
Что такое иерархическая модель организации данных объясните ее суть на примере каталога файловой
В большинстве современных файловых систем используется иерархическая модель организации данных: существует один каталог, объединяющий все данные в файловой системе - это "корень" всей файловой системы, корневой каталог. Корневой каталог может содержать любые объекты файловой системы, и в частности, подкаталоги. Подкаталоги также могут содержать любые объекты файловой системы и подкаталоги и т. д. Таким образом, все, что записано на диске - файлы, каталоги и специальные файлы - обязательно "принадлежит" корневому каталогу: либо непосредственно (содержится в нем), либо на некотором уровне вложенности.
Структуру файловой системы можно представить наглядно в виде дерева, "корнем" которого является корневой каталог, а в вершинах расположены все остальные каталоги. На рис. 1 изображено дерево каталогов, курсивом обозначены имена файлов, прямым начертанием - имена каталогов.
Рис. 1. Дерево каталогов в ext3fs
В любой файловой системе Linux всегда есть только один корневой каталог, который называется "/". Пользователь Linux всегда работает с единым деревом каталогов, даже если разные данные расположены на разных носителях: жестких или сетевых дисках, съемных дисках, CD-ROM и т. п. Такое представление отличается от технологии, применяемой в Windows, где для каждого устройства, на котором есть файловая система, используется свой корневой каталог, обозначенный литерой, например "a", "c", "d" и т. д. Для того чтобы отключать и подключать файловые системы на разных устройствах в состав одного общего дерева, используются процедуры монтирования и размонтирования. После того, как файловые системы на разных носителях подключены к общему дереву, содержащиеся на них данные доступны так, как если бы все они составляли единую файловую систему: пользователь может даже не знать, на каком устройстве какие файлы хранятся.
Положение любого каталога в дереве каталогов описывается при помощи полного пути. Полный путь всегда начинается от корневого каталога и состоит из перечисления всех вершин, встретившихся при движении по ветвям дерева до искомого каталога включительно. Названия соседних вершин разделяются символом "/" ("слэш"). В Linux полный путь, например, до каталога "methody" в файловой системе, приведенной на рис. 1, записывается следующим образом /home/methody.
1.2. Размещение компонентов системы: стандарт FHS
Фрагмент дерева каталогов типичной файловой системы Linux приведен на рис. 1. Утилита ls выведет список всего, что в этом каталоге содержится.
Пример 1. Стандартные каталоги в / . Использование утилиты ls
[student@localhost ~]$ ls /bin dev home lost+fount misc net proc tmp varboot etc lib sbin usr
Содержимое подкаталогов корневого каталога.
Стандарт FHS регламентирует не только перечисленные каталоги, но и их подкаталоги, а иногда даже приводит список конкретных файлов, которые должны присутствовать в определенных каталогах. Этот стандарт последовательно соблюдается во всех Linux-системах.
Командная оболочка "знает", что исполняемые файлы располагаются в каталогах /bin, /usr/bin и т. д. - именно в этих каталогах она ищет исполняемый файл cat. Благодаря этому каждая вновь установленная в системе программа немедленно оказывается доступна пользователю из командной строки. Для этого не требуется ни перезагружать систему, ни запускать какие-либо процедуры - достаточно просто поместить исполняемый файл в один из соответствующих каталогов.
Рекомендации стандарта по размещению файлов и каталогов основываются на принципе размещения файлов, которые по-разному используются в системе, в разных подкаталогах. По типу использования файлы можно разделить на следующие группы:
1.пользовательские/системные файлы
Пользовательские файлы - это все файлы, созданные пользователем и не принадлежащие ни одному из компонентов системы.
2.изменяющиеся/неизменные файлы
К неизмененным файлам относятся все статические компоненты программного обеспечения: библиотеки, исполняемые файлы и т. д. - все, что не изменяется само без вмешательства системного администратора. Изменяющиеся файлы изменяются без вмешательства человека в процессе работы системы: системные журналы, очереди печати и пр. Выделение неизменных файлов в отдельную структуру (например, /usr) позволяет использовать соответствующую часть файловой системы в режиме "только чтение", что уменьшает вероятность случайного повреждения данных и позволяет применять для хранения этой части файловой системы CD-ROM и другие носители, доступные только для чтения.
3.разделяемые/неразделяемые файлы
Это разграничение становится полезным, если речь идет о сети, в которой работает несколько компьютеров. Значительная часть информации при этом может храниться на одном из компьютеров и использоваться всеми остальными по сети (к такой информации относятся, например, многие программы и домашние каталоги пользователей). Однако часть файлов нельзя разделять между системами (например, файлы для начальной загрузки системы).
Полный путь к каталогу формально ничем не отличается от пути к файлу, т. е. по полному пути нельзя сказать наверняка, является его последний элемент файлом или каталогом. Чтобы отличать путь к каталогу, иногда используют запись с символом "/" в конце пути, например "/home/student/".
Структурная часть иерархической модели
Основными информационными единицами в иерархической модели данных являются сегмент и поле. Поле данных определяется как наименьшая неделимая единица данных, доступная пользователю. Для сегмента определяются тип сегмента и экземпляр сегмента. Экземпляр сегмента образуется из конкретных значений полей данных. Тип сегмента — это поименованная совокупность входящих в него типов полей данных.
Как и сетевая, иерархическая модель данных базируется на графовой форме построения данных, и на концептуальном уровне она является просто частным случаем сетевой модели данных. В иерархической модели данных вершине графа соответствует тип сегмента или просто сегмент, а дугам — типы связей предок — потомок. В иерархических структуpax сегмент — потомок должен иметь в точности одного предка.
Иерархическая модель представляет собой связный неориентированный граф древовидной структуры, объединяющий сегменты. Иерархическая БД состоит из упорядоченного набора деревьев.
Иерархическая база данных. Иерархическая модель данных
Стоит сказать, что иерархическая база данных является частным случаем сетевой модели данных, о которой мы говорили в предыдущей публикации. Но дело все в том, что и иерархическая модель данных, и сетевые базы данных являются мало эффективными, и постепенно от их использования отказываются. Иерархические и сетевые СУБД остались только в некоторых крупных фирмах, которые наполняли такие базы годами. И сейчас основной проблемой для таких фирм является проблема совместимости иерархических и сетевых баз данных с реляционными базами данных. Ну а сегодня мы просто поговорим про иерархическую базу данных.
Иерархическая модель данных
Иерархическая модель данных является частным случаем сетевой модели данных, структура иерархической базы данных немного проще сетевой и, соответственно, иерархические базы данных даже менее эффективны, чем сетевые. Иерархическая модель данных, как и сетевые БД опирается на теорию графов.
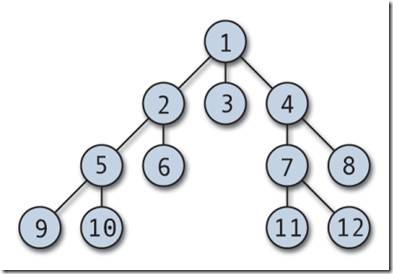
Иерархическая база данных. Иерархическая модель данных.
В основе иерархической модели данных лежит один главный элемент (главный узел), с которого все и начинается, такой элемент называет корневым элементом, в теории графов это называется корнем дерева. Вообще, по сути, что сетевая база данных, что иерархическая база данных имеет древовидную структуру. Все элементы или узлы, которые находятся ниже корневого узла иерархической модели, являются потомками корня. Стоит сказать, что и иерархическая база данных, и сетевая база данных оптимизированы на чтение информации из БД, но не на запись информации в базу данных, эта особенность обусловлена самой моделью данных.
Узлы дерева, которые находятся на одном уровне, обычно называются братьями. Узлы, которые находятся ниже какого-то определенного уровня, являются дочерними узлами по отношению к нему. Иерархическую модель данных можно сравнить с файловой системой компьютера. Компьютер умеет очень быстро работать с отдельными файлами: удалять конкретный файл, редактировать файл, копировать или перемещать файл. Но операция проверки компьютера антивирусом может происходить достаточно длительное время.
Точно такие же особенности присуще иерархической СУБД, то есть базы данных, имеющие иерархическую структуру, умеют очень быстро находить и выбирать информацию и отдавать ее пользователю. Но структура иерархической модели данных не позволяет столь же быстро перебирать информацию. Ну, это видно из рисунка, представленного выше. Допустим, что нам необходимо найти все записи, содержащие слово «сотрудник». Как будет поступать иерархическая СУБД в этом случае? А поступать она будет следующим образом: свой поиск она начнет с корневого элемента иерархической модели данных, проверив его, она начнет проверять его связи, если связей будет несколько, то она пойдет проверять в крайний левый дочерний элемент, расположенный на уровень ниже.
Затем иерархическая СУБД проверит содержимое этого элемента и его связи, если связей опять будет несколько, то она отправится опять-таки в крайний левый дочерний элемент, чтобы проверить его содержимое, проверив его содержимое она увидит, что у этого узла нет дочерних элементов и вернется в родительский узел этого узла, чтобы проверить, есть ли у него еще дочерние элементы. И так постепенно, узел за узлом, спуская и поднимаясь по иерархии узлов СУБД переберет все узлы и выдаст нам все записи, в которых есть слово «сотрудник». Ну, думаю, что с иерархической моделью данных мы более-менее разобрались (если не разобрались, то пишите в комментарии), можно приступить к рассмотрению структуры иерархической базы данных.
Иерархическая модель данных
Первые системы управления базами данных использовали иерархическую модель данных, и во времени их появление предшествует появлению сетевой модели.
Примеры
Например, если иерархическая база данных содержала информацию о покупателях и их заказах, то будет существовать объект «покупатель» (родитель) и объект «заказ» (дочерний). Объект «покупатель» будет иметь указатели от каждого заказчика к физическому расположению заказов покупателя в объект «заказ».
В этой модели запрос, направленный вниз по иерархии, прост (например: какие заказы принадлежат этому покупателю); однако запрос, направленный вверх по иерархии, более сложен (например, какой покупатель поместил этот заказ). Также, трудно представить не-иерархические данные при использовании этой модели.
Иерархической базой данных является файловая система, состоящая из корневого каталога, в котором имеется иерархия подкаталогов и файлов.
Управление иерархическими данными
У иерархической модели данных существует два средства управления данными: языковые средства описания данных (ЯОД) и языковые средства манипулирования данными (ЯМД). Физическая структура иерархической базы данных описывает: логическую структуру иерархической модели данных и саму структуру хранения базы данных.
При этом способ доступа устанавливает способ организации взаимосвязи физических записей. Определены следующие способы доступа:
- иерархически последовательный;
- иерархически индексно-последовательный;
- иерархически прямой;
- иерархически индексно-прямой;
- индексный.
Помимо того, что обязательно должно быть задано имя иерархической базы данных и способа доступа к каждому элементу иерархической модели данных, описание иерархической БД должно содержать определение типов каждого сегмента данных, входящих в базу данных, в соответствие с выстроенной иерархией. Описание типов сегмента следует начинать с корня иерархической модели. Особенностью иерархических баз данных является то, что каждая физическая база данных может содержать только один корень, но в одной иерархической системе может находиться несколько физических баз данных.
Среди операторов манипулирования данными для иерархической базы данных можно выделить операторы поиска данных, операторы поиска данных с возможностью модификации, операторы модификации данных. Набор операций манипулирования данными в иерархической модели данных не так уж обширен, но этого набора вполне достаточно для управления и поддержания иерархических баз данных. Примеры типичных операторов поиска данных:
- найти указанное дерево БД;
- перейти от одного дерева к другому;
- найти экземпляр сегмента, удовлетворяющий условию поиска;
- перейти от одного сегмента к другому внутри дерева;
- перейти от одного сегмента к другому в порядке обхода иерархии.
Примеры типичных операторов поиска данных с возможностью модификации:
- найти и удержать для дальнейшей модификации единственный экземпляр сегмента, удовлетворяющий условию поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр сегмента с теми же условиями поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр для того же родителя.
Примеры типичных операторов модификации иерархически организованных данных, которые выполняются после выполнения одного из операторов второй группы (поиска данных с возможностью модификации):
- вставить новый экземпляр сегмента в указанную позицию;
- обновить текущий экземпляр сегмента;
- удалить текущий экземпляр сегмента.
Иерархическая модель данных — представление базы данных в виде древовидной (иерархической) структуры, состоящей из объектов (данных) различных уровней.
Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка (объект более близкий к корню) к потомку (объект более низкого уровня), при этом возможна ситуация, когда объект-предок не имеет потомков или имеет их несколько, тогда как у объекта-потомка обязательно только один предок. Объекты, имеющие общего предка, называются близнецами.
Структурная часть иерархической модели
Основными информационными единицами в иерархической модели данных являются сегмент и поле. Поле данных определяется как наименьшая неделимая единица данных, доступная пользователю. Для сегмента определяются тип сегмента и экземпляр сегмента. Экземпляр сегмента образуется из конкретных значений полей данных. Тип сегмента — это поименованная совокупность входящих в него типов полей данных. Как и сетевая, иерархическая модель данных базируется на графовой форме построения данных, и на концептуальном уровне она является просто частным случаем сетевой модели данных. В иерархической модели данных вершине графа соответствует тип сегмента или просто сегмент, а дугам — типы связей предок — потомок. В иерархических структуpax сегмент — потомок должен иметь в точности одного предка. Иерархическая модель представляет собой связный неориентированный гpaф древовидной структуры, объединяющий сегменты. Иерархическая БД состоит из упорядоченного набора деревьев.
Примеры типичных операторов поиска данных
- найти указанное дерево БД;
- перейти от одного дерева к другому;
- найти экземпляр сегмента, удовлетворяющий условию поиска;
- перейти от одного сегмента к другому внутри дерева;
- перейти от одного сегмента к другому в порядке обхода иерархии.
Примеры типичных операторов поиска данных с возможностью модификации:
- найти и удержать для дальнейшей модификации единственный экземпляр сегмента, удовлетворяющий условию поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр сегмента с теми же условиями поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр для того же родителя.
Примеры типичных операторов модификации иерархически организованных данных, которые выполняются после выполнения одного из операторов второй группы (поиска данных с возможностью модификации):
- вставить новый экземпляр сегмента в указанную позицию;
- обновить текущий экземпляр сегмента;
- удалить текущий экземпляр сегмента.
В иерархической модели автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя
Иерархические базы данных могут быть представлены как дерево, состоящее из объектов различных уровней. Верхний уровень занимает один объект, второй — объекты второго уровня и т. д.
Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка (объект более близкий к корню) к потомку (объект более низкого уровня), при этом возможна ситуация, когда объект-предок не имеет потомков или имеет их несколько, тогда как у объекта-потомка обязательно только один предок. Объекты, имеющие общего предка, называются близнецами.
Иерархическая модель данных
Первые системы управления базами данных использовали иерархическую модель данных, и во времени их появление предшествует появлению сетевой модели.
Примеры типичных операторов поиска данных
- найти указанное дерево БД;
- перейти от одного дерева к другому;
- найти экземпляр сегмента, удовлетворяющий условию поиска;
- перейти от одного сегмента к другому внутри дерева;
- перейти от одного сегмента к другому в порядке обхода иерархии.
Примеры типичных операторов поиска данных с возможностью модификации:
- найти и удержать для дальнейшей модификации единственный экземпляр сегмента, удовлетворяющий условию поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр сегмента с теми же условиями поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр для того же родителя.
Примеры типичных операторов модификации иерархически организованных данных, которые выполняются после выполнения одного из операторов второй группы (поиска данных с возможностью модификации):
- вставить новый экземпляр сегмента в указанную позицию;
- обновить текущий экземпляр сегмента;
- удалить текущий экземпляр сегмента.
В иерархической модели автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя.
Примеры
Например, если иерархическая база данных содержала информацию о покупателях и их заказах, то будет существовать объект «покупатель» (родитель) и объект «заказ» (дочерний). Объект «покупатель» будет иметь указатели от каждого заказчика к физическому расположению заказов покупателя в объект «заказ».
В этой модели запрос, направленный вниз по иерархии, прост (например: какие заказы принадлежат этому покупателю); однако запрос, направленный вверх по иерархии, более сложен (например, какой покупатель поместил этот заказ). Также, трудно представить не-иерархические данные при использовании этой модели.
Иерархической базой данных является файловая система, состоящая из корневой директории, в которой имеется иерархия поддиректорий и файлов.
Управляющая часть иерархической модели
В рамках иерархической модели выделяют языковые средства описания данных (ЯОД) и средства манипулирования данными (ЯМД). Каждая физическая база описывается набором операторов, обусловливающих как её логическую структуру, так и структуру хранения БД. При этом способ доступа устанавливает способ организации взаимосвязи физических записей.
Определены следующие способы доступа:
- иерархически последовательный;
- иерархически индексно-последовательный;
- иерархически прямой;
- иерархически индексно-прямой;
- индексный.
Помимо задания имени БД и способа доступа описания должны содержать определения типов сегментов, составляющих БД, в соответствии с иерархией, начиная с корневого сегмента. Каждая физическая БД содержит только один корневой сегмент, но в системе может быть несколько физических БД.
Среди операторов манипулирования данными можно выделить операторы поиска данных, операторы поиска данных с возможностью модификации, операторы модификации данных. Набор операций манипулирования данными в иерархической БД невелик, но вполне достаточен.
Примеры типичных операторов поиска данных
- найти указанное дерево БД;
- перейти от одного дерева к другому;
- найти экземпляр сегмента, удовлетворяющий условию поиска;
- перейти от одного сегмента к другому внутри дерева;
- перейти от одного сегмента к другому в порядке обхода иерархии.
Примеры типичных операторов поиска данных с возможностью модификации:
- найти и удержать для дальнейшей модификации единственный экземпляр сегмента, удовлетворяющий условию поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр сегмента с теми же условиями поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр для того же родителя.
Примеры типичных операторов модификации иерархически организованных данных, которые выполняются после выполнения одного из операторов второй группы (поиска данных с возможностью модификации):
- вставить новый экземпляр сегмента в указанную позицию;
- обновить текущий экземпляр сегмента;
- удалить текущий экземпляр сегмента.
В иерархической модели автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя.
Примеры
Например, если иерархическая база данных содержала информацию о покупателях и их заказах, то будет существовать объект «покупатель» (родитель) и объект «заказ» (дочерний). Объект «покупатель» будет иметь указатели от каждого заказчика к физическому расположению заказов покупателя в объект «заказ».
В этой модели запрос, направленный вниз по иерархии, прост (например: какие заказы принадлежат этому покупателю); однако запрос, направленный вверх по иерархии, более сложен (например, какой покупатель поместил этот заказ). Также, трудно представить не-иерархические данные при использовании этой модели.
Иерархической базой данных является файловая система, состоящая из корневой директории, в которой имеется иерархия поддиректорий и файлов.
Преобразование концептуальной модели в иерархическую модель данных
Преобразование концептуальной модели в иерархическую структуру данных во многом схоже с преобразованием её в сетевую модель, но и имеет некоторые отличия в связи с тем, что иерархическая модель требует организации всех данных в виде дерева.
Преобразование связи типа «один ко многим» между предком и потомком осуществляется практически автоматически в том случае, если потомок имеет одного предка, и происходит это следующим образом. Каждый объект с его атрибутами, участвующий в такой связи, становится логическим сегментом. Между двумя логическими сегментами устанавливается связь типа «один ко многим». Сегмент со стороны «много» становится потомком, а сегмент со стороны «один» становится предком.
Ситуация значительно усложняется, если потомок в связи имеет не одного, а двух и более предков. Так как подобное положение является невозможным для иерархической модели, то отражаемая структура данных нуждается в преобразованиях, которые сводятся к замене одного дерева, например, двумя (если имеется два предка). В результате такого преобразования в базе данных появляется избыточность, так как единственно возможный выход из этой ситуации — дублирование данных.
Иерархическая модель базы данных состоит из объектов с указателями от родительских объектов к потомкам, соединяя вместе связанную информацию.
Иерархические базы данных могут быть представлены как дерево, состоящее из объектов различных уровней. Верхний уровень занимает один объект, второй — объекты второго уровня и т. д.
Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка (объект более близкий к корню) к потомку (объект более низкого уровня), при этом возможно, когда объект-предок не имеет потомков или имеет их несколько, тогда как у объекта-потомка обязательно только один предок. Объекты, имеющие общего предка, называются близнецами.
Известные иерархические СУБД
- Типичным представителем (наиболее известным и распространенным) является Information Management System (IMS) фирмы IBM.
- Time-Shared Date Management System (TDMS) компании Development Corporation;
- Mark IV MultiAccess Retrieval System компании Control Data Corporation;
- System 2000 разработки SAS Institute;
- Серверы каталогов, такие, как LDAP и Active Directory (допускают чёткое представление в виде дерева)
- По принципу иерархической БД построены иерархические файловые системы и Реестр Windows.
- InterSystems Caché Datastore API
Содержание
Управляющая часть иерархической модели
В рамках иерархической модели выделяют языковые средства описания данных (ЯОД) и средства манипулирования данными (ЯМД). Каждая физическая база описывается набором операторов, обусловливающих как ее логическую структуру, так и структуру хранения БД. При этом способ доступа устанавливает способ организации взаимосвязи физических записей.
Определены следующие способы доступа:
- иерархически последовательный;
- иерархически индексно-последовательный;
- иерархически прямой;
- иерархически индексно-прямой;
- индексный.
Помимо задания имени БД и способа доступа описания должны содержать определения типов сегментов, составляющих БД, в соответствии с иерархией, начиная с корневого сегмента. Каждая физическая БД содержит только один корневой сегмент, но в системе может быть несколько физических БД. Среди операторов манипулирования данными можно выделить операторы поиска данных, операторы поиска данных с возможностью модификации, операторы модификации данных. Набор операций манипулирования данными в иерархической БД невелик, но вполне достаточен.
Преобразование концептуальной модели в иерархическую модель данных
Преобразование концептуальной модели в иерархическую структуру данных во многом схоже с преобразованием ее в сетевую модель, но и имеет некоторые отличия в связи с тем, что иерархическая модель требует организации всех данных в виде дерева.
Преобразование связи типа «один ко многим» между предком и потомком осуществляется практически автоматически в том случае, если потомок имеет одного предка, и происходит это следующим образом. Каждый объект с его атрибутами, участвующий в такой связи, становится логическим сегментом. Между двумя логическими сегментами устанавливается связь типа «один ко многим». Сегмент со стороны «много» становится потомком, а сегмент со стороны «один» становится предком.
Ситуация значительно усложняется, если потомок в связи имеет не одного, а двух и более предков. Так как подобное положение является невозможным для иерархической модели, то отражаемая структура данных нуждается в преобразованиях, которые сводятся к замене одного дерева, например, двумя (если имеется два предка). В результате такого преобразования в базе данных появляется избыточность, так как единственно возможный выход из этой ситуации — дублирование данных.
Структурная часть иерархической модели
Основными информационными единицами в иерархической модели данных являются сегмент и поле. Поле данных определяется как наименьшая неделимая единица данных, доступная пользователю. Для сегмента определяются тип сегмента и экземпляр сегмента. Экземпляр сегмента образуется из конкретных значений полей данных. Тип сегмента — это поименованная совокупность входящих в него типов полей данных.
Как и сетевая, иерархическая модель данных базируется на графовой форме построения данных, и на концептуальном уровне она является просто частным случаем сетевой модели данных. В иерархической модели данных вершине графа соответствует тип сегмента или просто сегмент, а дугам — типы связей предок — потомок. В иерархических структуpax сегмент — потомок должен иметь в точности одного предка.
Иерархическая модель представляет собой связный неориентированный гpaф древовидной структуры, объединяющий сегменты. Иерархическая БД состоит из упорядоченного набора деревьев.
Управляющая часть иерархической модели
В рамках иерархической модели выделяют языковые средства описания данных (ЯОД) и средства манипулирования данными (ЯМД). Каждая физическая база описывается набором операторов, обусловливающих как ее логическую структуру, так и структуру хранения БД. При этом способ доступа устанавливает способ организации взаимосвязи физических записей.
Определены следующие способы доступа:
- иерархически последовательный;
- иерархически индексно-последовательный;
- иерархически прямой;
- иерархически индексно-прямой;
- индексный.
Помимо задания имени БД и способа доступа описания должны содержать определения типов сегментов, составляющих БД, в соответствии с иерархией, начиная с корневого сегмента. Каждая физическая БД содержит только один корневой сегмент, но в системе может быть несколько физических БД.
Среди операторов манипулирования данными можно выделить операторы поиска данных, операторы поиска данных с возможностью модификации, операторы модификации данных. Набор операций манипулирования данными в иерархической БД невелик, но вполне достаточен.
Содержание
Содержание
Преобразование концептуальной модели в иерархическую модель данных
Преобразование концептуальной модели в иерархическую модель данных происходит аналогично преобразованию в сетевую модель данных, но существую некоторые тонкости, о которых мы и поговорим. Эти тонкости связаны с тем, что структура иерархической базы данных должна быть представлена в виде дерева, то есть данные иерархической модели должны быть организованы в виде дерева.
Как вы помните: дуги, соединяющие узлы между собой, – это связи. Связи бывают один к одному и один ко многим. Преобразование связей один ко многим происходит автоматически в том случае, если потомок иерархического дерева имеет только одного предка. Происходит это следующим образом: Каждый объект с его атрибутами, участвующий в такой связи, становится логическим сегментом. Между двумя логическими сегментами устанавливается связь типа «один ко многим». Сегмент со стороны «много» становится потомком, а сегмент со стороны «один» становится предком. Согласитесь, что преобразование в иерархическую модель данных похоже на преобразование в сетевую модель.
Ситуация значительно усложняется, если потомок в связи имеет не одного, а двух и более предков. Так как подобное положение является невозможным для иерархической модели, то отражаемая структура данных нуждается в преобразованиях, которые сводятся к замене одного дерева, например, двумя (если имеется два предка). В результате такого преобразования в базе данных появляется избыточность, так как единственно возможный выход из этой ситуации — дублирование данных.
Структура иерархической базы данных
Самые первые в мире СУБД использовали иерархическую модель данных, иерархические базы данных появились даже раньше, чем сетевая модель хранения данных. Поэтому структура иерархической базы данных немного проще, чем структура сетевой БД. И так, основными информационными единицами иерархической модели данных являются сегмент и поле. Поле данных является наименьшей неделимой информационной единицей иерархической базы данных, доступной пользователю. У сегмента данных можно определить его тип и экземпляр сегмента.

Иерархическая база данных. Иерархическая модель данных.
Экземпляр сегмента образуется из конкретных значений полей данных. Тип сегмента – это именованная совокупность всех типов полей данных, входящих в данный сегмент. Если ориентироваться по рисунку выше, то тип сегмента – это родительский элемент и все его дочерние элементы. Как я уже говорил: иерархическая модель данных базируется на теории графов, но если структура сетевой БД описывается ориентированным графом (графом со стрелочками), то структура иерархической базы данных описывается неориентированным графом. Характерной особенностью структуры иерархической модели данных является то, что у любого потомка или дочернего элемента может быть только один предок или родительский элемент.
Каждый узел иерархического дерева или каждый элемент иерархической базы данных является сегментом данных. Линии, соединяющие сегменты – это связи между информационными объектами иерархической базы данных. Рисунок должен внести дополнительную ясность:
На концептуальном уровне иерархическая база данных является частным случаем сетевой модели данных.
Преобразование концептуальной модели в иерархическую модель данных
Преобразование концептуальной модели в иерархическую структуру данных во многом схоже с преобразованием ее в сетевую модель, но и имеет некоторые отличия в связи с тем, что иерархическая модель требует организации всех данных в виде дерева. Преобразование связи типа "один ко многим" между предком и потомком осуществляется практически автоматически в том случае, если потомок имеет одного предка, и происходит это следующим образом. Каждый объект с его атрибутами, участвующий в такой связи, становится логическим сегментом. Между двумя логическими сегментами устанавливается связь типа "один ко многим". Сегмент со стороны "много" становится потомком, а сегмент со стороны "один" становится предком. Ситуация значительно усложняется, если потомок в связи имеет не одного, а двух и более предков. Так как подобное положение является невозможным для иерархической модели, то отражаемая структура данных нуждается в преобразованиях, которые сводятся к замене одного дерева, например, двумя (если имеется два предка). В результате такого преобразования в базе данных появляется избыточность, так как единственно возможный выход из этой ситуации — дублирование данных.
Читайте также: