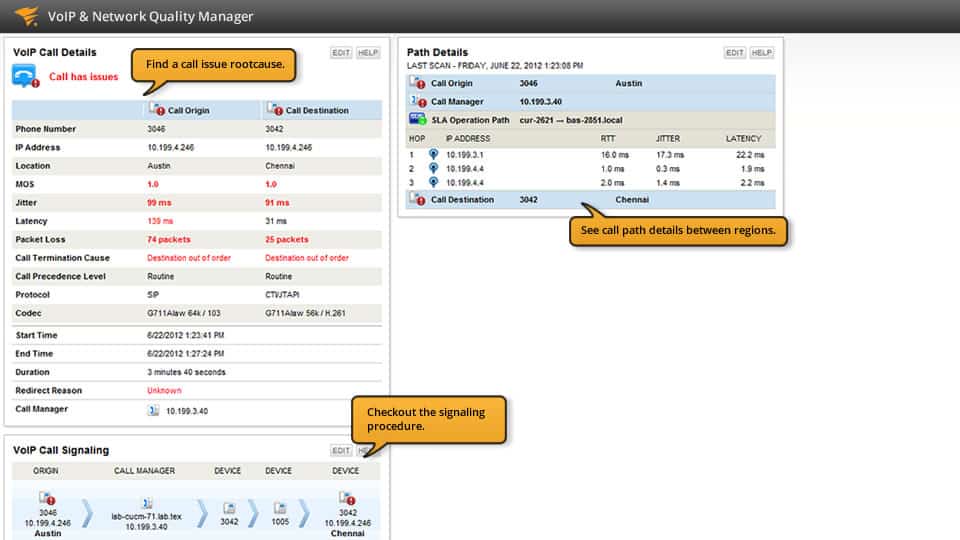
Чем определяется время задержки в сети ethernet

Я бы хотел опубликовать цикл статей об измерениях характеристик систем связи и сетей передачи данных. Эта статья вводная и в ней будут затронуты лишь самые основы. В дальнейшем планирую более глубокое рассмотрение в стиле «как это сделано».
Покупая продукт или услугу мы часто оперируем таким понятием как качество. Что же такое качество? Если мы обратимся к словарю Ожегова, то там увидим следующее: «совокупность существенных признаков, свойств, особенностей, отличающих предмет или явление от других и придающих ему определенность». Перенося определение на область сетей связи, приходим к выводу, что нам требуется определить «существенные признаки, свойства и особенности», позволяющие однозначно определить отличие одной линии или сети связи от другой. Перечисление всех признаков и свойств обобщаются понятием «метрика». Когда кто-то говорит о метриках сетей связи, он имеет в виду те характеристики и свойства, которые позволят точно судить о системе связи в целом. Потребность в оценке качества лежит большей частью в экономической области, хотя и техническая её часть не менее интересна. Я же попробую балансировать между ними, чтобы раскрыть все самые интересные аспекты этой области знаний.
Всех заинтересовавшихся прошу под кат.
Мониторинг и диагностика систем связи
Как я писал выше, метрики качества определяют экономическую составляющую владения сетью или системой связи. Т.е. стоимость аренды или сдачи в аренду линии связи напрямую зависит от качества этой самой линии связи. Стоимость, в свою очередь, определяется спросом и предложением на рынке. Дальнейшие закономерности описаны у Адама Смита и развиты Милтоном Фридманом. Даже во времена СССР, когда была плановая экономика, а о «рынке» думали, как о преступлении против власти и народа, существовал институт госприемки, как для военных, так и гражданских целей, призванный обеспечить надлежащее качество. Но вернемся в наше время и попробуем определить эти метрики.
Рассмотрим сеть на основе Ethernet, как самой популярной технологии на данный момент. Не будем рассматривать метрики качества среды передачи данных, поскольку они мало интересуют конечного потребителя (разве что материал самой среды иногда бывает интересен: радио, медь или оптика). Самая первая метрика, которая приходит в голову — пропускная способность (bandwidth), т.е. сколько данных мы можем передать в единицу времени. Вторая, связанная с первой,- пакетная пропускная способность (PPS, Packets Per Second), отражающая сколько фреймов может быть передано в единицу времени. Поскольку сетевое оборудование оперирует фреймами, метрика позволяет оценить, справляется ли оборудование с нагрузкой и соответствует ли его производительность заявленной.
Третья метрика — это показатель потери фреймов (frame loss). Если невозможно восстановить фрейм, либо восстановленный фрейм не соответствует контрольной сумме, то принимающая, либо промежуточная система его отвергнет. Здесь имеется ввиду второй уровень системы OSI. Если рассматривать подробнее, то большинство протоколов не гарантируют доставку пакета получателю, их задача лишь переслать данные в нужном направлении, а те кто гарантирует (например, TCP) могут сильно терять в пропускной способности как раз из-за перепосылок фреймов (retransmit), но все они опираются на L2 фреймы, потерю которых учитывает эта метрика.
Четвертая — задержка (delay, latency),- т.е. через сколько пакет отправленный из точки A оказаться в точке B. Из этой характеристики можно выделить еще две: односторонняя задержка (one-trip) и круговая (round-trip). Фишка в том, что путь от A к B может быть один, а от B к A уже совсем другим. Просто поделить время не получится. А еще задержка время от времени может меняться, или “дрожать”,- такая метрика называется джиттером (jitter). Джиттер показывает вариацию задержки относительно соседних фреймов, т.е. девиацию задержки первого пакета относительно второго, или пятого относительно четвертого, с последующим усреднением в заданный период. Однако если требуется анализ общей картины или интересует изменение задержки в течении всего времени теста, а джиттер уже не отражает точно картину, то используется показатель вариации задержки (delay variation). Пятая метрика — минимальный MTU канала. Многие не придают важности этому параметру, что может оказаться критичным при эксплуатации “тяжелых” приложений, где целесообразно использовать jumbo-фреймы. Шестой, и малоочевидный для многих параметр — берстность — нормированная максимальная битовая скорость. По этой метрике можно судить о качестве оборудования, составляющего сеть или систему передачи данных, позволяет судить о размере буфера оборудования и вычислять условия надежности.
Об измерениях
Поскольку с метриками определились, стоит выбрать метод измерения и инструмент.
Задержка
Известный инструмент, поставляемый в большинстве операционных систем — утилита ping (ICMP Echo-Request). Многие ее используют по нескольку раз на дню для проверки доступности узлов, адресов, и т.п. Предназначена как раз для измерения RTT (Round Trip Time). Отправитель формирует запрос и посылает получателю, получатель формирует ответ и посылает отправителю, отправитель замеряя время между запросом и ответом вычисляет время задержки. Все понятно и просто, изобретать ничего не нужно. Есть некоторые вопросы точности и они рассмотрены в следующем разделе.
Но что, если нам надо измерить задержку только в одном направлении? Здесь все сложнее. Дело в том, что помимо просто оценки задержки пригодится синхронизировать время на узле отправителе и узле-получателе. Для этого придуман протокол PTP (Precision Time Protocol, IEEE 1588). Чем он лучше NTP описывать не буду, т.к. все уже расписано здесь, скажу лишь то, что он позволяет синхронизировать время с точностью до наносекунд. В итоге все сводится к ping-like тестированию: отправитель формирует пакет с временной меткой, пакет идет по сети, доходит до получателя, получатель вычисляет разницу между временем в пакете и своим собственным, если время синхронизировано, то вычисляется корректная задержка, если же нет, то измерение ошибочно.
Если накапливать информацию об измерениях, то на основании исторических данных о задержке можно без труда построить график и вычислить джиттер и вариацию задержки — показатель важный в сетях VoIP и IPTV. Важность его связана, прежде всего, с работой энкодера и декодера. При “плавающей” задержке и адаптивном буфере кодека повышается вероятность не успеть восстановить информацию, появляется “звон” в голосе (VoIP) или “перемешивание” кадра (IPTV).
Потери фреймов
Проводя измерения задержки, если ответный пакет не был получен, то предполагается, что пакет был потерян. Так поступает ping. Вроде тоже все просто, но это только на первый взгляд. Как написано выше, в случае с ping отправитель формирует один пакет и отправляет его, а получатель формирует свой собственный о отправляет его в ответ. Т.е. имеем два пакета. В случае потери какой из них потерялся? Это может быть не важно (хотя тоже сомнительно), если у нас прямой маршрут пакетов соответствует обратному, а если это не так? Если это не так, то очень важно понять в каком плече сети проблема. Например, если пакет дошел до получателя, то прямой путь нормально функционирует, если же нет, то стоит начать с диагностики этого участка, а вот если пакет дошел, но не вернулся, то точно не стоит тратить время на траблшутинг исправного прямого сегмента. Помочь в идентификации могла бы порядковая метка, встраиваемая в тестовый пакет. Если на обоих концах стоят однотипные измерители, то каждый из них в любой момент времени знает количество отправленных и полученных им пакетов. Какие именно из пакетов не дошли до получателя можно получить сравнением списка отправленных и полученных пакетов.
Минимальный MTU
Измерение этой характеристики не то чтобы сложно, скорее оно скучно и рутинно. Для определения минимального размера MTU (Maximum transmission unit) следует лишь запускать тест (тот же ping) с различными значениями размеров кадра и установленным битом DF (Don't Fragmentate), что приведет к непрохождению пакетов с размером кадра больше допустимого, ввиду запрета фрагментации.
Например, так не проходит:
А так уже проходит:
Не часто используемая метрика с коммерческой точки зрения, но актуальная в некоторых случаях. Опять же, стоит отметить, что при асимметричном пути следования пакетов, возможен различный MTU в разных направлениях.
Пропускная способность
Наверняка многим известен факт, что количество переданной полезной информации в единицу времени зависит от размера фрейма. Связано это с тем, что фрейм содержит довольно много служебной информации — заголовков, размер которых не меняется при изменении размера фрейма, а изменяется поле “полезной” части (payload). Это значит, что несмотря на то, что даже если мы передаем данные на скорости линка, количество полезной информации переданной за тот же период времени может сильно варьироваться. Поэтому несмотря на то, что существуют утилиты для измерения пропускной способности канала (например iperf), часто невозможно получить достоверные данные о пропускной способности сети. Все дело в том, что iperf анализирует данные о трафике на основе подсчета той самой «полезной» части, окруженной заголовками протокола (как правило UDP, но возможен и TCP), следовательно нагрузка на сеть (L1,L2) не соответствует подсчитанной (L4). При использовании аппаратных измерителей скорость генерации трафика устанавливается в величинах L1, т.к. иначе было бы не очевидно для пользователя почему при измерении размера кадра меняется и нагрузка, это не так заметно, при задании ее в %% от пропускной способности, но очень бросается в глаза при указании в единицах скорости (Mbps, Gbps). В результатах теста, как правило, указывается скорость для каждого уровня (L1,L2,L3,L4). Например, так (можно переключать L2, L3 в выводе):

Пропускная способность в кадрах в секнду
Если говорить о сети или системе связи как о комплексе линий связи и активного оборудования, обеспечивающего нормальное функционирование, то эффективность работы такой системы зависит от каждого составляющего ее звена. Линии связи должны обеспечивать работу на заявленных скоростях (линейная скорость), а активное оборудование должно успевать обрабатывать всю поступающую информацию.
У всех производителей оборудования заявляется параметр PPS (packets per second), прямо указывающий сколько пакетов способно «переварить» оборудование. Ранее этот параметр был очень важен, поскольку подавляющее число техники просто не могло обработать огромное количество “мелких” пакетов, сейчас же все больше производители заявляют о wirespeed. Например, если передаются малые пакеты, то времени на обработку тратится, как правило, столько же, сколько и на большие. Поскольку содержимое пакета оборудованию не интересно, но важна информация из заголовков — от кого пришло и кому передать.
Сейчас все большее распространение в коммутирующем оборудовании получают ASIC (application-specific integrated circuit) — специально спроектированные для конкретных целей микросхемы, обладающие очень высокой производительностью, в то время как раньше довольно часто использовались FPGA (field-programmable gate array) — подробнее об их применении можно прочитать у моих коллег здесь и послушать здесь.
Бёрстность
Стоит отметить, что ряд производителей экономит на компонентах и использует малые буферы для пакетов. Например заявлена работа на скорости линка (wirespeed), а по факту происходят потери пакетов, связанные с тем, что буфер порта не может вместить в себя больше данных. Т.е. процессор еще не обработал скопившуюся очередь пакетов, а новые продолжают идти. Часто такое поведение может наблюдаться на различных фильтрах или конвертерах интерфейсов. Например предполагается, что фильтр принимает 1Gbps поток и направляет результаты обработки в 100Mbps интерфейс, если известно, что отфильтрованный трафик заведомо меньше 100Mbps. Но в реальной жизни случается так, что в какой-то момент времени может возникнуть «всплеск» трафика более 100Mbps и в этой ситуации пакеты выстраиваются в очередь. Если величина буфера достаточна, то все они уйдут в сеть без потерь, если же нет, то просто потеряются. Чем больше буфер, тем дольше может быть выдержана избыточная нагрузка.

Всем привет!
В этот раз подошло время рассмотреть стандартный тест RFC2544: для чего используется, как проводится, его достоинства и недостатки.
Со времени прошлой статьи ко мне поступили отзывы коллег с предложением писать ближе к делу: меньше воды — больше специфики. Так что предлагаю эту статью считать экспериментальной. В конце материала небольшой опрос.
Введение
Рекомендация RFC2544 была разработана в 1999 году и принята IETF . Существует перевод на русский язык. Сейчас эта рекомендация практически стандарт де-факто, благодаря широкому распространению и свободному доступу. Рекомендация “описывает и определяет набор тестов для определения характеристик устройств межсетевых соединений”, описывает форматы представления результатов тестирования.
Структура методики
Тестирование по методике RFC2544 сводится к выполнению набора тестов, четыре из которых присутствуют у большинства производителей измерительного оборудования, а два встречаются довольно редко (последние в списке).
- Throughput
- определяет пропускную способность DUT , по рекомендации RFC1242
- определяет нагрузку, при которой нет потерь пакетов
- определяет задержку, по рекомендации RFC1242
- измеряет задержку по кадрам выборочно
- определяет частоту потери кадров, по рекомендации RFC1242, во всем диапазоне скоростей данных и размеров кадра
- определяет зависимость потерь от нагрузки
- определяет возможность DUT по обработке кадров back-to-back, по рекомендации RFC1242
- измеряет длительность работы при заданной нагрузке
- определяет скорость восстановления DUT после перегрузки трафиком
- определяет скорость восстановления DUT после программного или аппаратного сброса
Пропускная способность
Определяется максимальное количество кадров в секунду, которое может передать устройство без ошибок. Скорость определяется методом бисекции. Тест начинается на максимальной скорости. В случае потерь, скорость уменьшается в два раза. Если потерь нет, то скорость увеличивается в два раза, по сравнению с предыдущей. И так далее. Максимальная скорость определяется по стабильности работы (нет потерь) на протяжении 60 секунд. Тестирование проводится для каждого размера кадра. Размеры задаются в параметрах теста RFC2544 перед запуском.
Задержка
Тест опирается на предыдущее измерение пропускной способности. Для каждого размера пакета с соответствующей ему максимальной скоростью генерируется поток данных. Поток должен иметь длительность минимум 120 секунд. В 1 пакет по прошествии 60 секунд вставляется метка времени. На передающей стороне записывается время отправки пакета. На приемной стороне определяется метка отправителя и записывается время приема пакета. Задержка — это разница времени получения и времени отправки. Тест должен повторяться минимум 20 раз. По результатам измерений вычисляется средняя задержка.
Потеря пакетов
Подсчитывается процент потери пакетов (отношение потерянных к отправленным). Измерение начинается на максимальной скорости и с каждой следующей попыткой уменьшается на 10% (или меньше). Скорость понижается до тех пор, пока два измерения подряд не пройдут без потерь.
Back-to-back
Тест заключается в проверке оборудования обработать кадры, идущие с минимальным межкадровым интервалом, т.е. спиной к спине (back-to-back). Начинается с установленного в параметрах теста RFC2544 количества кадров. Если потери не наблюдаются (на протяжении не менее 2 секунд), то количество кадров увеличивается, если присутствуют, то уменьшается. По итогам не менее 50 измерений вычисляется среднее значение.
Недостатки методики
Методика тестирования стара (разработана в 1999 году) и сегодня уже не соответствует требованиям рынка. Из недостатков выделяются:
невозможно постоянно измерять задержку (Frame Transfer Delay, FTD)
отсутствует измерение вариации задержки (Frame Delay Variation, FDV)
нет многопоточности, все выполняется по очереди
тест долгий (исходя из предыдущего пункта)Дополнения к методике
Jitter
Пакетный джиттер — это абсолютная разность задержек распространения двух последовательно принятых пакетов, принадлежащих одному потоку данных.
Идеальный вариант — полное отсутствие дрожания:
Возможный вариант — различная задержка между соседними пакетами:Complex traffic
Тест позволяет генерировать и принимать несколько потоков тестового трафика.
Измеряет пропускную способность и величину потерь кадров (Frame Loss Rate, FLR), но не позволяет измерять постоянно задержку (FTD) и вариацию задержки (FDV).Заключение
Методика RFC2544 сейчас присутствует в оборудовании большинства производителей, в первую очередь исторически, и можно сказать что сегодня она — такой же базовый тест для пакетных сетей Ethernet, как BERT для сетей TDM. Но стоит помнить, что RFC2544 не проводит всестороннее тестирование и даже при успешном прохождении всех тестов может возникнуть ситуация, что сеть не будет функционировать как ожидалось.
На смену методике RFC2544 приходит Y1564, которой собираюсь посвятить следующую статью.![]()
На Хабре уже была заметка о том, как работает PTPv2. Я же собираюсь рассказать о том, как и для чего данный метод высокоточной синхронизации был реализован в наших приборах.
Для чего это надо
Я работаю в российской компании НТЦ-Метротек, которая разрабатывает и выпускает кучу всякой аппаратуры (свичи, тестеры, балансировщики и т.д.) для систем связи, в том числе и тестеры для ethernet-сетей. Например, вот такой. Одним из параметров, измеряемых этим прибором, является задержка прохождения пакета в тестируемой сети. Ха, скажет читатель Хабрахабра — задержку можно и ping'ом померить. Так-то оно и есть, но при разной загруженности сети может быть разная задержка. Наш прибор может измерять задержку с точностью до нескольких наносекунд и при этом создавать нагрузку до 10 Гб/с.
Для измерения задержки в каждый пакет, генерируемый анализатором, вставляется метка времени, а при приёме этого пакета определяется разность между текущим временем и данными из метки. Эта разность и есть задержка. Но так как обычно трафик от анализатора идет до специального устройства (шлейф), которое заворачивает этот трафик обратно к тестеру, то измеренная задержка является суммой времени прохождения пакетов от тестера к шлейфу (upstream) и от шлейфа к тестеру (downstream). Если канал симметричный, то есть его параметры равны в обоих направлениях, то задержку в одном направлении можно получить просто поделив измеренное значение на два.![]()
В случае, когда канал не симметричный, надо измерять задержку отдельно в каждом из направлений. При этом используются два анализатора. Один генерирует тестовый трафик, второй его принимает и анализирует.
![]()
Тут-то и потребовалась высокоточная синхронизация времени, так как для корректного определения задержки необходимо, чтобы счетчики времени на обоих приборах имели одинаковое значение.
Как реализовано у нас
Упрощенную схему нашего прибора можно представить в следующем виде:
![]()
За отсчет времени отвечает FPGA, на ней реализован счетчик времени, работающий от частоты 125 МГц (отсюда и точность 8 нс). Счетчик времени может отличаться от эталонных часом смещением т.е. либо отставать, либо спешить на какое-то константное значение. Также может отличаться скорость изменения, то есть за секунду идеальный счетчик отсчитает 1*10^9 наносекунд, а реальный может насчитать либо больше, либо меньше, в результате чего смещение постоянно или увеличивается, или уменьшается. Для корректировки этих ошибок в FPGA реализована следующая схема:
![]()
Текущее значение счетчика можно изменить на заданную величину при помощи регистра offset. Для плавной подстройки используется дополнительный счетчик, при достижении им заданного значения (drift) счетчик времени либо пропускает один такт, либо вместо 1 увеличивается на 2. Т.е. если задать 10, то за десять тактов счетчик времени изменится на 11, за 20 тактов на 22 и т.д. Если задано отрицательное число, например -10 то за 10 тактов счетчик времени изменится на 9, за 20 тактов на 18 и т.д.
Если посмотреть на диаграмму обмена, то видно, что при реализации PTPv2 клиента (Slave) надо точно знать время, когда приходит пакет от сервера (t2) и время, когда был отправлен ему ответ(t3).
![]()
Для этих целей мы модифицировали в FPGA MAC-ядро. При приеме сетевых пакетов к каждому из них добавляется метка времени (t2). А при отправлении пакетов текущее значение счетчика времени (t3) помещается в специальный регистр. На основании этих значений микроконтроллер и рассчитывает текущее рассогласование времени между эталонным источником и прибором.
Для проверки нашей реализации в качестве сервера PTPv2 мы сначала использовали обычный компьютер, на котором был запущен демон ptpd. Чтобы демон мог работать с PTP поверх ethernet (по умолчанию от работает только поверх UDP), надо надо разрешить работу с libpcap. Для этого при конфигурировании надо задать ключ -with-pcap-config.
При запуске ptpd надо указать конфигурационный файл, например, вот такой:
ptpengine:interface = eth0
ptpengine:preset = masteronly
ptpengine:transport = ethernet
ptpengine:use_libpcap = Y
ptpengine:delay_mechanism = E2EДля начала решили посмотреть, как будут расходиться счетчики времени на компьютере и приборе, если не делать подстройку частоты.
![]()
Видно, что зависимость почти линейная, за секунду счетчик на приборе убегает вперед на двадцать с лишним микросекунд.
Затем вычисленное значение рассогласования стали записывать в регистр корректировки смещения (offset):
![]()
По этому графику также видно, что в среднем за секунду набегает ошибка около 22 микросекунд. Использовать подстройку при помощи смещения не очень хорошо, так как при этом происходит скачкообразное изменение счетчика, а так как это изменение происходит асинхронно на двух приборах, то это может приводить к большим ошибкам при измерении задержки. Лучше воспользоваться плавной подстройкой частоты, записать в регистр drift, такое значение, что бы счетчик в FPGA корректировался на 22 микросекунды за одну секунду.
Для автоматической подстройки реализовали ПИ регулятор. Для интегральной составляющей установили коэффициент равный 0.01 а для пропорциональной 0.05.
С ним зависимость рассогласования от времени выглядит так:
![]()
Видно, что рассогласование «шумит» и достигает 20 и более микросекунд. Это не удивительно, ведь в качестве PTP сервера используется обычный компьютер.
Когда мы проверили нашу реализацию с сервером точного времени Метроном-50, в котором реализована аппаратная поддержка PTP, то получили рассогласование величиной в десятки наносекунд, что вполне достаточно для корректного измерения задержки в асимметричном канале.
![]()
Выводы
Если задержка в тестируемом канале измеряется в миллисекундах, то в качестве PTP-сервера можно использовать обычный компьютер с демоном ptpd. Если же задержка в сети несколько микросекунд, то без сервера с аппаратной поддержкой PTP не обойтись.![Задержка против пропускной способности]()
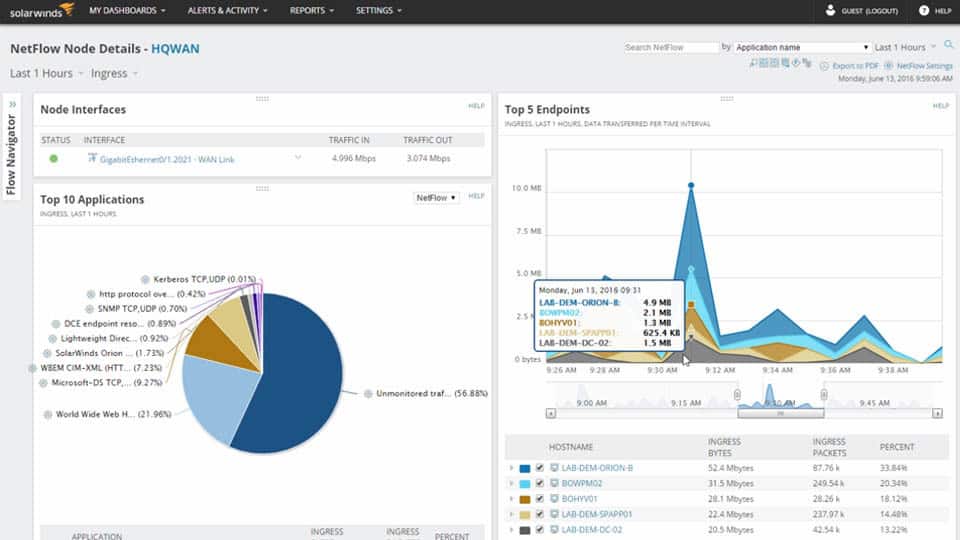
Существует ряд различных метрик, которые можно использовать для измерения скорости передачи данных по сети.. Возможность определить скорость вашего сервиса предоставляет вам метрику для измерения производительности сети. Пропускная способность и задержка являются одними из наиболее распространенных способов измерения сетей. Измерение уровня пропускной способности или задержки может помочь выявить проблемы с производительностью в вашей сети..
Однако эти понятия не одно и то же. В этой статье мы рассмотрим разница между задержкой и пропускной способностью и как они могут быть использованы для измерения того, что происходит. Прежде чем мы это сделаем, мы собираемся определить, что такое задержка и пропускная способность.
Вкратце, задержка и пропускная способность определяются следующим образом:
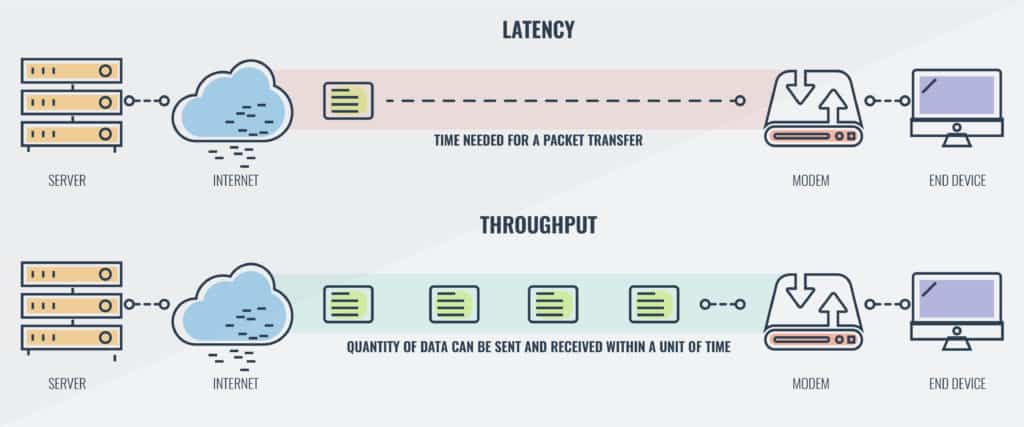
- Задержка - Время, необходимое для передачи пакета по сети. Вы можете измерить это как в одну сторону до места назначения или как туда и обратно.
- пропускная способность - Количество данных, отправляемых и получаемых в единицу времени
Мы рассмотрим их по отдельности более подробно ниже. Но сначала мы собираемся сравнить два непосредственно.
Мы подробно рассмотрим инструменты, представленные ниже, но если у вас есть время для быстрого взгляда, вот наш Список лучших инструментов для измерения пропускной способности сети и задержки сети:
- Пакет анализатора пропускной способности сети SolarWinds (БЕСПЛАТНАЯ ПРОБНАЯ ВЕРСИЯ) Основные инструменты анализа пропускной способности сети и мониторинга производительности, состоящие из монитора производительности сети и анализатора трафика NetFlow
- Пакет инструментов SolarWinds Flow (Бесплатный набор инструментов) Бесплатный инструмент для мониторинга потока трафика внутри сети.
- Датчик круговой передачи Paessler PRTG QoS (БЕСПЛАТНАЯ ПРОБНАЯ ВЕРСИЯ) Проанализируйте качество сетевого соединения, которое обменивается данными через два сетевых зонда.
Инструменты для измерения пропускной способности сети
Мониторинг QoS для телефонов VoIP: VoIP SolarWinds & Менеджер качества сети (БЕСПЛАТНАЯ ПРОБНАЯ ВЕРСИЯ)
![Скриншот монитора сети VoIP SolarWinds]()
Учитывая, что дрожание сети является проблемой, которая очень проблематична для вызовов VoIP, принятие Решение по мониторингу QoS для VoIP поможет вам устранить неполадки для поддержания этой важной службы. Инструменты сетевого мониторинга, такие как SolarWinds VoIP & Менеджер по качеству сети позволяют измерять такие показатели, как дрожание, задержка, и потеря пакета которые влияют на конечную производительность вызовов VoIP.
SolarWinds VoIP & Менеджер по качеству сети Это хороший выбор, потому что он не только отслеживает эти метрики, но и активно уведомляет вас при обнаружении джиттера. Это означает, что вы будете получать оповещение каждый раз, когда выполнение вызова падает против любого количества предопределенных параметров. Знание того, как именно ваш звонок терпит неудачу, позволяет вам устранять неполадки с гораздо большей информацией. SolarWinds VoIP & Менеджер по качеству сети доступна на 30-дневную бесплатную пробную версию для оценки.
Инструменты для измерения задержки сети
Как найти джиттер с помощью инструментов мониторинга сети
Развертывание инструмента мониторинга сети - один из лучших способов следить за развитием джиттера сети. Средство мониторинга сети сможет сообщить вам, когда служба работает на низком уровне, а также поможет вам увидеть, когда вы превысили текущие ограничения пропускной способности, установленные вашим провайдером..
Мониторинг джиттера очень важен, потому что он позволяет вам действовать в тот момент, когда он становится проблемой. Это также дает вам контекст проблемы производительности, чтобы вы могли проводить информированное устранение неполадок в будущем. Благодаря появлению возможности дрожания сети ваши усилия по устранению и предотвращению дрожания сети в будущем будут более информированными и эффективными..
В следующем разделе мы рассмотрим, как вы можете использовать инструменты мониторинга сети для реализации мониторинга QoS. Следя за проблемами производительности, такими как дрожание и задержка, вы сможете определить, когда ваша сеть работает хорошо и когда вам нужно вмешаться.
Вот два лучших инструмента для борьбы с дрожанием сети:
Соотношение между пропускной способностью, задержкой и пропускной способностью
Соотношение между пропускной способностью и задержкой основано на концепции пропускной способности. Пропускная способность это имя, данное количество пакетов, которые могут быть переданы по всей сети. Если вы думаете о канале, физический канал ограничивает количество контента, которое может передаваться через канал. В контексте сети это количество пакетов, которые могут быть переданы одновременно..
Время, необходимое для прохождения пакета от источника к месту назначения, называется задержкой. Задержка показывает, сколько времени требуется пакетам, чтобы добраться до места назначения. пропускная способность это термин, данный количество пакетов, которые обрабатываются в течение определенного периода времени. Пропускная способность и задержка напрямую связаны с тем, как они работают в сети.
Иными словами, отношения между этими тремя являются следующими:
- пропускная способность сети указывает максимальное количество разговоров, которое может поддерживать сеть. Беседы - это обмен данными из одной точки в другую..
- Задержка используется для измерения как быстро эти разговоры происходят. Чем больше задержка, тем дольше эти разговоры удерживаются.
- Уровень задержки определяет максимальную пропускную способность разговора. Пропускная способность - это количество данных, которое может быть передано в ходе разговора..
Естественно, объем данных, которые могут быть переданы в разговоре, уменьшается с увеличением задержки. Это связано с тем, что для передачи данных в ходе разговора требуется больше времени, поскольку пакетам требуется больше времени для достижения места назначения. Теперь мы собираемся взглянуть на эти концепции более подробно.
Что является причиной плохой пропускной способности сети?
Плохая пропускная способность сети может быть вызвана рядом факторов. Один из главных виновников низкая производительность оборудования. Если такие устройства, как маршрутизаторы, испытывают снижение производительности, сбои или просто устарели, вы можете получить низкую пропускную способность. Аналогично, если сети перегружены большим количеством трафика, произойдет потеря пакетов. Потеря пакетов - это когда пакеты теряются при передаче. Низкая пропускная способность сети часто возникает, когда пакеты теряются при передаче..
Конечные точки монитора
Один из способов ограничения задержки в сети - начать мониторинг ваших конечных точек. Конечные точки являются источником задержки, поскольку они могут использоваться для запуска приложений с интенсивным использованием полосы пропускания. Эти проблемы с пропускной способностью или ведущие разговоры занимают сетевые ресурсы и увеличивают задержку для других ключевых служб. Мониторинг этих конечных точек с помощью такого инструмента, как Монитор производительности сети SolarWinds или Paessler PRTG Сетевой монитор позволяет вам убедиться, что это не мошеннические приложения, вызывающие проблемы с задержкой.
Настройки QoS: расстановка приоритетов пакетов
Приоритизация пакетов - это тип настройки QoS, при котором вы устанавливаете приоритеты для определенного типа трафика, чтобы уменьшить перегрузку сети.. Ваш приоритетный трафик будет иметь права передачи по сравнению с другими типами трафика и будет отправлен первым в любом сценарии. Приоритет трафика зависит от услуги, которую вы хотите поддерживать. Как правило, приоритезация пакетов зарезервирована для тех критически важных приложений, которые всегда требуют высокой производительности.
Для поддержки вызова VoIP и обеспечения наилучшего качества вам необходимо убедиться, что любые пакеты, содержащие медиаданные VoIP, имеют приоритет над другим трафиком. Вы должны установить канал передачи данных с «высоким приоритетом», чтобы этот трафик обрабатывался раньше всего. В случае перегрузки канала передачи данных неприоритетный трафик будет отброшен до приоритетного трафика..
Чтобы расставить приоритеты VoIP-трафика, вы можете приоритезировать транспортный протокол в реальном времени (RTP) пакеты. Как это сделать, будет зависеть от дизайна вашего роутера. Например, на маршрутизаторе Linksys вы можете перейти к представлению QoS в веб-интерфейсе. Чтобы расставить приоритеты RTP-трафика, вы должны ввести следующее номера портов:
После перезапуска трафик RTP будет более привилегированным, чем любой другой трафик. Независимо от того, какое устройство вы используете, вы хотите сохранить настройки как можно более простыми, чтобы не перегружать свои конфигурации.
Мониторинг QoS для джиттера: PRTG Network Monitor (БЕСПЛАТНАЯ ПРОБНАЯ ВЕРСИЯ)
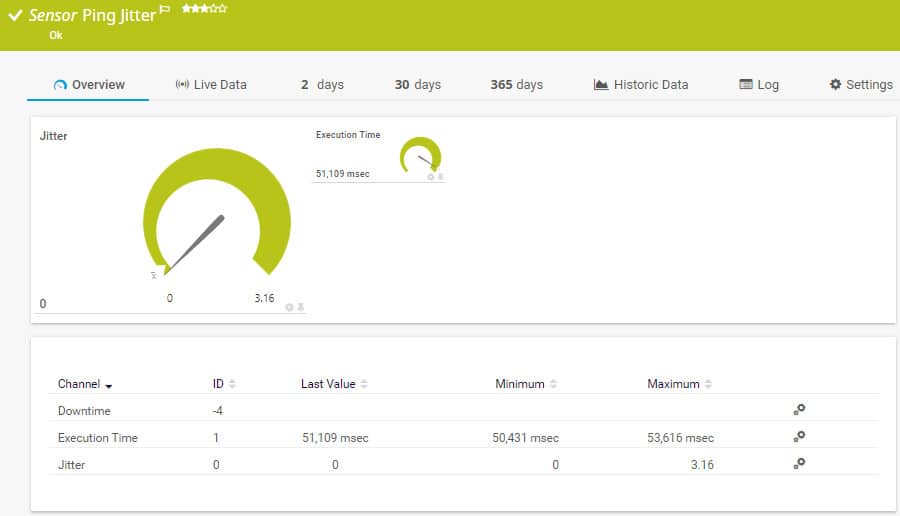
![Скриншот PRTG для сетевого монитора Ping Jitter Sensor]()
Paessler PRTG Сетевой монитор предлагает ряд функций, которые очень полезны для мониторинга джиттера. Инструмент включает в себя QOS датчик прохождения сигнала, Односторонний датчик QOS, Cisco IP SLA Sensor, и, в частности, Датчик дрожания пинга предназначен для измерения степени влияния джиттера на ваш сервис. Датчик Ping Jitter отправляет ICMP-запросы на URL для определения статистического значения джиттера и времени выполнения.
Результат показан на циферблатах с прозрачным цветом, как показано на рисунке выше. Эта функция полезна для тех, кто хочет определить, насколько сильно дрожание влияет на ключевой сервис. Также вы можете использовать PRTG Сетевой монитор настроить свои собственные уникальные оповещения, чтобы уведомлять вас, когда у службы возникают проблемы с производительностью. В реальной среде это помогает вам быстро реагировать на дрожание, когда оно происходит. Вы можете попробовать Paessler Ping Jitter Sensor который поставляется в комплекте в Paessler PRTG Сетевой монитор на 30-дневную бесплатную пробную версию.
Что такое джиттер?
Джиттер или дисперсия задержки пакета это термин, используемый для обозначения колебаний задержки при передаче пакетов по сети. Таким образом, джиттер является изменяющейся скоростью задержки в сети и измеряется в миллисекундах. Например, если у вас есть два компьютера, которые общаются друг с другом в офисе, произойдет обмен пакетами данных. В исправных сетях эти пакеты будут проходить с постоянным интервалом (примерно 10 мс задержки на пакет).
В сети, испытывающей дрожание, уровень задержки во время передачи будет колебаться и может привести к задержке 50 мс при передаче пакетов. Конечный результат перегрузка сети, когда устройства борются за одно и то же пространство. Чем больше трафика перегружено, тем больше вероятность потери пакетов..
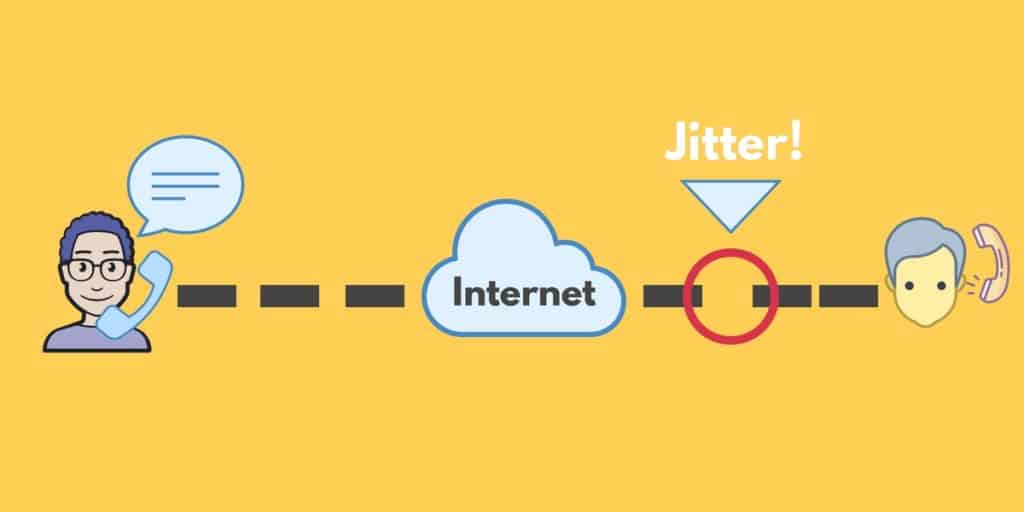
![что такое диаграмма джиттера]()
На изображении выше изображен диалог VoIP, в котором пакеты преобразуют звук голоса пользователя и транспортируют его в конечный пункт назначения. Как вы можете видеть с левой стороны, пакеты проходят через интервалы без изменений. Однако с правой стороны компоновка пакетов была нарушена, и конечный пользователь получает пакеты вне времени. Это приводит к аудио, которое трудно различить и понять.
Что такое пропускная способность сети?
Чем ниже пропускная способность, тем хуже работает сеть. Устройства полагаются на успешную доставку пакетов для связи друг с другом, поэтому, если пакеты не достигают пункта назначения, конечный результат будет низкого качества обслуживания. В контексте вызова VoIP низкая пропускная способность может привести к тому, что вызывающие абоненты будут иметь плохое качество вызова с пропусками звука.
Как предотвратить дрожание
Конечно, как только вы обнаружите, что у вас есть дрожание сети, вам нужно будет принять меры для его устранения. Есть несколько различных способов сделать это от приоритезации определенного трафика до развертывания буфера дрожания. В этом разделе мы собираемся обсудить некоторые из наиболее распространенных способов борьбы с дрожанием сети и вернуть сеть к полной работе..
Самое замечательное в большинстве этих техник состоит в том, что они удваиваются, чтобы уменьшить задержку. Некоторые из приведенных ниже шагов позволяют вам «убить двух зайцев одним выстрелом», чтобы устранить задержки и дрожание одновременно. Перед выполнением любого из этих изменений вы должны быть абсолютно уверены в влиянии джиттера на вашу сеть (идентифицируя его с помощью инструмента сетевого мониторинга).
Датчик круговой передачи Paessler PRTG QoS (БЕСПЛАТНАЯ ПРОБНАЯ ВЕРСИЯ)
Отслеживание наличия задержки помогает вам измерить стандарт вашего соединения и определить, что ваша служба работает хорошо без каких-либо узких мест в трафике.. Paessler PRTG Сетевой монитор имеет ряд функций мониторинга задержки сети, которые делают его идеальным для этой задачи. С PRTG Network Monitor вы можете контролировать пропускную способность вашей сети, чтобы увидеть силу вашего соединения.
![Задержка против пропускной способности - понимание разницы]()
Датчик прохождения сигнала QoS PRTG используется для мониторинга задержки, возникающей при передаче пакетов по сети. Датчик прохождения сигнала QoS может быть настроен как оповещение, чтобы уведомлять вас, когда задержка превышает определенные пороговые значения. Это очень удобно, если вы хотите убедиться, что задержка не станет проблемой для производительности вашей сети..
Буферы джиттера для минимизации джиттера
Всякий раз, когда скорость дрожания превышает пороговые значения приемлемого дрожания, намеченные Cisco, хорошей идеей будет рассмотреть возможность развертывания буфер дрожания. Буфер дрожания - это устройство, которое используется для противодействия задержке или задержке путем сохранения поступающих пакетов в течение короткого периода времени, прежде чем передать их конечному пользователю. Буферы дрожания настроены для буферизации трафика в течение 30-200 мс, прежде чем трафик будет отправлен конечному пользователю.
В контексте VoIP или видеовызова это привело бы к меньшему дрожанию и разговору, который остается понятным для обеих сторон. Буфер дрожания будет задержать пакеты данных перед отправкой в попытке чтобы убедиться, что пакеты поступают в последовательности. В вызове VoIP конечный результат сводит к минимуму дрожание и перерывы в качестве вызова.
Однако важно отметить, что с помощью буфера дрожания вы будете увеличивать общую задержку в вашей сети. Удерживая пакеты буфер дрожания буквально добавляет задержку на службу. Аналогично, вы должны быть осторожны с настройкой буферов дрожания при реализации полнодуплексной связи. В результате вы хотите проверить канал передачи перед развертыванием буфера дрожания.
Основная проблема с буферами дрожания состоит в том, что они являются решением проблемы с полосой. Они не обращаются к основной причине дрожания, они только обращаются к признакам. Если вы хотите полностью устранить дрожание сети, вам нужно углубиться в сердце вашего маршрутизатора. Добавление новых настроек QoS позволит вам начать решать корень проблемы и улучшить свой сервис.
Пакет анализатора пропускной способности сети SolarWinds (БЕСПЛАТНАЯ ПРОБНАЯ ВЕРСИЯ)
Учитывая влияние пропускной способности сети на производительность вашей сети, важно следить за ней. Для этого вам нужен инструмент мониторинга сети. Есть много разных инструментов, которые вы можете использовать, но один из лучших Пакет анализатора пропускной способности сети SolarWinds. Это решение может измерять пропускную способность сети для мониторинга потоковых данных пропускной способности наряду с доступностью сетевых устройств..
![Скриншот пакета анализатора пропускной способности SolarWinds Network]()
Пакет анализатора пропускной способности сети SolarWinds является хорошим выбором для адресации пропускной способности сети, поскольку она помогает вам указать на основную причину. Вы можете обнаружить проблемы с производительностью в вашей сети и принять меры для их устранения, чтобы пропускная способность упала до минимума.
Перезагрузите ваше оборудование
Перезагрузка оборудования при возникновении проблем с производительностью устраняет неполадки 101. Перезапуск роутера очищает кеш так что он может начать работать, как это было в прошлом. Это также может быть применено к вашим компьютерам. Хотя это кажется простым решением, вы будете удивлены, как много проблем с производительностью можно решить, выполнив эти основные шаги.
QoS останавливает дрожание сети
В большинстве случаев дрожание сети не является большой проблемой. Однако, если вы начнете использовать расширенные сервисы, такие как системы VoIP-телефонов и программное обеспечение для видеоконференций, вам, скорее всего, потребуется внедрить QoS для управления дрожанием сети. Даже если вы не страдаете от джиттера в сети, оставайтесь на связи и следите за качеством своих услуг с помощью монитора производительности сети, чтобы убедиться, что джиттер не станет нерешенной проблемой.
Как только дрожание сети становится очевидным, измерьте, насколько оно сильное. Если он превышает пороговые значения, указанные Cisco, тогда стоит вмешаться и принять меры. Вы можете сделать это, установив приоритет передачи критических пакетов и развернув буфер дрожания. Хотя обновление пропускной способности также является возможным решением, оно часто лучше оптимизировать текущую пропускную способность, чем просто покупать больше пропускной способности.
Принимая упреждающий подход к смягчению последствий дрожания сети, вы убедитесь, что в следующий раз, когда вы общаетесь с клиентом или коллегой, весь разговор протекает естественно. Помните, что плохое голосовое общение не только неудобно, но и потенциально может стоить вам значительной суммы денег (особенно если вы общаетесь с клиентом!). Инвестирование в инструменты мониторинга сети и другие решения теперь поможет вам сэкономить деньги в будущем.
Как уменьшить задержку и пропускную способность
Если вы установили, что задержка и пропускная способность являются проблемой в вашей сети, существует ряд шагов, которые можно предпринять, чтобы устранить проблему..
Что вызывает задержку в сети?
Задержка сети может быть вызвана целым рядом проблем, но, как правило, все зависит от состояния маршрутизаторов и расстояния между вашими сетевыми устройствами.. Чем больше маршрутизаторов проходит пакет, тем больше задержка это происходит потому, что каждый маршрутизатор должен обрабатывать пакет. В большинстве случаев эта задержка не заметна, но когда трафик проходит через Интернет, он может быть более выраженным (поскольку увеличивается количество маршрутизаторов, через которые проходит пакет).
Расстояние, которое проходит пакет, также может оказать существенное влияние на величину задержки в сети.. Пакет, который путешествует по миру, будет иметь задержку не менее 250 мс. В сетях уровня предприятия задержка присутствует в меньшей степени. Когда пакеты проходят через сеть к месту назначения, они редко передаются по узлу по прямой линии. Таким образом, величина задержки зависит от маршрута, который принимает пакет..
В хорошо спроектированной сети должны быть доступны эффективные маршруты, чтобы пакеты быстро доставлялись к месту назначения. Если сеть плохо спроектирована с непрямыми сетевыми путями, то задержка будет гораздо более выраженной.
Пропускная способность и пропускная способность
Пропускная способность - это термин, используемый для описания максимального объема данных, которые могут быть переданы по вашей сети.. Пропускная способность вашей сети ограничена стандартом вашего интернет-соединения и возможностями ваших сетевых устройств. Думайте о пропускной способности как о границах вашего сетевого подключения. Напротив, пропускная способность - это фактическая скорость передачи данных в вашей сети..
Безусловно что пропускная способность ниже, чем пропускная способность. Это связано с тем, что пропускная способность представляет собой максимальные возможности вашей сети, а не фактическую скорость передачи. Это наиболее важно отметить во время пиковых периодов или когда проблемы с производительностью нарастают, поскольку пропускная способность часто будет ниже пропускной способности.
Пропускная способность сети Базовые показатели сети
Одна из самых важных частей информации, которую вам необходимо знать при измерении пропускной способности сети, - это базовая линия вашей сети.. Базовая сеть - это то, где вы измеряете производительность вашей сети в режиме реального времени.. Другими словами, базовый уровень сети - это проверка прочности вашего живого соединения. Базовая сеть - это то, где вы отслеживать сетевой трафик для выявления тенденций, просмотреть распределение ресурсов, посмотреть историческое представление и выявить аномалии производительности. Базовая оценка вашей сети предоставляет вам систему координат, к которой вы можете обратиться при мониторинге производительности вашей сети..
Для мониторинга пропускной способности вашей сети вы бы хотели отслеживать такие факторы, как утилизация ресурсов и сетевой трафик чтобы увидеть, насколько хорошо работает сеть. Настройка базовых показателей сети может быть настолько простой или сложной, насколько вы хотите. Первые шаги должны составить схему сети для сопоставления вашей сети и к определить политику управления сетью. Схема сети предоставляет вам дорожную карту для ваших устройств, а политика определяет, какие службы разрешено запускать в вашей сети..
Как измерить задержку и пропускную способность
Задержка - один из самых надежных способов измерения скорости вашей сети.. Задержка измеряется в миллисекундах. Если вы хотите измерить объем данных, перемещающихся из одной точки в другую, вы будете использовать пропускную способность сети. Пропускная способность измеряется в битах в секунду (бит / с) в виде мегабит в секунду (Мбит / с) или гигабит в секунду (Гбит / с). Пропускная способность - это скорость, с которой пакеты успешно достигают своего назначения в течение определенного периода времени. Хотя вы можете рассчитать пропускную способность, проще измерить ее с помощью bps, чем выполнять вычисления.
Другие решения
Здесь мы рассмотрим некоторые другие решения, которые, тем не менее, не являются наиболее распространенными способами предотвращения дрожания сети, тем не менее, заслуживают рассмотрения..
1. Купите новый, более мощный маршрутизатор
2. Увеличьте пропускную способность или перейдите на высокоскоростное подключение к Интернету.
В ряде случаев проблема заключается не в вашей инфраструктуре, а в скорости вашего соединения. Низкие скорости соединения имеют тенденцию создавать дрожание, особенно при совместном использовании полосы пропускания с другими устройствами. Увеличение пропускной способности вашего текущего интернет-провайдера или смена поставщиков услуг может привести к заметному улучшению обслуживания, которое устраняет дрожание.
Что такое латентность сети?
Прежде всего, задержка является мерой задержки. Эта мера задержки определяет количество времени, которое требуется пакету для перемещения от источника к месту назначения через сеть. Как правило, это измеряется в обе стороны но это часто измеряется как путешествие в один конец. Задержка кругового обхода чаще всего используется, потому что компьютеры часто ждут, чтобы подтверждения были отправлены обратно с устройства-получателя, прежде чем отправлять всю информацию целиком (это подтверждает, что существует соединение для отправки данных).
Как следствие, наличие задержки указывает на то, что сеть работает медленно. Чем больше задержка, тем больше времени требуется, чтобы пакет достиг пункта назначения. Это приводит к медленным и нестабильным услугам. Например, если вы набираете что-то на удаленном устройстве, может пройти несколько секунд, прежде чем то, что вы набрали, появится на экране..
Почему задержка сети и пропускная способность важны?
Важна задержка и пропускная способность сети потому что они влияют на производительность вашей сети. Если задержка слишком высока, пакетам потребуется больше времени, чтобы достичь места назначения. Чем больше времени требуется пакетам для достижения места назначения, тем медленнее устройства, службы и приложения будут работать в сети. Аналогичным образом, чем меньше пропускная способность, тем меньше количество пакетов, обрабатываемых за определенный период времени..
Когда задержка и пропускная способность минимальны, они не являются большой проблемой. Однако, когда задержка становится слишком высокой или пропускная способность падает, ваша сеть останавливается. Это точка, в которой службы начинают работать медленно, поскольку пакеты не могут достичь своего места назначения со скоростью, которая может поддерживать полную работу вашей сети..
это важно измерить задержку и пропускную способность сети потому что это позволяет вам проверить, что ваша сеть не становится жертвой низкой производительности. Существует несколько способов измерения задержки и пропускной способности, но самый простой способ - использовать инструмент мониторинга сети. Этот тип инструмента сможет сообщить вам, когда задержка и пропускная способность достигли проблемных уровней.
Что такое приемлемый джиттер?
![диаграмма допустимого джиттера]()
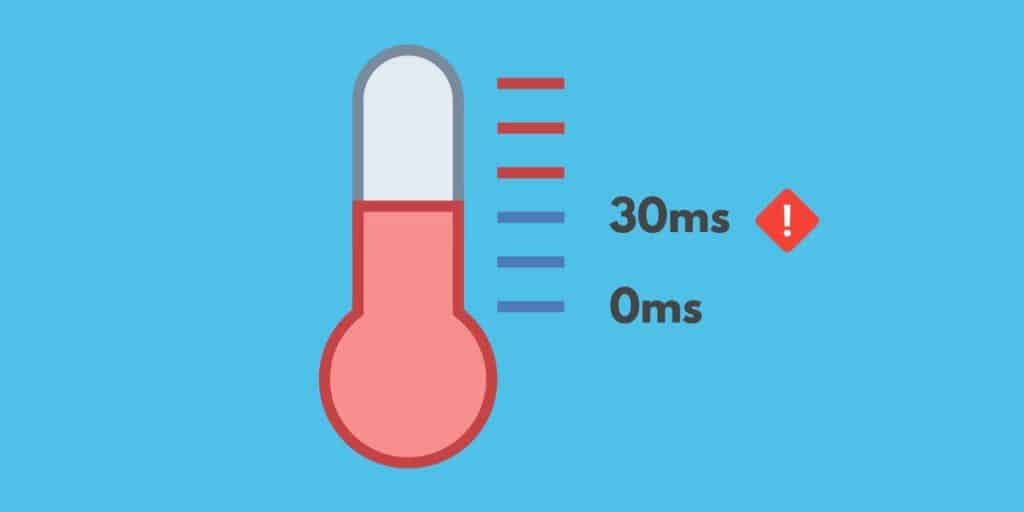
Хотя дрожание далеко не идеально, во многих случаях небольшое дрожание в вашей сети не окажет заметного влияния на вашу связь. Иногда возникают аномальные колебания, которые не имеют длительного эффекта. В этих случаях джиттер не является большой проблемой. Cisco предполагает, что приемлемые уровни дрожания или уровни допуска дрожания являются следующими:
- Джиттер ниже 30 мс
- Менее 1% от потери пакетов
- Общая задержка сети менее 150 мс
В идеале, вы должны стараться держать джиттер ниже 20 мс для лучшей производительности. Если ваш джиттер превышает 30 мс, это будет заметно влиять на качество ваших разговоров в реальном времени. На 30 мс или старше вы начнете испытывать искажения, которые сделают другого пользователя более трудным для понимания.
В случае, если ваш джиттер, потеря пакета или задержка превысят показатели, перечисленные выше, вам следует немедленно предпринять действия, чтобы найти причину проблемы. Поддерживая эти ключевые показатели ниже пороговых значений, вы можете гарантировать, что важные службы, включающие видеозвонки и VOIP-звонки, не испытывают серьезных проблем с производительностью.
Как джиттер влияет на сеть?
Эффект джиттера зависит от услуги, которую вы используете. На некоторых сервисах дрожание не будет очень заметным, но на других, таких как VoIP-звонки и видеозвонки, оно будет гораздо более выраженным. Джиттер оказывает наибольшее влияние на услуги реального времени, такие как трафик VoIP. Когда вы разговариваете по телефону VoIP, вы общаетесь с другим пользователем вживую, и все, что вы слышите, должно быть кристально чистым. Это означает, что поступающие аудиосигналы должны поддерживаться в последовательности, чтобы оставаться понятными.
То же самое нельзя сказать о загрузках файлов, когда вы не сможете определить, вызвало ли дрожание пакеты, которые были задержаны или скремблированы. Для разговоров по VoIP, что-либо меньшее, чем доставка сигнала в реальном времени, приведет к разговору с неразборчивыми аудиосигналами. Пропуски в аудио и шаткие звуковые сигналы характерны для джиттера, принимающего разговор.
Пакет инструментов SolarWinds Flow (Бесплатный набор инструментов)
![Набор инструментов SolarWinds NetFlow]()
Пакет инструментов SolarWinds Flow включает в себя три простых, но мощных средства:
- NetFlow Configurator
- NetFlow Replicator
- NetFlow Generator
Вы можете использовать NetFlow Configurator в пакете Flow Tool в качестве стандартного интерфейса, который связывается с данным маршрутизатором Cisco и настраивает его функции NetFlow для отправки данных вашему коллектору.
Две другие утилиты в комплекте помогают протестировать сеть и спланировать увеличение спроса с помощью анализа NetFlow..
NetFlow Replicator отправит пакеты NetFlow указанным адресатам в вашей сети. Это позволяет вам изучать возможности вашей инфраструктуры и помогает выявлять узкие места. NetFlow Generator создает дополнительный трафик для вашей сети. Это позволяет протестировать поведение балансировщиков нагрузки, брандмауэров и предупреждений о мониторинге производительности сети..
Flow Tool Bundle - отличная бесплатная утилита, которая дает вам возможность получить представление о готовности вашей сети к расширению услуг и спросу..
Комплект инструментов SolarWinds Flow Загрузите 100% БЕСПЛАТНО набор инструментов
Мониторинг пропускной способности и задержки для QOS
Мониторинг вашей задержки и пропускной способности - единственный способ убедиться, что ваша сеть работает на высоком уровне. Если есть высокая задержка и низкая пропускная способность, тогда ваша пропускная способность используется неэффективно. Чем раньше вы узнаете об этом, тем скорее сможете предпринять действия и начать устранение неполадок. Без решения для мониторинга сети будет намного сложнее отслеживать эти объекты. Несоблюдение этих требований приведет к снижению производительности сети..
В тот момент, когда вы видите, что, например, присутствует задержка, вы знаете, что пакетам требуется слишком много времени, чтобы достичь места назначения. Это может привести к пропускной способности, которая ограничивает количество пакетов, которые могут быть отправлены во время разговора. Это означает, что пришло время начать устранение неполадок по причине задержки и пропускной способности.
После мониторинга вашей сети вы можете затем искать различные исправления в вашей сети, чтобы увидеть, если проблема устранена. Если проблема не устраняется, вы просто продолжаете, пока не найти основную причину. После того, как вы закончили устранение неполадок, вы должны были найти причину проблемы и устранить ее. Имея четкие метрики для работы с сетевого монитора, вы сможете поддерживать свою производительность как можно скорее.
![Что такое сетевой джиттер и как его предотвратить?]()
Когда вы находитесь в центре телефонного звонка VoIP, есть несколько вещей, которые расстраивают, как дрожание сети. Джиттер - это одно из тех сбоев, которое ни один сетевой администратор не хочет видеть влияющим на их сервис. Джиттер находится в той же категории проблем с производительностью сети, что и задержка, задержка, и потеря пакета.
>>>Перейти к лучшим инструментам сетевого джиттера
Прежде чем идти дальше, полезно определить эти три понятия, поскольку они довольно часто встречаются вместе:
- дрожание - колебания скорости задержки по сети
- задержка - Сколько времени требуется пакету для перемещения из одной конечной точки в другую
- Задержка - Сколько времени требуется одному пакету, чтобы добраться из одной точки в другую
- Потеря пакета - отказ одного или нескольких пакетов достичь пункта назначения
В то время как дрожание сети влияет на некоторые приложения и сервисы гораздо сильнее, чем на другие, дрожание - это проблема, которую необходимо решить. В этой статье мы рассмотрим, что такое джиттер и как можно управлять джиттером в сети корпоративного уровня..
Задержка против пропускной способности
![Задержка против пропускной способности - понимание разницы]()
Задержка и пропускная способность - это две очень разные концепции, которые тесно связаны друг с другом. Задержка измеряет скорость передачи пакетов, тогда как пропускная способность используется для обозначения максимальной пропускной способности сети. Самый простой способ объяснить отношения между ними состоит в том, что пропускная способность относится к тому, насколько велика труба, а задержка используется для измерения скорости перемещения содержимого трубы к месту назначения..
Эти два имеют причинно-следственную связь. Например, чем меньше у вас пропускная способность, тем больше времени потребуется для того, чтобы ваши данные достигли места назначения, и тем больше будет задержка. Аналогично, чем больше у вас пропускная способность, тем быстрее пакеты достигнут места назначения. Это имеет место, даже если у вас низкая задержка.
Почему джиттер является такой проблемой для телефонных звонков VoIP?
Всякий раз, когда обсуждается дрожание сети, телефонные звонки VoIP являются одной из наиболее часто упоминаемых областей, где дрожание является вредным. Это в первую очередь из-за способа передачи данных VoIP. Когда вы говорите в VoIP телефон ваш голос преобразуется в данные, которые передаются через Интернет. Ваш голос разбивается на множество разных пакетов и затем передается вызывающему абоненту на другом конце.
Однако, пока ваши сегментированные речевые данные находятся в пути, они конкурируют с диапазоном другого трафика, проходящего через вашу сеть. Все эти данные влияют на сетевые ресурсы, что иногда приводит к задержке. Эта задержка может не проявляться при загрузке файла, но когда ваш голос проходит через неорганизованные пакеты, это может привести к путанице и искажению того, что вы первоначально сказали пользователю.
Напротив, когда вы отправляете электронное письмо, пакеты повторно собираются непосредственно перед тем, как они достигают пользователя на другом конце. С вызовами VoIP на это нет времени, и поэтому ваш голос звучит не по порядку. Именно по этой причине VoIP является одной из ключевых проблем, когда речь идет о дрожании сети, поскольку он является одним из наиболее восприимчивых. Это верно и для других сервисов реального времени, таких как видеозвонки и видеоигры..
Одной из наиболее распространенных причин дрожания услуг VoIP является отсутствие приоритетов пакетов. Если голосовые пакеты не имеют приоритета, то конечный пользователь, скорее всего, получит дрожание. Решение заключается в том, чтобы перейти к маршрутизатору и определить приоритеты пакетов, которые передаются по сети (подробнее о расстановке приоритетов мы рассмотрим ниже).
Ищите узкие места в сети
Иногда причина задержки сводится к узким местам в сети. Узкое место в сети возникает, когда поток пакетов ограничен сетевыми ресурсами. Существует множество различных способов устранения узких мест, но один из них улучшает дизайн вашей локальной сети.. Сегментирование вашей сети на VLAN может помочь повысить производительность. Вы также хотите убедиться, что сетевые карты сервера могут работать с более высокой скоростью, чем узлы в вашей сети..
Читайте также: