
Что такое файловая песня
Лет двадцать назад и выбора-то особо не было, в основном повсеместно встречался WAV. Толчок всему дал выход формата MP3 в 1997 году. А вскоре появился и первый конкурент – Vorbis OGG, и второй – FLAC. Теперь же форматов файлов намного больше, и у пользователей есть выбор: использовать форматы без сжатия, со сжатием без потерь или же ограничиться сжатием с потерями.
Сжатые музыкальные форматы с потерями и без
Когда при перекодировании аналоговой музыки в цифру используются кодеки, сжимающие данные, частичная потеря данных происходит в любом случае. Но в случае с так называемым сжатием без потерь, качество звучания сохраняется на довольно высоком уровне – отличия от несжатого цифрового аудио заметят только профессионалы и исключительно если будут слушать на звуковом оборудовании уровня PRO.
Сжатие с потерями позволяет сделать музыку максимально компактной, за что придется заплатить посредственным качеством звука. Впрочем, заметить все недостатки в пережатой мелодии с потерями получится только на дорогостоящей технике, в бюджетном динамике для сравнения сжатого с потерями и без не хватит частотного диапазона.
FLAC (Free Lossless Audio Codec, бесплатный аудиокодек без потерь) – самый топ среди контейнеров для аудио, сжатого без потерь. По размеру песня в FLAC будет примерно вдвое меньше, чем она же, сохраненная в WAV или AIFF, но в плане звучания заметных отличий не бывает, даже на самых крутых полупрофессиональных наушниках.
Для того, чтобы на CD поместилось больше песен и это не отразилось на качестве, нужно записывать файлы в FLAC. При разрешении до 32 бит и 192 кГц этот формат более компактный – минута звучания занимает до двух раз меньше свободного пространства на накопителе.
ALAC (Apple Lossless) и WMA Lossless (Windows Media Audio) – два идентичных формата, представленные главными конкурентами компьютерного мира Apple И Microsoft. Появились они давно, при этом особого распространения не получили. Большинство плееров, смартфонов и планшетов не смогут корректно воспроизвести ни ALAC, ни WMA Lossless без отдельно установленных кодеков или специального проигрывателя. Размер файлов с таким расширением бывает больше, чем у FLAC, что никак не влияет на качество звучания.
Формату MP3 представление не нужно – о нем, кажется знают и слышали все. Изначально он появился, как способ максимально компактно сжать звук. Помните о том, сколько альбомов при желании можно поместить на один MP3-диск для прослушивания в совместимых музыкальных центрах и автомагнитолах.
Когда память стоила дорого, а между профессиональной и бытовой акустическими системами была огромная пропасть, нещадно сжимать музыку было целесообразно. Сейчас же MP3 используют очень редко, обычно в качестве мелодий на звонки в бюджетных смартфонах и прослушивания на них же. Качество звучания, даже с высоким битрейтом, оставляет желать лучшего. Именно поэтому, за несколько лет у MP3 появилось сразу несколько «громких» конкурентов со звуком на голову выше при такой же компактности и хорошей поддержке всеми операционными системами.
AAC (Advanced Audio Coding, усовершенствованное кодирование звука) – аналог MP3, который за счет более оптимального алгоритма кодирования позволяет сохранить звучание более качественным. Именно этот тип аудио использует YouTube, многие другие стриминговые сервисы, включая платформы iTunes и Apple Music.
Ogg Vorbis – некоммерческий кодек, который не сильно-то продвигают, что зря. Контейнер OGG хранит сжатое до определенной степени аудио и сопутствующую информацию – всевозможные теги и мета-данные – в том же виде, что и MP3, а вот качество и оптимизация при потоковой передаче у Vorbis явно лучше.
Оглавление
WMA: все плохо, как всегда
Компания Microsoft разработала WMA как альтернативу MP3. Но, как и в случае с платформой Windows Phone, люди посмотрели на него, потыкали пальцем – и забросили на полку.
Потому как файл WMA изобилует мелкими неприятностями, которые сами по себе вроде бы и не так страшны (например, плохая устойчивость к ошибкам: чуть поврежденный файл про кодировании или передаче становится непригодным полностью), но в совокупности WMA становится несерьезным. К тому же, опять же декларировалось, что при меньшем битрейте WMA будет качественным. Серьезно?
Конечно, WMA сегодня поддерживает все, что поддерживает MP3. Конечно, декларируется, что поддерживается lossless-кодирование, начиная с версии 9.1. Ну поддерживается. А дальше-то что? Кто-то этим пользуется?

Плюс ко всему – в WMA можно зашивать DRM-защиту. От такого фактора потирают жадные лапки правообладатели, но говорят «фи» рядовые пользователи. Еще один гвоздь в крышку гроба WMA.
В общем, формат мутный и явно нежизнеспособный. Как и платформа Windows Phone. Как и Surface. У Microsoft хорошо получалось делать операционные системы, но вот сторонние проекты – слабовато.
Подпишитесь на наш канал в Яндекс.Дзен или telegram-канал @overclockers_news - это удобные способы следить за новыми материалами на сайте. С картинками, расширенными описаниями и без рекламы.
Хотите перекодировать аудио? Воспользуйтесь Movavi Конвертером Видео:
- Предустановленные настройки для конвертации аудио
- Поддержка популярных кодеков и форматов
- Пресеты для конкретных устройств
- Сжатие файлов под нужный размер
Есть разные форматы музыки и они отличаются между собой не только расширениями звуковых файлов: MP3, AAC, FLAC и пр. Для того, чтобы помочь вам разобраться, какой формат музыки самый качественный по звучанию, мы собрали в одной статье краткую информацию о самых популярных из них со сжатием и без сжатия. После прочтения вы сможете выбрать, какие форматы аудио оптимально использовать для хранения музыкальной библиотеки, и узнаете, что не так с популярным MP3 и выбор в пользу какого расширения позволит уместить на стандартный CD больше песен.
Начнем с того, что все аудиоформаты условно делят на три подгруппы:
- Без сжатия,
- Со сжатием без потери качества,
- Со сжатием с потерями.
Музыка высокого качества звучит действительно хорошо только на профессиональном оборудовании. Сохранить звук в аудио максимально качественным, живым и чистым можно только совершенно не используя сжатия данных: в PCM, WAV или в AIFF.
Сжатие без потерь в некоторой степени урезает качество, но оставляет его достаточно высоким для комфортного прослушивания классических концертов и рок-опер в наушниках и динамиках из высокого ценового сегмента. Форматы со сжатием без потерь – WMA Lossless, FLAC, ALAC, – достойный вариант для машины с хорошим автозвуком или для меломанов с «яблочными» девайсами.
Самые популярные форматы со сжатием с потерями – MP3 и его конкуренты – подходят, когда надо сохранить как можно больше места на накопителе. Например, именно их выбирают для бюджетных устройств для воспроизведения мультимедиа: за счет компактного размера на флешку получается записать больше музыки. Что касается звучания, на динамиках ноутбука или во «вкладышах» за 500 рублей разницу между сжатием с потерями и без точно никто не заметит, можно смело экономить память.
Как вы понимаете, при таких колоссальных отличиях выбрать самый лучший музыкальный формат никак не получится – ни один из них не универсальный.
Форматы музыки высокого качества
PCM (pulse code modulation) – импульсно кодовая модуляция аналогового звука в цифру. Проще говоря, это современный вид кодирования аналоговых сигналов в цифровой звук как есть – без сжатия. Именно такие звуковые дорожки, как правило, используют на дисках с лицензионными фильмами – на акустической системе крутого домашнего кинотеатра звучит впечатляюще реалистично. Реже, но все же в этом формате хранят концертные аудиозаписи, классическую музыку, оперы и оперетты для воспроизведения записей на достаточно мощном, обычно профессиональном оборудовании.
WAV/WAVE (Waveform audio format) – давно не новый формат, появившийся в 1991 году, один из первых разновидностей мультимедийных контейнеров для хранения несжатого аудио. Справедливости ради отметим, что сейчас WAV используют реже, иногда даже для хранения сжатых без потерь аудиодорожек. Компактным его не назовешь, как и все несжатые виды аудиоформатов, этот жадно расходует место на накопителе – минута звука будет весить не меньше 4–5 МБ. Позволять себе так опрометчиво расходовать место на накопителе имеет смысл только в том случае, когда аудио планируется слушать на профессиональных колонках или использовать, например, для сведения, мастеринга, монтажа профессиональных видеофильмов и клипов.
AIFF (Audio Interchange File Format) – еще один очень профессиональный тип контейнера, разработанный Apple. Как известно, «яблочная» компания всегда уделяла немало внимания качественному звуку, и все виды портативных плееров производителя без исключения имели поддержку этого несжатого формата, позволяя музыкантам и музыкальным гурманам насладиться практически идеальным звуком. По прожорливости к занимаемой памяти он не уступает WAV, всего минута звука в AIFF (44.1 кГц, 16 бит) – это около 10 Мб дискового пространства. Файлы с таким расширением содержат несколько кластеров: стандартный, маркерный, инструментальный, комментирующий, кластеры приложения, заголовка, авторских прав, описания, аудиозаписи, а также данные MIDI и ID3. Внутри эпловского мультимедийного контейнера может лежать чистый PCM или что-то попроще.
MP3: скорее отстреляться
Конечно, начать надо с MP3. И, перефразируя название фильма, – «и это все об MP3». Безусловно, все вы про него знаете, и быть Капитаном Очевидность здесь не вижу смысла. Все, что воспроизводит звук сегодня, поддерживает MP3, вплоть до максимума.

В чем его главные нарекания и минусы? В основном – в срезе верхних частот и «прореживании» всех остальных.
В этом и проявляется хваленая гибкость формата: можно сделать маленький файл и слушать покромсанную Верку Сердючку из динамика смартфона. А можно сделать большой файл, где сжатие с минимальными потерями и слушать… не на динамике смартфона как минимум.

У MP3 есть один, самый весомый и безусловный плюс, не считая хорошего качества звука и гибкости при кодировании – можно забить на качество и сделать тысячи MP3 128 кбит/с на одной флэшке. Или не забить на качество и сделать несколько сотен в 320 кбит/с.
Но плюс в том, что у него нет DRM и прочих видов защит от копирования, которые редиски-владельцы авторских прав могут ставить на свою музыку.

Отдельного абзаца заслуживает VBR. VBR – это сокращение от Variable BitRate, переменный битрейт. Основная идея VBR – то, что кодек автоматически выбирает нужный битрейт в зависимости от контента. Это происходит еще на этапе кодирования, и главное декларируемое преимущество технологии – меньший размер файла при вроде бы том же высоком качестве (разумеется, кодирование происходит все-таки «вокруг» заданной частоты).
В реальности же качество VBR заметно проигрывает своему оппоненту CBR (Constant BitRate – постоянный битрейт), плюс ко всему заметно нагружает процессор. Конечно, на современных многоядерных ЦП это не так что бы заметно, но – «как-то, доктор, неаккуратненько». В общем, смысл тут прост: VBR лучше не пользоваться, поскольку выигрыш в размерах минимален, microSD сегодня дешевы, HDD тоже не состояние стоят, а проблем от них больше. И, опять же, качество хромает.
Чем сегодня кодируют MP3? На заре формата было очень много разных декодеров, сегодня их тоже можно найти, если постараться, кто-то постоянно тоже изобретает велосипед, но безусловный авторитет уже долгие годы – LAME. Несмотря на стебный перевод названия (вольно – «хромуля»), кодек справляется со своей задачей блестяще.
Какой программой пользоваться для кодирования – тоже понятно, общепринятым авторитетом является грозный EAC (Exact Audio Copy, и он точно соответствует своему названию). И то, и другое распространяется совершенно бесплатно (более того – LAME в принципе встроен почти во все по умолчанию), так что можете попробовать свои силы в кодировании того, что и так уже сто раз кодировано.
реклама

Ищем лучший формат для скачивания музыки в Интернете
MP3 – истинно пиратский формат аудио. В нем можно найти не менее 90% всего оцифрованного аудио. Он не лучшим образом подходит для хранения музыкальной библиотеки «для души», потому что сильно портит качество звучания. Достаточно раз услышать, как MP3 звучит на профессиональных колонках, чтобы напрочь отпало желание с ним связываться. Зато как вариант послушать свежий альбом популярной группы перед покупкой – эдакий пиратский пробник – MP3 вполне сгодится, также он неплох для рингтонов и скачивания длинных подкастов на смартфон с небольшим запасом свободного места в памяти.
FLAC – формат пиратов ценителей качественного звука на аудио. Потому во всевозможных сообществах меломанов, предпочитающих находить и слушать музыку бесплатно, альбомы и сборники выкладывают именно в нем. Также во FLAC можно скачать концерты, аудиоспектакли, оперы, диджейские сеты и музыкальные мелодии в официальных магазинах мультимедийного контента.
AAC – сравнительно приятная для уха альтернатива MP3 с сопоставимой степенью сжатия файлов. Подойдет, если надо, чтобы и места мало было занято, и в средненьких наушниках музыка не превращалась в какофонию хрипов и скрипов. Из-за компактности выгодно сохранять из Интернета в AAC обрезки диалогов, песен, звуков для наложения на видеоряд влогов и тиктоков.

Однажды мне понадобилось решить простенькую (как мне тогда казалось) задачу – в PHP-скрипте узнать длительность mp3-файла. Я слышал о ID3 тегах и сразу подумал, что информация о длительности хранится либо в тегах, либо в заголовках mp3-файла. Поверхностные поиски в интернете показали что за пару-тройку минут решить эту задачу не получится. Поскольку от природы я довольно любопытен а время не поджимало — решил не использовать сторонние инструменты а разобраться в одном из самых популярных форматов самостоятельно.
Если Вам интересно, что там внутри – добро пожаловать под кат (трафик).
В данной статье мы не будем подробно останавливаться на извлечении ID3v2 тегов – это можно вынести в отдельную статью, так как там есть различные нюансы. А так же на фрагментах заголовков, которые практически не используются в настоящее время (например, часть Emphasis заголовка mp3-фрейма). Так же мы не рассматриваем структуру самих аудиоданных — тех самых, которые слышим из колонок.
ID3 (от англ. Identify a MP3) — формат метаданных, наиболее часто используемый в звуковых файлах в формате MP3. ID3 подпись содержит данные о названии трека, альбома, имени исполнителя и т. д., которые используются мультимедиапроигрывателями и другими программами, а также аппаратными проигрывателями, для отображения информации о файле и автоматического упорядочивания аудиоколлекции.
Существует две абсолютно разных версии ID3-данных: ID3v1 и ID3v2.
ID3v1 – имеет фиксированный размер в 128 байт, которые дописываются в конец mp3-файла. Там можно хранить: название трека, исполнитель, альбом, год, комментарий, номер трека (для версии 1.1) и жанр.
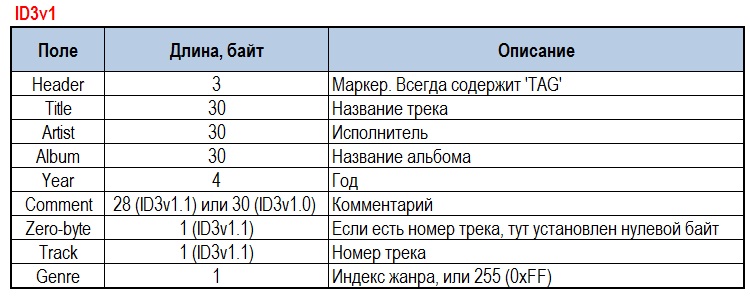
Довольно быстро всем стало понятно, что 128 байт – очень уж небольшое место для хранения таких данных. И поэтому, со временем, появилась и успешно используется вторая версия данных – ID3v2.
В отличии от первой версии, теги v2 имеют переменную длину и размещаются в начале файла, что позволяет поддерживать потоковое воспроизведение. (Формат ID3v2.4 позволяет так же хранить данные и в конце файла).
Данные ID3v2 состоят из заголовка и последующих фреймов ID3v2. Например, в версии ID3v2.3 существует более 70 типов фреймов.
- маркер всегда равен ‘ID3’
- В данный момент имеются три версии ID3v2.2, ID3v2.3 и ID3v2.4
Версия v2.2 считается устаревшей.
v2.3 – самая популярная версия.
v2.4 – набирает популярность. Одно из отличий от v2.3 в том, что позволяет использовать кодировку UTF-8 (а не только UTF-16) - Флаги. В настоящее время используются только три (5,6,7) бита:
bin: %abc00000
a ‘unsynchronisation’ – используется только с MPEG-2 и MPEG-2.5 форматами.
b ‘Extended header’ – указывает на наличие расширенного заголовка
с ‘Experimental indicator’ – эксперементальный индикатор - Длина. Особенность указания длины данных ID3v2 в том, что в каждом байте 7-й бит не используется и всегда установлен в 0.
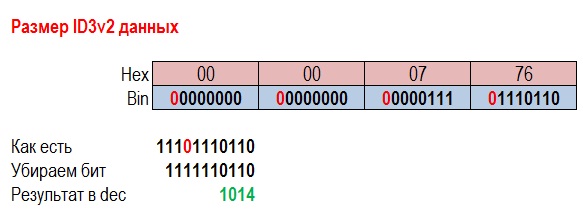
В данном случае вместе с заголовком ID3v2 (10 байт) – данные ID3v2 занимают 1024 байта.
После ID3v2-заголовка идут собственно теги. Подробный разбор чтения тегов ID3v2, как сказано выше, я решил не включать в эту статью.
Теперь у нас есть информация о наличии и длине тегов ID3 и мы можем приступать в разбору mp3-фрейма и понять-таки – где же хранится длительность. А заодно понять и всё остальное.
Весь mp3-файл состоит из фреймов, которые можно извлекать только последовательно. Фрейм содержит в себе заголовок и аудио-данные. Поскольку мы не ставим себе целью написать прошивку для магнитофона – нас интересует именно заголовок фрейма.
О нем подробнее (куча таблиц и сухой информации)
Размер заголовка – 4 байта.
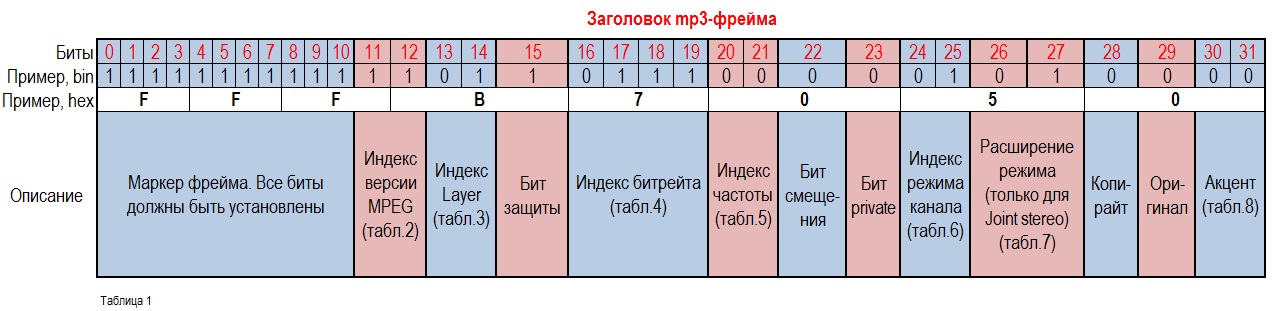
- 8 Маркер – 11 бит, заполненные единицами (Frame sync)
- 12 Индекс версии MPEG (Audio version ID)
- 13 Индекс версии Layer (Layer index)
Кстати, MP3 – это MPEG-1 Layer III - [15] Бит защиты (Protection bit)
1 – нет защиты
0 – заголовок защищен 16-бит. CRC (следует за заголовком) - 19 Индекс битрейта (Bitrate index)
В таблице хранятся значения битрейта в килобит/сек. Однако в данном формате подразумевается, что 1 килобит = 1000 бит, а не 1024. Таким образом 96 Кбит/сек = 96000 бит/сек. - 20 Индекс частоты дискретизации (Sampling rate index)
- [22] Бит смещения (Padding bit)
Если он установлен, то данные смещаются на 1 байт. Это важно для расчета размера фрейма. - [23] Бит private (только для информации)
- 24 Режим канала (Channel mode)
- 26 Расширение режима канала. (Mode extension) Используется только с Joint stereo
- [28] Копирайт (Copyright bit) – только для информации
- [29] Оригинал (Original bit) – только для информации.
- 31 Акцент (Emphasis) – в данный момент практически не используется.
Режимы сжатия данных или какой бывает битрейт
Существует 3 режима сжатия данных:
CBR (constant bitrate) – постоянный битрейт. Не меняется на всем протяжении трека.
VBR (variable bitrate) – переменный битрейт. При этом сжатии битрейт постоянно меняется на протяжении трека.
ABR (average bitrate) – усредненный битрейт. Это понятие используется только при кодировании файла. На «выходе» получается файл с VBR.
Если файл закодирован с постоянным битрейтом – то мы уже можем наконец-то! получить длительность нашего трека по следующей формуле:
Например, файл имеет размер 350670 байт. Есть ID3v1 теги (128 байт) и ID3v2 теги (1024 байта). Битрейт = 96. Следовательно размер аудиоданных равен 350670 – 128 – 1024 = 349518 байт.
Длительность = 349518 / 96000 * 8 = 29,1265 = 29 секунд
Необходимо пояснить – как определить режим сжатия. Всё просто. Если файл сжат с VBR – то добавляется VBR-заголовок. По его наличию мы и можем понять, что используется переменный битрейт.
Есть два вида заголовков: Xing и VBRI.
Xing размещается со смещением от начала первого mp3-фрейма в позиции, согласно таблице:
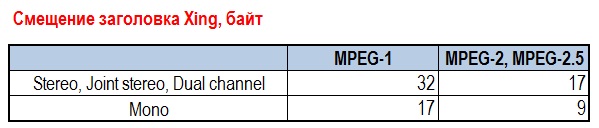
Например: у нас ID3v2 тег занимает 1024 байта. Если наш mp3-файл имеет режим канала «Стерео» — то заголовок VBR Xing будет начинаться со смещения 1024 + 32 = 1056 байт.
Заголовок VBRI всегда размещается со смещением +32 байта от начала первого mp3-фрейма.
Первые четыре байта в обоих заголовках содержат маркер ‘Xing’ или ‘Info’ для Xing. И ‘VBRI’ для VBRI.
Эти VBR заголовки имеют переменную длину и содержат различную информацию о кодировании файла. Подробнее о структуре заголовков VBR (и не только) можно почитать, например, тут.
Я же расскажу только о том, что нас интересует в данный момент. А именно – количество фреймов (Number of Frames). Это число длиной 4 байта.
В заголовке Xing оно содержится по смещению +8 байт от начала заголовка. В VBRI +14 байт от начала заголовка.
Используя таблицу Сэмплов на фрейм (Sampler Per Frame) мы можем получить длительность mp3-файла, закодированного с переменным битрейтом.
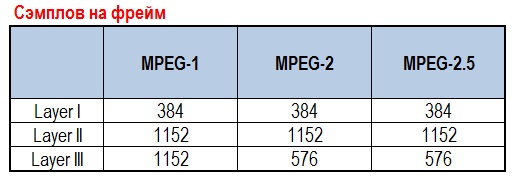
Например: из заголовка VBRI получили количество фреймов 1118, сэмплов на фрейм = 1152. Частота дискретизации = 44100.
Длительность = 1118 * 1152 / 44100 = 29.204 = 29 секунд.
На этом на сегодня всё. Если был кому-то полезен — спасибо.
Для тех, кто захочет немедленно поковырять внутренности mp3 — Тут лежат скрипт на php, которые я писал для себя одновременно с данной статьей и четыре небольших mp3-файла для теста.
Данное руководство предназначено для того, чтобы с минимальными затратами привести аудиоколлекцию к максимально упорядоченному виду. В отличие от общедоступной информации, которую можно найти в Интернет, здесь также присутствует мой личный опыт (как положительный, так и отрицательный). В итоге получаем полностью пересортированную коллекцию. Все нижесказанное можно применять для любых коллекций, однако оптимальный вариант — если коллекция по большей части состоит из полных официальных альбомов, с минимальным содержанием разрозненных треков.
Этап 1. Предварительная чистка
Сразу оговорюсь, что описания всех этапов носят по большей части рекомендательный характер, и пользоваться ими шаг за шагом нужно только в том случае, если вы хотите переделать все с нуля и упорядочить по максимуму.
Для начала нам нужно пройтись по всем файлам и папкам и бегло их почистить. Выбросить все лишнее, что вы не слушаете и вряд ли будете. Например, у меня было много переизданий (т.е. фактически дублей), бутлегов, всяких Live-раритетов, которых я даже ни разу не слушал, а просто держал для коллекции… В общем — удаляйте на ваше усмотрение, по возможности оставляйте только полные и официальные альбомы. Это не критичный, но довольно важный этап. Впоследствии благодаря этому вы сможете здорово сэкономить время.
Этап 2. Распознавание альбомов и композиций
Этот этап — самый важный. Здесь выполняется распознавание и сортировка композиций. Для этого нам нужна будет программа MusicBrainz Picard.
Чтобы не делать одну и ту же работу два раза, на этом и всех последующих этапах обязательно внимательно просматривайте настройки всех программ.
Рекомендую начать все переделывать с чистого листа. Для этого в настройках MusicBrainz включаем перенос файлов и указываем папку назначения. Также я бы рекомендовал очистить всю старую информацию в тегах.
Небольшое отступление по поводу тегов ID3. Версия 2.4 является более продвинутой, но не все программы умеют корректно с ней работать. В частности, Windows Explorer и Windows Media Player (до 12-й версии включительно) не понимают кодировку. Так что, если хотите совместимости — включайте 2.3. Если хотите более прогрессивного формата с плюшками типа UTF-8 и расширенным набором тегов — ставьте 2.4. Я во всех программах выставлял версию 2.4 (забегая наперед — foobar2000 и Google Music понимают без проблем; Winamp тоже должен).
Программа распознает два типа альбомов: обычные и сборники (компиляции). Сборники — это когда в альбоме больше одного исполнителя. У меня из сборников обнаружились различные трибьюты и сборник «The Best of Classics». Сборники скидываются в одну папку (обычно она называется Various Artists), которую можно впоследствии рассортировать.
Обратите внимание на пункт настроек «Перенос файлов», в нем настраивается переименование и сортировка по папкам. Там используется небольшой скриптовой язык (такой же, как в foobar2000), с его помощью вы сможете настроить шаблоны, как вам захочется. Установки по умолчанию довольно универсальные, но для себя я их немного подправил:
Первая строка — для альбомов, вторая — для компиляций. Обратите внимание, что здесь переменная %date% обозначает дату издания (или переиздания), а не дату выхода альбома.
Указанные шаблоны генерируют имена, подобные этим:
После того, как мы убедились, что все настройки выставлены правильно, можно скармливать всю свою коллекцию и идти пить кофе. Ну или спать, в зависимости от размера коллекции. Работает программа довольно медленно, в минуту обрабатывается порядка 20 файлов. Чем больше информации можно извлечь из тегов и названия — тем быстрее будет происходить обработка.
Для статьи я проводил тестирование в «экстрим»-режиме: взял несколько десятков треков, поудалял из них все теги, и переименовал случайным образом. Результат виден на скриншоте.
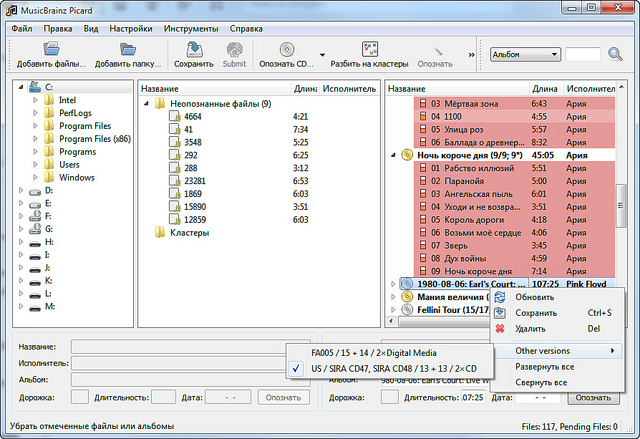
Справа отображаются опознанные треки, сгруппированные в альбомы. Но иногда нужно помогать программе распознавать треки. Файл может не опознаться, или в «кандидаты» на трек альбома может попасть несколько файлов. В этом случае придется выбирать вручную. Уровень совпадения обозначается цветом — от зеленого до красного. При проверке сравниваются некоторые теги и «fingerprint» трека.
Альбом помечается как золотой (в смысле, желтый :)), если в нем присутствуют все треки, и нет никаких множественных интерпретаций. Наша цель — добиться максимального количества золотых альбомов. Также обратите внимание, что содержимое альбома может меняться в зависимости от выпускающей студии, иногда ручное изменение редакции поможет добиться более точного соответствия. Обработанные альбомы периодически сохраняйте в папку назначения.
Этап 3a. Ручная доработка имен
Если бы мир был идеален, то кроме второго этапа нам больше ничего бы не понадобилось. Но увы, MusicBrainz может сделать довольно большую часть работы, но не всю. В его базе могут отсутствовать некоторые ваши альбомы. В этом случае у вас в исходной папке останется часть неотсортированной музыки.
Этапы ручной доработки довольно стандартные, так что воспринимайте написанное не более, чем как рекомендацию. Но я все-таки опишу их поподробнее, для целостности всего комплекса действий. Цель данного этапа — привести структуру файлов и каталогов к виду, который 1) был бы правильный, и 2) удовлетворял бы вашим требованиям.
Запускаем любимый файл-менеджер, идем в папку с оставшейся неотсортированной музыкой, и начинаем. Сначала мы должны привести структуру и названия к единому виду. Если у вас опозналась часть альбомов группы Чёрный кофе — проверьте, везде ли у вас одинаковое название группы. Если у вас в отсортированной музыке шаблон имени NN — Trackname.mp3 — переименуйте все оставшиеся файлы соответствующим образом. Для облегчения группового переименования можете воспользоваться Mp3tag. Как им пользоваться, я объяснять не буду. Мы должны добиться идеального соответствия структуры обеих папок, чтобы после их слияния нельзя было сказать, что откуда было.
После этого можно сливать две папки в одну. В принципе, на этом можно и закончить. Но многие захотят еще чуть-чуть дошлифовать файловую структуру. Например, по умолчанию сборники скидываются в папку Various Artists, но зачастую они в большей мере имеют отношение к какому-то одному исполнителю. Так что все содержимое из Various Artists можно смело раскидывать по другим каталогам. Также бывает, что альбомы слишком детализированы по исполнителям: Чиж, Чиж & Co, Чиж и Разные люди, Чиж и Паша, Чернецкий и Чиж, … Зачастую там находится всего по одному альбому. Меня это не совсем устраивало, поэтому я слил все подобные группы папок в одну.
Этап 3b. Ручная доработка тегов
- Посливал составные альбомы в один, прописав в тегах номер диска
- Конкретизировал всех исполнителей альбомов (там, где было Various Artists)
- Подкорректировал имена файлов, где служебные символы были заменены подчеркиванием
Этап 4. Определение жанра
После обработки тег Genre будет незаполненным. И хотя в MusicBrainz была опция автоматического заполнения жанров, но у меня она, почему-то, не сработала. Так что, придется искать другие средства. Впрочем, этот пункт можно пропустить, если вас не интересует информация о жанрах.
Как оказалось, с автоматическим определением жанра все туговато. А с жанрами для русских песен — еще хуже. Но я постарался выбрать лучшее из худшего, и остановился на комбайне MediaMonkey. Кстати, есть portable-вариант установки. Для поиска жанров к нему есть скрипт, называющийся Genre Finder. Насколько я понимаю, этот скрипт использует Last.fm API, поэтому нужно очень внимательно отнестись к настройкам: их немного, но от них очень сильно зависит конечный результат. Вполне вероятно, что вы захотите сделать несколько пробных проходов с различными вариантами настроек.
Первое, что хочу посоветовать — да, можете делать множественное определение жанров, но всегда ограничивайте сверху их количество. Поверьте, лучше уж пропустить какой-то жанр, чем потом вычищать хардкор типа «THE BEST EVER SONG IN MY LIFE. 11» или «Kill me I cant hear it!». Также обратите внимание на возможность установки whitelists/blacklists. Я этим пренебрег, и потом потерял время при ручной чистке. Готовые белые списки можно найти на форуме по ссылке выше.
Рекомендую сначала определить 2-3 жанра в режиме поиска альбомов. Можете после этого добавить еще пару жанров, но уже в режиме поиска по отдельным трекам. Здесь же, в MediaMonkey можно параллельно смотреть и шлифовать получившийся список жанров.
Стоит сделать небольшое уточнение касательно foobar2000: так получилось, что он не распознает множественные значения в одном теге, разделенные точкой с запятой (как их пишет MediaMonkey). С другими проигрывателями вроде таких проблем нет. Но проблема решается с помощью того же foobar'а. Выделите весь список своих песен, нажмите Alt+Enter (команда Properties), кликните по тегу Genre, и затем выберите Tools — Selection — Split values. . Данная команда разобьет значения из одного тега на «правильные» множественные теги.
Этап 5. Обложки альбомов
Ну и последний этап — cover arts. Здесь все намного лучше, чем с предыдущим пунктом. Есть много программ, умеющих искать обложки. Некоторые из них позволяют заливать миниатюры обложек напрямую в теги файла (правда, я довольно прохладно отношусь к этой «фиче»). Но, по моему скромному мнению, самые широкие возможности у Album Art Downloader.
В настройках я бы порекомендовал поднять минимальный размер обложки (хотя бы до 50 px), и включить опцию «Automatically close after saving».
Нам нужно будет сделать два прохода (установлено экспериментальным путем; никакие другие источники, включая iTunes, не дают лучшего результата). Сначала отключаем все источники (область справа), кроме Last.fm, и сканируем всю нашу музыку. После процесса поиска и анализа у нас появится окно Queue Manager, где будет список всех найденных альбомов. На этом этапе можно спокойно запустить автоматический режим (ссылка в нижней части окна Queue Manager) и ждать завершения.
Если у вас после первого прохода остались нераспознанные альбомы, меняем источник с Last.fm на Google Images, и запускаем обработку оставшихся альбомов. Здесь я бы порекомендовал быть осторожнее и проверять каждый альбом вручную. Лично мне хватило этих двух проходов; остальные источники были для меня совсем неадекватными, но вы можете попробовать — у каждого из них своя специфика.
Ну, вроде бы и все. Но есть еще маленький нюанс. Дело в том, что часть альбомов имеет обложку в формате PNG. Как оказалось, Google Music понимает только JPEG, да и вообще, этот формат как бы более распространен. Так что при желании можно все сконвертировать в JPEG.
Только мне что-то не удалось быстро найти бесплатную утилиту, которая просто бы рекурсивно нашла все PNG-файлы, и переименовала их в JPEG. Если знаете таковую — пользуйте. Можете сделать пакетную обработку в Photoshop'е. Можете призвать на помощь продвинутый файл-менеджер. Я же просто оставлю здесь PowerShell-скрипт, который как раз это и делает — выбирает рекурсивно все PNG, и конвертирует их. Оригинальные файлы при этом остаются, можете потом удалить их вручную.
Вот, собственно, и все. Такой себе коротенький мануал получился :)
В общем, да, процесс нетривиален, и при большой коллекции может быть длительным; кнопки «Сделать все как надо» здесь нет. Но, во-первых, в любом случае, правила, вкусы и предпочтения у каждого разные, соответственно, и настройки тоже у каждого будут разные. Во-вторых, на протяжении всего процесса нам помогали мощные программы, которые в значительной степени автоматизировали работу. Ну, и в-третьих, не обязательно с точностью повторять прохождение всех этапов; думаю, каждый может найти для себя оптимальный путь.
- Единую упорядоченную структуру на уровне файловой системы
- ID3-теги, полностью заполненные (вплоть до композитора) по единым правилам
- Возможность сортировки по жанрам и другим меткам
- Обложки ко всем альбомам
- Эстетическое удовольствие от осознания факта, что у вас практически идеальный порядок :)
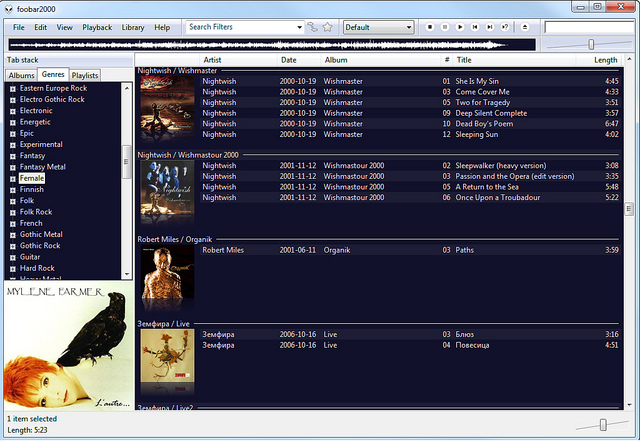
Теперь в таком виде коллекцию с радостью скушает любой медиакомбайн или Google Music.
Все указанные выше приложения бесплатны, все совпадения случайны, и конечно же, используйте данную информацию только в благих целях :)
Всем привет! Мы продолжаем запуски новых потоков по уже полюбившимся вам курсам и сейчас спешим сообщить о том, что у нас стартует новый набор по курсу «Администратор Linux», который запустится в конце апреля. К этому событию и будет приурочена новая публикация. С оригиналом материала можно ознакомиться тут.
Виртуальные файловые системы выполняют роль некой волшебной абстракции, которая позволяет философии Linux говорить, что «всё является файлом».

Что такое файловая система? Опираясь на слова одного из первых контрибьюторов и авторов Linux Робера Лава, «Файловая система – это иерархическое хранилище данных, собранное в соответствии с определенной структурой». Как бы то ни было, это определение в равной мере хорошо подходит для VFAT (Virtual File Allocation Table), Git и Cassandra (база данных NoSQL). Так что именно определяет такое понятие, как «файловая система»?
Основы файловой системы
Ядро Linux имеет определенные требования к сущности, которая может считаться файловой системой. Она должна реализовывать методы open() , read() и write() для постоянных объектов, которые имеют имена. С точки зрения объектно-ориентированного программирования, ядро определяет обобщенную файловую систему (generic filesystem) в качестве абстрактного интерфейса, а эти три большие функции считаются «виртуальными» и не имеют конкретного определения. Соответственно, реализация файловой системы по умолчанию называется виртуальной файловой системой (VFS).

Если мы можем открывать, читать и записывать в сущность, то эта сущность считается файлом, как мы видим из примера в консоли сверху.
Феномен VFS лишь подчеркивает наблюдение, характерное для Unix-подобных систем, которое гласит, что «всё является файлом». Подумайте, насколько странно, что тот маленький пример сверху с /dev/console показывает, как на самом деле работает консоль. На картинке изображена интерактивная Bash сессия. Отправка строки в консоль (virtual console device) отображает ее на виртуальном экране. VFS имеет другие, еще более странные свойства. Например, она дает возможность осуществлять поиск по ним.
Знакомые нам системы, такие как ext4, NFS и /proc имеют три важные функции в структуре данных С, которая называется file_operations. Кроме того, определенные файловые системы расширяют и переопределяют функции VFS привычным объектно-ориентированным способом. Как отмечает Роберт Лав, абстракция VFS позволяет пользователям Linux беспечно копировать файлы в или из сторонних операционных систем или абстрактных сущностей, таких как pipes, не беспокоясь об их внутреннем формате данных. Со стороны пользователя (userspace) с помощью системного вызова процесс может копировать из файла в структуры данных ядра с помощью метода read() одной файловой системы, а затем использовать метод write() другой файловой системы для вывода данных.
Определения функций, которые принадлежат к базовым типам VFS, находятся в файлах fs/*.c исходного кода ядра, в то время как подкаталоги fs/ содержат определенные файловые системы. В ядре также содержатся сущности, такие как cgroups , /dev и tmpfs , которые требуются в процессе загрузки и поэтому определяются в подкаталоге ядра init/ . Заметьте, что cgroups , /dev и tmpfs не вызывают «большую тройку» функций file_operations , а напрямую читают и пишут в память.
На приведенной ниже диаграмме показано, как userspace обращается к различным типам файловых систем, обычно монтируемых в системах Linux. Не показаны такие конструкции как pipes , dmesg и POSIX clocks , которые также реализуют структуру file_operations , доступ к которым проходит через слой VFS.

VFS — это «слой оболочки» между системными вызовами и реализациями определенных file_operations , таких как ext4 и procfs . Функции file_operations могут взаимодействовать либо с драйверами устройств, либо с устройствами доступа к памяти. tmpfs , devtmpfs и cgroups не используют file_operations , а напрямую обращаются к памяти.
Существование VFS обеспечивает возможность переиспользовать код, так как основные методы, связанные с файловыми системами, не должны быть повторно реализованы каждым типом файловой системы. Переиспользование кода – широкоприменяемая практика программных инженеров! Однако, если повторно используемый код содержит серьезные ошибки, от них страдают все реализации, которые наследуют общие методы.
/tmp: Простая подсказка
Простой способ обнаружить, что VFS присутствуют в системе – это ввести mount | grep -v sd | grep -v :/ , что покажет все смонтированные ( mounted ) файловые системы, которые не являются резидентами на диске и не NFS, что справедливо на большинстве компьютеров. Одним из перечисленных маунтов ( mounts ) VFS, несомненно, будет /tmp , верно?

Все знают, что хранение /tmp на физическом носителе – безумие! Источник.
Почему нежелательно хранить /tmp на физическом носителе? Потому что файлы в /tmp являются временными, а устройства хранения медленнее, чем память, где создается tmpfs. Более того, физические носители более подвержены износу при перезаписи, чем память. Наконец, файлы в /tmp могут содержать конфиденциальную информацию, поэтому их исчезновение при каждой перезагрузке является неотъемлемой функцией.
Помимо /tmp , VFS (виртуальные файловые системы), которые наиболее знакомы пользователям Linux – это /proc и /sys . ( /dev располагается в общей памяти и не имеет file_operations ). Почему именно эти два компонента? Давайте разберемся в этом вопросе.
procfs создает снимок мгновенного состояния ядра и процессов, которые он контролирует для userspace . В /proc ядро выводит информацию о том, какими средствами оно располагает, например, прерывания, виртуальная память и планировщик. Кроме того, /proc/sys – это место, где параметры, настраиваемые с помощью команды sysctl , доступны для userspace . Статус и статистика отдельных процессов выводится в каталогах /proc/ .

Здесь /proc/meminfo — это пустой файл, который тем не менее содержит ценную информацию.
Поведение /proc файлов показывает, какими непохожими могут быть дисковые файловые системы VFS. С одной стороны, /proc/meminfo содержат информацию, которую можно посмотреть командой free . С другой же, там пусто! Как так получается? Ситуация напоминает знаменитую статью под названием «Существует ли луна, когда на нее никто не смотрит? Реальность и квантовая теория», написанную профессором физики Корнельского университета Дэвидом Мермином в 1985 году. Дело в том, что ядро собирает статистику памяти, когда происходит запрос к /proc , и на самом деле в файлах /proc ничего нет, когда никто туда не смотрит. Как сказал Мермин, «Фундаментальная квантовая доктрина гласит, что измерение, как правило, не выявляет ранее существовавшего значения измеряемого свойства.» (А над вопросом про луну подумайте в качестве домашнего задания!)
Кажущаяся пустота procfs имеет смысл, поскольку располагающаяся там информация динамична. Немного другая ситуация с sysfs . Давайте сравним, сколько файлов размером не менее одного байта есть в /proc и в /sys .

Procfs имеет один файл, а именно экспортированную конфигурацию ядра, которая является исключением, поскольку ее нужно генерировать только один раз за загрузку. С другой стороны, в /sys лежит множество более объемных файлов, многие из которых занимают целую страницу памяти. Обычно файлы sysfs содержат ровно одно число или строку, в отличие от таблиц информации, получаемой при чтении таких файлов, как /proc/meminfo .
Цель sysfs – предоставить свойства доступные для чтения и записи того, что ядро называет «kobjects» в userspace. Единственная цель kobjects – это подсчет ссылок: когда удаляется последняя ссылка на kobject, система восстановит ресурсы, связанные с ним. Тем не менее, /sys составляет большую часть знаменитого «stable ABI для userspace» ядра, которое никто никогда, ни при каких обстоятельствах не может «сломать». Это не означает, что файлы в sysfs статичны, что противоречило бы подсчету ссылок на нестабильные объекты.
Стабильный двоичный интерфейс приложений ядра (kernel's stable ABI) ограничивает то, что может появиться в /sys , а не то, что на самом деле присутствует в данный конкретный момент. Листинг разрешений на файлы в sysfs обеспечивает понимание того, как конфигурируемые параметры устройств, модулей, файловых систем и т.д. могут быть настроены или прочитаны. Делаем логический вывод, что procfs также является частью stable ABI ядра, хотя это не указано явно в документации.

Файлы в sysfs описывают одно конкретное свойство для каждой сущности и могут быть читаемыми, перезаписываемыми или и то и другое сразу. «0» в файле говорит о том, что SSD не может быть удален.
Вторую часть перевода начнем с того, как наблюдать за VFS с помощью инструментов eBPF и bcc, а сейчас ждем ваши комментарии и традиционно приглашаем на открытый вебинар, который уже 9 апреля проведет наш преподаватель — Владимир Дроздецкий.
Сжатие с потерями и без
Для начала нужно определиться с тем, о чем мы будем говорить. Главное и основное: все форматы звуковых файлов сегодня делятся на:
- Форматы без сжатия (WAV, AIFF);
- Со сжатием без потерь – lossless в простонародье (FLAC, APE);
- Со сжатием с потерями – он же lossy (MP3, OGG).
Все, это была минутка Википедии.
И да, я раскрою вам правду на то, стоит ли тратить терабайты на lossless.
Вступление
Как всегда, начну со старческого брюзжания. Вот лет двадцать назад… Собственно говоря, двадцать лет назад и выбора-то особо не было.
реклама
Потому что были компакт-диски, которые превращались в WAV-файлы, занимавшие пространство среднего «винчестера» – ну и на ОС немножко места оставалось. И на BBS. И на игры. И на архив файлов. И все. Потому что средний размер жесткого диска тогда составлял какие-то сказочные сегодня 850 мегабайт. Да, именно что 850 – и именно мегабайт. Толчок всему дало появление формата MP3 в 1997 году, и это был очень знаменательный год!

Я очень хорошо помню те времена. Тогда мы с другом «возрадовались до плеши» и принялись активно кодировать компакт-диски в самые популярные 128 кбит/с с joint stereo (это когда фактически пишется один канал, и к нему добавляется информация об отличиях второй дорожки – если они есть). Еще бы, теперь альбом занимал смешные 50-70 мегабайт, и компьютерные пластиковые колонки казались вершиной прогресса. Различные звуковые карты за 200,500 или 800 долларов в журналах казались чем-то страшным и далеким. Зачем? Ведь есть MP3 128 кбит/с, смотрите, какое крутое качество!
Шли месяцы и годы (скорее ближе к месяцам). Менялись колонки, развивался MP3, и мы тогда, юные падаваны старшего школьного и начального студенческого возраста, экспериментировали с битрейтами и появившимся тогда первым конкурентом MP3 – таинственным Vorbis OGG. Сколько часов на самой разной акустике (а мы тогда уже открыли, что даже советская «Вега» уделывала все эти пластиковые недоразумения за десять баксов) было отслушано – не сосчитать.

В итоге выводы выкристаллизовались такие: OGG круче MP3 на средних битрейтах, а на высших все равны. Но преимущество OGG было в том, что на средних битрейтах файл не только лучше звучал, но и занимал меньше места. Недостатком – то, что при всех этих достоинствах OGG питался большим количеством оперативной памяти и ресурсов процессора. А в те времена мощности были, как понимаете, совсем не те.
Почему я так подробно пишу об отличиях OGG от MP3? Потому что уже начался рассказ про форматы, и все эти выводы справедливы и по сей день. Ну вот, теперь вы знаете почти все про OGG: а больше знать и не надо, поскольку его сегодня поддерживают не так уже много устройств.

И да, небольшой дисклеймер. Я не буду разводить воду про виды квантования и прочие страшные слова: если вам это интересно, то все прекрасно написано в Википедии. И форматов файлов на самом деле намного больше, чем будет перечислено далее. Вопрос в том, что они не только никому неизвестны, но и никем не поддерживаются. Почти.
И еще. Я не буду рассказывать о форматах многоканального звука. На сегодняшний день эта тема все еще в зачатке по причине своей дороговизны. И дисков выпускается мало, и также редко они перекодируются в звук. На коне по-прежнему старое доброе стерео. Очевидно, всем этого хватает. Ну или почти всем, но кто считает?
реклама
Оглавление
Читайте также: