
Чем рекурсия отличается от итерации dns
В своё время открыл для себя простую истину: хочешь запомнить что-то — веди конспект (даже при чтении книги), а хочешь закрепить и систематизировать — донеси до людей (напиши статью). Поэтому, после двух лет работы в системной интеграции (сфере, которую я в бытность свою системным администратором, считал просто рогом изобилия для жаждущих прокачки специалистов), когда я понял, что знания постепенно вытесняются навыками правки документации и конфигурированию по мануалам и инструкциям, для поддержания формы я начал писать статьи о базовых вещах. Например вот — о DNS. Делал тогда я это больше для себя, но подумал — вдруг кому пригодится.
Сервис в современных сетях если не ключевой, то один из таковых. Те, для кого служба DNS — не нова, первую часть могут спокойно пропустить.
Содержание:
(анкеров нет, поэтому содержание без ссылок)
1. Основные сведения
DNS — это база данных, содержащая, в основном, информацию о сопоставлении имён сетевых объектов их IP-адресам. «В основном» — потому что там и ещё кое-какая информация хранится. А точнее, ресурсные записи (Resource Records — RR) следующих типов:
А — то самое сопоставление символьного имени домена его IP адресу.
АААА — то же что А, но для адресов IPv6.
CNAME — Canonical NAME — псевдоним. Если надо чтобы сервер с неудобочитаемым именем, типа nsk-dc2-0704-ibm, на котором вертится корпоративный портал, откликался также на имя portal, можно создать для него ещё одну запись типа А, с именем portal и таким же IP-адресом. Но тогда, в случае смены IP адреса (всякое бывает), нужно будет пересоздавать все подобные записи заново. А если сделать CNAME с именем portal, указывающий на nsk-dc2-0704-ibm, то ничего менять не придётся.
MX — Mail eXchanger — указатель на почтовый обменник. Как и CNAME, представляет собой символьный указатель на уже имеющуюся запись типа A, но кроме имени содержит также приоритет. MX-записей может быть несколько для одного почтового домена, но в первую очередь почта будет отправляться на тот сервер, для которого указано меньшее значение в поле приоритета. В случае его недоступности — на следующий сервер и т.д.
NS — Name Server — содержит имя DNS-сервера, ответственного за данный домен. Естественно для каждой записи типа NS должна быть соответствующая запись типа А.
SOA — Start of Authority — указывает на каком из NS-серверов хранится эталонная информация о данном домене, контактную информацию лица, ответственного за зону, тайминги хранения информации в кэше.
SRV — указатель на сервер, держатель какого-либо сервиса (используется для сервисов AD и, например, для Jabber). Помимо имени сервера содержит такие поля как Priority (приоритет) — аналогичен такому же у MX, Weight (вес) — используется для балансировки нагрузки между серверами с одинаковым приоритетом — клиенты выбирают сервер случайным образом с вероятностью на основе веса и Port Number — номер порта, на котором сервис «слушает» запросы.
Все вышеперечисленные типы записей встречаются в зоне прямого просмотра (forward lookup zone) DNS. Есть ещё зона обратного просмотра (reverse lookup zone) — там хранятся записи типа PTR — PoinTeR — запись противоположная типу A. Хранит сопоставление IP-адреса его символьному имени. Нужна для обработки обратных запросов — определении имени хоста по его IP-адресу. Не требуется для функционирования DNS, но нужна для различных диагностических утилит, а также для некоторых видов антиспам-защиты в почтовых сервисах.
Кроме того, сами зоны, хранящие в себе информацию о домене, бывают двух типов (классически):
Основная (primary) — представляет собой текстовый файл, содержащий информацию о хостах и сервисах домена. Файл можно редактировать.
Дополнительная (secondary) — тоже текстовый файл, но, в отличие от основной, редактированию не подлежит. Стягивается автоматически с сервера, хранящего основную зону. Увеличивает доступность и надёжность.
Для регистрации домена в интернет, надо чтоб информацию о нём хранили, минимум, два DNS-сервера.
В Windows 2000 появился такой тип зоны как интегрированная в AD — зона хранится не в текстовом файле, а в базе данных AD, что позволяет ей реплицироваться на другие контроллеры доменов вместе с AD, используя её механизмы репликации. Основным плюсом данного варианта является возможность реализации безопасной динамической регистрации в DNS. То есть записи о себе могут создать только компьютеры — члены домена.
В Windows 2003 появилась также stub-зона — зона-заглушка. Она хранит информацию только о DNS-серверах, являющихся полномочными для данного домена. То есть, NS-записи. Что похоже по смыслу на условную пересылку (conditional forwarding), которая появилась в этой же версии Windows Server, но список серверов, на который пересылаются запросы, обновляется автоматически.
Итеративный и рекурсивный запросы.
DNS-сервер обращается к одному из корневых серверов интернета, которые хранят информацию о полномочных держателях доменов первого уровня или зон (ru, org, com и т.д.). Полученный адрес полномочного сервера он сообщает клиенту.
Клиент обращается к держателю зоны ru с тем же запросом.
DNS яндекса возвращает нужный адрес.
Такая последовательность событий редко встречается в наше время. Потому что есть такое понятие, как рекурсивный запрос — это когда DNS-сервер, к которому клиент изначально обратился, выполняет все итерации от имени клиента и потом возвращает клиенту уже готовый ответ, а также сохраняет у себя в кэше полученную информацию. Поддержку рекурсивных запросов можно отключить на сервере, но большинство серверов её поддерживают.
Клиент, как правило, обращается с запросом, имеющим флаг «требуется рекурсия».
Заголовок состоит из следующих полей:
Идентификация — в это поле клиентом генерируется некий идентификатор, который потом копируется в соответствующее поле ответа сервера, чтобы можно было понять на какой запрос пришёл ответ.
Флаги — 16-битовое поле, поделенное на 8 частей:
Вторая строка — ответ сервера: на указанный исходный порт с указанным идентификатором запроса. Ответ содержит одну RR (ресурсную запись DNS), являющуюся ответом на запрос, 2 записи полномочий и 5 каких-то дополнительных записей. Общая длина ответа — 196 байт.
3. TCP и UDP
Также передача зон от основных серверов к дополнительным осуществляется по TCP, поскольку в этом случае передаётся куда больше 512 байт.
4. DNS в Windows Server 2008 и 2012
В Windows 2008 появились следующие возможности:
Фоновая загрузка зон
- определяются все зоны, которые должны быть загружены;
- из файлов или хранилища доменных служб Active Directory загружаются корневые ссылки;
- загружаются все зоны с файловой поддержкой, то есть зоны, хранящиеся в файлах, а не в доменных службах Active Directory;
- начинается обработка запросов и удаленных вызовов процедур (RPC);
- создаются один или несколько потоков для загрузки зон, хранящихся в доменных службах Active Directory.
Поскольку задача загрузки зон выполняется отдельными потоками, DNS-сервер может обрабатывать запросы во время загрузки зоны. Если DNS-клиент запрашивает данные для узла в зоне, который уже загружен, DNS-сервер отправляет в ответ данные (или, если это уместно, отрицательный ответ). Если запрос выполняется для узла, который еще не загружен в память, DNS-сервер считывает данные узла из доменных служб Active Directory и обновляет соответствующим образом список записей узла.
Поддержка IPv6-адресов
Протокол Интернета версии 6 (IPv6) определяет адреса, длина которых составляет 128 бит, в отличие от адресов IP версии 4 (IPv4), длина которых составляет 32 бита.
DNS-серверы с ОС Windows Server 2008 теперь полностью поддерживают как IPv4-адреса, так и IPv6-адреса. Средство командной строки dnscmd также принимает адреса в обоих форматах. Cписок серверов пересылки может содержать и IPv4-адреса, и IPv6-адреса. DHCP-клиенты также могут регистрировать IPv6-адреса наряду с IPv4-адресами (или вместо них). Наконец, DNS-серверы теперь поддерживают пространство имен домена ip6.arpa для обратного сопоставления.
Изменения DNS-клиента
Разрешение имен LLMNR
Клиентские компьютеры DNS могут использовать разрешение имен LLMNR (Link-local Multicast Name Resolution), которое также называют многоадресной системой DNS или mDNS, для разрешения имен в сегменте локальной сети, где недоступен DNS-сервер. Например, при изоляции подсети от всех DNS-серверов в сети из-за сбоя в работе маршрутизатора клиенты в этой подсети, поддерживающие разрешение имен LLMNR, по-прежнему могут разрешать имена с помощью одноранговой схемы до восстановления соединения с сетью.
Кроме разрешения имен в случае сбоя в работе сети функция LLMNR может также оказаться полезной при развертывании одноранговых сетей, например, в залах ожидания аэропортов.
Изменения Windows 2012 в части DNS коснулись, преимущественно, технологии DNSSEC (обеспечение безопасности DNS за счет добавления цифровых подписей к записям DNS), в частности — обеспечение динамических обновлений, которые были недоступны, при включении DNSSEC в Windows Server 2008.
5. DNS и Active directory
Active Directory очень сильно опирается в своей деятельности на DNS. С его помощью контроллеры домена ищут друг друга для репликации. С его помощью (и службы Netlogon) клиенты определяют контроллеры домена для авторизации.
Для обеспечения поиска, в процессе поднятия на сервере роли контроллера домена, его служба Netlogon регистрирует в DNS соответствующие A и SRV записи.
SRV записи регистрируемые службой Net Logon:
_ldap._tcp.DnsDomainName
_ldap._tcp.SiteName._sites.DnsDomainName
_ldap._tcp.dc._msdcs.DnsDomainName
_ldap._tcp.SiteName._sites.dc._msdcs.DnsDomainName
_ldap._tcp.pdc._msdcs.DnsDomainName
_ldap._tcp.gc._msdcs.DnsForestName
_ldap._tcp.SiteName._sites.gc._msdcs. DnsForestName
_gc._tcp.DnsForestName
_gc._tcp.SiteName._sites.DnsForestName
_ldap._tcp.DomainGuid.domains._msdcs.DnsForestName
_kerberos._tcp.DnsDomainName.
_kerberos._udp.DnsDomainName
_kerberos._tcp.SiteName._sites.DnsDomainName
_kerberos._tcp.dc._msdcs.DnsDomainName
_kerberos.tcp.SiteName._sites.dc._msdcs.DnsDomainName
_kpasswd._tcp.DnsDomainName
_kpasswd._udp.DnsDomainName
Первая часть SRV-записи идентифицирует службу, на которую указывает запись SRV. Существуют следующие службы:
_ldap — Active Directory является службой каталога, совместимой с LDAP-протоколом, с контроллерами домена, функционирующими как LDAP-серверы. Записи _ldap SRV идентифицирует LDAP серверы, имеющиеся в сети. Эти серверы могут быть контроллерами домена Windows Server 2000+ или другими LDAP-серверами;
_kerberos — SRV-записи _kerberos идентифицируют все ключевые центры распределения (KDC — Key Distribution Centers) в сети. Они могут быть контроллерами домена с Windows Server 2003 или другими KDC-серверами;
_kpassword — идентифицирует серверы изменения паролей kerberos в сети;
_gc — запись, относящаяся к функции глобального каталога в Active Directory.
В поддомене _mcdcs регистрируются только контроллеры домена Microsoft Windows Server. Они делают и основные записи и записи в данном поддомене. Не-Microsoft-службы делают только основные записи.
Записи, содержащие идентификатор сайта SiteName, нужны для того чтобы клиент мог найти контроллер домена для авторизации в своём сайте, а не лез авторизовываться в другой город через медленные каналы.
DomainGuid — глобальный идентификатор домена. Запись, содержащщая его, нужна на случай переименования домена.
Как происходит процесс поиска DC
Во время входа пользователя, клиент инициирует DNS-локатор, при помощи удалённого вызова процедуры (Remote Procedure Call — RPC) службой NetLogon. В качестве исходных данных в процедуру передаются имя компьютера, название домена и сайта.
Служба посылает один или несколько запросов с помощью API функции DsGetDcName()
DNS сервер возвращает запрошенный список серверов, рассортированный согласно приоритету и весу. Затем клиент посылает LDAP запрос, используя UDP-порт 389 по каждому из адресов записи в том порядке, как они были возвращены.
Все доступные контроллеры доменов отвечают на этот запрос, сообщая о своей работоспособности.
После обнаружения контроллера домена, клиент устанавливает с ним соединение по LDAP для получения доступа к Active Directory. Как часть их диалога, контроллер домена определяет к в каком сайте размещается клиент, на основе его IP адреса. И если выясняется, что клиент обратился не к ближайшему DC, а, например, переехал недавно в другой сайт и по привычке запросил DC из старого (информация о сайте кэшируется на клиенте по результатам последнего успешного входа), контроллер высылает ему название его (клиента) нового сайта. Если клиент уже пытался найти контроллер в этом сайте, но безуспешно, он продолжает использовать найденный. Если нет, то инициируется новый DNS-запрос с указанием нового сайта.
Служба Netlogon кэширует информацию о местонахождении контроллера домена, чтобы не инициировать всю процедуру при каждой необходимости обращения к DC. Однако, если используется «неоптимальный» DC (расположенный в другом сайте), клиент очищает этот кэш через 15 минут и инициирует поиски заново (в попытке найти свой оптимальный контроллер).
Если у комьютера отсутствует в кэше информация о его сайте, он будет обращаться к любому контроллеру домена. Для того чтобы пресечь такое поведение, на DNS можно настроить NetMask Ordering. Тогда DNS выдаст список DC в таком порядке, чтобы контроллеры, расположенные в той же сети, что и клиент, были первыми.
Пример: Dnscmd /Config /LocalNetPriorityNetMask 0x0000003F укажет маску подсети 255.255.255.192 для приоритетных DC. По умолчанию используется маска 255.255.255.0 (0x000000FF)

Давайте для начала явно отметим отличие рекурсии (в общем смысле) от процесса. Эти понятия никак не связаны. Рекурсия — просто абстрактная концепция, которую можно наблюдать в природе, которая используется в математике и в других областях. Такая же абстрактная, как, например, музыкальная гармония.

пример рекурсии: художник рисует картину, в которой он рисует картину, в которой он рисует картину.
Теперь на секунду забудем про рекурсию, и просто подумаем про компьютеры. Для выполнения задач компьютерам нужны инструкции. Когда компьютер выполняет набор инструкций — это процесс. Ваш работающий сейчас браузер — это процесс. Простой цикл, выводящий на экран десять раз число "42" — это процесс. Некоторые задачи можно решать рекурсивно, то есть в инструкциях использовать эту концепцию, когда что-то является частью самого себя. В частности, функция может быть частью самой себя, то есть вызывать саму себя.
Есть два метода решения задач с использованием рекурсии: рекурсивный процесс и итеративный процесс. Рекурсия в них не отличается: в каждом из подходов функция вызывает саму себя, рекурсивно. Отличаются способы использования идеи рекурсии.
Если продолжить аналогию с музыкальной гармонией, то можно подумать про фортепиано. При написании музыки можно использовать эту концепцию — «гармонию звуков». И можно придумать разные способы: рассчитывать частоты звуков (ноты) математическими формулами или рассчитывать правильные расстояния между клавишами. Я в детстве научился находить правильные расстояния между клавишами на фортепиано, и получал гармоничные комбинации звуков, но понятия не имел, что это за ноты. А профессиональный музыкант знает теорию и подбирает гармонию другими методами. В любом случае, гармония есть гармония, эта концепция не меняется, меняются лишь способы ее использования.
В чем отличие итеративного процесса от рекурсивного?
Главная фишка в аккумуляторе или, иными словами, в запоминании.
Рекурсивный процесс постоянно говорит «я это запомню и потом посчитаю» на каждом шаге рекурсии. «Потом» наступает в самом конце.
- Когда рекурсивный процесс считает факториал 6, то ему нужно запомнить 5 чисел, чтобы посчитать их в самом конце, когда уже никуда не деться и рекурсивно двигаться вниз больше нельзя.
- Когда мы находимся в очередном вызове функции, то где-то снаружи этого вызова в памяти хранятся эти запомненные числа.
тут прямо физически видно, как растет использование памяти: процессу нужно запоминать все больше и больше чисел
Рекурсивный процесс — это процесс с отложенным вычислением.
Итеративный процесс постоянно говорит «я сейчас посчитаю все что можно и продолжу» на каждом шаге рекурсии. Ему не нужно ничего запоминать вне вызова, он всегда считает все в первый возможный момент, и каждый шаг рекурсии может существовать в изоляции от прошлых, потому что вся информация передается из шага в шаг.
- Когда итеративный процесс считает факториал 6, то ему не нужно запоминать числа. Нужно лишь считать и передавать результат дальше, в новый вызов.
- Когда мы находимся в очередном вызове функции, снаружи этого вызова в памяти ничего не нужно запоминать.
тут видно, что использование памяти не растет
Рекурсивный процесс это чувак, который все дела откладывает на вечер пятницы. В течение недели у него мало работы, а в пятницу завал. Но ему так нравится :)
Итеративный процесс это чувак, который все делает при первой возможности. У него работа равномерно распределена по неделе, а пятница — просто обычный день, но последний.
Работа DNS в сети интернет
В настоящее время интернет окружает нас повсюду — мы используем его в мобильных и настольных устройствах. Системы видеонаблюдения и даже чайники взаимодействуют друг с другом с помощью интернета, и для корректной связи с ними нужна система, с помощью которой пользователи смогут одним запросом в адресной строке подключиться к нужному сервису. Всё это ложится на плечи системы DNS, которая внутри себя хранит намного больше информации, чем просто IP-адрес и название устройств. Записи в DNS также отвечают за корректную отправку электронных писем, связывают друг с другом разные домены и доменные зоны.
DNS является распределённой системой, а значит она имеет множество узлов, каждый из которых ответственен за свою зону. Такое возможно благодаря тому, что сама по себе структура DNS является иерархической, то есть выделяет зоны ответственности, где каждый родитель знает о расположении своего дочернего сервера, и знает зону его ответственности.
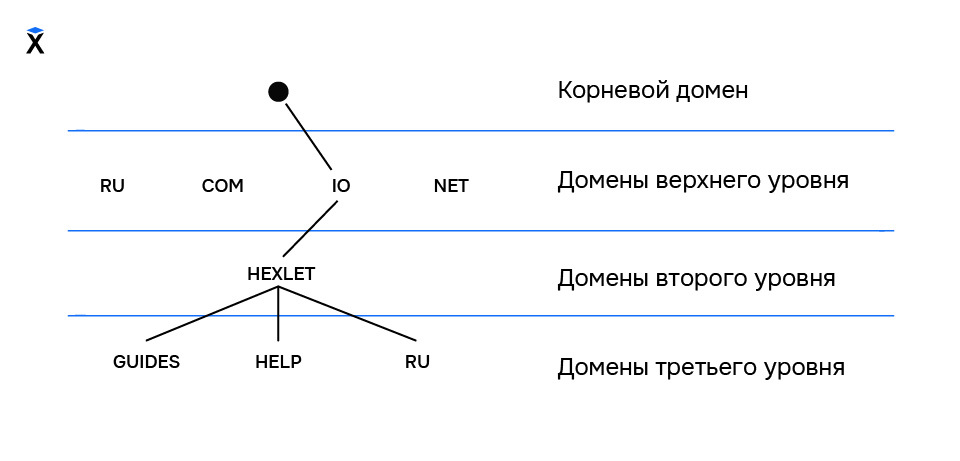
Рассмотрим работу DNS и её составных частей поближе.
Пример реальных записей DNS

Не пугайтесь такого длинного вывода. Уже сейчас можно понять почти всё, что тут указано. Разберём вывод каждой секции более детально.
Вывод состоит из нескольких частей:
- Шапка
- Секция запроса
- Секция ответа
- Служебная информация
Шапка запроса
Секция запроса
В секции запроса указывается домен, к которому происходит обращение, класс записи и те записи, которые мы хотим получить. ANY указывает на то, что нужно вывести все доступные ресурсные записи, но если вы хотите поэкспериментировать с утилитой сами, то можете с помощью специального ключа получить вывод только конкретных записей, которые интересуют в настоящий момент.
Секция ответа
Секция ответа достаточно большая, поэтому для удобства разобьём её по типам ресурсных записей.
Как запись A, так и AAAA-запись указывают на IP-адрес, который привязан к нашему домену. A-запись указывает IP в формате IPv4, а запись AAAA — в формате IPv6.
MX-запись также имеет параметр приоритета. Так как серверов для отправки почты может быть несколько, то и записей может быть много, поэтому для определения основного сервера указывается приоритет записи. Чем меньше число, тем выше приоритет.
Запись SOA (Start of Authority) указывает на несколько различных параметров:
- Сервер с эталонной информацией о текущем домене
- Контактную информацию ответственного лица
- Различные параметры кеширования записей
Бывают и некоторые более специфичные ресурсные записи, о которых здесь не было речи, но это не значит, что они бесполезны. Полный перечень таких записей всегда можно найти в документации (например по DNS-серверу BIND).
Подключение
Необходимо понимать, что доменное имя — это всего лишь абстракция для людей. Сам компьютер и приложения (например, браузер) обращается к сервисам внутри сети интернет только по IP-адресам.
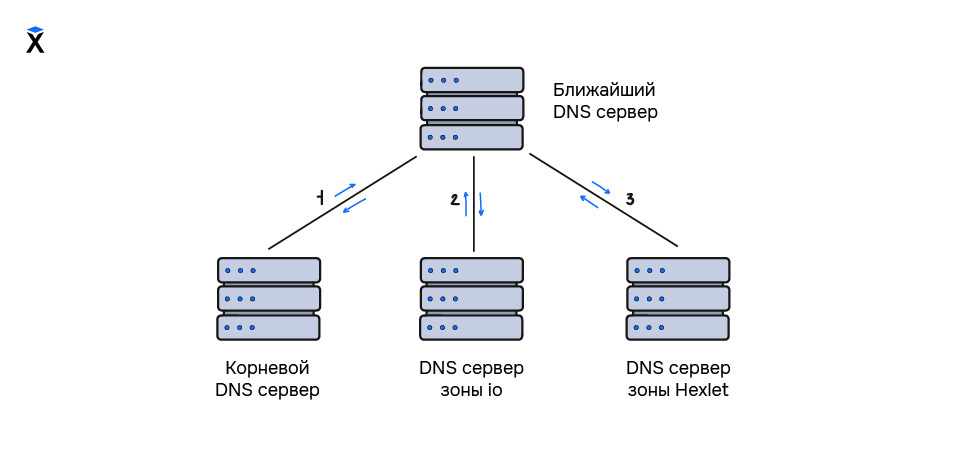
Рассмотрим процесс получения IP-адреса по доменному имени на примере домена ru.hexlet.io .
Возможны два варианта событий:
Компьютер посылает запрос на известный ему DNS-сервер. Чаще всего им является DNS-сервер поставщика интернет-услуг (провайдера): какой IP-адрес у домена ru.hexlet.io?. DNS-сервер провайдера находит в своей базе информацию о том, что домен ru.hexlet.io расположен по IP-адресу 104.25.238.104 и возвращает значение нашему компьютеру. Этот процесс похож на то, как использовался файл hosts.txt .
Ближайший известный DNS-сервер не имеет записи о том, по какому IP-адресу располагается домен ru.hexlet.io . В таком случае запускается цепочка процессов, благодаря которым наш компьютер получит IP-адрес домена:
Так как домен является иерархической структурой, и все DNS-сервера знают IP-адреса корневых DNS-серверов, то к ним и происходит запрос на получение IP-адреса домена.
Корневые DNS-сервера, в соответствии со своей зоной ответственности знают о том, где располагаются DNS-сервера доменов верхнего уровня. Эти адреса возвращаются DNS-серверу нашего провайдера, после чего на нужный DNS-сервер (в нашем случае на DNS-сервер домена .io) посылается запрос на получение IP-адреса домена ru.hexlet.
В соответствии со своей зоной ответственности DNS-сервер домена верхнего уровня возвращает IP-адрес DNS-сервера домена hexlet, на который посылается запрос на получение IP-адреса поддомена ru.
DNS-сервер возвращает IP-адреса поддомена ru, после чего DNS-сервер нашего провайдера возвращает полученный адрес на наш компьютер, который уже может обратиться к домену ru.hexlet.io по его IP-адресу.
Файл hosts — как первый шаг к созданию DNS
Для решения задачи разработчики решили использовать словарь, который связывал уникальное имя и IP-адрес каждого компьютера в сети. Таким словарём стал файл hosts.txt, который и отвечал за привязку IP-адреса к имени компьютера. Файл лежал на сервере Стэнфордского исследовательского института, и пользователи сети регулярно вручную скачивали этот файл на свои компьютеры, чтобы сохранять актуальность словаря, ведь новые компьютеры появлялись в сети почти каждый день.
Выглядел hosts.txt тогда (да и сейчас) таким образом:
При наличии такого файла на компьютере пользователя для связи с компьютером Майка, можно было не запоминать цифры, а использовать понятное латинское имя «MIKE-STRATE-PC».
Посмотрим, как выглядит файл и попробуем добавить туда новое имя, чтобы подключиться к компьютеру с использованием данного имени. Для этого отредактируем файл hosts. Вы можете найти его на своём компьютере по следующему адресу:
- В Unix-системах: /etc/hosts
- В Windows-системах: %Путь до папки Windows%/system32/drivers/etc/hosts
Компьютеру с IP-адресом 192.168.10.36, который находится внутри локальной сети мы указали имя «MIKE-STRATE-PC». После чего можно воспользоваться командой ping, которая пошлёт специальный запрос на компьютер Майка и будет ждать от него ответа. Похоже на то, как вы стучитесь в дверь или звоните в звонок, чтобы узнать, «есть ли кто дома?» Такой запрос можно послать на любой компьютер.
По мере развития сети и «обрастания» её новыми клиентами, такой способ становился неудобным. Всем пользователям компьютеров было необходимо всё чаще скачивать свежую версию файла с сервера Стэнфордского исследовательского института, который обновлялся вручную несколько раз в неделю. Для добавлений же новых версий было необходимо связываться с институтом и просить их внести в файл новые значения.
В 1984 году Пол Мокапетрис (Paul Mockapetris) описал новую систему под названием DNS (Domain Name System / Система доменных имён), которая была призвана автоматизировать процессы соотнесения IP-адресов и имён компьютеров, а также процессы обновления имён у пользователей без необходимости ручного скачивания файла со стороннего сервера.
Tail call optimization
Отмотаем назад и рассмотрим во взаимосвязи два утверждения относительно рекурсивных функций, использующих итеративный процесс:
- Во-первых, такие функции являются рекурсивными. Это значит, что для каждого (очередного) рекурсивного вызова в стек вызовов записывается вся информация, связанная с этим конкретным вызовом (параметры функции и её локальные переменные, адрес возврата в точку вызова). Т.е. выделяется дополнительная область памяти (лексический контекст функции, область видимости), обслуживающая данный рекурсивный вызов, а так как это стек вызовов, то контексты предыдущих рекурсивных вызовов также продолжают занимать память. Достижение большой глубины рекурсии (или же если она вовсе является бесконечной, т.е. не достигается терминальное условие выхода из рекурсии) приводит к переполнению стека (ведь он ограничен в размерах) и аварийному завершению всей программы.
- Во-вторых, в контексте каждого очередного рекурсивного вызова такой функции хранится вся необходимая информация для его успешного выполнения. Он самодостаточен и никак не зависит от предыдущих контекстов (помните, "этот чувак ничего не откладывает на потом, на вечер пятницы. "?!). В наших практиках на Хекслете мы реализовывали такое поведения благодаря использованию аккумулятора acc , передающегося в качестве аргумента из одного вызова в другой и накапливающего в себе результат вычисления необходимого значения. Получается, что, грубо говоря, на каком бы по уровню вложенности рекурсивном вызове мы не находились, все предыдущие уже не имеют значения и являются «бесполезной обузой», нагружающей память. В т.ч. это распространяется и на самый последний рекурсивный вызов (где срабатывает терминальное условие), который сразу готов вернуть готовое вычисленное значение из функции, ему не нужны для этого предыдущие контексты в стеке.
Отсюда напрашивается вопрос, как использовать рассмотренные преимущества итеративного процесса и одновременно избавиться от недостатка рекурсивных функций, т.е. от неумолимого роста использования памяти. И сразу же нарисовывается ответ - избавить процесс от заполнения стека "ненужными" контекстами предыдущих вызовов и обеспечить прямой возврат из функции при достижении терминального условия. Для этого служит так называемая Tail call optimization, или оптимизация хвостовой рекурсии (рассмотренный выше итеративный процесс как раз можно отнести к хвостовой рекурсии). Благодаря оптимизации состояния стека, она придаёт итеративному процессу вид "плоской" итерации (см. картинку выше), исключается его переполнение из-за большой глубины рекурсии.
Хвостовая рекурсия (и её оптимизация) широко используется при написании программ на функциональных языках программирования.
Вы когда-нибудь задавались вопросом, как браузер понимает, какую именно страницу открыть, когда вы вводите в строку адрес сайта? На самом деле, это глубокий вопрос, решать который стоит не непосредственно с перехода на сайты, а со связи компьютеров между собой.
В 70-х — 90-х годах 20 века существовала сеть под названием ARPANET. Это была попытка объединить множество компьютеров министерством обороны США для возможности передачи информации во время войны. Важность такого подхода заключалась в быстрой передаче информации на дальние расстояния. Впоследствии принципы работы ARPANET легли в основу современного интернета.
Изначально вся сеть объединяла компьютеры в четырёх различных институтах США:
- Калифорнийский университет в Лос-Анджелесе;
- Стэнфордский исследовательский центр;
- Университет Юты;
- Калифорнийский университет в Санта-Барбаре.
В самом начале компьютеров, подключённых к сети, было несколько десятков, и их идентификаторы было легко запомнить. Можно было записать эти адреса в блокнот и использовать его так же, как и телефонные книги.
Время шло, и уже к середине 80-х годов вместо нескольких десятков компьютеров сеть стала насчитывать несколько тысяч. И каждый из них имел уникальный идентификатор, который становилось всё сложнее учитывать вручную или запоминать. Необходима была система, которая позволит очеловечить имена компьютеров и хранить все адреса в одном месте, чтобы каждый компьютер в сети имел один и тот же набор всех идентификаторов.
Tail call optimization
Отмотаем назад и рассмотрим во взаимосвязи два утверждения относительно рекурсивных функций, использующих итеративный процесс:
- Во-первых, такие функции являются рекурсивными. Это значит, что для каждого (очередного) рекурсивного вызова в стек вызовов записывается вся информация, связанная с этим конкретным вызовом (параметры функции и её локальные переменные, адрес возврата в точку вызова). Т.е. выделяется дополнительная область памяти (лексический контекст функции, область видимости), обслуживающая данный рекурсивный вызов, а так как это стек вызовов, то контексты предыдущих рекурсивных вызовов также продолжают занимать память. Достижение большой глубины рекурсии (или же если она вовсе является бесконечной, т.е. не достигается терминальное условие выхода из рекурсии) приводит к переполнению стека (ведь он ограничен в размерах) и аварийному завершению всей программы.
- Во-вторых, в контексте каждого очередного рекурсивного вызова такой функции хранится вся необходимая информация для его успешного выполнения. Он самодостаточен и никак не зависит от предыдущих контекстов (помните, "этот чувак ничего не откладывает на потом, на вечер пятницы. "?!). В наших практиках на Хекслете мы реализовывали такое поведения благодаря использованию аккумулятора acc , передающегося в качестве аргумента из одного вызова в другой и накапливающего в себе результат вычисления необходимого значения. Получается, что, грубо говоря, на каком бы по уровню вложенности рекурсивном вызове мы не находились, все предыдущие уже не имеют значения и являются «бесполезной обузой», нагружающей память. В т.ч. это распространяется и на самый последний рекурсивный вызов (где срабатывает терминальное условие), который сразу готов вернуть готовое вычисленное значение из функции, ему не нужны для этого предыдущие контексты в стеке.
Отсюда напрашивается вопрос, как использовать рассмотренные преимущества итеративного процесса и одновременно избавиться от недостатка рекурсивных функций, т.е. от неумолимого роста использования памяти. И сразу же нарисовывается ответ - избавить процесс от заполнения стека "ненужными" контекстами предыдущих вызовов и обеспечить прямой возврат из функции при достижении терминального условия. Для этого служит так называемая Tail call optimization, или оптимизация хвостовой рекурсии (рассмотренный выше итеративный процесс как раз можно отнести к хвостовой рекурсии). Благодаря оптимизации состояния стека, она придаёт итеративному процессу вид "плоской" итерации (см. картинку выше), исключается его переполнение из-за большой глубины рекурсии.
Хвостовая рекурсия (и её оптимизация) широко используется при написании программ на функциональных языках программирования.
Вы когда-нибудь задавались вопросом, как браузер понимает, какую именно страницу открыть, когда вы вводите в строку адрес сайта? На самом деле, это глубокий вопрос, решать который стоит не непосредственно с перехода на сайты, а со связи компьютеров между собой.
В 70-х — 90-х годах 20 века существовала сеть под названием ARPANET. Это была попытка объединить множество компьютеров министерством обороны США для возможности передачи информации во время войны. Важность такого подхода заключалась в быстрой передаче информации на дальние расстояния. Впоследствии принципы работы ARPANET легли в основу современного интернета.
Изначально вся сеть объединяла компьютеры в четырёх различных институтах США:
- Калифорнийский университет в Лос-Анджелесе;
- Стэнфордский исследовательский центр;
- Университет Юты;
- Калифорнийский университет в Санта-Барбаре.
В самом начале компьютеров, подключённых к сети, было несколько десятков, и их идентификаторы было легко запомнить. Можно было записать эти адреса в блокнот и использовать его так же, как и телефонные книги.
Время шло, и уже к середине 80-х годов вместо нескольких десятков компьютеров сеть стала насчитывать несколько тысяч. И каждый из них имел уникальный идентификатор, который становилось всё сложнее учитывать вручную или запоминать. Необходима была система, которая позволит очеловечить имена компьютеров и хранить все адреса в одном месте, чтобы каждый компьютер в сети имел один и тот же набор всех идентификаторов.
Рекурсия в DNS
Можно заметить, что оба описанных выше варианта сильно различаются: в первом случае мы просто послали запрос и получили ответ, а во втором — возникла необходимость идти от самого корневого домена в процессе поиска нужной нам записи. Такой процесс является рекурсивным, потому что ближайший DNS-сервер непрерывно посылает запросы к другим DNS-серверам до тех пор, пока не получит необходимые ресурсные записи. Данный процесс можно визуализировать следующим образом:
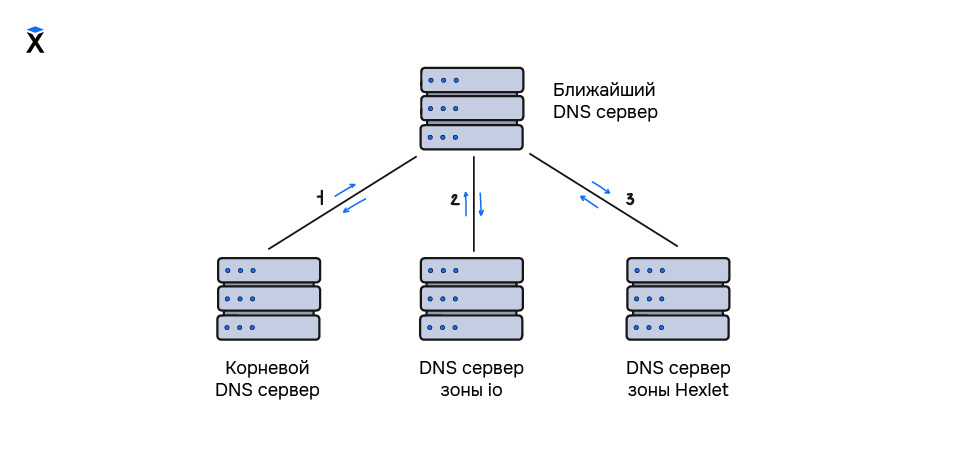
При запросах 1 и 2 ближайший сервер будет получать информацию о местонахождении DNS-серверов, которые входят в зону ответственности того сервера, на который был послан запрос. При запросе 3 будут получены необходимые ресурсные записи домена hexlet и его поддоменов.
Рекурсивный поиск — это достаточно долгая операция, которая к тому же сильно нагружает сеть и сами DNS-сервера. Именно для того, чтобы избавиться от рекурсии каждый DNS-сервер кеширует информацию о записях, которые получает, для быстрой отдачи этой информации пользователю.
Как видно, рекурсивный поиск предполагает нахождение конечного ответа на наш запрос путём поиска записи по всем необходимым DNS-серверам, начиная с корневого. В противовес такому способу также существует итеративный запрос, который в отличие от рекурсивного выполняет всего лишь одну итерацию — это запрос ближайшему DNS-серверу, от которого мы можем получить как закешированный ответ, так и данные той зоны, за которую он ответственен. Важно отметить, что итеративный запрос предполагает всего один такой запрос.
Чаще всего в интернете DNS-сервера умеют посылать рекурсивные запросы, потому что в таком случае ответ можно закешировать, что в дальнейшем позволит снизить нагрузку как на сам сервер, так и на другие DNS-сервера. Время, на которое DNS-сервер кеширует информацию, указывается в ресурсной записи DNS, о которой сейчас пойдёт речь.
Tail call optimization
Отмотаем назад и рассмотрим во взаимосвязи два утверждения относительно рекурсивных функций, использующих итеративный процесс:
- Во-первых, такие функции являются рекурсивными. Это значит, что для каждого (очередного) рекурсивного вызова в стек вызовов записывается вся информация, связанная с этим конкретным вызовом (параметры функции и её локальные переменные, адрес возврата в точку вызова). Т.е. выделяется дополнительная область памяти (лексический контекст функции, область видимости), обслуживающая данный рекурсивный вызов, а так как это стек вызовов, то контексты предыдущих рекурсивных вызовов также продолжают занимать память. Достижение большой глубины рекурсии (или же если она вовсе является бесконечной, т.е. не достигается терминальное условие выхода из рекурсии) приводит к переполнению стека (ведь он ограничен в размерах) и аварийному завершению всей программы.
- Во-вторых, в контексте каждого очередного рекурсивного вызова такой функции хранится вся необходимая информация для его успешного выполнения. Он самодостаточен и никак не зависит от предыдущих контекстов (помните, "этот чувак ничего не откладывает на потом, на вечер пятницы. "?!). В наших практиках на Хекслете мы реализовывали такое поведение благодаря использованию аккумулятора acc , передающегося в качестве аргумента из одного вызова в другой и накапливающего в себе результат вычисления необходимого значения. Получается, что, грубо говоря, на каком бы по уровню вложенности рекурсивном вызове мы не находились, все предыдущие уже не имеют значения и являются "бесполезной обузой", нагружающей память. В т.ч. это распространяется и на самый последний рекурсивный вызов (где срабатывает терминальное условие), который сразу готов вернуть готовое вычисленное значение из функции, ему не нужны для этого предыдущие контексты в стеке.
Отсюда напрашивается вопрос, как использовать рассмотренные преимущества итеративного процесса и одновременно избавиться от недостатка рекурсивных функций, т.е. от неумолимого роста использования памяти. И сразу же нарисовывается ответ - избавить процесс от заполнения стека "ненужными" контекстами предыдущих вызовов и обеспечить прямой возврат из функции при достижении терминального условия. Для этого служит так называемая Tail call optimization, или оптимизация хвостовой рекурсии (рассмотренный выше итеративный процесс как раз можно отнести к хвостовой рекурсии). Благодаря оптимизации состояния стека, она придаёт итеративному процессу вид "плоской" итерации (см. картинку выше), исключается его переполнение из-за большой глубины рекурсии.
Хвостовая рекурсия (и её оптимизация) широко используется при написании программ на функциональных языках программирования.
Основная цель DNS — это отображение доменных имен в IP адреса и наоборот — IP в DNS. В статье я рассмотрю работу DNS сервера BIND (Berkeley Internet Name Domain, ранее: Berkeley Internet Name Daemon), как сАмого (не побоюсь этого слова) распространенного. BIND входит в состав любого дистрибутива UNIX. Основу BIND составляет демон named, который для своей работы использует порт UDP/53 и для некоторых запросов TCP/53.
Основные понятия Domain Name System

Исторически, до появления доменной системы имен роль инструмента разрешения символьных имен в IP выполнял файл /etc/hosts, который и в настоящее время играет далеко не последнюю роль в данном деле. Но с ростом количества хостов в глобальной сети, отслеживать и обслуживать базу имен на всех хостах стало нереально затруднительно. В результате придумали DNS, представляющую собой иерархическую, распределенную систему доменных зон. Давайте рассмотрим структуру Системы Доменных Имён на иллюстрации:
Доменная структура DNS представляет собой древовидную иерархию, состоящую из узлов, зон, доменов, поддоменов и др. элементов, о которых ниже пойдет речь. «Вершиной» доменной структуры является корневая зона. Настройки корневой зоны расположены на множестве серверов/зеркал, размещенных по всему миру и содержат информацию о всех серверах корневой зоны, а так же отвечающих за домены первого уровня (ru, net, org и др). Информация о серверах корневой зоны расположена на данном сайте корневых серверов. Настройки корневой зоны всегда доступны тут. Серверы корневой зоны обрабатывают и отвечают на запросы, выдавая информацию только о доменах первого уровня (то есть отвечают на любые запросы, как на нерекурсивные)! Итак, уже много раз повторилось слово зона. Пора этот термин объяснить.
Домен — это именованная ветвь или поддерево в дереве имен DNS, то есть это определенный узел, включающий в себя все подчиненные узлы. Следующая цитата из книги Linux Network Administrators Guide хорошо проясняет картину относительно разницы между зоной и доменом:
Таким образом, пространство имен раздроблено на зоны ( zones), каждая из которых управляется своим доменом. Обратите внимание на различие между зоной (zone) и доменом (domain): домен groucho.edu затрагивает все машины в университете Groucho Marx, в то время как зона groucho.edu включает только хосты, которые работают в непосредственно компьютерном центре, например в отделе математики. Хост в отделе физики принадлежат другой зоне, а именно physics.groucho.edu.
Каждый узел в иерархии DNS отделен от своего родителя точкой. Если провести аналогию с файловой системой Linux, система доменных имен имеет похожую структуру, за тем исключением, что разделитель в файловой системе — слэш, а в DNS — точка. А так же DNS адрес читается справа налево (от корневого домена к имени хоста) в отличии от пути в файловой системе Linux. Доменное имя начинается с точки (корневого домена) и проходит через домены первого, второго и если нужно третьего и т.д. уровней и завершается именем хоста. Т.о. доменное имя полностью отражает структуру иерархии DNS. Часто (я бы сказал — всегда в повседневной жизни), последняя точка (обозначение корневого домена) в доменном имени опускается (то есть в браузере мы вводим не k-max.name., а k-max.name). Итак, разобрав структуру доменного имени, мы незаметно подошли к понятию FQDN.
FQDN (англ. Fully Qualifed Domain Name, полностью определённое имя домена) — это имя домена, однозначно определяющее доменное имя и включающее в себя имена всех родительских доменов иерархии DNS, в том числе и корневого. Своеобразный аналог абсолютного пути в файловой системе. Давайте разберем вышесказанное на примере имени домена mail.k-max.name:
Различие между FQDN и обычным доменным (неFQDN) именем появляется при именовании доменов второго, третьего (и т. д.) уровня. Для получения FQDN требуется обязательно указать в доменном имени домены более высокого уровня (например, mail является доменным именем, однако FQDN имя выглядит как mail.k-max.name.). Максимальный размер FQDN — 255 байт, с ограничением в 63 байта на каждое имя домена.
Поддомены, коротко говоря, это — подчиненные домены. По большому счету, все домены в интернете являются подчиненными за исключением корневого. Например домен k-max является поддоменом домена name, а name, в свою очередь — поддоменом корневого домена.
Ресурсные записи
Ресурсная запись — это то, собственно ради чего в конечном счете и существует DNS. Ресурсная запись — это единица хранения и передачи информации в DNS. Каждая такая запись несет в себе информацию соответствия какого-то имени и служебной информации в DNS, например соответствие имени домена — IP адреса.
Запись ресурса состоит из следующих полей:
Для бОльшего понимания, приведу пример. Делегирование управления поддоменом k-max.name другому лицу (в моем случае — хостеру) приводит к созданию новой зоны, которая администрируется независимо от остального пространства имен (независимо от вышестоящего name.). Зона k-max.name после делегирования полномочий теперь не зависит от name. и может содержать все (вернее сказать — любые имена, которые я захочу) доменные имена, которые заканчиваются на *.k-max.name. С другой стороны, зона name. содержит только доменные имена, оканчивающиеся на *.name., но не входящие в делегированные этой зоны, такие, например, как k-max.name или a-lab.name или любая другая. k-max.name может быть поделен на поддомены с именами вроде mail.k-max.name, ftp.k-max.name и некоторые из этих поддоменов могут быть выделены в самостоятельные зоны, и ответственность за данные зоны может так же быть делегирована. Если ftp.k-max.name будет являться самостоятельной зоной, то зона k-max.name не будет содержать доменные записи, которые заканчиваются на *.ftp.k-max.name.
Т.о. после делегирования ответственности, информация хранимая делегирующей зоной уже не включает информацию по делегированному поддомену и его ресурсным записям хостов, а хранит информацию о серверах имен, являющихся для делегируемого поддомена авторитативными. Это и есть «склеивающие» записи, о чем я выше уже говорил. В таком случае, если у DNS-сервера родительского домена запрашиваются данные об адресе, принадлежащем делегированному поддомену, в ответ предоставляется список DNS-серверов, которые обладают соответствующей информацией.
Серверы DNS
Выше, при рассмотрении типов ресурсных записей я упоминал о первичном и вторичном сервере. Кроме данных типов, существует еще один тип — кэширующий.
Главный сервер DNS (он же первичный, он же master, он же primary) — это авторитетный сервер (иногда называют — авторитативный, как правильнее называть — не знаю), который хранит главную копию файла данных зоны, сопровождаемую администратором системы.
Вторичный сервер — тоже является авторитетным, но он копирует главный файл зоны с первичного сервера. Отличие главного от вторичного лишь в том, что главный загружает свою информацию из конфигурационных файлов зоны, а вторичный — загружает (получает) настройки зон — с главного сервера. Вторичный DNS может получать свои данные и от другого вторичного сервера. Любой запрос относительно хоста в пределах зоны, за которую отвечает авторитетный сервер, будет в конце концов передан одному из этих серверов (главному или вторичному). Вторичных серверов может быть сколько угодно много. В зависимости от настроек, главный сервер может посылать вторичному сигнал о изменении зоны, при этом вторичный, получив сигнал производит копирование. Данное действие называется трансфер зоны (zone transfer). Существует два механизма копирования зоны: полное копирование (AXFR) и инкрементальное (incremental) копирование зоны (IXFR).
Кэширующие серверы НЕ АВТОРИТЕТНЫ, данные серверы хранят в памяти (кэше), ответы на предыдущие запросы, если данный сервер получил запрос, то он сначала просматривает информацию в кэше, и если в кэше не оказалось необходимого ответа, то отправляет запрос вышестоящему серверу DNS.
Возможно так же настроить DNS в режиме stels (т.н. невидимый), информацию о данном сервере невозможно получить используя прямые запросы. Это может быть полезно для организации primary сервера в защищенной среде и тем самым оградить зону от атак на зону.
Клиенты DNS (resolver)
Как же программы на конечных машинах знают куда и в каком виде посылать запросы DNS? Они этого не знают. Для разрешения имен и IP адресов клиентскими приложениями используется библиотека Resolver. Это не какое-то специальное приложение, это функциональность системы (ядра). Т.о. приложения посылают системные вызовы gethostbyname(2) и gethostbyaddr(2), а ядро уже на основании настроек в файле /etc/nsswitch.conf определяет по какому пути ему далее действовать. Данный файл определяет какие сервисы (будь то файл /etc/hosts или DNS) и в каком порядке использовать. В ранних версиях библиотеки Linux — libc, использовался файл /etc/host.conf. Вот фрагмент файла, который нас интересует:
Две строки данного фрагмента указывают ядру производить преобразование имен хостов в IP (строка hosts: files dns) сначала из файла hosts, затем силами DNS, а так же преобразование имен сетей в IP (строка networks: files) с помощью файла /etc/network.Возможны так же параметры nis или nisplu, определяющие использовать Network Information System (NIS) чтобы найти адрес. Порядок, в котором перечислены сервисы, определяет последовательность их опроса.
Если согласно /etc/nsswitch.conf запрос отправляется DNS, то используются настройки из файла /etc/resolv.conf, который определяет какие серверы DNS использовать. Вот типичный пример файла /etc/resolv.conf:
Директива nameserver определяет адрес сервера доменных имен, который будет выполнять рекурсивные запросы resolver. В данном файле указано использовать север имен сначала 192.168.1.1 затем, если первый не смог обработать запрос, 192.168.1.2. Рекомендуется не использовать более 3х параметров nameserver. Если опция nameserver не задана, то резолвер попытается соединиться с сервером на локальном хосте. Параметр domain определяет заданное по умолчанию имя домена, которое будет подставлено, когда DNS не удастся найти имя хоста. Существует так же опция search, которая задает дополнительные домены, в которых необходимо произвести поиск и разрешение имени хоста. Опции search и domain нельзя использовать совместно.

Кроме кэша на ДНС сервере, существуют кэши интернет-браузеров, кэши резолверов. Довольно прозрачную картину предоставляет Wikipedia:
Запросы DNS
В DNS имеются следующие типы запросов: итеративный (он же прямой), обратный и рекурсивный.
Итеративный (он же прямой, он же нерекурсивный) запрос посылает доменное имя DNS серверу и просит вернуть либо IP адрес этого домена, либо имя DNS сервера, авторитативного для этого домена. При этом, сервер DNS не опрашивает другие серверы для получения ответа. Так работают корневые и TLD серверы.
Рекурсивный запрос посылает DNS серверу доменное имя и просит возвратить IP адрес запрошенного домена. При этом сервер может обращаться к другим DNS серверам.
Обратный запрос посылает IP и просит вернуть доменное имя.
Любой DNS-server должен отвечать на итеративные запросы. Возможно настроить DNS отвечать и на рекурсивные запросы. Если DNS не настроен отвечать на рекурсивные запросы, он обрабатывает их как итеративные.
- Клиент (браузер, почтовая программа, либо любое другое приложение) отправляет запросрезолверу, резолвер на основании указанных конфигов определяет адрес настроенного сервера имен.
- Резолверпосылает запрос указанному серверу имен.
- Сервер имен принимает данный рекурсивный запрос и, т.к. не имеет информации ни о домене, ни, возможно, даже о зоне name., отправляет рекурсивный (или нерекурсивный в зависимости от настроек) запроссерверу, отвечающему за корневую зону.
- Сервер корневой зоны не обрабатывает рекурсивные запросы, в результате обрабатывает данный запрос как итеративный и возвращает имя и адрес сервера, авторитетного за зону name.
- Сервер последовательно продолжает опрашивать авторитативные сервера для последующих зон, в порядке убывания уровня зон в имени
- пока не получает удовлетворительный ответ, данных шагов может быть больше, в зависимости от длины доменного имени
- и «вложенности» доменных имен.
- В итоге, сервер получает необходимый ответ от сервера имен, хранящего необходимую ресурсную запись о хосте.
- Сервер провайдера локальной сети возвращает резолверу клиента запрошенные данные.
Для решения данного вопроса DNS-серверы BIND используют метрику, называемую временем отклика (roundtrip time, или RTT), для выбора среди авторитативных DNS-серверов одной зоны. RTT определяет задержку, с которой приходит ответ на запросы от удаленного сервера. Каждый раз, при передаче запроса удаленному серверу, DNS-сервер BIND запускает внутренний таймер. Таймер останавливается при получении ответа, и метрика фиксируется локальным сервером. Если приходится выбирать один из нескольких авторитативных серверов, выбор падает на сервер с наименьшим показателем RTT.
До того как BIND впервые послал запрос какому-либо серверу и получил от него ответ, удаленному серверу присваивается случайное значение RTT, которое меньше, чем все прочие, полученные на основании замеров. Таким образом, DNS BIND гарантированно опросит все авторитативные серверы для определенной зоны случайным образом, прежде чем начнет выбирать предпочтительный на основании метрики.
Ответы DNS сервера
- Авторитативный ответ (authoritative response) приходит от серверов, являющихся ответственными за зону.
- Неавторитативный ответ (non authoritative response) приходит от серверов, которые не отвечают за зону (от кэширующих).
- Запись заголовка — служебную информацию о запросе.
- Запись запроса — повторяет отправленный запрос.
- Запись ответа — собственно, сам ответ.
- Записи авторитетных серверов — информацию об авторитетных серверах, хранящих информацию по текущему запросу.
- Дополнительную информацию — дополнительные записи, например адреса NS-серверов.
Обратное преобразование имен
DNS используется в первую очередь для преобразования доменных имён в IP-адреса, но он также может выполнять обратный процесс, называемый Обратное преобразование имен или обратным отображением. Т.к. записи в прямой базе DNS структурированы иерархически по доменным именам, DNS не может эффективно выполнять поиск по IP адресу в такой базе. Для обратного преобразования в DNS используется специальный домен in-addr.arpa. Ресурсные записи в данном домене в поле Name содержат IP-адреса, в поле Type — PTR, а в поле Data — FQDN-имя соответствующее данному IP.

На схеме представлена структура домена arpa. Думаю, что тут все довольно наглядно. Домен arpa. имеет 2 поддомена in-addr и ip6, отвечающие за IPv4 и IPv6 адреса соответственно. Домен in-addr.arpa. имеет от *.0.in-addr.arpa. до *.255.in-addr.arpa. поддоменов, каждый из которых так же имеет по 256 поддоменов.
В целях уменьшения объёма нежелательной корреспонденции (спама) многие почтовые серверы могут проверять наличие PTR записи для хоста, с которого происходит отправка. В этом случае PTR запись для IP адреса должна соответствовать имени отправляющего почтового сервера, которым он представляется в процессе SMTP сессии.
Наглядно приведенную схему можно представить командами:
Имя 50.0.87.194 не заканчивается точкой и поэтому является относительным. Вопрос: относительным относительно чего? Ни в коем случае не относительно "www.ru". Для того чтобы эта запись была FQDN, домен по умолчанию должен называться «IN-ADDR.ARPA.». Этого можно добиться либо поместив записи PTR в отдельный файл, в котором доменное имя зоны по умолчанию — IN-ADDR.ARPA. (заданный в файле начальной загрузки демона named), либо изменив этот домен с помощью директивы $ORIGIN. Если домен по умолчанию определен как 0.87.194.IN-ADDR.ARPA., то запись можно представить так:
В двух словах хотел бы затронуть вопрос регистрации доменных имен.
Регистратор доменных имён — это организация, имеющая полномочия создавать (регистрировать) новые доменные имена и продлевать срок действия уже существующих доменных имён в домене, для которого установлена обязательная регистрация.
В завершение статьи хочу отметить так же о таком маркетинговом нюансе, что иногда домены второго уровня называют именами доменов ПЕРВОГО уровня, тем самым «опуская» значение корневого домена и принимая за корневой домен — домены TLD.
Так же хочу отметить, что доменный адрес и IP-адрес не тождественны — один IP-адрес может иметь множество имён, что позволяет поддерживать на одном компьютере множество веб-сайтов (это называется виртуальный хостинг). Обратное тоже справедливо — одному имени может быть сопоставлено множество IP-адресов: это позволяет создавать балансировку нагрузки.
Резюме
Итак, в сегодняшней статье я постарался как можно понятней описать работы доменной системы имен. Надеюсь, это у меня получилось. Мы рассмотрели иерархическую структуру базы данных DNS, а так же рассмотрели процессы взаимодействия клиентов и серверов DNS, а так же разновидности серверов DNS. В следующей статье я рассмотрю практические вопросы установки и настройки DNS сервера BIND на Linux. Буду рад Вашим комментариям.
Что еще почитать:
Разместил с разрешения mcsim85, у которого еще нет полноценного аккаунта на хабре, но который за такие качественный статьи безусловно его заслуживает! На всякий случай ссылка на оригинал.
Терминология
Основными компонентами DNS являются:
Домен (доменное имя) — символьное имя для обозначения сервера в сети интернет. Доменные имена являются иерархической структурой, в которой каждый уровень отделяется точкой. Основными уровнями являются:
DNS-сервер — система, ответственная за хранение и поддержание в актуальном состоянии записей о своих дочерних доменах. Каждый DNS-сервер ответственен только за свою зону, то есть DNS-сервер домена .io знает о том, где расположен домен hexlet, DNS-сервер которого знает о расположении своих поддоменов.
Корневой DNS-сервер — система, знающая расположение (IP-адреса) DNS-серверов доменов верхнего уровня.
Ресурсная запись — единица информации DNS-сервера. Каждая ресурсная запись имеет несколько полей:
- Имя (домен, к которому относится запись)
- Тип
- Параметры
- Значение
Ресурсные записи DNS
Рассмотрим, какие ресурсные записи используются, и на что они указывают. Основными ресурсными записями DNS являются:
A-запись — одна из самых важных записей. Именно эта запись указывает на IP-адрес сервера, который привязан к доменному имени.
MX-запись — указывает на сервер, который будет использован при отсылке доменной электронной почты.
NS-запись — указывает на DNS-сервер домена.
TXT-запись — в этой записи хранится текстовая информация о домене. Часто используется для подтверждения прав на владение доменом, посредством добавления определённой строки, которую присылает нам интернет-сервис.
Ресурсные записи почти всегда одинаковые, но для некоторых записей могут появляться другие поля, например в MX-записях также присутствует значение приоритета. В основном ресурсные записи имеют следующую структуру:
Имя записи — указывается домен, которому принадлежит данная ресурсная запись.
TTL (time to live / время жизни) — время в секундах, на которое будет закешировано значение ресурсной записи. Это необходимо для разгрузки DNS-серверов. Благодаря кешированию и возможна ситуация, что ближайший DNS-сервер знает IP-адрес запрашиваемого домена.
Класс — предполагалось, что DNS может работать не только в сети интернет, поэтому в записи указывается и её класс. На сегодняшний день поддерживается только одно значение — IN (Internet).
Тип — указывает тип ресурсной записи, основные из которых были разобраны выше.
Значение — непосредственно значение ресурсной записи. В зависимости от типа ресурсной записи значения могут быть представлены в разном виде.
Утилита dig является DNS-клиентом и входит в состав одного из самых распространённых DNS-серверов BIND.
Выводы
DNS-сервера сейчас составляют основу всего интернета и используются почти в каждом действии пользователя в сети, будь то переход на сайт, отправка электронной почты, работы с интернет-приложением на телефоне и так далее. Поэтому знания о принципах работы DNS-серверов и основных ресурсных записях, благодаря которым и возможно перемещение по сети интернет, являются важными для разработчика.
Давайте для начала явно отметим отличие рекурсии (в общем смысле) от процесса. Эти понятия никак не связаны. Рекурсия — просто абстрактная концепция, которую можно наблюдать в природе, которая используется в математике и в других областях. Такая же абстрактная, как, например, музыкальная гармония.
пример рекурсии: художник рисует картину, в которой он рисует картину, в которой он рисует картину.
Теперь на секунду забудем про рекурсию, и просто подумаем про компьютеры. Для выполнения задач компьютерам нужны инструкции. Когда компьютер выполняет набор инструкций — это процесс. Ваш работающий сейчас браузер — это процесс. Простой цикл, выводящий на экран десять раз число "42" — это процесс. Некоторые задачи можно решать рекурсивно, то есть в инструкциях использовать эту концепцию, когда что-то является частью самого себя. В частности, функция может быть частью самой себя, то есть вызывать саму себя.
Есть два метода решения задач с использованием рекурсии: рекурсивный процесс и итеративный процесс. Рекурсия в них не отличается: в каждом из подходов функция вызывает саму себя, рекурсивно. Отличаются способы использования идеи рекурсии.
Если продолжить аналогию с музыкальной гармонией, то можно подумать про фортепиано. При написании музыки можно использовать эту концепцию — «гармонию звуков». И можно придумать разные способы: рассчитывать частоты звуков (ноты) математическими формулами или рассчитывать правильные расстояния между клавишами. Я в детстве научился находить правильные расстояния между клавишами на фортепиано, и получал гармоничные комбинации звуков, но понятия не имел, что это за ноты. А профессиональный музыкант знает теорию и подбирает гармонию другими методами. В любом случае, гармония есть гармония, эта концепция не меняется, меняются лишь способы ее использования.
В чем отличие итеративного процесса от рекурсивного?
Главная фишка в аккумуляторе или, иными словами, в запоминании.
Рекурсивный процесс постоянно говорит «я это запомню и потом посчитаю» на каждом шаге рекурсии. «Потом» наступает в самом конце.
- Когда рекурсивный процесс считает факториал 6, то ему нужно запомнить 5 чисел чтобы посчитать их в самом конце, когда уже никуда не деться и рекурсивно двигаться вниз больше нельзя.
- Когда мы находимся в очередном вызове функции, то где-то снаружи этого вызова в памяти хранятся эти запомненные числа.
тут прямо физически видно, как растет использование памяти: процессу нужно запоминать все больше и больше чисел
Рекурсивный процесс — это процесс с отложенным вычислением.
Итеративный процесс постоянно говорит «я сейчас посчитаю все что можно и продолжу» на каждом шаге рекурсии. Ему не нужно ничего запоминать вне вызова, он всегда считает все в первый возможный момент, и каждый шаг рекурсии может существовать в изоляции от прошлых, потому что вся информация передается из шага в шаг.
- Когда итеративный процесс считает факториал 6, то ему не нужно запоминать числа. Нужно лишь считать и передавать результат дальше, в новый вызов.
- Когда мы находимся в очередном вызове функции, снаружи этого вызова в памяти ничего не нужно запоминать.
тут видно, что использования памяти не растет
Рекурсивный процесс это чувак, который все дела откладывает на вечер пятницы. В течение недели у него мало работы, а в пятницу завал. Но ему так нравится :)
Итеративный процесс это чувак, который все делает при первой возможности. У него работа равномерно распределена по неделе, а пятница — просто обычный день, но последний.
Читайте также: