
Xlfn floor math что это в эксель
На данный момент в Microsoft Excel имеется почти пять сотен функций рабочего листа, доступных через окно Мастера функций - кнопка fx в строке формул. Это весьма приличный набор, но, тем не менее, почти каждый пользователь рано или поздно сталкивается с ситуацией, когда в этом списке не оказывается нужной ему функции - просто потому, что её нет в Excel.
До сих пор единственным способом решить эту проблему были макросы, т.е. написание своей пользовательской функции (UDF = User Defined Function) на Visual Basic, что требует соответствующей программистской квалификации и бывает, порой, совсем непросто. Однако, с последними обновлениями Office 365 ситуация изменилась в лучшую сторону - в Excel была добавлена специальная "обёрточная" функция LAMBDA. С её помощью задача по созданию собственных функций теперь решается легко и красиво.
Давайте рассмотрим принцип её использования на следующем примере.
Как вы, скорее всего, знаете в Excel есть несколько функции для разборки даты позволяющие определить номер дня, месяца, недели и года для указанной даты. Но почему-то нет функции, определяющий номер квартала, который тоже часто нужен, правда? Давайте исправим этот недостаток и создадим с помощью LAMBDA собственную новую функцию для решения этой задачи.
Шаг 1. Пишем формулу
Начём с того, что вручную привычным образом напишем формулу в ячейке листа, которая вычисляет то, что нам нужно. В случае с номером квартала это можно сделать, например, так:

Шаг 2. Заворачиваем в LAMBDA и тестируем
Теперь пришло время применить новую функцию LAMBDA и завернуть в неё нашу формулу. Синтаксис у функции следующий:
=LAMBDA( Переменная1 ; Переменная2 ; . ПеременнаяN ; Выражение )
где сначала перечисляются имена одной или нескольких переменных, а последним аргументом всегда идёт формула или вычисляемое выражение, которое их использует. Имена переменных не должны быть похожи на адреса ячеек и не должны содержать точки.
В нашем случае переменная будет только одна - дата, для которой мы считаем номер квартала. Переменную для неё давайте назовем, допустим, d. Тогда завернув нашу формулу в функцию LAMBDA и подменив адрес исходной ячейки A2 на придуманное имя переменной, мы получим:

Обратите внимание, что после такого преобразования наша формула (по сути - правильная!) стала выдавать ошибку, т.к. теперь в неё не передается исходная дата из ячейки А2. Для тестирования и уверенности, можно передать ей аргументы, дописав их после функции LAMBDA в круглых скобках:

Шаг 3. Создаем имя
Теперь самая легкая и приятная часть. Открываем Диспетчер имен на вкладке Формулы (Formulas - Name Manager) и создаём новое имя кнопкой Создать (Create) . Придумываем и вводим имя для нашей будущей функции (например, НОМКВАРТАЛА), а в поле Ссылка (Reference) аккуратно копируем из строки формул и вставляем нашу функцию LAMBDA, только без последнего аргумента (А2):

Всё. После нажатия на ОК созданную функцию можно использовать в любой ячейке на любом листе этой книги:

Использование в других книгах
Поскольку созданные с помощью LAMBDA пользовательские функции представляет из себя, по сути, именованные диапазоны, то можно легко сделать их доступными не только в текущей книге. Достаточно будет скопировать ячейку с функцией и вставить в любое место листа другого файла.
LAMBDA и динамические массивы
Пользовательские функции, создаваемые с помощью функции LAMBDA успешно поддерживают работу с новыми динамическими массивами и их функциями (ФИЛЬТР, УНИК, СОРТ), добавленными в Microsoft Excel в 2020 году.
Допустим, мы хотим создать новую пользовательскую функцию, которая сравнивала бы два списка и выдавала разницу между ними - те элементы из первого списка, которые отсутствуют во втором. Жизненная задача, не правда ли? Раньше для такого использовали либо функции а-ля ВПР (VLOOKUP) , либо сводные таблицы, либо запросы Power Query. Теперь же можно обойтись одной формулой:

В английской версии это будет:
Здесь функция СЧЁТЕСЛИ подсчитывает количество вхождений каждого элемента первого списка во второй, а затем функция ФИЛЬТР отбирает только те из них, у кого этих вхождений не оказалось. Завернув эту конструкцию в LAMBDA и создав на её основе именованный диапазон с названием, например, ПОИСКОТЛИЧ - мы получим удобную функцию, выдающую результат сравнения двух списков в виде динамического массива:

Если в качестве исходных данных будут не обычные, а "умные" таблицы - наша функция тоже справится без проблем:

Другой пример - динамическое разделение текста путём превращения его в XML и последующего разбора по ячейкам с помощью функции ФИЛЬТР.XML, которое мы недавно разбирали. Чтобы не воспроизводить эту сложную формулу каждый раз вручную, проще будет завернуть её в LAMBDA и создать на её основе динамический диапазон, т.е. новую компактную и удобную функцию, назвав её, например, РАЗДТЕКСТ:

Первым аргументом этой функции будет ячейка с исходным текстом, а вторым - символ-разделитель, в возвращать результат она будет в виде горизонтального динамического массива. Код функции при этом будет следующим:
Список примеров можно продолжать бесконечно - в любой ситуации, где вам часто приходится вводить одну и ту же длинную и громоздкую формулу функция LAMBDA сделает жизнь ощутимо проще.
Рекурсивный перебор символов
Все предыдущие примеры демонстрировали только одну, наиболее очевидную, сторону функции LAMBDA - её применение в качестве "обёртки" для заворачивания в неё длинных формул и упрощения их ввода. На самом деле, у LAMBDA есть ещё одна, гораздо более глубокая, сторона, превращающая её почти что в полноценный язык программирования.
Дело в том, что принципиально важной особенностью LAMBDA-функций является возможность реализации в них рекурсии - логики вычислений, когда в процессе расчета функция вызывает сама себя. С непривычки, возможно, звучит жутковато, но в программировании рекурсия - обычное дело. Даже в макросах на Visual Basic можно её реализовать, а теперь, вот, как видите, дошло и до Excel. Давайте попробуем разобраться в этой технике на практическом примере.
Предположим, нам требуется создать пользовательскую функцию, которая удаляла бы из исходного текста все заданные символы. Полезность такой функции, думаю, доказывать вам не нужно - с её помощью было бы очень удобно очищать замусоренные входные данные, правда?
Однако, по сравнению с предыдущими, нерекурсивными примерами, нас ожидают две сложности.
- Нам придётся придумать название для нашей функции до того, как мы начнём писать её код, т.к. в нём это название уже будет использоваться для вызова функцией самой себя.
- Ввести такую рекурсивную функцию в ячейку и отлаживать её, указав после LAMBDA аргументы в скобках (как мы делали ранее) не получится. Придётся создавать функцию сразу "с нуля" в Диспетчере Имен (Name Manager) .
Назовём нашу функцию, допустим, ОЧИСТКА и хотелось бы, чтобы у неё было два аргумента - текст, который нужно почистить и список исключаемых символов в виде текстовой строки:

Создадим, как делали ранее, на вкладке Формулы в Диспетчере имён именованный диапазон, назовём его ОЧИСТКА и введём в поле Диапазон следующую конструкцию:
Здесь переменная t - это исходный очищаемый текст, а d - список символов на удаление.
Работает всё это следующим образом:
Итерация 1
Фрагмент ПОДСТАВИТЬ(t;ЛЕВСИМВ(d);""), как легко догадаться, заменяет в исходном тексте t первый слева символ из удаляемого набора d на пустую текстовую строку, т.е. удаляет букву "А". В качестве промежуточного результата получаем:
Вш зкз н 125 руб.
Итерация 2
Затем функция вызывает сама себя и в качестве входных данных (первый аргумент) получает уже то, что осталось после очистки на предыдущем шаге, а вторым аргументом задавая строку исключаемых символов начиная не с первого, а со второго символа, т.е. "БВГДЕЁЖЗИКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯ.," без начальной "А" - это делает функция ПСТР. Как и до этого, функция берет первый слева символ из оставшихся (Б) и заменяет его в данном ей тексте (Зкз н 125 руб.) на пустую строку - получаем в качестве промежуточного результата:
Вш зкз н 125 ру.
Итерация 3
Функция опять вызывает сама себя, получая в качестве первого аргумента то, что осталось от зачищаемого текста на предыдущей итерации (Вш зкз н 125 ру.), а в качестве второго - урезанный слева ещё на один символ набор исключаемых знаков, т.е. "ВГДЕЁЖЗИКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯ.," без начальной "Б". Затем опять берёт из этого набора первый символ слева (В) и удаляет его из текста - получаем:
И так далее - надеюсь, вы ухватили идею. С каждой итерацией список удаляемых символов будет обрезаться слева и мы будем искать и заменять на пустоту очередной символ из набора.
Когда все символы закончатся нам необходимо будет выйти из цикла - эту роль как раз и выполняет функция ЕСЛИ (IF) , в которую завернута наша конструкция. Если символов для удаления не осталось (d=""), то функция не должна больше вызывать саму себя, а просто должна вернуть зачищаемый текст (переменная t) в его финальном виде.
Рекурсивный перебор ячеек
Похожим образом можно реализовать и рекурсивный перебор ячеек в заданном диапазоне. Предположим, что мы хотим создать лямбда-функцию с именем ЗАМЕНАПОСПИСКУ для оптовой замены фрагментов в исходном тексте по заданному списку-справочнику. Выглядеть всё это в результате должно так:

Т.е. у нашей функции ЗАМЕНАПОСПИСКУ будет три аргумента:
- ячейка с текстом для обработки (исходный адрес)
- первая ячейка столбца со значениями для поиска из справочника
- первая ячейка столбца со значениями на замену из справочника
Функция должна проходить сверху-вниз по справочнику и заменять последовательно все варианты из левого столбца Найти на соответствующие варианты из правого столбца Заменить. Реализовать такое можно следующей рекурсивной лямбда-функцией:

Здесь в переменной t хранится исходный текст из очередной ячейки столбца Адрес, а переменные n и z указывают на первые ячейки в столбцах Найти и Заменить, соответственно.
Как и в предыдущем примере, сначала эта функция заменяет в исходном тексте с помощью функции ПОДСТАВИТЬ (SUBSTITUTE) данные по первой строке справочника (т.е. СПб на Санкт-Петербург ), а затем вызывает сама-себя, но со сдвигом по справочнику вниз на следующую строку (т.е. заменяет С-Пб на Санкт-Петербург ). Затем вызывает себя ещё раз со сдвигом вниз - и заменяет уже Питер на Санкт-Петербург и т.д.
Сдвиг вниз на каждой итериации реализован стандартной экселевской функцией СМЕЩ (OFFSET) , у которой в данном случае три аргумента - исходный диапазон, сдвиг по строкам (1) и сдвиг по столбцам (0).
Ну, и как только мы достигаем конца справочника (n=""), то должны закончить рекурсию - прекращаем вызывать сами себя и выводим то, что накопилось после всех выполненных замен в переменной исходного текста t.
Вот и всё. Никаких хитрых макросов или запросов Power Query - вся задача решается одной функцией.
Excel for Microsoft 365 Excel for Microsoft 365 for Mac Excel for the web Excel 2021 Excel 2021 for Mac Excel 2019 Excel 2019 for Mac Excel 2016 Excel 2016 for Mac Excel 2013 Excel for Mac 2011 More. Less
This article describes the formula syntax and usage of the FLOOR.MATH function in Microsoft Excel.
Description
Round a number down to the nearest integer or to the nearest multiple of significance.
Syntax
FLOOR.MATH(number, significance, mode)
The FLOOR.MATH function syntax has the following arguments.
Number Required. The number to be rounded down.
Significance Optional. The multiple to which you want to round.
Mode Optional. The direction (toward or away from 0) to round negative numbers.
Remarks
By default, positive numbers with decimal portions are rounded down to the nearest integer. For example, 6.3 is rounded down to 6, using the default Significance (1).
By default, negative numbers with decimal portions are rounded away from 0 to the nearest integer. For example, -6.7 is rounded to -7.
By using 0 or a negative number as the Mode argument, you can change the direction of the rounding for negative numbers. For example, rounding -6.3 with a Significance of 1 and a Mode of -1 rounds toward 0, to -6.
The Significance argument rounds the number down to the nearest integer that is a multiple of the significance specified. The exception is where the number to be rounded is an integer. For example, for a Significance of 3, the number is rounded down to the next integer that is a multiple of 3.
If Number divided by a Significance of 2 or greater results in a remainder, the result is rounded down.
Example
Copy the example data in the following table, and paste it in cell A1 of a new Excel worksheet. For formulas to show results, select them, press F2, and then press Enter. If you need to, you can adjust the column widths to see all the data.
Description (result)
Rounds 24.3 down to the nearest integer that is a multiple of 5 (20).
Rounds 6.7 down to the nearest integer (6).
Rounds -8.1 down (away from 0) to the nearest integer that is a multiple of 2 (-10).
Rounds -5.5 toward 0 to the nearest integer that is a multiple of 2, using a non-zero Mode, which reverses rounding direction (-4).

The Excel FLOOR.MATH function rounds a number down to a specified multiple. Unlike the FLOOR function, FLOOR.MATH defaults to a multiple of 1, and provides explicit support for rounding negative numbers.
- number - The number that should be rounded.
- significance - [optional] Multiple to use when rounding. Default is 1.
- mode - [optional] For rounding negative numbers toward or away from zero. Default is 0.
The Excel FLOOR.MATH function rounds a number down to a given multiple, where multiple is provided as the significance argument. If the number is already an exact multiple, no rounding occurs and the original number is returned.
The FLOOR.MATH function takes three arguments, number, significance, and mode. Number is the numeric value to round down, and is the only required argument. With no other input, FLOOR.MATH will round number down to the next integer.
The significance argument is the multiple to which number should be rounded. In most cases, significance is provided as a numeric value, but FLOOR.MATH can also understand time entered as text like "0:15". The default value of significance is 1.
The mode argument controls the direction negative values are rounded. By default, FLOOR.MATH rounds negative values away from zero. Setting mode to 1 or TRUE changes behavior so that negative values are rounded toward zero. The default value of mode is 0 or FALSE, so you can think of mode as a setting that means "round toward zero". Mode has no effect when number is positive.
Examples
By default, FLOOR.MATH rounds to the nearest integer, using a significance of 1.
Provide a value for significance to round to a different multiple:
Rounding negative numbers
Positive numbers with decimal values are rounded down to the nearest integer, and negative numbers with decimal values are rounded away from zero:
Control for rounding negative numbers toward zero or away from zero is provided with the (optional) mode argument. Mode defaults to zero or FALSE. When mode is omitted, FLOOR.MATH rounds negative numbers away from zero. When mode is set to TRUE, FLOOR.MATH rounds negative numbers toward zero. Mode has no effect on positive numbers.

The Excel CEILING.MATH function rounds a number up to a specified multiple. Unlike the CEILING function, CEILING.MATH defaults to a multiple of 1, and provides explicit control over rounding direction for negative numbers.
- number - The number that should be rounded.
- significance - [optional] Multiple to use when rounding. Default is 1.
- mode - [optional] Round negative numbers toward or away from zero. Default is 0.
The Excel CEILING.MATH function rounds a number up to a given multiple, where multiple is provided as the significance argument. If the number is already an exact multiple, no rounding occurs and the original number is returned.
The CEILING.MATH function takes three arguments, number, significance, and mode. Number is the numeric value to round up, and is the only required argument. With no other input, CEILING.MATH will round number up to the next integer.
The significance argument is the multiple to which number should be rounded. In most cases, significance is provided as a numeric value, but CEILING.MATH can also understand time entered as text like "0:15". The default value of significance is 1.
The mode argument controls the direction negative values are rounded. By default, CEILING.MATH rounds negative values up toward zero. Setting mode to 1 or TRUE changes behavior so that negative values are rounded away from zero. The default value of mode is 0 or FALSE, so you can think of mode as a setting that means "round away from zero". Mode has no effect when number is positive.
Examples
By default, CEILING.MATH rounds to the nearest integer, using a significance of 1.
Provide a value for significance to round to a different multiple:
Rounding negative numbers
By default, positive numbers with decimal portions are rounded up to the nearest integer and negative numbers with decimal portions are rounded toward zero:
Control for rounding negative numbers toward zero or away from zero is provided via the optional mode argument. Mode defaults to zero. When mode is zero, or omitted, CEILING.MATH rounds negative numbers toward zero. When mode is 1 or TRUE, CEILING.MATH rounds negative numbers away from zero. Mode has no effect on positive numbers.
CEILING.MATH vs CEILING
The CEILING.MATH function together with the CEILING.PRECISE function replace the original CEILING function, which is now classified as a "compatibility function". The behavior is very similar, but CEILING.MATH provides explicit control over how negative numbers are rounded. CEILING.MATH differs from CEILING in these key ways:

Despite how amazing Excel is there are times when you’ll find yourself shaking with fear! For example, have you ever seen anything as scary as this =ISERROR(FIND(_xlfn.CONCAT($A2:$E2),_xlfn.CONCAT($I$2:$M$6))) What is xlfn .
What’s The Story?
You open your friend’s Excel file and discover that some of the formulas aren’t working and include the letters XLFN ! You call your friend but he says that everything looks perfectly fine on his laptop. Did you get too much sun? Did you eat some bad fish? Did you smoke one of Oz du Soleil’s cigars?
What Is XLFN?
xlfn is a prefix added to functions that don’t exist in the version of Excel that you are using.
You have Excel 2013 and your friend has a newer version of Excel (Office 365 or Excel 2016). He uses a cool new function and sends the file to you. As you have Excel 2013 this cool new function doesn’t yet exist and you see xlfn in front of the function.
Recent XLFN Example
Last year I discovered David Hager’s Excel blog. He shares a lot of neat ideas. I recently saw this post: Conditional Format Rows in List 1 that are Not in List 2
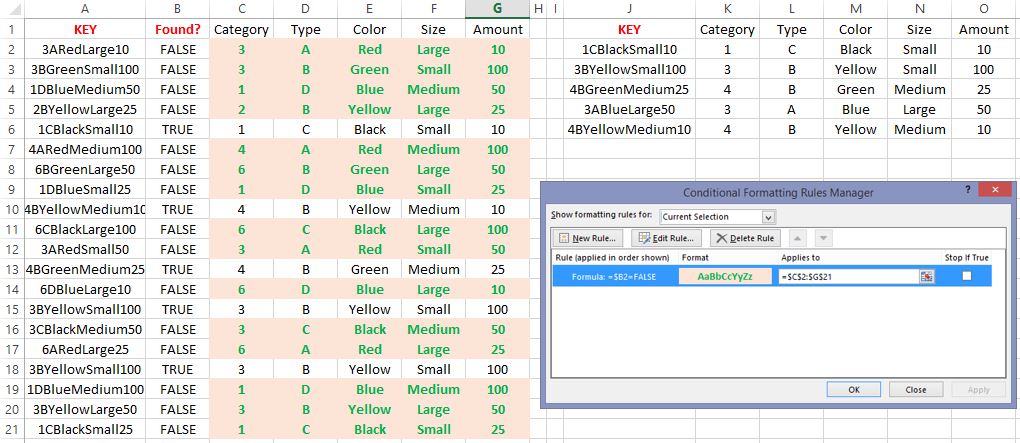
When I opened the file I noticed that the solution wasn’t working for me. I went back to David’s post and looked at this pic:

I noticed that David used the CONCAT function. This must be a new Excel 2016 (or Office365?) function! There are a bunch of really interesting new functions but I’m still using Excel 2013.
What Does Microsoft Recommend?
“Remove the unsupported functions, or if possible, replace the unsupported functions with supported functions.” Also, read this .
OK. So, Is There A Workaround?
Although not as easy as David’s solution we can still produce the same end result.
Here are the steps to my workaround solution:
- Use a helper formula to concatenate all values in both tables: (i.e. =K2&L2&M2&N2&O2 )
- Adding this =ISNUMBER(MATCH(A2,$J$2:$J$6,0)) shows whether or not the row is found (Cell A2 is key in table 1. Column J is key in table 2)
- Add this formula inside your conditional formatting rule: =$B2=FALSE
Excel 2013 Workaround Solution
Here is David’s Excel file that includes my workaround solution for those that don’t have Excel 2016.
Learn From Excel MVP David Hager
About Me

My name is Kevin Lehrbass. I live in Markham, Ontario, Canada. I’ve been studying, supporting, building, troubleshooting, teaching and dreaming in Excel since 2001. I’m a Data Analyst.
There are so many amazing things that you can do with Excel.
Check out my recommended Excel Training section.
Check out my videos and my blog posts .
Away from Excel I enjoy learning Spanish, playing Chess, hanging out with Cali and Fenton and reading Excel books 🙂
ABOUT THE AUTHOR
Kevin Lehrbass
5 Comments → I SEE “XLFN” . WHAT IS HAPPENING?
How about Microsoft make the stand alone version of Office 2016 match the Office 365 version of Excel!
This can also happen when you have teammates working in a different language Excel than you. the xlfn, acts just like a flag that your local Excel creates to indicate that it tried looking for that formula but didn’t find it.
I don’t really know who on Ms decided that formulas in Excel should be translated and not ported between languages when you open the workbook, most surely in an effort to increase end-user retention of the formulae.
BITRSHIFT is another function from older versions of excel. It’s available in LibreOffice Calc.
Edit: should be “missing from older versions”
Huh you can also just use replace _xlfn.CONCAT to CONCATENATE
Leave a Reply Cancel reply
Sometimes I write a practical 'how to' post and other times I explore a crazy idea and build something unique. I love working with data in Microsoft Excel!
Kevin Lehrbass
Читайте также: