
Для доступа к компонентам файла что используется
Аннотация: В настоящей лекции вводится понятие и рассматриваются основные функции и интерфейс файловой системы.
Введение
История систем управления данными во внешней памяти начинается еще с магнитных лент, но современный облик они приобрели с появлением магнитных дисков. До этого каждая прикладная программа сама решала проблемы именования данных и их структуризации во внешней памяти . Это затрудняло поддержание на внешнем носителе нескольких архивов долговременно хранящейся информации. Историческим шагом стал переход к использованию централизованных систем управления файлами . Система управления файлами берет на себя распределение внешней памяти , отображение имен файлов в адреса внешней памяти и обеспечение доступа к данным.
Файловая система - это часть операционной системы, назначение которой состоит в том, чтобы организовать эффективную работу с данными, хранящимися во внешней памяти , и обеспечить пользователю удобный интерфейс при работе с такими данными. Организовать хранение информации на магнитном диске непросто. Это требует, например, хорошего знания устройства контроллера диска, особенностей работы с его регистрами. Непосредственное взаимодействие с диском - прерогатива компонента системы ввода-вывода ОС, называемого драйвером диска. Для того чтобы избавить пользователя компьютера от сложностей взаимодействия с аппаратурой, была придумана ясная абстрактная модель файловой системы. Операции записи или чтения файла концептуально проще, чем низкоуровневые операции работы с устройствами.
Основная идея использования внешней памяти состоит в следующем. ОС делит память на блоки фиксированного размера, например, 4096 байт. Файл , обычно представляющий собой неструктурированную последовательность однобайтовых записей, хранится в виде последовательности блоков (не обязательно смежных); каждый блок хранит целое число записей. В некоторых ОС (MS-DOS) адреса блоков, содержащих данные файла , могут быть организованы в связный список и вынесены в отдельную таблицу в памяти. В других ОС (Unix) адреса блоков данных файла хранятся в отдельном блоке внешней памяти (так называемом индексе или индексном узле). Этот прием, называемый индексацией , является наиболее распространенным для приложений, требующих произвольного доступа к записям файлов . Индекс файла состоит из списка элементов, каждый из которых содержит номер блока в файле и сведения о местоположении данного блока. Считывание очередного байта осуществляется с так называемой текущей позиции, которая характеризуется смещением от начала файла . Зная размер блока, легко вычислить номер блока, содержащего текущую позицию. Адрес же нужного блока диска можно затем извлечь из индекса файла . Базовой операцией, выполняемой по отношению к файлу , является чтение блока с диска и перенос его в буфер , находящийся в основной памяти.
Файловая система позволяет при помощи системы справочников ( каталогов , директорий ) связать уникальное имя файла с блоками вторичной памяти, содержащими данные файла . Иерархическая структура каталогов , используемая для управления файлами , может служить другим примером индексной структуры. В этом случае каталоги или папки играют роль индексов, каждый из которых содержит ссылки на свои подкаталоги. С этой точки зрения вся файловая система компьютера представляет собой большой индексированный файл . Помимо собственно файлов и структур данных, используемых для управления файлами ( каталоги , дескрипторы файлов , различные таблицы распределения внешней памяти ), понятие " файловая система " включает программные средства , реализующие различные операции над файлами .
Перечислим основные функции файловой системы.
- Идентификация файлов . Связывание имени файла с выделенным ему пространством внешней памяти .
- Распределение внешней памяти между файлами . Для работы с конкретным файлом пользователю не требуется иметь информацию о местоположении этого файла на внешнем носителе информации. Например, для того чтобы загрузить документ в редактор с жесткого диска, нам не нужно знать, на какой стороне какого магнитного диска, на каком цилиндре и в каком секторе находится данный документ.
- Обеспечение надежности и отказоустойчивости. Стоимость информации может во много раз превышать стоимость компьютера.
- Обеспечение защиты от несанкционированного доступа.
- Обеспечение совместного доступа к файлам , так чтобы пользователю не приходилось прилагать специальных усилий по обеспечению синхронизации доступа.
- Обеспечение высокой производительности.
Иногда говорят, что файл - это поименованный набор связанной информации, записанной во вторичную память. Для большинства пользователей файловая система - наиболее видимая часть ОС. Она предоставляет механизм для онлайнового хранения и доступа как к данным, так и к программам для всех пользователей системы. С точки зрения пользователя, файл - единица внешней памяти , то есть данные, записанные на диск, должны быть в составе какого-нибудь файла .
Важный аспект организации файловой системы - учет стоимости операций взаимодействия с вторичной памятью. Процесс считывания блока диска состоит из позиционирования считывающей головки над дорожкой, содержащей требуемый блок, ожидания, пока требуемый блок сделает оборот и окажется под головкой, и собственно считывания блока. Для этого требуется значительное время (десятки миллисекунд). В современных компьютерах обращение к диску осуществляется примерно в 100 000 раз медленнее, чем обращение к оперативной памяти. Таким образом, критерием вычислительной сложности алгоритмов, работающих с внешней памятью , является количество обращений к диску.
В данной лекции рассматриваются вопросы структуры, именования, защиты файлов ; операции , которые разрешается производить над файлами ; организация файлового архива (полного дерева справочников). Проблемы выделения дискового пространства, обеспечения производительной работы файловой системы и ряд других вопросов, интересующих разработчиков системы, вы найдете в следующей лекции.
Общие сведения о файлах
Имена файлов
Файлы представляют собой абстрактные объекты. Их задача - хранить информацию, скрывая от пользователя детали работы с устройствами. Когда процесс создает файл , он дает ему имя. После завершения процесса файл продолжает существовать и через свое имя может быть доступен другим процессам.
Правила именования файлов зависят от ОС. Многие ОС поддерживают имена из двух частей (имя+расширение), например progr.c ( файл , содержащий текст программы на языке Си) или autoexec.bat ( файл , содержащий команды интерпретатора командного языка). Тип расширения файла позволяет ОС организовать работу с ним различных прикладных программ в соответствии с заранее оговоренными соглашениями. Обычно ОС накладывают некоторые ограничения, как на используемые в имени символы, так и на длину имени файла . В соответствии со стандартом POSIX, популярные ОС оперируют удобными для пользователя длинными именами (до 255 символов).
Типы файлов
Важный аспект организации файловой системы и ОС - следует ли поддерживать и распознавать типы файлов . Если да, то это может помочь правильному функционированию ОС, например не допустить вывода на принтер бинарного файла .
Основные типы файлов : регулярные (обычные) файлы и директории (справочники, каталоги ). Обычные файлы содержат пользовательскую информацию. Директории - системные файлы , поддерживающие структуру файловой системы. В каталоге содержится перечень входящих в него файлов и устанавливается соответствие между файлами и их характеристиками ( атрибутами ). Мы будем рассматривать директории ниже.
Напомним, что хотя внутри подсистемы управления файлами обычный файл представляется в виде набора блоков внешней памяти , для пользователей обеспечивается представление файла в виде линейной последовательности байтов. Такое представление позволяет использовать абстракцию файла при работе с внешними устройствами, при организации межпроцессных взаимодействий и т. д. Так, например, клавиатура обычно рассматривается как текстовый файл , из которого компьютер получает данные в символьном формате. Поэтому иногда к файлам приписывают другие объекты ОС, например специальные символьные файлы и специальные блочные файлы , именованные каналы и сокеты, имеющие файловый интерфейс. Эти объекты рассматриваются в других разделах данного курса.
Далее речь пойдет главным образом об обычных файлах.
Обычные (или регулярные) файлы реально представляют собой набор блоков (возможно, пустой) на устройстве внешней памяти , на котором поддерживается файловая система. Такие файлы могут содержать как текстовую информацию (обычно в формате ASCII), так и произвольную двоичную (бинарную) информацию.
Текстовые файлы содержат символьные строки, которые можно распечатать, увидеть на экране или редактировать обычным текстовым редактором.
Другой тип файлов - нетекстовые, или бинарные, файлы . Обычно они имеют некоторую внутреннюю структуру. Например, исполняемый файл в ОС Unix имеет пять секций: заголовок, текст, данные, биты реаллокации и символьную таблицу. ОС выполняет файл , только если он имеет нужный формат. Другим примером бинарного файла может быть архивный файл . Типизация файлов не слишком строгая.
Обычно прикладные программы, работающие с файлами , распознают тип файла по его имени в соответствии с общепринятыми соглашениями. Например, файлы с расширениями .c , .pas , .txt - ASCII-файлы, файлы с расширениями .exe - выполнимые, файлы с расширениями .obj , .zip - бинарные и т. д.
Атрибуты файлов
Кроме имени ОС часто связывают с каждым файлом и другую информацию, например дату модификации, размер и т. д. Эти другие характеристики файлов называются атрибутами . Список атрибутов в разных ОС может варьироваться. Обычно он содержит следующие элементы: основную информацию (имя, тип файла ), адресную информацию (устройство, начальный адрес, размер), информацию об управлении доступом (владелец, допустимые операции) и информацию об использовании (даты создания, последнего чтения, модификации и др.).
Список атрибутов обычно хранится в структуре директорий (см. следующую лекцию) или других структурах, обеспечивающих доступ к данным файла .
Организация файлов и доступ к ним
Программист воспринимает файл в виде набора однородных записей. Запись - это наименьший элемент данных , который может быть обработан как единое целое прикладной программой при обмене с внешним устройством. Причем в большинстве ОС размер записи равен одному байту. В то время как приложения оперируют записями, физический обмен с устройством осуществляется большими единицами (обычно блоками). Поэтому записи объединяются в блоки для вывода и разблокируются - для ввода. Вопросы распределения блоков внешней памяти между файлами рассматриваются в следующей лекции.
ОС поддерживают несколько вариантов структуризации файлов .
Последовательный файл
Простейший вариант - так называемый последовательный файл . То есть файл является последовательностью записей. Поскольку записи, как правило, однобайтовые, файл представляет собой неструктурированную последовательность байтов.
Обработка подобных файлов предполагает последовательное чтение записей от начала файла , причем конкретная запись определяется ее положением в файле . Такой способ доступа называется последовательным (модель ленты). Если в качестве носителя файла используется магнитная лента, то так и делается. Текущая позиция считывания может быть возвращена к началу файла ( rewind ).
Файл прямого доступа
В реальной практике файлы хранятся на устройствах прямого (random) доступа, например на дисках, поэтому содержимое файла может быть разбросано по разным блокам диска, которые можно считывать в произвольном порядке. Причем номер блока однозначно определяется позицией внутри файла .
Здесь имеется в виду относительный номер, специфицирующий данный блок среди блоков диска, принадлежащих файлу . О связи относительного номера блока с абсолютным его номером на диске рассказывается в следующей лекции.
Естественно, что в этом случае для доступа к середине файла просмотр всего файла с самого начала не обязателен. Для специфицирования места, с которого надо начинать чтение, используются два способа: с начала или с текущей позиции, которую дает операция seek. Файл , байты которого могут быть считаны в произвольном порядке, называется файлом прямого доступа .
Таким образом, файл , состоящий из однобайтовых записей на устройстве прямого доступа, - наиболее распространенный способ организации файла . Базовыми операциями для такого рода файлов являются считывание или запись символа в текущую позицию. В большинстве языков высокого уровня предусмотрены операторы посимвольной пересылки данных в файл или из него.
Подобную логическую структуру имеют файлы во многих файловых системах, например в файловых системах ОС Unix и MS-DOS. ОС не осуществляет никакой интерпретации содержимого файла . Эта схема обеспечивает максимальную гибкость и универсальность. С помощью базовых системных вызовов (или функций библиотеки ввода/вывода) пользователи могут как угодно структурировать файлы . В частности, многие СУБД хранят свои базы данных в обычных файлах .
Другие формы организации файлов
Известны как другие формы организации файла , так и другие способы доступа к ним, которые использовались в ранних ОС, а также применяются сегодня в больших мэйнфреймах (mainframe), ориентированных на коммерческую обработку данных.
Другой способ представления файлов - последовательность записей переменной длины, каждая из которых содержит ключевое поле в фиксированной позиции внутри записи (см. рис. 11.1). Базисная операция в данном случае - считать запись с каким-либо значением ключа. Записи могут располагаться в файле последовательно (например, отсортированные по значению ключевого поля) или в более сложном порядке. Метод доступа по значению ключевого поля к записям последовательного файла называется индексно-последовательным.
В некоторых системах ускорение доступа к файлу обеспечивается конструированием индекса файла . Индекс обычно хранится на том же устройстве, что и сам файл , и состоит из списка элементов, каждый из которых содержит идентификатор записи, за которым следует указание о местоположении данной записи. Для поиска записи вначале происходит обращение к индексу, где находится указатель на нужную запись. Такие файлы называются индексированными, а метод доступа к ним - доступ с использованием индекса.
Предположим, у нас имеется большой несортированный файл , содержащий разнообразные сведения о студентах, состоящие из записей с несколькими полями, и возникает задача организации быстрого поиска по одному из полей, например по фамилии студента. Рис. 11.2 иллюстрирует решение данной проблемы - организацию метода доступа к файлу с использованием индекса.
Следует отметить, что почти всегда главным фактором увеличения скорости доступа является избыточность данных.
Способ выделения дискового пространства при помощи индексных узлов, применяемый в ряде ОС (Unix и некоторых других, см. следующую лекцию), может служить другим примером организации индекса.
В этом случае ОС использует древовидную организацию блоков, при которой блоки, составляющие файл , являются листьями дерева, а каждый внутренний узел содержит указатели на множество блоков файла . Для больших файлов индекс может быть слишком велик. В этом случае создают индекс для индексного файла (блоки промежуточного уровня или блоки косвенной адресации).
Файловые системы поддерживают несколько функционально различных типов файлов, в число которых входят обычные файлы, содержащие информацию произвольного характера (текст, графика, звук и др.), файлы-каталоги, специальные файлы, именованные конвейеры, отображаемые в память файлы и др.
Обычные файлы, или просто файлы, или регулярные файлы, содержат информацию, которую в них заносит пользователь или которая образуется в результате работы системных и пользовательских программ. Большинство ОС не контролируют содержимое и структуру регулярных файлов, которые в основном являются ASCII-файлами либо двоичными файлами. ASCII-фалы состоят из текстовых строк. Они могут отображаться на экране и выводиться на печать без какого-либо преобразования, и могут редактироваться практически любым текстовым редактором. Двоичные файлы имеют определенную внутреннюю структуру, которая известна программе, использующей данный файл. При выводе двоичного файла на принтер получается случайный набор символов.
Каталоги – это системные файлы, обеспечивающие поддержку структуры файловой системы. Они содержат системную справочную информацию о наборе файлов, сгруппированных пользователем по какому-либо неформальному признаку (договоры, рефераты, курсовые проекты и т.п.). Во многих ОС в каталог могут входить другие файлы, в том числе другие каталоги, за счет чего образуется древовидная структура, удобная для поиска требуемого файла. Каталоги устанавливают соответствие между именами файлов и их характеристиками, используемыми файловой системой для управления файлами. В число таких характеристик входят тип файла, права доступа к файлу, его распоряжение на диске, размер, дата и время создания и др.
Специальные файлы – это фиктивные файлы, ассоциированные с устройствами ввода-вывода, которые используются для унификации механизма доступа к последовательным устройствам ввода-вывода, таким как терминалы, принтеры и др. (например, MS-DOS рассматривает монитор и клавиатуру как файлы со стандартным именем con – консоль, а принтер – как файл prn). Блочные специальные файлы используются для моделирования дисков.
Именованные конвейеры (каналы) представляют собой циклические буферы, позволяющие выходной файл одной программы соединить со входным файлом другой программы.
Наконец, отображаемые файлы – это обычные файлы, отображенные на адресное пространство процесса по указанному виртуальному адресу.
Файлы относятся к абстрактному механизму. Они предоставляют способ сохранять информацию на запоминающем устройстве и считывать ее позднее снова. При этом от пользователя должны скрываться такие детали, как способ и место хранения информации, а также детали работы устройства.
Во многих операционных системах имя файла состоит из двух частей, разделенных точкой. Часть имени после точки называется расширением файла и обычно означает его тип. Так, в MS-DOS имя файла может содержать от 1 до 8 символов, а расширение от 0 (отсутствует) до 3.
В некоторых ОС, например, Windows, расширение указывает на программу, создавшую файл. Другие ОС, например, UNIX, не принуждают пользователя строго придерживаться расширений. Некоторые типичные расширения файлов приведены ниже.
| Расширение | Значение |
| file.bak | Резервная копия файла |
| file.cpp | Исходный текст программы на С++ |
| file.jpg | Изображение формата GIF |
| file.hlp | Файл справки |
| file.html | Документ в формате HTML |
| file.jpg | Неподвижное изображение стандарта JPEG |
| file.mp3 | Музыка в формате MPEG-1 уровень 3 |
| file.mpg | Фильм в формате MPEG |
| file.obj | Объектный файл |
В иерархически организованных файловых системах обычно используются три типа имен файлов: простые, составные и относительные.

Простое (короткое) символьное имя идентифицирует файл в пределах одного каталога. Несколько файлов могут иметь одно и то же простое имя, если они принадлежат разным каталогам.
Составное (полное) символьное имя представляет собой цепочку, содержащую имя диска и имена всех каталогов, через которые проходит путь от корневого каталога до данного файла.
Относительное имя файла определяется через текущий каталог, т.е. каталог, в котором в данный момент времени работает пользователь. Таким образом, относительных имен у файла может быть достаточно много, и все они являются частью полного имени.
Понятие файла включает не только хранимые им данные и имя, но и информацию, описывающую свойства файла. Эта информация составляет атрибуты файла. Список атрибутов может быть различным в различных ОС. Пример возможных атрибутов приведен ниже.
| Атрибут | Значение |
| Тип файла | Обычный, каталог, специальный и т. д. |
| Владелец файла | Текущий владелец |
| Создатель файла | Идентификатор пользователя, создавшего файл |
| Пароль | Пароль для получения доступа к файлу |
| Время | Создания, последнего доступа, последнего изменения |
| Текущий размер файла | Количество байт в записи |
| Максимальный размер | Количество байт, до которого можно увеличивать размер файла |
| Флаг "только чтение" | 0 – чтение / запись, 1 – только чтение |
| Флаг "скрытый" | 0 – нормальный, 1 – не показывать в перечне файлов каталога |
| Флаг "системный" | 0 – нормальный, 1 – системный |
| Флаг "архивный" | 0 – заархивирован, 1 – требуется архивация |
| Флаг ASCII / двоичный | 0 – ASCII, 1 – двоичный |
| Флаг произвольного доступа | 0 – только последовательный доступ, 1 – произвольный доступ |
| Флаг "временный" | 0 – нормальный, 1 – удаление после окончания работы процесса |
| Позиция ключа | Смещение до ключа в записи |
| Длина ключа | Количество байт в поле ключа |
Пользователь может получить доступ к атрибутам, используя средства, предоставляемые для этой цели файловой системой. Обычно разрешается читать значение любых атрибутов, а изменять – только некоторые.
Значения атрибутов файлов могут содержаться в каталогах, как это сделано, например, в MS-DOS (рис. 7.7). Другим вариантом является размещение атрибутов в специальных таблицах, в этом случае в каталогах содержатся ссылки на эти таблицы.
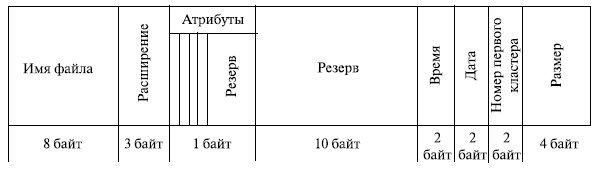
Рис. 7.7. Атрибуты файлов MS DOS
Логическая организация файла
В общем случае данные, содержащиеся в файле, имеют некоторую логическую структуру. Эта структура (организация) файла является базой при разработке программы, предназначенной для обработки этих данных. Поддержание структуры данных может быть целиком возложено на приложение либо в той или иной степени эту работу может взять на себя файловая система.
В первом случае, когда все действия, связанные со структуризацией и интерпретацией содержимого файла, целиком относятся к ведению приложения, файл представляется файловой системе неструктурированной последовательностью данных. Приложение формирует запросы к файловой системе на ввод-вывод, используя общие для всех приложений системные средства, например, указывая смещение от начала файла и количество байт, которые необходимо считать или записать. Поступивший к приложению поток байт интерпретируется в соответствии с заложенной в программе логикой. Следует подчеркнуть, что интерпретация данных никак не связана с действительным способом их хранения в файловой системе.
Модель файла, в соответствии с которой содержимое файла представляется неструктурированной последовательностью байт, стала популярной вместе с ОС UNIX, и теперь широко используется в современных ОС. Неструктурированная модель файла позволяет легко организовать разделение файла между несколькими приложениями, поскольку разные приложения могут по-своему структурировать и интерпретировать данные, содержащиеся в файле.
Другая модель файла – структурированный файл. В этом случае поддержание структуры файла поручается файловой системе. Файловая система видит файл как упорядоченную последовательность логических записей. ФС предоставляет приложению доступ к записи, а вся дальнейшая обработка данных, содержащихся в этой записи, выполняется приложением!
Известно пять фундаментальных способов организации файлов [10]:
- смешанный файл,
- последовательный файл,
- индексно-последовательный файл,
- индексируемый файл,
- файл прямого доступа.
При выборе способа организации файла нужно учитывать несколько критериев:
- быстрота доступа,
- легкость обновления,
- экономность хранения,
- простота обслуживания,
- надежность.
Смешанный файл. Это наименее сложная форма организации файла. Данные накапливаются в порядке поступления. Запись состоит из одного пакета данных. Записи могут иметь различные или одинаковые поля, расположенные в различном порядке (рис. 7.8). Каждое поле описывает само себя, включая как имя, так и значение. Длина каждого поля должна быть указана явно либо посредством применения разделителя.

Рис. 7.8. Смешанный файл
Поскольку смешанный файл не имеет никакой структуры, доступ к записи осуществляется полным перебором всех записей файла. Смешанные файлы применяются в том случае, когда данные накапливаются и сохраняются перед обработкой, или если данные неудобны для организации. Файлы этого типа рационально используют дисковое пространство, хорошо подходят для полного набора. Обновление записей достаточно сложно, так же как и вставка записи.
Последовательный файл. Для записей используется фиксированный формат. Все записи имеют одинаковую длину (но иногда и не одинаковую) и состоят из одинакового количества полей фиксированной длины, организованных в определенном порядке (рис. 7.9). Поскольку длина и позиция каждого поля известны, сохранению подлежат только значения полей. Атрибутами файловой структуры является имя и длина каждого поля.
Рис. 7.9. Последовательный файл
Одно определенное поле (или несколько полей) называется ключевым. Оно однозначно идентифицирует запись, так как это поле различно для каждой записи. Более того, записи сохраняются в "ключевой" последовательности: в алфавитном порядке для текстового ключа и в числовом – для числового. Последовательные файлы часто используются пакетными приложениями и обычно являются оптимальным вариантом, если эти приложения выполняют обработку всех записей. Удобно и то, что такой файл можно хранить как на диске, так и на магнитном диске.
Для диалоговых приложений последовательный файл малоэффективен, поскольку для нахождения нужной записи требуется последовательный перебор записи файла. Правда, если в оперативную память загрузить весь файл, возможен более эффективный метод поиска. Дополнения к файлу или изменения в записях создают проблемы.
Обычно последовательный файл сохраняется с последовательной организацией записей внутри блока, т.е. физическая организация файла в точности соответствует логической. Новые записи размещаются в отдельном смешанном файле, называемом журнальным файлом, или файлом транзакции. Периодически в пакетном режиме выполняется слияние основного и журнального файлов в новый файл с корректной последовательностью ключей.
Альтернативной организацией может быть физическая организация в виде списка с использованием указателей. В каждом физическом блоке сохраняется одна или несколько записей, и каждый блок содержит указатель на следующий блок. Для вставки новых записей достаточно изменить указатели, и нет необходимости в том, чтобы новые записи занимали определенную физическую позицию. Это удобство достигается за счет определенных накладных расходов и дополнительной работы. Если в последовательном файле записи имеют одну и ту же длину, то можно вычислить адрес требуемой записи по ее номеру, номеру текущей записи и длине записи. Если записи имеют переменную длину, такой подход невозможен.
Индексно-последовательный файл. Одним из методов преодоления недостатков последовательного файла является индексно-последовательная организация файла. В этом случае файл состоит из трех частей (файлов): главный файл, содержащий записи с последовательно идущими ключами, индексный файл, содержащий индексное поле, и указатель в главный с ключами, файл переполнения (рис. 7.10).

Рис. 7.10. Индексно-последовательный файл
Для поиска нужной записи по ее ключу сначала выполняется поиск в индексном файле. После того как в нем найдено наибольшее значение ключа, которое не превышает искомое, продолжается поиск в главном файле. Например, пусть последовательный файл (главный) содержит 1 млн записей. Для поиска определенного ключевого значения необходимо в среднем 0,5 млн операций доступа к записям. Если создать индексный файл, содержащий 1000 элементов, то потребуется в среднем 500 операций доступа к индексному файлу, после чего еще нужно в среднем 500 операций доступа к главному файлу. В результате средняя длина поиска уменьшилась с 0,5 млн до 1000. Еще лучшего результата можно достичь, используя многоуровневую индексацию. При этом нижний уровень индексного файла рассматривается как последовательный файл, для которого создается индексный файл верхнего уровня.
Дополнения к файлу обрабатываются следующим образом. В каждой записи главного файла содержится дополнительное поле, невидимое для приложения и являющееся указателем на файл переполнения. Если в файле производится вставка новой записи, она добавляется в файл переполнения. Запись в главном файле, непосредственно предшествующая новой записи в логической последовательности, обновляется и указывает на новую запись в файле переполнения. Время от времени выполняется слияние индексно-последовательного файла с файлом переполнения.
Индексированный файл. Индексно-последовательный файл сохраняет одно ограничение последовательного файла: эффективная работа с файлом ограничена работой с ключевым полем. Если необходимо производить поиск записи по какой-либо иной характеристике, отличной от ключевого поля, то оказываются непригодными обе организации последовательного файла, в то время как в некоторых приложениях эта гибкость крайне желательна.
Для достижения гибкости необходимо применение большого количества индексов, по одному для каждого типа поля, которое может быть объектом поиска. В обобщенном индексированном файле доступ к записям осуществляется только по их индексам. В результате в размещении записей нет никаких ограничений до тех пор, пока указатель по крайней мере в одном индексе ссылается на эту запись. Кроме того, в таком файле легко реализуются записи переменной длины.
Используется два типа индексов. Полный индекс содержит по одному элементу для каждого типа записей главного файла. Сам по себе индекс организовывается в виде последовательного файла для облегчения поиска. Частный индекс содержит элементы для записей, в которых имеется интересующее пользователя поле. При добавлении новой записи в главный файл необходимо обновлять все индексные файлы.
Индексированные файлы применяются теми приложениями, в которых время доступа к информации является критической характеристикой и редко требуется обработка всех записей в файле.
Файл прямого доступа. Такой файл использует возможность прямого доступа к блоку с известным адресом при хранении файлов на диске. В каждой записи в этом случае также имеется ключевое поле.
Смысл последовательного доступа заключается в том, что в каждый момент времени доступна лишь одна компонента из всей последовательности. Для того, чтобы обратиться (получить доступ) к компоненте с номером К, необходимо просмотреть от начала файла К-1 предшествующую компоненту. После обращения к компоненте с номером К можно обращаться к компоненте с номером К+1. Отсюда следует, что процессы формирования (записи) компонент файла и просмотра (чтения) не могут произвольно чередоваться. Таким образом, файл вначале строится при помощи последовательного добавления компонент в конец, а затем может последовательно просматриваться от начала до конца.
Рассмотренные ранее средства работы с файлами обеспечивают последовательный доступ.
TURBO PASCAL позволяет применять к компонентным и бестиповым файлам, записанным на диск, способ прямого доступа. Прямой доступ означает возможность заранее определить в файле блок, к которому будет применена операция ввода - вывода. В случае бестиповых файлов блок равен размеру буфера, для компонентных файлов блок - это одна компонента файла.
Прямой доступ предполагает, что файл представляет собой линейную последовательность блоков. Если файл содержит n блоков, то они нумеруются от 1 через 1 до n. Кроме того, вводится понятие условной границы между блоками, при этом условная граница с номером 0 расположена перед блоком с номером 1, граница с номером 1 расположена перед блоком с номером 2 и, наконец, условная граница с номером n находится после блока с номером n.
Реализация прямого доступа осуществляется с помощью функций и процедур FileSize, FilePos, Seek и Truncate.
Функция FileSize( var f ): Longint возвращает количество блоков в открытом файле f.
Функция FilePos( var f ): Longint возвращает текущую позицию в файле f. Позиция в файле - это номер условной границы. Для только что открытого файла текущей позицией будет граница с номером 0. Это значит, что можно записать или прочесть блок с номером 1. После чтения или записи первого блока текущая позиция переместится на границу с номером 1, и можно будет обращаться к ьлоку с номером 2. После прочтения последней записи значение FilePos равно значению FileSize.
Процедура Seek( var f; N: Longint) обеспечивает назначение текущей позиции в файле (позиционирование). В параметре N должен быть задан номер условной границы, предшествующей блоку, к которому будет производиться последующее обращение. Например, чтобы работать с блоком 4, необходимо задать значение N, равное 3. Процедура Seek работает с открытыми файлами.
Процедура Truncate( var f ) устанавливает в текущей позиции признак конца файла и удаляет (стирает) все последующие блоки.
Пример. Пусть на НМД имеется текстовый файл ID.DAT, который содержит числовые значения действительного типа по два числа в каждой строке - значения аргумента и функции соответственно. Количество пар чисел не более 200. Составить программу, которая читает файл, значения аргумента и функции записывает в одномерные массивы, подсчитывает их количество, выводит на экран дисплея и записывает в файл компонентного типа RD.DAT.
Аннотация: В настоящей лекции вводится понятие и рассматриваются основные функции и интерфейс файловой системы.
Введение
История систем управления данными во внешней памяти начинается еще с магнитных лент, но современный облик они приобрели с появлением магнитных дисков. До этого каждая прикладная программа сама решала проблемы именования данных и их структуризации во внешней памяти . Это затрудняло поддержание на внешнем носителе нескольких архивов долговременно хранящейся информации. Историческим шагом стал переход к использованию централизованных систем управления файлами . Система управления файлами берет на себя распределение внешней памяти , отображение имен файлов в адреса внешней памяти и обеспечение доступа к данным.
Файловая система - это часть операционной системы, назначение которой состоит в том, чтобы организовать эффективную работу с данными, хранящимися во внешней памяти , и обеспечить пользователю удобный интерфейс при работе с такими данными. Организовать хранение информации на магнитном диске непросто. Это требует, например, хорошего знания устройства контроллера диска, особенностей работы с его регистрами. Непосредственное взаимодействие с диском - прерогатива компонента системы ввода-вывода ОС, называемого драйвером диска. Для того чтобы избавить пользователя компьютера от сложностей взаимодействия с аппаратурой, была придумана ясная абстрактная модель файловой системы. Операции записи или чтения файла концептуально проще, чем низкоуровневые операции работы с устройствами.
Основная идея использования внешней памяти состоит в следующем. ОС делит память на блоки фиксированного размера, например, 4096 байт. Файл , обычно представляющий собой неструктурированную последовательность однобайтовых записей, хранится в виде последовательности блоков (не обязательно смежных); каждый блок хранит целое число записей. В некоторых ОС (MS-DOS) адреса блоков, содержащих данные файла , могут быть организованы в связный список и вынесены в отдельную таблицу в памяти. В других ОС (Unix) адреса блоков данных файла хранятся в отдельном блоке внешней памяти (так называемом индексе или индексном узле). Этот прием, называемый индексацией , является наиболее распространенным для приложений, требующих произвольного доступа к записям файлов . Индекс файла состоит из списка элементов, каждый из которых содержит номер блока в файле и сведения о местоположении данного блока. Считывание очередного байта осуществляется с так называемой текущей позиции, которая характеризуется смещением от начала файла . Зная размер блока, легко вычислить номер блока, содержащего текущую позицию. Адрес же нужного блока диска можно затем извлечь из индекса файла . Базовой операцией, выполняемой по отношению к файлу , является чтение блока с диска и перенос его в буфер , находящийся в основной памяти.
Файловая система позволяет при помощи системы справочников ( каталогов , директорий ) связать уникальное имя файла с блоками вторичной памяти, содержащими данные файла . Иерархическая структура каталогов , используемая для управления файлами , может служить другим примером индексной структуры. В этом случае каталоги или папки играют роль индексов, каждый из которых содержит ссылки на свои подкаталоги. С этой точки зрения вся файловая система компьютера представляет собой большой индексированный файл . Помимо собственно файлов и структур данных, используемых для управления файлами ( каталоги , дескрипторы файлов , различные таблицы распределения внешней памяти ), понятие " файловая система " включает программные средства , реализующие различные операции над файлами .
Перечислим основные функции файловой системы.
- Идентификация файлов . Связывание имени файла с выделенным ему пространством внешней памяти .
- Распределение внешней памяти между файлами . Для работы с конкретным файлом пользователю не требуется иметь информацию о местоположении этого файла на внешнем носителе информации. Например, для того чтобы загрузить документ в редактор с жесткого диска, нам не нужно знать, на какой стороне какого магнитного диска, на каком цилиндре и в каком секторе находится данный документ.
- Обеспечение надежности и отказоустойчивости. Стоимость информации может во много раз превышать стоимость компьютера.
- Обеспечение защиты от несанкционированного доступа.
- Обеспечение совместного доступа к файлам , так чтобы пользователю не приходилось прилагать специальных усилий по обеспечению синхронизации доступа.
- Обеспечение высокой производительности.
Иногда говорят, что файл - это поименованный набор связанной информации, записанной во вторичную память. Для большинства пользователей файловая система - наиболее видимая часть ОС. Она предоставляет механизм для онлайнового хранения и доступа как к данным, так и к программам для всех пользователей системы. С точки зрения пользователя, файл - единица внешней памяти , то есть данные, записанные на диск, должны быть в составе какого-нибудь файла .
Важный аспект организации файловой системы - учет стоимости операций взаимодействия с вторичной памятью. Процесс считывания блока диска состоит из позиционирования считывающей головки над дорожкой, содержащей требуемый блок, ожидания, пока требуемый блок сделает оборот и окажется под головкой, и собственно считывания блока. Для этого требуется значительное время (десятки миллисекунд). В современных компьютерах обращение к диску осуществляется примерно в 100 000 раз медленнее, чем обращение к оперативной памяти. Таким образом, критерием вычислительной сложности алгоритмов, работающих с внешней памятью , является количество обращений к диску.
В данной лекции рассматриваются вопросы структуры, именования, защиты файлов ; операции , которые разрешается производить над файлами ; организация файлового архива (полного дерева справочников). Проблемы выделения дискового пространства, обеспечения производительной работы файловой системы и ряд других вопросов, интересующих разработчиков системы, вы найдете в следующей лекции.
Общие сведения о файлах
Имена файлов
Файлы представляют собой абстрактные объекты. Их задача - хранить информацию, скрывая от пользователя детали работы с устройствами. Когда процесс создает файл , он дает ему имя. После завершения процесса файл продолжает существовать и через свое имя может быть доступен другим процессам.
Правила именования файлов зависят от ОС. Многие ОС поддерживают имена из двух частей (имя+расширение), например progr.c ( файл , содержащий текст программы на языке Си) или autoexec.bat ( файл , содержащий команды интерпретатора командного языка). Тип расширения файла позволяет ОС организовать работу с ним различных прикладных программ в соответствии с заранее оговоренными соглашениями. Обычно ОС накладывают некоторые ограничения, как на используемые в имени символы, так и на длину имени файла . В соответствии со стандартом POSIX, популярные ОС оперируют удобными для пользователя длинными именами (до 255 символов).
Типы файлов
Важный аспект организации файловой системы и ОС - следует ли поддерживать и распознавать типы файлов . Если да, то это может помочь правильному функционированию ОС, например не допустить вывода на принтер бинарного файла .
Основные типы файлов : регулярные (обычные) файлы и директории (справочники, каталоги ). Обычные файлы содержат пользовательскую информацию. Директории - системные файлы , поддерживающие структуру файловой системы. В каталоге содержится перечень входящих в него файлов и устанавливается соответствие между файлами и их характеристиками ( атрибутами ). Мы будем рассматривать директории ниже.
Напомним, что хотя внутри подсистемы управления файлами обычный файл представляется в виде набора блоков внешней памяти , для пользователей обеспечивается представление файла в виде линейной последовательности байтов. Такое представление позволяет использовать абстракцию файла при работе с внешними устройствами, при организации межпроцессных взаимодействий и т. д. Так, например, клавиатура обычно рассматривается как текстовый файл , из которого компьютер получает данные в символьном формате. Поэтому иногда к файлам приписывают другие объекты ОС, например специальные символьные файлы и специальные блочные файлы , именованные каналы и сокеты, имеющие файловый интерфейс. Эти объекты рассматриваются в других разделах данного курса.
Далее речь пойдет главным образом об обычных файлах.
Обычные (или регулярные) файлы реально представляют собой набор блоков (возможно, пустой) на устройстве внешней памяти , на котором поддерживается файловая система. Такие файлы могут содержать как текстовую информацию (обычно в формате ASCII), так и произвольную двоичную (бинарную) информацию.
Текстовые файлы содержат символьные строки, которые можно распечатать, увидеть на экране или редактировать обычным текстовым редактором.
Другой тип файлов - нетекстовые, или бинарные, файлы . Обычно они имеют некоторую внутреннюю структуру. Например, исполняемый файл в ОС Unix имеет пять секций: заголовок, текст, данные, биты реаллокации и символьную таблицу. ОС выполняет файл , только если он имеет нужный формат. Другим примером бинарного файла может быть архивный файл . Типизация файлов не слишком строгая.
Обычно прикладные программы, работающие с файлами , распознают тип файла по его имени в соответствии с общепринятыми соглашениями. Например, файлы с расширениями .c , .pas , .txt - ASCII-файлы, файлы с расширениями .exe - выполнимые, файлы с расширениями .obj , .zip - бинарные и т. д.
Атрибуты файлов
Кроме имени ОС часто связывают с каждым файлом и другую информацию, например дату модификации, размер и т. д. Эти другие характеристики файлов называются атрибутами . Список атрибутов в разных ОС может варьироваться. Обычно он содержит следующие элементы: основную информацию (имя, тип файла ), адресную информацию (устройство, начальный адрес, размер), информацию об управлении доступом (владелец, допустимые операции) и информацию об использовании (даты создания, последнего чтения, модификации и др.).
Список атрибутов обычно хранится в структуре директорий (см. следующую лекцию) или других структурах, обеспечивающих доступ к данным файла .
Организация файлов и доступ к ним
Программист воспринимает файл в виде набора однородных записей. Запись - это наименьший элемент данных , который может быть обработан как единое целое прикладной программой при обмене с внешним устройством. Причем в большинстве ОС размер записи равен одному байту. В то время как приложения оперируют записями, физический обмен с устройством осуществляется большими единицами (обычно блоками). Поэтому записи объединяются в блоки для вывода и разблокируются - для ввода. Вопросы распределения блоков внешней памяти между файлами рассматриваются в следующей лекции.
ОС поддерживают несколько вариантов структуризации файлов .
Последовательный файл
Простейший вариант - так называемый последовательный файл . То есть файл является последовательностью записей. Поскольку записи, как правило, однобайтовые, файл представляет собой неструктурированную последовательность байтов.
Обработка подобных файлов предполагает последовательное чтение записей от начала файла , причем конкретная запись определяется ее положением в файле . Такой способ доступа называется последовательным (модель ленты). Если в качестве носителя файла используется магнитная лента, то так и делается. Текущая позиция считывания может быть возвращена к началу файла ( rewind ).
Файл прямого доступа
В реальной практике файлы хранятся на устройствах прямого (random) доступа, например на дисках, поэтому содержимое файла может быть разбросано по разным блокам диска, которые можно считывать в произвольном порядке. Причем номер блока однозначно определяется позицией внутри файла .
Здесь имеется в виду относительный номер, специфицирующий данный блок среди блоков диска, принадлежащих файлу . О связи относительного номера блока с абсолютным его номером на диске рассказывается в следующей лекции.
Естественно, что в этом случае для доступа к середине файла просмотр всего файла с самого начала не обязателен. Для специфицирования места, с которого надо начинать чтение, используются два способа: с начала или с текущей позиции, которую дает операция seek. Файл , байты которого могут быть считаны в произвольном порядке, называется файлом прямого доступа .
Таким образом, файл , состоящий из однобайтовых записей на устройстве прямого доступа, - наиболее распространенный способ организации файла . Базовыми операциями для такого рода файлов являются считывание или запись символа в текущую позицию. В большинстве языков высокого уровня предусмотрены операторы посимвольной пересылки данных в файл или из него.
Подобную логическую структуру имеют файлы во многих файловых системах, например в файловых системах ОС Unix и MS-DOS. ОС не осуществляет никакой интерпретации содержимого файла . Эта схема обеспечивает максимальную гибкость и универсальность. С помощью базовых системных вызовов (или функций библиотеки ввода/вывода) пользователи могут как угодно структурировать файлы . В частности, многие СУБД хранят свои базы данных в обычных файлах .
Другие формы организации файлов
Известны как другие формы организации файла , так и другие способы доступа к ним, которые использовались в ранних ОС, а также применяются сегодня в больших мэйнфреймах (mainframe), ориентированных на коммерческую обработку данных.
Другой способ представления файлов - последовательность записей переменной длины, каждая из которых содержит ключевое поле в фиксированной позиции внутри записи (см. рис. 11.1). Базисная операция в данном случае - считать запись с каким-либо значением ключа. Записи могут располагаться в файле последовательно (например, отсортированные по значению ключевого поля) или в более сложном порядке. Метод доступа по значению ключевого поля к записям последовательного файла называется индексно-последовательным.
В некоторых системах ускорение доступа к файлу обеспечивается конструированием индекса файла . Индекс обычно хранится на том же устройстве, что и сам файл , и состоит из списка элементов, каждый из которых содержит идентификатор записи, за которым следует указание о местоположении данной записи. Для поиска записи вначале происходит обращение к индексу, где находится указатель на нужную запись. Такие файлы называются индексированными, а метод доступа к ним - доступ с использованием индекса.
Предположим, у нас имеется большой несортированный файл , содержащий разнообразные сведения о студентах, состоящие из записей с несколькими полями, и возникает задача организации быстрого поиска по одному из полей, например по фамилии студента. Рис. 11.2 иллюстрирует решение данной проблемы - организацию метода доступа к файлу с использованием индекса.
Следует отметить, что почти всегда главным фактором увеличения скорости доступа является избыточность данных.
Способ выделения дискового пространства при помощи индексных узлов, применяемый в ряде ОС (Unix и некоторых других, см. следующую лекцию), может служить другим примером организации индекса.
В этом случае ОС использует древовидную организацию блоков, при которой блоки, составляющие файл , являются листьями дерева, а каждый внутренний узел содержит указатели на множество блоков файла . Для больших файлов индекс может быть слишком велик. В этом случае создают индекс для индексного файла (блоки промежуточного уровня или блоки косвенной адресации).
Аннотация: В настоящей лекции вводится понятие и рассматриваются основные функции и интерфейс файловой системы.
Введение
История систем управления данными во внешней памяти начинается еще с магнитных лент, но современный облик они приобрели с появлением магнитных дисков. До этого каждая прикладная программа сама решала проблемы именования данных и их структуризации во внешней памяти . Это затрудняло поддержание на внешнем носителе нескольких архивов долговременно хранящейся информации. Историческим шагом стал переход к использованию централизованных систем управления файлами . Система управления файлами берет на себя распределение внешней памяти , отображение имен файлов в адреса внешней памяти и обеспечение доступа к данным.
Файловая система - это часть операционной системы, назначение которой состоит в том, чтобы организовать эффективную работу с данными, хранящимися во внешней памяти , и обеспечить пользователю удобный интерфейс при работе с такими данными. Организовать хранение информации на магнитном диске непросто. Это требует, например, хорошего знания устройства контроллера диска, особенностей работы с его регистрами. Непосредственное взаимодействие с диском - прерогатива компонента системы ввода-вывода ОС, называемого драйвером диска. Для того чтобы избавить пользователя компьютера от сложностей взаимодействия с аппаратурой, была придумана ясная абстрактная модель файловой системы. Операции записи или чтения файла концептуально проще, чем низкоуровневые операции работы с устройствами.
Основная идея использования внешней памяти состоит в следующем. ОС делит память на блоки фиксированного размера, например, 4096 байт. Файл , обычно представляющий собой неструктурированную последовательность однобайтовых записей, хранится в виде последовательности блоков (не обязательно смежных); каждый блок хранит целое число записей. В некоторых ОС (MS-DOS) адреса блоков, содержащих данные файла , могут быть организованы в связный список и вынесены в отдельную таблицу в памяти. В других ОС (Unix) адреса блоков данных файла хранятся в отдельном блоке внешней памяти (так называемом индексе или индексном узле). Этот прием, называемый индексацией , является наиболее распространенным для приложений, требующих произвольного доступа к записям файлов . Индекс файла состоит из списка элементов, каждый из которых содержит номер блока в файле и сведения о местоположении данного блока. Считывание очередного байта осуществляется с так называемой текущей позиции, которая характеризуется смещением от начала файла . Зная размер блока, легко вычислить номер блока, содержащего текущую позицию. Адрес же нужного блока диска можно затем извлечь из индекса файла . Базовой операцией, выполняемой по отношению к файлу , является чтение блока с диска и перенос его в буфер , находящийся в основной памяти.
Файловая система позволяет при помощи системы справочников ( каталогов , директорий ) связать уникальное имя файла с блоками вторичной памяти, содержащими данные файла . Иерархическая структура каталогов , используемая для управления файлами , может служить другим примером индексной структуры. В этом случае каталоги или папки играют роль индексов, каждый из которых содержит ссылки на свои подкаталоги. С этой точки зрения вся файловая система компьютера представляет собой большой индексированный файл . Помимо собственно файлов и структур данных, используемых для управления файлами ( каталоги , дескрипторы файлов , различные таблицы распределения внешней памяти ), понятие " файловая система " включает программные средства , реализующие различные операции над файлами .
Перечислим основные функции файловой системы.
- Идентификация файлов . Связывание имени файла с выделенным ему пространством внешней памяти .
- Распределение внешней памяти между файлами . Для работы с конкретным файлом пользователю не требуется иметь информацию о местоположении этого файла на внешнем носителе информации. Например, для того чтобы загрузить документ в редактор с жесткого диска, нам не нужно знать, на какой стороне какого магнитного диска, на каком цилиндре и в каком секторе находится данный документ.
- Обеспечение надежности и отказоустойчивости. Стоимость информации может во много раз превышать стоимость компьютера.
- Обеспечение защиты от несанкционированного доступа.
- Обеспечение совместного доступа к файлам , так чтобы пользователю не приходилось прилагать специальных усилий по обеспечению синхронизации доступа.
- Обеспечение высокой производительности.
Иногда говорят, что файл - это поименованный набор связанной информации, записанной во вторичную память. Для большинства пользователей файловая система - наиболее видимая часть ОС. Она предоставляет механизм для онлайнового хранения и доступа как к данным, так и к программам для всех пользователей системы. С точки зрения пользователя, файл - единица внешней памяти , то есть данные, записанные на диск, должны быть в составе какого-нибудь файла .
Важный аспект организации файловой системы - учет стоимости операций взаимодействия с вторичной памятью. Процесс считывания блока диска состоит из позиционирования считывающей головки над дорожкой, содержащей требуемый блок, ожидания, пока требуемый блок сделает оборот и окажется под головкой, и собственно считывания блока. Для этого требуется значительное время (десятки миллисекунд). В современных компьютерах обращение к диску осуществляется примерно в 100 000 раз медленнее, чем обращение к оперативной памяти. Таким образом, критерием вычислительной сложности алгоритмов, работающих с внешней памятью , является количество обращений к диску.
В данной лекции рассматриваются вопросы структуры, именования, защиты файлов ; операции , которые разрешается производить над файлами ; организация файлового архива (полного дерева справочников). Проблемы выделения дискового пространства, обеспечения производительной работы файловой системы и ряд других вопросов, интересующих разработчиков системы, вы найдете в следующей лекции.
Общие сведения о файлах
Имена файлов
Файлы представляют собой абстрактные объекты. Их задача - хранить информацию, скрывая от пользователя детали работы с устройствами. Когда процесс создает файл , он дает ему имя. После завершения процесса файл продолжает существовать и через свое имя может быть доступен другим процессам.
Правила именования файлов зависят от ОС. Многие ОС поддерживают имена из двух частей (имя+расширение), например progr.c ( файл , содержащий текст программы на языке Си) или autoexec.bat ( файл , содержащий команды интерпретатора командного языка). Тип расширения файла позволяет ОС организовать работу с ним различных прикладных программ в соответствии с заранее оговоренными соглашениями. Обычно ОС накладывают некоторые ограничения, как на используемые в имени символы, так и на длину имени файла . В соответствии со стандартом POSIX, популярные ОС оперируют удобными для пользователя длинными именами (до 255 символов).
Типы файлов
Важный аспект организации файловой системы и ОС - следует ли поддерживать и распознавать типы файлов . Если да, то это может помочь правильному функционированию ОС, например не допустить вывода на принтер бинарного файла .
Основные типы файлов : регулярные (обычные) файлы и директории (справочники, каталоги ). Обычные файлы содержат пользовательскую информацию. Директории - системные файлы , поддерживающие структуру файловой системы. В каталоге содержится перечень входящих в него файлов и устанавливается соответствие между файлами и их характеристиками ( атрибутами ). Мы будем рассматривать директории ниже.
Напомним, что хотя внутри подсистемы управления файлами обычный файл представляется в виде набора блоков внешней памяти , для пользователей обеспечивается представление файла в виде линейной последовательности байтов. Такое представление позволяет использовать абстракцию файла при работе с внешними устройствами, при организации межпроцессных взаимодействий и т. д. Так, например, клавиатура обычно рассматривается как текстовый файл , из которого компьютер получает данные в символьном формате. Поэтому иногда к файлам приписывают другие объекты ОС, например специальные символьные файлы и специальные блочные файлы , именованные каналы и сокеты, имеющие файловый интерфейс. Эти объекты рассматриваются в других разделах данного курса.
Далее речь пойдет главным образом об обычных файлах.
Обычные (или регулярные) файлы реально представляют собой набор блоков (возможно, пустой) на устройстве внешней памяти , на котором поддерживается файловая система. Такие файлы могут содержать как текстовую информацию (обычно в формате ASCII), так и произвольную двоичную (бинарную) информацию.
Текстовые файлы содержат символьные строки, которые можно распечатать, увидеть на экране или редактировать обычным текстовым редактором.
Другой тип файлов - нетекстовые, или бинарные, файлы . Обычно они имеют некоторую внутреннюю структуру. Например, исполняемый файл в ОС Unix имеет пять секций: заголовок, текст, данные, биты реаллокации и символьную таблицу. ОС выполняет файл , только если он имеет нужный формат. Другим примером бинарного файла может быть архивный файл . Типизация файлов не слишком строгая.
Обычно прикладные программы, работающие с файлами , распознают тип файла по его имени в соответствии с общепринятыми соглашениями. Например, файлы с расширениями .c , .pas , .txt - ASCII-файлы, файлы с расширениями .exe - выполнимые, файлы с расширениями .obj , .zip - бинарные и т. д.
Атрибуты файлов
Кроме имени ОС часто связывают с каждым файлом и другую информацию, например дату модификации, размер и т. д. Эти другие характеристики файлов называются атрибутами . Список атрибутов в разных ОС может варьироваться. Обычно он содержит следующие элементы: основную информацию (имя, тип файла ), адресную информацию (устройство, начальный адрес, размер), информацию об управлении доступом (владелец, допустимые операции) и информацию об использовании (даты создания, последнего чтения, модификации и др.).
Список атрибутов обычно хранится в структуре директорий (см. следующую лекцию) или других структурах, обеспечивающих доступ к данным файла .
Организация файлов и доступ к ним
Программист воспринимает файл в виде набора однородных записей. Запись - это наименьший элемент данных , который может быть обработан как единое целое прикладной программой при обмене с внешним устройством. Причем в большинстве ОС размер записи равен одному байту. В то время как приложения оперируют записями, физический обмен с устройством осуществляется большими единицами (обычно блоками). Поэтому записи объединяются в блоки для вывода и разблокируются - для ввода. Вопросы распределения блоков внешней памяти между файлами рассматриваются в следующей лекции.
ОС поддерживают несколько вариантов структуризации файлов .
Последовательный файл
Простейший вариант - так называемый последовательный файл . То есть файл является последовательностью записей. Поскольку записи, как правило, однобайтовые, файл представляет собой неструктурированную последовательность байтов.
Обработка подобных файлов предполагает последовательное чтение записей от начала файла , причем конкретная запись определяется ее положением в файле . Такой способ доступа называется последовательным (модель ленты). Если в качестве носителя файла используется магнитная лента, то так и делается. Текущая позиция считывания может быть возвращена к началу файла ( rewind ).
Файл прямого доступа
В реальной практике файлы хранятся на устройствах прямого (random) доступа, например на дисках, поэтому содержимое файла может быть разбросано по разным блокам диска, которые можно считывать в произвольном порядке. Причем номер блока однозначно определяется позицией внутри файла .
Здесь имеется в виду относительный номер, специфицирующий данный блок среди блоков диска, принадлежащих файлу . О связи относительного номера блока с абсолютным его номером на диске рассказывается в следующей лекции.
Естественно, что в этом случае для доступа к середине файла просмотр всего файла с самого начала не обязателен. Для специфицирования места, с которого надо начинать чтение, используются два способа: с начала или с текущей позиции, которую дает операция seek. Файл , байты которого могут быть считаны в произвольном порядке, называется файлом прямого доступа .
Таким образом, файл , состоящий из однобайтовых записей на устройстве прямого доступа, - наиболее распространенный способ организации файла . Базовыми операциями для такого рода файлов являются считывание или запись символа в текущую позицию. В большинстве языков высокого уровня предусмотрены операторы посимвольной пересылки данных в файл или из него.
Подобную логическую структуру имеют файлы во многих файловых системах, например в файловых системах ОС Unix и MS-DOS. ОС не осуществляет никакой интерпретации содержимого файла . Эта схема обеспечивает максимальную гибкость и универсальность. С помощью базовых системных вызовов (или функций библиотеки ввода/вывода) пользователи могут как угодно структурировать файлы . В частности, многие СУБД хранят свои базы данных в обычных файлах .
Другие формы организации файлов
Известны как другие формы организации файла , так и другие способы доступа к ним, которые использовались в ранних ОС, а также применяются сегодня в больших мэйнфреймах (mainframe), ориентированных на коммерческую обработку данных.
Другой способ представления файлов - последовательность записей переменной длины, каждая из которых содержит ключевое поле в фиксированной позиции внутри записи (см. рис. 11.1). Базисная операция в данном случае - считать запись с каким-либо значением ключа. Записи могут располагаться в файле последовательно (например, отсортированные по значению ключевого поля) или в более сложном порядке. Метод доступа по значению ключевого поля к записям последовательного файла называется индексно-последовательным.
В некоторых системах ускорение доступа к файлу обеспечивается конструированием индекса файла . Индекс обычно хранится на том же устройстве, что и сам файл , и состоит из списка элементов, каждый из которых содержит идентификатор записи, за которым следует указание о местоположении данной записи. Для поиска записи вначале происходит обращение к индексу, где находится указатель на нужную запись. Такие файлы называются индексированными, а метод доступа к ним - доступ с использованием индекса.
Предположим, у нас имеется большой несортированный файл , содержащий разнообразные сведения о студентах, состоящие из записей с несколькими полями, и возникает задача организации быстрого поиска по одному из полей, например по фамилии студента. Рис. 11.2 иллюстрирует решение данной проблемы - организацию метода доступа к файлу с использованием индекса.
Следует отметить, что почти всегда главным фактором увеличения скорости доступа является избыточность данных.
Способ выделения дискового пространства при помощи индексных узлов, применяемый в ряде ОС (Unix и некоторых других, см. следующую лекцию), может служить другим примером организации индекса.
В этом случае ОС использует древовидную организацию блоков, при которой блоки, составляющие файл , являются листьями дерева, а каждый внутренний узел содержит указатели на множество блоков файла . Для больших файлов индекс может быть слишком велик. В этом случае создают индекс для индексного файла (блоки промежуточного уровня или блоки косвенной адресации).
Читайте также: