
Что такое отладка на компьютере
Отладчик Visual Studio — очень эффективное средство. Прежде чем приступать к его использованию, следует ознакомиться с базовыми терминами, такими как отладчик, отладка и режим отладки. Когда позднее мы будем вести речь о поиске и устранении ошибок, мы будем иметь в виду то же самое.
Когда следует использовать отладчик
Отладчик — важнейший инструмент для поиска и устранения ошибок в приложениях. Однако большое значение имеет контекст. Важно использовать все средства, имеющиеся в вашем распоряжении, чтобы быстро устранять ошибки. Зачастую лучшим "средством" являются правильные методики написания кода. Зная, когда лучше использовать отладчик, а когда — другие средства, вы также сможете более эффективно использовать отладчик.
Отладчик и отладка
Термин отладка может иметь разные значения, но в первую очередь он означает устранение ошибок в коде. Делается это по-разному. Например, отладка может выполняться путем проверки кода на наличие опечаток или с помощью анализатора кода. Код можно отлаживать с помощью профилировщика производительности. Кроме того, отладка может производиться посредством отладчика.
Отладчик — это узкоспециализированное средство разработки, которое присоединяется к работающему приложению и позволяет проверять код. В документации по отладке для Visual Studio именно это обычно подразумевается под отладкой.
Правила отладки
- Повтори ошибку.
- Если ты не исправил ошибку, то она не исправлена.
- Пойми систему.
- Проверь штепсель.
- Разделяй и властвуй.
- Освежись.
- Это твой баг.
- Пять почему.
Повтори ошибку. Очень простое правило, поскольку, если ты не можешь повторить ошибку, то, возможно, и фиксить нечего. Но бывают разные случаи, особенно это касается багов в многопоточной среде. У нас как-то была ошибка, которая появлялась только на процессорах Itanium и только на продакшн-серверах. Поэтому первая задача в процессе отладки — найти такую конфигурации тестового стенда, на которой бы ошибка воспроизводилась.
Если ты не исправил ошибку, то она не исправлена. Иногда бывает такое: в баг-трекере лежит баг, который появлялся пол года назад, уже его давно никто не видел, и есть желание его просто закрыть. Но в этот момент мы упускаем шанс на знание, шанс на то, чтобы понять как работает наша система и что с ней действительно происходит. Поэтому любой баг — это новая возможность что-то выучить, узнать больше о своей системе.
Пойми систему. Брайан Керниган сказал как-то, что если мы были такие умные, чтобы написать эту систему, то нам нужно быть вдвойне умными, чтобы её дебажить.
Небольшой пример к правилу. Наш мониторинг рисует графики:
Это график количества запросов, обработанных нашим сервисом. Однажды посмотрев на него мы пришли к идеи о том, что можно было бы увеличить скорость работы сервиса. В этом случае график поднимется, возможно, удастся уменьшить количество серверов.
Оптимизация web-performance делается просто: берем PerfView, запускаем его на продакшн-машине, он снимает trace в течении 3-4 минут, мы этот trace забираем на локальную машину и начинаем его изучать.
Одна из статистик, которую показывает PerfView — garbage collector.
Посмотрев на эту статистику мы увидели, что 85% времени сервис тратит на сборку мусора. Можно в PerfView увидеть где конкретно тратится это время.
В нашем случае — это создание строк. Исправление напрашивается само самой: заменяем все string'и на StringBuilder'ы. Локально получаем прирост производительности на 20-30%. Деплоим на продакшн, смотрим результаты в сравнении со старым графиком:
Проверь штепсель. Если открыть документацию любого домашнего прибора, то там обязательно будет написано: если прибор не работает, проверь, что вилка вставлена в розетку. После нескольких часов в отладчике часто ловлю себя на мысли, что надо было просто перекомпилировать, либо просто забрать последнюю версию.
Правило «проверь штепсель» — это про факты и данные. Отладка не начинается с запуска WinDbg или PerfView на продакшн-машинах, она начинается с проверок фактов и данных. Если сервис не отвечает, возможно он просто не запущен.
Разделяй и властвуй. Это первое и, наверно, единственное правило, которое включает в себя отладку как процесс. Оно про гипотезы, их выдвижение и проверку.
Один из наших сервисов не хотел останавливаться.
Делаем гипотезу: возможно, в проекте есть цикл, который бесконечно что-то обрабатывает.
Проверить гипотезу можно по-разному, один из вариантов — это взять дамп памяти. Из дампа вытаскиваем call-stack'и всех потоков с помощью команды ~*e!ClrStack . Начинаем смотреть и видим три потока.
Первый поток находится в Main'е, второй — в обработчике OnStop() , а третий поток ждал какие-то внутренние задачи. Таким образом, наша гипотеза не оправдывается. Здесь нет зацикливания, все потоки чего-то ждут. Скорее всего, deadlock.
Наш сервис работает следующим образом. Есть две задачи — инициализационная и рабочая. Инициализационная открывает connection к базе данных, рабочая начинает обработку данных. Связь между ними происходит через общий флаг, который реализован с помощью TaskCompletionSource .
Делаем вторую гипотезу: возможно, у нас deadlock одной задачи на вторую. Чтобы это проверить, можно через WinDbg посмотреть каждую задачу по-отдельности.
Оказывается, одна из задач упала, а вторая — нет. В проекте мы увидели такой код:
Он означает, что инициализационная задача открывает connection и после этого выставляет TaskCompletionSource в true. А что, если здесь упадет Exception? Тогда мы не успеваем выставить SetResult в true, поэтому fix к этому багу был такой:
В этом примере мы выдвигали две гипотезы: о бесконечном цикле и о deadlock'e. Правило «разделяй и властвуй» помогает локализовать ошибку. Последовательными приближениями и решаются такие проблемы.
Самое важное в этом правиле — это гипотезы, поскольку со временем они превращаются в паттерны. И в зависимости от гипотезы мы применяем разные действия.
Освежись. Это правило о том, что надо просто встать из-за стола и пройтись, выпить воды, сока или кофе, сделать что угодно, но самое главное — отвлечься от своей проблемы.
Есть очень хороший метод под названием «уточка». Согласно методу мы должны рассказать о своей проблеме уточке. В качестве уточки можно использовать коллегу. Причем, ему не обязательно отвечать, достаточно слушать и соглашаться. И зачастую, после первых проговоров проблемы, ты сам находишь решение.
Это твой баг. Об этом правиле расскажу на примере.
Была проблема в одном AccessViolationException . Посмотрев в call-stack я увидел, что он возникал, когда мы генерировали LinqToSql-запрос внутри sql-клиента.
Для меня это вылилось в 11 месяцев работы с поддержкой Microsoft, конечно, не ежедневно, но от начала до fix'а прошло именно 11 месяцев. Кроме этого, мы отправили им десятки гигабайт дампов памяти, мы ставили сотни private-сборок, чтобы поймать эту ошибку. И все это время мы не могли сказать нашим клиентам, что виновата Microsoft, а не мы. Поэтому баг всегда ваш.
Пять почему. Мы у себя в компании используем Elastic. Elastic хорош для агрегации логов.
Ты приходишь с утра на работу, а Elastic лежит.
Первый вопрос — почему лежит Elastic? Практически сразу стало понятно — упали Master Nodes. Они координируют работу всего кластера и, когда они падают, то весь кластер перестает отвечать. Почему они не поднялись? Наверно, должен стоять автостарт? Поискав ответ, нашли — не соответствует версия плагина. Почему же Master Nodes вообще упали? Их убил OOM Killer. Это такая штука на linux-машинах, которая в случае нехватки памяти закрывает ненужные процессы. Почему же стало мало памяти? Потому что запустился процесс обновления, что следует из системных логов. Почему же раньше это работало, а сейчас нет? А потому что мы неделей раньше добавили новые узлы, соответственно Master Nodes понадобилось больше памяти для хранения индексов, конфигурации кластера.
Вопросы «почему?» помогают найти корень проблемы. В примере мы много раз могли свернуть с правильного пути, но полный fix выглядит так: обновляем плагин, запускаем сервисы, наращиваем память и делаем пометку на будущее, что в следующий раз, при добавлении новых узлов в кластер, нужно убедиться в достаточности памяти на Master Nodes.
Применение этих правил позволяет вскрыть реальные проблемы, сдвигает ваш фокус на решение этих проблем и помогает общаться. Но было бы еще лучше, если бы эти правила образовывали систему. И такая система есть, она называется — алгоритм отладки.
Как его включить?
Чтобы приступить к поиску и устранению неисправностей, необходимо перейти в режим Debugging. Для этого понадобится открыть меню с разными вариантами загрузки по следующему алгоритму:

- Перейдите в раздел «Обновление и безопасность», а затем – «Восстановление».
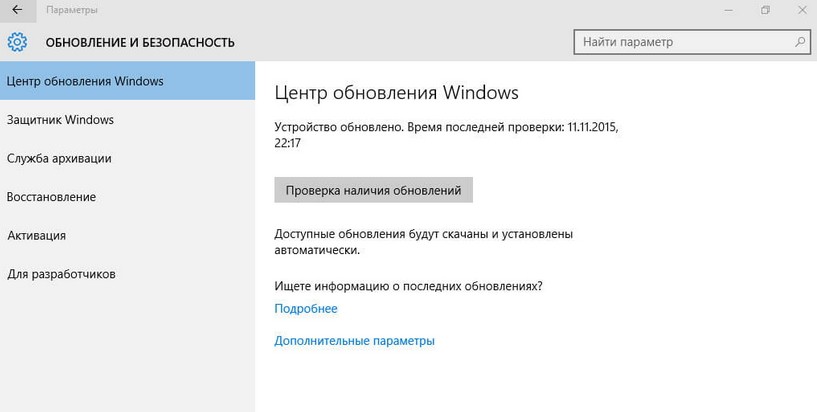
- Под заголовком «Особые варианты загрузки» нажмите на кнопку «Перезагрузить сейчас».

На заметку. Также вы можете открыть дополнительное меню, зажав клавишу «Shift» при выборе варианта «Перезагрузка» в «Пуске».
В случае правильного выполнения указанных действий компьютер перезагрузится, а при следующем включении вы увидите синий экран с выбором действий. Можно нажать на кнопку «Продолжить», чтобы запустить ПК в стандартном режиме, но нас интересует Debugging, поэтому действуйте иначе:
- Перейдите в раздел «Поиск и устранение неисправностей».

- Выберите «Дополнительные параметры», а затем – «Параметры загрузки».

- Найдите в списке пункт, отвечающий за отладку, и нажмите на клавишу, которая отвечает за ее активацию (как правило, это клавиша «F1»).

После этого устройство включится вместе с отладочным окном, которое поможет выполнить различные манипуляции для диагностики и решения проблем. Также в рассматриваемом режиме любые ошибки сохраняются в виде отдельных файлов «логов», аналогичным образом помогающих установить причины неполадок и своевременно устранить их.
Проактивная отладка
По своей сути проактивная отладка отвечает на вопрос «что произойдет, когда появится баг».
Важность техники проактивной отладки можно увидеть на диаграмме цикла жизни бага.
Проблема в том, что чем дольше баг живет, тем больше мы ресурсов (времени) на него тратим.
Правила отладки и алгоритм отладки фокусируют нас на моменте, когда баг найден и мы можем придумать что дальше с ним делать. На самом же деле мы хотим сместить свой фокус на момент создания бага. Я считаю, что мы должны делать Minimum Debuggable Product (MDP), то есть такой продукт, который имеет минимально необходимый набор инфраструктуры для эффективной отладки в продакшене.
MDP состоит из двух вещей: фитнес-функции и USE метода.
Фитнес-функции. Были популяризированы Нил Фордом и соавторами в книге «Building Evolutionary Architectures ». По своей сути фитнес-функции, по мнению авторов книги, выглядят так: есть архитектура приложения, которую мы можем разрезать под разными углами, получая такие свойства архитектуры, как maintainability, performance и прочее, и на каждый такой разрез мы должны писать тест — фитнес-функцию. Таким образом, фитнес-функция — это тест на архитектуру.
В случае MDP, фитнес-функция — это проверка debuggability. Для написания таких тестов можно использовать все что угодно: NUnit, MSTest и тд. Но, поскольку, отладка — это, зачастую, работа с внешними tool'ами, я покажу на примере использование Pester'а (powershell unit testing framework). Его плюс здесь в том, что он хорошо работает с командной строкой.
Например, внутри компании мы договариваемся, что будем использовать конкретные библиотеки для логирования; при логировании мы будем использовать конкретные паттерны; pdb-символы должны быть отданы всегда на symbol server. Это и будет являться теми условностями, которые мы будем проверять в наших тестах.
Этот тест проверяет, что все pdb-символы были отданы на symbol server и были отданы правильно, то есть те, которые содержат номера строк внутри. Для этого берем скомпилированную версию продакшена, находим все exe- и dll-файлы, пропускаем все эти бинарники через утилиту syschk.exe, которая входит в пакет «Debugging tools for windows». Утилита syschk.exe сверяет бинарник с symbol server'ом и, если находит там pdb-файл, печатает отчет об этом. В отчете мы ищем строку «Line numbers: TRUE». И в финале проверяем, чтобы результат был не «null or empty».
Такие тесты необходимо встраивать в continuous deployment pipeline. После того, как прошли интеграционные тесты и unit-тесты, запускаются фитнес-функции.
Покажу ещё один пример с проверкой нужных библиотек в коде.
В тесте мы берем все файлы packages.config и пытаемся найти в них библиотеки nlog. Аналогично мы можем проверить, что внутри поля nlog используется поле correlation id.
USE методы. Последнее, из чего состоит MDP — это метрики, которые нужно собирать.
Продемонстрирую на примере метода USE, который был популяризирован Бренданом Греггом. Идея простая: если в коде есть какая-то проблема, достаточно взять три метрики: utilization (использование), saturation (насыщение), errors (ошибки), которые помогут осознать где проблема.
Некоторые компании, например Circonus (они делают monitoring soft), свои дашборды выстраивают в виде обозначенных метрик.
Если посмотреть детально, например, на память, то использование — это количество свободной памяти, насыщение — это количество обращений к диску, ошибки — это любые ошибки, которые появлялись. Поэтому чтобы делать удобные для отладки продукты, нужно собирать USE-метрики для всех фич и всех частей подсистемы.
Если взять какую-нибудь бизнес-фичу, то, скорее всего, в ней можно выделить три метрики:
- Использование — время обработки запроса.
- Насыщение — длина очереди.
- Ошибки — любые исключительные ситуации.
Первая гипотеза, которую мы сделали, — сервис упал и надо его запустить заново. При проверке оказывается, что сервис работает, использует 4-5% CPU.

Вторая гипотеза — внутри сервиса падает ошибка, которую мы не видим. Воспользуемся утилитой etrace.
Утилита позволяет в realtime подписываться к ETW-events и выводить их на экран.
Видим, что падает OutOfMemoryException . Но, второй вопрос, почему его нет в логах? Ответ находится быстро — мы его перехватываем, пытаемся подчистить память, немного подождать и начать работать заново.
Следующая гипотеза — кто-то съедает всю память. Согласно дампу памяти, больше всего объектов находится в кэше.
Из кода видно, что каждый час кэш должен очищаться. Но памяти уже не хватало, до очистки даже не доходили. Посмотрим на пример метрики USE для кеша.
Установка средств отладки для Windows
средства отладки для Windows можно получить в составе пакета средств разработки или в виде отдельного набора средств.
В составе WDK
средства отладки для Windows входят в состав набора драйверов Windows (WDK). сведения о получении wdk см. в статье загрузка комплекта драйверов Windows (wdk).
в составе Windows SDK
средства отладки для Windows входят в состав пакета средств разработки Windows (SDK). сведения о загрузке установщика или ISO-образа см. в разделе Windows SDK на Windows Центр разработки.
В качестве автономного набора инструментов
средства отладки можно установить только для Windows без Windows SDK или WDK, запустив установку Windows SDK, а затем выбрав только средства отладки для Windows в списке устанавливаемых компонентов (и сняв все остальные компоненты). сведения о загрузке установщика или ISO-образа см. в разделе Windows SDK на Windows Центр разработки.
Отладка сред
если на компьютере установлен Visual Studio и WDK, то у вас есть шесть сред отладки. Описание этих сред см. в разделе Отладка сред.
все эти среды отладки предоставляют пользовательские интерфейсы для одного и того же базового модуля отладки, который реализуется в символьном подсистеме отладчика Windows (Dbgeng.dll). этот модуль отладки также называется отладчиком Windows, и шесть сред отладки вместе называются отладчиками Windows.
Следующие шаги
Начните здесь, чтобы получить общие сведения о средствах отладки для Windows. Этот набор средств включает WinDbg и другие отладчики.
Символы и файлы символов
Файлы символов хранят разнообразные данные, которые не требуются при запуске исполняемых двоичных файлов, но файлы символов очень полезны при отладке кода. дополнительные сведения о создании и использовании файлов символов см. в разделе символы для Windows отладки (WinDbg, KD, CDB, NTSD).
Утилиты отладки
Конечно, любой debugging невозможен без утилит для отладки. Моими любимыми являются:
-
, который помимо самого debugger'а, имеет богатый функционал по изучению дампов памяти. Дамп памяти — это срез состояния процесса. В нем можно найти значение полей объектов, call-stack'и, но, к сожалению, дамп памяти статичен.
— это профилировщик, написанный поверх ETW-технологии.
— утилита, написанная Марком Руссиновичем, которая позволяет чуть дальше копнуть внутрь устройства операционной системы.
Режим отладки и выполнение приложения

При первом запуске приложения в Visual Studio его можно запустить, нажав кнопку с зеленой стрелкой на панели инструментов (или клавишу F5). По умолчанию в раскрывающемся списке слева отображается элемент Отладка. Если вы не имеете опыта работы с Visual Studio, может показаться, что отладка приложения — это практически то же самое, что его запуск. На самом деле эти задачи хоть и связаны, но коренным образом различаются.

Значение Отладка соответствует конфигурации отладки. Когда вы запускаете приложение (нажимая зеленую стрелку или клавишу F5) в конфигурации отладки, оно запускается в режиме отладки. Это означает, что приложение запускается с присоединенным отладчиком. В результате вы получаете полный набор функций отладки, которые можно использовать для поиска ошибок в приложении.
Если у вас открыт проект, выберите в раскрывающемся списке Отладка элемент Выпуск.

При выборе этого параметра конфигурация отладки для проекта меняется на конфигурацию выпуска. Проекты Visual Studio имеют отдельные конфигурации выпуска и отладки для вашей программы. Производится построение отладочной версии для отладки и версии выпуска для окончательного выпуска программы. Сборка выпуска оптимизирована для обеспечения максимальной производительности, а отладочная сборка лучше подходит для отладки.
начало работы с отладкой Windows
чтобы приступить к работе с Windows отладкой, см. раздел начало работы с Windowsной отладкой.
Чтобы приступить к отладке драйверов в режиме ядра, см. раздел Отладка универсальных драйверов — пошаговая лаборатория (режим ядра echo). Это пошаговое лабораторное занятие, в котором показано, как использовать WinDbg для отладки эхо, пример драйвера, использующего Kernel-Mode Framework драйвера (КМДФ).
Следующие шаги
Отладчик Visual Studio — очень эффективное средство. Прежде чем приступать к его использованию, следует ознакомиться с базовыми терминами, такими как отладчик, отладка и режим отладки. Когда позднее мы будем вести речь о поиске и устранении ошибок, мы будем иметь в виду то же самое.
Что такое режим отладки в Windows 10
Для определения того, что собой представляет данный режим, необходимо определить значение слова «отладка» («Debugging»). В сфере компьютерной техники ею называют процесс, позволяющий найти и устранить ошибки, связанные с работой ПК.

Режим отладки позволяет решить массу проблем – от небольших сбоев Windows 10 до полного отказа от работы. Впрочем, к нему следует обращаться только опытным пользователям, которые способны найти объяснение каждому своему шагу. В остальных случаях, когда речь идет о новичке, исключать возможность применения режима тоже нельзя. Но в такой ситуации важно изучить инструкцию по активации Debugging и способах его применения на практике.
Когда следует использовать отладчик
Отладчик — важнейший инструмент для поиска и устранения ошибок в приложениях. Однако большое значение имеет контекст. Важно использовать все средства, имеющиеся в вашем распоряжении, чтобы быстро устранять ошибки. Зачастую лучшим "средством" являются правильные методики написания кода. Зная, когда лучше использовать отладчик, а когда — другие средства, вы также сможете более эффективно использовать отладчик.
Возможные проблемы
- Щелкните ПКМ по иконке «Пуск».
- Откройте Командную строку с правами Администратора.
- Введите запрос «bcdedit /set advancedoptions true».
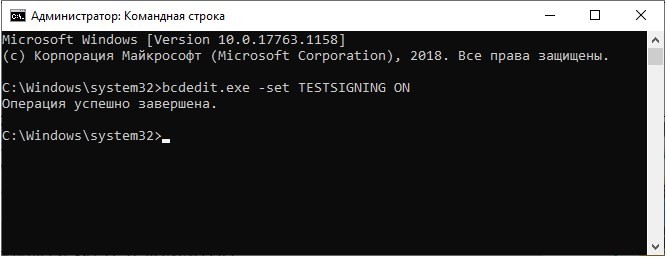
Следом произойдет перезапуск, и расширенные параметры откроются в принудительном порядке. Еще одна проблема связана с выходом из отладки. Чтобы компьютер включался в стандартной конфигурации, необходимо обработать запрос «deletevalue». Впечатать «bcdedit /deletevalue advancedoptions» в вышеупомянутой Командной строке или на появившемся синем экране выбрать опцию «Продолжить».
Существует мнение, что разработка занимает около 10% времени, а отладка — 90%. Возможно, это утверждение утрировано, но любой разработчик согласится с тем, что отладка — крайне затратный по ресурсам процесс, особенно в больших многопоточных системах.
Таким образом, оптимизация и систематизация процесса debugging'а может приносить весомые плоды в виде сэкономленных человеко-часов, повышения скорости решения проблем и, в конце концов, увеличения лояльности ваших пользователей.

Сергей Щегрикович (dotmailer) на конференции DotNext 2018 Piter предложил взглянуть на отладку как на процесс, который может быть описан и оптимизирован. Если вы до сих пор не имеете четкого плана поиска багов — под катом видео и текстовая расшифровка доклада Сергея.
(А еще в конце поста мы добавили обращение Джона Скита ко всем дотнетчикам, обязательно посмотрите)
Моя цель — ответить на вопрос: как фиксить баги эффективно и на чем должен быть фокус. Я думаю, что ответ на этот вопрос — процесс. Процесс debugging'а, который состоит из очень простых правил, и вы хорошо их знаете, но, наверно, используете неосознанно. Поэтому моя задача — это систематизировать их и на примере показать как стать более эффективными.
Мы выработаем общий язык общения во время отладки, а также увидим прямой путь к поиску основных проблем. На своих примерах я покажу что получалось из-за нарушения этих правил.
Алгоритм отладки
Впервые про алгоритм отладки я прочитал в книге Джона Роббинса «Debugging applications». Он описывает процесс отладки так:
Этот алгоритм полезен своим внутренним циклом — работой с гипотезой.
С каждым витком цикла мы можем себя проверить: знаем ли мы больше о системе или нет? Если мы выдвигаем гипотезы, проверяем, они не срабатывают, мы не узнаем ничего нового о работе системы, то, наверно, пора освежиться. Два актуальных вопроса на этот момент: какие гипотезы ты уже проверил и какую гипотезу проверяешь сейчас.
Этот алгоритм очень хорошо согласуется с правилами отладки, о которых мы говорили выше: повтори ошибку — это твой баг, опиши проблему — пойми систему, сформулируй гипотезу — разделяй и властвуй, проверь гипотезу — проверь штепсель, убедись что исправлено — пять почему.
На этот алгоритм у меня есть хороший пример. На одном из наших web-сервисов падал exception.
Первая наша мысль — это не наша проблема. Но по правилам, это все-таки проблема наша.
Во-первых, повторяем ошибку. На каждую тысячу запросов примерно один StructureMapException , поэтому воспроизвести проблему можем.
В-третьих, выдвигаем гипотезу о том, что StructureMap — это wrapper и внутри что-то есть, что кидает внутреннее исключение. Проверяем гипотезу с помощью procdump.exe.
Оказывается, что внутри лежит NullReferenceException .
Исследуя call-stack этого исключения понимаем, что оно происходит внутри object-builder'а в самом StructureMap.
Но NullReferenceException — это не сама проблема, а следствие. Нужно понять где оно возникает и кто его генерирует.
В WinDbg есть команда — List Near Objects: !lno . Она показывает, что интересный нам объект — это лямбда-функция, которая используется в следующем коде.
В этом коде мы сначала проверяем существует ли значение в Dictionary в _analyzedInterceptors , если не находим, то внутри lock добавляем новое значение.
По идее этот код никогда не сможет вернуть null. Но проблема здесь в _analyzedInterceptors , который использует обычный Dictionary в многопоточной среде, а не ConcurrentDictionary .
Корень проблемы найден, мы обновились до последней версии StructureMap'а, задеплоили, убедились, что все исправлено. Последний шаг нашего алгоритма — это «научись и расскажи». В нашем случае это был поиск в коде всех Dictionary , которые используются в lock'е и проверка, что все они используются правильно.
Итак, алгоритм отладки — это интуитивный алгоритм, который существенно экономит время. Он делает упор на гипотезу — а это самое главное в отладке.
Дополнительная документация
дополнительные сведения о средствах отладки для Windows см. в разделе отладка ресурсов. Сведения о новых возможностях отладчика см. в разделе Предварительная версия WinDbg — новыевозможности.
Компьютеры на базе Windows 10 поддерживают несколько способов запуска. Среднестатистические пользователи не придают этой опции значения, включая ПК в обычном режиме, когда доступны все основные службы. Но параллельно с этим существует режим отладки на операционной системе Windows 10, который может пригодиться опытным юзерам, желающим провести диагностику своего устройства.
Синие экраны и файлы аварийного дампа
если Windows перестанет работать и отобразится синий экран, компьютер был внезапно остановлен для защиты от потери данных и отображает код проверки ошибки. Дополнительные сведения см. в разделе Проверка ошибок (синие экраны). вы анализируете файлы аварийного дампа, созданные при Windows завершения работы с помощью WinDbg и других отладчиков Windows. дополнительные сведения см. в разделе анализ аварийного дампа с помощью Windows отладчики (WinDbg).
Режим отладки и выполнение приложения

При первом запуске приложения в Visual Studio его можно запустить, нажав кнопку с зеленой стрелкой на панели инструментов (или клавишу F5). По умолчанию в раскрывающемся списке слева отображается элемент Отладка. Если вы не имеете опыта работы с Visual Studio, может показаться, что отладка приложения — это практически то же самое, что его запуск. На самом деле эти задачи хоть и связаны, но коренным образом различаются.

Значение Отладка соответствует конфигурации отладки. Когда вы запускаете приложение (нажимая зеленую стрелку или клавишу F5) в конфигурации отладки, оно запускается в режиме отладки. Это означает, что приложение запускается с присоединенным отладчиком. В результате вы получаете полный набор функций отладки, которые можно использовать для поиска ошибок в приложении.
Если у вас открыт проект, выберите в раскрывающемся списке Отладка элемент Выпуск.

При выборе этого параметра конфигурация отладки для проекта меняется на конфигурацию выпуска. Проекты Visual Studio имеют отдельные конфигурации выпуска и отладки для вашей программы. Производится построение отладочной версии для отладки и версии выпуска для окончательного выпуска программы. Сборка выпуска оптимизирована для обеспечения максимальной производительности, а отладочная сборка лучше подходит для отладки.
Средства и служебные программы
Падающий сервис
Начнем с примера из моей жизни, в котором я покажу, как бессистемность процесса debugging'а ведет к неэффективности.
Наверно, у каждого такое бывало, когда ты приходишь в новую компанию в новую команду на новый проект, то с самого первого дня хочется нанести непоправимую пользу. Так было и у меня. В то время у нас был сервис, который на вход принимал html, а на выход выдавал картинки.
Есть проверенный инструмент что делать дальше — оборачиваем весь main в try-catch .
Идея простая: try-catch сработает, залогирует нам ошибку, мы её прочитаем и пофиксим сервис. Компилируем, деплоим в продакшн, сервис падает, ошибки нет. Добавляем ещё один catch .
Повторяем процесс: сервис падает, ошибок в логах нет. Последнее, что может помочь — это finally , который вызывается всегда.
Компилируем, деплоим, сервис падает, ошибок нет. За этим процессом проходит три дня, теперь уже приходят мысли о том, что надо наконец-то начать думать и делать что-нибудь другое. Делать можно много чего: попробовать воспроизвести ошибку на локальной машине, смотреть дампы памяти и тд. Казалось, еще дня два и я пофикшу этот баг…
Прошло две недели.
Я смотрел в PerformanceMonitor, где видел сервис, который падает, потом поднимается, потом снова падает. Это состояние называется отчаяние и выглядит вот так:
В этом разнообразии меток ты пытаешься понять, где же на самом деле проблема? После нескольких часов медитации проблема вдруг обнаруживается:
Красная линия — это количество нативных handle'ов, которыми владеет процесс. Нативный handle — это ссылка на ресурс операционной системы: файл, реестр, ключ реестра, мьютекс и тд. По какому-то непонятному стечению обстоятельств падение роста количества handle'ов совпадает с моментами падения сервиса. Это наталкивает на мысль о том, что где-то есть утечка handle'ов.
Берем дамп памяти, открываем его в WinDbg. Начинаем выполнять команды. Попробуем посмотреть очередь финализации тех объектов, которые должны быть освобождены приложением.
В самом конце списка я нашел web-браузер.
Решение простое — взять WebBrowser и вызывать для него dispose :
Выводы из этой истории можно сделать такие: две недели — это долго и слишком много, чтобы найти невызванный dispose ; то, что мы нашли решение проблемы — везение, так как не было какого-то определенного подхода, не было системности.
После этого у меня возник вопрос: а как дебажить эффективно и что для этого делать?
Для этого надо знать всего три вещи:
- Правила отладки.
- Алгоритм нахождения ошибок.
- Проактивные техники отладки.
отладчики Windows
Windows отладчики могут работать на процессорах на базе x86, x64 и ARM, а также выполнять отладку кода, который выполняется на этих архитектурах. Иногда отладчик и отлаживаемый код выполняются на одном компьютере, но в других случаях отладчик и отлаживаемый код выполняются на разных компьютерах. В любом случае компьютер, на котором работает отладчик, называется главным компьютером, а отлаживаемый компьютер называется конечным. Windows отладчики поддерживают следующие версии Windows как для узла, так и для конечных компьютеров.
- Windows 11 и Windows Server 2022
- Windows 10 и Windows Server 2016
- Windows 8.1 и Windows Server 2012 R2
- Windows 8 или Windows Server 2012
Отладчик и отладка
Термин отладка может иметь разные значения, но в первую очередь он означает устранение ошибок в коде. Делается это по-разному. Например, отладка может выполняться путем проверки кода на наличие опечаток или с помощью анализатора кода. Код можно отлаживать с помощью профилировщика производительности. Кроме того, отладка может производиться посредством отладчика.
Отладчик — это узкоспециализированное средство разработки, которое присоединяется к работающему приложению и позволяет проверять код. В документации по отладке для Visual Studio именно это обычно подразумевается под отладкой.
Читайте также: