
Unicode не отображается в браузере
Есть несколько символов Юникода, которые я просто вижу в виде блоков. Это происходит только в Chrome. Кодировка символов установлена в UTF-8, но автоопределение не помогает.
Пример: []
Вы увидите только две квадратные скобки, но на самом деле между ними находится Unicode Character World Joiner . Это неразрывный пробел нулевой ширины.
Я также собрал небольшое демо jsfiddle. Я не вижу персонажа World Joiner , но я могу видеть пространство для волос. (И, видя это, я на самом деле имею в виду, что не вижу этого. Ты видишь?)
Это также происходит, когда люди публикуют смайлики нового стиля и т.д.
Обновить:
Это происходит везде (Twitter, Facebook, вы называете это). Я не использую специальные шрифты или изменил что-то связанное со шрифтами в моей системе (Windows 7, 64-битная версия). Я ошибаюсь, если предположим, что это должно сработать?
Обновление 2:
Это сводит меня с ума. Есть еще так много символов, которые не отображаются.
Пример (упакованный подарок):

Как видите, Chrome не отображает символ по умолчанию. Только когда я явно устанавливаю шрифт в Segoe UI Symbol, это происходит. Почему Chrome не использует шрифт как запасной вариант автоматически?
Как заставить Chrome распознавать шрифт Segoe UI Symbol?
2 ответа 2
Шрифт Code2000 - Создан в 1998 году Джеймсом Кассом Code2000 - это работа в процессе. В настоящее время (версия 1.171) содержит более 60000 символов.
Хотя он более или менее читабелен в 12-18 точках, он гораздо яснее примерно в 24 точках. Некоторые из дингбатов должны быть не менее 36 баллов. Сглаживание шрифтов выглядит хорошо при нормальных размерах.
Вы обнаружили, что инструкции, упомянутые в блоге, сработали: распаковать zip-файл в папку шрифтов на панели управления и перезапустить Chrome.
Почему у меня не отображаются некоторые символы, выводятся квадратики, вопросики или вообще ничего не выводится. К сожалению, шрифт который используется в вашей системе, не поддерживает этот символ. Более подробно попробуем объяснить ниже.
Кодировки и шрифты
Кодировка, это соответствие числа в памяти компьютера и отображаемого символа. Вот, например, символ А . Мы видим на экране букву А , а компьютер видит число 1040 . Число 1040 говорит компьютеру, что нужно отрисовать букву А , но не говорит как: жирно, курсивно, с завитушками, какого размера. Начертание не дело кодировки, это дело шрифта.
С точки зрения компьютера, шрифт, это файл, в котором некоторым числам (кодовым позициям) сопоставлены картинки. То есть числу 1040 сопоставлено изображение буквы А . Только одно изображение буквы А . Если нам нужна курсивная буква А , нам нужно использовать другой шрифт, где будут нарисованы курсивные буквы. С засечками или без засечек? Для этого опять нужны разные шрифты. То есть, если у нас для отображения текста используется шрифт Arial-italic, компьютер, встречая число 1040, обращается к шрифту, получает от него изображение (курсивная заглавная буква А без засечек) и выводит его.
Наличие символов в шрифтах
По большому счёту, какие символы рисовать в соответствие каждому числу, на совести разработчика шрифта. Он может вместо буквы «А» нарисовать букву «Б» или вообще что-нибудь неприличное. И компьютер выведет это на экран не моргнув и глазом. Однако, шрифты, которые используются на компьютерах и в интернете обычно делают вменяемые люди и они соответствуют стандартам. То есть буква «Б», вместо буквы «А», скорее всего, не появится.
Другое дело, для всех ли букв в шрифте есть картинки. Стандарт Юникода определяет уже более ста тысяч символов. Среди них очень много таких экзотических, как египетские иероглифы или древневавилонская клинопись. Прорисовывать каждый иероглиф, это с одной стороны слишком утомительно, с другой, файл такого шрифта будет весить десятки мегабайт, что для использования в интернете слишком накладно. Поэтому обычно в шрифте рисуют только ограниченное количество символов — латинские буквы, цифры, основные знаки препинания. Для русских шрифтов ещё и кириллицу. Для арабских — арабские буквы, но кириллицы уже может и не быть.
Поэтому ответ на вопрос «почему при копировании символ не показывается» — на той странице с которой вы копировали и на той, на которую вы скопировали, используются разные шрифты. И если в первом шрифте этот символ отрисован, то во втором его разработчики поленились.
Символы на нашем сайте
Задача нашего сайта, показать все символы Юникода. Поэтому мы используем шрифты, где отрисовано большинство этих символов. И ведём постоянную работу над тем, чтобы нарисовать недостающие. Поэтому, у нас есть и мордочка котика и много другого интересного. Но в других шрифтах на других сайтах этого может не быть.
Вы можете зайти на страницу символа и посмотреть, как он выглядит в стандартных шрифтах, типа Arial, Times New Roman и других. Если при этом символ не превращается в квадратик, то скорее всего, он будет правильно отображаться на других сайтах.
Проблема ещё в том, что даже такие стандартные шрифты, как Arial, на разных операционных системах могут содержать различное количество символов.
Другая проблема: симпатичная мордочка котика в другом шрифте может оказаться не такой симпатичной.
Программы, не поддерживающие Юникод целиком
Все современные браузеры поддерживают последний стандарт Юникода (более 100 тысяч символов). Но некоторые другие (различные мессенджеры вроде ICQ), могут поддерживать не все символы (обычно, только первые 65 тысяч). Так как мордочка котика не попадает в этот лимит (её код — 128 049), то они не смогут её нормально отобразить.
Пути решения проблемы
Самый же радикальный, но работающий вариант — если это возможно, вставлять не символ, а картинку с ним.
Мы используем 🍪cookie, чтобы сделать сайт максимально удобным для вас. Подробнее
Вопрос пользователя
Здравствуйте.
Подскажите пожалуйста, почему у меня некоторые странички в браузере отображают вместо текста иероглифы, квадратики и не пойми что (ничего нельзя прочесть). Раньше такого не было.
Заранее спасибо.
Доброго времени суток!
Действительно, иногда при открытии какой-нибудь интернет-странички вместо текста показываются различные "крякозабры" (как я их называю), и прочитать это нереально.
Происходит это из-за того, что текст на страничке написан в одной кодировке (более подробно об этом можете узнать из Википедии ), а браузер пытается открыть его в другой. Из-за такого рассогласования, вместо текста — непонятный набор символов.

Исправляем иероглифы на текст
Браузер
Вообще, раньше Internet Explorer часто выдавал подобные крякозабры, 👉 современные же браузеры (Chrome, Яндекс-браузер, Opera, Firefox) — довольно неплохо определяют кодировку, и ошибаются очень редко. 👌
Скажу даже больше, в некоторых версиях браузера уже убрали выбор кодировки, и для "ручной" настройки этого параметра нужно скачивать дополнения, или лезть в дебри настроек за 10-ток галочек.
Итак, предположим браузер неправильно определили кодировку и вы увидели следующее (как на скрине ниже 👇).

Вместо текста одни лишь крякозабры // Браузер выставил кодировку неверно!
👉 Кстати!
Чаще всего путаница бывает между кодировками UTF (Юникод) и Windows-1251 (большинство русскоязычных сайтов выполнены в этих кодировках).
Поэтому, я рекомендую в ручном режиме попробовать их обе. Для этого нам понадобиться браузер MX5 (ссылка на офиц. сайт). Он один из немногих позволяет в ручном режиме выбирать кодировку (при необходимости):
- необходимо открыть нужный сайт;
- далее зайти в меню "Инструменты / кодировка" ;
- выбрать вручную UTF 8 или "Авто-определение" ;
- перезагрузить страницу. И, ву-а-ля, — иероглифы на страничке сразу же стали обычным текстом (скрин ниже 👇) !
👉 В помощь!
Если у вас иероглифы в браузере Chrome — ознакомьтесь с этим
Браузер MX5 — выбор кодировки UTF8 или авто-определение

Теперь отображается русский текст норм.
📌 Еще один совет : если вы в своем браузере не можете найти, как сменить кодировку (а дать инструкцию для каждого браузера — вообще нереально!), я рекомендую попробовать открыть страничку в другом браузере (например, в MX5). Очень часто другая программа открывает страницу так, как нужно!
Текстовые документы
Очень много вопросов по крякозабрам задаются при открытии каких-нибудь текстовых документов. Особенно старых, например, при чтении Readme в какой-нибудь программе прошлого века (скажем, к играм) .
Разумеется, что многие современные блокноты просто не могут прочитать DOS'овскую кодировку, которая использовалась ранее. Чтобы решить сию проблему, рекомендую использовать редактор Bread 3.
Попробуйте открыть в Bred 3 свой тексто вый документ (с которым наблюдаются проблемы) . Пример показан у меня на скрине ниже. 👇
Иероглифы при открытии текстового документа
Далее в Bred 3 есть кнопка для смены кодировки: просто попробуйте поменять ANSI на OEM — и старый текстовый файл станет читаемым за 1 сек.!
Исправление иероглифов на текст
👉 Для работы с текстовыми файлами различных кодировок также подойдет еще один блокнот — Notepad++. Вообще, конечно, он больше подходит для программирования, т.к. поддерживает различные подсветки, для более удобного чтения кода.
Пример смены кодировки показан ниже: чтобы прочитать текст, достаточно в примере ниже, достаточно было сменить кодировку ANSI на UTF-8.
Смена кодировки в блокноте Notepad++
Штирлиц
Сайт разработчика: http://www.shtirlitz.ru/
Эта программа специализируется на "расшифровке" текстов, написанных в разных кодировках: Win-1251, KOI-8r, DOS, ISO-8859-5, MAC и др.
Причем, программа нормально работает даже с текстами со смешанной кодировкой (что не могут др. аналоги). Пример см. на скрине ниже. 👇

Пример работы ПО "Штирлиц"
BAT-файлы (скрипты)
Для начала простой пример о чем идет речь. 👇
На скрине видно, что вместо русского текста отображаются различные квадратики, буквы "г" перевернутые, и пр. иероглифы.

Как выглядит русский текст при выполнении BAT-файла
- в начало BAT-файла добавить код @chcp 1251 ;
- установить программу Notepad++ и в меню выбрать OEM-866: "Кодировки/Кодировки/Кириллица/OEM-866" ;
- установить программу Akelpad, в разделе "Кодировки" выбрать "Сохранить в DOS-866" .
Документы MS WORD
Очень часто проблема с крякозабрами в Word связана с тем, что путают два формата Doc и Docx . Дело в том, что с 2007 года в Word (если не ошибаюсь) появился формат Docx (позволяет более сильнее сжимать документ, чем Doc, да и надежнее защищает его).
Так вот, если у вас старый Word, который не поддерживает этот формат — то вы, при открытии документа в Docx, увидите иероглифы и ничего более.
📌 Есть неск. путей решения:
- скачать на сайте Microsoft спец. дополнение, которое позволяет открывать в старом Word новые документы (с 2020г. дополнение с офиц. сайта удалено) . Только из личного опыта могу сказать, что открываются далеко не все документы, к тому же сильно страдает разметка документа (что в некоторых случаях очень критично) ;
- использовать 👉 аналоги Word (правда, тоже разметка в документе будет страдать);
- обновить Word до современной версии (2019+);
- если речь идет о документы TXT — открыть его в Notepad++.
Так же при открытии любого документа в Word (в кодировке которого он "сомневается"), он на выбор предлагает вам самостоятельно указать оную. Пример показан на рисунке ниже, попробуйте выбрать:
- Widows (по умолчанию);
- MS DOS;
- Другая.
Переключение кодировки в Word при открытии документа
Окна в различных приложениях Windows
Бывает такое, что какое-нибудь окно или меню в программе показывается с иероглифами (разумеется, прочитать что-то или разобрать — нереально).
📌 Могу дать несколько рекомендаций:
- Русификатор. Довольно часто официальной поддержки русского языка в программе нет, но многие умельцы делают русификаторы. Скорее всего, на вашей системе — данный русификатор работать отказался. Поэтому, совет простой: попробовать поставить другой;
- Переключение языка. Многие программы можно использовать и без русского, переключив в настройках язык на английский. Ну в самом деле: зачем вам в какой-то утилите, вместо кнопки "Start" перевод "начать" ?
- Если у вас раньше текст отображался нормально, а сейчас нет — попробуйте 👉 восстановить Windows, если, конечно, у вас есть точки восстановления;
- Проверить настройки языков и региональных стандартов в Windows, часто причина кроется именно в них (👇).
Языки и региональные стандарты в Windows
Чтобы открыть меню настроек:
- нажмите Win+R ;
- введите intl.cpl , нажмите Enter.
intl.cpl - язык и регион. стандарты
Проверьте чтобы во вкладке "Форматы" стояло "Русский (Россия) / Использовать язык интерфейса Windows (рекомендуется)" (пример на скрине ниже 👇).
Формат - русский / Россия
Во вкладке "Местоположение" — укажите "Россия" .
И во вкладке "Дополнительно" установите язык системы "Русский (Россия)" .
После этого сохраните настройки и перезагрузите ПК. Затем вновь проверьте, нормально ли отображается интерфейс нужной программы.
Текущий язык программ
PS
И напоследок, наверное, для многих это очевидно, и все же некоторые открывают определенные файлы в программах, которые не предназначены для этого: к примеру в обычном блокноте пытаются прочитать файл DOCX или PDF.
Естественно, в этом случае вы вместо текста будут наблюдать за крякозабрами, используйте те программы, которые предназначены для данного типа файла (WORD 2016+ и Adobe Reader для примера выше).
Случалось ли Вам получать и читать письма на “фиг каком пойми языке” или заходить на какой-нибудь интернет-ресурс и вместо привычных букв видеть сплошные кракозябры? Если да, тогда эта заметка для Вас, ибо в ней мы поговорим о кодировке страниц, её форматах, почему оная возникает и как впредь избежать непонятных иероглифов.

Итак, сегодня нас ждет не легкая софтовая статья, а суровая техническая, так что приготовьтесь: будем немного ударяться в суровые реалии.
Поехали.
Что такое кодировка текста и с чем ее едят?
Начать хотелось бы с того, что этой статьи могло бы и не быть, т.к. компьютерно-юзательная жизнь автора этих строк протекала вполне себе спокойно и достойно. Но вот в один прекрасный день, шляясь по просторам сети Интернет не со своего ПК, я столкнулся с непонятными явлениями на некоторых сайтах. Заходя на интернет-ресурсы, я видел не привычный нам русский алфавит и красивый понятный текст, а какую-то ересь в виде непонятной последовательности символов. Выглядела она примерно вот так (см. изображение).
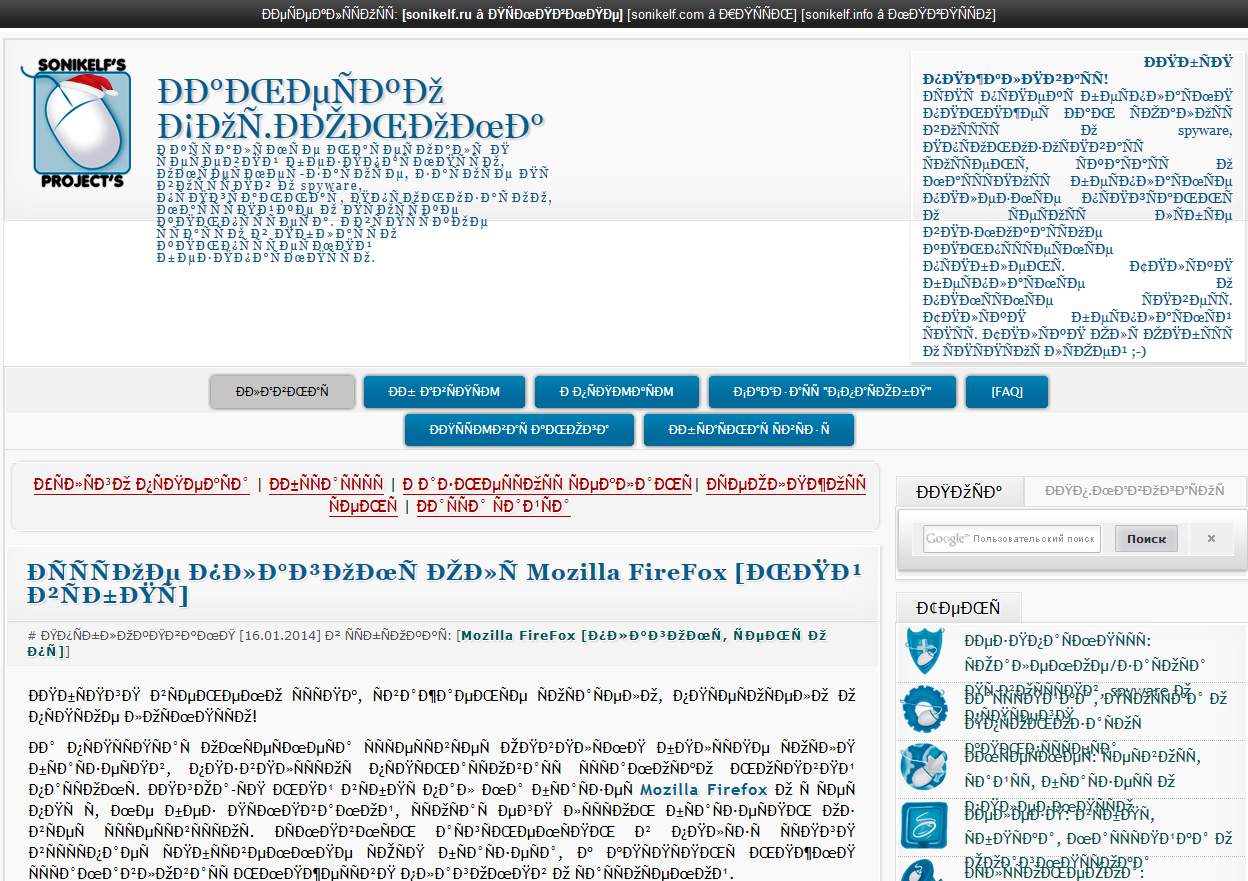
Сначала я подумал, что моя любимая Мозилка (браузер Firefox) перегрелась и ей пора вызывать неотложку, но потом начал понимать, что проблема, скорее всего, на стороне ресурса сети и кроется она в неправильно настроенной кодировке. Это действительно оказалось так, и пошаманив немного с бубном, проблемка была оперативно решена. Результатом же всех моих любовных похождений и стал сегодняшний материал. Собственно, поехали разбираться в деталях.
Всю информацию, представленную в цифровом виде и находящуюся в глобальной паутине, нужно рассматривать с двух сторон: первая - со стороны пользователя (красивый и ухоженный текст на экране монитора) и вторая – со стороны поисковой машины (некий программный код, состоящий из различных тегов/метатегов, таблицы символов и прочее).
Если Вы хоть немного знакомы с языком разметки гипертекста ( HTML ), то должны быть в курсе, что сайт глазами поисковых машин (Google, Яндекс ) видится не как обычный текст, а как структурированный документ, состоящий из последовательностей различного рода тегов. Чтобы было понятней, о чем я говорю, давайте взглянем на всеми нами любимый сайт Заметки Сис.Админа ” проекта [ Sonikelf's Project's ], но не глазами обычного пользователя, а "глазами" поисковика. Для этого нажимаем сочетание клавиш Сtrl+U (для браузеров Firefox и Chrome ) и видим следующую картину (см. изображение):
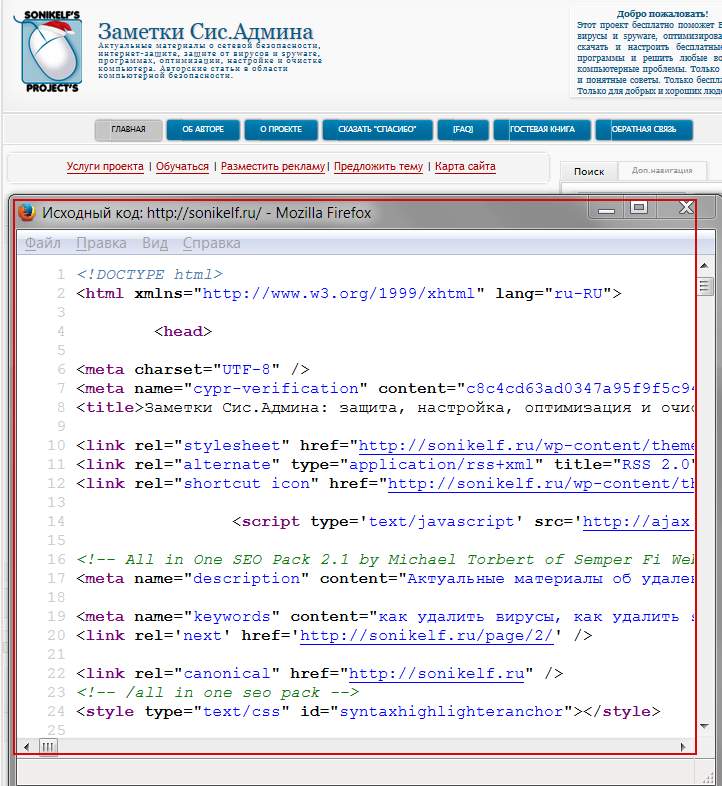
Теперь давайте разберемся, почему же происходит так, что порой на экране монитора мы видим кракозябры. Все очень просто, проблема кроется в открытии файла в неверной кодировке. Если перевести на бытовой язык, то допустим Вас послали в магазин за молоком, а Вы притарабанили хлеб, вроде бы тоже съестное, но совсем другой формат продукта.
Итак, теперь давайте разбираться с теорией и для этого введем некоторые определения.
- Кодировка (или “ Charset ”) – соответствие набора символов набору числовых значений. Нужна для “сливания” информации в интернет, т.е. текстовая информация преобразуется в биты данных;
- Кодовая страница (“ Codepage ”) – 1 байтовая ( 8 бит) кодировка;
- Количество значений, принимаемое 1 байтом – 256 (два в восьмой).
Соответствие “символ-изображение” задается с помощью специальных кодовых таблиц, где каждому символу уже присвоен свой конкретный числовой код. Таких таблиц существует достаточно много, и в разных таблицах один и тот же символ может идентифицироваться по-разному (ему могут соответствовать разные числовые коды).
Все кодировки различаются количеством байт и набором специальных знаков, в которые преобразуется каждый символ исходного текста.
Примечание:
Декодирование – операция, в результате которой происходит преобразование кода символа в изображение. В результате этой операции информация выводится на экран монитора пользователя.
В общем.. С определениями разобрались, а теперь давайте узнаем, какие же (кодировки) бывают.
Виды кодировок текста
А их, в общем-то, хватает.
Одной из самых “древних” считается американская кодировочная таблица ( ASCII , читается как “аски”), принятая национальным институтом стандартов. Для кодировки она использовала 7 битов, в первых 128 значениях размещался английский алфавит (в нижнем и верхнем регистрах), а также знаки, цифры и символы. Она больше подходила для англоязычных пользователей и не была универсальной.
Отечественный вариант кодировки, для которого стали использовать вторую часть кодовой таблицы – символы с 129 по 256 . Заточена под русскоязычную аудиторию.
- Кодировки семейства MS Windows : Windows 1250-1258 .
Универсальный стандарт кодирования символов, позволяющий описать знаки практически всех письменных языков. Обозначение “ U+xxxx ” (хххх – 16-ричные цифры). Самые распространенные семейства кодировок UTF (Unicode Transformation Format) : UTF-8, 16, 32 .
В настоящее время, как говорится, “рулит” UTF-8 – именно она обеспечивают наилучшую совместимость со старыми ОС , которые использовали 8 -битные символы. В UTF-8 кодировке находятся большинство сайтов в сети Интернет и именно этот стандарт является универсальным (поддержка кириллицы и латиницы).
Разумеется, я привел не все виды кодировок, а только наиболее ходовые. Если же Вы хотите для общего развития знать их все, то полный список можно отыскать в самом браузере. Для этого достаточно пройти в нем на вкладку “ Вид-Кодировка-Выбрать список ” и ознакомиться со всевозможными их вариантами (см. изображение).
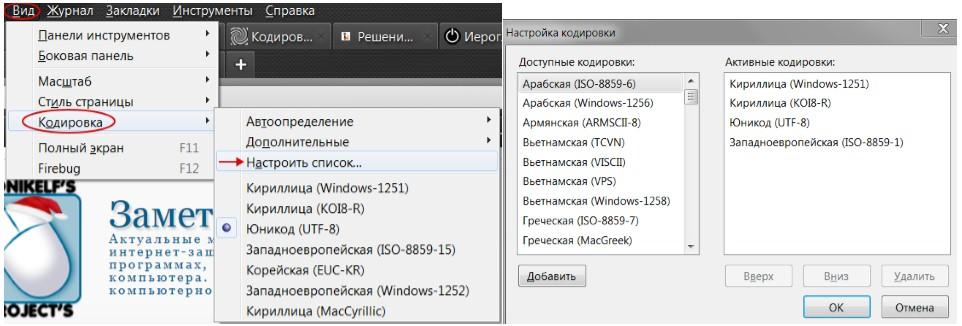
Думаю возник резонный вопрос: “ Какого лешего столько кодировок? ”. Их изобилие и причины возникновения можно сравнить с таким явлением, как кроссбраузерность/кроссплатформенность. Это когда один и тот же сайт сайт отображается по-разному в различных интернет-обозревателях и на различных гаджет-устройствах. Кстати у сайта " Заметки Сис.Админа " с этим, как Вы заметили всё в порядке :).
Ну вот, собственно, пока вся "базово необходимая" теория, которая позволит Вам “не плавать” в кодировочных вопросах, теперь переходим к практической части статьи.
Решаем проблемы с кодировкой или как убрать кракозябры?
Итак, наша статья была бы неполной, если бы мы не затронули пользовательско-бытовые вопросы. Давайте их и рассмотрим и начнем с того, как (с помощью чего) можно посмотреть кодировку?
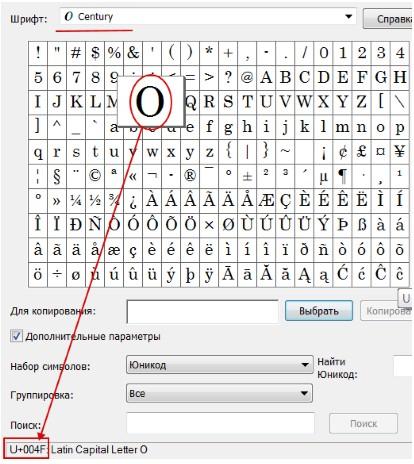
В любой операционной системе имеется таблица символов, ее не нужно докачивать, устанавливать – это данность свыше, которая располагается по адресу: “Пуск-программы-стандартные-служебные-таблица символов”. Это таблица векторных форм всех установленных в Вашей операционной системе шрифтов.
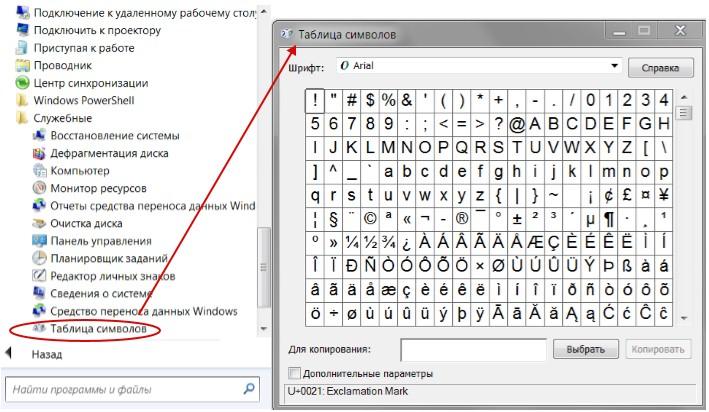
Выбрав “дополнительные параметры” (набор Unicode ) и соответствующий тип начертания шрифта, Вы увидите полный набор символов, в него входящих. Кликнув по любому символу, Вы увидите его код в формате UTF-16 , состоящий из 4 -х шестнадцатеричных цифр (см. изображение).
Теперь пара слов о том, как убрать кракозябры. Они могут возникать в двух случаях:
- Со стороны пользователя - при чтении информации в интернет (например, при заходе на сайт);
- Или, как говорилось чуть выше, со стороны веб-мастера (например, при создании/редактировании текстовых файлов с поддержкой синтаксиса языков программирования в программе Notepad ++ или из-за указания неправильной кодировки в коде сайта).
Рассмотрим оба варианта.

Также проверьте во всех вкладках, чтобы локализация была “ Россия/русский ” – это так называемая системная локаль.
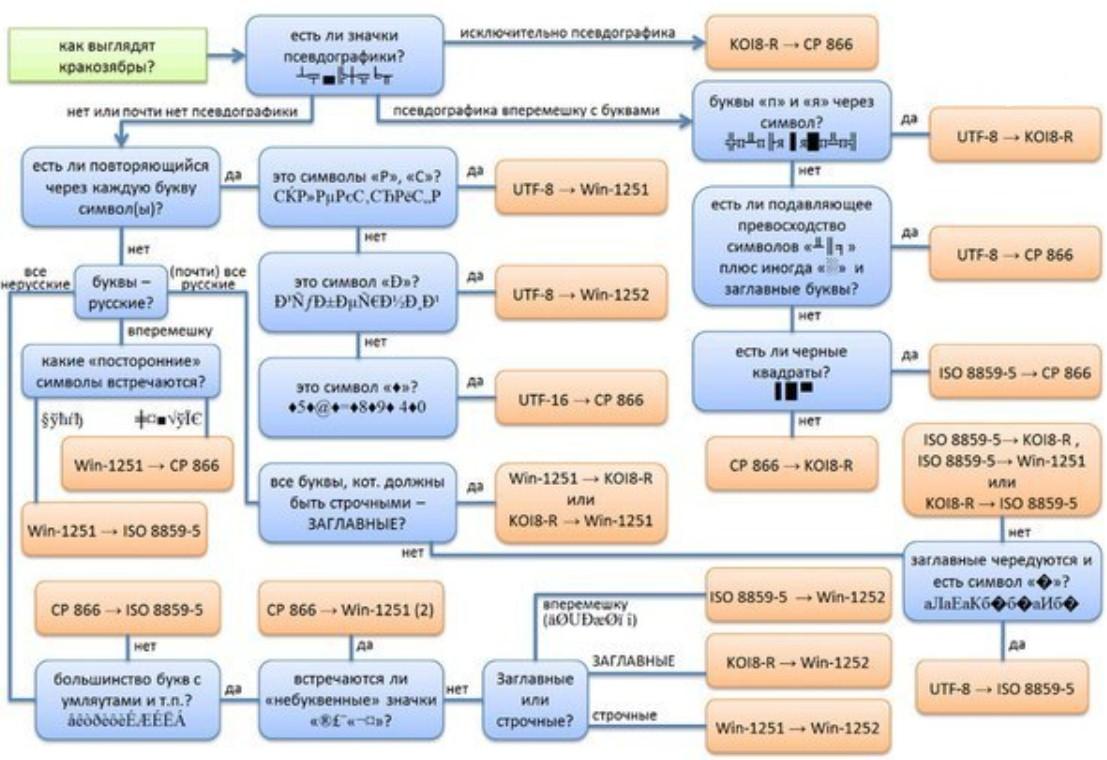
Если Вы открыли сайт и вдруг поняли, что почитать информацию Вам не дают иероглифы, тогда стоит поменять кодировку средствами браузера (“ Вид - Кодировка ”). На какую? Тут все зависит от вида этих кракозябр. Ориентируйтесь на следующую шпаргалку (см. изображение).
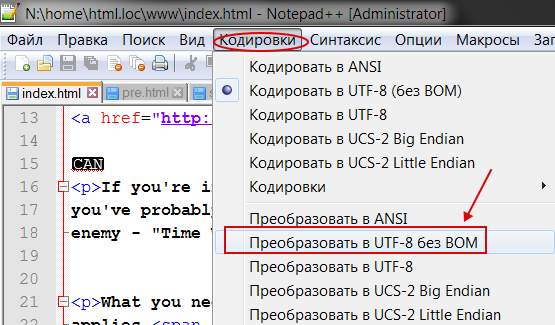
Чтобы такого не происходило, заходим в редактор Notepad++ и выбираем в меню пункт “ Кодировки ”. Именно он поможет преобразовать имеющийся документ. Спрашивается, какой? Чаще всего (если сайт на WordPress или Joomla ), то “ Преобразовать в UTF-8 без BOM ” (см. изображение).
Сделав такое преобразование, Вы увидите изменения в строке статуса программы.

Также во избежание кракозябр необходимо принудительно прописать информацию о кодировке в шапке сайта. Тем самым Вы укажите браузеру на то, что сайт стоит считывать именно в прописанной кодировке. Начинающему веб-мастеру необходимо понимать, что чехарда с кодировкой чаще всего возникает из-за несоответствия настроек сервера настройкам сайта, т.е. на сервере в базе данных прописана одна кодировка, а сайт отдает страницы в браузер в совершенной другой.
Для этого необходимо прописать “внаглую” (в шапку сайта, т.е, как частенько, в файл header.php ) между тегами < head> < /head>следующую строчку:
Прописав такую строчку, Вы заставите браузер правильно интерпретировать кодировку, и иероглифы пропадут.
Также может потребоваться корректировка вывода данных из БД (MySQL). Делается сие так:
mysql_query('SET NAMES utf8' );
myqsl_query('SET CHARACTER SET utf8' );
mysql_query('SET COLLATION_CONNECTION="utf8_general_ci'" ');
Как вариант, можно еще сделать ход конём и прописать в файл .htaccess такие вот строчки:
Все вышеприведенные методы (или некоторые из них), скорее всего, помогут Вам и Вашим будущим посетителям избавиться от ненавистных иероглифов и проблем с кодировкой. К сожалению, более подробно мы здесь инструкцию по веб-мастерским штукам рассматривать не будем, думаю, что они обязательно разберутся в подробностях при желании (как-никак у нас несколько другая тематика сайта).
Ну, вот и практическая часть статьи закончена, осталось подвести небольшие итоги.
Послесловие
Сегодня мы познакомились с таким понятием, как кодировка текста. Уверен, теперь при возникновении каракулей на мониторе компьютера Вы не спасуете, а вспомните все приведенные здесь методы и решите вопрос в свою пользу!
На сим все, спасибо за внимание и до новых встреч.
P.S. Комментарии, как и всегда, ждут Ваших горячих дискуссий и вопросов, так что отписываем.
P.P.S : За существование данной статьи спасибо члену команды 25 КАДР
Белов Андрей (Sonikelf) Заметки Сис.Админа [Sonikelf's Project's] Космодамианская наб., 32-34 Россия, Москва (916) 174-8226

Почему этот символ Юникода или другие подобные ему не отображаются в Google Chrome на Windows 7?
Я предполагаю, что это проблема замены шрифта.
Браузеры сталкиваются с проблемой "Выбранный глиф не в указанном шрифте". Отсюда можно пойти в двух направлениях: вы можете вытащить эквивалентный глиф из другого шрифта (который часто будет выглядеть испорченным, но пользователю может быть непонятно, почему ) или просто отобразить заполненный символом, который не найден (который всегда будет выглядеть разбитым, но, по крайней мере, очевидно, что так).
Я полагаю, что Firefox и Opera признают, что запрашиваемый глиф является символом, который безопасно извлечь из другого шрифта, в то время как остальные браузеры консервативны и просто показывают глиф "Uh . dunno".
Интересно. Это не просто Chrome - вы можете спросить, почему ни один из следующих браузеров не может отобразить его в Windows 7:

- Firefox (у)
- IE9 (n)
- Хром (н)
- Опера (у)
- Сафари (н)
Поэтому Firefox и Opera могут отображать этот символ Unicode в Windows 7, но другие браузеры не могут.
На вопрос «Почему этот символ Unicode [. ] не отображается в Google Chrome в Windows 7?»" это
Этот конкретный символ - просто кодовая точка Unicode, которая является произвольным числом. Существует много кодовых точек Юникода, которые не имеют «официального» символа. Даже если у них есть символ, это не обязательно тот случай, когда ваш шрифт имеет символ для этой кодовой точки. Если вы выберете другой шрифт, у вас может получиться другой символ.
Я посмотрел на CSS для страницы, и он показывает отображение этого символа в Arial (плюс куча других шрифтов, которые не имеют значения). Windows поставляется с Arial, поэтому он всегда должен сначала выбрать этот шрифт. Похоже , Arial не имеет символа для этого юникода элемента кода. Каждый раз, когда у вас нет глифа для кодовой точки, он вставляет некоторую форму поля, указывающего, что глифа нет (как указали другие).
Более важный вопрос заключается в том, что именно Firefox или другие браузеры делают там, где он работает в Windows. Я посмотрел на другие шрифты, перечисленные в CSS (я думал, что это может быть откат к следующему шрифту CSS), но у них также нет глифа для этой кодовой точки. Возможно, Firefox поставляется со своими собственными шрифтами.
Копаясь в firefox, я заметил некоторые шрифты для математических символов здесь: 'C:\Program Files (x86)\Mozilla Firefox\res\fonts'. Возможно, это то, откуда это исходит.
Читайте также: