тысяч долларов до 1.5 миллионов долларов).
И основной минус – у Let’s Encrypt сертификаты выдаются на 3 месяца. С другой стороны, есть готовые скрипты, готовые боты, которые продлевают сертификат. Для Apache – это certbot, а для IIS – это win-acme.
Храните логи в недоступном от злоумышленников месте
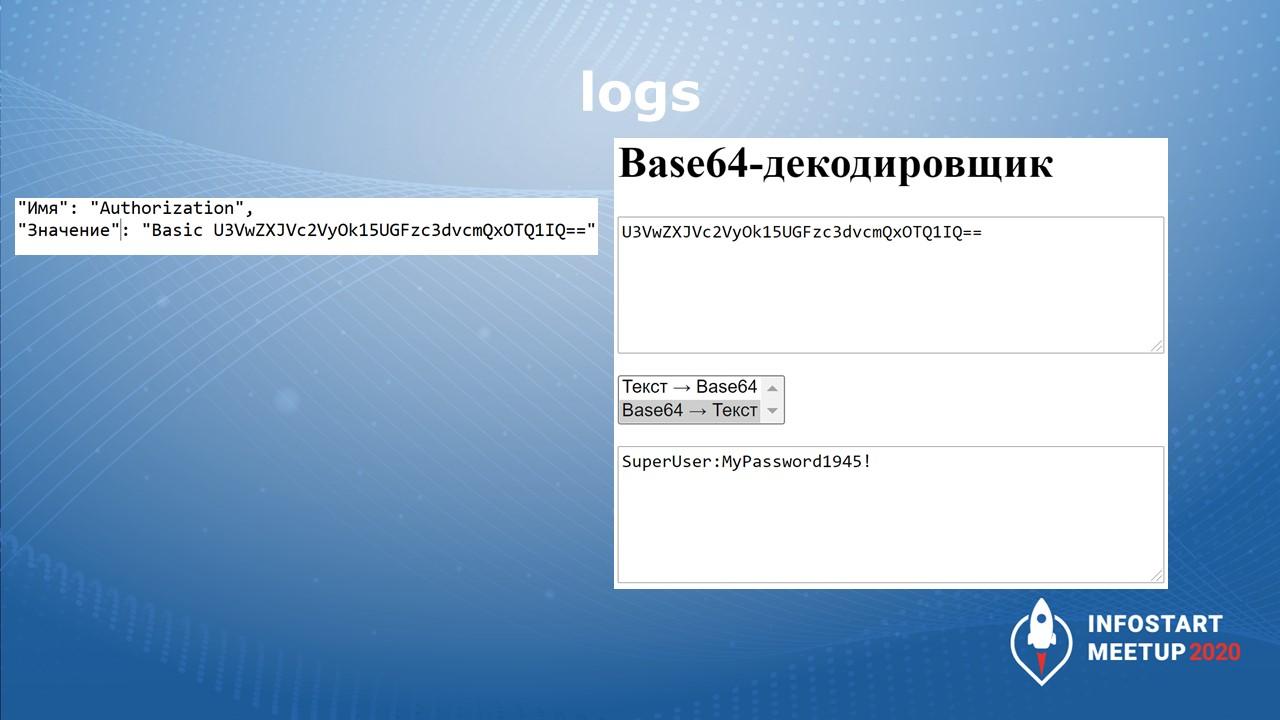
О чем еще важно помнить? Допустим, у вас есть логи, которые вы храните не очень защищенно. Логи тоже могут иметь некую конфиденциальную информацию.
Например, в логах хранится заголовок запросов с базовой авторизацией. Соответственно, если злоумышленник получит эти логи, он их без труда декодирует и получит доступ к вашей базе под этой учетной записью.
Заключение
Предположим, что он ввёл в адресной строке следующее:
Для этого вы можете воспользоваться любой подходящей утилитой командной строки. Например, telnet:
Например (такая стартовая строка может указывать на то, что запрашивается главная страница сайта):
URI (Uniform Resource Identifier, унифицированный идентификатор ресурса) — путь до конкретного ресурса (например, документа), над которым необходимо осуществить операцию (например, в случае использования метода GET подразумевается получение ресурса). Некоторые запросы могут не относиться к какому-либо ресурсу, в этом случае вместо URI в стартовую строку может быть добавлена звёздочка (астериск, символ «*»). Например, это может быть запрос, который относится к самому веб-серверу, а не какому-либо конкретному ресурсу. В этом случае стартовая строка может выглядеть так:
При этом учитывайте, что для переноса строки следует использовать символ возврата каретки (Carriage Return), за которым следует символ перевода строки (Line Feed). После объявления последнего заголовка последовательность символов для переноса строки добавляется дважды.
Как прочитать ответ?
Стартовая строка ответа имеет следующую структуру:
Версия протокола здесь задаётся так же, как в запросе.
Пояснение к коду состояния (Reason Phrase) — текстовое (но не включающее символы CR и LF) пояснение к коду ответа, предназначено для упрощения чтения ответа человеком. Пояснение может не учитываться клиентским программным обеспечением, а также может отличаться от стандартного в некоторых реализациях серверного ПО.
После стартовой строки следуют заголовки, а также тело ответа. Например:
Тело ответа следует через два переноса строки после последнего заголовка. Для определения окончания тела ответа используется значение заголовка Content-Length (в данном случае ответ содержит 7 восьмеричных байтов: слово «Wisdom» и символ переноса строки).
Но вот по тому запросу, который мы составили ранее, веб-сервер вернёт ответ не с кодом 200, а с кодом 302. Таким образом он сообщает клиенту о том, что обращаться к данному ресурсу на данный момент нужно по другому адресу.
В ответ на этот запрос веб-сервер Хабрахабра уже выдаст ответ с кодом 200 и достаточно большой документ в формате HTML.
Если вы уже успели вжиться в роль, то можете теперь прочитать полученный от сервера HTML-код, взять карандаш и блокнот, и нарисовать профайл Ализара — в принципе, именно этим бы на вашем месте браузер сейчас и занялся.
А что с безопасностью?
А есть дополнительные возможности?
Что-то ещё, кстати, используют?
Увеличение скорости обеспечивается посредством сжатия, приоритизации и мультиплексирования дополнительных ресурсов, необходимых для веб-страницы, чтобы все данные можно было передать в рамках одного соединения.
На данный момент поддержка протокола SPDY есть в браузерах Firefox, Chromium/Chrome, Opera, Internet Exporer и Amazon Silk.
И что, всё?
Ну и, конечно, не забывайте, что любая технология становится намного проще и понятнее тогда, когда вы фактически начинаете ей пользоваться.
Для правильной работы пакета NetX Web HTTP требуется установить NetX Duo 5.10 или более поздней версии. Кроме того, должен быть создан экземпляр IP, для которого включено использование протокола TCP. Для поддержки HTTPS также необходимо установить NetX Secure TLS 5.11 или более поздней версии (см. следующий раздел). Этот процесс показан в демонстрационном файле в разделе "Пример небольшой системы" главы 2.
Для правильной работы протокола HTTPS на основе пакета NetX Web HTTP требуется, чтобы были установлены NetX Duo 5.10 или более поздней версии и NetX Secure TLS 5.11 или более поздней версии. Кроме того, должен быть создан экземпляр IP, для которого включено использование протокола TCP для работы с протоколом TLS. Сеанс TLS необходимо будет инициализировать с помощью соответствующих криптографических процедур и сертификата доверенного ЦС. Кроме того, потребуется выделить пространство для сертификатов, которые будут предоставляться удаленными узлами сервера во время подтверждения TLS. Этот процесс показан в демонстрационном файле в разделе "Пример небольшой системы HTTPS" главы 2.
Дополнительные сведения о параметрах конфигурации TLS см. в документации по NetX Secure.
- HTM (или HTML): HTML-файлы (HTML);
- TXT: открытый текст ASCII;
- GIF: двоичное изображение GIF;
- XBM: двоичное изображение Xbitmap.
Когда нужна проверка подлинности? HTTP-сервер самостоятельно решает, требуется ли проверка подлинности для запрошенного ресурса. Если проверка подлинности нужна, но в запросе от клиента нет необходимых данных проверки подлинности, то клиенту возвращается ответ "HTTP/1.1 401 Unauthorized" с указанием требуемого типа проверки подлинности. Ожидается, что клиент в этом случае сформирует новый запрос с правильными данными проверки подлинности.
Формат подпрограммы обратного вызова проверки подлинности для приложения достаточно прост и определен ниже.
Определены следующие типы запроса:
HTTP-сервер поддерживает обратный вызов для запроса ограничений по возрасту и датам для определенного ресурса в приложении HTTP. Эти сведения позволяют определить, будет ли HTTP-сервер отправлять всю страницу клиенту по запросу GET. Если в запросе клиента нет строки "if modified since" (если изменено позднее) или это значение не совпадает с датой "last modified" (последнее изменение), полученной в обратном вызове запроса сведений из кэша, то клиенту отправляется вся страница.
Дополнительные сведения об использовании этих служб можно найти в главе 3 "Описание служб HTTP".
Дополнительные сведения об использовании этих служб можно найти в главе 3 "Описание служб HTTP".
NetX Web HTTP соответствует требованиям документов RFC 1945 "Hypertext Transfer Protocol/1.0" (Протокол передачи гипертекста, версия 1.0), RFC 2616 "Hypertext Transfer Protocol/1.1" (Протокол передачи гипертекста, версия 1.1), RFC 2581 "TCP Congestion Control" (Контроль перегрузки TCP), RFC 1122 "Requirements for Internet Hosts" (Требования к Интернет-узлам) и других связанных с ними документов RFC.
В третьей части я показал пример обращения ко всем возможным методам, и как работать с длительными операциями.
В четвертой части показал, как работать с порциями.

для обмена данными между информационными системами;
для обмена данными с сайтами и порталами;
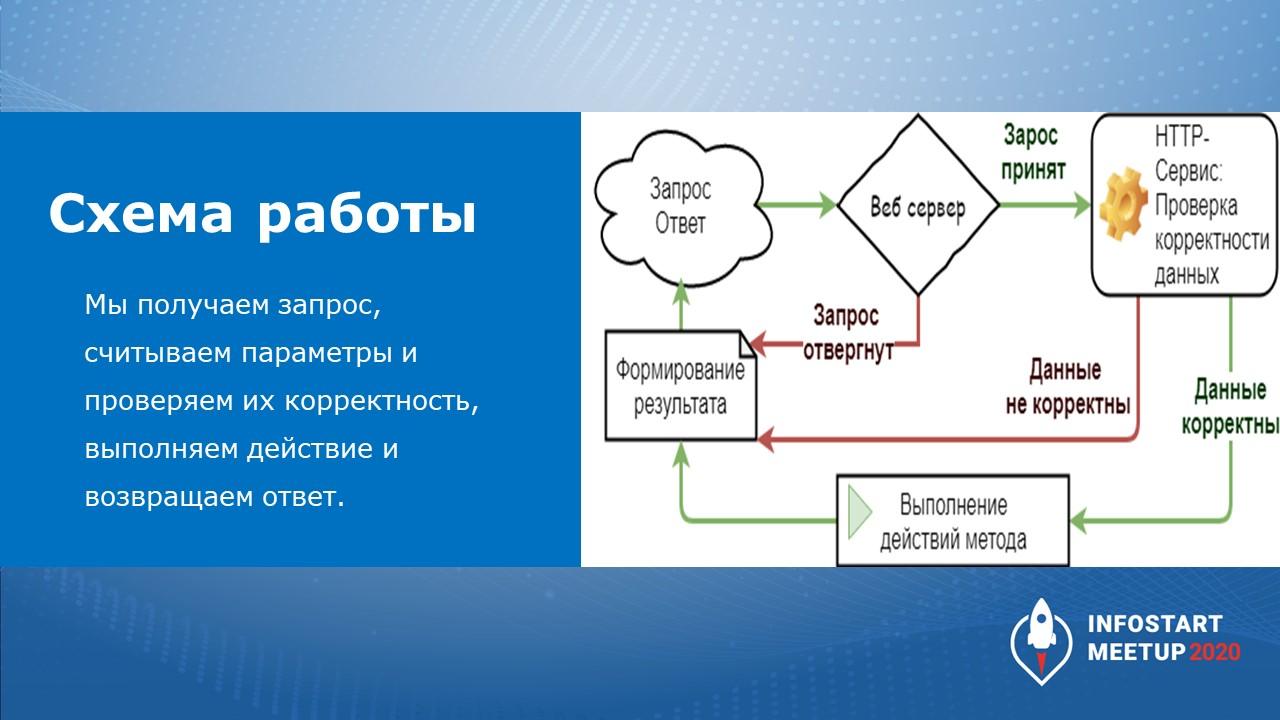
Клиент формирует запрос к веб-серверу.
Дальше запрос проходит какие-то проверки – проверяются заголовки, параметры, тело запроса (если сервис использует тело запроса).
Если все проверки пройдены, то выполняется некий метод в вашей конфигурации и формируется ответ с кодом состояния:
обычно, если все нормально отработало, код состояния равен 200;
если что-то пошло не так, код состояния может отличаться;
есть методики, когда используется JSON RPC – в этом случае код состояния всегда равен 200, а в теле запроса в определенной структуре JSON содержится ответ, где в параметре error пишется, какие были ошибки.

Есть ли какая-то универсальная микстура или принцип, как сделать определенные шаги для обеспечения безопасности всех сервисов, которые вы создаете? Такой микстуры, к сожалению, нет. Но есть какие-то практики, которые люди применяют в своей работе.
Структура протокола¶

Стартовые строки различаются для запроса и ответа. Строка запроса выглядит так:
Стартовая строка ответа сервера имеет следующий формат:
Например, на предыдущий наш запрос клиентом данной страницы сервер ответил строкой:
Проводите постоянный мониторинг
Нужно производить постоянный мониторинг системы. Даже если у вас все работает, следовать правилу «Работает – не трожь» не совсем правильно. Система работает до тех пор, пока вы ее обслуживаете. Соответственно, можно настроить какие-то сборы метрик, можно проверять логирование. В 2019 году на Инфостарте был очень хороший доклад «Ок, Лариса! Мониторинг проблем производительности с применением нейронных сетей». Докладчик рассказывал о том, как у них некая нейронная сеть отлавливает некие изменения в системе и на основании этих изменений делает какие-то действия, сообщает о каких-то ошибках.
Если пойти этим же путем, анализировать все эти метрики, логи, то в принципе тоже можно сделать такого автоадминистратора, который все эти вещи будет сам отлавливать. Я думаю, что даже в каких-то крупных ИТ-гигантах такие вещи уже сделаны и успешно работают.
Относитесь к паролям бережно
Еще раз напомню, что к паролям нужно относиться бережно. В практике моей компании был один случай: до 2018 года у нас администратора не было, состояние системы было подзаброшено, и мы наняли очень хорошего администратора, чтобы он все настроил. А потом директор решил проверить, действительно ли теперь все так хорошо, и обратился к моему коллеге, попросил его за хорошее вознаграждение взломать систему. У меня коллега далеко не хакер, он просто 1С-программист, который знал, что в компании есть некая база, которая опубликована наружу. Он открыл эту базу через браузер, быстро подобрал пароль к учетке пользователя-администратора с правом открытия внешних обработок, вошел в базу, открыл в ней обработку и сделал принтскрины, доказывающие, что у него полный доступ ко всем данным. Пароль был 123.
Вопросы
Какие вы можете порекомендовать средства для хранения паролей к внешним сервисам, с которыми интегрируется 1С?
1С рекомендует использовать для этого безопасное хранилище. Но я обычно делаю свое хранилище значений. И в нем уже в определенной структуре храню такие вещи.
В кейсе про мобильное приложение, о котором я рассказывал, я не гоняю пароль в явном виде, я просто гоняю некий хэш.
Вы говорите про то, как хранятся пароли внутри 1С, а снаружи? Если нужно обмениваться паролем между командой разработки и инфраструктурщиками? Используете ли вы какие-то сервисы для этого?
Можно хранить секреты в файле на сервере с ограниченным доступом, либо в специальном сервисе. В базу добавляем ПараметрСеанса, в который будем считывать секреты, и запрещаем доступ к этому параметру сеанса.
Вызов внешнего сервиса делаем таким образом
Если базу выгрузить, то секреты никуда не утекут.
Какие VPN-сервисы рекомендуете для внутренних сервисов? Или лучше написать свой?
OpenVPN – самый распространенный, используем его.
Как правильно выставлять сервис наружу? Лучше всегда закрывать веб-сервисы, которые выдаются наружу? Или в каких-то случаях не закрывать?
Если для вас это будет очень больно, лучше этого не делать. Если вы обслуживаетесь у каких-то аутсорсеров, а вас начнут проверять на прочность, то вам нужно будет сначала дозвониться, дождаться, когда специалист с вами через час свяжется, и только потом вам, может быть, помогут. В таких условиях лучше ничего не выставлять наружу.
Если вам нужно обмениваться с сайтом или сторонним сервисом, есть хорошие средства, я про них в докладе уже упоминал.
А есть какие-то готовые инструменты для защиты базы от внешнего доступа? Какими сервисами можно воспользоваться 1С-нику?
Очень многие используют nginx, это хорошее программное обеспечение, его можно использовать как реверсное прокси для балансировки и фильтрации запросов.
Данная статья написана по итогам доклада (видео), прочитанного на онлайн-митапе "Безопасность в 1С". Больше статей можно прочитать здесь.
Пройдите аудит ИБ

Даже если у вас все отлично настроено, все отлично работает, можно еще произвести аудит информационной безопасности. Это актуально, поскольку система развивается, в ней появляются новые дыры, и их надо своевременно отслеживать.
Какие-то фирмы проводят аудит раз в полгода, кто-то – раз в год. Какие-то фирмы начинают проводить аудит только тогда, когда с ними что-то случается.
Но проводить аудит – дело полезное. Вы получите обратную связь, получите отчет о том, что было проделано, узнаете, какие у вас есть дыры в безопасности. Если у вас нет возможности проводить аудит своими силами, есть сторонние организации, которые этим занимаются.
Настройте регулярное создание бэкапов

Простая проверка администратора на профпригодность – это поручение «Восстанови на тестовой базе вчерашний бэкап». Если администратор сможет восстановить бэкап только месячной давности, нет причин с ним дальше работать. За месяц многое может поменяться, поэтому такие вещи недопустимы, и не дай Бог с вами это произойдет.

Для чего нужен сервис?
Кто конечный потребитель?
Будет ли сервис выставлен наружу?
Эти три простых вопроса позволяют понять, какие вещи необходимо будет произвести для обеспечения безопасности.
Internet Transfer Control
Internet Transfer Control - фактически является интерфейсом к основной Internet библиотеке Windows WININET.DLL. Эта DLL - часть Win32 API. Как Вы думаете работает Internet Explorer? Да, да, да вызывая функции из этой самой библиотеки. А зачем нам тогда этот Internet Transfer Control? Да, в принципе и не нужен, если только Вы не боитесь заблудиться в темном лесу под названием WININET.DLL и флаг Вам в руки, если это так.
Синхронный метод. Метод OpenURL используется, чтобы получить доступ к документу в Internet и помещает его копию на локальном компьютере. URL, который передается как параметр для метода OpenURL, может быть любым документом. Все, что Вы должны определить - URL документа, который Вам требуется и тип документа icString (текстовый файл) или icByteArray (бинарный файл, для программ и архивов). Вначале посмотрим, как получить обычный текстовый файл:
Итак, файл получен. Что мы можем с ним сделать? Например сохранить на своем компьютере:
Файл получен и сохранен, теперь его можно посмотреть в любой программе, или написать свою для его просмотра. А что? Для этого можно использовать, например, Microsoft Internet Control.
Внимание: Метод OpenURL выполняется синхронно, т.е. управление в Вашу программу будет передано только тогда, когда передача запрашиваемого файла будет завершена. Иными словами, Ваша программа будет неспособна выполняться пока идет передача файла и, если файл большой, а связь медленная, то Вы можете испытывать некоторые трудности с использованием этого метода, дело в том, что Ваша программа окажется на пару часиков в случае если принимаемый файл имеет внушительные размеры, ну и кому это понравится? Зато легко, но не очень хорошо, но легко.
После, того, как Вы открыли файл методом OpenURL, Вам становятся доступны некоторые его свойства, которые тоже могут быть Вам полезны.
| Значение | Описание |
| Date | Возвращает время и дату передачи документа. Формат: Wednesday, 27-April-96 19:34:15 GMT |
| MIME-version | Возвращает версию протокола MIME. |
| Server | Возвращает название сервера. |
| Content-length | Возвращает размер документа в байтах. |
| Content-type | Возвращает MIME тип данных. |
| Last-modified | Возвращает дату и время последней модификации документа. Формат: Wednesday, 27-April-96 19:34:15 GMT |
Итак, допустим, что Вы хотите узнать размер открытого документа. Для этого используйте такой код:
Внимание: Метод GetHeader можно использовать только после принятия заголовка или открытия документа методом OpenURL. Если Вы захотите узнать, например размер еще не открытого документа, то произойдет ошибка. Поэтому перед приемом документа, я рекомендую узнать его заголовок. Это позволит Вам определить размер документа и контролировать прогресс его приема.
Если Вам нужно принять только заголовок документа, то воспользуйтесь следующим кодом:
Обратите внимание на переменную lLenthFile, которая равна размеру принимаемого файла. Это нам может потребоваться в дальнейшем.
Внимание: Если принимаемый документ не бинарный файл или не HTML документ, а является ASP или другим динамически формируемым документом, то принятый заголовок может содержать искаженную информацию, например о его размере. Это связано с тем, что получить размер еще не существующего документа невозможно.
Асинхронный метод. Для того, чтобы выполнение программы не прерывалось, существует способ асинхронной передачи файлов. Давайте рассмотрим его подробнее. Для асинхронной работы существует метод Execute.
Итак, допустим, что Вы запросили на сервере файл mydocument.zip. Сервер принял Вашу команду и начинает возвращать Вам данные. Для получения данных, которые были переданы на Ваш компьютер, Вам нужно обратиться к методу GetChunk. Но здесь не все так просто, дело в том, что данные передаются не все сразу, а по частям или порциями. Обычно (по умолчанию) размер каждой порции данных 1024 байт. Это означает, что, если Вы требовали файл, который имеет размер 100 Кб, то Вы должны вызвать GetChunk метод примерно 100 раз, чтобы получить все требуемые данные. Для чего это сделано? Представте себе, что Ваша программа принимает файл размером 1 Мб, а скорость Вашего соединения с Internet 19200 бод. Это означает, что Ваша программа будет принимать файл примерно в течении 10 минут. Как Вы думаете, стоит сообщать пользователю Вашей программы о том, какая часть файла уже принята и сколько осталось еще принять? Я думаю, что стоит. Более того, я сделал индикатор прогресса приема файла, чтобы пользователь мог пойти и спокойно попить, например кофе.
Да, кстати, если Вы думаете, что сервер всегда должен Вам возвратить данные, то Вы глубоко заблуждаетесь. Если Вы захотите удалить файл на сервере и пошлете ему правильную команду, то сервер сразу же скажет OK и удалит этот файл. А вот данных Вы от него никаких тогда не получите, но событие StateChanged произойдет и параметр State примет значение icResponseCompleted. Значит все в норме, и запрос был успешно выполнен.
Фух: Кажется все написал, теперь давайте посмотрим на код. Обратите внимание, что прием данных ведется в переменую vtData(), имеющую тип Byte. Это сделано для того, чтобы можно было принимать любые типы файлов: текстовые и бинарные. С той же целью метод GetChunk вызывается с параметром icByteArray:
Еще хочу, чтобы Вы посмотрели на код процедуры UpdateStatus. Она отвечает за вывод информации о прогрессе приема файла. Для этого используется глобальная переменная lLenthFile, содержащая размер документа на сервере и передаваемый размер уже принятых данных. Процедура очень простая и служит только для того, чтобы записать в строку состояния, сколько принято данных в процентах от их общего количества.
И ничего нет здесь сложного. Так, теперь мы знаем для чего нужно событие StateChanged и давайте посмотрим, какую информацию мы можем еще получать, используя его.
| Константа | Значение | Описание |
| icNone | 0 | Информация о состоянии не доступна |
| icResolvingHost | 1 | Поиск IP адреса сервера |
| icHostResolved | 2 | IP адрес сервера найден |
| icConnecting | 3 | Соединение с сервером |
| icConnected | 4 | Соединился с сервером |
| icRequesting | 5 | Запрос информации с сервера |
| icRequestSent | 6 | Запрос на сервер успешно отправлен |
| icReceivingResponse | 7 | Получение ответа от сервера |
| icResponseReceived | 8 | Ответ от сервера был успешно принят |
| icDisconnecting | 9 | Отключение от сервера |
| icDisconnected | 10 | Отключение от сервера выполнено |
| icError | 11 | Произошла ошибка во время сеанса связи с сервером |
| icResponseCompleted | 12 | Запрос выполнен, все данные получены |
Опубликуйте сервис и настройте на него права
Если вы организовываете внутреннюю сеть, достаточно внутри сети поставить веб-сервер – это может быть Apache, IIS, это может быть 1С:Публикатор или 1С:Линк (это тоже Apache, просто его версия от фирмы 1С с красивым интерфейсом).
К паролям нужно относиться очень бережно – про это я чуть дальше расскажу. Желательно, чтобы у сотрудников были хорошие пароли.
Коды состояния¶
Код состояния информирует клиента о результатах выполнения запроса и определяет его дальнейшее поведение. Набор кодов состояния является стандартом, и все они описаны в соответствующих документах RFC.
Каждый код представляется целым трехзначным числом. Первая цифра указывает на класс состояния, последующие - порядковый номер состояния (рис 1.). За кодом ответа обычно следует краткое описание на английском языке.
Введение новых кодов должно производиться только после согласования с IETF. Клиент может не знать все коды состояния, но он обязан отреагировать в соответствии с классом кода.
Коды статуса класса 3xx сообщают клиенту, что для успешного выполнения операции нужно произвести следующий запрос к другому URI. В большинстве случаев новый адрес указывается в поле Location заголовка. Клиент в этом случае должен, как правило, произвести автоматический переход (жарг. «редирект»).
Название параметра должно состоять минимум из одного печатного символа (ASCII-коды от 33 до 126). После названия сразу должен следовать символ двоеточия. Значение может содержать любые символы ASCII, кроме перевода строки (CR, код 10) и возврата каретки (LF, код 13).
Пробельные символы в начале и конце значения обрезаются. Последовательность нескольких пробельных символов внутри значения может восприниматься как один пробел. Регистр символов в названии и значении не имеет значения (если иное не предусмотрено форматом поля).
Пример заголовков ответа сервера:
Читайте также: