
3 вида памяти stack
Память — это одна из самых сложных тем в информатике, но понимание устройства памяти компьютера позволяет разрабатывать более эффективные программы, а для более низкоуровневого программирования, например, при разработке ОС, это понимание и вовсе является обязательным.
В этой статье будет рассмотрена модель памяти с высокоуровневой точки зрения — виды памяти, аллокаторы, сборщик мусора
Заключение
Итак, в статье были кратко описаны ключевые понятия, положенные в основу управления памятью в JavaScript. В ходе подготовки материала мне удалось разобраться с несколькими принципами, четкого представления о которых у меня раньше не было, – надеюсь, и вы почерпнете из этого обзора что-нибудь полезное для себя.
Память — одна из самых сложных тем в информатике, но понимание устройства памяти компьютера позволяет разрабатывать более эффективные программы, а для более низкоуровневого программирования, например, при разработке ОС, это понимание и вовсе является обязательным.
В этой статье будет рассмотрена модель памяти с высокоуровневой точки зрения — виды памяти, аллокаторы, сборщик мусора.
Утечки памяти
Теперь, вооружившись необходимыми знаниями об управлении памятью, мы готовы к анализу наиболее распространенных видов утечек памяти – обойти которые, к слову, не составляет особого труда, когда понимаешь все процессы изнутри.
Различные подходы
Современные языки программирования стараются максимально упростить работу с памятью и снять с разработчиков часть головной боли. И хотя некоторые почтенные языки всё ещё требуют ручного управления, большинство всё же предоставляет более изящные автоматические подходы. Порой в языке используется сразу несколько подходов к управлению памятью, а иногда разработчику даже доступен выбор какой из вариантов будет эффективнее конкретно для его задач (хороший пример — C++). Перейдём к краткому обзору различных подходов.
Ссылки вне DOM
Эта утечка памяти похожа на предыдущие: она возникает, когда элементы DOM хранятся в JavaScript.
Когда вы удаляете любой из элементов выше, позаботьтесь и об его удалении из массива – иначе сборщик мусора не станет обрабатывать соответствующие DOM-элементы.
Примечание переводчика В оригинале статьи некорректный пример. Нужен простой цикл, который будет удалять элементы из DOM. В примере же организован самомодифицирующийся итератор.
Так как каждый элемент DOM, ко всему прочему, содержит ссылку на родительский узел, своими действиями вы можете помешать сборщику мусора освободить память, занятую детьми и родителем элемента.
Куча (Heap)
Эта часть памяти хранит в памяти фактические объекты, на которые ссылаются переменные из стека. Например, давайте проанализируем, что происходит в следующей строке кода:
Ключевое слово new несет ответственность за обеспечение того, достаточно ли свободного места на куче, создавая объект типа StringBuilder в памяти и обращаясь к нему через «Builder» ссылки, которая попадает в стек.
Для каждого запущенного процесса JVM существует только одна область памяти в куче. Следовательно, это общая часть памяти независимо от того, сколько потоков выполняется. На самом деле структура кучи немного отличается от того, что показано на картинке выше. Сама куча разделена на несколько частей, что облегчает процесс сборки мусора.
Максимальные размеры стека и кучи не определены заранее - это зависит от работающей JVM машины. Позже в этой статье мы рассмотрим некоторые конфигурации JVM, которые позволят нам явно указать их размер для запускаемого приложения.
Таймеры и коллбэки
Забытые таймеры и коллбэки могут привести к тому, что приложение начнет использовать бо́льший объем памяти. В этом контексте следует быть особенно внимательными с одностраничными приложениями (SPA) и динамическим добавлением коллбэков и наблюдателей событий.
Забытые таймеры
Функция выше выполняется каждые 2 секунды. Если в вашем проекте есть похожий код, возможно, его выполнение не должно быть бесконечным.
Объекты, на которые есть ссылка в интервале, не будут уничтожены, пока не произойдет очистка интервала. Поэтому помните, что необходимо своевременно прописывать:
Особую важность это действие приобретает в SPA: даже если вы покидаете страницу, на которой нужен тот или иной интервал, его выполнение все равно продолжается в фоновом режиме.
Забытые коллбэки
Допустим, вы назначили наблюдателя onClick на кнопку, которую позже удалили за ненадобностью.
Освободить память, выделенную для такого наблюдателя, старые браузеры бы просто не смогли. Сейчас эта проблема уже в прошлом, но, несмотря на это, все еще рекомендуется явно удалять наблюдателей событий, в которых больше нет нужды:
Сборка мусора
Итак, мы рассмотрели, как JavaScript выделяет память для всевозможных типов объектов; теперь же, если вернемся к жизненному циклу памяти, нам остается последний этап – ее освобождение.
Как выделение, так и освобождение памяти за нас выполняет движок JavaScript. Правда, если быть более точным, память системе возвращает сборщик мусора.
Как только движок понимает, что в переменной или функции больше нет необходимости, он освобождает ранее выделенную под нее память.
Отсюда вытекает и главная проблема: однозначно решить, нужна определенная область памяти или уже нет, не представляется возможным. Другими словами, невозможно создать такой алгоритм, который освобождал бы всю память прямо в момент ее перехода в состояние «ненужности».
В то же время есть несколько алгоритмов, которые представляют собой если не точное решение вопроса, то довольно неплохую аппроксимацию. В этой части я расскажу о наиболее популярных из них: сборке мусора, основанной на подсчете ссылок, и так называемом «алгоритме пометок» (англ. mark and sweep).
Для чего используется оперативная память?
Когда программа выполняется в операционный системе компьютера, она нуждается в доступе к оперативной памяти (RAM) для того, чтобы:
- загружать свой собственный байт-код для выполнения;
- хранить значения переменных и структуры данных, которые используются в процессе работы;
- загружать внешние модули, которые необходимы программе для выполнения задач.
Стек используется для статичного выделения памяти. Он организован по принципу «последним пришёл — первым вышел» (LIFO). Можно представить стек как стопку книг — разрешено взаимодействовать только с самой верхней книгой: прочитать её или положить на неё новую.
- благодаря упомянутому принципу, стек позволяет очень быстро выполнять операции с данными — все манипуляции производятся с «верхней книгой в стопке». Книга добавляется в самый верх, если нужно сохранить данные, либо берётся сверху, если данные требуется прочитать;
- существует ограничение в том, что данные, которые предполагается хранить в стеке, обязаны быть конечными и статичными — их размер должен быть известен ещё на этапе компиляции;
- в стековой памяти хранится стек вызовов — информация о ходе выполнения цепочек вызовов функций в виде стековых кадров. Каждый стековый кадр это набор блоков данных, в которых хранится информация, необходимая для работы функции на определённом шаге — её локальные переменные и аргументы, с которыми её вызывали. Например, каждый раз, когда функция объявляет новую переменную, она добавляет её в верхний блок стека. Затем, когда функция завершает свою работу, очищаются все блоки памяти в стеке, которые функция использовала — иными словами, очищаются все блоки ее стекового кадра;
- каждый поток многопоточного приложения имеет доступ к своему собственному стеку;
- управление стековой памятью простое и прямолинейное; оно выполняется операционной системой;
- в стеке обычно хранятся данные вроде локальных переменных и указателей;
- при работе со стеком есть вероятность получать ошибки переполнения стека (stack overflow), так как максимальный его размер строго ограничен. Например, ошибка при составлении граничного условия в рекурсивной функции совершенно точно приведёт к переполнению стека;
- в большинстве языков существует ограничение на размер значений, которые можно сохранить в стек;
Использование стека в JavaScript. Объекты хранятся в куче и доступны по ссылкам, которые хранятся в стеке. Тут можно посмотреть в видеоформате
Куча используется для динамического выделения памяти, однако, в отличие от стека, данные в куче первым делом требуется найти с помощью «оглавления». Можно представить, что куча это такая большая многоуровневая библиотека, в которой, следуя определённым инструкциям, можно найти необходимую книгу.
- операции на куче производятся несколько медленнее, чем на стеке, так как требуют дополнительного этапа для поиска данных;
- в куче хранятся данные динамических размеров, например, список, в который можно добавлять произвольное количество элементов;
- куча общая для всех потоков приложения;
- вследствие динамической природы, куча нетривиальна в управлении и с ней возникает большинство всех проблем и ошибок, связанных с памятью. Способы решения этих проблем предоставляются языками программирования;
- типичные структуры данных, которые хранятся в куче — это глобальные переменные (они должны быть доступны для разных потоков приложения, а куча как раз общая для всех потоков), ссылочные типы, такие как строки или ассоциативные массивы, а так же другие сложные структуры данных;
- при работе с кучей можно получить ошибки выхода за пределы памяти (out of memory), если приложение пытается использовать больше памяти, чем ему доступно;
- размер значений, которые могут храниться в куче, ограничен лишь общим объёмом памяти, который был выделен операционной системой для программы.
Почему эффективное управление памятью важно?
В отличие от жёстких дисков, оперативная память весьма ограниченна (хотя и жёсткие диски, безусловно, тоже не безграничны). Если программа потребляет память не высвобождая её, то, в конечном итоге, она поглотит все доступные резервы и попытается выйти за пределы памяти. Тогда она просто упадет сама, или, что ещё драматичнее, обрушит операционную систему. Следовательно, весьма нежелательно относиться легкомысленно к манипуляциям с памятью при разработке ПО.
Стек (Stack)
Стековая память отвечает за хранение ссылок на объекты кучи и за хранение типов значений (также известных в Java как примитивные типы), которые содержат само значение, а не ссылку на объект из кучи.
Кроме того, переменные в стеке имеют определенную видимость, также называемую областью видимости. Используются только объекты из активной области. Например, предполагая, что у нас нет никаких глобальных переменных (полей) области видимости, а только локальные переменные, если компилятор выполняет тело метода, он может получить доступ только к объектам из стека, которые находятся внутри тела метода. Он не может получить доступ к другим локальным переменным, так как они не выходят в область видимости. Когда метод завершается и возвращается, верхняя часть стека выталкивается, и активная область видимости изменяется.
Возможно, вы заметили, что на картинке выше отображено несколько стеков памяти. Это связано с тем, что стековая память в Java выделяется для каждого потока. Следовательно, каждый раз, когда поток создается и запускается, он имеет свою собственную стековую память и не может получить доступ к стековой памяти другого потока.
Жизненный цикл памяти
В JavaScript, когда мы создаем функции, переменные и прочее, движок выделяет под них память и освобождает ее, как только память становится больше не нужна.
Выделение памяти – это процесс «резервирования» области памяти, в то время как ее освобождение – это возврат памяти системе, в результате чего занятое ранее пространство может быть использовано повторно.
Каждый раз, когда мы объявляем переменную или создаем функцию, необходимая для этого память проходит следующие этапы:
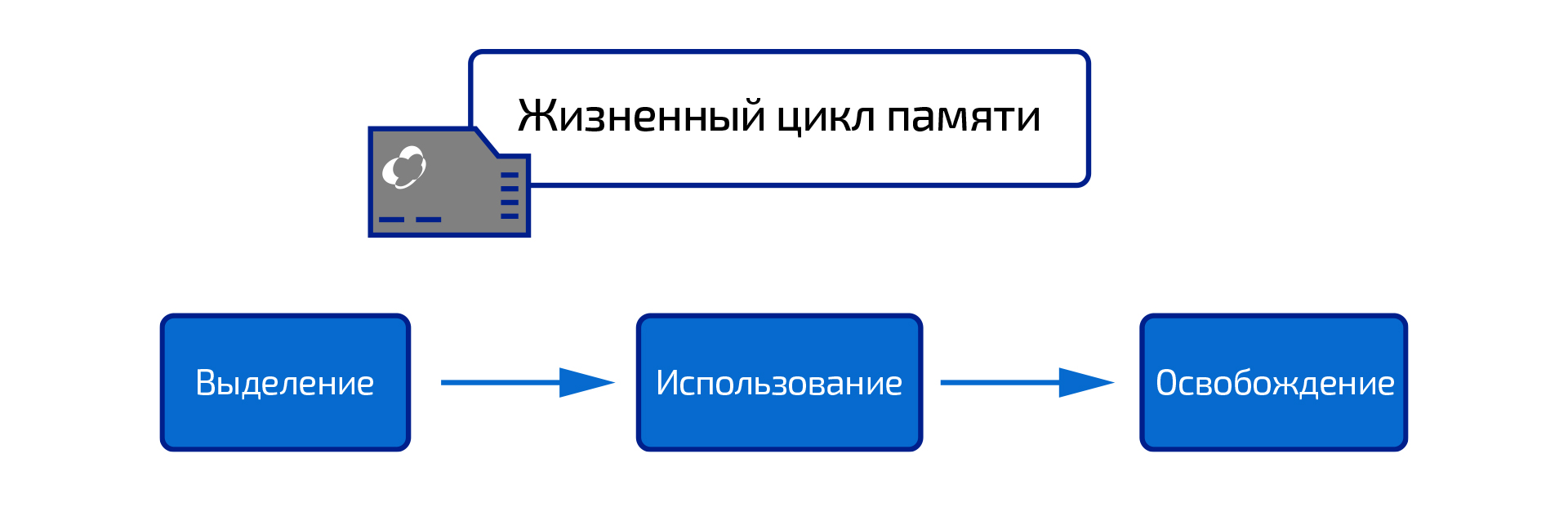
- Выделение памяти. JavaScript берет эту задачу на себя: он выделяет память, которая понадобится для созданного нами объекта.
- Использование памяти. Это то, что мы явно прописываем в коде: чтение и запись в память – не что иное, как чтение и запись в переменную.
- Освобождение памяти. Этот шаг также выполняет движок JavaScript: сразу после освобождения память можно использовать для других целей.
Примечание В контексте управления памятью «объекты» включают в себя не только объекты JavaScript, но и функции с областями их видимости.
Использование памяти
В связи с тем, что алгоритмы не способны определить, в какой именно момент память станет ненужной, приложения на JavaScript могут использовать бо́льший объем памяти, чем им необходимо на самом деле. К тому же, даже если объекты помечены как мусор, только сборщику решать, когда стоит – и стоит ли вообще – освободить выделенную память.
Если для вас важно, чтобы разрабатываемое приложение использовало память максимально эффективно, возможно, вместо JavaScript вам следует обратиться к низкоуровневому языку – но помните, что этот вариант тоже по-своему неидеален.
«Алгоритм пометок»
Проблему циклических зависимостей может решить «алгоритм пометок», или метод mark and sweep. Вместо обычного подсчета ссылок данный алгоритм определяет, возможно ли получить доступ к тому или иному объекту через корневой объект (в браузере таковым является window , а в Node.js – global ).
Алгоритм помечает (mark) недосягаемые объекты как «мусор», после чего «выметает» (sweep) их; корневые объекты при этом никогда не уничтожаются.
Как видим, такие циклические зависимости, как в примере выше, – больше не проблема: у нас нет доступа ни к dad, ни к son, следовательно, оба объекта будут помечены и обработаны, а память – возвращена системе.
С 2012 года все браузеры оснащаются сборщиками мусора, работающими по принципу mark and sweep: со временем были улучшены производительность и реализация алгоритма, однако его основная идея осталась неизменной.
Способы контроля динамической памяти
Из-за сложности программ очень трудно определить, когда необходимо освобождать память в ОС, и это вторая явная проблема динамической памяти. Если забыть вызвать munmap() или free() , то произойдет следующая ситуация: приложению память уже не нужна, но ОС всё ещё будет считать, что эта память используется программой. Эту проблему называют «утечкой памяти». Существуют несколько способов автоматического или полуавтоматического решения этой проблемы:
RAII (Получение ресурса есть инициализация) — в ООП — организация получения доступа к ресурсу в конструкторе, а освобождения — в деструкторе соответствующего класса. Достаточно реализовать управление памятью в конструкторах и деструкторах, а компилятор вызовет их автоматически. Например, немного урезанный класс String из статьи про Move-семантику. Выделяем память в конструкторе, очищаем в деструкторе:
Умные указатели на основе RAII — указатели, автоматически владеющие динамической памятью, то есть автоматически освобождающие её, когда она больше не нужна. Умные указатели инкапсулируют только управление памятью объекта, но не сам объект, как, например, происходит в String, который инкапсулирует объект целиком. Примеры умных указателей ниже.
std::unique_ptr — класс уникального указателя, является единственным владельцем памяти и очищает её в своём деструкторе. Поэтому объекты класса std::unique_ptr не могут иметь копий, но могут быть перемещены. Подробнее о семантике перемещения в этой статье.
std::shared_ptr — класс общего указателя, использующий атомарный счётчик ссылок для подсчёта количества владельцев памяти. В конструкторе счётчик инкрементируется, в деструкторе — декрементируется. Как только счётчик становится равным нулю, память освобождается.
Но у std::shared_ptr есть проблема, например, когда объект A ссылается на объект B, а объект B ссылается на объект A. В таком случае у обоих объектов счётчик ссылок никогда не будет меньше 1 и произойдёт утечка памяти. Решений у этой проблемы два. Использование std::weak_ptr , который ссылается на объект, но без счётчика ссылок, и не может быть разыменован без предварительной конвертации в std::shared_ptr . Вторым решением этой проблемы является сборщик мусора.
Сборка мусора — одна из форм автоматического управления динамической памятью, которая помечает все доступные из стека или статической памяти динамически выделенные объекты. Объекты, до которых нельзя добраться через цепочку указателей, начиная с автоматической или статической памяти, т. е. не помеченные сборщиком мусора, очищаются.
Умные указатели и RAII используются в основном в относительно низкоуровневых языках, например, С++ или Swift. В более высокоуровневых языках обычно используется сборщик мусора (Java), хотя может применяться комбинация умного указателя и сборщика мусора (Python).
У каждого способа управления динамической памятью есть свои плюсы и минусы. В основном приходится жертвовать производительностью программы ради скорости и простоты разработки, либо наоборот: высокая производительность, но и высокая требовательность к программистам, из-за чего вероятность ошибиться при разработке программы выше и медленней сам процесс.
Аллокатор
У динамической памяти есть две явные проблемы. Во-первых, любое выделение/освобождение памяти в ОС — системный вызов, замедляющий работу программы. Решением этой проблемы является аллокатор.
Аллокатор — это часть программы, которая запрашивает память большими кусками напрямую у ОС через системные вызовы (в POSIX-совместимых ОС это mmap для выделения памяти и unmap — для освобождения), затем по частям отдаёт эту память приложению (в Си это могут быть функции malloc() / free() ). Такой подход увеличивает производительность, но может вызвать фрагментацию памяти при длительной работе программы.
malloc() / free() и mmap / unmap — это не одно и то же. Первый является простейшим аллокатором в libc , второй является системным вызовом. В большинстве языков можно использовать только аллокатор по умолчанию, но в языках с более низкоуровневой моделью памяти можно использовать и другие аллокаторы.
Например, boost::pool аллокаторы, созданные для оптимальной работы с контейнерами ( boost::pool_allocator для линейных ( std::vector ), boost::fast_pool_allocator для нелинейных ( std::map, std::list )). Или аллокатор jemalloc, оптимизированный для решения проблем фрагментации и утилизации ресурсов CPU в многопоточных программах. Более подробно о jemalloc можно узнать из доклада с конференции C++ Russia 2018.
Заключение
Знание того, как организована память, дает вам преимущество в написании хорошего и оптимизированного кода с точки зрения ресурсов памяти. Преимущество заключается в том, что вы можете настроить свою работающую JVM, предоставив различные конфигурации, наиболее подходящие для запуска вашего приложения. Выявление и устранение утечек памяти - это очень просто, если использовать правильные инструменты.
Привет, Хабр! Представляю вашему вниманию перевод статьи «Demystifying memory management in modern programming languages» за авторством Deepu K Sasidharan.
В данной серии статей мне бы хотелось развеять завесу мистики над управлением памятью в программном обеспечении (далее по тексту — ПО) и подробно рассмотреть возможности, предоставляемые современными языками программирования. Надеюсь, что мои статьи помогут читателю заглянуть под капот этих языков и узнать для себя нечто новое.
Углублённое изучение концептов управления памятью позволяет писать более эффективное ПО, потому как стиль и практики кодирования оказывают большое влияние на принципы выделения памяти для нужд программы.
Ручное управление памятью
Язык не предоставляет механизмов для автоматического управления памятью. Выделение и освобождение памяти для создаваемых объектов остаётся полностью на совести разработчика. Пример такого языка — C. Он предоставляет ряд методов (malloc, realloc, calloc и free) для управления памятью — разработчик должен использовать их для выделения и освобождения памяти в своей программе. Этот подход требует большой аккуратности и внимательности. Так же он является в особенности сложным для новичков.
Сборка мусора, основанная на подсчете ссылок
Данный алгоритм – самый простой из существующих. Он уничтожает те объекты, на которые не указывает ни одна ссылка.
Обратимся к следующему примеру (ссылки представлены в виде линий):
Обратите внимание на то, как в конце остается только hobbies – это единственный объект в куче, на который сохранилась ссылка в стеке.
Циклы
Минус рассматриваемого алгоритма в том, что он не учитывает циклические ссылки: они возникают в случае, когда один или более объектов ссылаются друг на друга, при этом оказываясь вне зоны досягаемости с точки зрения кода.

Так как son и dad ссылаются друг на друга, алгоритм не станет освобождать выделенную под них память. Тем не менее, доступ к обоим объектам для нас уже навсегда утерян.
Так как алгоритм основан на подсчете ссылок, присвоение объектам null ничем не «поможет» сборщику мусора понять, что они больше не могут быть использованы – ведь у каждого из объектов все еще есть указывающая на него ссылка.
Стек и куча
Теперь мы знаем, что движок JavaScript выделяет память под все, что мы определяем в коде, и освобождает ее, когда в этой памяти больше нет нужды. Из этого следует вопрос: а где же все хранится?
В JavaScript есть два варианта хранения данных: в стеке и в куче; и то, и другое – названия структур данных, которые используются движком для различных целей.
Куча: динамическое выделение памяти
Куча (англ. memory heap) используется для хранения таких данных, как объекты и функции.
В отличие от случая со стеком, движок не знает, какой объем памяти понадобится для тех или иных объектов, а потому выделяет память по мере необходимости.
Такое выделение памяти называют динамическим.
Для наглядности сведем основные различия между стеком и кучей в таблицу:

Глобальные переменные
Хранение данных в глобальных переменных – тип утечек, который, пожалуй, встречается чаще всего.
В браузере, к примеру, использование var вместо const или let (не говоря уже об отсутствии ключевого слова в принципе) приведет к тому, что движок присоединит переменную к объекту window . То же самое произойдет и с функциями, определенными словом function .
Такой сценарий применим только по отношению к функциям и переменным, объявленным в глобальной области видимости; избежать проблем вам поможет выполнение кода в строгом режиме (англ. strict mode).
Создание глобальных переменных не всегда случайно: существует множество примеров, когда они объявляются вполне намеренно. Главное в этой ситуации – не забыть освободить память, как только пропадет необходимость в данных.
Для этого присвойте глобальной переменной null :
Стек: статическое выделение памяти
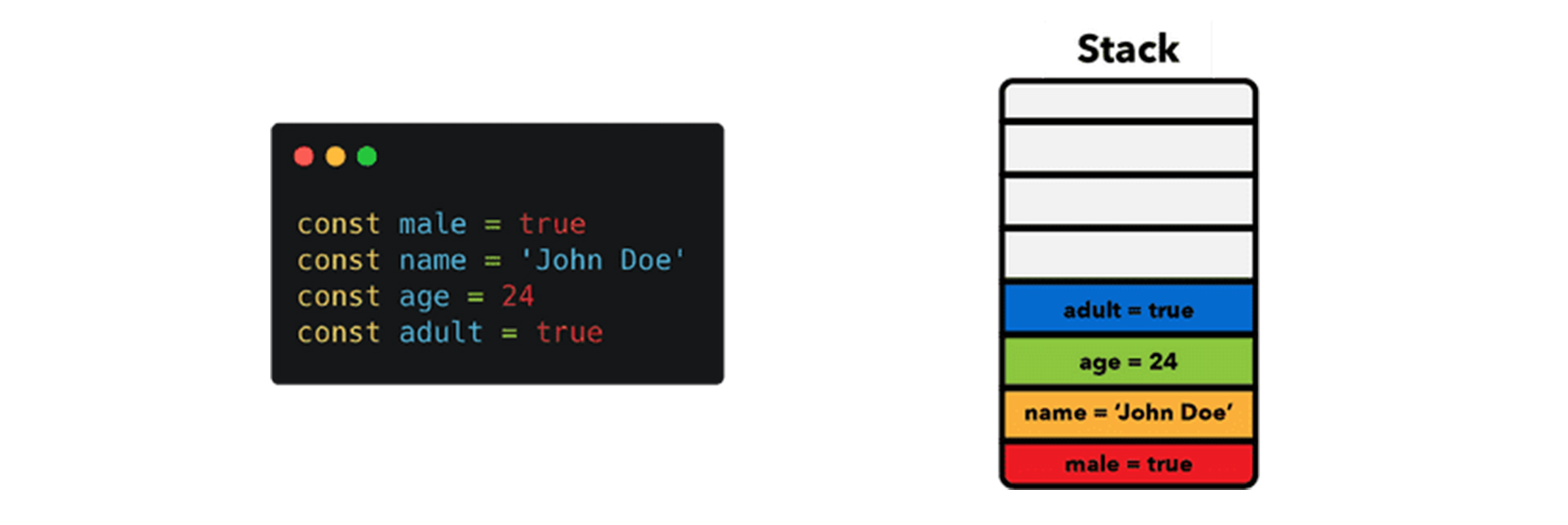
Все примитивные значения сохраняются в стеке.
Стек (англ. stack) – это структура данных, которая используется для хранения статических данных, т.е. тех, чей размер известен во время компиляции. В JavaScript сюда включаются примитивные значения ( string , number , boolean , undefined и null ) и ссылки на функции и объекты.
Движок знает, что размер данных не изменится, и поэтому выделяет фиксированный объем памяти для каждого значения.
Процесс выделения памяти прямо перед выполнением называется статическим.
Так как движок выделяет фиксированный объем памяти для подобных значений, логично предположить, что существует лимит на размер примитивных значений. В зависимости от используемого браузера эти ограничения, а также максимально допустимый размер всего стека могут варьироваться.
Владение

Это сочетание RAII с концепцией владения, когда каждое значение в памяти должно иметь только одну переменную-владельца. Когда владелец уходит из области выполнения, память сразу же освобождается. Можно сказать, что это примерно как подсчёт ссылок на этапе компиляции. Данный подход используется в Rust и при этом я не смог найти ни одного другого языка, который бы использовал подобный механизм.
В данной статье были рассмотрены основные концепции в сфере управления памятью. Каждый язык программирования использует собственные реализации этих подходов и оптимизированные для различных задач алгоритмы. В следующих частях, мы подробнее рассмотрим решения для управления памятью в популярных языках.
Читайте так же другие части серии:
Виды памяти
Существует 3 типа памяти: статический, автоматический и динамический.
Статический — выделение памяти до начала исполнения программы. Такая память доступна на протяжении всего времени выполнения программы. Во многих языках для размещения объекта в статической памяти достаточно задекларировать его в глобальной области видимости.
int // определение статической глобальной переменной
Автоматический , также известный как «размещение на стеке», — самый основной, автоматически выделяет аргументы и локальные переменные функции, а также прочую метаинформацию при вызове функции и освобождает память при выходе из неё.
Стек как структура данных работает по принципу LIFO («последним пришёл — первым ушёл»). Другими словами, добавлять и удалять значения в стеке можно только с одной и той же стороны.
Автоматическая память работает именно на основе стека, чтобы вызванная из любой части программы функция не затерла уже используемую автоматическую память, а добавила свои данные в конец стека, увеличивая его размер. При завершении этой функции её данные будут удалены с конца стека, уменьшая его размер. Длина стека останется той же, что и до вызова функции, а у вызывающей функции указатель на конец стека будет указывать на тот же адрес.
Проще всего это понять из примера на С++:
int main()
int a = 3;
int result = factorial(a);
std::cout >
int factorial(int n)
if (n return n * factorial(n - 1);
>
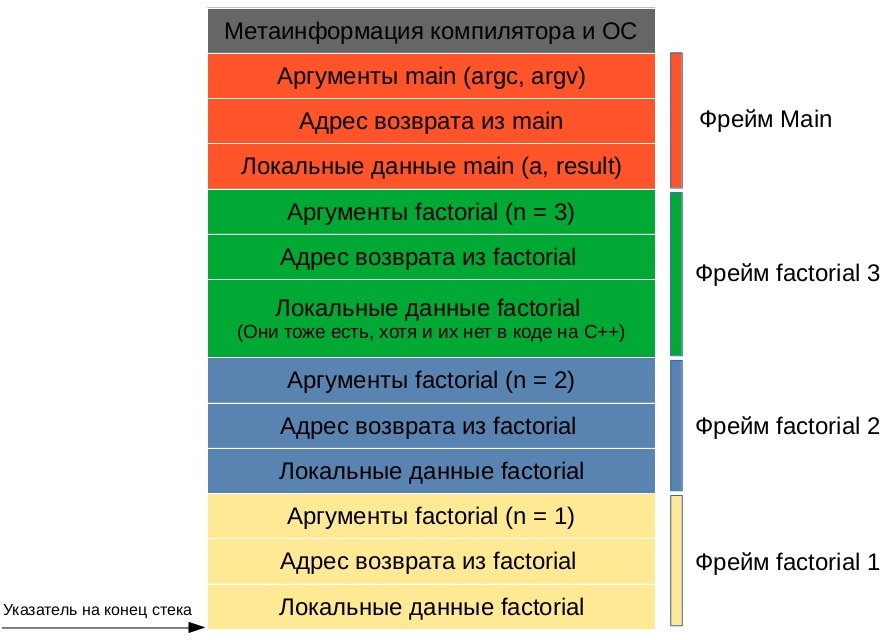
Стек при вызове последней рекурсивной функции будет выглядеть следующим образом:
Детали реализации автоматической памяти могут быть разными в зависимости от конкретной платформы. Например, кому очищать из стека метаинформацию функции и её аргументы: вызывающей функции или вызываемой? Как передавать результат: через стек или, что намного быстрее, через регистры процессора (память, расположенную прямо на кристалле процессора. В этой статье не рассматривается, т. к. в языках программирования высокого уровня зачастую нет прямого доступа к регистрам процессора). На все эти вопросы отвечает конкретная реализация calling convention — описание технических особенностей вызова подпрограмм, определяющее способы передачи параметров/результата функции и способы вызова/возврата из функции.
Таким образом, когда одна функция вызывает другую, последняя всегда в курсе, где ей взять свои аргументы: на конце стека. Но откуда ей знать, где конец стека? В процессоре для этого есть специальный регистр, хранящий указатель на конец стека. В большинстве случаев стек расположен ближе к концу виртуальной памяти и растёт в сторону начала.
Размер автоматической памяти, а он тоже фиксированный, определяется линковщиком (обычно — 1 мегабайт), максимальный размер зависит от конкретной системы и настроек компилятора/линковщика.
Если приложение выйдет за максимум автоматической памяти, то его там может ждать Page Fault (сигнал SIGSEGV в POSIX-совместимых системах: Mac OS X, Linux, BSD и т. д.) — ошибка сегментации, приводящая к аварийному завершению программы.
Динамическая — выделение памяти из ОС по требованию приложения.
Автоматическая и статическая память выделяются единоразово перед запуском программы. При их нехватке, либо если модель LIFO не совсем подходит, используется динамическая память.
Приложение при необходимости может запросить у ОС дополнительную память через аллокатор или напрямую через системный вызов. Пример использования динамической памяти с помощью аллокатора ниже на примере языка Си.
char *i = malloc(sizeof(char)); // просим у аллокатора память для char
if (i != NULL) // аллокатор может вернуть NULL (0)
<
*i = 120; // делаем что-то с памятью, на которую указывает указатель i
printf("Чтение символа из выделенной памяти: %c\n", *i);
free(i); // возвращаем память обратно аллокатору
>
После выделения памяти в распоряжение программы поступает указатель на начало выделенной памяти, который, в свою очередь, тоже должен где-то храниться: в статической, автоматической или также в динамической памяти. Для возвращения памяти обратно в аллокатор необходим только сам указатель. Попытка использования уже очищенной памяти может привести к завершению программы с сигналом SIGSEGV.
Языки сверхвысокого уровня используют динамическую память как основную: создают все или почти все объекты в динамической памяти, а на стеке или в статической памяти держат указатели на эти объекты.
Максимальный размер динамической памяти зависит от многих факторов: среди них ОС, процессор, аппаратная архитектура в целом, не говоря уже о самом очевидном — максимальном размере ОЗУ у конкретного устройства. Например x86_64 процессоры используют только 48 бит для адресации виртуальной памяти, что позволяет использовать до 256 ТБ памяти. В следующей статье про более низкоуровневую архитектуру памяти будет объяснено, почему не все 64 бита.
Производительность
Освобождение памяти, занятой неиспользуемыми объектами, обычно происходит с некоторой периодичностью – но вот когда конкретно запускается процесс «чистки», мы, как разработчики, предугадать не в силах.
Частая и/или «масштабная» сборка мусора может негативно отразиться на производительности, так как для выполнения алгоритма требуется определенная вычислительная мощность. Тем не менее, последствия в большинстве своем остаются незамеченными – как со стороны пользователя, так и со стороны разработчика.
Ссылки на String
Ссылки на тип String в Java обрабатываются немного по- другому. Строки неизменяемы, что означает, что каждый раз, когда вы делаете что-то со строкой, в куче фактически создается другой объект. Для строк Java управляет пулом строк в памяти. Это означает, что Java сохраняет и повторно использует строки, когда это возможно. В основном это верно для строковых литералов. Например:
При запуске этот код распечатывает следующее:
Strings are equal
Следовательно, оказывается, что две ссылки типа String на одинаковые строковые литералы фактически указывают на одни и те же объекты в куче. Однако это не действует для вычисляемых строк. Предположим, что у нас есть следующее изменение в строке // 1 приведенного выше кода.
Strings are different
В этом случае мы фактически видим, что у нас есть два разных объекта в куче. Если учесть, что вычисляемая строка будет использоваться довольно часто, мы можем заставить JVM добавить ее в пул строк, добавив .intern() метод в конец вычисляемой строки:
При добавлении вышеуказанного изменения создается следующий результат:
Виды памяти
Существует 3 типа памяти: статический, автоматический и динамический.
Статический — выделение памяти до начала исполнения программы. Такая память доступна на протяжении всего времени выполнения программы. Во многих языках для размещения объекта в статической памяти достаточно задекларировать его в глобальной области видимости.
Автоматический, также известный как «размещение на стеке», — самый основной, автоматически выделяет аргументы и локальные переменные функции, а также прочую метаинформацию при вызове функции и освобождает память при выходе из неё.
Стек, как структура данных, работает по принципу LIFO («последним пришёл — первым ушёл»). Другими словами, добавлять и удалять значения в стеке можно только с одной и той же стороны.
Автоматическая память работает именно на основе стека, чтобы вызванная из любой части программы функция не затёрла уже используемую автоматическую память, а добавила свои данные в конец стека, увеличивая его размер. При завершении этой функции её данные будут удалены с конца стека, уменьшая его размер. Длина стека останется той же, что и до вызова функции, а у вызывающей функции указатель на конец стека будет указывать на тот же адрес.
Проще всего это понять из примера на С++:
Стек при вызове последней рекурсивной функции будет выглядеть следующим образом:
Детали реализации автоматической памяти могут быть разными в зависимости от конкретной платформы. Например, кому очищать из стека метаинформацию функции и её аргументы: вызывающей функции или вызываемой? Как передавать результат: через стек или, что намного быстрее, через регистры процессора (память, расположенную прямо на кристалле процессора. В этой статье не рассматривается, т. к. в языках программирования высокого уровня зачастую нет прямого доступа к регистрам процессора). На все эти вопросы отвечает конкретная реализация calling convention — описание технических особенностей вызова подпрограмм, определяющее способы передачи параметров/результата функции и способы вызова/возврата из функции.
Таким образом, когда одна функция вызывает другую, последняя всегда в курсе, где ей взять свои аргументы: на конце стека. Но откуда ей знать, где конец стека? В процессоре для этого есть специальный регистр, хранящий указатель на конец стека. В большинстве случаев стек расположен ближе к концу виртуальной памяти и растёт в сторону начала.
Размер автоматической памяти, а он тоже фиксированный, определяется линковщиком (обычно — 1 мегабайт), максимальный размер зависит от конкретной системы и настроек компилятора/линковщика.
Если приложение выйдет за максимум автоматической памяти, его там может ждать Page Fault (сигнал SIGSEGV в POSIX-совместимых системах: Mac OS X, Linux, BSD и т. д.) — ошибка сегментации, приводящая к аварийному завершению программы.
Динамическая — выделение памяти из ОС по требованию приложения.
Автоматическая и статическая память выделяются единоразово перед запуском программы. При их нехватке, либо если модель LIFO не совсем подходит, используется динамическая память.
Приложение при необходимости может запросить у ОС дополнительную память через аллокатор или напрямую через системный вызов. Пример использования динамической памяти с помощью аллокатора ниже на примере языка Си.
После выделения памяти в распоряжение программы поступает указатель на начало выделенной памяти, который, в свою очередь, тоже должен где-то храниться: в статической, автоматической или также в динамической памяти. Для возвращения памяти обратно в аллокатор необходим только сам указатель. Попытка использования уже очищенной памяти может привести к завершению программы с сигналом SIGSEGV.
Языки сверхвысокого уровня используют динамическую память как основную: создают все или почти все объекты в динамической памяти, а на стеке или в статической памяти держат указатели на эти объекты.
Максимальный размер динамической памяти зависит от многих факторов: среди них ОС, процессор, аппаратная архитектура в целом, не говоря уже о самом очевидном — максимальном размере ОЗУ у конкретного устройства. Например x86_64 процессоры используют только 48 бит для адресации виртуальной памяти, что позволяет использовать до 256 ТБ памяти. В следующей статье про более низкоуровневую архитектуру памяти будет объяснено, почему не все 64 бита.
Типы ссылок
Если вы внимательно посмотрите на изображение структуры памяти, вы, вероятно, заметите, что стрелки, представляющие ссылки на объекты из кучи, на самом деле относятся к разным типам. Это потому, что в языке программирования Java используются разные типы ссылок: сильные, слабые, мягкие и фантомные ссылки. Разница между типами ссылок заключается в том, что объекты в куче, на которые они ссылаются, имеют право на сборку мусора по различным критериям. Рассмотрим подробнее каждую из них.
1. Сильная ссылка
Это самые популярные ссылочные типы, к которым мы все привыкли. В приведенном выше примере со StringBuilder мы фактически храним сильную ссылку на объект из кучи. Объект в куче не удаляется сборщиком мусора, пока на него указывает сильная ссылка или если он явно доступен через цепочку сильных ссылок.
2. Слабая ссылка
Попросту говоря, слабая ссылка на объект из кучи, скорее всего, не сохранится после следующего процесса сборки мусора. Слабая ссылка создается следующим образом:
Хорошим вариантом использования слабых ссылок являются сценарии кеширования. Представьте, что вы извлекаете некоторые данные и хотите, чтобы они также были сохранены в памяти - те же данные могут быть запрошены снова. С другой стороны, вы не уверены, когда и будут ли эти данные запрашиваться снова. Таким образом, вы можете сохранить слабую ссылку на него, и в случае запуска сборщика мусора, возможно, он уничтожит ваш объект в куче. Следовательно, через некоторое время, если вы захотите получить объект, на который вы ссылаетесь, вы можете внезапно получить null значение. Хорошей реализацией сценариев кеширования является коллекция WeakHashMap . Если мы откроем WeakHashMap класс в Java API, мы увидим, что его записи фактически расширяют WeakReference класс и используют его поле ref в качестве ключа отображения ( Map) :
После сбора мусора ключа из WeakHashMap вся запись удаляется из карты.
3. Мягкая ссылка
Эти типы ссылок используются для более чувствительных к памяти сценариев, поскольку они будут собираться сборщиком мусора только тогда, когда вашему приложению не хватает памяти. Следовательно, пока нет критической необходимости в освобождении некоторого места, сборщик мусора не будет касаться легко доступных объектов. Java гарантирует, что все объекты, на которые имеются мягкие ссылки, будут очищены до того, как будет выдано исключение OutOfMemoryError . В документации Javadocs говорится, что «все мягкие ссылки на мягко достижимые объекты гарантированно очищены до того, как виртуальная машина выдаст OutOfMemoryError».
Подобно слабым ссылкам, мягкая ссылка создается следующим образом:
4. Фантомная ссылка
Используется для планирования посмертных действий по очистке, поскольку мы точно знаем, что объекты больше не живы. Используется только с очередью ссылок, поскольку .get() метод таких ссылок всегда будет возвращаться null . Эти типы ссылок считаются предпочтительными для финализаторов.
Получение ресурса есть инициализация (RAII)
RAII — это программная идиома в ООП, смысл которой заключается в том, что выделяемая для объекта область памяти строго привязывается к его времени существования. Память выделяется в конструкторе и освобождается в деструкторе. Данный подход был впервые реализован в C++, а так же используется в Ada и Rust.
Пример
Ссылки – одно из центральных понятий в работе JavaScript. Однако их более детальное изучение – тема для отдельного разговора.
Аллокатор
У динамической памяти есть две явные проблемы. Во-первых, любое выделение/освобождение памяти в ОС — системный вызов, замедляющий работу программы. Решением этой проблемы является аллокатор.
Аллокатор — это часть программы, которая запрашивает память большими кусками напрямую у ОС через системные вызовы (в POSIX-совместимых ОС это mmap для выделения памяти и unmap — для освобождения), затем по частям отдаёт эту память приложению (в Си это могут быть функции malloc()/free()). Такой подход увеличивает производительность, но может вызвать фрагментацию памяти при длительной работе программы.
malloc()/free() и mmap/unmap — это не одно и то же. Первый является простейшим аллокатором в libc, второй является системным вызовом. В большинстве языков можно использовать только аллокатор по умолчанию, но в языках с более низкоуровневой моделью памяти можно использовать и другие аллокаторы.
Из-за сложности программ очень трудно определить, когда необходимо освобождать память в ОС, и это вторая явная проблема динамической памяти. Если забыть вызвать munmap() или free(), то произойдет следующая ситуация: приложению память уже не нужна, но ОС всё ещё будет считать, что эта память используется программой. Эту проблему называют «утечкой памяти». Существуют несколько способов автоматического или полуавтоматического решения этой проблемы:
RAII (Получение ресурса есть инициализация) — в ООП — организация получения доступа к ресурсу в конструкторе, а освобождения — в деструкторе соответствующего класса. Достаточно реализовать управление памятью в конструкторах и деструкторах, а компилятор вызовет их автоматически. Например, немного урезанный класс String из статьи про class String
<
public:
explicit String(const char *const c_string)
<
size = strlen(c_string) + 1;
this->c_string = new char[size]; // выделяем память
strcpy(this->c_string, c_string);
>
~String() noexcept
delete[] c_string; // очищаем память
>
private:
char *c_string;
size_t size;
>;
Умные указатели на основе RAII — указатели, автоматически владеющие динамической памятью, то есть автоматически освобождающие её, когда она больше не нужна. Умные указатели инкапсулируют только управление памятью объекта, но не сам объект, как, например, происходит в String, который инкапсулирует объект целиком. Примеры умных указателей ниже.
std::unique_ptr — класс уникального указателя, является единственным владельцем памяти и очищает её в своём деструкторе. Поэтому объекты класса std::unique_ptr не могут иметь копий, но могут быть перемещены. Подробнее о семантике перемещения в std::shared_ptr — класс общего указателя, использующий атомарный счётчик ссылок для подсчёта количества владельцев памяти. В конструкторе счётчик инкрементируется, в деструкторе декрементируется. Как только счётчик становится равным нулю, память освобождается.
Но у std::shared_ptr есть проблема, например, когда объект A ссылается на объект B, а объект B ссылается на объект A. В таком случае у обоих объектов счётчик ссылок никогда не будет меньше 1 и произойдёт утечка памяти. Решений у этой проблемы два. Использование std::weak_ptr, который ссылается на объект, но без счётчика ссылок, и не может быть разыменован без предварительной конвертации в std::shared_ptr. Вторым решением этой проблемы является сборщик мусора.
Сборка мусора — одна из форм автоматического управления динамической памятью, которая помечает все доступные из стека или статической памяти динамически выделенные объекты. Объекты, до которых нельзя добраться через цепочку указателей, начиная с автоматической или статической памяти, т. е. не помеченные сборщиком мусора, очищаются.
Умные указатели и RAII используются в основном в относительно низкоуровневых языках, например, С++ или Swift. В более высокоуровневых языках обычно используется сборщик мусора (Java), хотя может применяться комбинация умного указателя и сборщика мусора (Python).
У каждого способа управления динамической памятью есть свои плюсы и минусы. В основном приходится жертвовать производительностью программы ради скорости и простоты разработки, либо наоборот: высокая производительность, но и высокая требовательность к программистам, из-за чего вероятность ошибиться при разработке программы выше и медленней сам процесс.
Это глубокое погружение в управление памятью Java позволит расширить ваши знания о том, как работает куча, ссылочные типы и сборка мусора.
Вероятно, вы могли подумать, что если вы программируете на Java, то вам незачем знать о том, как работает память. В Java есть автоматическое управление памятью, красивый и тихий сборщик мусора, который работает в фоновом режиме для очистки неиспользуемых объектов и освобождения некоторой памяти.
Поэтому вам, как программисту на Java, не нужно беспокоиться о таких проблемах, как уничтожение объектов, поскольку они больше не используются. Однако, даже если в Java этот процесс выполняется автоматически, он ничего не гарантирует. Не зная, как устроен сборщик мусора и память Java, вы можете создать объекты, которые не подходят для сбора мусора, даже если вы их больше не используете.
Поэтому важно знать, как на самом деле работает память в Java, поскольку это дает вам преимущество в написании высокопроизводительных и оптимизированных приложений, которые никогда не будут аварийно завершены с ошибкой OutOfMemoryError . С другой стороны, когда вы окажетесь в плохой ситуации, вы сможете быстро найти утечку памяти.
Для начала давайте посмотрим, как обычно организована память в Java:

Структура памяти
Обычно память делится на две большие части: стек и куча. Имейте в виду, что размер типов памяти на этом рисунке не пропорционален реальному размеру памяти. Куча - это огромный объем памяти по сравнению со стеком.
Процесс сборки мусора
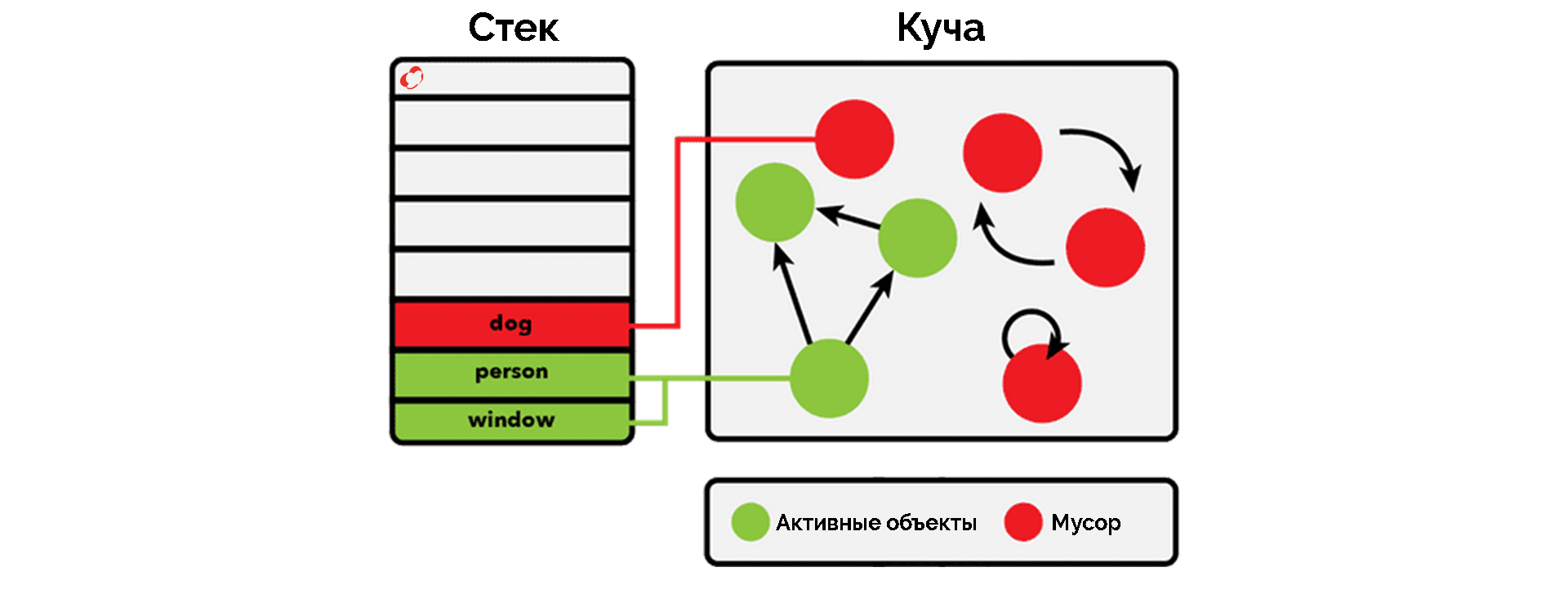
Как обсуждалось ранее, в зависимости от типа ссылки, которую переменная из стека содержит на объект из кучи, в определенный момент времени этот объект становится подходящим для сборщика мусора.

Объекты, подходящие для сборки мусора
Например, все объекты, отмеченные красным цветом, могут быть собраны сборщиком мусора. Вы можете заметить, что в куче есть объект, который имеет строгие ссылки на другие объекты, которые также находятся в куче (например, это может быть список, который имеет ссылки на его элементы, или объект, имеющий два поля типа, на которые есть ссылки). Однако, поскольку ссылка из стека потеряна, к ней больше нельзя получить доступ, так что это тоже мусор.
Чтобы углубиться в детали, давайте сначала упомянем несколько вещей:
Этот процесс запускается автоматически Java, и Java решает, запускать или нет этот процесс.
На самом деле это дорогостоящий процесс. При запуске сборщика мусора все потоки в вашем приложении приостанавливаются (в зависимости от типа GC, который будет обсуждаться позже).
На самом деле это более сложный процесс, чем просто сбор мусора и освобождение памяти.
Несмотря на то, что Java решает, когда запускать сборщик мусора, вы можете явно вызвать System.gc() и ожидать, что сборщик мусора будет запускаться при выполнении этой строки кода, верно?
Это ошибочное предположение.
Вы только как бы просите Java запустить сборщик мусора, но, опять же, Java решать, делать это или нет. В любом случае явно вызывать System.gc() не рекомендуется.
Поскольку это довольно сложный процесс и может повлиять на вашу производительность, он реализован разумно. Для этого используется так называемый процесс «Mark and Sweep». Java анализирует переменные из стека и «отмечает» все объекты, которые необходимо поддерживать в рабочем состоянии. Затем все неиспользуемые объекты очищаются.
Так что на самом деле Java не собирает мусор. Фактически, чем больше мусора и чем меньше объектов помечены как живые, тем быстрее идет процесс. Чтобы сделать это еще более оптимизированным, память кучи на самом деле состоит из нескольких частей. Мы можем визуализировать использование памяти и другие полезные вещи с помощью JVisualVM, инструмента, поставляемого с Java JDK. Единственное, что вам нужно сделать, это установить плагин с именем Visual GC, который позволяет увидеть, как на самом деле структурирована память. Давайте немного увеличим масштаб и разберем общую картину:

Поколения памяти кучи
Когда объект создается, он размещается в пространстве Eden (1). Поскольку пространство Eden не такое уж большое, оно заполняется довольно быстро. Сборщик мусора работает в пространстве Eden и помечает объекты как живые.
Если объект выживает в процессе сборки мусора, он перемещается в так называемое пространство выжившего S0(2). Во второй раз, когда сборщик мусора запускается в пространстве Eden, он перемещает все уцелевшие объекты в пространство S1(3). Кроме того, все, что в настоящее время находится на S0(2), перемещается в пространство S1(3).
Если объект выживает в течение X раундов сборки мусора (X зависит от реализации JVM, в моем случае это 8), скорее всего, он выживет вечно и перемещается в пространство Old(4).
Принимая все сказанное выше, если вы посмотрите на график сборщика мусора (6), каждый раз, когда он запускается, вы можете увидеть, что объекты переключаются на пространство выживших и что пространство Эдема увеличивалось. И так далее. Старое поколение также может быть обработано сборщиком мусора, но, поскольку это большая часть памяти по сравнению с пространством Eden, это происходит не так часто. Метапространство (5) используется для хранения метаданных о ваших загруженных классах в JVM.
Представленное изображение на самом деле является приложением Java 8. До Java 8 структура памяти была немного другой. Метапространство на самом деле называется PermGen область. Например, в Java 6 это пространство также хранит память для пула строк. Поэтому, если в вашем приложении Java 6 слишком много строк, оно может аварийно завершить работу.
Типы сборщиков мусора
Фактически, JVM имеет три типа сборщиков мусора, и программист может выбрать, какой из них следует использовать. По умолчанию Java выбирает используемый тип сборщика мусора в зависимости от базового оборудования.
1. Serial GC (Последовательный сборщик мусора) - однониточный коллектор. В основном относится к небольшим приложениям с небольшим использованием данных. Можно включить, указав параметр командной строки: -XX:+UseSerialGC.
2. Parallel GC (Параллельный сборщик мусора) - даже по названию, разница между последовательным и параллельным будет заключаться в том, что параллельный сборщик мусора использует несколько потоков для выполнения процесса сбора мусора. Этот тип GC также известен как сборщик производительности. Его можно включить, явно указав параметр: -XX:+UseParallelGC.
3. Mostly concurrent GC (В основном параллельный сборщик мусора). Если вы помните, ранее в этой статье упоминалось, что процесс сбора мусора на самом деле довольно дорогостоящий, и когда он выполняется, все потоки приостанавливаются. Однако у нас есть в основном параллельный тип GC, который утверждает, что он работает одновременно с приложением. Однако есть причина, по которой он «в основном» параллелен. Он не работает на 100% одновременно с приложением. Есть период времени, на который цепочки приостанавливаются. Тем не менее, пауза делается как можно короче для достижения наилучшей производительности сборщика мусора. На самом деле существует 2 типа в основном параллельных сборщиков мусора:
3.1 Garbage First - высокая производительность с разумным временем паузы приложения. Включено с опцией: -XX:+UseG1GC.
3.2 Concurrent Mark Sweep (Параллельное сканирование отметок) - время паузы приложения сведено к минимуму. Он может быть использован с помощью опции: -XX:+UseConcMarkSweepGC . Начиная с JDK 9, этот тип GC объявлен устаревшим.
Ссылки
Вы можете подписаться на автора статьи в Twitter и на LinkedIn.
За вычитку перевода отдельное спасибо Александру Максимовскому и Катерине Шибаковой
Когда вы кодите на JavaScript, в большинстве случаев вы вполне можете обойтись без знаний о том, как происходит управление памятью. В конце концов, движок JavaScript делает все за вас.
Однако рано или поздно вы столкнетесь с некоторыми проблемами – например, с утечками памяти, – и избавиться от них получится только тогда, когда вы поймете, как именно работает выделение памяти.
В этой статье я расскажу вам об управлении памятью и принципах работы сборщика мусора, а также объясню, как избежать наиболее распространенных видов утечек памяти.
Советы и приемы
Чтобы минимизировать объем памяти, максимально ограничьте область видимости переменных. Помните, что каждый раз, когда выскакивает верхняя область видимости из стека, ссылки из этой области теряются, и это может сделать объекты пригодными для сбора мусора.
Явно устанавливайте в null устаревшие ссылки. Это сделает объекты, на которые ссылаются, подходящими для сбора мусора.
Избегайте финализаторов (finalizer). Они замедляют процесс и ничего не гарантируют. Фантомные ссылки предпочтительны для работы по очистке памяти.
Не используйте сильные ссылки там, где можно применить слабые или мягкие ссылки. Наиболее распространенные ошибки памяти - это сценарии кэширования, когда данные хранятся в памяти, даже если они могут не понадобиться.
JVisualVM также имеет функцию создания дампа кучи в определенный момент, чтобы вы могли анализировать для каждого класса, сколько памяти он занимает.
Настройте JVM в соответствии с требованиями вашего приложения. Явно укажите размер кучи для JVM при запуске приложения. Процесс выделения памяти также является дорогостоящим, поэтому выделите разумный начальный и максимальный объем памяти для кучи. Если вы знаете его, то не имеет смысла начинать с небольшого начального размера кучи с самого начала, JVM расширит это пространство памяти. Указание параметров памяти выполняется с помощью следующих параметров:
Начальный размер кучи -Xms512m - установите начальный размер кучи на 512 мегабайт.
Максимальный размер кучи -Xmx1024m - установите максимальный размер кучи 1024 мегабайта.
Размер стека потоков -Xss1m - установите размер стека потоков равным 1 мегабайту.
Размер поколения -Xmn256m - установите размер поколения 256 мегабайт.
Если приложение Java выдает ошибку OutOfMemoryError и вам нужна дополнительная информация для обнаружения утечки, запустите процесс с –XX:HeapDumpOnOutOfMemory параметром, который создаст файл дампа кучи, когда эта ошибка произойдет в следующий раз.
Используйте опцию -verbose:gc , чтобы получить вывод процесса сборки мусора. Каждый раз, когда происходит сборка мусора, будет генерироваться вывод.
Автоматический подсчёт ссылок (ARC)
Данный подход весьма похож на сборку мусора с подсчётом ссылок, однако, вместо запуска процесса подсчёта в определённые интервалы времени, инструкции выделения и освобождения памяти вставляются на этапе компиляции прямо в байт-код. Когда же счётчик ссылок достигает нуля, память освобождается как часть нормального потока выполнения программы.
Автоматический подсчёт ссылок всё так же не позволяет обрабатывать циклические ссылки и требует от разработчика использования специальных ключевых слов для дополнительной обработки таких ситуаций. ARC является одной из особенностей транслятора Clang, поэтому присутствует в языках Objective-C и Swift. Так же автоматический подсчет ссылок доступен для использования в Rust и новых стандартах C++ при помощи умных указателей.
Сборщик мусора
Примеры
Рассмотрим несколько примеров (в комментариях указано, как происходит выделение памяти):
Оборотная сторона медали
Благодаря автоматической сборке мусора мы можем полностью сосредоточиться на создании продукта и не тратить свое драгоценное время на управление памятью. Однако не стоит забывать и о том, что у всего есть свои недостатки.
Часть 1: Введение в управление памятью
Управление памятью — это целый набор механизмов, которые позволяют контролировать доступ программы к оперативной памяти компьютера. Данная тема является очень важной при разработке ПО и, при этом, вызывает затруднения или же вовсе остаётся черным ящиком для многих программистов.
Ссылки в JavaScript
Все переменные в первую очередь указывают на стек. В случае, если значение не является примитивным, в стеке содержится ссылка на объект из кучи.
В куче нет какого-либо определенного порядка, в связи с чем ссылка на нужную нам область памяти должна храниться в стеке: в этом смысле объект в куче похож на дом, а ссылка – на его адрес.
Примечание JavaScript хранит объекты и функции в куче, в то время как примитивные значения и ссылки находятся в стеке.
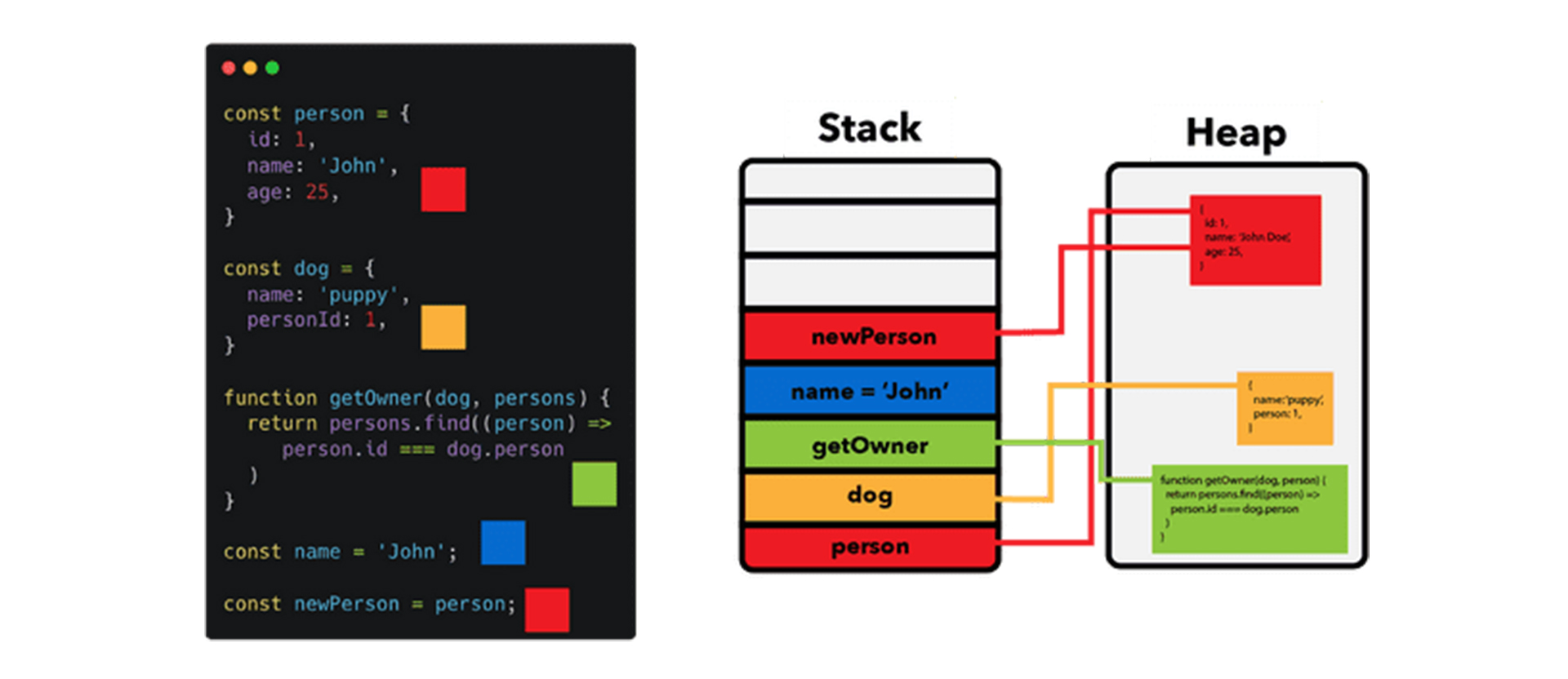
На этой картинке показано, как организовано хранение различных значений. Обратите внимание, что person и newPerson указывают здесь на один и тот же объект.
Читайте также: