
Edge analytics что это
31 января 2022 года Google выпустил URL Inspection API , позволяющий массово проверять состояние индексации URL-адресов на основе свойств в GSC.
В GSC всегда можно было проверять индексацию по одному URL-адресу. Но с помощью URL Inspection API впервые можно проверить состояние индексации URL-адресов массово на основе данных непосредственно от Google.
Используя эту систему для отслеживания индексирования, можно ежедневно или еженедельно проверять, проиндексированы ли ваши самые важные URL-адреса, не пропали ли они из индекса в результате технических проблем, проблем с качеством сайта или из-за требовательной системы индексирования Google.
У API есть ограничение — 2000 запросов в день (подсчитываются вызовы, которые относятся к одному и тому же сайту), что может стать проблемой для крупных сайтов. В статье я расскажу, как это обойти.
Что такое Analytics Edge
Analytics Edge — это надстройка для Excel, которая позволяет работать с несколькими API непосредственно в электронных таблицах и использовать полученные данные сразу после экспорта.
Я использую Analytics Edge для многих целей, в том числе и для массовой проверки URL-адресов с помощью URL Inspection API.
Вместо массовой проверки только одного свойства в GSC, мы будем проверять сразу несколько свойств и сайтов автоматически, без необходимости запускать каждый макрос по отдельности.
Цель состоит в том, чтобы вы открыли электронную таблицу, нажали кнопку «Обновить всё», и система проверила все ваши самые популярные URL-адреса на нескольких сайтах автоматически. Такой подход может сэкономить кучу времени.

Результат проверки в настроенной системе
Что же такое edge computing
Согласно определению Гартнера, edge computing — это подвид распределенных вычислений, в котором обработка информации происходит в непосредственной близости к месту, где данные были получены и будут потребляться. Это основное отличие edge computing от облачных вычислений, при которых информация собирается и обрабатывается в публичных или частных датацентрах. Основным отличием от локальных вычислений является то, что обычно edge computing — это часть большей системы, которая включает в себя сбор статистики, централизованное управление и удаленное обновление приложений на edge устройствах.
Что же такое edge устройство? Многие считают, что edge computing — это когда приложение работает на Raspberry Pi или других микрокомпьютерах. На самом деле edge computing может быть и на мобильных устройствах, персональных ноутбуках, умных камерах и других устройствах, на которых можно запустить приложение по обработке данных.
В целом, когда я изучал этот вопрос, у меня сложилось впечатление, что тема недооценена и что многие, пытаясь решить задачи edge computing, изобретают свой велосипед и применяют подходы, используемые при облачных вычислениях. Также достаточно часто происходит путаница в терминах IoT , edge computing и fog computing . Попробуем с этим разобраться.
Шаг 6. Выводим результаты в таблицу
В Analytics Edge выберите меню «File», а затем «Write to Worksheet». Дайте новому рабочему листу имя, например, «site1 Results» и нажмите OK.

Запись результатов в таблицу
Теперь у вас есть новый рабочий лист, содержащий результаты проверки списка URL-адресов, которые вы хотите отслеживать.
Шаг 9. Проверяем и выводим результаты второго рабочего листа
Далее проделайте те же действия, что и ранее, чтобы создать инструкции для чтения рабочего листа, использования URL Inspection API и вывода результатов в новый рабочий лист с именем «Результаты сайта 2».
В итоге у вас будет два макроса, которые обрабатывают URL-адреса из двух рабочих листов. И каждый макрос выводит результаты в новые рабочие листы для последующего анализа данных и работы с ними.

Результаты второго макроса
Теперь, когда вы создали два макроса, вы всегда можете открыть электронную таблицу и запустить их одновременно, чтобы проверить URL-адреса, которые вы хотите отслеживать по всем свойствам GSC.
Для этого откройте Analytics Edge и нажмите на кнопку «Refresh All» («Обновить всё»), которая находится в левом верхнем углу. Analytics Edge запустит оба макроса в алфавитном порядке. После выполнения макросов у вас будут свежие данные для анализа.
Сохраняйте каждую электронную таблицу под новым именем, чтобы можно было отслеживать результаты с течением времени.

Кнопка «Обновить всё» для выполнения сразу всех макросов
Поздравляем! Теперь ваша система отслеживания URL-адресов нескольких сайтов готова.
Вы можете отслеживать больше сайтов, добавив дополнительные макросы в электронную таблицу. И опять же, если у вас большой сайт, то добавление нескольких каталогов или поддоменов в качестве свойств GSC позволит вам обойти ограничение в 2 000 запросов в день. Таким образом, вы можете добавить несколько свойств GSC (из одного и того же сайта), а не только проверять разные сайты.
Граничные вычисления «Edge computing» — одна из самых важных технологических тенденций, которая, по мнению института Gartner, будет доминировать на рынке Интернета вещей (IoT) в этом году. С ростом популярности интеллектуальных устройств, подключенных к сети, а также развитием IoT, различные отрасли включая: производство, торговлю и автотранспорт начинают генерировать огромные объемы данных, целевым местом хранения которых являются серверы в «Облаке».
Согласно прогнозам глобальной исследовательской компании Markets & Markets, стоимость рынка Граничных вычислений «Edge computing» будет иметь годовой темп роста более 35% и возрастёт с 1,47 млрд. в 2017 году до 6,72 млрд. в 2022 году. В свою очередь, согласно отчету IDC FutureScape: Worldwide IoT 2017 Predictions, к 2019 году не менее 40% данных IoT будут храниться, обрабатываться и анализироваться с помощью граничных вычислений. Более того, количество интеллектуальных устройств будет расти из года в год, а использование искусственного интеллекта и машинного обучения позволит им непрерывно развиваться. Что такое Граничные вычисления «Edge computing»? — это одна из 10 стратегических технологических тенденций этого года

*Применительно к мобильной связи, чаще применяется термин Mobile Edge Computing (MEC). МЕС это своего рода аппаратурные (Hardware) решения для программных решений (Software) NFV (Network Functions Virtualization, виртуализация сетевых функций). Можно сказать, что МЕС является инфраструктурой для NFV. В данной статье мы созредоточимся на граничных вычислениях «Edge computing», но не стоит забывать что их работа не возможна без NFV.
Как обойти ограничение в 2 000 запросов в день
Из-за лимита через URL Inspection API вы можете обрабатывать только 2 000 запросов в день для каждого свойства GSC.
Но есть важное отличие между сайтом и свойством GSC. Помните, что вы можете настроить в GSC несколько свойств на один сайт, добавив каталоги и поддомены. Благодаря этому вы можете получать больше данных.

Несколько свойств в GSC
Наличие каталогов или поддоменов, настроенных в качестве свойств, позволит вам обрабатывать 2 000 запросов в день для каждого из этих свойств. Благодаря этому вы можете проверять гораздо больше URL-адресов на сайте.
А используя Analytics Edge, вы можете проверить состояние индексации URL-адресов по всем этим свойствам одновременно.
Концепция граничной аналитики «Edge Analytics»

Концепция граничной аналитики «Edge Analytics» основана на сборе, обработке и анализе данных на периферийных устройствах сети, рядом с датчиками, сетевым коммутаторами или другими подключенным устройствами, т. е. рядом с источником информации и исполняемыми элементами, например на производстве. Сам термин «Edge Сomputing» означает, что часть работы происходит на самом конце сети, в том месте где в системах IoT мир физических объектов связывается с Интернетом. Однако граничные вычисления Edge Computing — это гораздо больше, чем просто расчет и обработка данных. Его основная функция — плавная интеграция периферийных устройств и облачных вычислений, а также двусторонний обмен информацией.
Решение подразумевающее граничные вычисления дают возможность анализировать ключевые данные в режиме реального времени «на месте», не отправляя их на центральный сервер. «Граница сети» («Edge») разделена, и включает в себя модули принятие решений и модули временного хранения тех данных, которые настолько незначительны, что нужны только сейчас и нет смысла их хранить и использовать их в будущем.

Согласно прогнозу Института Gartnera, 90% собранных данных на первых порах будут бесполезны, потому что компании не знают, как их правильно анализировать и использовать. Но эти данные могут очень пригодится в будещем для различных отраслей, в которых получение данных и реагирование на них в режиме реального времени имеет решающее значение для правильного функционирования. Эта будет критично для промышленных предприятий, для которых каждый час простоя может быть связан с потерями от нескольких сотен до даже нескольких миллионов евро, поэтому так важно, чтобы аналитики могли использовать потенциал данных, полученных с помощью устройств IoT.
Шаг 2. Подключаем учётную запись Google
Подключитесь к учётной записи Google с доступом к свойствам GSC, которые вы хотите отслеживать.
В верхнем меню Excel откройте вкладку «Analytics Edge». Нажмите на «Google Search», а затем на «Accounts» в выпадающем меню.

Подключение к аккаунту Google
Теперь подключите учётную запись Google и пройдите авторизацию. Это займёт всего несколько секунд.
Принципы компании IBM при создании платформы edge computing
Компания IBM, являясь одним из лидеров в области гибридных облаков, использует определённые принципы при разработке решений для edge computing:
- Развивать инновации (Drive Innovation)
- Обеспечить безопасность данных (Secure data)
- Управлять в масштабе (Manage at scale)
- Открытость исходного кода (Open Source)
IBM применяет эти принципы при декомпозиции задачи построения фреймворка edge computing.

Как вы можете видеть, всё решение разбито на 4 сегмента использования:
- Edge-устройства
- Edge-сервера или шлюзы
- Edge-облако
- Гибридное облако в частном или публичном дата центре
Помимо основных принципов и подходов, IBM разработала референсную архитектуру для решений, основанных на edge computing. Референсная архитектура — это шаблон, показывающий основные элементы системы и детализированный настолько, чтобы иметь возможность адаптировать его под конкретное решение для заказчика. Давайте рассмотрим такую архитектуру более подробно.
Преимущества и недостатки edge computing
При выборе технологий для своего проекта я в первую очередь основываюсь на двух критериях — "Что я от этого получу?" и "Какие проблемы я от этого получу?".
Начнём с преимуществ:
- Во-первых, это снижение количества трафика, передаваемого по сети, за счет обработки информации на самом устройстве и передачи только результирующих данных. Особенно виден эффект при использовании edge computing при обработке видеопотока и большого количества фотографий, а также при работе с несжатым звуком.
- Во-вторых, это уменьшение задержек, если необходимо оперативно отреагировать на те или иные результаты обработки данных.
- Для многих систем также важно, чтобы персональные данные не выходили из определённого контура. С введением электронных медицинских карт данное требование является крайне актуальным на сегодняшний день.
- Возможность для устройства быть независимым, определённое время работать без доступа к центральным серверам также повышают отказоустойчивость системы. А централизованный сбор результирующей информации защищает от потери данных при отказе edge-устройства.
Хотя, конечно, проектируя систему с edge computing, не стоит забывать, что как и любую другую технологию её стоит использовать в зависимости от требований к системе, которую вам необходимо реализовать.
Среди недостатков edge computing можно выделить следующие:
- Крайне тяжело обеспечить гарантию отказоусточивости для всех edge-устройств.
- Устройства могут иметь различные платформы и версии OS, для чего, вероятно, потребуется создавать несколько версий сервисов (например, для x86 и ARM).
- Для управления большим количеством устройств потребуется платформа, решающая технические задачи edge computing.
С одной стороны, последний пункт является наиболее критичным, но, к счастью, консорциум Linux Foundation Edge (LF EDGE) включает в себя всё больше и больше проектов с открытым исходным кодом, а их зрелость стремительно растет.
Edge framework
Когда мы осознаем, что есть необходимость в управлении большим количеством сервисов на тысячах устройств и сотнями приложений в разных кластерах, наступает понимание, что надо бы использовать какой-то фреймворк для управления всем этим зоопарком и синхронизации между устройствами.
Именно наличие данного фреймворка раскрывает преимущества edge computing перед разнородными разнесёнными вычислениями.
Как мы видим, кроме центральной части по управлению сервисами и моделями в данном фреймворке присутствуют агенты, обеспечивающие контроль за управлением жизненным циклом сервисов на устройствах/кластерах на каждом из уровней использования.
Руководство: как настроить систему отслеживания индексации
Шаг 7. Создаём рабочий лист для второго свойства GSC или сайта
Мы хотим разом проверить несколько свойств GSC на разных сайтах. Поэтому давайте для этой цели создадим второй макрос, а затем запустим оба через Analytics Edge.
Создайте новый рабочий лист с URL-адресами второго сайта или второго свойства GSC для того же сайта, который вы проверяли ранее.
Для теста вы можете назвать этот рабочий лист «site2». И опять же, в будущем вы можете назвать его по названию сайта. Добавьте самые популярные URL-адреса второго сайта или свойства, индексацию которого вы хотите отслеживать. Опять же, сначала я бы добавил всего 10–20 URL-адресов. В качестве названия столбца можно снова использовать «page».

Список URL второго сайта или свойства
Применение граничных вычислений «Edge computing» в промышленности
Концепция граничных вычислений Edge Computing играет значительную роль, среди прочего и в современной промышленности.

Благодаря использованию данных, полученных от датчиков, мы можем контролировать работу машин в режиме реального времени. Пограничные «Edge» устройства постоянно анализируют временные графики выбранных параметров и предупреждают о нарушениях. Поэтому мы можем реагировать на событие до того, как произойдет сбой или остановка всей производственной линии, что дает огромную экономию для промышленных предприятий.
Важным преимуществом граничных вычислений является масштабируемость. Передача аналитических алгоритмов интеллектуальным датчикам и сетевым устройствам снижает нагрузку сети на обрабатываемые данные. Благодаря этому, когда количество подключенных устройств, внедряемых организацией увеличивается, объем генерируемых данных растёт, вычислительное «облако» нагружается меньше, чем в случае сбора данных только в вычислительном «облаке».
Шаг 5. Запускаем проверку URL Inspection
В меню Analytics Edge выберите «Google Search» → «URL Inspection». В диалоговом окне выберите учётную запись, которую вы настроили ранее, а затем свойство GSC, с которым вы хотите работать.
Теперь в этом же окне вы должны указать, где находятся URL-адреса в рабочем листе, добавив название столбца в поле URL. Чтобы добавить имя столбца, возьмите его в квадратные скобки. Так, если вы использовали в качестве имени столбца «page», как я, введите [page] в это поле и нажмите на кнопку OK.

Проверка URL на странице с помощью URL Inspection API
Теперь пусть URL Inspection API обработает все запросы. Это не должно занять много времени, поскольку мы тестируем всего несколько URL-адресов.
После завершения процесса на рабочем листе «Step Results» появится образец результатов, выделенный зелёным цветом. Теперь давайте выведем результаты на новый рабочий лист, где вы сможете анализировать данные и работать с ними.
Шаг 1. Устанавливаем Analytics Edge
После установки основного дополнения вы сможете быстро добавить модуль для подключения к Google Search Console. Вам понадобятся оба этих инструмента, чтобы воспроизвести те действия, о которых я рассказываю в статье.

Подключение модуля GSCПодключение модуля GSC
Что касается лицензий, есть бесплатные пробные версии как у основного дополнения, так и у модуля для подключения к GSC (30 дней). После завершения пробного периода основное дополнение будет стоить 99 долларов в год, а модуль для подключения к GSC — 50 долларов в год.
Референсная архитектура edge computing

Hybrid multicloud
Если мы говорим об использовании ML-модели, которая будет запускаться на десятках или тысячах устройств, то нам необходимо облако, которое сможет отвечать за обучение такой модели, обработку статистики, отображение сводной информации (правая часть архитектуры).
Шаг 8. Создаём второй макрос
Создайте новый макрос, который будет работать со вторым списком URL-адресов. Первый макрос уже настроен и будет работать с первым рабочим листом с URL-адресами. Второй макрос будет использовать новый список URL-адресов.
На панели задач Analytics Edge вы увидите текущий макрос. Откройте выпадающее меню и выберите «new macro».

Создание нового макроса
Назовите его так, как вам захочется. Я назвал его «Check Site 2».
Кроме того, если панель задач по какой-то причине не отображается, вы можете открыть её, открыв вкладку «Analytics Edge» в меню Excel, а затем нажав на кнопку «Task Pane», расположенную слева. Это большой значок рядом с меню «File».

Задаём имя новому макросу
Основные преимущества граничных вычислений «Edge computing»

Основными преимуществами решения «Edge computing», упоминаемыми экспертами, являются конфиденциальность, уменьшение задержек и минимизация проблем со связью. Для первого преимущества конфиденциальная информация предварительно обрабатывается на месте, и только данные, соответствующие политике конфиденциальности, передаются в облако для дальнейшего анализа. Второе преимущество, заключается в ограничении задержек и является наиболее часто упоминаемым преимуществом, связанным с использованием решений граничных вычислений Edge Computing. В настоящее время из-за огромного количества данных, отправляемых в облако, обрабатываемых там и передаваемых обратно на периферийные устройства, могут возникать задержки в получении выводов из анализа, что может иметь серьезные последствия для функционирования предприятия. В третьих, в случае Edge Computing, часть вычислений выполняется на периферийных устройствах, что не только снижает риск задержек, но и дает «потенциальную» гарантию того, что работа не будет прервана в случае ограниченного или прерывистого сетевого подключения. Это особенно важно, когда решения внедряются в труднодоступных местах, где охват сетями связи весьма ограничен.
Edge server and Edge micro data center
Как мы уже говорили, можно встретить промежуточные (близкие) кластеры обработки данных на уровне шлюзов или микро-датацентров с установленной поддержкой кластерных технологий.
Шаг 4. Создаём первый макрос
Создадим первый макрос для проверки URL-адресов с помощью URL Inspection API.
Analytics Edge предоставляет массу функциональных возможностей, которые можно использовать при создании макросов. Когда вы создаёте макрос в Analytics Edge, вы объединяете серию инструкций, которые будут выполняться последовательно.

Меню «Файл» в Analytics Edge
Для наших целей мы хотим:
- Прочитать список URL-адресов из нашего рабочего листа.
- Использовать URL Inspection API для проверки этих URL-адресов
- Записать результаты в новый рабочий лист, чтобы можно было проанализировать данные.
В Analytics Edge откройте меню «File» → щёлкните на «Read Worksheet». Эта функция извлечёт весь список URL-адресов, которые присутствуют на данном рабочем листе.

Пример макроса
В этом диалоговом окне рабочей книгой будет текущая рабочая книга, а рабочим листом — текущий рабочий лист. Вам не придётся ничего менять. Просто нажмите OK, чтобы прочитать рабочий лист.

Вкладка «Read Worksheet»
Обратите внимание, как на панели задач в Analytics Edge добавляется каждая часть нашего макроса по мере выполнения этих частей. После каждого шага вы увидите новую инструкцию, добавленную в макрос.
Analytics Edge создаёт временный рабочий лист под названием «Step Results», содержащий список URL-адресов, которые вы будете обрабатывать с помощью URL Inspection API. Теперь давайте воспользуемся этим API.
Граничные вычисления «Edge computing» не являются альтернативой ЦОД

Хотя «Edge Computing» обладает огромным потенциалом, его не следует рассматривать как альтернативу централизованному анализу данных. Это подход, который должен дополнять или расширять аналитические возможности в конкретных ситуациях, особенно когда быстрая реакция на нарушения может быть чрезвычайно важна для функционирования и экономии бюджета компании. Хотя это не идеальное решение, потому что, собирая часть объема данных локально, мы можем опустить некоторую информацию в самом «облаке». С другой стороны, граничные вычисления «Edge Analytics» позволяют нам справляться с потоком огромных объемов данных, соответствующим образом анализировать их и быстро делать самые полезные выводы для бизнеса.
Интересуетесь Умным городом, Умными домами, IoT, 5G и технологиями будущего? Почитайте наши статьи:
Вторая часть главы из моего электронного руководства Google Analytics 2019: Tutorial Book (скачать можно на главной странице), которая посвящена визуализации данных — тренду последних нескольких лет.
Google Analytics Edge позволяет импортировать данные из Google Analytics в Microsoft Excel, и работать с ними привычным способом.
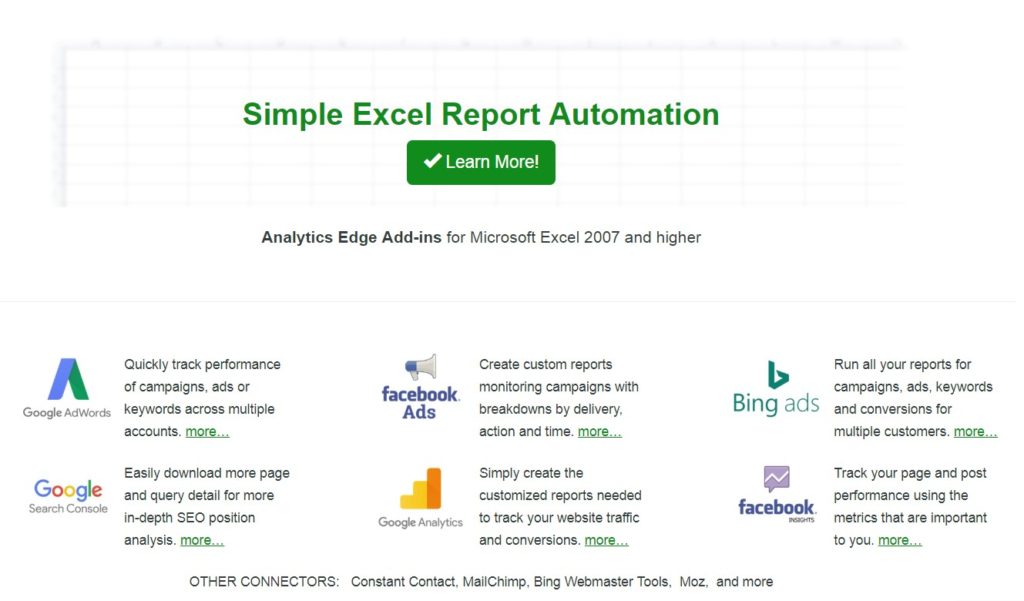
У продукта есть и другие коннекторы (Google Ads, Google Search Console, Facebook Ads, Bing Ads), но нас интересует именно Google Analytics Edge. Переходим к скачиванию надстройки на сайте.
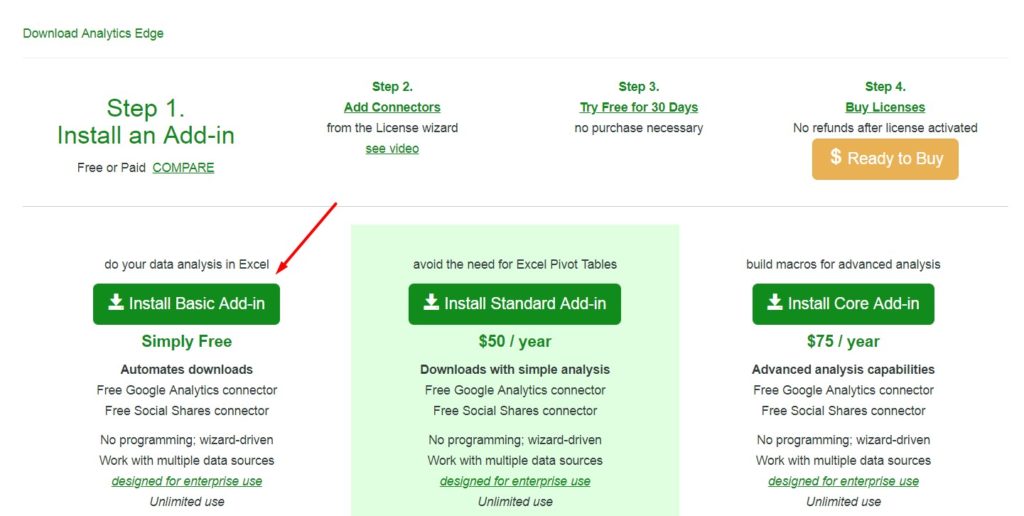
Install Basic Add-in
После установки в Excel у вас появится новая вкладка Analytics Edge:
Новая вкладка в Excel
Далее нам необходимо зарегистрироваться и активировать бесплатную лицензию. Для этого нажимаем на Register:
Затем принимаем пользовательское соглашение:
На следующем шаге активируем продукт по кнопке Active Free License:

Activate Free License
В случае успешной активации вы получите такое уведомление:
На вкладке License нам показывают какие у нас есть активированы инструменты и до какого года они доступны бесплатно. Free Google Analytics – до 1 января 2038 года.
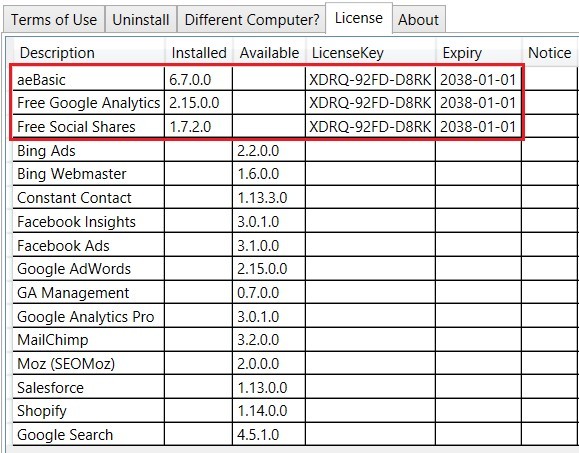
Все наши лицензии
Теперь при каждом заходе в Excel на вкладке Analytics Edge вы будете видеть значок активированной лицензии:

Первый этап завершен. Теперь добавим аккаунт Google Analytics, из которого хотим загружать данные. Для этого переходим в Free Google Analytics – Accounts.
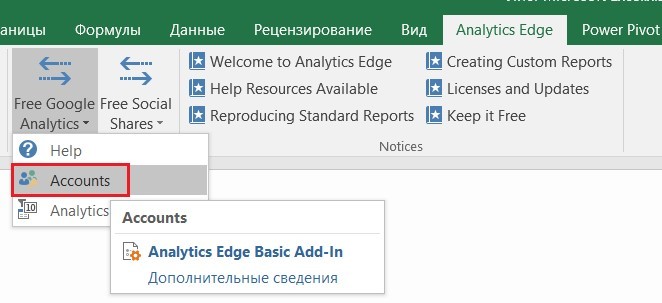
Free Google Analytics – Accounts
В открывшемся окне Analytics Accounts в поле Reference name вводим название аккаунта от Google Analytics (почта Gmail) и нажимаем Add Account:
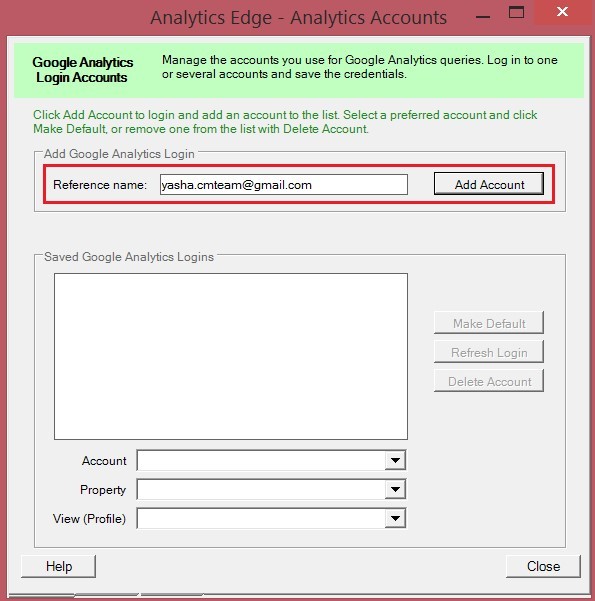
Добавление аккаунта через Reference name
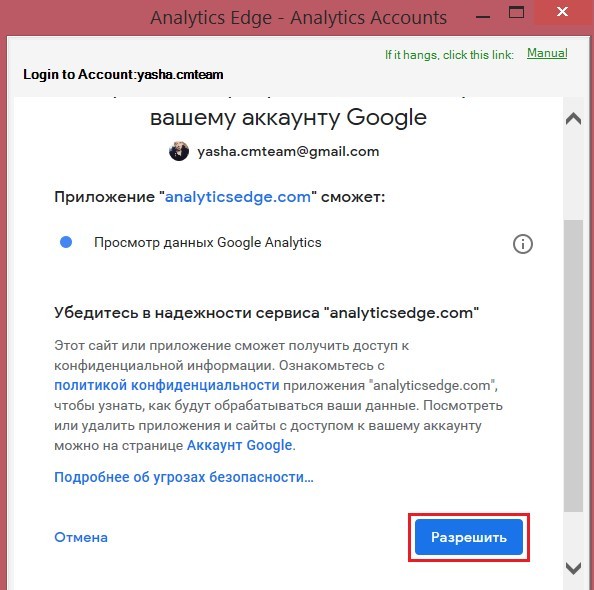
После этого данный аккаунт отобразиться в списке Saved Google Analytics Logins, а при его выборе в полях ниже станут доступны все ваши аккаунты этой учетной записи:
Все аккаунты в Saved Google Analytics Logins
- Account – Аккаунт
- Property – Ресурс
- View (Profile) – Представление
С помощью кнопки Make Default вы можете выбрать аккаунт, ресурс и представление по умолчанию, то есть тот проект, который вы будете использовать для работы и выгрузки данных на следующем шаге.
Закрываем диалоговое окно с помощью Cancel и идем в следующий раздел Free Google Analytics – Analytics Reporting, чтобы импортировать данные из Google Analytics.
Все аккаунты в Saved Google Analytics Logins
Откроется диалоговое окно с различными вкладками:
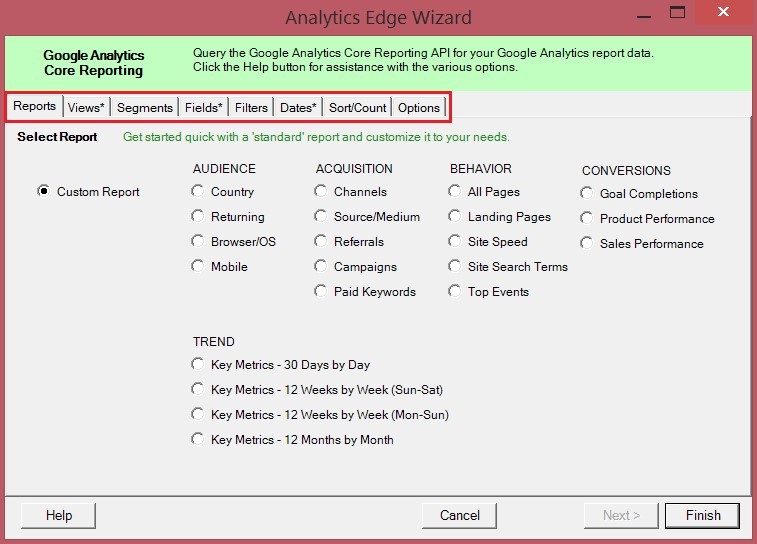
На вкладке Reports есть возможность выбора определенных метрик для кастомизированной выгрузки данных. В противном случае вы можете воспользоваться стандартными отчетами, что мы, собственно, и сделаем.
Вкладка Views позволяет выбрать аккаунт, ресурс и представление Google Analytics.
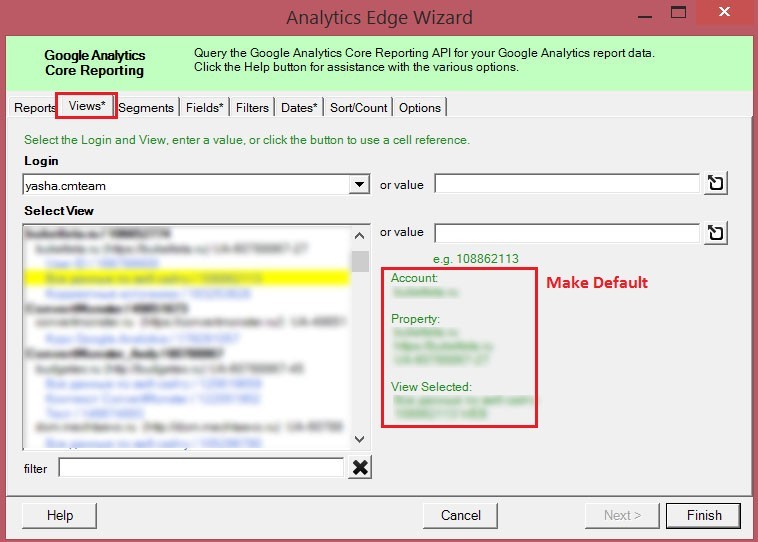
По умолчанию будут выбраны те настройки, которые мы указали на предыдущем шаге с помощью кнопки Make Default. Если представление не было выбрано, то из всех связанных аккаунтов будет выбрано первое по ID представление.
На вкладке Segments доступны все сегменты Google Analytics выбранного представления:
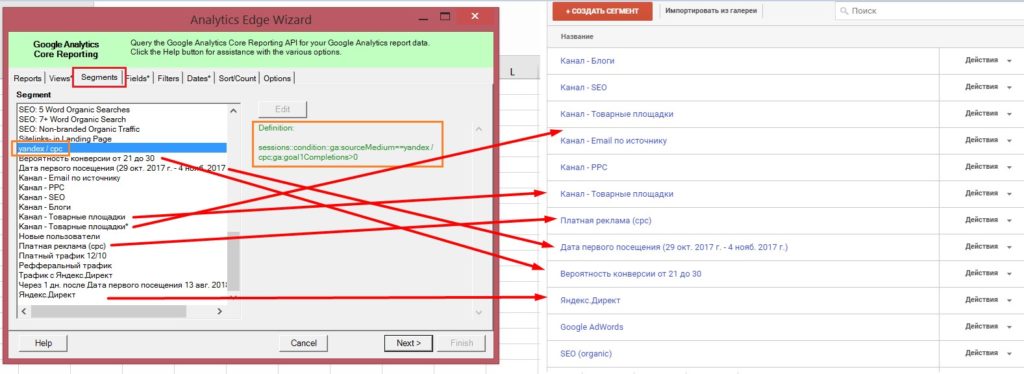
Сопоставление сегментов в Analytics Edge и Google Analytics
При выборе любого из них, например, yandex / cpc, в диалоговом окне справа будет определение сегмента в виде специальной конструкции:
sessions::condition::ga:sourceMedium==yandex / cpc;ga:goal1Completions>0
Он состоит из названия пространства имен (ga:), параметров и показателей (metrics & dimensions), разделенных запятой, которые представлены здесь, а также фильтра равно (==) и достигнутой цели 1, по условию >0. Все метрики в запросе разделяются запятой между собой. Подробнее об этом поговорим чуть ниже.
Если созданных сегментов недостаточно, вы можете в интерфейсе Excel создать свой собственный через DYNAMIC.

Настройки сегментов в Google Analytics Edge максимально приближены к интерфейсу Google Analytics. Сходство очевидно:
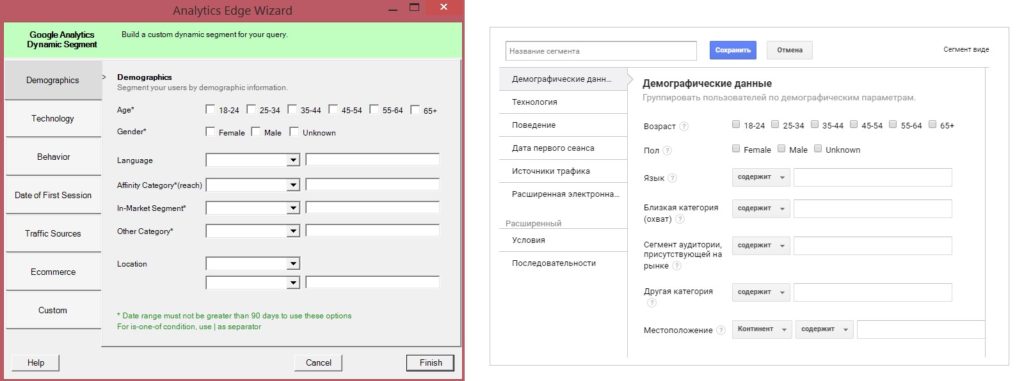
Создание сегмента – сравнение в Analytics Edge и Google Analytics
Вкладка Fields отвечает за выбор параметров (dimensions) и показателей (metrics).
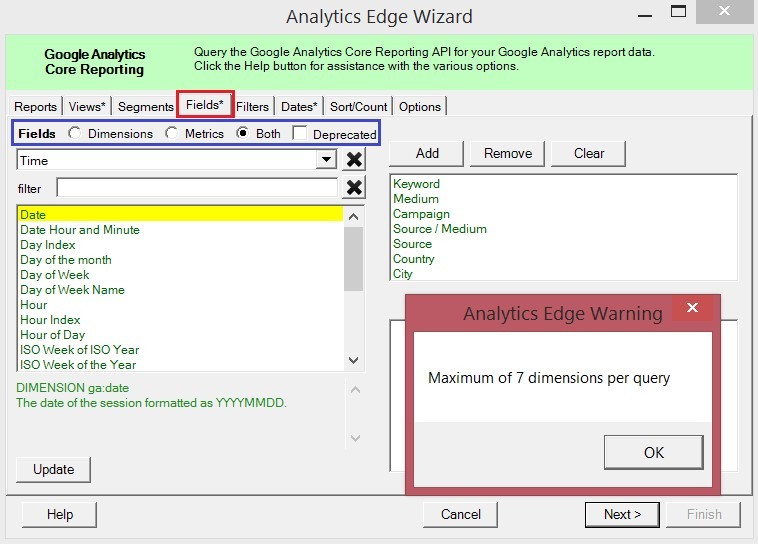
Одновременно можно импортировать 7 параметров (dimensions, зеленые в Analytics) и 10 показателей (metrics, синие в Analytics). Давайте на реальном примере сделаем это. Выгрузим данные из Google Analytics стандартного отчета «Источник/канал» без каких-либо фильтров и сегментов за последние 7 дней, чтобы получилось следующее:
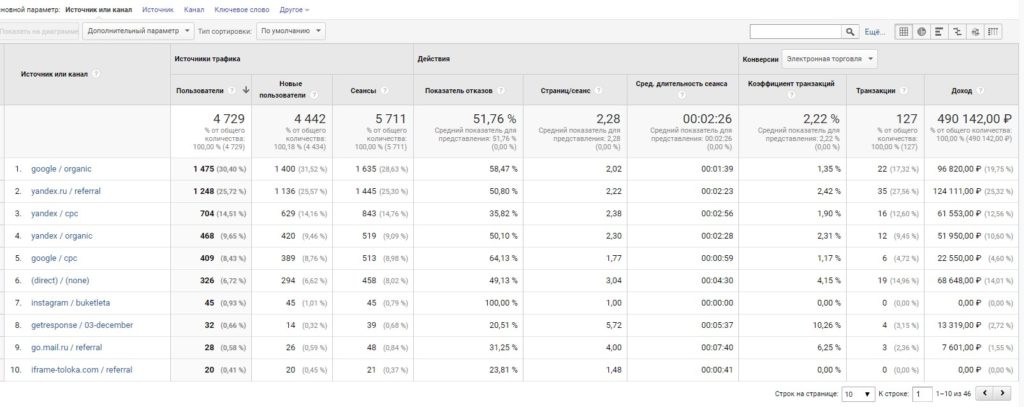
Будем выгружать отчет «Источник/канал»
Чтобы нам это сделать, необходимо знать, как называются параметры и показатели в API Google Analytics. Для этого переходим по ссылке и в соответствующих группах выбираем (ищем) нужные. У нас это будет 1 параметр (Источник или канал) и 9 показателей:
Добавляем эти метрики на вкладке Fields.
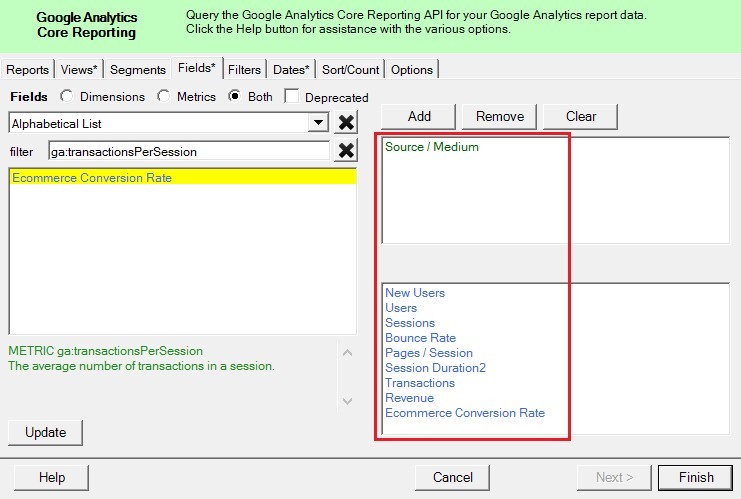
Добавление метрик в Analytics Edge
Не забываем, что параметры и показатели имеют разные области действия, и они не всегда могут сочетаться друг с другом. При выборе необходимых показателей и параметров часть пунктов в списке полей будет окрашено серым. Это означает, что данное поле не совместимо с выбранными вами ранее параметрами и показателями.
Перед выбором соответствующих метрик можно обновить все поля, что доступны в представлении выбранного ресурса. Для этого нажмите кнопку Update слева снизу:
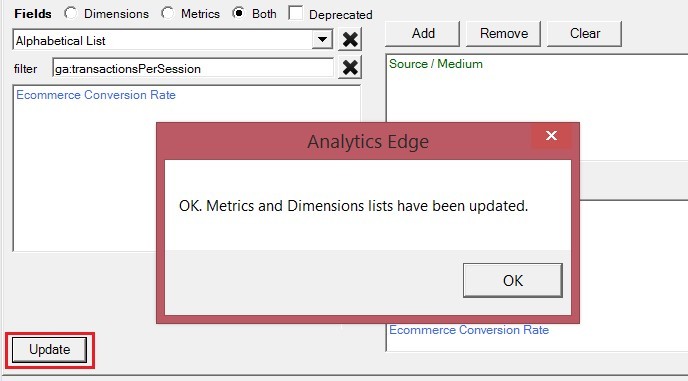
На вкладке Filters можно наложить на выгружаемые данные пользовательский фильтр. Например, выбрать показатель Date (дата) и задать конкретный день (Exact Match – точное соответствие).

При такой настройке у нас отфильтруются все данные, кроме 7 декабря 2018 года. Мы же к своей выгрузке никаких фильтров применять не будем, поэтому просто переходим к разбору следующей вкладки.
Вкладка Dates позволяет указать период, за которой вы планируете выгрузить данные из Google Analytics.
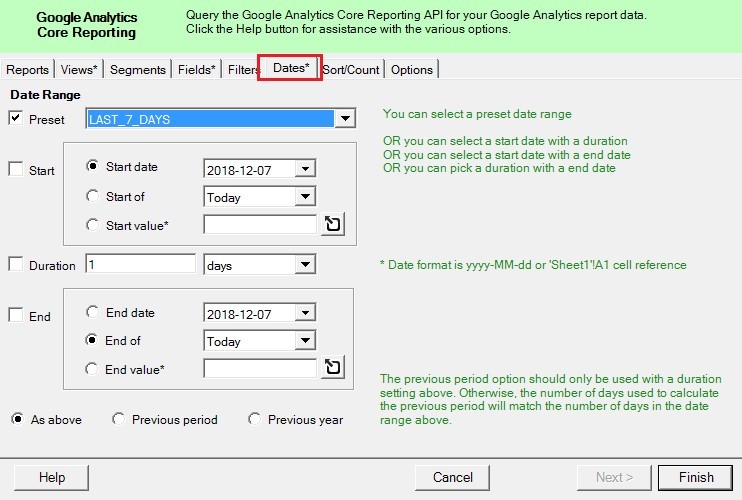
Задать диапазон дат можно с помощью нескольких способов:
- Preset (активирован по умолчанию) – по аналогии с интерфейсом Google Analytics:

Выбрав период из выпадающего списка, например, LAST_7_DAYS, при каждом обновлении отчета данные будут выводиться именно за последние 7 дней, то есть всегда сдвигаться, без привязки к дате начала.
- Start–End (дата) – диапазон дат, за которые вы хотите выгрузить отчет.

Можно указать статическую конечную дату отчета (End of). Для нашего примера мы выбираем Preset и LAST_7_DAYS.
На вкладке Sort/Count можно задать порядок сортировки данных по одному из выбранных параметров или показателей. Кнопка Ascending –по возрастанию, Descending – по убыванию.
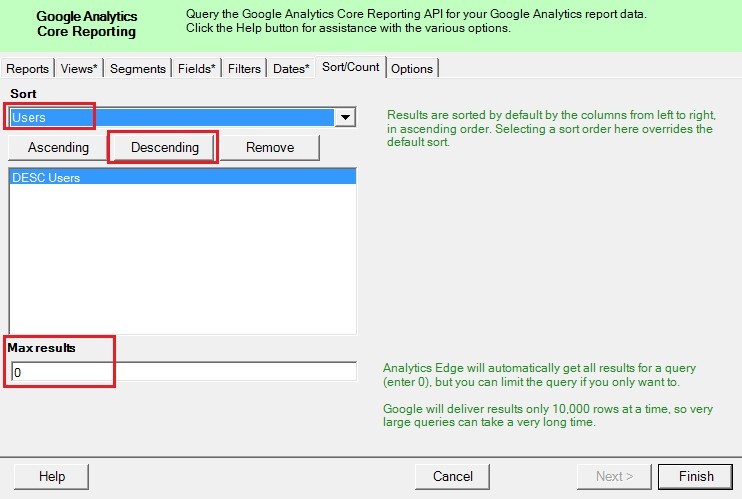
В стандартных отчетах Google Analytics сортировка осуществляется по убыванию первого столбца в таблице. В отчете «Источник/канал» это «Пользователи». Поэтому выбираем Sort – Users и нажимаем Descending.
Опция Max results ограничивает выводимое количество строк на листе в Excel. Как вы уже знаете, в интерфейсе Google Analytics по умолчанию в отчетах выводится 10 строк на странице, но мы можем расширить их количество до 5000. Иногда бывает, что «большие» запросы требуют более длительного времени на их обработку. Чтобы лимитировать количество строк, укажите значение, отличное от 0, поскольку 0 – это отсутствие лимита, данные будут выгружены все.
Последняя вкладка в Google Analytics Edge – это Options. Она отвечает за формат передачи данных в Excel, а именно:
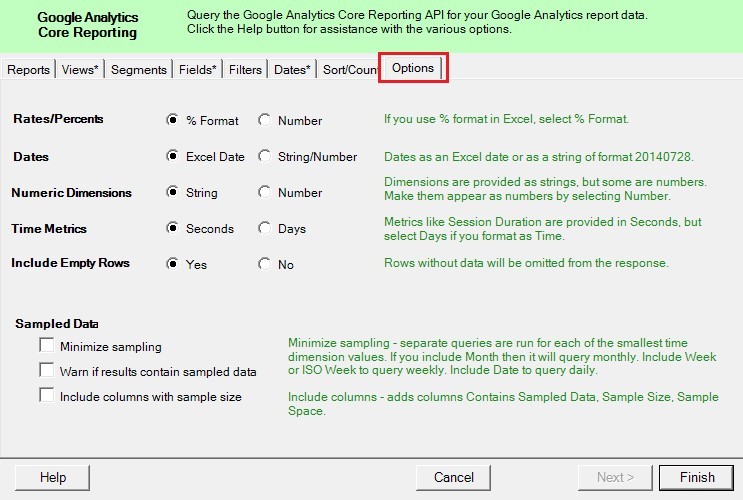
- Rates/Percents – % или числовой формат. Например, для показателя отказов или коэффициента конверсии. Analytics Edge преобразует % в доли (50% = 0.5), чтобы ячейки в Excel можно было форматировать;
- Dates – формат даты Excel Date (07.12.2018), привычный для русскоязычного пользователя или 20181207 (String/Numeric);
- NumericDimensions – числовые показатели выводить в ячейках как строки или число;
- TimeMetrics – временные метрики показывать в секундах или переводить в дни. Например, 15 секунд в Seconds – 15, а в Days - 00:00:15;
- IncludeEmptyRows – включение строк с нулевыми значениями показателей.
Опции Sampled data:

Дополнительные настройки сэмплов
- Minimizesampling – минимизация сэмплирования, разбивка запросов на максимальное количество частей по времени;
- Warnifresultcontainsampleddata – если вы хотите получать уведомления о сэмплированных данных, установите флажок;
- Include columns with sample size – включение столбцов с размеров выборки.
Подробнее о том, что такое сэмплирование, читайте в соответствующей главе руководства.
Все, что осталось сделать, это нажать на кнопку Finish. В результате мы получили такую таблицу:
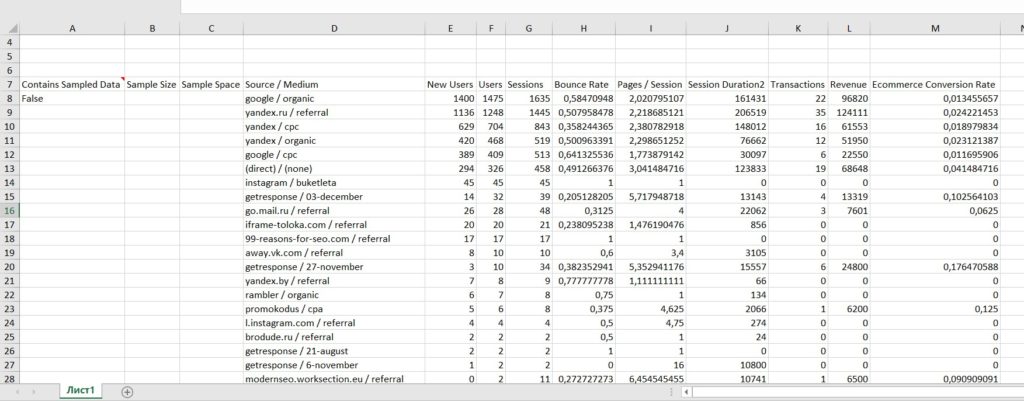
Импортированные данные в Excel
Contains Sampled Data – false означает, что в данном запросе не было сэмплированных данных. Отформатировав таблицу и удалив все лишнее, убедимся, что данные из Google Analytics выгружены верно:
Третья часть главы из моего электронного руководства Google Analytics 2019: Tutorial Book (скачать можно на главной странице), которая посвящена визуализации данных — тренду последних нескольких лет.
При работе с отчетами Google Analytics можно заметить, что некоторые отчеты неудобно анализировать в пользовательском интерфейсе. Если их выгружать в Excel, теряется динамика. В Google Таблицах вы можете использовать разные показатели и параметры, взятые из Google Analytics, которые при настройках будут обновляться и работать с ними как в обычном Exсel (переносить данные на разные листы, строить графики, использовать формулы и т.д.).
Google Таблицы – это альтернатива Microsoft Excel в онлайне. В этом и есть преимущество – если в первом случае, работая с Analytics Edge, вы импортируете данные и работаете с ними локально на компьютере, то благодаря Google Таблицам вы можете создавать электронные таблицы, редактировать их и работать над ними вместе с коллегами – где угодно и когда угодно.
Создание Google Таблицы
Первым делом, что необходимо сделать в новом файле, это поменять настройки таблицы. Это нужно для того, чтобы при автоматической выгрузке данных из Google Analytics получалось форматировать ячейку как число, дату или сумму в определенной валюте. По умолчанию у вас могут стоять региональные настройки России, в связи с этим в дальнейшем могут возникнуть трудности.
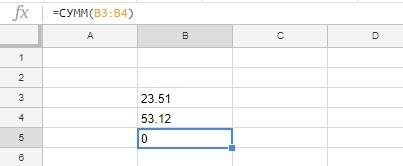
Изменение настроек таблицы
Например, данные по стоимости из Analytics выгружаются с точкой, и если мы захотим сложить два числа, у нас получится не совсем то, что должно быть. Поэтому открываем Файл – Настройки таблицы и меняем региональные настройки с «Россия» на «США» и сохраняем изменения.
На этом предварительная настройка таблицы завершена. Чтобы импортировать данные из Google Analytics в Google Таблицы, необходимо установить дополнение. Для этого переходим в Дополнения – Установить дополнения.
Дополнения – Установить дополнения
Откроется диалоговое окно, в котором выберите Google Analytics:

Дополнение – Google Analytics
Нажимаем на синюю кнопку «Бесплатно». Далее выбираем аккаунт для перехода в приложение «Google Analytics, а на последнем шаге разрешаем приложению доступ к вашему аккаунту Google. Данный процесс очень похож на тот, который мы с вами делали при установке Google Analytics Edge.
Если все сделали правильно, то всплывающее окно закроется, и вы вернетесь к созданной таблице.
Уведомление об успешной установке
После настройки дополнения можем приступить к выгрузке данных из Google Analytics. Переходим к Дополнения – Google Analytics – Create new report.
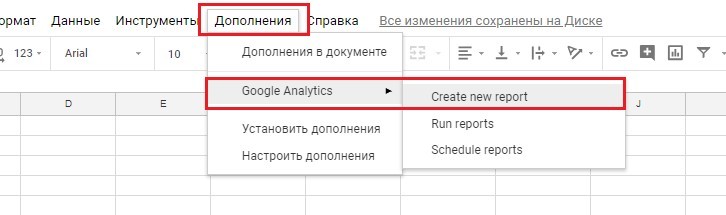
Создание нового отчета
Справа откроется меню, где следует задать настройки:
- Name – прописываем название отчета;
- Account, Property, View – это аккаунт, ресурс, представление из Google Analytics;
- Segments – сегменты. Есть возможность использовать собственные сегменты, настроенные в Google A
Добавляем метрики в отчет. У нас это будет 1 параметр (Dimensions - Источник или канал) и несколько показателей (Metrics), с которыми вы уже знакомы:
- Источник или канал – Source / Medium
- Пользователи - Users
- Новые пользователи – New Users
- Сеансы - Sessions
- Показатель отказов – Bounce Rate
- Средняя длительность сеанса – Avg.SessionDuration
- Коэффициент транзакций – Ecommerce Conversion Rate
- Транзакции - Transaction
- Доход - Revenue
Просто начинайте вводить название в соответствующее поле, и расширение само подскажет вам полный вариант. В одном отчете может быть до 10 показателей и до 7 параметров.
Название основных показателей:
- Сеансы - ga:sessions
- Отказы - ga:bounces
- Длительность сеанса - ga:sessionDuration
- Цель (достигнутые переходы к цели) - ga:goalXXCompletions
- Достигнутые цели - ga:goalCompletionsAll
- Пользователи - ga:users
- Новые пользователи - ga:newUsers
- Транзакции - ga:transactions
- Доход от продукта - ga:itemRevenue
- Показы - ga:impressions
- Клики - ga:adClicks
- Стоимость - ga:adCost
Dimensions – задаются параметры, по которым будем строить отчет. В одном отчете может быть до 7 показателей.
Название основных параметров:
- Источник - ga:source
- Канал - ga:medium
- Город - ga:city
- Длительность сеанса - ga:sessionDurationBucket
- Тип пользователя - ga:userType
- Тип устройства - ga:deviceCategory
- Группа объявлений - ga:adGroup
- Кампания - ga:campaign
- Ключевое слово - ga:keyword
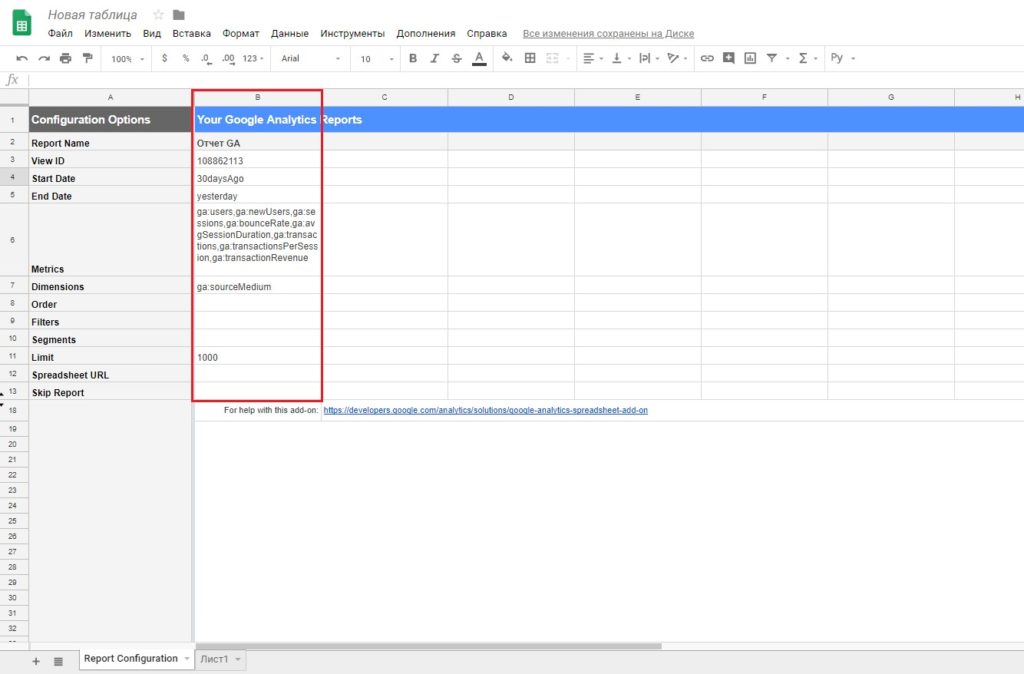
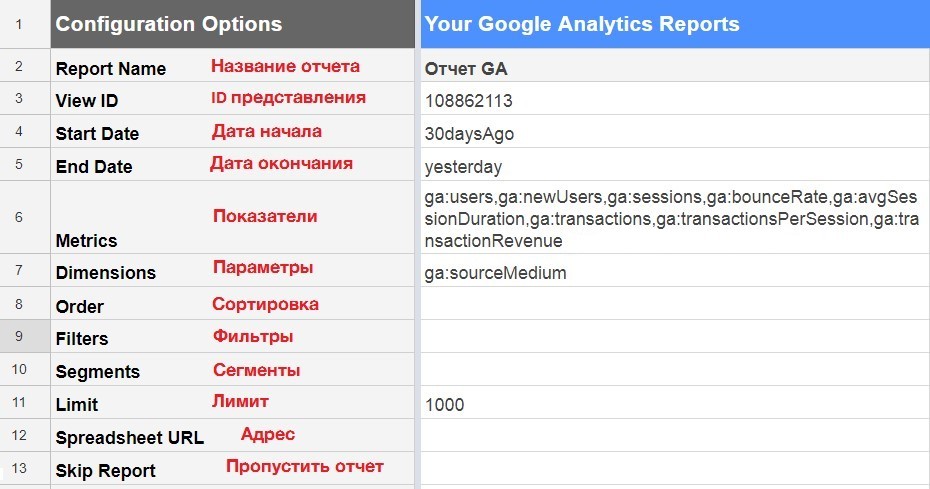
После заполнения базовых настроек создаем отчет «Create Report». После этого в своей таблице в столбце B вы увидите автоматически созданную конфигурацию Report Configuration, в которой будут указаны все ваши настройки.
Настройки полей
Report Name (название отчета) – аналог того, что мы указали при базовых настройках, соответствует названию листа;
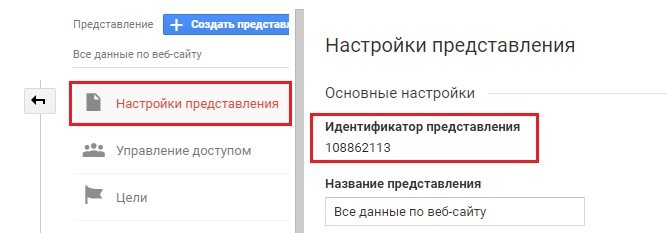
View ID – идентификатор представления в Google Analytics.
Чтобы узнать идентификатор представления, в Google Analytics перейдите в «Администратор», а затем на уровне представления выберите «Настройки представления».
Start Date и End Date – дата начала и окончания выгрузки данных из Google Analytics.
Metrics и Dimensions – параметры и показатели, разделяются запятыми или новой строкой.
Order – сортировка.
Если в поле order указать ga:users – данные по этому параметру отсортируются по убыванию, если указать -ga:users - данные отсортируются по возрастанию.
Filters – фильтры.
Фильтры задаются по параметрам и показателям с помощью формул. Например, ga:users>100.
Если применять в фильтре более 1 параметра, используйте операторы:
Segments – сегменты в Google Analytics.
Применяются аналогично фильтрам, с разницей в том, что в обработке данных сначала используется сегментирование, а затем агрегирование данных. Возможна агрегация по пользователям (users::condition::) или по сессиям (sessions::condition::)
Limit – максимальное количество строк. Если данное поле пустое – обработаются все данные на основе указанных настроек отчета.
Spreadsheet URL – url-таблицы вывода результатов. По умолчанию таблицы выводятся на текущий лист.
Skip Report - пропустить отчет. Если в поле прописано true, тогда данный отчет не будет выводить результаты.
Поскольку мы хотим получить такую же выгрузку данных, что и в примере с Analytics Edge, нам необходимо изменить дату начала и окончания:
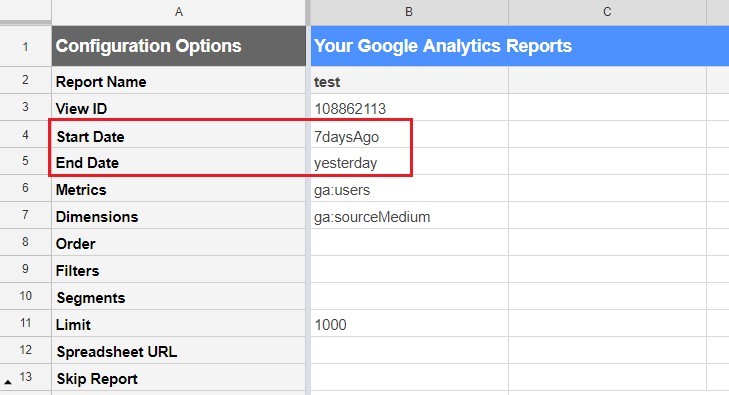
Указание даты импорта
Чтобы получить выгрузку данных в Google Таблицы, необходимо запустить отчет в Дополнения – Google Analytics – Run reports.
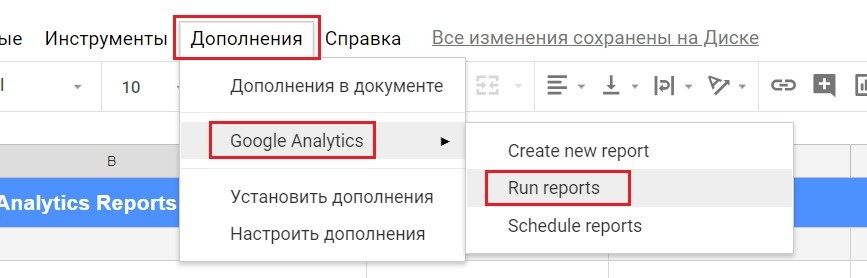
Запуск выгрузки данных
В результате мы получим выгрузку по заданным параметрам и показателям на соседнем листе документа:
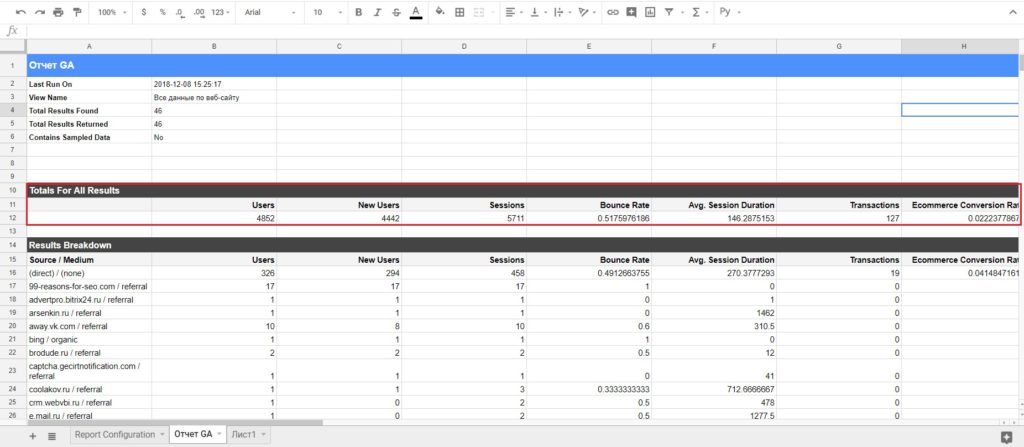
Выгрузка данных в Google Таблицы
Мы можем сопоставить данные из таблицы Totals For All Results с теми, что получили просто при экспорте отчета из Google Analytics и импорте данных с помощью Analytics Edge. Все сходится!
Теперь мы можем работать с выгруженными данными: редактировать их, строить отчеты, диаграммы, переносить значения с листа на лист, использовать дополнительные функции Google Таблиц (например, ВПР), чтобы в конечном счете получить автоматический отчет с выгрузкой по дням и любыми графиками:
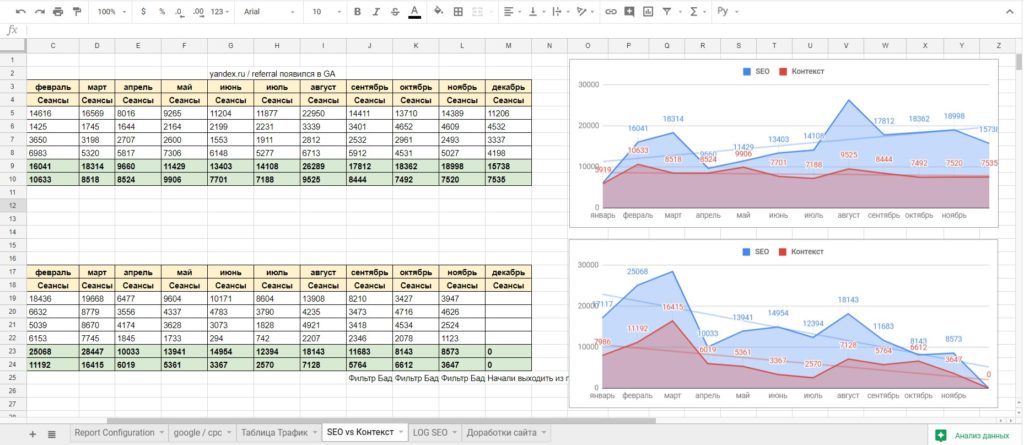
Пример импортированных данных и их визуализация
Если вы хотите работать с многоканальными последовательностями, то вместо core используйте mcf. Подробнее читайте в статье "Многоканальные последовательности в Google Data Studio"
Меня зовут Игорь Хапов. Я руководитель разработки в Научно-техническом центре IBM. И сегодня я хотел бы вам помочь окунуться в мир периферийных вычислений, или edge computing, как его ещё называют. Я расскажу о том, что же такое edge computing и как он может повлиять на наш с вами мир. Также хотелось бы пояснить различия между edge computing и fog computing, какие преимущества даёт этот подход. В статье я также описал референсную архитектуру приложения на edge computing. И под конец немного расскажу о проекте с открытым исходным кодом Open Horizon, который совсем недавно присоединился к Linux Foundation.

Шаг 3. Создаём рабочий лист со списком URL
Создайте рабочий лист, содержащий основные URL-адреса первого сайта, который вы хотите отслеживать.
В один рабочий лист можно включить до 2 000 URL-адресов. Сначала я советую добавить только 10 или 20 самых популярных URL-адресов сайта, чтобы вам не пришлось долго ждать, пока API обработает ваши запросы при создании этой системы отслеживания индексирования. После этого вы можете добавить до 2 000 URL-адресов на один рабочий лист.

Добавление списка URL
Убедитесь, что у столбца есть заголовок. В этом примере я использовал «page» в качестве заголовка, чтобы вам было удобно повторять шаги данного руководства.
Вы можете назвать рабочий лист как угодно, например, по названию сайта, но я использовал «site1».
edge computing vs fog computing
Когда я однажды рассказал коллеге про edge computing, он ответил — ”так это же fog computing”. Давайте попробуем разобраться, в чём же разница. С одной стороны, edge computing и fog computing часто используются как синонимы, однако fog computing, или "туманные вычисления", все-таки немного отличаются.
И edge computing, и fog computing — это вычисления, которые находятся в непосредственной близости к получаемым данным. Различие заключается в том, что при туманных вычислениях обработка осуществляется на устройствах, которые постоянно подключены к сети. В edge computing вычисления осуществляются как на сенсорах, умных устройствах – без передачи на уровень gateway, так и на уровне gateway и на микрокластерах.
Для меня было открытием, что edge computing может работать в кластерах Kubernetes или OpenShift. Оказывается, что существует достаточно много задач, где кроме оконечных устройств необходимо выполнять обработку информации в локальном кластере и передавать в централизованные дата центры только результирующие данные. И такие вычисления — тоже edge computing.
Open Horizon и IBM Edge Application Manager
Именно для решения задач в области edge computing IBM разработала и выложила в open-source проект Open Horizon. Если вы помните, один из принципов, которые IBM заложила в edge computing – все компоненты должны быть основаны на open source технологиях. В мае 2020 года проект Open Horizon вошел в Linux Foundation Edge — Международный фонд open-source технологий для созданий edge-решений. Также Open Horizon является ядром нового продукта от RedHat и IBM — IBM Edge Application Manager, решения для управления приложениями на всех устройствах edge computing: от Raspberry Pi до промежуточных кластеров обработки данных.

Несмотря на то, что проект Open Horizon вошел в консорциум только в мае, он уже достаточно давно развивается как open-source проект. И мы в Научно-техническом центре IBM не только успели его попробовать, но и довести свое решение до промышленного использования. О том, как мы разрабатывали проект с использованием edge computing, и что у нас получилось — будет отдельная статья, которая выйдет в ближайшие несколько недель.

С одной стороны, edge computing framework — это специализированное решение для определённого круга задач, но оно нашло применение во многих индустриях.
В своё время, когда я изучал работу московских камер “Стрелка”, я понял, что это в чистом виде edge computing, с вычислениями "прямо на столбе" и промежуточной обработкой данных в раздельных вычислительных кластерах у различных ведомств.
Сценарии нашлись в финансовом секторе, в продажах при самообслуживании, в медицине и секторе страхования, торговле и конечно при производстве. Именно в создании решения для автоматизации и оценки качества произведённого оборудования, основанного на edge computing, мне с коллегами из Научно-технического центра IBM и посчастливилось принять участие. И на своем опыте попробовать, как создаются решения edge computing.
Если Вас заинтересовала данная тематика, следите за обновлениями в хабраблоге компании IBM и смотрите видео в разделе Ссылки. Наши зарубежные коллеги к настоящему моменту уже осветили многие технические вопросы и описали, какие сценарии уже работают и применяются в различных отраслях.
Edge computing и IoT
Довольно часто звучит вопрос — "Чем же отличается edge computing от IoT". IoT можно назвать дедушкой edge computing. IoT — это множество устройств, связанных между собой, и способных передавать информацию друг другу. А edge computing это скорее подход к организации вычислений и управлению edge устройствами. Как вы отлично понимаете, любое приложение необходимо обновлять, мониторить и осуществлять прочие обслуживающие функции. В результате edge computing подразумевает использование определенных подходов и фреймворков, о которых я расскажу чуть позже.
Edge devices
В первую очередь, у нас есть какое-либо встроенное или дискретное edge-устройство, к которому подключены сенсоры, датчики или управляющие механизмы, например, для координации движения роборуки. Из сервисов/данных на таком устройстве могут находиться:
- Модель обработки данных, например, предобученная ML-модель
- Сервис аналитики, который является средой исполнения модели
- Пользовательский интерфейс для отображения результатов или инициирования аналитики
- Легковесная база данных для хранения промежуточных результатов и кеширования на случай сбоя связи с центральным сервером
- Любые другие сервисы в зависимости от решаемых на данном устройстве задач
Читайте также: