
Asr что это в компьютере
неизвестный
Категории форматов файлов включают в себя двоичные, текстовые, XML и Zip. Формат этого типа файла не был определен.
Сбор и разметка данных
Пожалуй, самая важная часть создания технологии распознавания речи — это подготовка данных. Если вы спросите разработчиков, сколько данных нужно для обучения – никто вам не ответит. Данных никогда не бывает слишком много. Нужны тысячи часов, чтобы получить хорошее распознавание. При этом, источники данных нужны именно такие, какие требуются для вашего продукта. Конечно, решения вроде уже упомянутого выше Wav2Vec позволяют значительно уменьшить потребность в аннотированных данных для обучения итоговой системы, но, как показала практика, с ростом количества этих данных качество всё равно растёт, и 10 минут размеченных аудио может и хватит для получения хороших результатов на довольно искусственном корпусе на английском языке, но этого совершенно недостаточно для промышленной системы. Стоит упомянуть, что, когда собираются датасеты – не все данные, которые вы получаете, например, от колл-центров, получится использовать для дообучения модели. Это могут быть какие-то мусорные данные, шумы, когда даже человеку невозможно распознать, что было сказано. Моделям на вход лучше подавать только те данные, в которых вы абсолютно уверены.
Итак, первый датасет, с которым мы начали работать – открытый 46-часовой датасет M-AILABS. Неплохой вариант для начала, содержащий очень чистые отрывки из аудиокниг, на нём мы проводили первые сравнения различных архитектур и фреймворков. Однако, в реальных условиях обученные на нём модели работали из рук вон плохо. Добавление аугментаций лишь немного спасало ситуацию. Также, конечно, стоит упомянуть проект Mozilla Common Voice, данные в котором уже менее лабораторные, и они периодически пополняются. Относительно недавно был опубликован датасет Open STT для русского языка, но перед использованием важно обратить внимание на происхождение данных в этом датасете + ограничения лицензии.
Отмечу, что если у вас есть конкретные алгоритмы на все компоненты ASR и датасет, то совершенно не гарантировано хорошее распознавание на новых целевых данных, сильно отличающихся от тех, на которых вы обучали нейронную сеть. Если вы собрали большое количество аудиокниг, и построили модели на них, то не факт, что ваш ASR будет успешно справляться с телефонными разговорами. Там, помимо сильно искаженного и сжатого сигнала аудио, сплошная живая человеческая речь, содержащая слова-паразиты, мычание, запинания и прочие моменты, которые совершенно не присущи речи профессиональных дикторов.
На подготовку своих собственных датасетов в достаточном для более-менее адекватного распознавания речи (не аудиокниг!) у нас ушло порядка 6 месяцев, и мы продолжаем подготовку данных, именно поэтому в начале для экспериментов мы рекомендуем брать уже готовые датасеты (тем более что сейчас в открытом доступе их стало значительно больше), и на них сравнивать различные решения.
В итоге на открытых датасетах мы сравнили качество, скорость обучения, простоту интерфейсов различных технологий, и остановились на wav2letter в качестве архитектуры для акустической модели системы, которую мы планировали дальше развивать. В дальнейшем мы переписали её архитектуру и код обучения на наш собственный нейросетевой фреймворк – PuzzleLib, стали подключать разные языковые модели, декодеры и прочее. Это заняло у нас несколько месяцев. Пример кода обучения базовой модели на нашем фреймворке можно найти в документации.
Новость. Недавно мы выложили свою нейросетевую библиотеку в Open Source. Всем, кому интересно пощупать, вот Github, а вот документация.
Для последующего обучения перед нами стояла задача собрать максимальный объем аудио, однако изначально у нас не было возможности скооперироваться с крупным колл-центром, как это делают другие крупные вендоры, поэтому следующим этапом стал сбор аудиокниг из открытых источников, лицензия которых позволяла использование. Так, мы нарезали и отекстовали аудио фрагментов на 1600+ часов. С книгами дополнительно было проще в плане текстов, они уже были подготовлены, и достаточно было лишь сравнивать после нарезки, что нарезанные кусочки не обрезаны, не содержат лишних призвуков и вообще соответствуют тексту. Сейчас инструменты для такого forced alignment можно без труда найти в интернете на свой вкус.
Чтобы повысить качество распознавания в телефонном тракте, а также повысить качество распознавания при работе с микрофонами конечных пользовательских устройств (смартфонов, ноутбуков и тд), мы в ходе обучения случайным образом добавляли различные аугментации, такие как вставка шумов окружения, добавление эффекта реверберации в аудио (имитация отражений звука от поверхностей), эквализация (в телефонных записях задраны средние частоты), замедление, ускорение, изменение высоты тона и многие другие.
Качество распознавания выросло, но из-за того, что сама речь в аудиокнигах записывалась в “лабораторных” условиях, модель, которую мы обучили на них, плохо себя показывала на живых разговорах. То есть дикторы в аудиокнигах зачитывали произвольные тексты, но обычные люди в жизни так не говорят. Также ошибочным шагом будет сбор данных, которые “начитывают” по листу, пусть даже непрофессиональные дикторы, пусть даже это записи из телефонного канала. Стало понятно, что нужно учиться самим добывать, нарезать и размечать данные (та же телефония и т. д.). Мы начали с внутренней телефонии компании, начали переговоры с потенциальными партнёрами, заинтересованными в автоматизации колл-центров. Абсолютно непригодна для сбора качественнго датасета Яндекс.Толока: добиться качественной работы с разметчиками Толоки не получится, нужна плотная работа с разметчиками.
Поэтому мы также начали разработку своего инструмента для разметки аудиозаписей – Маркера. Так у нас появился свой отдел разметки и качественный сервис, генерирующий нам датасеты.

Разметчики, которые отекстовывают аудио, могут допускать ошибки. Это все нужно валидировать, контролировать, организовывать коллективные проверки одного и того же аудио, и т. д. В Маркере есть механика распределения заданий по людям так, чтобы каждая запись попадала к несколькими специалистам, а потом – к эксперту в случае разрозненных мнений. Мы это называем “экспертной оценкой”. Еще в работе с разметчиками мы применяем логику honeypots. Её смысл заключается в том, что мы даем человеку 100 заданий на разметку, при этом, на самом деле, из этих ста заданий мы и так знаем правильный ответ на 10 заданий. И если человек путается даже в этих десяти заданиях, то мы принимаем решение что, вероятно, либо человек ленится, либо просто он неопытный, и стоит с ним еще провести тренинг. Разметчиков у нас сейчас порядка 100 человек, мы с ними постоянно ведем работу, учим их, разбираем ошибки, ввели рейтинговую систему, систему экспертов – это в итоге позволяет получать очень хорошее качество (менее 3% WER).
Параллельно со сбором данных к августу 2019 года у нас сформировалось понимание того, что делать с этими данными, автоматизировались процессы передачи данных в обучение, тестирования.
неизвестный
Категории форматов файлов включают в себя двоичные, текстовые, XML и Zip. Формат этого типа файла не был определен.
О файлах ASR
Наша цель - помочь вам понять, что такое файл с суффиксом * .asr и как его открыть.
Все типы файлов, описания форматов файлов и программы, перечисленные на этой странице, были индивидуально исследованы и проверены командой FileInfo. Мы стремимся к 100% точности и публикуем информацию только о тех форматах файлов, которые мы тестировали и проверяли.
Если вы хотите предложить какие-либо дополнения или обновления на этой странице, пожалуйста, сообщите нам об этом.
Мы в Наносемантике занимаемся виртуальными ассистентами (чат-ботами и голосовыми помощниками) для компаний с большими колл-центрами. Раньше мы использовали распознавание и синтез речи других компаний, а 1.5 года назад решили, что хотим быть самодостаточным вендором.

Если интересно, зачем нам это, что у нас получилось, а также для чего нам выкладывать ASR & TTS в Open Source – добро пожаловать под кат.
Делать ASR – интересно и сложно, но можно взять готовые Open Source ASR, в частности, наш SOVA ASR и датасеты для него. Ссылки см. в конце статьи.
Что такое ASR файл?
Файл ActionScript на стороне сервера, созданный с помощью Adobe Dreamweaver или Contribute; использует тот же язык и синтаксис, что и стандартный файл ActionScript ( .AS ), но может иметь доступ к встроенным серверным функциям ColdFusion; файл «Default.asr», установленный с Dreamweaver и Contribute, находится в папке NewDocuments.
Зачем нам нужен свой ASR
ASR (распознавание речи) мы используем для голосовых помощников. В основном, это проекты по роботам-консультантам и голосовым помощникам для крупных банков – для снижения нагрузки на колл-центры.
В наших проектах нам иногда приходится использовать решения Яндекса, ЦРТ и других вендоров: если у заказчика уже ASR внедрён, например, в IVR, и закуплен какой-то объём лицензий. В этом случае разработчик голосового робота (мы) сталкивается с довольно сложным процессом настройки бота, поскольку на чужой ASR тяжело повлиять.
NLU (движок анализа текстов) чат-бота всегда получает от ASR текст, который содержит ошибки распознавания, какой бы ASR ни был. Например, какие-то слова могут быть для ASR не знакомы. Не все движки/сервисы ASR позволяют проводить настройку, обучение языковой модели и прочее. Поэтому в NLU приходится закладываться на то, что могут прилететь «приколы» от ASR. Кроме того, качество поставленных в крупные компании годы назад ASR (с бессрочной лицензией) – ужасное.
Поэтому нам хотелось иметь в своём распоряжении собственный ASR. И TTS, аналогично.
Из чего состоит система распознавания речи?
Для приготовления ASR нужны два ингредиента – алгоритмы и обучающие данные.
ASR – это целый комплекс алгоритмов обработки сигналов и текстов. Традиционно системы распознавания речи состояли из нескольких компонентов:
- акустическая модель, которая переводит сегменты звука (например, 20-ти миллисекундные кадры спектрограмм) в фонемы,
- модель произношения, соединяющая фонемы вместе для формирования слов,
- языковая модель, выражающая вероятности построенных фраз на основе частотных характеристик совместной встречаемости слов в том или ином корпусе речи.
Эти данные (примеры) «показываются» алгоритму, обучающему акустическую и языковую модели. Механика процесса – классическое машинное обучение.
Тип файла 3Adobe Photoshop Scratch File
| разработчик | Adobe Systems |
| популярность | 2.0 (3 Голоса) |
| категория | Дата файлы |
| Формат | Бинарный Х |
двоичный
Этот файл сохраняется в двоичном формате, который требует определенной программы для чтения его содержимого.
Метрики качества
Сразу необходимо заметить, что ни одно из бесплатных или платных решений, существующих на данный момент, не дает 100% точность распознавания. Чего уж там, даже человек иногда не может однозначно понять, что было сказано другим, особенно, если второй человек произносит слова из тематики, с которой первый не знаком. Самый простой пример – вы наверняка слышали, как во время звонка кого-нибудь просят продиктовать фамилию по слогам, а то и по буквам, потому что фамилии достаточно разнообразны, и ни у кого в голове попросту не может находиться полный список всех фамилий и их написаний.
Здесь также можно привести пример про профессиональные термины: когда мы уже начали размечать данные из колл-центров отдела продаж SEO-услуг, мы даже составили для разметчиков небольшой словарь терминов поисковой оптимизации, так как люди просто не знали некоторых слов и поначалу неправильно отекстовывали или просто браковали непонятные им записи. Слова “аудит”, “пагинация”, “сео”, “сниппет”, “фавикон” и так далее – заимствованы из других языков и незнакомы большинству людей.
Добавлю, что даже если вы сможете прочитать по буквам новое незнакомое слово, оно все равно будет вызывать первое время заминку при прочтении, потому что вы его не ожидаете увидеть. Точно так же, если в лексиконе и языковой модели нет каких-то слов или словосочетаний, то система ASR попросту не сможет правильно распознать сказанное, и выдаст что-то близкое по звучанию. Если же кто-то скажет очень тихо и неразборчиво даже знакомое вам слово – вы, скорее всего, переспросите.
Для оценки качества распознавания существуют определенные метрики. Одна из наиболее популярных – WER (Word Error Rate) – мера оценки ошибки на уровне слов. Эта метрика – отношение суммы количества вставок лишних слов, удалений и замен слов к количеству слов в референсе (то есть к ручной отекстовке). По некоторым оценкам, на большом наборе произвольных аудиозаписей с речью даже человек допускает ошибки вплоть до WER = 0.05. Также можно рассматривать метрику CER (или LER, Character Error Rate/Letter Error Rate), которая рассчитывается аналогично, но на уровне букв, и по сути своей является расстоянием по Левенштейну.
Пример:
Оригинальная фраза: «жили у бабуси два весёлых гуся»
Предсказание: «пили у бабуси весёлых гуся да»
Посчитаем метрики качества: на уровне слов имеем «пили» вместо «жили» – замена, исчезло слово «два» – удаление, в конце появилось слово «да» – вставка. На уровне букв: «пили» вместо «жили» – замена буквы «ж» на «п», удаление букв «д», «в», «а» и одного пробельного символа из-за исчезнувшего слова «два», вставка букв «д» и «а» и пробельного символа из-за добавления слова «да» в конце. В оригинале 5 слов и 30 букв (вместе с пробелами), у нас всего 1 замена, 1 удаление и 1 вставка на уровне букв и 1 замена, 4 удаления и 3 вставки на уровне букв. Считаем WER = (1 + 1 + 1) / 5 = 0.6, считаем CER = (1 + 4 + 3) / 30 = 0.27. Пример искусственный и приведен для демонстрации подсчета метрик. Для понимания – чем ближе к нулю показатели WER и CER, тем лучше работает система.
Сейчас даже у всех игроков на рынке систем распознавания речи (Яндекс, Google, ЦРТ, Azure, Tinkoff, Наносемантика) метрика WER держится на одних наших тестовых датасетах не ниже 0.1-0.15, на других данных – не ниже 0.15-0.25, а есть коммерческие системы, которые доходят аж до 0.35-0.5. Это означает, что мы, грубо говоря, в лучшем случае получаем ошибку в каждом седьмом-десятом слове, в системах похуже – в каждом четвертом, а то и втором.
Поговорим подробнее про данные, на которых мы алгоритмы ASR учили и тестировали.
С чего мы начинали
Мы начали делать свой ASR зимой 2019 года. В начале нашей работы мы рассматривали готовые Open Source наборы инструментов и библиотек, которые можно было бы попробовать пощупать и сравнить между собой. Среди них были как древние системы, которые не использовали нейронные сети – решения, основанные на скрытых марковских моделях (HMM), так и проекты, использующие нейронные сети.
Сейчас уже можно найти end-to-end сети, которые преобразуют входной сигнал в слова, это attention-based сети, рекуррентные нейронные сети, LSTM, полностью сверточные нейронные сети – сразу очень сложно понять, что даст наилучший результат как с точки зрения качества распознавания речи, так и с точки зрения производительности системы и ресурсов, которые будет необходимо заложить на подготовку такой системы.
Среди прочего можно упомянуть наиболее на наш взгляд интересные разработки:
Как открыть файл ASR?
Отсутствие возможности открывать файлы с расширением ASR может иметь различное происхождение. К счастью, наиболее распространенные проблемы с файлами ASR могут быть решены без глубоких знаний в области ИТ, а главное, за считанные минуты. Ниже приведен список рекомендаций, которые помогут вам выявить и решить проблемы, связанные с файлами.
Шаг 1. Скачайте и установите Adobe Contribute

Проблемы с открытием и работой с файлами ASR, скорее всего, связаны с отсутствием надлежащего программного обеспечения, совместимого с файлами ASR на вашем компьютере. Наиболее очевидным решением является загрузка и установка Adobe Contribute или одной из перечисленных программ: Adobe Photoshop, Adobe Creative Suite, Adobe Creative Cloud. Выше вы найдете полный список программ, которые поддерживают ASR файлы, классифицированные в соответствии с системными платформами, для которых они доступны. Самый безопасный способ загрузки Adobe Contribute установлен - для этого зайдите на сайт разработчика (Adobe Systems Incorporated) и загрузите программное обеспечение, используя предоставленные ссылки.
Шаг 2. Проверьте версию Adobe Contribute и обновите при необходимости

Если у вас уже установлен Adobe Contribute в ваших системах и файлы ASR по-прежнему не открываются должным образом, проверьте, установлена ли у вас последняя версия программного обеспечения. Может также случиться, что создатели программного обеспечения, обновляя свои приложения, добавляют совместимость с другими, более новыми форматами файлов. Если у вас установлена более старая версия Adobe Contribute, она может не поддерживать формат ASR. Последняя версия Adobe Contribute должна поддерживать все форматы файлов, которые совместимы со старыми версиями программного обеспечения.
Шаг 3. Свяжите файлы ActionScript Remote Document с Adobe Contribute
После установки Adobe Contribute (самой последней версии) убедитесь, что он установлен в качестве приложения по умолчанию для открытия ASR файлов. Метод довольно прост и мало меняется в разных операционных системах.
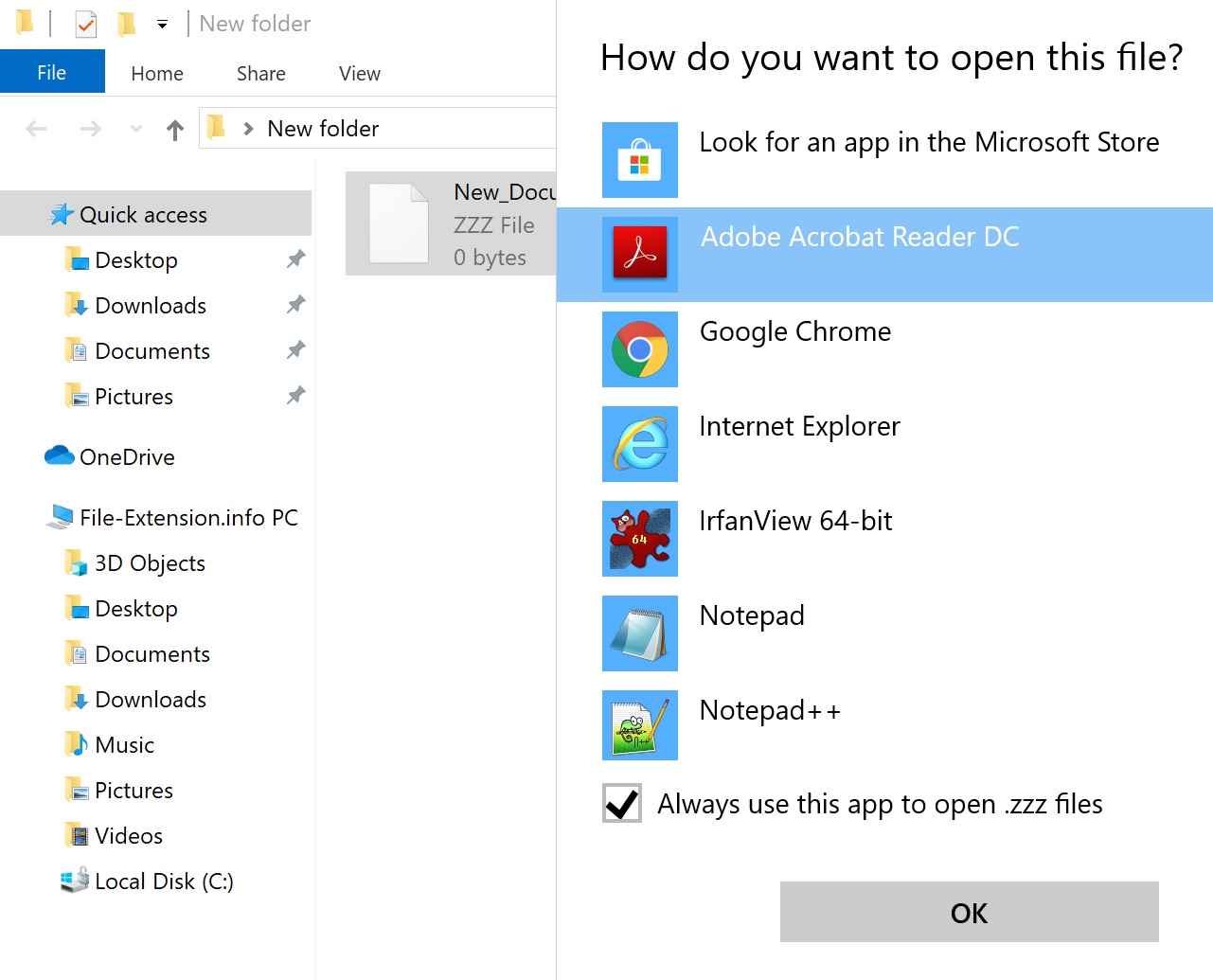
Процедура изменения программы по умолчанию в Windows
- Выберите пункт Открыть с помощью в меню «Файл», к которому можно щелкнуть правой кнопкой мыши файл ASR.
- Нажмите Выбрать другое приложение и затем выберите опцию Еще приложения
- Чтобы завершить процесс, выберите Найти другое приложение на этом. и с помощью проводника выберите папку Adobe Contribute. Подтвердите, Всегда использовать это приложение для открытия ASR файлы и нажав кнопку OK .
Процедура изменения программы по умолчанию в Mac OS
Шаг 4. Проверьте ASR на наличие ошибок
Если проблема по-прежнему возникает после выполнения шагов 1-3, проверьте, является ли файл ASR действительным. Вероятно, файл поврежден и, следовательно, недоступен.

1. Проверьте ASR файл на наличие вирусов или вредоносных программ.
Если файл заражен, вредоносная программа, находящаяся в файле ASR, препятствует попыткам открыть его. Сканируйте файл ASR и ваш компьютер на наличие вредоносных программ или вирусов. Если сканер обнаружил, что файл ASR небезопасен, действуйте в соответствии с инструкциями антивирусной программы для нейтрализации угрозы.
2. Убедитесь, что файл с расширением ASR завершен и не содержит ошибок
3. Проверьте, есть ли у пользователя, вошедшего в систему, права администратора.
Иногда для доступа к файлам пользователю необходимы права администратора. Переключитесь на учетную запись с необходимыми привилегиями и попробуйте снова открыть файл ActionScript Remote Document.
4. Проверьте, может ли ваша система обрабатывать Adobe Contribute
5. Убедитесь, что ваша операционная система и драйверы обновлены
Регулярно обновляемая система, драйверы и программы обеспечивают безопасность вашего компьютера. Это также может предотвратить проблемы с файлами ActionScript Remote Document. Возможно, файлы ASR работают правильно с обновленным программным обеспечением, которое устраняет некоторые системные ошибки.
Вы хотите помочь?
Если у Вас есть дополнительная информация о расширение файла ASR мы будем признательны, если Вы поделитесь ею с пользователями нашего сайта. Воспользуйтесь формуляром, находящимся здесь и отправьте нам свою информацию о файле ASR.
This file is saved in a binary format, which requires a specific program to read its contents.
.ASR вариант № 2
Сжатый архив, используемый в видеоиграх, таких как Sniper Elite, видеоигры второй мировой войны 2; содержит звуковые данные, такие как сердцебиение, игровая музыка и стрельба из оружия, упоминаемые во время игры.
ПРИМЕЧАНИЕ. Файл ASR находится в папке \ sounds \ каталога игры. Файл сжимается с помощью сжатия ZLIB, но может быть распакован с помощью программы форматирования и изменен для изменения звуков.
Тип файла 2Аудио потокового архива ресурсов
| разработчик | N / A |
| популярность | 3,0 (2 голоса) |
| категория | Сжатые файлы |
| Формат | N / A X |
Программы, обслуживающие файл ASR

Windows

MAC OS
Тип файла2 Audio Streaming Resource Archive
This file is saved in a binary format, which requires a specific program to read its contents.
Как устроена NLab Speech
Получив ядро, которое может переводить аудио в текст, мы начали добавлять в него различные косметические и функциональные улучшения. Во-первых, мы реализовали потоковое распознавание, изначально на web-сокетах, а затем занялись поддержкой протоколов gRPC и MRCP, поскольку на них был спрос у партнёров. В потоковом распознавании нужно учитывать, что использовать декодер с языковой моделью нужно по оконченным фразам, поэтому возникает потребность в определении тишины для выделения реплик, после которых наступают паузы. Для определения кусков с тишиной и голосом при потоковом распознавании мы используем Voice Activity Detector. Тут мы решили взять готовое решение WebRTC VAD. Наши внутренние тесты альтернативных решений подтвердили, что даже на наименее чувствительном уровне WebRTC VAD показывает лучшие результаты с определением кусков аудио, содержащих голос, как по точности, так и по полноте.
Есть несколько подходов по работе с потоковым распознаванием, можно либо после нарезки VAD прогонять собранные окна спектрограмм через акустическую модель, извлеченные из кусков аудио с речью, либо прогонять их постоянно небольшими батчами и выдавать результаты промежуточного распознавания (с жадным декодером), а по наступлению паузы прогонять всю фразу через CTC декодер и языковую модель. На выходе из акустической модели мы получаем набор наиболее вероятных с фонемной точки зрения кандидатов текста того, что было сказано, и дальше декодер при помощи заранее подготовленной языковой модели определяет, какие варианты наиболее вероятны из того, что было предсказано.
Языковая модель у нас в данный момент строится при помощи KenLM. Для её подготовки нужно собрать большой корпус разговорных неразмеченных текстов (гигабайты текстов): по предложению на строку в одном большом текстовом файле. Учимся мы на десятках гигабайтов текстов. В такой корпус мы подмешивали те данные, которые у нас были размечены из реальных аудио. В итоге получили достаточно неплохие результаты, однако здесь надо понимать, что данные надо также валидировать и очищать от различного мусора. Хороший буст качества для конкретного заказчика можно получить просто расширив языковую модель под его тематику.
Дальше к получаемым от ASR текстам мы применяем различные варианты улучшения внешнего вида. Например, мы обучили BERT восстанавливать пунктуацию. Он расставляет запятые, точки, вопросительные знаки просто по текстовому представлению. Также мы добавили перевод чисел, представленных словами, в цифры по словарю. В планах добавить аббревиатуры, зарубежные названия, имена, названия городов и компаний.
Ассоциация файлов .ASR 3
Сложности, которые мы преодолели
Поняв, что у нас большие проблемы с реальными данными, с аудиокниг мы переключились на альтернативные способы сбора данных. Так мы разработали свою систему для сбора аудио. Человек зачитывает то, что написано на экране, это сохраняется и попадает к нам. Таким образом у нас накопилась база в 1700+ часов. Большим плюсом такого подхода было то, что люди зачитывали текст с абсолютно разных устройств и микрофонов соответственно. Как уже было упомянуто, большой минус здесь – люди читают текст, а не общаются вживую. Однако, суммарно всех собранных на тот момент данных хватило, чтобы подготовить неплохой демонстрационный стенд, с которым уже, во-первых, не стыдно было ходить к потенциальным партнёрам из колл-центров, во вторых, предлагать бесплатно пользоваться распознаванием в обмен на данные, которые через этот стенд проходят и далее используются для обучения моделей.
Что касается разработки, как мы уже упомянули, мы перенесли всю архитектуру wav2letter на свой фреймворк PuzzleLib. Изначально весь пайплайн не отличался высоким качеством распознавания фраз, поскольку мы использовали Greedy Decoder. Далее, разобравшись с подключением языковых моделей, мы реализовали Beam Search. В итоге мы пришли к выводу, что самое лучшее качество можно достигнуть с помощью CTC (Connectionist Temporal Classification) Decoder. На нем и остановились, часть кода для него позаимствована из оригинального репозитория wav2letter++, написана на C++ и подключается при помощи Python-обвязки.
Существенно ускорило подготовку моделей появление компьютеров с несколькими GPU. Мы распараллелили код для обучения на нескольких видеокартах и смогли запускать обучение и быстро что-то сравнивать, проводить эксперименты. Например, мы сравнивали модели, работающие с разными признаками: спектрограммами, MF фичами, MFCC фичами. В итоге мы остановились на спектрограммах, потому что при одинаковых условиях мы могли получить модель с лучшим качеством за фиксированное количество эпох.
Мы поддержали обучение с данными в формате float16, что уменьшило расход памяти и увеличило скорость обучения. Если в двух словах, можно обучать на стандартных тензорах, в которых типы данных float32, а можно обучать на float16 — это числа с половинной точностью. Если всё правильно настроить, то, в целом, без сильной потери точности, можно уменьшить расход памяти в два раза. И, соответственно, можно увеличить размер батча и занять больше места на видеокарте. Все это приводит к ускорению обучения.
Что такое файл ASR?
Содержание:
Тип файла3 Adobe Photoshop Scratch File
| Разработчик | Adobe Systems |
| Категория | Дата файлы |
| Формат | Binary |
Binary
This file is saved in a binary format, which requires a specific program to read its contents.
Видео: Расширение файла ASR - Что такое файл .asr и как я могу его открыть?
Ассоциация файлов .ASR 2
Сжатый архив, используемый видеоиграми, такими как Sniper Elite, видеоигра от третьего лица от World War 2; содержит звуковые данные, такие как сердцебиение, игровая музыка и огнестрельное оружие, на которые ссылаются во время игры. Дополнительная информация
НОТА: Файл ASR находится в папке sounds каталога игры. Файл сжимается сжатием ZLIB, но может быть распакован программой offzip и изменен для изменения звуков.
.ASR вариант № 3
Файл, созданный Adobe Photoshop, приложение для редактирования графики; сохраняет изображение, редактируя или «царапает» информацию, когда пользователь изменяет изображение; используется для временного сохранения данных во время работы программы.
О ASR файлах
Наша цель - помочь вам понять за что отвечает файл с расширением * .asr и как его открыть.
Тип файла Adobe Photoshop Scratch File, описания программ для Mac, Windows, Linux, Android и iOS, перечисленные на этой странице, были индивидуально исследованы и проверены командой FileExt. Мы стремимся к 100-процентной точности и публикуем только информацию о форматах файлов, которые мы тестировали и проверяли.
Тип файла 1ActionScript Удаленный документ
| разработчик | Adobe Systems |
| популярность | 3,5 (10 голосов) |
| категория | Веб-файлы |
| Формат | N / A X |
Бенчмарк
Вот к таким результатам нам удалось прийти на сегодняшний день (сортировка по столбцу WER, меньше – лучше):
Windows – система крайне неустойчивая в неопытных руках, и склонна «слетать» даже у профессионалов, вызывая привычные колкости с их стороны по этому поводу.
Но профессиональные пользователи хотя бы заранее знают такой исход, вовремя архивируя свои данные, собирая удобные программы восстановления и всячески «подстилая соломку» в случае краха системы.
А вот о пользователях «попроще» хитрости ожидать не приходится, и для них любая проблема с системой превращается в локальный апокалипсис, вызывающий стрессы.
И, как правило, требующий вызова очередного «мастера», умеющего только отформатировать жесткий диск и криво поставить свою любимую «сборку», кишащую червями и прочими вирусами. А что делать – насильно знания в чужую голову не вложишь, но есть средства, которые позволяют разобраться в восстановлении системы в любом случае – набор ASR.
Сразу скажем, что, как и все в Windows, ASR крайне неудобна в обращении. Во-первых, она позволяет восстановить только данные с системного и загрузочного разделов (читай – диск C). Во-вторых, набор для восстановления нужно собирать самому, и довольно часто, указывая в нем необходимые папки для последующей реанимации. В-третьих, нужна будет чистая дискета – нереальное «удовольствие» в наше время. И, в-четвертых, вся эта система располагается на загрузочном компакт-диске Windows, если после выбора установки нажать F2.
А теперь скажите-ка быстро – где у вас лежит загрузочный диск Windows? Как правило, нигде, и это печально.
Таким образом, штатная система ASR, вроде бы формально соответствуя стандартам восстановления системы, является более сложной, чем другие системы.
Из штатных возможностей – все команды сохранения наборов данных и записи дискеты находятся в меню системы (Служебные – Архивация данных). Создание набора можно совместить с упаковкой, но, к примеру, контроля размера файла под FAT32 там нет – нужно реагировать самому. Дискета – прошлый век, и это ограничение практически не обойти. Единственная полезная вещь в этой системе – вы всегда будете помнить о том, чтобы держать установочный диск системы под рукой.
В любом случае, пакеты вроде Acronis, Ghost или Reflect, действуя по примерно тому же принципу, работают быстрее, эффективнее и проще. При этом Акронис, похоже, вообще скоро будет являться стандартом для восстановления систем, так как умеет работать, помимо прочего, с инкрементными архивами – это лучше, чем каждый раз создавать «глыбу» неделимого архива.
Вот на этой ноте я пожалуй и завершу свой надеюсь полезный рассказ .С нетерпением жду ваших комментариев .
Программы, которые поддерживают ASR расширение файла
Ниже вы найдете указатель программ, которые можно использовать для открытия файлов ASR, разделенных на категории 2 в соответствии с поддерживаемой системной платформой. Файлы с расширением ASR, как и любые другие форматы файлов, можно найти в любой операционной системе. Указанные файлы могут быть переданы на другие устройства, будь то мобильные или стационарные, но не все системы могут быть способны правильно обрабатывать такие файлы.
Читайте также: