
Что такое sdrs vmware
VASA это набор API, предоставляемый VMware и предназначенный для разработки провайдеров хранилищ (storage providers) для инфраструктуры vSphere. Storage provider-ы это программные компоненты, предоставляемые vSphere или разрабатываемые 3-ей стороной, предназначенные для интеграции (отслеживания) хранилищ (программных и аппаратных СХД) и фильтров ввода-вывода (VAIO) с инфраструктурой vSphere.
Storage provider (VASA-провайдер) нужен для того, чтобы виртуальная инфраструктура:
- получала информацию о статусе, характеристиках и возможностях СХД;
- могла работать с такими сущностями как Virtual SAN and Virtual Volumes;
- могла взаимодействовать с фильтры ввода-вывода (VAIO).
VASA-провайдеры сторонних разработчиков используются как сервисы отслеживания информации о данном хранилище для vSphere. Такие провайдеры требуют отдельной регистрации и установки соответствующих плагинов.
Встроенные storage provider-ы являются компонентами vSphere и не требуют регистрации. Так, например, провайдер для Virtual SAN автоматически регистрируется при её развертывании.
vSphere посредством storage provider собирает информацию о хранилищах (характеристики, статус, возможности) и сервисах данных (фильтрах VAIO) во всей инфраструктуре, данная информация становится доступной для мониторинга и принятия решений через vSphere Web Client.
Информацию, собираемую VASA-провайдерами, можно разделить на 3 категории:
- Возможности и сервисы хранилища. Это как раз то, на основе чего формируются правила Common rules и Rules Based on Storage-Specific Data Services в SPBM – возможности и сервисы, предоставляемые Virtual SAN, vVol и фильтрами ввода-вывода.
- Состояние хранилища. Информация о состоянии и событиях на стороне хранилищ, в т.ч. тревожные события, изменения конфигурации.
- Информация Storage DRS. Данная информация позволяет учитывать внутренние процессы управления хранилищами в работе механизма Storage DRS.
К одному storage provider-у могут одновременно обращаться несколько серверов vCenter. Один vCenter может одновременно взаимодействовать с множеством storage provider-ов (несколько массивов и фильтров ввода-вывода).
Final words ^
With much faster SDRS recommendation times, VMware is encouraging their customers to migrate to vSphere 6.7. Even on smaller infrastructures, it performs much better for clustered operations and especially for SDRS and VM operations.
VMware SDRS is a great technology that allows optimizing storage resources within your cluster. Your VM operations will initiate faster with less delay, which makes things finish earlier as well.
Storage Policy Based Management (SPBM)
Storage Policy Based Management (SPBM) is a storage policy framework that provides a single unified control plane across a broad range of data services and storage solutions. The framework helps to align storage with application demands of your virtual machines.
SPBM enables the following mechanisms:
- Advertisement of storage capabilities and data services that storage arrays and other entities, such as I/O filters, offer.
- Bidirectional communications between ESXi and vCenter Server on one side, and storage arrays and entities on the other.
- Virtual machine provisioning based on VM storage policies.

Administrators build policies by selecting the desired capabilities of the underlying storage array. The SPBM engine interprets the storage requirements of individual applications specified in policies associated with individual VMs and dynamically composes the storage service placing the VM on the right storage tier, allocating capacity, and instantiating the necessary data services (snapshots, replication, etc.). The available capabilities vary by storage vendor. Be sure to check with your storage vendor for details on what capabilities are available in their VVols implementation.
Let’s take a look at a few examples of how SPBM optimizes all aspects of storage management.

Where to enable SDRS?
After login via vSphere Web client go to Home > Storage > Datastores > Datastore Clusters
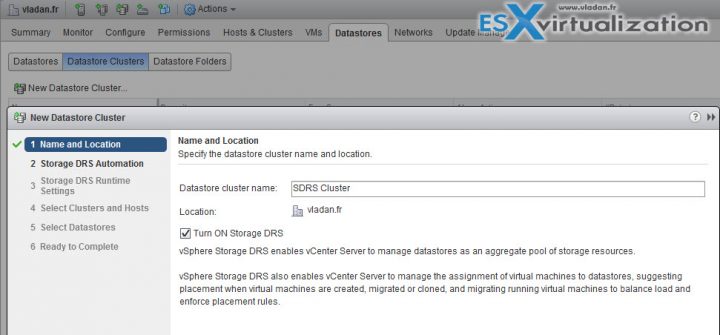
Then click New Datastore cluster button.
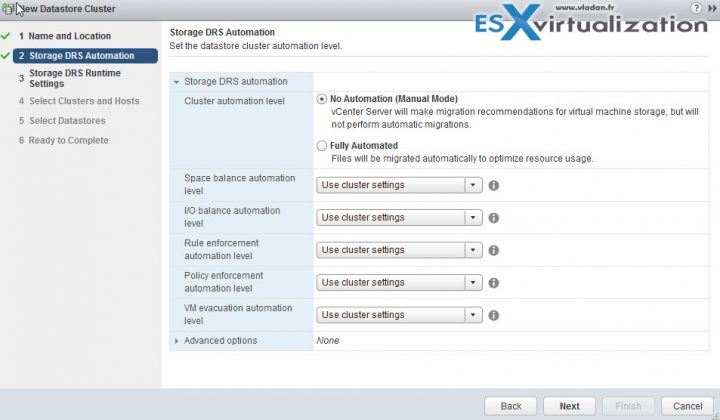
Each of the drop-down list presents some options…
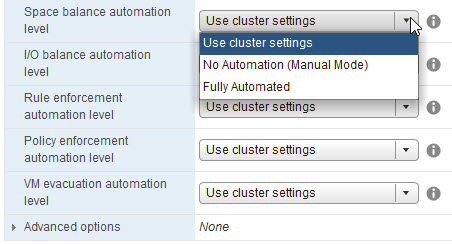
And the final screen of the assistant allows specifying further thresholds via I/O metrics…
As you can see, SDRS can be disabled and re-enabled. When you enable Storage DRS, the settings for the datastore cluster are restored to the point where Storage DRS was disabled.
SPBM integration with vRealize Automation
During the VMworld 2016 keynote VMware announced integrating the SPBM consumption model into vRealize Automation. This solution exposes vSphere VM Storage policies to the vRealize Automation service catalog allowing the ability to dynamically assign individual VM storage polcies to virtual disks based on their storage requirements characteristics (performance, availability, security, etc). More on this in a future post.
Recommendations ^
Let's look at some recommendation from VMware concerning SDRS.
- Don't mix disks: They recommend not mixing SSDs and hard disks in the same datastore cluster. Pick datastores that are as homogeneous as possible in terms of host interface protocol (i.e., FCP, iSCSI, or NFS), RAID level, and performance characteristics.
- Don't exceed the limits: You should not exceed 64 datastores per datastore cluster and 256 datastore clusters per vCenter.
- Optimize performance: While the minimum for an SDRS cluster is two datastores, it is not an optimal configuration for the system. SDRS will perform better when more than two datastores are in the SDRS cluster because it will be able to balance the loads and distribute the free space better.
- Disable Intra-VM affinity: To maximize SDRS performance, you can override the default intra-VM affinity rule at the VM level or at the cluster level.
Multipathing Storage APIs — Pluggable Storage Architecture (PSA) / Набор API для мультипафинга
Для управления мультипафингом гипервизор ESXi использует отдельный набор Storage APIs называемый Pluggable Storage Architecture (PSA). PSA – открытый модульный каркас (framework), координирующий одновременную работу множества плагинов мультипафинга (multipathing plug-ins – MPPs). PSA позволяет производителям разрабатывать (интегрировать) собственные технологии мультипафинга (балансировки нагрузки и восстановления после сбоя) для подключения своих СХД к vSphere.
PSA выполняет следующие задачи:
- Загружает и выгружает плагины мультипафинга
- Скрывает от ВМ специфику работы плагинов мультипафинга
- Направляет запросы ввода-вывода MPP
- Обрабатывает очереди ввода-вывода
- Распределяет полосу пропускания между ВМ
- Выполняет обнаружение и удаление физических путей
- Собирает статистику ввода-вывода
NMP в свою очередь также является расширяемым модулем, управляющим двумя наборами плагинов: Storage Array Type Plug-Ins (SATPs), and Path Selection Plug-Ins (PSPs). SATPs и PSPs могут быть встроенными плагинами VMware или разработками сторонних производителей. При необходимости разработчик СХД может создать собственный MPP для использования в дополнение или вместо NMP.
SATP отвечает за восстановление пути посте сбоя (failover): мониторинг состояния физических путей, информирование об изменении их состояния, переключение со сбойного пути на рабочий. NMP предоставляет SATPs для всех возможных моделей массивов, поддерживаемых vSphere, и осуществляет выбор подходящего SATP.
PSP отвечает за выбор физического пути передачи данных. NMP предлагает 3 встроенных варианта PSP: Most Recently Used, Fixed, Round Robin. Основываясь на выбранном для массива SATP, модуль NMP делает выбор варианта PSP по умолчанию. При этом vSphere Web Client дает возможность выбрать вариант PSP вручную.
Принцип работы вариантов PSP:
-
Most Recently Used (MRU) – хост выбирает путь который использовался последним (недавно). Если этот путь становится недоступен, то хост переходит на альтернативный путь. Возврат к первоначальному пути после его восстановления не происходит. Возможность задания предпочитаемого пути отсутствует. MRU – вариант по умолчанию для большинства active-passive массивов.
Today we'll get more details about another VMware technology called Storage DRS (SDRS). Storage DRS allows you to manage the aggregated resources of a datastore cluster, which means that you can balance a space and I/O load between different datastores within a datastore cluster. Also, SDRS manages the initial placement of virtual disks based on space and I/O workload. Today's post is entitled – What is VMware Storage DRS (SDRS)?
What is an initial placement you might ask? The initial placement is a process when you select a datastore within datastore cluster where you want to place a virtual machine disk and the system will propose you the best possible place. SDRS and initial placement are happening when for example you create a new virtual machine (VM) or clone VM. This also happens when a virtual machine disk (VMDK) is migrated to another datastore cluster, or when you add a disk to an existing VM.
SDRS enables or disables all of these components (I/O, initial placement, and space load balancing) at once. If necessary, you can disable I/O-related functions of Storage DRS independently of space balancing functions.
There is a manual mode which shows only recommendations, and there is automation mode which does move VMDKs around. SDRS recommend the placements of VM(s), their VMDKs, from which datastore (source) to which datastore (destination) and also it shows you what is the reason for the recommendation. It can be that the source datastore is running out of space or anti-affinity rules are violated or the datastore is entering maintenance mode.
Subscribe to 4sysops newsletter!
VMware continues to improve vSphere 6.7 with the latest vSphere 6.7 Update 3, which we wrote about a few weeks ago. Admins for vSAN will find out more details about their vSAN datastores and especially the storage consumption.
Last night while tearing our living room apart looking for the ROKU remote (that apparently grew legs and left our house forever) my daughter asked “why don’t you just download the ROKU remote control app to your phone?” Add that to the ever-growing list of ways I have now come to depend on my phone to do life. Directions, dining, fitness, translation, sleep diagnostics, photography, and yes, even changing the channel on my TV. It reminded me of one of my favorite quotes from the late Steve Jobs “A lot of times, people don’t know what they want until you show it to them” I often think about this quote when speaking to customers about the policy-based management framework in Virtual Volumes (VVols) and Virtual SAN (vSAN), Storage Policy-Based Management (SPBM).
With the introduction of vSAN and then later with VVols, VMware radically improved its approach to storage policy-based management. We did this to address some of the key challenges we see customers encountering with their traditional approaches to storage. In this article I am going to touch on a few of these challenges and discuss how SPBM works with our VVol partners to solve them.
VAAI — vSphere API for Array Integration / Набор API для интеграции массива
API данного типа можно разделить на 2 категории:
- Hardware Acceleration APIs. Предназначены для прозрачного переноса нагрузок по выполнению отдельных операций связанных с хранением с гипервизоров на СХД.
- Array Thin Provisioning APIs. Предназначены для мониторинга пространства на «тонких» разделах массивов для предотвращения ситуаций с нехваткой места и выполнения отзыва (неиспользуемого) пространства.
VMware SDRS enhancements in vSphere 6.7 ^
Now that we know what SDRS is about, let's talk about some of the enhancements and improvements added in vSphere 6.7.
While it's not possible to increase transfer speed between datastores where you'll hit the limit of your underlying hardware (such as network and storage system), it is certainly possible to speed up the decision-making process. VMware has put a lot of effort into this between vSphere 6.5 and 6.7.
In fact, most improvements are in this area. It takes significant time to calculate the placement recommendations for VM disks. VMware has greatly improved this latency in vSphere 6.7.
Additionally, this latency is even more "visible" when issuing multiple VM provisioning requests in parallel.
So this is why VMware made many changes in vSphere 6.7 to improve the time to generate placement recommendations for provisioning operations.
When creating several provisioning requests in parallel, and there are no storage reservations for VMDKs, the improvements in execution speed are quite substantial.
Other VMware products for automation and management, such as vRealize Automation, use blueprints to deploy a large number of VMs automatically. In this use case, users and admins will see a great improvement in provisioning times for situations when there are no reservations.
Also, VMware improved the inside DRS steps that happen before issuing recommendations. The time to issue those recommendations is now much shorter even for standalone provisioning requests without (or with) reservations.
VMware published a whitepaper where they conducted different tests for SDRS on the vSphere 6.7 platform. It came out with some great results showing, for example, a datastore enter maintenance improvement of almost 14x in vSphere 6.7 compared to vSphere 6.5.
The concurrent VM operations show an improvement of between 20x and 30x in vSphere 6.7 compared to vSphere 6.5. You can look at the detailed PDF here.
Storage Hardware Acceleration (VAAI для Hardware Acceleration)
Данный функционал обеспечивает интеграцию хостов ESXi и совместимых СХД, позволяет перенести выполнение отдельных операций по сопровождению ВМ и хранилища с гипервизора (хоста ESXi) на массив (СХД), благодаря чему увеличивается скорость выполнения данных операций, при этом снижается нагрузка на процессор и память хоста, а также на сеть хранения данных.
Storage Hardware Acceleration поддерживается для блочных (FC, iSCSI) и файловых (NAS) СХД. Для работы технологии необходимо, чтобы блочное устройство поддерживало стандарт T10 SCSI либо имело VAAI-плагин. Если блочный массив поддерживает стандарт T10 SCSI, то VAAI-плагин для поддержки Hardware Acceleration не нужен, все заработает напрямую. Файловые хранилища требуют наличия отдельного VAAI-плагина. Разработка VAAI-плагинов ложится на плечи производителя СХД.
В целом VAAI для Hardware Acceleration позволяют оптимизировать и переложить на массив следующие процессы:
- Миграция ВМ посредством Storage vMotion.
- Развертывание ВМ из шаблона.
- Клонирование ВМ или шаблонов ВМ.
- Блокировки VMFS и операции с метаданными для ВМ.
- Работа с «толстыми» дисками (блочный и файловый доступ, eager-zero диски).
- Full copy (clone blocks или copy offload). Позволяет массиву делать полную копию данных, избегая операций чтения-записи хостом. Данная операция сокращает время и сетевую нагрузку при клонировании, развертывании из шаблона или миграции (перемещении диска) ВМ.
- Block zeroing (write same). Позволяет массиву обнулять большое количество блоков, что значительно оптимизирует создание дисков типа «eager zero thick» для ВМ.
- Hardware assisted locking (atomic test and set — ATS). Позволяет избежать блокировки LUN-а с VMFS целиком (нет необходимости использовать команду SCSI reservation) благодаря поддержке выборочной блокировки отдельных блоков. Исключается потеря (снижается вероятность потери) производительности хранилища при внесении гипервизором изменений в метаданные на LUN с VMFS.
Пояснение
VMFS является кластерной ФС (файловая система) и поддерживает параллельную работу нескольких хостов ESXi (гипервизоров) с одним LUN-ом (который под неё отформатирован). На LUN-е с VMFS может размешаться множество файлов ВМ, а также метаданные. В обычном режиме, пока не вносятся изменения в метаданные, все работает параллельно, множество хостов обращается в VMFS, никто никому не мешает, нет никаких блокировок.
Если Hardware Acceleration (VAAI) не поддерживаются блочным устройством, то для внесения изменений в метаданные на VMFS каким-либо хостом приходится использовать команду SCSI reservation, LUN при этом передается в монопольное использование данному хосту, для остальных хостов на момент внесения изменений в метаданные этот LUN становится недоступен, что может вызвать ощутимую потерю производительности.
Метаданные содержат информацию о самом разделе VMFS и о файлах ВМ. Изменения метаданных происходят в случае: включения/выключения ВМ, создания фалов ВМ (создание ВМ, клонирование, миграция, добавление диска, создание снапшота), удаление файлов (удаление ВМ или дисков ВМ), смена владельца файла ВМ, увеличение раздела VMFS, изменение размера файлов ВМ (если у ВМ «тонкие» диски или используются снапшоты – это происходит постоянно).
Hardware Acceleration для VMFS не отработает и нагрузка ляжет на хост если:
- VMFS разделы источника и назначения имеют разные размеры блока
- Файл источник имеет формат RDM, файл назначения не-RDM
- Исходный файл «eager-zeroed-thick», файл назначения «тонкий»
- ВМ имеет снапшоты
- VMFS растянута на несколько массивов
- Full File Clone. Позволяет клонировать файлы ВМ на уровне устройства NAS.
- Reserve Space. Позволяет резервировать пространство для ВМ с «толстыми» дисками (по умолчанию NFS не резервирует пространство и не позволяет делать «толстые» диски).
- Native Snapshot Support. Поддержка создания снапшотов ВМ на уровне массива.
- Extended Statistics. Даёт возможность увидеть использование пространства на массиве.
SDRS is SPBM Aware
In the past when you had different tiers of datastores as part of the same datastore Cluster then SDRS could potentially move a VM which was assigned policy “gold” to a datastore which was associated with a “silver” policy. Now, with vSphere 6 and forward, SDRS is aware of storage policies in SPBM and will only move VMs to a datastore that can satisfy the requirements of the VM’s storage policy.
What are VMware Storage DRS Requirements?
- The use similar or interchangeable datastores for a datastore cluster is allowed.
- There can be a mix of datastores with different sizes and I/O capacities and can be from different arrays and vendors.
- You cannot use NFS and VMFS within the same datastore cluster.
- There cannot be used – Replicated datastores with non-replicated datastores in the same Storage-DRS-enabled datastore cluster.
- Datastores which are shared across multiple datacenters are not allowed.
- All hosts must be at least ESXi 5.0
- Best practice – do not include datastores with hardware acceleration enabled with datastores without hardware acceleration enabled.
VMware SDRS is invoked every 8 hours by default, or when one or more datastores exceeds the space utilization or I/O latency during an extended period of time. When Storage DRS is invoked, it checks each datastore's space utilization and I/O latency values against the threshold. Any of those two thresholds can invoke the SDRS action.
Automate all the things
When speaking with customers or other IT professionals the general consensus seems to be whenever possible, “automate all the the things”. Automation is at the heart of just about any cloud implementation. It can provide fast provisioning, resource monitoring and self-healing, capacity adjustment, and even automated billing. Also, automation can ensure consistency, prevent errors and free-up valuable staff time to work in more innovative projects. However, depending on who you ask automation can mean very different things. Andy Troup wrote an interesting article on automation where he identifies and defines three types of automation.

This image shows the frequency with which each of these types of automation should be used. As you can see, we should be aiming for as much policy implementation as possible with as little scripting as we can achieve. In short, whenever possible implement a policy. If you can’t implement a policy, consider orchestration and use scripting as a last resort. Fortunately, VMware customers have the benefit of automated policy-based provisioning and management using Storage Policy-Based Management (SPBM). Read the following article for a comprehensive overview on SPBM
Wrap Up:
What have we learned today? A group of datastores with shared resources and a shared management interface forms a datastore cluster. Datastore clusters are similar to what are clusters to hosts. When you create a datastore cluster within your environment, you can use vSphere Storage DRS to manage storage resources.
Before we share some information about Storage DRS (distributed resource scheduler), I think it is a good idea to discuss what Storage DRS (SDRS) is. SDRS is a vCenter Server feature that allows intelligent and efficient management of Virtual Machine File System (VMFS) and Network File System (NFS) storage.
Vladan Seget is an independent consultant, professional blogger, vExpert 2009-2021, VCAP-DCA/DCD and MCSA. He has been working for over 20 years as a system engineer.
- How to use VMware vSAN ReadyNode Configurator - Fri, Dec 17 2021
- VMware Tanzu Kubernetes Toolkit version 1.3 new features - Fri, Dec 10 2021
- Disaster recovery strategies for vCenter Server appliance VM - Fri, Nov 26 2021
The same way that DRS optimizes the performance and resources of your vSphere cluster, SDRS does this with storage.
Traditional DRS watches the resource consumption in your cluster and provides you with solutions to balance your workloads (your VMs) automatically. In case one of your hosts is getting overprovisioned, DRS takes care of the situation and redistributes the load.
You can either configure SDRS to execute the changes automatically with the Fully Automated mode (vMotion of VMs), or you can have just the messages telling you which VM vMotion will move and where. In this case, choose No Automation (Manual Mode).
SDRS works with datastores. It allows you to pull together different datastores in your datacenter and create a datastore cluster (SDRS cluster) of resources.
While it supports both NFS and VMFS, you can't add NFS storage to your VMFS-based SDRS cluster.
SDRS works with two storage metrics:
SDRS uses a storage I/O control to retrieve the I/O metrics required to create load-balancing recommendations.
VAAI — vSphere API for Array Integration / Набор API для интеграции массива
API данного типа можно разделить на 2 категории:
- Hardware Acceleration APIs. Предназначены для прозрачного переноса нагрузок по выполнению отдельных операций связанных с хранением с гипервизоров на СХД.
- Array Thin Provisioning APIs. Предназначены для мониторинга пространства на «тонких» разделах массивов для предотвращения ситуаций с нехваткой места и выполнения отзыва (неиспользуемого) пространства.
VMware SDRS main features ^
Let's look at the five different core storage features of VMware SDRS. These five core features are the main operations SDRS performs:
- Resource aggregation: Allows you to group multiple datastores into a single pool of storage, which then becomes a datastore cluster
- Initial placement: Ensures disk placement when initiating certain VM operations (create VM, add disk, clone, or relocate)
- Load balancing based on space and I/O: As stated, SRDS uses I/O as a metric. It dynamically balances the SDRS cluster imbalance. I/O and space are the two metrics it uses, and they have certain (modifiable) default thresholds. The default space threshold per datastore is 80%, whereas the default I/O latency threshold is 15 ms.
- Datastore maintenance mode: This helps you when performing hardware maintenance. SDRS will do a storage vMotion for all the VM files (all VMDKs stored in the datastore).
- Inter-/intra-VM affinity rules: It is possible to create affinity or anti-affinity rules between VMs or VMDKs and keep disks together (separate) on datastores.
Let's look at an overview of the SDRS configuration at the cluster level. From the vSphere Client, select Storage > Your datastore cluster > Edit Settings.

VMware SDRS settings
The Runtime Settings tab will let us enter different values or simply disable the I/O metric.

VMware SDRS runtime settings
The Advanced options tab gives us a view into the affinity settings where, for example, we can modify the I/O imbalance threshold or the minimum space usage difference.
The I/O imbalance threshold is the amount of imbalance SDRS should tolerate. When you use an aggressive setting, SDRS corrects small imbalances if possible. When you use a conservative setting, SDRS produces recommendations only when the imbalance across datastores is very high.

VMware SDRS advanced options
Provisioning Scenario
We can use a common provisioning scenario involving a Windows VM that is running an intensive 700GB database backed by a hybrid array. The operating system and user data have been separated onto their own individual VMDKs as per VMware’s recommended practice.
This image displays the traditional provisioning approach with both VMDKs housed by the same datastore backed by high performance media. This approach is fully functional and we have provisioned this way for years. Could we do better though?
In our example, it is only our database that is requiring the extra performance from the array. In comparison to our database, the operating system’s workload is very minor and would operate well within our performance SLAs on spinning disk. If we could relocate our operating system to a spinning disk tier, while leaving the database on all-flash, we would be able to reclaim 100GB of SSD capacity.

Using Storage Policy-Based Management we can create policies that assign detailed storage characteristics to individual disks. In this image there is only one datastore managing all disks in the array. The Silver policy which is “HDD only” is assigned to the operating system and the Gold policy which is “SSD only” is assigned to the database. This is great incentive to examine the rest of the environment for similar opportunities for optimization.
Keep in mind there are many different storage capabilities that can be defined in VM storage policies (i.e disk type, encryption, compression deduplication, snapshots, replication, and more). For VVols, each storage vendor determines which capabilities they surface up to SPBM via their VASA Provider.
Summary
Storage Policy Based Management is the foundation of the SDS Control Plane and enables vSphere administrators to over come upfront storage provisioning challenges, such as capacity planning, differentiated service levels and managing capacity headroom. Through defining standard storage Profiles, SPBM optimizes the virtual machine provisioning process by provisioning datastores at scale and eliminating the need to provision virtual machines on a case-by-case basis. PowerCLI, VMware vRealize Suite, vSphere API, Open Stack and other applications can leverage the vSphere Storage Policy Based Management API to automate storage management operations for the Software-Defined Storage infrastructure.

В пределах данной статьи я хочу познакомить вас с VMWare vSphere и рассмотреть базовые вопросы подбора её аппаратного и программного обеспечения.
Начнем с лицензирования. Продукт vSphere лицензируется по процессорным сокетам и физическим хостам виртуализации (в зависимости от редакции).
Для малого бизнеса существуют редакции Essentials (600$) и Essentials Plus (4500$). Основное отличие между ними – живая миграция (vMotion), вещь довольно полезная. Живая миграция позволяет без остановки виртуальной машины в реальном времени перемещать её на соседний физический сервер. При этом работа виртуальной машины не прерывается, и факт миграции не замечают ни приложения внутри этой машины, ни внешние клиенты, работающие с этими приложениями. Редакция Essentials, по сути, это просто лицензия на 3 отдельных гипервизора с общим управлением, не более того. Редакция Plus позволяет создавать кластер высокой доступности (HA Cluster). Данная технология позволяет в автоматическом режиме перезапустить (холодный рестарт) на «живом» хосте виртуальные машины, которые работали на вышедшем из строя хосте кластера. Естественно, некоторый перерыв сервиса будет, машинам необходимо время на загрузку и запуск сервисов. Но 3 минуты в автоматическом режиме это лучше, чем часы простоя при ручном вмешательстве на физическом оборудовании.
С точки зрения лицензирования эти редакции позволяют собрать кластер из максимум трех хостов виртуализации, и установить сервер управления vCenter Server в урезанной версии Foundation. Эта версия vCenter может работать максимум с тремя хостами и создана именно для малого бизнеса.
Далее следуют редакции Standart (1000$), Enterprise (2500$) и Enterprise Plus (3500$). Данные редакции лицензируются на каждый сокет хостов виртуализации. Например, если у вас 6 хостов по 4 сокета, то необходимо приобрести 24 лицензии vSphere. Для создания кластера необходимо дополнительно приобрести сервер управления vCenter Standart (7000$). Так же существуют бандлы, которые чуть дешевле, чем продукты в розницу. Но после выхода Operations Manager (который не особо продается), VMWare упразднили обычные бандлы и теперь они есть только с Operations Manager, что учитывая повышенную цену, становится не особо привлекательным.
Редакция vSphere Standart по функционалу практически идентична редакции Essentials Plus, разве что не имеет ограничения на количество хостов в кластере (техническое ограничение максимум 32 хоста на кластер). Так же в редакции Standart есть искусственные ограничения по размеру виртуальных машин (8 виртуальных ядер vCPU). К сожалению, во всех младших редакциях vSphere нет балансировщика нагрузки, который может в автоматическом режиме перемещать виртуальные машины по хостам кластера, тем самым выравнивая их нагрузку (технология DRS).
Функционал DRS включен в редакции Enterprise и Enterprise Plus.
Конечно, самой интересной является редакция Enterprise Plus. Она несет полный функционал, и является самой дорогой. Тут есть балансировка места на системах хранения (Storage DRS или просто SDRS), есть новая технология хранения данных vSAN, есть распределенный виртуальный свитч vDS, есть функция SSD кэширования vFRC. Конечно, список функций не ограничен только этими, но названные функции являются основными.
Пара слов про эти функции:
SDRS позволяет в автоматическом режиме производить живую миграцию виртуальной машины между хранилищами данных. Совместно с технологией vMotion, технология Storage vMotion (на которой базируется SDRS), позволяет полностью отвязать виртуальную машину от аппаратной части. Миграция происходит в реальном времени без остановки виртуальных машин. Появляется возможность полной замены аппаратного обеспечения кластера без нарушения аптайма (замена серверов, систем хранения, сетевого оборудования). Использование контроля производительности систем хранения позволяет в автоматическом режиме перемещать виртуальные машины на системы хранения, удовлетворяющие заданному для этих машин уровню производительности.
vSAN – последняя разработка VMWare, позволяет использовать локальные диски серверов виртуализации в качестве общего хранилища данных кластера. На базе локальных дисков собирается виртуальное «внешнее» хранилище, доступное всем хостам кластера. При включении данной функции выбирается степень отказоустойчивости данного хранилища (выход из строя какого количества хостов одновременно переживет эта технология). Необходимым требованием является наличие в хостах дисков SSD помимо обычных шпиндельных дисков. Желательным является наличие скоростной сети передачи данных между хостами (10 Gbit или более). Технология призвана сократить расходы на систему хранения данных. Я пытался анализировать бонусы технологии, но пришел к выводу о неочевидности её плюсов. Дело в том, что лицензируется она отдельно. Лицензируется по количеству сокетов в хостах виртуализации и стоит порядка 1300$ без учета подписки. Добавляем сюда стоимость дисков и получаем достаточно приличную сумму, вполне сравнимую с приличной внешней системой хранения.
vDS – распределенный виртуальный свитч. Очень полезная функция, особенно для крупных инфраструктур. По умолчанию на хостах виртуализации создаются стандартные виртуальные свитчи, vSS. Они конфигурируются на каждом хосте по отдельности. Соответственно, при усложнении виртуальной сетевой инфраструктуры на поддержку стандартных свитчей начинает уходить много сил и времени. Не исключены человеческие ошибки в настройке, которые вполне могут привести к простою сервисов. И тут на помощь приходят распределенные свитчи, vDS. Эти свитчи создаются на сервере управления vCenter Server и накладывают свою конфигурацию на необходимые хосты виртуализации. Все настройки производятся в одном месте и автоматически применяются по всем физическим серверам. Плюсом данного решения является возможность использования физических серверов с абсолютно различным составом и типом сетевых карт. Для каждого физического хоста выбирается уникальная методика наложения настроек распределенного свитча.
Помимо централизованного управления данный свитч имеет ряд дополнительных функций по обеспечению балансировки сетевой нагрузки. Стоит отметить, что помимо родного распределенного свитча от VMWare, существует возможность установки альтернативного распределенного свитча от стороннего вендора. Ярким примером может служить распределенный свитч от Cisco, Nexus 1000v (700$ за каждый сокет). Данный свитч имеет классическое управление и широкий функционал, которые привычны специалистам по Cisco.
vFRC – технология кэширования дисковых данных виртуальных машин на SSD накопители физических серверов виртуализации. Как это работает? SSD диски хоста объединяются в vFRC пул хоста. Этот объем становится доступен для создания кэша чтения для виртуальных машин. В настройках виртуальной машины, работающей на данном хосте, добавляется vFRC кэш. Указывается его объем в гигабайтах (этот объем физически находится на сконфигурированном выше SSD пуле). Далее в этот объем для каждой машины кэшируются её операции чтения на основе статистики, все достаточно просто. А как же быть с миграцией на другой хост? Необходимо иметь аналогичное свободное пространство в пуле vFRC на целевом хосте, тогда вместе с миграцией виртуальной машины, мигрирует и её vFRC кэш. Даже в случае потери по какой либо причине данного кэша, виртуальная машина продолжит работу в штатном режиме. Кэш работает только на чтение.
Итак, некоторые выводы по лицензированию. Учитывая методику лицензирования, становится логичным приобретать физические сервера с самыми мощными процессорами, с максимальным количеством ядер. Тогда КПД приобретаемых лицензий vSphere будет максимальным. Какой либо привязки к оборудованию не существует, посему всегда можно с легкостью произвести апгрейд аппаратного обеспечения.
С лицензированием немного разобрались, предлагаю двинуться в сторону железа. Что необходимо получить от виртуального датацентра? Скорость работы, надежность работы, необходимый объем ресурсов. Если с объемом ресурсов все достаточно прозрачно, то как быть со скоростью и надежностью?
Пару слов про скорость работы. Очевидно, производительность обеспечит максимальное количество ядер процессора, максимальная частота, объем кэш-памяти процессора. Необходимый объем (и частота) оперативной памяти хостов, исключающий сброс в своп оперативной памяти виртуальных машин. Использование производительных систем хранения. Применение низколатентных скоростных подключений для систем хранения. Использование технологий SSD кэширования для систем хранения или дисков виртуальных машин для снижения латентности. Использование широких сетевых подключений (10 Gbit или более). Использование агрегации подключений для повышения их производительности.
Основным методом обеспечения отказоустойчивости является резервирование, как минимум N+1. Сами физические хосты HA кластера должны иметь избыточность как минимум +1, а в идеале +2. Необходимо предусмотреть выход из строя одного хоста в то время, когда другой хост может находиться в режиме обслуживания. Дисковая система должна обеспечивать работоспособность при выходе из строя одного, в идеале двух дисков. Сетевое оборудование должно обеспечивать работу при выходе из строя любого звена. Стекирование свитчей, агрегация подключений к хостам и т.д. При определенных ситуациях необходимо создавать холодные или горячие резервные площадки, возможно даже метрокластеры.
В заключение хотелось бы сказать пару слов о дополнительных возможностях vSphere. Данная платформа виртуализации является достаточно дружелюбной для сторонних решений, имеет открытые API для различных платформ. Сторонние разработчики создали массу полезных продуктов, дополняющих основной функционал vSphere. Например, существует возможность централизованной антивирусной защиты виртуальных машин при помощи vShield. Данная технология встроена в гипервизор ESXi, имеет прямой доступ к содержимому диска виртуальных машин и является «проводником» для антивирусных модулей разработчиков антивирусного программного обеспечения. Антивирусные модули могут быть приобретены отдельно у предпочтительного вендора и интегрированы в vSphere. Установка каких либо антивирусных агентов в виртуальные машины не требуется, причем проверка на вирусы будет производиться даже при выключенной виртуальной машине (работа ведется с её диском со стороны гипервизора). Так же доступны продукты повышения безопасности виртуальной инфраструктуры vGate, а так же многие другие интересные дополнения.
На этом предлагаю закончить знакомство с VMWare vSphere. В следующей статье я расскажу глубоко технические рекомендации по оптимизации работы виртуальных машин в среде vSphere.
Operational Scenario
VM Storage Policies can easily be changed and/or reassigned if application requirements change. These changes are performed with no downtime and without the need to migrate (Storage vMotion) virtual machines from one LUN or volume to another. This approach makes it possible to assign and modify service levels based on specific application needs even though the virtual machines reside on the same datastore.
Читайте также: